雲端分散式計算平台 hadoop 安裝使用
DESCRIPTION
雲端分散式計算平台 Hadoop 安裝使用. Outline. Hadoop 簡介 Map-Reduce 架構 VM 安裝 Ubuntu Hadoop 安裝 & 設定 參考. Hadoop 簡介. Hadoop 是 Apache 底下 的開放原始碼計劃 (Open source project ) 以,以 java 寫成,可以提供大量資料的分散式運算 環境。 - PowerPoint PPT PresentationTRANSCRIPT

雲端分散式計算平台Hadoop 安裝使用

Outline
• Hadoop 簡介–Map-Reduce 架構– VM 安裝 Ubuntu– Hadoop 安裝 & 設定
• 參考

Hadoop 簡介• Hadoop 是 Apache 底下的開放原始碼計劃 (Open
source project) 以,以 java 寫成,可以提供大量資料的分散式運算環境。• Hadoop 中包括許多子計劃,其中 Hadoop
MapReduce 如同 Google MapReduce ,提供分散式運算環境、 Hadoop Distributed File System 如同Google File System ,提供大量儲存空間。 Hadoop 的 HBase 是一個類似 BigTable 的分散式資料庫 ,還有其他部份可用來將這三個主要部份連結在一起,方便提供整合的雲端服務。
Map-Reduce 架構• MapReduce 是一個分散式程式框架,讓服務開發者可以很簡單的撰寫程式,利用大量的運算資源,加速處理龐大的資料量• 一個 MapReduce 的運算工作可以分成兩個部份 :Map 和 Reduce ,大量的資料在運算開始的時候,會被系統轉換成一組組 (key, value) 的序對並自動切割成許多部份,分別傳給不同的 Mapper 來處理, Mapper 處理完成後也要將運算結果整理成一組組 (key, value) 的序對,再傳給 Reducer 整合所有 Mapper 的結果,最後才能將整體的結果輸出

Example wordcount
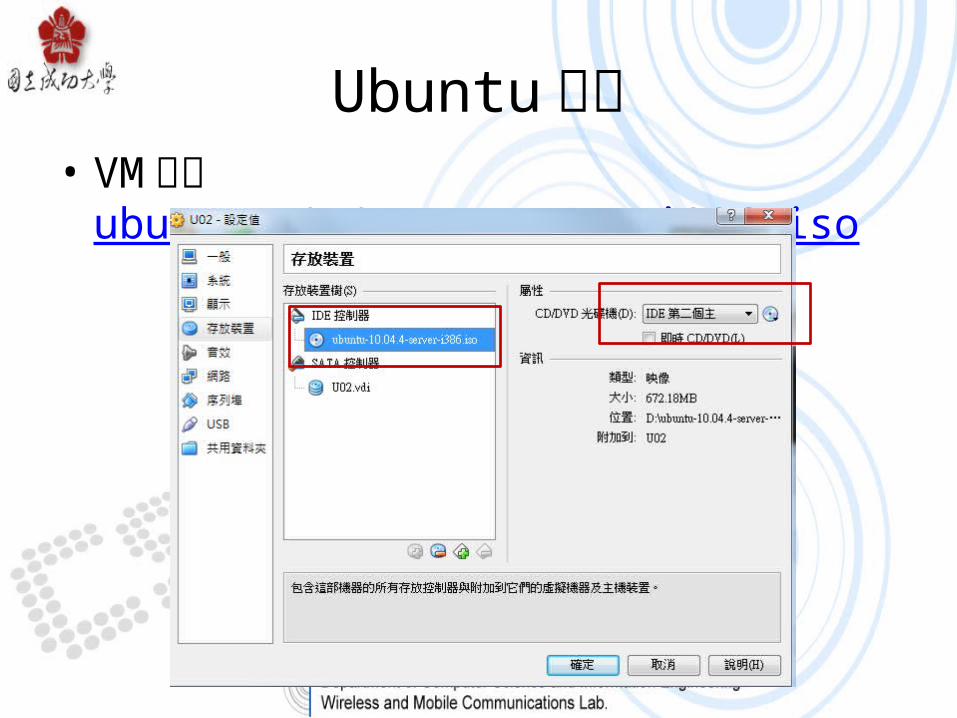
Ubuntu 安裝• VM 安裝 ubuntu-10.04.4-server-i386.iso


