5.model evaluation and improvement
TRANSCRIPT

Machine Learningwith Python
Model Evaluation and Improvement
1

ContactsHaesun Park
Email : [email protected]
Meetup: https://www.meetup.com/Hongdae-Machine-Learning-Study/
Facebook : https://facebook.com/haesunrpark
Blog : https://tensorflow.blog
2

Book파이썬라이브러리를활용한머신러닝, 박해선.
(Introduction to Machine Learning with Python, Andreas Muller & Sarah Guido의번역서입니다.)
번역서의 1장과 2장은블로그에서무료로읽을수있습니다.
원서에대한프리뷰를온라인에서볼수있습니다.
Github: https://github.com/rickiepark/introduction_to_ml_with_python/
3

교차검증
4
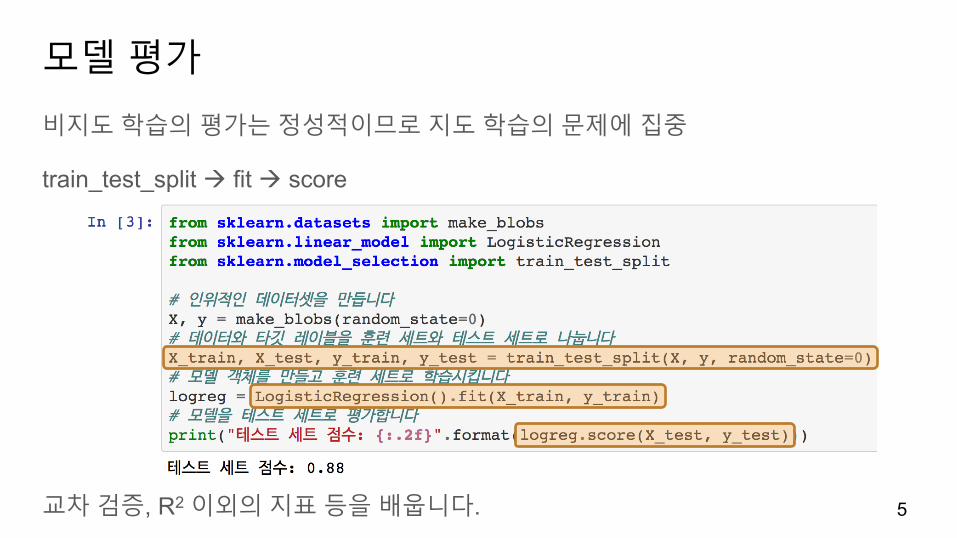
모델평가
비지도학습의평가는정성적이므로지도학습의문제에집중
train_test_split à fit à score
교차검증, R2 이외의지표등을배웁니다. 5

교차검증cross-validation
k-겹교차검증k-fold cross-validation (k=5 or k=10)
1. 훈련데이터를 k개의부분집합(폴드)으로나눕니다.
2. 첫번째폴드를테스트세트로하고나머지폴드로모델을훈련시킵니다.
3. 테스트폴드를바꾸어가며모든폴드가사용될때까지반복합니다.
6
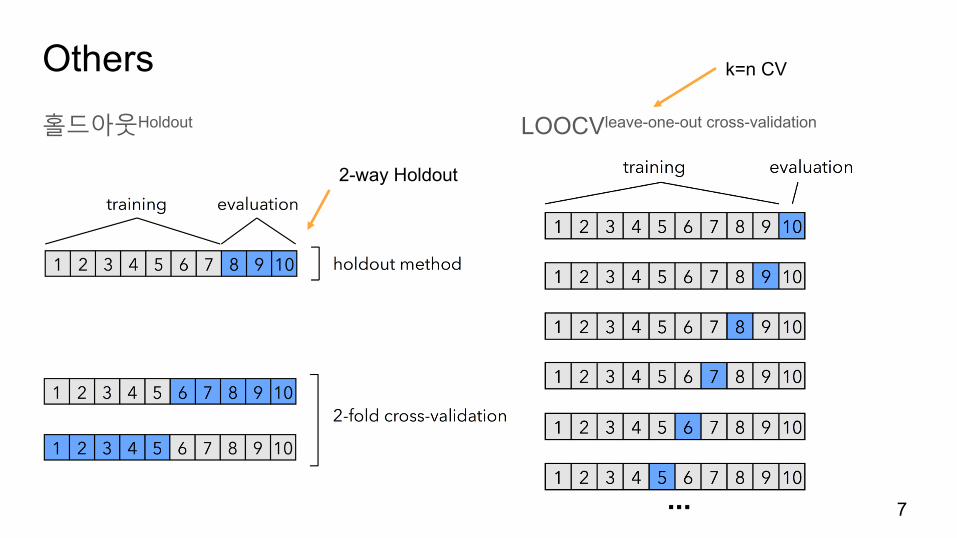
Others홀드아웃Holdout LOOCVleave-one-out cross-validation
7
2-way Holdout
k=n CV

