非技術者でもわかる(?)コンピュータビジョン紹介資料
DESCRIPTION
お仕事で作った資料。 全体紹介の資料としてはバランス悪いですが、どなたかのお役に立てれば。TRANSCRIPT

非技術者でもわかる(?)コンピュータビジョン紹介資料
ビジョン&ITラボ 皆川卓也

2
はじめに

この資料について
3
この資料は、とあるお客様のコンサルティング用に作成したものです。 お客様から許可を得て公開しています。
業務上関係なさそうな分野の説明は省略しているため、コンピュータビジョンの全体紹介としてはバランスを欠いてます。
「コンピュータビジョンってこんなことできるんだ!すげー!!」と思ってもらうのが目的です。 資料中にURLを埋め込んでいるので、埋め込み先にあるデモ動画
などを見ることをおすすめします。
参考に上げた論文は、state-of-the-artなものよりも考え方がわかるようなものを選んだつもりです。
自分が得意でない分野も含むので、誤っているところなどは優しく指摘していただけるとありがたいです。

自己紹介
4
テクニカル・ソリューション・アーキテクト
皆川 卓也(みながわ たくや)フリーエンジニア(ビジョン&ITラボ)「コンピュータビジョン勉強会@関東」主催博士(工学)
テクニカル・ソリューション・アーキテクト
皆川 卓也(みながわ たくや)フリーエンジニア(ビジョン&ITラボ)「コンピュータビジョン勉強会@関東」主催博士(工学)
略歴:1999-2003年日本HP(後にアジレント・テクノロジーへ分社)にて、ITエンジニアとしてシステム構築、プリセールス、プロジェクトマネジメント、サポート等の業務に従事
2004-2009年コンピュータビジョンを用いたシステム/アプリ/サービス開発等に従事
2007-2010年慶應義塾大学大学院 後期博士課程にて、コンピュータビジョンを専攻単位取得退学後、2014年に博士号取得
2009年-現在フリーランスとして、コンピュータビジョンのコンサル/研究/開発等に従事

(R:90, G:12, B:57)
(R:239, G:207, B:198)
コンピュータにとっての画像
画像の内容を認識する難しさ
5

コンピュータ・ビジョンとは?
画像に関する研究分野
カメラに映った顔が本人かどうか認証したい。
自動車に設置したカメラで道路、歩行者、対向車を認識したい
ビデオカメラで撮影した対象物の3次元モデルを自動生成したい
複数の画像をつなげて、パノラマ画像を自動生成したい
サッカーの試合の動画から、選手とボールの動きを追跡したい
手元にある風景画像がどこを撮影したものかを検索したい。
etc
6

なぜ今コンピュータビジョンなのか
Solution
コンピュータビジョン
Requirements
画像データの自動解析/検索技術向上
自然なインターフェース 新しいユーザ体験の生成
Problems
ネット上の画像データの増大 様々なリテラシーのユーザへ拡大 差別化の必要性
Situation
インターネットの拡大 カメラ付きスマートデバイスの普及Web/エレクトロニクス企業のグ
ローバル競争
7

なぜ今コンピュータビジョンなのか
8
様々な新型デバイスの登場!
Project TangoGoPro
Kinect
Lytro
Google Glass
Intel RealSense 3D
RICOH Theta

本日紹介するトピック
9
1. 人や顔の認識
2. 色々な物体の認識
3. 画像の加工/品質向上
4. 大量の画像からできること

10
人や顔の認識

人や顔を認識する
11
顔を認識する
顔検出
顔認証
顔器官検出
顔属性判定
人を認識する
人物検出
姿勢推定
その他
ペット認識

顔検出
12
顔が画像のどこにあるのかを判定する。

顔検出(原理)
13
代表的な手法:
Haar-like features + Cascaded Classifier [Viola2001]
plus
minus

顔検出(実装例)
14
アプリケーション
デジタルカメラのオートフォーカス
Amazon Fire Phoneの3次元IF
Google Street View
プライバシー保護目的
Nikon COOLPIX 5900

顔認証
15
写真に写っている人物が「誰か」を判定する。
Natalie Portman
Jean Reno

顔認証(原理)
16
代表的な手法
Eigen Face [Turk1991]
Bunch Graph Matching [Wiskott1997]
Deep Face [Taigman2014]
Eigen Face Credit: [Wikipedia]
Deep Face Credit: [Taiman2014]

顔認証(実装例)
17
アプリケーション
写真共有サイトにおける、顔によるラベルづけ/写真整理
Google+, Facebook
有名人の誰に似ているかを判定するエンタメサービス
顔ちぇき!
出会い系/結婚紹介サイトの好みの顔検索
http://internetcom.jp/webtech/20131220/3.html
http://www.gizmodo.jp/2014/06/matchcom.html

顔器官検出
18
目、鼻、口、輪郭など、顔の詳細パーツを抽出する。
顔向き推定、視線推定、目/口の開き、メガネの有無判定なども
Credit:[Cao2012]

顔器官検出(原理)
19
代表的な手法
Active Appearance Model [Matthews2004]
Constrained Local Model [Cristinacce2006]
Explicit Shape Regression [Cao2012]
)(pp
Constrained Local Model Credit:[Saragih2011]

顔器官検出(実装例)
20
アプリケーション
アバター(ゲーム等)
SOEmote https://www.youtube.com/watch?v=cde01HNKQVw
プリクラ(美顔、デカ目)
ゾンビちぇき!
バンダイナムコゲームス「Eye mix」

