第11讲 ids 技术(一 )
DESCRIPTION
第11讲 IDS 技术(一 ). 一、入侵知识简介. 1、入侵 ( Intrusion) 2、漏洞 3、主要漏洞 4、入侵者 5、侵入系统的主要途径. 1、入侵 ( Intrusion). 入侵是指未经授权蓄意尝试访问信息、窜改信息, 使系统不可靠或不能使用的行为。它企图破坏计算 机资源的: 完整性( Integrity): 指数据未经授权不能被改变。 机密性( Confidentiality): 指只有合法的授权用户才能对机密的或受限的数据进行存取。 可用性( Availability): 是指 计算机资源在系统合法用户需要使用时必须是可用的。 - PowerPoint PPT PresentationTRANSCRIPT

第 11 讲 IDS 技术(一)

一、入侵知识简介1 、入侵 (Intrusion)2 、漏洞3 、主要漏洞4 、入侵者5 、侵入系统的主要途径

1 、入侵 (Intrusion)入侵是指未经授权蓄意尝试访问信息、窜改信息,使系统不可靠或不能使用的行为。它企图破坏计算机资源的:完整性 (Integrity) :指数据未经授权不能被改变。机密性(Confidentiality):指只有合法的授权用户才能对机密的或受限的数据进行存取。 可用性(Availability):是指计算机资源在系统合法用户需要使用时必须是可用的。可控性(Controliability):是指可以控制授权范围内的信息流向及行为方式。有的也称不可否认性 (Non-
repudiation)。

2 、漏洞入侵要利用漏洞,漏洞是指系统硬件、操作系统、软件、网络协议等在设计上、实现上出现的可以被攻击者利用的错误、缺陷和疏漏。

3 、主要漏洞按照漏洞的性质,现有的漏洞主要有: 缓冲区溢出 拒绝服务攻击漏洞 代码泄漏、信息泄漏漏洞 配置修改、系统修改漏洞 脚本执行漏洞 远程命令执行漏洞 其它类型的漏洞

4 、入侵者入侵者可以是一个手工发出命令的人,也可是一个基于入侵脚本或程序的自动发布命令的计算机。入侵者一般可以分为两类:内部的(一般指系统中的合法用户但违规或者越权操作)和外部的(一般指系统中的非法用户) 。

5 、侵入系统的主要途径入侵者进入系统的主要途径有: 物理侵入:指一个入侵者对主机有物理进入权限,比如他们能使用键盘,有权移走硬盘等。 本地侵入 : 这类侵入表现为入侵者已经拥有在系统用户的较低权限。如果系统没有打最新的漏洞补丁,就会给侵入者提供一个利用知名漏洞获得系统管理员权限的机会。 远程侵入 : 这类入侵指入侵者通过网络远程进入系统。比如通过植入木马实现对目标主机的控制,从远程发起对目标主机的攻击等。

6 、攻击的一般步骤进行网络攻击是一件系统性很强的工作,其主要工作流程是:收集情报,远
程攻击,清除日志,留下后门。
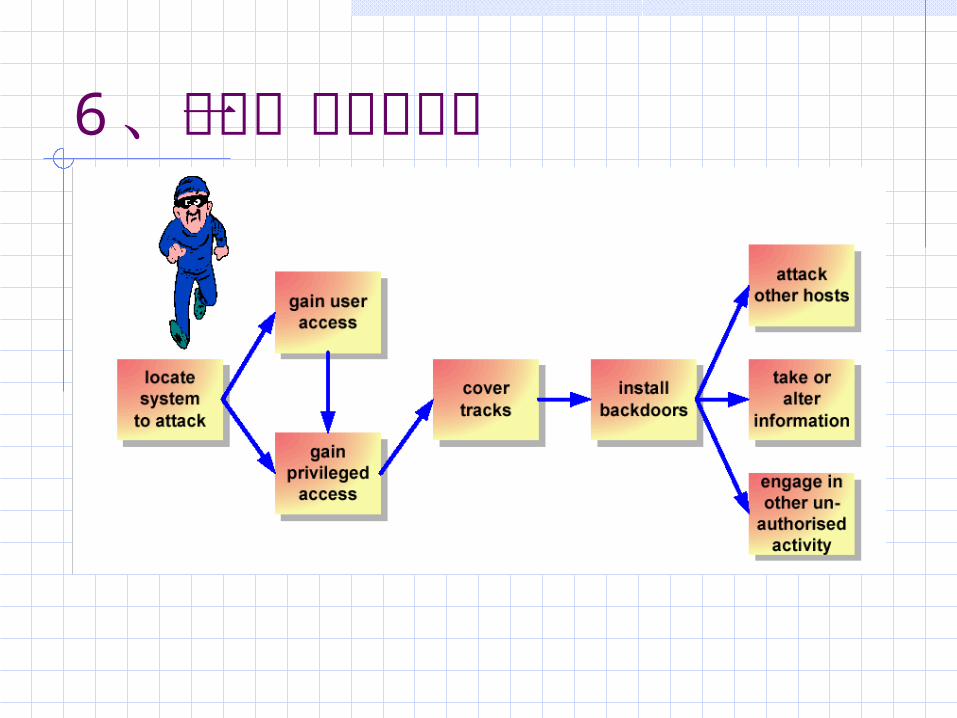
6 、攻击一般步骤总览
二、入侵检测系统基本知识1 、入侵检测与入侵检测系统2 、入侵检测系统在系统安全中的地位 3、 IDS 能做什么?4 、为什么需要 IDS?5、 IDS 的优点6、 IDS 的缺点7 、入侵检测的发展历史

