nsyncyun.tistory.comnsyncyun.tistory.com/attachment/cfile23.uf@116be647502bc... · web view2단계...
TRANSCRIPT

[오픈 상태에서 데이터파일을 이동하는 과정]1.단계 : 테이블 스페이스 오프라인2 단계 : 오프라인 확인3 단계 : 테이터 파일 이동4 단계 : 'alter tablespace' 명령어로 데이터 파일 정보 갱신5 단계 : 테이블 스페이스 온라인
[사용 명령어]1..alter tablespace <테이블 스페이스명> offline;2.alter tablespace <테이블 스페이스명> rename datafile <원래 데이터 파일명> to <이동한 테이터 파일명>;3.alter tablespace <테이블 스페이스명> online;
select * from dba_tablespaceswhere tablespace_name not in('SYSAUX','USERS','EXAMPLE','UNDOTBS2','UNDOTBS1','SYSTEM','TEMP')
select * from dba_data_fileswhere tablespace_name not in('SYSAUX','USERS','EXAMPLE','UNDOTBS2','UNDOTBS1','SYSTEM','TEMP')
dbms_stat 프로시저 유형
dbms_stats.gather_index_stats - 인덱스의 상태 정보를 수집dbms_stats.gather_table_stats - 테이블의 상태정보를 수집dbms_stats.gather_schema_stats - 특정 사용자의 모든 객체에 대한 상태 정보를 수집dbms_stats.gather_database_stats - DB내 모든 객체의 상태정보를 수집dbms_stats.gather_generate_stats - B*Tree, BitMap 인덱스의 상태 정보를 수집

-- undo segment --
select * from v$rollname a, v$rollstat bwhere a.usn= b.usn
select * from dba_data_fileswhere tablespace_name in('UNDOTBS1','UNDOTBS2')
select * from dba_tablespaceswhere tablespace_name in('UNDOTBS1','UNDOTBS2')
1. undo 테이블스페이스는 기본적으로 10 개 세그먼트 생성 2. 트랜잭션이 늘어남에 따라 자동으로 확장3. 각 트랙잰션당 가능한 1 개의 undo 세그먼트를 사용하도록 함4. 테이블 스페이스의 공간이 부족하게 되어 undo 세그먼트가 생성되지 못한다면, 트랜잭션들은 undo 세그먼트를 공유
sql*plus 에서 Autotrace 설정초기 설정autotrace 를 수행하려면..1. $ORACLE_HOME/rdbms/admin2. @utlxplan 실행3. create public synonym plan_table form plan_table; grant all on plan_table to public;
explain plan 명령어sql 문의 실행계획과 상태 값을 제공하는 명령어 1)옵티마이저의 유형2)옵티마이저에 의해 결정된 실행 계획3)실행 계획의 선택 기준(비용계산 결과)

4)sql 문을 실행하면서 사용한 DB 구조의 상태 값 * 데이터 파일로 부터 읽은 블록 수 * 네트워크를 통해 전송된 데이터의 바이트 수 * 사용된 데이터버퍼 캐시 블록 수 * sorting 작업 발생 시 사용된 메모리 블록 수 * 처리된 데이터 량
EXPLAIN PLAN SET STATEMENT_ID = 'DBA'FORSELECT * FROM SCOTT.EMP;
$ORACLE __HOME 오라클 S/W 가 설치되어 있는 경로$ORACLE _SID 오라클 데이터베이스 명
v$sql_plan 의 기타 컬럼(1) address : 커서의 핸들주소(v$sql, v$sqlarea 의 주소 값을 참조하여 실행합니다.)(2) hash_value : 라이브러리 캐시 영역에 작성된 실행계획을 구분하는 값(3) child_number : 해당 실행계획과 관련된 정보(4) CPU-cost : sql 문이 실행 되면서 사용하나 cpu 비용(5) io-cost : sql 문이 실행되면서 사용된 비용(6) temp_space : 해시 조인이 발생하면서 분류작업을 하기 위해 사용한 공간의 크기
Statistics---------------------------------------------------------- 4 recursive calls 0 db block gets 8 consistent gets 0 physical reads 0 redo size 556 bytes sent via SQL*Net to client 419 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client