顔属性判定
21
性別、表情、年齢などを判定する。
OKAO Visionのサイト[http://plus-sensing.omron.co.jp/technology/detail/]より画像転載
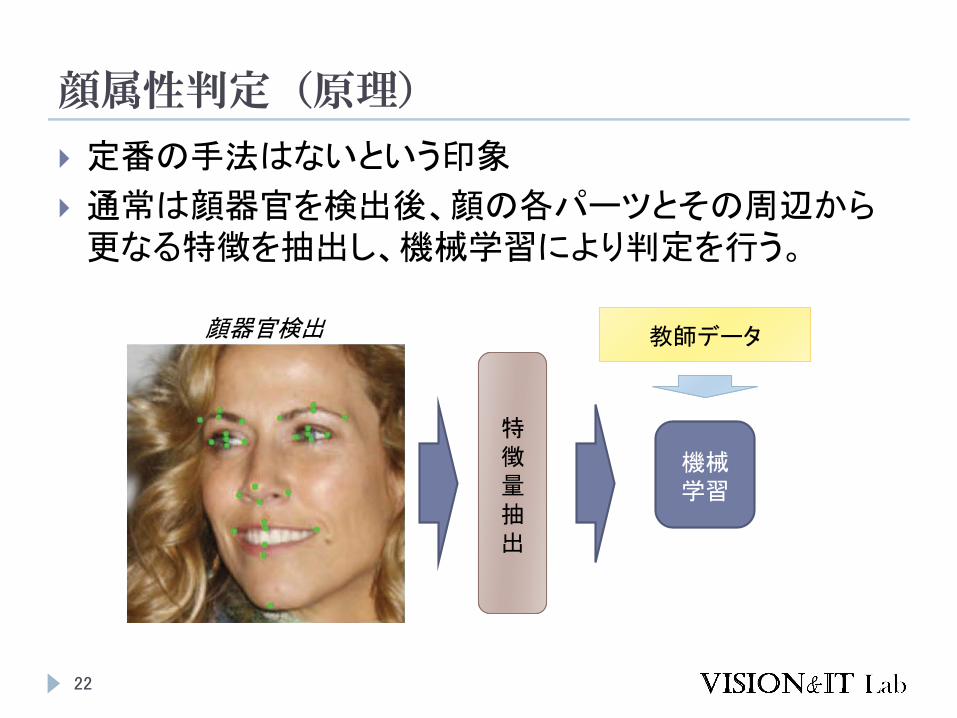
顔属性判定(原理)
22
定番の手法はないという印象
通常は顔器官を検出後、顔の各パーツとその周辺から更なる特徴を抽出し、機械学習により判定を行う。
顔器官検出
機械学習
教師データ教師データ
特徴量抽出
特徴量抽出

顔属性判定(実装例)
23
アプリケーション
スマイルシャッター(ソニー サイバーショット)
http://www.sony.jp/ServiceArea/impdf/pdf/44329430M.w-JP/jp/contents/04/02/11/11.html
笑っただけ払えば良いコメディ劇場
http://kyouki.hatenablog.com/entry/2014/06/12/064138
タバコ自販機による年齢確認
http://ja.wikipedia.org/wiki/成人識別自動販売機
自販機における自動商品推薦機能
http://www.itmedia.co.jp/news/articles/1008/10/news080.html

人検出
24
画像から人の位置を検出する

人検出(原理)
25
代表的な手法
Histogram of Oriented Gradients (HOG) [Dalal2005]
Deformable Part Model [Felzenszwalb2009]
Credit:[Felzenszwalb2009]
Root filter Parts filter Deformation

人検出(実装例)
26
アプリケーション
自動車の歩行者検出
http://www.zmp.co.jp/products/robovision-single?lang=jp
SNSにおける投稿画像の位置最適化 (Facebook)
http://www.advertimes.com/adobata/article/18824/gaiax-socialmedialab.jp/facebook/272/

人姿勢推定
27
画像から人物の姿勢を推定する。
Credit:[Toshev2014]

人姿勢推定(原理)
28
代表的な手法
静止画からポーズ推定(例:Pictorial Structure [Felzenswalb2005])
動画からポーズ推定(例:[Ferrari2008])
距離センサーを使用してポーズ指定(例::Kinect [Shotton2011])
Credit: [Shotton2011]
Credit: [Felzenswalb2005]

人姿勢推定(実装例)
29
アプリケーション
ゲーム (Kinect)
映画等のモーションキャプチャ
ジェスチャー認識
マーカレスモーションキャプチャ(東芝)

ペット検出
30
画像からペットの顔を検出する
OKAO Visionのサイト[http://plus-sensing.omron.co.jp/technology/movie/]より画像転載

ペット検出(原理)
31
論文としては多くないが、需要が高いためか製品としてはいくつか見かける。
顔検出で多く用いられるHaar-like特徴では不十分なため、エッジ情報等を加えて特徴量を工夫している。[Zhang2008][Kozakaya2009]
Credit:[Zhang2008]

ペット検出(実装例)
32
アプリケーション
デジタルカメラのペット検出オートーフォーカス
FinePix Z700EXR、Optio I-10、CX3
PiP
迷子のペット探し用スマートフォンアプリ
http://www.petrecognition.com/

ライブラリ
33
商用ライブラリ OMRON, OKAO Vision, http://plus-
sensing.omron.co.jp/technology/ 顔検出,顔認証,顔器官検出,顔属性判定(年齢、性別、表情、笑顔),
人検出,ペット検出(犬、猫),ハンドジェスチャー
沖電気, Face Sensing Engine (FSE), https://www.oki.com/jp/fse/ 顔検出,顔認証,顔器官検出
NEC, NeoFace, http://jpn.nec.com/face/ 顔検出,顔認証
PUX, FaceU, http://www.pux.co.jp/softsensor/faceu.html 顔検出,顔認証,顔器官検出,顔属性判定(年齢、性別、笑顔),ペット
検出(犬、猫、小鳥),ジェスチャー/ハンドジェスチャー Web APIあり
Microsoft, KinectSDK http://www.microsoft.com/en-us/kinectforwindowsdev/default.aspx 距離画像を用いた姿勢推定[Shotton2011]

ライブラリ
34
商用WebAPI
Orbeus Inc., ReKognition
http://rekognition.com/
顔検出,顔認証,顔器官検出,顔属性判定(年齢、性別、表情、笑顔、人種、美しさ)、猫認識
各OS用SDK提供あり
ゼータ・ブリッジ, フォトナビ
http://biz.photonavi.jp/
顔検出,顔器官検出,顔属性判定(年齢、性別、笑顔)
Face++
http://www.faceplusplus.com/
顔検出,顔認証,顔器官検出,顔属性判定(年齢、性別、人種、笑顔)

ライブラリ
35
Open Source
OpenCV, http://opencv.org/
顔検出([Viola2001]),顔器官検出([Viola2001]),顔認証(Eigen Face[Turk1991], Fisher Face[Belhumeur1997]),顔属性判定(性別、年齢),人検出([Dalal2005],[Felzenszwalb2009])
ccv, http://libccv.org/
人検出([Dalal2005],[Felzenszwalb2009])
学習用プログラムあり

ライブラリ
36
Open Source
Active Appearance Model
AAM-OpenCV https://code.google.com/p/aam-opencv/
AAM-API http://www2.imm.dtu.dk/~aam/
Constrained Local Model
https://sites.google.com/site/xgyanhome/home/projects/clm-implementation
[Saragih2011]のJavaScript実装https://github.com/auduno/clmtrackr
Pictorial Structure [Andriluka2009]
http://www.d2.mpi-inf.mpg.de/andriluka_cvpr09

参考文献
37
[Viola2001]Viola, P., & Jones, M. (2001). Rapid object detection using a boosted cascade of simple features. IEEE International Conference on Computer Vision and Pattern Recognition (CVPR).
[Turk1991]Turk, M., & Pentland, A. (1991). Eigenfaces for Recognition. Journal of Cognitive Neuroscienceo, 3(1), 71–86.
[Wiskott1997]Wiskott, L., Fellous, J.-M., Kruger, N., & Malsburg, C. von der. (1997). Face recognition by elastic bunch graph matching. IEEE Transactions on Pattern Analysis and Machine Intelligence, 19(7), 775–779.
[Taigman2014]Taigman, Y., Ranzato, M. A., & Wolf, L. (2014). DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[Belhumeur1997]Belhumeur, P. N., Hespanha, J. P., & Kriegman, D. J. (1997). Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection. IEEE Transaction on Pattern Analysis and Machine Intelligence, 19(7), 711–720.

