統計的学習の基礎 第2章後半
TRANSCRIPT

統計的学習の基礎第2章2.5 ~ 2.9
@Prunus1350

2.5 高次元での局所的手法

これまで学んだ予測のための二つの方法
• 線形モデル• 安定しているがバイアスが大きい
• k最近傍法
• 不安定だがバイアスが小さい
• 訓練データが十分多ければk最近傍法でいいのでは?
• →高次元において破綻をきたす(次元の呪い)
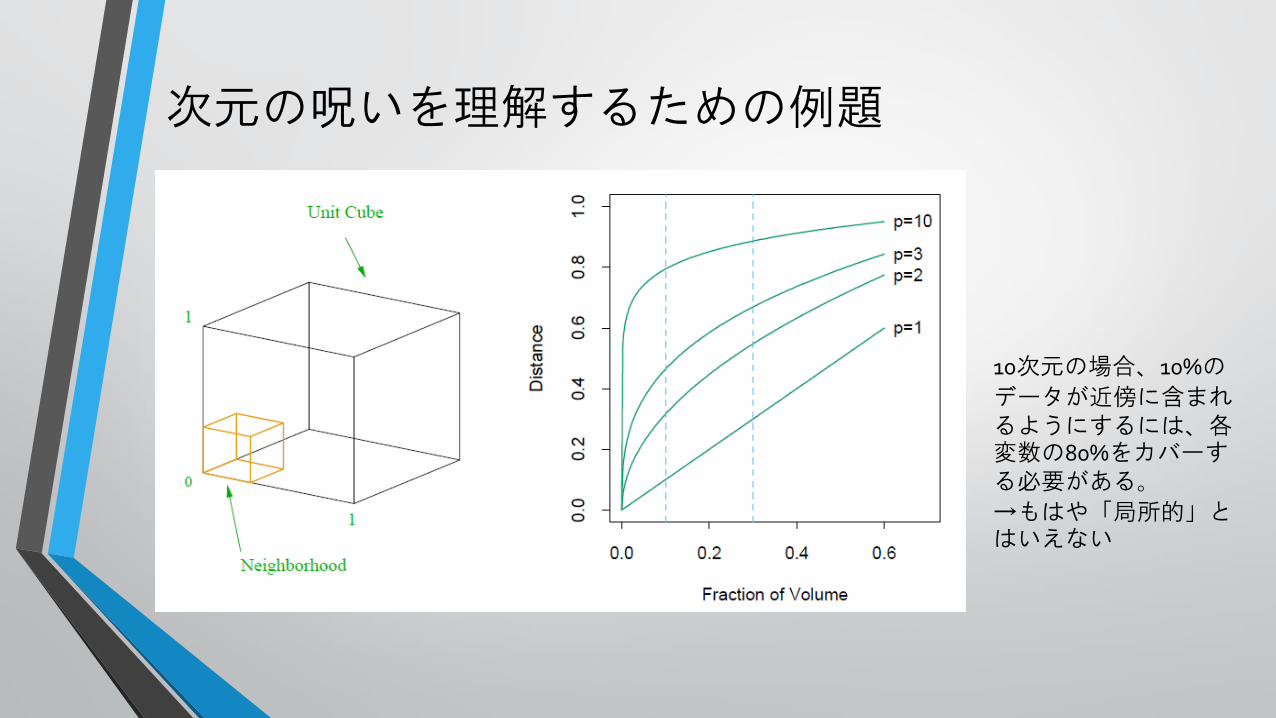
次元の呪いを理解するための例題
10次元の場合、10%の
データが近傍に含まれるようにするには、各変数の80%をカバーする必要がある。
→もはや「局所的」とはいえない

高次元空間から疎に標本を得ることに起因するもう一つの問題
• 原点を中心とする半径が1のp次元超球内にN個のデータ点が一様に分布しているとする。
• 原点に最も近いデータ点までの距離の中央値
• N = 500, p = 10 の場合、d(p, N) ≈ 0.52
• 超球の境界までの距離の半分以上にあたる。
• 近傍の点を用いた予測が、極めて不安定になってしまう。