Ubuntu 安裝 ( 續 )• 設定 hostname

Ubuntu 安裝 ( 續 )
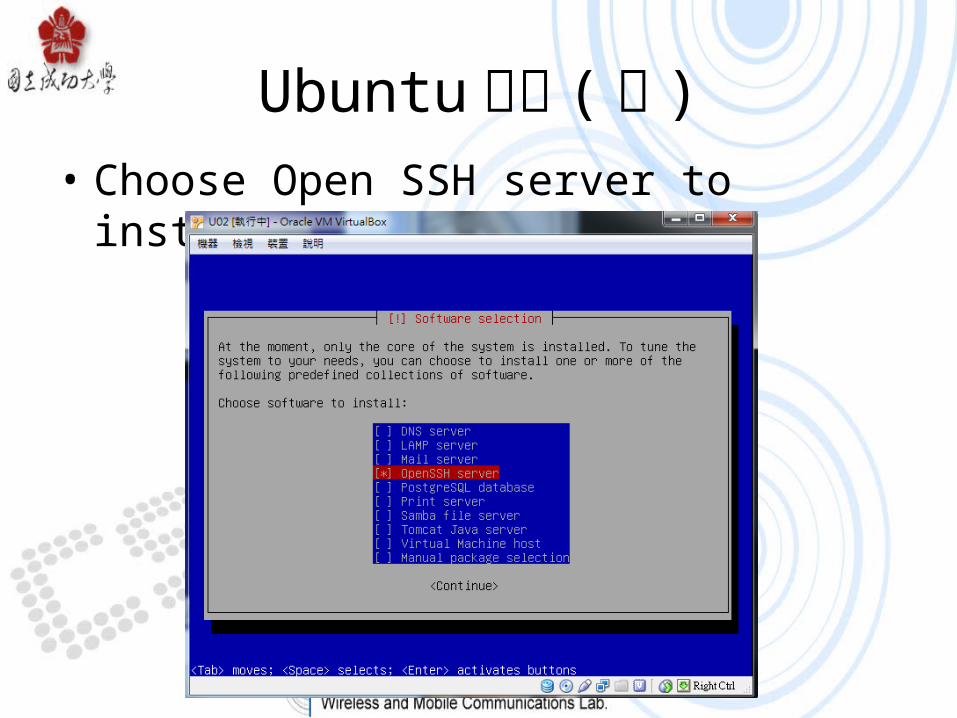
Ubuntu 安裝 ( 續 )• Choose Open SSH server to install

Ubuntu 安裝 ( 續 )

Ubuntu 安裝 ( 續 )• 輸入帳號密碼驗證安裝結果

Ubuntu 安裝 ( 續 )• 安裝完成

安裝 jdk• 取得 root 權限• 先取得軟體源,再安裝 JDK
– sudo apt-get install python-software-propertiessudo add-apt-repository ppa:ferramroberto/javasudo apt-get updatesudo apt-get install sun-java6-jdk

建立 hadoop 使用者• 使用 addgroup hadoop 指令建立新的群組• 使用 adduser –ingroup
hadoop hadoop 指令新增使用者 hadoop 至 hadoop 群組中• 使用 vim /etc/passwd 指令編輯 passwd 檔案

修改 sudo 權限• 最後一行 “ x” 刪除掉• 編輯 sudoer
– visudo– vim /etc/sudoer
• 加入 – hadoop ALL=(ALL) ALL– 使用者帳號 登入者的來源主機名稱 =( 可切換的身份 ) 可下達的指令
• 存檔離開– Ctrl+X– :wq

ssh 免密碼登入• 使用 su – hadoop 指令切換使用者為 Hadoop• 產生 key
– ssh-keygen –t rsa –P “”
• 將 public key 拷貝到遠端的電腦後 , 加到該 user的 .ssh/authorized_keys 中– cat /home/hadoop/.ssh/id_rsa.pub >>
/home/hadoop/.ssh/authorized_keys
• 離開切換回使用者 root

Hadoop 安裝• 下載 hadoop-1.2.1– wget http://140.116.82.153/~easer/hadoop-1.2.1.tar.gz
• 移動至 /usr/local 下解壓縮– mv hadoop-1.2.1.tar.gz /usr/local– cd /usr/local– tar –xvf hadoop-1.2.1.tar.gz

Hadoop 安裝 ( 續 )
• 改變檔案擁有者– chown –R hadoop:hadoop hadoop-1.2.1
• 製作捷徑到使用者 hadoop 的 home 下– ln –s hadoop-1.2.1/ /home/hadoop/hadoop
• 刪除下載的檔案– rm –rf hadoop-1.2.1.tar.gz

設定 /etc/hosts
• 使用 vi /etc/hosts 指令修改 etc 資料夾下的 hosts 檔案• 加入 192.168.56.101 u02 設定這個 ip 為自己