参考文献
38
[Matthews2004]Matthews, I., & Baker, S. (2004). Active appearance models revisited. International Journal of Computer Vision, 60(2), 135–164.
[Cristinacce2006]Cristinacce, D., & Cootes, T. (2006). Feature detection and tracking with constrained local models. In Proc. British Machine Vision Conference (Vol. 3, pp. 929–938).
[Saragih2011]Saragih, J. M., Lucey, S., & Cohn, J. F. (2011). Deformable Model Fitting by Regularized Landmark Mean-Shift. International Journal of Computer Vision, 91(2), 200–215.
[Cao2012]Cao, X., Wei, Y., Wen, F., & Sun, J. (2012). Face Alignment by Explicit Shape Regression. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[Dalal2005]Dalal, N., & Triggs, B. (2005). Histograms of Oriented Gradients for Human Detection. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).

参考文献
39
[Felzenswalb2009]Felzenszwalb, P. F., Girshick, R. B., McAllester, D., & Ramanan, D. (2009). Object detection with discriminatively trained part-based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9), 1627–1645.
[Toshev2014]Toshev, A., & Szegedy, C. (2014). DeepPose: Human pose estimation via deep neural networks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[Felzenszwalb2005]Felzenszwalb, P. F., & Huttenlocher, D. P. (2005). Pictorial Structures for Object Recognition. International Journal of Computer Vision, 61(1), 55–79.
[Ferrari2008]Ferrari, V., Mar, M., & Zisserman, A. (2008). Progressive Search Space Reduction for Human Pose Estimation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[Shotton2011]Shotton, J., Fitzgibbon, A., Cook, M., Sharp, T., Finocchio, M., Moore, R., Kipman A., Blake, A. (2011). Real-time human pose recognition in parts from single depth images. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).

参考文献
40
[Andriluka2009]Andriluka, M., Roth, S., & Schiele, B. (2009). Pictorial structures revisited: People detection and articulated pose estimation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[Zhang2008]Zhang, W., Sun, J., & Tang, X. (2008). Cat Head Detection -How to Effectively Exploit Shape. In IEEE conference on Computer Vision and Pattern Recognition (CVPR).
[Kozakaya2009]Kozakaya, T., Ito, S., Kubota, S., Yamaguchi, O. (2009). Cat face detection with two heterogeneous features., In IEEE International Conference on Image Processing (pp. 1209-1212)

41
色々な物体を認識

色々な物体を認識
42
特定物体認識
一般物体認識
一般物体検出
顕著性検出
Objectness検出
文字認識

特定物体認識
43
画像から事前に登録した画像と同一の物体を認識する。
パンフレット/パッケージ/ランドマークなど
コンピュータビジョン最先端ガイド1
カメラで撮影
認識!

特定物体認識(原理)
44
代表的な手法
SIFT等の局所特徴量+近似最近傍探索 [Lowe1999]
大規模なデータベースに対してはBag-of-Featuresを用いる[Sivic2003]
Histogram of Gradient Orientations
DB
・・・xx
xx
x
xx
xx
x
xxx
xx
x
xx x
x
マッチング+投票

特定物体認識(実装例)
45
アプリケーション
Google Goggles(ランドマークや書籍などの認識)
Amazon Fire Phone (書籍やCDジャケット等)
マーケティング/販促
TSUTAYA DVDジャケット撮影で作品情報提供
http://www.nikkei.com/article/DGXNASDD0301Y_T00C13A8TJC000/
楽天 スマホで撮った商品を自動検索
http://www.nikkei.com/article/DGXNASDD180LC_Y3A710C1TJ1000/
Google Goggles(Google)

一般物体認識
46
画像に写っている物体のカテゴリを判別する
飛行機 顔 自動車
入力画像
出力
カテゴリ認識

一般物体認識(詳細画像識別)
47
あるカテゴリ内のサブカテゴリを認識する
犬種:チワワ、プードル、シベリアンハスキー、ドーベルマン等
車種:アクセラ、スカイライン、ヴィッツ等
Scarlet Kingfisher African daisy
Flower

一般物体認識(原理)
48
代表的な手法1
Bags-of-Features (BoF)
Dictionary (Visual Words)
30
02
12
11
Histogram of visual words
Image
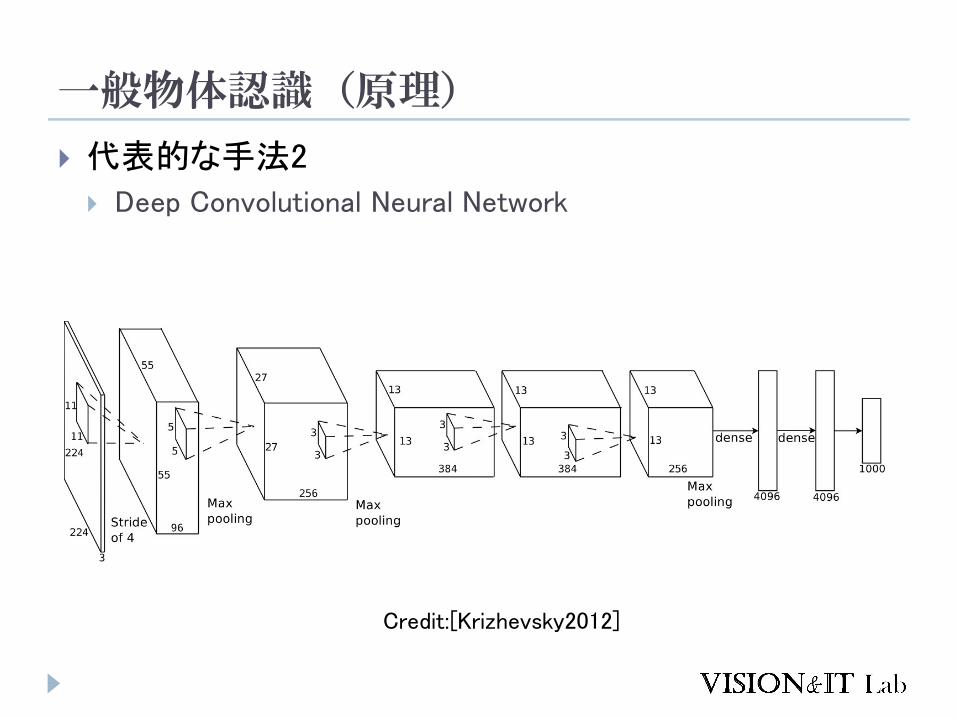
一般物体認識(原理)
代表的な手法2
Deep Convolutional Neural Network
Credit:[Krizhevsky2012]

