統計解析ソフト r の備忘録 pdf
TRANSCRIPT
- 統計解析ソフト R の備忘録 PDF -
統計解析ソフト R とは統計ソフト『 S 言語』・『 S-plus 』をフリーソフトとして移植されたものです.世界中の
専門家が開発に携わっていて日々新しい手法・アルゴリズムが付け加えられていますので機能的には 『 S-plus 』
を凌駕しているといっても過言ではなく, また,とにかく計算が速い上にグラフィックも充実しているので数値
計算などにも持ってこいです.LATEX同様,無料で使えるソフトにしては機能が充実し過ぎている代物です 1.R
では以下の様な手順を繰り返して作業を行うことになります.
(1) ユーザが式を入力すると R は式を読み,それを評価し,結果を表示する
(2) またユーザが式を入力すると R は式を読み ...
この R と対話しているような動作をする言語をインタプリタ言語といいます.C や JAVA などに代表されるプロ
グラム言語のように『コンパイルする』という動作を行わないので,計算などが手軽に行えます.しかも,インタ
プリタ言語にありがちな計算の遅さも R に関して云えば気にならない程,速い計算を行ってくれます.
この PDF では頁数などの関係上,統計解析に関する解説を省いております.これは『このパソコン全盛時代に
おいて,統計解析を行う際に理論的なことは気にしなくてもよい』ということではありません!私が自信を持って
解説することが出来るのは R の使用法のみであって,統計解析に関する理論的な流れは他の先生方に任せた方が
良いという意味で載せていないだけであります.もし,R を用いて統計解析をやろうという方で,統計解析の理
論的背景が知りたいという方は,以下の参考文献・参考サイトをご覧頂くことをお勧めします.
『 R による統計解析の基礎』 中澤 港 著 (ピアソンエデュケーション)
『工学のためのデータサイエンス入門』 間瀬 茂・神保 雅一・鎌倉 稔成・金藤 浩司 著 (数理工学社)
『THE R BOOK』 岡田 昌司 他 著 (九天社)
【 R による統計処理 (青木先生の HP ) 】:http://aoki2.si.gunma-u.ac.jp/R/
いずれも R の解説と統計の解説とが絶妙に融合したものだけを挙げております.統計解析のみを扱った本・解説
書・演習本・例解集の名著は書店に溢れておりますが,ここでは 2 冊だけ挙げます.
『数理統計学 (改訂版) 』 稲垣 宣生 著 (裳華房)
『統計学の基礎』 栗栖 忠・濱田 年男・稲垣 宣生 著 (裳華房)
(注) この PDF では,本文では半角 \ と半角 Y を Y で,R の命令例・ソースでは半角 \ と半角 Y を \ で表記しております.UNIX や LINUX ,Mac OS などでは半角バックスラッシュは \ と表示され,Windows で
は半角 Y で表示されると思いますが,お使いの OS の記号に適宜読み替えて下さい.
1 このコンテンツは Windows 版 R でコマンドを調べた足跡で,内容は R-tips:http://cse.naro.affrc.go.jp/takezawa/r-tips/r.htmlを PDF に直したものです (2004/05/26).

目 次
表紙と目次 1
第 1章 セットアップの簡単な説明 11
1.0 Rをインストールせずに試してみる . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.1 Rのセットアップ方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.1.1 Linux 版 R のセットアップ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.1.2 Machintosh版 R のセットアップ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.1.3 Windows 版 R のセットアップ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
第 2章 基本知識篇 14
2.1 最低限必要な知識 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1.1 起動 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1.2 終了 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1.3 オブジェクトと付値 (代入) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1.4 オブジェクトの確認・削除 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.1.5 コメント . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.1.6 履歴 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.1.7 ヘルプを見る (基本) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.1.8 ヘルプを見る (応用) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.1.9 作業ディレクトリの変更 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.1.10 注意事項 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2 Rの計算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2.1 基本的な計算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2.2 初等関数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2.3 複素数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2.4 特殊な計算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.2.5 ガンマ関数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.2.6 階乗の計算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.2.7 ベッセル関数ファミリー . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.3 出力+ライブラリ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.3.1 出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
オブジェクトの表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
書式付きでオブジェクトを表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
文字列オブジェクトの表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
オブジェクトの要約を表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
オブジェクトに注釈を加える . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
出力をファイルに送る . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.3.2 ライブラリ・パッケージ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
パッケージの説明 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
拡張パッケージをインストール . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.4 データの型について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2

R-Tips 3頁
2.4.1 空 → NULL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.4.2 不定データ → NA・非数 → NaN・無限大 → Inf . . . . . . . . . . . . . . . . . . . . . . . 27
2.4.3 実数 → numeric . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.4.4 複素数 → complex . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.4.5 文字列 → character . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.4.6 論理値 → logical . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.5 文字列の操作 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
” ” の中で ” を用いるとき . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
文字列を操作する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.6 論理・比較演算子 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.6.1 比較演算子 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.6.2 論理演算子 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.7 関数について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.7.1 引数の省略・略式指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
第 3章 ベクトル篇 32
3.1 ベクトルの基本 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.1.1 ベクトル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.1.2 ベクトルの作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.1.3 ベクトル演算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.1.4 ベクトルからある値に最も近い要素の添字を求める . . . . . . . . . . . . . . . . . . . . . . 35
3.1.5 集合演算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.2 複素・論理・文字型・因子ベクトル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.2.1 複素型ベクトル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.2.2 論理型ベクトル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.2.3 文字型ベクトル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
文字列操作 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.2.4 順序つき因子ベクトルと順序無し因子ベクトル . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.3 ベクトルの操作 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.3.1 要素の場所を指定して取り出す . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.3.2 ベクトル要素の置換・結合・挿入 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.4 データ型の変換とデータ構造の変換 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.4.1 データの型を調べる・変換する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.4.2 データ構造を調べる・変換する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.5 NULL・NA・NaN・Inf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.5.1 NULL・NA・NaN・Inf なのか否かを調べる . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.5.2 ベクトル要素にある NA の排除・置換 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.5.3 NULL の使い方の例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.6 リスト . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.6.1 リストの要素を取り出す . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.6.2 部分リストの抽出・置換・連結 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.6.3 全ての要素に関数を適用する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.7 行列の作成と基本操作 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.7.1 種々の行列作成方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.7.2 行列の大きさ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.7.3 行と列のラベル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.7.4 行列要素の抽出 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.7.5 行列の結合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52

R-Tips 4頁
3.8 行列の計算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
3.8.1 特定の列 (行)和に対する演算や操作 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
3.8.2 行列をある行・列に関してソートする . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
3.8.3 転置行列 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
3.8.4 単位行列・対角行列 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
3.8.5 三角行列 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.8.6 行列の成分の二乗の総和 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.8.7 連立方程式の解 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.8.8 逆行列 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.8.9 一般逆行列 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.8.10 クロス積 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.8.11 固有値と固有ベクトル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.8.12 QR分解 (行列のランク) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.8.13 コレスキー (Cholesky) 分解 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.8.14 特異値分解 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
3.8.15 行列の平方根 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.8.16 正方行列の指数乗 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.8.17 行列式 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.8.18 おまけ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.9 配列+ apply() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
3.9.1 行列,配列の各部分に関数を適用する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.9.2 配列の一般化転置 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
第 4章 関数・プログラミング篇 64
4.1 演算子と複合式 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.2 条件分岐 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.2.1 条件分岐:if ,else . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.2.2 条件分岐:switch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
4.2.3 演算子 && ,|| . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
4.3 繰り返し文 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
4.3.1 for による繰り返し . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
ループ範囲に整数値を指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
ループ範囲にリストを指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
その他の指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
4.3.2 while による繰り返し . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
4.3.3 repeat による繰り返し . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
4.3.4 break を用いて繰り返し文から抜ける . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
4.3.5 next を用いて強制的に次の繰り返しに移る . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.4 関数の定義 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.4.1 関数の作成例:二項演算子の定義 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
4.4.2 ファイルに保存してある関数定義を読み込む . . . . . . . . . . . . . . . . . . . . . . . . . . 73
4.4.3 関数を保存して次回に使えるようにする . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
4.4.4 関数の返す値 (返り値) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
返り値が一つの場合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
返り値が複数の場合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
返り値が関数の場合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
4.4.5 結果の自動表示を止める . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
4.4.6 エラー・警告を表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75

R-Tips 5頁
4.4.7 ローカル変数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
グローバル変数とローカル変数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
永続付値 << −について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.4.8 関数内での関数定義 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.4.9 関数についての情報を見る . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.4.10 関数終了時の後始末 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
4.5 引数について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
4.5.1 引数の省略 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
仮引数の宣言部で指定する方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
関数 missingを使う方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
4.5.2 任意個の引数を受けとる . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
4.5.3 引数に関数を渡す . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
4.6 再帰関数+微分・積分 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
4.6.1 再帰関数:再帰呼び出しを行う関数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
4.6.2 数値積分 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
4.6.3 普通の微分と精度の良い数値積分 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
4.7 デバッグについて . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
4.7.1 途中で変数の値を調べる cat() , print() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
4.7.2 評価の途中で変数を調べる browser() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
4.7.3 デバッグモードに入る debug() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
4.7.4 関数の呼び出しを追跡する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
4.8 関数定義の練習問題 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
4.8.1 問題篇 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
関数定義事始 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
if else 文の練習 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
if else 文の練習 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
for や while などの繰り返し文の練習 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
for や while などの繰り返し文の練習 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
plot()を行う関数定義の練習 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
4.8.2 解答篇 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
関数定義事始 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
if else 文の練習 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
if else 文の練習 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
for や while などの繰り返し文の練習 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
for や while などの繰り返し文の練習 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
for や while などの2重繰り返し文の練習 . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
plot()を行う関数定義の練習 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
第 5章 データ入力篇 94
5.1 データフレーム . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
5.1.1 データフレームとは??? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
5.1.2 データフレーム作成の例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
5.1.3 データの列の特徴を見る . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
5.1.4 データフレームからデータを取り出す . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
5.1.5 データの処理・編集 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5.1.6 attach() と detach() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
5.1.7 データの列の変更・追加・消去 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
5.1.8 2つのデータフレームを連結する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99

R-Tips 6頁
5.2 ファイルからのデータ入力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
5.2.1 read.table() を用いる方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
列名・行名の制御 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
データの区切りがスペース以外の場合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
5.2.2 scan() を用いる方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
決まった要素ごとに data.txt を読み込む . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
データについていくつかの注意 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
5.2.3 データ読み込みついての補足事項 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
組み込みデータにアクセスする方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
R以外ソフトで作成されたデータファイルの読み込み . . . . . . . . . . . . . . . . . . . . . 104
5.3 入力したデータの処理・編集 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
5.3.1 read.table() で読み込んだデータへのアクセス . . . . . . . . . . . . . . . . . . . . . . . . . 105
データを編集する・統計解析を行う . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
セル形式でデータを編集する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
5.3.2 scan() で読み込んだデータへのアクセス . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
5.4 ファイルへのデータ出力例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
5.4.1 区切り文字を付けたファイルへのデータ出力 . . . . . . . . . . . . . . . . . . . . . . . . . . 108
5.4.2 ファイルへのデータの出力例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
5.4.3 補足 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
第 6章 グラフィックス篇 111
6.1 作図の準備 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
6.1.1 作図を行うには . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
6.1.2 作図関数について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
高水準作図関数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
低水準作図関数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
対話的作図関数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
6.1.3 作図デバイスについて . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
作図デバイスとは . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
作図デバイスの種類 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
6.1.4 複数のデバイスドライバ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
6.2 とりあえず plot() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
6.2.1 plot() の形式指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
6.2.2 対数軸や軸の範囲の指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
6.2.3 タイトルなどの指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
6.2.4 図の重ね合わせ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
6.2.5 点の色を変数に応じて変える . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
6.2.6 図の消去 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
6.2.7 plot() の引数の与え方による出力の違い . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
6.3 高水準作図関数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
6.3.1 plot() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
6.3.2 curve() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
6.3.3 いくつかのデータを重ねる:matplot() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
6.3.4 一度に複数の曲線を描く:matplot() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
6.3.5 棒グラフ:barplot() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
6.3.6 ヒストグラム:hist() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
6.3.7 円グラフ:pie() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
6.3.8 ドットチャート:dotchart() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121

R-Tips 7頁
6.3.9 箱ひげ図:boxplot() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
6.3.10 星形図:stars() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
6.3.11 多変量データの図示 (1):symbols() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
6.3.12 多変量データの図示 (2):pairs() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
6.3.13 多変量データの図示 (3):coplot() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
6.3.14 3次元データの図示 (1):image() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
6.3.15 3次元データの図示 (2):persp() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
6.3.16 3次元データの図示 (3):scatterplot3d() . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
6.3.17 3次元データの図示 (4):contour() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
6.3.18 パッケージ:lattice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
6.4 低水準作図関数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
6.4.1 図の消去 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
6.4.2 点の描画 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
6.4.3 折れ線の描画 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
6.4.4 直線の描画 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
6.4.5 線分と矢印の描画 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
6.4.6 文字列の描画 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
6.4.7 枠の描画 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
6.4.8 タイトル・サブタイトルの描画 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
6.4.9 座標軸の描画 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
6.4.10 凡例の描画 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
6.4.11 多角形の描画 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
6.4.12 数式の描画 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
6.5 対話的作図関数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
6.5.1 座標値の入力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
6.5.2 点の認識 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
6.6 グラフィックスパラメータ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
6.6.1 グラフィックスパラメータ事始 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
6.6.2 グラフィックスパラメータの永続的変更 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
関数 par() の使い方 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
グラフィックスパラメータ値の一時退避と復帰 . . . . . . . . . . . . . . . . . . . . . . . . . 133
作図領域・余白・座標系 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
作図領域のサイズ・座標・形式を指定するパラメータ . . . . . . . . . . . . . . . . . . . . . 135
余白に関するパラメータ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
6.6.3 グラフィックスパラメータの一時的変更 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
プロットに用いられる色 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
プロットのマーカー . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
テキスト・フォントに関するパラメータ . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
線分の太さと形式 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
枠に関するパラメータ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
軸に関するパラメータ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
6.7 複数の図・重ねた図を描く . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
6.7.1 準備 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
6.7.2 画面を分割して図を描く . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
6.7.3 少し高度な画面分割 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
layout()を用いた画面分割 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
split.screen()を用いた画面分割 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141

R-Tips 8頁
6.7.4 重ねた図を描く . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
第 7章 統計解析篇 143
7.1 基本統計量 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
7.1.1 総和・平均・中央値 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
7.1.2 不偏分散と分散・標準偏差 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
7.1.3 分散共分散行列・相関行列 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
7.1.4 データの規準化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
7.2 確率分布と乱数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
7.2.1 関数の使い方 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
7.2.2 Rに用意されている確率分布 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
7.2.3 乱数の再現:関数 set.seed() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
7.2.4 3変量分布の乱数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
3変量正規乱数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
3変量 t乱数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
7.2.5 逆関数法による乱数の作り方 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
7.2.6 棄却法による乱数の作り方 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
7.2.7 周辺和を与えたランダムな 2 x 2 分割表 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
7.2.8 ランダム抽出・ブートストラップサンプリング . . . . . . . . . . . . . . . . . . . . . . . . . 151
7.3 データの分布とヒストグラム・密度推定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
7.3.1 データの分布 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
7.3.2 真の密度とデータの準備 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
7.3.3 ヒストグラムによる密度推定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
7.3.4 カーネルによる推定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
7.3.5 二次元データの密度推定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
7.3.6 lowess() による平滑化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
7.4 検定結果の見方 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
7.4.1 t 検定を行う関数 t.test() について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
7.4.2 引数の注意 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
7.4.3 返り値の説明 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
7.4.4 検定例: 一標本の場合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
7.4.5 検定例:二標本の場合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
7.5 一標本検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
7.5.1 グラフによる正規分布との比較 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
累積分布関数 (cdf) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
Q-Q プロット . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
7.5.2 正規性の検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
Shapiro-Wilk 検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
コルモゴロフ・スミルノフの検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
母平均の検定と推定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
7.6 二標本検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
7.6.1 ニ標本の検定:正規性を仮定する場合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
データの準備 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
データの読み込みと視覚化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
2つの母平均に差があるかどうかの検定:unpairedな場合 . . . . . . . . . . . . . . . . . . 164
2つの母分散が同等であるか否かの検定:F 検定 . . . . . . . . . . . . . . . . . . . . . . . . 165
2つの母平均に差があるかどうかの検定:二群の分散が等しいことを仮定する場合 . . . . . 165
7.6.2 ニ標本の検定:正規性を仮定しない場合 (1) . . . . . . . . . . . . . . . . . . . . . . . . . . 166

R-Tips 9頁
データの準備 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
2つの母代表値に差があるかどうか:ウィルコクソンの検定・マン・ホイットニーの U検定 166
7.6.3 累積分布関数の比較 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
累積分布関数の比較:プロットによる方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
累積分布関数の比較:コルモゴロフ・スミルノフの検定 . . . . . . . . . . . . . . . . . . . . 166
7.6.4 ニ標本の検定:正規性を仮定しない場合 (2) . . . . . . . . . . . . . . . . . . . . . . . . . . 167
対応のある 2つの母代表値に差があるかどうかの検定:ウィルコクソンの符号付順位和検定 167
対応のある 2変数の組について単に母代表値に差があるか検定:符号検定 . . . . . . . . . . 167
2つの母代表値に差があるかどうかの検定 (2) :マン・ホィットニーの U検定 . . . . . . . 168
7.6.5 参考:分散の均一性の検定:バートレットの方法 . . . . . . . . . . . . . . . . . . . . . . . 169
7.7 さまざまな検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
7.7.1 χ2 (カイ二乗) 検定:chisq.test() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
検定したいデータの形式 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
実際の検定データ入力例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
7.7.2 カテゴリーデータの検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
二群の比率の差の検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
フィッシャーの直接確率検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
フィッシャーの直接確率検定 (分割表が 2 × 2 よりも大きい場合) . . . . . . . . . . . . . . 170
マクネマー検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
マクネマー検定 (分割表が 2 × 2 よりも大きい場合) . . . . . . . . . . . . . . . . . . . . . . 171
実際の検定データ入力例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
7.7.3 相関係数についての検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
検定したいデータの形式 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
実際の検定データ入力例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
7.7.4 分散分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
検定したいデータの形式 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
実際の検定データ入力例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
フリードマン検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
7.8 直線回帰・最小二乗法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
7.8.1 最小二乗法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174
7.8.2 関数 lsfit() による最小二乗法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 176
7.9 回帰分析と重回帰分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177
7.9.1 関数 lm() による回帰 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177
関数 lm() の書式と引数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 178
回帰の例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
モデル情報を取り出す関数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
モデル情報を取り出す例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180
当てはめモデルの更新 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180
7.9.2 重回帰分析とモデル選択 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180
重回帰モデルの当てはめ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180
モデル選択の規準 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
7.10 関数の最大化と最小化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
7.10.1 関数の最大化・最尤推定法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
7.10.2 関数の最小化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
7.11 その他の分析方法の紹介 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184
7.11.1 因子分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184
7.11.2 主成分分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185

R-Tips 10頁
7.11.3 正準相関分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
7.11.4 判別分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 186
7.11.5 クラスター分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
7.11.6 生存時間解析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
7.11.7 ノンパラメトリック回帰 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
7.11.8 数理計画法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
第 8章 補足事項 190
8.1 『丸め』について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
8.2 属性:names 属性と要素のラベル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
8.3 apply() ファミリー . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192
8.4 関数定義に関する補足 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
8.4.1 引数のチェックを行う . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
8.4.2 引数のマッチングと選択 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
8.4.3 数値ベクトルの対話的入力 readline() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
8.4.4 メニューによる選択 menu 関数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
8.5 データを html ,LATEX形式で出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
8.6 グラフィックス関係の補足 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
8.6.1 時系列:ts.plot() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
8.6.2 barplot() あれこれ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
8.6.3 pie() あれこれ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
8.6.4 数式による注釈 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
8.7 eps ファイルの編集方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204
8.7.1 Tgif を用いる方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204
8.7.2 OpenOffice.org の draw を使う方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
8.8 関数 lm() に入れる演算子とシンボルの例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 206
8.9 色の名前と RGBコード . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 207
参考文献・参考サイト 209

第1章 セットアップの簡単な説明
1.0 Rをインストールせずに試してみる
RWeb (なかまさん):http://r.nakama.ne.jp/Rweb-jp/ で R を試すことが出来ます.とりあえず R を試してみ
たい方に是非お勧めします.
1.1 Rのセットアップ方法
『THE R BOOK』 (岡田 昌司 他,九天社) を買うか,以下のサイトから実行ファイルをダウンロードします.
• The R Project:http://www.r-project.org/
• 日本語化パッチ適用済バイナリ (なかまさん):http://r.nakama.ne.jp/
1.1.1 Linux 版 R のセットアップ
R のインストール方法に関する readme ファイルは以下にあります.
ftp://ftp.u-aizu.ac.jp/pub/lang/R/CRAN/src/base/INSTALL
一番簡単なのは R のバイナリを取ってくる方法でしょう.Red hat Linux 用 RPM や Vine 用 RPM などがある
ので,然るべきファイルをダウンロードします.あとは readme ファイルに従ってインストールするだけです1.
ftp://ftp.u-aizu.ac.jp/pub/lang/R/CRAN/bin/linux/(Linux distribution 名)/R-1.8.1.xxx
1.1.2 Machintosh版 R のセットアップ
まず,以下のサイトから RAqua.dmg をダウンロードします.2
ftp://ftp.u-aizu.ac.jp/pub/lang/R/CRAN/bin/macosx
ダウンロードした RAqua.dmg をダブルクリックすると RAqua という名前のボリュームがマウントされます.そ
れを開くと RAqua.pkg というインストーラがあるので,それをダブルクリックするとインストールが始まりま
す.3.
1.1.3 Windows 版 R のセットアップ
The R Projectにある実行ファイル ( rw1081.exeなど) や,なかまさんの HP にある実行ファイルをダウンロー
ドし,exe ファイルをダブルクリックすればインストールできます. R 1.9.x はバグがちらほら報告されているの
で,個人的には R 1.8.1 あたりをインストールすることをお勧めします.セットアップの方法ですが,基本的には
[Next] をクリックすればインストールできます.
1 UNIX 版は実行ファイルを make する必要があります.詳しくは山本先生の HP をご覧下さい.2 Mac OS 9 ならば R 1.7.1 までしか使えないようです.3 コマンドラインから使う場合にはもう少し設定が必要だそうです.詳しくは青木先生の HP をご覧下さい.

R-Tips 12頁
The R Project にある実行ファイルをダウンロードする場合,まず http://www.r-project.org/ の Download
[CRAN] (以下の赤い場所) をクリックします.
次に,以下のサイトの Japanのいずれかをクリックします.すると,FTP画面が出ますので,会津大学や筑波大学
のミラーサーバ ftp://ftp.u-aizu.ac.jp/pub/lang/R/CRAN/bin/windows/base/から rw1081.exeや rw1081pat.exe
(日本語パッチ適用済実行ファイル) をダウンロードします.
なかまさんの HP かダウンロードする場合で,バージョン 1.8.1 をインストールするのならば,
http://r.nakama.ne.jp/R-1.8.1/binary/ から実行ファイル rw1081 i18n 20031217.exe をダウンロードします.
実行ファイルをダブルクリックすると,インストールが開始されます.
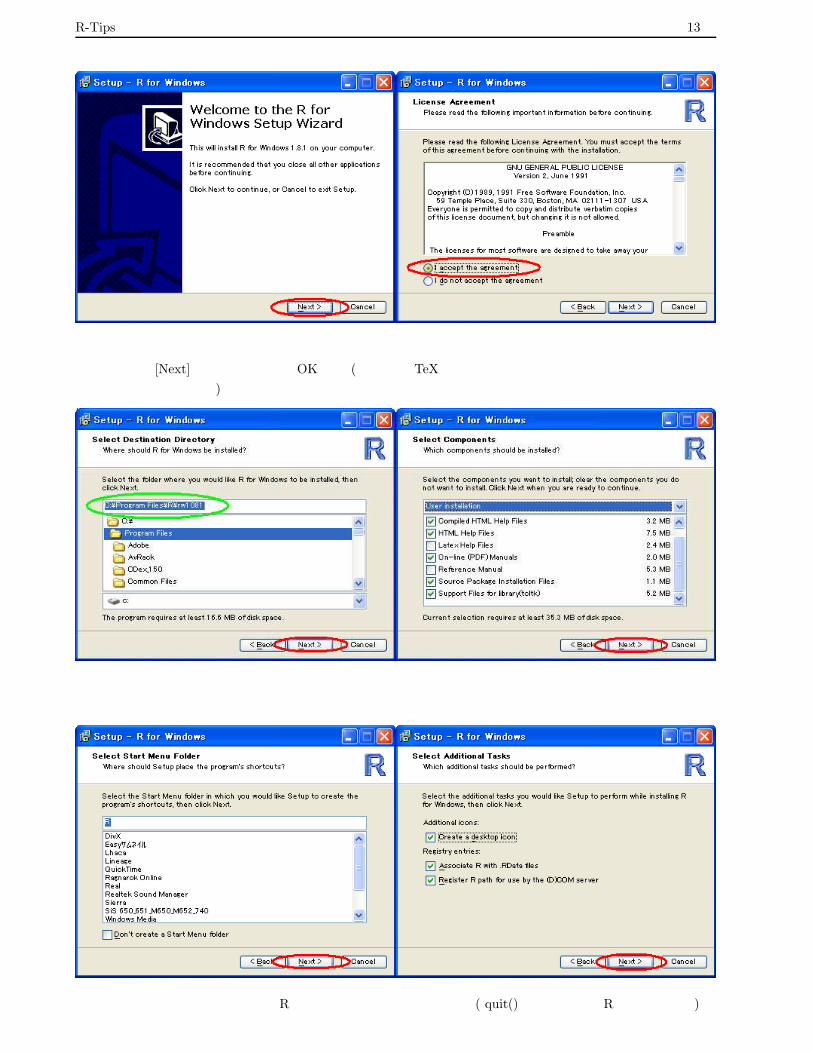
R-Tips 13頁
「インストールするフォルダ」 を指定した後,本体以外のオプションでどれをインストールするかを決めます.普
通はそのまま [Next] をクリックすればOK です ( 英語版の TeX のヘルプファイルや英語版のリファレンスマニュ
アルは普通は使いません) .
「スタートアップに登録するか否か・登録名を何にするか」 や「デスクトップにアイコンを作成するか」 などを
指定します.指定後にインストールが開始されます.
無事,インストールが終了すると,R が起動され画面が表示されます ( quit() を入力すると R を終了します) .

第2章 基本知識篇
2.1 最低限必要な知識
2.1.1 起動
Windows と Mac ならば R のアイコン(R.1.x.x 又は StartR)をクリックすれば起動する.Linux ならばプロ
ンプト画面で $ Rと入力すれば起動する.起動すると (Windows ならば)以下のような画面が出てくる.
上の様に,起動すると > を表示する1.これは R がユーザからの入力を待っていることを意味する.この状態で
計算式や関数を入力して [ENTER] キーを押せば計算してくれる.� �> 1+2 # 1+2 と入力した後 [ENTER] キーを押す
[1] 3
> sin(pi/2) # sin(pi/2) と入力した後 [ENTER] キーを押す
[1] 1� �
2.1.2 終了
R をやめるとき,ウインドウの右上の × をクリックしても良いが,平穏に終わるときは以下の 2通りの方法で
終了することが出来る.� �> q()
> quit()
� �
2.1.3 オブジェクトと付値 (代入)
R が作ったり操作した実体はオブジェクト (object) と呼ばれる.変数,数の配列,文字列関数,データ,関数そ
の他全てがそれにあたる (この頁の例で,x にベクトルを代入してみたが,この x がオブジェクトである) .難し1 プロンプト > の記号がお気に召さないならば options(prompt=”記号 ”) で変更することができる (例:options(prompt=”: ”) ).

R-Tips 15頁
くお考えにならなくてもよい.R をやる分には所詮,単なる モノ であるという理解でよい.「オブジェクトが・・・」
と言われたら「ああ,変数だか数値だか何かがあるんだなあ」と考えてもらえればよい.
オブジェクトには付値 (代入) によって名前をつけることが出来る.普通のプログラムで云えば変数に数値など
を代入する動作に当たる.付値によって名付けられたオブジェクトはその名前で参照することが出来る.次は x に
値 2 を,y に値 3 を代入するという意味であり,付値した名前は後に入力する式の中で自由に使うことが出来る.� �> x <- 2 # x に 2 を付値 (代入) する
> y <- 3 # y に 3 を付値 (代入) する
> x # x という名前のオブジェクト (変数)の中身
[1] 2
> y # y という名前のオブジェクト (変数)の中身
[1] 3
> x + y # x の中身と y の中身の足し算
[1] 5� �式の中で使われた場合,それは付値された値を意味する.例えば x < − 3 とした後で x + 5 と入力すれば,こ
れは 3 + 5 と認識される.式の中で使われた名前にその式を評価した結果を再度付値することも出来る.付値し
直すと,以前その名前で保存されていた値は単に捨てられ,新しい値が保存される.� �> x <- 2 # x に 2 を付値 (代入) する
> x <- 3 # x に 3 を付値 (代入) する
> x
[1] 3� �付値を行う場合は以下の 3 種類の演算子を使うことが出来る.普通の付値には < − を使う.式を入力している
途中で気が変わって結果を保存したくなった時は − > が便利である.C 言語や JAVA などのプログラム言語に
慣れた方には = が親しみやすい.
代入演算子 < − − > =
次の例は,すべて x に π/2 を評価した結果を付値している.� �> x <- pi/2
> pi/2 -> x
> x = pi/2
� �表示はされないが,代入式自体も値を返す.『代入式の値』 は『代入した値』である.よって,以下のように一
度にいくつかの名前に代入することが出来る.� �> y <- x <- 777
> y
[1] 777
> x
[1] 777� �以下の名前は R の処理系によって予約されているので,オブジェクトの名前として用いることは出来ない.
break else for function if in next repeat return while
R-Tips 16頁
2.1.4 オブジェクトの確認・削除
関数 objects() を使うことで,検索リストに含まれているディレクトリの中にどんなオブジェクトがあるかを調
べることが出来る.また,前に定義したオブジェクトを消す場合 (例えば x と y と z の定義や入っている値を消
したい場合) は関数 rm() を用いる.� �> objects()
[1] "last.warning" "oldpar" "x"
> objects(all=TRUE) # ドットで始まるファイル (隠しファイル)を表示する場合
[1] ".Traceback" "last.warning" "oldpar" "x"
> rm (x) # オブジェクト x を消す場合
> rm(list=ls(all=TRUE)) # 全てのオブジェクトを消す場合
� �特定のオブジェクトをファイルへ記録する場合は関数 save() を用いる (呼び出す場合は関数 load() を用いる) .
2.1.5 コメント
入力したコマンドの意味を書いておきたい場合がある.そのようなときは # 以下にコメントを書けば,# 以下
の文字列は無視されるので,プログラムの動作を気にすることなく好きなことを好きなだけ書くことが出来る.た
だし,英語版の R で日本語コメントを書いた場合は文字化けしてしまうので注意.� �> x <- c(1,2)
> x <- c(1,2) # vector x = (1, 2) だよ~~~~~~~~~~~~~~ん� �
2.1.6 履歴
前に使った命令を再度使う際,キーボードの上 ( [Ctlr] + [p] ) か下 ( [Ctlr] + [n] ) で前の命令を呼び出すこと
が出来る.
2.1.7 ヘルプを見る (基本)
プログラムを書いていて例えば『 solve 』をどう使うか分からなくなった場合は,以下の 2 通りの方法で solve
に関するヘルプを見ることが出来る.� �> help(solve)
> ?solve
> args(solve) # 関数の完全な解説は必要無いが,引数のみを知りたいという場合
� �関数に限らず R の文法などの総合的な解説やデータセットなどの解説も同じように見ることができる.例えば
文法の解説は以下のようにすると表示される.� �> ?Syntax
� �for などの予約語や,[ などの特殊記号の解説を見るには ””で囲む必要があるので注意が要る (> ?”for” で
も可)� �> help("for")
� �

R-Tips 17頁
2.1.8 ヘルプを見る (応用)
R のヘルプは英語なので日本人には読みにくい場合がある.手っ取り早く使い方が見たいという場合,例えば
solve の使い方が知りたい場合は以下のようにすれば例を出力してくれる.� �> example(solve)
� �ただし,グラフ出力がある場合で,グラフをいくつか含む場合は,単に example をやってしまうと数枚のグラ
フが一瞬で表示されきってしまう.動体視力に自信のない方は,以下を定義しておくだけでグラフの描画ごとに逐
一静止してくれる.� �> par(ask = TRUE)
� �また,パッケージにある関数やデータセットに関するヘルプを表示する場合は以下のようにする.� �> help.search("keyword") # keyword から情報を得ようとする場合
> help(package="MASS") # パッケージ ’MASS’ に関する関数の一覧
> base::log # base パッケージ中の関数 log の情報を得る
> base::"+" # base パッケージ中の演算子 "+" の情報を得る
> eda::medpolish(x) # eda パッケージを自動ロードするのでエラーにならない
> data() # 使用可能なデータセットを表示
> data(package = "base") # パッケージ base で使用可能なデータセットを表示
> data(USArrests, "VADeaths") # データセット ’USArrests’ と ’VADeaths’ をロード
> help(USArrests) # データセット ’USArrests’ に関するヘルプ
� �
2.1.9 作業ディレクトリの変更
ファイルからデータやプログラムを読み込んだり,ファイルにデータを書き出したりする場所を作業ディレクト
リという.起動時はホームディレクトリ ( R の実行ファイルがある場所) が作業ディレクトリとなっているが,変
更する場合はメニューの [File] − > [Change dir...] で指定するか,以下のような命令を与える.� �> setwd("c:\usr") # Windows では \ を指定しては駄目
Error in setwd(dir) : cannot change working directory
> setwd("c:/usr") # 作業ディレクトリを指定
> getwd() # 現在の作業ディレクトリを表示
[1] "c:/usr"� �これ以後,指定した作業ディレクトリにデータがセーブされたり,プロットした図が保存される.
2.1.10 注意事項
(a) 入力中に上 ( [Ctlr] + [p] ) か下 ( [Ctlr] + [n] ) を押すと,それぞれ一つ前と一つ後に入力したコマンドが出
たが,[Ctlr] + [a] か [Ctlr] + [e] を押すと,それぞれカーソルが行頭と行末に移動する.
(b) R は大文字と小文字を区別する.従って sin と SIN , Sin は全て異なるものとして R は認識する.
(c) 式を入力する際に,sin などの名前の中や後に出てくる文字列の中を除いて,空白はいくつあっても構わない.
例えば以下は全て同じ結果を返す.

R-Tips 18頁
� �> 1 + 2
[1] 3
> 1 + 2
[1] 3� �
(d) セミコロン ; で区切ることで,複数の式を一行に書くことも出来る.� �> 1+2; 3-4
[1] 3
[1] -1� �
(e) 括弧が閉じていない場合や演算式が終了していない場合など,式が未完成のままで改行を入力してしまうと,
R は通常のプロンプト>の代わりに式が継続していることを示す+を表示する.この場合,引き続いて続き
の式を入力することが出来る.� �> 1 +
+ 2
[1] 3� �
(注) S-PLUS や S 言語では,文字列を示す ” や ’ が閉じていない場合は文字列が継続していることが一目でわか
るように + の代わりに“ Continue string: +”が使われる.どちらもこの状態から式の続きを入力すること
が出来,式が完成した時点で評価が行なわれる.しかし R ではエラーが出る場合があるので注意.
(f) R は数値の他に論理値やベクトル,文字列などを扱うことができる.例えば x というベクトルを定義したけ
れば以下のようにすればよい.� �> x <- c(1,2)
� �本当に x にベクトル (1, 2) が入っているかを確かめてみる.� �> x
[1] 1 2� �
(g) 以下のように丸括弧 ( を用いると,付値と表示を同時に行なう.� �> x <- 1:4 # 付値のみで結果の表示はない
> (x <- 1:4) # 丸括弧で囲むと、付値した結果を表示
[1] 1 2 3 4
> test1 <- function(x) y <- 2*x
> test1(1:4) # 何も表示されない
> test2 <- function(x) (y <- 2*x)
> test2(1:4) # 丸括弧で囲むと付値した上で表示される
[1] 2 4 6 8� �
R-Tips 19頁
2.2 Rの計算
2.2.1 基本的な計算
四則演算は C 言語などと同じであるが,演算子の中には C 言語などと意味が異なる命令もあるので注意が必
要.下の表以外に ( や ) などの括弧も使うことが出来る.
記号 + ˆ − %/% ∗ %% /
意味 足し算 累乗 引き算 整数商 掛け算 剰余 割り算
計算例は以下の通り.� �> 1 + 2 - 3 * 4
[1] -9
> 5^6 %% 7
[1] 1� �
2.2.2 初等関数
R では次のような基本的な数学関数が用意されている.例えば x に 10 が入っている場合,log(x) と入力すれ
ば log(10) が得られる.
記号 sin(x) cos(x) tan(x) sinh(x) cosh(x) tanh(x)
意味 sin cos tan sinh cosh tanh
記号 asin(x) acos(x) atan(x) asinh(x) acosh(x) atanh(x)
意味 sinの逆関数 cosの逆関数 tanの逆関数 sinhの逆関数 coshの逆関数 tanhの逆関数
記号 log(x) log10(x) log2(x) log1px(x) exp(x) expm1(x)
意味 対数 常用対数 底が 2の対数 log(1+x) e exp(x)−1
記号 sqrt(x) round(x) trunc(x) floor(x) ceiling(x) signif(x,a)
意味 ルート 四捨五入 整数部分 小数を切捨 小数を切上 xを有効桁 a桁で丸め
atan(x) は x の逆正接関数 (tan の逆関数) を求めるが,atan(x, y) と引数を 2つ与えれば,直角座標 (y, x) に
対応する極座標の偏角が (-π, π] の範囲で求める (x と y の順番に注意) .この場合において,y == 1 とすれば
atan(x, y) == atan(x, 1) == atan(x) と定義される.
2.2.3 複素数
R では複素数を扱うことも出来る.� �> exp(1 + 2i)
[1] -1.131204 +2.4717275
> log(2 + 1i) - log(5 + 1i)
[1] -0.8243293+0.2662520i� �(注) 虚数 1 + iを表すときは 1+1i と表記すること.1+i とすると i はオブジェクト(変数など)と認識される.
(注) 行列,配列を引数とする関数の中には複素数を要素とする行列,配列を扱うことが出来ないものもある.
(注) 実数から複素数に自動的に型変換がなされることはない.以下にその例を示す.

R-Tips 20頁
� �> log(-2)
[1] NaN
Warning message:
NaNs produced in: log(x)
> log(-2+0i)
[1] 0.6931472+3.141593i� �これより,-2 と -2+0i は異なることが分かる.
2.2.4 特殊な計算
下の表以外に ”(”や ”) ”などの括弧も使うことが出来る.
記号 意味 記号 意味
: 公差± 1の数列を作る [ ] ベクトル,行列の要素の取り出し
%*% 行列積 [[ ]] リストの成分の取り出し
%o% 外積 (関数 outerと同じ) $ リストの成分の取り出し
外積の”o”はアルファベットの”o”である.上記の記号を使ったの計算例は以下の通り.� �> 1:4
[1] 1 2 3 4
> 2:5
[1] 2 3 4 5
> x <- c(1,2)
> y <- c(3,4)
> x %o% y
[,1] [,2]
[1,] 3 4
[2,] 6 8
� �
2.2.5 ガンマ関数
以下のガンマ関数ファミリーが用意されている.
beta(a, b) : ベータ関数 B(a,b) = (gamma(a)*gamma(b))/gamma(a+b).引数 a,b は零および負整数を除く
数値 (のベクトル).
lbeta(a, b) : ベータ関数の自然対数.直接計算しており,log(beta(a,b)) として計算しているわけではない.
gamma(x) : ガンマ関数.引数 x は零および負整数を除く数値 (のベクトル).正の整数 n に対する階乗 n! は
gamma(n+1) として計算するのが基本.
lgamma(x) : ガンマ関数の自然対数.直接計算しており,log(gamma(x)) として計算しているわけではない.
digamma(x) : lgamma の一階微分.
trigamma(x) : lgamma の二階微分.
tetragamma(x) : lgamma の三階微分.
pentagamma(x) : lgamma の四階微分.

R-Tips 21頁
choose(n, k) : 二項係数 (n 個から k 個を選ぶ場合の数).gamma(n+1)/(gamma(k+1)gamma(n-k+1)) とし
て計算しているので n, k が整数でなくても値は得られるが,結果は整数化されるようである (そもそも意味
はなさそうであるが).
lchoose(n, k) : 二項係数 choose(n,k) の自然対数.直接計算しており,log(choose(n,k)) として計算している
わけではない.
ガンマ関数:Γ(s) =
∫
∞
0
xs−1e−x dxの性質は以下の通り.
1©: Γ(1) = 1
2©: Γ(1
2) =
√π
3©: Γ(s) = (s− 1)Γ(s− 1) (s > 1)
4©: Γ(n) = (n− 1)! (n :整数)
2.2.6 階乗の計算
ガンマ関数 gamma() を用いる.prod() でも良いが 0! = 1 とは計算してくれない.� �n! = gamma(n+1) # +1 を忘れないこと!
� �
2.2.7 ベッセル関数ファミリー
引数 x は非負値,次数 nu は実数 (負の値の場合を含む) .
besselI(x, nu, expon.scaled = FALSE) : Modified Bessel function of first kind.
besselK(x, nu, expon.scaled = FALSE) : Modified Bessel function of second kind.
besselJ(x, nu) : Bessel function of first kind.
besselY(x, nu) : Bessel function of second order.
gammaCody(x) : ガンマ関数 ( gamma() とはコードが異なり,計算が少し速いが gamma() よりは精度が落
ちる)
2.3 出力+ライブラリ
2.3.1 出力
出力についての注意事項などを述べる.
オブジェクトの表示
関数の内部であるオブジェクトを表示するには関数 print() を使う.また,長いデータなどを表示する場合に,
別ウインドウでオブジェクトの値を構造付きで表示する関数 page() というものもある.

R-Tips 22頁
� �> x <- 1
> x # オブジェクト名だけを入れても表示されるが
[1] 1
> print(x) # 関数 print() を使うと,引数に quote ,max.levels ,width ,digits
[1] 1 # na.print ,zero.print ,justify などを入れることで出力をカスタマイズ
> print("one") # することが出来る
[1] "one"
> print("one", quote=F)
[1] one
> page(x) # 別ウインドウで x の値を構造付きで表示
� �最大表示桁数は 7 であるが,digits (整数) を変更することで最大桁数を変えることが出来る.最大 22桁まで指
定できる.� �> options(digits=15) # 表示桁数を 15桁に変える
� �また,R では 10000 は そのまま表現され,100000は指数表現 1e5 と表現しなおされるが,scipen (整数) を変
更することで指数部分に表現しなおされる基準の桁数を変えることが出来る.デフォルトの値は 0 で,値を増や
せば基準の桁数が増える.� �> options(scipen=0); print(1e5)
[1] 1e+05
> options(scipen=1); print(1e5)
[1] 100000� �
書式付きでオブジェクトを表示
書式付きでオブジェクトを表示するには関数 sprintf() を使う.� �> sprintf("%s is %f feet tall\n", "Sven", 7) # 文字列と浮動小数点数を出力
[1] "Sven is 7.000000 feet tall\n"
> sprintf("%s is %i feet tall", "Sven", as.integer(7)) # 文字列と整数値を出力
[1] "Sven is 7 feet tall\n"� �書式の指定コマンドには以下のような種類がある.� �> print(pi) # 普通の出力
[1] 3.141593
> sprintf("%d", as.integer(pi)) # 整数値の場合は as.integer() で要変換
[1] "3"
> sprintf("%3i", as.integer(pi)) # sprintf("%i", as.integer(pi)) と同じ
[1] " 3"
> sprintf("%f", pi) # f は小数点以下の桁数を指定 (デフォルトは 6)
[1] "3.141593"
> sprintf("%.3f", pi) # 小数点以下の桁数を 3 に指定
[1] "3.142"� �

R-Tips 23頁
� �> sprintf("%1.0f", pi) # 整数部分の桁数を 1 ,小数点以下の桁数を 0 (表示しない)
[1] "3"
> sprintf("%5.1f", pi) # 整数部分の桁数が余ったら空白が埋められる
[1] " 3.1"
> sprintf("%05.1f", pi) # 整数部分の空白の代わりに 0 が埋められる
[1] "003.1"
> sprintf("%+f", pi)
[1] "+3.141593"
> sprintf("% f", pi)
[1] " 3.141593"
> sprintf("%-10f", pi) # 左から順に埋める (足らない部分は右から空白を埋める)
[1] "3.141593 "
> sprintf("%e", pi) # 指数部分を表示 ( "E" の場合は "E+000" と表示)
[1] "3.141593e+000" # 亜種として "g" や "G" が指定できる
> sprintf("%s", as.character(pi)) # 数値を文字として出力する場合は as.integer() で要変換
[1] "3.14159265358979"� �
文字列オブジェクトの表示
任意の文字列を表示するには関数 cat() を使う.print() で文字列を表示すると前後にダブルクオートがつけら
れるが,cat() で表示すれはダブルクオートはつかない.cat() は文字列を引数として受け入れ,それらを順に表
示する.また文字列でないオブジェクトは文字列に強制変換される.書式の制御はほとんど出来ないが,簡単な
メッセージなどを表示するには便利な関数である.
cat() は最後に改行を付けないので,改行したければ文字列中に改行記号 ( ”Yn” )を含める必要がある.つけ
ないと見栄えが悪くなる.� �> cat("This is a pen.\n I am Washi.\n")
This is a pen.
I am Washi.
> x <- 10
> cat("x = ", x, "\n")
x = 10� �
オブジェクトの要約を表示
オブジェクトの内容を情報付きで簡潔に表示する場合は関数 str() を用いる.統計的な要約が欲しい場合は関数
summary() を用いる.� �> x <- 10
> str(x)
num 10� �

R-Tips 24頁
� �> ( x <- data.frame(matrix(1:9,3,3)) )
X1 X2 X3
1 1 4 7
2 2 5 8
3 3 6 9
> str(x)
‘data.frame’: 3 obs. of 3 variables:
$ X1: int 1 2 3
$ X2: int 4 5 6
$ X3: int 7 8 9� �
オブジェクトに注釈を加える
オブジェクトに備忘録的にコメントを残しておく場合は関数 comment() を用いる.付け加えたコメントは普通
の計算時には表示されない.� �> x <- matrix(1:8, 2, 4)
> comment(x) <- c("x : 2 x 4 matrix", "May 5, 2004") # x に二つの文字列属性を付ける
> x # コメントは表示されない
[,1] [,2] [,3] [,4] # print(x) でも表示されない
[1,] 1 3 5 7
[2,] 2 4 6 8
> comment(x) # コメントを表示する
[1] "x : 2 x 4 matrix" "May 5, 2004"
> str(x) # str(x) では表示される
int [1:2, 1:4] 1 2 3 4 5 6 7 8
- attr(*, "comment")= chr [1:2] "x : 2 x 4 matrix" "May 5, 2004"
> comment(x) <- c(comment(x), "Revised May 7, 2004") # コメントを付け足す
> comment(x)
[1] "x : 2 x 4 matrix" "May 5, 2004" "Revised May 7, 2004"
� �
出力をファイルに送る
関数 sink を使うと,通常はコマンドライン上に表示される R の出力をファイルに送ることが出来る.引数に
は送り先のファイル名を指定すればよい.例えば以下の様に入力すれば,以降の出力は全てファイル output.txt
に送られるようになる.同様の関数で,オブジェクトを後から再現できるようにテキスト形式でファイルにセー
ブする関数 dump() がある.� �> sink("output.txt")
� �出力をファイルに送るのを解除するには以下の様に入力すればよい.� �> sink()
� �
R-Tips 25頁
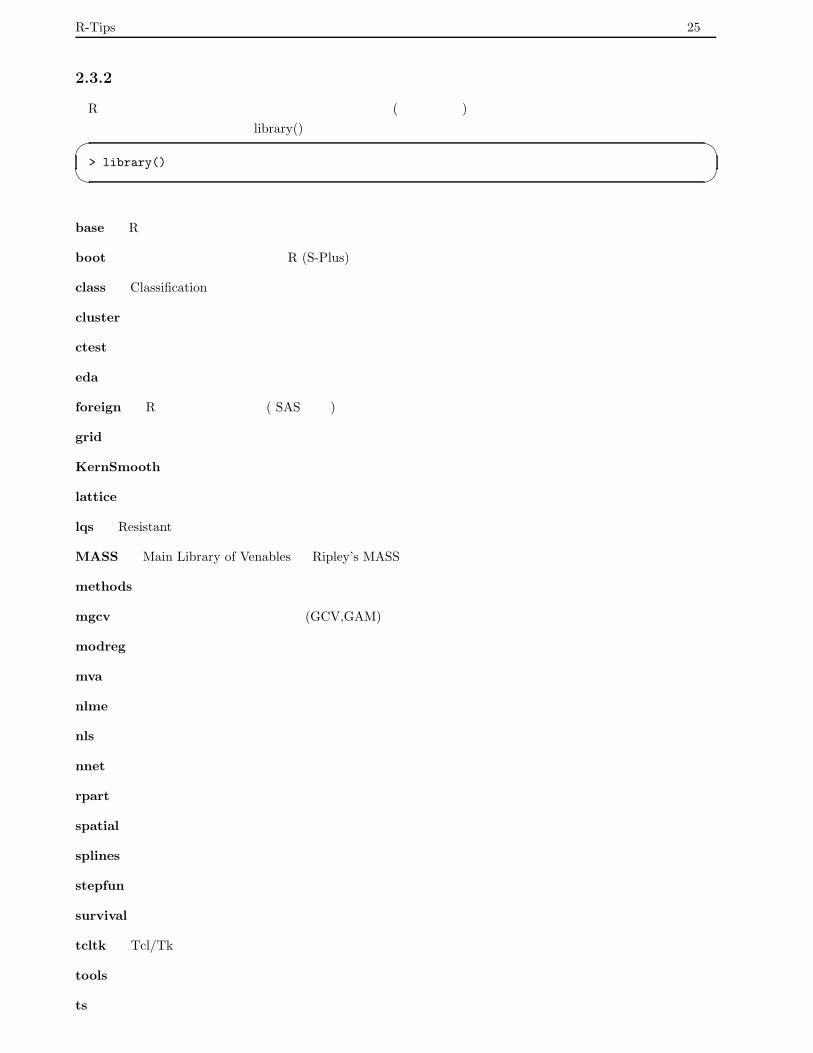
2.3.2 ライブラリ・パッケージ
R は関数及びデータを機能別に分類してライブラリ (パッケージ) という形にまとめている.どのようなパッ
ケージが準備されているかは,library()を実行することによって知ることが出来る.� �> library()
� �標準では以下のパッケージが利用出来る.
base : R の基礎パッケージ
boot : ブートストラップに関する R (S-Plus) の関数
class : Classification に関する関数
cluster : クラスター分析用関数
ctest : 古典的検定用関数
eda : 探索的データ分析
foreign : R 以外の統計ソフト ( SAS など) で作成されたデータファイルからデータを読むパッケージ
grid : グリッド・グラフィックス・パッケージ
KernSmooth : カーネル関数による密度推定用関数
lattice : ラティス・グラフィックス関数
lqs : Resistant 回帰と共分散推定
MASS : Main Library of Venables と Ripley’s MASS に関する関数
methods : 形式的なメソッドとクラス
mgcv : 多変量平滑化パラメータ推定 (GCV,GAM)
modreg : 平滑化と局所的回帰
mva : 古典的多変量回帰
nlme : 線形・非線形の混合結果モデル
nls : 非線形回帰
nnet : フィード・フォワード・ニューラル・ネットおよび多項式の対数線形モデル
rpart : 再起分割
spatial : クリギングと点パターン解析
splines : スプライン回帰
stepfun : 経験分布を含む階段関数
survival : ペナライズ尤度を含む生存時間解析
tcltk : Tcl/Tk へのインターフェース
tools : パッケージ開発と管理用ツール
ts : 時系列解析に関する関数
R-Tips 26頁
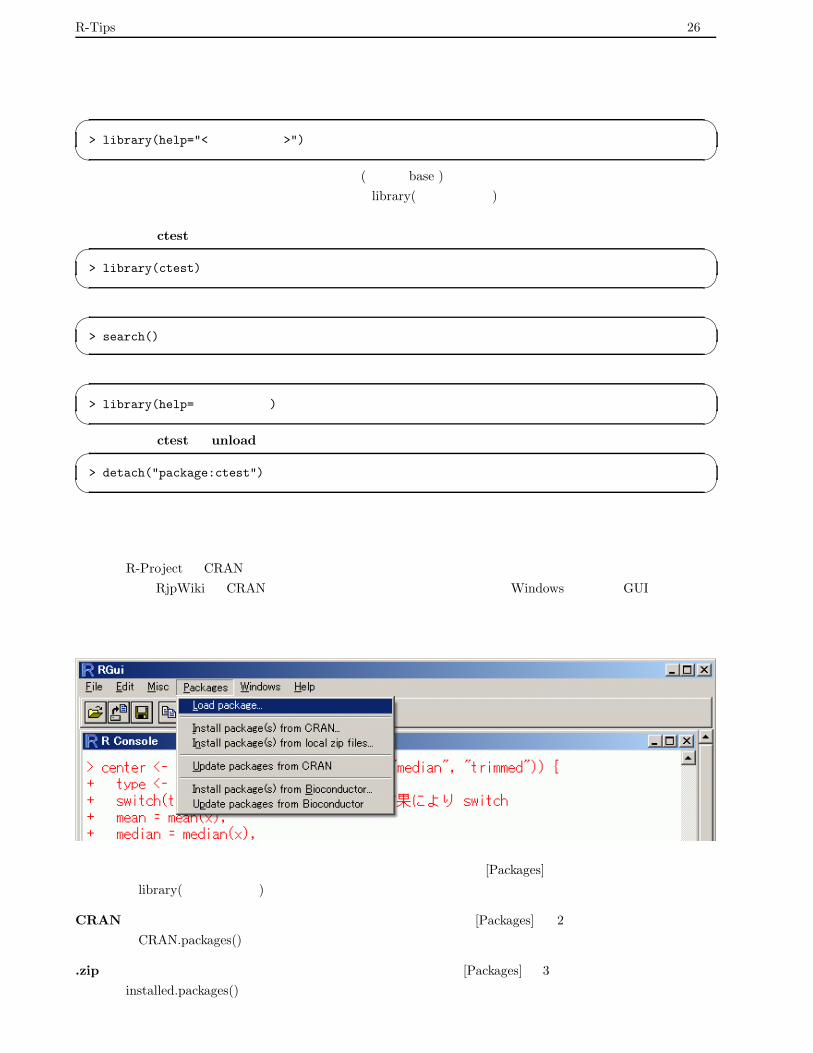
パッケージの説明
各パッケージの詳しい説明は以下のコマンドで表示される.� �> library(help="<パッケージ名>")
� �標準で検索リストに登録されているパッケージ (例えば base ) はそのまま使うことが出来る.それ以外のライ
ブラリを使用するには,パッケージ名を引数とする library(パッケージ名)を実行すれば良い.
パッケージ ctest を使用する場合� �> library(ctest)
� �現在読み込んでいるパッケージの一覧を見る場合� �> search()
� �読み込んだパッケージの中にどのようなオブジェクトが含まれているかを見る場合� �> library(help=パッケージ名)
� �パッケージ ctest を unload する場合� �> detach("package:ctest")
� �
拡張パッケージをインストール
また,R-Project の CRAN から拡張パッケージをインストールすることも出来る.日本語によるパッケージの
簡単な説明は RjpWiki の CRAN パッケージリストから見ることが出来る.Windows 版ならば GUI のメニュー
から簡単にパッケージをインストールすることが出来る.
既にインストールされているパッケージをロードする場合 : メニュー [Packages]の一番上の項目を指定するか,
関数 library(パッケージ名) を用いる.
CRAN から特定のパッケージをインストールする場合 : メニュー [Packages] の 2 番目の項目を指定するか,
関数 CRAN.packages() を用いる.
.zip ファイルからパッケージをインストールする場合 : メニュー [Packages]の 3 番目の項目を指定するか,関
数 installed.packages() を用いる.

R-Tips 27頁
CRAN 上のパッケージから自分の環境にあるパッケージをアップデートする場合 : メニュー [Packages] の 4
番目の項目を指定するか,関数 update.packages() を用いる.
2.4 データの型について
2.4.1 空 → NULL
例えば for などの反復演算を行うときの配列やデータリストの初期値 (何も入っていないリスト) として用いら
れたりする.0 と混同しがちだが,NULL は 『何もない・0 すらない』という意味である.これは配列の初期値
や names 属性などの属性を取り除くのに使われる.� �> x <- c() # x に何も入っていないベクトルを渡す
> x
NULL� �
2.4.2 不定データ → NA・非数 → NaN・無限大 → Inf
欠損値 (Not Available) は NA ,非数 (Not a Number) は NaN で表される.� �> NA # データの欠損を表す
[1] NA
> 0/0 # 数では表せないことを表す
[1] NaN
> 1/0 # 無限大になる場合は NaN とは別に Inf というものがある
[1] Inf� �
2.4.3 実数 → numeric
例えば,1e10 は 『 1× 10ˆ(10) = 10000000000』 を表す.また,円周率 πを表す pi も勿論実数である.� �> 123
[1] 123
> 1.25e3
[1] 1250
> 10^(10)
[1] 1e+10� �
2.4.4 複素数 → complex
1 と 1+0i は違う.また,虚数 i は 1i で表す.� �> 1 + 1i
[1] 1+1i
> 1 + 0i # 1 とは異なる
[1] 1+0i� �
R-Tips 28頁
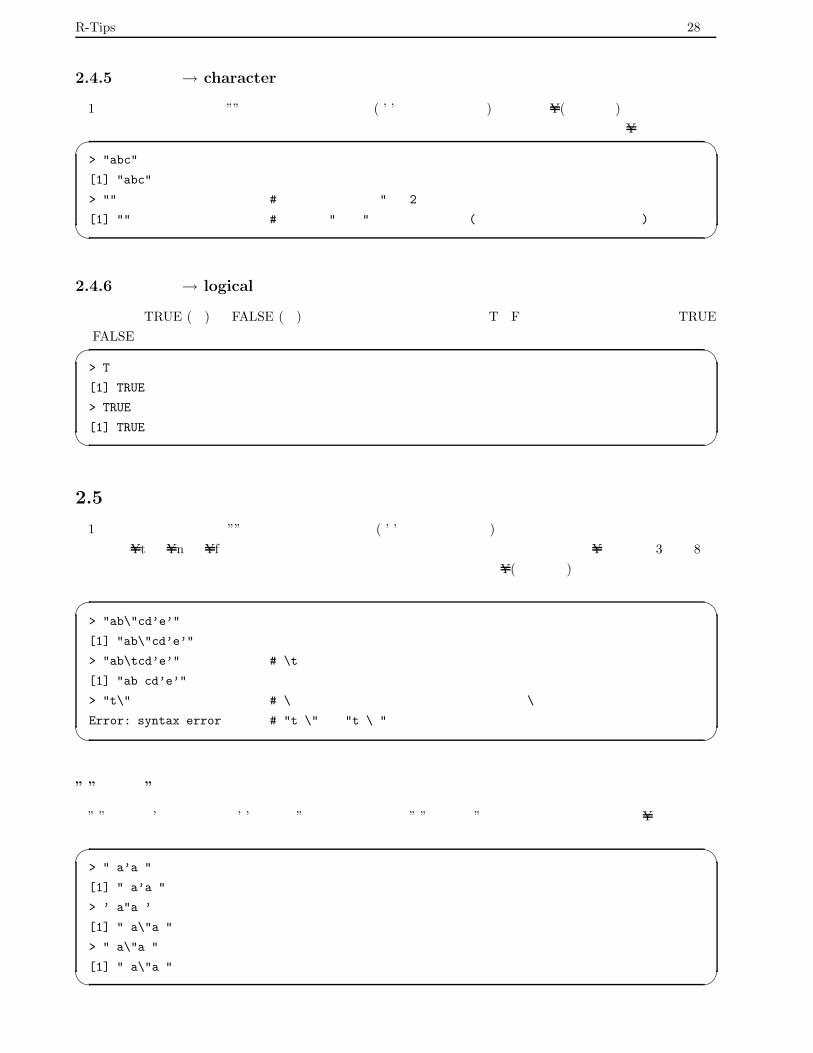
2.4.5 文字列 → character
1文字ではなく,引用符 ”” で囲んだ文字列が単位 ( ’ ’ で囲んでも良い) .ただし Y(改行文字) は例外.文字列
中にダブルクオートまたはシングルクオートを含めるには,これらの文字の前にバックスラッシュYを置けばよい.� �> "abc"
[1] "abc"
> "" # ダブルクオート " が 2 つあるという意味ではないので注意
[1] "" # 中身は " と " の中にあるもの (ここでは何も無いことを表す)
� �
2.4.6 論理値 → logical
論理値は TRUE (真) と FALSE (偽) の値をとる.これらはそれぞれ T,F と略記することも出来る.TRUE
や FALSE は文字列ではないので注意.� �> T
[1] TRUE
> TRUE
[1] TRUE� �
2.5 文字列の操作
1文字ではなく,引用符 ”” で囲んだ文字列が単位 ( ’ ’ で囲んでも良い) となっているオブジェクト. また,文
字列中で Yt , Yn , Yf を用いると,それぞれタブ,改行,改ページ文字を表す.さらに Yで始まる 3桁の 8進
数を書けば,文字列中に文字コードを直接記述することも出来る.ただし Y(改行文字) 単独で用いるとエラーが
起きるので注意.� �> "ab\"cd’e’"
[1] "ab\"cd’e’"
> "ab\tcd’e’" # \t はタブ記号
[1] "ab cd’e’"
> "t\" # \ マークと文字で特殊な命令を表すので,\ 単独ではエラーが出る
Error: syntax error # "t \" や "t \ " などもエラーの原因となる
� �
” ” の中で ” を用いるとき
” ” の中で ’ が使用でき,’ ’ の中で ” が使用できるが,” ” の中で ” を用いるときは,その前に Yを入れなけ
ればならない.� �> " a’a "
[1] " a’a "
> ’ a"a ’
[1] " a\"a "
> " a\"a "
[1] " a\"a "� �

R-Tips 29頁
文字列を操作する
文字列結合には関数 paste() を用いればよい.与えられた 2 つの文字列を 1 つの文字列に結合する.結合する
引数のうち,文字列ベクトルがあれば最も長いベクトルに合わせて他のベクトルの要素を巡回的に複製した上で
まとめる (結果は最も長いベクトルと同じ長さの文字列ベクトルとなる) .逆に,文字列でないものは文字列に強
制型変換したうえで結合する.その際,引数 sep に与えた文字列を間に挟む.この引数を省略したとき,値は空
白 1 つになる.� �> paste("Today is", date())
[1] "Today is Thu Jun 06 04:41:40 2002"
> paste(1:12, sep="a") # paste(1:12) と同じ
[1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11" "12"
> paste("A", 1:3) # A と 数字の間に空白を入れない場合
[1] "A 1" "A 2" "A 3" # は paste("A", 1:3, sep="") とする
> paste("A", 1:3, sep="V")
[1] "AV1" "AV2" "AV3"� �ベクトルの各要素を 1つにつなげた文字列を作りたいときは,引数 collapse に間に挟む文字 (列) を与えればよ
い.sep と同じように 空 ”” で与えてもよい.� �> ( vec <- paste(1:4) )
[1] "1" "2" "3" "4"
> paste(vec, collapse="abc")
[1] "1abc2abc3abc4"
> paste(vec, collapse="")
[1] "1234"� �文字列の長さを調べる際は,関数 nchar() を用いればよい.文字列ベクトルを与えれば各要素の文字列として
の長さを求める.� �> nchar("abcdefg")
[1] 7� �部分文字列を取り出す際は,関数 substring(文字列 , 要素の最初の位置 (整数), 要素の最後の位置 (整数) ) を用
いればよい.使い方は以下の通り.� �> substring("abcdefg", 2, 5)
[1] "bcde"� �似たような機能をする関数に substr() がある.他にも文字列ベクトルの要素を与えられたパターンに従って分
解する関数 strsplit() や文字列の部分的マッチングを行う関数 charmatch() があることを補足しておく.
2.6 論理・比較演算子
2.6.1 比較演算子
比較演算子には次のようなものがある.== は単なる = ではないことに注意 ( = は付値・代入) .
記号 == ! = >= > <= <
意味 等しい 等しくない ≥ > ≤ <
上の演算子で ASCII コード順の辞書式での文字列の比較も出来る.

