Поиск путей на графе - intel® software · ботанной и...
TRANSCRIPT

Нижегородский государственный университет им. Н.И. Лобачевского
Факультет вычислительной математики и кибернетики
Образовательный комплекс «Параллельные численные методы»
Лабораторная работа Поиск путей на графе
____________________
Козинов Е.А., Сиднев А.А.
При поддержке компании Intel
Нижний Новгород
2011

Содержание
ВВЕДЕНИЕ ........................................................................................................ 4
1. МЕТОДИЧЕСКИЕ УКАЗАНИЯ ....................................................... 5
1.1. ЦЕЛИ И ЗАДАЧИ РАБОТЫ ...................................................................... 5 1.2. СТРУКТУРА РАБОТЫ ............................................................................. 6 1.3. ТЕСТОВАЯ ИНФРАСТРУКТУРА .............................................................. 6 1.4. РЕКОМЕНДАЦИИ ПО ПРОВЕДЕНИЮ ЗАНЯТИЙ ..................................... 7
2. ПОИСК КРАТЧАЙШИХ ПУТЕЙ ДЛЯ ВСЕХ ПАР ВЕРШИН
НА ГРАФЕ ......................................................................................................... 7
2.1. ИСПОЛЬЗОВАНИЕ БИБЛИОТЕКИ BOOST ДЛЯ ПОИСКА КРАТЧАЙШИХ
ПУТЕЙ 14
3. ПРОСТЕЙШИЙ АЛГОРИТМ ПОИСКА КРАТЧАЙШИХ
ПУТЕЙ .............................................................................................................. 20
3.1. ОПИСАНИЕ ПОСЛЕДОВАТЕЛЬНОГО АЛГОРИТМА............................... 20 3.2. РЕАЛИЗАЦИЯ ПОСЛЕДОВАТЕЛЬНОЙ ВЕРСИИ ..................................... 22 3.3. ОПИСАНИЕ ПАРАЛЛЕЛЬНОГО АЛГОРИТМА ....................................... 33 3.4. РЕАЛИЗАЦИИ ПАРАЛЛЕЛЬНОЙ ВЕРСИИ С ИСПОЛЬЗОВАНИЕМ TBB . 34 3.5. РЕАЛИЗАЦИИ ПАРАЛЛЕЛЬНОЙ ВЕРСИИ С ИСПОЛЬЗОВАНИЕМ CILK . 41
4. АЛГОРИТМ ФЛОЙДА-ВАРШАЛЛА ............................................ 47
4.1. ОПИСАНИЕ ПОСЛЕДОВАТЕЛЬНОГО АЛГОРИТМА............................... 47 4.2. РЕАЛИЗАЦИЯ ПОСЛЕДОВАТЕЛЬНОЙ ВЕРСИИ ..................................... 48 4.3. ОПИСАНИЕ ПАРАЛЛЕЛЬНОГО АЛГОРИТМА ....................................... 53 4.4. РЕАЛИЗАЦИИ ПАРАЛЛЕЛЬНОЙ ВЕРСИИ С ИСПОЛЬЗОВАНИЕМ TBB . 53 4.5. РЕАЛИЗАЦИИ ПАРАЛЛЕЛЬНОЙ ВЕРСИИ С ИСПОЛЬЗОВАНИЕМ CILK . 59
5. АЛГОРИТМ ДЖОНСОНА ............................................................... 63
5.1. ОПИСАНИЕ ПОСЛЕДОВАТЕЛЬНОГО АЛГОРИТМА............................... 63 5.2. РЕАЛИЗАЦИЯ ПОСЛЕДОВАТЕЛЬНОЙ ВЕРСИИ ..................................... 65 5.3. ОПИСАНИЕ ПАРАЛЛЕЛЬНОГО АЛГОРИТМА ....................................... 73 5.4. РЕАЛИЗАЦИЯ ПАРАЛЛЕЛЬНОЙ ВЕРСИИ С ИСПОЛЬЗОВАНИЕМ
TBB 74 5.5. РЕАЛИЗАЦИЯ ПАРАЛЛЕЛЬНОЙ ВЕРСИИ С ИСПОЛЬЗОВАНИЕМ CILK . 82
6. ДОПОЛНИТЕЛЬНЫЕ ЗАДАНИЯ .................................................. 84
7. ЛИТЕРАТУРА .................................................................................... 85
7.1. ОСНОВНАЯ ЛИТЕРАТУРА .................................................................... 85 7.2. ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА ....................................................... 85

Параллельные численные методы 3
7.3. ИНФОРМАЦИОННЫЕ РЕСУРСЫ СЕТИ ИНТЕРНЕТ ............................... 85

Поиск путей на графе
4
Введение
оиск кратчайшего пути – важная задача, возникающая в разных
областях науки и техники: в экономике (при оптимизации перево-
зок), в робототехнике (при поиске роботом оптимального маршру-
та), в компьютерных играх (при перемещении отрядов в лабиринте в стра-
тегиях реального времени) и так далее. На этапе моделирования традици-
онно используются графы, вершины которых соответствуют пунктам
назначения, а ребра – прямым маршрутам из одного пункта в другой. Часто
ребру ставится в соответствие число, характеризующее условную «стои-
мость» перемещения. Выделяют четыре задачи поиска кратчайших путей
на графе:
между двумя вершинами (задача 1);
от заданной вершины ко всем вершинам (задача 2);
от всех вершин до заданной вершины (задача 3);
от всех вершин ко всем вершинам (задача 4).
Все перечисленные формулировки имеют прикладное значение. Решению
задачи в различных постановках посвящено немало литературы [1, 2, 3, 4,
5].
Возможный вариант состоит в том, чтобы решить четвертую задачу, со-
хранить результаты и использовать ее далее для решения задач 1–3. При
этом поиск решения задачи 4 занимает существенное время и выполняется
заранее, но задачи 1–3 решаются в режиме реального времени (к примеру,
можно использовать таблицы с вычислимым входом для хранения опти-
мальных путей). Главным недостатком такого подхода являются гигант-
ские затраты по памяти, что обуславливает невозможность его применения
в большинстве случаев. Другой подход связан с прямым решением задачи
«с нуля» в каждом случае, когда оно требуется. Реализацией этого подхода
являются алгоритмы Дэйкстры (задача 2), Джонсона (задача 4), Беллмана-
Форда (задача 2), Флойда-Варшалла1 (задача 4), алгоритм A* (задача 1) и
многие другие. Некоторые алгоритмы решают задачу точно, другие ис-
пользуют эвристики, что позволяет находить достаточно хорошее решение
1 В русскоязычной литературе фамилия одного из авторов алгоритма Floyd-Warshall имеет
несколько транслитераций: Флойд-Уоршелл, Флойд-Уоршолл, Флойд-Варшалл. Далее в
работе мы будем использовать последний вариант, использующийся в книге [1].
П

Параллельные численные методы 5
за приемлемое время. Другой подход заключается в предварительной
(обычно продолжительной) обработке графа. С использованием предобра-
ботанной и сохраненной информации поиск осуществляется достаточно
быстро. Обзор таких алгоритмов представлен в презентации известного
специалиста в указанной области Renato F. Werneck [2].
В лабораторной работе рассматривается задача поиска кратчайших путей
от всех вершин ко всем вершинам. Выполняется программная реализация и
распараллеливания следующих классических алгоритмов ( – количество
вершин графа, – количество рѐбер графа):
1. Алгоритм динамического программирования на матрицах кратчайших
путей. Идея этого алгоритма заключается в вычислении , где в
операции матричного умножения сложение заменено на поиск мини-
мума, а умножение – на сложение. Трудоѐмкость такого алгоритма со-
ставляет ( получается за счѐт рекуррентного развора-
чивания степени).
2. Алгоритм Флойда-Варшалла. Алгоритм логически вытекает из преды-
дущего. Идея алгоритма состоит в последовательном уменьшении рас-
стояний между каждой парой вершин, за счѐт просматривания пути че-
рез дополнительную промежуточную вершину. Если путь через про-
межуточную вершину оказывается короче, чем текущее значение рас-
стояния, то новый путь становится минимальным и значение расстоя-
ния между вершинами обновляется. Алгоритм Флойда-Варшалла как
правило, используется для плотных графов. Трудоѐмкость алгоритма
.
3. Алгоритм Джонсона. Идея этого алгоритма заключается в вызове для
каждой вершины алгоритма Дейкстры. Кроме того предварительно от-
рабатывает алгоритм Беллмана-Форда, который позволяет искать пути
в графе с отрицательными весами вершин. Трудоѐмкость алгоритма со-
ставляет .
Для всех указанных алгоритмов в лабораторной работе будут разработаны
параллельные реализации с использованием библиотеки Intel TBB и рас-
ширения языка C++ – Cilk Plus.
1. Методические указания
1.1. Цели и задачи работы
Цель данной работы – изучение некоторых алгоритмов поиска
кратчайших путей на графах и подходов к их
распараллеливанию в системах с общей памятью с
использованием Intel TBB и Cilk Plus .

Поиск путей на графе
6
Данная цель предполагает решение следующих основных задач:
1. Подготовка тестовой инфраструктуры для проведения экспериментов.
2. Ознакомление с доступными последовательными реализациями алго-
ритмов в стандартных библиотеках (на примере BOOST).
3. Изучение последовательных алгоритмов и их программная реализация.
Проведение вычислительных экспериментов.
4. Рассмотрение разных способов распараллеливания алгоритмов для си-
стем с общей памятью с использованием Intel TBB (включая task-based
параллелизм) и Cilk Plus.
1.2. Структура работы
Работа построена следующим образом: во введении представлен краткий
экскурс в проблематику разработки и применения алгоритмов поиска крат-
чайших путей. Далее формулируются цели лабораторной работы, а также
методические рекомендации по ее проведению. Описывается программная
инфраструктура для выполнения экспериментов. Приводятся результаты
запуска алгоритма из библиотеки BOOST. Рассматриваются три алгоритма
решения задачи, для каждого из них выполняется программная реализация
в последовательной и параллельной версии. В заключение формулируются
основные выводы и даются задания для самостоятельной проработки.
1.3. Тестовая инфраструктура
Вычислительные эксперименты проводились с использованием следующей
инфраструктуры (табл. 1).
Таблица 1. Тестовая инфраструктура
Процессор 2 четырехъядерных процессора Intel Xeon
E5520 (2.27 GHz)
Память 16 Gb
Операционная система Microsoft Windows 7
Среда разработки Microsoft Visual Studio 2008:
Version 9.0.21022.8
Microsoft (R) 32-bit C/C++ Optimiz-
ing Compiler Version 15.00.21022.08
for 80x86
Компилятор, профилиров- BoostPro 1.46.1

Параллельные численные методы 7
щик, отладчик, математиче-
ская библиотека
Intel Parallel Studio XE 2011:
Intel Composer XE 2011 (package
104):
o Intel(R) C++ Compiler XE
for applications running on
IA-32, Version 12.0.0.104
o Intel MKL v. 10.3.0.104
Intel Inspector XE 2011 (build
119192)
Intel VTune Amplifier XE 2011
(build 119041)
1.4. Рекомендации по проведению занятий
Для выполнения лабораторной работы рекомендуется следующая последо-
вательность действий.
1. Дать введение в проблематику решения задачи поиска кратчайших пу-
тей, обзор наиболее показательных алгоритмов.
2. Описать программную инфраструктуру для проведения экспериментов.
3. Вместе со слушателями воспользоваться алгоритмом поиска путей из
библиотеки BOOST.
4. Выполнить последовательную программную реализацию каждого из
трех рассматриваемых алгоритмов. Провести вычислительные экспе-
рименты. Убедиться в корректности, обратить внимание на производи-
тельность.
5. Распараллелить алгоритмы для систем с общей памятью с использова-
нием TBB и Cilk Plus. Провести эксперименты. Обсудить результаты.
6. Сформулировать основные выводы.
2. Поиск кратчайших путей для всех пар вершин на
графе
Перед кодированием и написанием программного кода определимся с дан-
ными, на которых будут проводиться эксперименты, и с форматом хране-
ния графов.
Графы для экспериментов можно генерировать с помощью специальных
генераторов или получить на основании реальных данных, например граф

Поиск путей на графе
8
сети дорог, содержащий расстояния или времена между узловыми точками.
В данной работе мы остановимся на втором варианте, взяв граф карты до-
рог Рима [10]. Граф задаѐтся в файле и имеет текстовый формат. Файл со-
держит строчки следующих типов:
1. Комментарий (строка начинается с символа 'c').
2. Формат и описание графа (строка начинается с символа 'p'). Например,
"p sp 2000 6000", означает, что граф разреженный и содержит 2000
вершин, 6000 рѐбер.
3. Рѐбра (строка начинается с символа 'a'). Например: "a 596 959 78",
означает ребро из вершины 596 в вершину 959 с весом 78.
Строка с описанием графа должна предшествовать перечислению списка
рѐбер.
Граф карты дорог Рима имеет разреженный формат, поэтому для хранения
графа в оперативной памяти компьютера будем использовать разреженный
формат аналогичный тому, что используется в работе «Разреженное умно-
жение матриц». Ориентированный граф сети дорог Рима содержит 3353
вершин и 8870 рѐбер.
Результатом работы программы будет плотная матрица расстояний между
каждой парой вершин. Для любого алгоритма поиска кратчайших путей
эта матрица должна содержать одинаковые значения при одинаковых
входных данных.
Итак, в среде Microsoft Visual Studio 2008, создадим новое Решение
(Solution), в которое включим первый Проект (Project) данной лаборатор-
ной работы. Последовательно выполните следующие шаги:
Запустите приложение Microsoft Visual Studio 2008.
В меню File выполните команду New→Project….
В диалоговом окне New Project в типах проекта выберите Win32, в
шаблонах Win32 Console Application, в поле Solution введите
ShortestPaths, в поле Name – 01_Boost, в поле Location укажите путь к
папке с лабораторными работами курса – c:\ParallelCalculus\. Нажмите
OK.
В диалоговом окне Win32 Application Wizard нажмите Next (или вы-
берите Application Settings в дереве слева) и установите флаг Empty
Project. Нажмите Finish.
В окне Solution Explorer в папке Source Files выполните команду кон-
текстного меню Add→New Item…. В дереве категорий слева выберите
Code, в шаблонах справа – C++ File (.cpp), в поле Name введите имя
файла main. Нажмите Add.

Параллельные численные методы 9
Перейдите к использованию компилятора Intel, выбрав проект в окне
Solution Explorer и выполнив команду контекстного меню Intel
Parallel Composer→Use Intel C++….
Перед реализацией первого проекта, выполняющего поиск пути на графе,
разработаем функцию загрузки графа из файла в отдельной статической
библиотеке. Для этого добавим в Решение новый проект с названием
GraphRoutine. Выполните следующую последовательность действий:
В меню File выполните команду Add→New Project….
Как показано на рис. 1, в диалоговом окне New Project в типах проекта
выберите Win32, в шаблонах Win32 Console Application, в поле Name
введите GraphRoutine. Нажмите OK.
Рис. 1. Добавление проекта в Решение лабораторной работы
В диалоговом окне Win32 Application Wizard нажмите Next (или вы-
берите Application Settings в дереве слева) и установите флаг Empty
Project. Нажмите Finish.
В окне Solution Explorer в папке Source Files выполните команду кон-
текстного меню Add→New Item…. В дереве категорий слева выберите
Code, в шаблонах справа – C++ File (.cpp), в поле Name введите имя
файла routine. Нажмите Add.
Перейдите к использованию компилятора Intel, выбрав проект в окне
Solution Explorer и выполнив команду контекстного меню Intel
Parallel Composer→Use Intel C++….
В свойствах проекта смените тип собираемого бинарного файла с .exe
на .lib. В меню Project выполните команду Properties. Перейдите на
вкладку Configuration Properties→ General и в поле Configuration
Type выберите Static Library (.lib).

Поиск путей на графе
10
Добавим к созданному проекту заголовочный файл DataStruct.h, который
будет содержать описание структуры графа в разреженном формате. Для
этого в окне Solution Explorer в папке Header Files выполните команду
контекстного меню Add→New Item…. В дереве категорий слева выберите
Code, в шаблонах справа – Header File (.h), в поле Name введите имя фай-
ла DataStruct. Нажмите Add.
В файле напишем следующий код:
#ifndef DATA_STRUCT
#define DATA_STRUCT
struct GraphMatrix
{
int *pointerB; // указатели на начало списка связаных
// ребер
int *column; // индексы связанных вершин
int *value; // веса ребер
int sizeV; // количество вершин
int sizeE; // количество ребер
};
#endif
Добавим к созданному проекту заголовочный файл routine.h, который бу-
дет содержать прототип функции ParseGraph загрузки графа из файла. Эта
функция будет принимать имя файла и двойной указатель на структурe
хранения разреженного графа. В файле напишем следующий код:
#ifndef ROUTINE_H
#define ROUTINE_H
#include "DataStruct.h"
int ParseGraph(char* graphPath, GraphMatrix **gr);
#endif
Теперь перейдѐм к реализации функции ParseGraph. Сначала в файле
routine.cpp подключим заголовочные файлы, которые понадобятся при
разработке. Далее объявим макрос BUF_SIZE, который будет содержать
количество элементов массива, необходимого для разбора строк файла.
Объявим структуру TEdge, которая описывает ребро графа, и реализуем
функцию, позволяющую сравнивать две структуры типа TEdge.
#include "routine.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>

Параллельные численные методы 11
#include <vector>
#include <algorithm>
#define BUF_SIZE 200
struct TEdge
{
int row;
int col;
int val;
};
bool CmpEdges( TEdge arg1, TEdge arg2 )
{
if(arg1.row<arg2.row)
return true;
else
if(arg1.row == arg2.row)
{
if(arg1.col<arg2.col)
return true;
}
return false;
}
Теперь приступим к реализации функции загрузки графа из файла.
int ParseGraph(char* graphPath, GraphMatrix **gr)
{
//Реализация будет тут
return 0;
}
Для начала проверим, доступен ли указанный файл с графом, открыв его на
чтение. Если функция fopen вернѐт 0, то завершим функцию
ParseGraph с кодом ошибки -1.
FILE * f;
int sizeV;
f = fopen(graphPath, "r");
if( f == NULL )
{
printf("The file (%s) was not opened\n", graphPath);
return -1;
}
Выделим память под структуру GraphMatrix и создадим контейнер
vector, в котором будут временно содержаться ребра графа.