一般物体認識(実装例)
50
アプリケーション
SNSの写真検索
Google+ / Picasa
食事画像認識によるカロリー管理
FoodLog(http://www.foodlog.jp/)
バーコードいらずのレジ
BakerlyScan, http://www.bakeryscan.com/
食パン識別
NECの画像認識レジ
http://www.itmedia.co.jp/enterprise/articles/1311/14/news050.html

一般物体認識(実装例)
51
アプリケーション
EUVISION Technologies, Impala
http://www.euvt.eu/impala-mobile-app-automatic-photo-album-and-picture-organizer/
一般物体認識をスマートフォン上で動かせるくらい軽量化したアプリ
Leaf snap
http://leafsnap.com/
植物識別アプリ[Kumar2012]
Bird snap
http://birdsnap.com
鳥識別アプリ[Berg2014]

一般物体検出
52
自動車、人、ボトル、牛、など一般的な物体の位置を画像から見つける。
顔検出、人検出も一般物体検出に含まれる。
顔
歩行者
車

一般物体検出(原理)
53
顔検出や人検出などで紹介したアルゴリズム、および一般物体認識で使用されるアルゴリズムは、一般物体検出でも広く使われている。
Haar-like features + Cascaded Classifier [Viola2001]
Histogram of Oriented Gradients (HOG) [Dalal2005]
Deformable Part Model [Felzenszwalb2009]
Deep Convolutional Neural Network

顕著性検出
54
画像の中で「目立つ」ところを探す。
元々は人間が目立つ箇所に無意識に注意が向く仕組み(ボトムアップ注意)をモデル化したもの
[木村2012]プレゼン資料より抜粋

顕著性検出(原理)
55
代表的な手法
Saliency Map model [Itti2000]
Credit: [Itti2000]

顕著性検出(実装例)
56
アプリケーション
Bing画像検索 [Wang2012]
http://www.bing.com/?scope=images
検索フィルタ(色)
背景の色を無視して対象の色を元に検索できる。(花など)
http://blogs.bing.com/search/2012/06/21/bing-image-search-updates-roll-out-today/

Objectness検出
57
画像から物体っぽいものを検出する。(それがどんな物体かまでは判別しない。)
一般物体検出の前処理として使われる。
Credit: [Cheng2014]

Objectness検出(原理)
58
代表的な手法
定番の方法は存在しないという印象
[Alexe2011]:Objectness検出の問題を提案
[Cheng2014]:BINGという最新の手法(CVPR2014)
Credit:[Cheng2014]

文字検出/認識
59
画像中の文字領域を検出する
画像中の文字を認識する
あ い う

文字検出/認識(原理)
60
代表的な手法
畳み込みニューラルネットワーク [LuCun1998]
deeplearning.netより画像転載[http://deeplearning.net/tutorial/lenet.html]

文字検出/認識(実装例)
アプリケーション
Evernote
画像中の文字を認識してIndex化。検索に利用
Google Goggles
Word Lens
https://www.youtube.com/watch?v=h2OfQdYrHRs
Googleが買収済み
61

ライブラリ
62
商用ライブラリ OMRON, OKAO Vision, http://plus-
sensing.omron.co.jp/technology/ シーン認識(一般物体認識)、被写体認識(顕著性検出)
顔検出,顔認証
PUX, 画像認識ソフトウェア他, http://www.pux.co.jp/softsensor/ シーン認識(一般物体認識),オブジェクト認識(特定物体認識)、手
書き文字認識、ナンバープレート認識
Web APIあり
メディアドライブ,OCRライブラリ等 http://mediadrive.jp/products/library/
活字や手書きなど様々な用途向けOCRライブラリ
特定物体認識SDKもあり

ライブラリ
63
商用WebAPI
Orbeus Inc., ReKognition
http://rekognition.com/
コンセプト認識(特定物体認識、一般物体認識)
各OS用SDK提供あり
ゼータ・ブリッジ, フォトナビ
http://biz.photonavi.jp/
一致検索(特定物体認識)

ライブラリ
64
Open Source OpenCV, http://opencv.org/
特定物体認識のためのSIFT、SURF、BRISK、ORB、FREAK等の局所特徴量+FLANN等の近似最近傍探索
Bags-of-Features
ccv, http://libccv.org/ 一般物体検出([Dalal2005],[Felzenszwalb2009])
HOG、Deformable Part Model
SIFT等の局所特徴量の実装もあり
VLFeat, http://www.vlfeat.org/ 特定物体認識、一般物体認識、一般物体検出のための特徴量
(SIFT、HOG、Fisher Vector、VLAD等)やアルゴリズム(k-mean, GMM, kd-tree, SVM等)
一般物体認識のサンプルアプリケーションあり

ライブラリ/ソフトウェア
65
Open Source 特定物体認識
OpenCV Markerless AR, https://github.com/takmin/OpenCV-Marker-less-AR 特定物体認識のコードが含まれている
顕著性検出 Saliency Toolbox (Matlab), http://www.saliencytoolbox.net/
[Itti2000]のPython実装, https://github.com/akisato-/pySaliencyMap/tree/master
ILab Neuromorphic Vision V++ Toolkit, http://ilab.usc.edu/toolkit/
Objectness検出 Objectness measure [Alexe2012], http://groups.inf.ed.ac.uk/calvin/objectness/
BING [Cheng2014], http://mmcheng.net/code-data/
文字認識 TessearctOCR, https://code.google.com/p/tesseract-ocr/
OpenCV3.0(自然画像からの文字列検出)

ソフトウェア/ライブラリ
66
Deep Learning Deep learning関係のソフトウェアまとめ
http://deeplearning.net/software_links/
Theano, http://deeplearning.net/software/theano Convolutional Neural Network(CNN), Deep Belief Net(DBN), Deep
Boltzmann Machine(DBM)のPython実装 with CUDA and BLAS
EBlearn, http://eblearn.cs.nyu.edu:21991/ CNNのC++実装 with IPP/SSE/OpenMP
cuda-convent, http://code.google.com/p/cuda-convnet ILSVRC2012という大規模一般物体認識のコンテストでぶっちぎり一位
になったCNN実装 with CUDA
Caffe, http://caffe.berkeleyvision.org/index.html CNNのC++実装 with CUDA
ConfnetJS, http://cs.stanford.edu/people/karpathy/convnetjs/ CNNのJavaScript実装

