基礎からのベイズ統計学 輪読会資料 第4章...
TRANSCRIPT

第4章 メトロポリス・ヘイスティングス法
基礎からのベイズ統計学 輪読会 第二回資料 2015/12/10 @kenmatsu4

こちらの本、
「基礎からのベイズ統計学」(豊田秀樹 著) の輪読会資料です!

MASAKARI Come On! щ(゜ロ゜щ)みんなで勉強しましょう!
https://twitter.com/_inundata/status/616658949761302528ご指摘は @kenmatsu4 まで

自己紹介: @kenmatsu4・Facebookページ https://www.facebook.com/matsukenbook ・Twitterアカウント @kenmatsu4 ・Qiitaでブログを書いています(統計、機械学習、Python等) http://qiita.com/kenmatsu4 (4600 contributionを超えました!)
・趣味 - バンドでベースを弾いたりしています。 - 主に東南アジアへバックパック旅行に行ったりします (カンボジア、ミャンマー、バングラデシュ、新疆ウイグル自治区 etc) 旅行の写真 : http://matsu-ken.jimdo.com
Twitterアイコン
Pythonタグで1位に なりました!(>∀<人)
http://goo.gl/yxNJgQ
http://goo.gl/JNPfv3
http://goo.gl/0Tqgrd

本発表の内容は対象の書籍を 発表者が読んで、解釈した内容を
もとに作成しています。 独自の解釈が入っている部分も ありますので、本スライドの内容 について著者の方に問い合わせ 等は行わないでください。

4.0 デモンストレーション
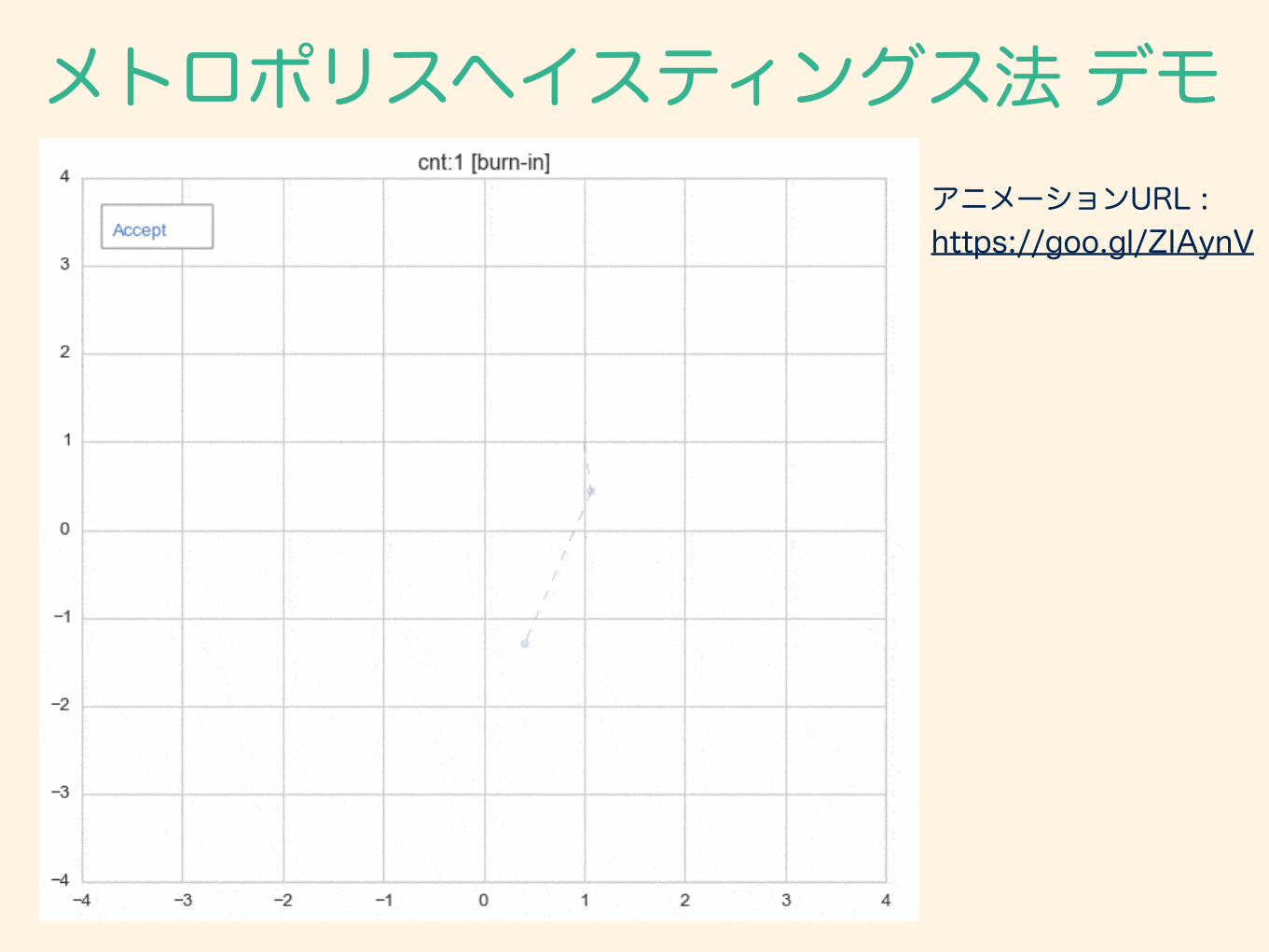
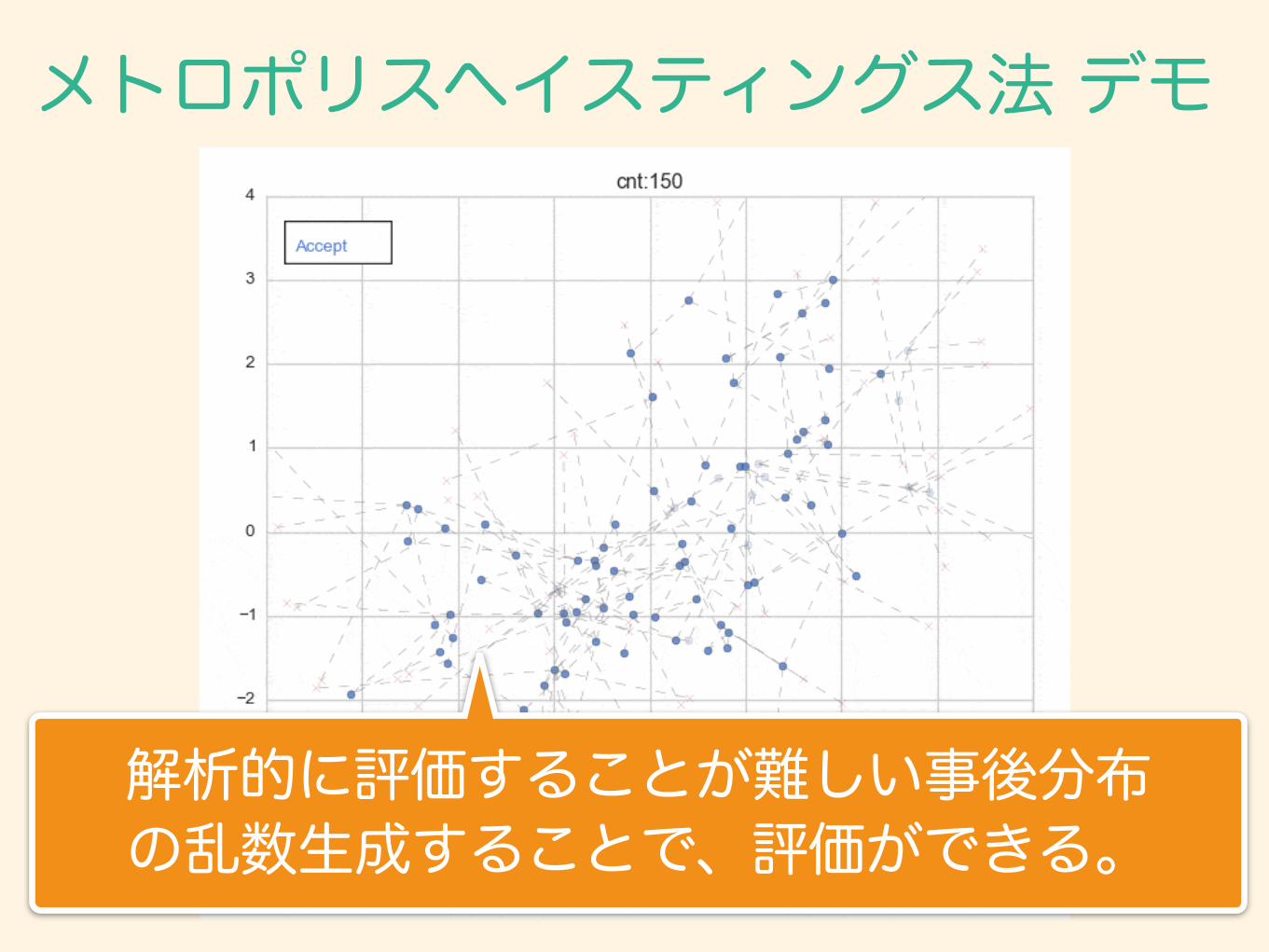
メトロポリスヘイスティングス法 デモ
解析的に評価することが難しい事後分布 の乱数生成することで、評価ができる。
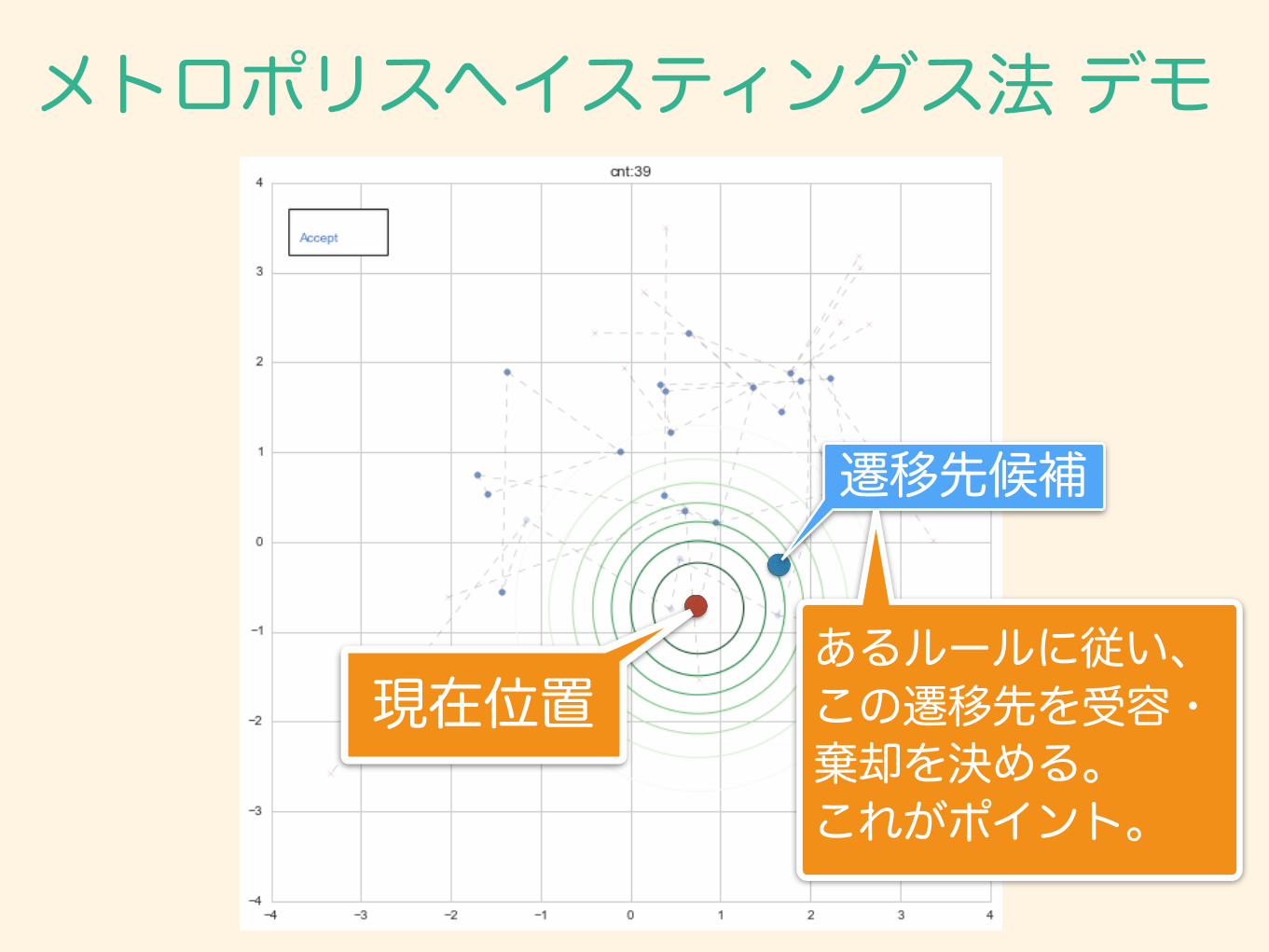
メトロポリスヘイスティングス法 デモ
遷移先候補
あるルールに従い、この遷移先を受容・ 棄却を決める。 これがポイント。
現在位置
こちらのシミュレーションのコードは
http://qiita.com/kenmatsu4/items/55e78cc7a5ae2756f9da
以降のデモンストレーションコードも GitHubに格納しています。
https://github.com/matsuken92/Qiita_Contents/blob/master/Bayes_chap_04/Bayes-stat_chapter04.ipynb

マルコフ連鎖モンテカルロ法
メトロポリス・ヘイスティングス法
本章で扱うもの
を解説します。

4.1事後分布からの乱数の発生
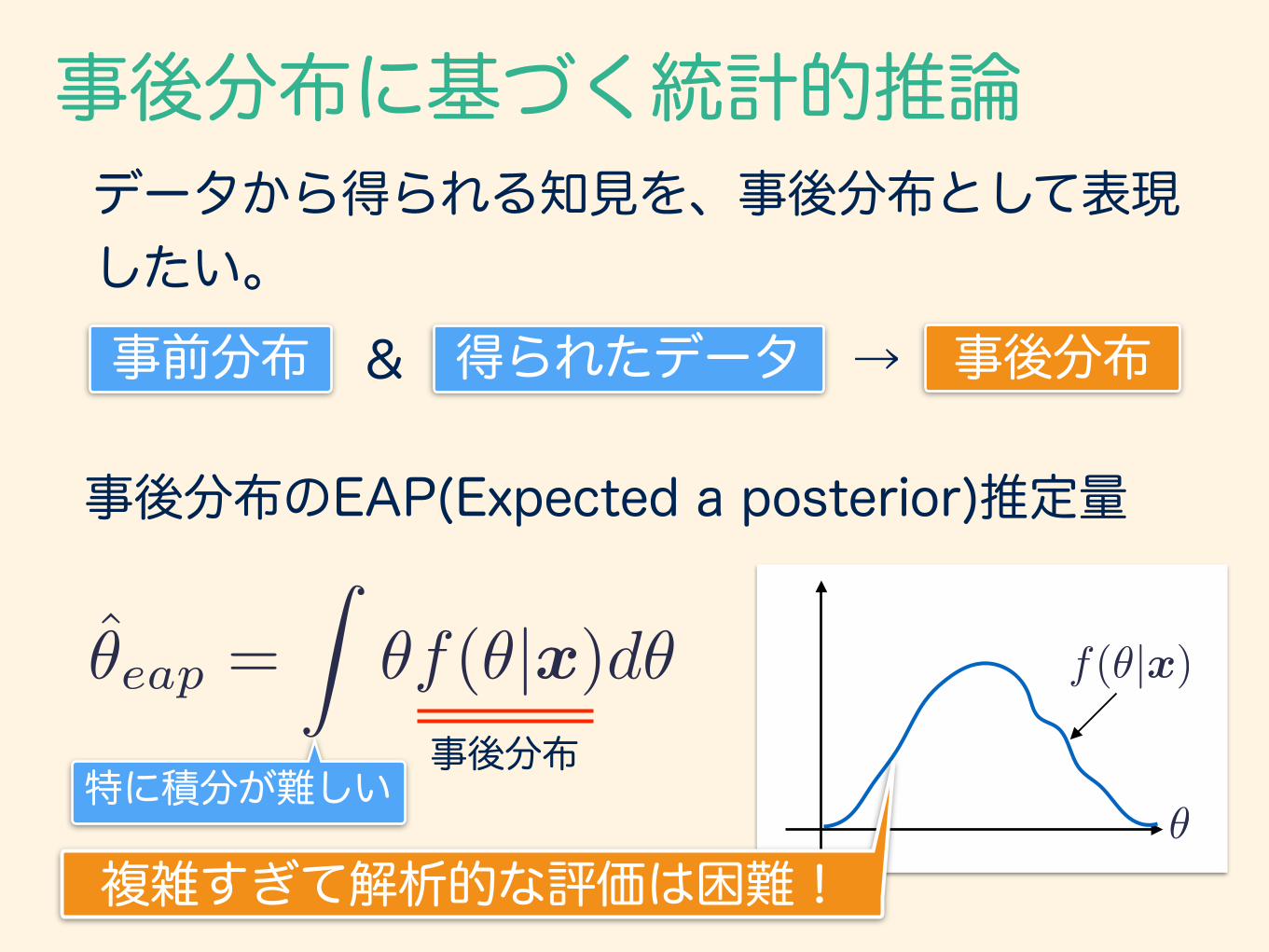
事後分布に基づく統計的推論
事後分布のEAP(Expected a posterior)推定量
✓̂eap =
Z✓f(✓|x)d✓
事後分布✓
f(✓|x)
データから得られる知見を、事後分布として表現したい。事前分布 & 得られたデータ → 事後分布
複雑すぎて解析的な評価は困難!
特に積分が難しい
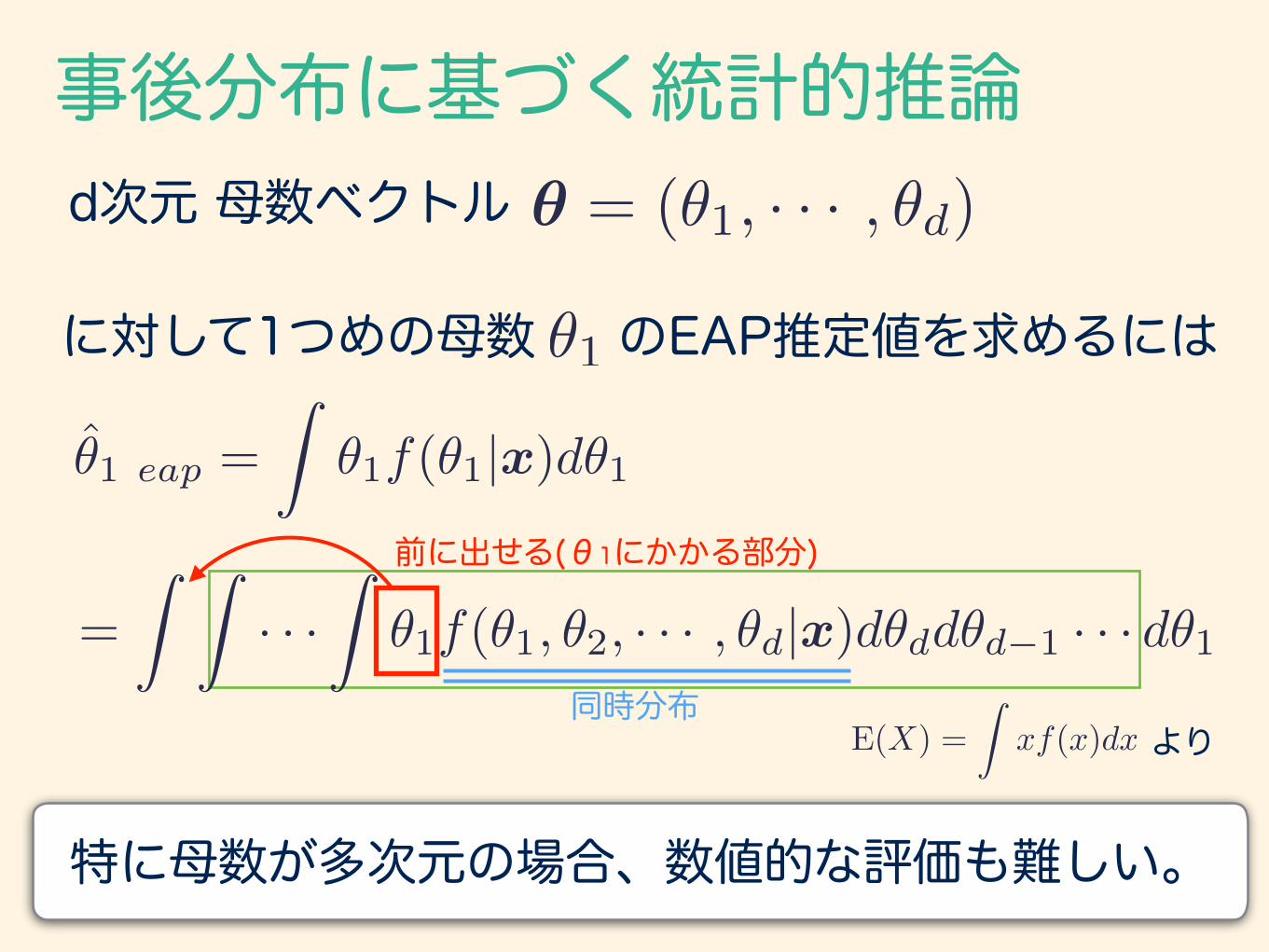
事後分布に基づく統計的推論✓ = (✓1, · · · , ✓d)d次元 母数ベクトル
に対して1つめの母数 のEAP推定値を求めるには✓1
✓̂1 eap =
Z✓1f(✓1|x)d✓1
=
Z Z· · ·
Z✓1f(✓1, ✓2, · · · , ✓d|x)d✓dd✓d�1 · · · d✓1前に出せる(θ1にかかる部分)
同時分布よりE(X) =
Zxf(x)dx
特に母数が多次元の場合、数値的な評価も難しい。