0 sorts (memory) 0 sorts (disk) 1 rows processed
recursive calls - 사용자가 실행한 non-recursive sql 문장과 파싱을 위해서 서버 프로세스는 자료사전 테이블로부터 테이블의 상태정보 및 통계정보를 참조하게 된다. 이때 다음과 같은 sql 문이 실행하게 되는데 이것을 recursive-sql 이라고 한다.
select * from user_table;select * from user_tab_columnsselect * from user_indexes;
4 는 자료사전 테이블로 부터 테이블 및 인덱스 정보를 참조하기 위해 읽은 블록수를 의미합니다. db block gets - dml 이 실행될 때 발생하는 변경 전 데이터(roll back data)를 잠시 저장하기 위한 임시 공간을 나타냅니다.consistent gets - sql 문을 실행될 때 디스크 상에 존재하는 테이블 및 인덱스를 저장하기 위한 메모리 공간을 의미합니다.physical reads - 데이터가 실제로 존재하는 디스크 상의 데이터 파일로부터 읽혀진 데이터 블록 수를 의미합니다.redo size - dml 문을 실행했을 때 변경 전 데이터와 변경 후 데이터를 로그버퍼 영역에 백업하기 위한 저장한 블록 수를 의미합니다.bytes sent via SQL*Net to client, bytes received via SQL*Net from client, SQL*Net roundtrips to/from client - 클라이언트와 서버간에 전송된 데이터를 바이트 단위로 표시했으며 왕복 전송된 횟수를 의미합니다.sorts (memory) - pga(program global area) 공간을 나타낸다sorts (disk) - 임시 테이블스페이스의 사용 블록수를 의미
pag_aggregate_target 파라메터에 의해 정의된 공간에서만 사용할 수 있기 때문에 대용량의 데이터를 분류 작업하는 경우에는 추가적인 공간이 요구되는데 이 공간이 임시 테이블스페이스(temporary tablespace)입니다. sql 문장 중 분류작업이 발생하는 경우는 ?* 인덱스를 생성하는 분법을 사용하는 경우(create index ~문)* 인덱스가 있는 테이블에 병렬로 데이터를 입력하는 경우(insert into~parallel(degree n)* order by, group by 사용하는 경우 * distinct 키워드를 사용하는 경우* union, intersect, minus 연결 연산자를 사용하는 경우* 인덱스가 없는 2 개의 테이블을 조인하는 경우* analyze 명령문을 사용하는 경우
rows processed - sql 문이 실행된 후 조건을 만족하는 행수를 의미합니다.

sql_trace show parameter timed_statistics <-true 로 설정 되어 있어야 함show parameter user_dump_dest show parameter max_dump_file_size
alter session set sql_trace=true;
tkprof MASSDB1_w000_4456.trc test.tkf sys=no explain=system/asd123
[oracle@rac1 trace]$ vi test3.tkf
TKPROF: Release 11.2.0.1.0 - Development on Tue Aug 14 01:21:11 2012
Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved.
Trace file: MASSDB1_ora_10647.trcSort options: default
********************************************************************************count = number of times OCI procedure was executedcpu = cpu time in seconds executingelapsed = elapsed time in seconds executingdisk = number of physical reads of buffers from diskquery = number of buffers gotten for consistent readcurrent = number of buffers gotten in current mode (usually for update)rows = number of rows processed by the fetch or execute call********************************************************************************
SQL ID: 2wsm2zjmzraw5Plan Hash: 3814977537select *from big_emp
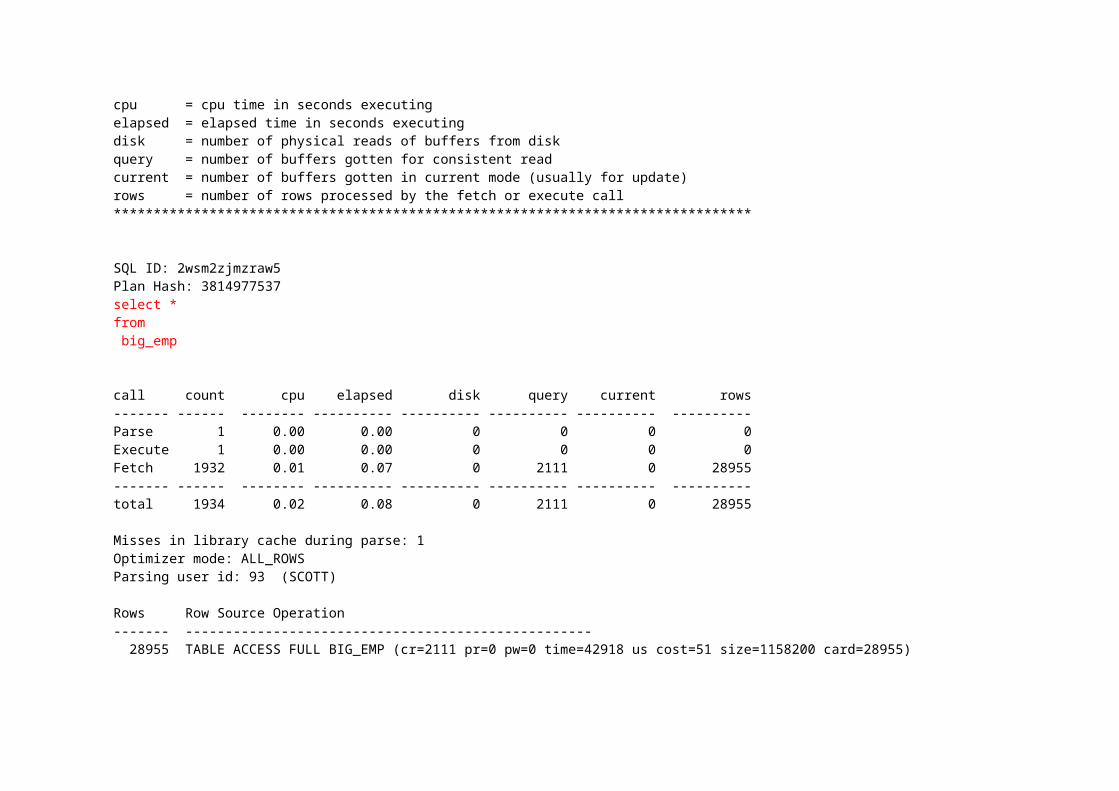
call count cpu elapsed disk query current rows------- ------ -------- ---------- ---------- ---------- ---------- ----------Parse 1 0.00 0.00 0 0 0 0Execute 1 0.00 0.00 0 0 0 0Fetch 1932 0.01 0.07 0 2111 0 28955------- ------ -------- ---------- ---------- ---------- ---------- ----------total 1934 0.02 0.08 0 2111 0 28955
Misses in library cache during parse: 1Optimizer mode: ALL_ROWSParsing user id: 93 (SCOTT)
Rows Row Source Operation------- --------------------------------------------------- 28955 TABLE ACCESS FULL BIG_EMP (cr=2111 pr=0 pw=0 time=42918 us cost=51 size=1158200 card=28955)
Misses in library cache during parse 의 값이 1 이 가지는 의미는 개발자가 실행한 sql 문이 다른 개발자에 의해 실행된 적이 없었던 문자임을 의미만약 0 이라면 이미 다른 사용자에 의해 실행된 적이 있었던 문장이기 때문에 파싱결과가 라이브러리 영역에 존재하고 있음을 의미한다.
select sql_text,version_count, loads, invalidations, parse_calls,sortsfrom v$sqlareawhere sql_text not like '%$%' and command_type in(2,3,6,7)order by sql_text;
command type 2 insertcommand type 3 select command type 6 updatecommand type 7 delete
version_count - 같은 id으로 실행하면 같은 version이지만 id이면 count가 증가한다.load - parsing후 sql문이 메모리 영역에 로더된 횟 수invalidation - parsing후 로더된 sql문에서 참조된 테이블이 alter, drop, analyze되면 parsing 정보를 재 사용할 수 없다.parse_call - 최초 parsing후 재사용된 횟 수
alter system flush shared_pool;