参考文献
67
[Lowe1999]Lowe, D. G. (1999). Object recognition from local scale-invariant features. In IEEE International Conference on Computer Vision(pp. 1150–1157 vol.2).
[Sivic2003]Sivic, J., & Zisserman, A. (2003). Video Google: a text retrieval approach to object matching in videos. In IEEE InternatinalConference on Computer Vision (CVPR).
[Csurka2004]Csurka, G., Dance, C. R., Fan, L., Willamowski, J., & Bray, C. (2004). Visual categorization with bags of keypoints. In Workshop on statistical learning in computer vision, ECCV (Vol. 1, p. 22).
[Krizhevsky2012]Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems (NIPS) (pp. 1106–1114).
[Kumar2012]Kumar, N., Belhumeur, P. N., Biswas, A., Jacobs, D. W., Kress, W. J., Lopez, I., & Soares, J. V. B. (2012). Leafsnap: A Computer Vision System for Automatic Plant Species Identification. In European Conference on Computer Vision.

参考文献
68
[Berg2014]Berg, T., Liu, J., Lee, S. W., Alexander, M. L., Jacobs, D. W., & Belhumeur, P. N. (2014). Birdsnap: Large-scale Fine-grained Visual Categorization of Birds. In IEEE conference on Computer Vision and Pattern Recognition (CVPR).
[Itti2000]Itti, L., & Koch, C. (2000). A saliency-based search mechanism for overt and covert shifts of visual attention. Vision Research, 40(10-12), 1489–506.
[Wang2012]Wang, P., Wang, J., Zeng, G., Feng, J., Zha, H., & Li, S. (2012). Salient object detection for searched web images via global saliency. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[木村2012]木村昭悟, 米谷竜, 平山高嗣. (2012). “[サーベイ論文]人間の視覚的注意の計算モデル”, 電気情報通信学会技術報告
[Alexe2012]Alexe, B., Deselaers, T., & Ferrari, V. (2012). Measuring the objectness of image windows. IEEE Transaction on Pattern Analysis and Machine Intelligence, 34(11), 1–14.

参考文献
69
[Cheng2014]Cheng, M.-M., Zhang, Z., Lin, W.-Y., & Torr, P. (2014). BING : Binarized Normed Gradients for Objectness Estimation at 300fps. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[LeCun1998]LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. In Proceedings of the IEEE (pp. 2278–2324).

70
画像の加工/品質向上

画像の加工/品質向上
71
フィルタによる画像加工
画質の品質を向上させる
画像から必要な物体だけ綺麗に切り抜く
画像同士を合成する
画像からいらない領域を取り除く
被写体を歪めずに画像をリサイズする
二次元の画像から三次元モデルを生成する

フィルタによる画像加工
72
Instagramのように画像に効果をつける処理
漫画カメラhttp://tokyo.supersoftware.c
o.jp/mangacamera/Instagram
http://instagram.com/エンボス
Rise
Original Toaster
Willow

画像の品質を向上させる
73
暗い画像を調整する(ダイナミックレンジ補正)
ヒストグラム伸張の例

画像の品質を向上させる
74
コントラストを強調する
ヒストグラム平坦化の例

画像の品質を向上させる
75
ノイズ除去
ガウシアンフィルタ、メディアンフィルタ、バイラテラルフィルタ[Tomasi1998]、ノンローカルミーンフィルタ[Buades2005]、BM3D[Dabov2007]、etc
ノイズ画像 ガウシアンフィルタ バイラテラルフィルタ

画像の品質を向上させる
76
ノイズ除去の原理
バイラテラルフィルタ[Tomasi1998]の場合
「隣り合う画素の値は近いはず」「ただし隣り合う画素の値が大きく違う場合はエッジ」
という知識を入れたフィルタ
入力画像 バイラテラルフィルタ 出力画像
Credit:[Tomasi1998]

画像の品質を向上させる
77
画像を元々の解像度以上に拡大する。(超解像)
画像のボケを補正する。
動画(複数枚画像)を使用する方法[Farsiu2003][Mitzel2009]
1枚の画像から復元する方法[Freeman2002][Yang2008]

画像の品質を向上させる
78
超解像/ボケ補正([Freeman2002]の例)
低解像度の画像パッチと高解像度の画像パッチとの関係を事前に学習しておくことで、1枚の画像から超解像を行う。
Credit:[Freeman2002]

画像から必要な物体だけきれいに切り抜く
79
物体の輪郭を求める
画像内を似た色や同じ物体同士で領域分割する
画像から前景を背景から分離する。
領域分割(Mean Shiftの例) 前景分離(Credit:[Rother2004])

画像から必要な物体だけきれいに切り抜く
80
代表的な手法
輪郭抽出
Snake, LevelSet[Osher1988]
領域分割
Watershed, k-means, 混合ガウス分布, mean shift [Comaniciu2002]
前景抽出
Grub cut [Rother2004]

画像から必要な物体だけきれいに切り抜く
81
Grab Cut[Rother2004]の例
1. 矩形の外を背景、中を前景の初期位置とする。
2. 背景の色分布と前景の色分布を確率分布(混合ガウス分布)で表す。
3. 前景領域と背景領域が以下の条件をできるだけ満たすようにGraph Cutと呼ばれる手法でそれぞれの領域を更新する。• 各画素の色が高い確率を示すよう
に前景か背景かをラベル付• 境界をまたいで隣り合う画素の色
が異なるように。4. 2と3を収束するまで繰り返す。

画像同士を合成する
82
背景画像に前景画像を「自然な形で」貼り合わせる
Credit: [Pérez2003]

画像同士を合成する
83
背景画像に前景画像を「自然な形で」貼り合わせる
代表的な手法: Poisson Image Editing [Pérez2003]
Srcの画像の勾配を維持
境界はDstの情報を維持
Src
Dst

画像同士を合成する
84
背景画像に前景画像を「自然な形で」貼り合わせる
応用例: フォトモンタージュ[Agarwala2004]
複数枚の画像から全員が笑って正面を向いている画像を合成
Credit:[Agarwala2004]

