05.tanımlayıcı istatistikler
DESCRIPTION
Biyoistatistik Ders Notları05.tanımlayıcı istatistiklerTRANSCRIPT

TANIMLAYICI TANIMLAYICI İSTATİSTİKLERİSTATİSTİKLER

GİRİŞ
• Dağılımlar yer (location), yaygınlık (spread) ve şekil shape) parametreleri olmak üzere 3 farklı ölçüm ile temsil edilirler. Bu ölçümler tanımlayıcı istatistikler olarak adlandırılır.
2Tanımlayıcı İstatistikler
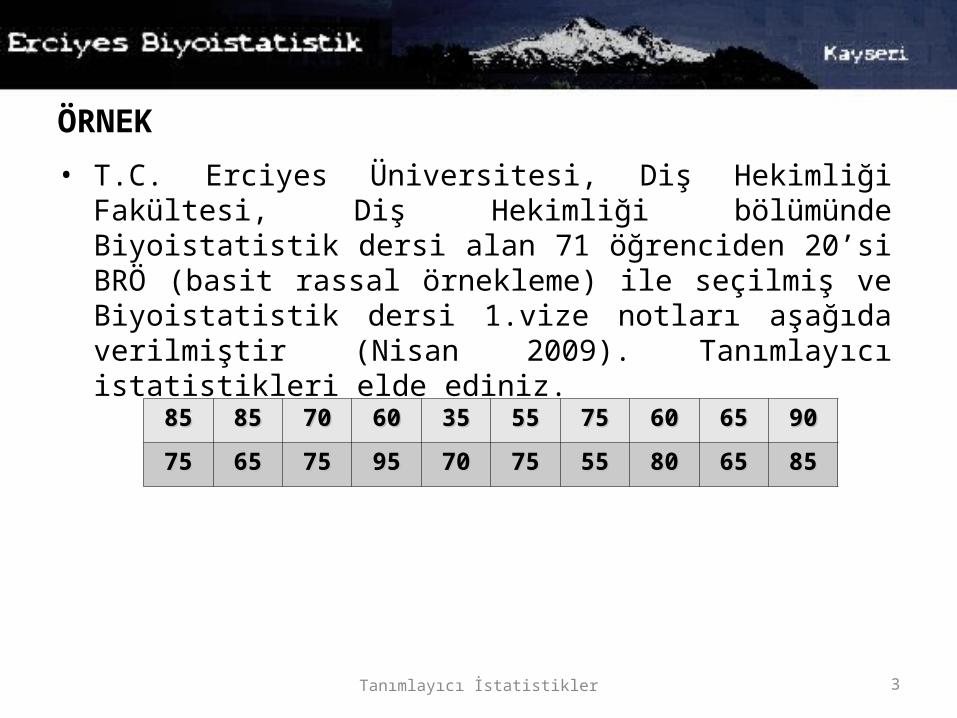
ÖRNEK
• T.C. Erciyes Üniversitesi, Diş Hekimliği Fakültesi, Diş Hekimliği bölümünde Biyoistatistik dersi alan 71 öğrenciden 20’si BRÖ (basit rassal örnekleme) ile seçilmiş ve Biyoistatistik dersi 1.vize notları aşağıda verilmiştir (Nisan 2009). Tanımlayıcı istatistikleri elde ediniz.
3Tanımlayıcı İstatistikler
8585 8585 7070 6060 3535 5555 7575 6060 6565 9090
7575 6565 7575 9595 7070 7575 5555 8080 6565 8585

YER ÖLÇÜLERİ
• Verilerin merkezde ve belirli noktalarda toplanma değerlerini gösteren istatistiklerdir. Tüm verileri özetleyen, tanıtan tipik değerlerdir.
• Aritmetik Ortalama (Mean)• Medyan (Median)• Mod (Mode)• Kantiller (Quantiles)
• Bu ölçülerden aritmetik ortalama, medyan ve mod ‘merkezi yer ölçüleri’ olarak da bilinmektedir.
4Tanımlayıcı İstatistikler