튜닝해야 할 sql 문의 분석--select sql_text,buffer_gets select sql_text,disk_reads from v$sqlarea where sql_text not like '%$%' and command_type in(2,3,6,7)--order by buffer_gets descorder by disk_reads desc

analyze table <테이블명>analyze index <인덱스명>analyze cluster <클러스터명>
compute statistics - 테이블에 저장되어 있는 모든 행을 대상으로 통계정보 수집estimate statistics - 오라클 서버의 자동화 알고리즘에 의해 부분 데이터를 추출하여 통계정보를 수집delete statistics - 수집되어 있는 통계 정보를 삭제
통계 정보의 수집 방법과 주의 사항analyze 명령어 중 대용량 데이터인 경우 compute statistics 절을 사용하게 되면 전체 데이터를 분석하기 때문에 이 작업 자체가 데이터베이스 성능 저하에 영향을 미칠 수도 잇다.20,000 건 이하가 되는 데이터에 관해서는 compute statistics 절의 사용을 권장하고 이상이 되는 데이터에 관해서는 estimate statistics 절의 사용을 권장.
analyze table big_dept compute statistics;
select table_name, blocks, num_rows, avg_row_len from dba_tableswhere table_name = 'BIG_DEPT';
blocks - 데이터가 저장되어 있는 블록 수num_rows - 데이터 블록 수avg_row_len - 하나의 행의 평균 길이
select table_name, column_name, low_value, high_value, num_distinct from dba_tab_columnswhere table_name = 'BIG_DEPT'
low_value - 해당 컬럼에 저장되어 있는 최소 값high_value - 해당 컬럼에 저장되어 있는 최대 값

num_distinct - 유일한 값의 수
select index_name, blevel, leaf_blocks, distinct_keys, clustering_factor, num_rowsfrom dba_indexeswhere table_name = 'BIG_EMP'
blevel - 인덱스의 깊이leaf_blocks - 리프 블록수distinct_keys - 인덱스 컬럼의 유일한 값의 수clustering_factor - 조건을 만족하는 데이터를 검색할 때 인덱스 키 값이 각 블록에 얼마나 잘 분산 저장되어 있는지를 나타내는 정도num_rows - 행 수
cardinality - 하나의 sql문을 실행 했을 때 전체 테이블 행에서 sql문의 조건을 만족시키는 컬럼의 유일한 값의 수로 나눈 결과를 커디널리티라고 한다. 커디널리티는 사용자가 실행한 sql문의 전체 테이블 스캔 또는 인덱스 스캔을 하느냐에 따라 결과 값을 계산하는 방법1)unique-key 컬럼을 검색하는 경우select count(*) from emp 가 카디널리티가 된다.2)non-unique-key인 경우테이블 전체 행수/distinct-key수3)group by 절에 의해 검색되는 경우cardinality = distinct-key수 -1
selectivity - sql문을 실행했을 때 조건을 만족하는 행이 선택될 수 있는 정도1) unique-key 또는 pramary-key인 경우 조건을 만족하는 행은 반드시 하나의 행이므로 선택도는 1입니다. 선택도 1은 가장 좋은 선택도 조건을 나타낸다.
2) unique-key 경우선택도는 (1/유일한 값)
3) 값을 가진 비동등 조건식이 아닌 경우emp 절에 사용된 컬럼에 대해 최대값이 29999이고 최소 값이 1일 경우
- case1