Поиск путей на графе
12
GraphMatrix *graph = new GraphMatrix;
(*gr) = graph;
std::vector<TEdge> edges;
Теперь загрузим из файла все рѐбра в контейнер edges и отсортируем,
используя для сравения функцию CmpEdges.
while(!feof(f))
{
char buf[BUF_SIZE];
char val_buf[4][BUF_SIZE/4];
memset(buf, 0, sizeof(buf));
fgets(buf, BUF_SIZE, f);
if(buf[0] != 'c' && buf[0] != 0)
{
memset(val_buf, 0, sizeof(val_buf));
int count = sscanf(buf,"%s %s %s %s",
val_buf[0], val_buf[1],
val_buf[2], val_buf[3]);
if(count != 4)
{
printf("The file (%s) was corrupted on line
(%s)\n", graphPath, buf);
return -2;
}
if(val_buf[0][0] == 'p')
sizeV = atoi(val_buf[2]);
if(val_buf[0][0] == 'a')
{
TEdge e = {atoi(val_buf[1]) - 1,
atoi(val_buf[2]) - 1, atoi(val_buf[3])};
edges.push_back(e);
}
}
}
std::sort(edges.begin(), edges.end(), CmpEdges);
Далее удаляем дубликаты рѐбер (оставляем ребро минимального веса).
//Удаляем дубликаты рѐбер
// (оставляем ребро минимального веса)
for(std::vector<TEdge>::iterator i = edges.begin();
i != edges.end()-1; )

Параллельные численные методы 13
{
std::vector<TEdge>::iterator j = i+1;
if( ((*i).row == (*j).row) && ((*i).col == (*j).col))
{
if((*j).val < (*i).val)
i = edges.erase(i);
else
{
i = edges.erase(j);
i--;
}
}
else
i++;
}
Заполняем структуру GraphMatrix.
graph->sizeV = sizeV;
graph->sizeE = edges.size();
graph->pointerB = new int[graph->sizeV + 1];
graph->column = new int[graph->sizeE];
graph->value = new int[graph->sizeE];
memset(graph->pointerB, 0,
sizeof(int) * (graph->sizeV + 1));
for(std::vector<TEdge>::iterator i = edges.begin();
i != edges.end(); i++)
{
int row = (*i).row;
graph->pointerB[row]++;
}
int sum = 0;
for(int i = 0; i < graph->sizeV; i++)
{
int tmp = graph->pointerB[i];
graph->pointerB[i] = sum;
sum += tmp;
}
graph->pointerB[graph->sizeV] = sum;
int *counter = new int[graph->sizeV];
for(int i = 0; i < graph->sizeV; i++)
counter[i] = 0;
for(std::vector<TEdge>::iterator i = edges.begin();
i != edges.end(); i++)

Поиск путей на графе
14
{
int pos;
int row = (*i).row;
int col = (*i).col;
int val = (*i).val;
pos = graph->pointerB[row] +
counter[row];
graph->column[pos] = col;
graph->value [pos] = val;
counter[row]++;
}
Выводим информацию о загруженном файле на экран и закрываем файл с
графом.
printf("Graph from file (%s) has loaded.\n", graphPath);
printf("Vertices: %i, Edges: %i.\n", graph->sizeV,
graph->sizeE);
fflush(stdout);
delete []counter;
fclose(f);
2.1. Использование библиотеки Boost для поиска кратчай-
ших путей
Для поиска кратчайших путей воспользуемся реализацией алгоритмов
Флойда-Варшалла и Джонсона из библиотеки Boost. Скачайте и установи-
те библиотеку Boost [9]. Внесите изменения в настройки проекта:
В свойствах проекта укажите дополнительные пути к нашим собствен-
ным заголовочным файлам и заголовочным файлам библиотеки Boost
(путь к заголовочным файлам библиотеки Boost может отличаться в за-
висимости от пути установки). В меню Project выполните команду
Properties. Перейдите на вкладку Configuration Proper-
ties→C/C++→General и в поле Additional Include Directories введите
..\GraphRoutine; C:\Program Files (x86)\boost\boost_1_46_1\.
Установите зависимости проекта в меню Project, выполнив команду
Project Dependencies… В открывшемся окне выберите проект
GraphRoutine. Нажмите OK.
Перейдѐм к написанию кода в файле main.cpp. Подключим требуемые за-
головочные файлы и пространство имѐн std. Объявим перечислимый тип
AlgType, определяющий какой алгоритм выбран для поиска пути.
#include <stdio.h>
#include <stdlib.h>

Параллельные численные методы 15
#include <time.h>
#include "windows.h"
#include <string>
#include "Boost.h"
using namespace std;
enum AlgType {Johnson, FloydWarshall, None};
Теперь приступим к разработке функции main(). Объявим необходимые
переменные.
int main(int argc, char **argv)
{
GraphMatrix *gr;
int *dist;
bool printOutput = false;
AlgType aType = None;
LARGE_INTEGER freq;
LARGE_INTEGER sQP, fQP;
QueryPerformanceFrequency(&freq);
Далее реализуем разбор аргументов командной строки (загрузку графа из
файла, определение используемого алгоритма и требуется ли вывод ре-
зультатов на жесткий диск).
if (argc < 3)
{
printf("\nUsage: program.exe <graph file> <Jo|FW> [-
o]\n");
return 1;
}
ParseGraph(argv[1], &gr);
if (string(argv[2]) == string("Jo"))
aType = Johnson;
if (string(argv[2]) == string("FW"))
aType = FloydWarshall;
if (argc == 4)
if(string(argv[3]) == string("-o"))
printOutput = true;
Выделим память под матрицу результатов и запустим соответствующий
алгоритма поиска пути, выполняя замеры времени его работы.
dist = new int[gr->sizeV * gr->sizeV];

Поиск путей на графе
16
switch (aType)
{
case Johnson:
QueryPerformanceCounter(&sQP);
JohnsonBoost(gr, dist);
QueryPerformanceCounter(&fQP);
printf("Boost Johnson time: %f\n",
(fQP.QuadPart-sQP.QuadPart)/
(double)freq.QuadPart );
break;
case FloydWarshall:
QueryPerformanceCounter(&sQP);
FloydWarshallBoost(gr, dist);
QueryPerformanceCounter(&fQP);
printf("Boost Floyd-Warshall time: %f\n",
(fQP.QuadPart-sQP.QuadPart)/
(double)freq.QuadPart );
break;
default:
printf("Nothing has been done.\n" );
};
Теперь сохраним матрицу расстояний на жесткий диск, если это требова-
лось и освободим динамическую память.
if(printOutput)
{
FILE *distFile=fopen("01_dist.dat", "wb");
fwrite(dist, sizeof(int), gr->sizeV * gr->sizeV,
distFile);
fclose(distFile);
printf("File (01_dist.dat) written.\n" );
}
delete[] gr->column;
delete[] gr->pointerB;
delete[] gr->value;
delete gr;
delete [] dist;
return 0;
}

Параллельные численные методы 17
Теперь осталось только реализовать сами функции поиска кратчайших пу-
тей. Для начала добавим в проект заголовочный файл Boost.h с описанием
прототипов функции поиска кратчайших путей.
#ifndef BOOST_H
#define BOOST_H
#include "routine.h"
void JohnsonBoost(GraphMatrix *gr, int *dist);
void FloydWarshallBoost(GraphMatrix *gr, int *dist);
#endif
Теперь добавим в наш проект файл Boost.cpp в котором напишем реализа-
цию функций поиска кратчайших путей. Для начала подключим требуемые
заголовочные файлы и пространство имѐн boost.
#include <boost/property_map/property_map.hpp>
#include <boost/graph/adjacency_list.hpp>
#include <boost/graph/johnson_all_pairs_shortest.hpp>
#include <boost/graph/floyd_warshall_shortest.hpp>
#include "routine.h"
using namespace boost;
Каждое ребро нашего графа имеет вес типа int. Объявим соответствую-
щий тип описания ребра графа.
typedef property<boost::edge_weight_t, int> EdgeWeight;
Далее объявим тип графа, указав, что граф будет ориентированным, а в
качестве описания рѐбер графа будет использоваться объявленный выше
тип.
typedef adjacency_list<vecS, vecS, directedS, no_property,
EdgeWeight > Graph;
Начнѐм реализацию функции поиска кратчайших путей с помощью алго-
ритма Джонсона.
void JohnsonBoost(GraphMatrix *gr, int *dist)
{
//Реализация будет тут
}
Создадим объект графа и добавим в него рѐбра.
int v = gr->sizeV;
Graph g;
for(int i = 0; i < v; i++)

Поиск путей на графе
18
{
int okr_s = gr->pointerB[i ];
int okr_f = gr->pointerB[i + 1];
for(int okr_i = okr_s; okr_i < okr_f; okr_i++)
add_edge(i, gr->column[okr_i],
EdgeWeight(gr->value[okr_i]), g);
}
Результат функции поиска кратчайших путей из библиотеки Boost сохра-
няется в массив массивов. Инициализируем соответствующую структуру.
int **d = new int*[v];
for(int i=0; i<v; i++)
d[i] = new int[v];
Выполним вызов функции поиска кратчайших путей с помощью алгоритма
Дейкстры из библиотеки Boost.
johnson_all_pairs_shortest_paths(g, d);
Скопируем результат в выходной массив и освободим память.
for(int i=0; i<v; i++)
for(int j=0; j<v; j++)
dist[i*v+j] = d[i][j];
for(int i=0; i<v; i++)
delete[] d[i];
delete [] d;
Программный код функции поиска кратчайших путей с помощью алгорит-
ма Флойда-Варшалла выглядит абсолютно также, за исключением назва-
ния вызываемой функции из библиотеки Boost.
void FloydWarshallBoost(GraphMatrix *gr, int *dist)
{
int v = gr->sizeV;
Graph g;
for(int i = 0; i < v; i++) {
int okr_s = gr->pointerB[i ];
int okr_f = gr->pointerB[i + 1];
for(int okr_i = okr_s; okr_i < okr_f; okr_i++)
add_edge(i, gr->column[okr_i],
EdgeWeight(gr->value[okr_i]), g);
}

Параллельные численные методы 19
int **d = new int*[v];
for(int i=0; i<v; i++)
d[i] = new int[v];
floyd_warshall_all_pairs_shortest_paths(g, d);
for(int i=0; i<v; i++)
for(int j=0; j<v; j++)
dist[i*v+j] = d[i][j];
for(int i=0; i<v; i++)
delete[] d[i];
delete [] d;
}
Выполним сбору проекта и запустим на тестовом графе rome99.gr. Резуль-
таты работы алгоритма Флойда-Варшалла из библиотеки Boost, получен-
ные авторами на тестовой инфраструктуре, представлены на рис. 2.
Рис. 2. Результат поиска кратчайших путей для всех пар вершин на
карте Рима с помощью алгоритма Флойда-Варшалла из биб-
лиотеки Boost
Результаты работы алгоритма Джонсона из библиотеки Boost, полученные
авторами на тестовой инфраструктуре, представлены на рис. 3.

Поиск путей на графе
20
Рис. 3. Результат поиска кратчайших путей для всех пар вершин на
карте Рима с помощью алгоритма Джонсона из библиотеки
Boost
Полученный после запуска программы с ключом “-o” выходной файл
01_dist.dat будем использовать как эталонный. Дальнейшие реализации
алгоритмов будут также записывать выходные файлы (ключ “-o”) и срав-
ниваться с полученным на данном этапе.
Результатов работы алгоритмов подтверждают теоретические оценки: ал-
горитм Джонсона эффективно работает на разреженных графах, а алгоритм
Флойда-Варшалла наиболее эффективен на плотных матрицах.
3. Простейший алгоритм поиска кратчайших путей
В этом разделе будет рассмотрен простейший алгоритм поиска кратчайших
путей для каждой пары вершин на графе. Этот алгоритм выводится из
принципов динамического программирования (подробнее об этом можно
прочитать в разделе 21.1 книги [1]). Будут рассмотрены последовательная
реализация алгоритма и параллельные реализации с использованием биб-
лиотеки Intel TBB и расширение языка программирования Cilk Plus.
3.1. Описание последовательного алгоритма
Исходными данными для алгоритма является матрица смежности , зада-
ющая ориентированный граф (будем полагать, что граф содержит вер-
шин). Эта матрица задаѐт веса рѐбер между парами соединѐнных вершин.
В том случае, если между вершиной и отсутствовало ребро, то
(при реализации вместо бесконечности мы будем использовать максималь-
ное число, которое можно разместить в переменной типа int, это число
доступно через макрос INT_MAX). Матрица W квадратная размерности

Параллельные численные методы 21
, нумерация строк и столбцов будет осуществляться с нуля (как это
принято в языке C/C++).
Одна итерация алгоритма поиска кратчайших путей состоит в том, чтобы
определить веса кратчайших путей, которые содержат не более одного до-
полнительного ребра графа. На очередной итерации алгоритма имеется
матрица весов кратчайших путей, содержащих не более рѐбер. Вес пу-
ти из вершины в вершину ( ) выбирается как минимальное значение
из веса кратчайшего пути, содержащего не более рѐбер, и всех путей,
проходящих через промежуточную вершину :
(1)
Исходный граф не содержит петель ( , ̅̅ ̅̅ ̅̅ ̅̅ ̅̅ ), поэтому при
получаем , т.е. формулу (1) можно упро-
стить (рис. 4):
(2)
После выполнения итерации алгоритма матрица будет содержать веса
кратчайших путей, которые содержат не более чем ребро.
Рис. 4. Итерация алгоритма поиска кратчайших путей
На первой итерации алгоритма в качестве матрицы берѐтся матрица .
После выполнения очередной итерации алгоритма в качестве матрицы
берѐтся матрица . Алгоритм завершается после выполнения итера-
ций. Таким образом, в полученной матрице будут содержаться веса крат-
чайших путей, которые содержат не более чем ребро.
Несложно заметить, что описанный алгоритм одной итерации поиска крат-
чайших путей (рис. 4) напоминает операцию матричного умножения, в ко-
торой операция суммирования заменена на поиск минимума, а умножение
на сложение. Таким образом, для нахождения матрицы кратчайших весов
необходимо посчитать , где в операции матричного умножения заме-
нены арифметические операции на поиск минимума и сложение. Трудоѐм-
кость такого алгоритма составит (трудоѐмкость матричного умно-
жения , потребуется выполнить умножения матриц).

Поиск путей на графе
22
Для того, чтобы эффективно посчитать величину , разложим по
степеням двойки:
∑
(3)
Получаем:
∏
(4)
Из разложения (4) видно, что на каждой итерации достаточно выполнять
операцию возведения в квадрат и домножать полученную матрицу на ре-
зультат, если . Трудоѐмкость полученного алгоритма будет состав-
лять . Этот алгоритм и будет реализован в данном разделе.
3.2. Реализация последовательной версии
Создайте новый проект с названием 02_AllPairsShortestPaths. Для этого
выполните следующую последовательность действий:
В меню File выполните команду Add→New Project….
Как показано на рис. 5, в диалоговом окне New Project в типах проекта
выберите Win32, в шаблонах Win32 Console Application, в поле Name
введите 02_AllPairsShortestPaths. Нажмите OK.
Рис. 5. Создание решения для лабораторной работы

Параллельные численные методы 23
В диалоговом окне Win32 Application Wizard нажмите Next (или вы-
берите Application Settings в дереве слева) и установите флаг Empty
Project. Нажмите Finish.
В окне Solution Explorer в папке Source Files выполните команду кон-
текстного меню Add→New Item…. В дереве категорий слева выберите
Code, в шаблонах справа – C++ File (.cpp), в поле Name введите имя
файла main. Нажмите Add.
Перейдите к использованию компилятора Intel, выбрав проект в окне
Solution Explorer и выполнив команду контекстного меню Intel
Parallel Composer→Use Intel C++….
В свойствах проекта укажите дополнительные пути к заголовочным
файлам. В меню Project выполните команду Properties. Перейдите на
вкладку Configuration Properties→C/C++→General и в поле Addi-
tional Include Directories введите ..\GraphRoutine.
Установите зависимости проекта в меню Project, выполнив команду
Project Dependencies… В открывшемся окне выберите проект
GraphRoutine. Нажмите OK.
В результате выполненной последовательности действий в окне редактора
кода Visual Studio будет открыт пустой файл main.cpp.
Далее создадим заготовку функции main(), в которую через аргумент
командной строки будем передавать параметры: имя входного файла, ко-
торый содержит описание графа, и опционально ключ “-o” определяющий
будет ли выводить информация о кратчайших путях в файл.
Функция main() будет выполнять следующую последовательность дей-
ствий:
1. разбор аргументов командной строки (для уменьшения объѐмам кода
будем использовать класс string из библиотеки STL);
2. загрузку графа из файла и запись графа в разреженном формате;
3. запуск алгоритма поиска кратчайших путей и измерение времени его
работы;
4. вывод матрицы кратчайших путей в файл (запись файла осуществляет-
ся в бинарном формате) при наличии ключа “-o” в аргументах ко-
мандной строки.
#include <stdio.h>
#include <stdlib.h>
#include "windows.h"
#include <string>
#include "AllPairsShortestPaths.h"

