生物计算整体解决方案 total solution of bio-computing
DESCRIPTION
生物计算整体解决方案 Total Solution of Bio-Computing. 张鑫磊 博士 生物信息部 经理 北京健数通科技有限公司. 大数据时代的生命科学产业 生命科学机构云体系 DNAdaptor 在蛋白质组学研究中的应用 天合生物计算一体机. 生物的复杂性决定了生物学大数据的必然性. Short of prior knowledge and hypothesis; even you have it, usually, you are wrong. 数据驱动的科研模式. 定义的更好的 新的假设. 多组学大数据 全景图. 试错模式. - PowerPoint PPT PresentationTRANSCRIPT


生物计算整体解决方案Total Solution of Bio-Computing
张鑫磊 博士生物信息部 经理北京健数通科技有限公司

大数据时代的生命科学产业 生命科学机构云体系 DNAdaptor 在蛋白质组学研究中的应用 天合生物计算一体机

生物的复杂性决定了生物学大数据的必然性Short of prior knowledge and hypothesis; even you have it, usually, you are wrong.
数据驱动的科研模式多组学大数据全景图 建立假设 试错模式 定义的更好的新的假设


由点及面:生命科学研究将面对海量的数据

从科研到医学应用—无创 DNA 产前检测
200,000×150bpSequence Alignment

大数据时代的生命科学产业 生命科学机构云体系
总体架构 生物计算整体解决方案
DNAdaptor 在蛋白质组学研究中的应用 天合生物计算一体机
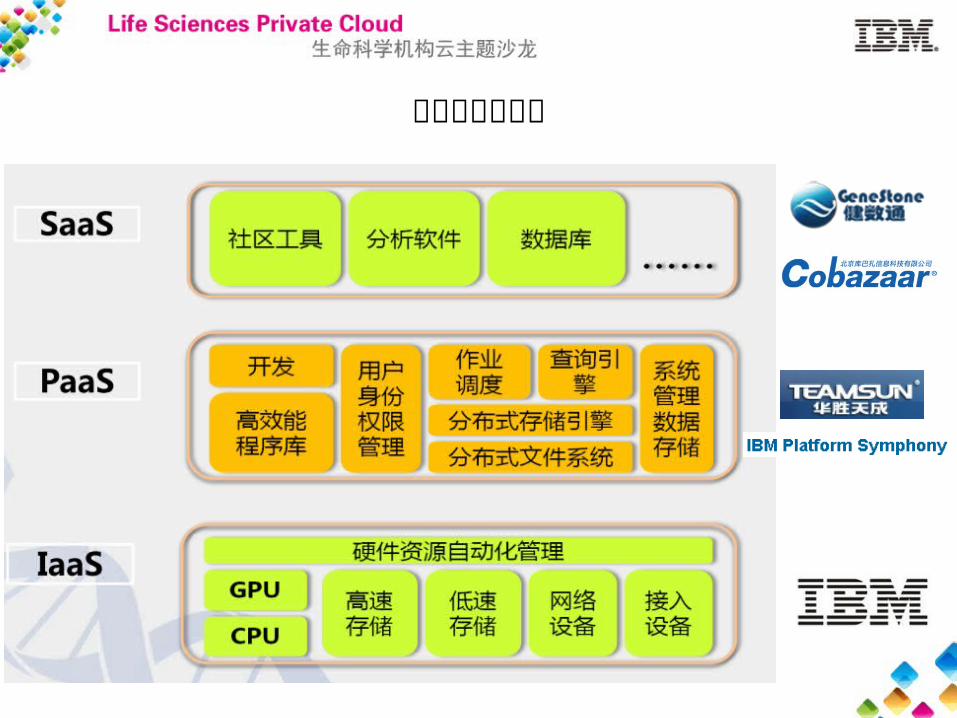
生命科学机构云

