「ビジネス活用事例で学ぶ データサイエンス入門」輪読会#1資料
TRANSCRIPT

「ビジネス活用事例で学ぶデータサイエンス入門」輪読会 #1
32 PAGES
Shintaro Nomura
R で 学 ぶ
2015.12.22 @ beez渋谷

本日の予定表
自己紹介×16=10分程度
(1人15-30秒程度で、名前[HN]、所属ま
たはどうしてこの輪読会に興味を持った
か、今後やりたいこと、アピールなど)
第1章・2章=20~30分程度
第3章=めざせ75分
(時間あまると嬉しい)
2

1~2章はテキスト参照
1~2章は文字通り輪読しちゃう編
(追加コメント・議論は歓迎です)
(とはいえ時間制約上、ぶった切ったら
ごめんなさい)
3章は、理解が早い方はぜひ周囲を
サポートいただけると助かります!
3

こんなブログがあります 4
↑ He says…

“データ分析職の最低限のスキル要件” 5

その他に…
みどりぼん程度の統計学の知識
はじパタ程度の機械学習の知識
RかPythonでコードが組める
SQLが書ける
6
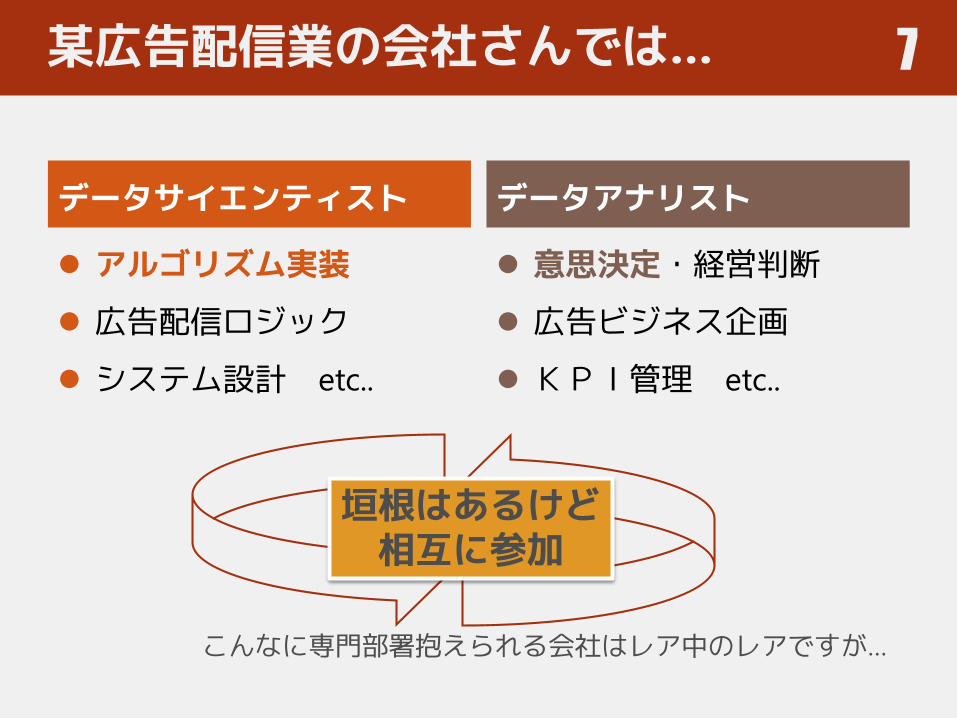
某広告配信業の会社さんでは…
データサイエンティスト
アルゴリズム実装
広告配信ロジック
システム設計 etc..
データアナリスト
意思決定・経営判断
広告ビジネス企画
KPI管理 etc..
7
こんなに専門部署抱えられる会社はレア中のレアですが…
垣根はあるけど相互に参加

出所:キャリアトレックさん 8
業界全般的に人は足りていないらしいです(IoT、機械学習は特にそうかも?)