1 、入侵检测与入侵检测系统入侵检测,顾名思义,是指对入侵行为的发觉。它通过在计算机网络或计算机系统中的若干关键点收集信息并对收集到的信息进行分析,从而判断网络或系统中是否有违反安全策略的行为和被攻击的迹象。入侵检测系统 (Intrusion Detection System) ,是完成入侵检测功能的软件、硬件及其组合它试图检测、识别和隔离“入侵”企图或计算机的不恰当未授权使用。
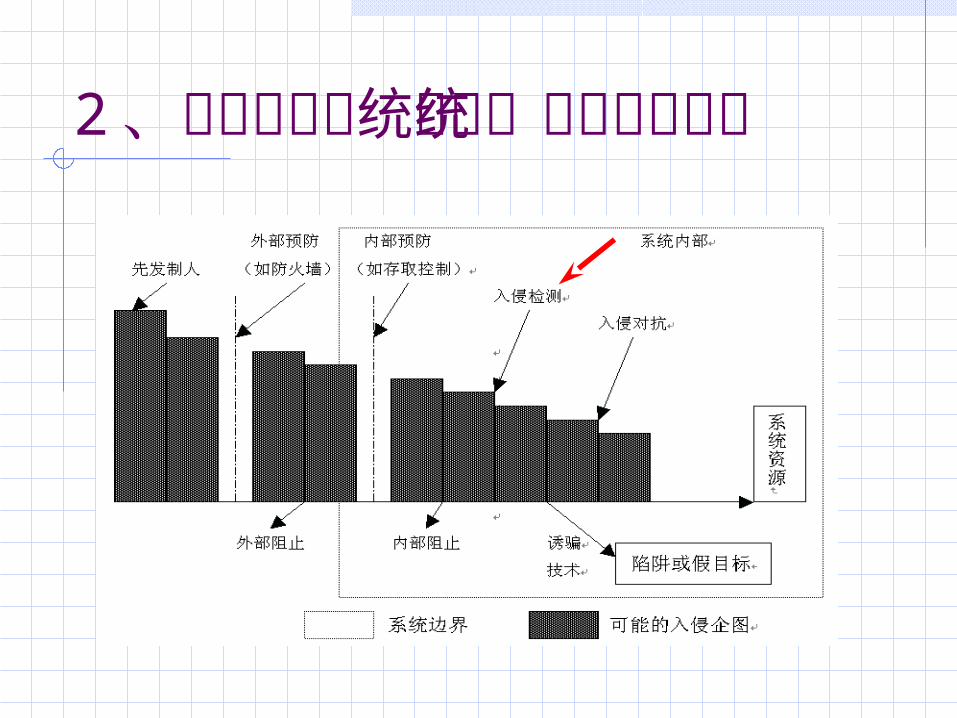
2 、入侵检测系统在系统安全中的地位

3、 IDS 能做什么? 监控、分析用户和系统的活动 发现入侵企图或异常现象 审计系统的配置和弱点 评估关键系统和数据文件的完整性 对异常活动的统计分析 识别攻击的活动模式 实时报警和主动响应

4 、为什么需要 IDS?入侵很容易 入侵教程随处可见 各种工具唾手可得防火墙不能保证绝对的安全 网络边界的设备 自身可以被攻破 对某些攻击保护很弱 不是所有的威胁来自防火墙外部 防火墙是锁,入侵检测系统是监视器

5、 IDS 的优点 提高信息安全构造的其他部分的完整性 提高系统的监控能力 从入口点到出口点跟踪用户的活动 识别和汇报数据文件的变化 侦测系统配置错误并纠正 识别特殊攻击类型,并向管理人员发出警报

6、 IDS 的缺点 不能弥补差的认证机制 需要过多的人为干预 不知道安全策略的内容 不能弥补网络协议上的弱点 不能分析一个堵塞的网络 不能分析加密的数据

7 、入侵检测的发展历史( 1 )1980年, James Anderson 最早提出入侵检测概念1987年, D. E.Denning首次给出了一个入侵检测的抽象模型,并将入侵检测作为一种新的安全防御措施提出。1988年, Morris蠕虫事件直接刺激了 IDS 的研究1988年,创建了基于主机的系统; 有: IDES,Haystack 等等1989年,提出基于网络的 IDS 系统; 有: NSM,NADIR,DIDS 等等

7 、入侵检测的发展历史( 2 )90 年代,不断有新的思想提出,如将人工智能、神经网络、模糊理论、证据理论、分布计算技术等引入 IDS 系统2000 年 2月,对Yahoo!、 Amazon、 CNN 等大型网站的DDOS 攻击引发了对 IDS 系统的新一轮研究热潮2001年~今, RedCode 、求职信等新型病毒的不断出现,进一步促进了 IDS 的发展。

三、入侵检测系统构件1、 IDS框架介绍2 、入侵检测系统构件3 、事件产生器4 、事件分析器5 、响应单元6 、事件数据库7 、管理器

1、 IDS框架介绍( 1 )理论界: CIDF Common Intrusion Detection Framework
由DARPA 于 1997年 3月开始着手制定 为了解决不同入侵检测系统
互操作性 共存问题

1、 IDS框架介绍( 2 )工业界: IDWG Intrusion Detection Work Group
IDS 系统之间、 IDS 和网管系统之间 共享的数据格式 统一的通信规程
草案 IDMEF( 入侵检测消息交换格式) IDXP (入侵检测交换协议) 最终成为 RFC ,尚需时日

2 、入侵检测系统构件( 1 )CIDF根据 IDS 系统的通用需求以及现有IDS 的系统结构,将 IDS 系统构成划分如下部分: 事件产生器 (Event Generators) 事件分析器 (Event analyzers) 响应单元 (Response units) 事件数据库 (Event databases)
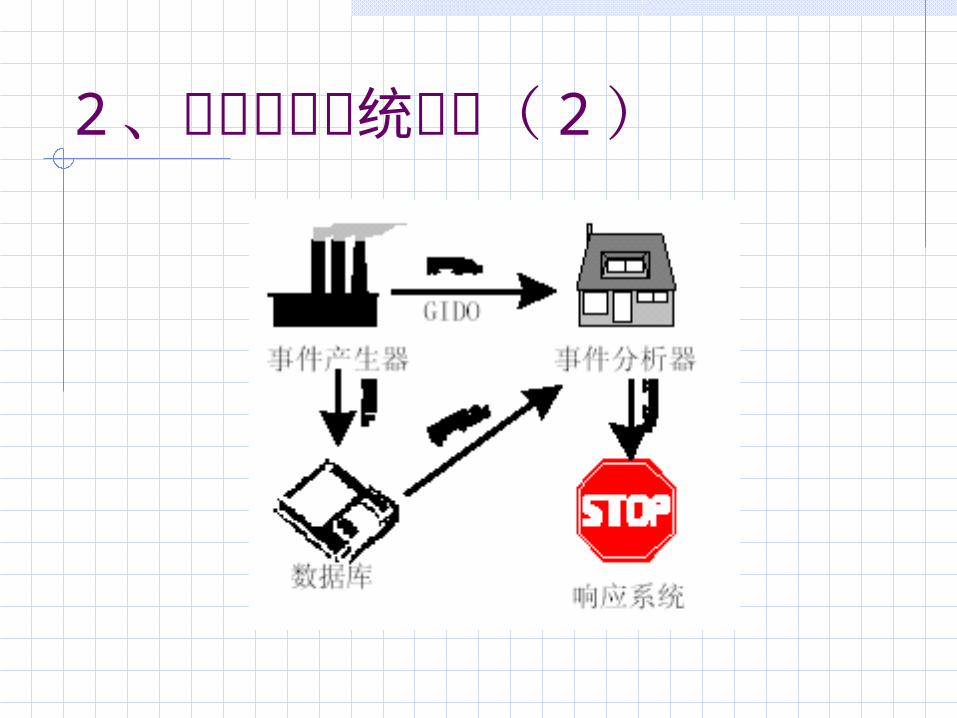
2 、入侵检测系统构件( 2 )
3 、事件产生器事件产生器的目的是从整个计算环境中获得事件,并向系统的其他部分提供此事件。入侵检测的第一步采集内容 系统日志 应用程序日志 系统调用 网络数据 用户行为 其他 IDS 的信息

