161218 cybozu sre
TRANSCRIPT

サイボウズの SRE
サイボウズ株式会社 運用本部 サービス運用部 SRE齊藤 倫德

SRE とは?
▌Site Reliability Engineer▌サイトの信頼性を向上させるソフトウェアエンジニア
/ チーム
▌Google が提唱して、様々な企業が取り入れている日本では以下など: インフラチーム改め Site Reliability Engineering (SRE) チームになりました - Mercari Engineering Blog http://tech.mercari.com/entry/2015/11/18/153421

サイボウズの SRE
▌ SRE チームを設立します - Cybozu Inside Out | サイボウズエンジニアのブログ
▌ http://blog.cybozu.io/entry/2016/09/01/080000
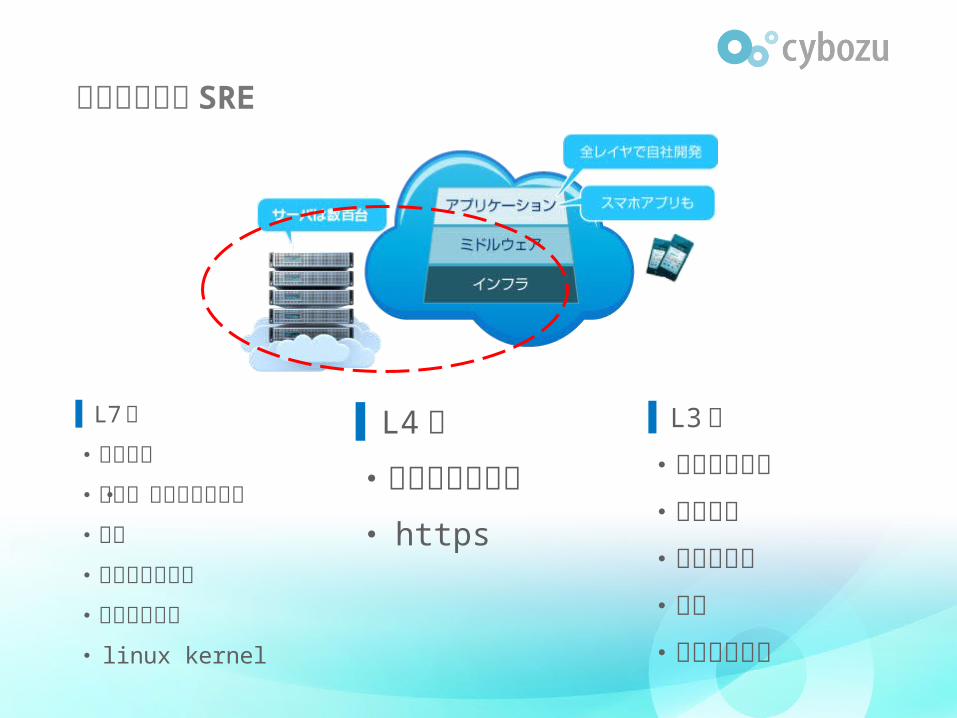
サイボウズの SRE
▌ L7〜
・デプロイ
・監視・メトリクス収集
・障害
・インフラツール
・ミドルウェア