データ分析の模範フロー
現状と
あるべ
き姿
問題
発見
データ
収集と
加工
データ
分析
アク
ション
9
ギャップから問題の構造を把握

問題発見のための3つの切り口
大きさ
を見る
• 現状とあるべき姿とのギャップ要素を洗い出す
• その複数の要因について影響度の大きい順に並べる
分解して
見る
• 起きている現象を、その構成要素に分解
• MECEに分解するよう心がける
比較して
見る
• 分解した要素どうしを比較する
• 時系列/類似商品・サービス/ユーザ属性…で比較
10

データ分析
データサイエンティスト
アルゴリズム実装
広告配信ロジック
システム設計 etc..
自動化・最適化
推定精度向上・計算量低減
機械学習・アルゴ構築
データアナリスト
意思決定・経営判断
広告ビジネス企画
KPI管理 etc..
意思決定支援
コミュニケーションコスト低減
クロス集計・指標予測
11

Rのダウンロード
「r download」で検索
(12/22時点での最新版は 3.2.3 です。)
または
http://j.mp/downloadr を参照
すでにインストールしていた方は3.2.3へ
の更新をオススメします
12

データ分析環境「Rstudio」が便利 13
Stanでの開発にもかなり使える説http://uribo.hatenablog.com/entry/2015/12/16/071644

こんなの立ち上がればひとまずOK 14

本書で用いるデータ
「DL76333.zip」が以下にあります
http://www.sbcr.jp/support/11915.html
zipファイルを解凍したファイルは、
作業ディレクトリに入れるとラクですよ
15

作業ディレクトリって?
データが入ったテキストファイル等から、データや
プログラムを読みこんだり、画像を書き出したりし
ます。これらのファイルのある場所を「作業ディレ
クトリ」といいます。
データは作業ディレクトリに入っていると便利!
作業ディレクトリを変えたいときは、
「File > Change dir…(ディレクトリの変更)」
またはコマンド: setwd(“C:/指定先”)
16

実際にデータを取り入れよう!
解凍したフォルダの「R」にある
”section3-dau.csv”を取り込む
Excelで開くとこんな感じの139,112人分の
データが入っています
Rで開くには、コマンドを使ってみましょう
17

Rで作業するときは 18
そのまま入力もできるけど新しいスクリプトを使おう

CSVファイルを読み込むとき
x <- ***
xという入れ物に数値や文字列、ベクトルや
関数、データなどを入れます
x <- read.csv(“***.csv”)
矢印の先にある入れ物にcsvファイルのデー
タを取り込みます
head(***)
***データの先頭数行を表示します
19

データの結合(merge)
merge(AAA, BBB, by = c(“***”))
データAAAとデータBBBが含む、***という
項目を紐付けて、データ同士を結合する。
再結合も可能
20

欠損値NA
今回、Excelで開くと「0」という値が、Rで
は「NA」と入っています
「NULL」も存在するが、厳密には別のもの
AA$BB[is.na(AA$BB)] <- 0
データAAにおける項目BB列のデータのうち、
「NA」となっている要素すべてに0を代入
21
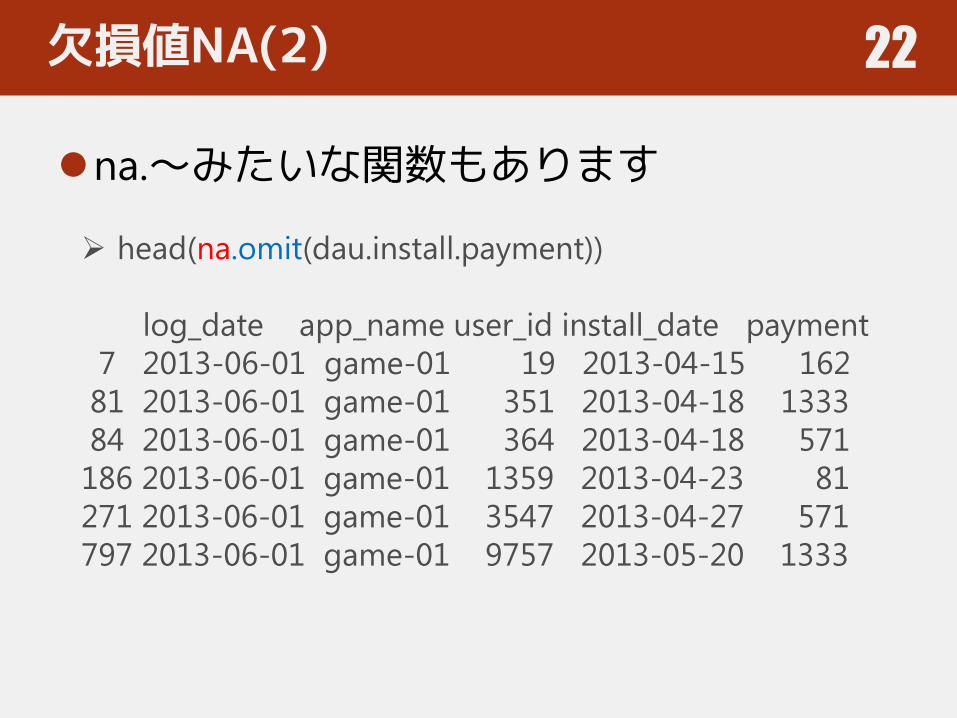
欠損値NA(2)
na.~みたいな関数もあります
22
head(na.omit(dau.install.payment))
log_date app_name user_id install_date payment
7 2013-06-01 game-01 19 2013-04-15 162
81 2013-06-01 game-01 351 2013-04-18 1333
84 2013-06-01 game-01 364 2013-04-18 571
186 2013-06-01 game-01 1359 2013-04-23 81
271 2013-06-01 game-01 3547 2013-04-27 571
797 2013-06-01 game-01 9757 2013-05-20 1333