標本化密度の観点から次元の呪いを理解する
• pを入力変数の次元、Nをデータ数とすると、標本化密度は𝑁 1𝑝に比例
する。
• 入力変数が1次元の場合に𝑁1 = 100であれば、十分に密なデータであると見なすことにする。
• 10次元の入力変数に関して同様に密であるためには、𝑁10 = 10010ものデータが必要になる。
• →ある程度次元の高い状況では、訓練データが入力空間で極めて疎に分布していると考えなければならない。
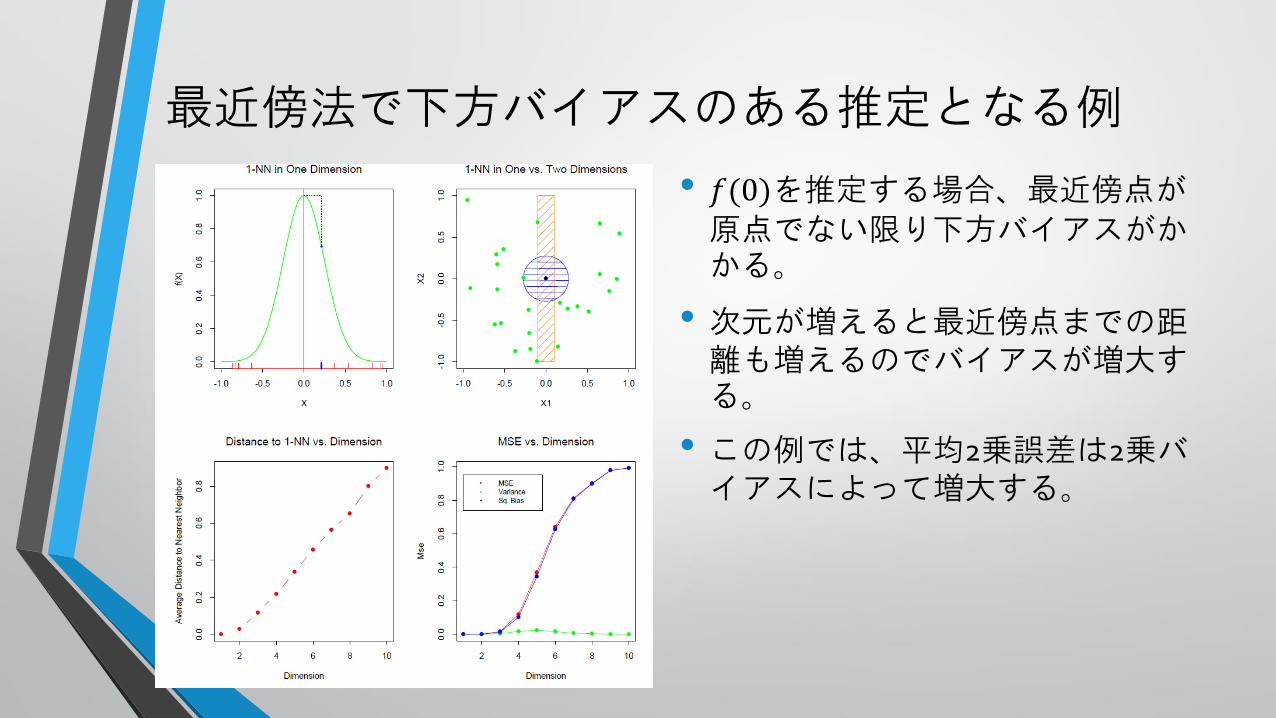
最近傍法で下方バイアスのある推定となる例
• 𝑓(0)を推定する場合、最近傍点が原点でない限り下方バイアスがかかる。
• 次元が増えると最近傍点までの距離も増えるのでバイアスが増大する。
• この例では、平均2乗誤差は2乗バイアスによって増大する。

2.6 統計モデル, 教師あり学習, 関数近似

2.6 統計モデル, 教師あり学習, 関数近似
• ここでの目的は、背後に潜む入出力関係f(x)の有用な近似を行うことである。
• 高次元に起因する問題を解決するためには、回帰関数f(x)の他のクラスの近似モデルを考えるのが有意義である。

2.6.1 同時分布Pr(X, Y)のための統計モデル
• ?