R-Tips 30頁
(注) 例えばオブジェクト x が NA であるかどうかを判断する場合は,x == NA では判断できない.NA である
か,NaN であるか,NULL であるかどうかを判断する関数はそれぞれ is.na() ,is.nan() ,is.null() が用意
されている.また,有限か無限 (Inf) かを判断する関数はそれぞれ is.finite() ,is.infinite() である.
(注) 通常の一致検査 x == y , x != y は ( x, y が異なったタイプである場合や長さが異なる場合に) しばしば不
具合をもたらす.返り値がベクトルになる可能性もあるので,関数 identical() を用いる方が安全である.
(注) 二つの R オブジェクトが『殆んど等しいか』どうかをチェックする場合は関数 all.equal() を使う.『殆んど
等しい』の意味はオブジェクトにより異なるが,数値ベクトルの場合は誤差の範囲内で一致するかどうかを
判断する.
� �> x <- 1; y <- 1.; z <- 1.00000000001;
> if (x == y) # R 的には好ましくない一致検査
> identical(all.equal(x, z), TRUE) # R お勧めの二つのオブジェクトの一致検査
[1] TRUE
> identical(1, 1.) # R では 1 と 1. はともに倍精度実数で表現
[1] TRUE
> identical(1, as.integer(1)) # as.integer(1) は整数型なので FALSE になる
[1] FALSE� �
2.6.2 論理演算子
論理演算子には次のようなものがある.
記号 ! && & || | xor(x,y)
意味 否定 条件論理積 論理積 条件論理和 条件付論理和 排他的論理和 (→関数)
&& は条件付論理演算子で,例えば (式 1) が FALSE のときは� �(式 1) && (式 2) # 例えば (x > 2) && (x < -2) など
� �の (式 2) は計算されない.また,|| も && と同じ条件付論理演算子で,例えば (式 1) が TRUE のときは� �(式 1) || (式 2) # 例えば (x < -2) || (x > 2) など
� �の (式 2) は計算されない.
2.7 関数について
R には特定の機能を果たす命令が多数あり,関数という形で呼び出すことが出来る.例えば R を終了する際に
用いた quit() は『 R を終了させる機能を持った関数』である.� �> date() # 現在の日時を得る:引数が一つもない関数の例
[1] "Mon Jul 21 16:31:52 2003" # 引数が一つもない場合でも,名前の後ろの括弧は必要である� �対数を計算する関数 log(x) は『 x の値の対数を計算する関数』であるが,関数に x の値を知らせる場合には
引数という形で関数に与える.

R-Tips 31頁
� �> x <- 2.71828182845 # x に 10 を付値
> log(x) # x を引数に与えて log(x) を計算させる
[1] 1� �引数に式や関数を指定すれば,それを評価した値が引数として使われる.また,引数が 2 個以上ある場合はコ
ンマ ,で区切って並べればよい.� �> x <- 2.71828182845 # x に 10 を付値
> log(x^2) # x^2 を計算した値を log に渡して計算
[1] 2
> log(10^2, base=10) # 底を指定する引数 base に 10 を指定して対数を計算
[1] 2� �
2.7.1 引数の省略・略式指定
関数の引数には省略可能なものがある.引数を省略した場合は,関数はあらかじめ決められた動作をする.引
数が省略できるか否かは関数のヘルプに載っている.� �> log(x) # base 省略時は,底 base=2.71828182845905 として計算
� �引数名を指定しなくても引数の順番さえあっていればよいので,base の文字を省略して以下のように計算して
も良い.� �> log(x, 2.718281828)
� �(注) 名前で引数を指定する場合,指定位置はどこでもOK.これは引数が名前で指定されるので,順番が違って
いてもどの引数が指定されたのか判断出来るからである.
� �> log(base=2.718281828, x)
[1] 1� �(注) 関数呼び出し時の引数中に『付値 (代入)を意味する式』を書くこともできるが,この方法は混乱の原因にな
るので避けた方がよい.代入式と関数呼び出しは別々に行なう方が見やすい上に計算効率の点から見ても優
れている.
� �> log(x <- 10) # x に 10 を代入してから log(x) を計算する場合,このようにするのは良くない
� �上の例を改善 : 2 つの手順を 2 行に分けて書くのが良い
� �> x <- 10
> log(x)
� �(注) plot() や box() などのように副作用 (この場合は図を描くということ) が目的の関数では返り値が表示され
ないことがあるが,表示されなくても関数によっては値を返している場合がありえる.このような関数の結
果をオブジェクトに付値したり,別の関数の引数に使ったりしても全然問題は無い.

第3章 ベクトル篇
3.1 ベクトルの基本
今さら何を云うんだという感はあるが,R で足し算を行う際は以下のように行った.� �> 1 + 2
[1] 3� �
1 + 2 だから単に 3 と返せばよいだけのはずだが,よく見ると [1] が前についている.この [1] は何だろうか?
3.1.1 ベクトル
R では論理数・実数・複素数・文字列などの基本的データを一つずつ単独で扱う代わりに,同じ型のデータを
いくつかまとめたベクトルと呼ばれる形で取り扱っている.よって,今までの例では数値や文字列を一つずつ単
独で扱っているかのように説明してきたが,実際には R はこれらの基本的データを,要素の個数が一つだけのベ
クトルとして扱っていたわけである.
上の結果は要素がひとつのベクトル同士の足し算を行っていたことになる.小難しく云えば 1 × 1のベクトル
(1) と 1× 1のベクトル (2) の足し算を行って,結果として 1× 1のベクトル (3) が返ってきたことになる.[1] は
『ベクトルの一つめの要素』という意味である.
3.1.2 ベクトルの作成
ベクトルを作成する基本的な関数は c() である.� �> c(1.0, 2.0, 3.0, 4.0, 5.0) # 長さ 5 のベクトルを作成する
[1] 1 2 3 4 5
> x <- c(1.0, 2.0, 3.0, 4.0, 5.0) # ベクトルを変数に付値 (代入)する場合も <- を用いる
[1] 1 2 3 4 5� �(注) c() という名前の関数があるからといって,オブジェクト名に c を使うことが出来ないというわけではない.
精神衛生上の問題は別にして,以下のようなことも出来る.
� �> ( c <- c(1.0, 2.0, 3.0, 4.0, 5.0) ) # c という名のオブジェクトにベクトルを付値 (代入)
[1] 1 2 3 4 5� �ベクトルの要素の個数をベクトルの長さと呼び,ベクトルの長さは関数 length() で調べる.� �> length(x) # 要素が 5 個あるベクトルの長さを調べる
[1] 5� �関数 c() 以外に規則的なベクトルを生成する関数が多数用意されている.
a:b : a から b (a < b) までの交差が 1 の数列を生成.a > b ならば交差が −1 の数列を生成.

R-Tips 33頁
seq(a, b, length = n) : a, b 間を n 等分する等差数列を生成.
seq(along = x) : 1:length(x) なる数列を生成.
seq(a, b, by = c) : a から b まで c づつ増加するベクトルを生成.
rep(a:b, times = c) : a から b まで 1 づつ増加する数列を c 個生成.c は数列でも可.
rep(a:b, length = c) : a から b まで 1 づつ増加する数列を,長さ c になるまで反復して生成.
numeric(n) : 0 を n 個並べたベクトルを生成.
� �> 1:5 # 1から 10まで 1づつ増加するベクトルを作る
[1] 1 2 3 4 5
> 3:-3 # 3から-3まで 1づつ減少するベクトルを作る
[1] 3 2 1 0 -1 -2 -3
> seq(1, 10, length=5) # 1 から 10 までを等分割した長さ 5 のベクトルを作る
[1] 1.00 3.25 5.50 7.75 10.00
> rep(1:3, length=5) # 1 から 3 まで 1 づつ増加する数列を長さ 5 になるまで反復生成
[1] 1 2 3 1 2
> rep(c(1.0, 2.0, 3.0), 1:3)
[1] 1 2 2 3 3 3� �関数 rep() を用いることで同一の数列の反復が生成できたが,関数 unique() によって同一の値の反復を除くこ
とも出来る.ベクトル要素の削除・探索・正規乱数生成をする場合も,関数 rep() によって同一の数列の反復を作
り,関数 unique() によって同一の値の反復を除くことで実現することができる.� �> x <- c(1.0, 2.0, 2.0, 3.0, 3.0, 3.0)
> unique(x) # 反復した値を除く
[1] 1 2 3
> match(x, c(1.0, 3.0)) # x の要素の中に (1.0, 3.0) の要素があるか否か
[1] 1 NA NA 2 2 2
> rnorm(5) # 正規分布に従った長さ 5 のベクトルを作る
[1] 0.58839577 -0.28366653 -1.73741631 -0.87824854 -0.03076927� �
3.1.3 ベクトル演算
同じ長さ同士のベクトルの演算 (算術演算,論理演算,比較演算) は,対応する各要素の演算となる.すなわち,
普通の数字と同様に + (加算),− (減算), ∗ (積), / (商), %/% (整数商),%% (剰余),ˆ (べき乗) が行える.� �> 1:5 + 6:10 # c(1+6, 2+7, 3+8, 4+9, 5+10)
[1] 7 9 11 13 15
> 1 / 2:5 # それぞれの要素の逆数
[1] 0.5000000 0.3333333 0.2500000 0.2000000
> c(1.0, 2.0) * c(3.0, 4.0) # c(1*3, 2*4)
[1] 3 8
> c(6.0, 5.0, 4.0, 3.0) - c(2.0, 1.0) # c(6-2, 5-1, 4-2, 3-1) と同じ
[1] 4 4 2 2� �

R-Tips 34頁
� �> c(1.0, 2.0, 3.0, 4.0, 5.0) - 1 # 全ての要素から 1 を引く
[1] 0 1 2 3 4
> c(5.0, 4.0, 3.0) - c(2.0, 1.0) # c(5-2, 4-1, 3-2) と同じだが警告が出る
[1] 3 3 1
Warning message:
longer object length
is not a multiple of shorter object length in: c(5, 4, 3) - c(2, 1)
� �ベクトル同士を比較演算子 < ,== ,> などによって比較することも出来る.算術演算の場合と同様,これら
の演算子はベクトルとベクトルの対応する要素同士を比較して,後述する論理型ベクトルを結果として返すこと
になる.� �> c(1, 20, 300, 4, 50) == c(1, 2, 3, 4, 5) # 1 == 1, 20 == 2, 30 == 3 ...
[1] TRUE FALSE FALSE TRUE FALSE
> c(1, 20, 300, 4, 50) == c(1.0, 2.0, 3.0, 4.0, 5.0) # 1 == 1.0, 20 == 2.0, 300 == 3.0 ...
[1] TRUE FALSE FALSE TRUE FALSE� �
2 つのベクトルの長さが異なる場合は算術演算の場合と同様,短い方の要素が循環的に使われることになる.� �> c(1, 20, 300, 4, 50) > 60 # 1 > 60 , 20 > 60 , 300 > 60 , 4 > 60 , 50 > 60
[1] FALSE FALSE TRUE FALSE FALSE� �数値を要素に持つベクトルの各要素に対して演算を行なう関数には以下のようなものがある.また,基本的な
計算の説でも紹介した関数 (sqrt() や cos() など) を適用することで,項別に関数を適用することも出来る.ただ
し,ベクトルの要素に一つでも NA があると結果も NA になるものもあるので注意しなければならない.
記号 sum() mean() median() var() cor() max() min()
意味 総和 平均 中央値 分散 相関係数 最大値 最小値
記号 range() cumsum() prod() diff() rev() pmax() pmin()
意味 範囲 累積和 総積 前進差分 要素を逆順 並列最大値 並列最小値
記号 sort() diff() rank() order()
意味 昇順整列 前進差分 整列した各要素の順位 整列した各要素の元の位置
関数 cumsum() の亜種について,数列の部分和・積、そして部分最大・最小値からなる数列を計算する関数が
それぞれ cumsum() , cumprod(), cummax(), cummin() と用意されている.� �> ( w <- (1:8)^2 )
[1] 1 4 9 16 25 36 49 64
> diff(w) # w[2] - w[1] , w[3] - w[2] , ...
[1] 3 5 7 9 11 13 15
> c(w[1], diff(cumsum(w))) # w[1] は ベクトル x の第 1 要素
[1] 1 4 9 16 25 36 49 64
> x <- seq(10,100,by=10) # x = (10, 20, 30, ..., 90, 100)
> mean(x) # x の平均を求める
[1] 100
> mean(x, 0.5) # x の小さい方と大きい方を合わせて
[1] 55 # 100*a % を除いた平均 (trimmed mean)
> rev(x) # x の要素を逆順にする
[1] 550 90 80 70 60 50 40 30 20 10� �

R-Tips 35頁
� �> y <- c(1, 3, 5, 7, 9, 2, 4, 6, 8, 55)
> sort(y) # y を整列する
[1] 1 2 3 4 5 6 7 8 9 55
> order(y) # y を整列したときの各要素の元の位置
[1] 1 6 2 7 3 8 4 9 5 10
> rank(y) # y を整列したときの各要素の順位
[1] 1 3 5 7 9 2 4 6 8 10
> z <- c(100, 81, 64, 49, 36, 25, 16, 9, 4, 1)
> pmax(x, y, z) # x, y, z の各要素を比較して一番大きいものを
[1] 550 90 80 70 60 50 40 30 20 55 # 順に返す
> pmin(x, y, z) # x, y, z の各要素を比較して一番小さいものを
[1] 1 3 5 7 9 2 4 6 4 1 # 順に返す� �
3.1.4 ベクトルからある値に最も近い要素の添字を求める
関数 which()を用いることで実現出来る.また,ベクトルの最大・小要素の位置を求める関数としてwhich.max(),
which.min() が用意されている.� �> x <- rnorm(30) # 30 個の正規乱数
> which( abs(x-1.0) == min(abs(x-1.0)) ) # 1.0 に最も近い値を持つ要素の背番号
[1] 21
> x[which( abs(x-1.0) == min(abs(x-1.0)) )] # 該当する要素の値
[1] 0.9373513� �
3.1.5 集合演算
x, y 等は (同一モードの)ベクトルで重複は無いとする.もし重複があっても union() , intersect() , setdiff() は
重複の無い結果を返す.
union(x, y) : 和集合.
intersect(x, y) : 積集合,
setdiff(x, y) : 差集合.
setequal(x, y) : 集合として等しいか否か.
is.element(a, set) : 要素 a は set に含まれるか否か.
%in% : is.element(a, set) の演算子版.
3.2 複素・論理・文字型・因子ベクトル
3.2.1 複素型ベクトル
複素型ベクトルは複素数を要素とするベクトルのことである.

R-Tips 36頁
� �> c(1+2i, 3+4i)
[1] 1+2i 3+4i
> c(1, 2+3i) # 要素に 1 つでも複素数が見つかれば要素全体が複素数となる
[1] 1+0i 2+3i� �(注) 虚数 1 + iを表すときは 1+1i と表記すること.1+i とすると i はオブジェクト(変数など)と認識される.
実部と虚部をベクトルで指定したり,絶対値と偏角を指定することでも複素型ベクトルを作ることが出来る.� �> complex(re=1:3, im=4:6) # re :実部 ,im :虚部
[1] 1+4i 2+5i 3+6i
> complex(mod=c(1,2,3), arg=c(-pi, 0, pi)) # mod:絶対値 ,arg:偏角
[1] -1-1.224606e-16i 2+0.000000e+00i -3+3.673819e-16i� �複素数を要素にもつベクトルを処理する場合は,基本的な関数に加えて以下の関数を用いることが出来る.
記号 Re(z) Im(z) Mod(z) abs(z) Arg(z) Conj(z)
意味 実部 虚部 絶対値 絶対値 偏角 共役複素数
3.2.2 論理型ベクトル
論理値を要素とするベクトルを論理型ベクトルと呼ぶ.� �> c(T, F, T, TRUE, FALSE) # 略記名 (T,F)でも正式名 (TRUE,FALSE)でも指定できる
[1] TRUE FALSE TRUE TRUE FALSE� �論理型ベクトルに対する論理演算子として,& (論理積) , | (論理和) ,! (否定) ,xor (排他的論理和) があり,
これらを用いると要素毎の演算を行なう.2 つのベクトルの長さが異なる場合は短い方の要素が循環的に使われる
ことになる.� �> c(T, F, T, F, T) | c(TRUE, FALSE, FALSE, TRUE, FALSE)
[1] TRUE FALSE TRUE TRUE TRUE
> !c(T, F, T, F, T) # 外側の括弧は UNIX コマンドの実行と区別するため
[1] FALSE TRUE FALSE TRUE FALSE # (Windows版では不要)
> xor(c(TRUE, FALSE, TRUE, FALSE, TRUE), c(TRUE, FALSE, FALSE, TRUE, FALSE))
[1] FALSE FALSE TRUE TRUE TRUE
> (x <- runif(5))
[1] 0.7570565 0.6157795 0.1984776 0.3451136 0.1566313
> (0.25 <= x) & (x <= 0.75) # 0.25 ~ 0.75 の範囲にあるか否か
[1] FALSE TRUE FALSE TRUE FALSE� �論理ベクトル全体を調べる関数として以下の様なものがある.
any() : 与えられた論理ベクトルの要素に TRUE が一つでもあれば TRUE を返す
all() : 与えられた論理ベクトルの要素がすべて TRUE なら TRUE を返す

R-Tips 37頁
� �> (x <- runif(5))
[1] 0.2012603 0.8350083 0.4880002 0.5619987 0.8283478
> any(x > 0.8) # x の中に 0.8 以上の要素が最低 1 つはあるか否か
[1] TRUE
> all(x < 0.8) # x の要素は全て 0.8 以下であるか否か
[1] FALSE� �
3.2.3 文字型ベクトル
文字列を要素とするベクトルを文字型ベクトルと呼ぶ.� �> c("a", "b", "c", "d", "e")
[1] "a" "b" "c" "d" "e"
> c("HOKKAIDO", "SENDAI", "TOKYO", "NAGOYA", "OSAKA", "HAKATA")
[1] "HOKKAIDO" "SENDAI" "TOKYO" "NAGOYA" "OSAKA" "HAKATA"� �文字列には辞書式順序(ASCII 配列)による大小関係があるので,この規則に従った文字型ベクトル同士の比
較演算を行なうことが出来る.� �> "TOKYO" > "OSAKA"
[1] TRUE
> "HAKATA" > "OSAKA"
[1] FALSE� �
文字列操作
複数の文字列を連結して一つの文字列にするには関数 paste() を用いる.� �> paste("May I", "help you ?")
[1] "May I help you ?"
� �引数がベクトルならばそれぞれの要素ごとに連結することになる.� �> paste(month.abb, 1:12, c("st", "nd", "rd", rep("th",9)) )
[1] "Jan 1 st" "Feb 2 nd" "Mar 3 rd" "Apr 4 th" "May 5 th" "Jun 6 th"
[7] "Jul 7 th" "Aug 8 th" "Sep 9 th" "Oct 10 th" "Nov 11 th" "Dec 12 th"
� �一つにつなげるときに間に挟む文字列は引数 sep で指定する (空文字列 ”” を与えれば何も挟まずにつなぐ) .� �> paste("/usr", "local", "bin", sep = "/") # / を間に挟んでつなぐ
[1] "/usr/local/bin"� �他にも以下のような関数が用意されている.
記号 grep() charmatch() toupper(), tolower()
意味 パターンマッチと置換 文字列の部分的マッチング 大 (小)文字に置換
記号 nchar() substr() strsplit()
意味 文字数 (バイト数) 部分文字列の切り出し 正規表現による文字列の分割

R-Tips 38頁
3.2.4 順序つき因子ベクトルと順序無し因子ベクトル
関数 factor() を用いることで,ベクトルの要素をカテゴリー要素などの因子としたベクトルを作成することが
出来る.まず,データの要素をグループ化するために関数 factor() を使い,次に関数 table() を用いることで度数
分布表を作ることが出来る.� �> data(warpbreaks) # 1台の織機当たりの反り破損の数
> attach(warpbreaks) # 使うデータを固定
> ( fc <- factor(tension) ) # 要素をグループ化
[1] L L L L L L L L L M M M M M M M M M H H H H H H H H H L L L L L L L L L M M
[39] M M M M M M M H H H H H H H H H
Levels: L M H
> levels(fc) # グループ化されているかを確認
[1] "L" "M" "H"
> str(fc) # オブジェクトの要約値を表示
Factor w/ 3 levels "L","M","H": 1 1 1 1 1 1 1 1 1 2 ...
� �関数 factor() では因子間に大小関係は無かったが,関数 ordered() で順序付きの因子ベクトルを作成すること
が出来る.� �> ( fc <- ordered(tension) )
[1] L L L L L L L L L M M M M M M M M M H H H H H H H H H L L L L L L L L L M M
[39] M M M M M M M H H H H H H H H H
Levels: L < M < H
> levels(fc) # グループ化されているかを確認
[1] "L" "M" "H"
> str(fc) # オブジェクトの要約値を表示
Ord.factor w/ 3 levels "L"<"M"<"H": 1 1 1 1 1 1 1 1 1 2 ...� �
3.3 ベクトルの操作
3.3.1 要素の場所を指定して取り出す
ベクトルの一部を取り出すには [ と ] を使う.[[ ]] でも取り出せるが,この場合は配列としてオブジェクトにア
クセスすることになる.� �> ( x <- c(1, 2, 3, 4, 5, 6, 7, 8, 9) ) # x <- 1:9 でも良い
[1] 1 2 3 4 5 6 7 8 9
> x[2] # 2 番目の要素を取り出す
[1] 2
> x[[2]] # 2 番目の要素を取り出す -> 配列としてアクセス
[1] 2
> ( x[4] <- 444 ) # 4 番目の要素を 444 に変更
[1] 444 # x[4] の値を表示
> ( x[[4]] <- 4 ) # 4 番目の要素を 4 に変更 -> 配列としてアクセス
[1] 4 # x[4] の値を表示� �

R-Tips 39頁
[ と ] の間には単一の添字だけでなく,添字のベクトル,負の整数のベクトル,論理型ベクトル,文字型ベクト
ルを指定することが出来る.このとき,[ と ] の間のベクトルの長さが元のベクトルの長さよりも小さければ巡回
的に評価が繰り返され,ベクトルの長さが長すぎるときはその部分の評価結果には NA が出力される.
正整数の添字 : ベクトル (オブジェクト名) の後に [ と ] の間に添字を書けば,いくつかの要素をまとめて取り
出すことが出来る.ここで,添字のベクトルの中に同じ添字が何度現れてもエラーにはならない (同じ要素
が何度も取り出される) .
� �> ( x <- c(1, 2, 3, 4, 5, 6, 7, 8, 9) ) # x <- 1:9 でも良い
[1] 1 2 3 4 5 6 7 8 9
> x[2]
[1] 2
> x[2:5] # x[2] ... x[5] を取り出す -> x[c(2,3,4,5)] と同じ
[1] 2 3 4 5
> x[0] # 添字として 0 を指定すると ...
numeric(0) # 長さ 0 で元のベクトルと同じ型のベクトルが返る
> x[7:10] # 要素が無い場合は NA が返る
[1] 7 8 9 NA� �負の整数の添字 : 正整数の代わりに負の整数を添字にすると,対応する添字の要素を取り除くことが出来る.た
だし,正整数と負の整数を混在させることは出来ない.
� �> ( x <- c(1, 2, 3, 4, 5, 6, 7, 8, 9) ) # x <- 1:9 でも良い
[1] 1 2 3 4 5 6 7 8 9
> x[-2] # x[2] 以外を取り出す -> x[c(1,3,4,5,6,7,8,9)] と同じ
[1] 1 3 4 5 6 7 8 9
> x[-(2:5)] # x[2], ..., x[5] 以外を取り出す
[1] 1 6 7 8 9
> x[c(-1,-3)] # x[1] と x[3] 以外を取り出す
[1] 2 4 5 6 7 8 9� �(注) ベクトルの添字は 1 から始まる.C や JAVA のように 0 から始まるわけではないので注意.
(注) Mathematica や Maple などの数式処理ソフトでは,負の整数の添字の扱いが R とは異なるので注意.
論理型ベクトル : [ と ] の間に論理値 ( T:TRUE , F:FALSE ) を書くことで,TRUE の要素に対応した要素が
抜き出される.また,比較式の結果を論理値として使うことも出来る.
� �> ( x <- c(1, 2, 3, 4, 5, 6) ) # x <- 1:6 でも良い
[1] 1 2 3 4 5 6
> x[c(FALSE, TRUE, TRUE, FALSE, FALSE, FALSE)] # 2番めと 3番めの要素を取り出す
[1] 2 3
> x[c(F, T, F, T, F, T, F, T)] # 最後の T を評価する要素が x には無い
[1] 2 4 6 NA� �

R-Tips 40頁
� �> ( y <- x%%3==0 )
[1] FALSE FALSE TRUE FALSE FALSE TRUE
> x[y] # 論理値ベクトル指定 -> x[x%%3==0]
[1] 3 6
> x <- rnorm(10) # 10個の正規乱数を生成
> x[0 < x] # 正の値を持つ要素を抽出
[1] 2.24322154 0.98568617 0.03433169 0.49952966
> x[0 < x & x < 0.5] # 0 ~ 0.5 の間の値を持つ要素を抽出
[1] 0.03433169 0.49952966
> (1:length(x))[0 < x & x < 0.5] # 何番目の要素が条件を満たしているか
[1] 9 20� �文字型ベクトル : ベクトルに names 属性 (『補足事項』の章の「属性・names 属性と属性のラベル」を参照) が
付けられているならば,要素ラベルを指定して要素を取り出すことが出来る.
� �> ( x <- c(1, 2, 3, 4, 5, 6) ) # x <- 1:6 でも良い
[1] 1 2 3 4 5 6
> names(x) <- c("A", "B", "c", "d", "E", "F") # 各要素にラベルを付ける
> x["A"] # ラベル A を持つ要素を取り出す
A
1
> x["a"] # ラベル a を持つ要素を取り出す
<NA> # (大文字と小文字は区別される)
NA
> x[c("B", "E")] # ラベル B, E を持つ要素を取り出す
B E
2 5� �
3.3.2 ベクトル要素の置換・結合・挿入
[ と ] の間に負の整数を入れることでベクトルの要素を削除することが出来たが,ベクトルの要素の一部を置き
換える場合は関数 replace() を用いることで実現できる.� �> x <- c(1, 2, 3, 4, 5, 6, 7, 8, 9) # x <- 1:9 でもよい
> y <- replace(x, c(2,5,8), c(0,0,0)) # x の 2, 5, 8 番目の要素を 0 に置き換える
> y # このとき x の要素自身は変更されない
[1] 1 0 3 4 0 6 7 0 9
> z <- replace(x, c(2,5,8), NA) # 今度は NA で置き換える
> z
[1] 1 NA 3 4 NA 6 7 NA 9
> replace(z, which(is.na(z)), 10) # z の中の NA を 10 で置き換える
[1] 1 10 3 4 10 6 7 10 9� �
2 個以上のベクトルを結合する場合は関数 c() を用いる.2 つのベクトルを結合するだけならば関数 append()
でも実現出来る.また,関数 append() を用いることで,ベクトルの指定の場所にベクトルを挿入させることも出
来る.

R-Tips 41頁
� �> ( x <- c(1, 2, 3) ) # x <- 1:3 でもよい
[1] 1 2 3
> ( y <- c(4, 5, 6) ) # y <- 4:6 でもよい
[1] 4 5 6
> ( z <- c(7, 8, 9) ) # z <- 7:9 でもよい
[1] 7 8 9
> c(x, y, z) # append(x, y, z) でもよい
[1] 1 2 3 4 5 6 7 8 9
> ( w <- append(x, z) ) # c(x, z) でもよい
[1] 1 2 3 7 8 9
> append(w, y, after=3) # w の 3 番目の要素の後に y を挿入
[1] 1 2 3 4 5 6 7 8 9� �
3.4 データ型の変換とデータ構造の変換
3.4.1 データの型を調べる・変換する
データの型を調べたり変換したりする場合は以下の関数が用意されている.その他,関数 paste() のように必要
に応じて引数に与えられたオブジェクトの型変換を自動的に行う関数もある.
型を検査 mode() is.numeric() is.complex() is.character() is.logical()
型を変換 storage.mode() as.numeric() as.complex() as.character() as.logical()
� �> x <- c(1, 0, 1, 0, 1)
> mode(x)
[1] "numeric"
> mode(x) <- "complex" # storage.mode(x) <- "complex" でも同じ
> x
[1] 1+0i 0+0i 1+0i 0+0i 1+0i
> mode(x) <- "logical"
> x
[1] TRUE FALSE TRUE FALSE TRUE� �(注) ベクトルの型の間には情報量の面から見て以下の大小関係がある.
character > complex > numeric > logical > NULL
ベクトルの要素は全て同じ型なので,異なった型のデータを集めてベクトルを作ろうとすると上記の変換規
則によって『最も大きい』型に揃えられる.
(注) 実数と論理数の間は自動的に変換される.つまり演算式中に実数値が期待されている時に論理数が表れると
以下のように計算される.
– TRUE → 1
– FALSE → 0
として計算される. 同様に,演算式中に論理数が期待されている時に数が表れると以下のようになる.
– 0 でない数 → TRUE (『0 でない数 → TRUE 』という点に注意!)

R-Tips 42頁
– 0 → FALSE
例えば if (2.718) などは TRUE になり,if 文の命令が実行されることになる.
(注) 複素数,文字列へも自動的に変換されるが,逆は意識的に行った方が良い.
(注) R では整数と実数は特に区別しない.区別する必要が生じるのは C の関数や Fortran でのサブルーチンを
用いて R 関数を定義するときのみである.
3.4.2 データ構造を調べる・変換する
データ構造を調べたり変換したりする場合は以下の関数が用意されている.例えば,オブジェクトが配列である
かどうかは is.array()でテスト出来,行列は 2 次元の配列なので is.array()でテストすると結果は TRUE になる.
構造を検査 is.vector() is.matrix() is.as.array() is.list() is.data.frame() is.factor() is.ordered()
構造を変換 as.vector() as.matrix() as.as.array() as.list() as.data.frame() as.factor() as.ordered()
� �> x <- NULL
> as.numeric(x) # as.character() や as.numeric() などで NULL を構造変換すると
numeric(0) # 指定された型の長さ 0 のベクトルになる
> x <- c(1, 0, 1, 0, 1, 0) # x にベクトルを付値
> is.list(x) # ベクトルはリストではない
[1] FALSE
> x <- as.list(x) # x をリストに変換
> is.list(x) # x はリストであり ...
[1] TRUE
> is.vector(x) # リストはベクトルでもある
[1] TRUE� �
3.5 NULL・NA・NaN・Inf
NULL (何も無い) ,Na (欠損値) ,NaN (非数) ,Inf (無限大) については既に扱ったが,これらの値にどのよ
うな演算を施しても,大抵はそのままの値 ( NA や NAN ) が返ってくる.すなわち,原則として NaN にどのよ
うな演算を施しても結果は NaN になる.よって,比較演算子 == すら使えないことになる.� �> x <- c(1.0, NA, 3.0, 4.0, 5.0) # NA がある要素はどれかを調べようとしているのだが ...
> x == NA # NA に対する演算は全て NA になってしまう
[1] NA NA NA NA� �
3.5.1 NULL・NA・NaN・Inf なのか否かを調べる
これら 4 つの値の検査を行う関数がそれぞれ用意されている.例えば,ある値が NA かどうかのテストは関数
is.na() で行なう (比較演算子 == では行なえないことに注意) が,これは NaN を代入しても TRUE が返ってし
まう.そこで NaN か否か (NA か否かではない) を判定するために is.nan() という関数が用意されている.
命令 is.null() is.na() is.nan() is.finite() is.infinite()
検査対象 NULL NA NaN 有限か否か 無限か否か

R-Tips 43頁
� �> is.na(NA)
[1] TRUE
> is.nan(NA)
[1] FALSE
> x <- c(1, NA, 3, 4)
> is.na(x)
[1] FALSE TRUE FALSE FALSE� �
3.5.2 ベクトル要素にある NA の排除・置換
引数に NA が含まれるとエラーになる関数がある.このような関数に NA が含まれるデータを渡す場合の対処
法としては以下のようなものがある.� �> ( a <- c(1,2,NA,4,5,NA) )
[1] 1 2 NA 4 5 NA
> a[!is.na(a)] # NAを単に取り除く
[1] 1 2 4 5
> a
[1] 1 2 NA 4 5 NA
> a <- ifelse(is.na(a), 0, a) # NA を 0 に置き換える
> a
[1] 1 2 0 4 5 0� �
NA を置き換えるのではなく,NA を要素に持つベクトルから,NA を読み飛ばして要素を読み取ることを考え
る.この場合は以下の様にすればよい.� �> x <- c(1, 2, NA, -4, 5, -6, 7, NA, 9, 10)
> y <- x[!is.na(x)] # NA 以外の x の要素を y に格納
> y
[1] 1 2 -4 5 -6 7 9 10� �上を応用すれば 『欠損値と負のデータを除去してデータを読み取る』ことも出来る.� �> x <- c(1, 2, NA, -4, 5, -6, 7, NA, 9, 10)
> y <- x[(!is.na(x)) & (x > 0)] # NA と負の値以外の x の要素を y に格納
> y
[1] 1 2 5 7 9 10� �
3.5.3 NULL の使い方の例
NULL は属性を取り出す関数が属性値がないときの値として返すなど『適当な結果がない』ことを示すために
使わる.NULL と欠損値 NA を混同してしまいがちだが,NA はベクトルの要素となり得るが,NULL はベクト
ルなのでそれ自身でベクトルの要素にはならない点が異なる.

R-Tips 44頁
� �> mode(NULL) # モード "NULL" を持つ
[1] "NULL"
> length(NULL) # 長さが 0 のベクトルである
[1] 0
> ( a <- 1:3 )
[1] 1 2 3
> names(a) # a には names 属性が付いていないので NULL が返る
NULL� �上の手順を逆手にとって,属性値に NULL を代入して属性値を除去することができる.� �> names(a) <- c("a", "b", "c")
> a
a b c
1 2 3
> names(a) <- NULL
> a
[1] 1 2 3
> names(a)
NULL� �他に,繰り返し文で処理を行うオブジェクトの初期値にも NULL が使われたりする.� �> x <- NULL # 長さ 0 のベクトル x を用意して
> for (i in 1:10) x <- append(x, i*i) # x に 1^2, 2^2, 3^2 ... を順に格納する
> x
[1] 1 4 9 16 25 36 49 64 81 100� �(注) NULL を長さが 0 の数値型ベクトルや文字型ベクトルと間違わないように注意.これらは型が異なるため,
異なるオブジェクトとなっている.
(注) as.character,as.numeric などの型変換関数を使って NULL をある型のベクトルに変換すると,指定された
型の長さが 0 のベクトルになる.
3.6 リスト
R では,ベクトルはデータの最小単位であった ( 1 や ”a” も長さ 1 のベクトルである) が,この最小単位のベ
クトルを集めて 1 個のオブジェクトにしたものがリストである.一つのリスト異なった型のベクトルを 1 個のリ
ストにまとめてもよいし,リストの要素としてリストを用いても構わない.逆に云えば,リストとは異なる構造の
データを一つのデータセットにまとめることが出来るオブジェクトである.リストは関数 list() を用いて作成する.� �> ( x <- list(1:5, "It’s my list.", c(T, F, T)) )
[[1]]
[1] 1 2 3 4 5
[[2]]
[1] "It’s my list."
[[3]]
[1] TRUE FALSE TRUE� �

R-Tips 45頁
� �> y <- list(x, c(1+2i, 3+4i)) # リストの要素としてリストを使っても良い.
> z <- list(y, array(1:9), matrix(1:9,3,3)) # 配列や行列も要素に使うことが出来る
> x <- as.list(NULL) # リスト x を初期化
> x[[1]] <- c(1:5) # リストの第 1 成分にベクトルを付値 (代入)
> x[[2]] <- "second list" # リストの第 2 成分に文字列を付値 (代入)
> x
[[1]]
[1] 1 2 3 4 5
[[2]]
[1] "second list"� �ベクトルの場合と同様,リストの長さも関数 length() で調べることが出来る.また,ベクトルの場合と同様,
要素の取りだし記法と < − を使ってリストの要素への代入が可能になる.ただし,リストの要素に NULL を代
入する操作は『その要素を取り除く』という意味で,『リストの成分に NULL を代入する』という意味ではないの
で注意.後者の意味にする場合は list(NULL) を付値 (代入) すればよい.� �> x <- list(1:5, "It’s my list.", c(T, F, T))
> length(x) # ベクトルが 3 個あるリストの長さ
[1] 3
> length(list(x, x)) # リスト x が 2 個あるようなリストの長さ
[1] 2
> x <- list(1:5, "It’s my list.", c(T, F, T))
> x[[2]] <- "No! This is my list!" # 第 2 成分へ別の値を付値 (代入)しなおす
> x[[3]] <- list(NULL) # 第 3 成分を NULL にする
> x
[[1]]
[1] 1 2 3 4 5
[[2]]
[1] "No! This is my list!"
[[3]]
[[3]][[1]]
NULL
> x[[3]] <- NULL # 第 3 成分をすっかり取り除く!
> x
[[1]]
[1] 1 2 3 4 5
[[2]]
[1] "No! This is my list!"
� �
3.6.1 リストの要素を取り出す
[[ と ]] の間に要素の番号を指定することによってリストの要素を取り出すことが出来る.[ と ] の間に要素の番
号を指定することでもリストの要素を取り出すことは出来るが,この場合はベクトルとして添字アクセスを行っ
ていることになる.

R-Tips 46頁
� �> x <- list(1:5, list("It’s my list.", c(1+2i, 3+4i)), c(T, F, T)) # x は入れ子構造リスト
> x[[1]] # x の第 1 成分を抽出
[1] 1 2 3 4 5
> x[[3]][1] # x の第 3 成分 ( x[[3]]:論理値ベクトル) の
[1] TRUE # 第 1 成分を抽出 ( x[[3]][[1]] でも可)
> x[[2]] # x の第 2 成分を抽出 (これもリスト)
[[1]]
[1] "It’s my list."
[[2]]
[1] 1+2i 3+4i
> x[[2]][[2]] # x の第 2 成分 ( x[[2]]:リスト) の第 2 成分
[1] 1+2i 3+4i # (複素数ベクトル) を抽出
> x[[2]][[2]][1] # x の第 2 成分 ( x[[2]]:リスト) の第 2 成分
[1] 1+2i # (複素数ベクトル) の第 1 成分を抽出� �(注) [[ と ]] によって取り出されるものは,リストの要素そのものであって要素を含んだリストではないことに注
意.この操作はベクトルの場合の [ と ] による部分ベクトルの取り出し (範囲指定による抽出) に対応する
ものではないことに注意.
names 属性 (『補足事項』の章を参照) を持つリスト,すなわち要素に名前が付けられたリストであれば番号の
代わりに名前で要素を取り出すことが出来る.この場合,リスト名$要素名 という指定方法が使える.� �> ( x <- list("vector"=1:5, strings="It’s my list.", "logical"=c(T, F, T)) )
$vector # names 属性を付けながらリスト x を作成
[1] 1 2 3 4 5
$strings
[1] "It’s my list."
$logical
[1] TRUE FALSE TRUE
> x[["strings"]] # strings と名付けられた要素にアクセス
[1] "It’s my list." # x["strings"] でもアクセス可
> x$logical # logical と名付けられた要素にアクセス
[1] TRUE FALSE TRUE
> temp <- "vector" # temp には文字列 "vector" が付値 (代入)されている
> x[[temp]] # [[ ]] の中身の式は評価されるので,これは
[1] 1 2 3 4 5 # x[[vector]] と認識される
> x$temp # $ の後の式は評価されないので,これは x$temp と
NULL # 認識されるので NULL が返る� �
3.6.2 部分リストの抽出・置換・連結
要素を取り出したいのではなくてリストの一部分を抽出する場合は,ベクトルの場合と同様に [ と ] を使えば
よい.ただし返り値はリストとなる.

R-Tips 47頁
� �> x <- list(1:5, "It’s my list.", c(T, F, T))
> x[1:2] # 第 1 , 2 成分を抽出
[[1]]
[1] 1 2 3 4 5
[[2]]
[1] "It’s my list."
> x[-1] # 第 1 成分以外を抽出
[[1]]
[1] "It’s my list."
[[2]]
[1] TRUE FALSE TRUE
> x[c(T,F,T)] # 第 1 , 3 成分を抽出
[[1]]
[1] 1 2 3 4 5
[[2]]
[1] TRUE FALSE TRUE� �記法< −でリストの一部だけを置き換える場合,置き換える要素がリストでなければ警告が出る上に正しく付
値 (代入)されないので注意.必ずリスト (またはリストに変換したもの) で置き換えること.また,置き換えられ
るリストに names 属性が付いている場合,置き換えるリストに要素名がなければ,置き換えられるリストの要素
名は変わらないが,置き換えるリストに要素名があれば置き換えられるリストの対応する要素名も置き換えられ
ることになる.� �> x[3] <- c(1+2i, 3+4i) # リストの一部分をベクトルで置き換えようとすると
Warning message: # 警告が出る
number of items to replace is not a multiple of replacement length
> x[3] <- list(c(1+2i, 3+4i)) # リストに変換してからリストの一部分を置き換える
> x
[[1]]
[1] 1 2 3 4 5
[[2]]
[1] "It’s my list."
[[3]]
[1] 1+2i 3+4i� �(注) 『置き換えるリストの要素の長さ』が『置き換えられる要素の長さ』よりも少ない場合は,置き換えるリス
トが循環的に使われて調節される.ただし,『置き換えるリストの要素の長さ』が『置き換えられる要素の長
さ』の倍数になっていない場合は警告が出る.逆に,『置き換えるリストの要素の長さ』が『置き換えられる
要素の長さ』よりも多い場合は余分な要素が無視される (この場合も警告が出る) .
ところで,ベクトルと同様にリストの連結も関数 c() や関数 append() で行なうことが出来る.� �> c( list(1:5), list(c(T, F, T)) ) # append(list(1:5), list(c(T, F, T))) でも可
[[1]]
[1] 1 2 3 4 5
[[2]]
[1] TRUE FALSE TRUE� �

R-Tips 48頁
� �> rep( list(1:5, "It’s my list."), 2) # rep() などのベクトル操作で御馴染みな関数も使用可
� �
3.6.3 全ての要素に関数を適用する
ある関数をリストの要素全てに適用したい場合は関数 lapply() ,sapply() を用いる.lapply() を用いた場合,
結果は各要素に関数を適用した結果の値のリストで返される.sapply() を用いた場合は,結果はベクトルで返さ
れるが,型は要素の中で『一番大きな型』に合わせられる.� �> x <- list(1:5, c(1+2i, 3+4i), c(T, F, T))
> lapply(x, sum)
[[1]] # 第 1 成分の和
[1] 15
[[2]] # 第 2 成分の和
[1] 4+6i
[[3]] # 第 3 成分の和 ( T=1 , F=0 として計算される)
[1] 2
> sapply(x, sum)
[1] 15+0i 4+6i 2+0i # 結果の型は全て複素型に合わせられる� �他にも,リストの要素を端からベクトルとして結合して 1 つのベクトルとしてまとめる関数 unlist() や,逆に
ベクトルをある基準で区分けしてリストとしてまとめる関数 split() がある.� �> ( x <- split(1:10, rep(c("odd", "even"), 5)) )
$even
[1] 2 4 6 8 10
$odd
[1] 1 3 5 7 9
> unlist(x)
even1 even2 even3 even4 even5 odd1 odd2 odd3 odd4 odd5
2 4 6 8 10 1 3 5 7 9� �
3.7 行列の作成と基本操作
R での行列とは行と列を持つ 2 次元配列を指す.普通は各要素が数値の行列で数値を要素とする行列しか扱わ
ないだろうが,論理値や文字列などを要素とする行列を作成することも出来る.行列を作成するには関数 matrix()
を使う (配列を生成しているという意味で関数 array() を用いても作成することが出来る) .� �> matrix(1:6, nrow=2, ncol=3) # nrow で行数,ncol で列数を指定する
[,1] [,2] [,3] # 略記として matrix(1:6, 2, 3) でも良いし
[1,] 1 3 5 # array(1:6, c(2,3)) でも良い
[2,] 2 4 6
> matrix(0, nrow=2, ncol=3) # ゼロ行列を生成
[,1] [,2] [,3]
[1,] 0 0 0
[2,] 0 0 0
� �

R-Tips 49頁
行列を作成する場合,指定された要素は左の列から順に (上から下へ) 埋められる.要素を上の行から順に (左
から右へ) 埋める場合は引数 byrow=T を指定すればよい.� �> matrix(1:6, nrow=2, ncol=3, byrow=T) # matrix(1:6, 2, 3, byrow=T) でも可
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
� �
3.7.1 種々の行列作成方法
まず,行ベクトルをあたえて行列を作る方法と,列ベクトルをあたえて行列を作る方法とを紹介する.� �> ( x <- rbind(c(1,2,3), c(4,5,6)) ) # 行ベクトルをあたえて行列を作る
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
> ( x <- cbind(c(1,2,3),c(4,5,6)) ) # 列ベクトルをあたえて行列を作る
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
� �行列作成に使われるベクトルの要素が足りなければ繰り返し使われることになる.この規則を用いると以下の
ような行列を作成することが出来る.� �> matrix(1:2, nrow=2, ncol=3) # 同じ列 (上:111 ,下:222) で構成される行列
> matrix(1:3, nrow=2, ncol=3, byrow=T) # 同じ行 (上:123 ,下:123) で構成される行列
> matrix(1, nrow=4, ncol=3) # 全ての要素が 1 である行列� �ところで,nrow,ncolの一方だけを与えると,行列のサイズからもう一方が暗黙のうちに決定される.matrix()
に指定した要素の長さが行列のサイズに足りないと,最初の方の要素から循環的に補充される.� �> x <- matrix(1:6, nrow=3) # 自動的に ncol = 2 とされる
> y <- matrix(1:6, ncol=2) # 自動的に ncrow = 3 とされる
� �行列を入れると行番号と列番号で満たされた同じ大きさの行列を返す関数 row() ,col() というものもある.� �> x <- matrix(1:6, nrow=2, ncol=3) # 2 * 3 の行列を作る
> row(x) # 各行の値が行番号と同じ行列を作る
[,1] [,2] [,3]
[1,] 1 1 1
[2,] 2 2 2
> col(x) # 各列の値が列番号と同じ行列を作る
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 1 2 3
� �

R-Tips 50頁
3.7.2 行列の大きさ
行列は dim 属性という次元の属性を持っており,(行数 ,列数) という長さ 2 の整数ベクトルの形をしている.
行列に付けられた dim 属性を見る場合は関数 dim() ,nrow() ,ncol() を用いる.� �> x <- matrix(1:6, nrow=2, ncol=3) # 2 * 3 の行列を作る
> dim(x) # dim 属性を調べる
[1] 2 3
> nrow(x) # 行数 : dim(x)[1] でも同じ結果が得られる
[1] 2
> ncol(x) # 列数 : dim(x)[2] でも同じ結果が得られる
[1] 3� �行列の大きさを変えるには,再度 matrix() を使う方法と dim を使って行列の大きさを強制変換する方法とが
ある.dim を用いる場合の変換結果は matrix() を使って行列サイズを変更した場合と同様である.� �> x <- matrix(1:6, nrow=2, ncol=3) # 2 * 3 の行列を作る
> dim(x) <- c(3, 2) # 3 * 2 の行列に強制変換
> matrix(as.vector(x), nrow=2, ncol=6) # 2 * 6 の行列に強制変換
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 3 5 1 3 5
[2,] 2 4 6 2 4 6
> matrix(x, nrow=2, ncol=6) # matrix() の第 1 引数はベクトルに変換されるので
[,1] [,2] [,3] [,4] [,5] [,6] # as.vector() を省略してもよい
[1,] 1 3 5 1 3 5
[2,] 2 4 6 2 4 6
� �
3.7.3 行と列のラベル
ベクトルやリストの場合 names 属性を与えることによって要素にラベルを付けることが出来た.行列の場合に
もラベルを付けることが出来る.� �> x <- matrix(1:6, nrow=2, ncol=3) # 2 * 3 の行列を作る
> rownames(x) <- c("up", "down") # 行の名前
> colnames(x) <- c("left", "center", "right") # 列の名前
> x
left center right
up 1 3 5
down 2 4 6
> x["up","right"] # 名前で要素にアクセスすることが出来る
[1] 5� �行と列のどちらかの (両方の) ラベルが不要なら dimnames 属性の対応する要素を NULL にすればよい.� �> rownames(x) <- NULL # 行列 x の行に付けられた名前を全て取り除く
> colnames(x) <- NULL # 行列 x の列に付けられた名前を全て取り除く
> dimnames(x) <- NULL # 両方のラベルが不要なら dimnames 属性自体を取り除く
� �

R-Tips 51頁
3.7.4 行列要素の抽出
行列の要素を取り出す場合は [ と ] の間にカンマで区切って行の添字と列の添字を指定すればよい.行列も
ベクトルの場合と同様,添字として整数ベクトルや論理値ベクトルを指定することが出来る.このとき,引数に
drop=FALSE を指定することで,行列の添字操作における結果のベクトル化を防ぐことも出来る (結果が複数行
で無い場合にベクトル化がなされる) .� �> ( x <- matrix(1:6, nrow=2, ncol=3) ) # 2 * 3 の行列を作る
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> x[1, 2] # 2 行 1 列目の成分を表示
[1] 3
> x[c(1,2), 2] # 1,2 行 2 列目の成分を表示
[1] 3 4
> x[2, c(1,2)] # 2 行 1,2 列目の成分を表示
[1] 2 4
> x[-1, c(T,F,T)] # 1 行目を非表示,2 行目の 1,3 成分を指定
[1] 2 6
> x[2, ] # 2 行目を取り出す
[1] 2 4 6
> x[ ,2] # 2 列目を取り出す
[1] 3 4
> x[ ,2, drop=F] # 2 列目を行列の形で取り出す
[,1]
[1,] 3
[2,] 4
� �[ と ] の間にベクトルや行列を指定して行列の一部分を取り出すことも出来る.� �> ( x <- matrix(1:12, nrow=3, ncol=4) ) # 3 * 4 の行列を作る
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> x[c(1, 3),c(1, 2, 4)] # 1,3 行と 1, 2,4 列を抽出した行列を作る
[,1] [,2] [,3]
[1,] 1 4 10
[2,] 3 6 12
> x[-c(1, 3), -c(1, 2, 4)] # 1,3 行と 1, 2,4 列を除外した行列を作る
[1] 8
> x[matrix(1:4, 2, 2)] # 行列で指定 -> x[cbind(c(1,2),c(3,4))] でも可
[1] 7 11
> x[1:4] # 行列がベクトルに変換されてから最初の 4 個
[1] 1 2 3 4 # の要素が取り出される� �要素を置換した結果は,出来るだけ元の行列の形を保存しようとする作用が働く.よって,要素を置換する際に
多少の型の不一致があっても自動的に調節されることになる .

R-Tips 52頁
� �> ( x <- matrix(1:12, nrow=3, ncol=4) ) # 3 * 4 の行列を作る
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> x[1:2, 3:4] <- c(333, 555, 777, 999) # 代入するベクトルは 2 x 2 の行列に変換される
> x
[,1] [,2] [,3] [,4]
[1,] 1 4 333 777
[2,] 2 5 555 999
[3,] 3 6 9 12
� �ある条件を満たす行列要素の添字を取り出す場合は関数 which () を引数 arr.ind=TRUE ( ”arr.ind” should
array indices be returned when ’x’ is an array?) 付きで使用すればよい.引数で arr.ind=FALSE とすると,行
列をベクトル化した上で要素の添字ベクトルを返す.� �> ( x <- matrix(1:6, nrow=2, ncol=3) ) # 2 * 3 の行列を作る
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> ( y <- which(x%%2==0, arr.ind=TRUE) ) # 2 の倍数である要素の行列添字を取り出す
row col
[1,] 2 1
[2,] 2 2
[3,] 2 3
� �ある条件を満たす行列の該当箇所にマーキングする方法もある.� �> x[x%%2==0] # 2 の倍数である x の全要素
[1] 0 0 0
> x[x%%2==0] <- "*" # 行列 x の偶数要素を全て * に置き換え
> x # 文字でマーキングしているので,全ての
[,1] [,2] [,3] # 要素が文字型になっていることに注意
[1,] "1" "3" "5"
[2,] "*" "*" "*"
� �
3.7.5 行列の結合
ベクトルや行列を結合することで新たな行列を作ることも出来る.行ベクトル単位で合成する場合は関数 rbind()
を,列ベクトル単位で合成する場合は関数 cbind() を使う.� �> ( x <- rbind(1:3, c(4, 5, 6), 7:9) ) # 3 個の行ベクトルを行列に合成する
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
� �

R-Tips 53頁
� �> ( y <- cbind(1:3, c(4, 5, 6), 7:9) ) # 3 個の列ベクトルを行列に合成する
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
� �
3.8 行列の計算
行列の和,差,積 などの基本的な行列演算は普通の数値と同じコマンドで行うことが出来る.ただし行列の積
は %*% 演算子によって求める点に注意.行列に対して * 演算子を用いると要素毎の積を計算を行ってしまう.� �> a <- matrix(1:4, 2, 2) # 2 * 2 行列
> b <- matrix(0:3, 2, 2) # 2 * 2 行列
> a + b - a %*% b # 和・差・積
> a * b # 要素ごとの掛け算
> a %o% b # 外積
> a %x% b # クロネッカー積 -> 関数 kronecker() でも可
� �演算子 ∗ については,定数部分にベクトルを持ってくることも出来る.また,似たような働きで / を用いるこ
とで,要素ごとの逆数を求めることも出来る.� �> a <- matrix(1:4, 2, 2) # 2 * 2 行列
> a*(1:2)
[,1] [,2]
[1,] 1 3
[2,] 4 8
> 1/a
[,1] [,2]
[1,] 1.0 0.3333333
[2,] 0.5 0.2500000
� �
3.8.1 特定の列 (行)和に対する演算や操作
関数 apply() を用いればよい.例えば行列の列 (もしくは行) の和を要素とするベクトルを作成する場合は以下
の様にすればよい.� �> ( x <- matrix(1:4, 2, 2) )
[,1] [,2]
[1,] 1 3
[2,] 2 4
> apply(x, 2, sum) # 列和 -> 関数 colSums(x)と同じ
[1] 3 7
> apply(x, 1, sum) # 行和 -> 関数 rowSums(x)と同じ
[1] 4 6� �また,行列の特定の列 (もしくは行) に関数を適用する場合は以下の様にすればよい.

R-Tips 54頁
� �> apply(x, 1, max) # 各行の最大値を求める
[1] 3 4
> apply(x, 2, min) # 各列の最小値を求める
[1] 1 3� �
3.8.2 行列をある行・列に関してソートする
関数 order() を用いればよい.行列の各列毎の最大要素の位置を求める場合は関数 max.col() を用いる.� �> ( x <- matrix(runif(4), 2, 2) )
[,1] [,2]
[1,] 0.4438584 0.1541547
[2,] 0.6533011 0.4914949
> order(x[,2])
[1] 1 2
> x[,order(x[,2])] # 第 2 列でソート
[,1] [,2]
[1,] 0.4438584 0.1541547
[2,] 0.6533011 0.4914949
> order(x[1,])
[1] 2 1� �
3.8.3 転置行列
関数 t() を使って求めることが出来る.� �> x <- matrix(1:4, 2, 2)
> t(x)� �
3.8.4 単位行列・対角行列
関数 diag() を使って生成するか,適当な正方行列 x を作ってから x[row(x) ! = col(x)] < − 0 とする.� �> ( x <- diag(2) ) # 引数が 1 個だけなら単位行列の大きさを表すと解釈される
[,1] [,2] # diag(1, ncol=2, nrow=2), diag(1, 3), diag(rep(1, 3))
[1,] 1 0 # diag(c(1,1)) などでも単位行列が得られる.
[2,] 0 1
> x <- matrix(0, ncol=2, nrow=2) # 全成分が 0 の行列
> diag(x) <- 1 # 対角成分を 1 にする
> x
[,1] [,2]
[1,] 1 0
[2,] 0 1
> diag(x) <- c(1, 2, 3) # 対角成分を 1, 2, 3 にする
� �

R-Tips 55頁
� �> x # diag(1:3) で直接作ることも出来る
[,1] [,2] [,3]
[1,] 1 0 0
[2,] 0 2 0
[3,] 0 0 3
� �
3.8.5 三角行列
まず適当な正方行列を作ってから upper.tri で要素を操作すればよい.つまり上三角行列を 0 にすればよい.� �> ( x <- matrix(1:9, 3) )
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> x[upper.tri(x)] <- 0 # 下三角行列 (対角を含む)を作る
> x # x[row(x) < col(x)] <- 0 でも可
[,1] [,2] [,3]
[1,] 1 0 0
[2,] 2 5 0
[3,] 3 6 9
> x[upper.tri(x, diag=TRUE)] <- 0 # 対角成分も 0 にする場合
� �上三角行列を作るときには lower.tri (もしくは x[row(x) > col(x)] < − 0 ) を使う.
3.8.6 行列の成分の二乗の総和
関数 sum(),diag() ,%*% を組み合わせることで求めることが出来る.� �> x <- array(runif(8),c(2,4))
> sum(diag(t(x)%*%x)) # sum(diag(x%*%t(x))) も同じ値となる
[1] 3.185785� �
3.8.7 連立方程式の解
A.x = b なる形の x についての連立方程式の解は関数 solve() を使って解く事が出来る.� �> a <- matrix(c(0,1,2,3,4,5,6,7,9), 3,3) # 3y + 6z = 1
> b <- matrix(c(1,0,-2)) # x + 4y + 7z = 0
> solve(a,b) # 2x + 5y + 9z = -2
[,1]
[1,] -2.333333
[2,] 2.333333
[3,] -1.000000
� �また係数行列が上三角行列の場合は,関数 backsolve() を使うことが出来る.backsolve() は係数行列の下三角部

R-Tips 56頁
分を無視するので下三角部分が 0 でない行列を係数行列に指定することも出来るが,この場合に連立一次方程式
の係数として使われるのは上三角の部分のみ使われる.また,下三角行列の場合は関数 forwardsolve()を用いる.� �> r <- rbind(c(1,2,3), # 上三角行列 r
+ c(0,1,1),
+ c(0,0,2))
> ( y <- backsolve(r, x <- c(8,4,2)) ) # -1 3 1
> r %*% y # == x = (8,4,2)
> ( y2 <- backsolve(r, x, transpose = TRUE)) # 8 -12 -5
> all(t(r) %*% y2 == x)
> all(y == backsolve(t(r), x, upper = FALSE, transpose = TRUE))
> all(y2 == backsolve(t(r), x, upper = FALSE, transpose = FALSE))
� �
3.8.8 逆行列
A.x = b で b に A の次数の単位行列を与えて関数 solve() で解くことで A の逆行列を求めることが出来る.� �> A <- array(runif(9),c(3,3))
> B <- solve(A) # 逆行列を求める方法 (1)
> a <- matrix(c(0,1,2,3,4,5,6,7,9), 3,3)
> b <- matrix(c(1,0,0,0,1,0,0,0,1), 3,3)
> solve(a,b) # 逆行列を求める方法 (2)
[,1][,2][,3]
[1,] -0.3333333 -1 1
[2,] -1.6666667 4 -2
[3,] 1.0000000 -2 1
� �
3.8.9 一般逆行列
ムーア・ペンローズ型一般逆行列を求めるには以下のようにする.� �> A <- matrix(c(1,2,3,4,5,6,7,8,9),c(3,3))
> B <- solve(A) # 行列 (フルランク)の逆行列を求めるコマンド
Error in solve.default(A) : singular matrix ‘a’ in solve
> library(MASS) # パッケージの呼び出し
> B <- ginv(A) # ムーア・ペンローズ型一般逆行列を求める
> B
[,1] [,2] [,3]
[1,] -0.6388889 -5.555556e-02 0.5277778
[2,] -0.1666667 -8.809143e-19 0.1666667
[3,] 0.3055556 5.555556e-02 -0.1944444
� �

R-Tips 57頁
3.8.10 クロス積
関数 crossprod()を用いればよい.行列 Aと B のクロス積 t(A) %*% B を求める.第 2引数を省略すると t(A)
%*% A を求めることになる ( t(A) は A の転置行列 ) .� �> a <- matrix(c(1,2,3,4))
> b <- matrix(c(0,-1,-2,1))
> crossprod(a,b) # クロス積
> crossprod(a) # 自身のクロス積
� �
3.8.11 固有値と固有ベクトル
行列の固有値 ( 実正方行列の固有値) と固有ベクトルは関数 eigen() で求められる.行列のスペクトル分解がリ
ストの成分として返される.� �> a <- matrix(c(0,1,2,3,4,5,6,7,9), 3,3)
> eigen(a)
$values
[1] 13.985686 -1.169156 0.183470
$vectors
[,1] [,2] [,3]
[1,] 0.5196922 0.9019333 -0.2035941
[2,] 0.6673238 0.1966967 0.7808836
[3,] 0.8777134 -0.2740985 -0.3966673
> z <- eigen(a)
> z$values
[1] 13.985686 -1.169156 0.183470
> z$vectors[,1] # 固有値 2 に対する固有ベクトル
[1] 0.5196922 0.6673238 0.8777134
> z$vectors[,2] # 固有値 1 に対する固有ベクトル
[1] 0.9019333 0.1966967 -0.2740985� �
3.8.12 QR分解 (行列のランク)
行列の QR 分解を計算する場合は関数 qr() を用いる.QR 分解は多くの統計的技法の中で重要な役目を果たし,
特に与えられた行列 A とベクトル b に関する方程式 Ax = b を解くのに使うことが出来る.
qr(x) : QR 分解を計算したい行列 x を引数に入れることで x の QR 分解を行なう.返り値の成分は,
qr : x と同じ次元の行列.上半三角部分は分解の R を含み,下半三角部分は分解の Q に関する情報を
含む.
qraux : 長さ ncol(x) のベクトルで,Q に関する追加情報を含む.
rank : 分解によって計算された x のランク.
pivot : 分解の過程で使われたピボット選択法に関する情報.
qr.coef(qr, y) : QR 分解された行列に当てはめた時に得られる係数.
qr.resid(qr, y) : QR 分解された行列に当てはめた時に得られる残差.