4 、事件分析器事件分析器分析得到的数据,并产生分析结果。分析是核心 效率高低直接决定整个 IDS 性能
5 、响应单元响应单元则是对分析结果作出作出反应的功能单元,功能包括:告警和事件报告终止进程,强制用户退出切断网络连接,修改防火墙设置 灾难评估,自动恢复 查找定位攻击者
6 、事件数据库事件数据库是存放各种中间和最终数据的地方的统称,它可以是复杂的数据库,也可以是简单的文本文件。

7 、管理器常规的管理功能 定位 控制
Console GUI 命令行 客户程序 Web方式
Database 日志 规则库 行为模式库

四、入侵检测系统的分类1 、入侵检测系统的分类2 、根据原始数据的来源3 、根据检测技术进行分类 4 、根据体系结构分类 5 、根据响应方式分类

1 、入侵检测系统的分类随着入侵检测技术的发展,到目前为止出现了很多入侵检测系统,不同的入侵检测系统具有不同的特征。根据不同的分类标准,入侵检测系统可分为不同的类别。对于入侵检测系统,要考虑的因素(分类依据)主要的有:信息源,入侵,事件生成,事件处理,检测方法等。

2 、根据原始数据的来源 基于主机的入侵检测系统
监控粒度更细、配置灵活、可用于加密的以及交换的环境 基于网络的入侵检测系统
视野更宽 、隐蔽性好 、攻击者不易转移证据

3 、根据检测技术进行分类 异常入侵检测
根据异常行为和使用计算机资源的情况检测出来的入侵。 误用入侵检测
利用已知系统和应用软件的弱点攻击模式来检测入侵。

4 、根据体系结构分类 集中式
多个分布于不同主机上的审计程序,但只有一个中央入侵检测服务器。 等级式 定义了若干个分等级的监控区域,每个 IDS负责一个区域,每一级 IDS只负责所监控区的分析,然后将当地的分析结果传送给上一级 IDS。 协作式
将中央检测服务器的任务分配给多个基于主机的 IDS ,这些 IDS不分等级,各司其职,负责监控当地主机的某些活动。

5 、根据响应方式分类 主动响应
对被攻击系统实施控制和对攻击系统实施控制。 被动响应 只会发出告警通知,将发生的不正常情况报告给管理员,本身并不试图降低所造成的破坏,更不会主动地对攻击者采取反击行动。

五、入侵检测的分析方式1 、入侵检测的分析方式2 、异常检测3 、误用检测4 、完整性分析 5 、入侵检测的过程

1 、入侵检测的分析方式异常检测( Anomaly Detection) 统计模型 误报较多
误用检测( Misuse Detection) 维护一个入侵特征知识库( CVE) 准确性高完整性分析
2 、异常检测( 1 )基本原理 正常行为的特征轮廓 检查系统的运行情况 是否偏离预设的门限?举例 多次错误登录、午夜登录

2 、异常检测( 2 )实现技术和研究重点实现技术 统计 神经网络研究重点 如何定义、描述和获取系统的行为知识 如何提高可信度、检测率,降低报警的虚警率

2 、异常检测( 3 )优点 可以检测到未知的入侵 可以检测冒用他人帐号的行为 具有自适应,自学习功能 不需要系统先验知识

2 、异常检测( 4 )缺点漏报、误报率高 入侵者可以逐渐改变自己的行为模式来逃避检测 合法用户正常行为的突然改变也会造成误警
统计算法的计算量庞大,效率很低 统计点的选取和参考库的建立比较困难
3 、误用检测( 1 )检测已知攻击 匹配
建立已出现的入侵行为特征 当前用户行为特征
举例 Land 攻击
源地址 =目标地址 ?
3 、误用检测( 2 )优点 算法简单 系统开销小 准确率高 效率高

3 、误用检测( 3 )缺点被动 只能检测出已知攻击 新类型的攻击会对系统造成很大的威胁 模式库的建立和维护难 模式库要不断更新 知识依赖于
硬件平台 操作系统 系统中运行的应用程序

4 、完整性分析 通过检查系统的当前系统配置,诸如系统文件的内容或者系统表,来检查系统是否已经或者可能会遭到破坏。 其优点是不管模式匹配方法和统计分析方法能否发现入侵,只要是成功的攻击导致了文件或其它对象的任何改变,它都能够发现。 缺点是一般以批处理方式实现,不用于实时响应。

5 、入侵检测的过程 信息收集
包括系统、网络、数据及用户活动的状态和行为。信息分析 分析收集到的信息,发现违背安全策略的行为。 响应 根据攻击或事件的类型或性质,做出相应的响应

六、异常检测技术1 、异常检测技术概念2 、异常检测技术的优势3 、主要方法4 、统计学5 、典型系统6 、数据挖掘技术7 、异常检测技术的缺陷8、异常检测技术的发展趋势
1 、异常检测技术概念 异常检测就是为系统中的用户、程序或资源建立正常行为模式,然后通过比较用户行为与正常行为模式之间的差异进行检测。

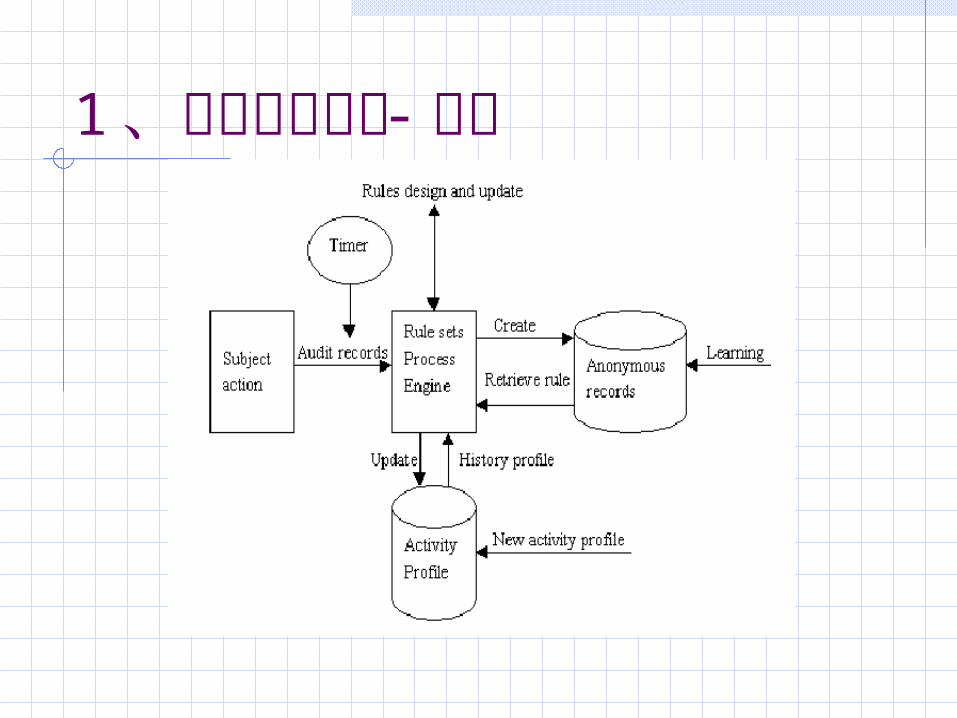
1 、异常检测技术概念 Denning 在 1987年提出的基于系统行为检测的入侵检测系统模型: 通过对系统审计数据的分析建立起系统主体的正常行为特征轮廓( Profile);检测时,如果系统中的审计迹数据与已建立的主体正常行为特征有较大出入,就认为系统遭到入侵。特征轮廓是借助主体登录的时刻、位置, CPU的使用时间以及文件的存取属性等,来描述主体的正常行为特征。当主体的行为特征改变时,对应的特征轮廓也相应改变。

