4. analytics 도구¹…데이터1031_6x9_9p... · weka는 마이닝 알고리즘을 모아놓은...
TRANSCRIPT

4. Analytics 도구
(1) 상용 분석도구
빅데이터 기술 이전부터 다양한 분석도구가 상용으로 제시되어 왔다. 주요한 것은 다음과 같다.
MS Excel:
SAS:
SPSS Modeler: 원래는 SPSS Clementine이었으나 IBM 인수.
Statistica: StatSoft사의 개발제품.
Mathematica
그 밖에도 Salford Systems, KXEN, Angoss 등과 수학분석에 많이 사용되는 MATLAB, Strata 등도
많이 사용된다.
(2) 오픈소스
가. R1
R 은 원래 1970 년대의 S 라는 통계프로그램에 기반하여 개발되었다. S 는 AT&T 에서 개발되어
Insightful Corporation 라는 회사에 라이선스 제공되었는데 이를 참조하여 뉴질랜드의 Ihaka 등이
1990 년대에 R 을 개발하였다. GPL 라이선스 조건을 가지는 공개 소프트웨어로서 다음과 같은 영역에서
장점을 가진다.
데이터 처리, 문자 및 수치 계산 등이 효율적이다.
행렬식 등 처리와 hash 테이블, 정규식 표현 등 기능이 풍부하다.
데이터 분석, 통계 함수 등이 풍부하다.
개발 초기부터 그래픽 기능이 뛰어나다.
프로그래밍 언어로 동작이 가능하다.
단, 올바른 사용을 위해 R 에 대해 다음을 유의할 필요가 있다.
R은 데이터베이스는 아니다. 단, DBMS에 연결은 가능하다.
원래 명령어 방식이다. 최근 일부 GUI 가 제시되고 있다. (R Studio와 Java, Tcl/Tk 등)
1 R 의 기본사용법에 대해서는 본서의 부록을 참조할 것.
한편 R 의 공식 사이트는: http://cran.r-project.org/

2
모든 계산이 메인메모리에서 진행되므로 메모리관리에 유의할 것.
스프레드 쉬트로 사용할 수는 없으나 Excel 등 연계는 가능하다.
무엇보다도 CRAN (Comprehensive R Archive Network)에서 패키지를 고를 수 있고 이를 통해 기능의
확장이 가능하다. 절차적 프로그래밍 언어로서 일반적으로 명령어 방식을 이용하지만 R Studio 가
이용가능하고 Eclipse 에 plugin 방식으로2 이용할 수도 있다.
나. WEKA
WEKA 는 마이닝 알고리즘을 모아놓은 인기있는 프로그램이다. 오픈소스 로서 java 기반이며 다음의
곳에서 다운로드 받을 수도 있고 많은 기술문서도 제공된다. http://www.cs.waikato.ac.nz/ml/weka/
다. 기타의 프로젝트
Storm & Kafka
Storm 과 Kafka 는 스트림 처리기술로서 많은 기업에서 활용하고 있다. 이들은 메모리 기반의 (in-
memory) 실시간 의사결정 지원시스템으로서 Hadoop 이 가지는 배치처리의 한계를 극복하게 해 준다.
Storm 은 Twitter 에서 개발한 “분산형 실시간 연산시스템”으로서 Hadoop 에서 batch 처리를 했던데
반해 이를 실시간 처리하게 해준다.
Kafka 는 LinkedIn 에서 개발한 메시징 시스템으로서 활동 스트림 (activity stream)과 그 배후의 데이터
처리 파이프라인 (data processing pipeline)의 기반기술로 작용한다.
Drill & Dremel
Drill 과 Dremel 은 대규모, ad-hoc query 를 하면서도 시간지체가 거의 없어서 특히 데이터의 탐색에
유용하다. 초당 petabyte 규모의 데이터를 스캔할 수도 있어서 ad hoc query 는 물론 시각화 작업에도
유용하고 현업분석자도 많이 사용하고 있다. Drill 은 Google 의 Dremel 에 해당하는 오픈소스 솔루션이다.
(Google 은 이미 BigQuery 라는 이름으로 Dremel-as-a-Service 를 제공하고 있다).
Drill 과 Dremel 모두 Hadoop 에 친화적이어서 MapReduce 와의 연계가 쉬우며 Sawzall, Pig 그리고
Hive 에 이르기까지 Hadoop 위에서 동작할 수 있도록 많은 인터페이스가 개발되어 있다.
라. R과 MapReduce의 통합
R 과 Hadoop 의 통합은 여러 가지 형태로 시도되고 이용되고 있는데 여기서는 특히 가장 많이 이용되는
3 가지를 선정하여 소개한다.
2 http://www.walware.de/goto/statet
3
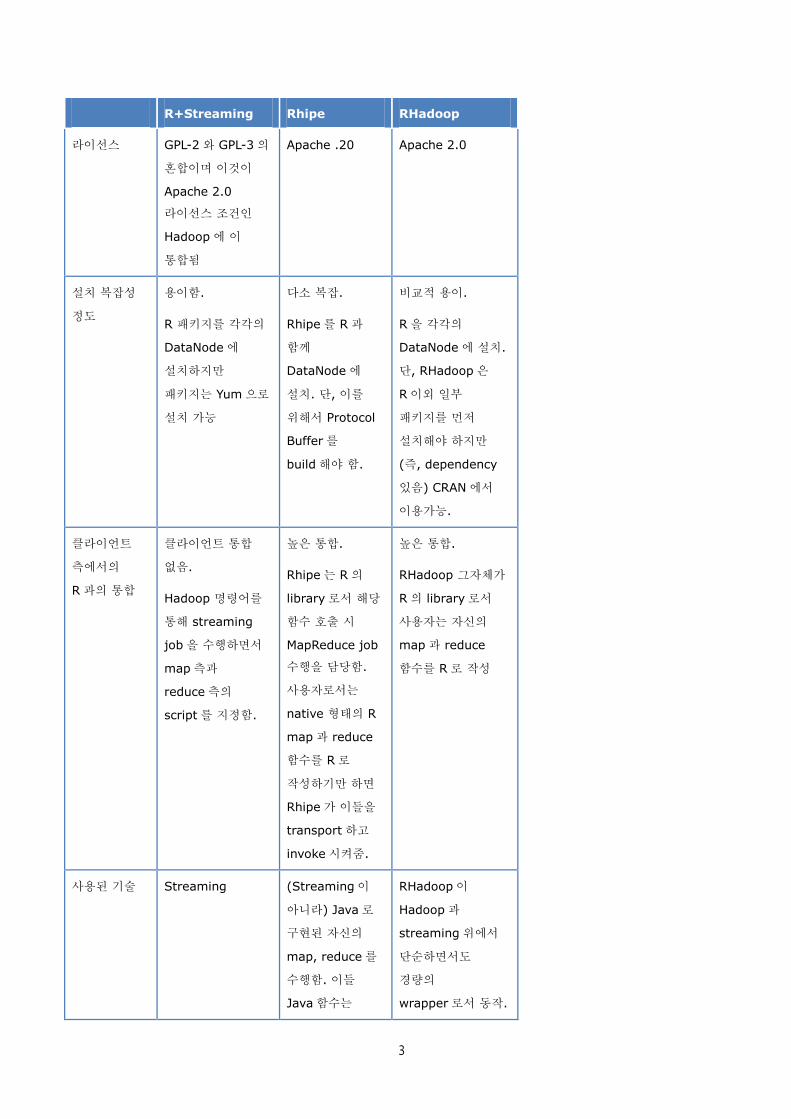
R+Streaming Rhipe RHadoop
라이선스 GPL-2 와 GPL-3 의
혼합이며 이것이
Apache 2.0
라이선스 조건인
Hadoop 에 이
통합됨
Apache .20 Apache 2.0
설치 복잡성
정도
용이함.
R 패키지를 각각의
DataNode 에
설치하지만
패키지는 Yum 으로
설치 가능
다소 복잡.
Rhipe 를 R 과
함께
DataNode 에
설치. 단, 이를
위해서 Protocol
Buffer 를
build 해야 함.
비교적 용이.
R 을 각각의
DataNode 에 설치.
단, RHadoop 은
R 이외 일부
패키지를 먼저
설치해야 하지만
(즉, dependency
있음) CRAN 에서
이용가능.
클라이언트
측에서의
R 과의 통합
클라이언트 통합
없음.
Hadoop 명령어를
통해 streaming
job 을 수행하면서
map 측과
reduce 측의
script 를 지정함.
높은 통합.
Rhipe 는 R 의
library 로서 해당
함수 호출 시
MapReduce job
수행을 담당함.
사용자로서는
native 형태의 R
map 과 reduce
함수를 R 로
작성하기만 하면
Rhipe 가 이들을
transport 하고
invoke 시켜줌.
높은 통합.
RHadoop 그자체가
R 의 library 로서
사용자는 자신의
map 과 reduce
함수를 R 로 작성
사용된 기술 Streaming (Streaming 이
아니라) Java 로
구현된 자신의
map, reduce 를
수행함. 이들
Java 함수는
RHadoop 이
Hadoop 과
streaming 위에서
단순하면서도
경량의
wrapper 로서 동작.
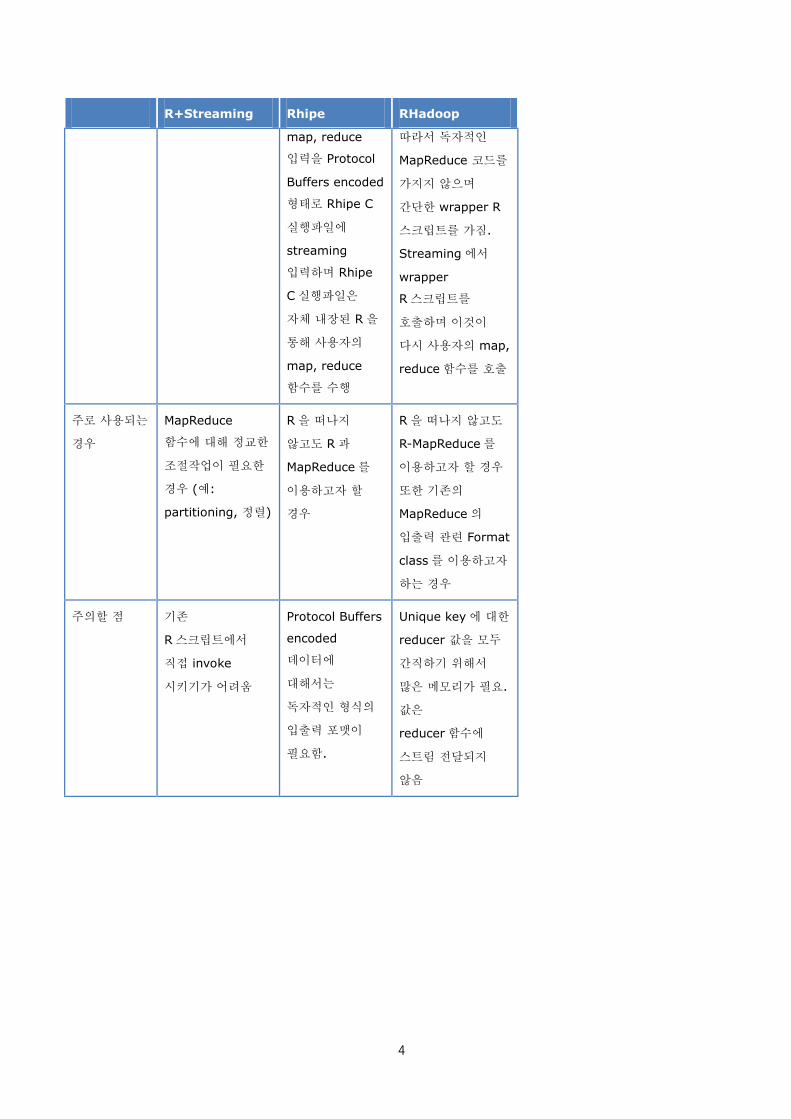
4
R+Streaming Rhipe RHadoop
map, reduce
입력을 Protocol
Buffers encoded
형태로 Rhipe C
실행파일에
streaming
입력하며 Rhipe
C 실행파일은
자체 내장된 R 을
통해 사용자의
map, reduce
함수를 수행
따라서 독자적인
MapReduce 코드를
가지지 않으며
간단한 wrapper R
스크립트를 가짐.
Streaming 에서
wrapper
R 스크립트를
호출하며 이것이
다시 사용자의 map,
reduce 함수를 호출
주로 사용되는
경우
MapReduce
함수에 대해 정교한
조절작업이 필요한
경우 (예:
partitioning, 정렬)
R 을 떠나지
않고도 R 과
MapReduce 를
이용하고자 할
경우
R 을 떠나지 않고도
R-MapReduce 를
이용하고자 할 경우
또한 기존의
MapReduce 의
입출력 관련 Format
class 를 이용하고자
하는 경우
주의할 점 기존
R 스크립트에서
직접 invoke
시키기가 어려움
Protocol Buffers
encoded
데이터에
대해서는
독자적인 형식의
입출력 포맷이
필요함.
Unique key 에 대한
reducer 값을 모두
간직하기 위해서
많은 메모리가 필요.
값은
reducer 함수에
스트림 전달되지
않음