事後分布に基づく統計的推論✓ = (✓1, · · · , ✓d)d次元 母数ベクトル
に対して1つめの母数 のEAP推定値を求めるには✓1
✓̂1 eap =
Z✓1f(✓1|x)d✓1
=
Z Z· · ·
Z✓1f(✓1, ✓2, · · · , ✓d|x)d✓dd✓d�1 · · · d✓1前に出せる(θ1にかかる部分)
同時分布よりE(X) =
Zxf(x)dx
特に母数が多次元の場合、数値的な評価も難しい。
解析的、数値計算的な評価が難しいが、 この分布に基づく乱数を生成できれば
それを観察して評価をできるかもしれない。
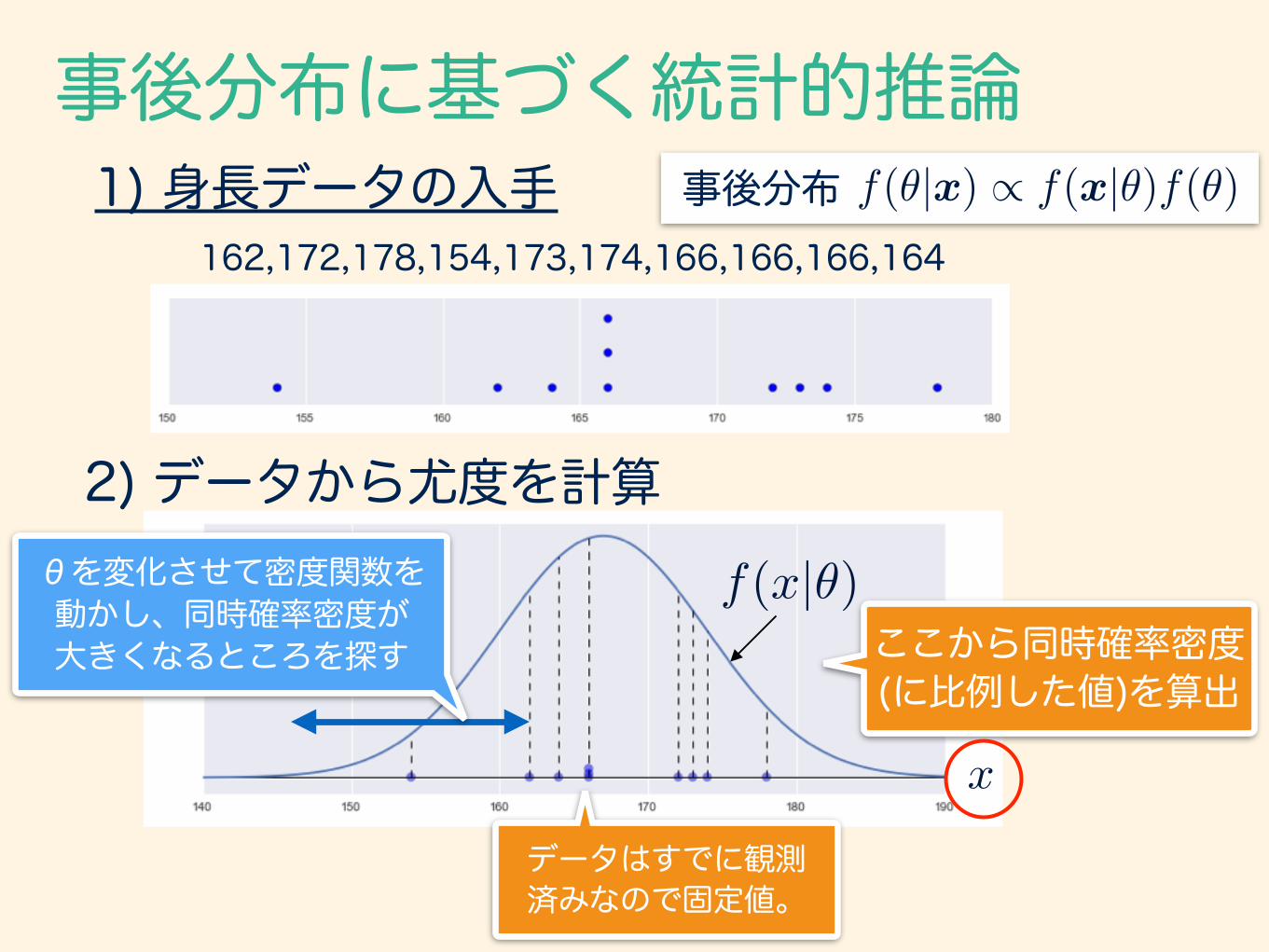
162,172,178,154,173,174,166,166,166,164
事後分布に基づく統計的推論1) 身長データの入手
2) データから尤度を計算
ここから同時確率密度 (に比例した値)を算出
x
f(x|✓)
f(✓|x) / f(x|✓)f(✓)事後分布
θを変化させて密度関数を動かし、同時確率密度が 大きくなるところを探す
データはすでに観測 済みなので固定値。
3) 尤度とθの事前分布を用いて、ベイズの定理に よる事後確率を計算する。
事後分布に基づく統計的推論
✓
f(✓|x)
事後分布に基づく統計的推論
✓
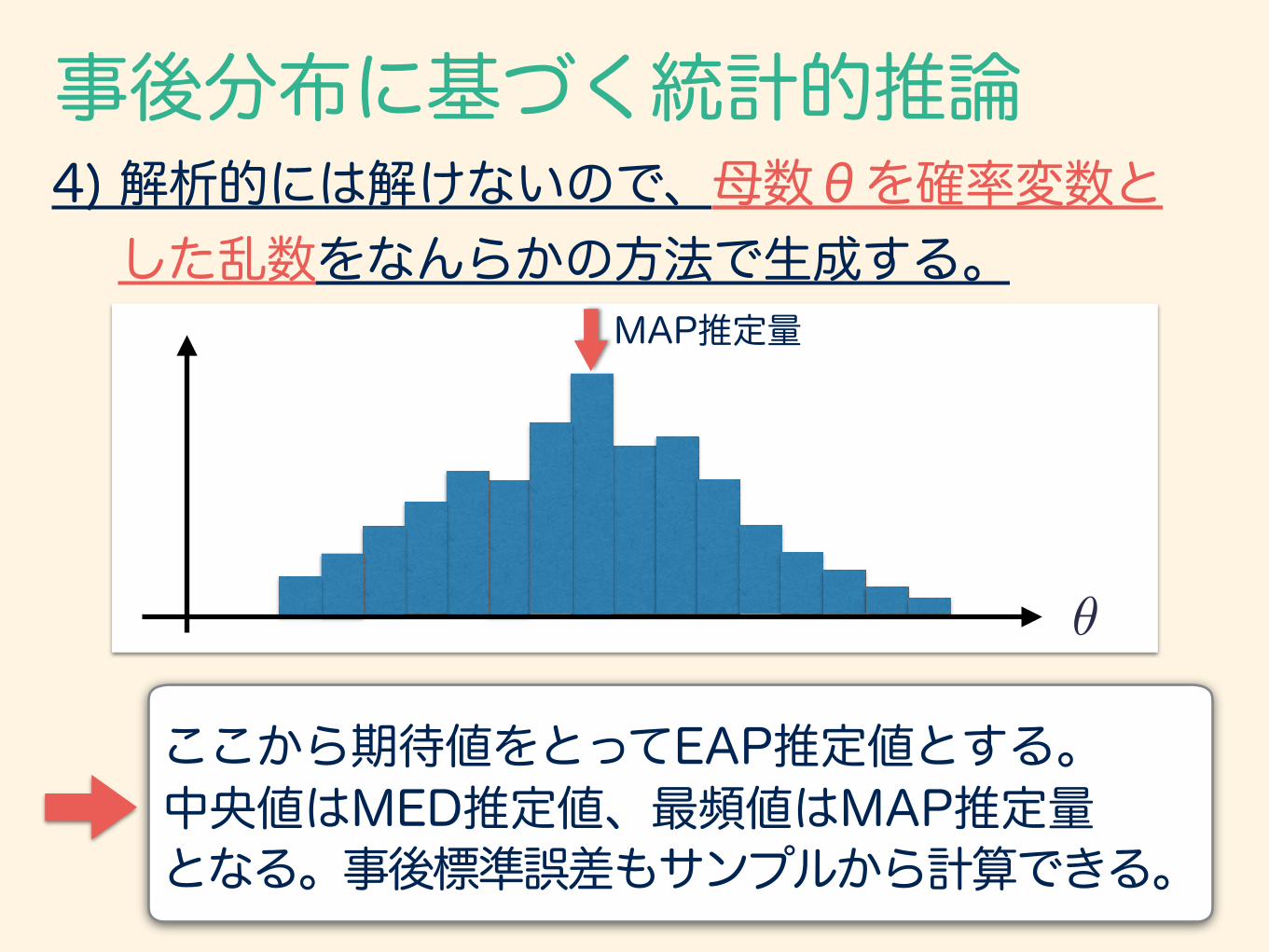
4) 解析的には解けないので、母数θを確率変数と した乱数をなんらかの方法で生成する。
ここから期待値をとってEAP推定値とする。 中央値はMED推定値、最頻値はMAP推定量 となる。事後標準誤差もサンプルから計算できる。
MAP推定量
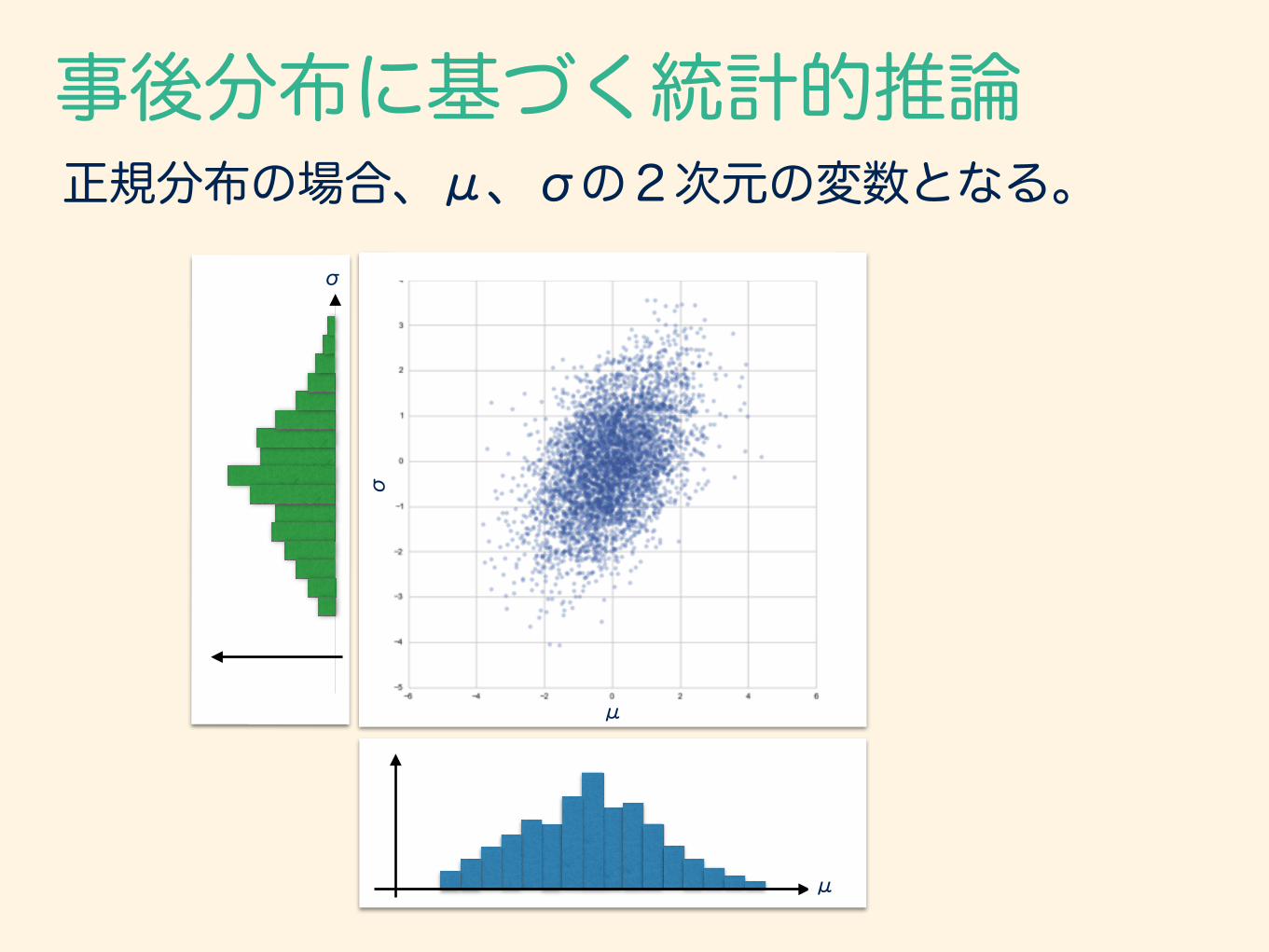
事後分布に基づく統計的推論正規分布の場合、μ、σの2次元の変数となる。
μ
σ
μ
σ

事後分布に基づく統計的推論
ただし、少し前で話があった「なんらかの方法で事後分布に基づく乱数を発生させる」ということが難しい。 「パラメーターが確率変数として扱われる乱数生成」 というものは、通常のライブラリ等には実装されてい ない。
課題1
課題2
正規化定数(積分して1にするための定数)が、高次元の積分のため評価できない。

事後分布に基づく統計的推論
ただし、少し前で話があった「なんらかの方法で事後分布に基づく乱数を発生させる」ということが難しい。 「パラメーターが確率変数として扱われる乱数生成」 というものは、通常のライブラリ等には実装されてい ない。
課題1
課題2
正規化定数(積分して1にするための定数)が、高次元の積分のため評価できない。
事後分布に基づく乱数が発生できる ような方法について次節以降で解説する。
正規化定数を必要としない方法について 次節以降で解説する。

4.2 マルコフ連鎖
猫ちゃんの遷移
https://github.com/topazS50/intro_hmc/blob/master/intro_hmc_2015_11.pdf
部屋A 部屋B
部屋C元ネタ:
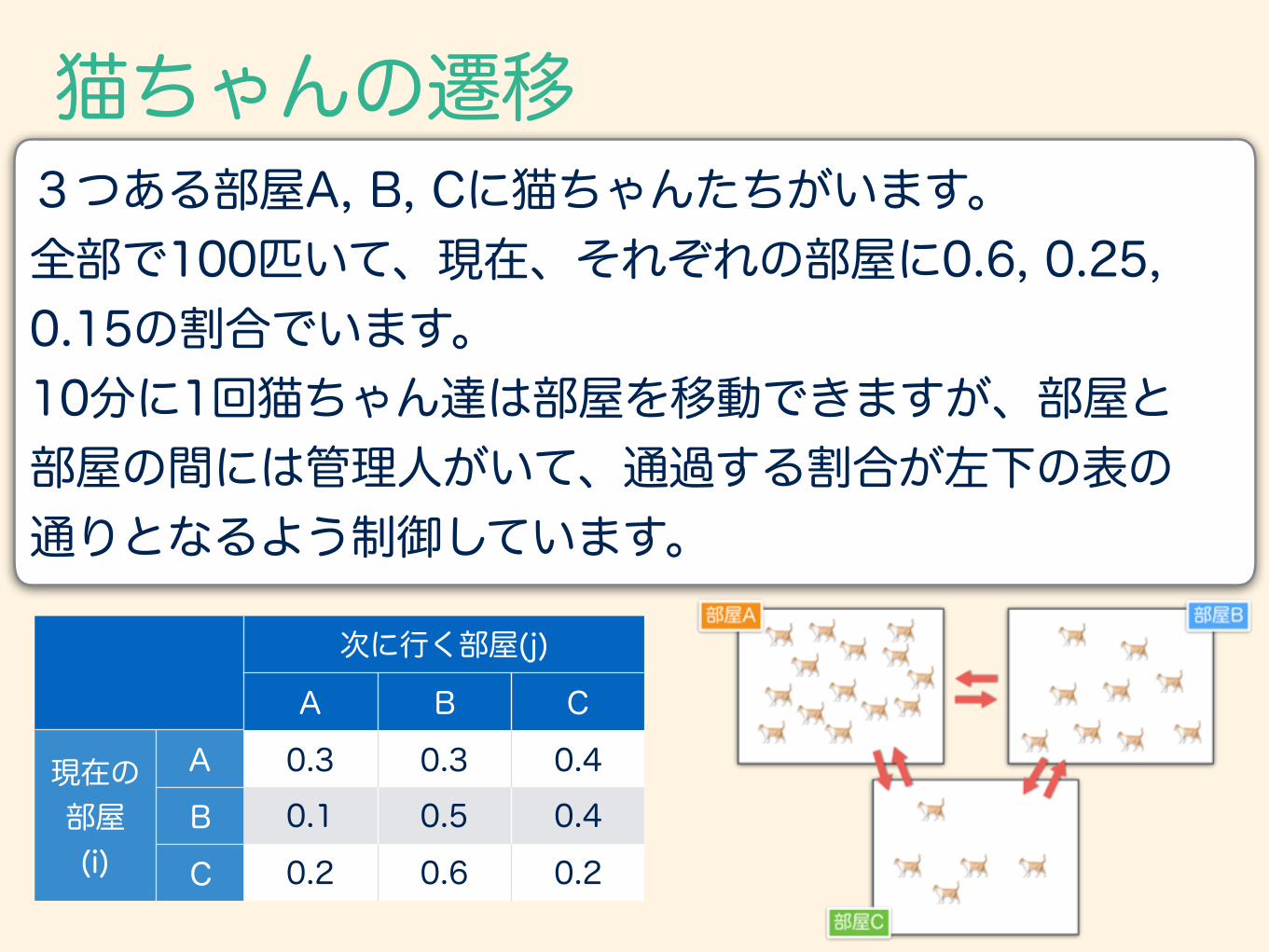
3つある部屋A, B, Cに猫ちゃんたちがいます。 全部で100匹いて、現在、それぞれの部屋に0.6, 0.25, 0.15の割合でいます。 10分に1回猫ちゃん達は部屋を移動できますが、部屋と 部屋の間には管理人がいて、通過する割合が左下の表の 通りとなるよう制御しています。
次に行く部屋(j)
A B C
現在の部屋 (i)
A 0.3 0.3 0.4B 0.1 0.5 0.4
C 0.2 0.6 0.2
猫ちゃんの遷移
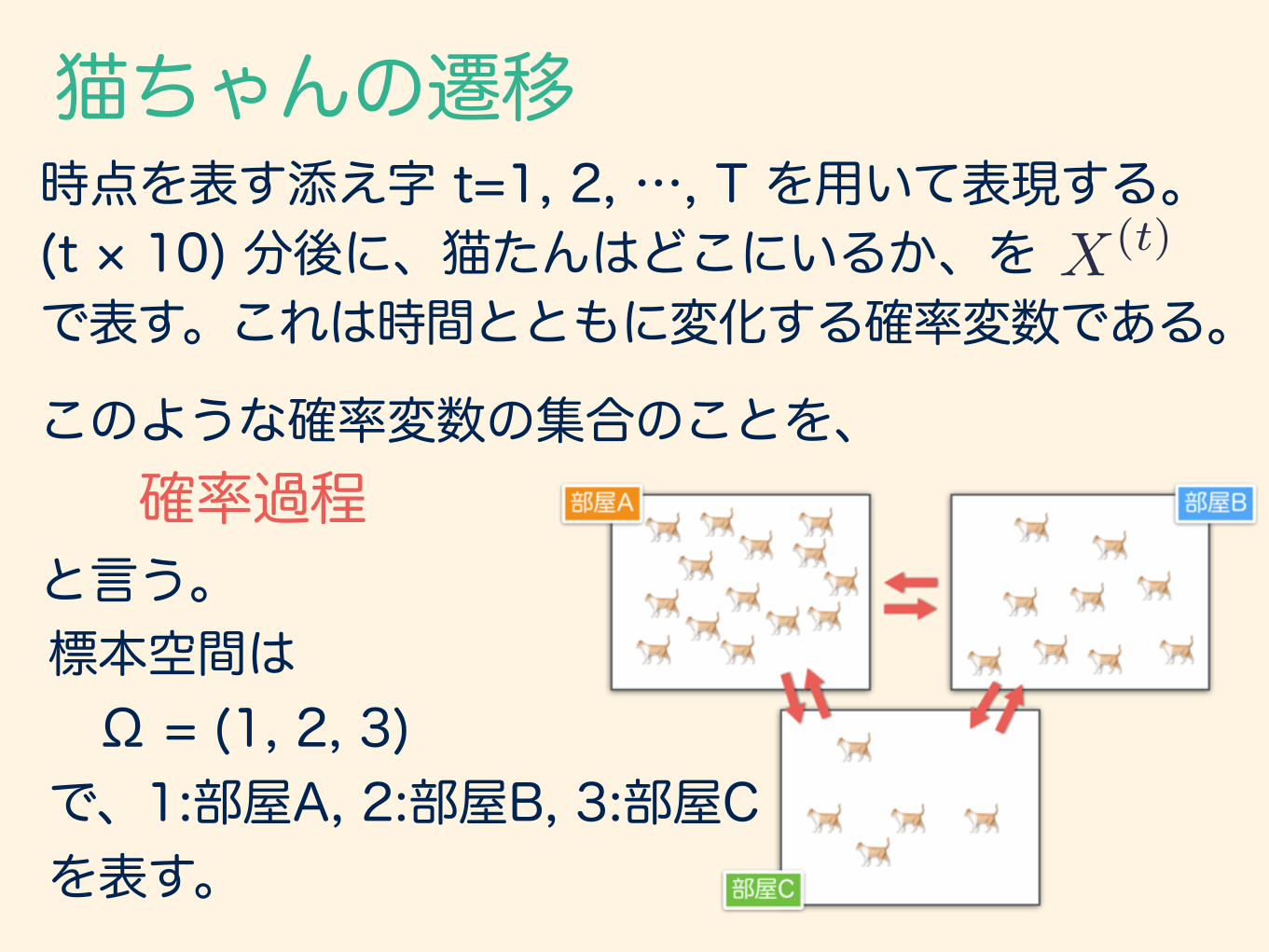
時点を表す添え字 t=1, 2, …, T を用いて表現する。 (t × 10) 分後に、猫たんはどこにいるか、を で表す。これは時間とともに変化する確率変数である。
このような確率変数の集合のことを、 確率過程 と言う。
猫ちゃんの遷移
標本空間は Ω = (1, 2, 3) で、1:部屋A, 2:部屋B, 3:部屋Cを表す。
X(t)