・ linux kernel
▌L3〜・ルーティング
・スイッチ
・物理サーバ
・回線
・データセンタ
▌L4〜・ロードバランス
・ https
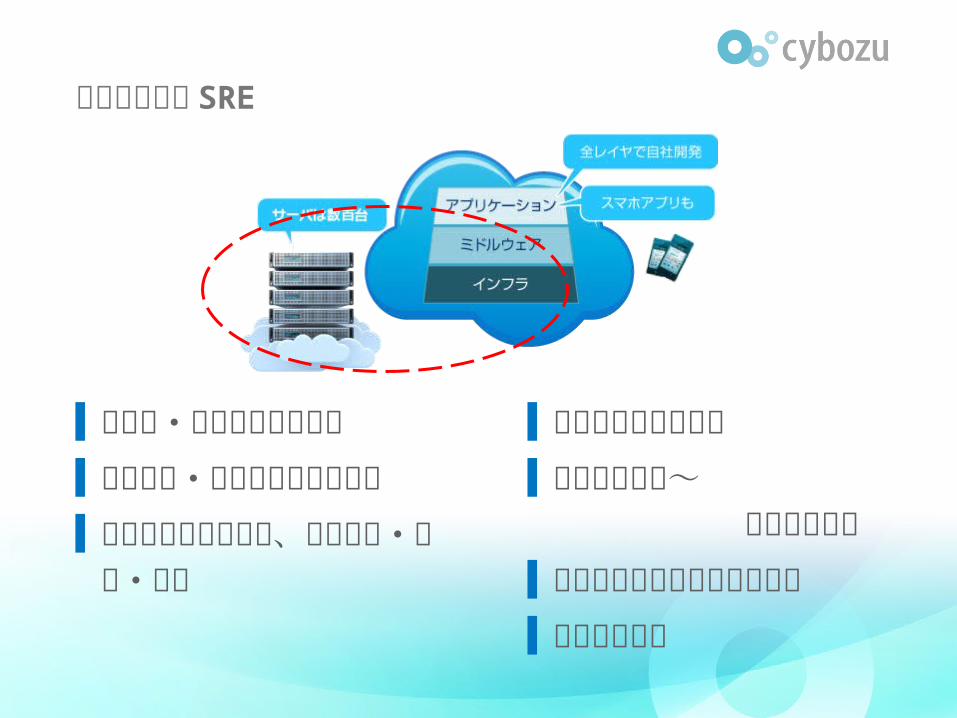
サイボウズの SRE
▌信頼性・可用性の維持向上
▌ログ収集・分析基盤の構築運用
▌需要予測に基づいて、機材増強・入替・構築
▌セキュリティの担保
▌緊急警告対応~ 根本対処まで
▌アプリケーションのデプロイ
▌調査依頼など
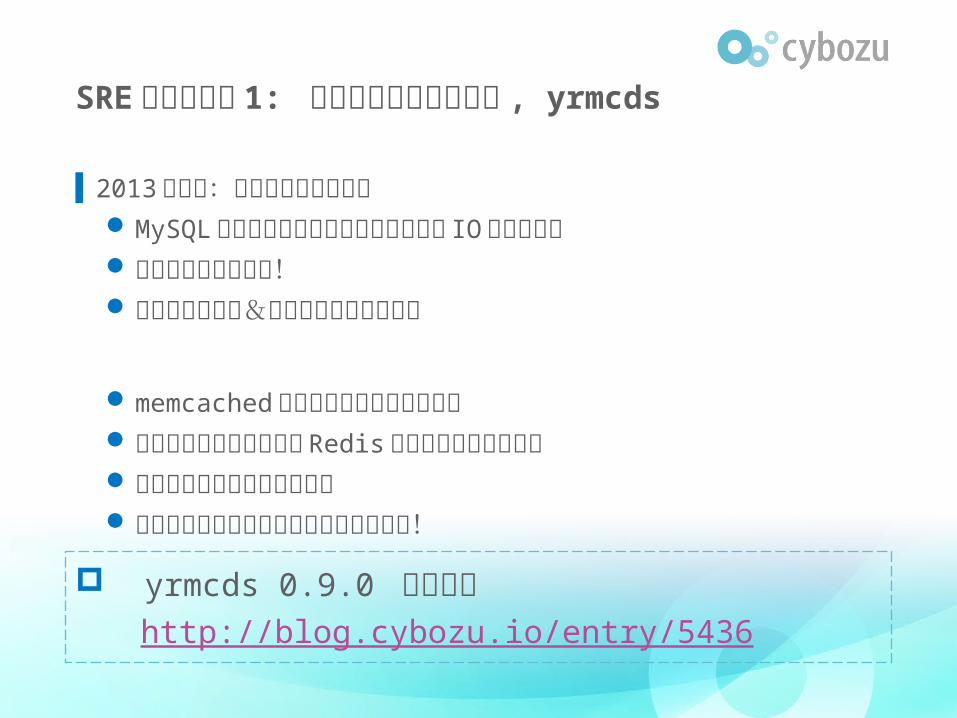
SRE の取り組み 1: セッションキャッシュ , yrmcds
▌2013 年ごろ:お客様が増えてきた MySQL にセッション入れてたけど遅いし IO 負荷すごい オンメモリ化しよう! 耐障害性ほしい&低コストで運用したい
memcached はレプリケーションがない レプリケーションがある Redis とかは運用が大変そう プロトコル簡単だし作ろう。 せっかくだからオープンソースにしよう!
yrmcds 0.9.0 リリース http://blog.cybozu.io/entry/5436