R-Tips 58頁
qr.fitted(qr, y, k = qr$rank) : QR 分解された行列に当てはめた時に得られる当てはめ値.
qr.qy(qr, y) : Q %∗% yを返す.
qr.qty(qr, y) : t(Q) %∗% y を返す.
qr.solve(a, b) : QR 分解によって線形方程式系を解く.
� �> hilbert <- function(n) { i <- 1:n; 1 / outer(i - 1, i, "+") }
> h9 <- hilbert(9);
> qr(h9)$rank
[1] 7
> qrh9 <- qr(h9, tol = 1e-10)
> qrh9$rank
[1] 9
> y <- 1:9 / 10 #-- Solve linear equation system H %*% x = y :
> x <- qr.solve(h9, y, tol = 1e-10) # or equivalently :
> x <- qr.coef(qrh9, y) #-- is == but much better than
> #-- solve(h9) %*% y
> h9 %*% x # = y
[,1]
[1,] 0.1
[2,] 0.2
.......
[9,] 0.9
� �
3.8.13 コレスキー (Cholesky) 分解
対称 (エルミート) 正定値符号正方行列 (正値対称行列) の Choleski 分解を計算する場合は関数 chol() を用い
る.すなわち A が正値対称行列の時
A = t(B) %*% B
を満たす上三角行列 B を求めることが出来る.よって返り値は Choleski 分解の上三角因子,つまり t(B) %*% B
= x となる行列 B となる.また,対称正定値符号行列の逆行列を Choleski 分解から求める関数 chol2inv() も用
意されており,引数に行列を入れると,分解された行列の逆行列が返る.� �> ( a <- matrix(c(5,1,1,3), 2, 2) )
[,1] [,2]
[1,] 5 1
[2,] 1 3
> ( b <- chol(a) )
[,1] [,2]
[1,] 2.236068 0.4472136
[2,] 0.000000 1.6733201
> crossprod(b) # t(b) %*% b
[,1] [,2]
[1,] 5 1
[2,] 1 3
� �

R-Tips 59頁
� �> cma <- chol(ma <- cbind(1, 1:3, c(1,3,7)))
> ma %*% chol2inv(cma)
[,1] [,2] [,3]
[1,] 1.000000e+00 0.000000e+00 0.000000e+00
[2,] 1.110223e-16 1.000000e+00 1.110223e-16
[3,] 1.110223e-16 6.661338e-16 1.000000e+00
� �
3.8.14 特異値分解
関数 svd() で行なうことが出来る.特異値分解をやる際は,svd() で行列 A を
A = U %*% D %*% t(V)
を満たす直交行列 U,A の特異値を対角成分とする対角行列 D ,直交行列 V に分解することが出来る. また,
svd が返す値は以下の要素からなるリストとなる.
u : 行列 U
d : 特異値を大きいものから準に並べたベクトル
v : 行列 V を転置したもの
基本的には z < − svd(x) に対して
x == z$u %*% diag(z$d) %*% t(z$v)
が成り立つが,数値計算上の誤差があるので上の式を R で実行した場合に必ず成り立つとは限らない.� �> a <- matrix(c(1,0.5,0.5,1),2)
> svd(a)
$d
[1] 1.5 0.5
$u
[,1] [,2]
[1,] -0.7071068 -0.7071068
[2,] -0.7071068 0.7071068
$v
[,1] [,2]
[1,] -0.7071068 -0.7071068
[2,] -0.7071068 0.7071068
> eigen(a)
$values
[1] 1.5 0.5
$vectors
[,1] [,2]
[1,] 0.7071068 0.7071068
[2,] 0.7071068 -0.7071068
� �

R-Tips 60頁
3.8.15 行列の平方根
関数 svd() を用いると,行列の平方根を求めることが出来る.� �> mu <- cbind(c(1,1,1)) # 平均ベクトル (縦ベクトル)
> A <- array(c(2,1,1,1,2,1,1,1,2), dim=c(3,3))
> U <- svd(A)$u
> V <- svd(A)$v
> D <- diag(sqrt(svd(A)$d))
> B <- U %*% D %*% t(V) # 行列 A の平方根
> A
[,1] [,2] [,3]
[1,] 2 1 1
[2,] 1 2 1
[3,] 1 1 2
> B
[,1] [,2] [,3]
[1,] 1.3333333 0.3333333 0.3333333
[2,] 0.3333333 1.3333333 0.3333333
[3,] 0.3333333 0.3333333 1.3333333
> B%*%B
[,1] [,2] [,3]
[1,] 2 1 1
[2,] 1 2 1
[3,] 1 1 2
� �
3.8.16 正方行列の指数乗
例えば正方行列 A に対する 2 乗操作 Aˆ2 は成分毎に 2乗した行列を与えるだけで,行列そのもののべき乗
A%*%A を与えてくれない.そこで A のべき乗 Aˆn を計算するには A の固有値分解 A = V %*% D %*% t(V)
を用いて Aˆn = V %*% Dˆn %*% t(V) と計算すればよい.D は対角行列だから Dˆn と D の行列としての n 乗
は一致する.例えば対照行列について計算することが出来る次の関数を定義する.この概念を応用すると行列の
指数乗が計算できる.� �> matpow <- function(x, pow=2) { # 行列の指数乗
+ y <- eigen(x)
+ y$vectors %*% diag( (y$values)^pow ) %*% t(y$vectors)
+ }
> matexp <- function(x) { # 行列の指数関数を定義
+ y <- eigen(x)
+ y$vectors %*% diag( exp(y$values) ) %*% t(y$vectors)
+ }
> matpow(diag(1:2)) # ( (1,0) , (0, 2)) 行列の 2 乗
[,1] [,2]
[1,] 1 0
[2,] 0 4
� �

R-Tips 61頁
� �> matexp(matrix(0, 2, 2)) # ゼロ行列の指数乗は単位行列
[,1] [,2]
[1,] 1 0
[2,] 0 1
> matexp(diag(2)) # e^E = ((e, 0) , (0, e))
[,1] [,2]
[1,] 2.718282 0.000000
[2,] 0.000000 2.718282
� �必ずしも対称でない正方行列の任意べき乗関数 (作:Martin Maechler 氏) は以下のように定義すればよい.例
えば X の 4 乗を (X %*% X) %*% (X %*% X) として計算することにより高速化を図っている.� �> matPower <- function(X, n) {
if(n != round(n)) {
n <- round(n)
warning("rounding exponent ‘n’ to", n)
}
phi <- diag(nrow = nrow(X))
pot <- X # the first power of the matrix.
while (n > 0) {
if (n %% 2) phi <- phi %*% pot
n <- n %/% 2
pot <- pot %*% pot
}
return(phi)
}� �
3.8.17 行列式
A が正方行列ならば,関数 det() を用いるか,関数 prod() と svd() を使って行列式の絶対値を計算することが
出来る.� �> a <- matrix(c(0,1,2,3,4,5,6,7,9), 3,3)
> prod(svd(a)$d)
[1] 3
> det(a)
[1] 3� �
3.8.18 おまけ
関数 image() を用いることにより,行列のイメージを画像として表現することも出来る.� �> x <- matrix(rep(0:1,81), 9, 9)
> image(x, col=c(5,9))
� �

R-Tips 62頁
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
3.9 配列+ apply()
配列とは行列を多次元に拡張したものである.行列は 2 次元であったが,配列はその次元に応じて 3 ,4 ,...
次元のものを作成することが出来る.配列は関数 array() で作成出来,引数 dim に各次元の要素の個数をベクト
ルを指定する.また,関数 dim() で配列の次元を調べることが出来る.� �> ( a <- array(1:16, dim=c(2, 4, 2)) )
, , 1
[,1] [,2] [,3] [,4]
[1,] 1 3 5 7
[2,] 2 4 6 8
, , 2
[,1] [,2] [,3] [,4]
[1,] 9 11 13 15
[2,] 10 12 14 16
� �行列の場合と同じように dimnames 属性によって names 属性を付けることが出来る.k 次元の配列に対する
dimnames 属性は長さ k のリストとなる.� �> dimnames(a) <- list(NULL, c("A", "B", "C", "D"), c("a", "b")) # ラベルが不要な次元である
> a # 要素には NULL を付値する
, , a
A B C D
[1,] 1 3 5 7
[2,] 2 4 6 8
, , b
A B C D
[1,] 9 11 13 15
[2,] 10 12 14 16
� �k 次元の配列は k 個の添字でアクセスする.� �> a[2, "D" ,1]
[1] 8
> a[, , "a"]
A B C D
[1,] 1 3 5 7
[2,] 2 4 6 8
� �

R-Tips 63頁
3.9.1 行列,配列の各部分に関数を適用する
例えば行列 x の各列ごとの平均を計算したい場合,列 i について以下のように計算すればよい.� �> mean(x[ ,i])
� �同様に,行ごとの平均は行 i について以下のように計算すればよい.� �> y[i] <- mean(x[i, ])
� �この計算は関数 apply() を用いても計算することが出来る.
apply(X, MARGIN, 関数, ...) : ベクトルや行列,配列の MARGIN に関数を適用し,その結果の配列かリ
ストを返す.ここで MARGIN = 1 ならば行に関して,MARGIN = 2 ならば列に関して,MARGIN =
c(1,2) ならば各要素に対して関数を適用する.
� �> apply(x, 2, mean) # 列について:mean(x[ ,i]) と同じ計算
> apply(x, 1, mean) # 行について:mean(x[i, ]) と同じ計算
� �3 次元配列 a に対して,全ての配列番号 i について mean(a[i,i, ]) を計算するには以下の様にすればよい.� �> a <- array(1:16, dim=c(2, 4, 2))
> apply(a, c(1,2), mean)
[,1] [,2] [,3] [,4]
[1,] 5 7 9 11
[2,] 6 8 10 12
� �(注) 行列演算として求められるものは apply() を使うより行列演算を使って求めた方が計算速度的に良い.例え
ば行列 x の行ごとの和は
� �> apply(x, 1, sum)
� �で求めることも出来るが,以下のように求めた方が高速となる.
� �> x %*% rep(1, ncol(x))
� �
3.9.2 配列の一般化転置
配列を転置する場合は関数 aperm() を用いればよい.引数 perm (置換) の部分に c(2,1) を入れれば行列の置
換と同じになる.例えば以下の様にして使えばよい.� �> x <- array(1:24, 2:4) # 4 次元配列 ( 2 * 3 が 4 個ある配列)
> xt <- aperm(x, perm=c(2,1,3)) # xt は x を転置した配列 ( 3 * 2 が 4 個ある配列)
� �
第4章 関数・プログラミング篇
4.1 演算子と複合式
R で用いる演算子を見てみる.上にあるものほど優先順位が高い (先に処理・計算される) が,括弧 ( ) をつけ
たものはそこが優先的に計算される.また,$ と [[ ]] は主にリストの要素にアクセスする場合 ( mylist$element ,
mylist[[1]] ) に用いられ,[ ] は主にベクトルの要素にアクセスする場合 ( x[2] ) に用いられる.
記号 意味
$ リストの要素
[ ,[[ データの一部分,要素,リストの要素
ˆ べき乗
− マイナス (単項演算子)
: 公差 ±1の等差数列
% 文字列 % 特殊二項演算
* ,/ 積,商
+ ,− 和,差
<,>,<=,>= 大小比較
== , != 等しい,等しくない
! 否定
&,|,&&,|| 論理積,論理和,かつ,または
<< − 永続付値
< −,− > 付値
複合式とはいくつかの式を { と } で括ったもので,それを構文的には一つの式として扱うものである.式はひとつだけでも構わない.このとき,改行・空白・タブは好きなように入れて構わない (動作や計算結果には影響し
ない) .また,セミコロンで式の区切りを表すことが出来るが,1 行で 2 つ以上の式を書かないのならば,文の最
後には何も (セミコロンを) 書かずにそのまま改行しても良い ( C や JAVA などとはこの点が異なる) .� �{
<式 1>
.....
<式 n>
}� �(注) 複合式の中身は先頭の式から順に評価され,最後の式の値 (だけ) がその複合式の値になる.
4.2 条件分岐
4.2.1 条件分岐:if ,else
ある条件で場合分けをして処理を行いたい場合は if 文,else 文を使う.以下の『条件式』にはTRUE や FALSE
の論理値を一つだけ返す式を入れなければならない.

R-Tips 65頁
� �if ( 条件式 ) {
< ... 式 1 ... > # 条件式が TRUE を返せば <式 1> が実行され <式 2> は無視される
} else {
< ... 式 2 ... > # 条件式が FALSE を返せば <式 2> が実行され <式 1> は無視される
}� �
if 文 の条件式が FALSE の時に else 以下がなければ何も処理を行わず if 式自体は NULL を返すことになる.� �> a <- rnorm(1) # 正規乱数を 1 つ発生
> if (a >= 0) {
> b <- a
> } else b <- -a # b には a の絶対値を代入
> a
[1] -0.4775119
> b
[1] 0.4775119
> if (a >= 0) b <- a else b <- -a # 上の if , else 文と同じ� �『式 1 』『式 2 』にいくつかの式を書きたい場合は『複合式』を使えばよい.� �> a <- rnorm(1) # 正規乱数を 1つ発生
> if (a > 0) {
+ if (a == 0) {
+ b <- "zero" # a == 0 なら b には zero を代入
+ } else b <- a # a > 0 なら b には a を代入
+ } else b <- -a # a < 0 なら b には -a を代入
> a
[1] 0.6702748
> b
[1] 0.6702748� �(注) 上のプログラムの 3∼5行目について if と else を括弧無しで複数行に分けるとエラーとなり,また 5・6行
目について } と else の間で改行するとエラーとなるので注意が必要である.
� �> a <- rnorm(1)
> if (a > 0) {
+ if (a == 0) b <- "zero"
+ else b <- a # この後エラーが出る
+ }
+ else b <- -a # この後エラーが出る
� �というのも,if (条件式) <式> の時点で R は 「一連の式が終わった」 と思うので,その次に else が出る
と 「 if が無いのに else が来た!」 と思ってエラーを出すのである.よって,『一連の式はここからここま
で』 ということを R に教えるために括弧で括るか,if の評価が終了して改行するまでに else を書く必要が
ある.例えば以下のような文ならばエラーは出ない.

R-Tips 66頁
� �> {
+ if (a > 0) {
+ if (a == 0) b <- "zero"
+ else b <- a # エラーは出ない
+ }
+ else b <- -a # エラーは出ない
+ return(c(a,b))
+ }� �
上記の理由により,関数定義内で以下の様にやってもエラーは出ない.
� �myfunc <- function(a,b) {
if (a > 0) {
if (a == 0) b <- "zero"
else b <- a # エラーは出ない
}
else b <- -a # エラーは出ない
return(c(a,b))
}� �条件分岐 if や else は以下の様な書き方も出来る.� �if (a < 0) { # 普通のプロンプト内ならば
print(0)
} else if (a < 1) {
print(1)
} else print(2)
myfunc <- function(a) { # 関数定義内ならば
if (a < 0) print(0)
else if (a < 1) print(1)
else print(2)
}� �また,関数 ifelse(条件式, 式 1, 式 2) というものもある.この関数は if (条件式) 『式 1 』 else 『式 2 』という
構文を簡略化したものである.
(注) if 文などの条件を入れる際に,空白 (スペース) を入れないと以下のような間違いを起こしてしまう.演算
子や数値,関数などの間には空白 (スペース) を適宜入れる習慣を付けた方が良いという例である.
� �> x = 2 # if (0) は FALSE になる
> if (3.1) cat(x,"\n") # if (0以外) は TRUE になる
2
> x <- -3
> if (x < -2) cat(x,"\n") # x と -2 の大小比較 (条件式は 0 ではないので TRUE になる!)
-3� �

R-Tips 67頁
� �> x <- -3
> if (x<-2) cat(x,"\n") # x<-2 は x に -2 を代入するという意味 (これも TRUE !)
2� �他にも自作関数作成時に有用な関数 stopifnot() などがある (詳しくはヘルプを参照) .
4.2.2 条件分岐:switch
条件式の評価結果がケース 1 ,ケース 2 ,ケース 3 , と多数あるで,その結果によって場合分けを行いたい
場合には switch 文を使う.例えば条件式が文字列を返す場合の switch 文は以下のような形になる.� �switch (<条件式>,
文字列 1 = <...式 1...>, # 条件式が 文字列 1 と合致したときにのみ <式 1> が実行される
文字列 2 = <...式 2...>, # 条件式が 文字列 2 と合致したときにのみ <式 2> が実行される
....................
文字列 n = <...式 n...>, # 条件式が 文字列 n と合致したときにのみ <式 n> が実行される
<...デフォルト式...> # 一致するものがない時は <デフォルト式> が実行される
)� �また,条件式が整数を返す場合の switch 文は以下のようになる.ただし,条件式が整数を返す場合は『デフォ
ルト式』を指定することが出来ないので注意.� �switch ( 条件式 ,
<... 式 1 ...>, # 条件式 (整数)が 1 のときにのみ実行される
<... 式 2 ...>, # 条件式 (整数)が 2 のときにのみ実行される
............. # 条件式 (整数)が 1...n でなければ NULL が返される
<... 式 n ...>, # 条件式 (整数)が n のときにのみ実行される
)� �『式 1 』,『式 2 』にいくつかの式を書きたい場合は『複合式』を使えばよい.� �> a <- 1
+ switch(a,
+ "1" = print("one"),
+ "2" = print("two"),
+ print("?")
+ )
[1] "one"
> a <- 2
+ switch(a,
+ print("one"),
+ print("two")
+ )
[1] "two"� �

R-Tips 68頁
4.2.3 演算子 && ,||
条件式に 2つ以上の条件が組み合わさった様な条件判定をさせたい場合は && (かつ) や || (または) を用いる.� �> a <- rnorm(1) # 正規乱数を 1つ発生 ( a には 0.468251 が付値されている)
> b <- rnorm(1) # 正規乱数を 1つ発生 ( b には -0.4981989 が付値されている)
> if ((a > 0) && (b > 0)) { # a > 0 かつ b > 0 という条件式
> c <- a*b # a * b = -0.2332821
+ } else c <- -a*b # c には a * b の絶対値 0.2332821 が付値されている
> c
[1] 0.2332821
> a <- rnorm(1) # 正規乱数を 1つ発生 ( a には 0.468251 が付値されている)
> b <- rnorm(1) # 正規乱数を 1つ発生 ( b には -0.4981989 が付値されている)
> if ((a < 0) || (b < 0)) { # a < 0 または b < 0 という条件式
> c <- -a*b # a * b = -0.2332821
+ } else c <- a*b # c には a * b の絶対値 0.2332821 が付値されている
> c
[1] 0.2332821� �
4.3 繰り返し文
4.3.1 for による繰り返し
ある処理を繰り返し行いたい場合,同じ文を何度も書く代わりに for 文を使う.� �for ( ループ制御変数 in リスト ) {
< ... 繰り返す式 ... > # ループ制御変数がリストの範囲内である限り式が繰り返される
}� �例えば以下の命令を実行すると,”hello.” と 5 回出力される.� �> for (i in 1:5) print("hello.") # i : ループ制御変数
[1] "hello."
[1] "hello." # i の最初の値は 1 となり,1 は 1:5 の範囲内なので
[1] "hello." # "hello." が 1 回出力される.その後,i の値は 2 と
[1] "hello." # なり,2 は 1:5 の範囲内なので "hello." が 1 回出力
[1] "hello." # される.これが i == 6 になるまで繰り返される.
> for (i in 1:5) {
+ print("hello.") # 上の for 文と同じ働き
+ }� �(注) R には繰り返し処理を出来るだけ速く行うためのさまざまな関数が用意されているので,計算速度を考える
ならば,なるべく for や while は用いない方が良い.例えば行列に対して要素ごとの処理を行う場合,for
や while などで一つ一つの要素にアクセスするよりも,apply ファミリー (関数 apply() や sapply() など)
を用いて一気に指定した方が速く計算できる.

R-Tips 69頁
ループ範囲に整数値を指定
例えば以下を実行すると x の各要素に 1 を足すことが出来る.� �> ( x <- matrix(1:4,2,2) )
[,1] [,2]
[1,] 1 3
[2,] 2 4
> for (i in 1:2) {
+ for (j in 1:2) {
+ x[i,j] <- x[i,j] + 1
+ }
+ }
> x
[,1] [,2]
[1,] 2 4
[2,] 3 5
> ( x <- matrix(1:4,2,2) )
[,1] [,2]
[1,] 1 3
[2,] 2 4
> for (i in 1:ncol(x)) {
+ for (j in 1:nrow(x)) {
+ x[i,j] <- x[i,j] + 1
+ }
+ }
> x
[,1] [,2]
[1,] 2 4
[2,] 3 5
� �『リスト』は最初に一回だけ評価される.『繰り返す式』の中で『リスト』中の変数を変更しても変数に順次付
値される値は変わらない.例えば� �> x <- 1:5
> for (i in x) x <- append(x, i)
> x
[1] 1 2 3 4 5 1 2 3 4 5� �として『繰り返す式』の中で『リスト』として使われた変数 x を変更しても i は x の最初の値である 1 から 5
までの間を変化する.よって,上の手続きは以下の文と同じ結果を返すことになる.� �> x <- 1:5
> for (i in 1:5) x <- append(x, i)
> x
[1] 1 2 3 4 5 1 2 3 4 5� �

R-Tips 70頁
ループ範囲にリストを指定
for ループのループ範囲にはベクトル以外にリストを与えることが出来る.これは 2 重ループを実現する際に有
用となる (計算時間も若干速くなる) .� �> for (i in 1:n) {
+ for (j in 1:n) f(i,j) # 普通の二重ループ
+ }
> rangelist <- multiplerange(1:n) # リストを用いた 2重ループ
> for (i in rangelist) f(i[1],i[2])
� �
その他の指定
ループ範囲には 1 次元の行列や配列を指定することも出来る (実際はベクトルとしてアクセス) .また,何故か
文字ベクトルを指定することも出来る.
4.3.2 while による繰り返し
同じ繰り返しでも,ある条件が成り立っている間繰り返しを続ける場合は whileを使う.ただし,条件式が TRUE
しかとり得ない場合は,プログラムが永遠に実行され続けて暴走してしまうので注意が必要である.� �while ( 条件式 ) {
< ... 繰り返す式 ... > # 条件式が TRUE である限り式が繰り返される
} # 最初に条件式が FALSE ならば式は 1 回も実行されない� �例えば以下を実行すると x の各要素に 1 を 5 回足すことが出来る.� �> ( x <- matrix(1:4,2,2) )
[,1] [,2]
[1,] 1 3
[2,] 2 4
> h <- 1
> while (h <= 5) {
+ for (i in 1:ncol(x)) {
+ for (j in 1:nrow(x)) {
+ x[i,j] <- x[i,j] + 1
+ }
+ }
+ h <- h+1
+ }
> x
[,1] [,2]
[1,] 6 8
[2,] 7 9
� �

R-Tips 71頁
4.3.3 repeat による繰り返し
repeat は無制限に繰り返しを行なう.� �repeat {
< ... 繰り返す式 ... > # break 文が見つかるまで式が繰り返される
}� �処理を止めるには次に説明する break 文を用いる.� �> ( x <- matrix(1:4,2,2) )
[,1] [,2]
[1,] 1 3
[2,] 2 4
> h <- 1
> repeat {
+ for (i in 1:ncol(x)) {
+ for (j in 1:nrow(x)) {
+ x[i,j] <- x[i,j] + 1
+ }
+ }
+ if (h <= 5) h <- h+1
+ else break # h > 5 ならば repeat 文から抜ける
+ }
> x
[,1] [,2]
[1,] 7 9
[2,] 8 10
� �
4.3.4 break を用いて繰り返し文から抜ける
for や while,repeat による繰り返しから break によって脱出することが出来る.動作は break が評価された
時点で最も内側の繰り返しから抜けることになる.� �> ( x <- matrix(1:9,3,3) )
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> for (i in 1:ncol(x)) {
+ for (j in 1:nrow(x)) {
+ if (i < j) break # 行の添字が列の添字より大きくなれば内側の for 文を抜ける
+ x[i,j] <- 0 # よって x の上三角要素以外を 0 にすることが出来る
+ }
+ }� �

R-Tips 72頁
� �> x
[,1] [,2] [,3]
[1,] 0 4 7
[2,] 0 0 8
[3,] 0 0 0
� �
4.3.5 next を用いて強制的に次の繰り返しに移る
next を使うと強制的に次の繰り返しを始めることが出来る.動作は,next が評価された時点でその回の繰り返
しは中止され,繰り返しの先頭に戻って次の繰り返しが開始される.例えば,以下は while で例示した 『実行す
ると x の各要素に 1 を 5 回足す』 プログラムに似ているが,繰り返したい文の前に next があるので,この個所
は一度も実行されずに終わることになる.� �> ( x <- matrix(1:4,2,2) )
[,1] [,2]
[1,] 1 3
[2,] 2 4
> h <- 1
> while (h <= 5) {
+ for (i in 1:ncol(x)) {
+ for (j in 1:nrow(x)) {
+ next # この時点で次のループに移る
+ x[i,j] <- x[i,j] + 1 # next のせいで実行されない
+ }
+ }
+ h <- h+1
+ }
> x
[,1] [,2]
[1,] 1 3
[2,] 2 4
� �
4.4 関数の定義
自分で関数を定義したい場合の基本的な形式は以下のようなものである.� �<関数名> <- function( <仮引数 1>, ・・・ , <仮引数 n> ) {
<関数本体>
}� �自分で関数を定義する場合は,元から存在する組み込み関数と同じ名前の関数を定義しないように注意しなけ
ればならない.定義してしまった場合,R では警告が表示されないことが多いので気付かないことになる.この
場合は関数 rm() などでそのオブジェクトを消去する必要がある.

R-Tips 73頁
� �> sin <- function(x) ifelse(x > 0, 1, -1) # 警告は出ない!
> sin(1)
[1] 1
> rm(sin) # オブジェクトを消去
> sin(1)
[1] 0.841471� �例えば二次元での 2点 (x1, y1), (x2, y2) の距離を求める関数 distance() を定義する例を挙げる.� �> distance <- function(x1, y1, x2, y2) sqrt((x1 - x2)^2 + (y1 - y2)^2)
> distance <- function(x1, y1, x2, y2) {
+ sqrt((x1 - x2)^2 + (y1 - y2)^2) # 上と同じ関数定義
+ }
> distance(0,0,1,2)
[1] 2.236068� �
4.4.1 関数の作成例:二項演算子の定義
関数 distance() の働きをした二項演算子(ここでは %d% )を定義することも出来る.この場合,新しく作成
した演算子を定義する際に ””で囲まなければならない.� �> "%d%" <- function(x, y) {
+ sqrt(sum(abs(x - y) ^ 2))
+ }
> c(0,0) %d% c(2,3)
[1] 3.605551� �
4.4.2 ファイルに保存してある関数定義を読み込む
上の例の関数 distance() のような短い関数ならば良いが,一般的に関数定義は長文であり,コマンドラインで
入力するとエラーが起きたときに修正が利かない.そこで普通は関数定義を別のエディタで作成して保存し,R で
ファイルを読み込む形式を取る.例えば関数 distance() が保存されてあるファイル dis.txt を読み込む場合は以下
の様にする.また,Windows 版ならばメニューの [FILE] − > [Source R Code] から読み込むことが出来る.こ
のとき,ファイルの種類を ALLFILES にしなければならないことに注意(ただし,拡張子を .r で保存すれば問
題は無い).� �> source("C:/R/dis.txt")
� �(注) 上の例のように,ファイル名だけでなくファイルのある場所 (パス) も書くのが確実であるが,作業ディレ
クトリのフルパスを指定しない場合は現在の作業ディレクトリで data.txt が探されることになる.作業ディ
レクトリの参照・変更方法は『最低限必要な知識』の節の「作業ディレクトリの変更」を参照のこと.初期
状態では R の実行ファイルなどが入っているディレクトリ (例 : C:YProgram FilesYRYrw1081) になっ
ている.

R-Tips 74頁
4.4.3 関数を保存して次回に使えるようにする
前述の通り,関数の定義を ”dis.R” に書き source(”dis.R”) 関数で読み込むことが出来るが,R の初期設定ファ
イル .Rprofile に行 source(”dis.R”) を入れておけば,いつも自動的に読み込まれる.また, R セッション中に関
数定義を save() 関数で Rdata ファイルに保存しておくことも出来る.これは関数 attach() で定義ファイルを読
み込むことが出来る.� �> distance <- function(x1, y1, x2, y2) sqrt((x1 - x2)^2 + (y1 - y2)^2)
> save(distance, file="dis.Rdata")
... 一旦終了 ...
> attach("dis.Rdata")� �
4.4.4 関数の返す値 (返り値)
R では手続きも関数も同じ関数と呼ぶのだが,本来の関数として用いるのならば返す値を明示的に指定すべき
である.返す値を明らかにするには関数 return() を使えばよい.動作は return() が評価された時点で関数の評価
は中止されて return() の引数が関数の返す値になる.
返り値が一つの場合
例えば数値ベクトルを引数とし,その総和を返す関数を考えてみる.この関数は sum() と同じだが,引数が数
値ベクトルでなければ NA を返すところが違う点である.� �mysum <- function(x) {
if (!is.numeric(x)) return(NA) # 数値でなければ NA を返す (この後の処理は無視)
return(sum(x))
}� �
return 文が実行されると関数は終了する(後の文は実行されない)のだが,この働きを関数の途中で抜け出す
ために用いることも出来る.また,return を書かなくても最後の文は複合文全体の返り値になるので,単に値だ
けを書くことで値を返すことが出来る.� �mysum <- function(x) {
if (!is.numeric(x)) return(NA) # 数値でなければ NA を返す (この後の処理は無視)
sum(x) # 数値ならば sum(x) を返す ( return する)
}� �
返り値が複数の場合
一つの関数から複数の値を返すには,ベクトル・配列等のオブジェクトを返り値とすれば良い.関数 return()
に複数の引数を与えると,それらは自動的にリストとして返される.このとき,リストの各成分には元の変数名
が名前タグとして自動的に付加される.

R-Tips 75頁
� �> test <- function(x){y <- log(x); z <- sin(x); return(x,y,z)}
> test(1:3)
$x
[1] 1 2 3
$y
[1] 0.0000000 0.6931472 1.0986123
[1] 0.8414710 0.9092974 0.1411200� �名前タグを自前で指定するには,明示的に名前付きリストを返り値にすれば良い.� �> test <- function(x){y <- log(x); z <- sin(x); return(list(value=x,log=y,sin=z))}
> test(1:3)
$value
[1] 1 2 3
$log
[1] 0.0000000 0.6931472 1.0986123
$sin
[1] 0.8414710 0.9092974 0.1411200� �
返り値が関数の場合
R の関数は R のオブジェクトを返すので,返り値として関数オブジェクトを返すことも出来る.� �> myfunc <- function(a, b, c) return( function (x, y, z) a*x + b*y + c*z )
> result <- myfunc(1, 2, 3) # result(x,y,z) は関数 x + 2*y + 3*z
> result(1,2,3)
[1] 14� �
4.4.5 結果の自動表示を止める
評価結果が自動表示されないようにするには関数が返す値を invisible() で囲めばよい.� �> mysum <- function(x) {
+ if (!is.numeric(x)) return(NA)
+ return(invisible(sum(x)))
+ }
> mysum(5) # 何も実行されない
> y <- mysum(10) # 変数に付値して初めて表示できる
> y
[1] 10� �
4.4.6 エラー・警告を表示
関数中で予期しない状況が起きたり関数に誤った引数が与えられた場合など,その関数を呼び出した式全体の
評価をやめてしまった方がよい場合,関数 stop() によってエラーを発生させることが出来る.

R-Tips 76頁
� �> mysum <- function(x) {
+ if (!is.numeric(x)) stop("not numeric !")
+ return(2*x)
+ }
> mysum(t)
Error in mysum(t) : not numeric !
� �エラーではなく,関数 warning() によって警告を発生させることも出来る.� �> mysum <- function(x) {
+ if (!is.numeric(x)) {
+ warning("not numeric !")
+ return(NA)
+ }
+ return(2*x)
+ }
> mysum(t)
[1] NA
Warning message:
not numeric . in: mysum(t)
� �
4.4.7 ローカル変数
グローバル変数とローカル変数
関数中で用いられる変数をローカル変数といい,ここでの値は普通の変数 (グローバル変数) に影響を与えない.
例えば,関数内で行なわれた< −による付値はその関数の中でのみ有効で,関数の終了とともに関数内で行なった付値も無効になってしまう.つまり,関数内で< −による付値を行なっても関数の外部にある同じ名前のオブジェクトの値は決して変わることがない.よって関数の内部では外部に及ぼす影響を考えずにオブジェクト名を
決めてもよいことになる.� �> x <- 10
> myfun <- function(x) {
+ x <- x + 999
+ return(x)
+ }
> x # x の値は 10
[1] 10
> myfun(1) # 普通の(グローバル)変数の x には影響を与えない
[1] 1000
> x # 確認
[1] 10� �

R-Tips 77頁
永続付値 << −について
大局的環境中のオブジェクトは任意の関数から直ちに参照することが出来るのだが,永続付値演算子 << −でグローバル変数にアクセスする場合,特に関数中でグローバル変数にアクセスする場合は注意が必要である.� �> v <- 1 # グローバル変数 v
> test <- function () {
+ v <- 2 # 関数 test() の中の変数 v (グローバル変数 v ではない!)
+ v <<- 3 # グローバル変数 v に 3 を付値する
+ cat("v =",v,"\n") # 関数 test() の中の変数 v の値を表示する
+ }
> test()
v = 2 # 関数 test() の返り値 (関数 test() の中の変数 v ) の値
> v # 関数 test() 内でグローバル変数 v の値を変えたので
[1] 3 # 実際,グローバル変数 v の値が 3 になっている� �非常にややこしい….上の例では,同じ名前だが実体が異なる二つの変数が登場する.関数中では単なる変数
v はローカル変数を指し,これは関数実行後は残らない.一方,グローバル変数 v は関数実行後も残る.すなわ
ち,慣れないうちはグローバル変数とローカル変数を同じ名前にしない方が良いということである.� �> test <- function () {v <- 1:3; v[2] <<- 0; cat("v =",v,"\n")}
> test()
v = 1 2 3 # 局所的な v の値
> v
[1] 1 0 3 # 大局的な v の値 (いつの間にかベクトルになっていることに注意)
� �
4.4.8 関数内での関数定義
関数内でもうひとつの関数を定義することも出来る.関数内部でしか使われない関数はその関数の内部で定義
した方が,プログラムが理解しやすくなるという点で良い.� �myfunc<- function(x) {
..........
subfunc <- function(a, b) {
..........
}
..........
}� �
4.4.9 関数についての情報を見る
関数の名前を入力すればその関数の定義が表示される.例えば以下のようにすることでmatrix の定義を見るこ
とが出来る.つまり,自分で定義した関数の定義も同様にしてみることが出来る.

R-Tips 78頁
� �> matrix
function (data = NA, nrow = 1, ncol = 1, byrow = FALSE, dimnames = NULL)
{
data <- as.vector(data)
if (missing(nrow))
nrow <- ceiling(length(data)/ncol)
else if (missing(ncol))
ncol <- ceiling(length(data)/nrow)
x <- .Internal(matrix(data, nrow, ncol, byrow))
dimnames(x) <- dimnames
x
}
<environment: namespace:base>
� �また,関数の形式引数を得る場合や形式引数を設定する場合は関数 fomrals() ,関数 alist() を用いればよい.� �> f <- function(x) a+b # 関数の定義
> fomrals(f) # 関数 f の形式的引数を調べる
$x
> formals(f) <- alist(a=, b=3) # 形式的引数 x を a ,b ( b は既定値 3 )
> f # f の定義を確認
function (a, b = 3)
a + b
> f <- function() x
> formals(f) <- alist(x = , y = 2, ... = ) # 「その他」の引数 ... の設定
> f
function (x, y = 2, ...)
x� �
4.4.10 関数終了時の後始末
ある関数を終了する時に確実に後始末をしたいことがある.例えば,作図パラメータを変更して常に 2番の色
で作図する関数 myplot() を考えてみる.� �myplot <- function(x, y, labels) {
old.col <- par(col=2) # 最初に作図パラメータを変更する
plot(x, y, type="n")
# もし,途中の処理でエラーが起きてしまうと,その時点で
.............. # 関数の評価が中断されてしまい,作図パラメータが元に
# 戻らなくなってしまう
text(x, y, labels)
par(old.col) # 最後に作図パラメータを元に戻す
}� �作図パラメータを変更するような場合は,正常か異常かにかかわらず関数が終了した時点で作図パラメータを
元に戻す (par(old.col) を実行する) 必要がある.これは関数 on.exit() を用いて『 関数が終了する時の処理 』を
指定すればよい.on.exit() によって指定された処理は正常か異常かにかかわらず,この関数が終了する時に必ず

R-Tips 79頁
実行される.上の例を on.exit() を用いて書き換えると以下の様になる.� �myplot <- function(x, y, labels) {
old.col <- par(col=2) # 作図パラメータを変更する
on.exit(par(old.col)) # myplotの終了時に par(old.col)を実行する
plot(x, y, type="n")
.............. # 途中でエラーが起きても作図パラメータは元に戻る
text(x, y, labels)
}� �
on.exit() の引数 add によって終了処理を追加するのか置き換えるのかを指定することが出来る.また on.exit()
で指定した関数終了時の処理を無効にするには引数なしで on.exit() を実行すればよい.� �myplot <- function(x, y, labels) {
..........
old.col <- par(col=2) # 作図パラメータを変更する
on.exit(par(old.col)) # myplot() の終了処理として par(old.col)が指定される
temp <- tempfile("mytmp") # 一時ファイルを作る
on.exit(unlink(temp), add=T) # 終了処理として par(old.col) と unlink(tem) を指定
..........
on.exit(par(old.col), add=F) # 終了処理として par(old.col) だけが再指定される
..........
on.exit() # 終了処理の指定をすべて解除する
..........
}� �
4.5 引数について
4.5.1 引数の省略
組み込み関数には引数の省略を許すものが多くあるが,自分で定義した関数でも引数の省略を許すように作る
ことが出来る.これを実現する方法は次の 2つがある.
仮引数の宣言部で指定する方法
仮引数の宣言部で,仮引数に対する実引数が省略された時の値を指定する方法である.� �仮引数名 = 式
� �例えば以下のような関数を定義すると y は省略可能な引数となり,省略した場合の y の値は 1 となる.� �> myfunc <- function(x, y=1) {
+ return(x*y) # 2つの引数の掛け算を行う
+ }
> myfunc(2,5)
[1] 10
> myfunc(2) # 引数を1つにすると引数をそのまま返す
[1] 2� �

R-Tips 80頁
省略時の値を指定する部分には任意の好きな式を書くことが出来る.しかも式の中で他の仮引数を参照するこ
とも可能である.� �> myfunc <- function(x, y=x^2) {
+ return(x*y)
+ }
> myfunc(2,5)
[1] 10
> myfunc(2)
[1] 8� �以下のように仮引数を互いに参照しあってしまうと無限ループになってしまう可能性があるので注意.� �mybadfunc <- function(x = y + 30, y = sqrt(x)) {
............
}� �
関数 missingを使う方法
引数が省略されたかどうかを調べる関数 missing() を使って関数本体でチェックする方法もある.missing() は
関数本体内でのみ使える特殊な関数で,指定された仮引数に対する実引数が省略されていれば TRUE を返す.� �> myfunc <- function(x, y) {
+ if (missing(y)) return(x)
+ else return(x*y)
+ }
> myfunc(2,5)
[1] 10
> myfunc(2)
[1] 2� �仮引数の宣言部に省略時の値が指定されていても missing() によって実引数が省略されたかどうかを調べること
が出来る.例えば,『変数 y が省略されたときには警告が表示されるようにする』ということも出来る.� �> myfunc <- function(x, y = 1) {
+ if (missing(y)) {
+ warning("y isn’t inputted.")
+ return(x)
+ }
+ else return(x*y)
+ }
> myfunc(2,5)
[1] 10
> myfunc(2)
[1] 2
Warning message:
y isn’t inputted. in: myfunc(2)
� �

R-Tips 81頁
4.5.2 任意個の引数を受けとる
組み込み関数 list() は引数の個数の制限が無く,2 個でも 10 個でも好きなだけ引数を与えることが出来る.こ
のような任意個の引数を受け付ける関数を定義する場合,記号 ... で表される特殊な仮引数を使う.この特殊な仮
引数 ... はそのままの形で他の関数に渡さなければならない.� �myplotfunc <- function(x, y, ...) {
plot(x, y, ...)
abline(lsfit(x, y), lty=2)
............
}
myfunc <- function(...) {
args <- list(...) # 引数をリストにする
narg <- length(args) # 引数の個数
arg1 <- args[[1]] # 第一引数
arg2 <- args[[2]] # 第二引数
arg2.name <- names(args)[[2]] # 例えば第二引数が『名前 = 値』の形で与えられていれば
............ # このようにして『名前 (属性)』を得ることが出来る
}� �関数の引数 ... の後にさらに仮引数を持つ関数を定義することもことも出来る.� �myfunc <- function(... , y = 1) {
............
}� �(注) 関数の呼出時にはこのような引数は必ず <名前 > = <値 > の形で与えなければならず,引数名の省略も
許されないことに注意.
4.5.3 引数に関数を渡す
関数 apply() や lapply() などの様に引数に関数をとる関数がある.引数に関数を要求する関数には,関数名の
代わりに関数オブジェクトを与えることが出来ることから,以下のように直接関数オブジェクトを書くことも出
来る.これも自分で定義した関数にも当てはまる.� �> lapply(list(1,2,3), function(x) { x + 10 } )
� �また,引数に関数をとることができる関数を作ることも出来る.例えば以下の関数はリスト x の各要素に対し
て myfunc() に渡された関数を実行し,結果をまたリストとして返す関数である.� �> myfunc <- function(x, func) {
+ result <- list() # 結果を保持するためのリストを初期化
+ for (i in x) {
+ result <- c(result, list(func(i))) # x の各要素に対して func を実行する
+ }
+ return(result)
+ }� �

R-Tips 82頁
� �> myfunc(list(1:5, 7:10), max) # 1...5 の最大値と 6...10 の最大値を求める
[[1]]
[1] 5
[[2]]
[1] 10
> myfunc(list(1:5, 7:10), function(x){x*x}) # 自分で定義した関数を入れることも出来る
[[1]]
[1] 1 4 9 16 25
[[2]]
[1] 49 64 81 100� �
4.6 再帰関数+微分・積分
4.6.1 再帰関数:再帰呼び出しを行う関数
以下のような入れ子になったリストを考えてみる.� �> list(10, list(list(30, 20), 1:10), list(2:5))
� �ここで,このようなリストの末端にある数値を全て足す関数を定義してみる.このリストの個々の要素は同じ
構造の (ただし入れ子が一段少ない) リストなので,個々の要素を自分自身を呼び出すことによって (再帰呼び出
しによって) 処理することが出来る.� �# リスト x の末端にある数値の総和を求める関数
myfunc <- function(x) {
if (is.atomic(x)) return(sum(x)) # リストでなければ単に和を返す
s <- 0 # 変数を初期化
for (i in x) { # リストの要素それぞれについて
s <- s + myfunc(i) # 末端の数値の和を計算してそれを加算していく
}
return(s) # 総和を返す
}� �次は再帰プログラムの例ではありきたりの階乗を求めるプログラムである.� �myfunc <- function(n) {
if (n <= 1) return(1)
else n * myfunc(n-1)
}
> func(5)
[1] 120� �

R-Tips 83頁
� �> myfunc2 <- function(x) { # 改良版:ベクトルの各要素ごとに階乗を求められる
recurse <- ( x > 1 )
x[!recurse] <- 1
if (any(recurse)) {
y <- x[recurse]
x[recurse] <- y*myfunc2(y-1)
}
return(x)
}
> func(5)
[1] 120
> func(1:10)
[1] 1 2 6 24 120 720 5040 40320 362880 3628800� �関数 Recall() によって関数の名前に依存せずに再帰呼び出しを行なうことも出来る.先の例では関数名を変え
ると本体で自分自身を呼び出しているところも変更しなければならなかったが,関数 Recall() を使って再帰呼び
出しを行なっていればその必要はなくなる.� �> fib <- function(n) {
+ if (n <= 2) { if(n>=0) 1 else 0 }
+ else Recall(n-1) + Recall(n-2)
+ }
>
> fib(10)
[1] 55� �
4.6.2 数値積分
再帰関数を用いることで,数値積分を行うことが出来る.以下は数値積分を行う関数 area(関数, 左端の点, 右端
の点) である.� �area <- function(f, a, b, eps = 1.0e-06, lim = 10) {
fun1 <- function(f, a, b, fa, fb, a0, eps, lim, fun) { # 関数 fun1 は area の中からだけ
見える
d <- (a + b)/2; h <- (b - a)/4; fd <- f(d)
a1 <- h * (fa + fd); a2 <- h * (fd + fb)
if (abs(a0 - a1 - a2) < eps || lim == 0) return(a1 + a2)
else return(fun(f, a, d, fa, fd, a1, eps, lim - 1, fun) +
fun(f, d, b, fd, fb, a2, eps, lim - 1, fun))
}
fa <- f(a); fb <- f(b); a0 <- ((fa + fb) * (b - a))/2
fun1(f, a, b, fa, fb, a0, eps, lim, fun1)
}� �上の関数 area() を定義すると,以下のように積分計算が出来る.

R-Tips 84頁
� �> area(sin, 0, pi/2)
[1] 0.999987� �
4.6.3 普通の微分と精度の良い数値積分
上は関数定義の例として数値積分をしたが,普通の微分と精度の良い数値積分を行う関数を紹介する.� �> D(expression(x^2),"x") # 微分
2 * x
> integrate(sin, 0, pi) # 積分
2 with absolute error < 2.2e-14
> integrate(x^2, 0, 1) # 既存にない関数をそのまま積分するとエラー
Error in get(x, envir, mode, inherits) : variable "x" of mode "function" was not found
> myfunc <- function(x) x^2 # 関数を定義してから積分すること
> integrate(myfunc, 0, 1)
0.3333333 with absolute error < 3.7e-15
> integrate(dnorm, -Inf, 1.96) # 無限を範囲に取ること (広義積分)も可
0.9750021 with absolute error < 1.3e-06� �
4.7 デバッグについて
長めの命令や関数を定義して実行した際に,エラーメッセージが出力されたり期待通りの動作をしないという
ことは少なくない.そのような場合,関数ならばどこに誤りがあるのかを探して見つけて修正しなければならな
くなる.この誤りを修正する一連の作業のことをデバッグという.デバッグの方法はいろいろあるが,便利なこと
に R にはデバッグを支援するための関数がいくつか用意されている.
4.7.1 途中で変数の値を調べる cat() , print()
関数の途中で cat() や print() を使って,バグの原因かもしれない怪しい変数の値を,関数の途中で評価途中で
表示させる方法がある.この方法は手軽で確実にデバッグできる (ただし手間がかかりすぎるという欠点がある) .
例えば関数 myfunc() を定義したときに,変数 x ,y ,s の途中の値が知りたい場合は以下のようにする.� �myfunc <- function(z) {
x <- rnorm(1)
y <- rnorm(1)
cat("x =", x, "\n") # ここまで評価が進んだ時点で x の値を調べる
cat("y =", y, "\n") # ここまで評価が進んだ時点で y の値を調べる
if ((x < 0) || (y < 0)) s <- -x*y
else s <- x*y
cat("s =", s, "\n") # ここまで評価が進んだ時点で s の値を調べる
return(s*z)
}� �

R-Tips 85頁
4.7.2 評価の途中で変数を調べる browser()
関数の途中で cat() や print() を使ってデバッグする方法では十分な情報が得られないことがある.こういった
場合,状況を調べたい場所に関数 browser() を挿入すればよい ( browser() は関数中に何個入れてもよい) .例え
ば以下のような関数を定義したとする.� �myfunc <- function(z) {
x <- rnorm(1)
y <- rnorm(1)
if ((x < 0) || (y < 0)) s <- -x*y
else s <- x*y
browser() # ここまで評価が進んだ時点で状況を調べる
return(s*z)
}� �この関数を実行すると,browser() の文で処理が止まり,入力待ちのモードになる.� �> myfunc(10)
Called from: myfunc(10)
Browse[1]>� �ここで入力できるコマンドは以下のようなものがある.もし関数内に c や n という名前の変数があれば,それ
らを評価するために print(c) や print(n) を使う必要が出てくる.
c ,cont: 関数の実行を継続する.
n ,next: デバッグ付のステップ実行を開始し,関数の残りの部分を一度に一行ずつステップ実行する.
ls() : 現在までに生成されたオブジェクト (変数) を全て表示.
関数中の変数 : この例では z のような引数,x や y といったローカル変数などを入力すると現時点の値を表示
してくれる.
関数中の式 : 式を評価し値を表示することも出来る.エラーが起きてもデバッグモードに戻るだけで,関数評価
自体には影響を及ぼさない.
where : 現在のスタックの記録 (全ての関数) を表示する.
return() : 関数評価に戻る.
Q : 終了する.
� �> myfunc(10)
Called from: myfunc(10)
Browse[1]> x # x の値を調べてみる
[1] 0.8610376
Browse[1]> y # y の値を調べてみる
[1] -0.6385286
Browse[1]> x*y # 式 x*y の値を調べてみる
[1] -0.5497971
Browse[1]> return()
[1] 5.497971� �

R-Tips 86頁
4.7.3 デバッグモードに入る debug()
関数をステップ実行 (1行ずつ実行) するには関数 debug() を用いる.もし関数内に c や n という名前の変数
があれば,それらを評価するために print(c) や print(n) を使う必要が出てくる.デバッグ中に入力できるコマン
ドは browser() で使用できるコマンドと同じなので,そちらも参照されたい.デバッグモードを抜ける場合は関
数 undebug() を実行する.� �> debug(myfunc)
> myfunc(10)
debugging in: myfunc(10)
debug: {
....................
}
Browse[1]> n
debug: x <- rnorm(1)
Browse[1]> n
debug: y <- rnorm(1)
Browse[1]> ls()
[1] "x" "z"
Browse[1]> x
[1] -1.264834
Browse[1]> z
[1] 10
Browse[1]> c
exiting from: myfunc(10)
[1] -0.3135861� �
4.7.4 関数の呼び出しを追跡する
関数 trace() によって関数の呼び出しを追跡することがる.関数 trace() によって指定された関数が呼び出され
るたびに呼び出された形が表示される.ただし,trace() を用いるためにライブラリ methods を呼び出す必要が
あるので,呼び出してから trace() を実行する.詳しくはヘルプを参照して頂きたいのだが,例えば browser()を
呼び出しながら関数を追跡する場合は以下の様にすればよい.� �> library(methods)
> trace(myfunc, browser, exit = browser)
[1] "myfunc"
> myfunc(10)
Tracing myfunc(10) on entry
Called from: myfunc(10)
Browse[1]> x
[1] -0.5571034
Browse[1]> y
[1] 0.357289
Browse[1]> n
[1] 1.990469� �
recover を指定して関数を追跡すると,メニュー 0, 1, 2, ... から選択出来る様になる.

R-Tips 87頁
� �> library(methods)
> trace(myfunc, recover)
[1] "myfunc"
> myfunc(5)
Tracing myfunc(5) on entry
Enter a frame number, or 0 to exit
1:myfunc(5)
Selection: # 入力待ち� �追跡モードを止める場合は関数 untrace() を用いる.� �> untrace("myfunc")
> untrace(c("func", "myfunc"))
� �他にもデバッグする際に有用なコマンド traceback() と debugger() がある.また,シミュレーション等で同じ
操作を何度も繰り返す際に,ある段階でエラーが起きても残りを実行する関数 try() ,計算速度の高速化を図る際
に,プログラムの実行時間を計る関数 system.time() ,プログラムの実行を指定秒数中断する関数 Sys.sleep() が
ある.詳しくはヘルプを参照されたい.
4.8 関数定義の練習問題
以下の内容はあくまでプログラミングをやったことが無い人の為の練習問題です.ヒントで紹介している関数以
外の特殊な関数はなるべく使わずに解けるように問題を作っていますので,分からない場合でもすぐに解答を見
ずに自分でしばらく考えてから解答を見るようにして頂ければ幸いです.
4.8.1 問題篇
問題の説明文の後に動作例が示されるので,問題の説明文と例の 2つに合致するように動作する関数を定義し
なさい.ただし,関数 return() はいくらでも使って構いません.
関数定義事始
(1) 数値を入れると入力した数値が 2倍されたものが結果として返ってくる関数mydouble() を定義しなさい.
(2) 2つの数値を入れると入力した数値の積が結果として返ってくる関数 mytimes() を定義しなさい.
(3) 2つの数値を入れると入力した数値の積が結果として返り,1つしか数値を入れないと入力した数値の 2乗が
返ってくるような関数 mymultiply() を定義しなさい.
� �> mydouble(5)
[1] 10
> mytimes(3,4)
[1] 12
> mymultiply(3,4)
[1] 12
> mymultiply(3)
[1] 9� �

R-Tips 88頁
if else 文の練習
以下の問題は既存の関数 ( abs() など) を使わないこと!
(1) 2つの数値 a, b を入れると入力した数値の差が結果として返ってくる関数myabs() を定義しなさい.ただし,
差は正の数であるものとする ( → |a − b| を計算することになる) .
(2) 2つの数値 a, b を入れると入力した数値の差が結果として返り,a と b が同じ数ならば a を結果として返す
関数 mydistance() を定義しなさい.ただし,差は正の数であるものとする
� �> myabs(2,1)
[1] 1
> myabs(1,2)
[1] 1
> mydistance(2,3)
[1] 1
> mydistance(3,2)
[1] 1
> mydistance(3,3)
[1] 3� �
if else 文の練習 2
以下の問題は既存の関数 ( rev() など) を使わないこと!
(1) 2つの要素が入ったベクトル x < − c(1,2) を受け取った場合に,要素の順番が入れ替わったベクトル (2,1) を
返す関数 myrev() を定義しなさい.
(2) 以下の関数 myswitch() を if, else 文で書き直しなさい.
� �> x <- 1:2
> myrev(x)
[1] 2 1
> myswitch <- function(x) {
+ switch(x,
+ "1" = print("one"),
+ "2" = print("two"),
+ "3" = print("three"),
+ print("?")
+ )
+ }
> myswitch(1)
[1] "one"
> myswitch(2)
[1] "two"
> myswitch(3)
[1] "three"
> myswitch(4)
[1] "?"� �

R-Tips 89頁
for や while などの繰り返し文の練習
以下の問題は関数 is.na(), length() 以外の既存の関数 ( sum() など) を使わないこと!
(1) 整数値 n を入れると 1 から n までの和を返す関数 mysum() を定義しなさい.
(2) 1つのベクトル x< − c(1,2,3,NA,4,5,NA)について,NAは足さずに他の要素を足し算するような関数myplus()
を定義しなさい.ここで
• 数値 a が NA かどうかを判定する関数 is.na(a) を用いればよいかもしれない.
• ベクトル x の要素の数 (大きさ,長さ) を求める関数 length(x) を用いればよいかもしれない.
� �> mysum(3)
[1] 6
> x <- c(1,2,3,NA,4,5,NA)
> x[2] # ベクトル x の 2 番目の要素
[1] 2
> length(x) # ベクトル x の長さ
[1] 7
> is.na(x[3]) # 3 番目の要素が NA であるかどうか
[1] FALSE
> is.na(x[4]) # 4 番目の要素が NA であるかどうか
[1] TRUE
> mysum(x)
[1] NA
> myplus(x)
[1] 15� �
for や while などの繰り返し文の練習 2
以下の問題は関数 length() 以外の既存の関数 ( mean() や max() など) を使わないこと!
(1) ベクトル x の成分の平均を求める関数 mymean() を定義しなさい.ここでベクトル x の要素の数 (大きさ,
長さ) を求める関数 length(x) を用いればよいかもしれない.
(2) 2つ以上の要素を持つベクトル x の成分の最大値を求める関数 mymax() を定義しなさい.ここでベクトル x
の要素の数 (大きさ,長さ) を求める関数 length(x) を用いればよいかもしれない.
� �> mymean(x)
[1] 5.5
> x < - runif(10) # 一様乱数を 10個生成
> x
[1] 0.20083773 0.92717616 0.65237950 0.36021424 0.05886773 0.57731434
[7] 0.03062795 0.19076784 0.73807242 0.02811492
> mymax(x)
[1] 0.9271762� �

R-Tips 90頁
plot()を行う関数定義の練習
ベクトル x < − c(NA,2,5,3,4,7,NA,8,9,NA,11) を受け取ってプロット plot(x) を行う関数 myplot() が途中ま
で定義されている.この関数定義を完成させなさい.ただし,関数内で以下の操作を行うものとする.
(1) x には NA (欠損値) があるが,欠損値の要素は 0 で置き換えること
(2) 各要素は欠損値を除いたベクトルの要素の平均を引いたものをプロットすること (これは既に用意してある)
� �myplot <- function(x) {
y <- x[!is.na(x)] # 欠損値を除く手続き
xmean <- mean(y) # 欠損値を除いたベクトルの要素の平均
##
## ここに残りの命令を書く
##
}� �
4.8.2 解答篇
あくまで解答の一例です.1つの問題に解答が 2つ以上あるものもあります.また,返り値は return() で返す
のが正統でしょうが,そうでない関数も多々あるので,わざと混在させています.
関数定義事始
� �mydouble <- function(x) return(2*x)
mytimes <- function(x,y) x*y
mymultiply <- function(x,y=x) x*y
mymultiply <- function(x, y) {
if (missing(y)) return(x^2) # 関数 missing() を使う方法
else return(x*y)
}� �
if else 文の練習
� �myabs <- function(a, b) {
if (a > b) {
a-b
} else {
b-a
}
}
myabs <- function(a, b) ifelse (a > b, a-b, b-a)
� �

R-Tips 91頁
� �myabs <- function(a, b) {
if (a > b) a-b
else b-a
}
mydistance <- function(a, b) {
if (a > b) {
return(a-b)
} else {
if (a == b) return(a)
else return(b-a)
}
}
mydistance <- function(a, b) {
if (a > b) return(a-b)
else if (a == b) return(a)
else return(b-a)
}� �
if else 文の練習 2
� �myrev <- function(x) {
a <- x[1]
x[1] <- x[2]
x[2] <- a
return(x)
}
myrev <- function(x) c(x[2],x[1])
myfunc <- function(x) {
if (x == 1) print("one")
else if (x == 2) print("two")
else if (x == 3) print("three")
else print("?")
}� �
for や while などの繰り返し文の練習
� �mysum <- function(n) {
i <- 0
for (j in 1:n) i <- i+j
return(i)
}� �

R-Tips 92頁
� �mysum <- function(n) {
i <- 0
j <- 1
while (j <= n) {
i <- i+j
j <- j+1
}
return(i)
}
myplus <- function(x) {
i <- 0
for (j in 1:length(x)) {
if (!is.na(x[j])) i <- i+x[j]
}
return(i)
}
myplus <- function(x) {
x[is.na(x)] <- 0
i <- 0
for (j in 1:length(x)) {
i <- i+x[j]
}
return(i)
}� �
for や while などの繰り返し文の練習 2
� �mymean <- function(x) {
i <- 0
for (j in 1:length(x)) i <- i+x[j]
return(i/length(x))
}
mymax <- function(x) {
i <- x[1]
for (j in 2:length(x)) {
if (i <= x[j]) i <- x[j]
}
return(i)
}
mymax <- function(x) { # 要素が 1つのベクトルにも対応した関数 mymax()
if (length(x)==1) return(x[1])
i <- x[1]
for (j in 2:length(x)) if (i <= x[j]) i <- x[j]
return(i)
}� �

R-Tips 93頁
for や while などの2重繰り返し文の練習
� �mysum <- function(n) {
h <- 0
for (i in 1:n) {
for (j in 1:i) h <- h+i
}
return(h)
}
myplus <- function(n) {
h <- 0
for (i in 1:n) {
for (j in 1:i) h <- h+j
}
return(h)
}� �
plot()を行う関数定義の練習
� �myplot <- function(x) {
y <- x[!is.na(x)]
xmean <- mean(y) # 欠損値を除いたベクトルの要素の平均
x[is.na(x)] <- xmean
x <- x - xmean
plot(x)
}� �

第5章 データ入力篇
5.1 データフレーム
手っ取り早くデータ入力を行いたい方は次の節に進んでいただきたい.ここではデータ入力の準備としてデー
タフレームについて簡単に説明する.
5.1.1 データフレームとは???
データフレームとは data.frame クラスを持つリストのことであり,同じ長さの複数の数値ベクトル,文字ベク
トル等を成分とする data.frame 属性を持つリストであるが,そのものとしては行列のような外見を持つ.分かり
にくい方は,次のデータフレーム作成の例に進んでもらいたい.
• データフレームの各行・列はラベルを必ず持ち,それを用いた添字操作が可能である.具体的には,データフレームの各行は一つの観測値として,データフレームの各列は一つの変数 (項目) として認識される.よっ
てベクトルやリストをデータフレームに変換することで,統計解析がやりやすくなるのである.
• 言い換えれば,データフレームは『異なったモードや属性を持つ列』を持つ行列とみなすことが出来る.つまりデータフレームは行列形式で表示することが出来,その行や列は行列のインデックス形式で抜き出せる
ことが出来るのである.よって抽出が簡単になるので統計解析がやりやすくなるのである.
• 手っ取り早くデータフレームを作成するには,read.table() を用いて外部ファイルからデータファイルを読
み込む方法である.
データフレームに入れることの出来るリストには以下のような制限がある.
• 成分はベクトル,因子,数値行列,リスト,もしくは他のデータフレームに限られる.行列やリスト,データフレームはそれぞれが持つ列,要素,変数と同じ数の変数を新しいデータフレームに付け加えることが出
来る.数値ベクトルと因子はそのままの状態で含まれ,非数値ベクトルは因子に強制変換される.データフ
レームに変数として現れるベクトル構造は全て同じ『長さ』を,行列構造は同じ『行サイズ』を持たなけれ
ばならない.
5.1.2 データフレーム作成の例
データフレームの作成例を以下に挙げる.例えば以下の様なデータがあったとし,統計的な計算を行うとする.
A 氏 B 氏 C 氏 D さん E さん
身長 171 158 163 178 163
体重 62.6 49.8 68.7 75.4 55.7
性別:男 (M) / 女 (F) M M M F F
身長,体重,性別をそれぞれ 3 つのベクトルにしても扱いにくいだろうし,行列として読み込んだとしても,出
来た行列には『身長』や『体重』などの名前はつかない.そこで関数 data.frame() を用いてデータフレームとい
う形にすることで,要素それぞれに『身長』や『体重』などの属性を付けることが出来るようになる.こうする
ことで,データに対して属性名でアクセスすることが出来るようになる.

R-Tips 95頁
� �> height <- c(171, 158, 163, 178, 163) # とりあえず身長を表すベクトルを定義
> weight <- c(62.6, 49.8, 68.7, 75.4, 55.7) # とりあえず体重を表すベクトルを定義
> ( sex <- c(rep("M", time=3),rep("F",time=2)) ) # 前 3 人が男,残りが女
[1] "M" "M" "M" "F" "F"
> ( sexf <- factor(sex) ) # 文字列ベクトルから因子オブジェクトに
[1] M M M F F # データフレームを作成するだけならば
Levels: F M # 因子オブジェクトに変換する必要はない
> ( df <- data.frame(height=height, weight=weight, sex=sexf) )
height weight sex # データフレーム df の内容
1 171 62.6 M
2 158 49.8 M
3 163 68.7 M
4 178 75.4 F
5 163 55.7 F
> ( x <- matrix(1:6, nrow=2, ncol=3) ) # 行列からもデータフレーム作成可能
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> data.frame(x) # ラベル名を指定しない場合は自動で
X1 X2 X3 # ラベル名が振り分けられる
1 1 3 5
2 2 4 6� �
5.1.3 データの列の特徴を見る
データフレームという形にすることで,要素それぞれに『身長』や『体重』などの属性を付けることに成功し
た.その恩恵の一つとして,関数 summary() を使うことでデータフレーム df の列ごとの特徴を見ることが出来
る.すると上から順に 『最小値,4 分位点,中央値,平均,4 分の 3 位点,最大値』 が表示される.� �> summary(df) # データフレームなのでモデルとして扱うことが可能
height weight sex
Min. :158.0 Min. :49.80 F:2
1st Qu.:163.0 1st Qu.:55.70 M:3
Median :163.0 Median :62.60
Mean :166.6 Mean :62.44
3rd Qu.:171.0 3rd Qu.:68.70
Max. :178.0 Max. :75.40� �
5.1.4 データフレームからデータを取り出す
データフレームからデータを取り出す場合,『身長』や『体重』などの属性名で取り出すことも出来るし,行列
から要素を取り出すのと同じ方法を適用することも出来る.

R-Tips 96頁
� �> df$height # データフレーム名$変量名でアクセス
[1] 171 158 163 178 163 # リストオブジェクトとしてアクセス
> df[["height"]] # データフレーム列 "height" にアクセス
[1] 171 158 163 178 163 # この場合 names 属性が取り除かれる
> df[[1]] # データフレームの 1 列目にアクセス
[1] 171 158 163 178 163 # この場合も names 属性が取り除かれる
> df[[1,3]] # [ 1 行目,3 列目 ] にアクセス
[1] 2 # df[[1]][3] と同じ
> df[[1,"sex"]] # F -> 1 , M -> 2 と読み替えられる
[1] 2 # (文字列は辞書式配列順で 1,2,3,... )
� �[[ ]] の代わりに [ ] を使うことも出来る.[ ] を用いた場合は names 属性が付いてくる.� �> df[1] # 1 列目を取り出す
height # この場合は names 属性が付く
1 171 # df["height"] でも可
2 158
3 163
4 178
5 163
> df[1,3] # 1 行目 3 列目にアクセス (属性付き)
[1] M # df[1,"sex"] でも可
Levels: F M
> df[,1] # [ 行番号 , 列番号 ] で指定
[1] 171 158 163 178 163 # 行番号を省略すると列を取り出す
> df[1,]
height weight sex # 列番号を省略すると行を取り出す
1 171 62.6 M # この場合は names 属性が付く
> df[c(1,3)] # 1 列目と 3 列目だけを取り出す
height sex # df[,c(1,3)] と同じ
1 171 M
2 158 M
3 163 M
4 178 F
5 163 F
> df[c(1,3),] # 1 行目と 3 行目だけを取り出す
height weight sex
1 171 62.6 M
3 163 68.7 M� �
5.1.5 データの処理・編集
height の列だけを足し算したい場合は以下のように $ を付けてラベルを指定し,それごと関数 sum() に放り込
んでやればよい.

