一种支持 cuda 应用的软件容错系统
DESCRIPTION
2010 硕士开题报告. 一种支持 CUDA 应用的软件容错系统. 报告人:赵 力 导 师:马 捷 2010.09. 摘要. 研究背景 相关研究 研究目标、内容和拟解决的关键技术 拟采取的研究方法、技术路线及可行性分析 预期研究成果及创新之处 已有工作基础 研究计划及预期进展. 研究背景. 曙光 6000 是中科院计算所研发的运算速度达到每秒千万亿次的超级计算机,它采用异构架构,控制芯片为 X86 架构 CPU ,使用了龙芯 3 号 CPU 和 Nvidia GPU 作为加速部件。. 研究背景. 曙光 6000 结构示意图. 研究背景. - PowerPoint PPT PresentationTRANSCRIPT

一种支持 CUDA 应用的软件容错系统
报告人:赵 力导 师:马 捷2010.09
2010 硕士开题报告

摘要
研究背景 相关研究 研究目标、内容和拟解决的关键技术 拟采取的研究方法、技术路线及可行性分析 预期研究成果及创新之处 已有工作基础 研究计划及预期进展

研究背景
曙光 6000 是中科院计算所研发的运算速度达到每秒千万亿次的超级计算机,它采用异构架构,控制芯片为 X86 架构 CPU ,使用了龙芯3 号 CPU 和 Nvidia GPU 作为加速部件。

研究背景
曙光 6000 结构示意图
Sl ave OS
Sl aveOS
Sl ave OS
Master OS
龙芯3 龙芯3 龙芯3 X86
Mem Mem Mem Mem
HPP节点控制器
X86 CPU X86 CPU
X86 CPU X86 CPU
系统控制器
Fermi GPU
HPC分区 HTC分区
Infi niband

研究背景
CPU 与 GPU 芯片的晶体管使用示意图

研究背景
GPU VS CPU 计算能力

研究背景
GPGPU 计算执行过程 1. 复制存储器至 GPU 2. CPU 指令驱动 GPU 3. GPU 平行处理每一内
核 4. GPU 将结果传回主存

研究背景
超级计算机为了取得更高的运算速度,提高计算的并行性,必须使用更多的运算部件,特别是异构的运算部件。
随着系统的规模不断扩大,计算机发生硬件和软件故障的概率也随之增大。对于异构的计算机系统,由于结构的特殊性,如何提高系统的可靠性更是一个棘手的问题。

研究背景
曙光星云 IBM 走鹃 天河一号
CPU 类型 Intel westmeter
AMD Opteron Intel Nehalem
CPU 数量 9280 6120 5120
加速器类型 Nvidia C2050 IBM Cell 8i ATI 4870X2
加速器数量 4640 12240 2560
加速器校验 ECC ECC N/A
计算网络 QDR IB DDR IB QDR IB
实测峰值 1.271 PFops 1.042 PFlops 0.562 PFlops
超级计算机系统规模比较

研究背景
国防科技大学研制的天河一号是我国首台千万亿次超级计算机系统 ,属于异构计算机系统。
天河一号结构图

研究背景
由于显卡硬件没有相应的容错校验设计,系统软件本身未对 GPU 进行容错处理,为提高系统的可靠性,天河一号采用的 Radeon HD 4870X2 加速卡降低了工作频率。

研究背景
检查点技术可以使系统和应用从已发生的故障中恢复,从而减少计算损失,是一种广泛使用的软件容错技术。
在目前主流的计算机平台上,已经研发出了许多研究性的检查点容错系统。但是这些检查点系统只能针对传统的计算程序,对于 GPU 异构计算还缺乏支持。

相关研究
Berkeley Lab Checkpoint/Restart (BLCR) 是一个开源的内核级单进程检查点容错软件,对用户进程完全透明,基于 Linux 系统实现,支持 x86 、 ppc等平台,广泛应用到 LAM-MPI ,MVAPICH2 等系统中。
BLCR 本身仅支持简单的单进程检查点,不支持通信及 GPU 加速部件。