YER ÖLÇÜLERİ > ARİTMETİK ORTALAMA
• Bir seriyi temsil eden ve serideki bütün birim değerlerini hesaplamaya alan tipik bir değerdir.
• Bu ortalama istatistikte en çok kullanılan ortalamadır. • Anakütle aritmetik ortalaması µ ile, örneklem aritmetik ortalaması
ile gösterilir.
5
X
Tanımlayıcı İstatistikler

YER ÖLÇÜLERİ > ARİTMETİK ORTALAMA
ÖRNEĞİN ÇÖZÜMÜ:
6Tanımlayıcı İstatistikler
7120
95...553520
XX
20
1ii

YER ÖLÇÜLERİ > MEDYAN (Ortanca)
• Medyan, sıralanmış verilerin orta noktasını temsil eder.• Seriyi birim sayısı bakımından iki eşit parçaya ayıran gözlem
değeridir.• Örnek hacmi tek sayıda ise medyan ortadaki değerdir
((n+1)/2. birim değeri).• Örnek hacmi çift sayıda ise medyan ortadaki iki değerin
ortalamasıdır ((n/2. birim değeri ile (n+2)/2. birim değerinin ortalaması).
7Tanımlayıcı İstatistikler

YER ÖLÇÜLERİ > MEDYAN
ÖRNEĞİN ÇÖZÜMÜ:
8Tanımlayıcı İstatistikler
Veriler sıralanmış !n = 20 örnek hacmi çiftn/2. birim değeri = 10. birim değeri = 70(n+2)/2. birim değeri = 11. birim değeri= 75
Medyan = (70 + 75) / 2 = 72,5

YER ÖLÇÜLERİ > MOD (Tepe Değeri)
• Diğer 2 merkezi yer ölçüsünden daha az kullanılmaktadır.• Bir seride en çok tekrarlanan birim değeridir.• Bazı serilerde mod olmayabilirken, bazılarında ise birden fazla mod
değeri olabilir. Bu durumda serimiz çok modlu seri olur ki bu seriler işimize yaramamaktadır.
9Tanımlayıcı İstatistikler

YER ÖLÇÜLERİ > MOD
ÖRNEĞİN ÇÖZÜMÜ:
10Tanımlayıcı İstatistikler
75 değeri seride en fazla tekrarlanan değer olup, 4 kez tekrarlanmıştır.

ORTALAMA ve MEDYAN KARŞILAŞTIRMASI• Ortalama seriyi çok iyi temsil eden ve istatistikte en çok kullanılan yer
ölçüsü iken, medyan ortalamanın kullanılamadığı durumlarda kullanılan alternatif bir yer ölçüsüdür.
• Ortalamada tüm birimler işleme girerken, medyanda yalnızca en ortadaki birim/birimler işleme girmektedir.
• Serideki aşırı değerler (outliers) ortalamanın büyüklüğünü de etkileyerek olması gerekenden çok büyük veya çok küçük çıkmasına neden olur. Medyanda ise böyle bir durum söz konusu değildir. Kısaca ortalama aşırı değerlere duyarlı, medyan ise duyarsızdır.
• Medyan çarpık (skewed) dağılımları ortalamadan daha iyi temsil eder.
11Tanımlayıcı İstatistikler

5 6 5 6 4 5 5 4 5 3 95
Ortalama = 13 Standart Sapma = 27,21 Medyan = 5

YER ÖLÇÜLERİ > KANTİLLER (Qh/r)
13Tanımlayıcı İstatistikler
• Bir seriyi eşit parçalara bölen istatistiklere kantiller adı verilir. Bu istatistiklerden en sık kullanılanı kartiller (dörde bölen , Qh/4 , quartiles) ve persantillerdir (yüze bölen , Qh/100 , percentiles).

Tanımlayıcı İstatistikler 14
PERSANTİL (Yüzdelik)
Persantiller veri setindeki küçükten büyüğe sıralandırılmış verileri yüzdeliklere bölerek yorum yapılmasını sağlayan istatistiklerdir.
Bir veri setindeki persantil değerine ulaşmak için öncelikle aşağıdaki formül yardımı ile istenen persantil birimine ulaşılır.
PB : Veri setinin istenen persantil birimiP : İlgilenilen persantil (yüzdelik)n : Veri setindeki birim sayısıPersantil değeri ise veri setinde persantil birimine karşılık gelen değerdir.