5
IV. 빅 데이터 분석의 실제 예
1. Mahout3를 이용한 군집 분석
(1) 개요
가. Mahout 프로젝트의 배경
Mahout 는 Apache 프로젝트의 한 분과로 진행되고 있는 기계학습용 Java 라이브러리이다.
기계학습이란4 요컨대 '대상 데이터에 대해 컴퓨터가 알아서 분석할 수 있도록 로직을 구성하는 것'을
말하는데 그간 이런 기능이 데이터마이닝 솔루션들로 구현되어 이미 활발히 사용되고 있었다. 그러다가 최근
Hadoop 의 MapReduce 프레임워크 활용을 전제로 한 기계학습 프로그램으로 Mahout 가 개발되어 인기를
끌고 있다.
Mahout 는 Lucene 프로젝트가 모태가 되어 시작되었다. 텍스트 검색 및 텍스트 처리 프로젝트인
Lucene 에서 텍스트 마이닝 관련된 프로그램이 꾸준히 축적되었고 2008 년 이를 Mahout 프로젝트로
독립시키게 된 것이다. 그리고 별도 프로젝트로 독립한 초기에 Mahout 는 Taste 라는 별도의 기계학습용
프로그램도 흡수하여 짧은 시간 내에 도약의 계기를 맞이했다. 아래 그림에서 Mahout 와 관련된 각종
프로젝트가 그림으로 표현되어 있다.
무엇보다 중요한 것은 Mahout 가 데이터 마이닝 알고리즘 몇 가지를 구현했다는 것 외에도 이들을
구현함에 있어 Hadoop 의 MapReduce 프레임워크와 결합을 이루었다는 것이다. 수학 계산이 많은
마이닝은 고성능 컴퓨터의 큰 메모리와 연산기능을 요구하지만 Mahout 는 최대한 MapReduce 기능을
활용하여 빅 데이터 분석이 보다 용이해졌다.
3 Mahout 는 흔히 '머하우트'라고 발음한다.
4 앞서 기계학습을 “인공지능의 한 영역으로서 사람이 아닌 컴퓨터가 학습할 수 있도록 알고리즘을 연구 및 분석, 개발하는
기술”로 정의한 바 있다.

6
나. Mahout의 설치
Mahout 도 다른 Java 응용프로그램 설치와 마찬가지로 JVM 위에서 동작하므로 이에 대한 환경구축이
우선 이루어져야 한다. 그리고 이 위에 Maven 의 추가 설치가 필요하다. 이는 Mahout 가 현재 활발히 개발
진행 중이어서 update 와 upgrade 가 빈번하므로 이들 관리를 자동화하기 위한 것이다. 즉, 라이브러리
의존관계 및 컴파일 관리를 Maven 라는 build 및 release 관리 프로그램을 통해 실시한다.
또 다른 요건으로는 Mahout 는 특히 Hadoop 의 MapReduce 분산처리 기능의 활용을 전제로 하므로
Mahout 의 운영을 위해서는 Hadoop 을 설치하여야 한다. 아울러 프로그램의 개발 및 수정을 위한
개발환경5을 선택한다. 즉, 선택한 IDE 내에서 Mahout 프로젝트를 생성하는 방식으로 Mahout 를 설치한다.
다. Mahout가 제공하는 기능
Mahout 는 그 어떤 프로젝트 못지않게 활발히 개발진행 중이며 속속 새로운 기능들이 추가되고 있으므로
해당 프로젝트 현황을 홈페이지를 통해 확인할 필요가 있다. 2013 년 7 월 현재6 Mahout 는 다음과 같은
기능을 제공한다.
Collaborative Filtering
추천 서비스 – 예: Amazon의 구매이력 분석에 따른 책 추천.
군집화 (clustering)
K-Means,
Fuzzy K-Means
Mean Shift clustering
Dirichlet process clustering
LDA (Latent Dirichlet Allocation)
빈발패턴 마이닝
분류 (Classification)
Naive Bayes 분류기
Random forest 의사결정트리 분류기
여기서는 Mahout 의 군집화에 대해서만 살펴 본다. 이외의 기능에 대해서는 Mahout 프로젝트 사이트
(mahout.apache.org)를 참조.
5 Eclipse, NetBeans 등을 개인의 취향에 따라 선택.
6 version 0.7

7
(2) Mahout에서의 군집화 기능7
가. 첫 시도: 단순 좌표데이터의 군집화 사례
군집화 구현에서 중요한 것은 무엇보다 각 항목간의 유사성과 이질성을 어떻게 판단하고 이를 어떻게
프로그램에 표현할 것인가의 문제라 하겠다.
또 한편, 앞서 우리는 여러가지 군집화 관련 접근법을 살펴 본 바 있는데 Mahout 에서 이용하는 구체적
알고리즘 중 여기서는 특히 대표적인 알고리즘의 하나인 k-means 를 이용하기로 한다.
k-means
fuzzy k-means
canopy
기타
단순한 예를 통해 Mahout 이용방법을 살펴 본다. 다음과 같이 x-y 좌표계 상의 점으로 표현되는 9 개의
점(point)데이타가 주어졌다고 하자.
다음 페이지의 도표에 해당 9 개 점 데이터가 제시되었고 오른편에서 이를 x-y 좌표면에 표시하였다.
이제 이들 9 개 점을 Mahout 를 이용하여 2 개 그룹으로 군집화하려는 것이 여기서의 작업내용이다. 우선
이들 각 점 데이터를 프로그램에 입력하기 위해서는 이진의 벡터 포맷을 SequenceFile 로 표현한다.
(x 좌표, y
좌표)
(1,1)
(2,1)
(1,2)
(2,2)
(3,3)
(8,8)
(8,9)
(9,8)
(9,9)
7 Mahout를 이용한 군집화 사례에 대한 설명은 Sean Owen (외), Mahout
In Action, 2012의 해당부분을 인용 및 수정하였다.

8
흔히 벡터(vector)란 '크기와 방향을 동시에 나타내는 물리량'을 뜻하지만 Mahout 에서는 각 데이터의
수치정보를 ordered list 의 형태로 표현한 것을 의미한다. 특히 단순한 예제에서는 이를 2 차원 좌표상의
점에 대한 데이터를 ordered list 로 표현한 것으로 볼 수 있겠다.
먼저 k-means 알고리즘에 필요한 함수에 다음 파라미터를 지정한다.
SequenceFile: 입력할 벡터 정보와, 군집별 중심에 대한 정보를 초기화한다.
유사도 평가에 대한 척도. 유사도 평가로서의 다양한 거리 개념에 대해 앞서 살펴본 바 있다.
EuclideanDistanceMeasure의 경우 Euclide 거리를 적용할 때 사용된다.
convergenceThreshold : 초기화된 정보를 출발점으로 군집화 작업이 반복적으로 진행되는데 이러한
반복작업을 계속할지 여부에 대한 판단기준을 나타낸다.
입력데이터에 대한 Vector 정보
이들 정보를 가지고 다음의 순서로 군집화 작업을 수행한다.
입력 데이터
Vectorizatoin
· 입력데이터를 vector형태로 변환
· Vector를 해당 위치에 기록
중심부 초기화
· 목표 군집 (grouping)의 중심위치를 지정
군집화 (clustering)
작업을 반복수행
출력디렉토리서 작업결과를 획득
이제 이 작업을 수행하는 Java 프로그램이 다음과 같이 제시되어 있다.
public class MahoutClusterFirst {
public static final double[][] points
={{1,1},{2,1},{1,2},{2,2},{3,3},{8,8},{9,8},{8,9},{9,9}};
public static void writePointsToFile(List<Vector> points,
String fileName,
FileSystem fs,
Configuration conf) throws IOException {
Path path = new Path(fileName);
SequenceFile.Writer writer
= new SequenceFile.Writer(fs, conf,
path, LongWritable.class, VectorWritable.class);
long recNum = 0;
VectorWritable vec = new VectorWritable();
for (Vector point : points) {
vec.set(point);
writer.append(new LongWritable(recNum++), vec);
}
writer.close();
}
public static List<Vector> getPoints(double[][] raw) {
List<Vector> points = new ArrayList<Vector>();
for (int i = 0; i < raw.length; i++) {
double[] fr = raw[i];

9
Vector vec = new RandomAccessSparseVector(fr.length);
vec.assign(fr);
points.add(vec);
}
return points;
}
public static void main(String args[]) throws Exception {
int k = 2;
List<Vector> vectors = getPoints(points);
File testData = new File("testdata");
if (!testData.exists()) {
testData.mkdir();
}
testData = new File("testdata/points");
if (!testData.exists()) {
testData.mkdir();
}
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
writePointsToFile(vectors,"testdata/points/file1",fs,conf);
Path path = new Path("testdata/clusters/part-00000");
SequenceFile.Writer writer = new SequenceFile.Writer(
fs, conf, path, Text.class, Cluster.class);
for (int i = 0; i < k; i++) {
Vector vec = vectors.get(i);
Cluster cluster = new Cluster(
vec, i, new EuclideanDistanceMeasure());
writer.append(new Text(cluster.getIdentifier()),
cluster);
}
writer.close();
KMeansDriver.run(conf, new Path("testdata/points"),
new Path("testdata/clusters"),
new Path("output"),
new EuclideanDistanceMeasure(),
0.001, 10, true, false);
SequenceFile.Reader reader = new SequenceFile.Reader(fs,
new Path("output/" + Cluster.CLUSTERED_POINTS_DIR
+ "/part-m-00000"), conf);
IntWritable key = new IntWritable();
WeightedVectorWritable value
= new WeightedVectorWritable();
while (reader.next(key, value)) {
System.out.println(
value.toString() + " belongs to cluster "
+ key.toString());
}
reader.close();
}}
위 프로그램에서는 주어진 데이터를 2 개의 그룹으로 나누기 위한 군집화 작업의 출발점으로 (1,1)과
(2,1)의 2 개 점을 지정하였는데 그 수행에 따른 산출물이 다음에 표시되어 있다.