1 、异常检测技术概念Denning IDS模型:主体(用户、主机、关键的程序、文件等)对象(系统资源)审计记录 <Subject, Action, Object,
Exception-Condition, Resource-Usage, Time-Stamp> 活动简档异常记录<Event, Time-stamp, Profile> 活动规则
1 、异常检测技术 -概念

2 、异常检测技术的优势 入侵检测技术分为滥用检测和异常检测两种。滥用检测技术的局限性:
不能检测未知攻击和新的攻击,特征库需要不断升级更新检测系统知识库中的入侵攻击知识与系统的运行环境有关 对于系统内部攻击者的越权行为,由于他们没有利用系统的缺陷,因而很难检测出来

2 、异常检测技术的优势不需要操作系统、协议等安全性缺陷专门知识 检测冒充合法用户入侵的有效方法 智能技术的引进使其能够检测未知攻击

3 、主要方法基于统计的方法专家系统神经网络数据挖掘遗传算法、计算机免疫技术等等

4 、统计学通过对系统审计迹中的数据进行统计处理,并与描述主体正常行为的统计性特征轮廓进行比较,然后根据二者的偏差是否超过指定的门限来进一步判断、处理。 利用统计理论提取用户或系统正常行为的特征轮廓 ;

4 、统计学 统计性特征轮廓由主体特征变量的频度、均值、方差、被监控行为的属性变量的统计概率分布以及偏差等统计量来描述。 典型的系统主体特征有:系统的登录与注销时间、资源被占用的时间以及处理机、内存和外设的使用情况等
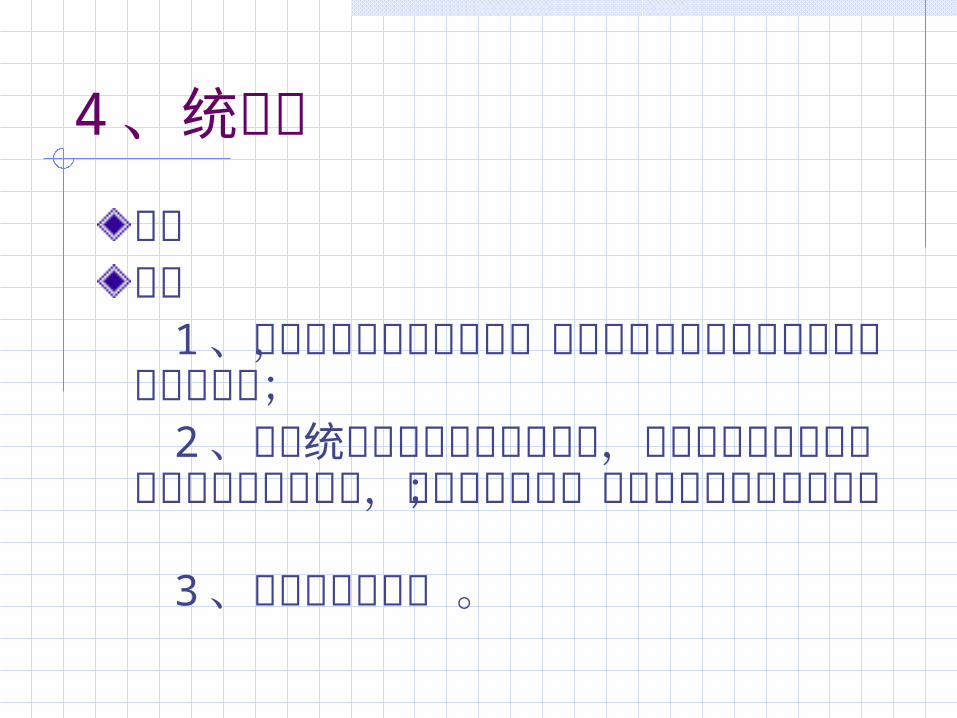
4 、统计学优点缺点 1 、未考虑事件的发生顺序,所以对利用事件顺序关系的攻击难以检测; 2 、利用统计轮廓的动态自适应性,通过缓慢改变其行为来训练正常特征轮廓,最终使检测系统将其异常活动判为正常; 3 、难以确定门限值 。

5 、典型系统SRI的 IDES和NIDES 目前已经实现的监测包括: CPU 的使用时间,
I/O 的使用通道和频率,常用目录的建立和删除,文件的读写、修改、删除等一般项目,还有一些特定项目,例如习惯使用的编辑器和编译器,最常用的系统调用、用户 ID存取、文件和目录的使用等等。 NIDES增加了一些主体,例如可以监控网络主机、可信任程序、用户组和网络。 NIDES增加了一个 Resolver组件,将基于统计的分析结果和基于规则的分析结果进行整合

5 、典型系统HAYSTACK 1 、生成一系列“怀疑对象”,通过二十四个特征检测用户行为 (加权) 2 、检测用户行为的变化,通过比较以前会话记录和最近会话记录的特征变化(趋势)进行判断。

6 、数据挖掘技术 数据挖掘是指从大型数据库或数据仓库中提取人们感兴趣的知识 ,这些知识是隐含的、事先未知的潜在有用信息 ,提取的知识一般可表示为概念
(Concepts) 、规则 (Rules) 、规律 (Regularities) 、模式 (Patterns) 等形式。