cross_val_score
8
모델, 데이터, 타깃
기본폴드수 : 3
폴드수변경

교차검증의장점
train_test_split는무작위로데이터를나누기때문에우연히평가가좋게혹은나쁘게나올수있음à모든폴드가테스트대상이되기때문에공평함
train_test_split는보통 70%~80%를훈련에사용함à 10겹교차검증은 90%를훈련에사용하기때문에정확한평가를얻음
모델이훈련데이터에얼마나민감한지가늠할수있음[1, 0.967, 0.933, 0.9, 1] à 90~100% Accuracy
[단점]: 데이터를한번나누었을때보다 k개의모델을만드므로 k배느림
[주의]: cross_val_score는교차검증동안만든모델을반환하지않습니다!9
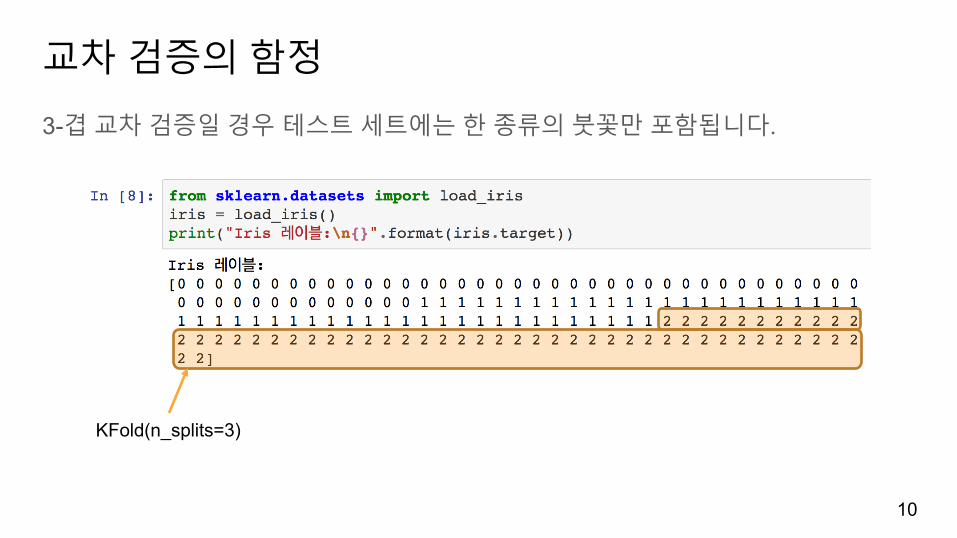
교차검증의함정
3-겹교차검증일경우테스트세트에는한종류의붓꽃만포함됩니다.
10
KFold(n_splits=3)

계층별 k-겹교차검증Stratified k-fold CV
11
분류문제일경우 cross_val_score는기본적으로 StratifiedKFold()를사용합니다. 회귀에서는 KFold()를사용합니다.

교차검증분할기
분류에 KStratifiedFold() 대신기본 KFold()를적용하기위해 cv 매개변수를사용합니다.
12

분류와기본 KFold()
13StratifiedKFold(n_splits=3): [0.961, 0.922, 0.958]

LOOCVleave-one-out cross-validation
k=n 인 k-겹교차검증
데이터셋이클때는시간이오래걸리지만, 작은데이터셋에서는이따금좋음.
14

임의분할교차검증shuffle-split CV
훈련세트크기 : train_size, 테스트세트크기 : test_size, 폴드수 : n_splits
ShuffleSplit(train_size=5, test_size=2, n_splits=4)
15

ShuffleSplittest_size, train_size에비율을입력할수있음
test_size + train_size < 1 일경우부분샘플링subsampling이됨
분류에사용할수있는 StratifiedShuffleSplit도있음
16

그룹별교차검증
타깃에따라폴드를나누지않고입력특성에따라폴드를나누어야할경우
예를들어 100장의사진데이터로사람의표정을분류하는문제에서한사람이훈련세트와테스트세트에모두나타날경우분류기의성능을정확히측정할수없습니다.(의료정보나음성인식등에서도)
입력데이터의그룹정보를받을수있는 GroupKFold()를사용합니다.
cross_val_score(model, X, y, groups, cv=GroupKFold(n_splits=3))...cv.split(X, y, groups)...
17

GroupKFold
18

그리드서치Grid Search
19

매개변수튜닝
매개변수를튜닝하여모델의일반화성능(교차검증)을증가시킵니다.
Scikit-Learn에는 GridSearchCV와 RandomizedSearchCV가있습니다.
RBF 커널 SVM의여러가지매개변수조합을테스트합니다.
20