10
1.0: [1.000, 1.000] belongs to cluster 0
1.0: [2.000, 1.000] belongs to cluster 0
1.0: [1.000, 2.000] belongs to cluster 0
1.0: [2.000, 2.000] belongs to cluster 0
1.0: [3.000, 3.000] belongs to cluster 0
1.0: [8.000, 8.000] belongs to cluster 1
1.0: [9.000, 8.000] belongs to cluster 1
1.0: [8.000, 9.000] belongs to cluster 1
즉, 맨 처음 입력되었던 9 개의 점들이 좌표데이터에 따라 cluster-0 와 cluster-1 의 2 개 그룹으로
군집화되었음을 알 수 있다.
앞서 보았듯8 거리개념에는 여러가지가 있어서 상황에 따라 선택하게 되는데 Mahout 라이브러리에서도
EucliideanDistanceMeasure 외에 다음의 다양한 거리척도가 제공되고 있다.
SquredEucliideanDistanceMeasure
ManhattanDistanceMeasure
CosineDistanceMeasure
TanimotoDistanceMeasure
WeightedDistanceMeasure
이들 각각의 내용은 그 이름으로 쉽게 눈치챌 수 있고 각 거리척도에 대한 설명이 이 책 앞 부분에
있으므로 주요 거리척도 적용을 그림으로 표현한 것을 제시하는 것으로 대신한다.
8 III.분석기법 ▶ 3. 주요분석기법 ▶ (5) 군집이론 ▶ (나) 구간척도

11
위 그림 중 왼쪽에서 Euclid 거리와 Manhattan 거리 계산을 비교하고 있다. 오른쪽에서는 cosine 각도에
의한 거리 계산방식을 보여주고 있다.
한편 우리가 살펴본 9 개의 점에 대한 좌표데이터에 위의 서로 다른 거리척도를 적용한 결과가 다음과
같다.
거리척도 반복작업
회수
0 번 군집에
속하는 vector
1 번 군집에
속하는 vector
EucliideanDistanceMeasure 3 0,1,2,3,4 5,6,7,8
SquredEucliideanDistanceMeasure 5 0,1,2,3,4 5,6,7,8
ManhattanDistanceMeasure 3 0,1,2,3,4 5,6,7,8
CosineDistanceMeasure 1 1 0,2,3,4,
5,6,7,8
TanimotoDistanceMeasure 3 0,1,2,3,4 5,6,7,8
위 결과를보면 각각 반복 회수도 다르고 결과 또한 차이가 있음을 알 수 있다. 이는 각 거리척도의 절대적
우열 때문이라기 보다 적용 분야에 따라 고유한 특성을 가지는 것으로 볼 수 있을 것이다.
나. 둘째 시도: 이미지 패턴의 군집화 사례
실제의 군집화 작업에서는 앞서 좌표데이터와 같이 입력데이터가 단순한 형태로 주어지지 않으므로
분석대상이 되는 객체의 데이터를 올바르게 vector 데이터로 변환하는 작업이 선행되어야 한다.
Mahout 에서는 다음 3 가지 class 를 통해 vector 데이터를 표현한다.
DenseVector: vector 데이터를 double 데이터 타입의 배열의 형태로 표현하는 class이다.
RandomAccessSparseVector: HashMap으로 구현된 random access 용의 sparse vector이다.
SequentialAccessSparseVector: 순차작업 용 vector이다.
이들 중 어떤 클래스를 이용해서 분석 대상이 되는 객체데이터를 vector 로 표현할 것인가는 적용
알고리즘에 따라 달라진다. Mahout 에서는 vector 를 Java 의 interface 형태로 제공하고 있는데 특히 관련
vector 데이터 중 빈 항목이 많은 경우 - 즉, sparse 인 경우 - 이를 sparse vector 라 하고 대부분의

12
vector 데이터가 실 데이터로 채워진 경우를 dense vector 라고 한다. Mahout 에는 이 밖에도 매우 다양한
vector 연산을 할 수 있도록 class 지정이 되어 있다.
이제 또 하나의 예제로서 사과를 분류하는 예를 살펴본다. 사과를 분류할 때는 우선 크기, 색깔, 무게 등의
어떤 분류기준을 적용할 것인지 정해야 한다. 물론 측정만 가능하다면 그 어떤 것이든 분류기준으로 삼을 수
있고 이들 여러가지를 가중치 적용하여 종합적 판단도 가능하다. 편의상 우리는 다음과 같이 아래 표와 같이
무게 (Kg 단위), 색깔 (녹색, 빨강, 노랑), 크기 (Small, Large, Medium)가 제각각 다른 5 개의 사과가
주어졌다고 하자.
사과 무게 (Kg) 색깔(RGB) 크기 Vector
분석대상 0 차원 1 차원 2 차원 데이터 표현
Small,round, green 0.11 510 1 [0.11,
510,1]
Large, oval, red 0.23 650 3 [0.23,
650,3]
Small,elongated,
red
0.09 630 1 [0.09,630,1]
Large, round, yellow 0.25 590 3 [0.25,590,3]
Medium, Oval,
green
0.18 520 2 [0.18,520,2]
Mahout 에서 이들 데이터의 vector 표현은 이들 속성데이터를 각각 하나의 차원으로 표현하는데 위 표의
제일 마지막 열에 표시되어 있다. 이제 사과를 분류하기 위한 vector 생성 프로그램은 다음과 같다.
public class MahoutClsterSecond {
public class MahoutClusterFirst {
public static final double[][] points
= {{1, 1}, {2, 1}, {1, 2},
{2, 2}, {3, 3}, {8, 8}, {9, 8}, {8, 9}, {9, 9}};
public static void writePointsToFile(List<Vector> points,
String fileName,
FileSystem fs,
Configuration conf) throws IOException {
Path path = new Path(fileName);
SequenceFile.Writer writer
=new SequenceFile.Writer(fs, conf, path,
LongWritable.class,
VectorWritable.class);
long recNum = 0;
VectorWritable vec = new VectorWritable();
for (Vector point : points) {
vec.set(point);
writer.append(new LongWritable(recNum++), vec);
}
writer.close();

13
}
public static List<Vector> getPoints(double[][] raw) {
List<Vector> points = new ArrayList<Vector>();
for (int i = 0; i < raw.length; i++) {
double[] fr = raw[i];
Vector vec=new RandomAccessSparseVector(fr.length);
vec.assign(fr);
points.add(vec);
}
return points;
}
public static void main(String args[]) throws Exception {
int k = 2;
List<Vector> vectors = getPoints(points);
File testData = new File("testdata");
if (!testData.exists()) {
testData.mkdir();
}
testData = new File("testdata/points");
if (!testData.exists()) {
testData.mkdir();
}
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
writePointsToFile(vectors,
"testdata/points/file1", fs, conf);
Path path = new Path("testdata/clusters/part-00000");
SequenceFile.Writer writer = new SequenceFile.Writer(
fs, conf, path, Text.class, Cluster.class);
for (int i = 0; i < k; i++) {
Vector vec = vectors.get(i);
Cluster cluster = new Cluster(
vec, i, new EuclideanDistanceMeasure());
writer.append(new Text(cluster.getIdentifier()),
cluster);
}
writer.close();
KMeansDriver.run(conf, new Path("testdata/points"),
new Path("testdata/clusters"),
new Path("output"),
new EuclideanDistanceMeasure(),
0.001, 10, true, false);
SequenceFile.Reader reader
= new SequenceFile.Reader(fs,new Path("output/"
+ Cluster.CLUSTERED_POINTS_DIR
+ "/part-m-00000"), conf);
IntWritable key = new IntWritable();
WeightedVectorWritable value
= new WeightedVectorWritable();
while (reader.next(key, value)) {
System.out.println(
value.toString() + " belongs to cluster "
+ key.toString());
}
reader.close();
}
}}

14
그리고 이렇게 표현된 vector 데이터에 대해 앞서 좌표점을 분류에서와 같이 알고리즘을 선택하여
수행하면 분류작업이 완성되게 된다.

15
2. 병렬형 빈발패턴 알고리즘
Apriori 알고리즘과 FP-Growth 알고리즘은 데이터의 크기가 커질 경우 가지치기 작업을 통해9
계산부담을 해결했다. 그러나 빅데이터의 경우 그 규모가 워낙 커서 다른 방식의 개선이 필요해졌는데
Apriori 알고리즘의 경우 알고리즘 자체의 개선을 위한 노력이 기울여진 반면 FP-Growth 알고리즘은 그
자체가 Apriori 보다 훨씬 빨랐으므로 알고리즘 자체의 수정 못지않게 FP-Growth 를 병렬처리하려는 데에도
촛점이 맞추어졌다.
(1) FP-Growth 알고리즘
FP-Growth 알고리즘은 기본적으로 분할정복 방식을 취한다. 이를 위해 다음의 준비작업을 한다.
DB scan 으로 빈발항목 리스트를 정렬한 결과 (F-List)를 얻고
두번 째의 DB scan 을 통해 F-List 를 FP-Tree 로 압축시킨다.
이제 이 결과물을 가지고 FP-Growth 는 지지도가 의미있는 숫자 이상인 것들을 재귀적으로 탐색한다.
다음은 알고리즘을 간략화 한 것이다.
FP-Growth용 Algorithm 1
위의 Algorithm 1 에서 F-List 를 계산하는데 있어서의 시간복잡성은 해싱기법에 의할 때 O(DBSize)
이다.
9 III. 분석기법 ▶ 3. 주요분석 기법 ▶ (3) 데이터 상호관련성의 분석 ▶ 가. 빈발항목 분석.

16
FP-Growth용 Algorithm 2
Algorithm2 에서의 Growth()의 계산은 다항식 관계로서 FPGrowth()는 Growth()라는 프로시저를
재귀적으로 호출한다. 이때, 다단계 조건에 따라 메모리에서 처리하므로 병목현상의 원인이 되는 등 다음과
같은 문제를 가진다.
스토리지 문제 - 대형 DB 에서 FP-tree 가 커지면 한꺼번에 메모리에 탑재하기가 어려워서
여러개 작은 DB 로 나누어야 했고 결국 이들 소형 DB 별로 local FP-tree 를 생성해야 했다.
계산 및 분배 문제 - 모든 단계를 병렬화 할 필요가 있다.
통신 오버헤드 - 분산 FP-tree 는 상호 의존성이 있어서 이들 thread 처리 도중 동기화의 부담이
컸다.
지지도 값 - 분석 애플리케이션에 따라 지지도 값을 낮게 책정해야 할 경우 계산의 부담이
엄청났다.
(2) 병렬형 FP-Growth 알고리즘
FP-Growth 알고리즘을 보다 고속으로 처리하고자 하는 욕구가 커졌다. 그 이유는 특히 웹 검색과 같은
경우 long-tail10의 성격이 강조되면서 지지도가 낮은 수 많은 질의를 무시할 수 없는 경우가 많기 때문이다.
즉, 과거와 달리 아무리 작은 요청이나 질의항목도 모두 고속 검색으로 해결을 해주지 않으면 안되게 되었다.
10 소수의 히트 상품(항목)이 절대적 위력을 발휘했던 과거의 시장 패턴에서 이제는 꼬리 부분에 있는 다수의 상품(항목)들의
중요성이 더욱 커지고 있는 사회현상을 말한다. 예컨대 전자상거래의 경우 인터넷 검색을 통해 누구나 쉽게 원하는 물건을
찾아낼 수 있게 되어 특정 인기품목 못지않게 틈새상품이 중요해지는 새로운 경제 패러다임이 형성된 것이다. '롱테일'은
판매곡선에서 불룩 솟아오른 머리 부분에 이어 길게 늘어지는 꼬리부분을 가리킨다.