Поиск путей на графе
24
using namespace std;
int main(int argc, char **argv)
{
LARGE_INTEGER freq;
LARGE_INTEGER sQP, fQP;
QueryPerformanceFrequency(&freq);
if (argc < 2)
{
printf("\nUsage: program.exe <graph file> [-o]\n");
return 1;
}
GraphMatrix *gr;
int *dist;
bool printOutput = false;
ParseGraph(argv[1], &gr);
if (argc == 3)
if(string(argv[2]) == string("-o"))
printOutput = true;
// дистанция до вершины
dist = new int[gr->sizeV * gr->sizeV];
QueryPerformanceCounter(&sQP);
AllPairsShortestPaths(gr, dist);
QueryPerformanceCounter(&fQP);
printf("AllPairsShortestPaths time: %f\n",
(fQP.QuadPart-sQP.QuadPart)/(double)freq.QuadPart);
if(printOutput)
{
FILE *distFile=fopen("02_dist.dat", "wb");
fwrite(dist, sizeof(int),
gr->sizeV * gr->sizeV, distFile);
fclose(distFile);
printf("File (02_dist.dat) written.\n" );
}
delete[] gr->column;
delete[] gr->pointerB;
delete[] gr->value;
delete gr;
delete [] dist;

Параллельные численные методы 25
return 0;
}
В представленном коде полужирным начертанием выделен код, связанный
с измерением времени. Прокомментируем его.
Тип данных LARGE_INTEGER – это объединение, представляющее собой
64-битное целое число. Поле QuardPart позволяет работать с ним, как с
__int64. Этот тип необходим в Windows API функциях для определения
частоты высокоточного таймера (QueryPerformanceFrequency) и за-
мера времени с его помощью (QueryPerformanceCounter). Более по-
дробные сведения интересующиеся могут найти в справочной системе
MSDN.
Теперь займѐмся реализацией функции поиска кратчайших путей для всех
пар вершин. Создадим заголовочный файл AllPairsShortestPaths.h,
содержащий прототип функции. Для этого в окне Solution Explorer в пап-
ке Header Files выполните команду контекстного меню Add→New Item….
В дереве категорий слева выберите Code, в шаблонах справа – Header File
(.h), в поле Name введите имя файла AllPairsShortestPaths. Нажмите Add.
В файле напишите следующий код:
#ifndef ALL_PAIRS_SHORTEST_PATHS_H
#define ALL_PAIRS_SHORTEST_PATHS_H
#include "routine.h"
#include <algorithm>
void AllPairsShortestPaths(GraphMatrix *gr, int *dist);
#endif
Создадим файл AllPairsShortestPaths.cpp, содержащий реализацию
функции поиска кратчайших путей. Для этого в окне Solution Explorer в
папке Source Files выполните команду контекстного меню Add→New
Item…. В дереве категорий слева выберите Code, в шаблонах справа – С++
File (.cpp), в поле Name введите имя файла AllPairsShortestPaths. Нажми-
те Add.
В начале файла добавим требуемые заголовочные файлы и объявим мак-
рос, определяющий пороговое значение для перехода с разреженного фор-
мата хранения графа на плотное (нами выбрана заполненность матрицы на
величину в 20%, т.е. матрица содержит не менее 80% «нулевых» элемен-
тов).
#include "AllPairsShortestPaths.h"
#include <vector>
#define DENSE_THRESHOLD 20

Поиск путей на графе
26
using namespace std;
Добавим программный код вспомогательной функции, которая записывает
нули в главную диагональ матрицы, хранящейся в разреженном формате. С
помощью этой функции обеспечивается свойство отсутствия петель в гра-
фе.
void InsertZeros(GraphMatrix *gr)
{
int *col, *pb, *val, f;
int i, k;
int okr_i, okr_s, okr_f;
int n = gr->sizeV;
col = gr->column;
pb = gr->pointerB;
val = gr->value;
gr->sizeE += n;
gr->column = new int [gr->sizeE];
gr->value = new int [gr->sizeE];
gr->pointerB = new int [n + 1];
gr->pointerB[0] = 0;
k = 0;
for(i = 0; i < n; i++){
okr_s = pb[i];
okr_f = pb[i + 1];
f = 0;
for(okr_i = okr_s; okr_i < okr_f ; okr_i++)
{
gr->column[k] = col[okr_i];
gr->value [k] = val[okr_i];
if(col[okr_i] == i){
gr->value [k] = 0;
f = 1;
}
k++;
}
if(f == 0)
{
gr->column[k] = i;
gr->value [k] = 0;
k++;
}
gr->pointerB[i + 1] = k;

Параллельные численные методы 27
}
delete []col;
delete []pb;
delete []val;
}
Добавим функции инициализации структуры для хранения графа в разре-
женном формате и освобождения выделенной памяти.
void InitializeGraph(int sizeV, int sizeE, GraphMatrix *gr)
{
gr->sizeE = sizeE;
gr->sizeV = sizeV;
gr->value = new int[sizeE];
gr->column = new int[sizeE];
gr->pointerB = new int[sizeV+1];
}
void FreeGraph(GraphMatrix *gr)
{
delete[] gr->value;
delete[] gr->column;
delete[] gr->pointerB;
}
Добавим функции инициализации единичной матрицы в разреженном
формате. Заметим, что для задачи поиска пути на графе единичной матри-
цей будет считаться матрица, содержащая нули на главной диагонали.
void InitializeIdentityGraph(int sizeV, GraphMatrix *gr)
{
InitializeGraph(sizeV, 0, gr);
memset(gr->pointerB, 0, sizeof(int)*(sizeV+1));
InsertZeros(gr);
}
Реализуем функцию копирования графа, хранящегося в разреженном фор-
мате.
void CopyGraph(GraphMatrix *igr, GraphMatrix *ogr)
{
InitializeGraph(igr->sizeV, igr->sizeE, ogr);
for(int i=0; i < igr->sizeE; i++) {
ogr->value[i] = igr->value[i];
ogr->column[i] = igr->column[i];
}
for(int i=0; i < igr->sizeV + 1; i++)
ogr->pointerB[i] = igr->pointerB[i];

Поиск путей на графе
28
}
Реализуем функцию преобразования разреженной матрицы в плотную.
void ConvertSparseToDense(GraphMatrix *gr, int *dist)
{
int n = gr->sizeV;
for (int i = 0; i < n * n; i++)
dist[i] = INT_MAX;
for(int i = 0; i < n; i++)
{
int okr_s = gr->pointerB[i ];
int okr_f = gr->pointerB[i + 1];
for(int okr_i = okr_s; okr_i < okr_f; okr_i++)
{
int j = gr->column[okr_i];
if(dist[i * n + j] > gr->value[okr_i])
dist[i * n + j] = gr->value[okr_i];
}
}
}
Функцию «умножения» матриц позаимствуем из лабораторной работы
«Разреженное умножение матриц», заменив операции умножения на сло-
жение, а сложение на поиск минимума. Функцию транспонирования мат-
риц также необходимо реализовать.
void Transpose(GraphMatrix *igr, GraphMatrix *ogr)
{
InitializeGraph(igr->sizeV, igr->sizeE, ogr);
memset(ogr->pointerB, 0, (ogr->sizeV + 1) * sizeof(int));
for (int i = 0; i < ogr->sizeE; i++)
ogr->pointerB[igr->column[i] + 1]++;
int s = 0;
for (int i = 1; i <= igr->sizeV; i++)
{
int tmp = ogr->pointerB[i];
ogr->pointerB[i] = s;
s = s + tmp;
}
for (int i = 0; i < igr->sizeV; i++)
{
int j1 = igr->pointerB[i];
int j2 = igr->pointerB[i+1];
int col = i; // Столбец в AT - строка в А

Параллельные численные методы 29
for (int j = j1; j < j2; j++)
{
int V = igr->value[j]; // Значение
int RIndex = igr->column[j]; // Строка в AT
int IIndex = ogr->pointerB[RIndex + 1];
ogr->value[IIndex] = V;
ogr->column[IIndex] = col;
ogr->pointerB[RIndex + 1]++;
}
}
}
void SparseGraphMult(GraphMatrix *gr, GraphMatrix *gr2,
GraphMatrix *ogr)
{
int n = gr->sizeV;
int i, j, k;
int NZ = 0;
GraphMatrix *grT = new GraphMatrix;
Transpose(gr2, grT);
vector<int> columns;
vector<int> values;
vector<int> row_index;
int *temp = new int[n];
row_index.push_back(0);
for (i = 0; i < n; i++)
{
// i-я строка матрицы
// Обнуляем массив указателей на элементы
memset(temp, -1, n * sizeof(int));
// Идем по ненулевым элементам строки и заполняем
массив указателей
int ind1 = gr->pointerB[i], ind2 = gr->pointerB[i + 1];
for (j = ind1; j < ind2; j++)
{
int col = gr->column[j];
temp[col] = j; // Значит, что a[i, НОМЕР] лежит
// в ячейке массива Value с номером temp[НОМЕР]
}
// Построен индекс строки i матрицы
// Теперь необходимо умножить ее на каждую
// из строк матрицы
for (j = 0; j < n; j++)
{

Поиск путей на графе
30
// j-я строка матрицы B
int ind3 = grT->pointerB[j], ind4 =
grT->pointerB[j + 1];
int v = INT_MAX;
// Все ненулевые элементы строки j матрицы B
for (k = ind3; k < ind4; k++)
{
int bcol = grT->column[k];
int aind = temp[bcol];
if (aind != -1)
{
if( v - gr->value[aind] > grT->value[k] )
{
v = grT->value[k] + gr->value[aind];
}
}
}
if(v != INT_MAX)
{
columns.push_back(j);
values.push_back(v);
NZ++;
}
}
row_index.push_back(NZ);
}
InitializeGraph(n, NZ, ogr);
for (j = 0; j < NZ; j++)
{
ogr->column[j] = columns[j];
ogr->value[j] = values[j];
}
for(i = 0; i <= n; i++)
ogr->pointerB[i] = row_index[i];
delete [] temp;
FreeGraph(grT);
delete grT;
}
Реализуем функцию «умножения» плотных матриц.
void DenseGraphMult(int *gr1, int *gr2, int *ogr, int size)

Параллельные численные методы 31
{
for(int i=0; i<size*size; i++)
ogr[i] = INT_MAX;
for(int i=0; i<size; i++)
for(int k=0; k<size; k++)
{
int v = gr2[i*size+k];
for(int j=0; j<size; j++)
if( ogr[i*size+j] - gr1[k*size+j] > v )
ogr[i*size+j] = v + gr1[k*size+j];
}
}
Реализуем рекурсивную функцию возведения плотной матрицы в степень.
int ComputeResult(int *rez, int *st, int *tem, int size,
int k)
{
int sm = 1;
if (k != 1)
{
int *t;
if (k % 2 == 1)
DenseGraphMult(st, rez, tem, size);
t = tem;
tem = rez;
rez = t;
DenseGraphMult(st, st, tem, size);
t = tem;
tem = st;
st = t;
if (k >> 1 != 0)
sm += ComputeResult(rez, st, tem, size, k >> 1);
}
else
{
DenseGraphMult(st, rez, tem, size);
}
return sm;
}

Поиск путей на графе
32
Реализуем основную функцию, выполняющую возведение исходной мат-
рицы смежности, хранящейся в разреженном формате, в степень . Как
только плотность матрицы будет достаточно высокой (это задаѐтся через
макрос DENSE_THRESHOLD) будет выполнен переход с разреженного
формата на плотный. Далее матричное «умножение» будет выполняться в
плотном формате.
void AllPairsShortestPaths(GraphMatrix *gr, int *dist)
{
GraphMatrix *rezGr = new GraphMatrix;
GraphMatrix *stGr = new GraphMatrix;
GraphMatrix *inpGr = new GraphMatrix;
InitializeIdentityGraph(gr->sizeV, rezGr);
CopyGraph(gr, inpGr);
InsertZeros(inpGr);
int k = (inpGr->sizeV - 1);
for (; k > 0; k >>= 1)
{
If (100 * inpGr->sizeE / (double)(
inpGr->sizeV * inpGr->sizeV) > DENSE_THRESHOLD)
break;
SparseGraphMult(inpGr, inpGr, stGr);
if (k % 2 == 1)
{
GraphMatrix tmpGr = *rezGr;
SparseGraphMult(inpGr, rezGr, rezGr);
FreeGraph(&tmpGr);
}
GraphMatrix *tmp = inpGr;
inpGr = stGr;
stGr = tmp;
FreeGraph(stGr);
}
int *st = new int[gr->sizeV * gr->sizeV];
int *tem = new int[gr->sizeV * gr->sizeV];
ConvertSparseToDense(rezGr, dist);
ConvertSparseToDense(inpGr, st);
Параллельные численные методы 33
int sm = ComputeResult(dist, st, tem, gr->sizeV, k);
if(sm % 3 == 1)
memcpy(dist, tem, sizeof(int) * (gr->sizeV*gr->sizeV));
if(sm % 3 == 2)
memcpy(dist, st, sizeof(int) * (gr->sizeV*gr->sizeV));
delete[] tem;
delete[] st;
FreeGraph(rezGr);
FreeGraph(inpGr);
delete rezGr;
delete stGr;
delete inpGr;
}
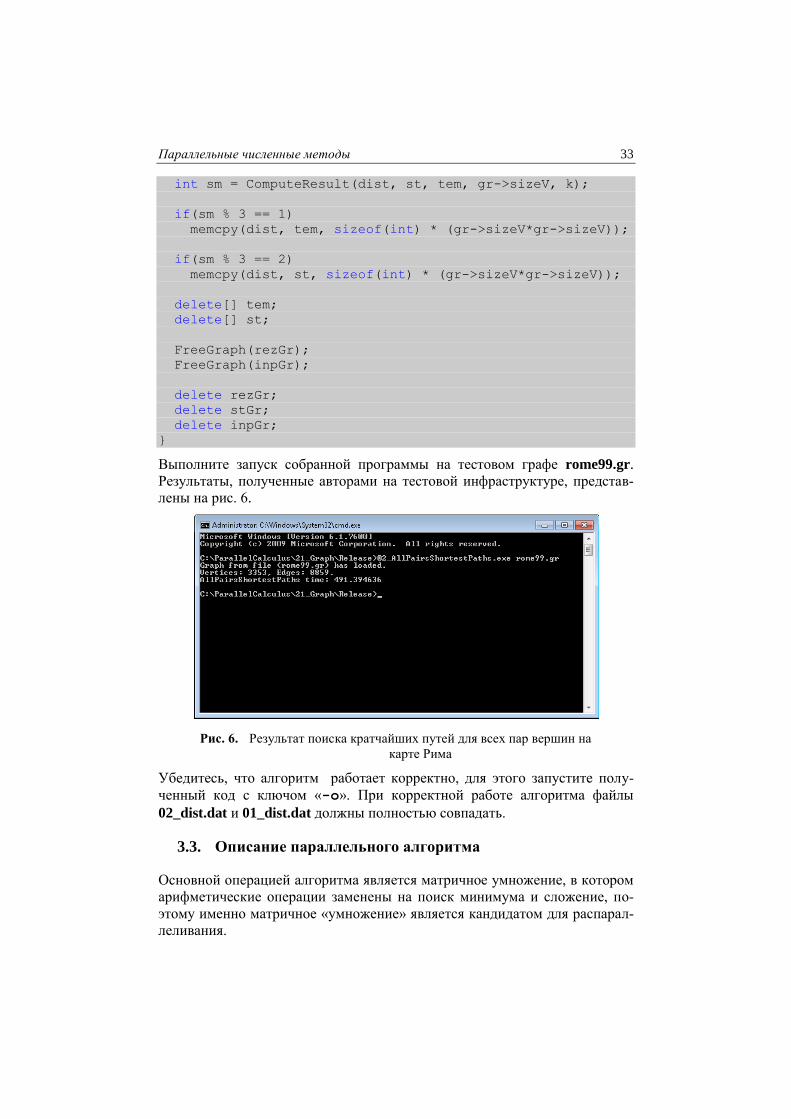
Выполните запуск собранной программы на тестовом графе rome99.gr.
Результаты, полученные авторами на тестовой инфраструктуре, представ-
лены на рис. 6.
Рис. 6. Результат поиска кратчайших путей для всех пар вершин на
карте Рима
Убедитесь, что алгоритм работает корректно, для этого запустите полу-
ченный код с ключом «-o». При корректной работе алгоритма файлы
02_dist.dat и 01_dist.dat должны полностью совпадать.
3.3. Описание параллельного алгоритма
Основной операцией алгоритма является матричное умножение, в котором
арифметические операции заменены на поиск минимума и сложение, по-
этому именно матричное «умножение» является кандидатом для распарал-
леливания.