Tanımlayıcı İstatistikler 15
Örnek: Aşağıda 99 birimlik sıralanmış bir veri seti bulunmaktadır. Bu veri setinin 10. ve 85. persantil değerlerini bulup yorumlayınız.
P = 10, n=99, PB=10, Persantil değeri 10 nolu birime karşılık gelen 259 değeridir. Veri setindeki birimlerin %10’u 259 değerinin altındadır.
P = 85, n=99, PB=85, Persantil değeri 85 nolu birime karşılık gelen 334 değeridir. Veri setindeki birimlerin %85’i 334 değerinin altındadır.

Tanımlayıcı İstatistikler 16
Persantillerin olağan dışı ölçümleri tespit etmek ve çeşitli risk
faktörleri açısından alt ve üst limitleri belirlemek gibi kullanım
alanları vardır. Örneğin; 0-6 yaş arası çocuklarda beden kitlesi
ölçümü için (kg/m2) 95.persantil ve üstü obez, 85.-95.persantiller
arası aşırı kilolu, 5.persantil ve altı da aşırı zayıf olarak
değerlendirilmektedir.

Tanımlayıcı İstatistikler 17
Yukarıda da görüldüğü gibi; medyan, 2.kartil ve 50.persantil değerleri birbirine eşittir. Aynı zamanda 1.kartil, 25.persantile; 3.kartil de 75.persantile eşittir.
KARTİLLER(Çeyreklik)
Veri setini 4 parçaya (çeyreğe) bölen 25., 50. ve 75. persantil değerleridir.

YER ÖLÇÜLERİ > KANTİLLER
ÖRNEĞİN ÇÖZÜMÜ:
18Tanımlayıcı İstatistikler
Örneğin 1.kartil (25.persantil), 2.kartil (50.persantil, medyan) ve 3.kartili (75.persantil) bulalım.
1.kartil= Q1/4 = [(21*25)/100].birim değeri = 5,25.birim değeriQ1/4 = 61,25
2.kartil= Q2/4 =[(21*50)/100].birim değeri = 10,5.birim değeriQ2/4 = 72,5
3.kartil= Q3/4 =[(21*75)/100].birim değeri = 15,75.birim değeriQ3/4 = 83,75
Sınıfın %25’i 61,25’ten düşük puan alırken, %25’i de 83,75’ten yüksek puan almıştır.

YAYGINLIK ÖLÇÜLERİ• Merkezi yer ölçüleri bir dağılımı tanımlamada yeterli midir?
• İki sınıfın puanları üstteki gibi olsun. İki sınıfın da puan ortalamaları 50’dir. Kırmızı ile gösterilen sınıfın yaygınlığı (değişkenliği) mavi ile gösterilen sınıfa göre daha yüksektir.
19Tanımlayıcı İstatistikler

YAYGINLIK ÖLÇÜLERİ
20Tanımlayıcı İstatistikler
• Bir seri homojenlikten uzaklaştıkça (birimler birbirinden farklılaştıkça) ona ait aritmetik ortalamanın ve diğer merkezi yer ölçülerinin temsil yeteneği giderek zayıflar. Bu yüzden yalnızca ortalamanın veya diğer merkezi yer ölçülerinin hesaplanması seriyi temsil etmek için yetmemektedir, onun yanında yaygınlık ölçülerinden de yararlanmak gerekir.
Ranj (Range)
Kartiller Arası Uzaklık (Interquartile Range)
Varyans ve Standart Sapma (Variance and Standart Deviation)

YAYGINLIK ÖLÇÜLERİ > RANJ
• Ranj serideki en büyük değer ile en küçük değer arasındaki uzaklıktır.
• İstatistiksel araştırmaların bulgularında medyan ile birlikte verilen bir yaygınlık ölçüsüdür.
• Seride bulunan bir tane aşırı değer bile serinin ranjının çok büyük çıkmasına neden olabileceğinden, çok sık kullanılmaz.
21Tanımlayıcı İstatistikler
minmax XXRanj

YAYGINLIK ÖLÇÜLERİ > RANJ
ÖRNEĞİN ÇÖZÜMÜ:
22Tanımlayıcı İstatistikler
603595RanjXXRanj minmax