画像同士を合成する
85
背景画像に前景画像を「自然な形で」貼り合わせる
応用例: Sketch2Photo[Chen2009]
ユーザがスケッチした画像をインターネット上の画像を用いて合成する。
http://www.ece.nus.edu.sg/stfpage/eletp/Projects/Sketch2Photo/ (デモ動画あり)http://www.mist.co.jp/product/sketch.html (製品)
スケッチ 検索された画像 合成結果画像
Credit:[Chen2009]

画像同士を合成する
86
複数の画像からパノラマ画像、あるいはより広範な画像を生成する。
代表的な手法: Image Mosaicing [], Image Stitching [Brown2003]
Output:
Input:
Credit: [Brown2003]

画像同士を合成する
87
Image Stitching [Brown2003]の原理
特徴点同士の対応関係を見つけて、画像変換する。
Modified from [Brown2003]

画像同士を合成する
88
2つの画像から中間画像を生成する。(Morphing)
中間画像 BにAのテクスチャを合成
BA

画像同士を合成する
89
2つの視点の異なる画像から、中間の視点から見た画像を生成する。(View Morphing [Seitz1996])
プロジェクトページ(動画あり) http://www.cs.cmu.edu/~seitz/vmorph/vmorph.html

画像同士を合成する
90
View Morphing[Seitz1996]の原理
1. 2台のカメラで撮影した画像 𝐼0 、𝐼1からそれぞれのカメラの位置を推定する。• 2つのカメラに写っている
共通の被写体の見えからカメラ位置を逆算できる
2. 2つのカメラ位置を仮想的に並行にする。( 𝐼0, 𝐼1)
3. 中間画像 𝐼𝑠をモーフィングで生
成する。4. カメラ位置𝐼𝑠へ射影する。
Credit:[Seitz1996]

画像からいらない領域を切り取る
91
いらない領域を削除して、周辺の領域の情報から削除した領域の穴埋めを行う。(Inpainting)
credit:[Bertalmio2000]
credit:[Criminisi2004]

画像からいらない領域を切り取る
92
Inpaintingの原理([Criminisi2004]の場合)
a. 元画像(Source region)と埋めたい領域(Target region)
b. 勾配が大きく、勾配の向きとできるだけ直行した境界上の点を選択
c. 等高線上からできるだけ類似したパッチを選択
d. 選択したパッチで穴埋め
Credit:[Criminisi2004]

画像からいらない領域を切り取る
93
いらない領域を削除して、インターネット上の画像を使って削除した領域の穴埋めを行う。[Hays2007]
Credit:[Hays2007]
(a) (b) (c) (d)
a. 原画像b. 不要な領域の除去c. 似た色と配置を持つ画像を検索d. ユーザが選択した画像で除去した領域を補間

被写体を歪めずに画像をリサイズする
94
画像の中の被写体を歪めることなく、画像の縦横比を気にせずに自由に画像を拡大/縮小する(Retargeting) 代表的な手法:Seam Carving [Avidan2007]
デモ動画 https://www.youtube.com/watch?v=6NcIJXTlugc
ソフトウェア https://code.google.com/p/seam-carving-gui/
Credit:[Avidan2007]
通常の拡縮
Seam Carving

画像のサイズ変更/穴埋め/加工を自然に行う
95
Structural Image Editing
変形したい箇所と類似するテクスチャを画像内から探索して、穴埋め、再構成、サイズ変更を行う
Credit:[Barnes2009]

画像のサイズ変更/穴埋め/加工を自然に行う
96
Structural Image Editing
代表的な手法
PatchMatch [Barnes2009]
デモ動画https://www.youtube.com/watch?v=UcJgnC9M_nY
高速に類似パッチを探すa. ランダムに対応
するパッチを決定
b. 青の近傍(赤、緑)がより近いパッチに対応していないか
c. 対応いていたら、その周辺を探索

二次元の画像から三次元モデル生成
97
1枚の入力画像から三次元的なボリュームを推定する。
[Blanz1999]
1枚の顔画像から3次元復元
[Hoiem2005]
1枚の風景画像から3次元復元

二次元の画像から三次元モデル生成
98
代表的な手法(プロジェクトページヘのリンク)
3D Morphable Model [Blanz2005]
デモ動画あり
http://gravis.cs.unibas.ch/Sigg99.html
Automatic Photo Pop-up [Hoiem2005]
デモ動画、Matlabコードあり
http://www.cs.uiuc.edu/~dhoiem/projects/popup/
Make3D [Saxena2008]
デモ動画、コード(Matlab/C++)あり
http://make3d.cs.cornell.edu/

二次元の画像から三次元モデル生成
99
代表的な手法
3D Morphable Model [Blanz1999]
Automatic Photo Pop-up [Hoiem2005]
データベース内の3次元顔画像を組合せて、二次元画像と近い見た目の三次元モデルを作成する
領域分割して、各領域の平面を推定する。

二次元の画像から三次元モデル生成
100
アプリケーション
モーションポートレート
http://www.motionportrait.com/
https://www.youtube.com/watch?v=P-mBdV3icMY

ライブラリ/ソフトウェア
101
Open Source OpenCV (http://opencv.org)
ヒストグラム伸張、ヒストグラム平滑化 ガウシアンフィルタ、メディアンフィルタ、バイラテラルフィルタ
[Tomasi1998]、ノンローカルミーンフィルタ[Buades2005] 超解像 [Farsiu2003][Mitzel2009] Inpainting[Bertalmio2000] [Telea2004] Image Stitching 領域分割( k-mean, 混合ガウスモデル, Watershed、Mean Shift
Filtering)
Insight Segmentation and Registration Toolkit (ITK) http://www.itk.org/ 領域分割や輪郭抽出、レジストレーションのアルゴリズム実装
モーフィング https://github.com/takmin/ImageMorphing 昔自分が書いたコード

参考文献
102
[Tomasi1998]Tomasi, C., & Manduchi, R. (1998). Bilateral filtering for gray and color images. International Conference on Computer Vision (CVPR).
[Buades2005]Buades, A., Coll, B., & Morel, J.-M. (2005). A non-local algorithm for image denoising. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[Dabov2007]Dabov, K., Foi, A., Katkovnik, V., & Egiazarian, K. (2007). Image denoising by sparse 3D transform-domain collaborative filtering. IEEE Transactions on Image Processing, 16(8), 2080–2095.
[Freeman2002]Freeman, W. T., Jones, T. R., & Pasztor, E. C. (2002). Example-based super-resolution. Computer Graphics and Applications, 22(2), 56–65.
[Yang2008]Yang, J., Wright, J., Ma, Y., & Huang, T. (2008). Image super-resolution as sparse representation of raw image patches. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).