設定 interfaces
• 先查看網卡編號• ifconfig -a

• 使用 vim /etc/network/interfaces 指令修改interfaces 檔案

Hadoop 設定 ( 續 )
• 使用 /etc/init.d/networking restart 指令重開網路• 使用 ifconfig –a 查看目前網路設定是否改為設定的結果

Hadoop 設定• 使用 su – hadoop 指令改變使用者為 Hadoop• cd ~/hadoop or cd /usr/local/hadoop-1.2.1• 使用 vim conf/hadoop-env.sh 指令修改檔案• 加入 export JAVA_HOME=/usr/lib/jvm/java-6-sun及 export HADOOP_OPTS=“-
Djava.net.preferIPv4Stack=true”
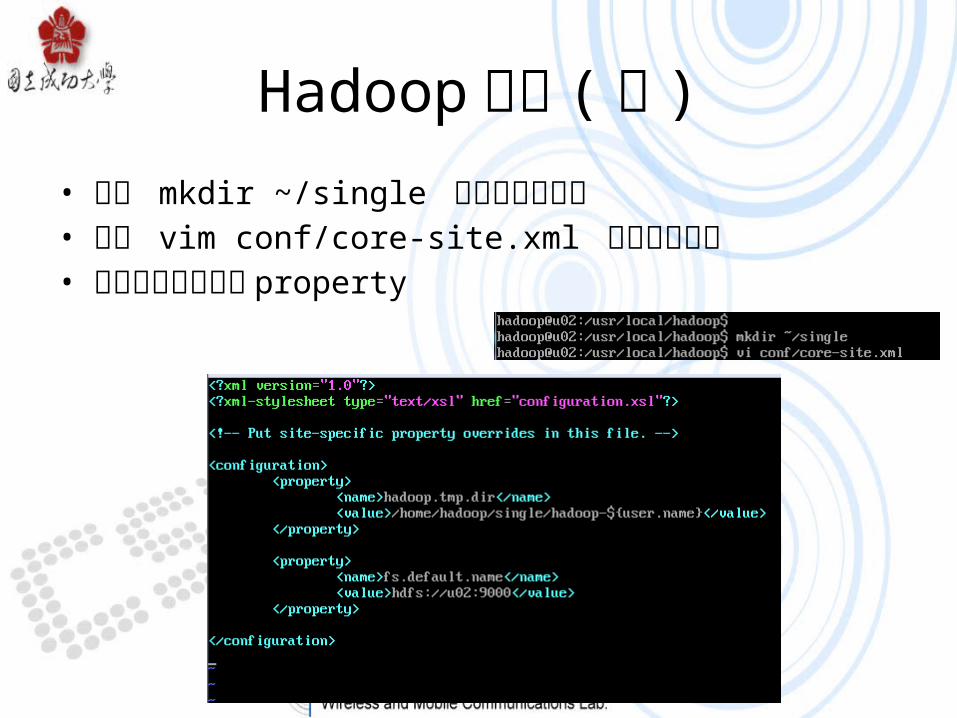
Hadoop 設定 ( 續 )• 使用 mkdir ~/single 指令新增資料夾• 使用 vim conf/core-site.xml 指令修改檔案• 加入圖示中之兩個 property

Hadoop 設定 ( 續 )• 使用 vim conf/mapred-site.xml 指令修改檔案• 加入圖示中之 property

Hadoop 設定 ( 續 )
• 使用 vim conf/hdfs-site.xml 指令修改檔案• 加入圖示中之 property

Hadoop 設定 ( 續 )
• 使用 vim conf/masters 指令修改 masters 檔案• 設定 master 僅有 u02• 使用 vim conf/slaves 指令修改 slaves 檔案• 設定 slave 僅有 u02