猫ちゃんの遷移一般に、時刻t における確率過程 はそれ以前の 値、 に依存して決定 され、その確率は
X(t)
X(t�1), X(t�2), · · · , X(1)
※確率過程とは、共通の確率モデル上で定義される乱数の無限集合である。これらの確率変数は通常、よく時間と解釈される整数、もしくは実数によってインデックスされている。
“STOCHASTIC PROCESSES: Theory for Applications” R. G. Gallager http://www.rle.mit.edu/rgallager/documents/6.262lateweb1.pdf
p(X(t)|X(t�1), X(t�2), · · · , X(1))
と、過去の確率変数の条件付き確率として表記される。
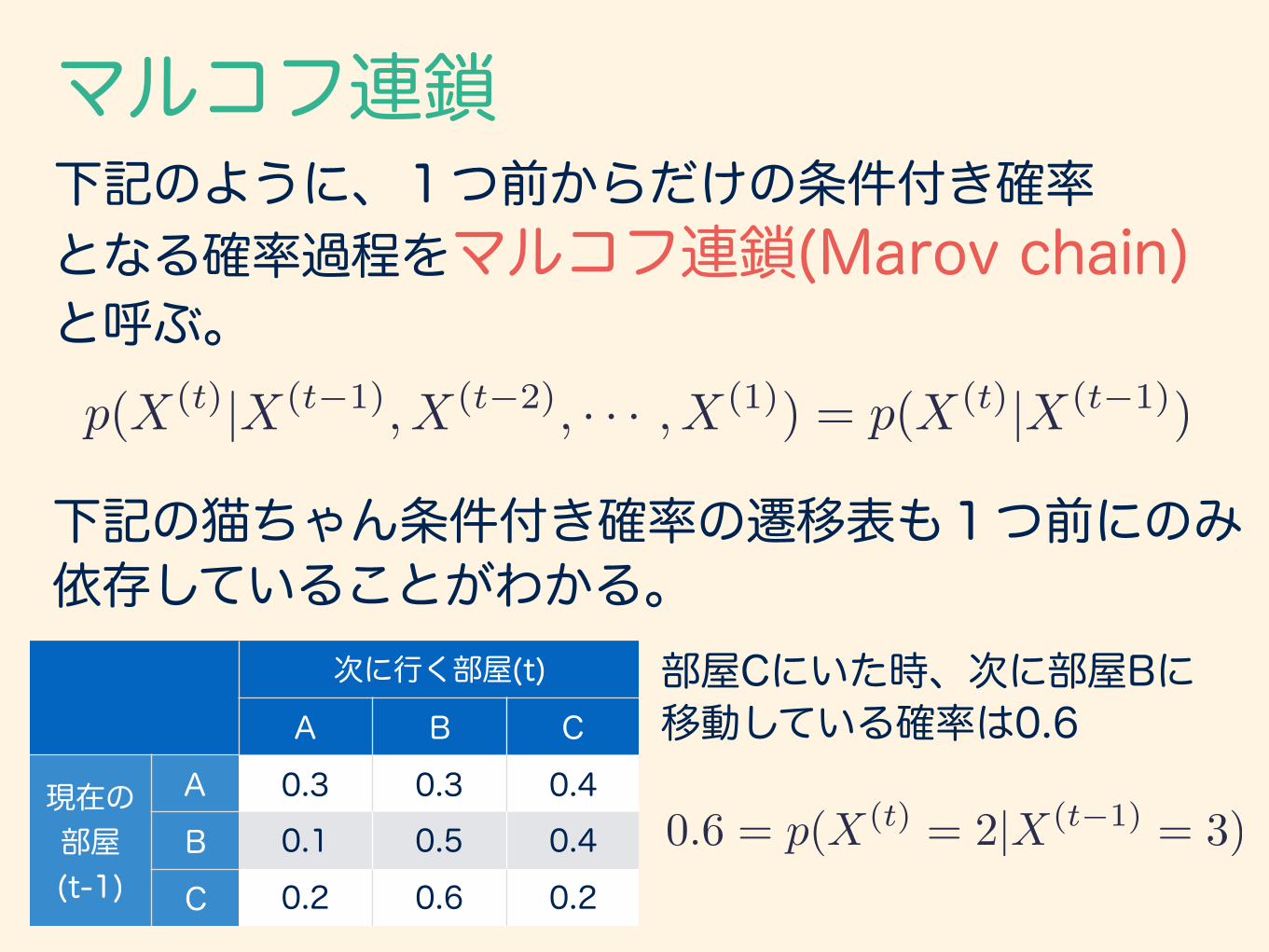
マルコフ連鎖下記のように、1つ前からだけの条件付き確率 となる確率過程をマルコフ連鎖(Marov chain) と呼ぶ。p(X(t)|X(t�1), X(t�2), · · · , X(1)) = p(X(t)|X(t�1))
次に行く部屋(t)
A B C
現在の部屋 (t-1)
A 0.3 0.3 0.4B 0.1 0.5 0.4
C 0.2 0.6 0.2
下記の猫ちゃん条件付き確率の遷移表も1つ前にのみ 依存していることがわかる。
0.6 = p(X(t) = 2|X(t�1) = 3)
部屋Cにいた時、次に部屋Bに 移動している確率は0.6
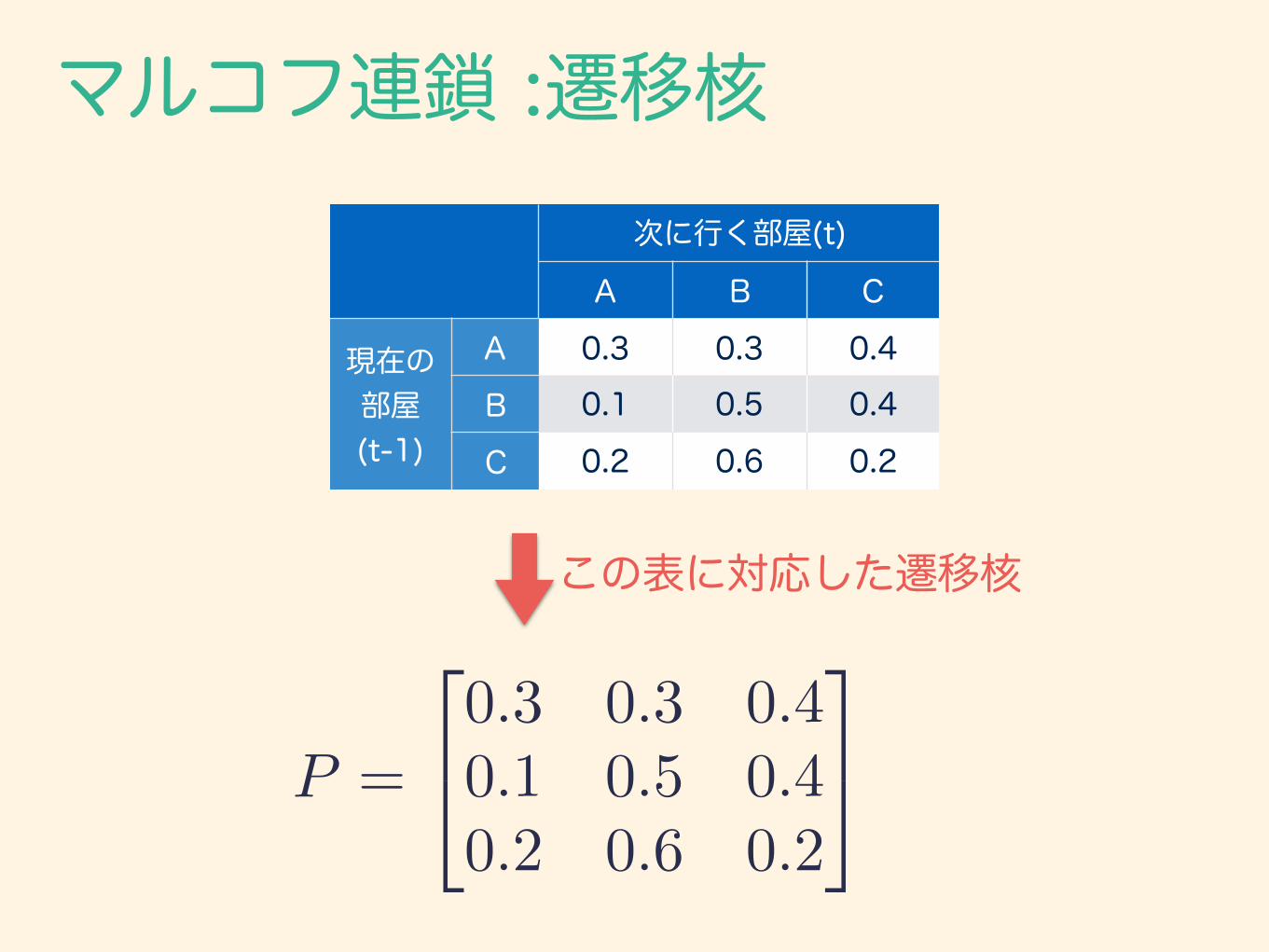
マルコフ連鎖 :遷移核
P =
2
40.3 0.3 0.40.1 0.5 0.40.2 0.6 0.2
3
5
この表に対応した遷移核
次に行く部屋(t)
A B C
現在の部屋 (t-1)
A 0.3 0.3 0.4B 0.1 0.5 0.4
C 0.2 0.6 0.2

4.3 定常分布への収束

定常分布への収束 の確率分布は とすると p(t)i = p(X(t) = i)X(t)
p(t) = (p(t)1 , p(t)1 , p(t)1 )
であり、初期状態 の確率分布はX(1)
p(1) = (0.6, 0.25, 0.15)
このとき、10分後(次の状態)の猫ちゃんの分布は
p(2) = p(1)
2
40.3 0.3 0.40.1 0.5 0.40.2 0.6 0.2
3
5 = (0.6, 0.25, 0.15)
2
40.3 0.3 0.40.1 0.5 0.40.2 0.6 0.2
3
5部屋A 部屋B 部屋C
→ = 0.235p(2)1= (0.235, 0.395, 0.37)
1 13 3

の確率分布の要素は
定常分布への収束p(t)
p(X(t) = j) =3X
i=1
p(X(t) = j|X(t�1) = i)p(X(t�1) = i)
で計算できる。これを確率過程の遷移と言う。(4.11)

遷移核を何度も掛け合わせると、ある数値に収束する。 なので、猫ちゃんの分布も収束するはず。
A B C1 0.600000 0.250000 0.1500002 0.235000 0.395000 0.3700003 0.184000 0.490000 0.3260004 0.169400 0.495800 0.3348005 0.167360 0.499600 0.333046 0.166776 0.499832 0.3333927 0.166694 0.499984 0.3333228 0.166671 0.499993 0.3333369 0.166668 0.499999 0.333333
10 0.166667 0.500000 0.333333
P = [[0.3, 0.3, 0.4], [0.1, 0.5, 0.4], [0.2, 0.6, 0.2]]
def calc(x, l, num): tmp = copy.copy(x) for i in range(num): tmp = np.dot(tmp, P) l.append(tmp)
result = []init = [0.6, 0.25, 0.15]result.append(init)calc(x1, result, 10)print tabulate(np.array(result), ["A", "B", "C"], tablefmt="pipe")
定常分布への収束
教科書に、この最初の期間をバーンインとすると記載がありました がサンプリングでないときでも、バーンインと呼ぶのか、がわからず…
1/6 1/2 1/3

この、変化しなくなった確率分布 p を 当該マルコフ連鎖の定常分布(stationary distribution) という。
定常分布への収束
また、この挙動を定常分布への収束と言う。

初期状態が異なる3つのパターンでも、同じ状態に 収束している。
A B C A B C A B C1 0.600000 0.250000 0.150000 0.300000 0.300000 0.400000 0.100000 0.100000 0.800000
2 0.235000 0.395000 0.370000 0.235000 0.395000 0.370000 0.235000 0.395000 0.370000
3 0.184000 0.490000 0.326000 0.184000 0.490000 0.326000 0.184000 0.490000 0.326000
4 0.169400 0.495800 0.334800 0.169400 0.495800 0.334800 0.169400 0.495800 0.334800
5 0.167360 0.499600 0.333040 0.167360 0.499600 0.333040 0.167360 0.499600 0.333040
6 0.166776 0.499832 0.333392 0.166776 0.499832 0.333392 0.166776 0.499832 0.333392
7 0.166694 0.499984 0.333322 0.166694 0.499984 0.333322 0.166694 0.499984 0.333322
8 0.166671 0.499993 0.333336 0.166671 0.499993 0.333336 0.166671 0.499993 0.333336
9 0.166668 0.499999 0.333333 0.166668 0.499999 0.333333 0.166668 0.499999 0.333333
10 0.166667 0.500000 0.333333 0.166667 0.500000 0.333333 0.166667 0.500000 0.333333
定常分布への収束

マルコフ連鎖の収束条件条件1:既約的 (irreducible)有限回の推移で状態空間の要素すべてが互いに到達可能である性質。 ex) 部屋Cに入ってしまうと2度と部屋Aには入れない、ということが あるとこれを満たさなくなる。
条件2:正再帰的 (positive recurrent)状態空間の任意の要素は、限りなく何度も訪問される性質。 ex) ある時期以降、部屋Bには誰も入らなくなる、ということがあると これを満たさなくなる。
条件3:非周期的 (aperiodic)連鎖の状態が一定の周期を有していないと言う性質。 ex) 部屋Aの次は必ず部屋Bに行く、部屋Bの後は必ず部屋C、部屋Cの 後は必ず部屋Aであると周期的になってしまう。

マルコフ連鎖の収束条件3つの条件は、事後分布の乱数を発生させるようなデータ解析の実践場面ではほぼ満たされると考えて良い。 ただし、収束が保証されても、その収束にかかる時間が どのくらいかかるか は別問題。 (10億年かかるかも!?)

4.4 詳細釣り合い条件

詳細釣り合い条件
猫ちゃん問題は遷移核が既知で、定常分布が未知
取組む問題は遷移核が未知で、定常分布が既知
逆!
マルコフ連鎖が定常分布に収束するために、 詳細釣り合い条件を満たすことが、十分条件。
詳細釣り合い条件
サンプリングしたい分布 (今の場合事後分布)目標分布 (target distribution)
✓
f(✓|x)

マルコフ連鎖モンテカルロ法猫ちゃん問題は遷移核が明らかな状態であった。
事後分布が明らかで、それに従う乱数を入手本章の目標
事後分布が定常分布になるように遷移核を設計する
サンプリングしたい分布に対して、それを 定常分布とするマルコフ連鎖を構成する方法を
マルコフ連鎖モンテカルロ法 と総称する。
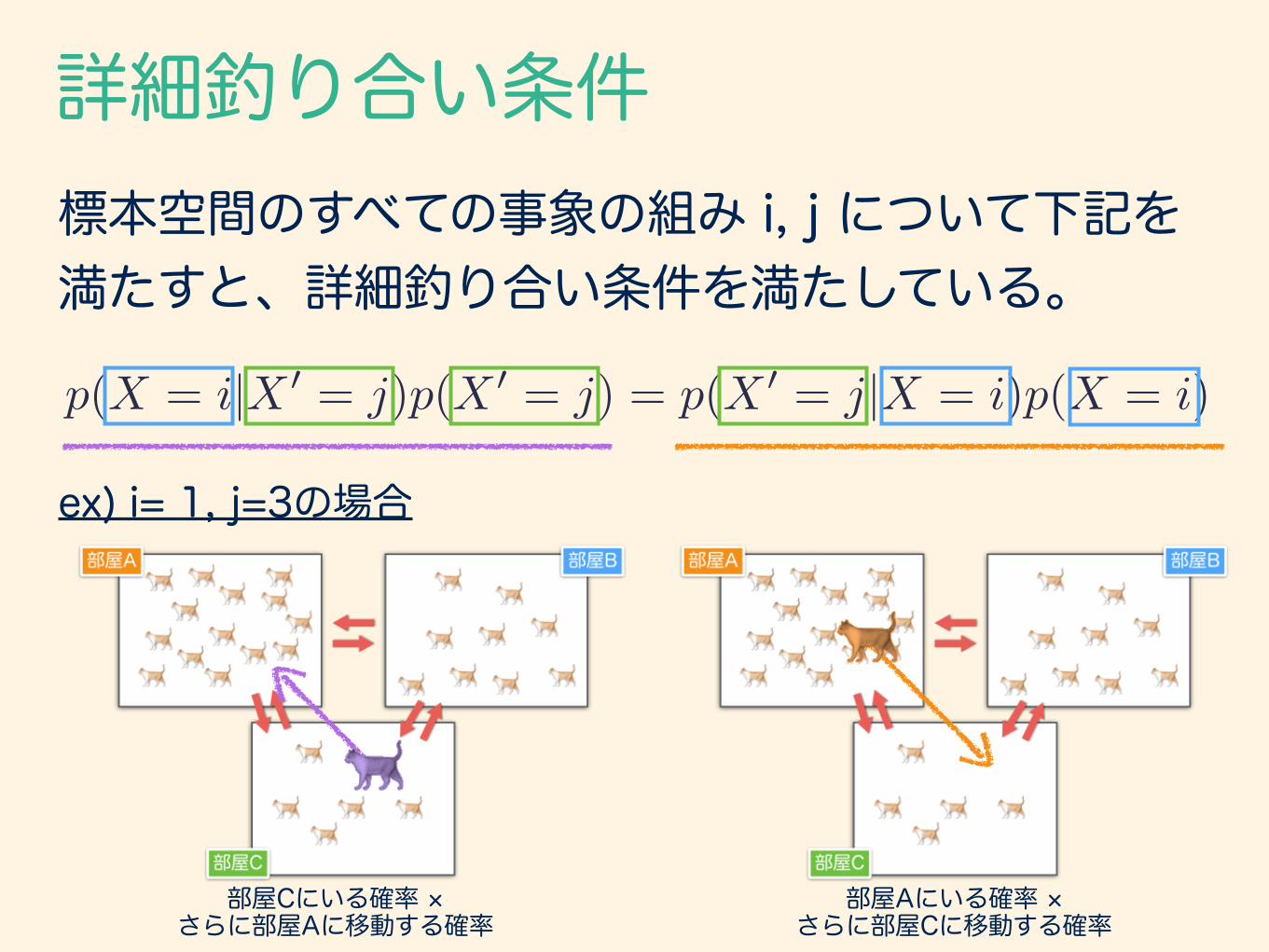
標本空間のすべての事象の組み i, j について下記を 満たすと、詳細釣り合い条件を満たしている。
詳細釣り合い条件
p(X = i|X 0 = j)p(X 0 = j) = p(X 0 = j|X = i)p(X = i)
ex) i= 1, j=3の場合
部屋Cにいる確率 × さらに部屋Aに移動する確率
部屋Aにいる確率 × さらに部屋Cに移動する確率

いま、定常分布が詳細釣り合い条件
✤ 部屋A : 1/6 ✤ 部屋B : 1/2 ✤ 部屋C : 1/3
であると分かっているので、具体的に遷移核(条件 付き確率)と照らし合わせて、
次に行く部屋(j)A B C
現在の部屋 (i)
A 0.3 0.3 0.4B 0.1 0.5 0.4C 0.2 0.6 0.2
遷移核
p(B|C)p(C) = p(C|B)p(B) ! 0.6⇥ 1/3 = 0.4⇥ 1/2
p(A|B)p(B) = p(B|A)p(A) ! 0.1⇥ 1/2 = 0.3⇥ 1/6
p(A|C)p(C) = p(C|A)p(A) ! 0.2⇥ 1/3 = 0.4⇥ 1/6
ちゃんと釣り合っている!