select * from emp where empno < 200; empno가 200보다 작은 경우 =(범위값-최소값)/(최대값-최소값)=(200-1)/(29999-1)=199/29998=0.007
- case2select * from emp where empno > 200;=(범위값-최소값)/(최대값-최소값)=(29799-1)/(29999-1)=29798/29998=0.9
- case3select * from emp where empno between 100 and 200;=(최대조건값-최소조건값)/(최대값-최소값)=(200-100)/(29999-1)=100/29998=0.003
4) 바인드 변수를 사용하는 경우select * from emp where empno < :A; 선택도는 25%이다.select * from emp where empon between :A and :b; 선택도는 50%
-히스토그램이 적용되어 있는지 확인 하는 방법select table_name, column_name, num_distinct, num_buckets, sample_sizefrom dba_tab_columnswhere table_name ='BIG_EMP'
(1) SQL문의 WHERE절에 바인드 변수가 사용된 경우(2) 조건 검색되는 컬럼의 값들이 균등하게 잘 분산되어 있는 경우(3) 조건절에 EQUAL문을 통해 검색되며 해당컬럼의 값이 UNIQUE한 경우(4) RULE-BASED 옵티마이져를 적용하거나, HINT 절에 의해 실행계획이 결정되는 경우
문법

analyze table <table name> compute statisticsfor tablefor columns <column_name> size [N] ->카디널리티 값for all indexed columns size[N] -> 인덱시 적용시
-- histogram-- 사용자의 모든 테이블 컬럼구조와 데이터의 유형을 분석한다.-- 스크립트 실행전에 반드시 SQL> @Table_ANALYZE.SQL을 실행하라.Set feed off echo off pages 100set linesize 200col cluster_name format a11 headi 'Cluster'col table_name format a13 headi 'Table'col column_id noprintcol row_type noprintcol num_rows format 9,999,990 headi 'Rows'col blocks format 99990 headi 'Blocks'col empty_blocks format 99990 headi 'Empty|Blocks'col avg_row_len format 999990 headi 'Ave Row|Length'col pct_free format 90 headi 'Pct|Free'col pct_used format 90 headi 'Pct|Used'col chain_cnt format 90 headi 'Chain|Count'col column_name format a15 headi 'Column'col num_distinct format 9,999,990 headi 'Distinct|Values'col index_name format a10 headi 'Index'
break on cluster_name skip 1 on table_name skip 1 -on num_rows on blocks on empty_blocks on avg_row_len on row_type on pct_free on pct_used on chain_cnt skip
1
spool stats.datselect t.owner, decode(clu.cluster_name, null, 'Unclustered', clu.cluster_name) cluster_name, t.table_name, 'C' row_type, col.column_id, t.num_rows,

t.blocks, t.empty_blocks, t.avg_row_len, t.pct_free, t.pct_used, t.chain_cnt, col.column_name, col.num_distinctfrom dba_tables t, dba_tab_columns col, dba_clusters cluwhere t.num_rows is not nulland clu.cluster_name (+) = t.cluster_nameand t.table_name = col.table_nameand t.table_name <> 'PLAN_TABLE'--and t.owner = 'SCOTT'--and t.table_name = 'LARGE_EMP'/spool offset feed on echo onSet feed off echo off pages 24
테이블스페이스를 move하는 방법?select '-----------TABLE RENAME--------' from dualunion allselect 'alter table ' || table_name || ' rename to ' || table_name || '_OLD;' from dba_tableswhere table_name in ('LARGE_EMP')union allselect '-----------INDEX RENAME--------' from dualunion allselect 'alter index ' || index_name || ' rename to ' || index_name || '_OLD;' from dba_indexes where table_name in ('LARGE_EMP');--------------------------------------------
alias asm_stat='sqlplus -S "/as sysdba" @testpora/script/dba/asm_usage_status.sql'