Hadoop 設定 ( 續 )• 使用 bin/hadoop namenode –format 指令啟用 namenode 及查看設定• 使用 bin/start-all.sh 開啟系統
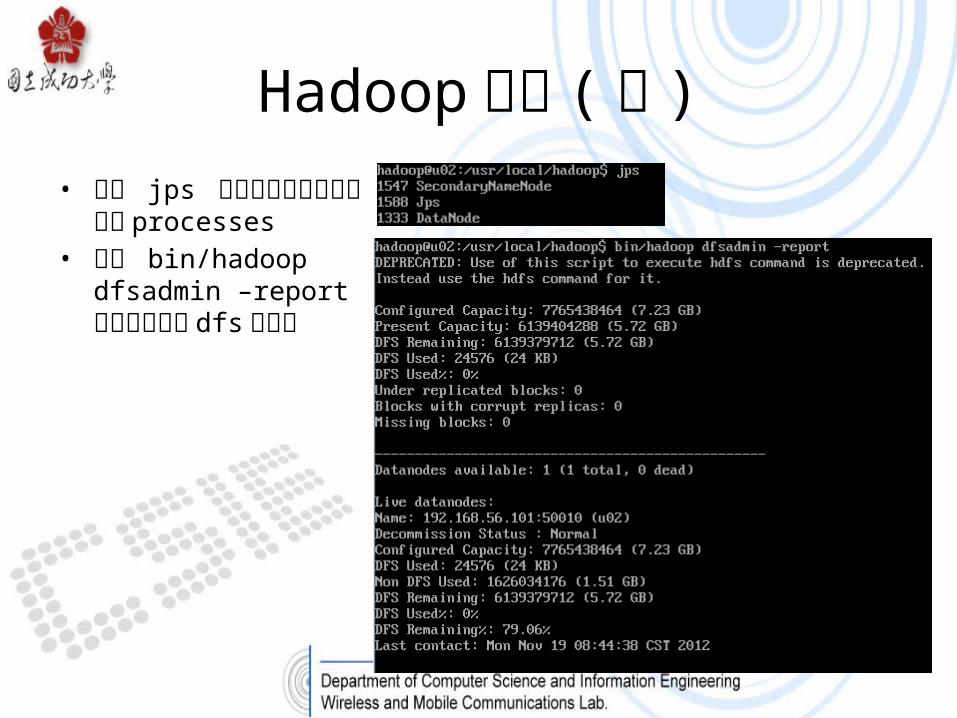
Hadoop 設定 ( 續 )• 使用 jps 指令查看目前開啟之相關 processes• 使用 bin/hadoop
dfsadmin –report 指令查看目前 dfs 之報告

Hadoop 設定 ( 續 )• 使用 bin/hadoop dfsadmin –safemode leave 指令離開安全模式• 使用 bin/hadoop dfs –mkdir input 新增 input 資料夾• 使用 bin/hadoop dfs –lsr 指令• 編輯 single.txt

Hadoop 設定 ( 續 )
• 編輯 single.txt• 輸入一段文字以利使用 example 範例之 wordcount程式• bin/hadoop dfs –put single.txt input

Hadoop 設定 ( 續 )• 使用 bin/hadoop jar hadoop-1.2.1.example.jar wordcount
input output 指令執行 wordcount

Hadoop 設定 ( 續 )
• 看結果– bin/hadoop dfs –cat output/part-r-00000

Web interface• 修改 windows 中 C:\Windows\System32\
drivers\etc\hosts 檔案• 加入 192.168.56.101 u02設定此 IP 為 u02

Web interface ( 續 )• 打開瀏覽器網址輸入 http://u02:50070/可察看目前之使用情形
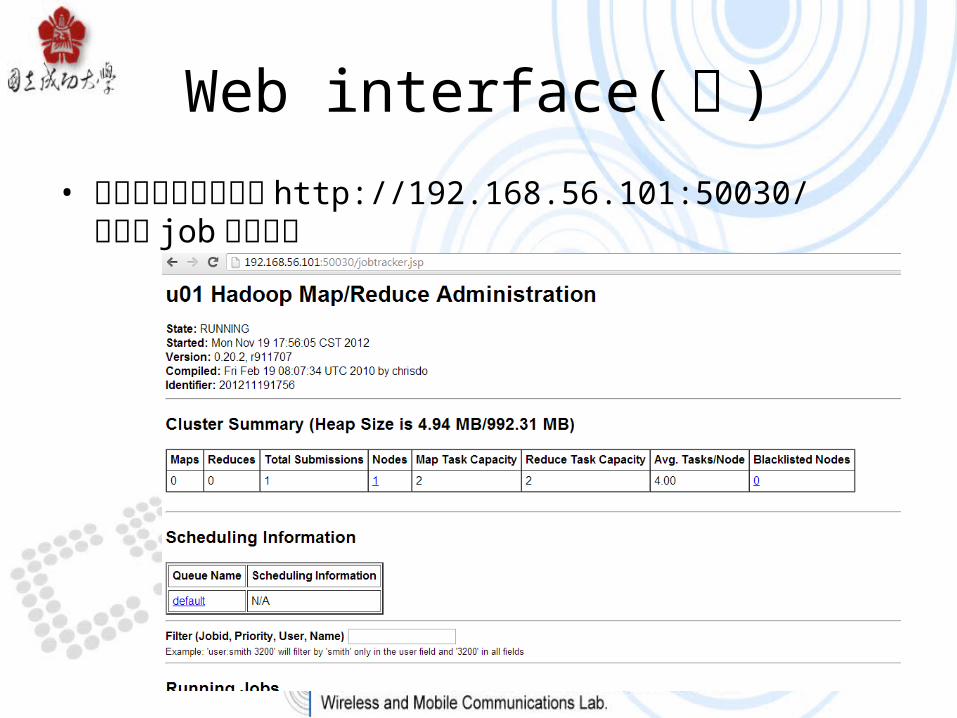
Web interface( 續 )• 打開瀏覽器網址輸入 http://192.168.56.101:50030/可察看 job 使用情形