2.6.2 教師あり学習
• 機械学習の観点から関数当てはめの問題を説明しておく。
• 学習中のシステムの入力と出力の両方を観察し、それらを集めて観測値の訓練集合を構成する。
• 観測された𝑥𝑖を人工システムへ入力すると、その出力 𝑓(𝑥𝑖)を得る。
• 真のシステムによる出力𝑦𝑖と人工システムによる出力 𝑓(𝑥𝑖)の違いに応じて入出力関係 𝑓を修正していく。(例による学習)
• 学習プロセスを終えた段階では、真のシステムと人工システムの出力が十分に近いことが期待される。
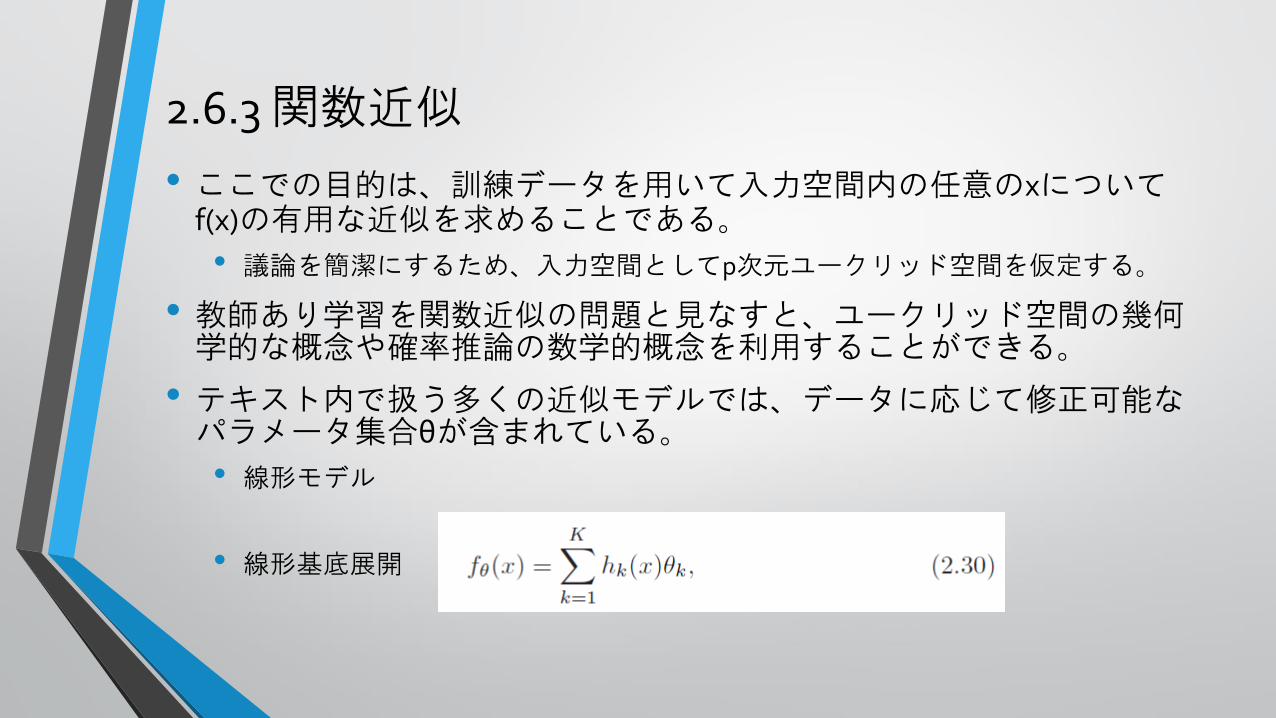
2.6.3 関数近似
• ここでの目的は、訓練データを用いて入力空間内の任意のxについてf(x)の有用な近似を求めることである。
• 議論を簡潔にするため、入力空間としてp次元ユークリッド空間を仮定する。
• 教師あり学習を関数近似の問題と見なすと、ユークリッド空間の幾何学的な概念や確率推論の数学的概念を利用することができる。
• テキスト内で扱う多くの近似モデルでは、データに応じて修正可能なパラメータ集合θが含まれている。
• 線形モデル
• 線形基底展開