substr{}:文字列の抜き出し
AA$CC <- substr{AA$BB, 開始字数, 終了字
数}
データAAにおける項目BB列の開始字数~
終了字数までの文字列を抜き出し、デー
タAAの項目CC列に代入
23

パッケージを使うとパワーアップ!
Rにはパッケージと呼ばれる、有志が作った
拡張機能のようなものがあります。
処理を一気にやってくれるものや、高度な統
計分析を自動で行ってくれるもの、また、シ
ミュレーションツールなど豊富に存在します。
install.packages(***)→library(***)で使用可能
24

ddplyパッケージ
データ前処理には必須のパッケージ!?
くわしくは…http://rstudio-pubs-static.s3.amazonaws.com/1112_a4db493e67ed427b9e01a57312159105.html
または 「plyrパッケージの使い方メモ」でググろう
ddply{AAA,. {B, C}, summarize, YYY
=sum(XXX))
AAAデータの項目B, Cをグループ化してYYY
を加算集計して項目XXXを作成
25

ddplyパッケージ(2)
mau.payment.summary <-
ddply(mau.payment, .(log_month, user.type), summarize,
total.payment = sum(payment) )
たしかに集計結果:total.payment項目が出来ています
26
> head(mau.payment.summary)
log_month user.type total.payment
1 2013-06 existing 177886
2 2013-06 install 49837
3 2013-07 existing 177886
4 2013-07 install 29199

ddplyパッケージ(3)
ddply(AAA, .(BBB), nrow)
AAAのデータをBBB毎に分割
分割された各データの行数を計算(nrow)
分割した結果を結合してarray型として返
却
27

ifelse
ifelse(条件式, 式1, 式2)
「条件式」を満たすなら「式1」、それ以
外なら「式2」
比較演算子”==“はふつうの等号と思おう
28
mau.payment$user.type <-
ifelse(mau.payment$install_month
== mau.payment$log_month,
"install", "existing")

3章で用いるその他のパッケージ
ggplot2
• きれいなグラフが非常に効率的に作れる
• ご参考:http://id.fnshr.info/2011/10/22/ggplot2/
scales
• 今回はグラフの軸に3桁区切りを導入する
ために使用されています
29

棒グラフを描く
ggplot(mau.payment.summary,
aes(x = log_month, y = total.payment, fill =
user.type))
+ geom_bar(stat="identity")
+ scale_y_continuous(label = comma)
くわしくは…
http://stat.biopapyrus.net/ggplot/geom-bar.html
30
x軸・y軸指標の指定
user.type毎に集計

ヒストグラムを描く
ggplot(mau.payment[mau.payment$payment
> 0 & mau.payment$user.type == “install”, ],
aes(x = payment, fill = log_month)) +
geom_histogram(position = "dodge",
binwidth = 2000)
くわしくは…
http://stat.biopapyrus.net/ggplot/geom-histogram.html
31
ユーザ属性を”install”に絞っています

次回担当してくれる方はいませんか
第4章
[ケーススタディ2]どの属性の顧客が離脱
しているのか?
第5章
[ケーススタディ3]どっちのバナーの反応
が良いか?
32