参考文献
103
[Osher1988]Osher, S., & Sethian, J. A. (1988). Fronts propagating with curvature-dependent speed: algorithms based on Hamilton-Jacobi formulations. Journal of Computational Physics, (1988), 12–49.
[Comaniciu2002]Comaniciu, D., & Meer, P. (2002). Mean shift: A robust approach toward feature space analysis. IEEE Transaction on Pattern Analysis and Machine Intelligence, 24(5), 603–619.
[Rother2004]Rother, C., Kolmogorov, V., & Blake, A. (2004). Grabcut: Interactive foreground extraction using iterated graph cuts. In Conference on Computer Graphics and Interactive Techniques (SIGGRAPH).
[Pérez2003]Pérez, P., Gangnet, M., & Blake, A. (2003). Poisson image editing. In Conference on Computer Graphics and Interactive Techniques (SIGGRAPH).
[Agarwala2004]Agarwala, A., Dontcheva, M., Agrawala, M., Drucker, S., Colburn, A., Curless, B., … Cohen, M. (2004). Interactive digital photomontage. In Conference on Computer Graphics and Interactive Techniques (SIGGRAPH) (Vol. 23).

参考文献
104
[Chen2009]Chen, T., Cheng, M.-M., Tan, P., Shamir, A., & Hu, S.-M. (2009). Sketch2Photo: internet image montage. In Conference on Computer Graphics and Interactive Techniques (SIGGRAPH).
[Brown2003]Brown, M., & Lowe, D. G. (2003). RecognisingPanoramas. In International Conference on Computer Vision (CVPR).
[Seitz1996]Seitz, S. M., & Dyer, C. R. (1996). View morphing. Conference on Computer Graphics and Interactive Techniques (SIGGRAPH).
[Bertalmio2000]Bertalmio, M., Guillermo, S., Caselles, V., & Ballester, C. (2000). Image inpainting. In Conference on Computer Graphics and Interactive Techniques (SIGGRAPH) (pp. 417–424).
[Criminisi2004]Criminisi, A., Pérez, P., & Toyama, K. (2004). Region filling and object removal by exemplar-based image inpainting. IEEE Transactions on Image Processing : A Publication of the IEEE Signal Processing Society, 13(9), 1200–12.

参考文献
105
[Telea2004]Telea, A. (2004). An image inpainting technique based on the fast marching method. Journal of Graphics Tools, 9(1), 25–36.
[Avidan2007]Avidan, S., & Shamir, A. (2007). Seam carving for content-aware image resizing. In Conference on Computer Graphics and Interactive Techniques (SIGGRAPH).
[Hays2007]Hays, J., & Efros, A. A. (2007). Scene completion using millions of photographs. Conference on Computer Graphics and Interactive Techniques (SIGGRAPH).
[Barnes2009]Barnes, C., Shechtman, E., Finkelstein, A., & Goldman, D. B. (2009). PatchMatch: A randomized correspondence algorithm for structural image editing. In Conference on Computer Graphics and Interactive Techniques (SIGGRAPH).
[Blanz1999]Blanz, V., & Vetter, T. (1999). A morphable model for the synthesis of 3D faces. In Conference on Computer Graphics and Interactive Techniques (SIGGRAPH) (pp. 187–194).

参考文献
106
[Hoiem2005]Hoiem, D., & Efros, A. A. (2005). Automatic photo pop-up. In Conference on Computer Graphics and Interactive Techniques (SIGGRAPH).
[Saxena2008]Saxena, A., Sun, M., & Ng, A. Y. (2008). Make3D: Depth Perception from a Single Still Image. In AAAI national conference on Artificial intelligence (pp. 1571–1576).

107
大量の画像を使ってできること

大量の画像を使ってできること
108
たくさんの画像を集めて街を三次元復元する
画像から撮影者の位置を推定
SNSの画像を集めてストーリーラインを作る
写真の品質を評価する

画像を集めて街を三次元復元する
109
Flickr等の写真共有サイトには観光地などの写真が大量に集まる。それらを使用して観光地の三次元モデルを構築する。
Credit:[Frahm2010]

画像を集めて街を三次元復元する
110
代表的なプロジェクト(リンク先にデモ動画等あり)
Photo Tourism[Snavely2006]
http://phototour.cs.washington.edu/
Building Rome in a Day[Agarwal2009]
http://grail.cs.washington.edu/rome/
Building Rome on a cloudless day [Frahm2010]
https://www.youtube.com/watch?v=4cEQZreQ2zQ

画像を集めて街を三次元復元する
112
ライブラリ Bundler [http://phototour.cs.washington.edu/bundler/]
Bundle Adjustmentというアルゴリズムを用いて、カメラキャリブレーションを行う。
Multicore Bundle Adjustment [http://grail.cs.washington.edu/projects/mcba/] Bundle Adjustmentをマルチコア、GPU上で計算できるようにしたソフト
ウェア
Patch-based Multi-view Stereo Software[http://grail.cs.washington.edu/software/pmvs/] Multi-view Stereoのソフトウェア。入力として画像+キャリブレーション
データを与えると密な3次元モデルを生成してくれる。
Clustering Views for Multi-view Stereo (CMVS) [http://grail.cs.washington.edu/software/cmvs/] SfMソフトからの出力を元に画像をクラスタリングして、MVSソフトへの入
力を効率化してくれる。

写真の撮影場所を推定
113
ユーザが撮影した画像がどの場所から撮影されたものかを、Geo Tagがつけられたネット上の大量の画像から推定する。
Credit:[Hays2008]

写真の撮影場所を推定
114
代表的な手法([Chen2011]の場合)データベース構築1. GPS情報のついた画像を
大量に集める2. GPS情報を元に画像を観
光地ごとにまとめる3. ユーザごとの写真の撮影
順序から、観光ルートを確率モデル化
推定1. ユーザが撮影した一連の
写真を撮影時間を元にグループ分け
2. グループごとにDBとマッチングして場所推定
3. 観光ルートのモデルを元に推定を補強