17
나아가 Facted Search11와 같이 다차원의 검색이 필요한 경우 관련항목의 검색을 위해 관련질의를 신속히
처리하는 것은 미루거나 피할 수 없는 기능이 되었다.
그동안 FP-Growth 알고리즘의 성능개선을 위해 작업 (task)의 병렬처리에 주된 관심이 있었다. 즉,
모듈간의 통신 오버헤드를 극복하고 공유메모리를 이용한 다중 thread 의 처리에 집중되어 왔다.
그러나 소규모 환경 에서는 확실한 성능개선을 보이던 것이 대규모 환경에서는 메모리에서 병목현상이
일어날 뿐만 아니라 cache 처리의 문제, 메모리와 I/O 간의 불균형 문제 등이 발생하게 되었다. 특히 중요한
것은 장애극복 (fault-recovery)의 문제였다. 다수 노드 클러스터 환경에서 특정 노드에서의 장애가
빈번했기 때문이다.
이에 MapReduce 를 적용한 병렬형 FP-Growth 알고리즘이 소개되었다. 특히 대규모의 FP-Growth
작업을 수평 분할 (즉, sharding)하여 독립적 작업단위로 나누고 이들을 MapReduce job 으로 처리하는데
그 결과 거의 선형의 성능개선 (near-linear scalability)은 거둘 뿐 아니라 작업실패 시 자동 재계산도
가능해졌다.
이하에서 병렬형 FP-Growth 알고리즘을 소개한다.12
11 정보를 여러 측면으로 - 즉, 다차원으로 - 분류하여 제공하고 사용자는 이를 필터를 통해 원하는 것 결과만 얻도록 하는
것을 말한다. 예를 들어 사용자가 'apple'을 검색하면 과일 사과에 관련된 항목 (사과에 대한 생물학/영양학)과 시장동향
(재배기술/가격동향/수급동향)은 물론 미국 Apple 사의 정보(주가동향/'iPod' 및 'iPhone' 신제품)가 검색되어 체계적으로
분류되고 제시되어야 한다. 이를 위해서는 제반 항목에 대한 분류 (faceted classification) 작업을 실시간으로 수행하는 것이
중요하다.
12 http://infolab.stanford.edu/~echang/recsys08-69.pdf 의 논문.
18
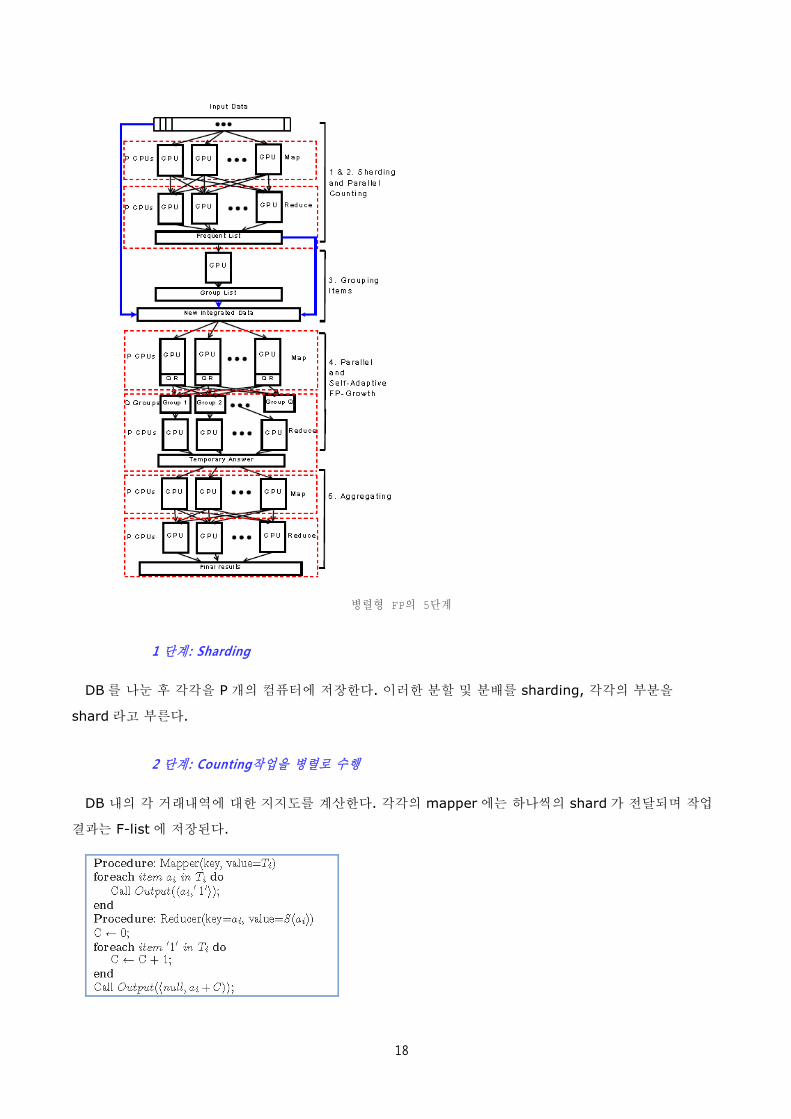
병렬형 FP의 5단계
1 단계: Sharding
DB 를 나눈 후 각각을 P 개의 컴퓨터에 저장한다. 이러한 분할 및 분배를 sharding, 각각의 부분을
shard 라고 부른다.
2 단계: Counting작업을 병렬로 수행
DB 내의 각 거래내역에 대한 지지도를 계산한다. 각각의 mapper 에는 하나씩의 shard 가 전달되며 작업
결과는 F-list 에 저장된다.

19
3 단계: 항목의 Grouping 작업
F-List 에서의 모든 항목을 나누어 Q 그룹에 전달하는데 이때의 그룹 리스트를 group list (G-list)라고
부른다. 한편 F-list 와 G-list 는 크기가 작고 복잡도가 낮아서 한대 컴퓨터로도 가능한다.
4 단계: 병렬의 FP-Growth
PFP 의 가장 핵심적인 부분. 완전한 MapReduce 작업이 이루어진다.
Mapper - group 별 거래내역을 생성한다. 각각의 mapper instance 에는 1 단계에서의 DB
shard 가 전달되는데 먼저 G-list 를 읽은 후 shard 의 거래항목을 처리한다. 각 mapper 는
작업의 수행결과를 key-value pair 의 형태로 작성한다. (key: group-id, value: 생성된
group 별 거래).
Reducer - group-dependent shard 에 대한 FP-Growth 작업: 모든 mapper instance 가
작업을 끝내면 각각의 group-id 에 대해 MapReduce 프레임워크가 자동으로 모든 그룹 별
거래항목을 정렬시켜서 shard 로 만든다.
각각의 reducer instance 에는 group-dependent shard 가 전달되어 이를 처리하게 되고 각각의
shard 에는 reducer instance 가 local FP-tree 를 작성한다. 재귀적 처리작업 동안 발견된 패턴을
출력한다.
5 단계: 종합 (Aggregating)
4 단계에서의 작업결과를 종합한다.

20

21
3. R을 MapReduce에 적용한 시계열 데이터분석
R 을 MapReduce 적용하는 방법을 알아 보기 위해 단순한 예를 중심으로 살펴 본다. 13 시계열 형태의
비행기 운항 데이터를 항공사, 공항, 비행기 별로 추출, 분석하는 프로젝트14로서 mapper 및 reducer
함수를 R 언어로 작성하여 수행하였다.
구체적으로는 다음 2 단계로 작업이 이루어졌다.
(1) CSV 타입의 데이터를 압축하여 R 로 읽어 들인다.
# load list of all files
flights.files <-list.files(path=flights.folder.path, pattern="*.csv.gz")
# read files in data.table
flights <- data.table(read.csv(flights.files[i], stringsAsFactors=F))
(2) 그런 후 비행기 별, 항공사 별, 공항 별로 분석을 실시하여 중간 결과를 도출한다. 다음은 운항일지를
항공사 별로 뽑아내는 프로그램이다.
getFlightsStatusByAirlines <- function(flights, yr){
# 연도별 추출
if(verbose) cat("Getting stats for airlines:", '\n')
airlines.stats <- flights[, list(
dep_airports=length(unique(origin)),
flihts=length(origin),
flights_cancelled=sum(cancelled, na.rm=T),
flights_diverted=sum(diverted, na.rm=T),
flights_departed_late=length(which(depdelay > 0)),
flights_arrived_late=length(which(arrdelay > 0)),
total_dep_delay_in_mins=sum(depdelay[which(depdelay>0)]),
avg_dep_delay_in_mins=round(
mean(depdelay[which(depdelay > 0)])),
median_dep_delay_in_mins=round(
median(depdelay[which(depdelay > 0)])),
miles_traveled=sum(distance, na.rm=T)
), by=uniquecarrier][, year:=yr]
#change col order
setcolorder(airlines.stats,
c("year",colnames(airlines.stats)[-ncol(airlines.stats)]))
#save this data
saveData(airlines.stats, paste(flights.folder.path,
"stats/5/airlines_stats_", yr, ".csv", sep=""))
#clear up space
rm(airlines.stats)
13 R 의 사용법 및 프로그래밍에 대하여는 이 책의 부록을 참조할 것.
14 https://github.com/datadolphyn/R 에 프로그램 소스가 있으며 원래 1억 2 천만개의 record, 12 GB 데이터를 대상으로
하는 프로젝트이다.
한편 본 설명의 촛점이되는 map-reduce 와 직접 관련되지는 않지만 프로그램 에서 사용되는 data.table 에 대하여는
http://datatable.r-forge.r-project.org/ 를 볼 것.

22
# continue.. see git full code
}
# map 함수의 시작
#
mapFlightStats <- function(){
for(j in 1:period) {
yr<-as.integer(gsub("[^0-9]","",gsub("(.*)(\\.csv)","\\1",
flights.files[j])))
flights.data.file
<-paste(flights.folder.path,flights.files[j],sep="")
if(verbose) cat(yr, ": Reading : ", flights.data.file, "\n")
flights <- data.table(read.csv(flights.data.file,
stringsAsFactors=F))
setkeyv(flights,c("year","uniquecarrier","dest","origin","month"))
# call functions
getFlightStatsForYear(flights, yr)
getFlightsStatusByAirlines(flights, yr)
getFlightsStatsByAirport(flights, yr)
}
}
이상과 같이 항공사 및 공항 별로 운항일지를 뽑아낸 후 디스크에 저장하고 총량분석 데이터를 가지는
132 개의 중간데이터를 추출하였다. 이제 reduce 함수를 통해 다음과 같이 중간 데이터를 집계하여 (비행기,
항공사, 공항 별)최종결과를 도출하였다.
#reduce 함수로서 통합 집계 작업
reduceFlightStats <- function(){
n <- 1:6
folder.path <- paste("./raw-data/flights/stats/", n, "/", sep="")
print(folder.path)
for(i in n){
filenames <- paste(folder.path[i],
list.files(path=folder.path[i],pattern="*.csv"), sep="")
dt <- do.call("rbind",
lapply(filenames, read.csv, stringsAsFactors=F))
print(nrow(dt))
saveData(dt, paste("./raw-data/flights/stats/", i, ".csv", sep=""))
}
}

23
4. Social CRM과 Social 네트워크 분석
(1) 배경 – 전통적 (분석) CRM
전통적 CRM 특히 분석 CRM 은 전사적 차원에 일관성 있는 통일적 관점을 제공하고 전 부서가 고객의
단계별 상황에 맞춘 대 고객행위를 할 수 있게 된다.
Direct Marketing 을 예로 하여 CRM 을 이용한 BI 구현을 살펴 본다.
(1) 예측변수를 이용해서 고객을 등급 메긴다. - 예측변수는 각각의 고객에 대한 측정 값으로서 예컨대
recency15 (최근성)를 통해 새로 마케팅 캠페인을 했을 때 호응도를 가늠해 볼 수 있다. 가장 최근 구입한
사람이 가장 호응도가 높은 것이라는 것이다
(2) 여러 예측변수를 가중치 적용하여 조합한다 – 예측모델을 만든다. 앞서 recency 에 소득을 추가하고
가중치를 반영한 공식을 만들 수 있다.
2 x recency + personal income
위 모델에서 우리는 단순 선형관계를 가정하였으나 이 외에도 조건에 따른 규칙을 정의함으로써 business
rule 을 정의할 수도 있다.
If 고객이 지방거주자이고, and 월 지출액이 높다면,
then 계약관계를 지속할 확률이 높다.
또는
If 고객이 도시거주자이고, and 신 상품 구매비율이 높다면,
then 이번 캠페인에는 참여하지 않을 것이다.
(3) 실 고객 데이터를 통해 컴퓨터로 모델을 수립한다
15 RFM 분석에서는 Recency (얼마나 최근 구입했는가), Frequency (얼마나 빈번하게 구입했는가), Monetary amount (총
구입금액이 얼마인가)의 3 가지를 통해 제품구입가능성이 높은 고객들을 추려낸다. RFM 의 한계를 극복한 것이 고객 평생가치
(customer lifetime value) 평가법 이다.