6 、数据挖掘技术 数据挖掘系统的理想情况是一个自治的学习代理,自动的探索有用的和令人感兴趣的信息,并以适当的形式报告其发现结果。数据挖掘要经过数据采集、预处理、数据分析、结果表述等一系列过程,最后将分析结果呈现在用户面前。
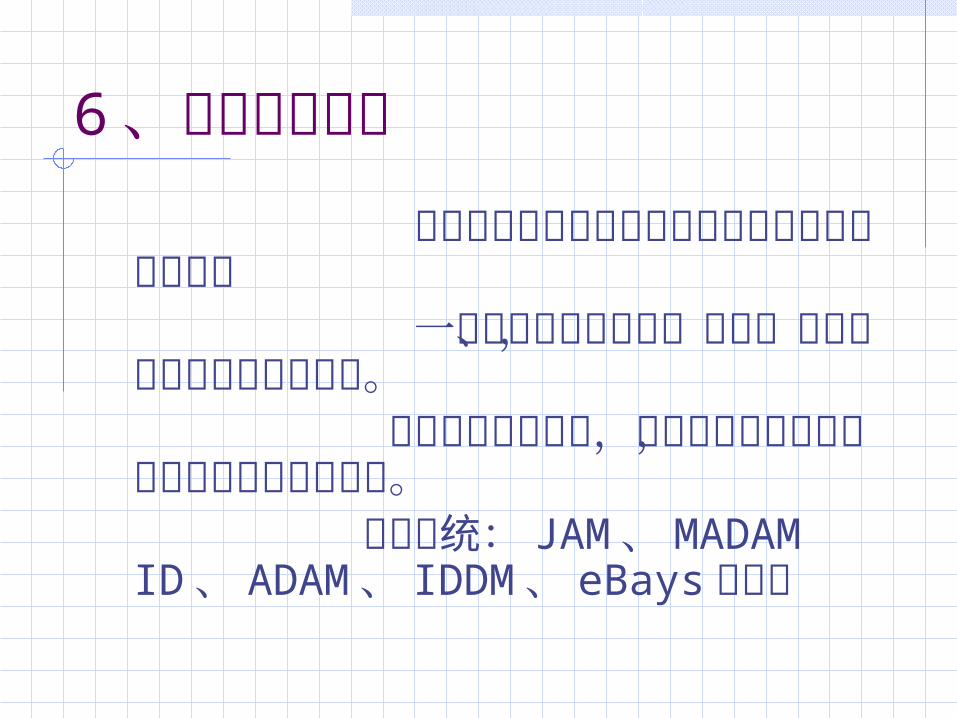
6 、数据挖掘技术 数据挖掘技术在入侵检测领域有两个方向的应用: 一是发现入侵的规则、模式,与模式匹配检测方法相结合。 二是用于异常检测,找出用户正常行为,创建用户的正常行为库。 典型系统: JAM、MADAM
ID、 ADAM、 IDDM、 eBays 等等。

7 、异常检测技术的缺陷在许多环境中,为用户建立正常行为模式的特征轮廓和对用户活动的异常性报警的门限值的确定都比较困难。 有经验的入侵者还可以通过缓慢地改变他的行为,来改变入侵检测系统中的用户正常行为模式,使其入侵行为逐步变为合法。 从系统性能方面考虑,由于应用系统越来越复杂,许多主体活动很难以简单的统计模型来刻画,而复杂的统计模型在计算量上不能满足实时的检测要求。

8、异常检测技术的发展趋势网络异常检测 异常检测与滥用检测的结合 传统意义上的异常检测技术研究

七、一个攻击检测实例1、 Sendmail 漏洞利用2 、简单的匹配3 、检查端口号4 、深入决策树5 、更加深入6 、响应策略

1、 Sendmail 漏洞利用老版本的 Sendmail 漏洞利用 $ telnet mail.victim.com 25 WIZ shell 或者 DEBUG # 直接获得 rootshell

2 、简单的匹配检查每个 packet 是否包含:
“ WIZ”| “DEBUG”

3 、检查端口号缩小匹配范围
Port 25:{“WIZ”| “DEBUG”
}

4 、深入决策树只判断客户端发送部分
Port 25:{Client-sends: “WIZ” |Client-sends: “DEBUG”
}

5 、更加深入状态检测 + 引向异常的分支 Port 25:{stateful client-sends: “WIZ” |stateful client-sends: “DEBUG”after stateful “DATA” client-sends line > 1024 bytes means possible buffer overflow
}
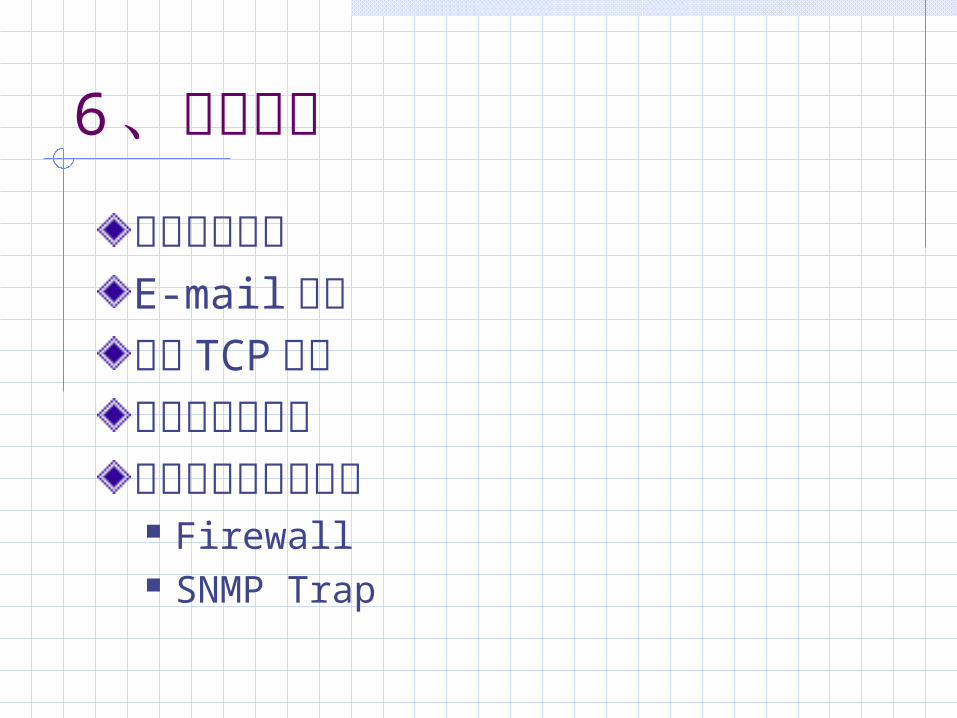
6 、响应策略弹出窗口报警E-mail 通知切断 TCP连接执行自定义程序与其他安全产品交互 Firewall SNMP Trap