研究目标、内容和拟解决的关键技术
研究目标 对 CUDA 应用进行可靠性分析 设计针对 CUDA 应用的容错机制和软件实现 提高 CUDA 应用的可靠性

研究目标、内容和拟解决的关键技术
研究内容 研究 CUDA 异构应用的加速原理和实现机制,分
析 CUDA代码的编译、执行过程,对 CUDA 应用进行可靠性分析,找到 CUDA 应用的脆弱点。
在已有的单进程检查点软件 BLCR 基础上,设计基于检查点技术的异构应用容错框架,实现 GPU状态的保存和恢复,最终实现 CUDA 应用的检查点的触发、保存、恢复。

研究目标、内容和拟解决的关键技术
研究内容 设计实现 CUDA 应用的 GPU代码部分冗余执行,通过比较结果来实现 CUDA 应用的检错,在出错时重新执行 GPU代码部分,提高 CUDA 应用的可靠性。

研究目标、内容和拟解决的关键技术
拟解决的关键技术 设计 GPU状态的高效的保存和恢复机制以及状态保存时 CPU 与 GPU 的状态同步
为 CUDA 应用提供冗余计算机制,通过比较结果来判断出错并重新计算。

拟采取的研究方法、技术路线及可行性分析 研究方法
以现有的检查点工具 BLCR 为基础,增加 GPGPU容错的功能
由于 CUDA底层硬件的封闭性和复杂性,采用黑箱的处理方法。不直接访问 GPU 的硬件来获得 GPU信息,在主机中实时维护一个 GPU 的状态信息表,通过访问 GPU状态表来得到 GPU 的状态。

拟采取的研究方法、技术路线及可行性分析 技术路线
使用 GPGPU 进行通用计算时,在程序中必须使用GPGPU 的专用 API 。通过记录应用程序对 GPGPU API 的使用,就可以实现对 GPU状态列表的实时维护。
根据 GPU 的状态信息,将显存中分配的资源(起始地址,长度,内容)写入检查点映像文件中;恢复时依据映像文件中的 GPU状态信息,在显存中重新分配资源。

拟采取的研究方法、技术路线及可行性分析 技术路线: GPU状态信息表
将 GPU状态信息表组织成一个双向链表,每个节点代表一个被分配的 GPU 显存块,节点中保存显存块的起始地址 Address 和块的大小 Length 。 CUDA 应用分配显存时按照起始地址在表中插入相应的节点,释放显存时删除相应的节点。
Address=100Length=40
Address=150Length=80
Address=230Length=32
Address=300Length=100
Head

拟采取的研究方法、技术路线及可行性分析 技术路线:检查点映像文件
原始检查点映像文件
包含 GPU状态的检查点映像文件
CPU状态 进程Si gnalPI D,UI D,
GI D等 Memory状态
CPU状态 进程Si gnalGPU状态
(GPU资源列表)
PI D,UI D,GI D等 Memory状态
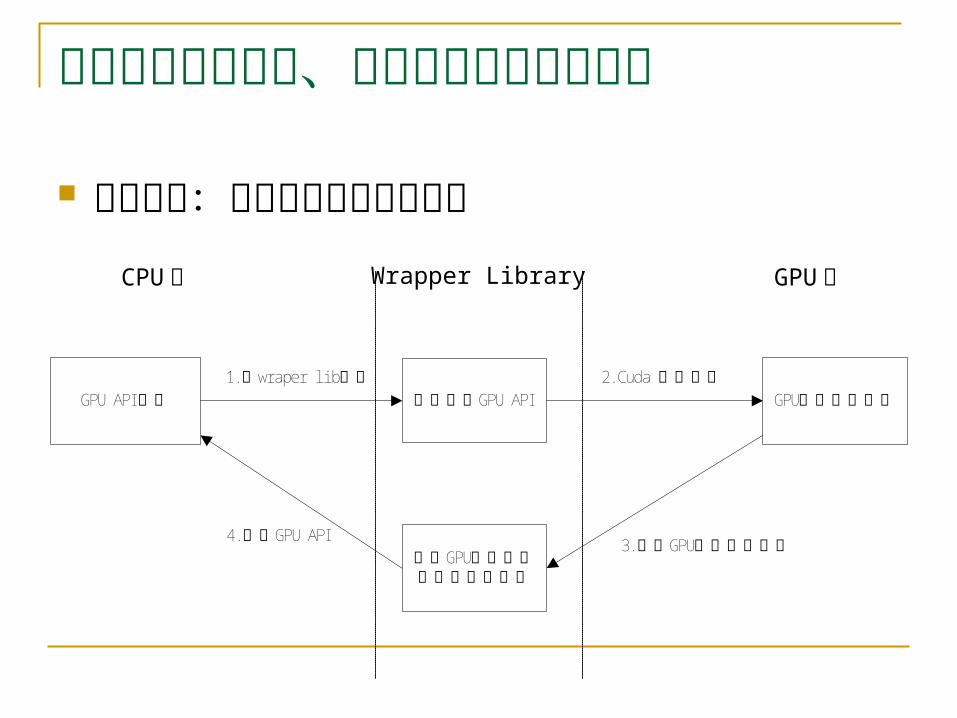
拟采取的研究方法、技术路线及可行性分析 技术路线:软件容错框架执行过程
CPU端 Wrapper Library GPU端
GPU API调用 调用真正GPU API1.被wraper l i b拦截
GPU执行资源分配2. Cuda 驱动程序
根据GPU资源分配结果修改资源表
4.返回GPU API3.返回GPU资源分配结果