SRE の取り組み 2: DoS 対策 , yrmcds
▌2014 年ごろ:お客様がよくキーボードの上に本を落とすよ! F5 だよ!同時アクセス数を制限しよう作った yrmcds でカウントしよう!
nginx の拡張モジュールを書いて DoS 対策をした http://blog.cybozu.io/entry/8363
yrmcds 1.1.1 + libyrmcds 1.2.0 をリリースしました http://blog.cybozu.io/entry/8453

SRE の取り組み 3: オープンソース化 , golang, cybozu-go
▌最近では Go を採用していて、 Go 系のオープンソースも公開
Go でいい感じのコマンドを作れるツールキットの紹介 http://blog.cybozu.io/entry/cybozu-go-cmd
Cybozu Go · GitHub https://github.com/cybozu-go/

SRE の取り組み 4: データ移行 , gosyncd
▌新システムへのデータ移行のやり方の一つ: 初期同期:バックアップ・スナップショットから新環境にコ
ピー 差分同期:変更されたファイルを監視して新環境にコピー
▌通常運用負荷に同期負荷が乗るので障害になりやすい 同期速度で負荷をコントロール ファイルキャッシュを汚さない
gosyncd - 安定して、データ移行を行うためのツール

SRE の取り組み 5: 透過 SOCKS プロキシ
▌NAT -> 透過 SOCKS プロキシに切り替え
▌メール周りの障害が少なくなり、調査がぐっとやりやすく!SPAM フィルタ問題 tcp_tw_recycle 問題
NAT をやめて、透過 SOCKS プロキシを導入した
http://blog.cybozu.io/entry/2016/03/14/130000
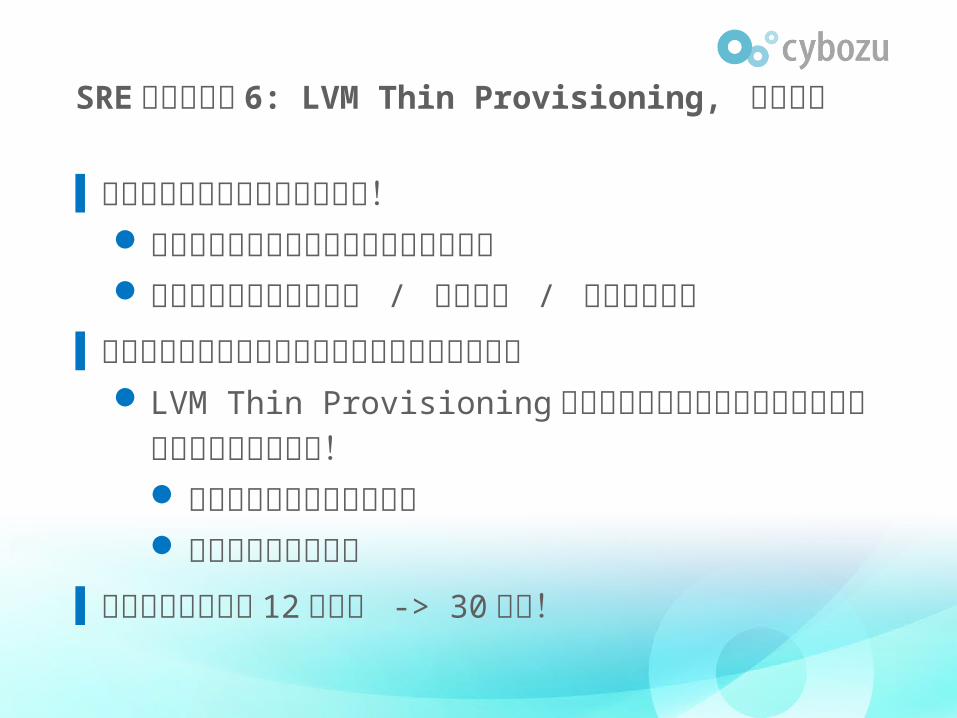
SRE の取り組み 6: LVM Thin Provisioning, リストア
▌バックアップのリストアが遅い!毎月の全環境のアップデートリハーサルバックアップベリファイ / 障害調査 / リストア
依頼
▌リストア時にブロック差分を都度マージしていたLVM Thin Provisioning を導入してスナップ
ショットの形でバックアップしよう! スナップショットとり放題 いつでもすぐ使える
▌全環境リストアは 12 時間強 -> 30 分に!