R-Tips 97頁
� �> sum(x$height)
[1] 833� �実はこの height の列データの単位は cm (センチメートル) なのだが,これを m (メートル) に直して元の x に
格納し直す場合は以下のようにする.� �> x$height <- x$height/100
> x
height weight age sex
1 1.71 62.6 23 M
2 1.58 49.8 25 M
3 1.63 68.7 42 M
4 1.78 75.4 33 F
5 1.63 55.7 28 F� �
height の列データの単位を m (メートル) に直して別のオブジェクトに入れることも出来る.� �> y <- x$height/100
� �
5.1.6 attach() と detach()
リストの要素を参照するときは『リスト名$要素のグループ』と $ を用いて参照する.しかしリスト名をいちい
ち指定するのが面倒だという場合もある.リストやデータフレームの成分を,リスト名を明示的に指定すること
なしに指定できれば楽である.例えば myframe が myframe$u ,myframe$v ,myframe$w を持つデータフレー
ムであるとする.このとき関数 attach(myframe) を実行することで,myframe$ を付けすに u,v,w だけで変数
にアクセスすることが出来るようになる.� �> myframe <- list(c("a","b","c"), c(1:3), c(1.5,3.2,-0.8))
> names(myframe) <- c("u", "v", "w")
> attach(myframe) # attach() を実行することで
> u # myframe$u などと入力しなくても u だけでアクセス出来る.ただし,
[1] "a" "b" "c" # 直前までに u という名前の変数を使っていると不具合が出るので注意� �この関数は組み込みデータを使う際にも有用な関数となる.� �> data(sleep) # R に標準で用意されているデータ (sleep)
> sleep # ちなみにこれは W.S.Gosset (Student) の睡眠薬の比較データ
extra group
1 0.7 1
2 -1.6 1
3 -0.2 1
..............
> attach(sleep) # attach() を実行することで
> extra # sleep$extra と入力しなくても extra だけでアクセス出来る
[1] 0.7 -1.6 -0.2 -1.2 -0.1 3.4 3.7 0.8 0.0 2.0 1.9 0.8 1.1 0.1 -0.1
[16] 4.4 5.5 1.6 4.6 3.4� �データフレームを検索リストから外すには関数 detach() を用いればよい.これ以後,myframe$u の値を参照す

R-Tips 98頁
るには, u だけを入力しても参照することは出来ない.関数などの繰り返し文中等で同じデータフレームを何度
も attach する場合は,一まとまりの処理が終って不要になったらこまめに detach() (例:on.exit(dettach(sleep)
) を関数本体に入れる) しないいと,処理時間が次第に遅くなるとので注意.� �> search() # どのようなリストやデータフレームが追加されているかを調べる
> detach(sleep) # sleep を外す
� �処理時間の問題が気になる場合は,attach() に代わる関数 with() を用いる.with() はデータフレームなどから
専用の環境を作ってその中で作業を行う.結果として attach() せずに成分を参照することが出来,with() の作業
が終了すればこの環境もなくなるので,上記の様な不具合が起きない.� �> data(sleep)
> with(sleep, { # データフレーム sleep から専用の環境を作って
+ x <- extra[group==1] # その中で作業:グループ 1 のデータを x に
+ y <- extra[group==2] # グループ 2 のデータを y に付値
+ var.test(x, y) # 分散の同一性の検定
+ })
F test to compare two variances
data: x and y
F = 0.7983, num df = 9, denom df = 9, p-value = 0.7427
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval: 0.198297 3.214123
sample estimates: ratio of variances
0.7983426� �
5.1.7 データの列の変更・追加・消去
データの変更や追加,消去はベクトルや行列とほぼおなじようにすることで実現出来る.� �> df # データフレーム df を用意
height weight sex
1 171 62.6 M
2 158 49.8 M
3 163 68.7 M
4 178 75.4 F
5 163 55.7 F
> x$pond <- x$weight * 0.45359237 # x に新たに列を追加して,
> x # weight(単位は kg)をポンドに変換したデータを追加
height weight age sex pond
1 1.71 62.6 23 M 28.39488
2 1.58 49.8 25 M 22.58890
3 1.63 68.7 42 M 31.16180
4 1.78 75.4 33 F 34.20086
5 1.63 55.7 28 F 25.26510
> df[[2]] <- 1:5 ) # 第 2列を [ 1 2 3 4 5 ] に置き換え� �

R-Tips 99頁
� �> ( df[c(1,3,4),] ) # 第 1,3,4行を抜き出す (結果もデータフレーム)
height weight sex
1 171 62.6 M
3 163 68.7 M
4 178 75.4 F
> df[[2]] <- NULL # 第 2列を消去:列の消去は NULL を代入すればよい
> df <- df[,-c(2)] # 同じ結果� �データフレームのデータ自体ではなく,ラベルを変更することも出来る.� �> rownames(df) # 行ラベルの取り出し
[1] "1" "2" "3" "4" "5"
> colnames(df) # 列ラベルの取り出し
[1] "height" "weight" "sex"
> rownames(df) <- c("i","ii","iii","iv", "v") # 行ラベルの変更
> df # 列ラベルの変更も同様に行える
height weight sex
i 171 62.6 M
ii 158 49.8 M
iii 163 68.7 M
iv 178 75.4 F
v 163 55.7 F� �
5.1.8 2つのデータフレームを連結する
関数 cbind() で行ラベルが同じ二つのデータフレームを連結 (変数を増やす) ことが出来,関数 rbind() で列ラ
ベルが同じ 2つのデータフレームを連結 (つまりデータ数を増やす) ことが出来る.ただし,rbind() を行う 2 つ
の変数の列名は一致させておく必要がある.� �> x # データフレーム x
room grade
1 101 A
2 102 B
> y # データフレーム y
floor beds Ch
1 11 2 Yes
2 7 1 No
> u <- cbind(x,y) # データフレーム x と y を連結
> u # 列数が 5 個である新たなデータフレーム u を生成
room grade floor beds Ch
1 101 A 11 2 Yes
2 102 B 7 1 No
> z # データフレーム z
room grade floor beds Ch
1 103 S 10 2 Yes� �

R-Tips 100頁
� �> rbind(u,z) # データフレーム u と z を連結
room grade floor beds Ch
1 101 A 11 2 Yes
2 102 B 7 1 No
11 103 S 10 2 Yes # 重複する行ラベルは自動的に ( 1 から 11 に) 付け替えられる� �最後に,データフレームを行列に変換する場合は関数 data.matrix() を,データフレームに関する詳細な情報を
得る場合は関数 str() を,データフレームオブジェクトかどうかを検査する場合は関数 is.data.frame() を,条件
に合うデータフレームの一部分を取り出す場合は関数 subset() を用いることを補足しておく.
5.2 ファイルからのデータ入力
ここではファイルからデータを読み込む方法を 2つ挙げる.まず,以下の (読込み用) データを data.txt という
名前でテキストファイルに保存する.� �# data.txt
height weight age sex(1:m/0:w)
01 171 62.6 23 1
02 158 49.8 25 0
03 163 68.7 42 1
04 178 75.4 33 1
05 163 55.7 28 0� �(注) フォルダの中の『フォルダオプション』から『拡張子を表示しない』のチェックを外した方が良い.どうし
てもチェックを外したくない方は,テキストファイルを開いて data という名前で保存すること.
5.2.1 read.table() を用いる方法
手っ取り早くデータを読み込む場合は関数 read.table() を用いる.ここでは x にデータ (データフレーム) を読
み込んでいる.read.table() を用いる場合,# 以下の文字は無視される (コメントとして扱われる) ので,data.txt
の場合は 2 行目から読み込まれることになる1.� �> x <- read.table("C:/data.txt") # read.table("data.txt", header = TRUE) と同じ
> x
height weight age sex.1.m.0.w. # read.table() の引数
1 171 62.6 23 1 #
2 158 49.8 25 0 # dec="." : decimal points の記号を指定
3 163 68.7 42 1 # nrows : 読み込む最大行数 (設定しない場合は負の値)
4 178 75.4 33 1 # skip=0 : 最初から読み飛ばす行数を指定
5 163 55.7 28 0 # na.strings = "NA" : 欠損値を表す文字列を指定
� �(注) ”C:/data.txt” について,”C:Ydata.txt” と Yにするのはエラーが出るので注意 (Windows版のみ?) .ど
うしても Yを使いたい場合は YYで Yを表すことが出来る.
(注) ファイル名だけでなく,ファイルのある場所 (パス) も書くのが確実であるが,作業ディレクトリのフルパス
を指定しない場合は現在の作業ディレクトリで data.txt が探されることになる.作業ディレクトリの参照・1 コメントを表す記号# を変更する場合は read.table() の引数 comment.char で指定する.例えば : にする場合は
read.table(”C:/data.txt”, comment.char = ”:”) とすればよい.

R-Tips 101頁
変更方法は『最低限必要な知識』の節の「作業ディレクトリの変更」を参照のこと.初期状態では R の実
行ファイルなどが入っているディレクトリ (例 : C:YProgram FilesYRYrw1081) になっている.
もし data.txt に行や列の名前が書かれていない場合� �171 62.6 23 1
158 49.8 25 0
163 68.7 42 1
178 75.4 33 1
163 55.7 28 0� �は header = FALSE とヘッダ部分に何も無いことを知らせる必要がある.� �> x <- read.table("data.txt", header=FALSE)
> x
V1 V2 V3 V4
1 171 62.6 23 1
2 158 49.8 25 0
................� �
列名・行名の制御
引数 row.names と col.names にそれぞれ行名と列名を示す文字型ベクトルを指定することができる.
row.names=NULL : 1 から始まる番号が行名として生成される.
row.names=”列名” : 指定した列のデータが行名として使われる.使われた列はデータフレームの変量として
は取り除かれることになる.
row.names=列番号 : 上記と同じ.
row.names=文字型ベクトル : ベクトルの各要素が行名となる.ただし行数と同じ長さのベクトルでなければ
ならない.
データの区切りがスペース以外の場合
もし data.txt の中のデータの区切りがスペース (空白) ではなくコンマ ( ,) で区切られていた場合は以下のよ
うにして読み込むことになる.� �x <- read.table("data.txt",header=FALSE, sep=",")
� �ところで,read.table() のラッパークラスとして,以下のような関数が用意されている.他にもカテゴリー変数
宣言を行う関数 as.factor(data.txt) ,順序変数を宣言するための関数 as.ordered(data.txt),量的な変数であるこ
とを宣言する関数 as.single(data.txt) がある.
• read.csv(file, header = TRUE, sep = ”,”, quote=”Y””, dec=”.”, fill = TRUE, ...)
: 区切りがコンマの場合
• read.csv2(file, header = TRUE, sep = ”;”, quote=”Y””, dec=”,”, fill = TRUE, ...)
: 区切りがコンマの場合 (小数点がコンマ)
• read.delim(file, header = TRUE, sep = ”Yt”, quote=”Y””, dec=”.”, fill = TRUE, ...)
: 区切りがタブの場合

R-Tips 102頁
• read.delim2(file, header = TRUE, sep = ”Yt”, quote=”Y””, dec=”,”, fill = TRUE, ...)
: 区切りがタブの場合 (小数点がコンマ)
例えば data.txt の中のデータの区切りがスペース (空白) ではなくコンマ ( ,) で区切られていた場合に,上の
関数を用いて読み込むには以下のようにすれば良い.� �x <- read.csv("data.txt", header=FALSE)
� �
5.2.2 scan() を用いる方法
次に関数 scan() を用いる方法を挙げる.data.txt は以下のようになっているものとする.� �# data.txt
171 62.6 23 1
158 49.8 25 0
163 68.7 42 1
178 75.4 33 1
163 55.7 28 0� �(注) R でファイルからデータを読み込むのは関数 read.table() の方が便利であると思われるが,scan() よりもメ
モリを多く必要として実行速度も scan() より劣る.本格的に多くのデータを取り込む場合,複雑な規則で
データの読み込みを行いたい場合には scan()を使用した方が良い.また,データの出力は,関数 read.table()
に対して関数 write.table() や write() で実現できる.
最も簡単に data.txt を読み込むには以下のようにすれば良い.ここでは x にデータ (データフレーム) を読み
込んでいる.� �> x <- scan("data.txt", skip=1, nlines=6)
Read 20 items
> x
[1] 171.0 62.6 23.0 1.0 158.0 49.8 25.0 0.0 163.0 68.7 42.0 1.0
[13] 178.0 75.4 33.0 1.0 163.0 55.7 28.0 0.0� �引数の説明は以下の通り.
what = double(0) : データのタイプを指定する.’logical’ ,’integer’ ,’numeric’ ,’complex’ ,’character’
,’list’ が指定できる.
nmax = -1 , n = -1 : データを読み込む個数を指定する.nmax について,what にリストが指定されていた
らリストを読み込む個数を指定することが出来る.
skip : 最初の行 (タイトルが書かれてある) から読み飛ばす行数を指定する.(指定しない場合はファイルの 1 行
目から読む) .
nline : 何行目まで読むかを指定する (指定しない場合はファイルの終わりまで読む) .
その他 : sep = ”” , quote = ”” , nlines = 0, na.strings = ”NA” などがある.

R-Tips 103頁
決まった要素ごとに data.txt を読み込む
上ではデータを 1 行 20 列のデータとして読み込んでしまっている.ここで 5 行 4 列のデータとして読み込ま
せるには list (ダミーのリスト) を用いる.ラベルをつける場合は,該当する列の ”” にラベルを入れるだけでよ
い.以下はデータの型が全て文字型であると R に指定していることになる.� �> x <- scan("data.txt", list("",weight="","",sex=""),skip=1, nlines=6)
Read 5 records
> x
[[1]]
[1] "171" "158" "163" "178" "163"
$weight
[1] "62.6" "49.8" "68.7" "75.4" "55.7"
[[3]]
[1] "23" "25" "42" "33" "28"
$sex
[1] "1" "0" "1" "1" "0"� �データの型を数値であると R に指定してする場合は ラベル = 0 (または ラベル = 1 など) とすればよい.以
下では sex は性別なので文字型,それ以外は数値として読み込んでいる.� �> x <- scan("data.txt", list(h=0,w=1,a=0,s=""),skip=1)
Read5 records
> x
$h
[1] 171 158 163 178 163
$w
[1] 62.6 49.8 68.7 75.4 55.7
$a
[1] 23 25 42 33 28
$s
[1] "1" "0" "1" "1" "0"� �
データについていくつかの注意
• データに ” や ’ が出てくると,対応する引用符までひとつの文字列として読み込まれる.
• 未充足の行がある場合は fill = TRUE とすること.
• もし分離記号が指定されているならば,文字欄の先頭,空白が続いている箇所は欄の一部とみなされてしまう.空白を取り去るには引数に strip.write = TRUE と指定すればよい.
• read.line() では空行は無視される.blank.lines.skip = FALSE とすればこれを欠損として読み込ませること
が出来る. fill = TRUE と組み合わせる場合がある.
5.2.3 データ読み込みついての補足事項
組み込みデータにアクセスする方法
R には多数のデータセットが用意されている.これは関数 data() を用いることで一覧を見ることが出来る.

R-Tips 104頁
� �> data() # 全てのデータセットを表示
> data(package = base) # base パッケージのデータセットを表示
> data(USArrests, "VADeaths") # ‘USArrests’ と ‘VADeaths’ のデータをロード
> help(USArrests) # データ ‘USArrests’ のヘルプを見る
� �もしデータがライブラリの中に入っている場合は,先にライブラリを呼び出す必要がある.� �> library(nls) # ライブラリ nls の呼び出し
> data(Puromycin) # データ ‘Puromycin’ の呼び出し
� �
R以外ソフトで作成されたデータファイルの読み込み
R 以外の統計ソフト ( SAS など) で作成されたデータファイルからデータを読む場合は,パッケージ foreign中
の関数を用いる.� �library(foreign) # ライブラリ foreign の呼び出し
read.spss("datafile", use.value.labels=FALSE) # SPSS data file を読み込む
� �R の foreign パッケージには以下の関数が用意されている.
lookup.xport() : SAS XPORT フォーマットライブラリについての情報を探す.
read.dta() : Stata binary files を読み込む.
read.epiinfo() : Epi Info data files を読み込む.
read.mtp() : Minitab Portable Worksheet を読み込む.
read.spss() : SPSS data file を読み込む.
read.ssd() : read.xport() によって SAS のパーマネント・データセットからデータフレームを得る.
read.xport() : SAS XPORT format library を読み込む.
write.dta() : Stata binary format をファイルに書き出す.
5.3 入力したデータの処理・編集
読み込むデータ data.txt は以下のようなものを考える.� �# data.txt
height weight age sex(1:m/0:w)
01 171 62.6 23 1
02 158 49.8 25 0
03 163 68.7 42 1
04 178 75.4 33 1
05 163 55.7 28 0� �
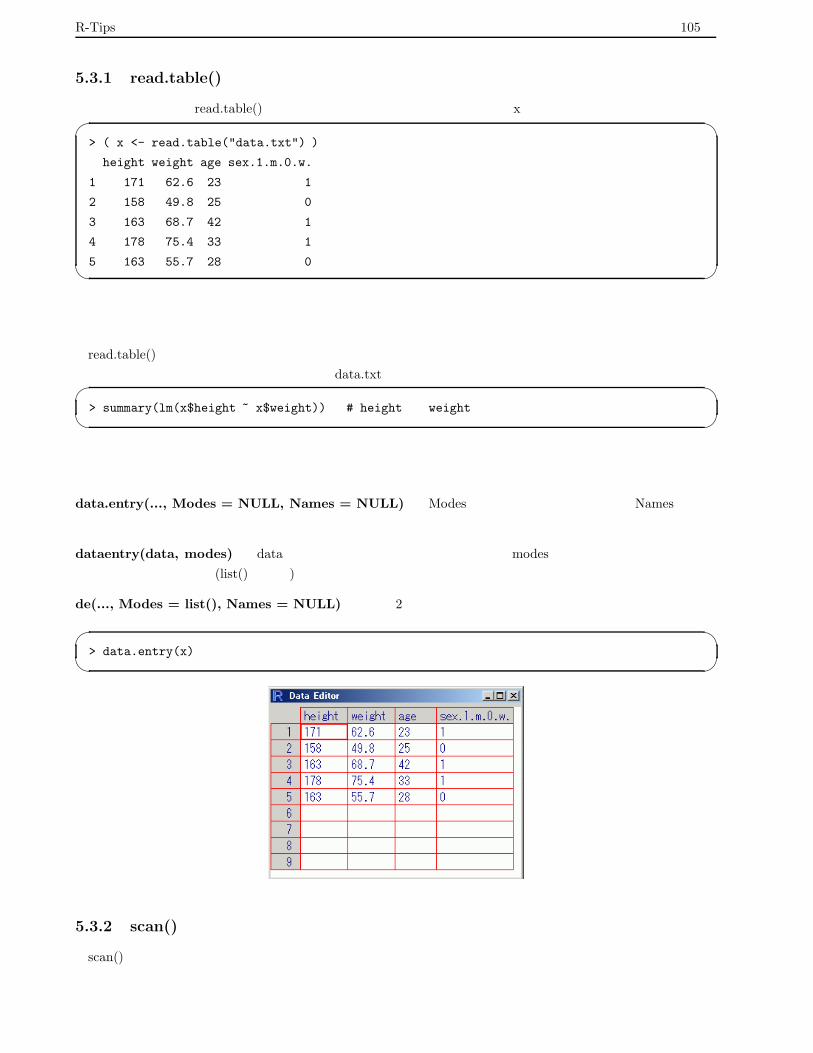
R-Tips 105頁
5.3.1 read.table() で読み込んだデータへのアクセス
上のデータを関数 read.table() を用いてデータを読み込み,オブジェクト x に格納したとする.� �> ( x <- read.table("data.txt") )
height weight age sex.1.m.0.w.
1 171 62.6 23 1
2 158 49.8 25 0
3 163 68.7 42 1
4 178 75.4 33 1
5 163 55.7 28 0� �
データを編集する・統計解析を行う
read.table() で読み込んだデータは『データフレーム』の章で扱った編集方法で編集することが出来る.よって,
説明が重複するので解説は割愛する.例えば data.txt のデータを統計的に処理する場合は以下のようにする.� �> summary(lm(x$height ~ x$weight)) # height と weight で回帰分析
� �
セル形式でデータを編集する
data.entry(..., Modes = NULL, Names = NULL) : Modes で変数に使用されるモード,Names で変数
に使用される名前を指定してセルで編集する.
dataentry(data, modes) : data で数値および文字ベクトルのリストを,modes で変数のモードを与えるデー
タの長さのリスト (list()でも可) を指定してセルで編集する.
de(..., Modes = list(), Names = NULL) : 上の 2 つとほぼ同様.
� �> data.entry(x)
� �
5.3.2 scan() で読み込んだデータへのアクセス
scan() で読み込んだデータへのアクセスについて説明する.

R-Tips 106頁
� �# data.txt
171 62.6 23 1
158 49.8 25 0
163 68.7 42 1
178 75.4 33 1
163 55.7 28 0� �これを関数 scan() を用いて次のように読み込んだとする.� �> x <- scan("data.txt", list(h=0,w=1,a=0,s=""),skip=1)
Read5 records
> x
$h
[1] 171 158 163 178 163
$w
[1] 62.6 49.8 68.7 75.4 55.7
$a
[1] 23 25 42 33 28
$s
[1] "1" "0" "1" "1" "0"� �このときラベルを付けない場合は R の方で勝手にラベルをつける.以下では sex は性別なので文字型,それ以
外は数値として読み込んでいる. あとは read.table() で読み込んだのと同様にしてアクセスすることが出来る.
もちろん,data.entry() を使って編集することも出来る.� �> x$h <- x$h/100
> x
$h
[1] 1.71 1.58 1.63 1.78 1.63
$w
[1] 62.6 49.8 68.7 75.4 55.7
$a
[1] 23 25 42 33 28
$s
[1] "1" "0" "1" "1" "0"� �
5.4 ファイルへのデータ出力例
read.table() に対して関数 write.table() や write() で実現できる. 例えば以下の様なデータ data.txt が ( C:/
に) あったとする.� �0.9, 1.2, 1.9
1.3, 1.6, 2.7
2.0, 3.5, 3.7
1.8, 4.0, 3.1
0.9, 1.2, 1.9
� �

R-Tips 107頁
� �1.3, 1.6, 2.7
2.0, 3.5, 3.7
1.8, 4.0, 3.1
2.2, 5.6, 3.5
2.2, 5.6, 3.5
3.5, 5.7, 7.5
1.9, 6.7, 1.2
2.7, 7.5, 3.7
2.1, 8.5, 0.6
3.6, 9.7, 5.1
� �このデータ data.txt を read.table() で読み込んで, write.table() でファイル output.txt に出力してみる.� �> x <- read.table("C:/data.txt")
> x
V1 V2 V3
1 0.9, 1.2, 1.9
2 1.3, 1.6, 2.7
3 2.0, 3.5, 3.7
4 1.8, 4.0, 3.1
..............
15 3.6, 9.7, 5.1
> write.table(x,"C:/output.txt") # quote=F にしないと,要素に "" がつく
> write.table(x,"C:/output.txt", append=T,
quote=F, col.names=F) # append = F にするとファイルに上書きする
� �データフレームを出力する際は write.table() が使いやすいが,リストをファイルに出力する場合は write() が
使いやすい.それぞれの関数の書式は以下のようになっている.『出力するファイルのパス』 は,空文字列 ”” な
ら標準出力に出力される.
• write(リスト名, ”出力するファイルのパス”, append = T, ncolumns = 一行の要素の数)
• write.table(データフレーム名, ”出力するファイルのパス”, append=T, quote=F, col.names=F)
write() 関数について使い方の例を以下に挙げる.� �> x <- matrix(1:8, ncol=2) # 4 x 2 の行列
> write(x, file="x.data") # ファイル x.data に書き出し
> scan("x.data") # scan 関数で再読み込み (結果はベクトルになっている)
Read 8 items
[1] 1 2 3 4 5 6 7 8
> y <- matrix(scan("x.data"), ncol=4) # また行列に変換
Read 8 items
> y
[,1] [,2] [,3] [,4]
[1,] 1 3 5 7
[2,] 2 4 6 8
� �

R-Tips 108頁
� �# ファイルそのものを直接編集しない場合
> save(x, file="temp.data") # こうすると x の構造をそのまま記録してくれる
> rm(x) # (ファイル temp.data はテキストデータではない!)
> load("temp.data") # オブジェクト x が復元される
� �
5.4.1 区切り文字を付けたファイルへのデータ出力
リストに入ったデータを,例えばカンマ ,で区切ってファイルに出力する場合,{データ ,カンマ,データ ,カンマ,· · · } というリストを作っておいて 1 行ごとにファイルに出力すればよい.� �> x <- c(1:9)
> out <- NULL
> for (i in 1:(length(x)-1)) {
+ out <- cbind(out, x[i])
+ out <- cbind(out, ",")
+ }
> out <- cbind(out, x[length(x)])
> write(out, file="C:/output.txt", ncolumns = 2*length(x))
� �また,関数 writeLines(paste(z), sep=”,”) とすれば区切り文字を綿密に指定してファイルに書き込みを行うこ
とが出来る.この際,明示的に改行 Yn を指定しないと改行されない.� �out <- file("output.txt", "w") # ファイルを書き込みモードで開く
for (i in 1:10) {
if (i < 5) writeLines(paste(i), out, sep=", ")
else if (i == 5) writeLines(paste(i), out, sep="\n")
else if (i < 10) writeLines(paste(i), out, sep=", ")
else writeLines(paste(i), out, sep="")
}
close(out) # ファイルを閉じる� �
5.4.2 ファイルへのデータの出力例
ここで,データ data.txt の上 5 行 ,中 5 行 ,下 5 行) を別々に (合計 3 回) 重回帰分析することを考える (それぞれ 1 列目が目的変数で 2 , 3 列目が説明変数であるとする) .そして重回帰分析を行った結果を,以下の様な形式のファイル output.txt に出力したいと思う.� �定数項の推定値 , t 値 , t 値の p-value , β 1 の推定値 , t 値 , t 値の p-value , … , R^2 , adjust R^2 , ダービンワトソン比定数項の推定値 , t 値 , t 値の p-value , β 1 の推定値 , t 値 , t 値の p-value , … , R^2 , adjust R^2 , ダービンワトソン比定数項の推定値 , t 値 , t 値の p-value , β 1 の推定値 , t 値 , t 値の p-value , … , R^2 , adjust R^2 , ダービンワトソン比
� �
C:/ にある data.txt について重回帰分析を行った結果を output.txt に出力するには,以下の様な関数 myre-
gression() を定義することで実現できる. 出力されたファイルの要素はカンマ , で区切られている.

R-Tips 109頁
� �myregression <- function(dataadress, outputadress, n, k) {
for (i in 0:(k-1)) {
# Read dataset
tmpdata <- read.table(dataadress, sep=",", skip=i*n, nrows=n);
m <- length(tmpdata)-1
y <- tmpdata[[1]]
if (m == 1) x <- tmpdata[[2]]
else {
x <- cbind(tmpdata[[2]],tmpdata[[3]])
if (m >= 3) {
for (j in 3:m) x <- cbind(x,tmpdata[[j+1]])
}
}
# Fitting Linear Models
result <- summary(lm(y ~ x))
# Output
out <- NULL
for (i in 1:(m+1)) {
out <- cbind(out, result$coefficient[[i,1]]); out <- cbind(out, ",")
out <- cbind(out, result$coefficient[[i,3]]); out <- cbind(out, ",")
out <- cbind(out, result$coefficient[[i,4]]); out <- cbind(out, ",")
}
out <- cbind(out, result$r.squared); out <- cbind(out, ",")
out <- cbind(out, result$adj.r.squared); out <- cbind(out, ",")
# Calc of DW
res <- (result$residuals[[1]])^2
res2 <- 0
for (i in 2:length(result$residuals)) {
res <- res + (result$residuals[[i]])^2
res2 <- res2 + (result$residuals[[i]]-result$residuals[[i-1]])^2
}
out <- cbind(out, res2/res)
write(out, file=outputadress, append = T, ncolumns = 6*(m+1)+5)
}
}� �� �# 関数の書式 -> n, k : n > k をみたす正の整数
# myregression("C:/mydata.txt", "C:/output.txt", グループ内のデータ数 n , グループ数 k )
> myregression("C:/mydata.txt", "C:/output.txt", 5, 2) # 10行目まで解析する
� �10行目まで解析した場合,output.txt は以下のようになる.� �-0.0956549673250608 , -12.8909399854269 , ... , 0.999954286798342 , 3.48681988398559
-0.114578674300027 , -8.43963008004229 , ... , 0.999942494217474 , 1.98430092137043
� �(注) このような形式で出力することにより S-Plus や EXCEL などで読み込むことが出来るようになる .

R-Tips 110頁
(注) summary.lm 関数は F 統計量の p 値自体は計算しない (print.summary.lmの中で計算される) .次のよう
にすれば計算可能である.
� �> x <- 1:10; y <- c(rnorm(5), rnorm(5,mean=1))
> z <- summary(lm(y ~ x))
> w <- z$fstatistic
> pf(w[1], w[2], w[3], lower.tail=FALSE)
[1] 0.1643454� �(注) 普通の lm() 関数が返すオブジェクトには属性 ”lm” がつく.これに summary 関数を適用すると暗黙のう
ちに summary.lm 関数が呼び出され,さらにそれを表示しようとすると print.summary.lm 関数が呼び出さ
れる.lm オブジェクト による内容表示の際も暗黙のうちに適当な print method が選ばれ,それに応じて
整形されて出力されると思われる.
(注) 自動化せずにデータを一つ一つ入力して普通に重回帰分析を行う場合は以下のようにすればよい.
� �> mydata <- read.table("C:/data.txt", sep=",", skip=0, nrows=5)
> y <- mydata[[1]]
> m <- length(mydata)-1
> if (m == 1) {
+ x <- mydata[[2]]
+ } else {
+ x <- cbind(mydata[[2]],mydata[[3]])
+ if (m >= 3) {
+ for (i in 3:m) x <- cbind(x,mydata[[i+1]])
+ }
+ }
> result <- summary(lm(y~x))
� �
5.4.3 補足
入力ファイル data.txt を EXCEL から作成する場合の一つの例を示す.
(1) EXCEL ファイルを開き,メニューの [ファイル] の [開く] から,[名前をつけて保存] を選択する.
(2) 保存する名前をつけた後,[ファイルの種類] から [CSV カンマ区切り]を選択して保存する.出力するファイ
ルには,何も入っていないファイルもしくは存在しないファイルを指定すること.
出力されたファイル output.txt を EXCEL から読み込む場合の一つの例を示す.
(1) メニューの [ファイル]の [開く]から,出力されたファイルを開く.その際,ファイルの拡張子によっては [ファ
イルの種類] から [すべてのファイル] を指定しなければいけない場合があるので注意.
(2) [テキスト ファイル ウィザード] の画面が出たら,[カンマやタブの区切り文字によって...] を選択して [次に]
をクリックする.
(3) 区切り文字の種類を聞かれますので,[カンマ] と [スペース] を選択して [次に] をクリックする.
(4) 最後に [完了] をクリックすればセルにデータが読み込まれる.
最後に,MASS ライブラリ中の関数 write.matrix() も write.table() と同様の機能を持つことを補足しておく.

第6章 グラフィックス篇
6.1 作図の準備
今すぐ作図を行いたいという方は,この節は読み飛ばして関数 plot() の章へ読み進んで下さい.
6.1.1 作図を行うには
R の作図機能は極めて多彩である.さまざまな種類の統計グラフを描述することが出来,また全く新しい種類
のグラフを描くことも出来る.R で作図を行なうには作図関数,作図デバイスの 2つを用いて図を描く.
作図関数 : 実際に何かを描画する関数
作図デバイス : 図を出力する装置 (デバイス)1
6.1.2 作図関数について
作図関数は出力装置に依存せず,例えば X ウインドウ上へ描画する場合でも,ポストスクリプト形式で作図出
力を得る場合でも, (出力装置を指定する部分を除けば) 同じ関数を使って同じ手順で作図が行なえるようになっ
ている.作図命令は以下の 3 つの基本的なグループに分けられる.
高水準作図関数
高水準作図関数は一枚の完成された図を作成するためのもので,例えば散布図や関数,ヒストグラムなどは高
水準作図関数で作成する.このグループの関数は与えられたデータから座標軸や座標系を適切に設定し,データ
を作図し,軸のラベルなどを描き加えることになる.
低水準作図関数
低水準作図関数を用いると,既存の図に追加の点・直線・ラベルなどを追加することが出来る.このグループ
には,線や点,文字列や多角形の塗りつぶしなどのプリミティブな関数や,座標軸を描く,タイトルを記入すると
いった図のパーツを描くための関数がある.これらの関数は高水準作図関数によって作った図に何かを描き加え
るために使われるほか,ユーザ独自の作図関数を作る際の道具として使われることになる.
対話的作図関数
対話的作図関数を用いると,マウスなどで図表からプロット点を追加したり除いたりすることが出来る.対話
的に図を描く場合,一番簡単なのが関数 locator() を使ってウインドウ上の任意の位置の座標を入力することであ
る.入力方法は作図デバイスにより異なるが,例えば x11 の場合は locator() を呼び出すとウインドウ上に ”+”
マーク (クロスヘア) が表示されるので,これをマウスで操作すればよい.
1 作図関数は high (low) level plotting function と graphics function の 2 通りの英語があるので困るのだが,作図関数と作図デバイスはそれぞれ,グラフィックス関数やグラフィックスデバイスという訳が適切なのかもしれない · · · ので,適宜読み替えて頂きたい.ただし,パ
ラメータに関しては RjpWiki の記事にあったので,グラフィックスパラメータと訳している.

R-Tips 112頁
6.1.3 作図デバイスについて
R はいろいろな作図関数を備えており,作図結果を様々な出力装置から得ることが出来る.出力する装置のこ
とを R では作図デバイスあるいは作図機器と呼ぶ.
作図デバイスとは
Rが起動されたとき,自動的に UNIX , Linux , Mac OS X では X11() 命令で,Windows では Windows () 命
令で,( Mac OS 8/9 ならば macintosh() 命令で ) デバイスドライバが初期化される.一度デバイスドライバが
稼動し始めれば,R の作図命令で様々なグラフ表示や自分でグラフ表示を定義することが出来るようになる.た
だし,通常作図デバイスは『 R が起動されたときに自動的に呼び出される』ので,グラフィックスを行う際に作
図デバイス云々を気にする必要はほとんどない.
作図デバイス指定関数を呼び出すと,その作図デバイスがアクティブな作図デバイスになる.アクティブな作図
デバイスは一度に一つだけである故,それまでアクティブだった作図デバイスはアクティブでなくなる.すなわ
ちそれ以降の作図出力は全て新しく指定された方の作図デバイスに対して行なわることになる.例えば Windows
でデバイスを開いて作業する場合は作図デバイスとして以下の関数を実行することによりデバイスウインドウを
開くことが出来る.� �> windows()
� �
作図デバイスの種類
R がサポートしている作図デバイスは help(”Devices”) で調べることが出来るが,代表的な作図デバイスには
以下のようなものがある.
デバイス 種類 デバイス 種類
x11() x11 ( UNIX のデフォルトドライバ) windows() Windows のデフォルトドライバ
postscript() ポストスクリプト pdf() ADOBE の PDF
pictex() LATEXファイル win.metafile() メタファイル
xfig() XFIG win.print() 普通のプリント
bitmap() ビットマップ bmp() ビットマップ
png() PNG jpeg() JPEG
あるデバイスの利用が終了した場合に dev.off() でデバイスを閉じることも出来る.例えば postscript() でポス
トスクリプトファイルを作成する場合,ファイルが壊れる不具合を防ぐには dev.off() でデバイスをすぐに閉じれ
ばよい.� �> data(cars) # PSデバイスを開き,出力 fileを指定
> postscript("myplot.eps", horizontal=FALSE, height=9, # horizontal = FALSE を指定しないと
width=14, pointsize=15) # TeXに取り込んだ際,横にひっくり返る
> plot(cars, main = "Speed and Stopping Distances of Cars")
> dev.off() # 必要な出力がすべて終ったらすぐにデバイスを閉じると不具合が起こりにくい
null device
1� �(注) 作業ディレクトリのフルパスを指定しない限り,画像ファイル (この場合は myplot.eps ) は現在の作業ディ
レクトリに保存される.作業ディレクトリの参照・変更方法は『最低限必要な知識』の節の「作業ディレク
トリの変更」を参照のこと.

R-Tips 113頁
6.1.4 複数のデバイスドライバ
同時に複数の作図デバイスを持つということがある.もちろん一度に一つの作図デバイスだけが作図命令を受
け入れることが出来る (このデバイスをカレントデバイスという) のだが,複数のデバイスが開かれているときは,
それらは待機状態としてデバイスリストを成していることになる.複数のデバイスを操作するための主要な命令
は以下の通りである.
x11() : [UNIX]
windows() : [Windows]
postscript() ,pdf(),... : デバイスドライバ関数の新規呼び出しは新しい作図デバイスを開き,待機状態を
表すデバイスリストを更新する.そして今呼び出されたデバイスが現在のデバイス (カレントデバイス) と
なり,そこにグラフ出力が送られることになる.
dev.list() : アクティブなデバイスの番号と名前を返す.
dev.next() : カレントデバイスの次の位置の作図デバイスの番号と名前を返す.
dev.prev() : カレントデバイスの前の位置の作図デバイスの番号と名前を返す.
dev.set(which=k) : デバイスリストの k 番目の作図デバイスの番号と名前を返す.
dev.off(k) : デバイスリストの k 番目の作図デバイスを終了させる.
dev.copy(device, ... , which=k) : 作図デバイス k のコピーを作成する.device は postscript などのデバ
イス関数を引数にする.
dev.copy2eps(file=”filename.eps”, width=x, height=y, family=”fontname”) :
dev.copy(device=postscript, onefile=FALSE, horizontal=FALSE, paper=special) と同じ動作を行う.フォ
ント (引数 family ) は AvantGarde ,Bookman ,Courier ,Helvetica ,Helvetica-Narrow ,NewCentu-
rySchoolbook ,Palatino ,Times ,URWGothic ,URWBookman ,NimbusMon ,NimbusSan ,Nim-
busSanCond ,CenturySch ,URWPalladio ,NimbusRom ,ComputerModern が指定できる.
dev.print(device, ... , which=k) : アクティブな作図デバイス k のコピーを作成し,他のグラフィックスデ
バイス (既定では postscript) に再出力する.複製されたデバイスは直ちに閉じられ,ハードコピー印刷な
どの終了処理がなされる.device は postscript などのデバイス関数を引数にする.
graphics.off() : 無効なデバイスを取り除き,リスト中の全てのデバイスを終了する.
例えば図を eps 形式で保存する場合は以下のようにするか,Windows ならば図を右クリックしてメニューから
出力する.� �> X11() # X11 デバイスを開く ( OS によっては省略可)
> plot(x)
> dev.copy2eps(file="finename.eps", width=6) # 幅と高さの一方を省略してもよい
> # または... dev.print() でコピー出力すると...
> X11() # X11 デバイスを開く ( OS によっては省略可)
> plot(x) # X11 デバイスに出力
> dev.print(file="finename.eps", # 既定で EPS ファイルに出力
width=10, height=10, horizontal=FALSE)
� �メニューの機能は上から『 metafile としてクリップボードにコピー』『 bmp としてとしてクリップボードにコ
ピー』『 metafile (.emf) 形式で保存』『 postscript (.ps , .eps) 形式で保存』『プリントアウト』となっている.
R-Tips 114頁
同様にして,図を PDF ファイルに保存する場合は以下のようにする.後者の方法ならば,png() ,bmp() ,
jpeg() を指定することで,それぞれの形式の画像ファイルが得られる.� �> plot(x)
> dev.copy(pdf, file="finename.pdf")
> dev.off() # 必要な出力がすべて終ったらすぐにデバイスを閉じる
> # または ... 前述の作図デバイスで同じことをやると ...
> pdf() # pdf デバイスを開く ()
> plot(x) # プロット -> Rplots.pdf に出力
> dev.off() # 必要な出力がすべて終ったらすぐにデバイスを閉じる� �
6.2 とりあえずplot()
R で一番良く使われる高水準作図関数が関数 plot() である.最も基本的で機能も多い関数も plot() である.こ
の関数を使って散布図や折れ線グラフなどを描くことが出来る.例えばデータが入っているベクトル x ,y を点
の座標として以下の様に入力する.� �> x <- 1:10
> y <- 1:10
> plot(x, y) # 範囲は自動で決まる (xlim=c(1,10)を指定した場合と同じ)
> plot(x, y, xlim=c(10,1)) # x 軸の正の向きを左向きにすることも出来る
� �すると散布図の出力が得られる.プロット範囲は引数 xlim, ylim で決めることが出来る.
2 4 6 8 10
24
68
10
x
y
10 8 6 4 2
24
68
10
x
y
また,数学関数を与えてそのグラフを出力することも出来る.� �> plot(sin, -pi, 2*pi)
> gauss.density <- function(x) 1/(2*pi)*exp(-x^2/2) # 標準正規分布の密度
> plot(gauss.density,-3,3)
� �

R-Tips 115頁
−2 0 2 4 6
−1.
0−
0.5
0.0
0.5
1.0
x
sin
(x)
−3 −2 −1 0 1 2 3
0.00
0.05
0.10
0.15
x
gaus
s.de
nsity
(x)
ちなみに,3 次元的にプロットする場合は関数 persp() を用いる.� �> x <- seq(-3,3,length=50) # x 方向の分点
> y <- x # y 方向の分点
> rho <- 0.9 # 2次元正規分布の定数
> gauss3d <- function(x,y) { # 2次元正規分布の関数
+ 1/(2*pi*sqrt(1-rho^2))*exp(-(x^2-2*rho*x*y+y^2) / (2*(1-rho^2)))
+ }
> z <- outer(x,y,gauss3d) # 外積をとって z 方向の大きさを求める
> z[is.na(z)] <- 1 # 欠損値を 1で補う
> persp(x, y, z, theta = 30, phi = 30, expand = 0.5, col = "lightblue")
� �
x
y
z
6.2.1 plot() の形式指定
関数 plot() の引数 type によって様々な形式でプロットすることが出来る.type には次の 8種類の文字のいず
れかを指定することが出来る.
”p” : 点プロット (デフォルト)
”l” : 線プロット (折れ線グラフ)
”b” : 点と線のプロット
”c” : ”b” において点を描かないプロット
”o” : 点プロットと線プロットの重ね書き
”h” : 各点から x軸までの垂線プロット
”s” : 左側の値にもとづいて階段状に結ぶ
”S” : 右側の値にもとづいて階段状に結ぶ
”n” : 軸だけ描いてプロットしない (続けて低水準関数でプロットする)

R-Tips 116頁
� �> x <- rnorm(10)
> plot(x, type="l")
� �
6.2.2 対数軸や軸の範囲の指定
軸に関する設定を行なう為に以下の引数を追加することが出来る.
log : ”x” ( x 対数軸) ,”y” ( y 対数軸) ,”xy” (両対数軸) の何れかを指定することが出来る (常用対数のみ) .
xlim,ylim : 長さ 2 のベクトルで x 座標, y 座標の最小値と最大値を与える,他にも xlog, ylog で対数プロッ
トが出来る.ベクトルを降順に並べる (例:c(2,-2)) と,プロットの向きが逆になる.
axes=FALSE : 軸の生成を抑制する.軸の他に表題,刻み,目盛も描くかどうかを論理値で指定する(省略時
は TRUE).他に xaxs, yaxs が指定出来る.
� �> x <- rnorm(10)
> plot(x, ylim=c(-30, 30), type = "l")
� �
6.2.3 タイトルなどの指定
表題などに関する設定を行なう為に以下の引数を追加することが出来る.
main : タイトルを与える文字列を指定する.この引数を省略するとは表題は描かれない.
sub : サブタイトルを与える文字列を指定する.この引数を省略すると副題は描かれない.
xlab,ylab : それぞれ x 座標名, y 座標名を与える文字列を指定する.省略すると,x 軸のデータとして与え
られた引数の名前が座標名として描かれる.また,引数 ann = F とすることで軸のラベルを描かないよう
にすることも出来る ( xlab = ”” ,ylab = ”” を同時に指定した場合と同じ.) .
tmag : プロットの別の注釈するテキストに関する主なタイトルのテキストの拡大率を指定する.
� �> x <- rnorm(10)
> plot(x, main="Simple Time Series")
� �
6.2.4 図の重ね合わせ
図を重ね合わせるには,関数 par() を用いるか,引数に add=T を入れる.
(注) plot()以外の関数は add=T が効かない場合が多いので注意.
� �> plot(sin, -pi, pi, xlab="", ylab="", lty=2) # sin(x) を描く
> par(new=T) # 上書き指定
> plot(cos, -pi, pi, xlab="x", ylab="y") # cos(x) を上書き
> plot(sin, -pi, pi, xlab="x", ylab="y", lty=2) # 新たに sin(x) を描く
> plot(cos, -pi, pi, add=T) # cos(x) を上書き
� �
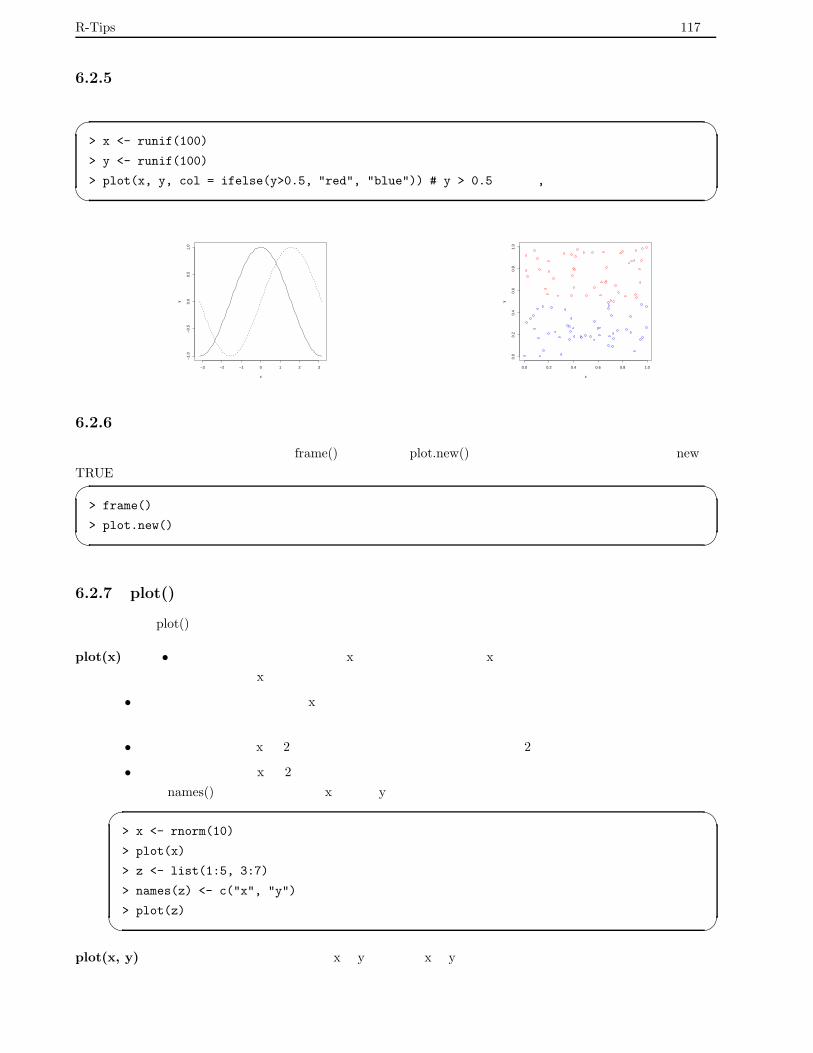
R-Tips 117頁
6.2.5 点の色を変数に応じて変える
点の色を変数に応じて変える場合は以下のように条件分岐すればよい.� �> x <- runif(100)
> y <- runif(100)
> plot(x, y, col = ifelse(y>0.5, "red", "blue")) # y > 0.5 なら赤, その他は青
� �『図の重ね合わせ』の例と共に,出力結果を以下に載せる.
−3 −2 −1 0 1 2 3
−1.
0−
0.5
0.0
0.5
1.0
x
y
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
x
y
6.2.6 図の消去
プロットした図を消去するには関数 frame() または関数 plot.new() を使う.グラフィックスパラメータ new が
TRUE ならば図は消去されない.� �> frame()
> plot.new()
� �
6.2.7 plot() の引数の与え方による出力の違い
以下,関数 plot() の引数の与え方による出力の違いを順に見ていくことにする.
plot(x) : • データが入っているベクトル x の要素が実数ならば,x は時系列データとみなされ,横軸を自
然数,縦軸をデータ x 要素とする時系列プロットが描かれる.
• データが入っているベクトル x の要素が複素数ならば,横軸を実数,縦軸を虚部とするプロットが描
かれる.
• データが入っている x が 2列の行列ならば,横軸を一列目,縦軸を 2列目とするプロットが描かれる.
• データが入っている x が 2次元リストならば,その要素を横軸,縦軸としてプロットが描かれる.た
だし names() を使ってどちらが x なのか y なのかラベルをつける必要がある.� �> x <- rnorm(10)
> plot(x)
> z <- list(1:5, 3:7)
> names(z) <- c("x", "y")
> plot(z)
� �plot(x, y) : データが入っているベクトル x ,y やリスト x ,y を点の座標として与えると散布図を描く.

R-Tips 118頁
� �> x <- rnorm(10)
> y <- rnorm(10)
> plot(x,y)
� �plot(y ˜ x) : 以下の様に回帰式として入力することも出来る.
� �> x <- rnorm(10)
> y <- rnorm(10)
> plot(y ~ x)
� �plot(f) : f は因子オブジェクト,y は数値ベクトルである. y の棒グラフを描く.
plot(f, y) : f は因子オブジェクト,y は数値ベクトルである.f の各水準に対する y の箱型図を描くときに使う.
plot(df, y) : df はデータフレーム,y は任意のオブジェクト,expr は ”+” で仕切られたオブジェクト名のリ
スト(例えば a+b+c )である.データフレーム中の変量の分布関数のプロットを行う.
plot(˜ expr) : expr は ”+” で仕切られたオブジェクト名のリスト (例えば a+b+c ) である.名前が与えられ
たオブジェクトの分布関数のプロットを行う.
plot(df, y),plot(˜ expr),plot(y ˜ expr) : df はデータフレーム,y は任意のオブジェクト,expr は ”+”
で仕切られたオブジェクト名のリスト(例えば a+b+c )である.expr に名前が与えられた全てのオブジェ
クトに対して y のプロットを行う.
6.3 高水準作図関数
以下に種々の高水準作図関数を紹介する.
6.3.1 plot()
plot() の詳しい説明は前章を御覧頂きたい.例えばデータが入っているベクトル x ,y を点の座標として以下の
様に入力すると,散布図の出力が得られる.また,数学関数を与えてそのグラフを出力することも出来るが,こ
の場合は先に関数を与える必要があることに注意する.� �> x <- rnorm(10)
> y <- rnorm(10)
> plot(x,y)
� �
6.3.2 curve()
関数 curve() を用いれば,関数を直接指定してグラフを出力することも出来る.引数 n でポイントの数を指定
することが出来る.� �> curve(sin(x^2)*exp(-x^2),-pi,pi)
> curve(sin(x^2)*exp(-x^2),-pi,pi,n=20) # n が小さいので線が滑らかではない
� �
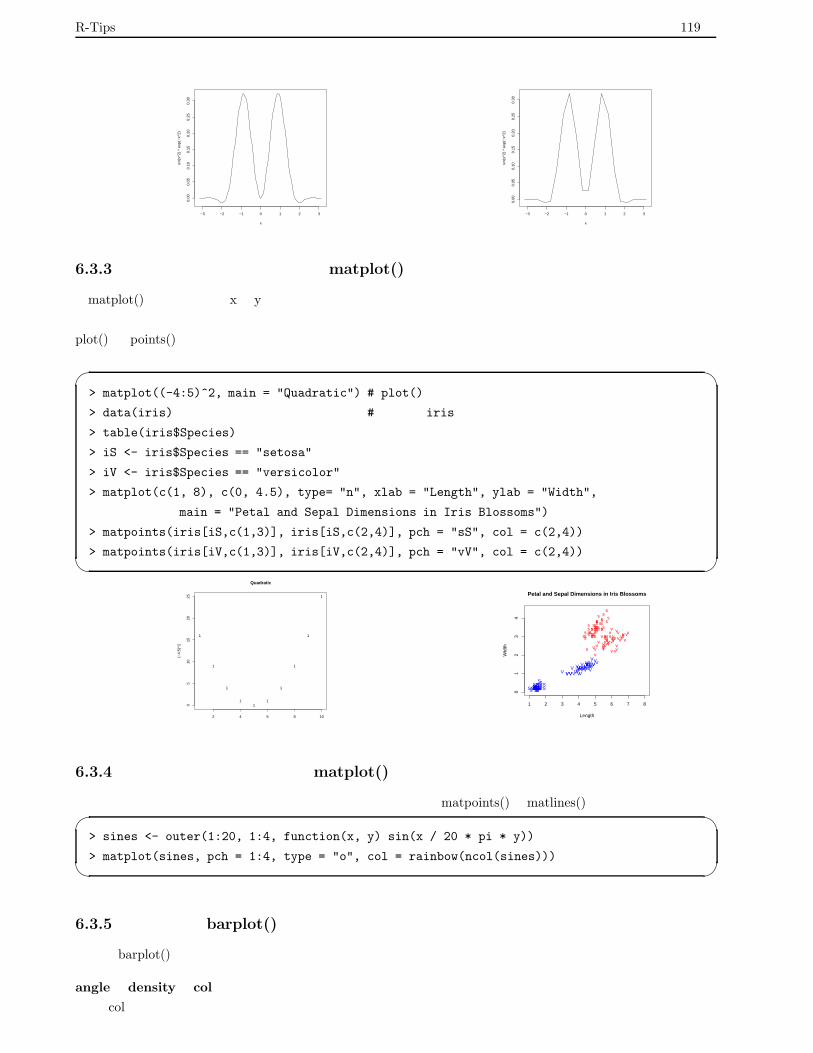
R-Tips 119頁
−3 −2 −1 0 1 2 3
0.00
0.05
0.10
0.15
0.20
0.25
0.30
x
sin(
x^2)
* e
xp(−
x^2)
−3 −2 −1 0 1 2 3
0.00
0.05
0.10
0.15
0.20
0.25
0.30
x
sin(
x^2)
* e
xp(−
x^2)
6.3.3 いくつかのデータを重ねる:matplot()
matplot() は二つの行列 x ,y を引数にとり,その各列についてプロットを行う.この関数の便利なところは,
座標設定や列ごとにマーカーの色や形を自動的に変えてくれて,見た目に区別がつくようにする点である.関数
plot() と points() を組み合わせてもデータの重ね合わせは実現できるが,座標設定やマーカーの色は手動で行わ
なければいけない.� �> matplot((-4:5)^2, main = "Quadratic") # plot() とほぼ同じ
> data(iris) # データ iris
> table(iris$Species)
> iS <- iris$Species == "setosa"
> iV <- iris$Species == "versicolor"
> matplot(c(1, 8), c(0, 4.5), type= "n", xlab = "Length", ylab = "Width",
main = "Petal and Sepal Dimensions in Iris Blossoms")
> matpoints(iris[iS,c(1,3)], iris[iS,c(2,4)], pch = "sS", col = c(2,4))
> matpoints(iris[iV,c(1,3)], iris[iV,c(2,4)], pch = "vV", col = c(2,4))
� �
1
1
1
11
1
1
1
1
1
2 4 6 8 10
05
1015
2025
Quadratic
(−4:
5)^2
1 2 3 4 5 6 7 8
01
23
4
Petal and Sepal Dimensions in Iris Blossoms
Length
Wid
th
s
sss
ss
s s
ss
ss
ss
s
s
s
sss
sssss
s
s ssss
s
s s
ssss
s
ss
s
sss
s
s
s
s
s
SSSSSSSSSSSSSSS
SSS SSSS
SS
SSS
SSSSSSSSSSSSSSSS
SSSSSSS
vv v
v
vv
v
v
vv
v
v
v
vvvv
v
vv
v
vv
v v vv
vvv
vvv v
v
vv
v
v
vv
v
vv
vvv v
vv
VV VV
VV
V
VVV
V
V
V
VV VV
V
V
V
V
VV
VVV VV
V
V VVV
VVVVVVV V
VV
VVVVVV
V
6.3.4 一度に複数の曲線を描く:matplot()
以下のようにすることで実現できる.また,上書き用に 関数 matpoints() ,matlines() が用意されている.� �> sines <- outer(1:20, 1:4, function(x, y) sin(x / 20 * pi * y))
> matplot(sines, pch = 1:4, type = "o", col = rainbow(ncol(sines)))
� �
6.3.5 棒グラフ:barplot()
関数 barplot() で棒グラフ描くことが出来る.以下に取り得る引数を紹介する.
angle ,density ,col : 棒を塗り分ける線分の角度,塗り分ける際の線分の本数,塗り分けの色を指定する.
col だけを与えればブロックごとに塗りつぶしを行う.
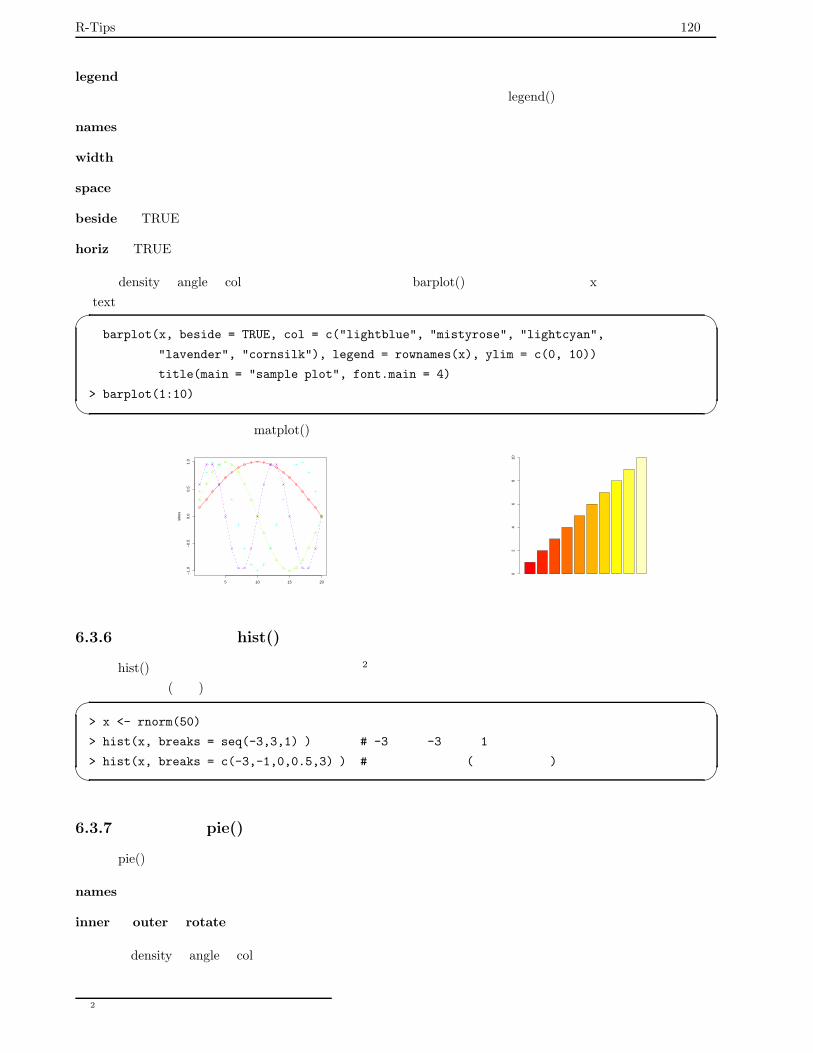
R-Tips 120頁
legend : 右上に凡例を描く.この引数には塗り分けされた各部分につけるラベルのベクトルを指定すればよい.
凡例はいつも右上に描かれるが,他の場所に凡例を描きたければ関数 legend() を使うことで実現できる.
names : 各棒のラベルを定める文字型ベクトル指定することが出来る.
width : 各棒の相対的な幅を定める(ベクトル).
space : 各棒の間の間隔.値ならば全体がその値で等間隔に並ぶ.
beside : TRUEにすると,引数に与えられた行列の列毎でブロック分けせずにそれぞれの値ごとに棒を描く.
horiz : TRUEにすると棒を水平にする(この場合,データは下から順に並ぶ).
他にも density ,angle ,col などの引数が使える.また,barplot() は各棒の中心位置の x 座標を返す.この値
と text などの低水準作図関数を使えば,さらに細かい装飾が出来る.� �barplot(x, beside = TRUE, col = c("lightblue", "mistyrose", "lightcyan",
"lavender", "cornsilk"), legend = rownames(x), ylim = c(0, 10))
title(main = "sample plot", font.main = 4)
> barplot(1:10)
� �『一度に複数の曲線を描く:matplot()』の例と共に,出力結果を以下に載せる.
5 10 15 20
−1.
0−
0.5
0.0
0.5
1.0
sine
s
02
46
810
6.3.6 ヒストグラム:hist()
関数 hist() でヒストグラムを描くことが出来る 2 .異なる区切り幅のヒストグラムを描くことも出来るが,主
観的なバイアス (偏り) が入る危険があるのでお勧めは出来ない.� �> x <- rnorm(50)
> hist(x, breaks = seq(-3,3,1) ) # -3 から -3 まで 1 ずつの幅で描く
> hist(x, breaks = c(-3,-1,0,0.5,3) ) # 異なる区切り幅 (出力例は省略)
� �
6.3.7 円グラフ:pie()
関数 pie() で円グラフ描くことが出来る.以下に取り得る引数を紹介する.
names : 各扇形のラベルを定める文字型ベクトル指定することが出来る.
inner , outer ,rotate : ラベルの位置や向きなどを細かく調整する.
他にも density ,angle ,col などの引数が使える.さらに細かい装飾も出来る.
2詳しくは『データの分布とヒストグラム・密度推定』で扱う

R-Tips 121頁
� �> x <- 1:10
> pie(x)
� �『ヒストグラム:hist()』の例と共に,出力結果を以下に載せる.
Histogram of x
x
Fre
quen
cy
−3 −2 −1 0 1 2 3
05
1015
1
2
3
4
56
7
8
9
10
6.3.8 ドットチャート:dotchart()
関数 dotchart() でドットチャートを描く.これは棒グラフの棒の代わりに点でプロットする.� �> x <- 1:10
> dotchart(x,labels=paste("sample", 1:10))
� �• 引数 labels にデータのラベルを指定することも出来る.
• 引数 groups に類別オブジェクトを指定すると,それに従ってデータをグループ分けして表示することが出
来る.
• 引数 gdata に『グループごとの平均』などの要約値を指定することで,要約値をグループを表すラベルの位
置に追加することが出来る.
6.3.9 箱ひげ図:boxplot()
複数のデータの分布の違いを比較する際は,関数 boxplot() で箱ひげ図を描く.� �> x <-rnorm(50)
> y <-rnorm(50)
> z <-rnorm(50)
> boxplot(x,y,z)
� �『ドットチャート:dotchart()』の例と共に,出力結果を以下に載せる.
sample 1
sample 2
sample 3
sample 4
sample 5
sample 6
sample 7
sample 8
sample 9
sample 10
2 4 6 8 10
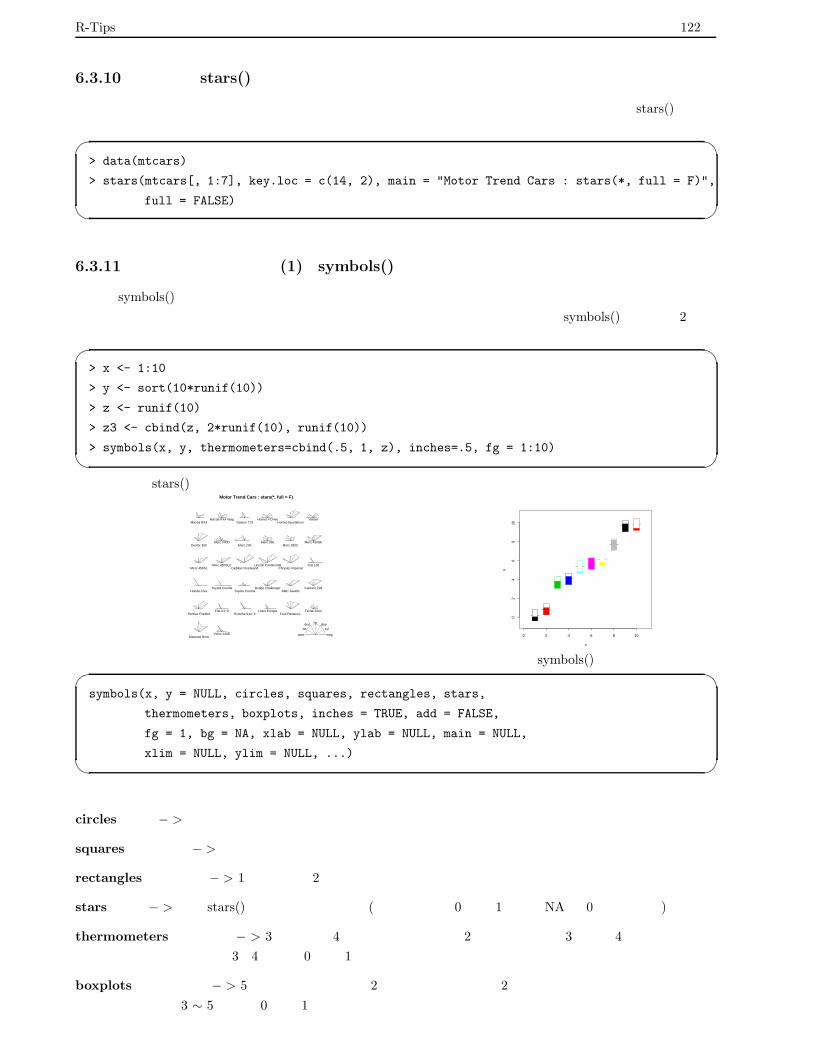
R-Tips 122頁
6.3.10 星形図:stars()
複数のデータがある場合において,全体の傾向を見たりサンプルの分類を行なう場合には,関数 stars() で星形
図を描くことが出来る.� �> data(mtcars)
> stars(mtcars[, 1:7], key.loc = c(14, 2), main = "Motor Trend Cars : stars(*, full = F)",
full = FALSE)� �
6.3.11 多変量データの図示 (1):symbols()
関数 symbols() で多変量データを図示することが出来る.この関数を用いると,散布図に描かれるマーカーの
代わりに,他の変量の情報を使って円や矩形,星形図などを描くことが出来る.関数 symbols() は,まず 2 変量
の座標データをとり,さらにその座標に描く図形に対するパラメータとして別のデータを指定することになる.� �> x <- 1:10
> y <- sort(10*runif(10))
> z <- runif(10)
> z3 <- cbind(z, 2*runif(10), runif(10))
> symbols(x, y, thermometers=cbind(.5, 1, z), inches=.5, fg = 1:10)
� �『星形図:stars()』の例と共に,出力結果を以下に載せる.
Motor Trend Cars : stars(*, full = F)
Mazda RX4Mazda RX4 Wag
Datsun 710Hornet 4 Drive
Hornet SportaboutValiant
Duster 360Merc 240D
Merc 230Merc 280
Merc 280CMerc 450SE
Merc 450SLMerc 450SLC
Cadillac FleetwoodLincoln Continental
Chrysler ImperialFiat 128
Honda CivicToyota Corolla
Toyota CoronaDodge Challenger
AMC JavelinCamaro Z28
Pontiac FirebirdFiat X1−9
Porsche 914−2Lotus Europa
Ford Pantera LFerrari Dino
Maserati BoraVolvo 142E mpg
cyldisp
hpdrat
wt
qsec 0 2 4 6 8 10
02
46
810
x
y
上では温度計の記号を用いたが他にも様々な記号で表すことが出来る.以下に symbols() の書式を紹介する� �symbols(x, y = NULL, circles, squares, rectangles, stars,
thermometers, boxplots, inches = TRUE, add = FALSE,
fg = 1, bg = NA, xlab = NULL, ylab = NULL, main = NULL,
xlim = NULL, ylim = NULL, ...)
� �引数の部分で指定することにより,以下の記号で表すことが出来る.
circles : 円 − > 半径を表すベクトル
squares : 正方形 − > 辺の長さを表すベクトル
rectangles : 長方形 − > 1 列目が幅,2 列目が辺の高さを表す行列
stars : 星 − > 関数 stars() に与えるような行列 (ただしすべて 0 以上 1 以下,NA は 0 に置き換え)
thermometers : 温度計 − > 3 列または 4 列の行列で,最初の 2 列が幅と高さ,3 列目,4 列目が中を塗り
つぶす比率 (ただし 3,4列目は 0 以上 1 以下)
boxplots : 箱ひげ図 − > 5 列の行列で,最初の 2 列が幅と高さ,次の 2 列がひげの長さ,最後が中央線の位
置 (ただし 3 ∼ 5 列目は 0 以上 1 以下)

R-Tips 123頁
6.3.12 多変量データの図示 (2):pairs()
関数 pairs() は対散布図を描くことで多変量データを図示する.この関数は数値行列またはデータフレームを引
数としてとり,各列同士の組合せ全てについて図を描く.各変量間の関係をつかみたい時に便利である.� �> x <- 1:10
> y <- rnorm(10)
> z <- x*y
> C <- matrix(c(x,y,z),10,3)
> C
[,1] [,2] [,3]
[1,] 1 -0.1437944 -0.1437944
[2,] 2 1.6915864 3.3831729
[3,] 3 1.6495483 4.9486448
...............................
> pairs(C)
� �関数 pairs()の引数 panel に個々の図を描く関数を指定することで,それぞれのパネルに現れるプロットのタイ
プをカスタマイズすることが出来る.この引数の値には x ,y 座標とグラフィックスパラメータを引数とする任
意の関数を指定することが出来るが,座標系の設定は pairs が行なうので,この引数には重ね描きを行なう低水準
作図関数 (既定値では散布図を生成する points() ) を指定することになる.
6.3.13 多変量データの図示 (3):coplot()
3 つ以上の変量が含まれる場合は関数 coplot() で共変量プロットを行えば良い.この関数は数値ベクトル x ,y
,z ( z は因子オブジェクトでも可) を引数としてとり,z の与えられた値における y に対する x の散布図を複数
生成する.
• z が因子ならば,z の水準ごとに x が y に対してプロットされる.
• z が数値ならば,いくつかの『条件を与える区間』に分割され,その区間ごとに,区間に含まれる z の値に
対して x が y に対してプロットされる.
以下の z の部分を z1 * z2 にすると,2 変量 z1 ,z2 に条件付けされた,y に対する x の散布図を生成するこ
とになる.� �> x <- 1:10
> y <- rnorm(10)
> z <- x*y
> coplot(x ~ y | z)
� �『多変量データの図示 (2):pairs()』の例と共に,出力結果を以下に載せる.
var 1
−1 0 1 2
24
68
10
−1
01
2
var 2
2 4 6 8 10 −10 −5 0 5
−10
−5
05
var 3
24
68
10
−1.5 −1.0 −0.5 0.0 0.5 1.0
−1.5 −1.0 −0.5 0.0 0.5 1.0 −1.5 −1.0 −0.5 0.0 0.5 1.0
24
68
10
y
x
−6 −4 −2 0 2 4
Given : z

R-Tips 124頁
関数 pairs(),引数 panel に個々の図を描く関数を指定することで,それぞれのパネルに現れるプロットのタ
イプをカスタマイズすることが出来る.この引数の値には x ,y 座標とグラフィックスパラメータを引数とする
任意の関数を指定することが出来るが,座標系の設定は pairs が行なうので,この引数には重ね描きを行なう低
水準作図関数 (既定値では散布図を生成する points() ) を指定することになる.この場合の便利なパネル関数は
panel.smooth() である.
6.3.14 3次元データの図示 (1):image()
3次元データを図示する場合は関数 image() で描く.この関数は数値ベクトル x ,y ,z を引数としてとり,z
の値を表すために矩形の格子を描く.� �> x <- y <- seq(-4*pi, 4*pi, len=27)
> r <- sqrt(outer(x^2, y^2, "+"))
> image(z = z <- cos(r^2)*exp(-r/6), col=gray((0:32)/32))
> image(z, axes = FALSE, main = "Math can be beautiful ...",
+ xlab = expression(cos(r^2) * e^{-r/6}))
� �
6.3.15 3次元データの図示 (2):persp()
関数 persp() で 3 次元データを描く.persp() は引数として x-y 平面の格子点上の z の値を要求する.このと
き,関数 persp() は NA を受け付けないので事前に取り除く必要がある.ここではトリッキーな例を挙げている
ので,まともな例は『とりあえず plot()』の章の例を参照されたい.� �> x <- seq(-10, 10, length= 50); y <- x
> f <- function(x,y) { r <- sqrt(x^2+y^2); 10 * sin(r)/r }
> z <- outer(x, y, f)
> z[is.na(z)] <- 1 # 関数 persp() は NA を受け付けない
> persp(x, y, z, theta = 30, phi = 30, expand = 0.5, col = rainbow(50), border=NA)
> # col で色を指定 (ベクトル指定可), border の指定は削除可� �『3次元データの図示 (1):image()』の例と共に,出力結果を以下に載せる.
Math can be beautiful ...
cos(r2)e−r 6
x
y
z
6.3.16 3次元データの図示 (3):scatterplot3d()
パッケージ scatterplot3d には 3次元的に表示する散布図を描く関数が入っている.まず,パッケージを呼び出
す必要がある.