八、 Snort1 、概述2、 Snort 规则3、 Snort 配置4、 Snort 检测

1 、概述轻量级入侵检测系统: 可配置性 可移植性 (结构性好,公开源代码 ) 可扩充性(基于规则)网络入侵检测系统 数据包捕获( libpcap 等) 数据包分析误用入侵检测系统 特征模式进行匹配

2、 Snort 规则( 1 )规则描述语言 规则是特征模式匹配的依据,描述语言易于扩展,功能也比较强大 每条规则必须在一行中,其规则解释器无法对跨行的规则进行解析 逻辑上由规则头和规则选项组成。规则头包括:规则行为、协议、源 /目的 IP 地址、子网掩码、方向以及源 /目的端口。规则选项包含报警信息和异常包的信息 (特征码 ) ,使用这些特征码来决定是否采取规则规定的行动。

2、 Snort 规则( 2 )规则描述语言举例
alert tcp any any -> 192.168.1.0/24 111(content:"|00 01 86 a5|";msg:"mountd access";) 从开头到最左边的括号属于规则头部分,括号内的部分属于规则选项。规则选项中冒号前面的词叫做选项关键词。注意对于每条规则来说规则选项不是必需的,它们是为了更加详细地定义应该收集或者报警的数据包。只有匹配所有选项的数据包, Snort才会执行其规则行为。如果许多选项组合在一起,它们之间是逻辑与的关系。让我们从规则头开始。

2、 Snort 规则( 3 )规则头:哪些数据包、数据包的来源、什么类型的数据包,以及对匹配的数据包如何处理。规则行为( rule action ): Alert :使用选定的报警方法产生报警信息,并且记录数据包; Log :记录数据包; Pass :忽略数据包; Activate :报警,接着打开其它的 dynamic规则; Dynamic :保持空闲状态,直到被 activate规则激活,作为一条 log规则

2、 Snort 规则( 4 )协议( protocol ) : 每条规则的第二项就是协议项。当前, snort 能够分析的协议是:
TCP、UDP和 ICMP 。将来,可能提供对ARP、 ICRP、GRE、OSPF、RIP、 IPX 等协议的支持。
IP 地址: 规则头下面的部分就是 IP 地址和端口信息。关键词 any 可以用来定义任意的 IP 地址。 snort 不支持对主机名的解析,所以地址只能使用数字 /CIDR 的形式, CIDR (无级别域内路由)指明应用于 IP 地址的掩码。 /24 表示一个C类网络; /16 表示一个B类网络;而 /32 表示一台特定的主机地址。在规则中,可以使用否定操作符 (negation operator)对 IP 地址进行操作。它告诉 snort除了列出的 IP 地址外,匹配所有的 IP 地址。否定操作符使用 !表示。例如,使用否定操作符可以很轻松地对上面的规则进行改写,使其对从外部网络向内的数据报警。

2、 Snort 规则( 5 )端口号: 有几种方式来指定端口号,包括: any 、静态端口号
(static port)定义、端口范围以及使用非操作定义。 any 表示任意合法的端口号。静态端口号表示单个的端口号,例如:111(portmapper)、 23(telnet)、 80(http) 等。使用范围操作符 : 可以指定端口号范围。有几种方式来使用范围操作符 :达到不同的目的,例如: log udp any any -> 192.168.1.0/24 1:1024 记录来自任何端口,其目的端口号在 1 到 1024之间的 UDP数据包

2、 Snort 规则( 6 )方向操作符 (direction operator): 方向操作符 ->表示数据包的流向。它左边是数据包的源地址和源端口,右边是目的地址和端口。此外,还有一个双向操作符 <>,它使 snort 对这条规则中,两个 IP 地址 /端口之间双向的数据传输进行记录 /分析,例如 telnet 或者 POP3 对话。下面的规则表示对一个 telnet 对话的双向数据传输进行记录: log !192.168.1.0/24 any <>
192.168.1.0/24 23

2、 Snort 规则( 7 )规则选项:规则选项构成了 snort 入侵检测引擎的核心,它们非常容易使用,同时又很强大和容易扩展。在每条 snort规则中,选项之间使用分号进行分割。规则选项关键词和其参数之间使用冒号分割。下面是一些常用的规则选项关键词,其中对部分重要关键词进行详细解释:

2、 Snort 规则( 8)msg:在报警和日志中打印的消息;logto:把日志记录到一个用户指定的文件,而不是输出到标准的输出文件;ttl:测试 IP包头的 TTL域的值;tos :测试 IP包头的 TOS域的值;id :测试 IP 分组标志符 (fragment ID)域是否是一个特定的值 ipoption /fragbits /dsize /flags /seq /……

3、 Snort 配置( 1 )Snort 本身的一些配置,例如变量、预处理插件、输出插件、规则集文件等,也是通过解析规则进行的。在snort2.0 版本中,有一个总体规则文件 snort.conf ,大部分配置规则都在此文件中。

3、 Snort 配置( 2 )Include varriables 在 snort 规则文件中可以定义变量。格式为: var
<name><value> ,例如: var MY_NET192.168.1.0/24,10.1.1.0/24]<alert tcp any any -> $MY_NET any (flags:S;msg: "SYNMETA packet";) 。最重要的默认变量是HOME_NET、 EXTERNAL_NET、HTTP_PORTS、RULE_PATH 等,分别表示本地网络的 IP 地址范围、外部网络的 IP 地址范围、 web 服务的端口、规则集文件的路径。

3、 Snort 配置( 3 )预处理器: 从 snort-1.5开始加入了对预处理器(也叫预处理插件)的支持。有了这种支持,用户和程序员能够比较容易地编写模块化的插件,扩展 snort的功能。预处理器在调用检测引擎之前,在数据包被解码之后运行。通过这种机制, snort可以以一种
out of band的方式对数据包进行修改或者分析。预处理器可以使用 preprocessor关键词来加载和配置,格式如下: preprocessor <name>: <options>。例如: preprocessor minfrag: 128。以下是一个预处理器的例子:

3、 Snort 配置( 4 ) HTTP decode预处理插件: HTTP解码预处理模块用来处理 HTTP URI字符串,把它们转换为清晰的 ASCII字符串。这样就可以对抗 evasice web URL扫描程序和能够避开字符串内容分析的恶意攻击者。这个预处理模块使用WEB端口号作为其参数,每个端口号使用空格分开。格式:
http_decode:< 端口号列表 > ,例如:preprocessor http_decode: 80 8080