SRE の取り組み 7: WalB
▌現在のバックアップ形式:日次スナップショットからブロックデバイス単位でバイナリ差分を取得 バックアップ取得負荷がきつい。
▌常に取り続けられるように!書き込まれる都度にバックアップ! サイボウズ・ラボの星野・光成が開発して、 SRE
と一緒に導入 WalB v1.0 リリース
http://blog.cybozu.io/entry/5130

SRE の取り組み 8: Zabbix, Datadog
▌サービスインより、メトリクス監視は Zabbix で運用
▌現在は自社 DC も複数サイト運用し、監視対象は1000台を越える2-3 年後にはさらに 2倍の規模も見えてくる
▌さすがに Zabbix では辛いので、よりよい監視の導入を検討
Cloud Monitoring as a Service | Datadog https://www.datadoghq.com/
SRE の取り組み 9: artifactory
▌Subversion での管理 -> JFrog Artifactory の導入
▌apt や Python などのレポジトリとして透過的に扱えるように!
アーティファクトの管理について、あるいは go-apt-cacher / go-apt-mirror の紹介 http://blog.cybozu.io/entry/2016/07/19/103000
Artifactory - Universal Artifact Repository Manager https://www.jfrog.com/artifactory/

SRE の取り組み 10: その他
▌presto(hadoop) アクセスログの基盤として先行投入 1 日分の集計に 13 時間 -> 20秒に! アプリケーションログ・ syslog などの収集・分析基盤も導入検討中
▌可視化! ggplot2 で Web サーバのレスポンスタイムをざっくり可視化す
る方法 http://blog.cybozu.io/entry/8039
▌現在 Ubuntu 16.04 への移行作業中 upstart から systemd へ
▌NVMe SSD の導入高速化: MySQL / ElasticSearch
▌Graylogネットワークスイッチのログ収集
▌DC 運用cybozu.com のラック設計
http://blog.cybozu.io/entry/6766▌AS 運用
131912 CYBOZU JP00137545https://www.nic.ad.jp/ja/ip/as-numbers.txt
SRE の取り組み 11: その他

SRE チームを作ったわけ
▌サービスイン当初は全員で運用も開発もしていた。
▌規模が大きくなるにつれ、障害対応や調査、特殊な対応など、優先度の高い割り込みが増加 集中して開発できない
Dev と Ops を分割
→ しばらくはうまくいっていたが…

Dev と Ops チームの間で問題が…
▌Ops チームの開発スキルが上がらない!最初は Ops メンバーもコードを書いていた新メンバーも増えるにつれ、徐々に開発が少なく
▌Dev チームの作ったシステムの移行・運用コストが高すぎる!ある日のデプロイから突然始まる、計画外の三ヶ
月間の 巨大オペレーションプロジェクト… ( とても良い機能だけど… )

SRE チームに統合!
▌Dev/Ops に分かれるのをやめて、役割を固定しすぎないように。
▌ソフトウェアエンジニアに立ち戻る!

現在の課題
▌アーキテクチャが古くなっている サービスイン当初から基本的に変わってない ストレージまわりが特にやばい! 刷新する人手が足りない (>_<)
▌若手の教育 プログラミング初心者もいるので、底上げが必要

SRE でやりたいこと!
▌ログ収集・分析基盤
▌検索基盤
▌デプロイ
▌サービスディスカバリ
▌リソースプール
アーキテクチャ刷新プロジェクト「Neco」 の概要 http://blog.cybozu.io/entry/2016/03/11/080000
▌分散基盤
▌より簡易なオペレーション
▌リソースの統合監視
▌キャパシティプランニング

▌懇親会にも出ますので、お気軽にお声がけください!