R-Tips 125頁
� �> library(scatterplot3d)
> temp <- seq(-pi, 0, length = 50)
> x <- c(rep(1, 50) %*% t(cos(temp)))
> y <- c(cos(temp) %*% t(sin(temp)))
> z <- 10 * c(sin(temp) %*% t(sin(temp)))
> color <- rep("green", length(x))
> temp <- seq(-10, 10, 0.01)
> x <- c(x, cos(temp))
> y <- c(y, sin(temp))
> z <- c(z, temp)
> color <- c(color, rep("red", length(temp)))
> scatterplot3d(x, y, z, color, pch=20, zlim=c(-2, 10), main="scatterplot3d - 3")
� �
6.3.17 3次元データの図示 (4):contour()
3次元データを等高線図で図示する場合は関数 contour() で描く.関数 persp() と違ってこの関数は NA を受
け付けるので事前に取り除かなくても一応のプロットは出来る.� �> x <- -6:16
> contour(outer(x, x), method = "edge", vfont = c("sans serif", "plain"))
� �『3次元データの図示 (3):scatterplot3d()』の例と共に,出力結果を以下に載せる.
scatterplot3d − 3
−1.0 −0.5 0.0 0.5 1.0
−2
0 2
4 6
810
−1.0
−0.5
0.0
0.5
1.0
x
y
z
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
6.3.18 パッケージ:lattice
lattice には高水準関数の代替パッケージが入っている.詳しくはヘルプを参照されたい.� �> library(lattice)
� �
R-Tips 126頁
6.4 低水準作図関数
高水準作図関数のみでは自分が欲しい図が描けない場合がある.高水準関数で作図した図に追加要素を加える
場合には低水準作図関数を用いる.なお,これらの関数はグラフィックスパラメータも引数として受け入れること
が出来る.
6.4.1 図の消去
プロットした図を消去するには関数 frame() または関数 plot.new() を使う.グラフィックスパラメータ new が
TRUE ならば図は消去されない.� �> frame()
> plot.new()
� �
6.4.2 点の描画
points(x, y) , points(c(x, y)) : 各点の x 座標と y 座標を指定することで点列を描く (規定では points() に
対して,作図関数の引数に ”p” を与える) .マーカーの形式はグラフィックスパラメータ pch によって指定
する.
� �> plot(-4:4, -4:4, type = "n")
> points(rnorm(200), rnorm(200), pch="+", col = "red")
� �
6.4.3 折れ線の描画
lines(x, y) , lines(c(x, y)) : 各点の x 座標と y 座標を指定することで,それぞれの点を通る直線・曲線を描
く.点列を描く (規定では lines() に対して,作図関数の引数に ”l” を与える) . 以下は,関数 lines() を用
いて関数による曲線を描く例である.
� �> x <- seq(0, 10, by=0.1)
> y <- seq(0, 1, by=0.01)
> plot(x, y, ylab="", type=’n’, main = "Title\n- subtitle -")
> for(i in 1:5) lines(x, beta(x,i), col = i)
� �『点の描画』の例と共に,出力結果を以下に載せる.
−4 −2 0 2 4
−4
−2
02
4
−4:4
−4:
4
++
+
+
+
++
++ +
+
+
+
+
+
+
+
+
+
++
+
++
+
++
+
+
++
++
+
+
+
+++
+
+
++
+
+
+
+
+
+
+
+
+
++
++
+
+
+ +++
+
++
+
+
++ +
+ +
++
+
+
+
+
+
+ +
+
++
+
++
+
+
++
+ +++
+
+
+
++
+ ++
+ +
+
+
+ +
+
+
+ ++ +
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
++
+++
++ + +
+
++
+
+
+
+
+
+
+
+
+
+ +
+
+
+
+
+
+ +
+
+
++
+ +
+
+
+
+
++
+
++ ++
+
+
+
+
+++
+
+
+
+
+
+
++
++
+
+
0 2 4 6 8 10
0.0
0.2
0.4
0.6
0.8
1.0
Title− subtitle −
x
R-Tips 127頁
6.4.4 直線の描画
abline(a, b) , abline(c(a, b)) : a ,b は切片と傾きを表し,直線 y = a + bx を描く.
abline(h = y) , abline(v = x) : h = y では,ベクトルで与えられた y 座標の (図表を横切る) 水平線を引
く.v = x では,ベクトルで与えられた x 座標の (図表を縦に切る) 垂直線を引く.
abline(lm.obj) : lm.obj は 長さ 2 の coefficients 成分を持つリストで,それらは順に引かれるべき直線の切片
と傾きとなる.例えば,lm.obj$coef が長さ 2 のベクトルならばそれらを切片と傾きとする直線を描く.ま
た,長さが 1 ならそれを傾きとして切片 0 の直線を描く.
� �> plot(1:10)
> abline(a=0, b=1) # 切片 0 ,傾き 1 の直線
> abline(h=1:10, v=1:10, lty=2) # abline を使って格子を入れる
� �
2 4 6 8 10
24
68
10
Index
1:10
2 4 6 8 10
24
68
10
Index
1:10
6.4.5 線分と矢印の描画
segments(x1, y1, x2, y2)): 始点の座標 (x1,y1) と,終点の座標 (x2 ,y2) を通る線分を描く.
arrows(x1, y1, x2, y2)): 始点の座標 (x1,y1) と,終点の座標 (x2 ,y2) を通る矢印を描く.
� �> plot(1:10)
> segments(2,2,3,3) # 点 (2,2) と点 (3,3) を通る線分を描く
> arrows(5,5,7,7) # 点 (5,5) と点 (7,7) を通る矢印を描く� �
2 4 6 8 10
24
68
10
Index
1:10
2 4 6 8 10
24
68
10
Index
1:10
6.4.6 文字列の描画
text(x, y, labels): 画面上の任意の位置に文字列を描画する.座標値,文字列ともにベクトルで指定すること
が出来,この場合は各点 ( x[i] , y[i] ) に文字列 labels[i] を出力する.
mtext(text, side = 3, line = 0, at = NA): 書き込む文字列を引数 text で指定し,side に文字列を書き込
む余白位置を表す番号 (下:1,左:2,上:3,右:4) を指定する.ここで line には図形領域から何行離す
かを指定し,at には文字列を書き込む座標を指定することも出来る.

R-Tips 128頁
� �> plot(1:10) # text() と locator() の組み合わせ
> text(locator(1), labels = "値") # 座標を一つだけ得て,その位置に文字列を描き込む
> plot(1:10, (-4:5)^2, main="Parabola Points",
+ xlab="xlab", ylab="")
> mtext("subtitle") # 関数 mtext() を普通に使う場合
> for(s in 1:4) # 引数 side などを変化させた場合
+ mtext(paste("mtext(..., line= -1, {side, col, font} = ",s, ", cex = ",
+ (1+s)/2, ")"), line = -1, side=s, col=s, cex= (9+s)/10)
� �
2 4 6 8 10
24
68
10
Index
1:10
値
2 4 6 8 10
05
1015
2025
Parabola Points
xlab
subtitle
mtext(..., line= −1, {side, col, font} = 1 , cex = 1 )
mte
xt(.
.., li
ne=
−1,
{si
de, c
ol, f
ont}
= 2
, ce
x =
1.5
)
mtext(..., line= −1, {side, col, font} = 3 , cex = 2 )
mte
xt(.
.., li
ne=
−1,
{si
de, c
ol, f
ont}
= 4
, ce
x =
2.5
)
text の引数に srt = − (回転角) を入れることで,プロットの x 軸ラベルを 45度回転させることが出来る.� �> plot(x, y, xaxt="n")
> axis(1, labels=FALSE)
> pr <- pretty(x)
> par(xpd=TRUE)
> text(pr, par("usr")[3], pr, adj=0, srt=-45) # srt=-45 で時計回りに 45度回転
� �
6.4.7 枠の描画
box() : 軸や目盛を描かず枠だけ描く.
box(lty=’1373’, col = ’red’) : 引数に色や線の太さを指定することも出来る.この場合は図の枠に赤い模様
が付く.
6.4.8 タイトル・サブタイトルの描画
title(main, sub) : 引数 main に上部余白に描かれるメインタイトルを,引数 sub に下部余白に描かれるサブ
タイトルを指定して,図の上下の余白部分にタイトルを追加する.省略すると,それぞれメインタイトルと
サブタイトルが描かれなくなる.また,引数 tmag でプロットの別の注釈するテキストに関する主なタイト
ルのテキストの拡大率を指定することが出来る.
� �> plot(rnorm(50), rnorm(50))
> title(main="Main Title", sub = "Sub Title")
� �
6.4.9 座標軸の描画
axis(side=4, labels=F) : 座標を描く (1:下,2:左,3:上,4:右).引数 labels に FALSE を指定すると
目盛のラベルは描かれなくなる.
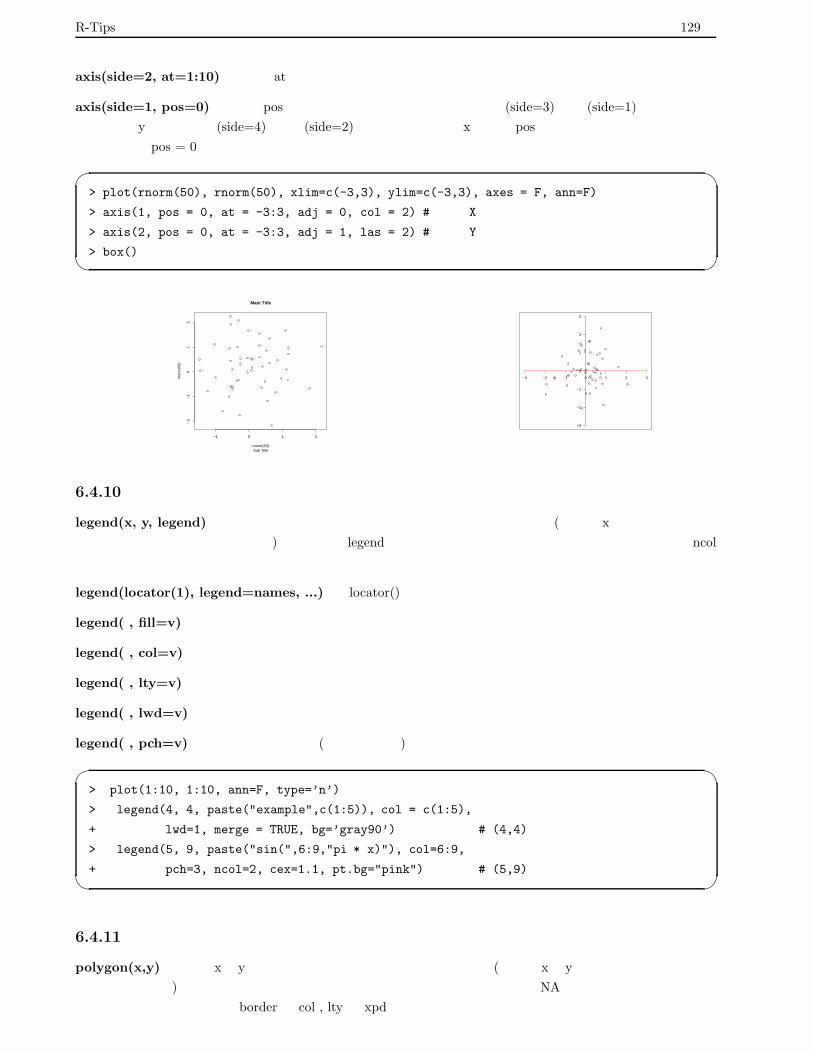
R-Tips 129頁
axis(side=2, at=1:10) : 引数 at で目盛のラベルを指定する.
axis(side=1, pos=0) : 引数 pos によって軸を描く位置を指定する.上 (side=3) か下 (side=1) に軸を描く場
合は y 座標を,右 (side=4) か 左 (side=2) に軸を描く場合は x 座標を pos に与えればよい.例えば以下の
ように pos = 0 とすれば原点を通る座標軸を描くことが出来る.
� �> plot(rnorm(50), rnorm(50), xlim=c(-3,3), ylim=c(-3,3), axes = F, ann=F)
> axis(1, pos = 0, at = -3:3, adj = 0, col = 2) # 赤で X 軸を描く
> axis(2, pos = 0, at = -3:3, adj = 1, las = 2) # 黒で Y 軸を描く
> box()� �『タイトル・サブタイトルの描画』の例と共に,出力結果を以下に載せる.
−1 0 1 2
−2
−1
01
2
rnorm(50)
rnor
m(5
0)
Main Title
Sub Title
−3 −2 −1 0 1 2 3
−3
−2
−1
0
1
2
3
6.4.10 凡例の描画
legend(x, y, legend) : 凡例を追加する.最初の引数で凡例をつける位置を定め (座標が x のみならば凡例の
枠の左上の位置と見なされる) ,次に引数 legendにそれぞれの文字列ベクトルを指定する.また,引数 ncol
に列数を指定することにより,複数列に渡る凡例を作ることも出来る.
legend(locator(1), legend=names, ...) : locator() により対話的に位置を決定する.
legend( , fill=v) : 箱を塗りつぶす色を指定する.
legend( , col=v) : 点や線を描く色を指定する.
legend( , lty=v) : 線の種類を指定する.
legend( , lwd=v) : 線の幅を指定する.
legend( , pch=v) : プロット用の文字 (文字ベクトル) を指定する.
� �> plot(1:10, 1:10, ann=F, type=’n’)
> legend(4, 4, paste("example",c(1:5)), col = c(1:5),
+ lwd=1, merge = TRUE, bg=’gray90’) # (4,4) に凡例を描画
> legend(5, 9, paste("sin(",6:9,"pi * x)"), col=6:9,
+ pch=3, ncol=2, cex=1.1, pt.bg="pink") # (5,9) に凡例を描画
� �
6.4.11 多角形の描画
polygon(x,y) : 引数 x ,y に多角形の頂点の座標ベクトルを指定して (または x ,y 成分を持つリストや行列
を指定して) 多角形を描いて中を塗りつぶすか,中に斜線を入れる.要素に NA があると,多角形の生成は
終了する.引数は他に border や col , lty や xpd を指定することが出来る.
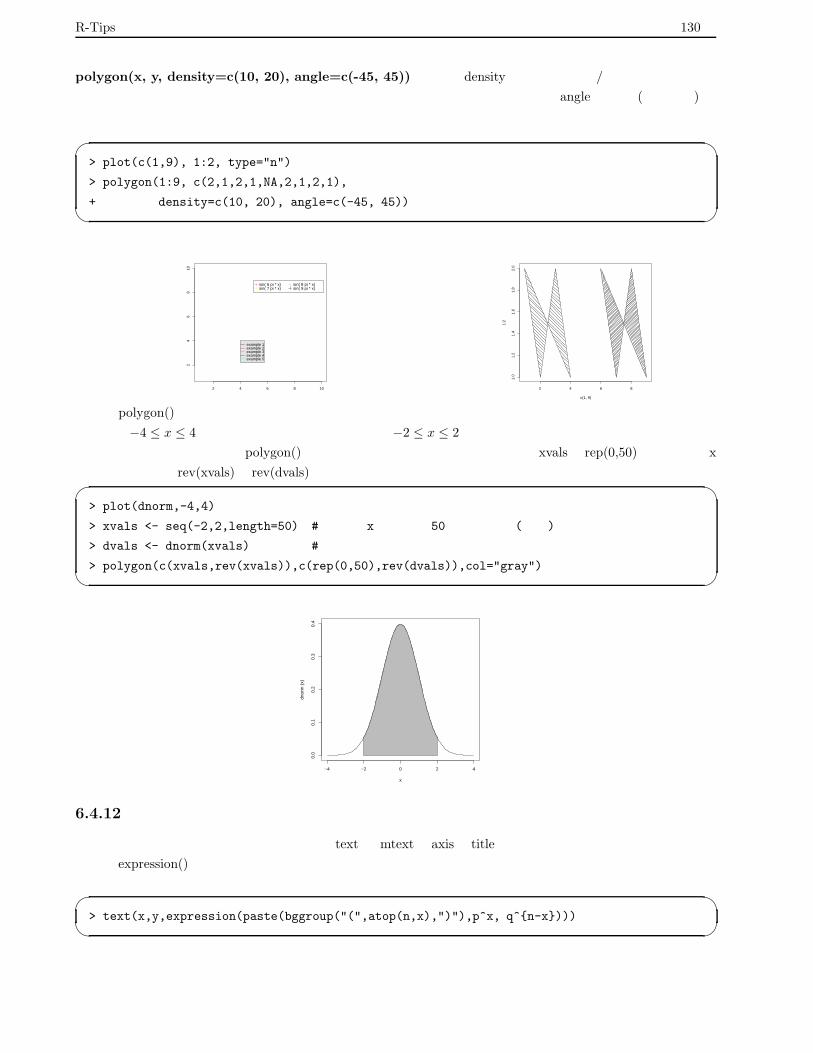
R-Tips 130頁
polygon(x, y, density=c(10, 20), angle=c(-45, 45)) : 引数 density により,ビット/インチで太さを指定
したラインを使って多角形の内部に影を入れることが出来る.このとき,引数 angle で角度 (左回りに) を
与えて線の傾斜を指定することが出来る.
� �> plot(c(1,9), 1:2, type="n")
> polygon(1:9, c(2,1,2,1,NA,2,1,2,1),
+ density=c(10, 20), angle=c(-45, 45))
� �『凡例の描画』の例と共に,出力結果を以下に載せる.
2 4 6 8 10
24
68
10
example 1example 2example 3example 4example 5
sin( 6 pi * x)sin( 7 pi * x)
sin( 8 pi * x)sin( 9 pi * x)
2 4 6 8
1.0
1.2
1.4
1.6
1.8
2.0
c(1, 9)
1:2
関数 polygon() を用いることで,グラフの一部に影を付けることが出来る.まず,標準正規分布の密度関数の
グラフを−4 ≤ x ≤ 4の範囲でプロットする.そのうち−2 ≤ x ≤ 2の範囲に灰色の影を付けるには,以下の様に
多数の多角形に分割して関数 polygon() で塗りつぶしをすればよい.具体的には xvals ,rep(0,50) の組合せで x
軸上の辺を結び,rev(xvals) ,rev(dvals) の組合せでグラフに沿った辺を結べばよい.� �> plot(dnorm,-4,4)
> xvals <- seq(-2,2,length=50) # 領域を x軸方向に 50個の多角形 (台形)に等分割
> dvals <- dnorm(xvals) # 対応するグラフの高さ
> polygon(c(xvals,rev(xvals)),c(rep(0,50),rev(dvals)),col="gray")
� �
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
dnor
m (
x)
6.4.12 数式の描画
プロットに数学記号や式を使いたい場合で text , mtext ,axis ,title のいずれかを使う場合は,文字列の代
わりに expression() を指定すればよい.例えば以下は二項分布の確率関数の公式を書く.使うことが出来る表現
の一覧は補足事項の章をご覧頂きたい.� �> text(x,y,expression(paste(bggroup("(",atop(n,x),")"),p^x, q^{n-x})))
� �

R-Tips 131頁
6.5 対話的作図関数
R では,マウスなどで図表からプロット点を追加したり除いたりすることが出来る.これを対話的作図関数と
いう.
6.5.1 座標値の入力
対話的に図を描く場合,一番簡単なのが関数 locator() を使ってウインドウ上の任意の位置の座標を入力するこ
とである.入力方法は作図デバイスにより異なるが,例えば x11 の場合は locator() を呼び出すとウインドウ上
に ”+” マーク (クロスヘア) が表示されるので,これをマウスで操作すればよい.マウスの左ボタンをクリック
するとその点が入力され,入力された位置にはマーカーが表示される.このマーカーは locator() の実行が終了す
ると消える.UNIX や Windows ならばマウスの中央のボタンをクリックすることによって,Mac グラフィック
ウインドウの外でクリックすることで入力を終了することが出来る.� �> locator() # 引数無しで使うと,入力終了操作が行なわれるまで座標値の入力をする
> locator(10) # 10 点入力した時点で終了 (既定値は 512 点まで)
� �locator() は入力した位置の座標 x と y を成分とするリストを返すので,マウスでプロットする際に,以下の様
に命令すれば入力した位置の座標を保存することが出来る.� �> z <- locator() # z に入力した位置の座標 x と y を成分とするリストが付値
� �外れ値の近くに目印のテキストを置きたい場合は以下の様にすればよい.� �> text(locator(1), "Outlier", adj=0)
� �
6.5.2 点の認識
対話的に図表中のある点の情報 (観測番号,座標) を得るには関数 identify() を使用する.identify() は座標値
の入力を行なうために内部で locator() を呼び出す.従って locator() と同様にマウスで ”+” マークを操作し,識
別したい点を入力することになる.� �> x <- rnorm(20) # x に正規乱数を 20 個入れて
> y <- rnorm(20) # y に正規乱数を 20 個入れて
> plot(x,y) # (x, y) をプロットする
> identify(x,y,x) # マウスでクリックした観測点の x 座標が知りたいとき
> identify(x,y,y) # マウスでクリックした観測点の y 座標が知りたいとき
> identify(x,y) # マウスでクリックした観測点の観測番号が知りたいとき
[1] 8 11 16 20� �
identify() の第 3 引数には各点のラベルを指定することが出来,識別された点の近くに指定したラベルの座標が
描かれる.この引数を省略すると座標ベクトル中の点の番号が描かれることになる.
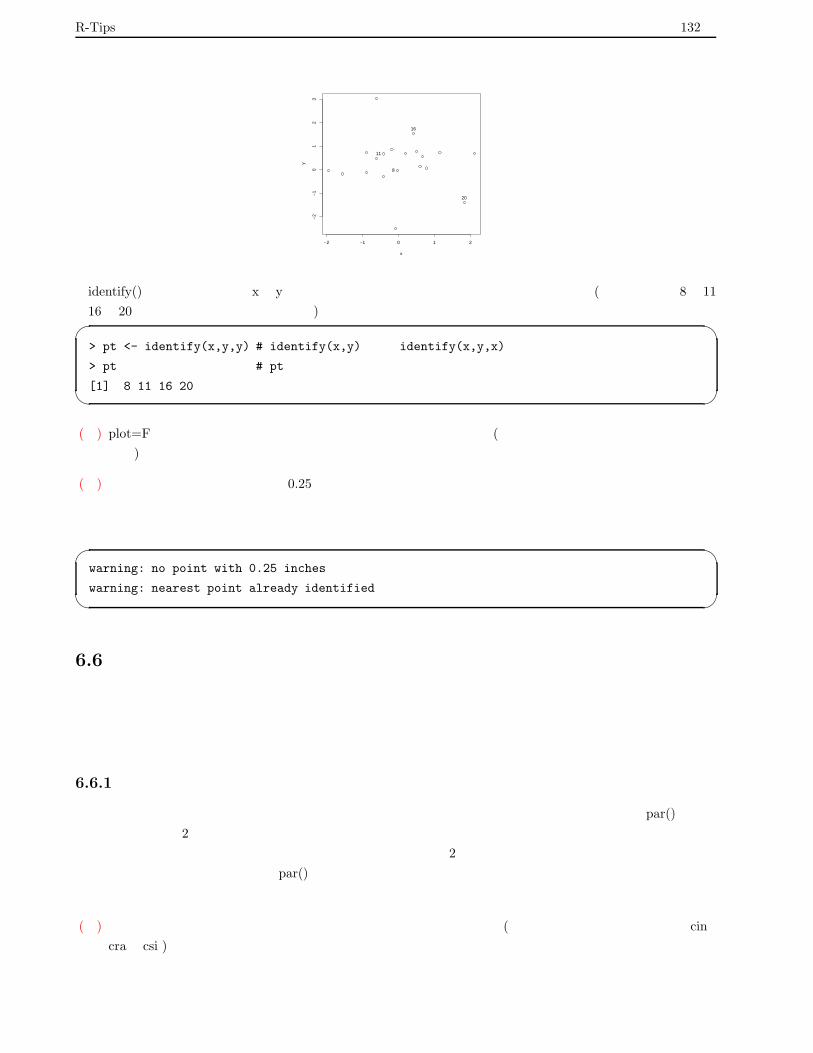
R-Tips 132頁
−2 −1 0 1 2
−2
−1
01
23
x
y
8
11
16
20
identify() は,認識した点が x ,y の何番目のデータであるかを表す観測番号が返される (上記の例では 8 ,11
,16 ,20番目の点が順に識別されている) .� �> pt <- identify(x,y,y) # identify(x,y) でも identify(x,y,x) でも
> pt # pt には観測番号が格納される
[1] 8 11 16 20� �(注) plot=F と指定すればラベルを描き込まずに点の認識だけを行なう (認識された点の番号のベクトルは返さ
れる) .
(注) 例えばクリックした位置の周囲 0.25インチ以内に点が無い場合や近くに既に指定済みの点がある場合は,入
力された座標値に対して認識し得る点がなかったということで,エラー音と共に以下の様なメッセージが表
示されてしまい,ラベルも表示されない.
� �warning: no point with 0.25 inches
warning: nearest point already identified
� �
6.6 グラフィックスパラメータ
高水準作図関数や低水準作図関数で作図する場合,作図関数固有のパラメータ以外にもグラフィックスパラメー
タと呼ばれるパラメータを指定することが出来る.これにより作図結果の微妙なカスタマイズを行うことが出来,
自分好みの出力結果を得ることが出来る.
6.6.1 グラフィックスパラメータ事始
グラフィックスパラメータを設定する方法は,作図関数の引数にパラメータを与える方法と,関数 par() を使っ
て設定する方法の 2 通りがある.前者は一時的にパラメータ値が変更され,後者は永続的にパラメータ値が変更
される.重要なことは,グラフィックスパラメータの全てがこの 2 通りの方法で変更出来るわけではなく,一部
のグラフィックスパラメータは関数 par() を使ってしかパラメータ値を変更することが出来ない点を理解すること
である.
(注) 一部のグラフィックスパラメータには読み取り専用・変更不可なもの (例:テキスト関係のパラメータ cin ,
cra ,csi ) があるが,ここでは値の変更方法などは扱わないことにする.ただ,これらのほとんどが文字の
幅と高さや解像度などに関するものである.

R-Tips 133頁
6.6.2 グラフィックスパラメータの永続的変更
まず,関数 par() を使わなければ変更できないグラフィックスパラメータを紹介する.この種のパラメータは領
域,余白,座標系などを設定する機能であるものがほとんどであり,一旦変更すると,改めて変更するまでは元に
戻らない.
関数 par() の使い方
par() : 全てのグラフィックスパラメータの現在値がリストとして得られる.
par(”文字列”) : パラメータ名を文字列で指定すると,そのグラフィックスパラメータの現在値が得られる.パ
ラメータの値を変更する際は,まずこの命令でパラメータ値を確認する.
par(”文字列”, ”文字列”) ,par(c(”文字列”, ”文字列”)) : パラメータ名を複数指定することも出来る.
par(col=2) : <パラメータ名 >=<値 > の形で設定することにより,パラメータの値を変更する.
par(col=2, lty=3) ,par(list(col=2, lty=3)) : 複数のグラフィックスパラメータを一度に変更することも
出来る.
par() の使い方を以下に挙げる.� �> par(new=T) # new を TRUE に設定すると,現在の作図に次の作図を上書きする
> par(ask=TRUE) # 作図する前に『作図してよいですか?』と質問させるようにする
> help(par) # 全てのグラフィックスパラメータのヘルプが表示される
� �(注) パラメータ new を 事前に TRUE にしておくと,高水準作図関数は『画面はすでに消去されている』 と解
釈して,画面を消去せずに図を描く.
(注) パラメータ ask を 事前に TRUE にしておくと,help の example を閲覧する際に作図例が一瞬で流れてし
まうのを防ぐことが出来る.
グラフィックスパラメータ値の一時退避と復帰
関数 par() を使わなければ変更できないグラフィックスパラメータの値を変更する場合は,適当な変数に現在の
パラメータの値を保存しておくのが得策である.R では便利なことに,グラフィックスパラメータの値を 1 コマ
ンドで一切合財保存することが出来る.� �> oldpar <- par(no.readonly = TRUE) # 現在のグラフィックスパラメータの値を退避
>
> ... グラフィックスパラメータを変更しつつ作業を行う ...
>
> par(oldpar) # 作業前のグラフィックスパラメータ値に戻す
>
> oldpar <- par(col=2, lty=3) # 一部のパラメータ値だけ保存することも出来る
>
> ... グラフィックスパラメータを変更しつつ作業を行う ...
>
> par(oldpar) # 作業前のグラフィックスパラメータ値に戻す
� �
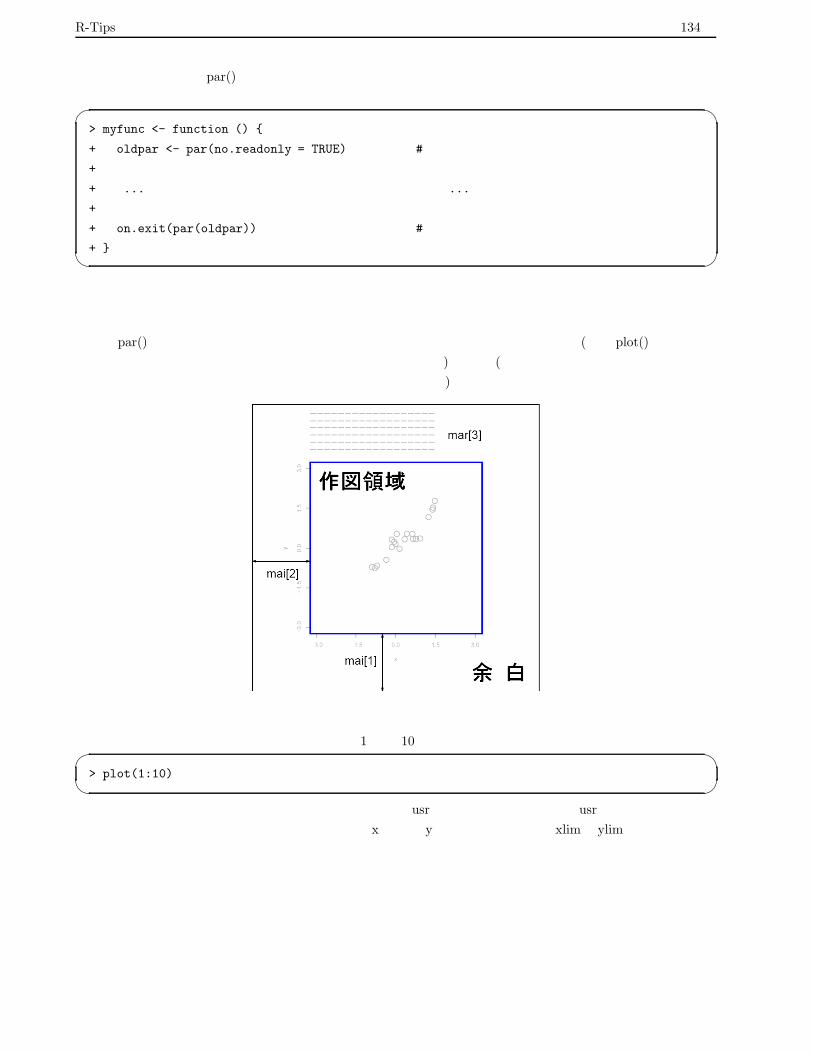
R-Tips 134頁
関数定義内で,関数 par() を使ってグラフィックスパラメータを変更する場合も,元のグラフィックスパラメー
タの値を一切合財保存した上で作業をし,関数の最後に元に戻すことをお勧めする.� �> myfunc <- function () {
+ oldpar <- par(no.readonly = TRUE) # 現在のグラフィックスパラメータの値を退避
+
+ ... グラフィックスパラメータを変更しつつ作業を行う ...
+
+ on.exit(par(oldpar)) # 関数がエラー中断してもパラメータを復帰
+ }� �
作図領域・余白・座標系
関数 par() を使わなければ変更できないグラフィックスパラメータは,大抵が作図領域 (関数 plot() で散布図を
描いた場合:四角の枠とその中に描かれた点や線などがある領域) と余白 (作図領域の周囲,すなわち枠の外側の
目盛や目盛のラベル,軸のラベルやタイトルなどが描かれる部分) に関するパラメータとなっている.
作図領域の座標は絶対的なものではなく,出力の見栄えが良くなる様に逐一自動的に変更される.例えば以下
のようなプロットを行えば,座標系は縦横ともに 1 から 10 までに設定される.� �> plot(1:10)
� �これをユーザーの好きなように変更するにはパラメータ usr を変更する.パラメータ usr は出力の見栄えが良
くなる様に逐一自動的に変更されるが,作図範囲の x 座標と y 座標を指定する引数 xlim ,ylim を指定すると自
動的に変更されなくなる.

R-Tips 135頁
� �> par(usr=c(1,10,1,10)) # x 座標が x1 ~ x2 ,y 座標が y1 ~ y2 の領域となる様に
> par("usr") # 変更する場合は usr = c(x1, x2, y1, y2) とする
[1] 1 10 1 10 # この場合は X 座標が 1 ~ 10 ,Y 座標が 1 ~ 10 の領域
> plot(1:5, xlim=par("usr")[1:2]) # 指定した座標系のままプロットする場合は xlim で指定する
> par("usr")[1:2] # (ただし,xlim=c(1,10) とやっていることは変わらない…)
[1] 0.64 10.36 # 座標系が変わっていないことに注意
> plot(1:5) # 普通にプロットすると (usr を明示的に変更していなくとも)
> par("usr")[1:2]
[1] 0.84 5.16 # 値は自動的に変更される� �
作図領域のサイズ・座標・形式を指定するパラメータ
fig = c(x1, x2, y1, y2) : 作図領域の x ,y 軸方向の両端の位置の比率を指定する.初期値は c(0,1,0,1) で,
これは作図領域をフルに使用していることを示しており,c(0,0.5,0.5,1)と変更すれば左上の方に作図される
ことになる.このパラメータを設定すると,パラメータ new が TRUE になる.
fin = c(5,5): 作図領域の幅と高さを指定する.例えば par(”fin”) で調べた結果が [6.968749 6.958332] であっ
た場合に c(5,5) を指定すれば,作図結果は少し小さめの出力となる.
pin = c(6,6) : プロットした図の幅と高さをインチ単位で指定する.
plt = c(0.1, 0.9, 0.1, 0.9) : プロットした図の x ,y 軸方向の両端の位置の比率を指定する.c(0,1,0,1) と変
更すれば余白が全くない出力が得られる.
ps = 12 : 文字とシンボルの大きさを整数値で指定する.
pty = ”m” : ”s” は正方形の作図領域、”m” は最大の作図領域を生成する.”m” を設定した場合,作図領域で
も余白でもない空白部分が出来る場合もある .
余白に関するパラメータ
余白をあまり小さくしてしてしまうと軸のラベルなどが描けなくなってしまうので注意.
mai = c(0.85, 0.68, 0.68, 0.35) : 底辺,左側,上側,右側の順に余白の大きさをインチ単位で指定する.
mex = 1 : プロットの余白の座標を指定するのに使われる文字サイズの拡大率を指定する.このパラメータを
変更すると,余白の大きさもそれに応じて変化する.複数図表を使う場合は,このパラメータ値が自動的に
0.5 に変更されることがあるので注意.
mar = c(5,4,4,2) : 底辺,左側,上側,右側の順に余白の大きさを行の高さ (mex) で指定する.デフォルトで
は高水準作図関数は軸のラベルを 3 行分離して描くので,底辺と左部には最低でも 4 行分 ( 4 mex 分) の
余白が必要となる.
omi = c(0,0,0.8,0) : 底辺,左側,上側,右側の順に外周の大きさをインチ単位で表した (outer margins in
inches) もので指定する.
oma = c(2,0,3,0) : 外周の底辺,左側,上側,右側の順に外側余白 (outer margin) を行の高さ (mex) で指定
する.
omd = c(0,1,0,1): ウインドウ全体を 0から 1の範囲として,外周を除いた複数図表の両端の位置 (x1, x2, y1, y2)
を指定する.この場合,外周は存在しないことになる.

R-Tips 136頁
xpd = F : プロットの作図領域内に刈り込みを指示する論理値.FALSE ならば全ての作図は作図領域内に刈
り込まれるが,TRUE ならば全てのプロットは作図領域内に刈り込まれる.NA なら全てのプロットはデバ
イス領域内に刈り込まれることになる.
6.6.3 グラフィックスパラメータの一時的変更
この節で紹介するグラフィックスパラメータは,関数 par() で設定することが出来るし,関数 plot() や多くの
高水準作図関数の引数としてグラフィックスパラメータを設定することも出来る.例えばプロット点の形を指定す
るパラメータ pch に関しては,以下の 2 通りの設定方法を用いることが出来る.ただし,関数 par() で設定した
場合は,設定した後はもう一度パラメータ値を変更するまではそのままの設定値が使われるが,作図関数の引数
としてグラフィックスパラメータを設定した場合は,そのときの作図の場合のみ設定値が使われる (それ以後は直
前までの設定値が使われる) .� �> plot(1:10, pch="+") # 一時的にプロット点の形を "+" に変更する
> par(pch="+") # これ以後,プロット点の形をずっと "+" に変更する
> plot(1:10) # プロット点の形は "+" となる
> plot(1:20) # これもプロット点の形は "+" となる
� �以下にグラフィックスパラメータの一覧を示す.
プロットに用いられる色
col = 1, col = blue : 作図に用いる色 (color) を引数 col = 番号または色名で指定する (初期値は 1 ) .
col = rgb(1,0,0) : black,white, blue, azure などの名前で色を決めることも出来るが,引数 col = rgb(赤,緑,
青) で指定して色を決めることも出来る.
他にも虹色で 12段階を指定するなど,引数に rainbow(n) ,heat.colors(n) ,terrain.colors(n) ,topo.colors(n) ,
cm.colors(n) などで色を決めることも出来る.同様の命令で col.axis, col.lab, col.main, col.sub でそれぞれ軸,ラ
ベル,タイトル,サブタイトルの色を指定することが出来る.
プロットのマーカー
pch = 値 ,pch = ”文字” : 点をプロットするときに用いるプロット文字 (plotting character) を値 ( 0 から
255 の整数) や文字 ( ピリオドや ”+” など) で指定する.例えば 0 は四角となる.
テキスト・フォントに関するパラメータ
文字列に関するグラフィックスパラメータには以下のようなものがある.以下の引数によって文字の大きさや描
画方向などを設定することが出来る.
adj = 0 : テキスト文字列の調節 ( 0:左揃え,0.5:中心揃え,1:右揃え) を行う.また,adj = c(x,y) で x 軸
および y 軸方向を別々に揃えることも出来る.
par(”cin”) , par(”cra”) , par(csi) : それぞれ,インチ単位の既定文字サイズ (幅と高さ) ,ピクセル単位の
既定文字サイズ (幅と高さ) ,インチ単位で与えた既定サイズの文字の高さを確認することが出来る.
cex = 1 : 標準の大きさを 1 として,文字の拡大率を指定する.csi を変更すると,このグラフィックスパラメー
タもその値に応じて自動的に変化する.同様の命令で cex.axis, cex.lab, cex.main, cex.sub でそれぞれ軸,
ラベル,タイトル,サブタイトルの拡大率を指定する.

R-Tips 137頁
par(ps = 20) : テキストと記号の大きさをポイント単位で指定する.
text(x, y, labels=”文字列”, srt=90) : 座標 (x, y) に labels で指定した文字列を表示する際に,文字の回転
角を (単位は度で) 指定する ( x 軸を基準とする) .また,引数 crt では文字の回転角を (単位は度で) 指定
する.
col = 1 : 色を指定する.同様の命令で col.axis, col.lab, col.main, col.sub でそれぞれ軸,ラベル,タイトル,
サブタイトルの色を指定する.
font = 1 : フォント番号を指定する ( 1:プレイン,2:ボールド,3:イタリック,4:ボールドイタリック) .同
様の命令で font.axis, font.lab, font.main, font.sub でそれぞれ軸,ラベル,タイトル,サブタイトルのフォ
ント番号を指定する.
線分の太さと形式
lwd = 1 : 線分の幅 (line width) を番号で指定する.値が大きいほど太い線になる.
lty = 1 : 線分の形式 (line type) を番号または文字列で指定する.
lty=0 ,lty=”blank” : 無し (透明の線)
lty=1 ,lty=”solid” : 実線
lty=2 ,lty=”dashed” : ダッシュ
lty=3 ,lty=”dotted” : ドット
lty=4 ,lty=”dotdash” : ドットとダッシュ
lty=5 ,lty=”longdash” : 長いダッシュ
lty=6 ,lty=”twodash” : 二つのダッシュ
枠に関するパラメータ
bg = ”blue” : 背景の色を指定する.fg で前面の色も指定できる.
bty = ”o” : 枠の形を定める文字を指定する.
”o” : 枠が箱型,四方が囲まれている形になる.
”l” : 枠が L 字型,左と下部だけに枠の線が引かれる.
”7” : 枠が 7 型,上部と右だけに枠の線が引かれる.
”c” : 枠が C 字型,右部を除き枠の線が引かれる.
”u” : 枠が u 字型,上部を除き枠の線が引かれる.
” ” :] 枠が ] 字型,左部を除き枠の線が引かれる.
”n” : 枠を描かない (箱を描く) .
軸に関するパラメータ
las = 0 : それぞれの目盛の位置に書かれるラベルの書式を指定する.
las = 0 : 各軸に並行して描く.
las = 1 : すべて水平に描く.
las = 2 : 軸に対して垂直に描く.

R-Tips 138頁
las = 3 : すべて垂直に描く.
lab = c(5,5,7) : 長さ 3 の数値ベクトルの最初の二つで x ,y 軸につける目盛の数を指定する.最後の一つは
ラベルのサイズを指定するはずだが,今のところ ( R 1.8.1 ) は移植されていない.
mgp = c(3,1,0) : 長さ 3 の数値ベクトルでそれぞれ軸タイトル,軸ラベル,軸線が描かれる位置を枠から何
行分 (mex 単位) 外側にするかを指定する.
tck = NA : 軸の目盛線の長さを枠の大きさに対する割合で指定し,値が正ならば線が図の内側に,値が負な
らば図の外側に目盛線が描かれる.ここで tck = 1 とすれば,図に格子を入れることが出来る.初期値は
NA だが,これは tcl = −0.5 を用いるという意味である.
tcl = −0.5: 軸の目盛線の長さをテキスト行の高さ (mex) の割合で指定する.正の値を指定すれば目盛を内側
に向かって描き,負の値なら外側に描く.もし tcl = NA とすれば,tck に −0.01 がセットされる.
xaxt = ”s” ,yaxt = ”s” : 軸を描くか否かを指定する.
”s” : 通常の軸が使われていることを示す.
”n” : 軸を描かない.元に戻すには”s”と指定すればよい.xaxt = ”n” と yaxt = ”n” を同時に指定する
と axes = F と同じになる.
”l” : ”s” と同じ ( S 言語ならば常用対数軸が使われていることを示す).
”t” : ”s” と同じ ( S 言語ならば時間軸が使われていることを示す).
xaxs = ”s” ,yaxs = ”s” : それぞれ x ,y 軸のスタイルを指定する.スタイルは一般にデータ範囲か,も
し与えられていれば xlim で決まる.
”r” : まずデータ範囲を両側 4 % 広げ,次に範囲内でラベルがきれいに表示できる軸を見つける.
”i” : データ範囲内できれいに表示できる軸を見つける.
”s” : ラベルがきれいに表示できる軸で目盛内に収まるようなものを見つける (移植待ち) .
”e” : 軸を目盛内に収まるよう設定する.両端の目盛上にデータがある場合は一文字分軸を広げる (移植
待ち) .”s” を指定した場合に似ているが,bounding box 内に記号をプロットする分の余裕を確保す
る点が異なる.
”d” : 現在の軸を次の作図時にも用いるようにする.ユーザの直接指定を表す (移植待ち) .移植されれ
ば,まずこれを指定し,次に xaxp ,yaxp で目盛りの区切りを設定することが出来る.
par(xaxp) ,par(yaxp) : x,y 軸の目盛りの区切りを参照する.最初の二つが両端の目盛りの座標,最後の
値がその内側の区切りの個数を表す.値自体を変更してもあまり意味が無い.
xlog = F ,ylog = F : それぞれ対数 x 軸,対数 y 軸の使用を論理値で指定する.もし TRUE ならば対数軸
が使われる.新しいデバイスに対しては既定値は FALSE に設定される.
6.7 複数の図・重ねた図を描く
以下に出てくるパラメータの説明はグラフィックスパラメータと割り付けパラメータの節で扱っている.
6.7.1 準備
まず,画面 (デバイス) の外周の空白を指定するパラメータがどこにあるかを紹介する.
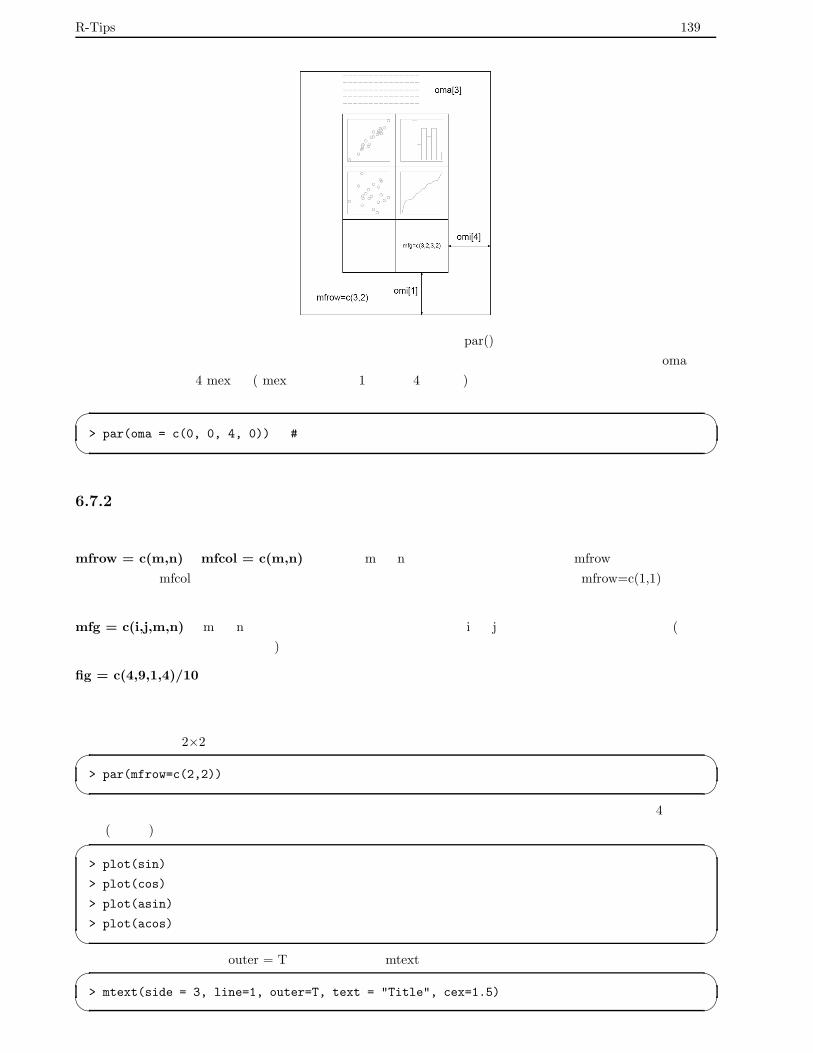
R-Tips 139頁
タイトルや注釈テキストを入れる場合で,空白を指定する場合は par() の引数に以下のパラメータを入れて指
定する.タイトルや注釈テキストを入れない場合は指定する必要は無い.ここで紹介する例では,まず oma で外
周を確保して上部に 4 mex 分 ( mex の初期値は 1 なので 4 文字分) のスペースをとる.これは全体のタイトル
を描く分のスペースである.� �> par(oma = c(0, 0, 4, 0)) # 下・左・上・右の順で余白を設定
� �
6.7.2 画面を分割して図を描く
画面を分割するパラメータは以下の様なものがある.
mfrow = c(m,n) ,mfcol = c(m,n): 画面が m 行 n 列の複数図表に分割される.mfrow で指定した場合は
行順に,mfcol で指定した場合は列順にグラフが描かれる.複数図表をやめるには mfrow=c(1,1) とすれば
よい.
mfg = c(i,j,m,n): m 行 n 列に複数図表を指定しているとして,i 行 j 列の場所に次のグラフを描く (順番に
図を描きたくない場合に使う).
fig = c(4,9,1,4)/10: そのぺーじにおける現在の図表の位置を指定するパラメータで,ページ内の任意の位置
に図表をおくためのものである.値は左下から図ったページの百分率としての左側・右側・底辺・上側の位
置である.例の値はページの右下に図を置くためのものである.
ここでは画面を 2×2 に分割する.� �> par(mfrow=c(2,2))
� �画面が分割できたら,それぞれのグラフを画面分割をしていない時と同じように,逐次図を描けば,4枚のグラ
フが (行順に) 一度に表示される出力が得られる.� �> plot(sin)
> plot(cos)
> plot(asin)
> plot(acos)
� �上を描き終わってから,outer = T と指定してから mtext を使うことで全体のタイトルを外周に書き込む.� �> mtext(side = 3, line=1, outer=T, text = "Title", cex=1.5)
� �
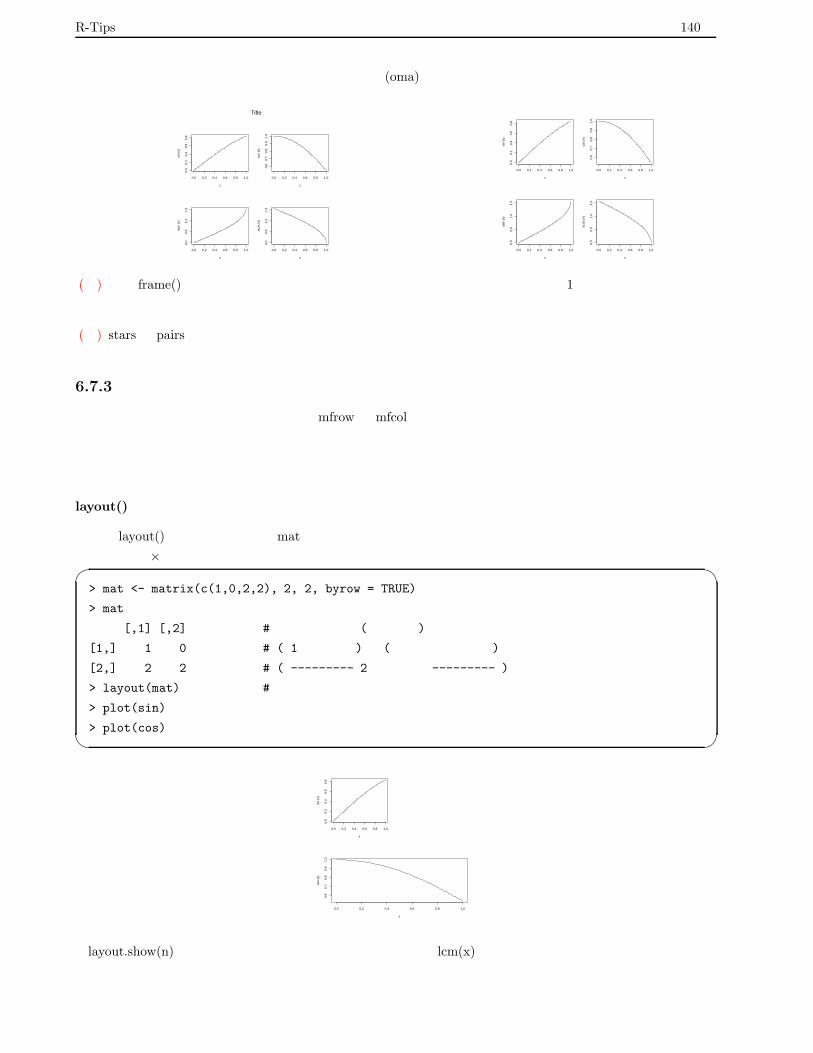
R-Tips 140頁
すると以下の左図のようになる.ここで最初の余白 (oma) を設定していなければ右図のようにタイトルがはみ
出すことになる.
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
x
sin
(x)
0.0 0.2 0.4 0.6 0.8 1.0
0.6
0.7
0.8
0.9
1.0
x
cos
(x)
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.5
1.0
1.5
x
asin
(x)
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.5
1.0
1.5
xac
os (
x)
Title
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
x
sin
(x)
0.0 0.2 0.4 0.6 0.8 1.0
0.6
0.7
0.8
0.9
1.0
x
cos
(x)
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.5
1.0
1.5
x
asin
(x)
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.5
1.0
1.5
x
acos
(x)
(注) 関数 frame() で図を消去すると図が消去されるが,このとき,図表番号の順番も 1 つ後に進んでいることに
注意したい.
(注) starsや pairsなど,内部で複数図表を用いている高水準作図関数は,複数図表と同時に使うことは出来ない.
6.7.3 少し高度な画面分割
上で紹介したグラフィックスパラメータ mfrow や mfcol を用いることで画面を複数に分割することが出来るの
だが,以下で紹介する関数を用いることで規則的な画面分割に限らず,自由に画面を分割することが出来るよう
になる.
layout()を用いた画面分割
関数 layout() を用いると,行列 mat で行数と列数を指定して画面を分割することが出来る.このとき画面は
『行列の行数 × 行列の列数』に分割され,行列の成分が作図の順番となる.� �> mat <- matrix(c(1,0,2,2), 2, 2, byrow = TRUE)
> mat
[,1] [,2] # このとき画面 (デバイス) は
[1,] 1 0 # ( 1 番目の図) (ここは空白のまま)
[2,] 2 2 # ( --------- 2 番目の図 --------- )
> layout(mat) # と分割される
> plot(sin)
> plot(cos)
� �
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
x
sin
(x)
0.0 0.2 0.4 0.6 0.8 1.0
0.6
0.7
0.8
0.9
1.0
x
cos
(x)
layout.show(n) でデバイス番号を確認することが出来,また lcm(x) で長さを指定することも出来る.
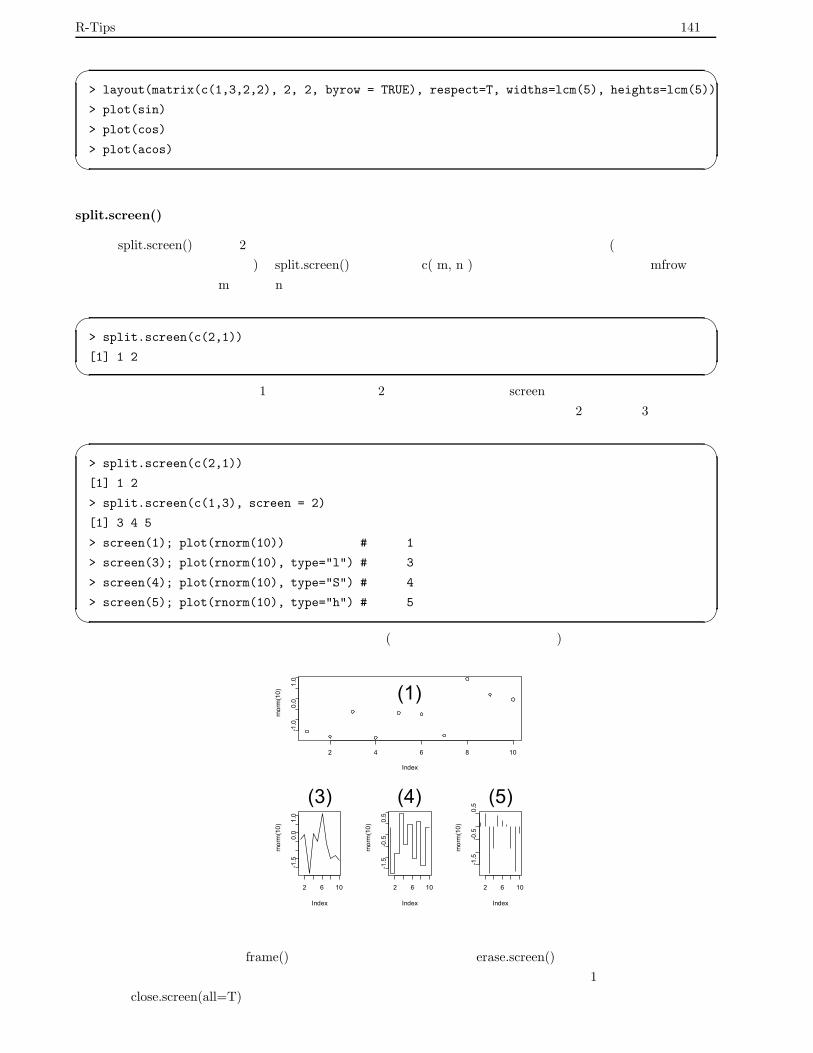
R-Tips 141頁
� �> layout(matrix(c(1,3,2,2), 2, 2, byrow = TRUE), respect=T, widths=lcm(5), heights=lcm(5))
> plot(sin)
> plot(cos)
> plot(acos)
� �
split.screen()を用いた画面分割
関数 split.screen() に長さ 2 のベクトルを引数に与えることで画面を分割することも出来る (行列を引数にして
も画面分割を行うことも出来る) .split.screen() にベクトル c( m, n ) を与えると,作図パラメー タ mfrow によ
る画面分割と同様に,縦 m 個,横 n 個に画面を分割することが出来る.例えば上下二つに画面を分割するには以
下のようにする.� �> split.screen(c(2,1))
[1] 1 2� �上記の例では上側が画面番号 1 ,下側が画面番号 2 になる.ここで引数 screen に分割する画面番号を指定す
ることによって,その画面をさらに分割することも出来る.例えば上の例で出来た画面 2 をさらに 3 つに分割し
てプロットすると以下のようになる.� �> split.screen(c(2,1))
[1] 1 2
> split.screen(c(1,3), screen = 2)
[1] 3 4 5
> screen(1); plot(rnorm(10)) # 画面 1 にプロット
> screen(3); plot(rnorm(10), type="l") # 画面 3 にプロット
> screen(4); plot(rnorm(10), type="S") # 画面 4 にプロット
> screen(5); plot(rnorm(10), type="h") # 画面 5 にプロット
� �以下の出力結果で括弧つきの番号は画面番号を表す (実際の出力には表示されない) .
画面消去をする場合は関数 frame() で消去することが出来る.関数 erase.screen() は図を消去するのではなく,
背景色で塗りつぶすだけなのでメモリを食うので使用は控えた方が良い.ここで,通常の 1 画面形式に戻る場合
は,関数 close.screen(all=T) を実行すればよい.