写真の品質を判定する
115
写真の審美性/良さ/人気を自動判定する。
評価/教師データとしてDPChallenge[http://www.dpchallenge.com/]というユーザが投稿画像に対して審美性のスコアをつけるサイトを利用[Dhar2011][Nishiyama2011]
プロとアマチュアの写真を集めて、高品質と低品質を投票によってラベル付したデータベース[Luo2011]
230万枚のFlickr画像とその閲覧数を元に、どのような画像がどれだけ閲覧されるかを予測[Khosla2014]
プロジェクトページ(APIあり)[http://popularity.csail.mit.edu/]
余談:記事「50万件の投稿分析でわかった人気の出る写真の法則」
Pinterestの画像を分析
http://wired.jp/2013/06/06/this-is-the-perfect-pinterest-picture/
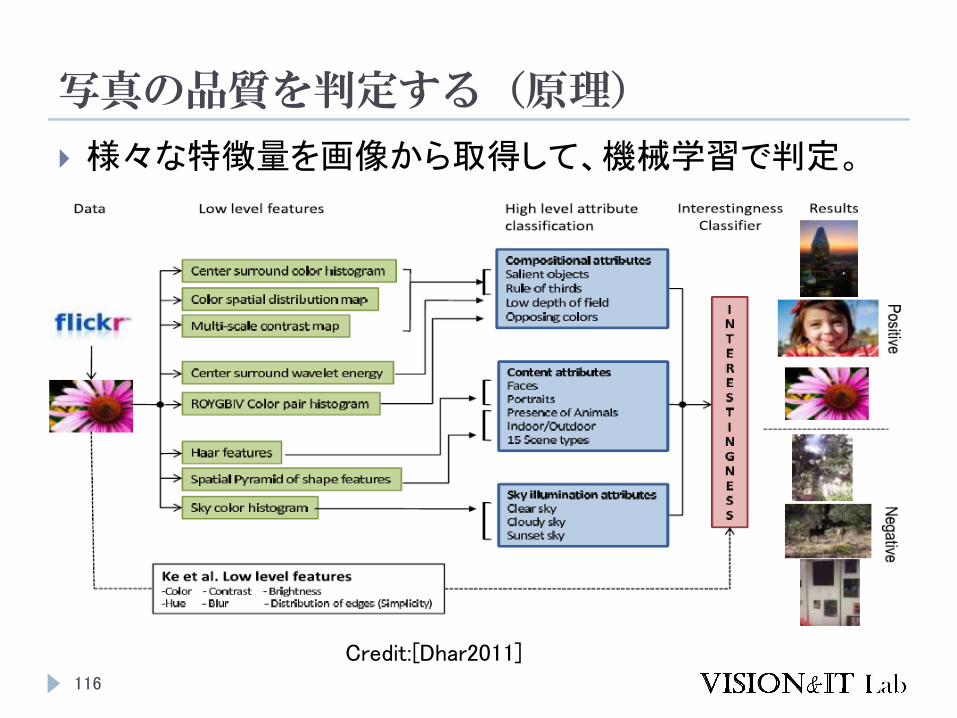
写真の品質を判定する(原理)
116
様々な特徴量を画像から取得して、機械学習で判定。
Credit:[Dhar2011]

SNSの画像を集めてストーリーラインを作る
117
各ユーザの友人関係(つながり)と、各ユーザが撮影した画像を集めて、例えば1つのトピックに関する画像を時系列に自動で要約する。[Kim2014]
例えば、ユーザが撮影できなかったシーンを他の友人の画像で推薦するなどの使い方ができる。
プロジェクトページ[http://www.cs.cmu.edu/~gunhee/r_storygraph.html]
Credit:[Kim2014]

参考文献
118
[Snavely2006]Snavely, N., Seitz, S. M., & Szeliski, R. (2006). Photo tourism: exploring photo collections in 3D. In Conference on Computer Graphics and Interactive Techniques (SIGGRAPH).
[Agarwal2009]Agarwal, S., Snavely, N., Simon, I., Seitz, S. M., & Szeliski, R. (2009). Building Rome in a day. In International Conference on Computer Vision (pp. 72–79).
[Frahm2010]Frahm, J., Fite-georgel, P., Gallup, D., Johnson, T., Raguram, R., Wu, C., … Pollefeys, M. (2010). Building Rome on a Cloudless Day. In European Conference on Computer Vision (pp. 368–381).
[Hays2008]Hays, J., & Efros, A. A. (2008). IM2GPS: estimating geographic information from a single image. In IEEE conference on Computer Vision and Pattern Recognition (CVPR) .
Chen, C.-Y., & Grauman, K. (2011). Clues from the beaten path: Location estimation with bursty sequences of tourist photos. In IEEE conference on Computer Vision and Pattern Recognition (CVPR).

参考文献
119
[Dhar2011]Dhar, S., Berg, T. L., & Brook, S. (2011). High Level Describable Attributes for Predicting Aesthetics and Interestingness. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[Nishiyama2011]Nishiyama, M., Okabe, T., Sato, I., & Sato, Y. (2011). Aesthetic quality classification of photographs based on color harmony. In IEEE conference on Computer Vision and Pattern Recognition (CVPR).
[Tang2011]Tang, X., Luo, W., & Wang, X. (2011). Content-Based Photo Quality Assessment. In IEEE Internatinal Conference on Computer Vision.
[Khosla2014]Khosla, A., Sarma, A. Das, & Hamid, R. (2014). What makes an image popular? In International World Wide Web Conference (WWW).
[Kim2014]Kim, G., & Xing, E. P. (2014). Reconstructing Storyline Graphs for Image Recommendation from Web Community Photos. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).

120
今回説明しきれなかった技術

三次元再構成
121
2台以上のカメラ、または複数の画像、動画から撮影対象の三次元モデルを生成する。
物体の影の付き方から三次元モデルを生成する。
物体に既知のパターン光をあてて、その歪み具合をカメラで撮影することで三次元モデルを生成する。
物体に既知の光源から光を当てて、その反射の具合から三次元モデルや表面反射モデルを推定する。
パターンが既知の画像を撮影することでカメラの位置や向きを推定する。

動画像処理
122
動画中の人の動作を認識する。
歩行、スポーツ、料理、ジェスチャー、手話、etc
動画中のシーンを認識する。
スポーツシーン解析
ドラマのシーン解析
喧嘩や事故などの異常検出
動画の内容を要約する。
動画編集
移動体追跡
歩行者、車、マーカーなど
手ぶれ補正

もっと勉強するために(全体像がわかる参考資料)
123
Richard Szeliski, “コンピュータビジョン アルゴリズムと応用”, 共立出版
Gary Bradski, “詳解 OpenCV”, オライリージャパン 林昌希,“コンピュータビジョンのセカイ ―今そこにあるミライ”, マイ
ナビニュース, http://news.mynavi.jp/series/computer_vision/menu.html
藤吉弘亘, “-SSIIの技術-過去・現在,そして未来 [領域]認識”(Slideshare), SSII2014, http://www.slideshare.net/hironobufujiyoshi/ssii-35734246
田中正行, “見えない画像を見るための2次元画像再構成 -画像を見る・学ぶ・作る-”(Slideshare), SSII2014, http://www.slideshare.net/masayukitanaka1975/ssii2014
中山英樹, “タカとハヤブサはどこが違う?-新たな認識領域「詳細画像識別」の展開と応用-”(Slideshare), SSII2014, http://www.slideshare.net/nlab_utokyo/ssii2014-fgvc-os2