Поиск путей на графе
34
В работе используется два алгоритма матричного «умножения»: «умноже-
ние» в разреженном формате и «умножение» плотных матриц. Напишем
параллельные реализации обоих алгоритмов. «Умножение» в разреженном
формате рассмотрено в соответствующей лабораторной работе (здесь мы
используем ту же самую реализацию), а «умножение» плотных матриц до-
пускает эффективное распараллеливание по внешнему циклу (т.е. по стро-
кам матрицы ). Таким образом, реализация параллельного алгоритма за-
тронет только те функции, в которых реализовано «умножение» матриц.
3.4. Реализации параллельной версии с использованием TBB
Для начала создадим новый проект с названием
03_AllPairsShortestPathsTBB как это описано выше. Разработку TBB вер-
сии проекта мы будем вести на основании последовательной версии, по-
этому скопируйте все исходные файлы из проекта
02_AllPairsShortestPaths. Переименуем файл AllPairsShortestPaths.h в
AllPairsShortestPathsTBB.h, а AllPairsShortestPaths.cpp в
AllPairsShortestPathsTBB.cpp.
Для начала внесѐм изменения в функцию main(). Для этого откроем файл
main.cpp и добавим заголовочный файл task_scheduler_init.h, со-
держащий описание класса инициализации библиотеки TBB. Также изме-
ним название заголовочного файла с прототипом функции поиска крат-
чайших путей.
#include "tbb\task_scheduler_init.h"
#include "AllPairsShortestPathsTBB.h"
Добавим ещѐ один параметр в аргументы командной строки, через кото-
рый будет задаваться количество потоков, создаваемых библиотекой TBB.
Внесѐм изменения в программный код, выполняющий разбор дополни-
тельного аргумента командной строки, и добавим инициализацию библио-
теки TBB.
if (argc < 3)
{
printf("\nUsage: program.exe <graph file> <num threads>
[-o]\n");
return 1;
}
tbb::task_scheduler_init init(
tbb::task_scheduler_init::deferred);
GraphMatrix *gr;
int *dist;

Параллельные численные методы 35
bool printOutput = false;
int numThreads = 0;
ParseGraph(argv[1], &gr);
numThreads = atoi(argv[2]);
if (argc == 4)
if(string(argv[3]) == string("-o"))
printOutput = true;
init.initialize(numThreads);
Внесѐм несколько «косметических» правок: поменяем название метода по-
иска кратчайших путей и вывод на экран.
QueryPerformanceCounter(&sQP);
AllPairsShortestPathsTBB(gr, dist);
QueryPerformanceCounter(&fQP);
printf("Parallel TBB AllPairsShortestPaths time: %f\n",
(fQP.QuadPart - sQP.QuadPart) / (double)freq.QuadPart);
if (printOutput)
{
FILE *distFile=fopen("03_dist.dat", "wb");
fwrite(dist, sizeof(int), gr->sizeV * gr->sizeV,
distFile);
fclose(distFile);
printf("File (03_dist.dat) written.\n");
}
Внесѐм изменения в заголовочный файл AllPairsShortestPathsTBB.h, за-
менив названия макросов и функции поиска кратчайших путей.
#ifndef ALL_PAIRS_SHORTEST_PATHS_TBB_H
#define ALL_PAIRS_SHORTEST_PATHS_TBB_H
#include "routine.h"
#include <algorithm>
void AllPairsShortestPathsTBB(GraphMatrix *gr, int *dist);
#endif
Реализацию параллельного алгоритма поиска кратчайших путей напишем в
файле AllPairsShortestPathsTBB.cpp. Для начала добавим заголовочные
файлы, содержащие описание требуемых функций и классов TBB.
#include "AllPairsShortestPathsTBB.h"
#include <vector>
#include "windows.h"

Поиск путей на графе
36
#include "tbb/blocked_range.h"
#include "tbb/parallel_for.h"
#define DENSE_THRESHOLD 20
using namespace tbb;
Для реализации параллельного «умножения» плотных матриц используем
функцию parallel_for(). Распараллеливание будет происходить по
внешнему циклу матричного «умножения». Для использования функции
parallel_for() потребуется реализовать функтор, который будет вы-
полнять умножение строк матрицы на матрицу .
void DenseGraphMultIter(int *gr1, int *gr2, int *ogr,
int size, int i)
{
for (int k=0; k<size; k++)
{
int v = gr2[i*size+k];
for (int j=0; j<size; j++)
if (ogr[i*size+j] - gr1[k*size+j] > v)
ogr[i*size+j] = v + gr1[k*size+j];
}
}
class DenseGraphMulter
{
private:
int *gr1;
int *gr2;
int *ogr;
int size;
public:
DenseGraphMulter(int *_gr1, int *_gr2, int *_ogr,
int _size): gr1(_gr1), gr2(_gr2), ogr(_ogr),
size(_size) {}
void operator()(const blocked_range<int>& r) const
{
int begin = r.begin(), end = r.end();
for (int i = begin; i < end; i++)
DenseGraphMultIter(gr1, gr2, ogr, size, i);
}
};
void DenseGraphMult(int *gr1, int *gr2, int *ogr, int size)

Параллельные численные методы 37
{
for (int i=0; i<size*size; i++)
ogr[i] = INT_MAX;
parallel_for(blocked_range<int>(0, size),
DenseGraphMulter(gr1, gr2, ogr, size),
auto_partitioner());
}
Реализацию параллельного «умножения» разреженных матриц позаим-
ствуем из работы «Разреженное матричное умножение», заменив операцию
умножения на сложение, а сложение на поиск минимума.
class SparseGraphMultiplicator
{
GraphMatrix A, B;
vector<int>* columns;
vector<int>* values;
int *row_index;
public:
SparseGraphMultiplicator(GraphMatrix& _A,
GraphMatrix& _B, vector<int>* &_columns,
vector<int>* &_values, int *_row_index) :
A(_A), B(_B), columns(_columns), values(_values),
row_index(_row_index)
{}
void operator()(const blocked_range<int>& r) const
{
int begin = r.begin();
int end = r.end();
int N = A.sizeV;
int i, j, k;
int *temp = new int[N];
for (i = begin; i < end; i++)
{
memset(temp, -1, N * sizeof(int));
int ind1 = A.pointerB[i], ind2 = A.pointerB[i + 1];
for (j = ind1; j < ind2; j++)
{
int col = A.column[j];
temp[col] = j;
}
for (j = 0; j < N; j++)
{
int ind3 = B.pointerB[j], ind4 = B.pointerB[j + 1];
int v = INT_MAX;
// Все ненулевые элементы строки j матрицы B
for (k = ind3; k < ind4; k++)

Поиск путей на графе
38
{
int bcol = B.column[k];
int aind = temp[bcol];
if (aind != -1)
if( v - A.value[aind] > B.value[k] )
v = B.value[k] + A.value[aind];
}
if (v != INT_MAX)
{
columns[i].push_back(j);
values[i].push_back(v);
row_index[i]++;
}
}
}
delete [] temp;
}
};
void SparseGraphMult(GraphMatrix *gr, GraphMatrix *gr2,
GraphMatrix *ogr)
{
int N = gr->sizeV;
int i;
GraphMatrix *grT = new GraphMatrix;
Transpose(gr2, grT);
vector<int>* columns = new vector<int>[N];
vector<int> *values = new vector<int>[N];
int* row_index = new int[N + 1];
memset(row_index, 0, sizeof(int) * N);
parallel_for(blocked_range<int>(0, N),
SparseGraphMultiplicator(*gr, *grT, columns, values,
row_index));
int NZ = 0;
for(i = 0; i < N; i++)
{
int tmp = row_index[i];
row_index[i] = NZ;
NZ += tmp;
}
row_index[N] = NZ;
InitializeGraph(N, NZ, ogr);
Параллельные численные методы 39
int count = 0;
for (i = 0; i < N; i++)
{
int size = columns[i].size();
memcpy(&(ogr->column[count]), &columns[i][0],
size * sizeof(int));
memcpy(&(ogr->value[count]), &values[i][0],
size * sizeof(int));
count += size;
}
memcpy(ogr->pointerB, &row_index[0],
(N + 1) * sizeof(int));
delete [] row_index;
delete [] columns;
delete [] values;
}
Переименуем функцию, выполняющую поиск кратчайших путей.
void AllPairsShortestPathsTBB(GraphMatrix *gr, int *dist)
{
...
}
Выполним сборку проекта и запуск собранной программы на тестовом
графе rome99.gr. Результаты, полученные авторами на тестовой инфра-
структуре, представлены на рис. 7.
Рис. 7. Результат работы параллельного TBB алгоритма поиска
кратчайших путей для всех пар вершин на 8 потоках на карте
Рима
Убедитесь, что алгоритм работает корректно. Для этого запустите полу-
ченный код с ключом «-o». При корректной работе алгоритма файлы
03_dist.dat и 01_dist.dat должны полностью совпадать.
Поиск путей на графе
40
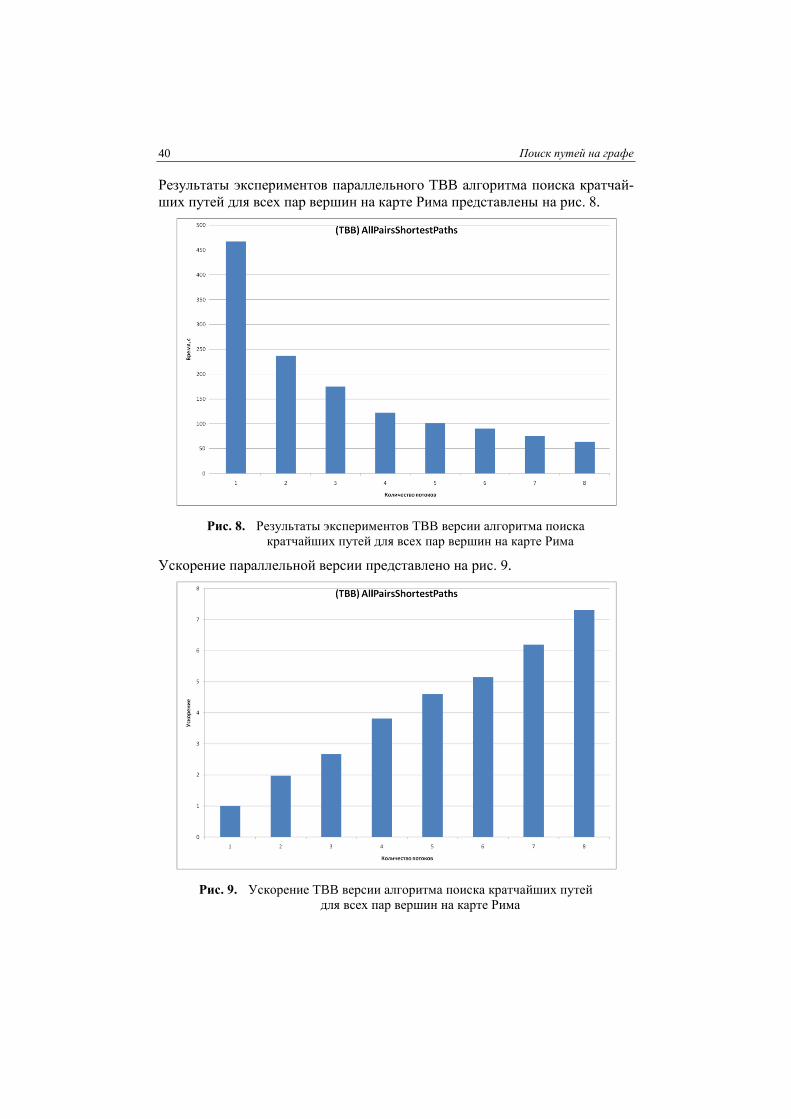
Результаты экспериментов параллельного TBB алгоритма поиска кратчай-
ших путей для всех пар вершин на карте Рима представлены на рис. 8.
Рис. 8. Результаты экспериментов TBB версии алгоритма поиска
кратчайших путей для всех пар вершин на карте Рима
Ускорение параллельной версии представлено на рис. 9.
Рис. 9. Ускорение TBB версии алгоритма поиска кратчайших путей
для всех пар вершин на карте Рима

Параллельные численные методы 41
Как можно видеть, ускорение близко к линейному. На 8-ми потоках уско-
рение составило 7.3.
3.5. Реализации параллельной версии с использованием Cilk
Как и в случае TBB-версии разработку параллельной версии с использова-
нием Cilk Plus будем вести на основе последовательной реализации. Со-
здайте проект 04_AllPairsShortestPathsCilk как это описано выше. Пере-
именуйте файл AllPairsShortestPaths.h в AllPairsShortestPathsCilk.h, а
AllPairsShortestPaths.cpp в AllPairsShortestPathsCilk.cpp.
Внесѐм изменения в функцию main(). Для этого откройте файл main.cpp
и добавьте заголовочный файл cilk/cilk_api.h, содержащий функ-
цию для установки параметров времени выполнения Cilk Plus. Так же из-
мените название заголовочного файла с прототипом функции поиска крат-
чайших путей.
#include <cilk/cilk_api.h>
#include "AllPairsShortestPathsCilk.h"
Добавим ещѐ один параметр в аргументы командной строки, через кото-
рый будет задаваться количество потоков. Внесѐм изменения в программ-
ный код, выполняющий разбор дополнительного аргумента командной
строки, и добавим вызов функции для установки количества потоков.
if (argc < 3)
{
printf("\nUsage: program.exe <graph file> <num threads>
[-o]\n");
return 1;
}
GraphMatrix *gr;
int *dist;
bool printOutput = false;
int numThreads = 0;
ParseGraph(argv[1], &gr);
numThreads = atoi(argv[2]);
if (argc == 4)
if(string(argv[3]) == string("-o"))
printOutput = true;
char nt[9];
itoa(numThreads, nt, 10);
__cilkrts_set_param("nworkers", nt);

Поиск путей на графе
42
Внесѐм несколько «косметических» правок: поменяем название метода по-
иска кратчайших путей и вывод на экран.
QueryPerformanceCounter(&sQP);
AllPairsShortestPathsCilk(gr, dist);
QueryPerformanceCounter(&fQP);
printf("Parallel Cilk AllPairsShortestPaths time: %f\n",
(fQP.QuadPart-sQP.QuadPart)/(double)freq.QuadPart);
if(printOutput)
{
FILE *distFile=fopen("04_dist.dat", "wb");
fwrite(dist, sizeof(int), gr->sizeV * gr->sizeV,
distFile);
fclose(distFile);
printf("File (04_dist.dat) written.\n" );
}
Внесѐм изменения в заголовочный файл AllPairsShortestPathsCilk.h.
#ifndef ALL_PAIRS_SHORTEST_PATHS_TBB_H
#define ALL_PAIRS_SHORTEST_PATHS_TBB_H
#include "routine.h"
#include <algorithm>
#ifndef __cilk
#include <cilk/cilk_stub.h>
#endif
#include <cilk/cilk.h>
void AllPairsShortestPathsCilk(GraphMatrix *gr, int *dist);
#endif
Реализацию параллельного алгоритма поиска кратчайших путей напишем в
файле AllPairsShortestPathsCilk.cpp. Для начала добавим заголовочный
файл AllPairsShortestPathsCilk.h.
#include "AllPairsShortestPathsCilk.h"
#include <vector>
#include "windows.h"
Реализация параллельного «умножения» плотных матриц будет осуществ-
лена с использованием конструкции cilk_for(). Распараллеливание бу-
дет происходить по внешнему циклу матричного «умножения».
void DenseGraphMultIter(int *gr1, int *gr2, int *ogr,
int size, int i)
{

Параллельные численные методы 43
for(int k=0; k<size; k++)
{
int v = gr2[i*size+k];
for(int j=0; j<size; j++)
if( ogr[i*size+j] - gr1[k*size+j] > v )
ogr[i*size+j] = v + gr1[k*size+j];
}
}
void DenseGraphMult(int *gr1, int *gr2, int *ogr, int size)
{
for(int i=0; i<size*size; i++)
ogr[i] = INT_MAX;
cilk_for(int i=0; i<size; i++)
DenseGraphMultIter(gr1, gr2, ogr, size, i);
}
Как и для TBB-версии реализацию параллельного «умножения» разрежен-
ных матриц позаимствуем из работы «Разреженное матричное умноже-
ние», заменив операции умножения на сложение, а сложение на поиск ми-
нимума.
void SparseGraphMultiplicate(int begin, int end,
GraphMatrix A, GraphMatrix B, vector<int>* columns,
vector<int>* values, int* row_index)
{
int N = A.sizeV;
int i, j, k;
int *temp = new int[N];
for (i = begin; i < end; i++)
{
memset(temp, -1, N * sizeof(int));
int ind1 = A.pointerB[i], ind2 = A.pointerB[i + 1];
for (j = ind1; j < ind2; j++)
{
int col = A.column[j];
temp[col] = j;
}
for (j = 0; j < N; j++)
{
int ind3 = B.pointerB[j], ind4 = B.pointerB[j + 1];
int v = INT_MAX;
// Все ненулевые элементы строки j матрицы B
for (k = ind3; k < ind4; k++)
{
int bcol = B.column[k];

