マルウェア分類に用いられる特徴量 kaggle - malware classification challenge勉強会
TRANSCRIPT

マルウェア検出/分類に用いられる特徴量

自己紹介
@sonicair
高専4年
github.com/IshitaTakeshi
ウサギィで機械学習バイト
CTFちょっとやってたけど
マルウェア関連は初心者

内容
・そもそも特徴抽出とは
・マルウェアからの特徴抽出方法
n-gram フーリエ変換
Binary Texutre Analysis・まとめ
精度比較はちょっとむずかしい (論文によって評価方法が違う )

特徴抽出とはマルウェアを学習器に入れても学習できない
1

最も単純な検出方法
Icons are designed by freepik

最も単純な検出方法
Icons are designed by freepik

最も単純な検出方法
マルウェアだ!!
Icons are designed by freepik
最も単純な検出方法
Icons are designed by freepik

最も単純な検出方法
Icons are designed by freepik

最も単純な検出方法
??
Icons are designed by freepik

未知のマルウェアを検出できない

機械学習を使う
マルウェアだ!!
Icons are designed by freepik

しくみ
特徴抽出アルゴリズム 学習器
特徴量
Icons are designed by freepik

しくみ
特徴抽出アルゴリズム
マルウェアだな!
学習器特徴量
Icons are designed by freepik

学習器だけでは・・・
学習器
Icons are designed by freepik
学習器だけでは・・・
学習器
マルウェアじゃないぞ!!
Icons are designed by freepik

学習器は万能じゃない
学習器
データのどこにどの程度重要な情報があるかを学習器は知ることができない
マルウェアのどこを見ればいいの?

入力データをそのまま学習器に入力しても学習できない

特徴抽出する理由
マルウェアのどこを見ればいいのかを学習器に教えてあげる
▪ 挙動 (動的解析)▪ 中身や構造 (静的̅解析)

特徴抽出する理由
マルウェアのどこを見ればいいのかを学習器に教えてあげる
▪ 挙動 (動的解析) (詳しくない)▪ 中身や構造 (静的̅解析)

静的解析の手法パッカーとは向き合いたくない
2

結局マルウェアのどこを見ればいいの?
実行される命令列を見れば
動作もだいたいわかるよね?

結局マルウェアのどこを見ればいいの?
実行される命令列を見れば
動作もだいたいわかるよね?
パッカー「させねぇよ」

パッカーをどうするか
あきらめる

じゃあどうするの?
unpackしなくても
そこそこうまくいく特徴量を使う

今回紹介する手法
▪ n-gram▪ フーリエ変換▪ Binary Texture Analysis
※精度については論文によって評価方法が違うので述べません

n-gram単純だけどバリエーション豊富
2.1

n-gram
自然言語処理に用いられる特徴量
文章に含まれる部分文字列の出現回数をカウントする

n-gramの例 (n=3)
The cow jumps over the moon
The cow jumps cow jumps over jumps over the over the moon

何を単語と定義するか
▪ バイナリの1バイトを1単語とする
▪ 逆アセンブルしたときのオペコードを単語とする

何を単語と定義するか
バイナリの1バイトを1単語とする
55 48 89 e5 b8 00 00 00
有用な情報はあまり得られないけどそこそこの精度は出るらしい
55 48 8948 89 e589 e5 b8b8 00 0000 00 00
Abdurrahman Pektaş, Mehmet Eriş, Tankut Acarman, Proposal of n-gram Based Algorithm for Malware Classification, SECURWARE 2011

何を単語と定義するか
逆アセンブルしたときのオペコードを単語とする
識別にあまり関係ないものを取り除ける
逆アセンブル難しいんじゃない?→IDA Pro使えばわりといけるっぽい (approximately 74% of the malware files)
A.Shabtai, R. Moskovitch, C. Feher, S. Dolev, and Y. Elovici, Detecting unknown malicious code by applying classification techniques on opcode patterns, 2012.

識別方法 (KNNの場合)
1. n-gram同士の類似度を測定する
2. 未知ファイルと似ているファイルをいくつか(k個)取ってくる
3. マルウェアがいっぱい取れたら未知ファイルをマルウェアとみなす

何を類似度(距離)とするか
X: 入力されたファイルの部分文字列集合
Y: クラスが既知のファイルの部分文字列集合
f(x) : XとY両方に含まれる部分文字列xのXにおける出現回数
距離定義の例
Igor Santos, Yoseba K. Penya, Jaime Devesa, Pablo Garcia Bringas, N-Grams-based file signatures for malware
detection, International Conference on Enterprise Information Systems - ICEIS , pp. 317-320, 2009

n-gramの欠点
n-gramは大量のメモリを必要とする
「15000個のファイルを解析したらメモリが250GB必要になった」
S. Ponomarev et al. (2013)
→データ構造を使う DTrie
→フーリエ変換を使う

n-gramの欠点
n-gramは大量のメモリを必要とする
「15000個のファイルを解析したらメモリが250GB必要になった」
S. Ponomarev et al. (2013)
→データ構造を使う DTrie
→フーリエ変換を使う

n-gramの欠点
n-gramは大量のメモリを必要とする
バイト列の出現パターンがわかればいいんでしょ?
→フーリエ変換使えばいけるんじゃね?
命令の出現頻度を周波数情報として保存できる
メモリ食わないし最強じゃん?

フーリエ変換メモリ消費量を抑えられる
2.2Stanislav Ponomarev, Nathan Wallace, and Travis Atkison, Fourier Transform as a Feature Extraction Method for Malware Classification, 2014.