YAYGINLIK ÖLÇÜLERİ > KARTİLLER ARASI UZAKLIK
• Kartiller arası uzaklık 1. ve 3. kartiller arası uzaklığı ifade eder.
• İstatistiksel araştırmaların bulgularında medyan ile birlikte verilen bir yaygınlık ölçüsüdür.
• Ranja göre aykırı değerlerden daha az etkilenen bir yaygınlık ölçüsü olduğu için medyanın yanında kartiller arası uzaklığın verilmesi daha doğrudur.
23Tanımlayıcı İstatistikler
4143 QQIQR

YAYGINLIK ÖLÇÜLERİ > KARTİLLER ARASI UZAKLIK
ÖRNEĞİN ÇÖZÜMÜ:
24Tanımlayıcı İstatistikler
205,625,824143
IQR
QQIQR

KARTİLLER ARASI UZAKLIK ve AYKIRI DEĞERLER
• Bir gözlem değeri aşağıdaki koşullarda aykırı değer olarak kabul edilir.
• Örneğimizde IQR = 20; Q1/4 = 62,5; Q3/4 =82,5 için 112,5 değerinin üstündeki değerler ve 32,5 değerinin altındaki değerler aykırı olarak değerlendirilebilir.
25Tanımlayıcı İstatistikler
IQRQXii
IQRQXi
i
i
*5,1.
*5,1.
43
41

YAYGINLIK ÖLÇÜLERİ > VARYANS ve STANDART SAPMA• İstatistikte en çok kullanılan yaygınlık ölçüleridir.
• Yer ölçülerinden ortalamada olduğu gibi varyans ve standart sapmada tüm birimler işleme girer.
• İstatistiksel araştırmaların bulgularında ortalama ile verilen bir yaygınlık ölçüsüdür.
• Anakütle varyansı σ2 ile, örneklem varyansı s2 ile gösterilir. Anakütle standart sapması σ ile, örneklem standart sapması s ile gösterilir.
• Simgelerden de anlaşılacağı üzere standart sapma varyansın kareköküdür.
26Tanımlayıcı İstatistikler

YAYGINLIK ÖLÇÜLERİ > VARYANS ve STANDART SAPMA
27Tanımlayıcı İstatistikler
22ss
N
XN
ii
1
2 1
1
2
n
XXn
ii
N
XN
ii
1
2 1
1
2
n
XXn
ii
NN
XX
N
i
N
ii
i
1
2
12
11
2
12
nn
XX
n
i
n
ii
i
NN
XX
N
i
N
ii
i
1
2
12
11
2
12
nn
XX
n
i
n
ii
i
• Bir serinin standart sapması ne kadar küçükse (sıfıra yakınsa) seri o kadar homojen, ne kadar büyükse (sıfırdan uzaksa) seri o kadar heterojendir. • Varyans ve standart sapma formülleri aşağıdaki gibidir:

YAYGINLIK ÖLÇÜLERİ > VARYANS ve STANDART SAPMA
ÖRNEĞİN ÇÖZÜMÜ:
28Tanımlayıcı İstatistikler
58,201
193830
11
2
2
n
XXs
n
ii
58,20119
201420104650
1
2
1
2
12
2
nn
XX
s
n
i
n
ii
i
2,1458,2012 ss
Örneklem varyansı 201,58 ; standart sapması 14,2 olarak elde edildi.

YAYGINLIK ÖLÇÜLERİ > VARYANS ve STANDART SAPMA
STANDART SAPMANIN YORUMLANMASI:
29Tanımlayıcı İstatistikler
• Gözlemlerin yaklaşık %68,26’sı aralığında bulunur.
• Gözlemlerin yaklaşık %95,00’i aralığında bulunur.
• Gözlemlerin yaklaşık %95,44’ü aralığında bulunur.
• Gözlemlerin yaklaşık %99,00’u aralığında bulunur.
• Gözlemlerin yaklaşık %99,90’u aralığında bulunur.
sX
sX *96,1
sX *58,2
sX *2
sX *28,3