R-Tips 142頁
6.7.4 重ねた図を描く
単純な作図ならば,引数に add=T を入れることで重ねた図を描くことができる.� �> plot(sin, -pi, pi, xlab="x", ylab="y", lty=2)
> plot(cos, -pi, pi, add=T)
� �しかし,通常の高水準作図関数は add=T を引数にもってくることが出来ない.そこで,新たに作図する前に画
面を消去するか否かを指定するパラメータ new を指定することによって,重ねた図を描くことが出来る.例えば
以下のようにすると 2 つのプロットを重ね合わせることが出来る.二度目の plot() によって軸と軸のラベルが重
ね書きされるのを避けるため,axes=F , xlab=””,ylab=”” としていることに注意されたい.� �> plot(1:5,type="l")
> par(new=T)
> plot(rnorm(5), type="l", axes=F, xlab="", ylab="", lty=2)
� �また,以下のようにすることで,二度目の plot() が描くはずだった y 軸を図の右側の余白に描くことが出来る.� �> axis(side=4)
� �
1 2 3 4 5
12
34
5
Index
1:5
−1.
5−
1.0
−0.
50.
00.
51.
01.
5
この軸に対するラベルは以下のコマンドで描くことが出来る.� �> mtext(side=4, line=3, text="random plot")
� �凡例も付けることが出来る.位置は locator() で読み込めばよい.� �> legend(locator(1), legend=c("line", "random plot"), lty=1:2)
� �

第7章 統計解析篇
7.1 基本統計量
四則演算や初等数学関数は既に扱ったので,ここでは基本的な統計量を求める関数を紹介する.
7.1.1 総和・平均・中央値
データの総和,平均,中央値,クォンタイル点,4 分位偏差 (第 3 四分位数から第 1 四分位数を引いた値),5
数要約 ( 『最小値・下側ヒンジ・中央値・上側ヒンジ・最大値』のベクトル) はそれぞれ関数 sum() ,mean() ,
median() ,quantile() ,IQR() ,fivenum() で求める.� �> x <- runif(10)
> x
[1] 0.960081136 0.004685302 0.218082140 0.388709308 0.195903633 0.381514692
[7] 0.247954824 0.463938469 0.021061223 0.869638253
> sum(x)
[1] 3.751569
> quantile(x, prob=0.8, name=F) # 下から確率 0.8の位置にあるデータ
[1] 0.5450784
> fivenum(x) # 最小値・下側ヒンジ・中央値・上側ヒンジ・最大値
[1] 0.004685302 0.195903633 0.314734758 0.463938469 0.960081136� �
7.1.2 不偏分散と分散・標準偏差
データの不偏分散は関数 var() で求める.この関数 var() は不偏分散を求める関数であって,分散を求める関数
ではないことに注意.すなわち,データ x のデータ数を n ,平均を求める関数を E() とすると,var(x) は以下を
求めている.
var(x) =n
n− 1
[
E(x2) − {E(x)}2]
そこで普通の分散 (標本分散) を求める場合は var() の結果を (n-1)/n 倍する必要がある.� �> x <- c(5,5,5,5,10)
> var(x) # 不偏分散
[1] 5
> variance <- function(x) var(x)*(length(x)-1)/length(x) # 分散を求める関数を定義
> variance(x)
[1] 4
> sqrt(variance(x)) # 標準偏差
[1] 2� �

R-Tips 144頁
7.1.3 分散共分散行列・相関行列
2 次元以上のデータに対する不偏共分散,不偏共分散行列も関数 var() で求めることが出来る.引数は 1 次元
データを 2 つ与えても,行列を与えても,どちらでも良い.この関数 var() は不偏共分散,不偏共分散行列を求め
る関数であって,普通の共分散,共分散行列を求める関数ではないことに注意.つまり 2 次元の場合ならば,デー
タ x ( y ) のデータ数を n ,平均を求める関数を E() とすると,var(x, y) は
var(x, y) =1
n− 1
∑
{x− E(x)}{y − E(y)}
を求めている.そこで普通の共分散 (標本共分散) を求める場合は var() の結果を (n-1)/n 倍する必要がある.
また,相関係数,相関行列は関数 cor() で求めることが出来る.引数は 1 次元データを 2 つ与えても,行列を
与えても,どちらでも良い.� �> x <- c(168,178,164,172,172,170,162,169,176,173,166,167,170,183,169)
> y <- c(56,64,53,63,61,59,57,60,70,57,62,56,53,93,52)
> var(x,y)
[1] 42.6
> cor(x,y)
[1] 0.7815054� �偏相関行列は以下の関数を定義することで求めることが出来る.� �> my.cor <- function(x) {
+ tmpcor <- cor(x)
+ if (det(tmpcor) != 0) sol <- solve(tmpcor)
+ else {
+ library(MASS)
+ sol <- ginv(tmpcor)
+ }
+ d <- diag(sol)
+ sol <- -sol/sqrt(outer(d,d))
+ rownames(sol) <- paste("Var", 1:ncol(x))
+ colnames(sol) <- paste("Var", 1:ncol(x))
+ return(sol)
+ }
> x <- matrix(c(1:9), ncol=3, byrow=T)
> my.cor(x)
Var 1 Var 2 Var 3
Var 1 -1 -1 -1
Var 2 -1 -1 -1
Var 3 -1 -1 -1� �
7.1.4 データの規準化
各列が変量となっているデータ行列 x の各変量の単位が異なる場合に,各変量を平均が 0 ,分散が 1 になるよ
うに変換することがある.これを規準化または標準化という.関数 scale(x) を用いることで,データ行列 x を標
準化することが出来る.標準化は平均を 0 にするためのセンタリング (それぞれの変量からその変量の平均を引
く) ,分散を 1 にするためのスケーリング (それぞれの変量をその変量の標準偏差で割る) の 2 つの操作によって
行なわれる.なお,スケーリングを行う際には,センタリングを行なった後の標準偏差が使われる.

R-Tips 145頁
� �> x <- c(168,178,164,172,172,170,162,169,176,173,166,167,170,183,169)
> scale(x)
[,1]
[1,] -0.4795122
[2,] 1.3647656
[3,] -1.2172233
..............
[15,] -0.2950844
> attr(,"scaled:center")
[1] 170.6
> attr(,"scaled:scale")
[1] 5.422177� �(注) 関数 scale() に center=F と指定することによってセンタリングを抑制することが出来,scale=F と指定す
ることによってスケーリングを抑制することが出来る.
7.2 確率分布と乱数
R ではさまざまな理論分布の確率密度 f(x),累積分布 P (X ≤ x) ,確率点min{x : P (X ≤ x) > q} ,及びその分布に従う乱数を求めることが出来る.
7.2.1 関数の使い方
後に紹介する分布のコード名を実際に使うには,以下のような対応表を用いればよい.
用途 関数名 (コード名:xxx ) 説明
確率密度 (pdf) dxxx(q) q は確率点を表す.例えばコード名が norm ならば dnorm(q)
となる.
累積分布 (cdf) pxxx(q) q は確率点を表す.例えばコード名が norm ならば pnorm(q)
となる.
確率点 (quantile) qxxx(p) p は確率を表す.例えばコード名が norm ならば qnorm(p) と
なる.
乱数 rxxx(n) n は生成する乱数の個数を表す.例えばコード名が norm なら
ば rnorm(n) となる.
上は,コード名が xxx である分布の確率点は“qxxx”で求めることが出来ることを表す.例えば t 分布ならば,
この累積分布は pt ,確率点は qt で求めることが出来る.これらの値を利用すれば検定を行なうことが出来る.
binom についての書式は以下の通り.� �dbinom(x, size, prob, log = FALSE)
pbinom(q, size, prob, lower.tail = TRUE, log.p = FALSE)
qbinom(p, size, prob, lower.tail = TRUE, log.p = FALSE)
rbinom(n, size, prob)
� �x, q : quantile のベクトル
p : 確率ベクトル
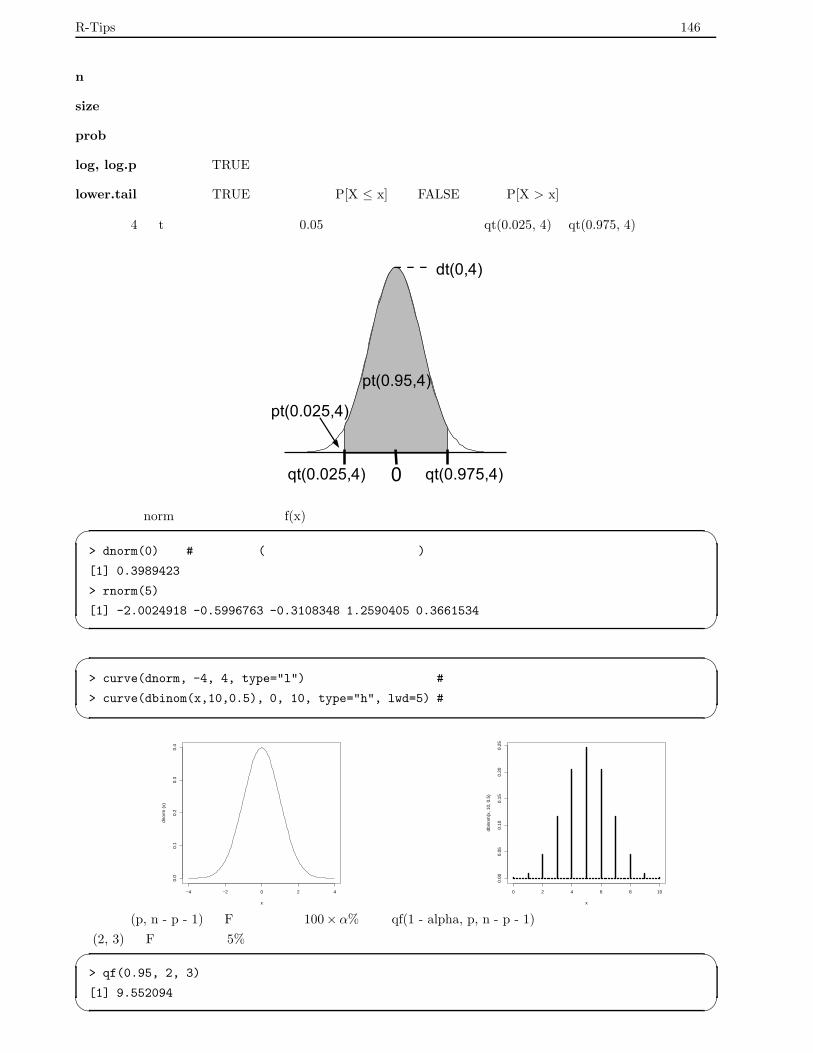
R-Tips 146頁
n : 観測の数
size : 試行数
prob : 成功の確率
log, log.p : 論理値.TRUE ならば対数を取ったものが返される.
lower.tail : 論理値.TRUE ならば確率は P[X ≤ x] で,FALSE ならば P[X > x] .
自由度 4 の t 分布において有意水準 0.05 で両側検定を行なう場合は qt(0.025, 4) ,qt(0.975, 4) として確率点
を求めれば良いことが分かる.
正規分布 norm について確率密度 f(x) ,その分布に従う乱数を求めるには以下の様にすればよい.� �> dnorm(0) # 確率密度 (離散分布の場合は確率関数)
[1] 0.3989423
> rnorm(5)
[1] -2.0024918 -0.5996763 -0.3108348 1.2590405 0.3661534� �また,確率密度のグラフを描くには以下のようにする.� �> curve(dnorm, -4, 4, type="l") # 正規分布
> curve(dbinom(x,10,0.5), 0, 10, type="h", lwd=5) # 二項分布
� �
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
dnor
m (
x)
0 2 4 6 8 10
0.00
0.05
0.10
0.15
0.20
0.25
x
dbin
om(x
, 10,
0.5
)
自由度 (p, n - p - 1) の F 分布の上側 100× α%点は qf(1 - alpha, p, n - p - 1) で求められるので,例えば自由
度 (2, 3) の F 分布の上側 5% 点は以下の様にして求めることが出来る.� �> qf(0.95, 2, 3)
[1] 9.552094� �

R-Tips 147頁
7.2.2 Rに用意されている確率分布
R では以下の理論分布が用意されている.ただし,スチューデント化された分布は qtukey (確率点) と ptukey
(累積分布) を求める関数のみしか用意されていない.
分布名 コード名 パラメータ
ベータ分布 beta shape1, shape2, ncp
二項分布 binom size, prob
コーシー分布 cauchy location, scale
カイ二乗分布 chisq df, ncp
指数分布 exp rate
F分布 f df1, df2, ncp
ガンマ分布 gamma shape, scale
幾何分布 geom prob
超幾何分布 hyper n, m, k
対数正規分布 lnorm meanlog, sdlog
ロジスティック分布 logis location, scale
負の二項分布 nbinom size, prob
正規分布 norm mean, sd
ポアソン分布 pois lambda
t 分布 t df, ncp
一様分布 unif min, max
スチューデント化された分布 tukey nmeans, df
ワイブル分布 weibull shape, scale
ウィルコクソン wilcox m, n
7.2.3 乱数の再現:関数 set.seed()
疑似乱数は R 起動時に初期化され,毎回異なった乱数が発生される (ちなみに R は脅威のメルセンヌ・ツイス
ター法により一様乱数を生成している) .乱数を再現したい場合は,乱数の種を関数 set.seed() で指定すればよい.� �> runif(5) # 一様乱数を 5 個生成すると
[1] 0.8039566 0.6593698 0.8120159 0.1279622 0.1115031
> runif(5) # 当然毎回違った乱数が得られる
[1] 0.5694816 0.4504077 0.1823374 0.4573758 0.9061499
> set.seed(101); runif(5) # 乱数の種 (seed)を指定
[1] 0.37219838 0.04382482 0.70968402 0.65769040 0.24985572
> set.seed(101); runif(5) # 乱数の種を同じにすれば乱数を再現することが出来る
[1] 0.37219838 0.04382482 0.70968402 0.65769040 0.24985572� �
7.2.4 3変量分布の乱数
3変量正規乱数
まず,3 変量正規分布に従う乱数を生成する関数 r3norm() を定義する.

R-Tips 148頁
� �r3norm <- function(mu, A, n) {
U <- svd(A)$u
V <- svd(A)$v
D <- diag(sqrt(svd(A)$d))
B <- U %*% D %*% t(V) # 行列 A の平方根
w <- c()
for (i in 1:n)
w <- append(w, list(mu + B%*%cbind(rnorm(3))))
return(w)
}
> mu <- cbind(c(1,1,1)) # 平均ベクトル (縦ベクトル)
> A <- array(c(2,1,1,1,2,1,1,1,2), dim=c(3,3))
> w <- r3norm(mu, A, 2000)
� �
3変量 t乱数
アルゴリズムを書く代わりに命題みたいなものを示す.
R: 自由度mのカイ二乗分布に従う確率変数
Z: p変量正規分布 N(0,Ip)に従う確率ベクトル(独立な標準正規乱数がズラッと縦に並んでいる)
V: 正定値対称行列(ちらばりを表す行列で分散共分散行列とは少し異なるもの)
V = C%*%t(C): コレスキー分解
X = sqrt(m/R)*Z p変量楕円 t分布met(p,m,0,Ip)に従う
Y = µ+C%*%X p変量楕円 t分布met(p,m,µ,V)に従う
次に,3 変量楕円 t 分布に従う乱数を生成する関数 met3() を定義する.� �met3 <- function(m, mu, V, n) {
# m : 自由度, mu : 平均ベクトル, V : 散らばり行列, n : 乱数の個数
U <- svd(V)$u
V1 <- svd(V)$v
D <- diag(sqrt(svd(V)$d))
B <- U %*% D %% t(V1)
w <- c()
for (i in 1:n) {
R <- 0
for (j in 1:m) {
R <- R + rnorm(1)^2
}
w <- append(w, list(mu + B %*% (cbind(rnorm(3))*sqrt(m/R))))
}
return(w)
}� �

R-Tips 149頁
この分布の平均ベクトルは µ,分散共分散行列はm/(m− 2) ∗ V (m > 2)なので,多変量楕円 t乱数がうまく
出来ているかどうかはこれで確かめることが出来る.� �> mu <- cbind(c(1,1,1))
> V <- array(c(2,1,1,1,2,1,1,1,2), dim=c(3,3))
> n <- 1000
> w <- met3(5, mu, V, n)
> sm <- 0
> for (i in 1:n) { sm <- sm + w[[i]] }
> sm <- sm/n
> sv <- 0
> for (i in 1:n) { sv <- sv + (w[[i]]-sm) %*% t(w[[i]]-sm) }
> sv <- sv/n� �
7.2.5 逆関数法による乱数の作り方
上に紹介している分布に無い分布に従う乱数を生成したくなる場合がある.まず,U を一様分布に従う確率変
数とし,X = F−1(U)は
P (X ≤ x) = P (F−1(U) ≤ x) = P (U ≤ F (x)) = F (x)
となることよりX は分布関数 F に従う.よって,分布関数の逆関数の引数に一様乱数を入れてやれば欲しい分布
の乱数が得られる.
例えば,指数分布の分布関数 F (x) = 1 − exp(−x)の逆関数は − log(1 − x)なので,X = − log(1 − U)とすれ
ばX は平均 1 の指数分布に従う.さらに,1−U と U は同分布なので,X = − log(U)の U に一様乱数を入れて
やることで平均 1 の指数乱数が得られる (ただし x > 0) .
また,ラプラス分布 (両側指数分布) の密度関数は f(x) = 1/2 exp(−|x|)だが,この場合は一様乱数 U1, U2を
生成し,U1が 1/2以上ならば− log(U2)を,U1が 1/2未満ならば log(U1)を採択すればラプラス分布に従う乱数
が得られる.
7.2.6 棄却法による乱数の作り方
逆関数法は理論的には正しい方法なのだが,コンピュータは有限な値しか生成できないので,無限のサポート
を持っている分布の裾の方の乱数の精度が悪くなる場合がある (例:棄却法で生成した指数乱数) ,そこで以下に棄
却法による乱数生成の方法を紹介する.用いる関数を先に説明する.
f(x) : 生成したい乱数が従う分布の密度関数
g(x) : 乱数生成が容易な分布の密度関数
c(≥ 1) : f(x) ≤ c · g(x) が成り立つ定数 (小さい方が良い)
h(x) : = f(x)/{c · g(x)}
生成するアルゴリズムはこちら.
(1) u < − runif(1)
(2) v < − g(x)に従う乱数
(3) u ≤ h(v) ならば v を乱数として採択する
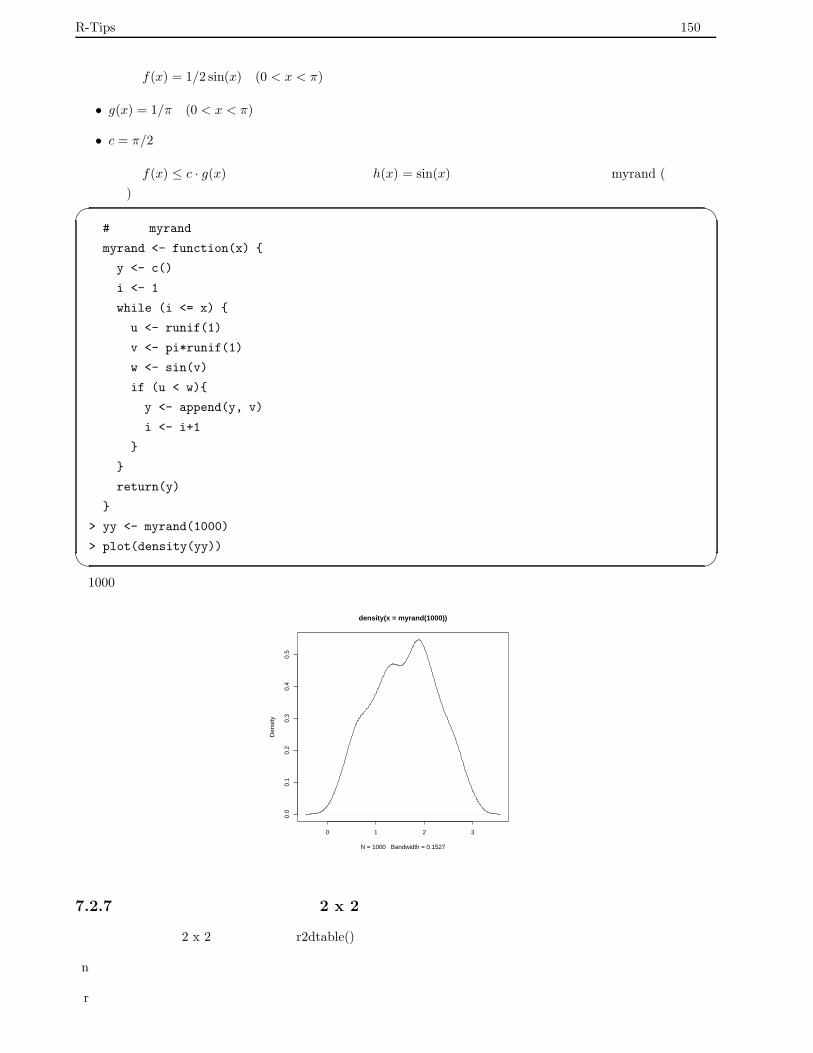
R-Tips 150頁
例として f(x) = 1/2 sin(x) (0 < x < π) という分布に従う乱数を生成することを考える.このとき
• g(x) = 1/π (0 < x < π)
• c = π/2
とおくと f(x) ≤ c · g(x)が成り立ち,この場合は h(x) = sin(x)となる.よって以下の関数 myrand (生成する
乱数の数) で生成することが出来る.� �# 関数 myrand を定義
myrand <- function(x) {
y <- c()
i <- 1
while (i <= x) {
u <- runif(1)
v <- pi*runif(1)
w <- sin(v)
if (u < w){
y <- append(y, v)
i <- i+1
}
}
return(y)
}
> yy <- myrand(1000)
> plot(density(yy))
� �1000個生成した乱数の概要はこちら.
0 1 2 3
0.0
0.1
0.2
0.3
0.4
0.5
density(x = myrand(1000))
N = 1000 Bandwidth = 0.1527
Den
sity
7.2.7 周辺和を与えたランダムな 2 x 2 分割表
周辺和を与えて 2 x 2 分割表を関数 r2dtable() で作成することが出来る.引数は以下の通り.
n :生成する分割表の数
r :行和を与えるベクトル

R-Tips 151頁
c :列和を与えるベクトル (c、r の総和は一致する必要)
返り値は『行・列和がそれぞれ r,c であるランダムな 2x2 分割表 n 個のリスト」となる.� �> x <- r2dtable(2, c(10,10), c(15,5))
> x
[[1]]
[,1] [,2]
[1,] 8 2
[2,] 7 3
[[2]]
[,1] [,2]
[1,] 6 4
[2,] 9 1
� �
7.2.8 ランダム抽出・ブートストラップサンプリング
長さ n の与えられたベクトルの要素から長さ m の部分ベクトルをランダムに取り出すには関数 sample() を用
いることで実現出来る.� �> x <- 1:n # 1:n の代わりに単に n としても良い
> sample(x,m,replace=TRUE) # 同じ要素が選ばれても良い
> sample(x,m,replace=FALSE) # 同じ要素は選ばれ無い (既定動作)
> sample(x) # 特に m=n とするとランダムな置換になる
> sample(c(0,1), 100, replace = TRUE) # 100個のベルヌーイ試行
> p <- runif(n); p <- p/sum(p) # オプションの確率ベクトルを与えると
> sample(x,m,replace=TRUE,prob=p) # 各要素が選ばれる確率を指定できる (既定値は等確率 1/n)
� �オプションの確率ベクトルを与えると,各要素が選ばれる確率を指定することが出来る (既定値は等確率 1/n ) .� �> p <- runif(n); p <- p/sum(p)
> sample(x,m,replace=TRUE,prob=p)
� �
7.3 データの分布とヒストグラム・密度推定
7.3.1 データの分布
まず,データの要素をグループ化するには,順序無し因子を生成する関数 factor() を使い,関数 table() を用い
ることで度数分布表を作ることが出来る.� �> data(warpbreaks) # 1台の織機当たりの反り破損の数
> attach(warpbreaks) # 使うデータを固定
> fc <- factor(tension) # 要素をグループ化
> levels(fc) # グループ化されているかを確認
[1] "L" "M" "H"� �

R-Tips 152頁
� �> table(fc) # グループ化したデータ fc に関する度数分布表
fc
L M H
18 18 18� �関数 cut() と組み合わせると,以下の様なことも出来る.� �> tb <- factor(cut(breaks, breaks = 10+10*(0:6)))
> table(tb, fc)
fc
tb L M H
(10,20] 3 6 8
(20,30] 7 7 7
(30,40] 1 4 1
(40,50] 2 1 1
(50,60] 3 0 0
(60,70] 2 0 0
� �また,データの平均や分散を計算する場合は関数 tapply() を用いる.tapply() の書式と例は以下の通り.� �tapply(数値ベクトル,数値ベクトルと同じ長さの文字列ベクトル,適用したい関数)
> mymeans <- tapply(breaks, fc, mean) # breaks の平均をグループごとに計算
> mymeans
L M H
36.38889 26.38889 21.66667
> sder <- function(x) sqrt(var(x)/length(x)) # 標本標準偏差を求める関数を定義して
> mysd <- tapply(breaks, fc, sder) # グループごとに計算することも出来る
> mysd
L M H
3.876474 2.149843 1.968709� �ところで,データの集合の要約は関数 summary() と fivenum() で,度数表示は stem() で知ることが出来る.
stem() は,stem(z, x) で幹の長さが既定値 (=1)の x 倍になる.� �> stem(breaks)
The decimal point is 1 digit(s) to the right of the |
1 | 0234555667788899
2 | 001111445666678889999
3 | 00156699
4 | 1234
5 | 124
6 | 7
7 | 0� �
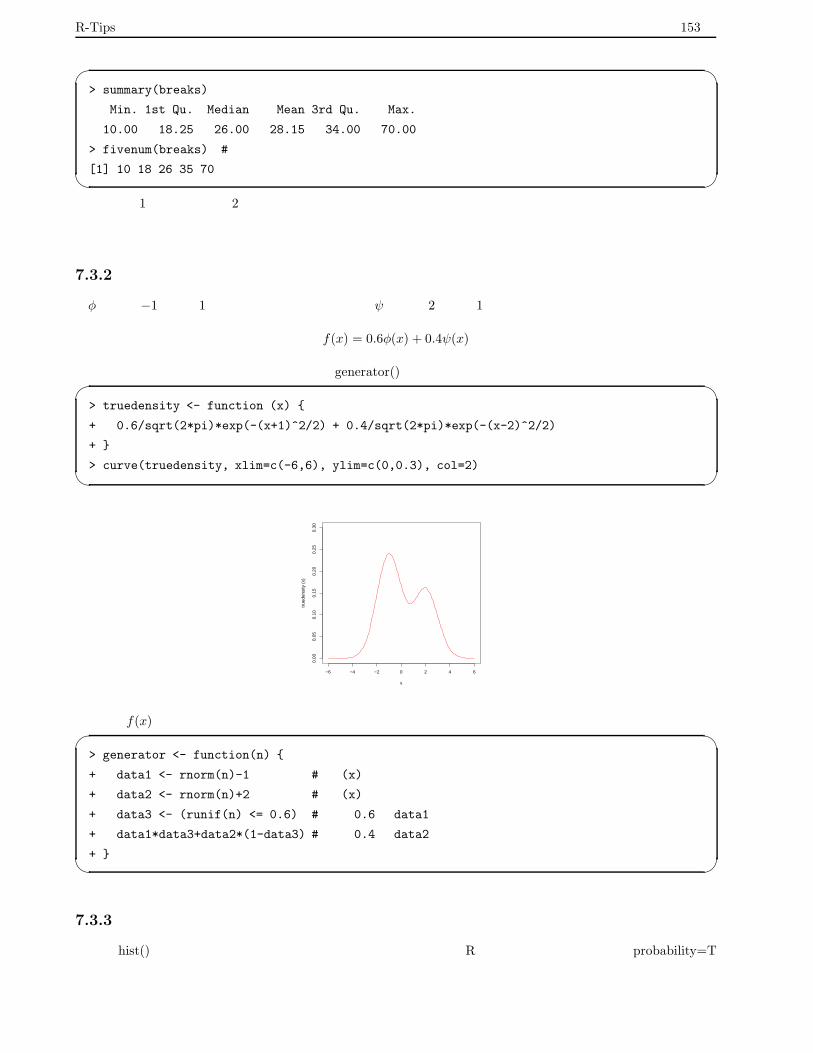
R-Tips 153頁
� �> summary(breaks)
Min. 1st Qu. Median Mean 3rd Qu. Max.
10.00 18.25 26.00 28.15 34.00 70.00
> fivenum(breaks) # 最小値・下側ヒンジ・中央値・上側ヒンジ・最大値
[1] 10 18 26 35 70� �しかし,1 次元データや 2 次元データならば視覚的に見た方がデータの特徴をつかみやすい場合が多い.そこ
でヒストグラムと密度推定の方法を以下で述べることにする.
7.3.2 真の密度とデータの準備
φを平均−1,分散 1の正規分布に従う確率変数,ψを平均 2,分散 1の正規分布に従う確率変数として
f(x) = 0.6φ(x) + 0.4ψ(x)
となる密度から得られる乱数を生成する関数 generator() を定義する.� �> truedensity <- function (x) {
+ 0.6/sqrt(2*pi)*exp(-(x+1)^2/2) + 0.4/sqrt(2*pi)*exp(-(x-2)^2/2)
+ }
> curve(truedensity, xlim=c(-6,6), ylim=c(0,0.3), col=2)
� �
−6 −4 −2 0 2 4 6
0.00
0.05
0.10
0.15
0.20
0.25
0.30
x
true
dens
ity (
x)
次に,f(x)に従う乱数を生成する関数を定義する.� �> generator <- function(n) {
+ data1 <- rnorm(n)-1 # φ (x) に従う乱数
+ data2 <- rnorm(n)+2 # ψ (x) に従う乱数
+ data3 <- (runif(n) <= 0.6) # 確率 0.6で data1を採択し,
+ data1*data3+data2*(1-data3) # 確率 0.4で data2を採択するための手続
+ }� �
7.3.3 ヒストグラムによる密度推定
関数 hist() でヒストグラムを表示することも出来る.区切り幅は R が適当に選択してくれる.probability=T
と指定することによって相対度数で作図するように変更することが出来る.
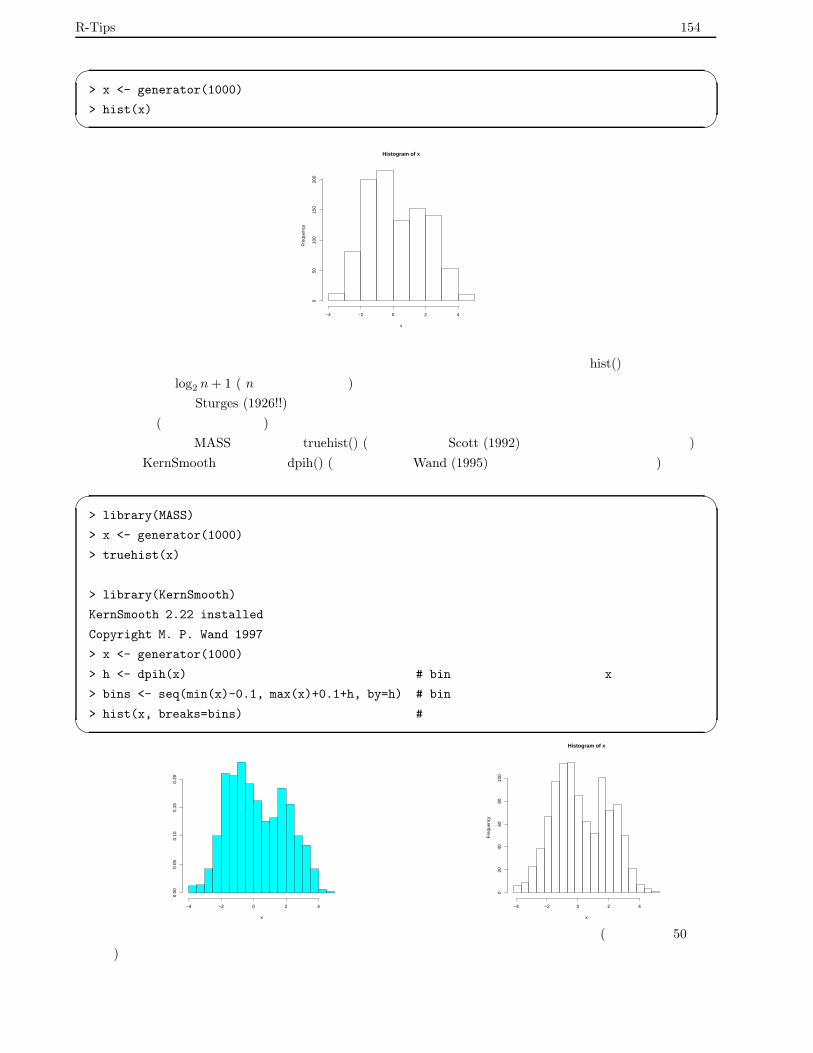
R-Tips 154頁
� �> x <- generator(1000)
> hist(x)� �
Histogram of x
x
Fre
quen
cy
−4 −2 0 2 40
5010
015
020
0
区切り幅は『適当に選択される』が『適切に選択される』わけではない.というのも,hist() のデフォルトは
『データの範囲を log2 n+ 1 ( n はデータの個数) 個の階級に分割して各階級に属するデータの数を棒グラフとし
て作図する』という Sturges (1926!!) の方法を用いているため,まず平滑化をし過ぎる嫌いがあり,さらにデー
タが正規分布 (正確には二項分布) から遠ざかれば遠ざかるほど当てはめが悪くなる.
そこでパッケージ MASS にある関数 truehist() (この関数では Scott (1992) が提唱した方法を用いている) や,
パッケージ KernSmooth にある関数 dpih() (この関数では Wand (1995)が提唱した方法を用いている) を用いる
ことで,より正確なヒストグラムを描くことが出来る.� �> library(MASS)
> x <- generator(1000)
> truehist(x)
> library(KernSmooth)
KernSmooth 2.22 installed
Copyright M. P. Wand 1997
> x <- generator(1000)
> h <- dpih(x) # bin には区切り幅の点を表す x 座標を指定
> bins <- seq(min(x)-0.1, max(x)+0.1+h, by=h) # bin が等差数列でなければ区切り幅の横幅
> hist(x, breaks=bins) # もバラバラな長さになる� �
−4 −2 0 2 4
0.00
0.05
0.10
0.15
0.20
x
Histogram of x
x
Fre
quen
cy
−4 −2 0 2 4
020
4060
8010
0
ただし,ヒストグラムは左端の端点の位置によって形が変わってしまうという欠点がある (データ数が 50 未満
の場合) .
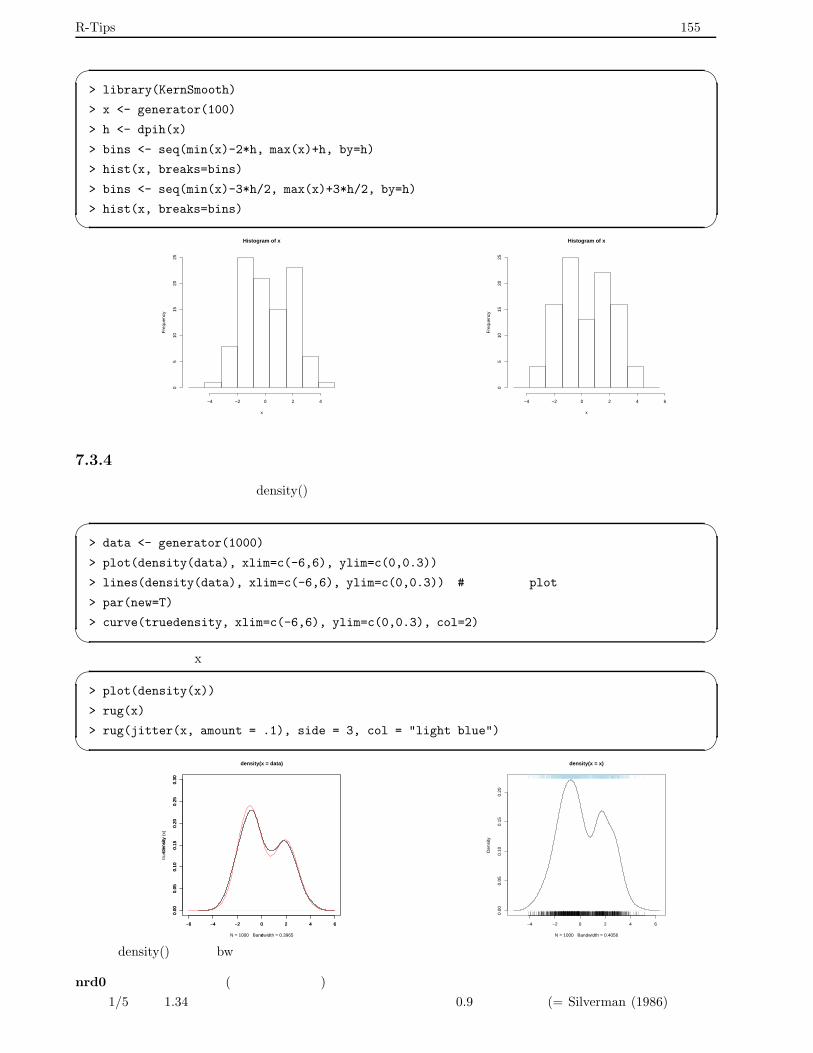
R-Tips 155頁
� �> library(KernSmooth)
> x <- generator(100)
> h <- dpih(x)
> bins <- seq(min(x)-2*h, max(x)+h, by=h)
> hist(x, breaks=bins)
> bins <- seq(min(x)-3*h/2, max(x)+3*h/2, by=h)
> hist(x, breaks=bins)
� �Histogram of x
x
Fre
quen
cy
−4 −2 0 2 4
05
1015
2025
Histogram of x
x
Fre
quen
cy
−4 −2 0 2 4 6
05
1015
2025
7.3.4 カーネルによる推定
前述のデータについて,関数 density() で密度推定することも出来る.この関数は与えられたカーネル関数とバ
ンド幅を用いて密度関数推定を行う.ここでは,上のヒストグラムに上書きすることにする.� �> data <- generator(1000)
> plot(density(data), xlim=c(-6,6), ylim=c(0,0.3))
> lines(density(data), xlim=c(-6,6), ylim=c(0,0.3)) # ここでは plot と同じ働き
> par(new=T)
> curve(truedensity, xlim=c(-6,6), ylim=c(0,0.3), col=2)
� �データに対応する x 軸上の点に縦線で印を付ける場合は以下のようにする.� �> plot(density(x))
> rug(x)
> rug(jitter(x, amount = .1), side = 3, col = "light blue")
� �
−6 −4 −2 0 2 4 6
0.00
0.05
0.10
0.15
0.20
0.25
0.30
density(x = data)
N = 1000 Bandwidth = 0.3965
Den
sity
−6 −4 −2 0 2 4 6
0.00
0.05
0.10
0.15
0.20
0.25
0.30
x
true
dens
ity (
x)
−4 −2 0 2 4 6
0.00
0.05
0.10
0.15
0.20
density(x = x)
N = 1000 Bandwidth = 0.4056
Den
sity
関数 density() の引数 bw には以下を指定することが出来る.
nrd0 : 平滑化カーネル (ガウスカーネル) の標準偏差になるようにスケール化される.その既定値は標本数の
1/5 乗の 1.34 倍で割った標準偏差と四分偏差の小さい方を 0.9 倍したもの (= Silverman (1986) の 『経
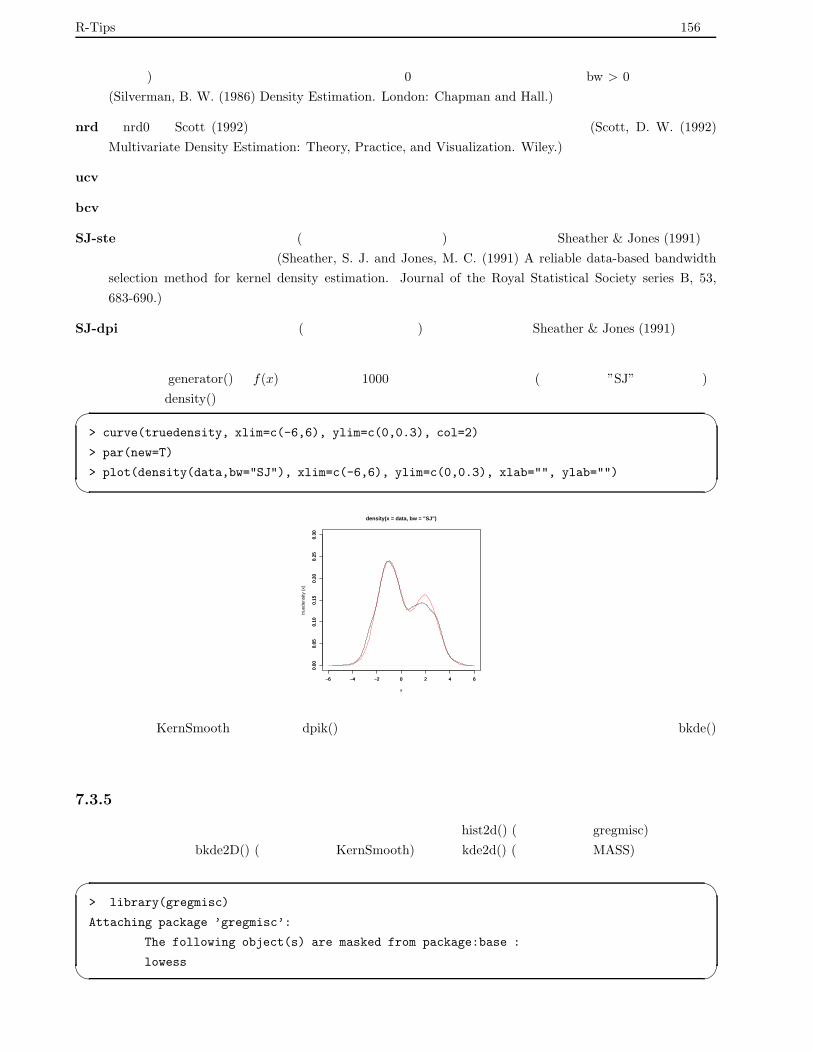
R-Tips 156頁
験則』) でバンド幅を選択する.ただし四分偏差が 0の場合は除かれ,このときは bw > 0 が保証される.
(Silverman, B. W. (1986) Density Estimation. London: Chapman and Hall.)
nrd : nrd0 を Scott (1992) の方法により一般的したものを用いてバンド幅を選択. (Scott, D. W. (1992)
Multivariate Density Estimation: Theory, Practice, and Visualization. Wiley.)
ucv : バイアス無しのクロスバリデーション規準によりバンド幅を選択.
bcv : バイアス付きのクロスバリデーション規準によりバンド幅を選択.
SJ-ste : パイロット評価を使用して (方程式を解くことにより) 帯域幅を選択する Sheather & Jones (1991)の
方法でバンド幅を選択する.(Sheather, S. J. and Jones, M. C. (1991) A reliable data-based bandwidth
selection method for kernel density estimation. Journal of the Royal Statistical Society series B, 53,
683-690.)
SJ-dpi : パイロット評価を使用して (プラグイン法により) 帯域幅を選択する Sheather & Jones (1991)の方法
でバンド幅を選択する.
前で定義した generator() で f(x)に従う乱数を 1000 個生成して密度推定した (バンド幅は ”SJ” により選択) .
真の密度を赤,density() で推定した密度を黒としてプロットしている.� �> curve(truedensity, xlim=c(-6,6), ylim=c(0,0.3), col=2)
> par(new=T)
> plot(density(data,bw="SJ"), xlim=c(-6,6), ylim=c(0,0.3), xlab="", ylab="")
� �
−6 −4 −2 0 2 4 6
0.00
0.05
0.10
0.15
0.20
0.25
0.30
x
true
dens
ity (
x)
−6 −4 −2 0 2 4 6
0.00
0.05
0.10
0.15
0.20
0.25
0.30
density(x = data, bw = "SJ")
パッケージ KernSmooth にある関数 dpik() ならば,もっとデータに合わせた推定を行う.他にも関数 bkde()
などが用意されている.
7.3.5 二次元データの密度推定
二次元データの当てはめを行う場合は,頻度ポリゴンを描く関数 hist2d() (パッケージ:gregmisc) ,カーネル
密度推定を行う関数 bkde2D() (パッケージ:KernSmooth) ,関数 kde2d() (パッケージ:MASS) などが用意さ
れている.� �> library(gregmisc)
Attaching package ’gregmisc’:
The following object(s) are masked from package:base :
lowess� �

R-Tips 157頁
� �> x <- rnorm(2000, sd=4) # データ:無相関な 2変量正規乱数
> y <- rnorm(2000, sd=1) # 遠近法プロット (persp) のためのデータを
> # hist2d() を使用して作成
> h2d <- hist2d(x, y, show=FALSE, same.scale=TRUE, nbins=c(20,30))
> persp( h2d$x, h2d$y, h2d$counts,
+ ticktype="detailed", theta=60, phi=30,
+ expand=0.5, shade=0.5, col="cyan", ltheta=-30)
> library(MASS) # 関数 width.SJ() を使うので MASS を呼び出し
> library(KernSmooth) # 関数 bkde2D() を使うので KernSmooth を呼び出し
> x <- rnorm(2000, sd=4) # データの準備
> y <- rnorm(2000, sd=1) # データの準備
> f1 <- bkde2D(cbind(x, y), bandwidth=c(width.SJ(x), width.SJ(y)))
> persp(f1$fhat, phi = 30, theta = 20, d = 5)
� �
h2d$x
−10
−5
0
5
10
h2d$y
−10
−5
0
5
10
h2d$counts
0
20
40
60
f1$fhat
Y
Z
7.3.6 lowess() による平滑化
関数 lowess() によってデータの平滑化を行うことも出来る.lowess() は平滑結果の座標を与える成分 x と y の
リストを返す.平滑化は関数 lines() を用いて元の散布図に追加することが出来る.書式は以下の通り.� �lowess(x, y, f=2/3, iter=3, delta=.01*diff(range(x)))
� �引数の説明は以下の通り.
x ,y : 散布図中のプロットの座標を与えるベクトル.単一のプロット構造を指定しても良い.
f : 平滑幅.これは各位置での平滑に影響を及ぼすプロットの点の割合を与える.値が大きい程より滑らかになる.
iter : 実行されるべき頑健化繰り返しの数.小さな iter の値は lowess の実行を速くする.
delta : 互いに距離 delta 以内に位置する x の値は lowess の出力で単一の値に置き換えられる.
以下に使用例を示す.
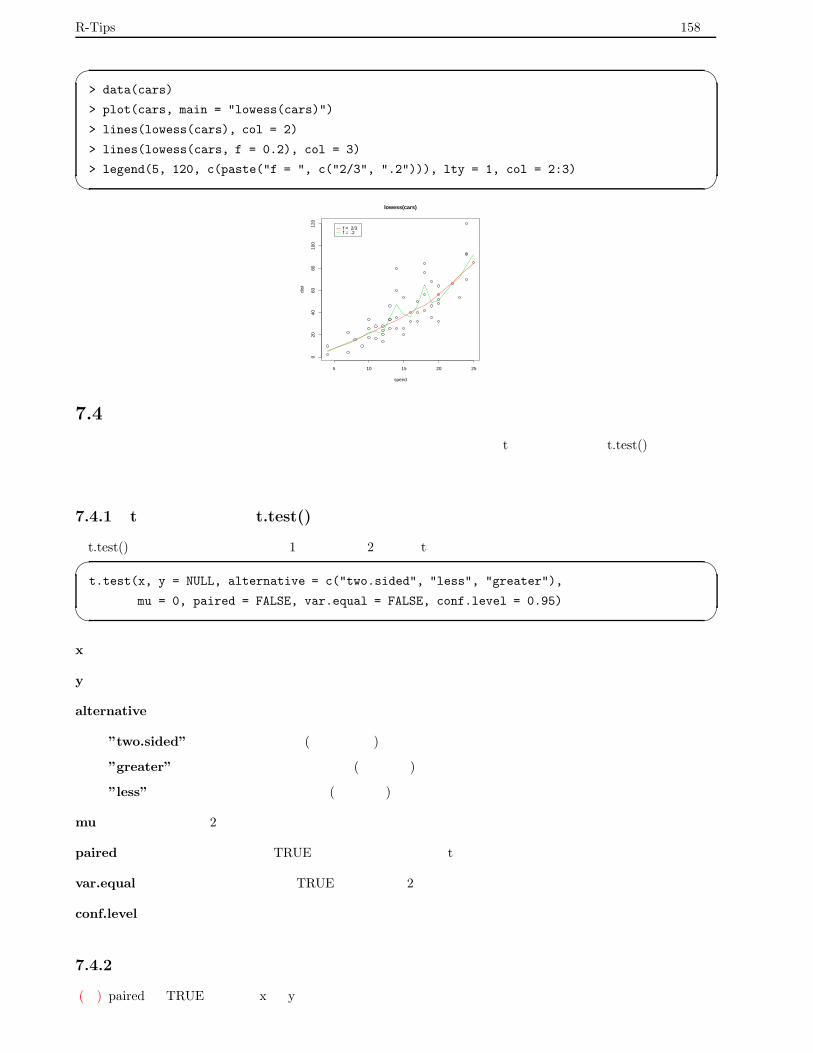
R-Tips 158頁
� �> data(cars)
> plot(cars, main = "lowess(cars)")
> lines(lowess(cars), col = 2)
> lines(lowess(cars, f = 0.2), col = 3)
> legend(5, 120, c(paste("f = ", c("2/3", ".2"))), lty = 1, col = 2:3)
� �
5 10 15 20 25
020
4060
8010
012
0
lowess(cars)
speed
dist
f = 2/3f = .2
7.4 検定結果の見方
慣れないうちは検定結果を見てもよく分からないことがある.ここでは t 検定を行う関数 t.test() を例に出し
て,検定例とその結果の出力について説明していく.
7.4.1 t 検定を行う関数 t.test() について
t.test() はデータベクトルに対して 1標本または 2 標本の t 検定を行う.書式と引数は以下の通り.� �t.test(x, y = NULL, alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, var.equal = FALSE, conf.level = 0.95)
� �x : データ値の数値ベクトル.
y : 追加のデータ値.一標本について検定を行う場合は省略,二標本検定を行う場合はデータを入れる.
alternative : 対立仮説を示す文字列を入力.これは重要.これを省略すると両側検定が行われる.
”two.sided” : 両側検定を行う (デフォルト) .
”greater” : より大きいかどうかの検定 (片側検定) .
”less” : より小さいかどうかの検定 (片側検定) .
mu : 真の平均の値.2 標本検定の場合は平均の差を入力.
paired : 論理値を入力.ここに TRUE を入れると対応のある t 検定をする.
var.equal : 論理値を入力. ここに TRUE を入れると 2 つの標本の分散が等しいと仮定される.
conf.level : 区間の信頼度.
7.4.2 引数の注意
(注) paired が TRUE ならば,x と y は同じ長さのベクトルを与えなければならない.

R-Tips 159頁
(注) 欠損値は取り除かれる.paired が TRUE の場合は対で除かれる.
(注) var.equal が TRUE ならば 2 標本をプールした場合の分散の値が推定値として使われ,FALSE ならば分散
はそれぞれの標本毎に推定される.推定には Welch (ウェルチ) の近似自由度が使われる.
7.4.3 返り値の説明
結果の出力として,以下の項目を含む”htest”クラスのリストが返される.
statistic : t 統計値の値.
parameters : t 統計値の自由度.
p.value : 検定の p値.特に重要.有意水準 5% で検定している場合,この値が 0.05 よりも小さければ帰無仮
説が棄却され有意とされる.逆ならば対立仮説が棄却され,有意ではないとされる.
∗∗percent confidence interval : 平均の ∗ ∗ %信頼区間.
estimate : 1標本の場合は推定された平均の値.2標本の場合は推定された平均の差.重要.
null.value : 1標本の場合は仮定された平均の値.2標本の場合は仮定された平均の差. 重要.
alternative : 対立仮説を表す文字列.
method : t-検定の種類を表す文字列.
data.name : データの名前を表す文字列.
7.4.4 検定例: 一標本の場合
ある会社のトイレットペーパーは 65m 巻きとされている.この会社のトイレットペーパーから 10 個を抽出し
て長さを計測したところ,以下のようなデータが得られた (トイレットペーパーの長さは正規分布に従っていると
仮定する) .このとき,トイレットペーパー (下のデータ A ) の長さが表示に従っているかを検定する.� �> A <- c(64.7, 63.8, 62.5, 64.3, 64.5, 64.8, 65.2, 61.8, 63.5, 65.2)
� �次に,母平均が 65 であるかどうかを検定して,ついでに 95%信頼区間を求めることを考える.この場合はパッ
ケージ ctest の中の t.test を用いればよい.� �> library(ctest)
> t.test(A, mu=65)
� �� �One Sample t-test
data: A
t = -2.6879, df = 9, p-value = 0.02488
alternative hypothesis: true mean is not equal to 65
95 percent confidence interval:
63.21364 64.84636
sample estimates:
mean of x
64.03� �出力結果を解説する.

R-Tips 160頁
� �data: A # データの名前
t = -2.6879 # t の値:これが棄却域に入っているかを見ている
df = 9 # t の自由度
p-value = 0.02488 # p 値:これが 0.05 より小さければ有意差がある
alternative hypothesis
: true mean is not equal to 65 # 対立仮説:平均が 65 ではない
95 percent confidence interval: # ここで有意水準の値が分かる
63.21364 64.84636 # 信頼区間は [63.21364, 64.84636]
sample estimates: # 推定値:今は標本平均を推定している
mean of x
64.03� �結果を図で表すと以下の様になる.
今は両側検定を行ったが,片側検定を行うことも出来る.� �> t.test(A, mu=65, alternative="greater") # 対立仮説:母平均が 65よりも大きい
One Sample t-test
data: A
t = -2.6879, df = 9, p-value = 0.9876 # 有意差無:母平均が 65以上で
alternative hypothesis: true mean is greater than 65 # あるとは云えない
95 percent confidence interval:
63.36847 Inf
sample estimates:
mean of x
64.03
> t.test(A, mu=65, alternative="less") # 対立仮説:母平均が 65よりも小さい
One Sample t-test
data: A
t = -2.6879, df = 9, p-value = 0.01244 # 有意差有:母平均が 65以下で
alternative hypothesis: true mean is less than 65 # あると云える
95 percent confidence interval:
-Inf 64.69153
sample estimates:
mean of x
64.03� �

R-Tips 161頁
7.4.5 検定例:二標本の場合
以下は,氷の溶解時の潜熱 (cal/gm) に関するデータの組である.この 2 つの標本の母平均に差があるかどう
かを検定する.� �> A <- c(79.98, 80.04, 80.02, 80.04, 80.03, 80.03, 80.04, 79.97, 80.05, 80.03,
80.02, 80.00, 80.02)
> B <- c(80.02, 79.94, 79.98, 79.97, 79.97, 80.03, 79.95, 79.97)
� �今のところデータの組 A ,B に関して何ら情報が無い.そのようなときは普通の t 検定 (ウェルチの検定) を
行う.この場合,2つの標本の母集団が正規分布に従っていることを仮定している事に注意.� �> t.test(A,B)
Welch Two Sample t-test
data: A and B
t = 3.2499, df = 12.027, p-value = 0.00694 # 0.05 よりも小さい!
alternative hypothesis # 2つの平均の差が 0とは異なる
: true difference in means is not equal to 0 # という仮設が採択される
95 percent confidence interval: #
0.01385526 0.07018320 # 結果は有意な差が出ていることを
sample estimates: # 示している!
mean of x mean of y
80.02077 79.97875� �
7.5 一標本検定
7.5.1 グラフによる正規分布との比較
累積分布関数 (cdf)
パッケージ stepfum の中の関数 ecdf() で累積分布関数 (cdf) を描くことが出来る.stepfun は階段関数を扱う
ライブラリで,特に経験分布関数の作図ができる.� �> library(stepfun) # パッケージの呼び出し
> data <- rnorm(30) # データを用意
> Fn <- ecdf(data) # ecdf()でデータフレームを作成
> Fn # 中身を確認
> summary(Fn) # Fn の要約
> summary.stepfun(Fn) # Fn の詳しい要約
> plot(Fn) # 経験分布関数をプロット
> plot(Fn, do.point=F, verticals=T) # 点を描かず,ジャンプ線 (縦の線)を描く
� �この累積分布関数に正規分布の分布関数を上書きしてみる.� �> x <- seq(-3,3,0.01)
> lines(x, pnorm(x, mean=mean(data), sd=sqrt(var(data))), col=2)
� �

R-Tips 162頁
−1 0 1 2
0.0
0.2
0.4
0.6
0.8
1.0
ecdf(data)
x
Fn(
x)
−1 0 1 2
0.0
0.2
0.4
0.6
0.8
1.0
ecdf(data)
x
Fn(
x)
−1 0 1 2
0.0
0.2
0.4
0.6
0.8
1.0
ecdf(data)
x
Fn(
x)
Q-Q プロット
qqnorm(x) : x に対する期待正規ランクスコアをプロットする.データが正規分布に従っているかどうかを調
べるために用いられ,qqnorm() によって描かれた散布図の点がほぼ直線上に並んでいればそのデータは正
規分布に従っていると考えられる.
qqline(x) : 上のプロットにデータの上四分位点と下四分位点を結ぶ直線を描く.
qqplot(x,y) : x の確率点に対する y の確率点 ( Quantile-Quantile Plot:Q-Q プロット) を描く.
自由度 5 の t 分布に従う乱数を 50個生成してデータが正規分布に従っているかどうかを調べる.� �> par(pty="s")
> x <- rt(50, df=5)
> qqnorm(x)
> qqline(x)
� �このランダム標本とで Q-Q プロットを描いてみる.� �> qqplot(qt(ppoints(50), df=5), x)
> qqline(x)
� �
−2 −1 0 1 2
−2
02
4
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
−3 −2 −1 0 1 2 3
−2
02
4
qt(ppoints(50), df = 5)
x
qqplotはプロットした点の座標のベクトル x ,y を要素に持つリストを返す.点列に大体当てはまる直線を上
書きする場合は lsfit() を使って回帰直線を求めて,それを abline() を用いて重ね描きすればよい.� �> x <- rt(50, df=5)
> xy <- qqplot(qt(ppoints(50), df=5), x)
> abline(lsfit(xy$x, xy$y), lty=2)
� �データが他の理論分布,例えば対数正規分布に従っているかどうかを調べるには以下の様にすればよい.x は
データ,ppoints() はQQプロット用の確率ベクトルを作る関数,qlnorm() は対数正規分布の確率点を求める関数
である.� �> plot(qlnorm(ppoints(x)), sort(x))
� �

R-Tips 163頁
−3 −2 −1 0 1 2 3
−2
02
4
qt(ppoints(50), df = 5)x
0 2 4 6 8 10
−2
02
4
qlnorm(ppoints(x))
sort
(x)
qlnorm() の代わりに他の理論分布の確率点を求める関数を使えば,その分布に従っているかどうかを調べるこ
とも出来る.
7.5.2 正規性の検定
Shapiro-Wilk 検定
パッケージ ctest の中の関数 shapiro.test() で Shapiro-Wilk 検定 を行うことが出来る.� �> data(faithful)
> long <- faithful$eruptions[faithful$eruptions > 3]
> long # データの確認
> library(ctest)
> shapiro.test(long)
Shapiro-Wilk normality test
data: long
W = 0.9793, p-value = 0.01052
� �
コルモゴロフ・スミルノフの検定
同様に,パッケージ ctest の中の関数 ks.test() で Kolmogorov-Smirnov検定を行うことが出来る.� �> data(faithful)
> ( long <- faithful$eruptions[faithful$eruptions > 3] ) # データ出力は省略
> ks.test(long, "pnorm", mean=mean(long), sd=sqrt(var(long)))
One-sample Kolmogorov-Smirnov test
data: long
D = 0.0661, p-value = 0.4284
alternative hypothesis: two.sided
� �
母平均の検定と推定
ここで,データ long の母平均が 4 であるかどうかを検定して,ついでに 95%信頼区間を求めることを考える.
この場合はパッケージ ctest の中の t.test() を用いればよい.� �> data(faithful)
> ( long <- faithful$eruptions[faithful$eruptions > 3] ) # データ出力は省略
> library(ctest)
� �

R-Tips 164頁
� �> t.test(long, mu=4)
One Sample t-test
data: long
t = 9.3795, df = 174, p-value = < 2.2e-16
alternative hypothesis: true mean is not equal to 4
95 percent confidence interval:
4.230005 4.352601
sample estimates:
mean of x
4.291303� �
7.6 二標本検定
7.6.1 ニ標本の検定:正規性を仮定する場合
データの準備
以下は,氷の溶解時の潜熱 (cal/gm) に関するデータの組である.� �Method A : 79.98, 80.04, 80.02, 80.04, 80.03, 80.03, 80.04, 79.97,
80.05, 80.03, 80.02, 80.00, 80.02
Method B : 80.02, 79.94, 79.98, 79.97, 79.97, 80.03, 79.95, 79.97
� �
データの読み込みと視覚化
まずデータの組 A ,B を読み込んで,それぞれの箱ひげ図を描く.すると,A の方が B よりも高いという結
果が見て取れる.� �> A <- c(79.98, 80.04, 80.02, 80.04, 80.03, 80.03, 80.04, 79.97, 80.05, 80.03,
80.02, 80.00, 80.02)
> B <- c(80.02, 79.94, 79.98, 79.97, 79.97, 80.03, 79.95, 79.97)
> boxplot(A,B)
� �
1 2
79.9
479
.96
79.9
880
.00
80.0
280
.04
2つの母平均に差があるかどうかの検定:unpairedな場合
今のところデータの組 A ,B に関して何ら情報が無い.そのようなときは普通の t 検定 (ウェルチの検定) を
行う.この場合,2つの標本の母集団が正規分布に従っていることを仮定している.