24
가장 중요하고도 어려운 점은 예측모델을 만드는 것이다.
(4) 적용결과를 다각도로 검증한다.
컴퓨터상의 모델링이 완료되면 이를 검증한다. 이익곡선과 현장에서의 캠페인을 통한 이익증가 추이를
비교하는데 처음에는 고객접촉이 늘수록 이익도 증가하지만 얼마 후부터는 이익증가가 감소하고 약 70%
고객접촉 이후부터는 이익 자체가 감소됨을 보여준다. 시간과 예산을 투입해도 캠페인 비용증가에 비해
매출증가가 이루어지지 않기 때문이다.
전형적인 이익곡선의 모습
CRM과 데이터 관리
(1 단계) 필요 데이터의 판별 – 고객별로 필요한 데이터와 전략지표 (예: 수익률, 해지율)를 식별하고 한다.
(2 단계) 데이터를 획득, 통합한다 – 데이터 소스를 확인하고 획득 방안을 수립한다. 과거 엄두내지
못했던 데이터도 과감하게 포함시킨다.
(3 단계) 분류 – 큰 범주별 분류와 세부 기준에 분류한다.
고객 서술형 (Descriptive) 데이터
소비자 행동(Behavioral) 관련 데이터
경영환경 및 여건에 관한 데이터 (Contextual data)
(4 단계) 고객정보 통합 CDI (customer data integration)
기업 내부에서 발생된 정보와 외부로부터 새로 획득된 정보
과거실적과 미래 예측정보 및 정형정보와 비정형 정보

25
빅데이터와 관련하여서는 위의 2~3 단계에 빅데이터 기술이 동원될 수 있는데 이처럼 빅데이터 분석과
CRM 의 통합하면 각종 정책변수 상의 상호관련성을 찾아내고, 패턴을 분류하며 숨겨진 추세를 발견할 수
있다.
(2) Social CRM
가. 일반론
그동안 CRM 은 주로 POS (Point of Sale), 전화/fax, 메일, 대면접촉 일지 등의 정형 데이터 중심이었다.
반면 Social CRM 이란 고객을 보다 심도있게 이해하기 위해 SNS 의 정보를 이용하는 방식으로 CRM 을
확장하는 것을 말한다. 소비자 욕구가 다양해지고 비정형 정보가 생성교환되면서 이를 분석할 수 있는
토대가 마련되었고 모든 상품과 서비스는 개인화되는 추세이므로 특히 중요해졌다.
나. 분석방법
분석 대상
SNS 에서의 각종 대화/댓글/논평 등을 지속적으로 수집하고 관리한다. 과거 막연했던 브랜드 충성도나
광고의 효과 분석도 구매정보뿐 아니라 홈페이지 방문자의 각종 방문기록과 댓글을 측정하는 방식으로
분석한다.
정형화된 고객관리 DB 의 분석
전자메일, SNS 에서의 각종 기록, 댓글 등을 수집, 분석
홈페이지 및 각종의 웹 사이트에 대한 방문 및 클릭 동향
ETL 2.0
SNS 의 데이터는 다양한 소셜 미디어와 전통적 CRM 을 통합하는 것이 중요하다. 특히 기존 CRM 의 정형
데이터와 SNS 의 비정형 데이터가 서로 다르게 정의되었으므로 ETL 의 기능이 확장되어야 한다16. 예컨대
SugarCRM 의 경우 SNS 고객접촉 데이터를 연결하고 LinkedIn 의 업종 및 분야별 전문가와 통합,
그들과의 대화를 수집, 분석하는 방식을 취한다. 이들은 대개 REST API 17또는 웹서비스 방식을 통해
Hadoop 을 연결하며 일부 클라우드 방식으로 상용 aggregation 서비스를 제공한다.
16 이처럼 연결/추출의 대상범위를 확대하거나 스트림 데이터와 같은 대량 데이터를 위해 확장한 것을 ETL 2.0 이라고
부르기도 한다.
17 REST 는 Representational State Transfer 의 약자로서 HTTP 의 GET, POST, PUT, DELETE method 만을 사용해서
작업하는 것을 말한다.

26
군집화(clustering) 모델에서는 수집된 고객정보를 통해 동일한 행태, 태도 및 관심을 가지는 부류로 그룹화, 군집
화한다.
다. 이용전략
최근 의미기반 (semantic) 분석, sentiment 분석 등을 자연어 처리 (NLP) 기법으로 해결하려는
움직임이 활발하다. 블로그나 SNS 의 컨텐츠가 자연어 형태를 가지기 때문이다. 특히 sentiment 분석은
텍스트로부터 고객이 가진 주관적인 정보를 획득하고 분석하는 것을 말한다. 예를 들면
실제로 좋아하는지? 어떤 점을 좋아하고 싫어하는지? 또한 이러한 선호도는 각종 고객집단별로
어떠한 특성과 변화행태를 보이는지?
자사가 실시하는 광고가 호응을 얻고 있는지? 호응도와 반대의견은 어떠한지?
특정 사건이나 정책에 대한 여론 동향은 어떤지? 특정 매체나 유력인사의 의견뿐만 아니라 실제
논의되는 동향들은 어떠한지?
아직 자연어 처리와 여러 감정처리 (예: 비꼬거나 빈정거리는 것)에 한계가 있지만 여러 시점의
분석결과를 축적, 비교함으로써 맥락 (context)을 분석하는 등의 방식을 통해 상당부분 대안이 제시되고
있다.
한편 push 전략도 가능하다. SNS/포털 사이트에서 자사의 존재를 알리고 대화하거나 자체의 커뮤니티
사이트를 구축하는 것 등이다.
전략
모든 정보를 한 곳에 모아서 전사적으로 축적, 관리, 공유한다. 이때 어떤 범위까지 수집,
분석할지에 대한 전략을 수립한다. (예: 특정 hash tag, 특정 고객집단 및 주제어 등으로 한정)
CRM 과 다른 시스템을 통합한다. e-Commerce 의 경우 추천 시스템과 연계하고 조직 내
업무규칙과 절차를 재조정한다.

27
Social Marketing 과 연계한다. 여기에는 SNS + Commerce + M-commerce + LBS, NFS 등이
모두 포함된다.
(3) 소셜 네트워크 분석
가. 개요
소셜 네트워크 분석 (SNA: Social network analysis)은 사람, 집단, 기관, 컴퓨터, URL, 지식 들 간의
상호 관련성과 그 정도를 보다 본격적으로 측정, 분석하는 것을 말한다. 이때 네트워크 내에서의 node 는
사람 내지 집단을 의미하고 link 는 node 들 사이의 관계 또는 흐름을 뜻하게 된다. 간단하게는 그림으로
표현하고 이를 직관적으로 알아볼 수 있지만 복잡한 관계는 수학적 기법을 사용하게 된다.
우선 네트워크 내에서의 대상이 되는 객체의 위치를 이해할 필요가 있다. 여기서 위치란 노드의 중앙부
(centrality)18를 파악하는 것을 말한다. 이를 통해 이들이 차지하는 역할과 (예컨대 전문가 그룹, 연결자,
지도자 (leader), 교량 역할, 고립자 등으로 분류할 수도 있다.) 어떻게 그룹을 이루는지를 알 수 있기
때문이다.
나. 세부기법 – MCL과 DBSCAN
앞서 본 여러 군집화 기법에 추가하여 그래프 분석이론이 동원된다. 그래프 이론 기반의 군집화 기법에는
Markov Clustering Algorithm (MCL)를 들 수 있는데 이는 random walk 를 시뮬레이션 하는 방식으로
꼭지점 (clusters of vertices)을 발견해 내는 것이 그 핵심이다. 즉, 만약 그래프 내에 군집이 존재한다면
군집 내의 링크는 군집 간에서보다 link 의 갯수가 더 많을 것이라는 점에 착안한다. 하나의 꼭지점
(vertex)에서 그래프를 임의로 탐사하면 하나의 군집 내에서 더 자주 최종점에 도달할 것이고 이러한
random walk 를 통해 군집을 발견해 낸다. 이때 Random walk 는 Markov Chain 기법을 동원한다.
Markov Chain 은 X1, X2, X3, ... 등의 일련의 상태정보로 표현된다.
현재 어떤 상태가 주어졌다면 과거 및 미래의 상태는 이와 독립적일 것이다. 즉, 시스템의 다음 상태는
현재상태에 따라서만 달라질 수 있다.
Pr(Xn+1=x|X1=x1,X2=x2,X3=x3, ....,Xn=xn)=Pr(Xn+1=x|Xn=xn)
Pr 함수를 통해 Markov Chain 내에서의 확률값을 계산하지만 Pr 은 Xn을 입력받을 경우에만 Xn+1에
대해 동일한 상태값을 얻을 수 있게 된다. 또한 MCL 에서 상태는 확률 matrix 로 표현된다. 즉,
그래프에서는 vertex 를 벡터로 여기고 모서리 (Edge)를 벡터의 항목으로 간주한다. 이들 모든 노드 벡터를
그래프에 위치시키면 그래프의 연결상태를 보여주는 행렬이 만들어진다.
18 중심도 (centrality)에도 여러가지가 있으나 세부 설명을 생략한다.
http://faculty.ucr.edu/~hanneman/nettext/index.html 참조

28
행렬식의 생성
이제 행렬식을 중심으로 군집을 찾는데 있어서 소셜네트워크 표현이 sparse matrix 의 경우 특히 Map-
Reduce 프레임워크를 이용하면 성능과 확장성에 있어 더욱 큰 효과를 보게 된다.19
이제 MCL 알고리즘에 대한 추가의 세부설명 대신에 이것이 Map-Reduce 프레임워크에 어떻게
적용되는지에 대해서만 간단히 살펴본다.
Markov Matrix 군집화 알고리즘
(목적)
Markov Matrix 기법을 통해 Social Network 의 군집화 분석을 실시
(입력사항)
connectivity (similarity)sparse matrix
(출력사항)
markov (probability) matrix
class MarkovMapper
method map(column)
sum=sum(column)
for all entry∈ column do
entry.value=entry.value/sum
collect{column.id, {out, entry.id, entry. value}}
collect{entry.id, {in, column.id, entry.value}}
class MarkovReducer
method reduce(key, list {sub-key, id, value}})
newcolumn=Ø
19 http://www.diva-portal.org/smash/get/diva2:556816/FULLTEXT01.pdf