ただし、詳細釣り合い条件は、マルコフ連鎖が定常分布 に収束するための十分条件であり、必要条件ではない ということに注意。
詳細釣り合い条件
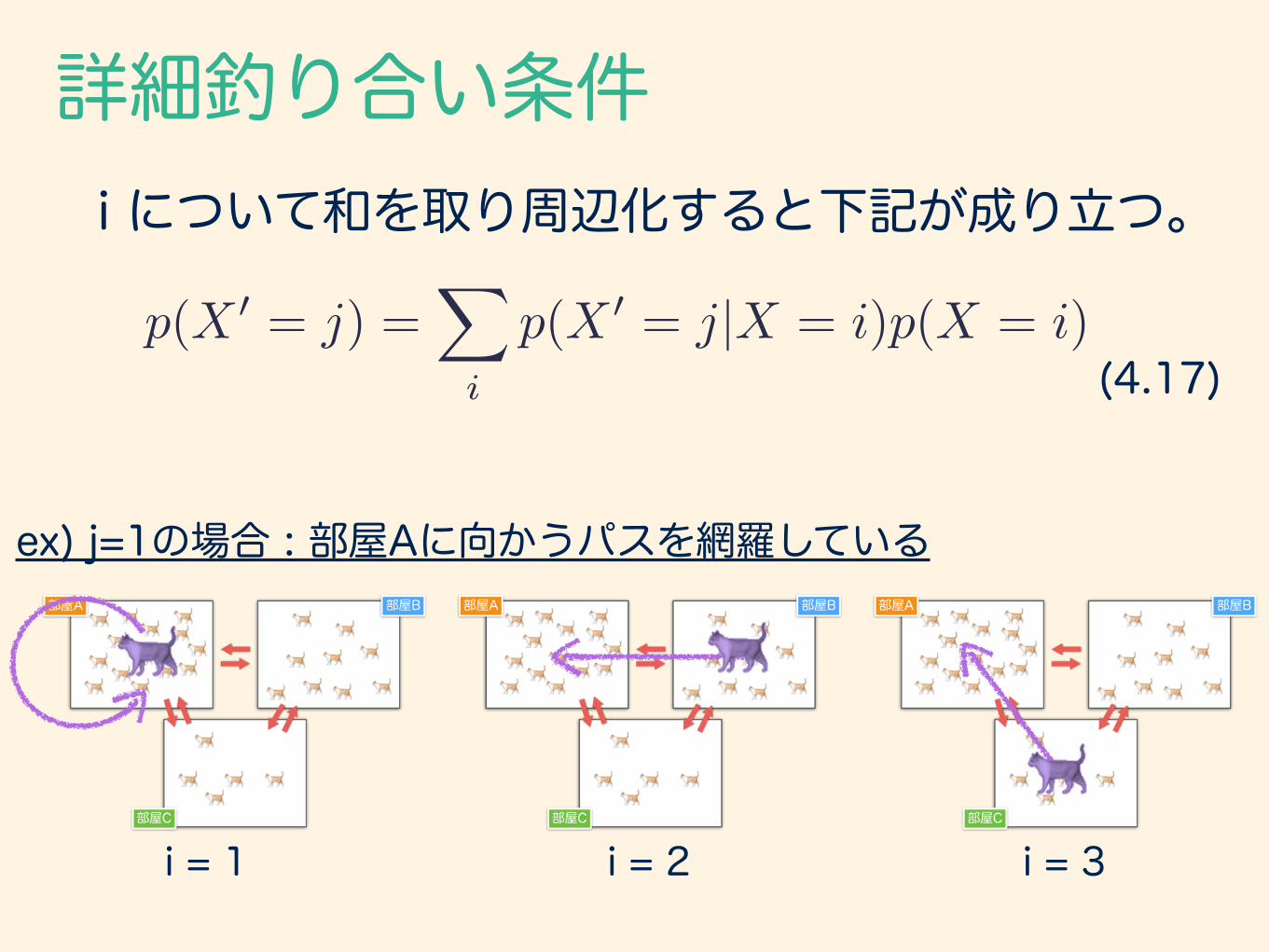
i について和を取り周辺化すると下記が成り立つ。
詳細釣り合い条件
p(X 0 = j) =X
i
p(X 0 = j|X = i)p(X = i)
ex) j=1の場合 : 部屋Aに向かうパスを網羅している
i = 1 i = 2 i = 3
(4.17)

(4.11)と(4.17)は同じ形をしているが、
詳細釣り合い条件
p(X(t) = j) =3X
i=1
p(X(t) = j|X(t�1) = i)p(X(t�1) = i)
(4.11)
p(X 0 = j) =X
i
p(X 0 = j|X = i)p(X = i)
(4.17)
恒等式
方程式なので、意味が違う。
詳細釣り合い条件とは、分布が変化しないよう に制約を入れた全確率の公式と考えられる。
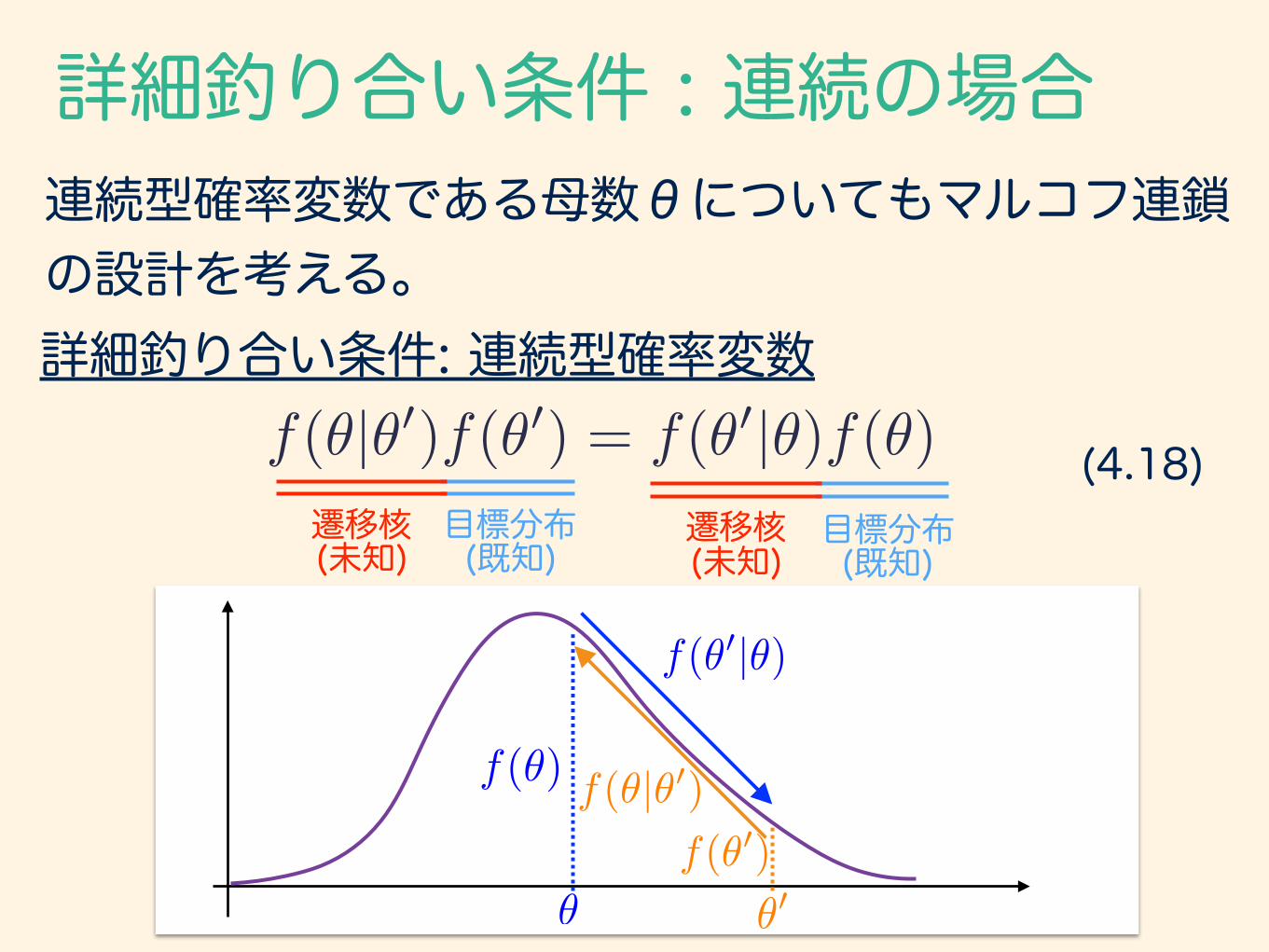
連続型確率変数である母数θについてもマルコフ連鎖 の設計を考える。
詳細釣り合い条件 : 連続の場合
詳細釣り合い条件: 連続型確率変数
f(✓)
✓
f(✓0|✓)
f(✓|✓0)f(✓0)
✓0
f(✓|✓0)f(✓0) = f(✓0|✓)f(✓) (4.18)目標分布 (既知)
遷移核 (未知)
遷移核 (未知)
目標分布 (既知)
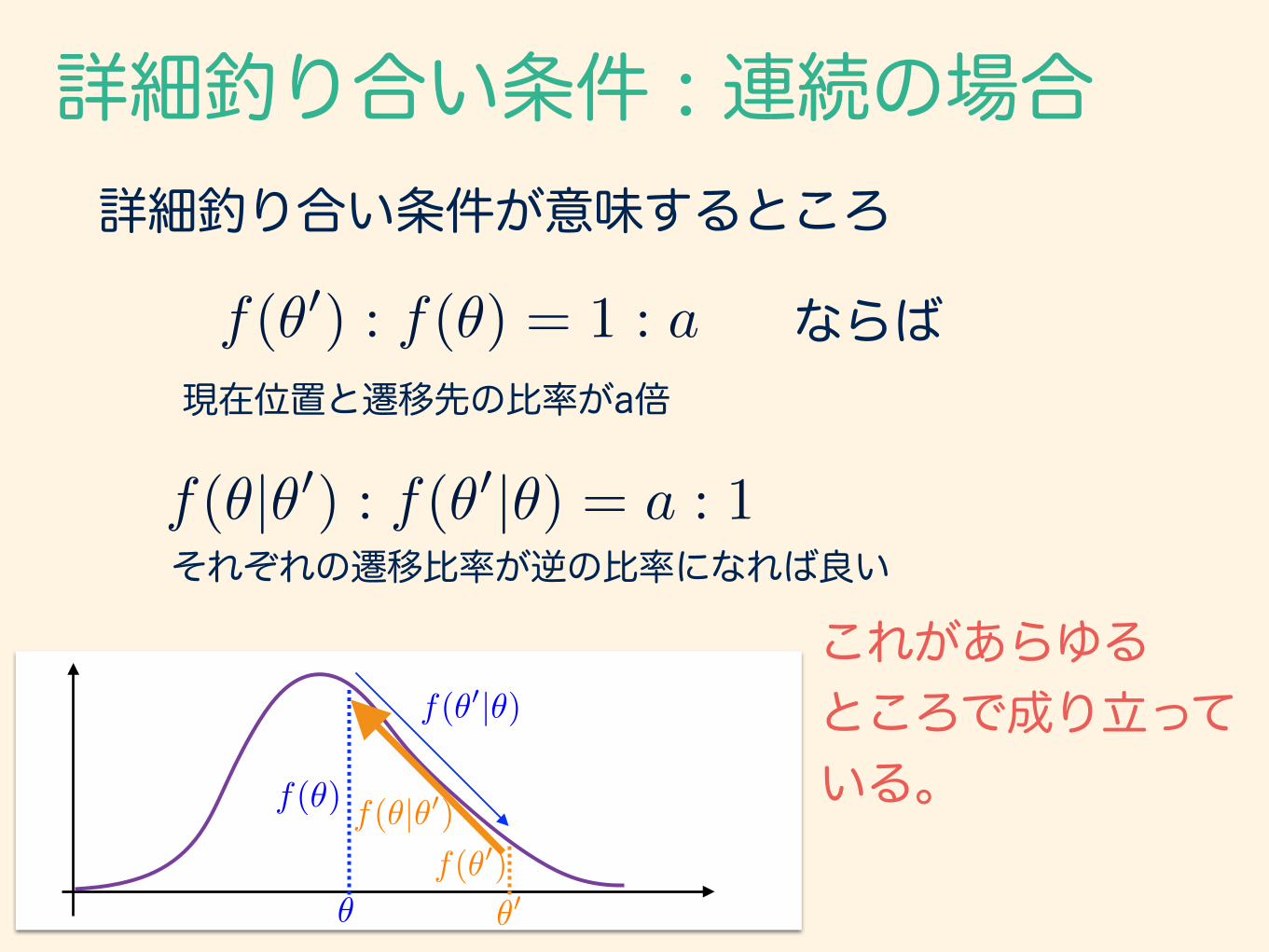
詳細釣り合い条件が意味するところ
詳細釣り合い条件 : 連続の場合
f(✓0) : f(✓) = 1 : a
f(✓|✓0) : f(✓0|✓) = a : 1
ならば現在位置と遷移先の比率がa倍
それぞれの遷移比率が逆の比率になれば良い
これがあらゆる ところで成り立って いる。f(✓)
✓
f(✓0|✓)
f(✓|✓0)f(✓0)
✓0
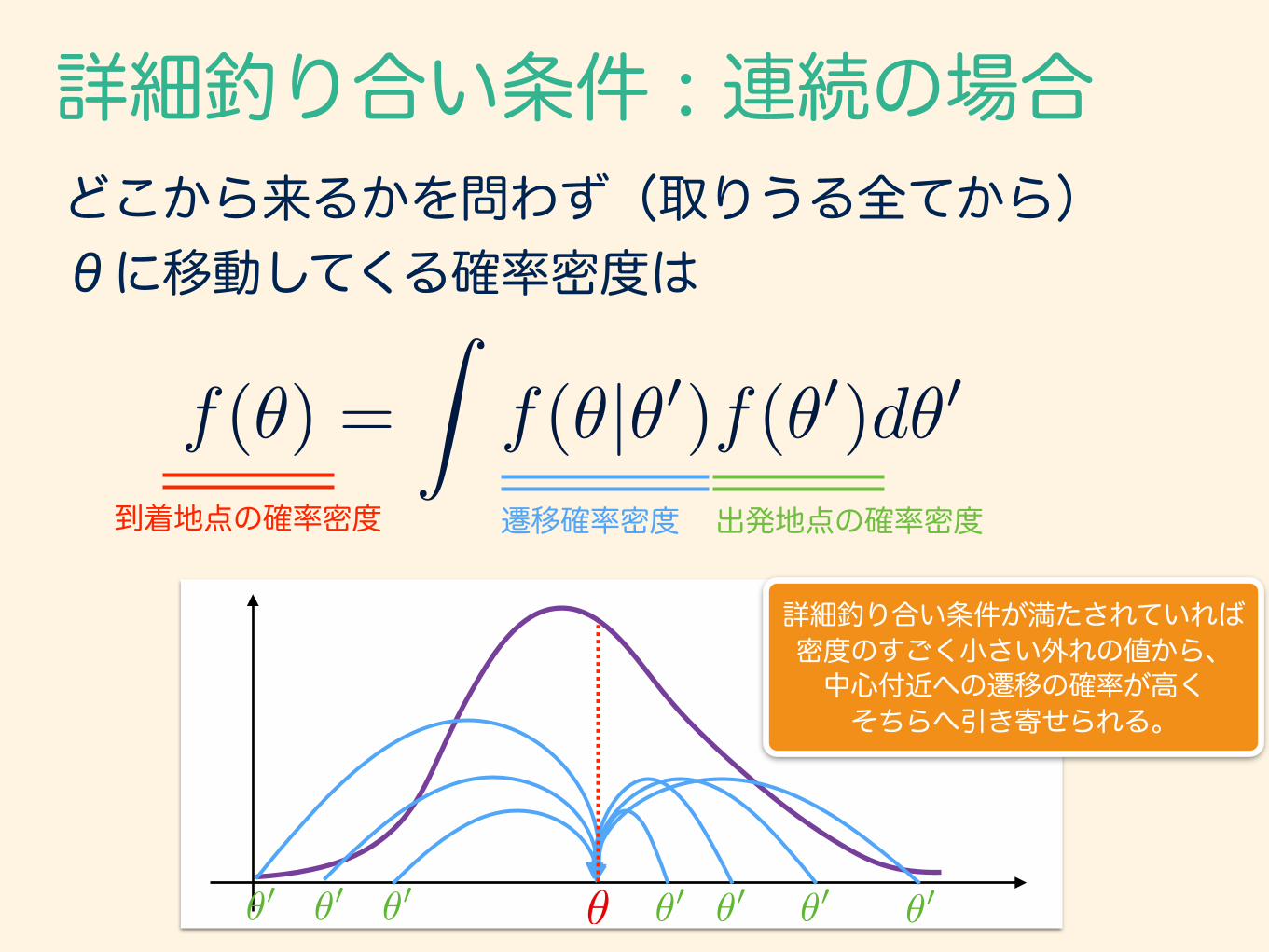
どこから来るかを問わず(取りうる全てから) θに移動してくる確率密度は
詳細釣り合い条件 : 連続の場合
f(✓) =
Zf(✓|✓0)f(✓0)d✓0
到着地点の確率密度 出発地点の確率密度遷移確率密度
✓0✓ ✓0✓0✓0✓0✓0✓0
詳細釣り合い条件が満たされていれば 密度のすごく小さい外れの値から、 中心付近への遷移の確率が高く そちらへ引き寄せられる。