R-Tips 165頁
� �> t.test(A,B)
Welch Two Sample t-test
data: A and B
t = 3.2499, df = 12.027, p-value = 0.00694 # 結果は有意な差が出ていることを示している
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval: 0.01385526 0.07018320
sample estimates: mean of x mean of y
80.02077 79.97875� �
2つの母分散が同等であるか否かの検定:F 検定
ここで,データの組 A ,B の母分散が等しいかどうかの検定を行う.ここで母分散が等しいと分かったならば
対応のある t 検定 (ウェルチの検定) を行うことが出来る.ただし,パッケージ ctest を読み込む必要があること
に注意.すると,結果に有意差が出なかった.� �> library(ctest)
> var.test(A,B)
F test to compare two variances
data: A and B
F = 0.5837, num df = 12, denom df = 7, p-value = 0.3938
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval: 0.1251097 2.1052687
sample estimates: ratio of variances
0.5837405� �
2つの母平均に差があるかどうかの検定:二群の分散が等しいことを仮定する場合
データの組 A ,B は分散が同等であることが分かった.そこで 対応のある場合 (二群の分散が等しいことを仮
定する場合) の t 検定を行う.この場合,2つの標本の母集団が正規分布に従っていることを仮定している.結果
は有意な差が出ていることを示している.� �> t.test(A,B,var.equal=T)
Two Sample t-test
data: A and B
t = 3.4722, df = 19, p-value = 0.002551
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval: 0.01669058 0.06734788
sample estimates: mean of x mean of y
80.02077 79.97875� �

R-Tips 166頁
7.6.2 ニ標本の検定:正規性を仮定しない場合 (1)
データの準備
データは上で出てきた氷の溶解時の潜熱 (cal/gm) に関するデータの組とし,それぞれ変数 A ,B にデータが
読み込まれているものとする.� �Method A : 79.98, 80.04, 80.02, 80.04, 80.03, 80.03, 80.04, 79.97,
80.05, 80.03, 80.02, 80.00, 80.02
Method B : 80.02, 79.94, 79.98, 79.97, 79.97, 80.03, 79.95, 79.97
� �
2つの母代表値に差があるかどうか:ウィルコクソンの検定・マン・ホイットニーのU検定
今のところデータの組 A ,B に関して何ら情報が無いとする.先程は 2つの標本の母集団が正規分布に従って
いることを仮定して検定したのだが,この仮定が誤りであったならば今までの検定も誤りとなる.そこで,以下
では分布の仮定を置かずに (ノンパラメトリックな,帰無仮説として同一の連続分布であることを仮定して) 検定
を行うことにする.結果の警告は,各標本に同一値があるのでデータが離散分布からきていることを強く示唆し
ているものである.� �> library(ctest)
> wilcox.test(A,B)
Wilcoxon rank sum test with continuity correction
data: A and B
W = 89, p-value = 0.007497
alternative hypothesis: true mu is not equal to 0
Warning message:
Cannot compute exact p-value with ties in: wilcox.test.default(A, B)
� �
7.6.3 累積分布関数の比較
累積分布関数の比較:プロットによる方法
パッケージ stepfun の中の関数 ecdf() により,二標本の累積分布関数を描くことで分布の違いを見ることが出
来る.� �> A <- c(79.98, 80.04, 80.02, 80.04, 80.03, 80.03, 80.04, 79.97,
+ 80.05, 80.03, 80.02, 80.00, 80.02)
> B <- c(80.02, 79.94, 79.98, 79.97, 79.97, 80.03, 79.95, 79.97)
> library(stepfun)
> plot(ecdf(A), do.points=F, verticals=T, xlim=range(A,B))
> plot(ecdf(B), do.points=F, verticals=T, add=T)
� �
累積分布関数の比較:コルモゴロフ・スミルノフの検定
コルモゴロフ・スミルノフの検定は,同一の連続分布を仮定し,2つの累積分布関数の差異を検定する.ただし,
データが離散的である場合や,2つのカテゴリーに分かれるもの,2つのカテゴリーにうまく圧縮出来るものは符

R-Tips 167頁
号分布のような二項分布を用いる検定のほうが検出力が高くなる.� �> ks.test(A,B)
Two-sample Kolmogorov-Smirnov test
data: A and B
D = 0.5962, p-value = 0.05919
alternative hypothesis: two.sided
Warning message:
cannot compute correct p-values with ties in: ks.test(A, B)
� �
7.6.4 ニ標本の検定:正規性を仮定しない場合 (2)
対応のある 2つの母代表値に差があるかどうかの検定:ウィルコクソンの符号付順位和検定
もし,データの組 A ,B の要素が互いに対応している場合 (例:20 人に対して寝ている時の脈拍と立っている
ときの脈拍のデータ → 脈拍に変化はあるか) で,2つのデータの母集団の分布が等しいか否かの検定を行いたい
場合はウィルコクソンの符号付順位和検定を行う.� �> library(ctest)
> x <- c(70,72,62,64,71,76,60,65,74,72)
> y <- c(70,74,65,68,72,74,61,66,76,75)
> wilcox.test(x, y, paired = T)
Wilcoxon signed rank test with continuity correction
data: x and y
V = 5, p-value = 0.04235
alternative hypothesis: true mu is not equal to 0
Warning messages:
1: Cannot compute exact p-value with ties in: wilcox.test.default(x, y, paired = T)
2: Cannot compute exact p-value with zeroes in: wilcox.test.default(x, y, paired = T)
� �
対応のある 2変数の組について単に母代表値に差があるか検定:符号検定
データの組 A ,B の 2 変数の組で,単に『どちらがが優れているか劣っているか,あるいは同等であるか』の
みしか分からないときで,2つのデータの母集団の分布が等しいか否かの検定を行いたい場合は符号検定を行う.
このとき,どの程度優れているか劣っているかが量的に定義できるときはウィルコクソンの符号順位検定を用いる.� �> library(ctest)
> binom.test(c(682, 243), p = 3/4) # binom.test(成功数, 失敗数, 成功確率)
� �

R-Tips 168頁
� �Exact binomial test # この場合は帰無仮説が採択されている
data: 682 and 682 + 243
number of successes = 682, number of trials = 925, p-value = 0.3825
alternative hypothesis: true probability of success is not equal to 0.75
95 percent confidence interval: 0.70767 0.76541
sample estimates: probability of success
0.7373
> binom.test(682, 682 + 243, p = 3/4) # やっていることは上と同じ
> x <- c(1,1,1,2,2,3,3,3,3,3,4,4,4,5,5) # 15人に 2つの商品を 5段階で評価
> y <- c(2,3,2,3,3,2,4,1,4,2,3,5,5,3,4) # してもらう
> binom.test(c(length(x[x > y]), length(x[x < y]))) # binom.test(c(成功数,失敗数))
Exact binomial test # 有意水準 0.05で帰無仮説が採択
data: 6 and 15
number of successes = 6, number of trials = 15, p-value = 0.6072
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.16336 0.67713
sample estimates:
probability of success
0.4� �
2つの母代表値に差があるかどうかの検定 (2) :マン・ホィットニーのU検定
アンケートなどで 2つの物や項目を 5段階評価することを考える.例えば 2 つの製品 A ,B について,街頭で
アンケートをしたとする.
(5:大変良い ∼3:普通 ∼1:悪い) 5 4 3 2 1 計
製品 A 8 11 9 2 3 33
製品 B 4 6 10 8 4 32
この 2 群の母代表値の差を有意水準 5% で両側検定する.検定結果は Wilcoxon Test と出るが,これはマン・
ホイットニーの U 検定である.� �> library(ctest)
> A <- c(rep(5, 8), rep(4, 11), rep(3, 9), rep(2, 2), rep(1, 3))
> B <- c(rep(5, 4), rep(4, 6), rep(3, 10), rep(2, 8), rep(1, 4))
> wilcox.test(A, B, correct=F) # correct=F は連続性の修正を行わないことを指定
Wilcoxon rank sum test
data: A and B
W = 406.5, p-value = 0.008627
alternative hypothesis: true mu is not equal to 0
Warning message:
Cannot compute exact p-value with ties in: wilcox.test.default(A, B, correct = F)
� �

R-Tips 169頁
7.6.5 参考:分散の均一性の検定:バートレットの方法
2つのデータの分散の同等性は上で出てきたウェルチの方法で検定が行えた.データの組が 3 つ以上の場合は
バートレットの方法で検定を行うことになる.
例えば,A,B ,C の 3 つの場所のリンゴの葉の長さを調べてみたところ,次のようなデータが取られた.この
とき,場所により葉の分散に差があると云えるかを有意水準 5% で検定する場合にバートレットの方法を用いる.
場所 葉の長さのデータ
A 80 73 80 82 74
B 73 68 81 85
C 85 93 88
関数は bartlett.test() を用いる.� �> x <- c(80,73,80,82,74,73,68,81,85,85,93,88)
> b <- c(rep(1, 5), rep(2, 4), rep(3, 3))
> bartlett.test(x, b)
Bartlett test for homogeneity of variances
data: x and b
Bartlett’s K-squared = 1.5451, df = 2, p-value = 0.4618
� �
7.7 さまざまな検定
7.7.1 χ2 (カイ二乗) 検定:chisq.test()
適合度検定や独立性の検定は全て同じ関数 chisq.test() で行うことが出来る.この場合,引数のデータの形式と
引数に確率を入れるかで検定内容が異なる.
検定したいデータの形式
以下の (1), (2) が適合度検定,(3) ∼ (5) が独立性の検定である.いずれの場合も引数に correct=F を入れるこ
とで連続性の補正を抑制することが出来る.
(1) 1つのベクトルを引数にする場合 → c(8, 12, 10, 9, 5, 6) : 例えばサイコロを振った結果を入れて,この
サイコロが正しいサイコロであるかどうか (1∼6の生起確率が全て等しいのか) を検定する場合は 1つのベ
クトルを引数にすればよい.
(2) 1つのベクトルと生起確率を引数にする場合 → c(20,8,5,2), p=c(4, 3, 2, 1)/10 : 35人の血液型を調べ,
これより日本人の血液型は A,B,O,AB の順で 40%,30%,20%,10% の比率になっているかどうかを
検定する場合は 1つのベクトルと,その生起確率を引数にすればよい.
(3) 2列の行列を引数にする場合 → matrix(c(20, 15, 16, 4, 15, 7, 9, 4), ncol=4, byrow=T) : 男女 90
人の血液型を調べて,男女の血液型の分布が同じかどうかを検定する場合は 2列の行列を引数にすればよい.
(4) 2行 2列の行列を引数にする場合 → matrix(c(20, 15, 16, 9), ncol=2, byrow=T) : 男女 60人に喫煙
の有無を調べ,男女の喫煙率に差があるかどうかを検定する場合は 2行 2列の行列を引数にすればよい.
(5) m 列の行列を引数にする場合 → matrix(c(20, 15, ... ), ncol=n, byrow=T) : 例えば都道府県別に決
まった人数を抽出して血液型を調べ,都道府県と血液型の間に関係があるかどうかを検定する場合は m 列
(m≥2) の行列を引数にすればよい.

R-Tips 170頁
実際の検定データ入力例
上のデータ形式それぞれの入力例である.� �> chisq.test(c(8, 12, 10, 9, 5, 6))
> chisq.test(c(20,8,5,2), p=c(4, 3, 2, 1)/10)
> chisq.test(matrix(c(20, 15, 16, 4, 15, 7, 9, 4), ncol=4, byrow=T))
> chisq.test(matrix(c(20, 15, 16, 9), ncol=2, byrow=T))
> chisq.test(matrix(c(20, 15, 16, 4, 15, 7, 9, 4, 10), ncol=3, byrow=T))
� �
7.7.2 カテゴリーデータの検定
二群の比率の差の検定
「あなたは納豆が好きですか?」 という質問に対して,東京では 300 人中 245 人が,大阪では 250 人中 157
人が好きだと答えた場合に,好きな人の割合に差があるかどうか検定する場合は関数 prop.test() を使う.このと
き,correct=F を引数に与えることで,連続性の補正を抑制することが出来る. 例えばオッズ比とその信頼区間
を求める場合はパッケージ vcd を呼び出した後で summary(oddsratio(table(A,B),log=F)) を実行すればよい (対
数オッズ比を計算する場合は,引数 log=F をつけない) .また,2 回の繰り返しの一致度を測る κ (カッパ) 係数
はパッケージ vcd を呼び出した後で関数 Kappa(table(C,D)) を実行すればよい.さらに,コクラン・アーミテー
ジの検定は関数 prop.trend.test() で行えばよい.
フィッシャーの直接確率検定
例えば以下のようなデータが取られた場合に,『第一外国語の単位を取得する』ことと『第二外国語の単位を取
得する』ことに関連があるかを検定する場合はフィッシャーの直接確率検定を用いる.関数は fisher.test() を使い,
引数には 2 × 2の行列を与えればよい.
第一外国語 合
単位取得 単位取得不可 計
第二 単位取得 14 8 22
外国語 単位取得不可 4 17 21
合計 18 25 43
フィッシャーの直接確率検定 (分割表が 2 × 2 よりも大きい場合)
上の場合は 2× 2 の行列を引数に与えたが,分割表が 2× 2 より大きい場合 (第二外国語を細分化する場合など)
は,同じサイズの行列を引数に与えてフィッシャーの直接確率検定を用いればよい.
マクネマー検定
異なる状況下で同じ個体 (例えば学生) から 2回データを取った場合など,関連のある (対応のある) 2つの集団
からデータが取られた場合に,半年の間に単位取得状況に変化があるかを検定する場合はマクネマー検定を用い
る.関数は mcnemar.test() を使い,引数には 2 × 2の行列を与えればよい.このとき,correct=F を引数に与え
ることで,連続性の補正を抑制することが出来る.
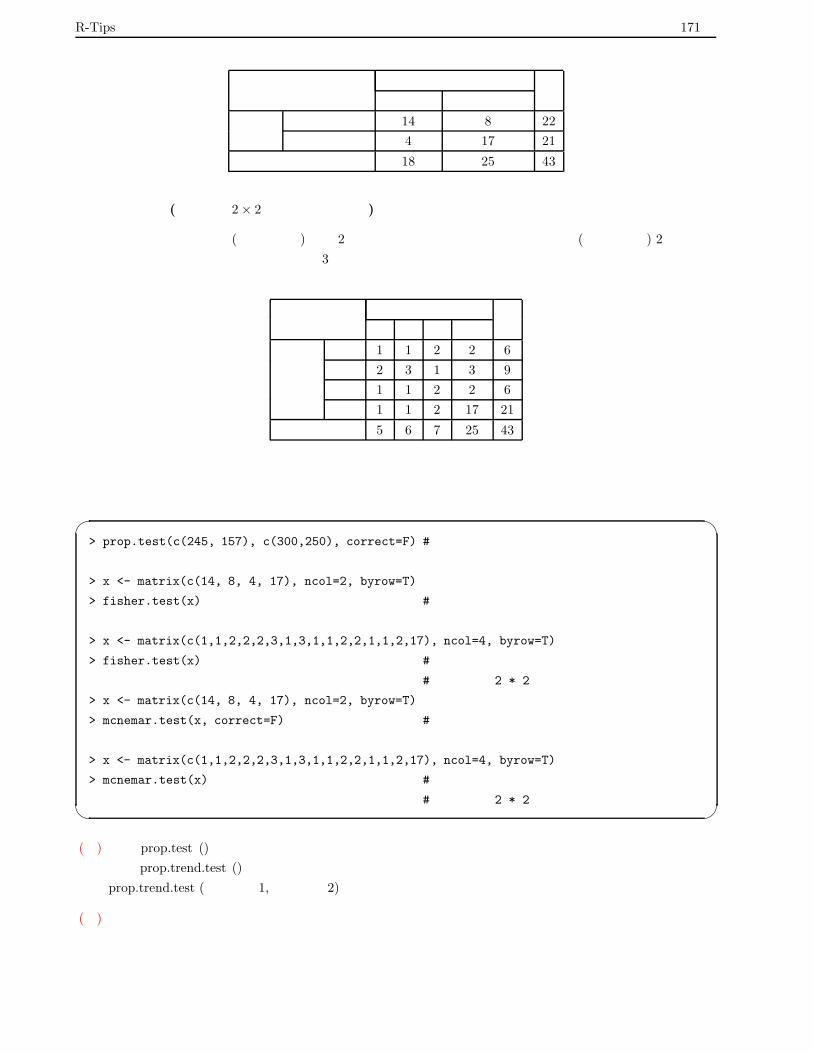
R-Tips 171頁
前期の英語 合
単位取得 単位取得不可 計
後期 単位取得 14 8 22
の英語 単位取得不可 4 17 21
合計 18 25 43
マクネマー検定 (分割表が 2 × 2 よりも大きい場合)
異なる状況下で同じ個体 (例えば学生) から 2回データを取った場合など,関連のある (対応のある) 2つの集団
からデータが取られた場合に,調査項目が 3つ以上で,半年の間に単位取得状況に変化があるかを検定する場合
もマクネマー検定を用いる.この時,引数には分割表と同じサイズの行列を与えればよい.
前期の英語 合
優 良 可 不可 計
優 1 1 2 2 6
後期 良 2 3 1 3 9
の英語 可 1 1 2 2 6
不可 1 1 2 17 21
合計 5 6 7 25 43
実際の検定データ入力例
上のデータ形式それぞれの入力例である.� �> prop.test(c(245, 157), c(300,250), correct=F) # 二群の比率の差の検定
> x <- matrix(c(14, 8, 4, 17), ncol=2, byrow=T)
> fisher.test(x) # フィッシャーの直接確率検定
> x <- matrix(c(1,1,2,2,2,3,1,3,1,1,2,2,1,1,2,17), ncol=4, byrow=T)
> fisher.test(x) # フィッシャーの直接確率検定
# 分割表が 2 * 2 よりも大きい場合
> x <- matrix(c(14, 8, 4, 17), ncol=2, byrow=T)
> mcnemar.test(x, correct=F) # マクネマー検定
> x <- matrix(c(1,1,2,2,2,3,1,3,1,1,2,2,1,1,2,17), ncol=4, byrow=T)
> mcnemar.test(x) # マクネマー検定
# 分割表が 2 * 2 よりも大きい場合� �(注) 関数 prop.test () の中に,いくつかの群の比率が独立変数と線形傾向があるかどうかを検定するための
関数 prop.trend.test () がある.これはコクラン・アーミテージ検定といわれる検定方法である.引数は
prop.trend.test (ベクトル 1, ベクトル 2) とすればよい.
(注) 符号検定,二項検定 も似たようなデータに対する検定方法である.

R-Tips 172頁
7.7.3 相関係数についての検定
検定したいデータの形式
以下のような 2 組のデータ x ,y に相関があるかどうかの検定を行う場合は関数 cor.test() を使う.� �> x <- c(70,72,62,64,71,76,60,65,74,72)
> y <- c(70,74,65,68,72,74,61,66,76,75)
� �このとき,引数 method に次の文字列を入れることで検定方法を代えることが出来る.
”pearson” : ピアソンの積率相関係数の有意性検定を行う.
”kendall” : ケンドールの順位相関係数の有意性検定を行う.
”spearman” : スピアマンの順位相関係数の有意性検定を行う.
実際の検定データ入力例
上のデータ形式それぞれの入力例である.� �> x <- c(70,72,62,64,71,76,60,65,74,72)
> y <- c(70,74,65,68,72,74,61,66,76,75)
> cor.test(x, y, method="pearson")
> cor.test(x, y, method="kendall")
> cor.test(x, y, method="spearman")
� �
7.7.4 分散分析
分散分析は各群の分散が等しいことを前提にしているので,前もって F 検定やバートレットの方法等で各群の
分散が等しいか否かを検定するのが良い.
検定したいデータの形式
例えば,A ,B ,C の 3 つの場所のリンゴの葉の長さを調べてみたところ,次のようなデータが取られた.
場所 葉の長さのデータ
A 80 73 80 82 74
B 73 68 81 85
C 85 93 88
一元配置分散分析: 場所により葉の長さの母平均に差が出るかどうかを検定する場合は関数 oneway.test() を用
いる.このとき引数はベクトルで与える.
クラスカル・ウォリス検定: 場所により葉の長さの母平均に差が出るかどうかを検定する場合は関数 kruskal.test()
でも良い.その後,ホルムの方法で調整されたウイルコクソンの順位和検定を関数 pairwise.wilcox.test()で
行うことも出来る.
正規分布する量がグループ間で差がないかどうかを一元配置分散分析 (と多重比較)で検定する場合,まず等分散が
仮定されているなら関数 aov(Y˜X)で一元配置分散分析を行い,Xの主効果が有意ならば TukeyHSD(aov(Y˜X))か
pairwise.t.test(Y,X).で多重比較を行う.また,パッケージ multcompの中にある simtest(Y˜X,type=”Dunnett”)

R-Tips 173頁
でダネットの多重比較法 (→対照群との比較) ,simtest(Y˜X,type=”Williams”) でウイリアムズの多重比較を行
うことが出来る.対照群との対比較ならばダネットの方法,単調性を想定した対比較ならばウイリアムズの方法
が優れている.
実際の検定データ入力例
上のデータ形式それぞれの入力例である.� �> x <- c(80,73,80,82,74,73,68,81,85,85,93,88)
> b <- c(1,1,1,1,1,2,2,2,2,3,3,3)
> oneway.test(x ~ b, var=T) # 一元配置分散分析
> kruskal.test(x, b) # クラスカル・ウォリス検定
> x <- c(80,73,80,82,74)
> y <- c(73,68,81,85)
> z <- c(85,93,88)
> kruskal.test(x, y, z) # クラスカル・ウォリス検定
Kruskal-Wallis rank sum test
data: x[, 1] and x[, 2]
Kruskal-Wallis chi-squared = 5.8408, df = 2, p-value = 0.05391
� �
フリードマン検定
例えば,A ,B ,C の 3 つの場所について,肥料の量を変えてリンゴを育てていき,しばらく育てた後のリン
ゴの重さを調べてみたところ,次のようなデータが取られた.
場所 \肥料の量 10 20 30 40
A 180 193 200 201
B 150 189 186 190
C 144 178 166 173
肥料の効果があるかどうかを 5% の有意水準で検定する場合はフリードマン検定を行う.� �> x <- matrix(c(180,193,200,201,
+ 150,189,186,190,
+ 144,178,166,173), ncol=4, byrow=T)
> friedman.test(x)
Friedman rank sum test
data: x
Friedman chi-squared = 7, df = 3, p-value = 0.0719
� �
7.8 直線回帰・最小二乗法
直線回帰・最小二乗法では,y = a + bx + e ( e は誤差項) の a と b を推定する.つまり,y に被説明変数の
データを与え,x には計画行列,すなわち説明変数 (データ) を与えたときに,誤差を最小にする a と b を推定
することになる.

R-Tips 174頁
7.8.1 最小二乗法
関数 lm() と predict() を用いて最小二乗法を行うことができる.例えば以下のようなデータ data.txt があった
とする.� �# 父親 (x) と 息子 (y) の身長
x y
1 154.2 163.9
2 155.4 172.4
3 156.3 171.8
4 157.1 166.1
5 158.5 168.5
6 159.2 160.6
7 159.3 166.7
8 159.9 174.2
9 160.2 164.2
10 161.2 166.4
11 161.2 168.6
12 161.4 169.2
13 162.6 163.2
14 162.7 159.8
15 163.6 171.4
16 163.8 169.0
17 164.0 180.4
18 164.1 175.7
19 164.9 177.5
20 165.3 173.1
21 165.6 166.7
22 165.8 174.0
23 166.2 171.0
24 166.4 179.0
25 166.4 184.0
26 166.8 176.2
27 167.1 174.0
28 167.9 176.3
29 168.4 163.2
30 168.9 171.4
31 169.0 172.0
32 170.7 165.9
33 170.9 171.2
34 171.2 179.6
35 171.6 180.7
36 172.7 178.9
37 173.6 166.4
38 174.6 179.8
39 177.0 181.8
40 177.3 171.9� �
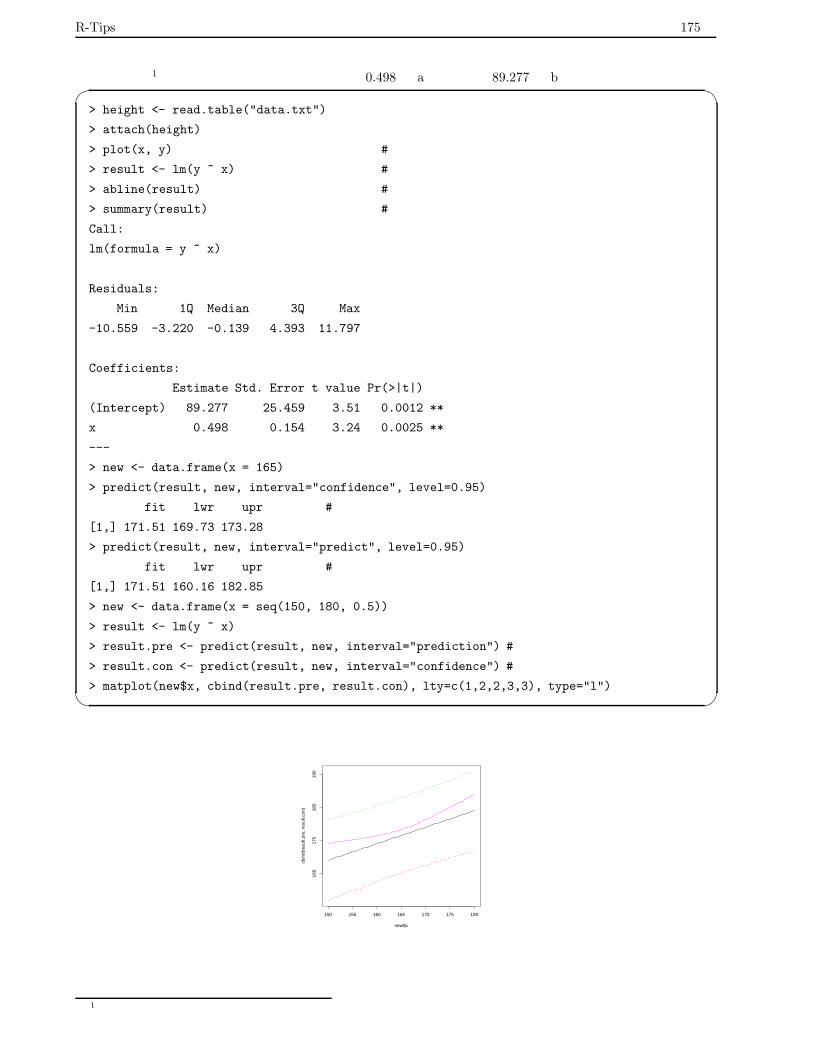
R-Tips 175頁
このデータ1に関して最小二乗法を行う.以下の 0.498 が a の推定値,89.277 が b の推定値である.� �> height <- read.table("data.txt")
> attach(height)
> plot(x, y) # 散布図を描く
> result <- lm(y ~ x) # 単回帰分析
> abline(result) # 推定回帰直線を描く
> summary(result) # 分析結果の要約
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-10.559 -3.220 -0.139 4.393 11.797
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 89.277 25.459 3.51 0.0012 **
x 0.498 0.154 3.24 0.0025 **
---
> new <- data.frame(x = 165)
> predict(result, new, interval="confidence", level=0.95)
fit lwr upr # 推定値とその信頼区間の両端の値
[1,] 171.51 169.73 173.28
> predict(result, new, interval="predict", level=0.95)
fit lwr upr # 推定値と予測値の信頼区間の両端の値
[1,] 171.51 160.16 182.85
> new <- data.frame(x = seq(150, 180, 0.5))
> result <- lm(y ~ x)
> result.pre <- predict(result, new, interval="prediction") # 予測区間
> result.con <- predict(result, new, interval="confidence") # 信頼区間
> matplot(new$x, cbind(result.pre, result.con), lty=c(1,2,2,3,3), type="l")
� �プロット結果は以下のようになる.
150 155 160 165 170 175 180
160
170
180
190
new$x
cbin
d(re
sult.
pre,
res
ult.c
on)
1 「数理統計学」(稲垣宣生,裳華房)より引用.

R-Tips 176頁
7.8.2 関数 lsfit() による最小二乗法
関数 lsfit() により,y = X b + e の b を推定する.y には被説明変数のベクトルを与え,X には計画行列,す
なわち説明変数 (それぞれがベクトル) を cbind したものを与える.つまり,この行列の各列が説明変量で各列が
観測値となる.この行列は回帰式の定数項に対応する (全て 1 からなる) 列を含んでいる必要はない.逆に,説明
行列が定数項に対応する列を含んでいる場合,あるいは回帰式に定数項を含めたくない場合は intercept=F と指
定する必要がある.
lsfit() の書式は以下の通り.� �lsfit(x, y, wt=NULL, intercept=TRUE, tolerance=1e-07, yname=NULL)
� �引数の説明は以下の通り.
x : 説明変数の行列
y : 被説明変数のベクトル
wt : 重みをつける場合はここに指定する
intercept : 計画行列が定数項に対応する列を含んでいる場合,あるいは回帰式に定数項を含めたくない場合は
TRUE を指定すること
例えば 10 人の体重データが入った x ,同じ 10 人の身長のデータが入った y から係数 b を推定する場合は以
下の様にすればよい.� �> x <- c(64,70,58,66,81,73,75,72,90,53)
> y <- c(177,175,162,176,184,170,179,177,188,157)
> z <- lsfit(x,y) # 推定結果を z に格納
> print(z) # coefficients, residuals, intercept, qr を出力
� �出力の説明は以下の通り.
coef : 回帰係数ベクトル.intercept=T (デフォルト) ならば第 1 要素が回帰式の定数項とる.
residuals : 残差ベクトル.
intercept : 引数 interceptと同じ値で,説明行列が定数項に対応する列を含んでいるか否かを示す.
qr : x に定数項に対応する列を追加した行列を QR分解した結果.この要素の副要素 qt は t(Q)% *% y を表
し ( t(Q) は Q の転置行列) ,この要素の qt 以外の副要素は関数 qr が返す要素をそのまま保持している.
回帰による予測値を求める場合は,出力 z について以下の様に入力すればよい.� �> y - z$residuals
[1] 169.6581 174.3438 164.9724 171.2200 182.9343 176.6867
[7] 178.2486 175.9057 189.9628 161.0677� �また,重相関係数 R = (予測値の分散) / (被説明変数の分散) を求める場合には以下の様に入力すればよい.� �> sqrt(var(y - z$residuals)/var(y))
[1] 0.897304� �以下のように lsfit() の結果を abline() に渡すことによって,回帰直線を描くことも出来る.

R-Tips 177頁
� �> plot(x,y)
> abline(z,col=2)
� �さらに,lsfit() による回帰の結果 z から,予測値は c(1, x) %*% z$coef で求めることが出来,新しい説明変数
のセットがいくつかある場合は,それらを各行とする行列 x に対して cbind(1, x) %*% z$coef で説明変数のセッ
トそれぞれに対する予測値が求まる.
さらなる情報は,関数 ls.diag() で知ることが出来る.� �> ls.diag(z) # std.dev, hat, std.res, stud.res, cooks, dfits などを出力
� �出力の説明は以下の通り.
std.dev : 残差の標準偏差.
hat : ハット行列 H の対角成分 hii.
std.res : 規準化残差.
stud.res : スチューデント化残差.
cooks : Cook の距離.
dfits : DFITS 統計量.
correlation : 回帰係数推定量の相関行列.
std.err : 回帰係数推定量の標準偏差.
cov.scaled : 係数行列の Scaled covariance matrix.
cov.unscaled : 定数項に対応する列を含めた計画行列を QR分解したときの {t(R).R}−1,すなわち {t(x).x}−1
.cov.unscaled * std.devˆ2 で回帰係数推定量の分散共分散行列を求めることが出来る.
7.9 回帰分析と重回帰分析
回帰分析2の対象となるモデルは以下のような線形モデルである.
yi =
k∑
j=0
βjxij + εi (εi ∼ (0, σ2), i = 1, · · · , n)
上式をベクトル表記すると y = Xb + e となる.このときの y は応答ベクトル,X は説明変数のベクトル (モ
デル行列) で,x0 は切片項 (要素が全て 1 である列ベクトル) となっている.
7.9.1 関数 lm() による回帰
関数 lm() により線形モデルの当てはめを行うことが出来る.この関数により,回帰分析,分散分析,そして共
分散分析を行うことが出来る (ただし,分散分析,共分散分析を行う際は通常 aov() を用いる) .
2 詳しい解説は『工学のためのデータサイエンス入門』(間瀬・神保・鎌倉・金藤 共著,数理工学社) を参照のこと.分散分析や非線形回帰についても詳しい解説が載っている.また,ここでは詳しく扱わないが,関数 nlm() や glm() で一般線形モデルによる回帰を行うことが出来る.詳しくはヘルプを参照されたい.

R-Tips 178頁
関数 lm() の書式と引数
書式は以下の通りである.� �lm(formula, data, subset, weights, na.action,
method = "qr", model = TRUE, x = FALSE, y = FALSE, qr = TRUE,
singular.ok = TRUE, contrasts = NULL, offset = NULL, ...)
� �引数の説明は以下の通りである.
formula : 当てはめられるモデルに対するシンボリックな記述.
data : モデル中の変量を含むオプションのデータフレーム.既定では変量は lm が呼び出された環境から取ら
れる.
subset : 当てはめの過程で使われる観測値の一部分を指定するオプションのベクトル.
weights : 使用されるオプションの重みのベクトル.これが指定されれば重みつき最小自乗法が重み weights を
用いて行われる (つまり sum(w*eˆ2) を最小化する) .指定されなければ普通の最小自乗法が行われる.
na.action : データが NA を含んでいたときにどうすべきかを指示する関数.既定は options の na.action 設定
であり,もしこれが未設定なら na.fail が使われる.当初の既定は na.omit .
method : 現在のところ,method=”qr” だけが使える.
model, x, y, qr : ここには論理値を指定する.もし TRUE ならば対応する当てはめの成分 (モデルフレーム・
モデル行列・応答値・QR 分解) が返される.
singular.ok : 論理値を指定する.既定は TRUE で,FALSE はまだ移植されていない.
contrasts : オプションのリスト.詳しくは model.matrix.default の contrasts.arg を参照されたい.
offset : これは当てはめの過程で線形予測子に含められるべき a priori に既知の成分を指定するのに使われる.
lm() に対するモデルは以下の様にシンボリックに指定され,y ˜ x という型式を持つ.基本的なルールは以下
のようになっている.
y ˜ ... : 左辺の目的変数を、右辺の説明変数の線形式で線形回帰
+ A : 説明変数 A を加える
- A : 説明変数 A を除く
+ 0 または −1 : 切片 (定数)項の除外
A:B : 二つの説明変数 A, B の交互作用項 (A と B の積からなる説明変数)
A * B : 同上
(...)*(...) : 右括弧内の変数と左括弧内の変数の掛け合わせ (交互作用) すべての組合せを表す.ただし Aˆ2,
Aˆ2*B 等はそれぞれ A, A*B と解釈
(A+B)ˆ2 : (A+B)*(A+B) と同じ.A + B + A:B の意味
� �> lm(y ~ * x1 * x2 * x3 * ... )
� �ここで y は応答ベクトル, x1 ,x2 ,x3 ,... は y に対する線形予測子を指定する一連の項である.また, *
は + か − 等を指定し,この場合はある項をモデルに含めるか除外するかを指定する.

R-Tips 179頁
例えば形式 first+secondの項の指定は,first中のすべての項と second中の重複を除いたすべての項を指定する.
また,形式 first:second は first 中のすべての項と second 中のすべての項の相互差用を取ることにより得られる項
の集まりを指示する.指示 first*secondは first と second の cross を指示する.これは first+second+first:second
と同じことである.詳しくは後で述べる.
回帰の例
以下は単回帰モデルの当てはめを行う.� �> x <- 1:10
> y <- rnorm(1)*x
> fm1 <- lm(y ~ x)
> fm1
Call:
lm(formula = y ~ x)
Coefficients:
(Intercept) x
-7.241e-17 -2.223e+00� �また,両対数を取ってから線形回帰モデルの当てはめを行うこともできる.� �> x <- 1:10
> y <- rnorm(1)*x
> fm3 <- lm(log(y) ~ log(x))
> fm3
Call:
lm(formula = log(y) ~ log(x))
Coefficients:
(Intercept) log(x)
-1.81 1.00� �
モデル情報を取り出す関数
lm() の返り値は当てはめられたモデルのオブジェクトとなっている.これは以下の関数によって表示,抽出,プ
ロットを行うことが出来る.
add1 coef effects kappa predict residuals
alias deviance family labels print step
anova drop1 formula plot proj summary
この中からよく使うものを説明する.
anova(obj1 , obj2) : モデルを比較して分散分析表を生成する.
coefficients(obj) : 回帰係数 (行列) を抽出.coef(obj) と省略できる.
deviance(obj) : 重みつけられた残差平方和.
formula(obj) : モデル式を抽出.

R-Tips 180頁
plot(obj) : 残差,当てはめ値などの 4 種類のプロットを生成.
predict(obj, newdata=data.frame) : 提供されるデータフレームが元のものと同じラベルを持つことを強
制する.値は data.frame 中の非ランダムな変量に対する予測値のベクトルまたは行列となる.
print(obj) : オブジェクトの簡略版を表示.
residuals(obj) : 適当に重みつけられた残差 (の行列) を抽出する.resid(obj) と省略できる.
step(obj) : 階層を保ちながら,項を加えたり減らしたりして適当なモデルを選ぶ.この探索で見つかった最大
の AIC (赤池情報量規準) を持つモデルが返される.
summary(obj) : 回帰分析の完全な要約が表示される.
モデル情報を取り出す例
以下はモデルの情報を取り出す一つの例である.� �> x <- 1:10
> y <- rnorm(1)*x
> fm1 <- lm(y ~ x)
> plot(fm1)
� �
当てはめモデルの更新
説明項に多少の変更を加えた場合でモデルの当てはめをやり直す場合には関数 update() を用いるのが便利で
ある.� �> fm1 <- lm(y~x1+x2+x3+x4, data=production)
> fm2 <- update(fm1, . ~ +x5) # 説明変数に x5 を取り入れて当てはめ
> fm3 <- update(fm2, sqrt(.) ~ . ) # 目的変数に平方根変換を施して当てはめ
> fm4 <- lm(y~ . , data=production) # データフレーム production の全ての変数を用いる
� �
7.9.2 重回帰分析とモデル選択
以下で紹介する関数の他に,ハット行列の対角要素,てこ率を求める関数 hat() などがある.
重回帰モデルの当てはめ
関数 lm() により重回帰モデルの当てはめを行うことが出来る.� �> x1 <- runif(20)
> x2 <- 1:20
> x3 <- runif(20)
> x4 <- x1 * x2
> y <- runif(1) * x4
> result <- lm(y ~ x1 + x2 + x3 + x4) # 重回帰分析結果を resultに付値
� �

R-Tips 181頁
� �> summary(result) # 結果を表示
Call:
lm(formula = y ~ x1 + x2 + x3 + x4)
Residuals:
Min 1Q Median 3Q Max
-9.32e-16 -2.90e-16 4.46e-17 2.88e-16 7.82e-16
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.00e-16 5.40e-16 7.40e-01 0.47
x1 -1.30e-15 7.54e-16 -1.72e+00 0.11
x2 -2.99e-17 3.08e-17 -9.70e-01 0.35
x3 1.89e-16 5.21e-16 3.60e-01 0.72
x4 6.40e-01 5.48e-17 1.17e+16 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.6e-16 on 15 degrees of freedom
Multiple R-Squared: 1, Adjusted R-squared: 1
F-statistic: 2.32e+32 on 4 and 15 DF, p-value: <2e-16
� �x1 ∼ x4 の右端に付いている記号 ( . や ∗ ) は,各変数についての t 値に対する確率の大きさを表している ( ∗ ∗ ∗:0 ∼ 0.001 ,∗∗:0.001 ∼ 0.1 ,∗:0.01 ∼ 0.05 ,.:0.05 ∼ 0.1 ,(無印):0.1 ∼ ) .これを元に削るべき変数を
削って再度解析すればよいのだが,この作業を行う際に有用となる関数が step() である.� �> result2 <- step(result) # 削らない場合と変数を 1つ削った場合の解析を全通り
Start: AIC= -1408.3 # 行って (この場合は 5通り)各結果の AIC を比較する
y ~ x1 + x2 + x3 + x4
Df Sum of Sq RSS AIC
- x3 1 3.0e-31 3.5e-30 -1409 # この場合は x3 を削った場合に AIC が最も小さくなる
<none> 3.2e-30 -1408
- x1 1 3.9e-30 7.1e-30 -1394
- x2 1 5.2e-30 8.4e-30 -1391
- x4 1 29 29 15
Step: AIC= -1419.8
y ~ x1 + x2 + x4
Df Sum of Sq RSS AIC
<none> 2.0e-30 -1420
- x2 1 9.9e-31 3.0e-30 -1414
- x1 1 1.2e-29 1.4e-29 -1383
- x4 1 32 32 15
> summary(result2) # x3 を削った場合の重回帰分析結果
Call: lm(formula = y ~ x1 + x2 + x4)
� �

R-Tips 182頁
� �Residuals:
Min 1Q Median 3Q Max
-5.03e-16 -2.66e-16 -1.43e-17 2.41e-16 6.55e-16
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.10e-16 2.91e-16 1.75e+00 0.099 .
x1 -1.36e-15 5.15e-16 -2.64e+00 0.018 *
x2 -2.81e-17 2.34e-17 -1.20e+00 0.248
x4 6.40e-01 4.01e-17 1.60e+16 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.52e-16 on 16 degrees of freedom
Multiple R-Squared: 1, Adjusted R-squared: 1
F-statistic: 5.32e+32 on 3 and 16 DF, p-value: <2e-16
� �
モデル選択の規準
パッケージ wle を入れることで,関数 mle.cp(),mle.aic(),mle.cv() を用いることによりそれぞれ Cp 統計量,
AIC,クロス・バリデーション規準により重回帰モデルの選択を行う.� �> library(wle)
> data(hald)
> result <- mle.cp(y.hald~x.hald)
> summary(result)
Call:
mle.cp(formula = y.hald ~ x.hald)
Mallows Cp:
(Intercept) x.hald1 x.hald2 x.hald3 x.hald4 cp
[1,] 1 1 1 0 0 2.678
[2,] 1 1 1 0 1 3.018
[3,] 1 1 1 1 0 3.041
........................................................
Printed the first 6 best models
> result <- mle.aic(y.hald~x.hald)
> summary(result)
Call:
mle.aic(formula = y.hald ~ x.hald)
Akaike Information Criterion (AIC):
(Intercept) x.hald1 x.hald2 x.hald3 x.hald4 aic
[1,] 1 1 1 0 0 62.83
[2,] 1 1 1 0 1 63.17
........................................................
Printed the first 20 best models� �

R-Tips 183頁
� �> result <- mle.cv(y.hald~x.hald)
> summary(result)
Call:
mle.cv(formula = y.hald ~ x.hald)
Cross Validation selection criteria:
(Intercept) x.hald1 x.hald2 x.hald3 x.hald4 cv
[1,] 1 1 1 0 0 9.851
[2,] 1 1 1 0 1 12.260
........................................................
Printed the first 20 best models� �パッケージ wle を入れることで,関数 wle.cp(),wle.aic(),wle.cv() を用いることによりそれぞれ 重み付けさ
れた Cp 統計量,AIC,クロス・バリデーション規準により重回帰モデルの選択を行うことも出来る.
7.10 関数の最大化と最小化
関数の最大化と最小化・最尤推定法を行なう場合は関数 optim() ,nlm() を用いる.
7.10.1 関数の最大化・最尤推定法
optim() はデフォルトでは最小化を行なうのだが,最大化をするには制御リスト control の fnscale に負の値を
与えればよい (例 : fnscale=-1) .本来の目的関数の代わりに,値にマイナスを掛けた目的関数を用意する方法
もある.� �# ベルヌーイ試行 10回を行って成功が 3回であった場合のパラメータ (ここでは確率)pの推定
> LL < - function (p) choose(10,3)*p^(3)*(1-p)^(7) # 同時密度分布関数
> optim(c(0, 1), LL, control=list(fnscale=-1)) # 初期パラメータ (0,1)で最大化
$par
[1] 0.30 0.95
$value # 関数を最小にするパラメータ値
[1] 0.2668279 # 真の値は 0.3
......................� �
7.10.2 関数の最小化
関数の最小化を行なう場合は関数 nlm() を用いる.この関数は非線形回帰を行う際によく用いられる3.� �# ベルヌーイ試行 10回を行って成功が 3回であった場合のパラメータ (ここでは確率)pの推定
> LL <- function (p) -choose(10,3)*p^(3)*(1-p)^(7) # 同時密度分布関数
> nlm(LL, 0.5, fscale=-1) # 初期パラメータ 0.5 で最大化
$minimum
[1] -0.26683
$estimate # 関数を最小にするパラメータ値
[1] 0.3 # 真の値は 0.3
......................� �3 非線形回帰の詳しい解説は『工学のためのデータサイエンス入門』(間瀬・神保・鎌倉・金藤 共著,数理工学社) を参照のこと.

R-Tips 184頁
7.11 その他の分析方法の紹介
詳しくは (その関数のパッケージを library() で呼び出してから) それぞれの関数のヘルプを御覧頂きたい.
7.11.1 因子分析
データ v2 はデータ v1 にノイズを加えたデータで,v4 と v3 ,v6 と v5 も同様な関係となっている.� �> library(mva)
> v1 <- c(1,1,1,1,1,1,1,1,1,1,3,3,3,3,3,4,5,6)
> v2 <- c(1,2,1,1,1,1,2,1,2,1,3,4,3,3,3,4,6,5)
> v3 <- c(3,3,3,3,3,1,1,1,1,1,1,1,1,1,1,5,4,6)
> v4 <- c(3,3,4,3,3,1,1,2,1,1,1,1,2,1,1,5,6,4)
> v5 <- c(1,1,1,1,1,3,3,3,3,3,1,1,1,1,1,6,4,5)
> v6 <- c(1,1,1,2,1,3,3,3,4,3,1,1,1,2,1,6,5,4)
> m1 <- cbind(v1,v2,v3,v4,v5,v6)
> cor(m1)
v1 v2 v3 v4 v5 v6
v1 1.0000000 0.9393083 0.5128866 0.4320310 0.4664948 0.4086076
v2 0.9393083 1.0000000 0.4124441 0.4084281 0.4363925 0.4326113
v3 0.5128866 0.4124441 1.0000000 0.8770750 0.5128866 0.4320310
v4 0.4320310 0.4084281 0.8770750 1.0000000 0.4320310 0.4323259
v5 0.4664948 0.4363925 0.5128866 0.4320310 1.0000000 0.9473451
v6 0.4086076 0.4326113 0.4320310 0.4323259 0.9473451 1.0000000
> factanal(m1, factors=3) # varimax is the default
Call:
factanal(x = m1, factors = 3)
Uniquenesses:
v1 v2 v3 v4 v5 v6
0.005 0.101 0.005 0.224 0.084 0.005
Loadings:
Factor1 Factor2 Factor3
v1 0.944 0.182 0.267
v2 0.905 0.235 0.159
v3 0.236 0.210 0.946
v4 0.180 0.242 0.828
v5 0.242 0.881 0.286
v6 0.193 0.959 0.196
Factor1 Factor2 Factor3
SS loadings 1.893 1.886 1.797
Proportion Var 0.316 0.314 0.300
Cumulative Var 0.316 0.630 0.929
The degrees of freedom for the model is 0 and the fit was 0.4755
� �よって,v2 と v1 ,v4 と v3 ,v6 と v5 が上手く選別できていることが分かる.
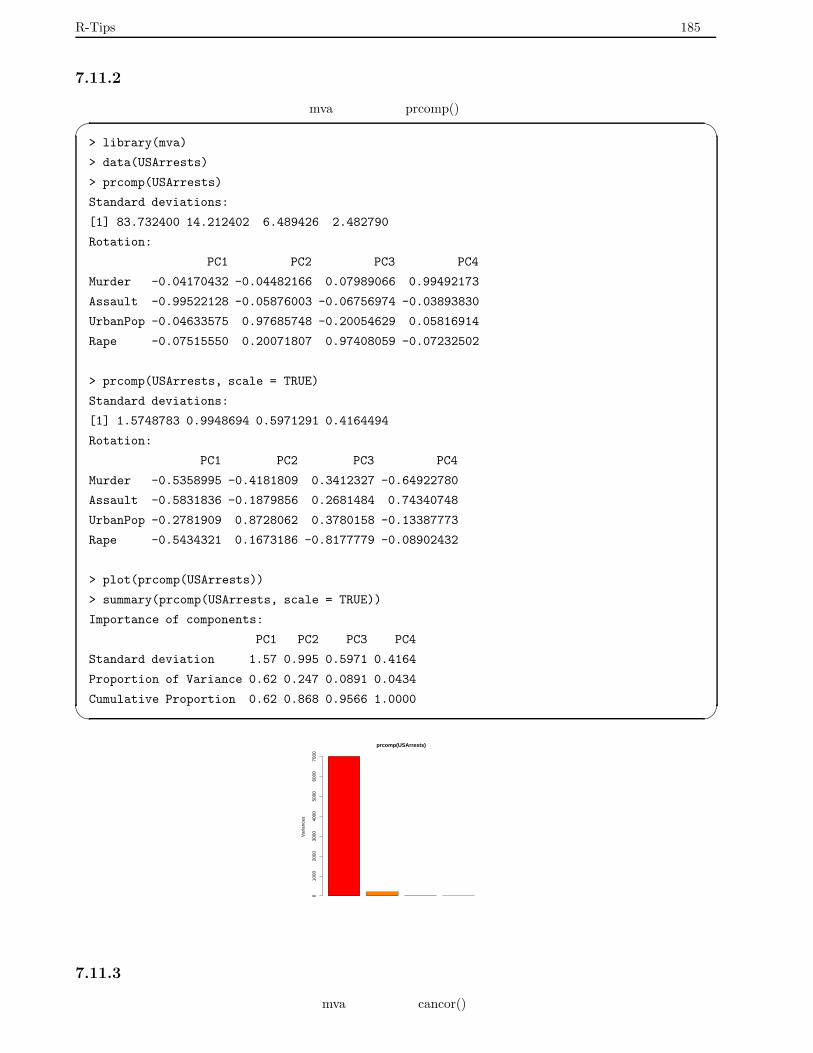
R-Tips 185頁
7.11.2 主成分分析
主成分分析を行なう場合はパッケージ mva の中の関数 prcomp() を用いる.� �> library(mva)
> data(USArrests)
> prcomp(USArrests)
Standard deviations:
[1] 83.732400 14.212402 6.489426 2.482790
Rotation:
PC1 PC2 PC3 PC4
Murder -0.04170432 -0.04482166 0.07989066 0.99492173
Assault -0.99522128 -0.05876003 -0.06756974 -0.03893830
UrbanPop -0.04633575 0.97685748 -0.20054629 0.05816914
Rape -0.07515550 0.20071807 0.97408059 -0.07232502
> prcomp(USArrests, scale = TRUE)
Standard deviations:
[1] 1.5748783 0.9948694 0.5971291 0.4164494
Rotation:
PC1 PC2 PC3 PC4
Murder -0.5358995 -0.4181809 0.3412327 -0.64922780
Assault -0.5831836 -0.1879856 0.2681484 0.74340748
UrbanPop -0.2781909 0.8728062 0.3780158 -0.13387773
Rape -0.5434321 0.1673186 -0.8177779 -0.08902432
> plot(prcomp(USArrests))
> summary(prcomp(USArrests, scale = TRUE))
Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 1.57 0.995 0.5971 0.4164
Proportion of Variance 0.62 0.247 0.0891 0.0434
Cumulative Proportion 0.62 0.868 0.9566 1.0000
� �prcomp(USArrests)
Var
ianc
es
010
0020
0030
0040
0050
0060
0070
00
7.11.3 正準相関分析
正準相関分析を行なう場合はパッケージ mva の中の関数 cancor() を用いる.

R-Tips 186頁
� �> library(mva)
> data(LifeCycleSavings)
> pop <- LifeCycleSavings[, 2:3]
> oec <- LifeCycleSavings[, -(2:3)]
> cancor(pop, oec)
$cor # 変数群の固有値 (正準相関係数)
[1] 0.8247966 0.3652762
$xcoef # 変数 x の推定係数
[,1] [,2]
pop15 -0.009110856 -0.03622206
pop75 0.048647514 -0.26031158
$ycoef # 変数 y の推定係数
[,1] [,2] [,3]
sr 0.0084710221 3.337936e-02 -5.157130e-03
dpi 0.0001307398 -7.588232e-05 4.543705e-06
ddpi 0.0041706000 -1.226790e-02 5.188324e-02
$xcenter # 変数 x を調節するのに使った値
pop15 pop75
35.0896 2.2930
$ycenter # 変数 y を調節するのに使った値
sr dpi ddpi
9.6710 1106.7584 3.7576� �
7.11.4 判別分析
線形を仮定した判別分析を行なう場合はパッケージ MASS の中の関数 lda() を用いる.関連のある関数として
predict.lda() というものもある.� �> library(MASS)
> data(iris3)
> Iris <- data.frame(rbind(iris3[,,1], iris3[,,2], iris3[,,3]),
Sp = rep(c("s","c","v"), rep(50,3)))
> train <- sample(1:150, 75)
> table(Iris$Sp[train])
# your answer may differ
c s v # c s v
25 25 25 # 22 23 30
> z <- lda(Sp ~ ., Iris, prior = c(1,1,1)/3, subset = train)
> predict(z, Iris[-train, ])$class
[1] s s s s s s s s s s s s s s s s s s s s s s s s s c c c c c c c c c c c c c
[39] c c v c c c c c c c c c v v v v v v v v v v v v v v v v c v v v v v v v v
Levels: c s v� �二次の判別分析を行なう場合はパッケージMASSの中の関数 qda()を用いる.関連のある関数として predict.qda()

R-Tips 187頁
というものがある.� �> data(iris3)
> tr <- sample(1:50, 25)
> train <- rbind(iris3[tr,,1], iris3[tr,,2], iris3[tr,,3])
> test <- rbind(iris3[-tr,,1], iris3[-tr,,2], iris3[-tr,,3])
> cl <- factor(c(rep("s",25), rep("c",25), rep("v",25)))
> z <- qda(train, cl)
> predict(z,test)$class
[1] s s s s s s s s s s s s s s s s s s s s s s s s s c c c c c c c c c c c c c
[39] c c c c c v c c c c c c v v v v v v v v v v v v v v v v v v c v v v v v v
Levels: c s v� �
7.11.5 クラスター分析
クラスター分析を行なう場合はパッケージ mva の中の関数 hclust() を用いる.� �> library(mva)
> data(USArrests)
> hc <- hclust(dist(USArrests), "ave")
> plot(hc)
> plot(hc, hang = -1)
� �� �> hc <- hclust(dist(USArrests)^2, "cen")
> memb <- cutree(hc, k = 10); cent <- NULL
> for(k in 1:10) cent <- rbind(cent, colMeans(USArrests[memb == k, , drop = FALSE]))
> hc1 <- hclust(dist(cent)^2, method = "cen" , members = table(memb))
> opar <- par(mfrow = c(1, 2))
> plot(hc, labels = FALSE, hang = -1, main = "Original Tree")
> plot(hc1, labels = FALSE, hang = -1, main = "Re-start from 10 clusters")
> par(opar)
� �
Flo
rida
Nor
th C
arol
ina
Cal
iforn
iaM
aryl
and
Ariz
ona
New
Mex
ico
Del
awar
eA
laba
ma
Loui
sian
aIll
inoi
sN
ew Y
ork
Mic
higa
nN
evad
aA
lask
aM
issi
ssip
piS
outh
Car
olin
aW
ashi
ngto
nO
rego
nW
yom
ing
Okl
ahom
aV
irgin
iaR
hode
Isla
ndM
assa
chus
etts
New
Jer
sey
Mis
sour
iA
rkan
sas
Ten
ness
eeG
eorg
iaC
olor
ado
Tex
asId
aho
Neb
rask
aK
entu
cky
Mon
tana
Ohi
oU
tah
Indi
ana
Kan
sas
Con
nect
icut
Pen
nsyl
vani
aH
awai
iW
est V
irgin
iaM
aine
Sou
th D
akot
aN
orth
Dak
ota
Ver
mon
tM
inne
sota
Wis
cons
inIo
wa
New
Ham
pshi
re
050
100
150
Cluster Dendrogram
hclust (*, "average")dist(USArrests)
Hei
ght
050
0010
000
1500
020
000
Original Tree
hclust (*, "centroid")dist(USArrests)^2
Hei
ght
050
0010
000
1500
020
000
Re−start from 10 clusters
hclust (*, "centroid")dist(cent)^2
Hei
ght
k-means アルゴリズムによるクラスター分析を行う場合は以下のようにする.

R-Tips 188頁
� �> library(mva)
> x <- rbind(matrix(rnorm(100, sd = 0.3), ncol = 2),
+ matrix(rnorm(100, mean = 1, sd = 0.3), ncol = 2)) # 2D example
> cl <- kmeans(x, 2, 20)
> plot(x, col = cl$cluster) # プロット結果は省略
> points(cl$centers, col = 1:2, pch = 8)
� �
7.11.6 生存時間解析
詳しくは『Rによる統計解析の基礎』 (中澤 港 著,ピアソン・エデュケージョン) を参照されたい.� �> library(survival)
> data(aml)
> fit <- survfit(Surv(time, status) ~ x, data=aml) # Kaplan-Meier 法による当てはめ
> plot(fit)
> summary(fit) # 要約値を表示
� �
7.11.7 ノンパラメトリック回帰
詳しくは『みんなのためのノンパラメトリック回帰 (上・下)』 (竹澤 邦夫 著,吉岡書店) を参照されたい.ま
ず,ナダラヤ・ワトソン推定量を用いた平滑化は以下のようにすれば良い.� �> library(modreg)
> data(cars)
> with(cars, {
+ plot(speed, dist)
+ lines(ksmooth(speed, dist, "normal", bandwidth=2), col=2)
+ lines(ksmooth(speed, dist, "normal", bandwidth=5), col=3)
+ })� �平滑化スプラインによる平滑化を行う場合は以下のようにする.� �> data(cars)
> attach(cars)
> plot(speed, dist, main = "data(cars) & smoothing splines")
> ( cars.spl <- smooth.spline(speed, dist) )
Call:
smooth.spline(x = speed, y = dist)
Smoothing Parameter spar= 0.7801305 lambda= 0.1112206 (11 iterations)
Equivalent Degrees of Freedom (Df): 2.635278
Penalized Criterion: 4337.638
GCV: 244.1044� �

R-Tips 189頁
� �> lines(cars.spl, col = "blue")
> lines(smooth.spline(speed, dist, df=10), lty=2, col = "red")
> legend(5,120,c(paste("default [C.V.] => df =",round(cars.spl$df,1)),
+ "s( * , df = 10)"), col = c("blue","red"), lty = 1:2, bg=’bisque’)
� �ペナルティ付き平滑化スプラインを行う場合は以下のようにする.� �> library(survival)
> data(cancer)
> lfit6 <- survreg(Surv(time, status)~pspline(age, df=2), cancer)
Loading required package: splines
> plot(cancer$age, predict(lfit6), xlab=’Age’, ylab="Spline prediction")
> title("Cancer Data")
> fit0 <- coxph(Surv(time, status) ~ ph.ecog + age, cancer) # 結果を格納
> fit1 <- coxph(Surv(time, status) ~ ph.ecog + pspline(age,3), cancer) # 結果を格納
> fit3 <- coxph(Surv(time, status) ~ ph.ecog + pspline(age,8), cancer) # 結果を格納
� �
5 10 15 20 25
020
4060
8010
012
0
speed
dist
5 10 15 20 25
020
4060
8010
012
0
data(cars) & smoothing splines
speed
dist
default [C.V.] => df = 2.6s( * , df = 10)
40 50 60 70 80
300
350
400
450
500
550
600
Age
Spl
ine
pred
ictio
n
Cancer Data
7.11.8 数理計画法
パッケージ lpSolve の中の関数 lp() で数理計画を行うことが出来る.� �# Set up problem: maximize: x1 + 9 x2 + x3 subject to
# x1 + 2 x2 + 3 x3 <= 9
# 3 x1 + 2 x2 + 2 x3 <= 15
> f.obj <- c(1, 9, 3)
> f.con <- matrix (c(1, 2, 3, 3, 2, 2), nrow=2, byrow=TRUE)
> f.dir <- c("<=", "<=")
> f.rhs <- c(9, 15)
# Now run.
> library(lpSolve)
> lp ("max", f.obj, f.con, f.dir, f.rhs)
Success: the objective function is 40.5
> lp ("max", f.obj, f.con, f.dir, f.rhs)$solution
[1] 0.0 4.5 0.0
# Run again, this time requiring that all three variables be integer
> lp ("max", f.obj, f.con, f.dir, f.rhs, int.vec=1:3)
Success: the objective function is 37
> lp ("max", f.obj, f.con, f.dir, f.rhs, int.vec=1:3)$solution
[1] 1 4 0� �
第8章 補足事項
8.1 『丸め』について
round(x, digits = 0) : 丸め関数.digits で指定した (小数点以下の) 桁で IEEE 式丸めを行なう.既定では
digits = 0,つまり小数以下を丸める.IEEE 方式は『一番近い偶数に丸める』が基本で,場合によると『 5
捨』になることもある.
ceiling(x) : x 未満でない最小の整数を返す.
floor(x) : x 以上でない最大の整数を返す.
signif(x, digits = 6) : digits で指定された有効桁数 (既定値 6 桁)に丸める
trunc(x) : x を『 0 へ向かって』整数化する.
zapsmall(x, digits= getOption(”digits”)) : round(x, digits = dr) の丸め位置桁 dr を「0 に近い値」がゼ
ロになるように定めて丸める.
R における数値丸め処理の基本は関数 round() であるが,これは IEEE 規約に基づいたものなので四捨五入と
は微妙に異なる (五入ばかりでなく五捨もあり得る!) .JIS (日本工業規格) や ISO (国際標準化機構) では任意
の桁位置における丸め処理法を次のように定めている (JIS Z 8401方式,ISO 3110 方式) .
(1) 一番近い丸め結果候補が 1つだけなら,その数に丸める.
(2) 一番近い丸め結果候補が 2つある場合は,末尾が偶数のものに丸める.
(3) 丸め処理は 1段階で行なわなければならない.
この規則は丸めによる誤差が最小になる利点がある.ただし,規則 (2) が適用される場合は通常の四捨五入とは
異なる結果になる場合がある.また,規則 (3) は,例えば 12.451 は直に 12 と丸めるべきであって,まず 12.5 と
してから,次に 13 としてはならないことを主張している.
命令 round(122.5) round(122.51) round(123.5) round(123.461)
結果 122 123 124 123
規則 (2):五捨! (1):五入 (2):五入 (1)と (3):四捨
8.2 属性:names 属性と要素のラベル
ベクトルには names 属性と呼ばれる属性情報を付け加えることが出来,要素の名前を持つベクトルは名前を
使って要素を取り出すことが出来る.例えば各月の日数のベクトル mday と R に標準で用意されている月の名前
のベクトル month.name1を考えてみる.� �> mday <- c(31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31)
> month.name
[1] "January" "February" "March" "April" "May" "June" "July" "August" ...
� �1 R に標準で用意されている定数は LETTERS (アルファベットの大文字) ,letters (アルファベットの小文字) ,month.abb (月の名前
の略称) ,month.name (月の名前) ,pi (円周率) の 5 つがある.