29
newrow=Ø
for all element∈list do
if sub-key is “out” then newcolumn.add({key, id, value})
else newrow.add({id, key, value})
collect newcolumn
collect newrow
그 밖에 MCL 을 Map-Reduce 적용할 때 다양한 대안이 있을 수 있다. 그 밖에 DBSCAN 의 Map-Reduce
방식에 대해서는 설명을 생략한다.20
20 MCL 과 DBSCAN 기법을 MapReduce 방식으로 Social Network 분석에 활용하는 세부 구현방법은 다음 문서를 참조할
것. http://www.diva-portal.org/smash/get/diva2:556816/FULLTEXT01.pdf
30
5. 얼굴인식(보안)과 Hadoop
(1) 사례: 미국 보스톤 마라톤 폭발 사건
(사례) 2013 년 8 월 15 일 미국 보스톤 마라톤 경주 중 폭발사건으로 3 명이 사망하고 수십명이
부상당하는 사건이 발생하였다.
FBI 는 휴대폰 중계기의 통화기록(call log), 문자 메시지, SNS 데이터, 사진, 민간 제보, 단서 등 자료를
확보하고 10 TB 의 영상화면을 분석해서 4 일만에 범인을 검거하였다. 우리는 화상데이터 분석을 통한
얼굴인식 처리문제 만을 빅데이터와의 관점에서 살펴본다. 21
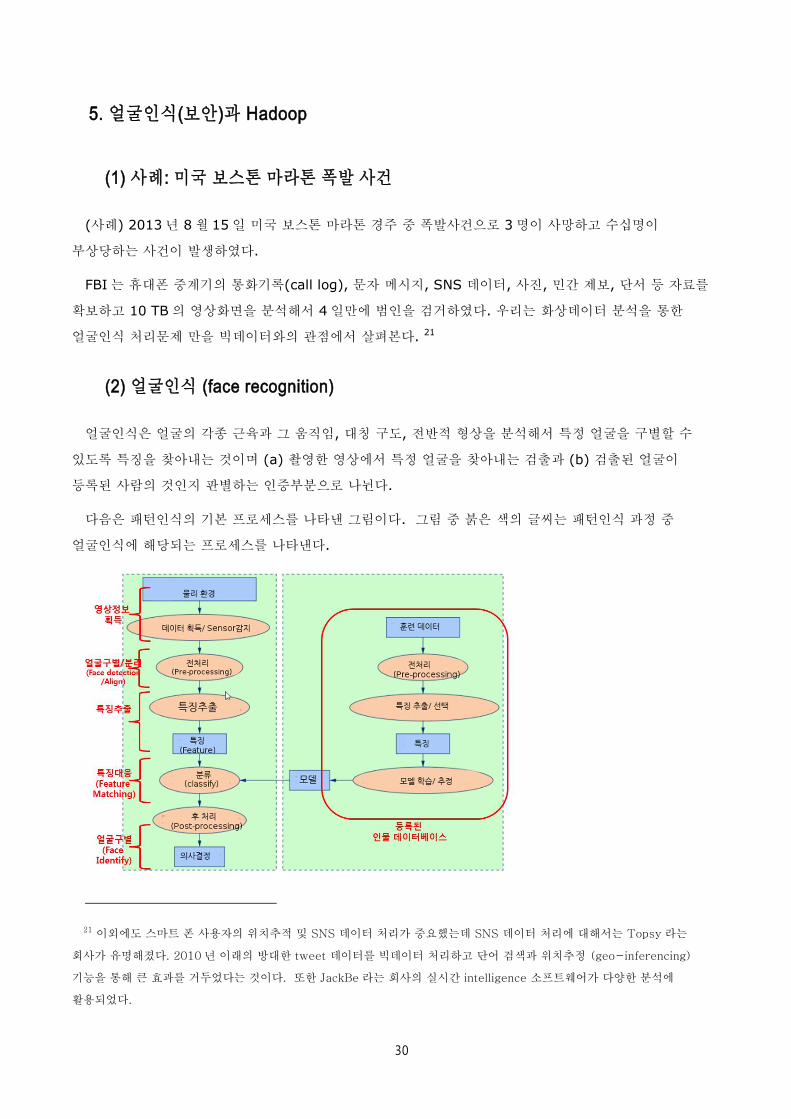
(2) 얼굴인식 (face recognition)
얼굴인식은 얼굴의 각종 근육과 그 움직임, 대칭 구도, 전반적 형상을 분석해서 특정 얼굴을 구별할 수
있도록 특징을 찾아내는 것이며 (a) 촬영한 영상에서 특정 얼굴을 찾아내는 검출과 (b) 검출된 얼굴이
등록된 사람의 것인지 판별하는 인증부분으로 나뉜다.
다음은 패턴인식의 기본 프로세스를 나타낸 그림이다. 그림 중 붉은 색의 글씨는 패턴인식 과정 중
얼굴인식에 해당되는 프로세스를 나타낸다.
21 이외에도 스마트 폰 사용자의 위치추적 및 SNS 데이터 처리가 중요했는데 SNS 데이터 처리에 대해서는 Topsy 라는
회사가 유명해졌다. 2010 년 이래의 방대한 tweet 데이터를 빅데이터 처리하고 단어 검색과 위치추정 (geo-inferencing)
기능을 통해 큰 효과를 거두었다는 것이다. 또한 JackBe 라는 회사의 실시간 intelligence 소프트웨어가 다양한 분석에
활용되었다.

31
PCA (주요인 분석: Principal Components Analysis)
SVM (Support Vector Machines)
Gabor Wavelets22
Hough Transform23
얼굴인식의 특징적 절차로 다음과 같은 것을 들 수 있다.
탐지 기법에는 크게 다음과 같은 방법이 있다.
지식기반 방법 – 전형적 얼굴에 대한 지식을 규칙으로 표현
변치 않는 특징 (feature invariant) 분석- 표정, 얼굴 가장자리, 피부 질감 등 변화에도 변치
않는 특징을 추출한다.
구조적 유사성 탐지 (structural matching)
템플리트 기반의 유사성 탐지 (Template matching)
외양(appearance)에 의한 인식과 인공신경망의 이용
정규화란 얼굴특징을 이루는 점의 위치정보를 받아 개별 파라미터를 생성하고 클래스 내에 존재하는
차이점을 제거하는 것이고 특징추출은 정규화된 이미지를 기반으로 얼굴을 표현하는 key 를 출력하고 이를
비교하는 것이다. PCA 와 Gabor Wavelets 등을 이용한다.
22 질감 특성을 나타내기 위한 기법의 하나이다. 영상검색에는 이외에도 색상 특성을 표현하는 칼라 히스토그램, 모양특성을
표현하는 경계영역 기술(boundary description) 등이 있다.
23 Hough ('허프'라고 읽는다) 변환은 이미지가 불완전할 때 파라미터 공간에서 일종의 투표방식을 통해 객체를 선정하는
기법이다. 이후 GHT (generalized Hough transform)로 확장되었다.

32
(3) HIPI
가. 개요
HIPI 란 Hadoop Image Processing Interface for Image-based MapReduce Tasks 의 약어로서
Hadoop 기능을 이미지 처리에 접목시키고자 하는 오픈소스 프로젝트로서24 주된 목적은 다음과 같다.
이미지 프로세싱과 컴퓨터 비전을 MapReduce 프레임워크를 통해 구현하도록 확장가능한
개방형 라이브러리의 개발
이미지에 대한 필터링을 손쉽게 적용할 수 있도록 함.
HIPI 는 Hadoop 의 MapReduce 프레임워크를 위한 라이브러리로서 분산환경에서 이미지
프로세싱을 할 수 있도록 API 를 제공한다.
Hadoop MapReduce 가 데이터 입출력에는 효율적이지만 이미지 표출에 그리 효율적이지 못한 점에
주목하고 이를 해결하는데에 HIPI 라이브러리 설계의 초점이 주어졌다.
HIPI의 Image Bundle로 입력 이미지 파일을 지정하면 이후의 작업 특히 병렬처리를 위한 제반 작업은 HIPI 라이브
러리가 자동으로 처리한다.
또한 사용자가 pixel 단위로 이미지 제어할 수 있도록 float 이미지 형태로 배포된다. 즉, 모든 이미지는
표준 형식 (예: jpeg, png 등)으로 저장되지만 HIPI 가 float 이미지로 encode/decode 하므로 이미지의
평균 픽셀 값의 계산 등이 자유롭게 수행될 수 있다.
24 참고: HIPPI 가 보스톤 폭발사건 해결에 직접 사용되었는지는 알 수 없으나 대규모 이미지 처리에 Hadoop 이 사용된 것은
분명한 것으로 알려진다.
프로젝트 홈페이지는 http://hipi.cs.virginia.edu/

33
나. MapReduce용 이미지 프로세싱 API
HIPI 에서 가장 많이 사용되는 class 는 다음과 같다.
HIPI Image Bundle (HIB)
이미지 파일을 저장 시 HIPI Image Bundle 이라는 타입을 이용하는데 여기서는 실제 파일과 Index 파일
(메타데이터)를 구별하여 저장한다.
Unix 에서의 tar 파일과 흡사하며 HipiImageBundle 클래스를 통해 구현된다. 이 파일은 Hadoop
MapReduce 에서 직접 사용된다.
Float Image
HIPI 에 대한 주된 입력 파일 클래스로서 이미지 파일을 pixel 단위로 표현하되 각각의 pixel 을 단일
floating-point precision 으로 표시한다.
Cull Mapper
이미지를 수집 또는 버릴 수 있도록 설계된 것으로서 CullMapper::cull 라는 함수를 가진 특별한 Mapper
타입을 정의하는 역할을 한다.
다. HIPI에서의 Job
HIPI 는 Hadoop 의 표준 job 클래스를 확장해서 이미지 처리를 위한 작업 시 손쉽게 필요한 파라미터
설정을 할 수 있도록 해준다. HipiJob 을 이용할 떄의 2 가지 주요한 작업은 다음과 같다.

34
투기적 실행25의 활성화/비활성화 – HipiJob::set{Map,Reduce}SpeculativeExecution 를
이용하며 특정 노드에서 작업이 늦어질 때 해당 task 를 종료(kill)하거나 다른 task 의 결과를
이용할 수도 있다.
Map 출력 레코드의 압축을 활성화/비활성화 – HipiJob::setCompressMapOutput 를 이용하며
Map task 가 끝난 후 redoce task 로 전달되기 전에 출력물을 압축할지 여부를 결정한다.
(4) 덧붙이는 말 – Minority Report?
가. 동향
얼마 전 영화 "Minority Report"가 큰 주목을 끌었다. 2054 년 미국 워싱턴을 배경으로 범죄 발생 전에
범죄를 예측해 처벌하는 특수기동부서 "PreCrime"의 이야기였다.
영화 자체는 다소 과장되었으나 이와 유사한 현상이 현실화되고 있다. 이미 미국에서 가석방 심사 시
대상자의 각종 자료를 분석, 활용하는 곳이 50%를 넘어섰고 L.A.같은 곳에서는 빅데이터를 활용한
"예방치안 (predictive policing)"을 실시 중에 있다고 한다. 범죄 취약지역을 선정하여 예방조치 하는
것이다. 이 기술의 하나가 FAST (Future Attribute Screening Technology)로서 개인 행태를 분석하면
타인에게 위해를 끼치려는 의도를 알아차릴 수 있다. 이미 범인 프로파일링 기법이 법원으로부터 정당성을
인정받았고 금융기관의 신용평가 등에도 이미 상당부분 적용되고 있는데 Hadoop 을 중심으로 한 빅데이터
처리기술이 그 핵심이 되고 있는 것으로 알려져 있다.
나. 범죄 프로파일링
이제 우리의 관심인 빅데이터 기술의 측면에서 중범죄자 분류엔진 (felony classifier)을 보자. 이것은
데이터를 분석하여 프로파일링하여 예컨대 경범죄를 저지른 사람이 중범죄로 이어질 가능성을 분석한다.
위의 분류모델은 2 억 5 천만명의 경범죄 피고와 4 천만명의 피고 데이터를 분석하고 이에 대해 다음
기능을 가지는 분석엔진을 적용한다.
데이터 획득과 교환
25 “II. Hadoop ▶3. Hadoop 의 기능요소 ▶ (2) MapReduce ▶ 라. Task 의 투기적 실행” 을 참조할 것

35
Noise filter
Blocking
Linking
군집화
분석엔진의 핵심인 분류작업에는 지역별 분류는 물론 15,000 개의 label (특성)을 기준으로 한
예측인자가 포함된다고 한다.
다음은 모델에서의 특성정보의 예로서 몸에 문신여부, 성별과 머리, 눈, 피부의 색을 구분하고 어떤
범죄경험이 있는지 등을 나타내고 있다.
Personal Profile
Person.NumBodyMarks
Person.HasTattoo
Person.IsMale
Person.HairColor
Person.EyeColor
Person.SkinColor
Criminal Profile
Offenses.NumOffenses
Offenses.OnlyTraffic
다음은 이러한 특성정보를 프로그램화 하는 일부 예이다.
class EyeColor(Extractor):
normalizer = {
'bro': 'brown’,'blu': 'blue', 'blk': 'black', 'hzl': 'hazel’,
'haz’: 'hazel’, 'grn': 'green’}
schema = {'type': 'enum', 'name': 'EyeColors','symbols':
('black','brown','hazel','blue','green','other','unknown')}
def extract(self, record):
recorded = record['profile'].get('EyeColor', None)
if recorded is None:
return 'unknown'recorded = recorded.lower()
if recorded in self.normalizer:
recorded = self.normalizer[recorded]
for i in self.schema['symbols']:
if recorded.startswith(i):
recorded = i
if recorded in self.schema['symbols']:
return recorded
else:
return 'other'
이러한 기본 사항에 대해 훈련데이터를 가지고 모델의 훈련을 실시한다.