--- asm_usage_status.sql set lin 250col name format a10col USABLE_FILE_GB format 999,999.00col TOTAL_GB format 999,999.00col FREE_GB format 999,999.00col USABLE_CALC_GB format 999,999.00select name,USABLE_FILE_MB/1024 USABLE_FILE_GB,total_mb/1024 TOTAL_GB, free_mb/1024 FREE_GB,100-round(free_mb/total_mb*100) "usgae(%)",((FREE_MB - REQUIRED_MIRROR_FREE_MB))/1024 USABLE_CALC_GB,state, type, group_number`from v$asm_diskgroup;exit;
[oraptest@testd1:/testpora] asm_statNAME USABLE_FILE_GB TOTAL_GB FREE_GB usgae(%) USABLE_CALC_GB STATE TYPE GRP------- -------------- ----------- ----------- ---------- -------------- ----------- ------ ----DATA XXX.99 X,XXX.75 XXX.99 47 821.99 CONNECTED EXTERN 1RECO XX.76 XX.44 XX.76 29 26.76 CONNECTED EXTERN 2[oraptest@testd1:/testpora]
----------------------------------------------
※ 현재 상황은 VM 상황이라 서버를 종료한 후 디스크를 추가하지만 실제에는 Hot Swap 라는 기능이 있어 장비 종료 없이 작업이 가능하다.1. 디스크 추가하기1) 리눅스 종료 후 디스크 5g 추가후 fdisk -Lvm 으로 파티셩닝한다.2) pvcreate3) vgcreate4) lvcreate
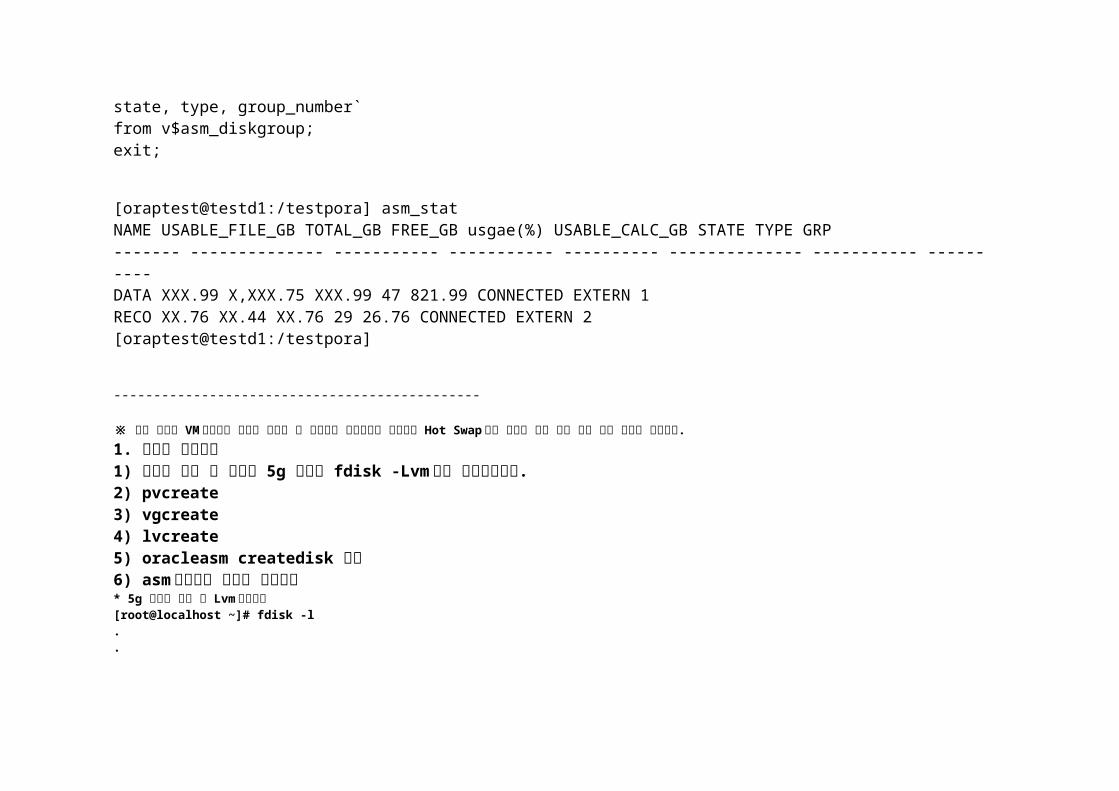
5) oracleasm createdisk 수행6) asm 명령어로 디크스 추가하기* 5g 디스크 추가 후 Lvm 파티셔닝[root@localhost ~]# fdisk -l..Disk /dev/sdm: 5368 MB, 5368709120 bytes255 heads, 63 sectors/track, 652 cylindersUnits = cylinders of 16065 * 512 = 8225280 bytesDisk /dev/sdm doesn't contain a valid partition table[root@localhost ~]# fdisk /dev/sdmDevice contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabelBuilding a new DOS disklabel. Changes will remain in memory only,until you decide to write them. After that, of course, the previouscontent won't be recoverable.Warning: invalid flag 0x0000 of partition table 4 will be corrected by w(rite)Command (m for help): nCommand actione extendedp primary partition (1-4)pPartition number (1-4): 1First cylinder (1-652, default 1):엔터Using default value 1Last cylinder or +size or +sizeM or +sizeK (1-652, default 652):엔터Using default value 652Command (m for help): tSelected partition 1Hex code (type L to list codes): 8eChanged system type of partition 1 to 8e (Linux LVM)Command (m for help): wThe partition table has been altered!Calling ioctl() to re-read partition table.Syncing disks.[root@localhost ~]# pvcreate /dev/sdm1Physical volume "/dev/sdm1" successfully created[root@localhost ~]# vgcreate asm2 /dev/sdm1Volume group "asm2" successfully created[root@localhost ~]# lvcreate -L 2G -n asm3 asm2/dev/cdrom: open failed: 읽기전용 파일 시스템Logical volume "asm3" created