3、 Snort 配置( 5 )输出插件: snort 输出模块是从 1.6 版加入的新特征,使 snort 的输出更为灵活。 snort 调用其报警或者日志子系统时,就会调用指定的输出模块。设置输出模块的规则和设置预处理模块的非常相似。在 snort 配置文件中可以指定多个输出插件。如果对同一种类型 ( 报警、日志 ) 指定了几个输出插件,那么当事件发生时 ,snort 就会顺序调用这些插件。使用标准日志和报警系统,默认情况下,输出模块就会将数据发送到 /var/log/snort 目录,或者用户使用 -l 命令行开关指定的目录。在规则文件中,输出模块使用 output 关键词指定:格式: output name:< 选项> ,例如: output alert_syslog: LOG_AUTH LOG_ALERT 。下面是几个常用的输出插件:

4、 Snort 检测( 1 )协议匹配。通过协议分析模块,将数据包按照协议分析的结果对协议相应的部分进行检测。比如对 TCP包的标志位的匹配。 alert tcp $EXTERNAL_NET any -> $HOME_NET
any (msg:"SCAN NULL";flags:0; seq:0; ack:0; reference:arachnids,4; classtype:attempted-recon; sid:623; rev:1;)
其中就对 TCP 的 flags、 seq、 ack进行了协议位置的匹配。协议匹配需要对特定协议进行分析, Snort对 IP/TCP/UDP/ICMP进行了分析,但是没有对应用协议分析。其它一些商用的 IDS进行了高层的应用协议分析,可以显著地提高匹配的效率。

4、 Snort 检测( 2 )字符串匹配。目前这是大多数 IDS 最主要的匹配方式,事件定义者根据某个攻击的数据包或者攻击的原因,提取其中的数据包字符串特征。通常 IDS 经过协议分析后,进行字符串的匹配。 比如: Snort 中的一条事件定义, alert tcp
$EXTERNAL_NET any ->$HTTP_SERVERS $HTTP_PORTS (msg:"WEB-ATTACKS ps command attempt";flow:to_server, established; uricontent:"/bin/ps"; nocase;sid:1328; classtype:web-application-attack; rev:4;)
该事件中要进行匹配的字符串就是 "/bin/ps" 。字符串匹配主要就是算法问题,因为 IDS 的规则多数属于字符串匹配,因此优秀的字符串匹配算法也能够显著提高 IDS 的效率,比如 Boyer-Moore、 Aho-Corasick、 Set-wise Boyer-Moore 算法。

4、 Snort 检测( 3 )大小匹配,或者长度匹配。多数情况下,这也应该属于字符串匹配的一种,不过,这种匹配方式对数据包中某段数据的长度而不是对具体的字符串进行匹配。 比如,通过数据长度限制来对缓冲区溢出攻击进行检测。比如:alert tcp $EXTERNAL_NET any -> $HTTP_SERVERS $HTTP_PORTS(msg:"WEB-IIS ISAPI .ida attempt"; uricontent:".ida?"; nocase;dsize:>239; flow:to_server,established; classtype:web-application-attack; reference:bugtraq,1065;sid:1243; rev:6;)
其中的关键字 dsize 就是对数据包的负载进行匹配,如果请求的命令总长度大于 239,那么就检测出一条 .ida溢出企图的事件。

4、 Snort 检测( 4 )累积匹配,或者量匹配。通过对某些事件出现的量(次数或者单位时间次数)来产生新的事件,比如,某个 IP 在 1 分钟内统计出了 100条 CGI事件,那么就属于一次 CGI扫描事件。 Snort 的一些预处理插件可以进行此类匹配,例如portscan。