パラメータの推定
• 線形基底関数のパラメータθを推定するには、線形モデルの場合と同様、最小2乗法を用いて残差2乗和
を最小化すればよい。
2入力の関数に最小2乗法で関数を当てはめた例

2.7 構造化回帰モデル

2.7.1 なぜ問題が困難なのか
• 全ての訓練データ点を通るような関数は無数に存在する。• 残差2乗和は最小化されるが、汎化性能が低い。
• データ数が有限の場合、解となる関数の集合を限定し、残差2乗和の解を制限して考える必要がある。
• 学習に用いられる制約は、さまざまな形式の複雑度(complexity)として表現されることが多い。
• 複雑度とは、入力空間内の小さな近傍領域内でのある種の規則性である。
• 制約の強さは近傍の大きさによって決まる。• 制約の性質は入力空間の計量に依存する。

2.8 制限付き推定法

2.8 制限付き推定法
• ノンパラメトリックな回帰や学習のためには、さまざまな方法が存在する。
• 本節では概要を述べるに留め、詳しくは以降の章で解説する。
• ここでは、三つの代表的なクラスを紹介する。• 粗度に対する罰則とベイズ法
• カーネル法と局所回帰
• 基底関数と辞書による方法

2.8.1 粗度に対する罰則とベイズ法
• このクラスの方法では、残差2乗和 RSS(f) に粗度に対する罰則を加え
を最小化することで関数のクラスを制限する。
• ユーザーが指定する汎関数 J(f) は、関数fが入力空間の小さな領域で急激に変化する場合に大きな値をとる。
• 罰則関数や正則化(regularization)を用いると、推定対象の関数にある特定の滑らかさを持たせることができる。
• 粗度に関する罰則を用いたアプローチ⇒第5章
• ベイズ的な枠組み⇒第8章

2.8.2 カーネル法と局所回帰
• このクラスの方法では、局所的な近傍をどのように決めるか、どのような関数を局所的に当てはめるか、といった事項を直接指定し、回帰関数や条件付き期待値を明示的に推定する。
• 局所的な近傍はカーネル関数(kernel function)を用いて定義される。
• 例えば、ガウスカーネル
• 当然、高次元データに用いる際には、次元の呪いを避けるための工夫が必要⇒第6章

2.8.3 基底関数と辞書による方法
• このクラスのモデルは基底関数(basis function)を線形展開した
の形式で表される。
• ⇒ 5.2節および第9章のCARTモデルやMARSモデル
• 動径基底関数(radial basis function)
• ある特定の点を中心として対称的な広がりを持つp次元のカーネル
• ⇒推定については6.7節

2.8.3 基底関数と辞書による方法
• 出力層が線形の単層フィードフォワード・ニューラルネットワーク
• は活性化関数(activation function)として知られている
• ⇒詳細は第11章
• このような基底関数を用いる方法は、辞書による方法(dictionary method)として知られている。