練習• 架設兩台 node• 執行更大的檔案• 編譯 wordcount 程式
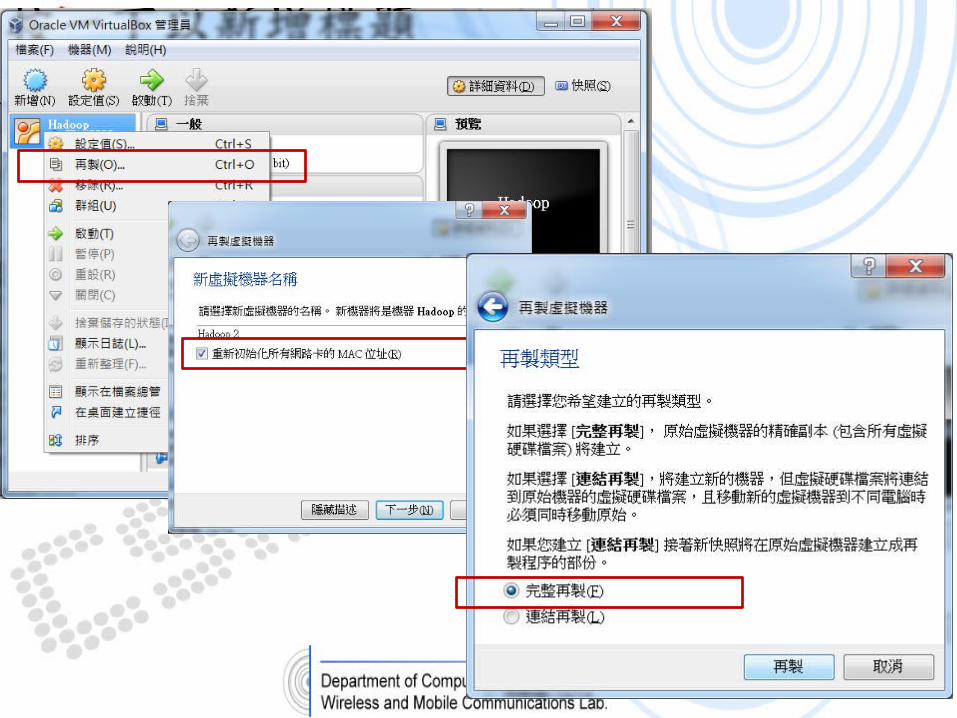

新增 node 設定• 在第一個 node– 編輯 /etc/hosts 增加 node 2 的 IP 與 hostname– 重新啟動網卡– 編輯 ~/hadoop/conf/slaves 增加 node 2 的
hostname• 在第二個 node– 編輯 /etc/hosts 增加 node 2 的 IP 與 hostname– 修改網卡設定 指派 node 2 的 IP – 重新啟動網卡– 編輯 ~/hadoop/conf/slaves 增加 node 2 的
hostname

重新格式化與執行 Hadoop
• 因 Node 1 為 master ,故在 Node 1 操作– 刪除 node 1 & 2 的 Hadoop tmp 資料夾• rm –r ~/single/hadoop-hadoop
– 格式化 namenode– 啟動 hadoop

編譯程式• 下載– 原始碼 WordCount.java• wget http://140.116.82.153/~easer/WordCount.java
– 編譯檔 Makefile• wget http://140.116.82.153/~easer/makefile
– Input 資料• wget http://140.116.82.153/~easer/textfile• ~/hadoop/bin/hadoop dfs –mkdir input2 • ~/hadoop/bin/hadoop dfs –put textfile input2/ • make clean• make

參考• http://www.youtube.com/watch?
v=Vf1HD4TjMDM&list=UUblZ4zYwgBx2j_B4ciTJMfg&index=40&feature=plcp
• http://en.wikipedia.org/wiki/Apache_Hadoop• http://hadoop.apache.org/• http://www.slideshare.net/waue/hadoop-map-
reduce-3019713