4、 Snort 检测( 5 )逻辑匹配,或者是集合匹配。一些有更强事件检测能力的 IDS ,通过对不同类型的事件组合来进行判断,从而获得新的事件。少数 IDS 对多种事件的组合来构成逻辑推理,增强检测的智能。 Snort 对此类匹配支持的功能较弱,仅在 stream 等预处理插件中有一些。
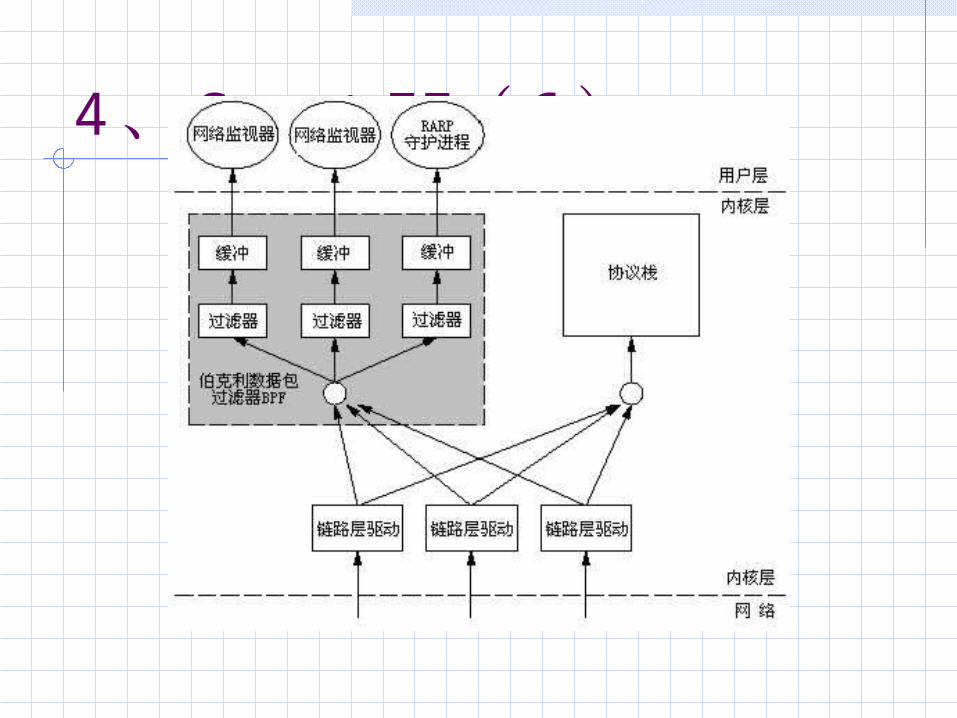
4、 Snort 检测( 6 )
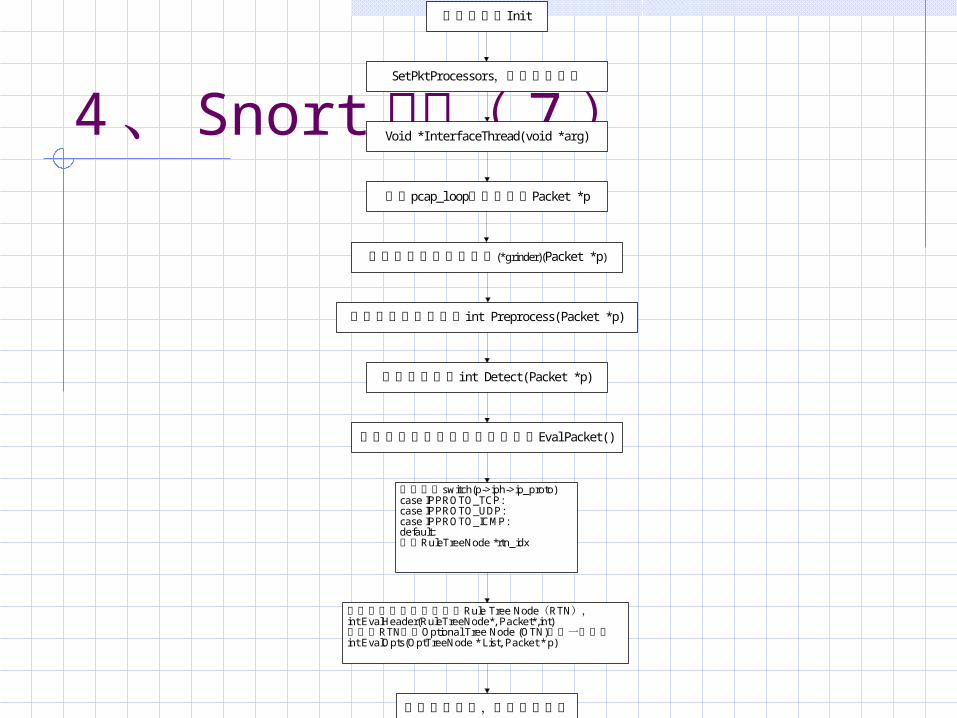
4、 Snort 检测( 7 )I ni t程序初始化
SetPktProcessors,设置包处理器
Voi d *I nterfaceThread(voi d *arg)
pcap_l oop Packet *p通过 获得数据包
i nt Preprocess(Packet *p)对数据包进行预处理
i nt Detect(Packet *p)进入检测函数
Eval Packet()选择规则树准备开始分类作匹配
对数据包进行协议分析(*grinder)(Packet *p)
检查协议switch(p->iph->ip_proto)case IPPROTO_TCP:case IPPROTO_UDP:case IPPROTO_ICMP:default:设置RuleTreeNode *rtn_idx
先从头部进行匹配并选择Rule Tree Node(RTN),int EvalHeader(RuleTreeNode*, Packet*,int)然后对RTN树下Optional Tree Node (OTN)作进一步匹配int EvalOpts(OptTreeNode * List, Packet * p)
若匹配到规则,调用输出插件
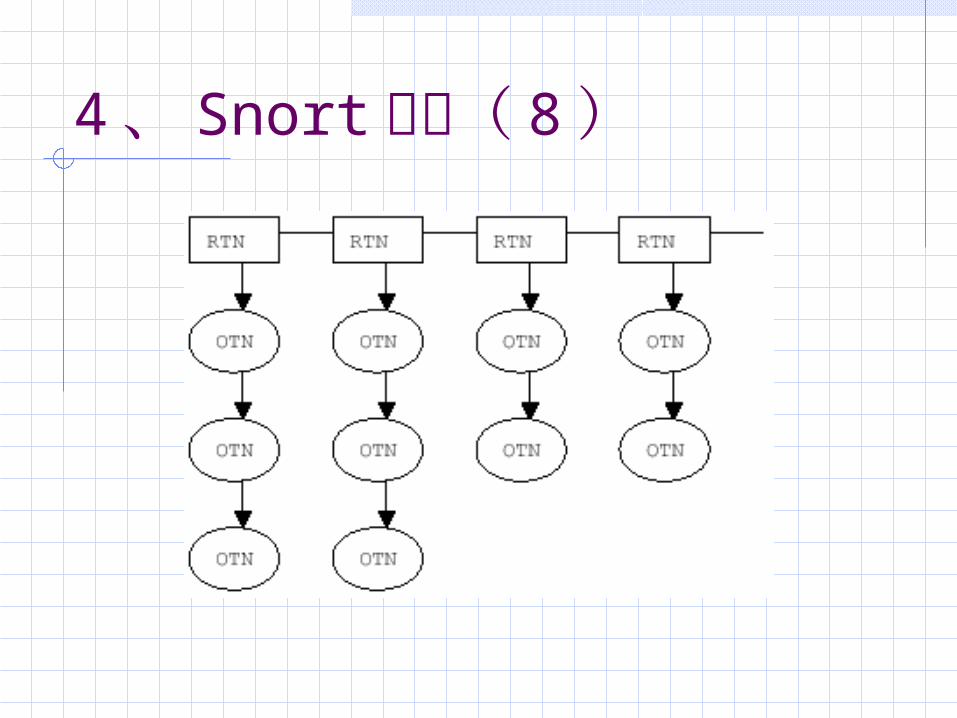
4、 Snort 检测( 8)
4、 Snort 检测( 9)对规则头解析的结果填入 RTN ,对规则选项解析的结果填入 OTN。抓取数据包后 Snort 要先进行一定程度的协议解析工作,主要是用相应的指针指向数据的各个域,这可以加快以后检测的匹配速度。然后数据包需要经过各个预处理器进行预处理,例如IP碎片重组、 HTTP解码等。接下来就进入 Snort 的模式匹配过程,主要是遍历规则树试图匹配各个规则节点。如前所述, Snort 主要进行的是协议匹配、字符串匹配和长度匹配,而检测引擎中没有两次或者多次匹配的过程,也就是累计匹配和逻辑匹配,因此它不能检测分布事件,也不能检测流量异常,而只能通过端口协议字符串等来检测那些具有字符串数据特征的特定拒绝服务攻击工具的事件,这可以从 snort的 DDOS 规则集看得出来。当然 Portscan和 Stream4 等预处理器的增加使 snort 在累计匹配和逻辑匹配上有一些表现,比如, Portscan预处理器可以跟踪端口扫描事件的速率。从 Snort 提供的规则也可以得到上面的结果,因为规则中所体现的基本都是对IP、 ICMP、 TCP、 UDP 这样的三、四层上的协议进行了解析,而对更上面的协议,比如第七层的应用协议等基本没有作协议分析,这些规则中主要进行的也是前三种方式的单包匹配。当然这里的重点不是在匹配算法上,而更看重整个检测的结构和过程。首先能够看到的问题就是 snort 的规则树形结构过于简单,也就造成可能某些 RTN 下的 OTN链比较庞大;没有对高层协议分析也是一个大问题,因为,协议分析可以更有效地定位匹配位置,加快匹配速率。因此,现在很多 IDS将规则树更平坦,尽量让深度和宽度不失调,同时进行高层协议分析,这一代的 IDS结构也就基本如此了。同时,有些 IDS采用多层引擎的方式,来实现和加强累计匹配和逻辑匹配的检测能力。其实现在 Snort 的结构发展也基本是对这些问题的解决。