Поиск путей на графе
44
int aind = temp[bcol];
if (aind != -1)
if( v - A.value[aind] > B.value[k] )
v = B.value[k] + A.value[aind];
}
if(v != INT_MAX)
{
columns[i].push_back(j);
values[i].push_back(v);
row_index[i]++;
}
}
}
delete [] temp;
}
void SparseGraphMult(GraphMatrix *gr, GraphMatrix *gr2,
GraphMatrix *ogr)
{
int N = gr->sizeV;
int i;
GraphMatrix *grT = new GraphMatrix;
Transpose(gr2, grT);
vector<int>* columns = new vector<int>[N];
vector<int> *values = new vector<int>[N];
int* row_index = new int[N + 1];
memset(row_index, 0, sizeof(int) * N);
cilk_for(int i=0; i<N; i++)
SparseGraphMultiplicate(i, i+1, *gr, *grT, columns,
values, row_index);
int NZ = 0;
for(i = 0; i < N; i++)
{
int tmp = row_index[i];
row_index[i] = NZ;
NZ += tmp;
}
row_index[N] = NZ;
InitializeGraph(N, NZ, ogr);
int count = 0;
for (i = 0; i < N; i++)
{
int size = columns[i].size();
Параллельные численные методы 45
memcpy(&(ogr->column[count]), &columns[i][0],
size * sizeof(int));
memcpy(&(ogr->value[count]), &values[i][0],
size * sizeof(int));
count += size;
}
memcpy(ogr->pointerB, &row_index[0],
(N + 1) * sizeof(int));
delete [] row_index;
delete [] columns;
delete [] values;
}
Переименуем функцию, выполняющую поиск кратчайших путей.
void AllPairsShortestPathsCilk(GraphMatrix *gr, int *dist)
{
}
Выполним сборку проекта и запуск собранной программы на тестовом
графе rome99.gr. Результаты, полученные авторами на тестовой инфра-
структуре, представлены на рис. 10.
Рис. 10. Результат работы параллельного Cilk алгоритма поиска
кратчайших путей для всех пар вершин на 8 потоках на карте
Рима
Убедитесь, что алгоритм работает корректно. Для этого запустите полу-
ченный код с ключом «-o». При корректной работе алгоритма файлы
04_dist.dat и 01_dist.dat должны полностью совпадать.
Результаты экспериментов параллельного Cilk алгоритма поиска кратчай-
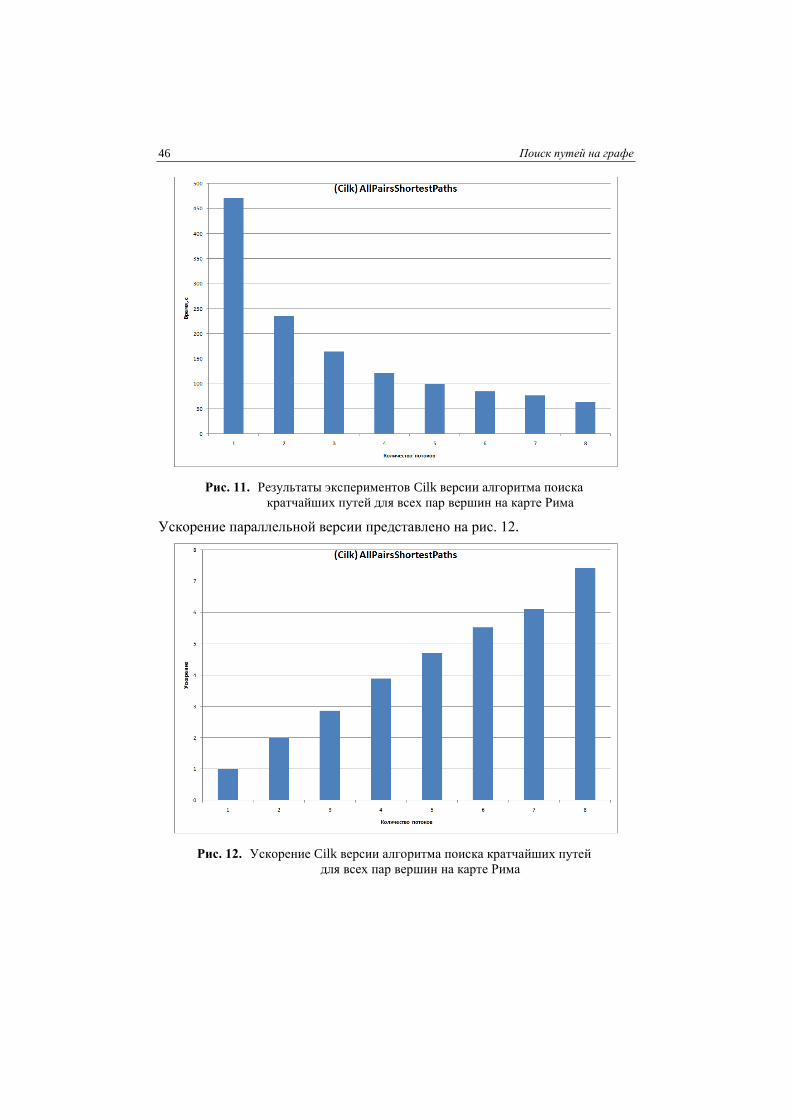
ших путей для всех пар вершин на карте Рима представлены на рис. 11.
Поиск путей на графе
46
Рис. 11. Результаты экспериментов Cilk версии алгоритма поиска
кратчайших путей для всех пар вершин на карте Рима
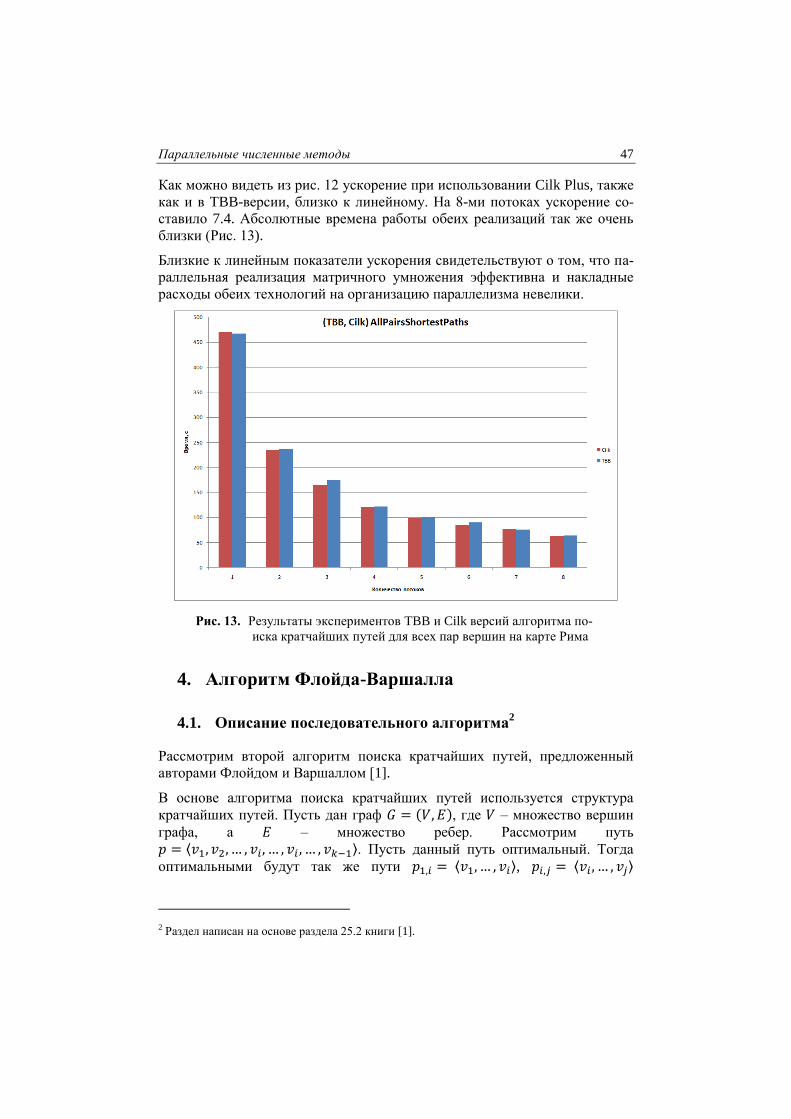
Ускорение параллельной версии представлено на рис. 12.
Рис. 12. Ускорение Cilk версии алгоритма поиска кратчайших путей
для всех пар вершин на карте Рима
Параллельные численные методы 47
Как можно видеть из рис. 12 ускорение при использовании Cilk Plus, также
как и в TBB-версии, близко к линейному. На 8-ми потоках ускорение со-
ставило 7.4. Абсолютные времена работы обеих реализаций так же очень
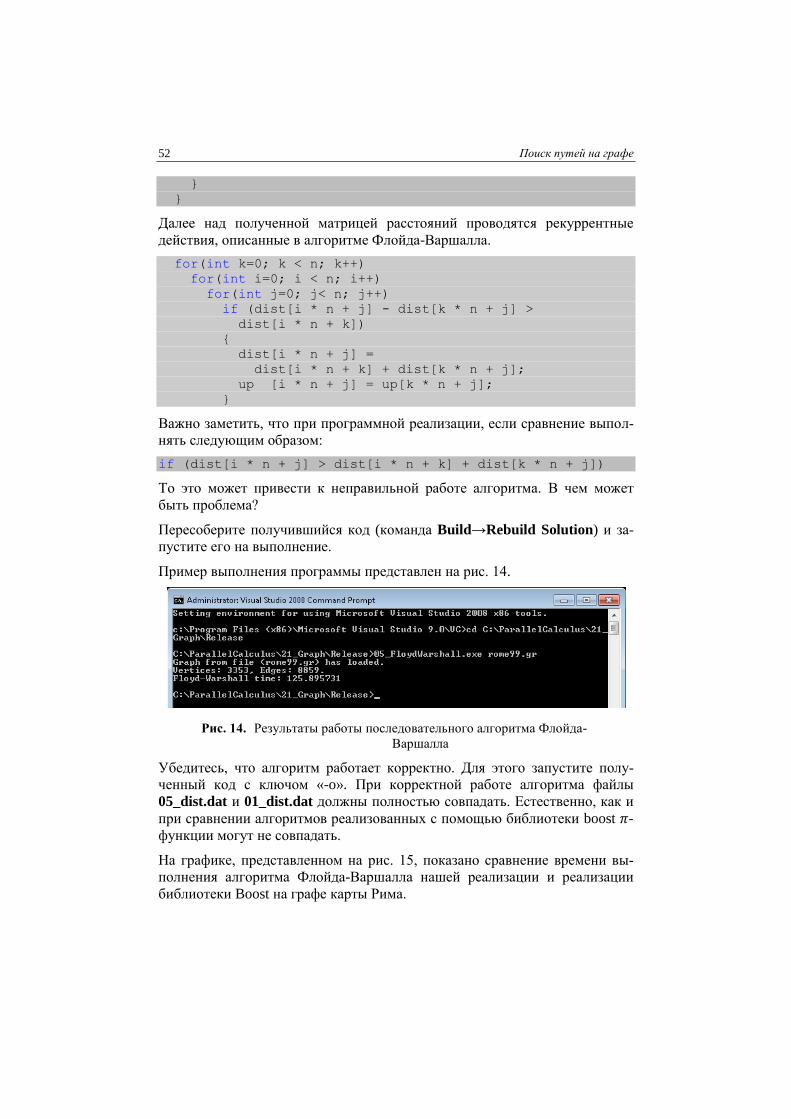
близки (Рис. 13).
Близкие к линейным показатели ускорения свидетельствуют о том, что па-
раллельная реализация матричного умножения эффективна и накладные
расходы обеих технологий на организацию параллелизма невелики.
Рис. 13. Результаты экспериментов TBB и Cilk версий алгоритма по-
иска кратчайших путей для всех пар вершин на карте Рима
4. Алгоритм Флойда-Варшалла
4.1. Описание последовательного алгоритма2
Рассмотрим второй алгоритм поиска кратчайших путей, предложенный
авторами Флойдом и Варшаллом [1].
В основе алгоритма поиска кратчайших путей используется структура
кратчайших путей. Пусть дан граф , где – множество вершин
графа, а – множество ребер. Рассмотрим путь
⟨ ⟩. Пусть данный путь оптимальный. Тогда
оптимальными будут так же пути ⟨ ⟩, ⟨ ⟩
2 Раздел написан на основе раздела 25.2 книги [1].

Поиск путей на графе
48
и ⟨ ⟩. Этот факт легко обосновать на основании того, что
стоимость пути складывается из суммы весов его частей.
Пусть к пути необходимо добавить вершину . Тогда существует два
варианта:
1. Стоимость пути меньше стоимости пути ⟨ ⟩, тогда в
этом случае оптимальный путь не изменится.
2. Стоимость пути больше стоимости пути ⟨ ⟩, тогда оп-
тимальным путем будет ⟨ ⟩. Данный факт
опять же следует из того условия, что вес пути складывается из стои-
мости путь и оставшихся частей.
Используя данные утверждения, алгоритм можно построить следующим
образом. Пусть – стоимость оптимального пути из вершины в верши-
ну , с проверенной возможностью прохождения через вершину . При
значения совпадают с весом перехода из вершины в
вершину . Если ребро отсутствует, то . Далее рекуррентное
соотношение можно определить следующим образом:
{
(
)
Используя данное рекуррентное соотношение, можно найти матрицу
(
), содержащую веса кратчайших путей для всех пар вершин
.
Для поиска кратчайших путей часто вычисляют матрицу предшествования
. Для этого существуют простые рекуррентные соотношения:
{
{
4.2. Реализация последовательной версии
Для начала реализуем последовательную версию алгоритма Флойда-
Варшалла. Для этого, добавьте в решение ShortestPaths новый проект с
названием 05_FloydWarshall. Повторите все действия, описанные в § 2, с
той лишь разницей, что начать нужно с выбора решения ShortestPaths в

Параллельные численные методы 49
окне Solution Explorer и выполнения команды контекстного меню
Add→New Project…. При добавлении файла в проект задайте имя main.
После получения пустого файла main.cpp подключите в нем все необхо-
димые заголовочные файлы.
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "windows.h"
#include <string>
#include "FloydWarshall.h"
using namespace std;
Из проекта 02_AllPairsShortestPaths скопируйте код разбора параметров
командной строки и чтения графа из файла.
int main(int argc, char **argv){
LARGE_INTEGER freq;
LARGE_INTEGER sQP, fQP;
QueryPerformanceFrequency(&freq);
if (argc < 2){
printf("\nUsage: program.exe <graph file> [-o]\n");
return 1;
}
GraphMatrix *gr;
int *up;
int *dist;
bool printOutput = false;
ParseGraph(argv[1], &gr);
if (argc == 3)
if(string(argv[2]) == string("-o"))
printOutput = true;
Далее выделите память под матрицы расстояний и поиска кратчайших пу-
тей ( -функцию).
// pi - функция
up = new int[gr->sizeV * gr->sizeV];
// дистанция до вершины
dist = new int[gr->sizeV * gr->sizeV];
После выполненных действий можно запустить алгоритм Флойда-
Варшалла с замером времени работы алгоритма.
QueryPerformanceCounter(&sQP);
FloydWarshall(gr, up, dist);

Поиск путей на графе
50
QueryPerformanceCounter(&fQP);
printf("Floyd-Warshall time: %f\n",
(fQP.QuadPart-sQP.QuadPart) / (double) freq.QuadPart );
if(printOutput)
{
FILE *distFile=fopen("05_dist.dat", "wb");
fwrite(dist, sizeof(int), gr->sizeV * gr->sizeV,
distFile);
fclose(distFile);
printf("File (05_dist.dat) written.\n" );
}
В финале необходимо высвободить всю выделенную память.
delete[] gr->column;
delete[] gr->pointerB;
delete[] gr->value;
delete gr;
delete [] up;
delete [] dist;
return 0;
}
Реализовав основную функцию программы, перейдем к реализации самого
алгоритма Флойда-Варшалла. Для этого в проекте создайте заголовочный
файл FloydWarshall.h и файл с реализацией FloydWarshall.cpp. В
заголовочном файле поместите объявление функции поиска кратчайших
путей и подключите необходимые заголовочные файлы.
#ifndef FLOYD_WARSHALL_H
#define FLOYD_WARSHALL_H
#include "routine.h"
#include <algorithm>
//API
// void FloydWarshall(graphMatrix *gr, int *up, int *dist);
// Алгоритм Флойда-Уоршелла поиска кратчайших путей между
// каждой парой вершин.
//
//INPUT
// graphMatrix - взвешенный граф
//
//OUTPUT
// int * - pi-функция
// int * - растояние до вершин

Параллельные численные методы 51
void FloydWarshall(GraphMatrix *gr, int *up, int *dist);
#endif
В файле FloydWarshall.cpp необходимо разработать реализацию алгорит-
ма. Для этого необходимо сначала сформировать исходную матрицу рас-
стояний. Исходная матрица расстояний совпадает с матрицей смежности
исследуемого графа. При построении все элементы на диагонали равны 0,
то есть стоимость перехода в текущую вершину равна 0. Все остальные
элементы формируются следующим образом. Если в матрице смежности
графа существует ребро, то значение берется из графа, иначе в качестве
расстояния берется некое очень большое число.
//API
// void FloydWarshall(graphMatrix *gr, int *up, int *dist);
// Алгоритм Флойда-Уоршелла поиска кратчайших путей между
// каждой парой вершин
//
//INPUT
// graphMatrix - взвешенный граф
//
//OUTPUT
// int * - pi-функция
// int * - растояние до вершин
void FloydWarshall(GraphMatrix *gr, int *up, int *dist)
{
int i, j;
// переменные прохода по окрестности вершины графа
int okr_s, okr_f, okr_i;
int n = gr->sizeV;
for (i = 0; i < n * n; i++)
dist[i] = INT_MAX;
for (i = 0; i < n; i++)
{
dist[i * n + i] = 0;
up [i * n + i] = i;
}
for(i = 0; i < n; i++)
{
okr_s = gr->pointerB[i];
okr_f = gr->pointerB[i + 1];
for(okr_i = okr_s; okr_i < okr_f; okr_i++)
{
j = gr->column[okr_i];
if(dist[i * n + j] > gr->value[okr_i])
dist[i * n + j] = gr->value[okr_i];
up[i * n + j] = i;
Поиск путей на графе
52
}
}
Далее над полученной матрицей расстояний проводятся рекуррентные
действия, описанные в алгоритме Флойда-Варшалла.
for(int k=0; k < n; k++)
for(int i=0; i < n; i++)
for(int j=0; j< n; j++)
if (dist[i * n + j] - dist[k * n + j] >
dist[i * n + k])
{
dist[i * n + j] =
dist[i * n + k] + dist[k * n + j];
up [i * n + j] = up[k * n + j];
}
Важно заметить, что при программной реализации, если сравнение выпол-
нять следующим образом:
if (dist[i * n + j] > dist[i * n + k] + dist[k * n + j])
То это может привести к неправильной работе алгоритма. В чем может
быть проблема?
Пересоберите получившийся код (команда Build→Rebuild Solution) и за-
пустите его на выполнение.
Пример выполнения программы представлен на рис. 14.
Рис. 14. Результаты работы последовательного алгоритма Флойда-
Варшалла
Убедитесь, что алгоритм работает корректно. Для этого запустите полу-
ченный код с ключом «-o». При корректной работе алгоритма файлы
05_dist.dat и 01_dist.dat должны полностью совпадать. Естественно, как и
при сравнении алгоритмов реализованных с помощью библиотеки boost -
функции могут не совпадать.
На графике, представленном на рис. 15, показано сравнение времени вы-
полнения алгоритма Флойда-Варшалла нашей реализации и реализации
библиотеки Boost на графе карты Рима.