2.9 モデル選択と, バイアスと分散のトレードオフ

モデルに含まれるパラメータ
• 多くのモデルが、平滑化パラメータ(smoothing parameter)や複雑度パラメータ(complexity parameter)を有している。
• これらのパラメータはユーザーが指定するもので• 罰則項の乗数
• カーネルの幅
• 基底関数の数
などの形でモデルに含まれている。
• これらパラメータを決めるために訓練データの残差2乗和を使うと残差が0になり過学習を起こす。

バイアスと分散のトレードオフ
• 𝑥0における期待予測誤差は
と分解できる。
• 第2項(バイアス項)と第3項(分散)はユーザーが制御可能な項である。
• 両者はトレードオフの関係にある。
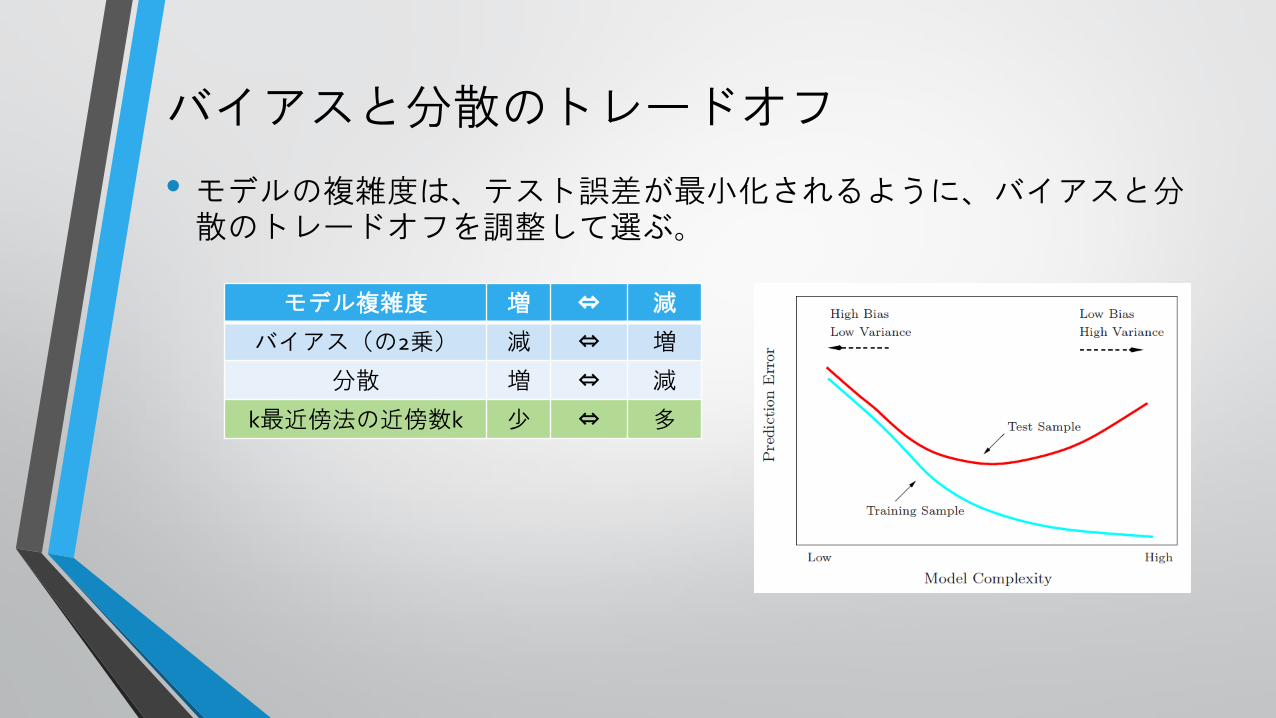
バイアスと分散のトレードオフ
モデル複雑度 増 ⇔ 減
バイアス(の2乗) 減 ⇔ 増
分散 増 ⇔ 減
k最近傍法の近傍数k 少 ⇔ 多
• モデルの複雑度は、テスト誤差が最小化されるように、バイアスと分散のトレードオフを調整して選ぶ。

ご清聴ありがとうございました。