STANDART HATA (STANDARD ERROR)
• Anakütleden çekilen örneklemin istatistikleriyle, anakütle parametreleri hakkında tahmin yapılır. Anakütlenin tümüyle çalışılmadığı için de bir hata yapılır ki, bu hata standart hata ile ölçülür.
• Örnek hacmi büyüdükçe standart hata küçülür. Bu yüzden çalışılan örnek hacmi yeterli sayıda olmalıdır.
• Ortalamanın standart hatası ile gösterilir ve aşağıdaki gibi hesaplanır:
30Tanımlayıcı İstatistikler
Xs
ns
nssX 2

GÜVEN ARALIĞI(CONFIDENCE INTERVAL, CI)
• Hesaplanan standart hata yardımıyla anakütle ortalamasının (veya diğer parametrelerin) 1-α olasılıkla hangi değerler arasında olduğunu gösterir.
31Tanımlayıcı İstatistikler
)()( XX sXsX
)*96.1()*96.1( XX sXsX
)*58.2()*58.2( XX sXsX
)*28.3()*28.3( XX sXsX

NEDEN ARALIK TAHMİNİNDE %95 KULLANILIR?
• Çalışmalarda güven düzeyi olarak genelde %95 seçilmektedir.
• Bunun sebebi, %95’ten büyük güven düzeyleri için daha güvenilir sonuçlar alınmasına rağmen kestirim aralığının büyümesidir. %95’ten küçük güven düzeylerinde ise daha dar aralıklarda kestirim yapılabilmesine rağmen güven düzeyi düşmektedir.
• %95 değeri maksimum güvenilirlik ve en dar aralıkta kestirim için belirlenmiş optimum bir değerdir.
32Tanımlayıcı İstatistikler

STANDART HATA ve GÜVEN ARALIĞI
ÖRNEĞİN ÇÖZÜMÜ:• Standart hata:
• Güven aralığı:
• Yorum: T.C. Erciyes Üniversitesi Diş Hekimliği Fakültesi, Diş Hekimliği bölümünde Biyoistatistik dersi alan 71 öğrenciden basit rassal örnekleme (BRÖ) ile seçilen 20 kişilik örnekleme ilişkin Biyoistatistik 1.vize notları yardımıyla yapılan anakütle parametresi tahmininde, Diş Hekimliği sınıfının Biyoistatistik 1.vize notları ortalaması %95 olasılıkla 64,77 ile 77,23 arasında, %5 olasılıkla bu aralıklar dışındadır.
33Tanımlayıcı İstatistikler
18,3202,14
nSS X
)18,3*96.171()18,3*96.171( 23,7777,64

DEĞİŞİM KATSAYISI(COEFFICIENT of VARIATION)
• Değişim (varyasyon) katsayısı birim sayıları ve ölçü birimleri birbirlerinden farklı olan değişkenlerin ortalamaya göre yayılışlarını karşılaştırmak için yararlanılan bir ölçüdür.
• Değişkenin ortalama ve standart sapmasından yararlanılarak hesaplanır ve DK% ile gösterilir:
• DK <%10 ise serinin homojen dağıldığı varsayılır. • %10 DK%<%20 ise serinin homojenliğinin orta seviyede dağıldığı
varsayılır.• DK% %20 ise değişkenin heterojen dağıldığı varsayılır.
34Tanımlayıcı İstatistikler
100*%XsDK

DEĞİŞİM KATSAYISI(COEFFICIENT of VARIATION)
35Tanımlayıcı İstatistikler
ÖRNEĞİN ÇÖZÜMÜ:Değişim katsayısı:
Yorum: Serinin dağılımı homojenlik göstermemektedir.
20100*712,14100*%
XSDK