Параллельные численные методы 53
Рис. 15. Сравнение времени работы последовательного алгоритма Флойда-
Варшалла
4.3. Описание параллельного алгоритма
Идея параллельного алгоритма Флойда-Варшала состоит в следующем.
Пусть выбрана очередная ведущая вершина с помощью, которой
предположительно можно уменьшить путь. Тогда, если фиксировать стро-
ку в матрице расстояний, то для всех пар вершин расстояние
может быть обновлено независимо. Так как в результате алгоритма строка
в любом случае останется неизменой, элементы данной строки можно не
копировать в отдельный буфер.
Если для каждого расстояния из вершины в вершину обновление произ-
водить в отдельном потоке, то эффективность распараллеливания будет
низкой, из-за больших расходов на организацию параллелизма. Для повы-
шения эффективности предлагается матрицу расстояний разделить на бло-
ки и процесс обновления производить для целого блока.
После обновления расстояний из всех вершин в вершины через
вершину необходимо произвести синхронизацию изменений.
Алгоритм продолжает свою работу до тех пор, пока в качестве ведущей
вершины не побывают все вершины из множества вершин .
4.4. Реализации параллельной версии с использованием TBB
Для реализации параллельного алгоритма Флойда-Варшалла с использова-
нием технологии TBB, добавьте в решение ShortestPaths новый проект с
названием 06_FloydWarshallTBB. Повторите все действия, описанные в
§ 2, с той лишь разницей, что начать нужно с выбора решения
ShortestPaths в окне Solution Explorer и выполнения команды кон-
текстного меню Add→New Project…. При добавлении файла в проект за-
дайте имя main.

Поиск путей на графе
54
После получения пустого файла main.cpp, как и в случае последовательно-
го алгоритма подключите необходимые заголовочные файлы.
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "windows.h"
#include <string>
#include "tbb\task_scheduler_init.h"
#include "FloydWarshallTBB.h"
Реализуйте код разбора параметров командной строки, организуйте чтение
графа из файла и проинициализируйте планировщик библиотеки TBB.
using namespace std;
int main(int argc, char **argv){
LARGE_INTEGER freq;
LARGE_INTEGER sQP, fQP;
QueryPerformanceFrequency(&freq);
if (argc < 3)
{
printf("\nUsage: program.exe <graph file> <num threads>
[-o]\n");
return 1;
}
tbb::task_scheduler_init init(
tbb::task_scheduler_init::deferred);
GraphMatrix *gr;
int *up;
int *dist;
bool printOutput = false;
int numThreads = 0;
ParseGraph(argv[1], &gr);
numThreads = atoi(argv[2]);
if (argc == 4)
if (string(argv[3]) == string("-o"))
printOutput = true;
init.initialize(numThreads);

Параллельные численные методы 55
Выделите память под матрицы расстояний и поиска путей ( -функцию) и
вызовите параллельную реализацию алгоритма Флойда-Варшалла с заме-
ром времени.
// pi - функция
up = new int[gr->sizeV * gr->sizeV];
// дистанция до вершины
dist = new int[gr->sizeV * gr->sizeV];
QueryPerformanceCounter(&sQP);
FloydWarshallTBB(gr, up, dist);
QueryPerformanceCounter(&fQP);
printf("Parallel TBB Floyd-Warshall time: %f\n",
(fQP.QuadPart-sQP.QuadPart)/(double)freq.QuadPart);
if (printOutput)
{
FILE *distFile=fopen("06_dist.dat", "wb");
fwrite(dist, sizeof(int), gr->sizeV * gr->sizeV,
distFile);
fclose(distFile);
printf("File (06_dist.dat) written.\n" );
}
В конце основной функции необходимо высвободить выделенную память.
delete[] gr->column;
delete[] gr->pointerB;
delete[] gr->value;
delete gr;
delete [] up;
delete [] dist;
return 0;
}
Реализовав главную функцию, разработайте параллельную реализацию
алгоритма Флойда-Варшалла. Для этого создайте заголовочный файл
FloydWarshallTBB.h подключите в нем необходимые заголовочные файлы
и объявите прототип функции поиска кратчайших путей.
#ifndef FLOYD_WARSHALL_TBB_H
#define FLOYD_WARSHALL_TBB_H
#include <stdio.h>
#include "routine.h"
#include <algorithm>
#include "tbb/blocked_range2d.h"
#include "tbb/parallel_for.h"
using namespace std;

Поиск путей на графе
56
//API
// void FloydWarshallTBB(graphMatrix *gr, int *up,
// int *dist);
// Параллельный алгоритм Флойда-Уоршелла поиска кратчайших
// путей между каждой парой вершин
//
//INPUT
// graphMatrix - взвешенный граф
//
//OUTPUT
// int * - пи-функция
// int * - растояние до вершин
void FloydWarshallTBB(GraphMatrix *gr, int *up, int *dist);
#endif
Далее создайте файл реализации FloydWarshallTBB.cpp. Согласно опи-
санному параллельному алгоритму на каждой итерации матрицу расстоя-
ний необходимо разделять на блоки и параллельно обновлять значения
расстояний между вершинами. Для параллельной обработки матрицы рас-
стояний в данном алгоритме удобно применить конструкцию TBB:
tbb::parallel_for(<итерационное пространство>,
<класс-функтор>)
В нашем случае итерационным пространством является матрица. Для опи-
сания такой ситуации в TBB реализован шаблон двумерного итерационно-
го пространства:
tbb::blocked_range2d<тип>(<индекс начала строки >,
<индекс конца строки >, <индекс начала столбца>,
<индекс конеца столбца>)
Таким образом, нам необходимо лишь реализовать класс-функтор для об-
работки блока матрицы Multiplicator. Данный класс должен прини-
мать матрицу расстояний, матрицу предшествования, их размер и номер
вершины, через которую возможно уменьшить путь.
class Multiplicator
{
private:
int *dist; // матрица расстояний
int *up; // pi - функция
int n; // размер матрици расстояний
int k; // текущая транзитная вершина
public:
Multiplicator(int *_up, int *_dist, int _n, int _k):
up(_up), dist(_dist), k(_k), n(_n) {}

Параллельные численные методы 57
};
В данном классе необходимо перегрузить operator(), используемый в
tbb::parallel_for для вычислений.
void operator()(const tbb::blocked_range2d<int>& r) const
{
int l1 = r.rows().begin();
int r1 = r.rows().end();
int l2 = r.cols().begin();
int r2 = r.cols().end();
for(int i=l1; i < r1; i++)
for(int j=l2; j< r2; j++)
if (dist[i * n + j] - dist[k * n + j] >
dist[i * n + k])
{
dist[i * n + j] =
dist[i * n + k] + dist[k * n + j];
up[i * n + j] = up[k * n + j];
}
}
Полученный класс будет использован в реализации параллельного алго-
ритма. Как и в последовательной версии вычисление кратчайших путей
будут происходить над плотной матрицей, поэтому преобразуем граф из
разреженного представления в плотный. Программный код инициализации
плотной матрицы расстояний уже был написан в последовательной реали-
зации, поэтому скопируем его в функцию FloydWarshallTBB().
//API
// void FloydWarshallTBB(graphMatrix *gr, int *up,
// int *dist);
// Параллельный алгоритм Флойда-Уоршелла поиска кратчайших
// путей между каждой парой вершин
//
//INPUT
// graphMatrix - взвешенный граф
//
//OUTPUT
// int * - пи-функция
// int * - растояние до вершин
void FloydWarshallTBB(GraphMatrix *gr, int *up, int *dist)
{
int i, j;
// переменные прохода по окрестности вершины графа
int okr_s, okr_f, okr_i;
int n = gr->sizeV;
for (i = 0; i < n * n; i++)
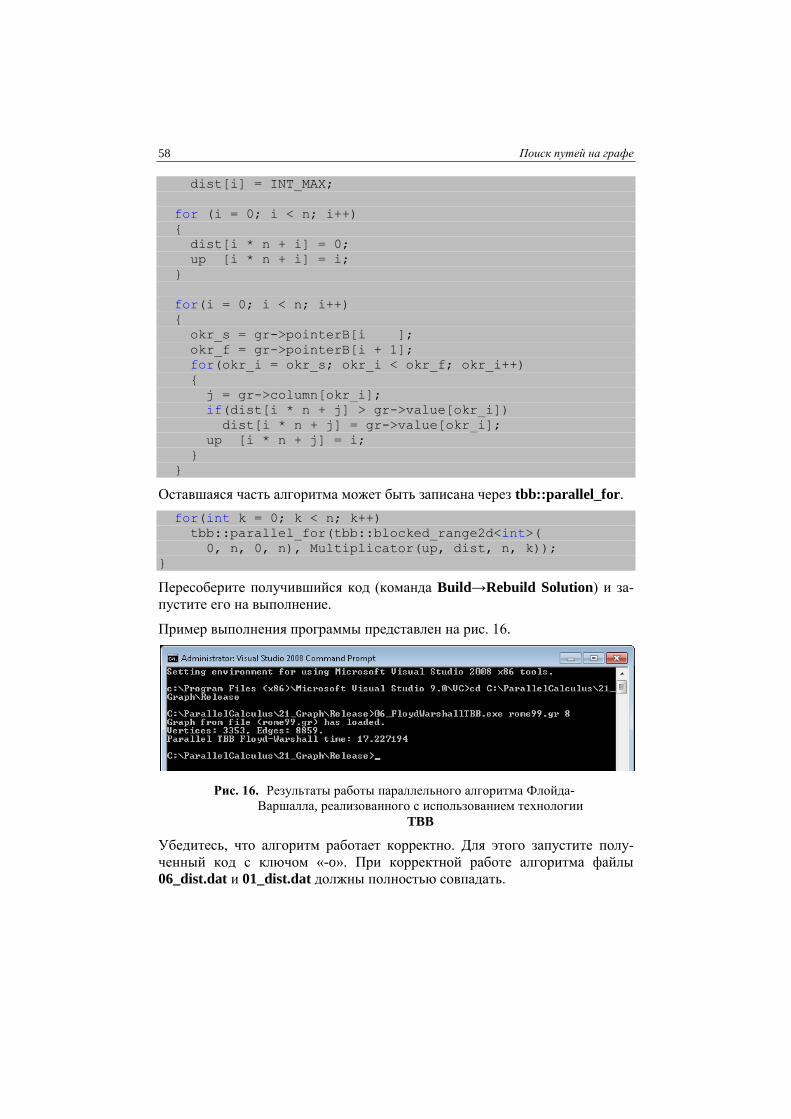
Поиск путей на графе
58
dist[i] = INT_MAX;
for (i = 0; i < n; i++)
{
dist[i * n + i] = 0;
up [i * n + i] = i;
}
for(i = 0; i < n; i++)
{
okr_s = gr->pointerB[i ];
okr_f = gr->pointerB[i + 1];
for(okr_i = okr_s; okr_i < okr_f; okr_i++)
{
j = gr->column[okr_i];
if(dist[i * n + j] > gr->value[okr_i])
dist[i * n + j] = gr->value[okr_i];
up [i * n + j] = i;
}
}
Оставшаяся часть алгоритма может быть записана через tbb::parallel_for.
for(int k = 0; k < n; k++)
tbb::parallel_for(tbb::blocked_range2d<int>(
0, n, 0, n), Multiplicator(up, dist, n, k));
}
Пересоберите получившийся код (команда Build→Rebuild Solution) и за-
пустите его на выполнение.
Пример выполнения программы представлен на рис. 16.
Рис. 16. Результаты работы параллельного алгоритма Флойда-
Варшалла, реализованного с использованием технологии
TBB
Убедитесь, что алгоритм работает корректно. Для этого запустите полу-
ченный код с ключом «-o». При корректной работе алгоритма файлы
06_dist.dat и 01_dist.dat должны полностью совпадать.

Параллельные численные методы 59
На графике, представленном на рис. 17 и рис. 18, показано сравнение вре-
мени выполнения параллельного алгоритма Флойда-Варшалла с использо-
ванием различного количества вычислительных элементов на примере
графа карты Рима.
Рис. 17. Сравнение времени работы параллельного алгоритма Флой-
да-Варшалла при разном количестве вычислительных эле-
ментов
Рис. 18. Ускорение параллельного алгоритма Флойда-Варшалла
Как видно из представленных графиков в параллельном алгоритме удалось
добиться неплохой масштабируемости.
4.5. Реализации параллельной версии с использованием Cilk
Для реализации параллельного алгоритма Флойда-Варшалла с использова-
нием технологии Cilk снова возьмем последовательную версию в качестве
заготовки. Для начала добавьте в решение ShortestPaths новый проект с

Поиск путей на графе
60
названием 07_FloydWarshallCilk. Повторите все действия, описанные в
§ 2, с той лишь разницей, что начать нужно с выбора решения
ShortestPaths в окне Solution Explorer и выполнения команды кон-
текстного меню Add→New Project…. В файл main.cpp перенесите содер-
жимое файла main.cpp последовательной версии, заменив подключаемый
файл FloydWarshall.h на FloydWarshallCilk.h и вызов функции
FloydWarshall() на FloydWarshallCilk() соответственно.
В заголовочном файле FloydWarshallCilk.h добавьте подключение заголо-
вочных файлов Сilk.
#ifndef __cilk
#include <cilk/cilk_stub.h>
#endif
#include <cilk/cilk.h>
Реализуйте функцию обновления расстояний для строки.
void relax(int k, int i, int n, int * dist, int * up)
{
for(int j=0; j< n; j++)
if( dist[i * n + j] - dist[k * n + j] >
dist[i * n + k])
{
dist[i * n + j] = dist[i * n + k] + dist[k * n + j];
up [i * n + j] = up [k * n + j];
}
}
Используя данную функцию, алгоритм Флойда-Варшалла может быть реа-
лизован на Cilk следующим образом.
void FloydWarshallCilk(GraphMatrix *gr, int *up,
int *dist)
{
...
for(int k=0; k < n; k++)
{
cilk_for(int i=0; i < n; i++)
{
relax(k, i, n, dist, up);
}
}
}
Пересоберите получившийся код (команда Build→Rebuild Solution) и за-
пустите его на выполнение.
Пример выполнения программы представлен на рис. 19.

Параллельные численные методы 61
Рис. 19. Результаты работы алгоритма Флойда-Варшалла, реализо-
ванного с использованием технологии Cilk
Убедитесь, что алгоритм работает корректно, для этого запустите полу-
ченный код с ключом «-o». При корректной работе алгоритма файлы
07_dist.dat и 01_dist.dat должны полностью совпадать.
На графике, представленном на Рис. 20 и Рис. 21, показано сравнение вре-
мени выполнения параллельного алгоритма Флойда-Варшалла с использо-
ванием различного количества вычислительных элементов на примере
графа карты Рима.
Рис. 20. Сравнение времени работы параллельных алгоритмов Флой-
да-Варшалла
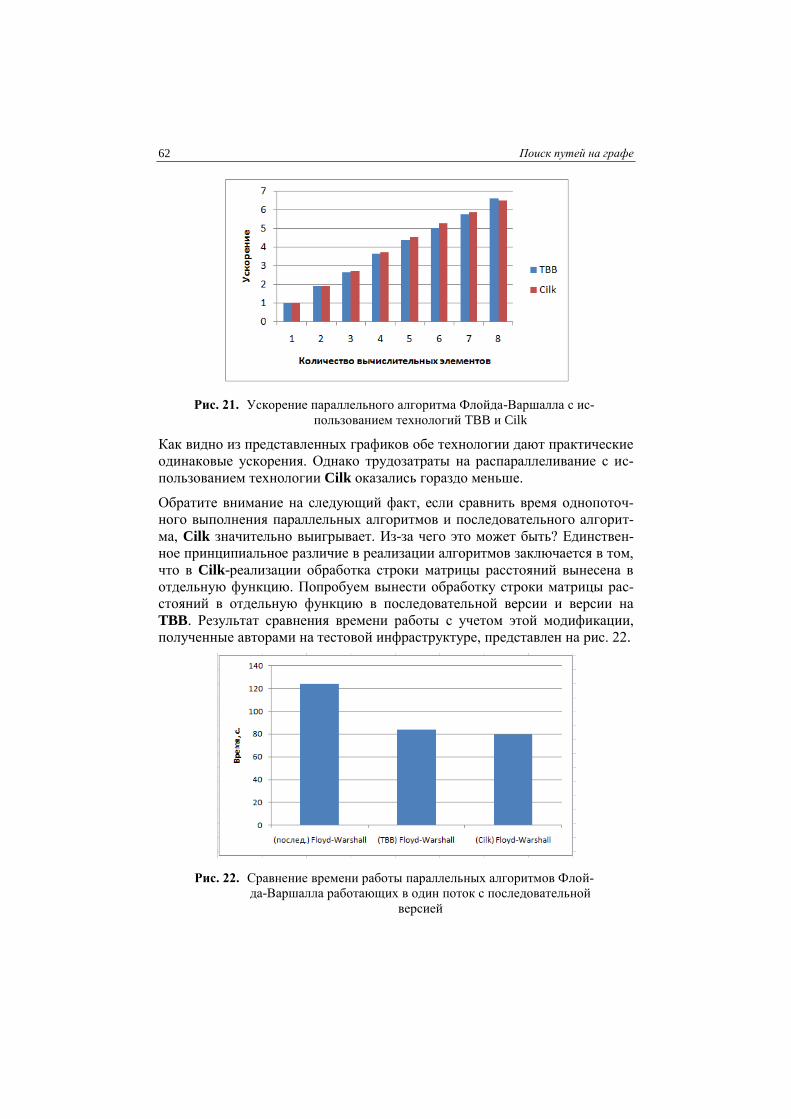
Поиск путей на графе
62
Рис. 21. Ускорение параллельного алгоритма Флойда-Варшалла с ис-
пользованием технологий TBB и Cilk
Как видно из представленных графиков обе технологии дают практические
одинаковые ускорения. Однако трудозатраты на распараллеливание с ис-
пользованием технологии Cilk оказались гораздо меньше.
Обратите внимание на следующий факт, если сравнить время однопоточ-
ного выполнения параллельных алгоритмов и последовательного алгорит-
ма, Cilk значительно выигрывает. Из-за чего это может быть? Единствен-
ное принципиальное различие в реализации алгоритмов заключается в том,
что в Cilk-реализации обработка строки матрицы расстояний вынесена в
отдельную функцию. Попробуем вынести обработку строки матрицы рас-
стояний в отдельную функцию в последовательной версии и версии на
TBB. Результат сравнения времени работы с учетом этой модификации,
полученные авторами на тестовой инфраструктуре, представлен на рис. 22.
Рис. 22. Сравнение времени работы параллельных алгоритмов Флой-
да-Варшалла работающих в один поток с последовательной
версией