R-Tips 191頁
month.name の各文字列を mday の各要素の名前とする ( mday の name 属性としてmonth.name を付け加え
る) には以下のようにする.ただし names 属性の値はベクトルと同じ長さの文字型ベクトルでなければならない.� �> names(mday) <- month.name
> mday
January February March April May June July August ...
31 28 31 30 31 30 31 31 ...� �
names 属性を付ける事で,ベクトルに名前でアクセスすることが出来る (オブジェクト mday の names 属性を
取り出すには names(mday) で取り出すことが出来る) .� �> mday["January"]
January
31
> mday["January"][[1]]
[1] 31� �ベクトルと同じようにリストも names 属性を持つことが出来る.names 属性の意味付けもベクトルの場合と同
じで,リストの要素の名前として扱われる.� �> x <- list(1:5, "abc")
> names(x) <- c("sequence", "letters")
> x
$sequence
[1] 1 2 3 4 5
$letters
[1] "abc"
> x$letters # 名前 letters で要素にアクセスする
[1] "abc"� �リストの作成時に <名前>=<要素> の形で要素を指定することによって,要素に名前を付けることも出来る.� �> list(sequence=1:5, "letters"="abc")
$sequence
[1] 1 2 3 4 5
$letters
[1] "abc"� �ベクトルやリストの場合 names 属性を与えることによって要素にラベルを付けることが出来た.行列の場合は
dimnames 属性を使って行と列にラベルを付けることが出来る.行列に dimnames 属性をつけると、その行列を
表示する際にそれが使われる.� �> a <- matrix(1:8, nrow=2, ncol=4) # 2*4の行列を作る
> dimnames(a) <- list(c("row1","row2"), c("col1","col2","col3","col4"))
> a
col1 col2 col3 col4
row1 1 3 5 7
row2 2 4 6 8� �行と列のどちらかのラベルが不要なら dimnames 属性の対応する要素を NULL にし,両方のラベルが不要なら

R-Tips 192頁
dimnames 属性自体を取り除けばよい.� �> dimnames(a) <- list(c("row1", "row2"), NULL) # 列のラベルを NULLに
> dimnames(a) <- NULL # ラベル不要� �もっと広い話をすれば,R には本質的属性 (attribute) と呼ばれる付加情報を持つことが出来,オブジェクトは
必ず mode と length という 2 つの属性を持っている ( names 属性の様に明示的に与える必要は無く,自動的に
属性が付けられる).この mode と length 以外に names 属性や,因子オブジェクト ( factor ) ならば levels 属性
を,行列ならば dim 属性を持つことになる.オブジェクトが持つ mode と length 以外の全ての属性を調べるに
は関数 attributes() を使い,mode の変更には関数 as.<データ型名>() を使う.また,関数 attr() により任意の
属性を操作することも出来る.� �> x <- 1:4
> mode(x) # x の属性を調べる
> attributes(x) # mode と length 以外の全ての属性を調べる
> attr(x, "dim") <- c(2,2) # x に dim 属性を付けることで 2 * 2 行列であるかのように扱う
� �
8.3 apply() ファミリー
関数 apply() ファミリーには apply(), mapply(), lapply(), sapply(), tapply() が用意されている.一つの関数を
複数のオブジェクトに適用して得られた結果をベクトルや行列,リストとして一括で返す.例えば m× n 行列 X
の全ての要素に 1 を足す場合,R では繰り返し文 (for や while) を使わなくても X < − X+1 で手軽かつ高速に
実現できるが,この apply() ファミリーに属する関数の機能もこれに似ている.すなわち,C や JAVA ならば複
数オブジェクトを個別に与えて繰り返し文で回さなければいけないような場面でも,apply() ファミリーの関数を
使えば簡潔な記述で高速に計算できる場面が出てくるということである.
apply(X, MARGIN, 関数, ...) : ベクトルや行列,配列の MARGIN に関数を適用し,その結果の配列かリ
ストを返す.ここで MARGIN = 1 ならば行に関して,MARGIN = 2 ならば列に関して,MARGIN =
c(1,2) ならば各要素に対して関数を適用する.
lapply(X, 関数, ...) ,sapply(X, 関数, ...) : リストに関数を適用し,lapply() は結果のリストを,sapply()
は結果の『 names 属性付きのベクトル』か『 names 属性付きの行列』を返す.ベクトルや行列にこれらを
適用すると,各成分について関数を適用するのでエラいことになってしまう.
tapply(X, INDEX, 関数, ...) : グループ化された変数について,グループごとに関数を適用する.INDEX
は X の要素をグループに分ける因子の組み合わせのリスト (通常は文字列ベクトル) を与え,各グループに
関数を適用した結果をベクトルもしくはリストで返す.
mapply(関数 F , x, y, z, ... ) : sapply()の多変量版.x, y, z, はベクトルや行列などを複数個指定でき,関数
F(x,y,z,...) の結果をベクトルのリストで返す.例えばmapply(sum, 1:3, 4:6) ならば [ sum(1,4), sum(2,5),
sum(3,6) ] = [ 5, 7, 9 ] が,mapply(sum, 1:3, 4:5) ならば [ sum(1,4), sum(2,5), sum(3,4) ] = [ 5, 7, 7 ] が
返ってくる (要素の数が引数ごとで異なる場合は反復して用いられる) 2.
行列の処理でよく使う関数が apply() である.以下の最後に紹介する関数 scale() は列毎の操作を行うので,行
毎に正規化を行う場合はまず転置して処理を行ってから,一番最後に転置し直せば良い.
2 ただし warning メッセージが出る.
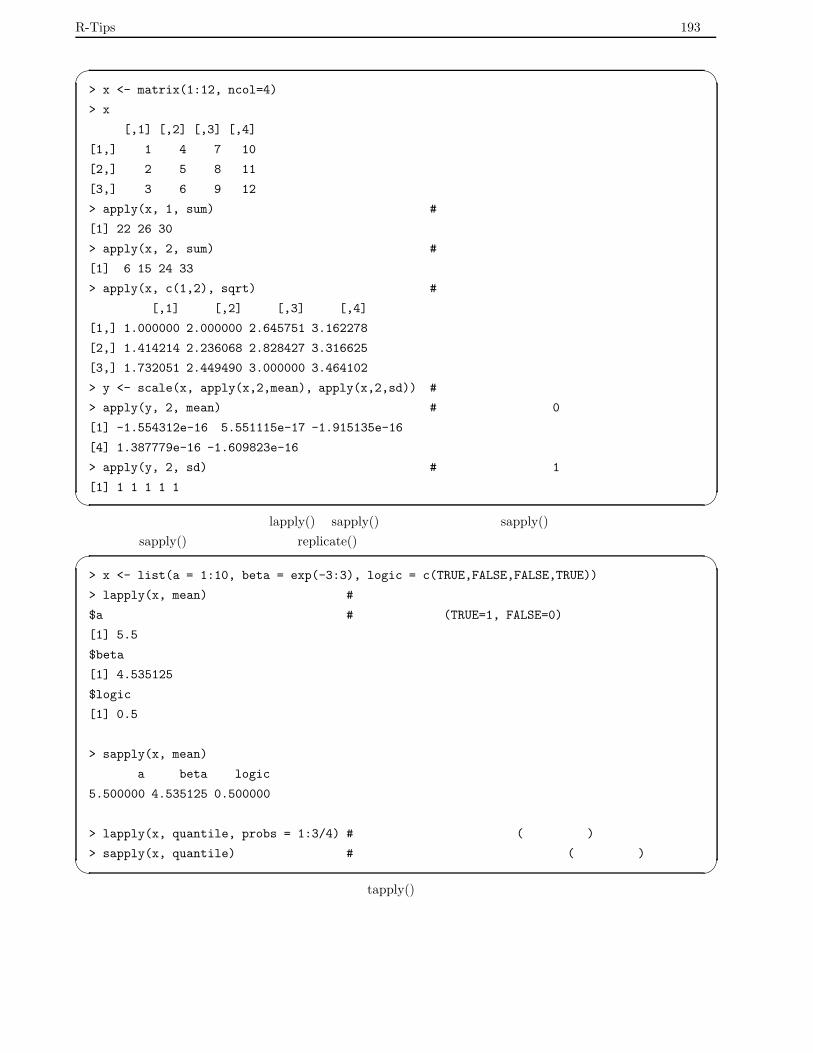
R-Tips 193頁
� �> x <- matrix(1:12, ncol=4)
> x
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> apply(x, 1, sum) # 各行の最大値を求める
[1] 22 26 30
> apply(x, 2, sum) # 各列の最大値を求める
[1] 6 15 24 33
> apply(x, c(1,2), sqrt) # 各要素の平方根を求める
[,1] [,2] [,3] [,4]
[1,] 1.000000 2.000000 2.645751 3.162278
[2,] 1.414214 2.236068 2.828427 3.316625
[3,] 1.732051 2.449490 3.000000 3.464102
> y <- scale(x, apply(x,2,mean), apply(x,2,sd)) # 行列の各列毎に正規化
> apply(y, 2, mean) # 各列の平均はほぼ 0
[1] -1.554312e-16 5.551115e-17 -1.915135e-16
[4] 1.387779e-16 -1.609823e-16
> apply(y, 2, sd) # 標準偏差はすべて 1
[1] 1 1 1 1 1� �リストの処理でよく使う関数が lapply() ,sapply() である.一般的には sapply() の方が,計算結果が扱いやす
い.また,sapply() のラッパー関数に replicate() というものがある.詳しくはヘルプを参照されたい.� �> x <- list(a = 1:10, beta = exp(-3:3), logic = c(TRUE,FALSE,FALSE,TRUE))
> lapply(x, mean) # リストの三つの成分の平均値からなるリストを計算
$a # 論理値は整数 (TRUE=1, FALSE=0) と見なされる
[1] 5.5
$beta
[1] 4.535125
$logic
[1] 0.5
> sapply(x, mean)
a beta logic
5.500000 4.535125 0.500000
> lapply(x, quantile, probs = 1:3/4) # 結果がリストで返ってくる (出力は省略)
> sapply(x, quantile) # 結果が属性付きの行列で返ってくる (出力は省略)
� �グループ化されたデータの処理でよく使う関数が tapply()である.最初はとっつきにくいが,カテゴリカルデー
タを扱うは結構役に立つ.

R-Tips 194頁
� �> data(warpbreaks) # 1台の織機当たりの反り破損の数
> attach(warpbreaks) # 使うデータを固定
> fc <- factor(tension) # 要素をグループ化
> levels(fc) # グループ化されているかを確認
[1] "L" "M" "H"
> ( mymeans <- tapply(breaks, fc, mean) ) # breaks の平均をグループごとに計算
L M H
36.38889 26.38889 21.66667
> sder <- function(x) sqrt(var(x)/length(x)) # 標本標準偏差を求める関数を定義して
> ( mysd <- tapply(breaks, fc, sder) ) # グループごとに計算することも出来る
L M H
3.876474 2.149843 1.968709� �トリッキーな使い方かもしれないが,mapply() を使えば規則的なリストを簡単に作成することが出来る.� �> mapply(rep, 1:3, 3:1) # rep(1,3), rep(2,2), rep(3,1) を並べたリストを生成
> mapply(rep, 1:3, 3:1) # rep(3,1), rep(2,2), rep(1,3) を並べたリストを生成
� �
8.4 関数定義に関する補足
自作関数を作る際に有用な技法・命令を紹介する.
8.4.1 引数のチェックを行う
特定の引数に対して関数の手続きを変更したい場合は,if 文などの条件分岐で場合分けをすればよい.� �> temp <- function (n) ifelse(n==0, 1, prod(1:n)) # n=0 の時は 1 を返す
> temp(0)
[1] 1
> temp(5)
[1] 120� �また,関数の引数に整数を期待する場合において,整数以外の引数が与えられたら不具合が生じてしまう場合
がある.その場合,関数のメイン部分の前に条件分岐で引数のチェックを行えばよい.不具合を起こすような引数
が見つかれば return() で関数を終了させればよい.� �> myprod <- function(n) {
+ if (n != floor(n) || n < 0) return() # 引数が自然数以外ならば何もしない
+ else return(gamma(n+1)) # 引数が自然数ならば階乗の計算
+ }
> myprod(3)
[1] 6
> myprod(-1) # 何もしない
� �(注) 実際,条件分岐だけで完全な引数のチェックを行うことは難しい.上のプログラムでは myprod(4.0) として
も実行されてしまう.

R-Tips 195頁
また,関数を使用する際に与えられた引数の数が場合によっては足らない場合があるので,ある引数が実際に
存在するかどうかを関数 missing() でチェックする必要が起こる.ただし,missing(y) は y が関数中で変更され
ると信頼できなくなる (例:y < − match.arg() の後では必ず FALSE になる) .� �myplot <- function(x, y) {
if(missing(y)) { # 引数 y が足らない (入力されていない)ならば
y <- x # もし仮引数 y が与えられなければ y <- x とする
x <- 1:length(y)
}
plot(x,y)
}� �
8.4.2 引数のマッチングと選択
関数の引数は省略形で指定することが出来る.すなわち,綴りの途中までだけで特定の引数であることが認識
できれば,引数をある程度省略して記述することが出来る.これを部分的マッチングと呼ぶ.� �> plot(sin, xlab = "x-title") # x 軸にタイトルをつける
> plot(sin, xla = "x-title") # "xla" でも "xlab" と分かるので OK
> plot(sin, xl = "x-title") # "xl" では "xlab" と分からない ( "xlim" の可能性もある)
Error in if (from == to || length.out < 2) by <- 1 :
missing value where TRUE/FALSE needed
� �関数の引数に与えられた値が候補のどれに一致するかどうかをチェックする場合は関数 match.arg() を用いる
(このとき部分的マッチングが行われる) .ただし,該当する項目がなければエラーが出る.� �> myfunc <- function(a, b, do = c("sum", "minus", "mult", "div")) {
+ do <- match.arg(do)
+ switch(do, sum = a+b, # do (match.arg の返り値) の結果で条件分岐
+ minus = a-b,
+ mult = a*b,
+ div = a/b)
+ }
> myfunc(3, 2, "minus")
[1] 1
> myfunc(3, 2, "mi") # 引数の省略:"mi" でも "minus" だと分かるので OK
[1] 1
> myfunc(3, 2, "m") # "m" では "minus" だと分からない...
Error in match.arg(do) : ARG should be one of sum, minus, mult, div
� �
8.4.3 数値ベクトルの対話的入力 readline()
関数 readline() を用いると,キー入力があるまでプログラムの実行を停止することが出来る.これにより対話
的な入力を行うことが出来る.

R-Tips 196頁
� �> myfunc <- function() {
+ ANSWER <- readline("Are you a satisfied R user? : ")
+ if ((substr(ANSWER, 1, 1) == "n") || (substr(ANSWER, 1, 1) == "N"))
+ cat("This is impossible. YOU LIED!\n")
+ else cat("I knew it.\n")
+ }
> myfunc()
Are you a satisfied R user? : No. # "No." と入力してみる
This is impossible. YOU LIED! # 「んなこたぁない」と返ってくる
� �(注) キー入力があるまでプログラムの実行を停止するのではなく,秒数を指定してプログラムを停止する場合は
関数 Sys.sleep(time) を用いればよい.
readline() を用いることで数値ベクトルを読み込ませるようにすることが出来る.手順は,対話的に文字列を入
力 (任意の分離記号を指定できる) させ,次に関数 strsplit() で文字列リストに変換してから関数 unlist() で文字
列ベクトル化,最後に関数 as.numeric() で数値化する.ここで ”,” で区切ったベクトルを入力することが出来る
関数 myfunc() を定義してみた.� �> myfunc <- function () {
+ Str <- readline("Enter : ")
+ as.numeric(unlist(strsplit(Str, ",")))
+ }
> x <- myfunc()
Enter : 1,2,3,4,5
> x
[1] 1 2 3 4 5� �オブジェクト名を入力して読み込ませる場合は以下のようにする.� �> x <- 1:10
> y <- get(readline())
x
> y
[1] 1 2 3 4 5 6 7 8 9 10� �
8.4.4 メニューによる選択 menu 関数
関数 menu() でメニュー選択を実現できる.引数 choices で選択肢を示す文字列ベクトル, 引数 title でメニュー
のタイトルとして出力される文字列を指定する.0, 1, 2, ...を選択することが出来,0 を入力したらメニュー選
択から抜けることが出来る.

R-Tips 197頁
� �# 選択肢番号により switch 文で実行内容を変える
> switch(menu(c("List letters", "List LETTERS"), title="0:exit") + 1,
+ cat("Nothing done\n"), letters, LETTERS)
1:List letters
2:List LETTERS
Selection: 1
[1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o"
[16] "p" "q" "r" "s" "t" "u" "v" "w" "x" "y" "z"
� �
8.5 データを html ,LATEX形式で出力
以下のデータ x を,LaTeX の表を出力する命令に書き直す場合は関数 xtable() を用いる.� �> library(xtable)
> x <- matrix(1:24,4,6)
> mytable <- xtable(x)
> print(mytable)
% latex table generated in R 1.8.1 by xtable 1.2-1 package
% Sun May 04 12:31:01 1980
\begin{table}[ht]
\begin{center}
\begin{tabular}{rrrrrrr}
\hline
& 1 & 2 & 3 & 4 & 5 & 6 \\
\hline
1 & 1.00 & 5.00 & 9.00 & 13.00 & 17.00 & 21.00 \\
2 & 2.00 & 6.00 & 10.00 & 14.00 & 18.00 & 22.00 \\
3 & 3.00 & 7.00 & 11.00 & 15.00 & 19.00 & 23.00 \\
4 & 4.00 & 8.00 & 12.00 & 16.00 & 20.00 & 24.00 \\
\hline
\end{tabular}
\end{center}
\end{table}� �このデータ x を,html の表を出力する命令に書き直す場合は以下のようにする.� �> print(mytable,type="html") # 出力結果は省略
� �
8.6 グラフィックス関係の補足
8.6.1 時系列:ts.plot()
関数 ts.plot()は任意個の時系列ベクトルを与えてそれらを一度にプロットさせることが出来る (ts: time series)3.また,色や線の種類,点の記号などを時系列ベクトル毎に変更することも出来る.plot.ts () という関数もある
3 plot() に時系列ベクトルを与える場合は,一つの時系列だけしか与えることが出来ないことに注意.
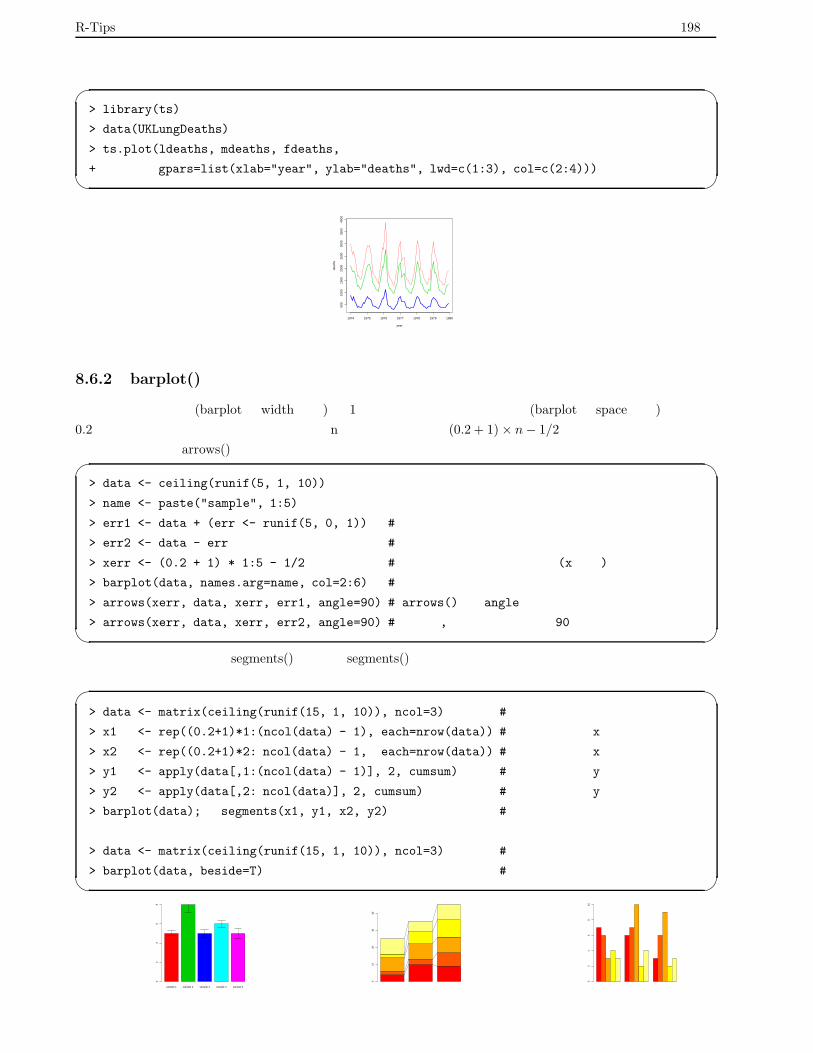
R-Tips 198頁
が,詳しくはヘルプを参照されたい.� �> library(ts)
> data(UKLungDeaths)
> ts.plot(ldeaths, mdeaths, fdeaths,
+ gpars=list(xlab="year", ylab="deaths", lwd=c(1:3), col=c(2:4)))
� �
year
deat
hs
1974 1975 1976 1977 1978 1979 1980
500
1000
1500
2000
2500
3000
3500
4000
8.6.2 barplot() あれこれ
棒グラフの棒の幅 (barplotの width引数) は 1 になっていて,棒と棒の間隔 (barplotの space引数) は標準で
0.2 になっている.そしてこの状態で左から n 番目の棒の中心は (0.2 + 1) × n− 1/2 になっている.これを利用
することで,関数 arrows() で誤差範囲が表示できる.� �> data <- ceiling(runif(5, 1, 10))
> name <- paste("sample", 1:5)
> err1 <- data + (err <- runif(5, 0, 1)) # 誤差範囲のデータ
> err2 <- data - err # 誤差範囲のデータ
> xerr <- (0.2 + 1) * 1:5 - 1/2 # エラーバーを表示する位置 (x座標)
> barplot(data, names.arg=name, col=2:6) # 棒グラフの描画
> arrows(xerr, data, xerr, err1, angle=90) # arrows() の angle は矢印の傾きを
> arrows(xerr, data, xerr, err2, angle=90) # 指定し,直角になるように 90にしてある
� �棒グラフの間の線は関数 segments() で引く.segments() には線分の始点と終点を与えないといけないのでまず
それを計算している.また,棒グラフを横に並べることも出来る.� �> data <- matrix(ceiling(runif(15, 1, 10)), ncol=3) # サンプルデータ
> x1 <- rep((0.2+1)*1:(ncol(data) - 1), each=nrow(data)) # 線分の始点の x座標
> x2 <- rep((0.2+1)*2: ncol(data) - 1, each=nrow(data)) # 線分の終点の x座標
> y1 <- apply(data[,1:(ncol(data) - 1)], 2, cumsum) # 線分の始点の y座標
> y2 <- apply(data[,2: ncol(data)], 2, cumsum) # 線分の終点の y座標
> barplot(data); segments(x1, y1, x2, y2) # 棒グラフと線分を描く
> data <- matrix(ceiling(runif(15, 1, 10)), ncol=3) # サンプルデータ
> barplot(data, beside=T) # 棒グラフを横に並べる
� �
sample 1 sample 2 sample 3 sample 4 sample 5
02
46
8
010
2030
40
02
46
810

R-Tips 199頁
8.6.3 pie() あれこれ
ラベルや色の指定を行う場合は以下のようにする.� �> pie(rep(1, 24), col = rainbow(24), radius = 0.9)
> pie.sales <- c(0.12, 0.3, 0.26, 0.16, 0.04, 0.12)
> names(pie.sales) <- c("AA", "BB", "cc", "dd", "EE", "ff")
> pie(pie.sales)
> pie.sales <- c(0.12, 0.15, 0.15, 0.16, 0.10, 0.16, 0.04, 0.12)
> pie(pie.sales)
� �
1
2
3
4
567
8
9
10
11
12
13
14
15
16
1718 19
20
21
22
23
24
AA
BB
cc
dd
EE
ff
1
23
4
5
6
7
8
� �# 色の指定 (1)
> pie.sales <- c(0.12, 0.3, 0.26, 0.16, 0.04, 0.12)
> pie(pie.sales, col = c("purple", "violetred1", "green3", "cornsilk", "cyan", "white"))
# 色の指定 (2)
> pie.sales <- c(0.12, 0.3, 0.26, 0.16, 0.04, 0.12)
> pie(pie.sales, col = gray(seq(0.4,1.0,length=6)))
# 境界線を書かない場合
> n <- 200
> pie(rep(1,n), labels="", col=rainbow(n), border=NA,
+ main = "pie(*, labels=\"\", col=rainbow(n), border=NA,..")
� �
1
2
3
4
5
6
1
2
3
4
5
6
pie(*, labels="", col=rainbow(n), border=NA,..
8.6.4 数式による注釈
プロットに数学記号や式を使いたい場合で text() , mtext() ,axis() ,title() のいずれかを使う場合は,文字
列の代わりに expression() を指定すればよい.例えば以下は二項分布の確率関数の公式を書く.� �> text(x,y,expression(paste(bggroup("(",atop(n,x),")"),p^x, q^{n-x})))
� �一覧はオンラインマニュアルで御覧頂ける.
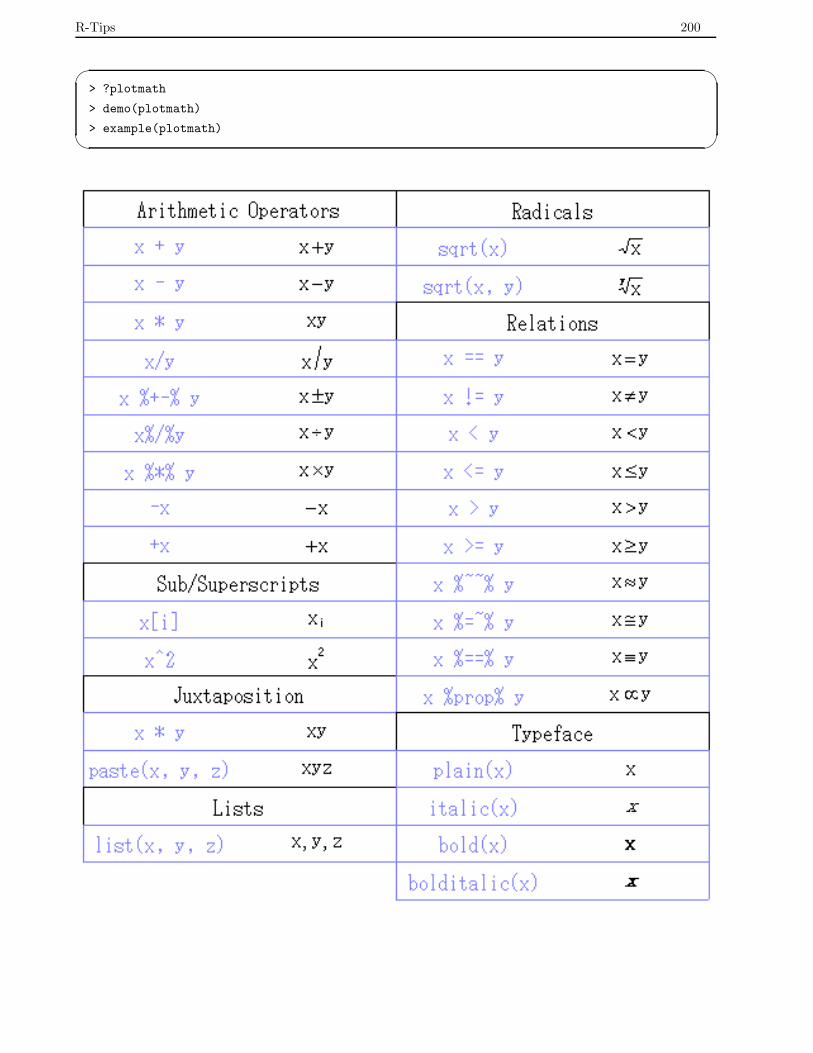
R-Tips 200頁
� �> ?plotmath
> demo(plotmath)
> example(plotmath)
� �以下に書式と出力例を挙げる.

R-Tips 201頁

R-Tips 202頁

R-Tips 203頁
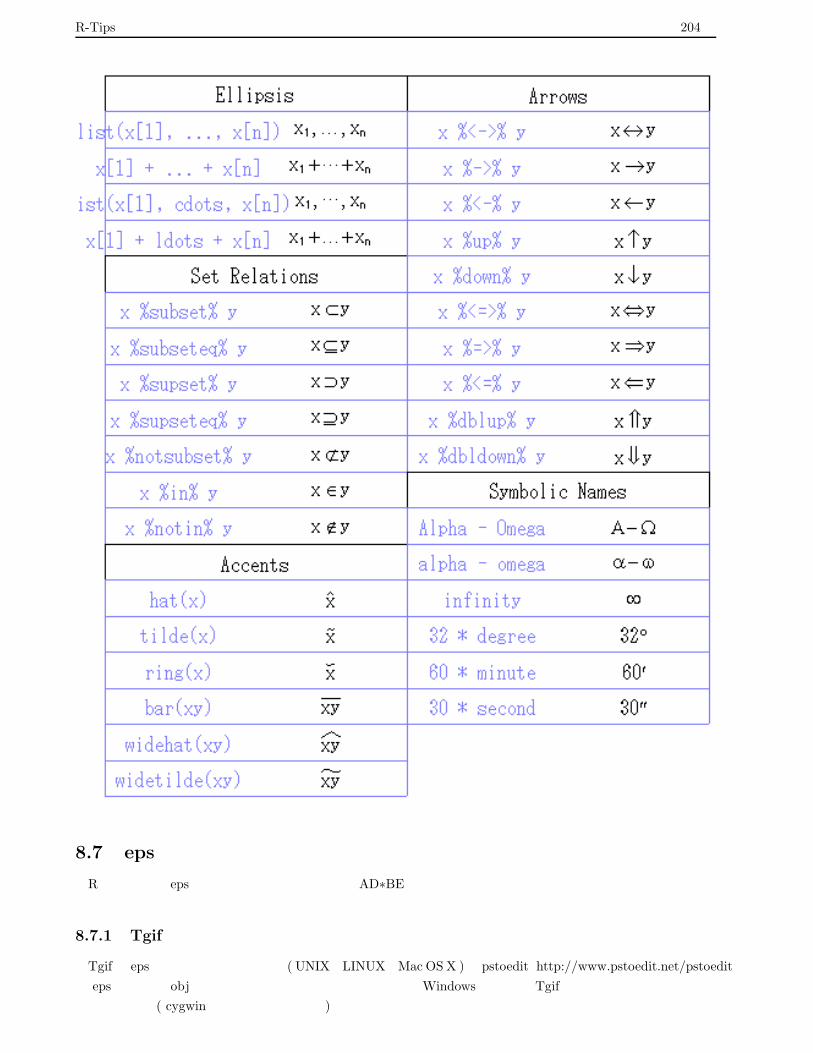
R-Tips 204頁
8.7 eps ファイルの編集方法
R で出力した eps ファイルを編集する場合で,AD∗BE ソフトなどの有料ソフトを使わない方法を紹介する.
8.7.1 Tgif を用いる方法
Tgifで epsファイルを編集する場合 ( UNIX,LINUX,Mac OS X )は pstoedit:http://www.pstoedit.net/pstoedit
で eps 形式から obj 形式に変換してから編集する.ただし,Windows の場合は Tgif が最初から入っているわけ
ではないので ( cygwin を入れる必要がある) ,次の方法をお勧めする.
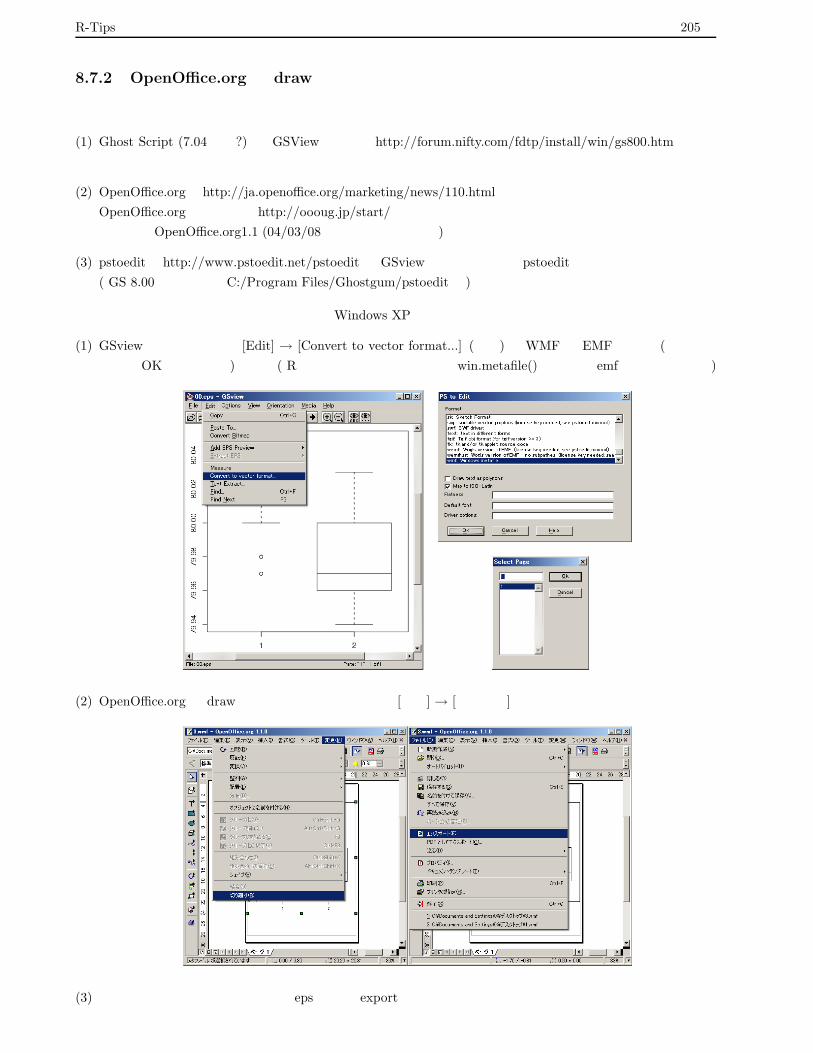
R-Tips 205頁
8.7.2 OpenOffice.org の draw を使う方法
セットアップの手順は以下の通り.
(1) Ghost Script (7.04以降?) と GSView の設定:http://forum.nifty.com/fdtp/install/win/gs800.htm の設定
を済ます.
(2) OpenOffice.org :http://ja.openoffice.org/marketing/news/110.htmlの
OpenOffice.org の入り口 :http://oooug.jp/start/
に従って OpenOffice.org1.1 (04/03/08現在の日本語最新版) をダウンロードしてインストールする.
(3) pstoedit :http://www.pstoedit.net/pstoedit を GSview フォルダの下に pstoedit フォルダを作ってそこに
( GS 8.00 の標準では C:/Program Files/Ghostgum/pstoedit に) インストールする.
実際の動作手順は以下の通り.動作確認は Windows XP で行った.
(1) GSview のメニューから [Edit] → [Convert to vector format...] (左図) でWMF や EMF に変換 (右上・右
下図で OK をクリック) する.( R のグラフを編集する場合は win.metafile() を使って emf 形式で出力する)
(2) OpenOffice.org の draw に読み込んで,メニューの [変更] → [切り離す] で切り離してから編集する.
(3) ページサイズや余白を変えてから eps 形式で export する.以上.

R-Tips 206頁
8.8 関数 lm() に入れる演算子とシンボルの例
以下にいくつかの演算子の例を挙げる.
Y ˜ M : Y は M と同様のモデル.
Y ˜ M − 1 : 切片項のない原点を通るモデル.
Y ˜ M + 0 : 同上.
Y ˜ M1 + M2 : Y を M1 と M2 と切片項で重回帰.
Y ˜ M1 + M2 − 1 : Y を切片項を含まない M1 と M2 と切片項で重回帰.
M1 + M2 : M1 と M2 を含める.
M1 − M2 : M1 を含めて M2 を除外する.
M1 : M2 : M1 と M2 のテンソル積.もし両者が因子なら『サブクラス因子』となる.
M1 %in% M2 : M1 : M2 と同じ.
M1 * M2 : M1 + M2 + M1 : M2 と同じ.
M1 / M2 : M1 + M2 %in% M1 と同じ.
Mˆn : Mの全ての項と n 次までの交互作用を表す.
I(M) : 恒等関数.M の中では,全ての演算子は通常の数値演算での意味を持ち,その項は説明行列に出てくる.
以下にいくつかのシンボリックな例を挙げる.
y ˜ x ,y ˜ 1+x : y の x への単純な線形回帰を意味する.前者は切片項が明示されておらず,後者は明示さ
れている.
y ˜ 0+x ,y ˜ −1+x ,y ˜ x − 1 : 原点を通る (つまり切片項を通らない) y の x への単純な線形回帰を意
味する.
log(y) ˜ x1 + x2 : log(y) の x1 + x2 への重回帰を意味する.暗黙のうちに切片項を持っている.
y ˜ poly(x,2) ,y ˜ 1+x+I(xˆ2) : y の x への二次線形回帰を意味する.前者は基底関数として直行多項式
を,後者は単なるべき乗式が用いられている.
y ˜ X + poly(x,2) : 行列 X と x の二次多項式からなる説明行列を持つ y の重回帰を意味する.
y ˜ A,y ˜ A + x : 前者は A で定まるクラスを持つ y の一元配置の分散分析.後者は A で定まるクラスと,
共変量 x を持つ y の一元配置の共分散分析.
y ˜ A*B ,y ˜ A + B + A:B ,y ˜ B %in% A ,y ˜ A/B : 2つの因子 Aと B を持つ y の二次元配置
の non-additiveなモデル.最初の 2つは同じ crossed classificationを,残りの 2つは同じ nested classification
を指定する (これらは同じ説明空間であることに注意) .
y ˜ (A + B + C)ˆ2 ,y ˜ A*B*C - A:B:C : 主効果と二次交互作用のみを持つ三因子実験.両者は同じモ
デルを指定する.
y ˜ A*x ,y ˜ A/x ,y ˜ A/(1+x) - 1: A の 水準内で y を x に回帰する様々な単純な線形回帰を意味す
る (コーディングが違うだけ) .3番目の形は A に含まれる水準と同じ数の,異なった切片と傾きの推定値
を与える.
y ˜ A*B + Error(C) : 2 つの処理因子 A と B と,因子 C が定める誤差層を持つ実験.例えば,因子 C か
ら定まる全区画を持つ分割区画実験をする場合はこの書式となる.
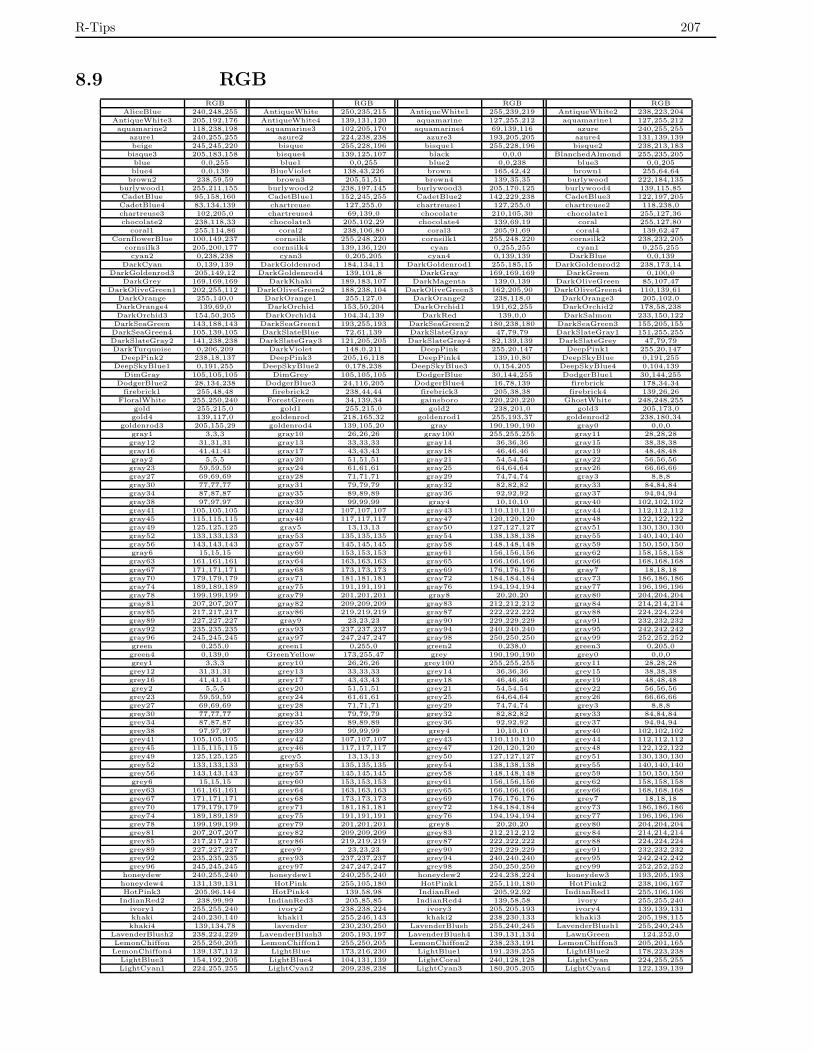
R-Tips 207頁
8.9 色の名前とRGBコード名前 RGB 名前 RGB 名前 RGB 名前 RGB
AliceBlue 240,248,255 AntiqueWhite 250,235,215 AntiqueWhite1 255,239,219 AntiqueWhite2 238,223,204
AntiqueWhite3 205,192,176 AntiqueWhite4 139,131,120 aquamarine 127,255,212 aquamarine1 127,255,212
aquamarine2 118,238,198 aquamarine3 102,205,170 aquamarine4 69,139,116 azure 240,255,255
azure1 240,255,255 azure2 224,238,238 azure3 193,205,205 azure4 131,139,139
beige 245,245,220 bisque 255,228,196 bisque1 255,228,196 bisque2 238,213,183
bisque3 205,183,158 bisque4 139,125,107 black 0,0,0 BlanchedAlmond 255,235,205
blue 0,0,255 blue1 0,0,255 blue2 0,0,238 blue3 0,0,205
blue4 0,0,139 BlueViolet 138,43,226 brown 165,42,42 brown1 255,64,64
brown2 238,59,59 brown3 205,51,51 brown4 139,35,35 burlywood 222,184,135
burlywood1 255,211,155 burlywood2 238,197,145 burlywood3 205,170,125 burlywood4 139,115,85
CadetBlue 95,158,160 CadetBlue1 152,245,255 CadetBlue2 142,229,238 CadetBlue3 122,197,205
CadetBlue4 83,134,139 chartreuse 127,255,0 chartreuse1 127,255,0 chartreuse2 118,238,0
chartreuse3 102,205,0 chartreuse4 69,139,0 chocolate 210,105,30 chocolate1 255,127,36
chocolate2 238,118,33 chocolate3 205,102,29 chocolate4 139,69,19 coral 255,127,80
coral1 255,114,86 coral2 238,106,80 coral3 205,91,69 coral4 139,62,47
CornflowerBlue 100,149,237 cornsilk 255,248,220 cornsilk1 255,248,220 cornsilk2 238,232,205
cornsilk3 205,200,177 cornsilk4 139,136,120 cyan 0,255,255 cyan1 0,255,255
cyan2 0,238,238 cyan3 0,205,205 cyan4 0,139,139 DarkBlue 0,0,139
DarkCyan 0,139,139 DarkGoldenrod 184,134,11 DarkGoldenrod1 255,185,15 DarkGoldenrod2 238,173,14
DarkGoldenrod3 205,149,12 DarkGoldenrod4 139,101,8 DarkGray 169,169,169 DarkGreen 0,100,0
DarkGrey 169,169,169 DarkKhaki 189,183,107 DarkMagenta 139,0,139 DarkOliveGreen 85,107,47
DarkOliveGreen1 202,255,112 DarkOliveGreen2 188,238,104 DarkOliveGreen3 162,205,90 DarkOliveGreen4 110,139,61
DarkOrange 255,140,0 DarkOrange1 255,127,0 DarkOrange2 238,118,0 DarkOrange3 205,102,0
DarkOrange4 139,69,0 DarkOrchid 153,50,204 DarkOrchid1 191,62,255 DarkOrchid2 178,58,238
DarkOrchid3 154,50,205 DarkOrchid4 104,34,139 DarkRed 139,0,0 DarkSalmon 233,150,122
DarkSeaGreen 143,188,143 DarkSeaGreen1 193,255,193 DarkSeaGreen2 180,238,180 DarkSeaGreen3 155,205,155
DarkSeaGreen4 105,139,105 DarkSlateBlue 72,61,139 DarkSlateGray 47,79,79 DarkSlateGray1 151,255,255
DarkSlateGray2 141,238,238 DarkSlateGray3 121,205,205 DarkSlateGray4 82,139,139 DarkSlateGrey 47,79,79
DarkTurquoise 0,206,209 DarkViolet 148,0,211 DeepPink 255,20,147 DeepPink1 255,20,147
DeepPink2 238,18,137 DeepPink3 205,16,118 DeepPink4 139,10,80 DeepSkyBlue 0,191,255
DeepSkyBlue1 0,191,255 DeepSkyBlue2 0,178,238 DeepSkyBlue3 0,154,205 DeepSkyBlue4 0,104,139
DimGray 105,105,105 DimGrey 105,105,105 DodgerBlue 30,144,255 DodgerBlue1 30,144,255
DodgerBlue2 28,134,238 DodgerBlue3 24,116,205 DodgerBlue4 16,78,139 firebrick 178,34,34
firebrick1 255,48,48 firebrick2 238,44,44 firebrick3 205,38,38 firebrick4 139,26,26
FloralWhite 255,250,240 ForestGreen 34,139,34 gainsboro 220,220,220 GhostWhite 248,248,255
gold 255,215,0 gold1 255,215,0 gold2 238,201,0 gold3 205,173,0
gold4 139,117,0 goldenrod 218,165,32 goldenrod1 255,193,37 goldenrod2 238,180,34
goldenrod3 205,155,29 goldenrod4 139,105,20 gray 190,190,190 gray0 0,0,0
gray1 3,3,3 gray10 26,26,26 gray100 255,255,255 gray11 28,28,28
gray12 31,31,31 gray13 33,33,33 gray14 36,36,36 gray15 38,38,38
gray16 41,41,41 gray17 43,43,43 gray18 46,46,46 gray19 48,48,48
gray2 5,5,5 gray20 51,51,51 gray21 54,54,54 gray22 56,56,56
gray23 59,59,59 gray24 61,61,61 gray25 64,64,64 gray26 66,66,66
gray27 69,69,69 gray28 71,71,71 gray29 74,74,74 gray3 8,8,8
gray30 77,77,77 gray31 79,79,79 gray32 82,82,82 gray33 84,84,84
gray34 87,87,87 gray35 89,89,89 gray36 92,92,92 gray37 94,94,94
gray38 97,97,97 gray39 99,99,99 gray4 10,10,10 gray40 102,102,102
gray41 105,105,105 gray42 107,107,107 gray43 110,110,110 gray44 112,112,112
gray45 115,115,115 gray46 117,117,117 gray47 120,120,120 gray48 122,122,122
gray49 125,125,125 gray5 13,13,13 gray50 127,127,127 gray51 130,130,130
gray52 133,133,133 gray53 135,135,135 gray54 138,138,138 gray55 140,140,140
gray56 143,143,143 gray57 145,145,145 gray58 148,148,148 gray59 150,150,150
gray6 15,15,15 gray60 153,153,153 gray61 156,156,156 gray62 158,158,158
gray63 161,161,161 gray64 163,163,163 gray65 166,166,166 gray66 168,168,168
gray67 171,171,171 gray68 173,173,173 gray69 176,176,176 gray7 18,18,18
gray70 179,179,179 gray71 181,181,181 gray72 184,184,184 gray73 186,186,186
gray74 189,189,189 gray75 191,191,191 gray76 194,194,194 gray77 196,196,196
gray78 199,199,199 gray79 201,201,201 gray8 20,20,20 gray80 204,204,204
gray81 207,207,207 gray82 209,209,209 gray83 212,212,212 gray84 214,214,214
gray85 217,217,217 gray86 219,219,219 gray87 222,222,222 gray88 224,224,224
gray89 227,227,227 gray9 23,23,23 gray90 229,229,229 gray91 232,232,232
gray92 235,235,235 gray93 237,237,237 gray94 240,240,240 gray95 242,242,242
gray96 245,245,245 gray97 247,247,247 gray98 250,250,250 gray99 252,252,252
green 0,255,0 green1 0,255,0 green2 0,238,0 green3 0,205,0
green4 0,139,0 GreenYellow 173,255,47 grey 190,190,190 grey0 0,0,0
grey1 3,3,3 grey10 26,26,26 grey100 255,255,255 grey11 28,28,28
grey12 31,31,31 grey13 33,33,33 grey14 36,36,36 grey15 38,38,38
grey16 41,41,41 grey17 43,43,43 grey18 46,46,46 grey19 48,48,48
grey2 5,5,5 grey20 51,51,51 grey21 54,54,54 grey22 56,56,56
grey23 59,59,59 grey24 61,61,61 grey25 64,64,64 grey26 66,66,66
grey27 69,69,69 grey28 71,71,71 grey29 74,74,74 grey3 8,8,8
grey30 77,77,77 grey31 79,79,79 grey32 82,82,82 grey33 84,84,84
grey34 87,87,87 grey35 89,89,89 grey36 92,92,92 grey37 94,94,94
grey38 97,97,97 grey39 99,99,99 grey4 10,10,10 grey40 102,102,102
grey41 105,105,105 grey42 107,107,107 grey43 110,110,110 grey44 112,112,112
grey45 115,115,115 grey46 117,117,117 grey47 120,120,120 grey48 122,122,122
grey49 125,125,125 grey5 13,13,13 grey50 127,127,127 grey51 130,130,130
grey52 133,133,133 grey53 135,135,135 grey54 138,138,138 grey55 140,140,140
grey56 143,143,143 grey57 145,145,145 grey58 148,148,148 grey59 150,150,150
grey6 15,15,15 grey60 153,153,153 grey61 156,156,156 grey62 158,158,158
grey63 161,161,161 grey64 163,163,163 grey65 166,166,166 grey66 168,168,168
grey67 171,171,171 grey68 173,173,173 grey69 176,176,176 grey7 18,18,18
grey70 179,179,179 grey71 181,181,181 grey72 184,184,184 grey73 186,186,186
grey74 189,189,189 grey75 191,191,191 grey76 194,194,194 grey77 196,196,196
grey78 199,199,199 grey79 201,201,201 grey8 20,20,20 grey80 204,204,204
grey81 207,207,207 grey82 209,209,209 grey83 212,212,212 grey84 214,214,214
grey85 217,217,217 grey86 219,219,219 grey87 222,222,222 grey88 224,224,224
grey89 227,227,227 grey9 23,23,23 grey90 229,229,229 grey91 232,232,232
grey92 235,235,235 grey93 237,237,237 grey94 240,240,240 grey95 242,242,242
grey96 245,245,245 grey97 247,247,247 grey98 250,250,250 grey99 252,252,252
honeydew 240,255,240 honeydew1 240,255,240 honeydew2 224,238,224 honeydew3 193,205,193
honeydew4 131,139,131 HotPink 255,105,180 HotPink1 255,110,180 HotPink2 238,106,167
HotPink3 205,96,144 HotPink4 139,58,98 IndianRed 205,92,92 IndianRed1 255,106,106
IndianRed2 238,99,99 IndianRed3 205,85,85 IndianRed4 139,58,58 ivory 255,255,240
ivory1 255,255,240 ivory2 238,238,224 ivory3 205,205,193 ivory4 139,139,131
khaki 240,230,140 khaki1 255,246,143 khaki2 238,230,133 khaki3 205,198,115
khaki4 139,134,78 lavender 230,230,250 LavenderBlush 255,240,245 LavenderBlush1 255,240,245
LavenderBlush2 238,224,229 LavenderBlush3 205,193,197 LavenderBlush4 139,131,134 LawnGreen 124,252,0
LemonChiffon 255,250,205 LemonChiffon1 255,250,205 LemonChiffon2 238,233,191 LemonChiffon3 205,201,165
LemonChiffon4 139,137,112 LightBlue 173,216,230 LightBlue1 191,239,255 LightBlue2 178,223,238
LightBlue3 154,192,205 LightBlue4 104,131,139 LightCoral 240,128,128 LightCyan 224,255,255
LightCyan1 224,255,255 LightCyan2 209,238,238 LightCyan3 180,205,205 LightCyan4 122,139,139
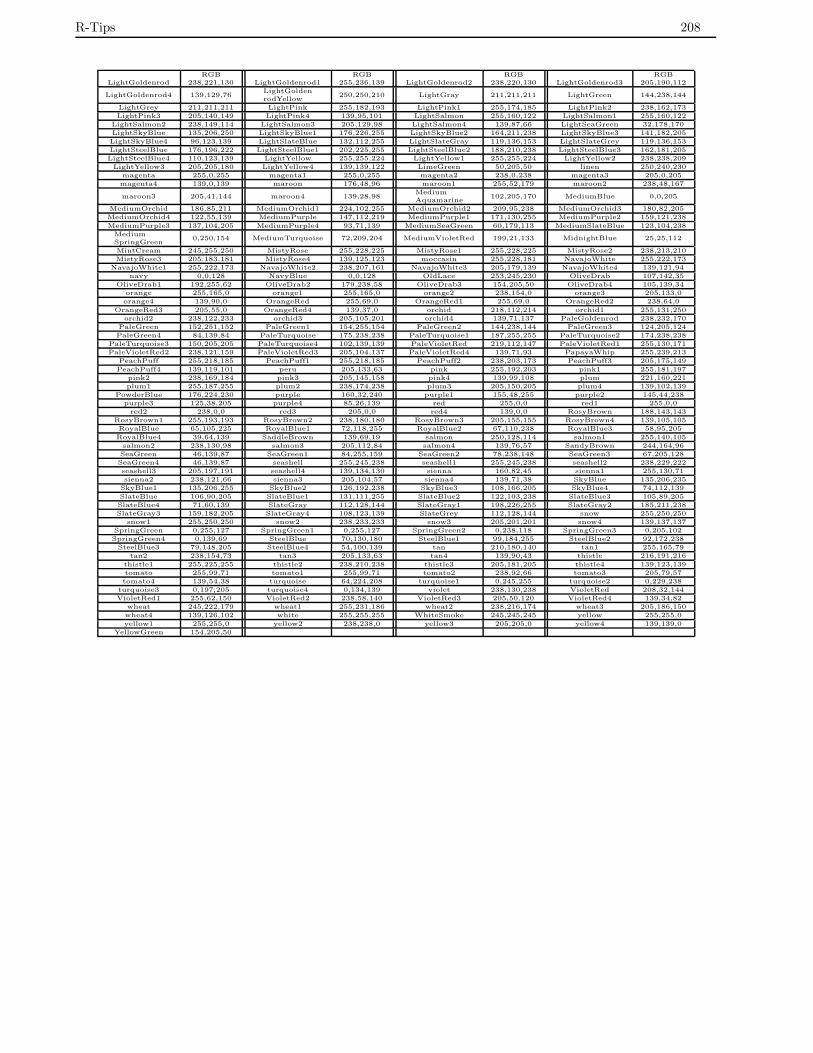
R-Tips 208頁
名前 RGB 名前 RGB 名前 RGB 名前 RGB
LightGoldenrod 238,221,130 LightGoldenrod1 255,236,139 LightGoldenrod2 238,220,130 LightGoldenrod3 205,190,112
LightGoldenrod4 139,129,76LightGolden
rodYellow250,250,210 LightGray 211,211,211 LightGreen 144,238,144
LightGrey 211,211,211 LightPink 255,182,193 LightPink1 255,174,185 LightPink2 238,162,173
LightPink3 205,140,149 LightPink4 139,95,101 LightSalmon 255,160,122 LightSalmon1 255,160,122
LightSalmon2 238,149,114 LightSalmon3 205,129,98 LightSalmon4 139,87,66 LightSeaGreen 32,178,170
LightSkyBlue 135,206,250 LightSkyBlue1 176,226,255 LightSkyBlue2 164,211,238 LightSkyBlue3 141,182,205
LightSkyBlue4 96,123,139 LightSlateBlue 132,112,255 LightSlateGray 119,136,153 LightSlateGrey 119,136,153
LightSteelBlue 176,196,222 LightSteelBlue1 202,225,255 LightSteelBlue2 188,210,238 LightSteelBlue3 162,181,205
LightSteelBlue4 110,123,139 LightYellow 255,255,224 LightYellow1 255,255,224 LightYellow2 238,238,209
LightYellow3 205,205,180 LightYellow4 139,139,122 LimeGreen 50,205,50 linen 250,240,230
magenta 255,0,255 magenta1 255,0,255 magenta2 238,0,238 magenta3 205,0,205
magenta4 139,0,139 maroon 176,48,96 maroon1 255,52,179 maroon2 238,48,167
maroon3 205,41,144 maroon4 139,28,98Medium
Aquamarine102,205,170 MediumBlue 0,0,205
MediumOrchid 186,85,211 MediumOrchid1 224,102,255 MediumOrchid2 209,95,238 MediumOrchid3 180,82,205
MediumOrchid4 122,55,139 MediumPurple 147,112,219 MediumPurple1 171,130,255 MediumPurple2 159,121,238
MediumPurple3 137,104,205 MediumPurple4 93,71,139 MediumSeaGreen 60,179,113 MediumSlateBlue 123,104,238
Medium
SpringGreen0,250,154 MediumTurquoise 72,209,204 MediumVioletRed 199,21,133 MidnightBlue 25,25,112
MintCream 245,255,250 MistyRose 255,228,225 MistyRose1 255,228,225 MistyRose2 238,213,210
MistyRose3 205,183,181 MistyRose4 139,125,123 moccasin 255,228,181 NavajoWhite 255,222,173
NavajoWhite1 255,222,173 NavajoWhite2 238,207,161 NavajoWhite3 205,179,139 NavajoWhite4 139,121,94
navy 0,0,128 NavyBlue 0,0,128 OldLace 253,245,230 OliveDrab 107,142,35
OliveDrab1 192,255,62 OliveDrab2 179,238,58 OliveDrab3 154,205,50 OliveDrab4 105,139,34
orange 255,165,0 orange1 255,165,0 orange2 238,154,0 orange3 205,133,0
orange4 139,90,0 OrangeRed 255,69,0 OrangeRed1 255,69,0 OrangeRed2 238,64,0
OrangeRed3 205,55,0 OrangeRed4 139,37,0 orchid 218,112,214 orchid1 255,131,250
orchid2 238,122,233 orchid3 205,105,201 orchid4 139,71,137 PaleGoldenrod 238,232,170
PaleGreen 152,251,152 PaleGreen1 154,255,154 PaleGreen2 144,238,144 PaleGreen3 124,205,124
PaleGreen4 84,139,84 PaleTurquoise 175,238,238 PaleTurquoise1 187,255,255 PaleTurquoise2 174,238,238
PaleTurquoise3 150,205,205 PaleTurquoise4 102,139,139 PaleVioletRed 219,112,147 PaleVioletRed1 255,130,171
PaleVioletRed2 238,121,159 PaleVioletRed3 205,104,137 PaleVioletRed4 139,71,93 PapayaWhip 255,239,213
PeachPuff 255,218,185 PeachPuff1 255,218,185 PeachPuff2 238,203,173 PeachPuff3 205,175,149
PeachPuff4 139,119,101 peru 205,133,63 pink 255,192,203 pink1 255,181,197
pink2 238,169,184 pink3 205,145,158 pink4 139,99,108 plum 221,160,221
plum1 255,187,255 plum2 238,174,238 plum3 205,150,205 plum4 139,102,139
PowderBlue 176,224,230 purple 160,32,240 purple1 155,48,255 purple2 145,44,238
purple3 125,38,205 purple4 85,26,139 red 255,0,0 red1 255,0,0
red2 238,0,0 red3 205,0,0 red4 139,0,0 RosyBrown 188,143,143
RosyBrown1 255,193,193 RosyBrown2 238,180,180 RosyBrown3 205,155,155 RosyBrown4 139,105,105
RoyalBlue 65,105,225 RoyalBlue1 72,118,255 RoyalBlue2 67,110,238 RoyalBlue3 58,95,205
RoyalBlue4 39,64,139 SaddleBrown 139,69,19 salmon 250,128,114 salmon1 255,140,105
salmon2 238,130,98 salmon3 205,112,84 salmon4 139,76,57 SandyBrown 244,164,96
SeaGreen 46,139,87 SeaGreen1 84,255,159 SeaGreen2 78,238,148 SeaGreen3 67,205,128
SeaGreen4 46,139,87 seashell 255,245,238 seashell1 255,245,238 seashell2 238,229,222
seashell3 205,197,191 seashell4 139,134,130 sienna 160,82,45 sienna1 255,130,71
sienna2 238,121,66 sienna3 205,104,57 sienna4 139,71,38 SkyBlue 135,206,235
SkyBlue1 135,206,255 SkyBlue2 126,192,238 SkyBlue3 108,166,205 SkyBlue4 74,112,139
SlateBlue 106,90,205 SlateBlue1 131,111,255 SlateBlue2 122,103,238 SlateBlue3 105,89,205
SlateBlue4 71,60,139 SlateGray 112,128,144 SlateGray1 198,226,255 SlateGray2 185,211,238
SlateGray3 159,182,205 SlateGray4 108,123,139 SlateGrey 112,128,144 snow 255,250,250
snow1 255,250,250 snow2 238,233,233 snow3 205,201,201 snow4 139,137,137
SpringGreen 0,255,127 SpringGreen1 0,255,127 SpringGreen2 0,238,118 SpringGreen3 0,205,102
SpringGreen4 0,139,69 SteelBlue 70,130,180 SteelBlue1 99,184,255 SteelBlue2 92,172,238
SteelBlue3 79,148,205 SteelBlue4 54,100,139 tan 210,180,140 tan1 255,165,79
tan2 238,154,73 tan3 205,133,63 tan4 139,90,43 thistle 216,191,216
thistle1 255,225,255 thistle2 238,210,238 thistle3 205,181,205 thistle4 139,123,139
tomato 255,99,71 tomato1 255,99,71 tomato2 238,92,66 tomato3 205,79,57
tomato4 139,54,38 turquoise 64,224,208 turquoise1 0,245,255 turquoise2 0,229,238
turquoise3 0,197,205 turquoise4 0,134,139 violet 238,130,238 VioletRed 208,32,144
VioletRed1 255,62,150 VioletRed2 238,58,140 VioletRed3 205,50,120 VioletRed4 139,34,82
wheat 245,222,179 wheat1 255,231,186 wheat2 238,216,174 wheat3 205,186,150
wheat4 139,126,102 white 255,255,255 WhiteSmoke 245,245,245 yellow 255,255,0
yellow1 255,255,0 yellow2 238,238,0 yellow3 205,205,0 yellow4 139,139,0
YellowGreen 154,205,50

引用文献・参考文献・引用サイト・参考サイト
[1] The R Project:http://www.r-project.org/R の総本山です.
[2] 『Sによるデータ解析』渋谷 政昭,柴田里程 著 (共立出版)
[3] 『S言語 - データ解析とグラフィックスのためのプログラミング環境 (1) -』渋谷 政昭,柴田里程 訳 (共立出版)
[4] isac の S のリファレンスマニュアル:http://s.isac.co.jp/(上の 3つについて) S のコマンドの 9割以上が R で使えますし,基本的な命令は (元が同じなので) 全く差異を感じることなく移植できます.よって,これらの書籍やホームページの内容は R を勉強する上で大いに参考になります.
[5] 間瀬先生の HP:http://www.is.titech.ac.jp/ mase/R.html日本語の R の総本山とも云うべきサイトです.英語版マニュアルの日本語訳や,英語のヘルプの日本語訳などが置かれています.この頁を作成するに当たっては英語版マニュアルの日本語訳『 R 入門』『 R の言語仕様』などを参考にしました.
[6] R による統計処理 (青木先生の HP):http://aoki2.si.gunma-u.ac.jp/R/膨大な数の統計解析用プログラム,そこに付随する明快な解説,分かりやすい例,とにかく有益なサイトです.Mac 版R のインストール方法なども載っています.
[7] 山本先生の HP:http://datamining.tama.ac.jp/ yama/R/R の情報がたくさん詰まったサイトです.Win 版 R ,Linux 版 R のインストール方法などが載っています.
[8] なかまさんの HP:http://r.nakama.ne.jp/日本語化パッチや,日本語化パッチ適用済のバイナリやソースが置かれています.感謝々々 !!
[9] RjpWiki (岡田先生) :http://www.okada.jp.org/RWiki/index.php?RjpWikiRjpWiki はオープンソースの統計解析システム R に関する日本語による情報交換を目的とした Wiki です.ここではWiki とよばれるシステムを採用し,どなたでも自由にページを追加・編集できます.
[10] R・HTMLマニュアル検索 (岡田さん):http://www.okada.jp.org/cgi-bin/Rsearch/namazu.cgi/R の html マニュアルを検索することが出来ます.これは非常に便利です!本当に便利です!
[11] 『Rによる統計解析の基礎』 中澤 港 著 (ピアソンエデュケーション)R 人口が爆発的に増えるきっかけとなった中澤先生の本です.統計解析に関する詳しい解説と便利な R のソースで埋め尽くされています.しっかし,この中澤先生の知識量は何なのでしょうか!
[12] 『工学のためのデータサイエンス入門』 間瀬 茂・神保 雅一・鎌倉 稔成・金藤 浩司 著 (数理工学社)間瀬先生が遂に R と統計に関する本を執筆. R ソースの解説と統計に関する解説が絶妙なバランスを保っています.非常に興味深いコラムやシミュレーションに関する章も見逃せない一冊です.
[13] 『THE R BOOK』 岡田 昌司 他 著 (九天社)遂に R のバイブルが登場!OS 別実行ファイル,R の使用法の丁寧な解説,豪華執筆陣による R の凄まじいアプリケーションが 1 冊にまとまっています.商用ソフトならこれだけで数十万円する代物ですよ,これは!
[14] 『みんなのためのノンパラメトリック回帰 (上・下)』 竹澤 邦夫 著 (吉岡書店)私がノンパラ密度推定を勉強する際にお世話になり,今は R-Tips を管理をお任せしているということでお世話になっている竹澤先生の著書.ノンパラ回帰・ウェーブレット・ヒストグラムの平滑化と密度推定を勉強しようという方にはお勧
め.詳細な解説と膨大な R ( と S-Plus ) のソースが用意されています.
[15] 『数理統計学 (改訂版) 』 稲垣 宣生 著 (裳華房)日本には数少ない,数理統計に関する中級者向けの書籍です.
[16] 『統計学の基礎』 栗栖 忠・濱田 年男・稲垣 宣生 著 (裳華房)『数理統計学 (改訂版) 』が難しいという方にはこちらから入門されることをお勧めします.
[17] 『基礎 演習 確率・統計』 和田 秀三 著 (サイエンス社)私が学部時代に愛用していた演習本です.一見地味な本ですが,さまざまな種類の演習問題があり,しかも各問ごとに詳
しい解答が載っているので,統計初学者にとってはありがたい一冊です.
この PDF はこの頁で終了です.これまで (04/05/26) にたくさんの時間と視力とキータッチ,ビールとおつまみを消費して
きまして,やっと満足のいく内容になったと勝手に悦に入っております.ビールとつまみを口に運びながらの作業は至福でさ
えありました.たった一つ断言できることは,以上の書籍・ウェブ頁・掲示板が無ければ,この PDF を作成することは出来
なかったということです.これらの書籍の執筆者の方々,ウェブ頁の管理人様,RjpWiki の投稿者の方々に深くお礼を申し上
げます.最後に,この PDF を管理して頂いている竹澤邦夫先生に心から感謝を申し上げます.