ŞEKİL ÖLÇÜLERİ• Bir dağılım hakkında karar verirken yer ölçüleri ve yaygınlık ölçülerinin
yanında dağılımların şekil ölçüleri de bu ölçülerle birlikte değerlendirilmelidir.
• Şekil ölçüleri α3 ve α4 moment katsayıları ile hesaplanır.
36Tanımlayıcı İstatistikler
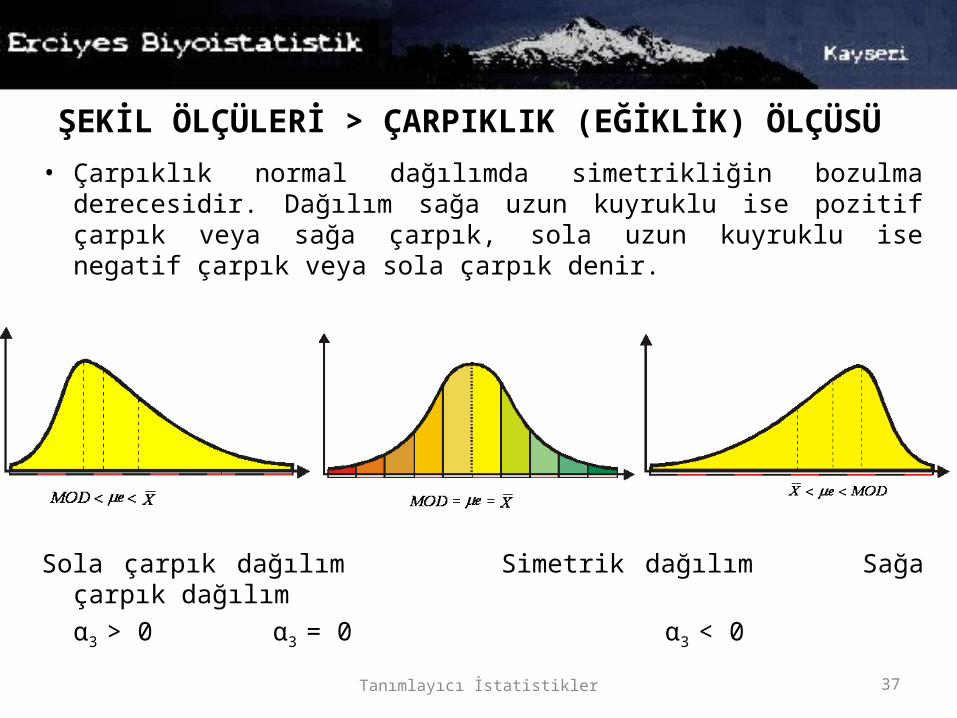
ŞEKİL ÖLÇÜLERİ > ÇARPIKLIK (EĞİKLİK) ÖLÇÜSÜ • Çarpıklık normal dağılımda simetrikliğin bozulma derecesidir. Dağılım
sağa uzun kuyruklu ise pozitif çarpık veya sağa çarpık, sola uzun kuyruklu ise negatif çarpık veya sola çarpık denir.
Sola çarpık dağılım Simetrik dağılım Sağa çarpık dağılım α3 > 0 α3 = 0 α3 < 0
37Tanımlayıcı İstatistikler

ŞEKİL ÖLÇÜLERİ > BASIKLIK ÖLÇÜSÜ • Normal dağılım eğrisinin sivrilik veya yayvanlık derecesi basıklık olarak
adlandırılır.
38Tanımlayıcı İstatistikler

Tanımlayıcı İstatistikler 39
66 71 66 70 64 76 63 58 58 72
77 52 53 56 65 66 55 66 52 59
60 76 72 67 66 86 47 49 59 81
84 75 59 47 78 67 51 68 50 64
84 45 75 68 76 66 50 59 82 46
65 58 62 68 66 57 62 57 68 73
57 75 59 68 61 53 49 49 94 73
55 65 79 60 52 72 78 71 88 74
75 62 68 76 80 71 70 75 69 61
66 63 74 80 65 61 65 67 62 68
UYGULAMA-1

Tanımlayıcı İstatistikler 40
44 31 4 37 44 73 67 185 21 29
74 6 53 78 28 34 40 15 122 30
31 78 21 123 3 29 64 46 91 16
56 41 170 82 8 34 11 18 77 29
85 38 119 105 151 21 141 30 12 111
195 107 79 215 64 150 6 16 63 12
27 119 21 11 13 30 152 161 128 28
85 7 238 51 11 23 81 143 39 58
6 114 72 4 10 146 102 65 218 16
34 34 110 48 31 28 117 49 118 15
UYGULAMA-2

Tanımlayıcı İstatistikler 41
SORULARINIZ?