Параллельные численные методы 63
Как видим, TBB-версия практически сравнялась с Cilk-версией и теперь
также выигрывает у последовательной реализации. С чем связан подобный
эффект объяснить сложно. Наиболее вероятная причина заключена в раз-
личной оптимизации кода компилятором.
5. Алгоритм Джонсона
5.1. Описание последовательного алгоритма3
Алгоритм Джонсона позволяет найти пути между всеми парами вершин за
время . Если данный алгоритм применять для разрежен-
ных графов, таких как карты дорог, то алгоритм Джонсона работает значи-
тельно быстрее алгоритма возведения матриц в степень количества вершин
и алгоритма Флойда-Варшалла [1].
Идея алгоритма Джонсона состоит в применении алгоритма Дейкстры для
каждой вершины. Алгоритм Дейкстры позволяет быстро найти расстояние
от источника до всех вершин, но у него есть существенное ограничение –
алгоритм применим только для графов с неотрицательными весами ребер.
Чтобы свести граф с отрицательными весами ребер (но не содержащий
циклов с отрицательным весом) к графу без ребер с отрицательными веса-
ми применяется алгоритм Беллмана-Форда.
Рассмотрим алгоритм более детально. Чтобы перейти от графа с отрица-
тельными весами к графу без отрицательных весов, можно ввести следую-
щую весовую функцию:
Данная замена обладает одним замечательным свойством. Пусть дан путь
⟨ ⟩, тогда вес пути до и после замены связаны следующим
соотношением:
Используя данное свойство, можно найти кратчайшие пути для графа с ве-
сами и затем вернуться к исходному графу. Для применения алгоритма
Дейкстры необходимо найти такую функцию , чтобы веса ребер стали
положительными и при этом кратчайшие пути не изменились.
Теоритически показано, что для поиска функции применима следующая
процедура. Пусть дан исходный граф . Построим новый граф
следующим образом:
1.
3 Раздел написан на основе раздела 25.3 книги [1].

Поиск путей на графе
64
2. 3.
В полученном графе необходимо найти веса кратчайших путей из вершины
во все. Так как сконструированный граф все еще содержит ребра с отри-
цательными весами, то алгоритм Дейкстры по-прежнему не применим, но
для поиска можно применить алгоритм Беллмана-Форда. Алгоритм Белл-
мана-Форда на псевдокоде может быть записан следующим образом.
bool BellmanFord ( , , out )
For do
For i = 1 to | | do
For для всех do
If then
For для всех do If then return false return true
Алгоритм возвращает «истину», если в графе нет циклов с отрицательным
весом. Можно показать, что в качестве можно взять кратчайшее расстоя-
ние до вершины из источника , то есть:
Алгоритм Дейкстры на псевдокоде может быть записан следующим обра-
зом:
void Dijkstra ( , , out , out )
For do begin
end
// – приоритетная очередь, // содержащая пары (<расстояние>, <вершина>)
While do For смежных с do
If then begin
end

Параллельные численные методы 65
Таким образом, алгоритм Джонсона может быть сформулирован в виде
следующего псевдокода.
void Johnson( , , out , out )
Построить граф
f = BellmanFord ( , , ) If f = false then
Print(“граф содержит циклы с отрицательным весом”)
Return
For для всех do For для всех do
Dijkstra ( , , , )
For для всех do
5.2. Реализация последовательной версии
Для реализации последовательного алгоритма Джонсона добавьте в реше-
ние ShortestPaths новый проект с названием 08_Johnson. Повторите все
действия, описанные в § 2, с той лишь разницей, что начать нужно с выбо-
ра решения ShortestPaths в окне Solution Explorer и выполнения команды
контекстного меню Add→New Project…. При добавлении файла в проект
задайте имя main.
Реализацию главной функции алгоритма Джонсона, как и раньше, следует
начать с подключения заголовочных файлов и загрузки графа из файла.
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "windows.h"
#include <string>
#include "Johnson.h"
using namespace std;
int main(int argc, char **argv){
LARGE_INTEGER freq;
LARGE_INTEGER sQP, fQP;
QueryPerformanceFrequency(&freq);
if (argc < 2){
printf("\nUsage: program.exe <graph file> [-o]\n");
return 1;
}
GraphMatrix *gr;

Поиск путей на графе
66
int *up;
int *dist;
bool printOutput = false;
ParseGraph(argv[1], &gr);
if (argc == 3)
if(string(argv[2]) == string("-o"))
printOutput = true;
Далее должен последовать вызов функции поиска кратчайших путей с
предварительным выделением памяти и замером времени.
// pi - функция
up = new int[gr->sizeV * gr->sizeV];
// дистанция до вершины
dist = new int[gr->sizeV * gr->sizeV];
QueryPerformanceCounter(&sQP);
Johnson(gr, up, dist);
QueryPerformanceCounter(&fQP);
printf("Johnson time: %f\n",
(fQP.QuadPart-sQP.QuadPart)/ (double)freq.QuadPart );
if(printOutput)
{
FILE *distFile=fopen("08_dist.dat", "wb");
fwrite(dist, sizeof(int), gr->sizeV * gr->sizeV,
distFile);
fclose(distFile);
printf("File (08_dist.dat) written.\n" );
}
В конце необходимо освободить память.
delete[] gr->column;
delete[] gr->pointerB;
delete[] gr->value;
delete gr;
delete [] up;
delete [] dist;
return 0;
}
Далее для реализации алгоритма Джонсона необходимо реализовать два
алгоритма поиска кратчайших путей из источника во все вершины: алго-
ритм Дейкстры и алгоритм Беллмана-Форда.

Параллельные численные методы 67
Начнем с реализации алгоритма Дейкстры. Создайте заголовочный файл
Dijkstra.h и объявите в нем прототип функции реализуемого алгоритма.
#ifndef DIJKSTRA_H
#define DIJKSTRA_H
#include "routine.h"
#include <cstdio>
#include <queue>
#include <algorithm>
//API
// void Dijkstra(graphMatrix *gr, int givenNode, int *up,
// int *dist);
// Алгоритм Дейкстры поиска кратчайших путей из источника
// во все вершины
//
//INPUT
// graphMatrix - взвешенный граф
// int - вершина источник
//
//OUTPUT
// int * - pi-функция
// int * - растояние до вершин
void Dijkstra(GraphMatrix *gr, int givenNode, int *up,
int *dist);
#endif
Далее создайте файл Dijkstra.cpp и реализуйте в нем соответствующий
алгоритм. Для этого разработайте вспомогательную структуру, позволяю-
щие хранить пару элементов – вершину и оценку расстояния до нее. Также
для работы с приоритетной очередью из библиотеки STL нам потребуется
перегруженный оператор сравнения для введенной структуры.
struct Pair
{
int dist;
int node;
};
bool operator<(Pair p1, Pair p2)
{
// более приоритетны меньшие элементы!
return (p1.dist > p2.dist);
}
Прежде всего, в реализации алгоритма необходимо установить исходные
значения для массива расстояний – расстояние до всех вершин должно
быть проинициализировано очень большим числом, а источник нулем.

Поиск путей на графе
68
void Dijkstra(GraphMatrix *gr, int givenNode, int *up,
int *dist)
{
//все вершины бесконечно удалены
for (int i=0; i < gr->sizeV; i++)
dist[i] = INT_MAX;
dist[givenNode] = 0;
up[givenNode] = givenNode;
Далее следует создать приоритетную очередь и поместить в нее начальную
вершину.
priority_queue<Pair> pq;
//помещаем стартовую вершину в приоритетную очередь
Pair t = {0,givenNode};
pq.push(t);
Затем необходимо реализовать цикл, в котором, пока очередь не пуста, из
нее изымается элемент с минимальным расстоянием, и с помощью вы-
бранного элемента производится попытка уменьшить расстояния до всех
смежных вершин (данная модификация алгоритма Дейкстры известна так
же как алгоритм Мура[8]).
//поиск кратчайших путей
while(!pq.empty())
{
// изымаем элемент из очереди
Pair s = pq.top();
pq.pop();
// для изъятой вершины проверяем окрестность
// на предмет уменьшения длин пути
int okr_s = gr->pointerB[s.node];
int okr_f = gr->pointerB[s.node + 1];
for(int okr_i = okr_s; okr_i < okr_f; okr_i++)
{
int j = gr->column[okr_i];
//релаксация
if (dist[j] > (dist[s.node] + gr->value[okr_i]))
{
dist[j] = (dist[s.node] + gr->value[okr_i]);
up[j] = s.node;
//помещаем вершину в очередь, т.к. она может
// уменьшить путь
Pair p = {dist[j],j};
pq.push(p);
}
}

Параллельные численные методы 69
}
}
Теперь займемся реализацией алгоритмов Беллмана-Форда и Джонсона.
Создайте заголовочный файл Johnson.h, где объявите соответствующие
прототипы функций.
#ifndef JOHNSON_H
#define JOHNSON_H
#include "Dijkstra.h"
//API
// bool BellmanFord(graphMatrix *gr, int givenNode,
// int *dist);
// Алгоритм поиска кратчайшего пути во взвешенном графе из
// источника во все вершины
//
//INPUT
// graphMatrix - взвешенный граф
// int - вершина источник
//
//OUTPUT
// int * - растояние до вершин
bool BellmanFord(GraphMatrix *gr, int givenNode,
int *dist);
//API
// void Johnson(graphMatrix *gr, int *up, int *dist);
// Алгоритм Джонсона поиска кратчайших путей между каждой
// парой вершин
//
//INPUT
// graphMatrix - взвешенный граф
//
//OUTPUT
// int * - pi-функция
// int * - растояние до вершин
void Johnson(GraphMatrix *gr, int *up, int *dist);
#endif
Создайте файл Johnson.cpp и реализуйте в нем алгоритм Беллмана-Форда
в функции BellmanFord(). Для этого проинициализируйте начальные
расстояния до вершин. Как и в алгоритме Джонсона, начальные расстояния
до всех вершин равны очень большому числу, а у стартовой вершины оно
нулевое.
bool BellmanFord(GraphMatrix *gr, int givenNode,
int *dist){
// переменные прохода по окрестности вершины графа

Поиск путей на графе
70
int okr_s, okr_f, okr_i;
int i, j, k;
// пока все вершины бесконечно удалены
for (i=0; i < gr->sizeV; i++)
dist[i] = INT_MAX;
// растояние до начальной вершины равно 0
dist[givenNode] = 0;
Далее размещаем реализацию алгоритма поиска путей Беллмана-Форда.
//поиск циклов и расстояний до вершин
for (k=0; k < gr->sizeV - 1; k++)
{
for (i=0; i < gr->sizeV; i++)
{
//для изъятой вершины проверяем окрестность
// на предмет уменьшения длин пути
okr_s = gr->pointerB[i ];
okr_f = gr->pointerB[i + 1];
for(okr_i = okr_s; okr_i < okr_f; okr_i++)
{
j = gr->column[okr_i];
//релаксация
if (dist[j] - gr->value[okr_i] > dist[i])
{
dist[j] = dist[i] + gr->value[okr_i];
}
}
}
}
И, наконец, реализуем проверку на наличие циклов с отрицательными ве-
сами.
for (i = 0; i < gr->sizeV; i++)
{
okr_s = gr->pointerB[i ];
okr_f = gr->pointerB[i + 1];
for(okr_i = okr_s; okr_i < okr_f; okr_i++)
{
j = gr->column[okr_i];
if (dist[j] > (dist[i] + gr->value[okr_i]))
return false;
}
}
return true;
}

Параллельные численные методы 71
Теперь, используя алгоритмы Дейкстры и Беллмана-Форда, реализуйте ал-
горитм Джонсона.
Вначале необходимо создать граф с дополнительной вершиной. У введен-
ной вершины должны быть ребра до всех вершин в графе с весами равны-
ми нулю.
void Johnson(GraphMatrix *gr, int *up, int *dist)
{
int i, j, n;
int okr_s, okr_f, okr_i;
int *h;
GraphMatrix gr_h;
n = gr->sizeV;
gr_h.sizeV = n + 1;
gr_h.sizeE = gr->sizeE + n;
gr_h.column = new int [gr->sizeE + n];
gr_h.value = new int [gr->sizeE + n];
gr_h.pointerB = new int [n + 2];
h = new int [n + 1];
for(i = 0; i < gr->sizeE; i++)
{
gr_h.column[i + n] = gr->column[i] + 1;
gr_h.value [i + n] = gr->value [i];
}
gr_h.pointerB[0] = 0;
for(i = 0; i < n; i++)
{
gr_h.pointerB[i + 1] = gr->pointerB[i] + n;
gr_h.column[i] = i;
gr_h.value [i] = 0;
}
gr_h.pointerB[i + 1] = gr->pointerB[i] + n;
Для полученного графа, примените разработанную программную реализа-
цию алгоритма Беллмана-Форда. Алгоритм позволит определить, есть ли в
графе циклы с отрицательными весами, а также величины, которые необ-
ходимо прибавить к весам ребер исходного графа, чтобы избавиться от от-
рицательных весов и одновременно не изменить кратчайшие пути.
bool f = false;
f = BellmanFord(&gr_h, 0, h);
if (!f)
{

Поиск путей на графе
72
printf("exist negativ circle\n");
return;
}
Временный граф больше не понадобится, как следствие, можно освободить
занимаемую им память.
delete [] gr_h.column;
delete [] gr_h.value;
delete [] gr_h.pointerB;
Используя полученные веса, модифицируйте исходный граф.
for (i = 0; i < n; i++)
{
okr_s = gr->pointerB[i ];
okr_f = gr->pointerB[i + 1];
for(okr_i = okr_s; okr_i < okr_f; okr_i++)
{
j = gr->column[okr_i];
gr->value[okr_i] += h[i + 1] - h[j + 1];
}
}
Далее примените алгоритм Дейкстры с источником во всех вершинах по-
очередно.
for(i = 0; i < n; i++)
Dijkstra(gr, i, up + n * i, dist + n * i);
Для получения решения верните веса ребер и веса путей к весам исходного
графа.
for (i = 0; i < n; i++)
{
okr_s = gr->pointerB[i ];
okr_f = gr->pointerB[i + 1];
for(okr_i = okr_s; okr_i < okr_f; okr_i++)
{
j = gr->column[okr_i];
gr->value[okr_i] -= h[i + 1] - h[j + 1];
}
}
for(i = 0; i < n; i++)
for(j = 0; j < n; j++)
dist[n * i + j] += h[j + 1] - h[i + 1];
delete []h;
}

Параллельные численные методы 73
Пересоберите получившийся код (команда Build→Rebuild Solution) и за-
пустите его на выполнение.
Пример выполнения программы представлен на рис. 23.
Рис. 23. Результаты работы последовательного алгоритма Джонсона
Убедитесь, что алгоритм работает корректно. Для этого запустите полу-
ченный код с ключом «-o». При корректной работе алгоритма файлы
08_dist.dat и 01_dist.dat должны полностью совпадать.
На графике, представленном на рис. 24, показано сравнение времени вы-
полнения разработанной реализации последовательного алгоритма Джон-
сона и реализации из библиотеки Boost на примере графа карты Рима.
Рис. 24. Сравнение времени работы последовательных реализаций
алгоритма Джонсона
5.3. Описание параллельного алгоритма
Преобразование исходного графа к графу без отрицательных весов занима-
ет незначительное время от общего времени работы алгоритма. Следова-
тельно, распараллеливать в реализации алгоритма Джонсона имеет смысл
применение алгоритма Дейкстры. Алгоритм Дейкстры с разными источни-
ками может работать параллельно, так как граф не изменяется во времени
и массивы расстояний и предшествования независимы.