生物计算整体解决方案

DNAdaptor
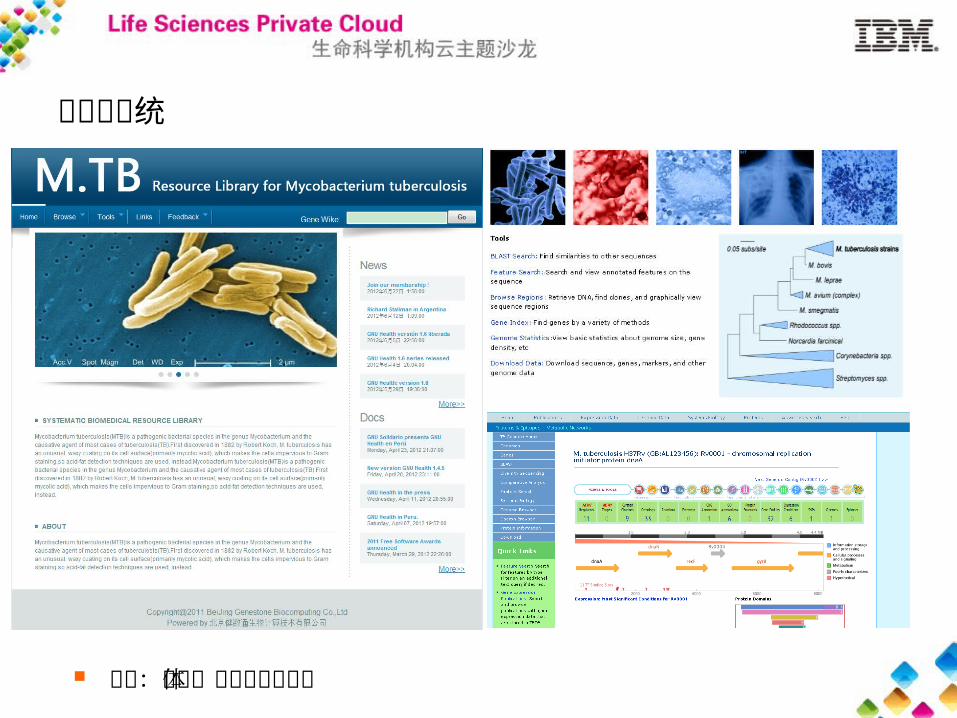
数据库系统
案例:病原体系统医学资源库

大数据时代的生命科学产业 生命科学机构云体系 DNAdaptor 在蛋白质组学研究中的应用 天合生物计算一体机

项目背景与客户需求 作为人类蛋白质组计划( HPP )的重要组成部分,国际染色体蛋白质组计划
( C-HPP )于 2011 年由 HUPO 启动。 C-HPP 计划旨在识别每条人类染色体上基因编码的所有蛋白质,同时获取它们相关的丰度、组织表达特异性、亚细胞定位、翻译后修饰和相互作用组等信息。 C-HPP 组织采用了“ chromosome-by-chromosome” 的研究策略,人类 24 条染色体和线粒体的研究任务分别由全球 25 个研究团队承担。 C-HPP 计划的实施产生了大量蛋白质组学数据。
如何从这些不同来源、类型和置信度的海量数据中挖掘生物学知识是亟待解决的问题。一个整合不同数据分析工具、满足科研人员订制化研究需求、且具有良好交互性的软件平台是不可或缺的。

产品设计
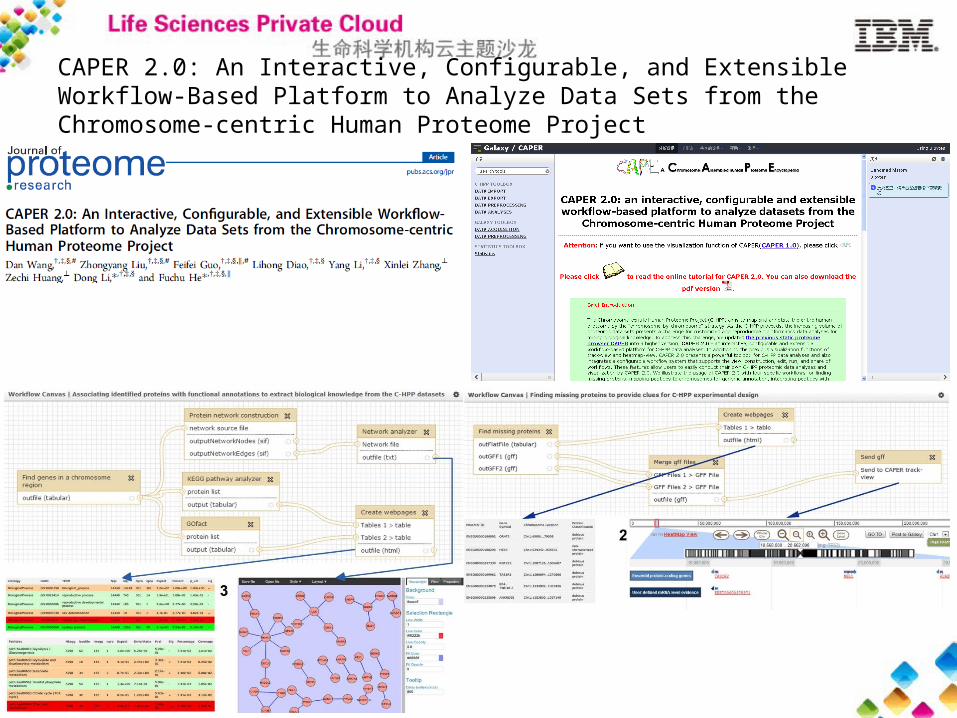
CAPER 2.0: An Interactive, Configurable, and Extensible Workflow-Based Platform to Analyze Data Sets from the Chromosome-centric Human Proteome Project

大数据时代的生命科学产业 生命科学机构云体系 DNAdaptor 在蛋白质组学研究中的应用 天合生物计算一体机


根据用户需求选择硬件配置

Hadoop 与 Symphony
Hadoop 是一个分布式系统基础架构,由 Apache 基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
IBM Platform Symphony包含了兼容 Apache Hadoop 的 MapReduce 实施,针对低延迟、可靠性和资源共享进行优化。

全基因组关联分析( GWAS )
面对 30亿像素的照片玩儿“找茬”游戏

IBM针对 GWAS 应用的解决方案

基准测试硬件环境primary server
Secondaryserver data node data node
quorum node quorum nodequorum node
GPFS组件
MasterServer
SlaveServer
DataNode
DataNode
Symphony组件主机 D主机 C主机 B主机 A
GPFS 节点角色:Primary Server :主管理节点Secondary Server :备份管理节点Data Node :数据节点Quorum node :法定节点,超半数节点失效,整个集群失效
Symphony 节点角色:Master Server :主管理节点;Slave Server :从管理节点;Data node :数据节点

Contrail 测试结果( Symphony vs Hadoop )
针对于大肠杆菌子数据集 (10K reads) 的运行时间比较 作业调度程序之间的比较

生命科学机构云

谢 谢