36
다음은 이들 분석 후 출력된 예측데이터의 포맷이다.
key: e926f511b7f8289c64130a266c66411e
val:
offenses:
- {CaseID: MDAOC206059-2, CaseInfo: 'CASE DISPO: TRIAL, CJIS CODE: 3 5010', Disposition: STET,
Key: hyg-MDAOC206059, OffenseClass: M, OffenseCount: '2', OffenseDate: '20041205',
OffenseDesc: 'THEFT:LESS $500 VALUE'}
- {CaseID: MDAOC206060-1, CaseInfo: 'CASE DISPO: TRIAL, CJIS CODE: 1 4803', Disposition:
GUILTY,
Key: hyg-MDAOC206060, OffenseClass: M, OffenseCount: '1', OffenseDate: '20040928',
OffenseDesc: FALSE STATEMENT TO OFFICER}
profile: {BodyMarks: 'TAT L ARM; ,TAT L SHLD: N/A; ,TAT R ARM: N/A; ,TAT R SHLD:
N/A; ,TAT RF ARM; ,TAT UL ARM; ,TAT UR AR', DOB: '19711206', DOB.Completeness: '111',
EyeColor: HAZEL, Gender: m, HairColor: BROWN, Height: 5'8", SkinColor: FAIR,
State: 'DE,MD,MD,MD,MD,MD,MD,MD,MD,MD,MD,MD,MD’, Weight: 180 LBS}
Training Labels:
key: e926f511b7f8289c64130a266c66411e
val:
label: true
offenses:
- {CaseID: MDAOC206065-4, CaseInfo: 'CASE DISPO: TRIAL, CJIS CODE: 1 6501', Disposition: NOLLE
PROSEQUI, Key: hyg-MDAOC206065, OffenseClass: F, OffenseCount: '1', OffenseDesc: ARSON
2ND DEGREE}
다음은 판별을 위한 의사결정 트리의 일부분이다.

37
5. 부정 탐지와 MapReduce
부정탐지(Fraud Detection) 는 빅데이터의 주요 응용분야 중 하나이며 넓은 개념으로서의 부정행위
분석(fraud analysis)26중 하나이다.
사기행위에는 부정확한 대출신청, 사기성 거래, 명의도용 및 부정 보험청구. 신용카드 부정사용 등 다양한
종류가 있는데 예측모델을 통해 잘못된 거래를 방지하거나 회피하고 이에 대한 노출위험 자체를 낮추고자
한다. 예측모델의 수립은 특별히 관리해야 할 유형을 식별하고 이들 예측변수에 대한 적절한 가중치를
부여하는 등의 순서를 거친다.
부정 탐지 관련 빅데이터 분석기술에는 다음과 같은 것이 포함된다.
(1) Deduplication 에 MapReduce 기술을 적용한다.
앞서27 데이터 축소에 대해 언급한 바 있는데 Deduplication 도 중복된 내용 (chunk 또는 extent 라고도
함)을 줄이는 기법의 하나이다. 특히 통신사의 CDR28 또는 동일한 데이터 패킷이 전송될 때 이를 최적화하는
데 자주 사용된다.
보통 데이터 Deduplication 을 위해서 hashing, binary 비교, delta differencing 등을 사용했었지만
이제 MapReduce 를 통해서 보다 효율적으로 데이터 중복을 해소하게 되었다.
실제로 MapReduce 와 HDFS, 스트리밍 등의 기술을 조합하여 다양한 방법이 제안되어 활발히 사용되고
있는데 부정탐지에서 deduplication 을 빅데이터 처리함으로써 저장공간도 줄이고 통신 대역을 효율적으로
사용하여 실시간 처리가 한결 용이해졌다. 다음이 대표적이다.
Entity matching - 이름, 전화번호, 주소 등의 일치 여부 확인.
SNS 신원확인 - 소셜 네트워크 상의 프로파일을 통해 소비자의 신원을 밝힌다. (단, 프라이버시
문제가 있음을 유의할 것.)
(2) 이상행위 (outlier) 탐지 – 가장 전형적인 부정탐지 작업이다. 업무별 이상 특징을 반영하여 알고리즘
작성하는데 여기에는 군집화, 확률분포, 경로 분석, sessionization, tokenization 및 attribution, 회귀분석
및 상관분석, 그래프 분석 및 시각화 기술이 포함된다.
26 부정행위 분석에는 부정의 탐지 (detection), 예방 (prevention), 억제 (reduction) 등 3 가지가 모두 포함된다.
27 III. 분석이론 ▶ 2.모델링과 데이터 전처리
28 III.분석이론 ▶ 3. 분석기법 ▶ (8) 스트림데이터에서 설명한 바 있음.

38
(3) 업무 프로세스 (Workflow)에 반영 - Transaction streaming, 감독, 경고 발송 (alert forwarding),
추가 진행 제한 (transaction blocking) 등을 이용해서 업무규칙을 업무 프로세스에 일체화시킴으로써
프로세스 자체를 자동화하는 것을 말한다.
한편 빅데이터를 이용한 부정탐지 업무는 다음과 같은 특징을 가진다.
(1) 업무 특성상 DW 를 그대로 사용하는 경우는 거의 없다. 부정 알고리즘을 효과적으로 수립하고 유연한
분석을 위해 데이터 분석 시 고정된 스키마 대신 별도의 (custom) 스크립트를 사용한다.
(2) 신속한 대처를 위해서는 빠른 처리가 관건이다. 이런 의미에서 index, 백업 등의 DB 의 부담은 일체
없애는 것이 좋으며 흔히 Flume 같은 도구를 이용해서 데이터를 신속하게 적재한다.
여기서는 사기탐지에 많이 이용되는 KNN 알고리즘을 Map-Reduce 방식으로 수행하는 것을 간단히
소개한다.
KNN 알고리즘의 Map-Reduce 적용
(목적)
KNN 알고리즘을 Map-Reduce 프레임워크를 이용하여 수행함으로서
처리효율과 확장성을 높임.
Map()
(입력항목)
모든 점
질의 점(query point) p
(출력항목)
k nearest neighbors (로컬)
Emit the k closest points to p
--
Reduce()
(입력항목)
– Key: null; values: local neighbors
– 질의 점 p
(출력항목)
k nearest neighbors (전역: global)
Emit the k closest points to p among all local neighbors

39
이제 신용카드에서의 사기탐지를 간략화한 예를 살펴 본다29. 우선 신용카드 결제 시 다음의 4 가지
속성데이터가 제공된다고 가정한다.
승인신청번호 ID
신청시간
금액
가맹점 분류
그리고 다음의 샘플 데이터 중 제일 마지막 것이 이상치라고 하자.
YX66AJ9U 1025 20.47 약국
98ZCM6B1 1910 55.50 식당
XXXX7362 0100 1875.40 보석판매점
작업 순서
(1) 우선 거리계산을 한다. 거리의 개념에는 Euclidean, Manhattan 거리 등 다양한 선택이 가능하다.
수치 데이터의 경우 (예: 금액) 수치 차이가 거리가 된다.
카테고리 데이터의 경우 (예: 상점 분류) 동일타입이면 0, 다른 타입이면 1 이다.
카테고리 데이터가 계층구조를 가지는 경우에는 하나의 node 에서 다른 node 로 옮아가는
edge 의 최소 숫자가 거리가 된다.
(2) 그리고 이들 각 속성별 거리를 합산한다. 이때 적용분야에 따라 비중을 달리할 수도 있다.
이들 거리를 계산함에 있어 Map-Reduce 방식을 적용한다. 특히 거리계산의 비용은 O(nxn)인데 즉,
1 백만개의 승인신청이 있다면 1 백만 x 1 백만 = 1 조개의 계산이 수행되어야 한다는 것을 의미한다.
(3) 이들 작업은 나뉘어 수행된 후 reducer 로 전달된다. 100 개의 Hadoop node 가 있고 node 당
10 개의 reducer slot 이 있다면 각각의 reducer 에는 대략 10 억개의 거리계산 작업이 수행된다.
이때 이러한 작업을 어떻게 배분할 것인가가 문제되는데 partitioned hashing 방식을 사용하면 편리하다.
If h1 = hash(id1) and h2 = hash(id2) then
use function of h1 and h2 as the key of the mapper output.
이제 h1 또는 h2 에 hash 된 id 를 가지는 모든 승인신청은 하나의 reducer 에 배정될 것이다. 다음은
해당 분야의 코드 예이다.
String partition=partOrdinal>=0 ? items[partOrdinal] : "none";
29 http://www.slideshare.net/pkghosh99/outlier-and-fraud-detection 의 사례보고를 참조하였다.

40
hash =(items[idOrdinal].hashCode() %
bucketCount+bucketCount) / 2 ;
for (int i = 0; i < bucketCount; ++i) {
if (i < hash){
hashPair = hash * 1000 + i;
keyHolder.set(partition, hashPair,0);
valueHolder.set("0" + value.toString());
} else {
hashPair = i * 1000 + hash;
keyHolder.set(partition, hashPair,1);
valueHolder.set("1" + value.toString());
}
context.write(keyHolder, valueHolder);
그리고 나서 각각의 데이터 점을 중심으로 k 개의 최근접 점을 찾은 후 거리에 따라 정렬한다. 앞서의
Map-Reduce 에 의하면 다음과 같이 key, value 가 산출될 것이다.
key -> (6JHQ79UA, 5) value -> (JSXNUV9R, 5)
key -> (JSXNUV9R,, 5) value -> (6JHQ79UA, 5)
key -> (6JHQ79UA, 89) value -> (Y1AWCM5P, 89)
key -> (Y1AWCM5P, 89) value -> (6JHQ79UA, 172)
reducer 에서는 reducer 가 수행될 때 key 로 transaction ID 와 value 로서 이웃 transaction ID 및
거리 pair 의 리스트가 생성된다. reducer 에서는 각 value 에 대해 반복해서 거리 평균을 계산해 낸 후
이들을 출력한다.
1IKVOMZE 5
1JI0A0UE, 173
1KWBJ4W3, 278
...........
XXXX7362, 538
거리개념에 기반한 계산을 통해서 당초 이상치 거래신청이 예외사항으로 보고됨을 알 수 있다.
물론 위 설명이 지나치게 단순한 것이 사실이다. 실무에서는 그룹화를 위한 grouping comparator 등
다양한 항목이 추가될 것이다. 또한 k 를 어떻게 정할 것인가는 KNN 의 여전한 과제이다. K 값이 너무
낮으면 low bias 현상이 발생하고 너무 크면 low variance 현상이 발생하므로 최적값을 정하기 위해 다소의
실험이 필요하다.
이제 또 다른 예로서 다음은 우리나라에서의 특히 전자금융거래에 대한 탐지에 대한 한 보고서이다.30
30 이상 금융 거래 탐지 및 대응 프레임워크, TTA (한국정보통신기술협회) 정보통신단체표준 (TTAK.KO-12.0178),
2011 년 12 월 21 일
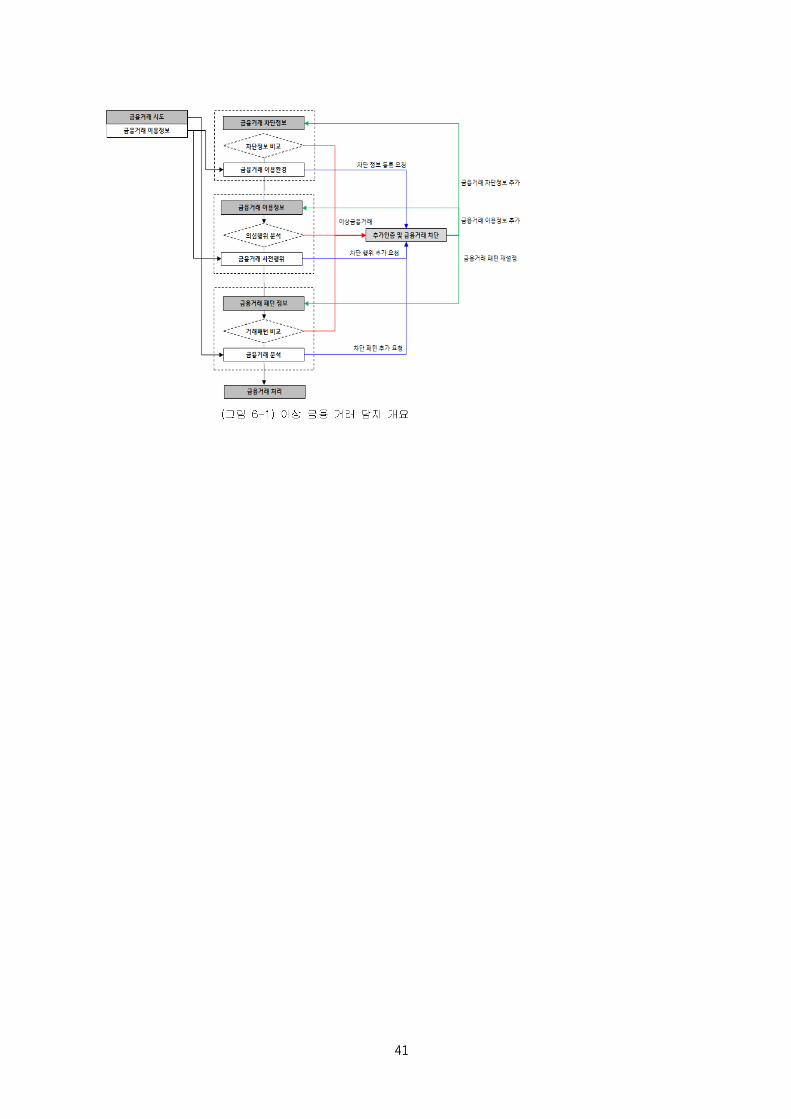
41