Поиск путей на графе
74
5.4. Реализация параллельной версии с использованием TBB
При реализации параллельной версии алгоритма Джонсона используем
шаблон параллельного программирования «мастер-рабочие».
Прежде всего, добавьте в решение ShortestPaths новый проект с названием
09_JohnsonTBB. Повторите все действия, описанные в § 2, с той лишь раз-
ницей, что начать нужно с выбора решения ShortestPaths в окне
Solution Explorer и выполнения команды контекстного меню
Add→New Project…. При добавлении файла в проект задайте имя main.
После получения пустого файла main.cpp, как и в случае последовательно-
го алгоритма подключите необходимые заголовочные файлы.
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "windows.h"
#include <string>
#include "tbb\task_scheduler_init.h"
#include "JohnsonTBB.h"
Реализуйте код разбора параметров командной строки, организуйте чтение
графа из файла и проинициализируйте планировщик библиотеки TBB.
int main(int argc, char **argv){
LARGE_INTEGER freq;
LARGE_INTEGER sQP, fQP;
QueryPerformanceFrequency(&freq);
if (argc < 3)
{
printf("\nUsage: program.exe <graph file> <num threads>
[-o]\n");
return 1;
}
tbb::task_scheduler_init
init(tbb::task_scheduler_init::deferred);
GraphMatrix *gr;
int *up;
int *dist;
bool printOutput = false;
int numThreads = 0;
ParseGraph(argv[1], &gr);

Параллельные численные методы 75
numThreads = atoi(argv[2]);
if (argc == 4)
if(string(argv[3]) == string("-o"))
printOutput = true;
init.initialize(numThreads);
Вызовите функцию поиска кратчайших путей с предварительным выделе-
нием необходимой памяти и замером времени.
// pi - функция
up = new int[gr->sizeV * gr->sizeV];
// дистанция до вершины
dist = new int[gr->sizeV * gr->sizeV];
QueryPerformanceCounter(&sQP);
JohnsonTBB(gr, up, dist);
QueryPerformanceCounter(&fQP);
printf("Parallel TBB Johnson time: %f\n",
(fQP.QuadPart-sQP.QuadPart)/ (double)freq.QuadPart );
if(printOutput)
{
FILE *distFile=fopen("09_dist.dat", "wb");
fwrite(dist, sizeof(int), gr->sizeV * gr->sizeV,
distFile);
fclose(distFile);
printf("File (09_dist.dat) written.\n" );
}
В конце освободите выделенную память.
delete[] gr->column;
delete[] gr->pointerB;
delete[] gr->value;
delete gr;
delete [] up;
delete [] dist;
return 0;
}
Далее для реализации параллельного алгоритма Джонсона скопируйте в
разрабатываемый проект файлы, содержащие последовательные реализа-
ции алгоритмов Дейкстры и Беллмана-Форда.
Создайте заголовочный файл JohnsonTBB.h, в котором объявите два клас-
са. Первый класс – класс-мастер, подготавливающий граф к применению

Поиск путей на графе
76
алгоритма Дейкстры с разными источниками и создающий необходимые
подзадачи.
class ParallelJohnson : public tbb::task
{
GraphMatrix * gr; // граф для поиска путей
int *up; // pi-функция
int *dist; // матрица расстояний между парами вершин
public:
ParallelJohnson(GraphMatrix * _gr, int * _up,
int * _dist): gr(_gr), up(_up), dist(_dist){ }
tbb::task* execute();
};
Второй класс – класс-рабочий, применяющий алгоритм Дейкстры для ис-
точников из заданного диапазона.
class ChildJohnson : public tbb::task
{
int startV; // начало множества обрабатываемых вершин
int endV; // конец множества обрабатываемых вершин
GraphMatrix * gr; // граф для поиска путей
int *up; // pi-функция
int *dist; // матрица расстояний между парами вершин
public:
ChildJohnson(int startV, int _endV, GraphMatrix *_gr,
int *_up, int *_dist):
startV(_startV), endV(_endV), gr(_gr),
up(_up), dist(_dist) {}
tbb::task* execute();
};
Также, заголовочный файл должен содержать объявление интерфейсной
функции поиска кратчайших путей.
#ifndef PARALLEL_JOHNSON_H
#define PARALLEL_JOHNSON_H
#include "tbb/task.h"
#include "Johnson.h"
// максимальное количество задач
#define CNT_TASK 8
using namespace std;
class ParallelJohnson : public tbb::task
{
...
};

Параллельные численные методы 77
class ChildJohnson : public tbb::task
{
...
};
//API
// void Johnson_TBB(graphMatrix *gr, int *up, int *dist);
// Параллельный алгоритм Джонсона поиска кратчайших
// путей между каждой парой вершин
//
//INPUT
// graphMatrix - взвешенный граф
//
//OUTPUT
// int * - пи-функция
// int * - растояние до вершин
void JohnsonTBB(GraphMatrix *gr, int *up, int *dist);
#endif
Создайте в проекте файл JohnsonTBB.cpp и реализуйте в нем метод
execute() класса-мастера. Вначале необходимо определить диапазоны
стартовых вершин для классов-работников.
tbb::task* ParallelJohnson::execute()
{
int i;
int startV[CNT_TASK];
int endV [CNT_TASK];
for(i = 0; i < CNT_TASK; i++)
{
startV[i] = i * (gr->sizeV / CNT_TASK);
endV [i] = (i + 1) * (gr->sizeV / CNT_TASK);
}
endV[CNT_TASK - 1] = gr->sizeV;
Далее, как и в последовательном алгоритме, применяется алгоритм Белл-
мана-Форда для модификации графа.
int j, n;
int okr_s, okr_f, okr_i;
int *h;
GraphMatrix gr_h;
n = gr->sizeV;
gr_h.sizeV = n + 1;
gr_h.sizeE = gr->sizeE + n;
gr_h.column = new int [gr->sizeE + n];

Поиск путей на графе
78
gr_h.value = new int [gr->sizeE + n];
gr_h.pointerB = new int [n + 2];
h = new int [n + 1];
for(i = 0; i < gr->sizeE; i++)
{
gr_h.column[i + n] = gr->column[i] + 1;
gr_h.value [i + n] = gr->value [i];
}
gr_h.pointerB[0] = 0;
for(i = 0; i < n; i++)
{
gr_h.pointerB[i + 1] = gr->pointerB[i] + n;
gr_h.column[i] = i;
gr_h.value [i] = 0;
}
gr_h.pointerB[i + 1] = gr->pointerB[i] + n;
bool f = false;
f = BellmanFord(&gr_h, 0, h);
if (!f)
{
printf("exist negativ circle\n");
return;
}
delete [] gr_h.column ;
delete [] gr_h.value ;
delete [] gr_h.pointerB;
for (i = 0; i < n; i++)
{
okr_s = gr->pointerB[i ];
okr_f = gr->pointerB[i + 1];
for(okr_i = okr_s; okr_i < okr_f; okr_i++)
{
j = gr->column[okr_i];
gr->value[okr_i] += h[i + 1] - h[j + 1];
}
}
После модификации графа класс-мастер должен породить необходимое
количество подчиненных задач.
tbb::task_list list;

Параллельные численные методы 79
//параллельный частичный поиск путей
int count = 1;
for(i = 0; i < CNT_TASK; i++)
{
list.push_back(*new(allocate_child())
ChildJohnson(startV[i], endV[i], gr, up, dist));
count++;
}
set_ref_count(count);
spawn_and_wait_for_all(list);
В конце, как и в последовательном алгоритме, верните граф к исходному
состоянию и модифицируйте длины путей.
for (i = 0; i < n; i++)
{
okr_s = gr->pointerB[i ];
okr_f = gr->pointerB[i + 1];
for(okr_i = okr_s; okr_i < okr_f; okr_i++)
{
j = gr->column[okr_i];
gr->value[okr_i] -= h[i + 1] - h[j + 1];
}
}
for(i = 0; i < n; i++)
for(j = 0; j < n; j++)
dist[n * i + j] += h[j + 1] - h[i + 1];
delete []h;
}
Далее реализуйте метод execute() класса-работника. Суть метода сво-
дится к последовательному вызову алгоритма Дейкстры из заданного диа-
пазона.
tbb::task* ChildJohnson::execute()
{
int i, n;
n = gr->sizeV;
for (i = startV; i < endV; i++)
Dijkstra(gr, i, up + n * i, dist + n * i);
return NULL;
}
Пересоберите получившийся код (команда Build→Rebuild Solution) и за-
пустите его на выполнение.
Пример выполнения программы представлен на рис. 25.

Поиск путей на графе
80
Рис. 25. Результаты работы параллельного алгоритма Джонсона
с использованием технологии TBB
Убедитесь, что алгоритм работает корректно. Для этого запустите полу-
ченный код с ключом «-o». При корректной работе алгоритма файлы
09_dist.dat и 01_dist.dat должны полностью совпадать.
На графике, представленном на рис. 26 и рис. 27, показано сравнение вре-
мени выполнения параллельного алгоритма Джонсона с использованием
различного количества вычислительных элементов на примере графа кар-
ты Рима.
Рис. 26. Сравнение времени работы параллельного алгоритма Джон-
сона при разном количестве вычислительных элементов

Параллельные численные методы 81
Рис. 27. Ускорение параллельного алгоритма Джонсона
Как видно из представленных графиков в параллельном алгоритме не уда-
лось добиться приемлемого ускорения. Попробуем выяснить, почему так
произошло, используя инструмент Intel Amplifier XE 2011. Для получения
корректной информации о ходе работы программы сделаем функцию
BellmanFord() невстраиваемой, разместив перед ее объявлением дирек-
тиву __declspec(noinline).
Запустите инструмент в режиме поиска горячих точек. Результат поиска
представлен на рис. 28.
Рис. 28. Результат поиска горячих точек инструментом Intel Amplifier
XE 2011
Как видно из рисунка, алгоритм Беллмана-Форда занимал 9,5% от общего
времени выполнения. Попробуем оценить максимально возможный парал-
лелизм, используя закон Амдаля. Пусть f есть доля последовательных вы-
числений в применяемом алгоритме обработки данных, тогда, в соответ-
ствии с законом Амдаля, ускорение процесса вычислений при использова-
нии p процессоров ограничивается величиной [6] .

Поиск путей на графе
82
При количестве процессов и доле последовательного кода
из закона Амдаля . Следовательно, полученное ускорение согласу-
ется с теоретическими выводами.
В качестве дополнительного задания предлагается распараллелить алго-
ритм Беллмана-Форда.
5.5. Реализация параллельной версии с использованием Cilk
Для реализации параллельного алгоритма Джонсона с использованием технологии Cilk добавьте в решение ShortestPaths новый проект с назва-нием 10_JohnsonCilk. Повторите все действия, описанные в § 2, с той лишь разницей, что начать нужно с выбора решения ShortestPaths в окне Solution Explorer и выполнения команды контекстного меню Add→New Project…. Далее скопируйте весь код из последовательного алгоритма и выполните два действия.
Первое – в заголовочном файле алгоритма Джонсона подключите заголо-вочные фалы Cilk.
#ifndef __cilk
#include <cilk/cilk_stub.h>
#endif
#include <cilk/cilk.h>
Второе, в функции Johnson() замените строки
for (i = 0; i < n; i++)
Dijkstra(gr, i, up + n * i, dist + n * i);
на
cilk_for(i = 0; i < n; i++)
Dijkstra(gr, i, up + n * i, dist + n * i);
Пересоберите получившийся код (команда Build→Rebuild Solution) и за-пустите его на выполнение.
Пример выполнения программы представлен на рис. 29.
Рис. 29. Результаты работы параллельного алгоритма Джонсона
с использованием технологии Cilk
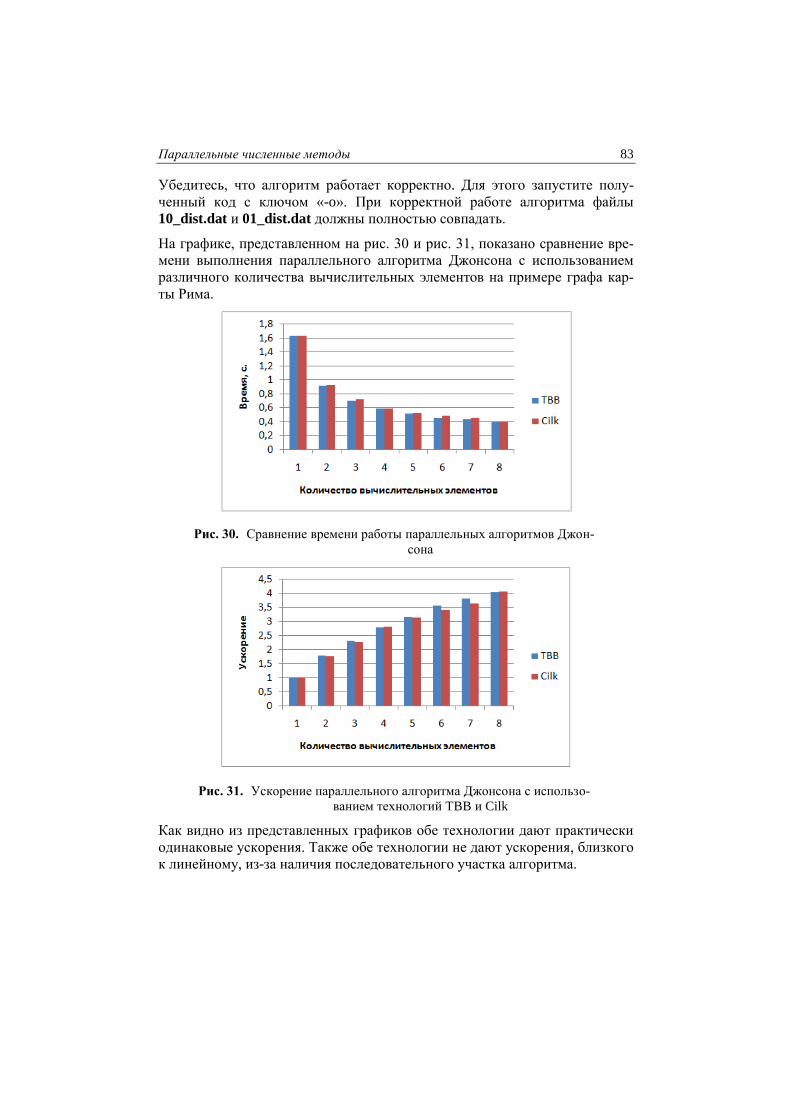
Параллельные численные методы 83
Убедитесь, что алгоритм работает корректно. Для этого запустите полу-
ченный код с ключом «-o». При корректной работе алгоритма файлы
10_dist.dat и 01_dist.dat должны полностью совпадать.
На графике, представленном на рис. 30 и рис. 31, показано сравнение вре-
мени выполнения параллельного алгоритма Джонсона с использованием
различного количества вычислительных элементов на примере графа кар-
ты Рима.
Рис. 30. Сравнение времени работы параллельных алгоритмов Джон-
сона
Рис. 31. Ускорение параллельного алгоритма Джонсона с использо-
ванием технологий TBB и Cilk
Как видно из представленных графиков обе технологии дают практически
одинаковые ускорения. Также обе технологии не дают ускорения, близкого
к линейному, из-за наличия последовательного участка алгоритма.

Поиск путей на графе
84
6. Дополнительные задания
Дополнительные задания имеют разный уровень сложности. Некоторые из
них являются достаточно трудоемкими и требуют изучения дополнитель-
ной литературы.
Все задания предполагают выполнение реализаций для систем с общей па-
мятью.
1. Реализуйте алгоритм из раздела 3 с построением матрицы поиска крат-
чайших путей ( - функция). Примените изменения для параллельных
версий с использованием TBB и Cilk. Выполните оценку эффективно-
сти полученного параллельного алгоритма и обоснуйте полученные ре-
зультаты.
2. Реализуйте параллельный алгоритма Беллмана-Форда в алгоритме
Джонсона с использованием TBB. Выполните оценку эффективности
полученного параллельного алгоритма и обоснуйте полученные ре-
зультаты.
3. Реализуйте параллельный алгоритма Беллмана-Форда в алгоритме
Джонсона с использованием Cilk. Выполните оценку эффективности
полученного параллельного алгоритма и обоснуйте полученные ре-
зультаты.
4. Реализуйте улучшение Йена алгоритма Беллмана-Форда в алгоритме
Джонсона. Реализуйте параллельный алгоритм с использованием TBB.
Выполните оценку эффективности полученного параллельного алго-
ритма и обоснуйте полученные результаты.
5. Реализуйте улучшение Йена алгоритма Беллмана-Форда [1] в алгорит-
ме Джонсона. Реализуйте параллельный алгоритм с использованием
Cilk. Выполните оценку эффективности полученного параллельного
алгоритма и обоснуйте полученные результаты.
6. Реализуйте алгоритм Габова для масштабирования кратчайших путей
из одной вершины [1]. Используя этот алгоритм, реализуйте алгоритм
поиска кратчайших путей для всех пар вершин. Реализуйте параллель-
ный алгоритм с использованием Cilk. Выполните оценку эффективно-
сти полученного параллельного алгоритма и обоснуйте полученные ре-
зультаты.
7. Реализуйте алгоритм Габова для масштабирования кратчайших путей
из одной вершины [1]. Используя этот алгоритм, реализуйте алгоритм
поиска кратчайших путей для всех пар вершин. Реализуйте параллель-
ный алгоритм с использованием TBB. Выполните оценку эффективно-

Параллельные численные методы 85
сти полученного параллельного алгоритма и обоснуйте полученные ре-
зультаты.
7. Литература
7.1. Основная литература
1. Кормен Т., Лейзерсон Ч., Ривест Р., Штайн К. Алгоритмы: построение
и анализ. 2-е издание. – М.: Вильямс, 2010. – 1296 c.
2. Shortest Paths and Experimental Evaluation of Algorithms.
[http://logic.pdmi.ras.ru/midas/sites/default/files/midas-werneck.pdf]
3. Алексеев В. Е., Таланов В. А. Графы и алгоритмы. Структуры данных.
Модели вычислений. – Интернет-Университет Информационных Тех-
нологий/Бином. Лаборатория Знаний, 2006. – 320 c.
4. Tarjan R. E. Data structures and network algorithms. – Philadelphia: Society
for Industrial and Applied Mathematics, 1983. – 140 p.
5. Sedgewick R. Algorithms in C++ Part 5: Graph Algorithms, 3rd Edition. –
Addison-Wesley Professional, 2001. – 528 p.
7.2. Дополнительная литература
6. Гергель В.П. Теория и практика параллельных вычислений. // Интуит
Бином. Лаборатория знаний. 2007. - 424 с.
7. Dijkstra E.W. A note on two problems in connexion with graphs // Numer-
ische Mathematik. V. 1 (1959). – P. 269-271.
8. Pape U. Implementation and efficiency of moor-algorithms for the shortest
route problem // Mathematical programming 7 (1974). – P. 212-222.
7.3. Информационные ресурсы сети Интернет
9. BoostPro Computing. [http://www.boostpro.com/download/]
10. 9th DIMACS Implementation Challenge - Shortest Paths.
[http://www.dis.uniroma1.it/~challenge9/download.shtml]