4.5 メトロポリス・ ヘイスティングス法

の代わりに、適当な遷移核 を 提案分布(proposal distribution)として利用する。
※ と は違う関数であることに注意
遷移核 → 未知
メトロポリスヘイスティングス法目標分布 → 既知f(·)
f( | )
f(·) f( | )
という状況で、f(✓|✓0)f(✓0) = f(✓0|✓)f(✓) (4.18)
を満たす を探してくるのは難しい。f( | )
f( | ) q( | )
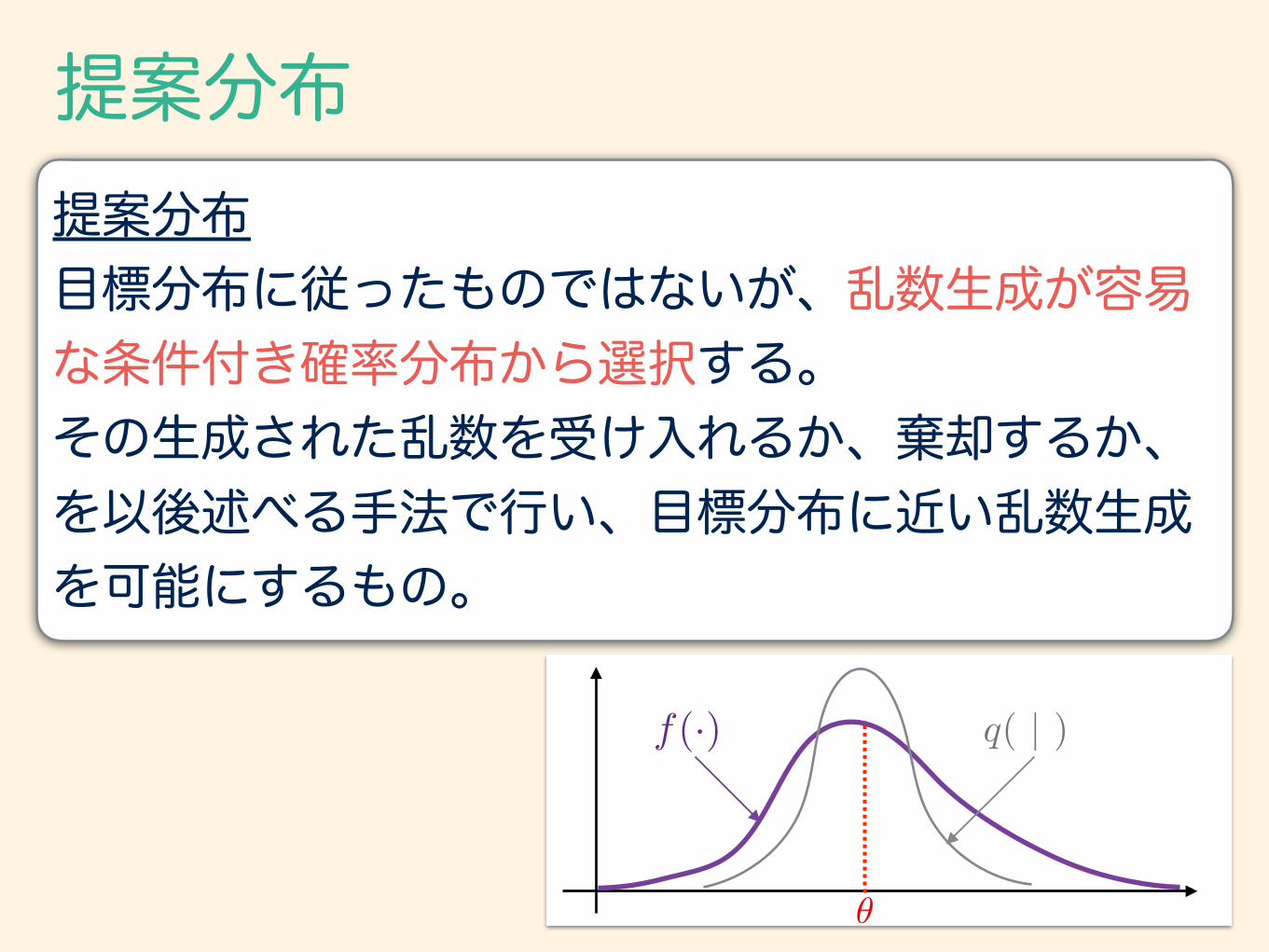
提案分布提案分布 目標分布に従ったものではないが、乱数生成が容易な条件付き確率分布から選択する。 その生成された乱数を受け入れるか、棄却するか、 を以後述べる手法で行い、目標分布に近い乱数生成 を可能にするもの。
✓
q( | )f(·)
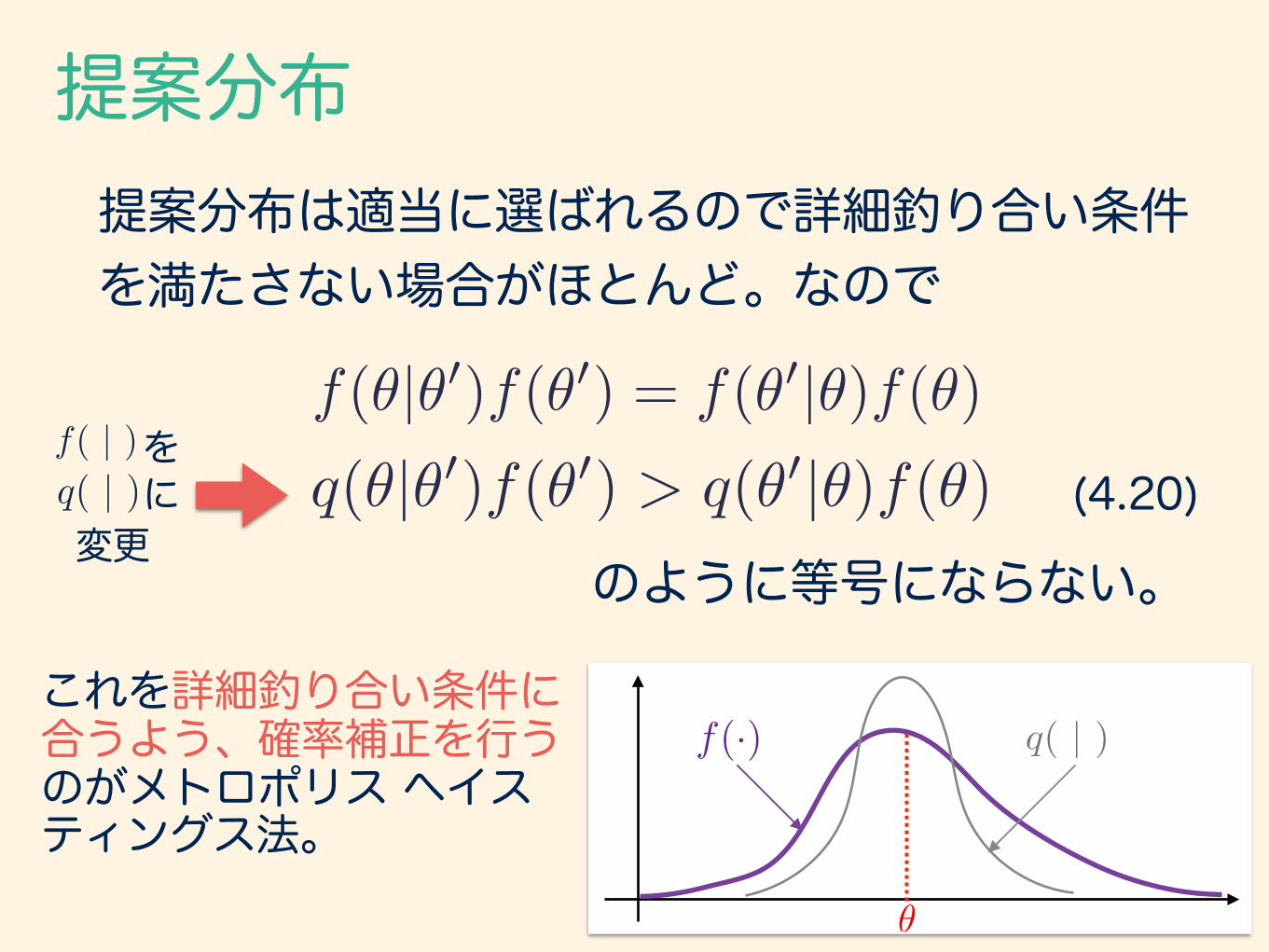
提案分布は適当に選ばれるので詳細釣り合い条件 を満たさない場合がほとんど。なので
提案分布
✓
q( | )f(·)
f(✓|✓0)f(✓0) = f(✓0|✓)f(✓)q(✓|✓0)f(✓0) > q(✓0|✓)f(✓)
f( | )q( | )
をに
変更のように等号にならない。
これを詳細釣り合い条件に合うよう、確率補正を行うのがメトロポリス ヘイスティングス法。
(4.20)
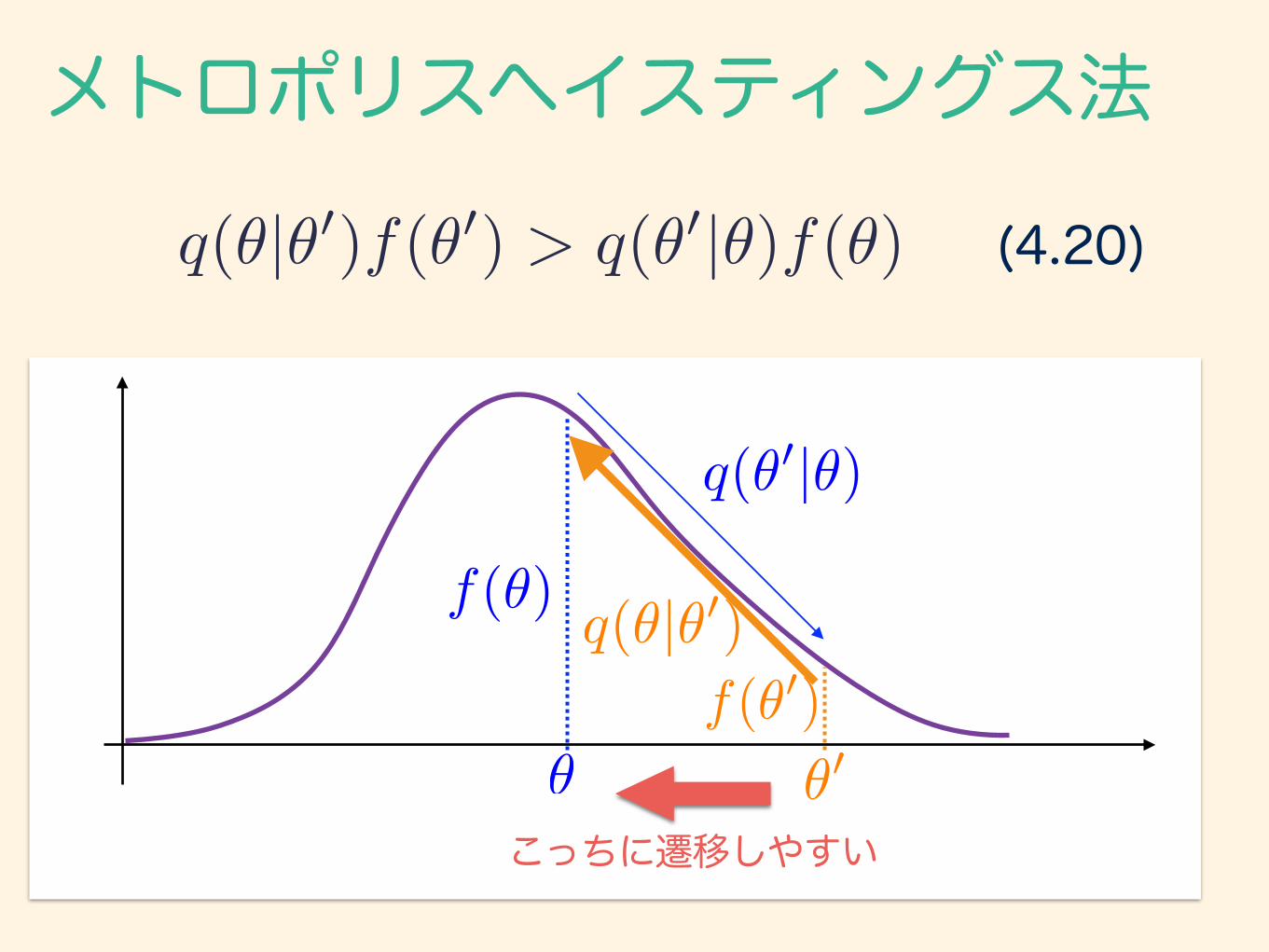
(4.20)q(✓|✓0)f(✓0) > q(✓0|✓)f(✓)
メトロポリスヘイスティングス法
f(✓)
✓f(✓0)
✓0
q(✓0|✓)
q(✓|✓0)
こっちに遷移しやすい

正しい遷移確率になるよう補正を行うため、符号が 正の未知の変数 c と c’ を導入し、
メトロポリスヘイスティングス法
f(✓|✓0) = c q(✓|✓0)f(✓0|✓) = c0 q(✓0|✓)
f(✓|✓0)f(✓0) = f(✓0|✓)f(✓)とする。
(4.18) に代入して
c q(✓|✓0)f(✓0) = c0 q(✓0|✓)f(✓) (4.23)
が得られ、提案分布で等号が成り立った。

ただし、問題が2つ残る。
メトロポリスヘイスティングス法
1つの方程式に、未知の変数がc, c’と2つある。問題1:
確率的補正を行う目的だが、補正の係数が0以上 1以下に収まっていない。
問題2:

2つの問題を同時に解く方法
メトロポリスヘイスティングス法
→ 両辺をc’で割り、c/c’で方程式を解く。
r =c
c0=
q(✓0|✓)f(✓)q(✓|✓0)f(✓0) (4.24)
また、r’ を下記のように定義する。
r0 =c0
c0= 1 (4.25)

(4.20) を変形すると
q(✓|✓0)f(✓0) > q(✓0|✓)f(✓)
メトロポリスヘイスティングス法
→ 1 >q(✓0|✓)f(✓)q(✓|✓0)f(✓0) = r
なので、 r < 1 が成り立つ。

まとめると、(4.24)より
メトロポリスヘイスティングス法
r = r0q(✓0|✓)f(✓)q(✓|✓0)f(✓0)
→ rq(✓|✓0)f(✓0) = r0q(✓0|✓)f(✓)目標分布遷移核目標分布遷移核
これで、詳細釣り合い条件を満たす遷移核が 出来たので、遷移が実現できる。
(4.26)
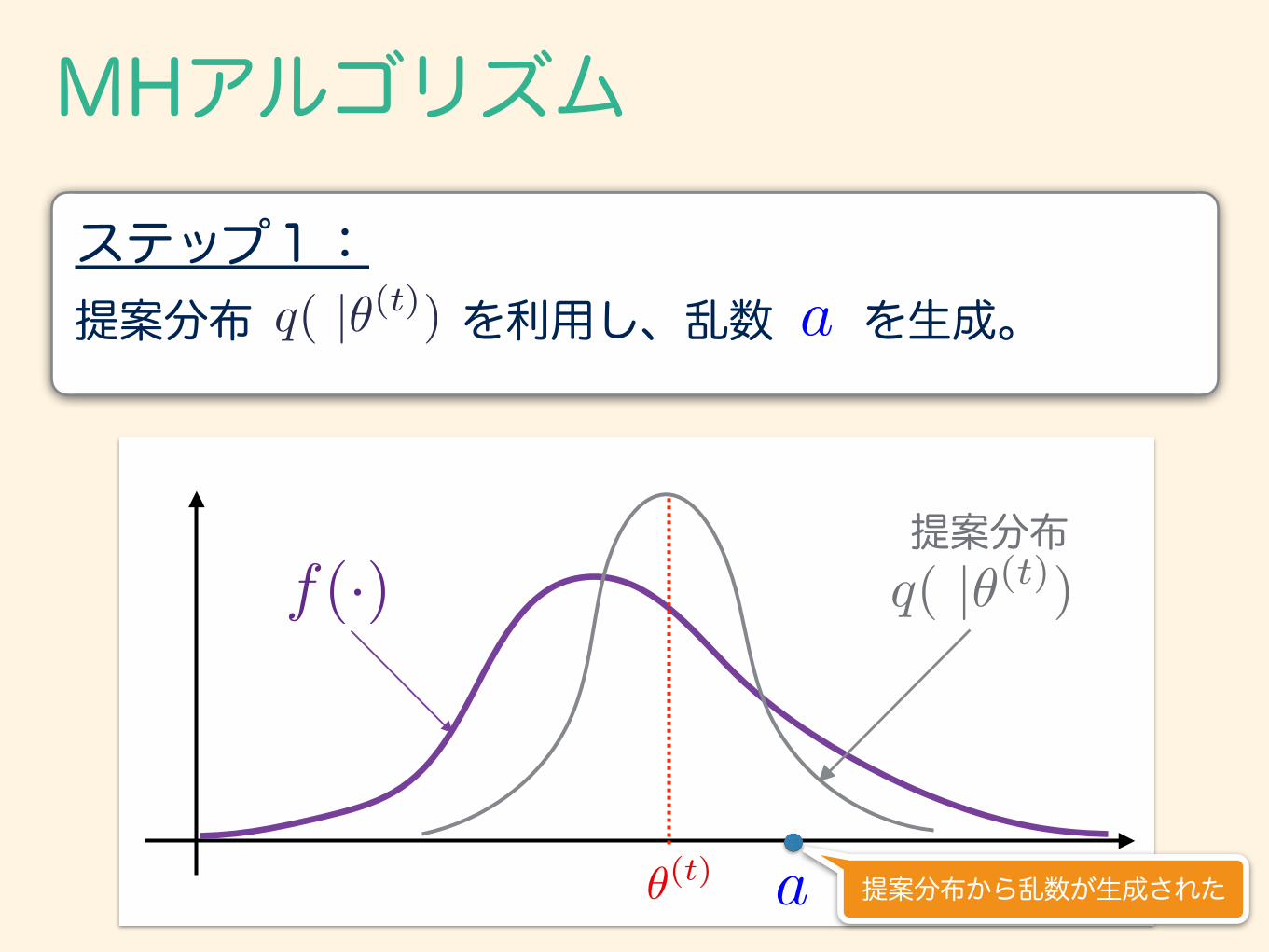
MHアルゴリズム
提案分布 を利用し、乱数 を生成。 ステップ1:
q( |✓(t)) a
f(·) q( |✓(t))
✓(t) a
提案分布
提案分布から乱数が生成された
f(✓)✓
f(✓0|✓)
f(✓|✓0)
f(✓0)
✓0
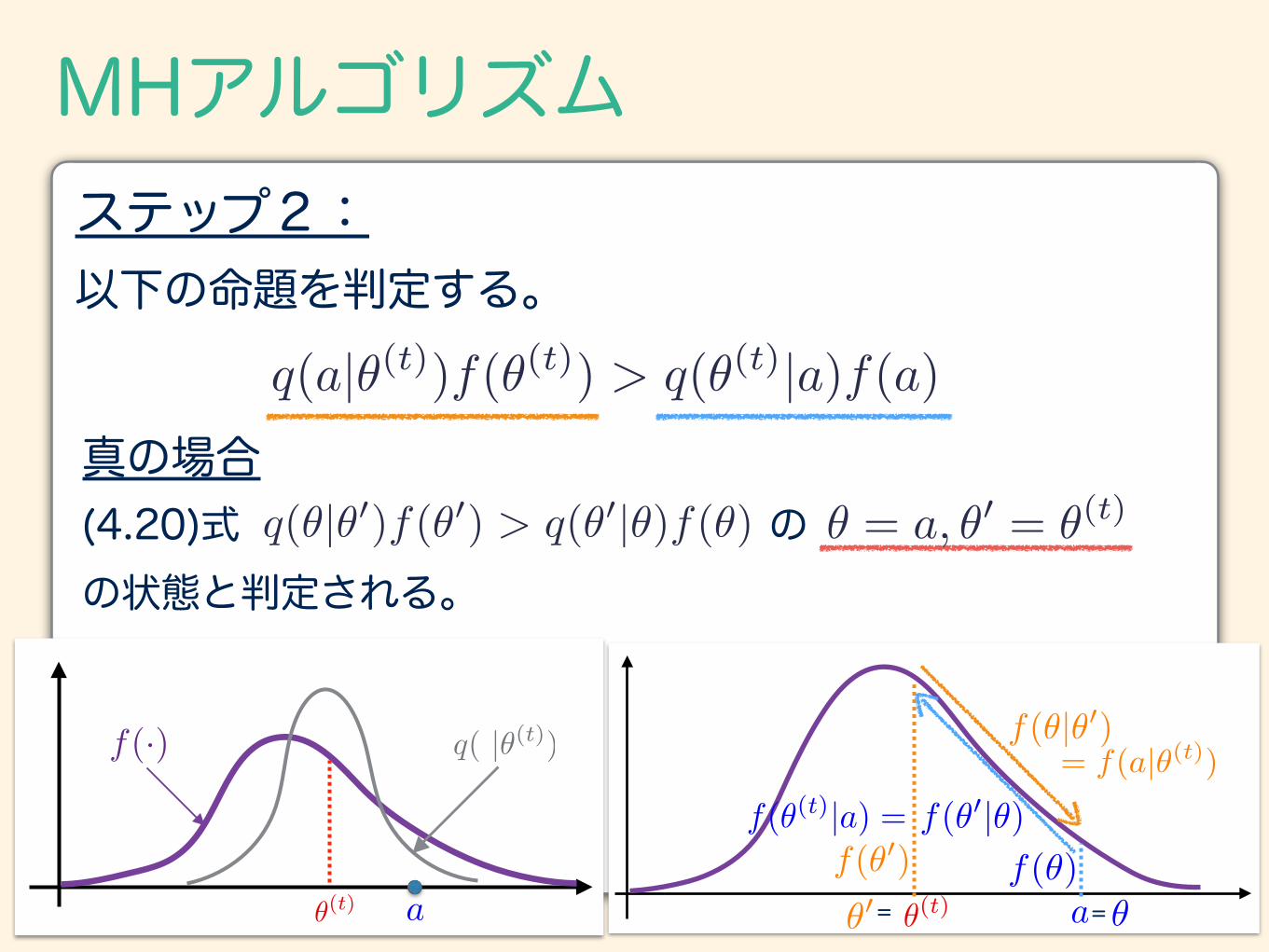
MHアルゴリズム
以下の命題を判定する。ステップ2:
q(a|✓(t))f(✓(t)) > q(✓(t)|a)f(a)真の場合(4.20)式 の の状態と判定される。
q(✓|✓0)f(✓0) > q(✓0|✓)f(✓) ✓ = a, ✓0 = ✓(t)
f(·) q( |✓(t))
✓(t) a a=✓(t)=
= f(a|✓(t))f(✓(t)|a) =
f(·)
✓(t) a
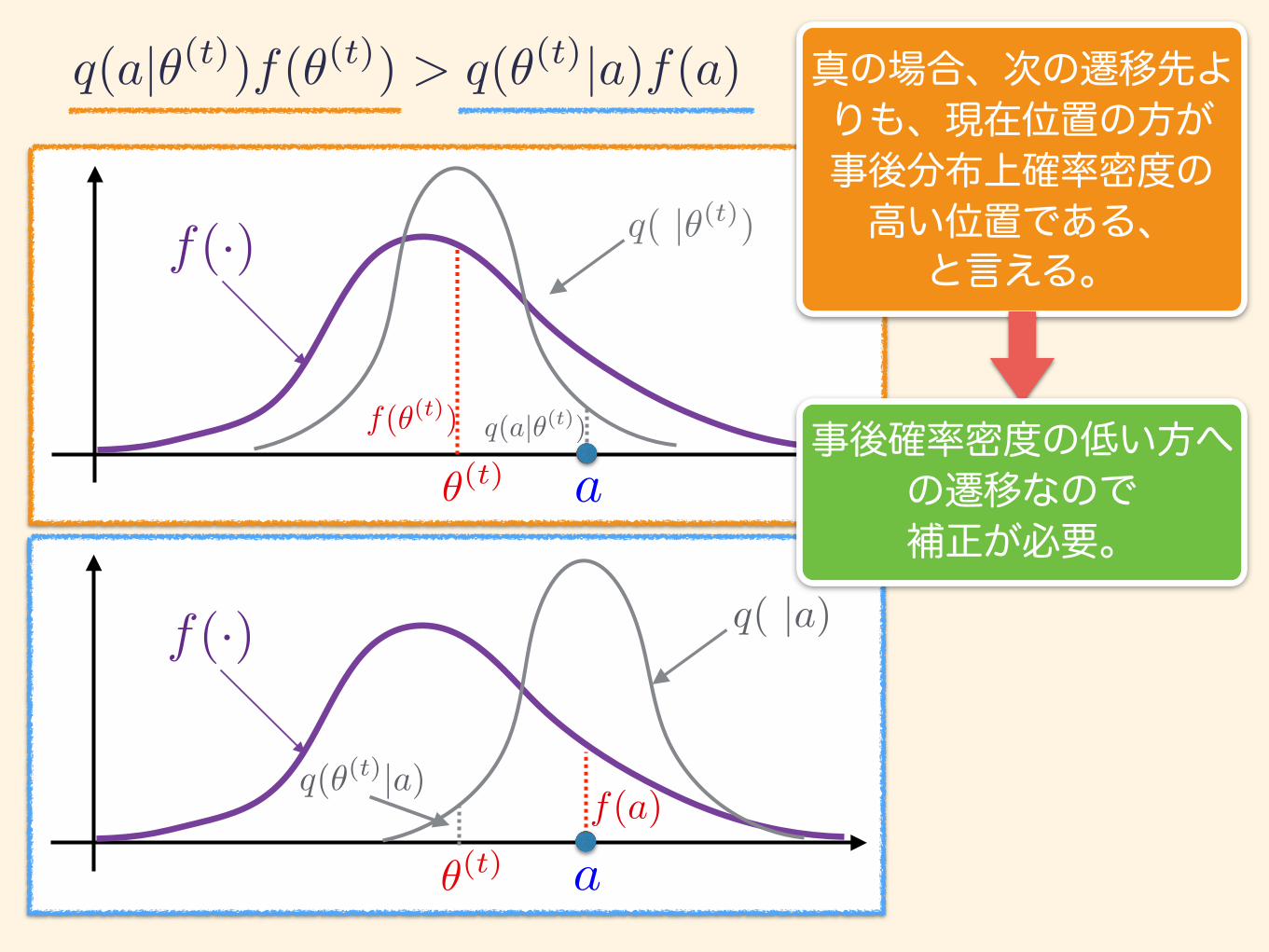
q(a|✓(t))f(✓(t)) > q(✓(t)|a)f(a)
f(·) q( |✓(t))
✓(t) aq(a|✓(t))f(✓(t))
q(✓(t)|a)f(a)
q( |a)
真の場合、次の遷移先よりも、現在位置の方が 事後分布上確率密度の 高い位置である、
と言える。
事後確率密度の低い方への遷移なので 補正が必要。