42
6. 스트리밍을 이용한 R과 Hadoop의 혼용
앞서 리눅스에서의 stream 방식을 통해 Hadoop 과 다른 프로그래밍 언어를 함께 이용할 수 있다고
하였는데31 여기서는 이 기법을 통해 Hadoop 과 R 을 함께 이용하기로 한다. 특히 Hadoop 을 이용한
빅데이터 처리에 있어 R 을 이용하되 map 만으로 구성하는 경우와 Map 과 Reduce 를 모두 구성하는
경우를 비교하면서 살펴 본다. 32
(1) R을 이용한 map 기능만의 구현
MapReduce 에서 일반적으로 그러하듯이 R 을 이용하면서도 map 함수만을 적용할 수 있다. 데이터를
join 하거나 그룹화할 필요도 없고 별도의 sort 작업도 필요없는 경우 reduce 함수를 생략해도 무방하기
때문이다.
여기서는 주식 가격의 일별 평균을 구하는 경우를 살펴 보는데 데이터 파일이 다음 column 으로 구성되는
csv 포맷이라고 가정하자. 다음 데이터 파일에서 보듯이 각 줄마다 개별 주식의 주가가 나열되어 있다.
Symbol,Date,Open,High,Low,Close,Volume,Adj Close
$ head -6 test-data/stocks.txt
AAPL,2009-01-02,85.88,91.04,85.16,90.75,26643400,90.75
AAPL,2008-01-02,199.27,200.26,192.55,194.84,38542100,194.84
AAPL,2007-01-03,86.29,86.58,81.90,83.80,44225700,83.80
AAPL,2006-01-03,72.38,74.75,72.25,74.75,28829800,74.75
AAPL,2005-01-03,64.78,65.11,62.60,63.29,24714000,31.65
AAPL,2004-01-02,21.55,21.75,21.18,21.28,5165800,10.64
이제 위의 데이터를 읽고 계산하는 작업을 다음의 R 코드에서 수행한다.
1 #! /usr/bin/env Rscript
2 options(warn=-1)
3 sink("/dev/null")
4 input <- file("stdin", "r")
5
6 while(length(currentLine<-readLines(input,n=1,warn=FALSE))>0) {
7
8 fields <- unlist(strsplit(currentLine, ","))
9
10 lowHigh <- c(as.double(fields[3]), as.double(fields[6]))
11
12 stock_mean <- mean(lowHigh)
13
31 II. Hadoop ▶ 4. Hadoop 설치운영과 프로그래밍 ▶ (2) ▶‘나’ 항목 (Java 와 다른 언어의 혼용)을 참조할 것.
32 Alex Holmes, Hadoop in Practice, Manning Publications, 2012

43
14 sink()
15
16 cat(fields[1], fields[2], stock_mean, "\n", sep="\t")
17
18 sink("/dev/null")
19
20 }
21 close(input)
맨 첫 줄에서 Rscript 가 수행될 환경을 지정하였는데 이는 Linux/Unix 에서의 shell 지정과 마찬가지이다.
둘째 줄의 옵션을 통해 warning 메시지의 출력을 억제한 후 결과가 출력될 곳을 /dev/null 로 지정하였다.
다음으로 4 번 줄의 input 명령어를 통해 입력파일을 읽기 mode 로 지정하였다.
이제 6~20 번 줄 사이에 있는 while 문의 블록에서 파일의 각 줄 별로 반복 작업의 내용을 지정하였다.
8 번줄의 Unlist 를 통해 읽어들인 각각의 문자열을 콤마 (,)를 기준으로 분리 (split)시킨 후 그 결과의
리스트를 벡터로 옮긴 후 다음 10 번 줄에서 새로운 vector 를 만들고 3 번째 및 6 번째 column 의 데이터,
즉, 주식의 시가와 종가를 lowHigh 라는 벡터변수로 저장하였다.
12 번 줄에서 평균계산을 한 후, 14 번 줄에서 sink() 명령에 대해 아무런 argument 를 지정하지
않음으로써 표준 출력 (standard output)을 복원하였다.
16 번 줄에서 cat 명령으로 1, 2 번 필드와 함께 연결한 후 18 번 줄에서 스트리밍 처리라는 환경을
반영하여 모든 출력을 다시 /dev/null 로 변경하였다.
이제 map-only 의 스트리밍 작업 구조가 다음 그림에 표시되어 있다.
실제 위의 프로그램을 수행하면 다음과 같은 결과가 출력된다.
$ cat test-data/stocks.txt | src/main/test/stock_day_avg.R

44
AAPL 2009-01-02 88.315
AAPL 2008-01-02 197.055
AAPL 2007-01-03 85.045
AAPL 2006-01-03 73.565
...
출력결과가 정상임을 확인한 후 이를 Hadoop 의 job 으로서 수행한다.
$ export HADOOP_HOME = /usr/lib/hadoop
$ ${HADOOP_HOME}/bin/hadoop fs -rmr output
$ ${HADOOP_HOME}/bin/hadoop fs
-put test-data/stocks.txt stocks.txt
$ ${HADOOP_HOME}/bin/hadoop \
jar ${HADOOP_HOME}/contrib/streaming/*.jar \
-D mapreduce.job.reduces=0 \
-inputformat org.apache.hadoop.mapred.TextInputformat \
- input stocks.txt \
- output output \
- mapper `pwd'/src/main/test/stock_day_avg.R \
- file `pwd`//src/main/test/stock_day_avg.R
여기서는 linux 상의 export 명령을 통해 Hadoop 의 설치장소를 밝히고, 출력장소 등에 대한 정리작업
(housekeeping)을 하였다. 그런 후 jar 명령을 통해 스트리밍 프로그램의 위치를 지정하였다.
유의할 것은 -D 옵션에서 mapreduce.job.reduces=0 로 지정함으로써 reducer 함수는 적용되지
않도록 한 점이다. 이후 입출력 파일을 지정한 후 -mapper 에서 map 함수로 수행할 프로그램을
지정하였다.
위와 같이 mapper 함수를 통한 수행을 하여도 출력 결과는 앞서 R 프로그램 수행과 동일하게 된다.
(2) R 을 Map과 Reduce 모두에 적용하는 경우
map 과 reduce 를 모두 적용하는 경우를 본다. 여기서는 단순평균뿐 아니라 이동평균 (CMA:
cumulative moving average)을 계산한다.
#! /usr/bin/env Rscript
options(warn=-1)
sink("/dev/null")
outputMean <- function(stock, means) {
stock_mean <- mean(means)
sink()
cat(stock, stock_mean, "\n", sep="\t")
sink("/dev/null")
}
input <- file("stdin", "r")
prevKey <- ""

45
means <- numeric(0)
while(length(currentLine <- readLines(input,n=1,warn=FALSE))>0) {
fields <- unlist(strsplit(currentLine, "\t"))
key <- fields[1]
mean <- as.double(fields[3])
if( identical(prevKey, "") || identical(prevKey, key)) {
prevKey <- key
means <- c(means, mean)
} else {
outputMean(prevKey, means)
prevKey <- key
means <- c(means, mean)
}
}
if(!identical(prevKey, "")) {
outputMean(prevKey, means)
}
close(input)
위 R 스크립트의 output<- function(stock, means) { ... } 함수에서 주식코드와 평균에 대한
vector 를 입력받은 후 CMA 를 계산하고 그 결과를 표준출력장치로 보내도록 지정하였다.
이후 while()문 내에서 실제 작업이 이루어지는데 특히 while () 안에서의 if..else.. 문에서 새로운 key 를
발견하면 함수를 호출해서 CMA 를 계산한 후 이를 표준출력장치에 보내도록 outputMean() 함수를
호출하고 있다.
위에서 보았듯이 MapReduce 는 map 에서의 결과물을 정렬하고 그룹화하는데 위에서는 주가 코드별로 -
즉, 이것을 key 로 하여 - 이들 작업이 진행되었다.
이제 위의 R 스크립트를 stock_cma.R 라는 이름의 파일로 저장한 후 다음과 같은 명령어로 그 결과를
확인한다.
$ cat test-data/stocks.txt | src/main/test/stock_day_avg.R | sort --key 1,1 |
src/main/test/stock_cma.R
AAPL 68.997
CSCO 49.94775
GOOG 123.9468
MSFT 101.297
YHOO 94.55789
다음 그림에서는 스트리밍 작업과 R 스크립트가 함께 reduce 측에 적용되는 구조를 보여주고 있다.

46
이제 이 작업도 Hadoop 의 job 으로 수행할 수 있다.
$ export HADOOP_HOME = /usr/lib/hadoop
$ ${HADOOP_HOME}/bin/hadoop fs -rmr output
$ ${HADOOP_HOME}/bin/hadoop fs -put test-data/stocks.txt stocks.txt
$ ${HADOOP_HOME}/bin/hadoop \
jar ${HADOOP_HOME}/contrib/streaming/*.jar \
-inputformat org.apache.hadoop.mapred.TextInputformat \
- input stocks.txt \
- output output \
- mapper `pwd'/src/main/test/stock_day_avg.R \
- reducer `pwd'/src/main/test/stock_day_cma.R \
- file `pwd`//src/main/test/stock_day_avg.R
이 명령어를 보면 앞서 map 만으로 구성된 프로그램의 수행과 동일하며 단지 -reducer ... 문장을 통해
reduce 함수만이 추가되었음을 알 수 있다. 그리고 이러한 Hadoop 수행명령의 결과 역시 위의
R 수행결과와 동일함은 물론이다.