バイナリを信号とみなす
55 48 89 e5 b8 00 00 00 00 e8 dd ff ff ff→[85, 72, 137, 229, 184, 0, 0, 0, 0, 232, 221, 255, 255, 255]

フーリエ変換する
N/2 < 最大ファイルサイズ < N となるようにする
バイナリ:55 48 89 e5 b8 00 00 00 00 e8 dd ff ff ff十進表現:[85, 72, 137, 229, 184, 0, 0, 0, 0, 232, 221, 255, 255, 255]

フーリエ変換する
ファイルの10進表現 (サイズ 14)
フーリエ変換の入力 (サイズ 16 = 24)
N=2pとなるようにする
ファイルサイズがNになるように空き部分を0で埋める
周波数特性Xkを特徴量とする
[85, 72, 137, 229, 184, 0, 0, 0, 0, 232, 221, 255, 255, 255]
[85, 72, 137, 229, 184, 0, 0, 0, 0, 232, 221, 255, 255, 255, 0, 0]

n-gramと比較すると?
論文では他の手法とは精度の比較をしていませんでした...
フーリエ変換すると命令1つずつの情報って失われるのでは...

Binary Texture Analysis画像にしたらうまくいった・・・
2.3Lakshmanan Nataraj, Vinod Yegneswaran, Phillip Porras, Jian Zhang, A Comparative Assessment of Malware Classification using Binary Texture Analysis and Dynamic Analysis, 2011
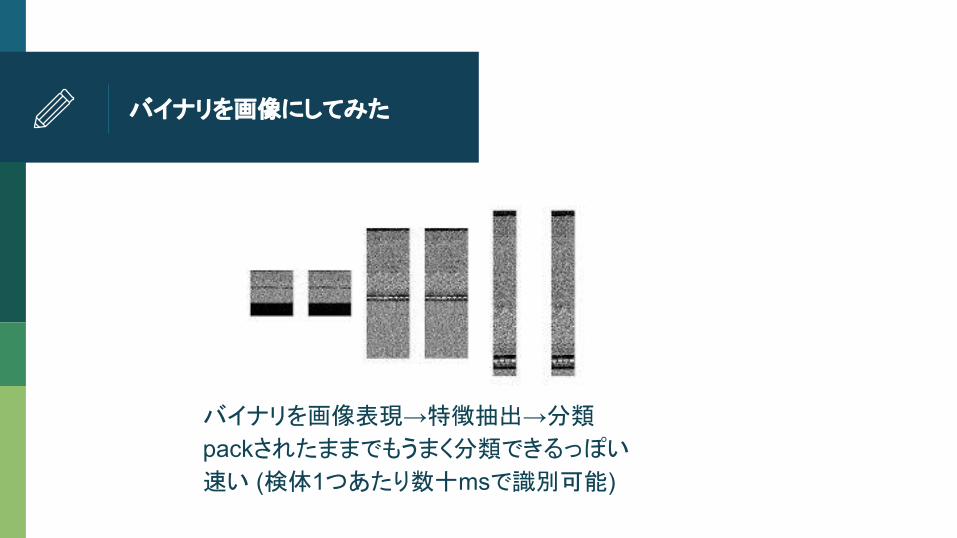
バイナリを画像にしてみた
バイナリを画像表現→特徴抽出→分類
packされたままでもうまく分類できるっぽい
速い (検体1つあたり数十msで識別可能)

画像表現の方法
バイナリを8ビット符号なし整数の列とみなす
→任意のバイナリを1次元配列として表現可能
→1次元配列を一定幅で折りたためば2次元配列(画像)になる
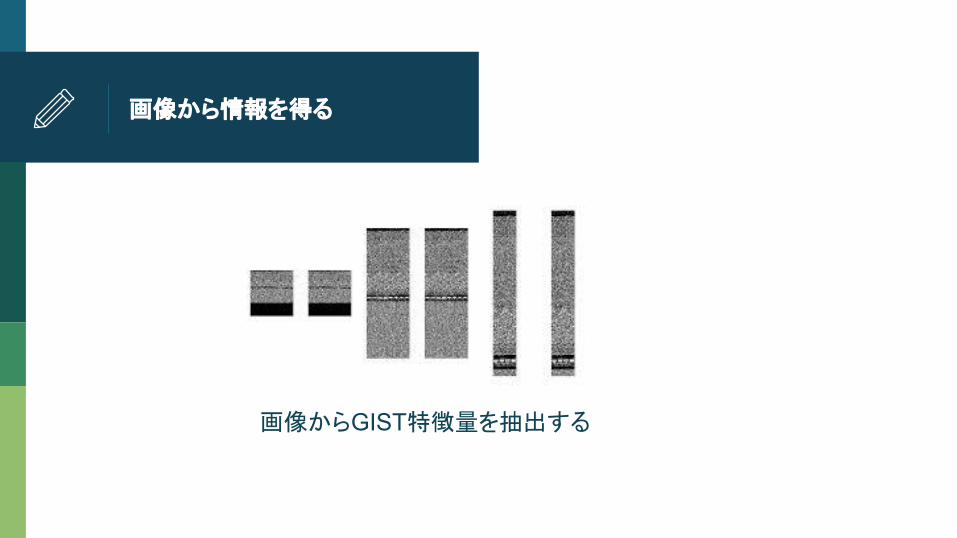
画像から情報を得る
画像からGIST特徴量を抽出する

GIST特徴量とは
画像を分割したときの各部分のgradient情報
シーン認識とかに使われる
局所的な情報よりも全体を見ている
正直よくわかんないけどライブラリはあるみたい (pyleargist)
University of Southern California, iLab and Prof. Laurent Itti, http://ilab.usc.edu/siagian/Research/Gist/Gist.html, 2000

まとめ特徴抽出方法の比較
3

n-gram フーリエ変換 Binary Texture Analysis
最も単純な手法
単語の定義方法など工夫できる
メモリ消費量が大きい
省メモリ
精度...
高速
unpackしなくてもうまくいく