MHアルゴリズム
ステップ2:真の場合 (続き) 補正の手順
r は 0 ≦ r ≦ 1 のため、[0, 1]の一様乱数を生成し、rと比べ ・乱数 > r のとき受容 ・乱数 ≦ r のとき棄却 して θ = θ とする。
r =q(✓(t)|a)f(a)q(a|✓(t))f(✓(t))
(4.28)
a→θ の条件付き遷移確率密度(t)
θ →a の条件付き遷移確率密度(t)
(t+1) (t)
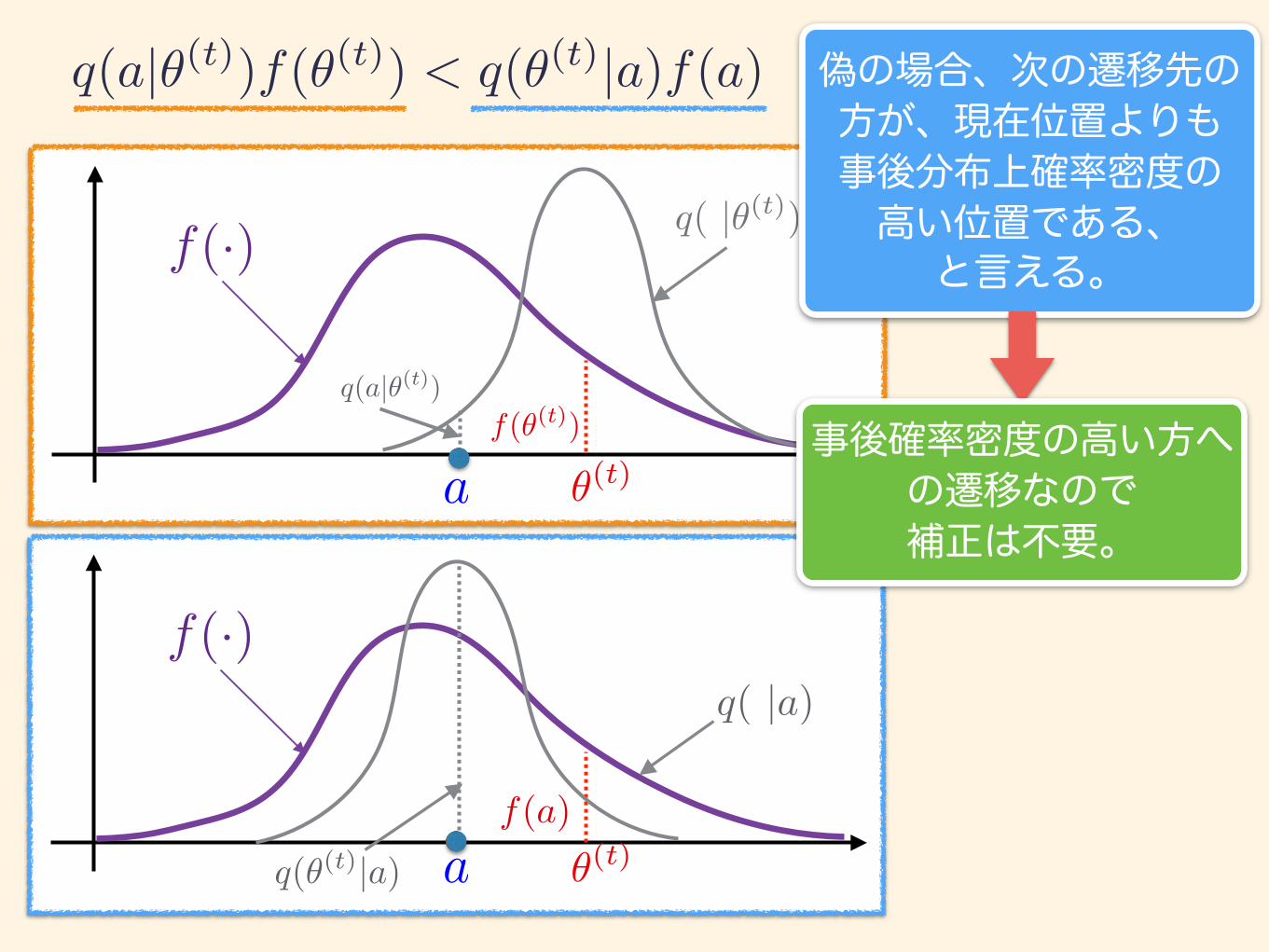
f(·)
✓(t)a
f(·) q( |✓(t))
✓(t)a
q(a|✓(t))f(✓(t))
q(✓(t)|a)f(a)
q( |a)
偽の場合、次の遷移先の方が、現在位置よりも 事後分布上確率密度の 高い位置である、
と言える。
q(a|✓(t))f(✓(t)) < q(✓(t)|a)f(a)
事後確率密度の高い方への遷移なので 補正は不要。

MHアルゴリズムステップ2:偽の場合 q(a|✓(t))f(✓(t)) > q(✓(t)|a)f(a) ⇒ False
✓0 = a, ✓ = ✓(t)
の状態と判定。この場合提案分布
(4.20)式 の の状態と判定される。
q(✓|✓0)f(✓0) > q(✓0|✓)f(✓)
θ → a の遷移なので、提案分布は を使う。 このときの確率的補正には r’ を使うが、これは r’ = 1なので 必ず a を受容し θ = a とする。 (事実上、補正なし)
(t) q(✓0|✓)
(t+1)
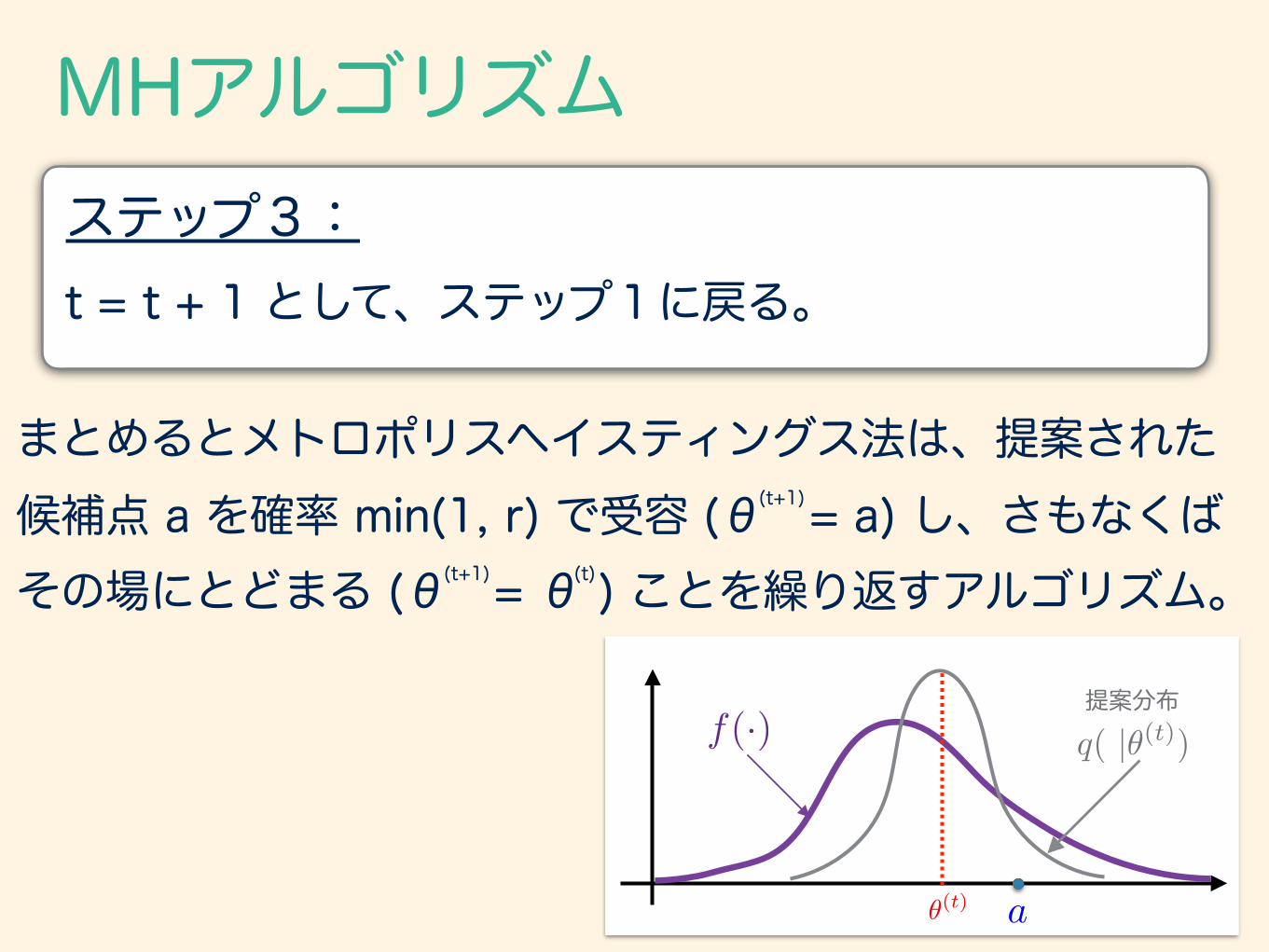
MHアルゴリズム
t = t + 1 として、ステップ1に戻る。ステップ3:
まとめるとメトロポリスヘイスティングス法は、提案された 候補点 a を確率 min(1, r) で受容 (θ = a) し、さもなくば その場にとどまる (θ = θ ) ことを繰り返すアルゴリズム。
(t+1)
(t+1) (t)
f(·) q( |✓(t))
✓(t) a
提案分布

正規化定数を取り除く
r =q(✓(t)|a)f(a)q(a|✓(t))f(✓(t))
式(4.28) のf(・)は 事後分布 だったので、代入して整理 します。また、生成した乱数 aを と書き直すと、
f( · |x)✓a
r =q(✓(t)|✓a)f(✓a|x)q(✓a|✓(t))f(✓(t)|x)
またベイズの定理より
r =q(✓(t)|✓
a
) f(x|✓a)f(✓a)f(x)
q(✓a
|✓(t)) f(x|✓(t))f(✓(t))f(x)
=q(✓(t)|✓a)f(x|✓a)f(✓a)
q(✓a|✓(t))f(x|✓(t))f(✓(t))
事後分布の正規化定数 f(・)が約分 されてきてたので、カーネルだけになり
計算できるようになった!
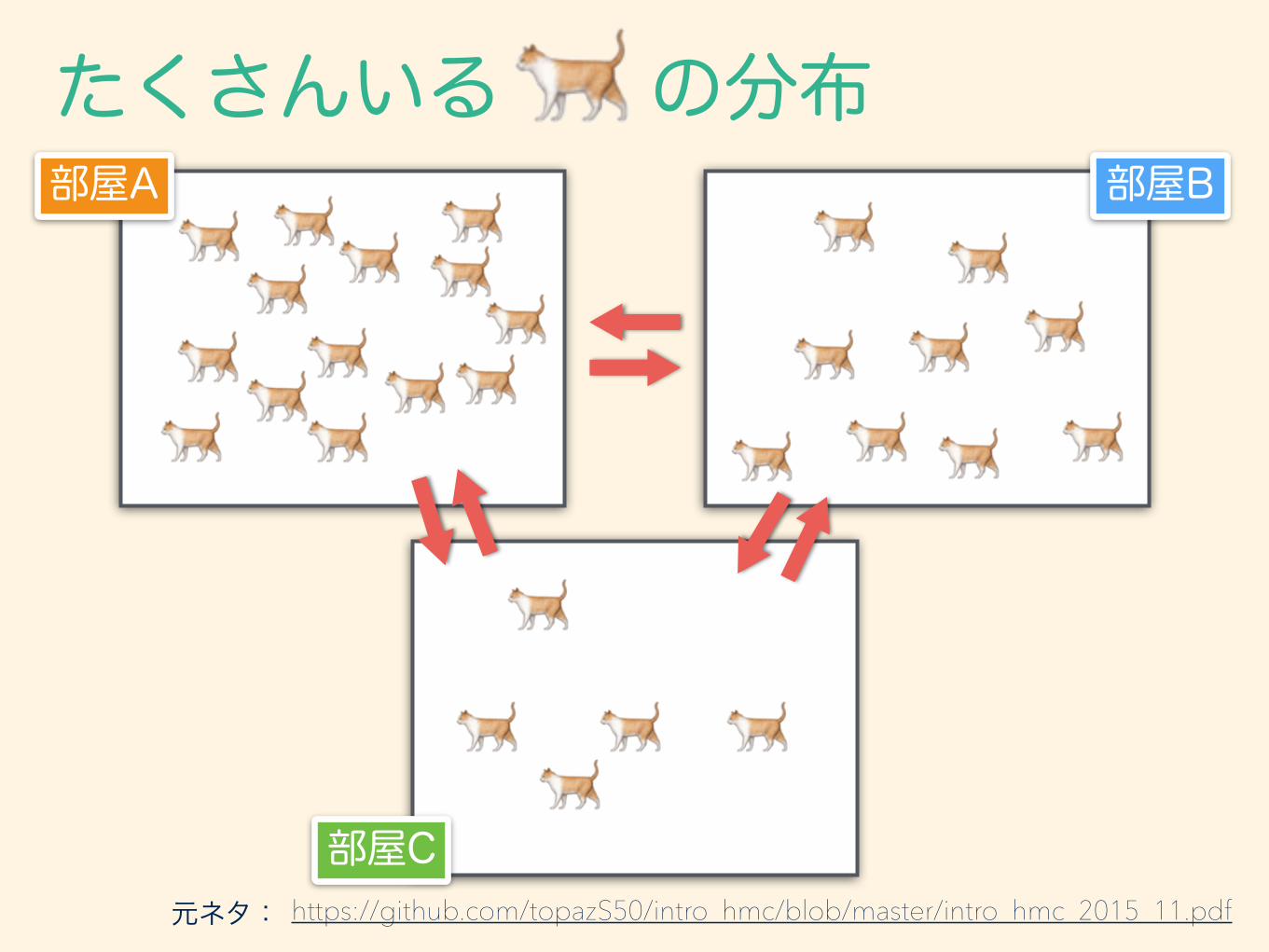
https://github.com/topazS50/intro_hmc/blob/master/intro_hmc_2015_11.pdf
部屋A 部屋B
部屋C元ネタ:
たくさんいる の分布
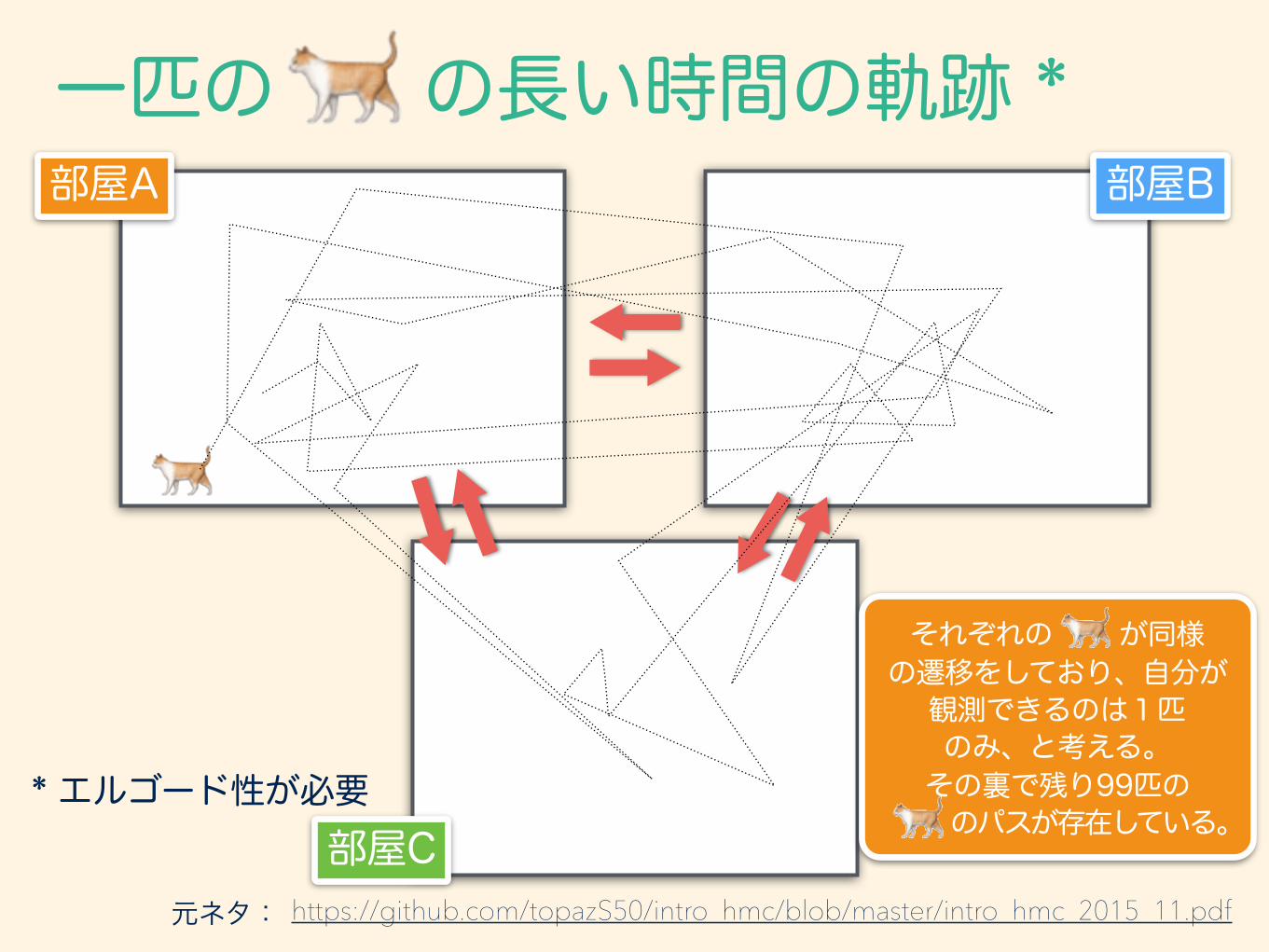
一匹の の長い時間の軌跡 *
https://github.com/topazS50/intro_hmc/blob/master/intro_hmc_2015_11.pdf
部屋A
部屋C元ネタ:
部屋B
* エルゴード性が必要
それぞれの が同様 の遷移をしており、自分が
観測できるのは1匹 のみ、と考える。
その裏で残り99匹の のパスが存在している。