[root@localhost ~]# lvcreate -L 2.5G -n asm4 asm2/dev/cdrom: open failed: 읽기전용 파일 시스템Logical volume "asm4" created[root@localhost ~]# lvscanACTIVE '/dev/asm2/asm3' [2.00 GB] inheritACTIVE '/dev/asm2/asm4' [2.50 GB] inheritACTIVE '/dev/asm/asm1' [7.50 GB] inheritACTIVE '/dev/asm/fra1' [2.40 GB] inheritasm 디스크로 등록[root@localhost ~]# /etc/init.d/oracleasm createdisk asm2 /dev/asm2/asm3Marking disk "asm2" as an ASM disk: [ OK ][root@localhost ~]# /etc/init.d/oracleasm createdisk asm3 /dev/asm2/asm4Marking disk "asm3" as an ASM disk: [ OK ]
[oracle@localhost ~]$ export ORACLE_SID=+ASM[oracle@localhost ~]$ sqlplus / as sysdba;SQL*Plus: Release 10.2.0.5.0 - Production on Tue Feb 28 02:03:38 2012Copyright (c) 1982, 2010, Oracle. All Rights Reserved.Connected to an idle instance.SYS/+ASM> startupSYS/+ASM> set line 200SYS/+ASM> col path for a15SYS/+ASM> select group_number, mount_status, path, total_mb2 from v$asm_disk where mount_status='CLOSED'; //disk 중 사용하지 않는 녀석 조회GROUP_NUMBER MOUNT_STATUS PATH TOTAL_MB------------ -------------- --------------- ----------0 CLOSED ORCL:ASM3 25600 CLOSED ORCL:ASM2 2048SYS/+ASM> alter diskgroup data add disk'ORCL:ASM2' rebalance power 5; //디스크 추가Diskgroup altered.Disk 추가 후 다시 asm disk 상태 조회SYS/+ASM> select group_number, disk_number, name, mount_status, path, total_mb2 from v$asm_disk; GROUP_NUMBER DISK_NUMBER NAME MOUNT_STATUS PATH TOTAL_MB------------ ----------- ---------- -------------- --------------- ----------0 2 CLOSED ORCL:ASM3 25601 0 ASM1 CACHED ORCL:ASM1 76801 1 ASM2 CACHED ORCL:ASM2 20482 0 FRA1 CACHED ORCL:FRA1 2460나머지 한개 더 추가하기SYS/+ASM> alter diskgroup data add disk 'ORCL:ASM3' rebalance power 10;

Diskgroup altered.SYS/+ASM> select group_number, disk_number, name, mount_status, path, total_mb2 from v$asm_disk;GROUP_NUMBER DISK_NUMBER NAME MOUNT_STATUS PATH TOTAL_MB------------ ----------- ---------- -------------- --------------- ----------1 0 ASM1 CACHED ORCL:ASM1 76801 1 ASM2 CACHED ORCL:ASM2 20481 2 ASM3 CACHED ORCL:ASM3 25602 0 FRA1 CACHED ORCL:FRA1 2460
2. 디스크 삭제하기SYS/+ASM> set line 200SYS/+ASM> col group_name for a10SYS/+ASM> col disk_name for a10SYS/+ASM> select b.name as group_name, a.name as disk_name, a.header_status, a.state, a.free_mb2 from v$asm_disk a, v$asm_diskgroup b3 where a.group_number=b.group_number;GROUP_NAME DISK_NAME HEADER_STATUS STATE FREE_MB---------- ---------- ------------------------ ---------------- ----------DATA ASM1 MEMBER NORMAL 7130DATA ASM2 MEMBER NORMAL 1899DATA ASM3 MEMBER NORMAL 2375FRA FRA1 MEMBER NORMAL 2232디스크 삭제SYS/+ASM> alter diskgroup data drop disk asm3;Diskgroup altered.SYS/+ASM> select * from v$asm_operation;GROUP_NUMBER OPERATION STATE POWER ACTUAL SOFAR EST_WORK EST_RATE EST_MINUTES------------ ---------- -------- ---------- ---------- ---------- ---------- ---------- -----------1 REBAL RUN 1 1 269 274 763 0SYS/+ASM> col name for a10SYS/+ASM> select name, header_status, state, free_mb from v$asm_disk where group_number=1;NAME HEADER_STATUS STATE FREE_MB---------- ------------------------ ---------------- ----------ASM1 MEMBER NORMAL 6987ASM2 MEMBER NORMAL 1859디스크 그룹 1번 asm3번이 삭제되었습니다.3. 디스크 그룹 추가 / 삭제