拟采取的研究方法、技术路线及可行性分析 技术路线: CPU 与 GPU状态同步
根据 GPGPU 加速计算时的工作原理, CPU 与 GPU通过 PCI-E总线传递数据。只有在数据传输时,CPU 与 GPU 的状态同步;当 GPU端执行计算时,CPU 与 GPU 异步运行,状态不同步。
CPU 与 GPU 的状态同步,本质上是 CPU端与 GPU端显存上的数据的一致性。只要保证检查点中保存的 GPU状态数据在检查点后不会被修改,即可保证 CPU 与 GPU 的状态一致性。

拟采取的研究方法、技术路线及可行性分析
CPU 与 GPU 的数据一致性 与检查点时机
CPU端源数据:H_A, H_B结果:H_C
GPU端复制得到CPU端数据D_A=H_AD_B=H_B
GPU执行计算D_C[1]=. . .D_C[2]=. . .
.
.D_C[i ]=. . .
.
.D_C[n]=. . .
GPU初始化GPU端
源数据:D_A,D_B结果:D_C
GPU计算结束,传递结果
从GPU端传回结果H_C=D_C
非同步检查点时机点
CPU端向CPU端传送数据,等待GPU计
算完成
CPU端 GPU端
同步检查点时机点

拟采取的研究方法、技术路线及可行性分析 技术路线: GPU冗余计算过程
对 GPU端代码的入口 kernel拦截,将每个 kernel 执行多次并比较结果,若相同则执行正确返回,否则再次执行 kernel 。
CPU code;Kernel <<<arg1, arg2…>>>;cudaThreadSynchroni ze();
crgpu拦截kernel执行 GPU执行kernel
GPU冗余执行kernelcrgpu比较计算结果:
相同- -返回不同- -重新执行kernel
2. 1正常执行1. kernel执行
2. 2冗余执行
3. 2冗余返回
3. 1正常返回4. 1结果相同返回应用程序
4. 2结果不同重新执行

任务评测
1.通过使 GPU正常频率运行,降低频率,测量基准测试程序在 GPU 异构平台上运行的平均运行时间。
2. 相同平台上,使用本项目实现的容错软件对相同的基准测试程序做检查点,测量其运行时间。
3. 对比两种运行方法的结果,得出使用进行软件容错的优缺点。

预期研究成果及创新之处
开发出基于 BLCR 的 CR_GPU 容错软件,实现对 GPU 加速部件的检查点容错,通过冗余执行提高 GPU 计算本身的可靠性。

已有工作基础
完成了 BLCR想龙芯平台的移植 初步完成了 BLCR 对 GPU 的支持

研究计划及预期进展
2010.08-2010.10 完成 BLCR 对 GPU 的支持
2010.11-2010.12 增加 CUDA 的 kernel冗余执行
2011.01-2011.04 整体优化,论文写作