4.6 独立メトロポリス ヘイスティングス法

独立MH法 : 条件なし提案分布
特殊ケースである独立メトロポリスヘイスティングス法 について。
→ 一時点前の条件が付いていない、無条件提案分布を 使用する。

波平釣果問題ポアソン分布の母数 θ: 平均的に釣れる魚の数実際の釣果データによる尤度から事後分布は のガンマ分布となった。f(✓|↵ = 11,� = 13)
事後カーネルは
となる。f(✓) = e�13✓✓10
正規化定数カーネル
f(✓|↵,�) = �↵
�(↵)e��✓✓↵�1
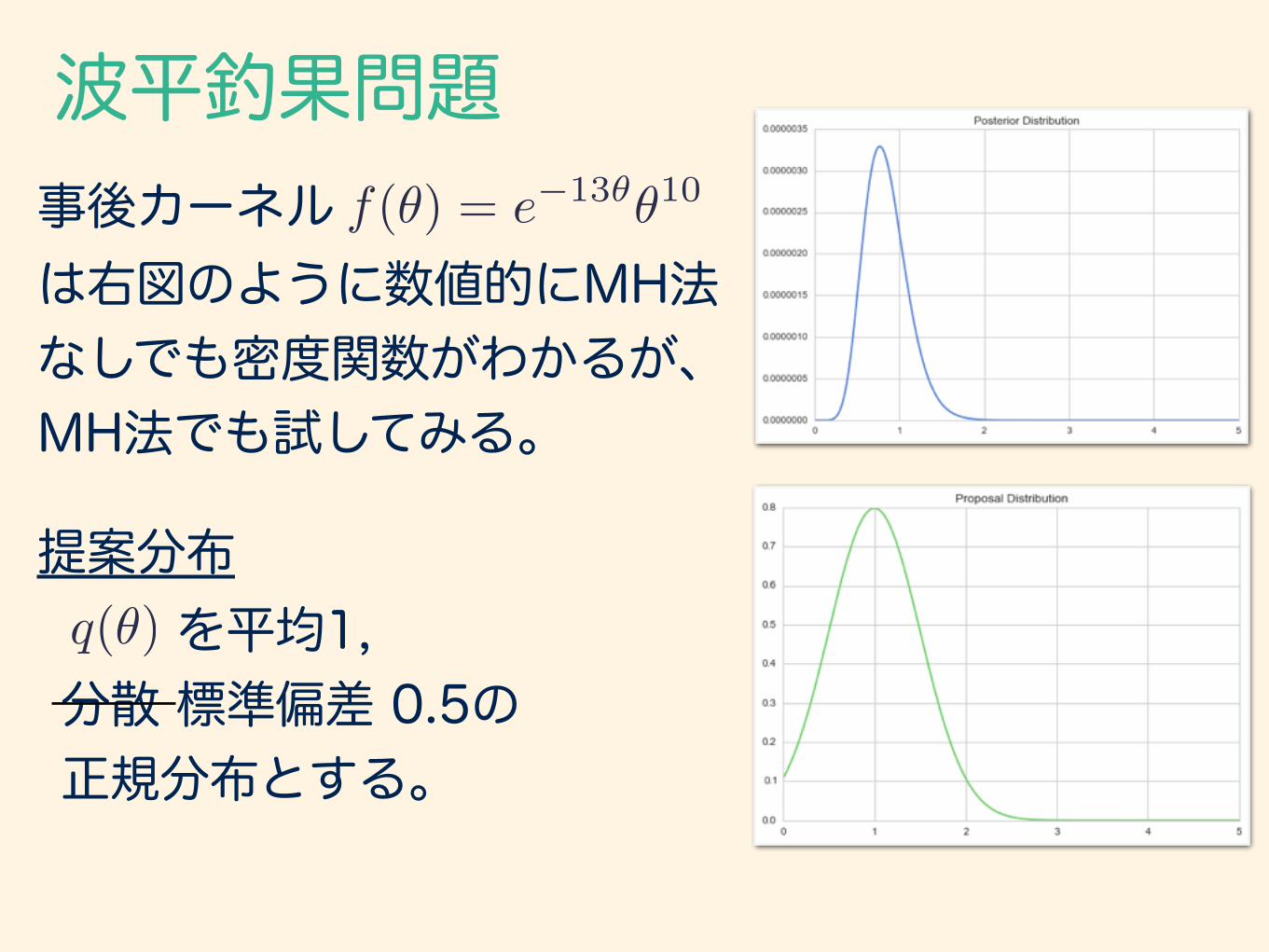
を平均1, 分散 標準偏差 0.5の 正規分布とする。
波平釣果問題事後カーネルは右図のように数値的にMH法 なしでも密度関数がわかるが、 MH法でも試してみる。
提案分布q(✓)
f(✓) = e�13✓✓10
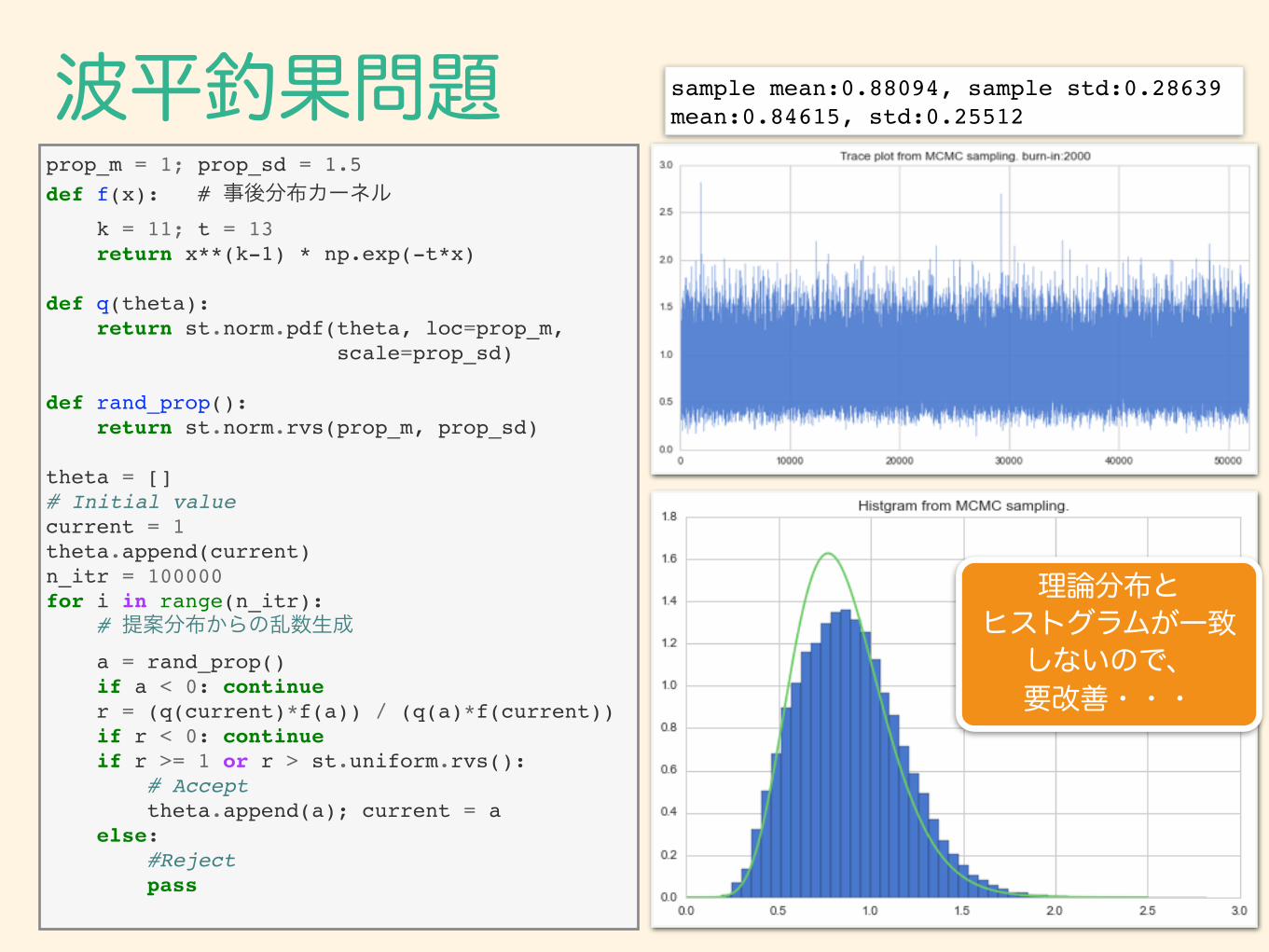
波平釣果問題prop_m = 1; prop_sd = 1.5def f(x): # 事後分布カーネル k = 11; t = 13 return x**(k-1) * np.exp(-t*x)
def q(theta): return st.norm.pdf(theta, loc=prop_m, scale=prop_sd)
def rand_prop(): return st.norm.rvs(prop_m, prop_sd)
theta = []# Initial valuecurrent = 1theta.append(current)n_itr = 100000for i in range(n_itr): # 提案分布からの乱数生成 a = rand_prop() if a < 0: continue r = (q(current)*f(a)) / (q(a)*f(current)) if r < 0: continue if r >= 1 or r > st.uniform.rvs(): # Accept theta.append(a); current = a else: #Reject pass
sample mean:0.88094, sample std:0.28639mean:0.84615, std:0.25512
理論分布と ヒストグラムが一致
しないので、 要改善・・・
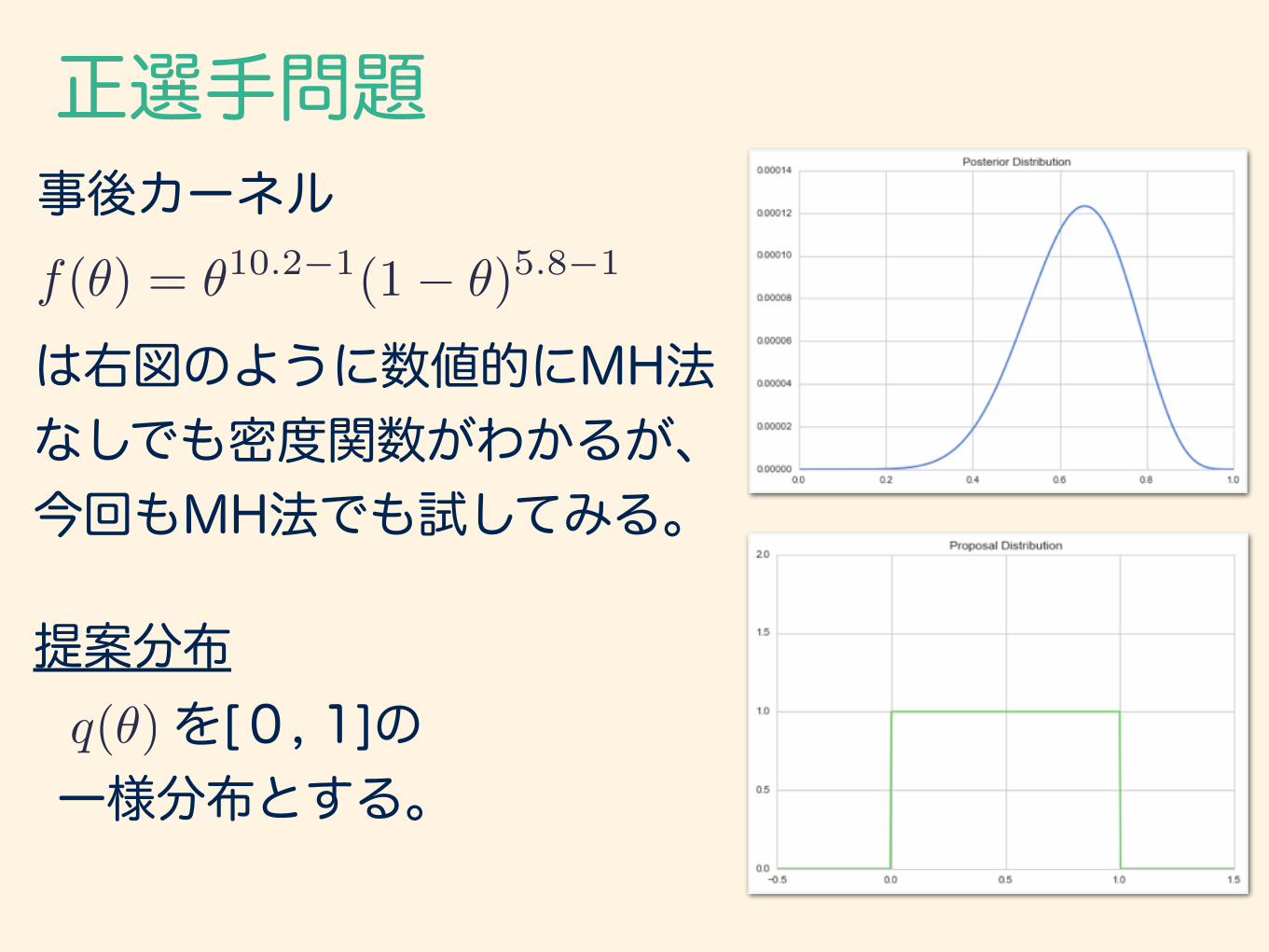
正選手問題事後カーネル
は右図のように数値的にMH法 なしでも密度関数がわかるが、 今回もMH法でも試してみる。
提案分布 を[0, 1]の 一様分布とする。
f(✓) = ✓10.2�1(1� ✓)5.8�1
q(✓)
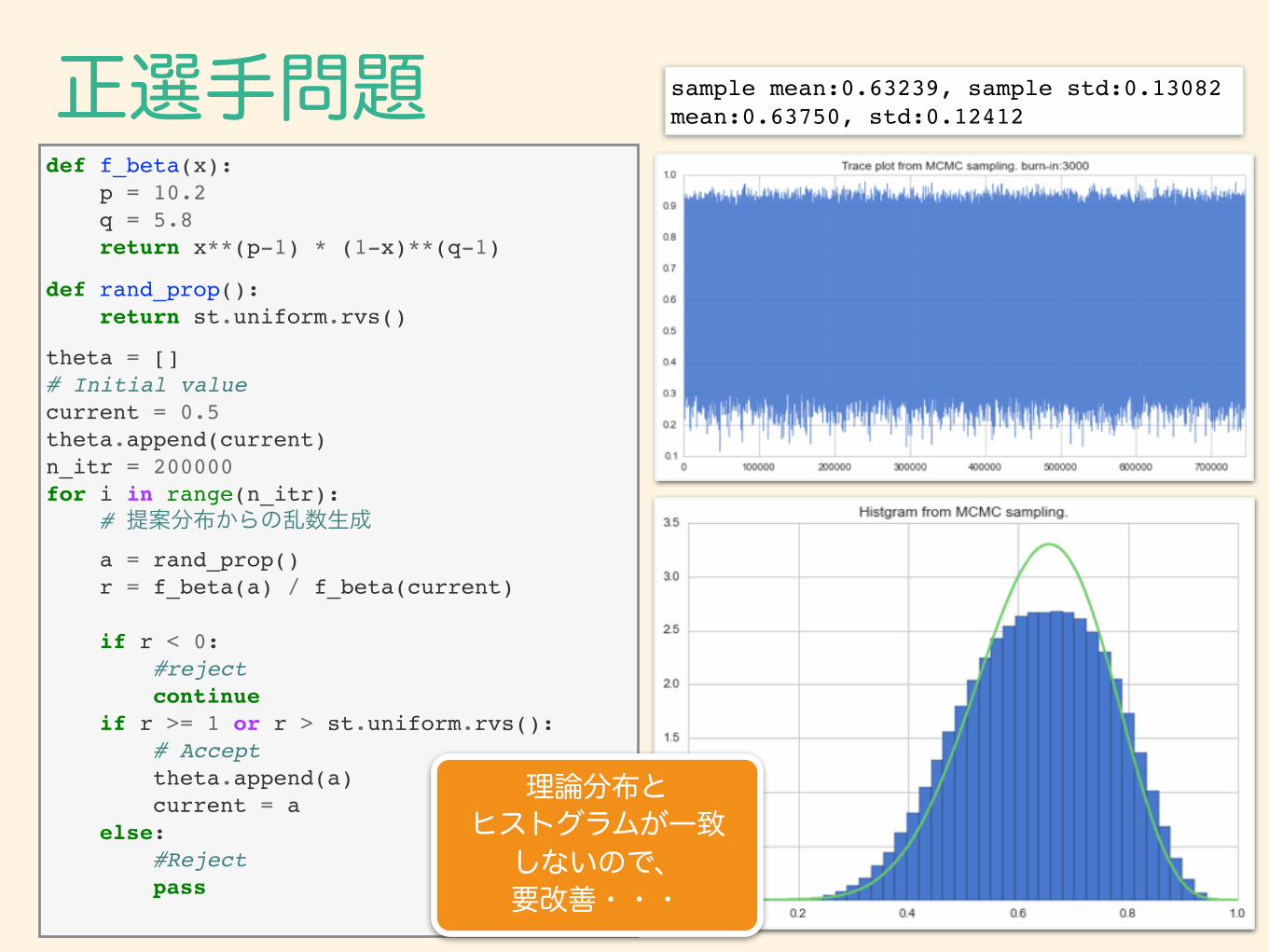
def f_beta(x): p = 10.2 q = 5.8 return x**(p-1) * (1-x)**(q-1)
def rand_prop(): return st.uniform.rvs()
theta = []# Initial valuecurrent = 0.5theta.append(current)n_itr = 200000for i in range(n_itr): # 提案分布からの乱数生成 a = rand_prop() r = f_beta(a) / f_beta(current)
if r < 0: #reject continue if r >= 1 or r > st.uniform.rvs(): # Accept theta.append(a) current = a else: #Reject pass
正選手問題 sample mean:0.63239, sample std:0.13082mean:0.63750, std:0.12412
理論分布と ヒストグラムが一致
しないので、 要改善・・・
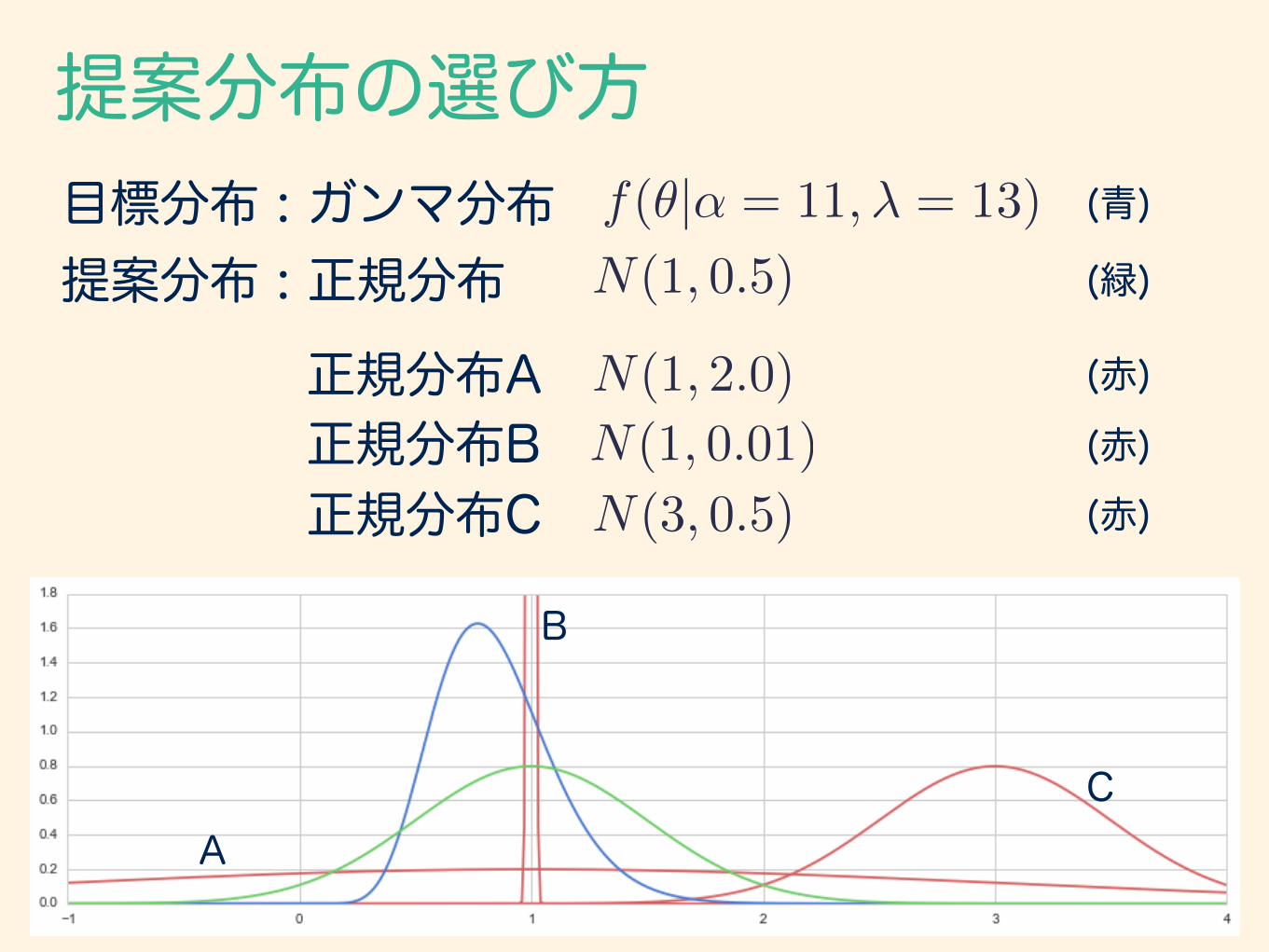
提案分布の選び方目標分布 : ガンマ分布 f(✓|↵ = 11,� = 13)
提案分布 : 正規分布(青)
N(1, 0.5) (緑)
正規分布A正規分布B正規分布C
N(1, 2.0) (赤)
N(1, 0.01)
N(3, 0.5)
(赤)(赤)
C
B
A
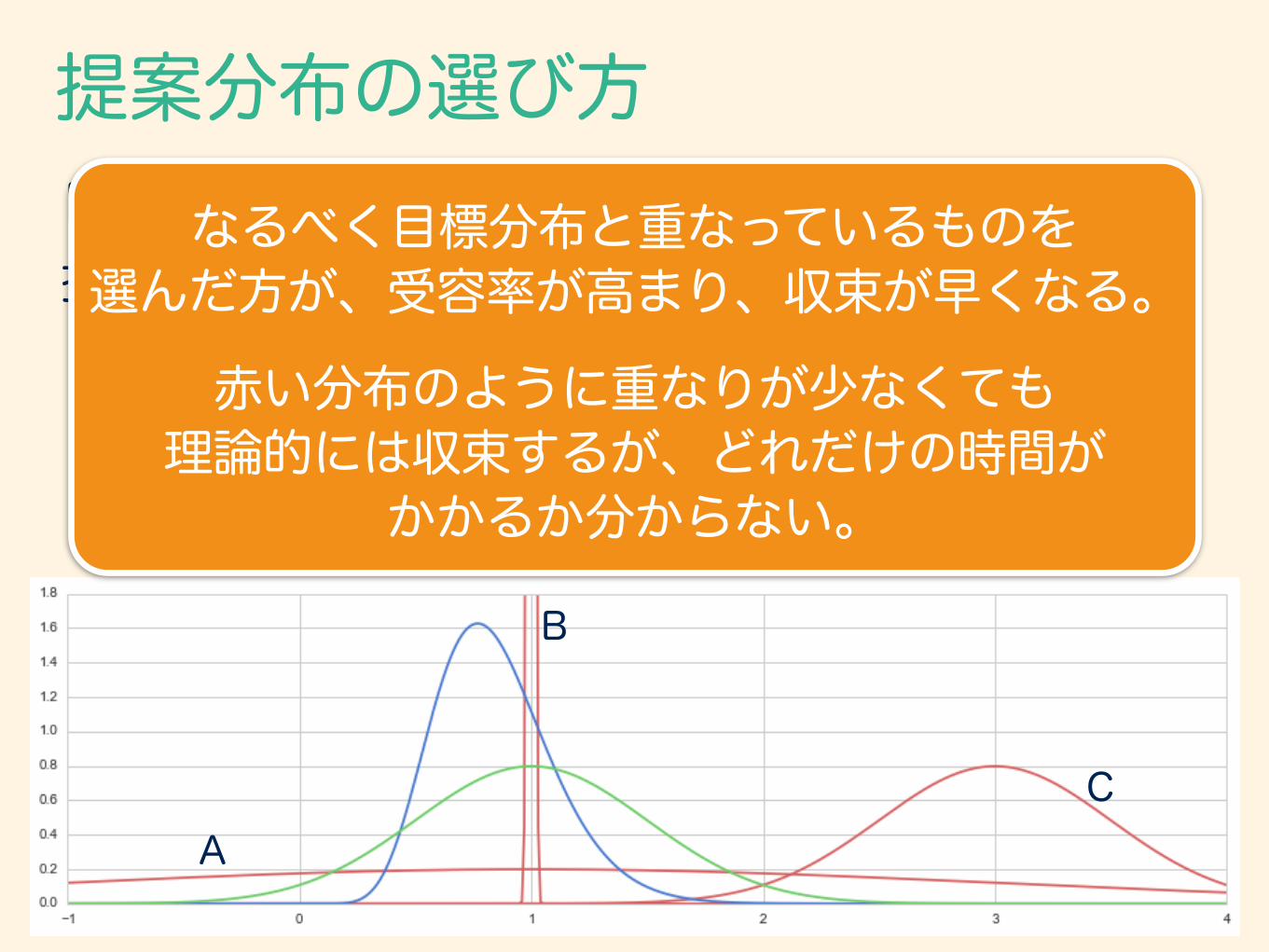
提案分布の選び方目標分布 : ガンマ分布 f(✓|↵ = 11,� = 13)
提案分布 : 正規分布(青)
N(1, 0.5) (緑)
正規分布A正規分布B正規分布C
N(1, 2.0) (赤)
N(1, 0.01)
N(3, 0.5)
(赤)(赤)
C
B
A
なるべく目標分布と重なっているものを 選んだ方が、受容率が高まり、収束が早くなる。
赤い分布のように重なりが少なくても 理論的には収束するが、どれだけの時間が
かかるか分からない。