3.1 현재 디스크 그룹 내역 확인SYS/+ASM> select group_number, name, state from v$asm_diskgroup;GROUP_NUMBER NAME STATE------------ ---------- ----------------------1 DATA MOUNTED2 FRA MOUNTED
3.2 디스크 그룹 추가 - new_asm 으로SYS/+ASM> col path for a10SYS/+ASM> select name, path, state from v$asm_disk;NAME PATH STATE---------- ---------- ----------------ORCL:ASM3 NORMALASM1 ORCL:ASM1 NORMALASM2 ORCL:ASM2 NORMALFRA1 ORCL:FRA1 NORMALSYS/+ASM> create diskgroup new_asm external redundancy //디스크 그룹 추가2 disk 'ORCL:ASM3';Diskgroup created.SYS/+ASM> select group_number, name, state from v$asm_diskgroup;GROUP_NUMBER NAME STATE------------ ---------- ----------------------1 DATA MOUNTED2 FRA MOUNTED3 NEW_ASM MOUNTED4. Disk Group 마운트 / 언마운트SYS/+ASM> alter diskgroup new_asm dismount;Diskgroup altered.SYS/+ASM> select group_number, name, state from v$asm_diskgroup;GROUP_NUMBER NAME STATE------------ ---------- ----------------------1 DATA MOUNTED2 FRA MOUNTED0 NEW_ASM DISMOUNTEDSYS/+ASM> alter diskgroup new_asm mount;Diskgroup altered.SYS/+ASM> select group_number, name, state from v$asm_diskgroup;

GROUP_NUMBER NAME STATE------------ ---------- ----------------------1 DATA MOUNTED2 FRA MOUNTED3 NEW_ASM MOUNTED5. asmcmd[oracle@localhost ~]$ asmcmdASMCMD> helpasmcmd [-p] [command]The environment variables ORACLE_HOME and ORACLE_SID determine theinstance to which the program connects, and ASMCMD establishes abequeath connection to it, in the same manner as a SQLPLUS / ASSYSDBA. The user must be a member of the SYSDBA group.Specifying the -p option allows the current directory to be displayedin the command prompt, like so:ASMCMD [+DATAFILE/ORCL/CONTROLFILE] >[command] specifies one of the following commands, along with itsparameters.Type "help [command]" to get help on a specific ASMCMD command.commands:--------cd //디렉토리 변경du //사용 용량 확인find //특정 파일 찾기helplslsctlsdgmkaliasmkdirpwdrmrmaliasCP ----11g 부터 지원. OS <-> asm, asm <-> asm 파일 복사lsdsk---11g 부터 지원. ASM 디크스 헤더를 읽어서 요약 정보를 보여준다.remap--11g 부터 지원. ASM 디스크 장애시 다른 디스크로 remapping 시켜주고 기존 장애 디스크 unusable 로 변경

ALTER USER user_name IDENTIFIED BY new_password;alter user system account unlock;
stty erase ^H
source .bash_profile
SQL> alter user scott 2 identified by asd123;
User altered.
SQL> drop user scott cascade;
User dropped.
SQL> create user scott 2 identified by asd123;
User created.
SQL> grant connect, resource, dba to scott;
Grant succeeded.
[oracle@rac1 test]$ imp system/asd123 full=y file=NEW_SCOTT_10.DMP
Import: Release 11.2.0.1.0 - Production on Wed Aug 15 22:22:25 2012
Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved.
Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - ProductionWith the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP,

Data Mining and Real Application Testing o
Export file created by EXPORT:V10.02.01 via conventional pathimport done in US7ASCII character set and AL16UTF16 NCHAR character setimport server uses KO16MSWIN949 character set (possible charset conversion)export client uses KO16MSWIN949 character set (possible charset conversion). importing SYSTEM's objects into SYSTEM. importing SCOTT's objects into SCOTTIMP-00008: unrecognized statement in the export file: . . importing table "ACCOUNT" 28969 rows imported. . importing table "BIG_DEPT" 289 rows imported. . importing table "BIG_EMP" 28955 rows imported. . importing table "DEPT" 4 rows imported. . importing table "EMP" 14 rows imported. . importing table "LARGE_ACCOUNT" 460938 rows imported. . importing table "LARGE_DEPT" 289 rows imported. . importing table "LARGE_EMP" 1091410 rows imported. . importing table "PLAN_TABLE" 0 rows imported. . importing table "S_CHANGGO" 3 rows imported. . importing table "S_CHULHAJISI" 802095 rows imported. . importing table "S_GOGAEK" 378789 rows imported. . importing table "S_JAEGO" 274276 rows imported. . importing table "S_MAECHE" 140 rows imported. . importing table "S_PROMOTION" 1063 rows imported. . importing table "S_SANGPUM" 592 rows imported. . importing table "S_SPINOUT" 154673 rows imported. . importing table "S_SUJU" 827447 rows imported. . importing table "S_SUJU_DTL" 4136970 rows imported. . importing table "S_ZIPCODE" 49033 rows importedImport terminated successfully with warnings.
통계정보 기본값cardinality - num_of_blocks*(block_size-cache-layer)/avg_row_lenaverage row length - 100bytenumber of blocks - 100

levels - 1leaf blocks - 25leaf blocks /key - 1data blocks/key - 1distinct keys - 100cluster factor - 800(8* number of blocks)
SQL> show user USER is "SCOTT"SQL> SET SERVEROUTPUT ONSQL> ANALYZE TABLE BIG_EMP DELETE STATISTICS;
Table analyzed.
SQL> DECLARE 2 NUM_ROWS NUMBER; 3 NUM_BLOCKS NUMBER; 4 AVG_ROW_LEN NUMBER; 5 BEGIN 6 DBMS_STATS.GET_TABLE_STATS('SCOTT','BIG_EMP',NULL, NULL, NULL, NUM_ROWS, NUM_BLOCKS,AVG_ROW_LEN); 7 DBMS_OUTPUT.PUT_LINE('NUM_ROWS=' || NUM_ROWS ||',NUM_BLOCK='||NUM_BLOCKS||',AVG_ROW_LEN='||AVG_ROW_LEN); 8 END; 9 /DECLARE*ERROR at line 1:ORA-20000: Unable to get values for table BIG_EMPORA-06512: at "SYS.DBMS_STATS", line 5997ORA-06512: at "SYS.DBMS_STATS", line 6014ORA-06512: at line 6
SQL> SET SERVEROUTPUT ONSQL> SQL> DECLARE 2 NUM_ROWS NUMBER;

3 NUM_BLOCKS NUMBER; 4 AVG_ROW_LEN NUMBER; 5 BEGIN 6 DBMS_STATS.GET_TABLE_STATS('SCOTT','BIG_EMP',NULL, NULL, NULL, NUM_ROWS, NUM_BLOCKS,AVG_ROW_LEN); 7 DBMS_OUTPUT.PUT_LINE('NUM_ROWS=' || NUM_ROWS ||',NUM_BLOCK='||NUM_BLOCKS||',AVG_ROW_LEN='||AVG_ROW_LEN); 8 END; 9 /NUM_ROWS=28955,NUM_BLOCK=184,AVG_ROW_LEN=40
PL/SQL procedure successfully completed.
SQL> execute dbms_stats.create_stat_table('SCOTT','MY_STAT_20120815'); -> 통계정보를 저장할 테이블 생성
PL/SQL procedure successfully completed.
SQL> execute dbms_stats.export_schema_stats('SCOTT','MY_STAT_20120815'); -> scott 스키마 통계정보 백업
PL/SQL procedure successfully completed.
SQL> execute dbms_stats.delete_table_stats('SCOTT','BIG_EMP'); -> scott 테이블에 big_emp 컬럼의 통계정보를 삭제 한다
PL/SQL procedure successfully completed.
SQL> execute dbms_stats.import_table_stats('SCOTT','BIG_EMP',null,'MY_STAT_20120815'); -> 백업한 통계정보를 import 한다
PL/SQL procedure successfully completed.
dbms_stats 패키지를 통한 히스토그램의 수집execute dbms_stats.gather_table_stats ('SCOTT','EMP',METHOD_OPT =>'FOR COLUMNS SIZE 10 SAL');scott 사용자의 emp 테이블에 대해 통계정보를 수집. sal 컬럼의 값을 10 bucket 으로 나누고 histogram 을 수집한다.

execute dbms_stats.gather_schema_stats ('SCOTT', ESTIMATE_PERCENT => DBMS_STATS.AUTO_SAMPLE_SIZE);해당 테이블에 있는 일부 테이블을 이용하여 통계 정보를 수집할 때 사용하는 명령어
VARIABLE JOBNO NUMBER;
BEGINDBMS_JOB.SUBMIT(:JOBNO, 'DBMS_STATS.GATHER_TABLE_STATS(''SCOTT'',''BIG_EMP'');',SYSDATE, 'SYSDATE+1');COMMIT;END;/
PRINT JOBNO
EXECUTE DBMS_JOB.RUN(:JOBNO); -->예약 작업의 시작
SQL> EXECUTE DBMS_JOB.BROKEN(:JOBNO, FALSE); ->예약작업 취소
PL/SQL procedure successfully completed.
SQL> EXECUTE DBMS_JOB.REMOVE(:JOBNO); ->예약작업 삭제
PL/SQL procedure successfully completed.
EXECUTE DBMS_STATS.GATHER_DATABASE_STATS(OPTIONS=>'GATHER EMPTY');
DBMS_STAT 패키지의 OPTIONS 절의 유형(1) GATHER - 모든 통계정보를 생성(2) GATHER EMPTY - 통계정보가 수집되어 있지 않은 객체의 통계정보 만 수집(3) GATHER AUTO - 해당 조건으로 통계 정보를 자동 수집(4) LIST STALE - 현재 통계정보를 가지고 있는 객체들에 대한 목록을 생성(5) LIST EMPTY - 통계정보가 수집되어 있지 않은 객체에 대한 목록을 생성