4.7 ランダムウォークメトロポリス ヘイスティングス法
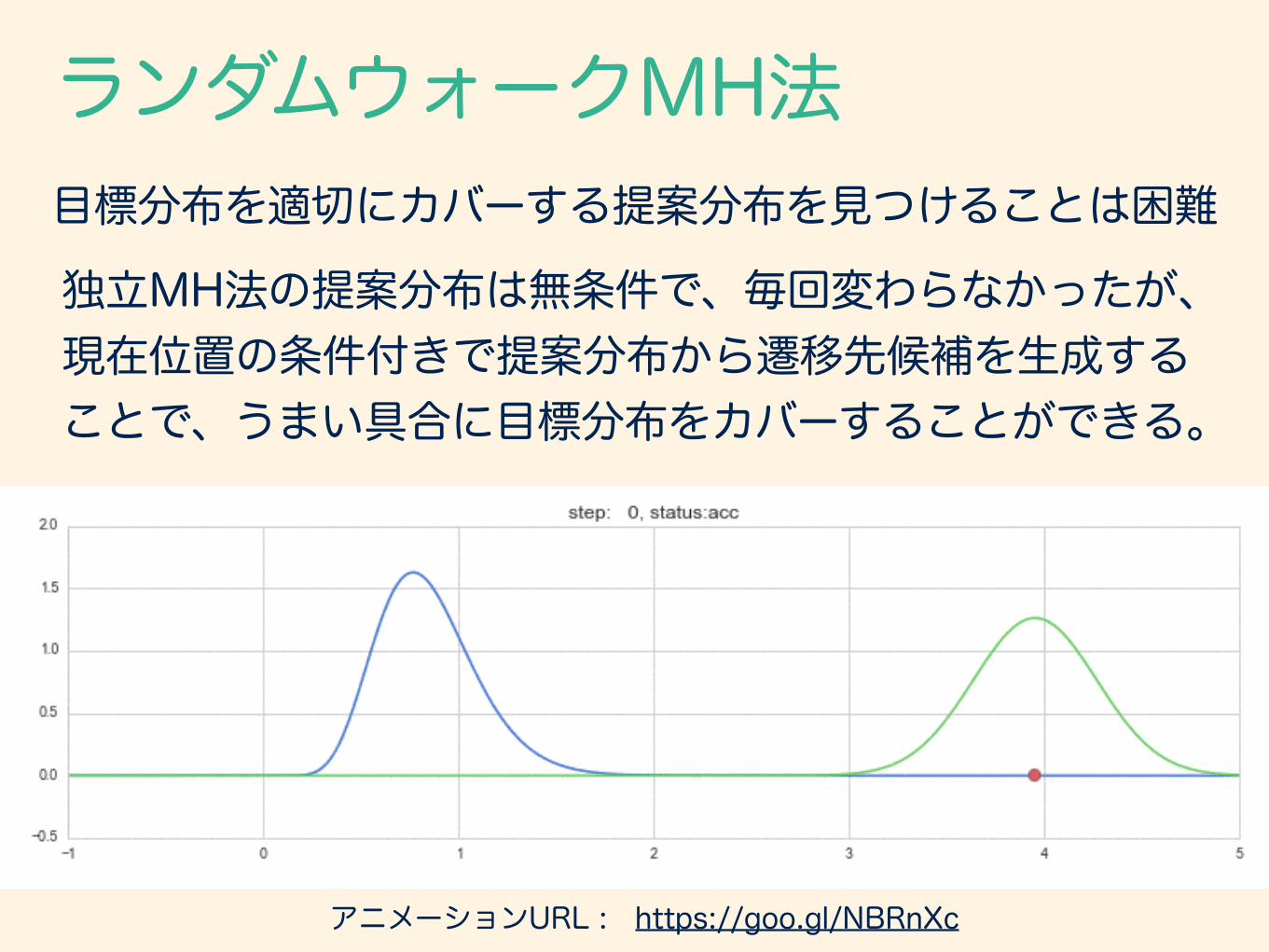
ランダムウォークMH法
独立MH法の提案分布は無条件で、毎回変わらなかったが、 現在位置の条件付きで提案分布から遷移先候補を生成する ことで、うまい具合に目標分布をカバーすることができる。
目標分布を適切にカバーする提案分布を見つけることは困難
https://goo.gl/NBRnXcアニメーションURL :
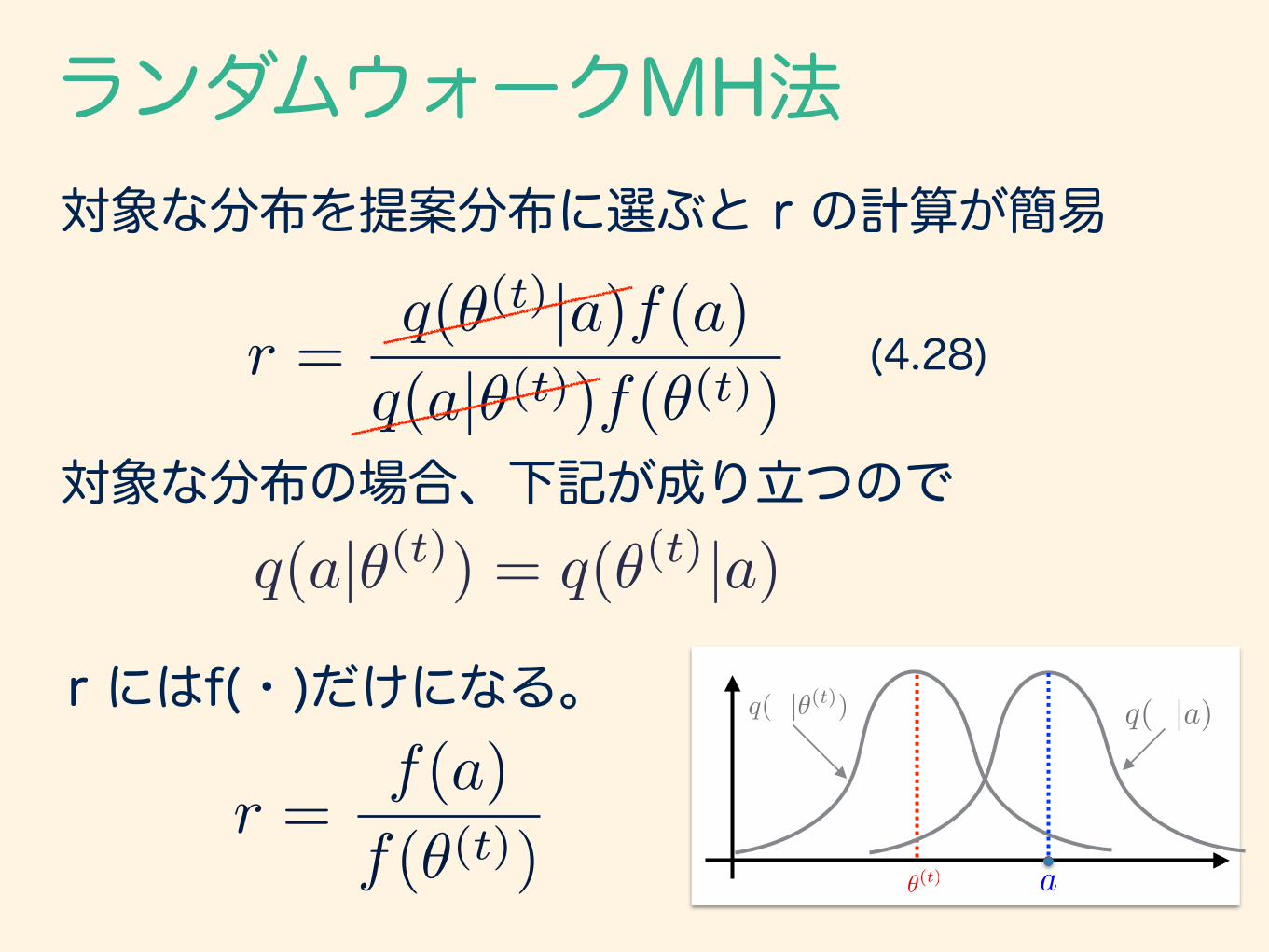
対象な分布を提案分布に選ぶと r の計算が簡易
ランダムウォークMH法
r =q(✓(t)|a)f(a)q(a|✓(t))f(✓(t))
(4.28)
q(a|✓(t)) = q(✓(t)|a)
✓(t) a
q( |a)q( |✓(t))
対象な分布の場合、下記が成り立つので
r =f(a)
f(✓(t))
r にはf(・)だけになる。
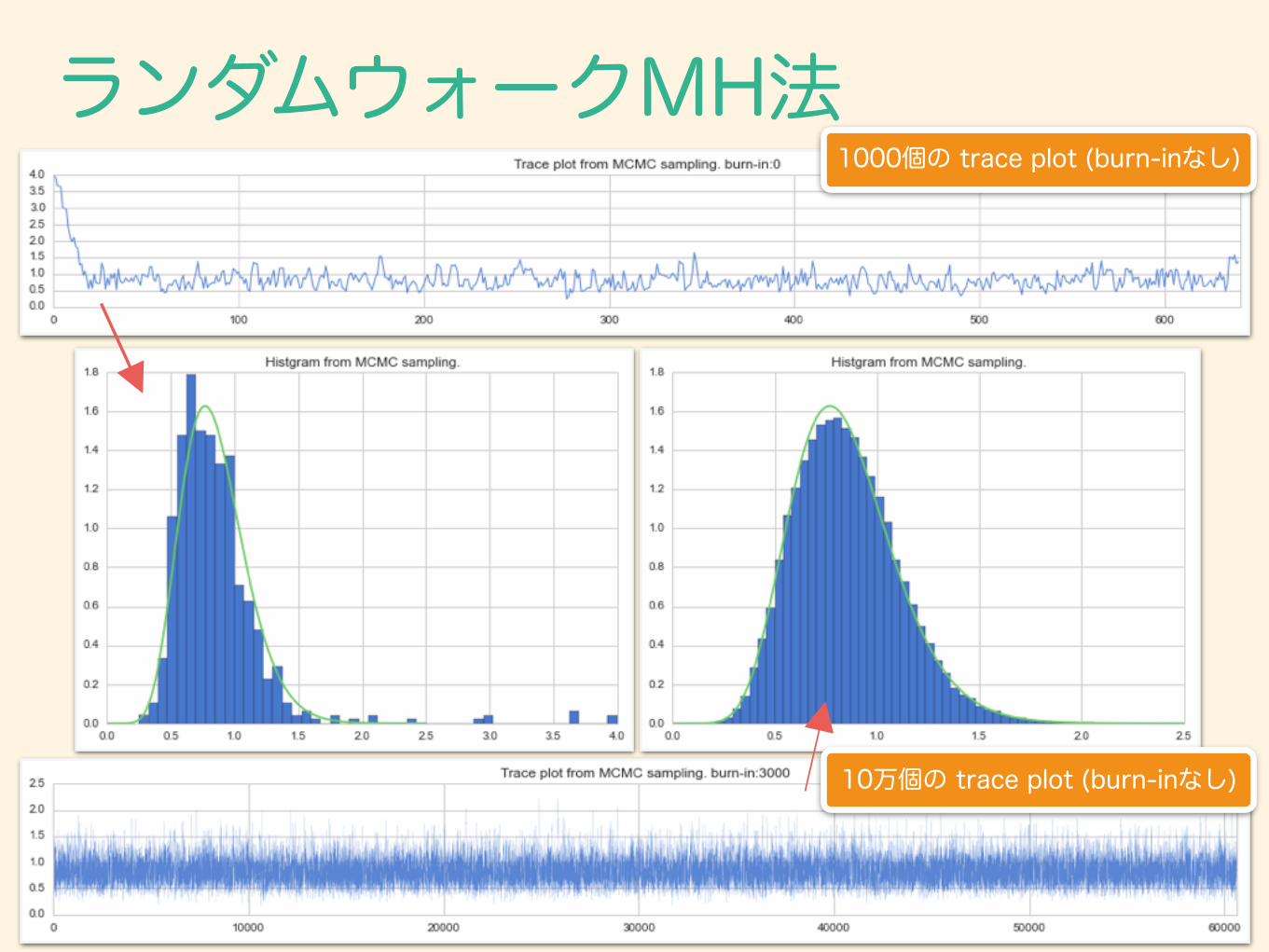
ランダムウォークMH法1000個の trace plot (burn-inなし)
10万個の trace plot (burn-inなし)
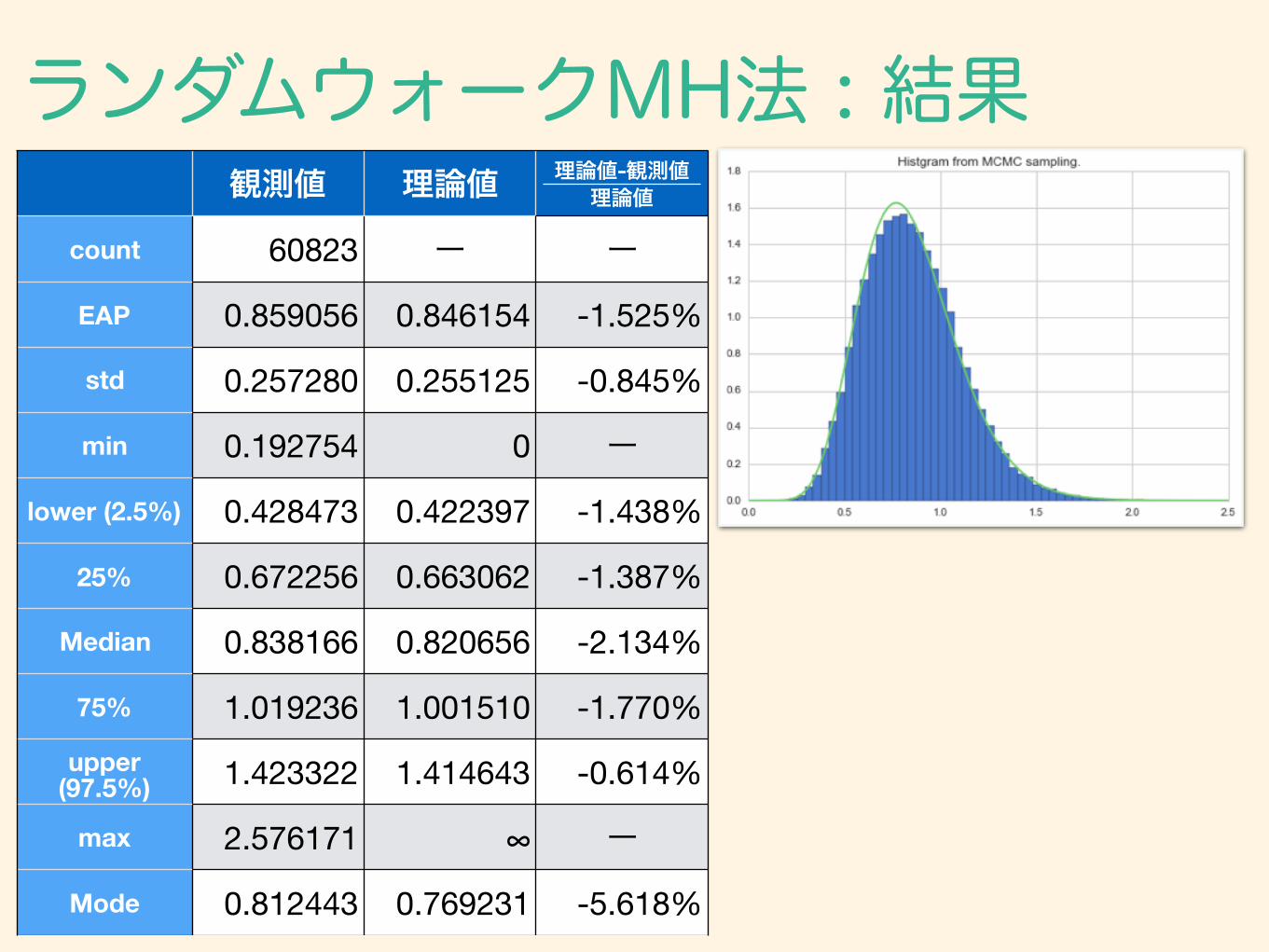
ランダムウォークMH法 : 結果観測値 理論値 理論値-観測値
理論値
count 60823 ー ー
EAP 0.859056 0.846154 -1.525%
std 0.257280 0.255125 -0.845%
min 0.192754 0 ー
lower (2.5%) 0.428473 0.422397 -1.438%
25% 0.672256 0.663062 -1.387%
Median 0.838166 0.820656 -2.134%
75% 1.019236 1.001510 -1.770%upper
(97.5%) 1.423322 1.414643 -0.614%
max 2.576171 ∞ ー
Mode 0.812443 0.769231 -5.618%

参考・グラフや計算をしたPythonコード (Github) https://github.com/matsuken92/Qiita_Contents/blob/master/Bayes_chap_04/Bayes-stat_chapter04.ipynb
・基礎からのベイズ統計学 http://www.asakura.co.jp/books/isbn/978-4-254-12212-1/
・計算統計 II マルコフ連鎖モンテカルロ法とその周辺 https://www.iwanami.co.jp/.BOOKS/00/0/0068520.html
・マルコフ連鎖モンテカルロ法(MCMC)によるサンプリングをアニメーションで解説してみる。(Qiita) http://qiita.com/kenmatsu4/items/55e78cc7a5ae2756f9da
・hybrid Monte Carlo法の紹介 (topazS50@GitHub) https://github.com/topazS50/intro_hmc/blob/master/intro_hmc_2015_11.pdf