그리드서치구현
21
gamma와 C에대한반복루프
36개의모델이만들어짐
가장좋은테스트점수를기록
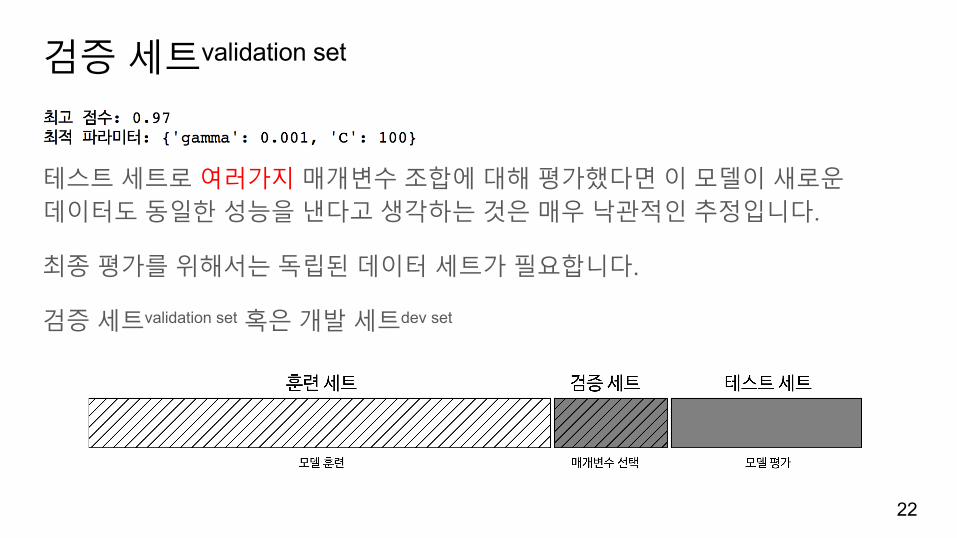
검증세트validation set
테스트세트로여러가지매개변수조합에대해평가했다면이모델이새로운데이터도동일한성능을낸다고생각하는것은매우낙관적인추정입니다.
최종평가를위해서는독립된데이터세트가필요합니다.
검증세트validation set 혹은개발세트dev set
22

검증세트구현
23
훈련데이터à훈련검증세트, 테스트세트훈련검증세트à훈련세트, 검증세트

두구현의결과비교
모델시각화, 탐색적분석, 모델선택에테스트세트를사용하면안됩니다.
24

검증세트 + cross_val_score
25

매개변수탐색의전체과정
26

GridSearchCV교차검증을사용한그리드서치
검색하려는매개변수를키로하는딕셔너리를사용함
27
모델, 매개변수그리드, 폴드수회귀:KFold, 분류:StratifiedKFold
fit, predict, score, predict_proba, decision_function 제공

그리드서치모델테스트
GridSearchCV에사용하지않은테스트세트로평가
28
훈련데이터로교차검증한점수

결과분석
간격을넓게하여그리드서치를시작하고결과를분석해검색영영을조정합니다.
RandomizedSearchCV는매개변수조합이매우많거나 C와같이연속형값을조정할때많이사용됩니다.
29
grid_search.cv_results_
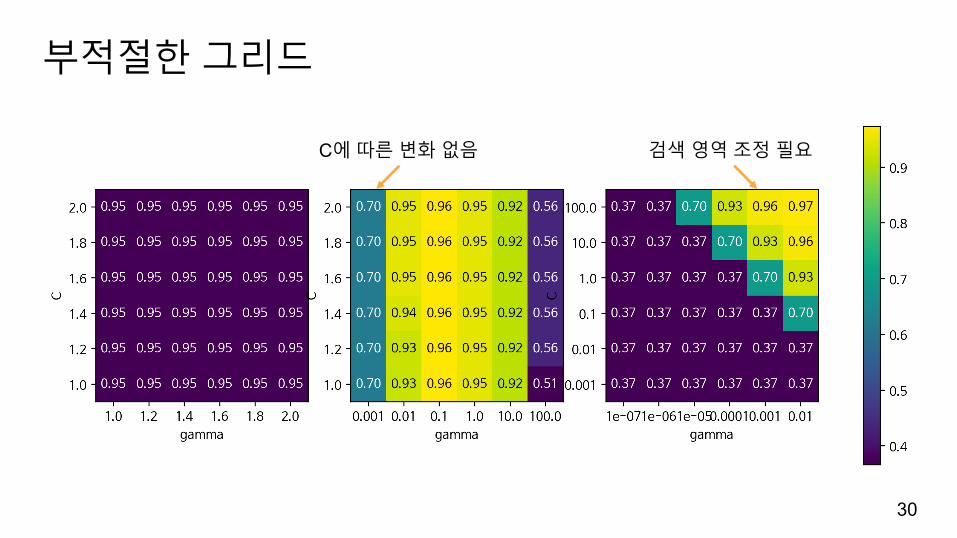
부적절한그리드
30
C에따른변화없음 검색영역조정필요

비대칭그리드서치
다른매개변수에의해선택적으로그리드서치를수행할수있습니다.
매개변수그리드를딕셔너리의리스트로만듭니다.
31
linear 커널일경우에는 gamma 매개변수를지정하지않습니다.

비대칭그리드서치결과
32
ShufflSplit()

중첩교차검증nested CV
훈련데이터(cross_val_score) à훈련세트(SVC)와테스트세트à평가
훈련데이터à훈련세트(GridSearchCV) à튜닝à모델à테스트세트à평가
훈련데이터(cross_val_score) à훈련세트(GridSearchCV)와테스트세트à평가
33
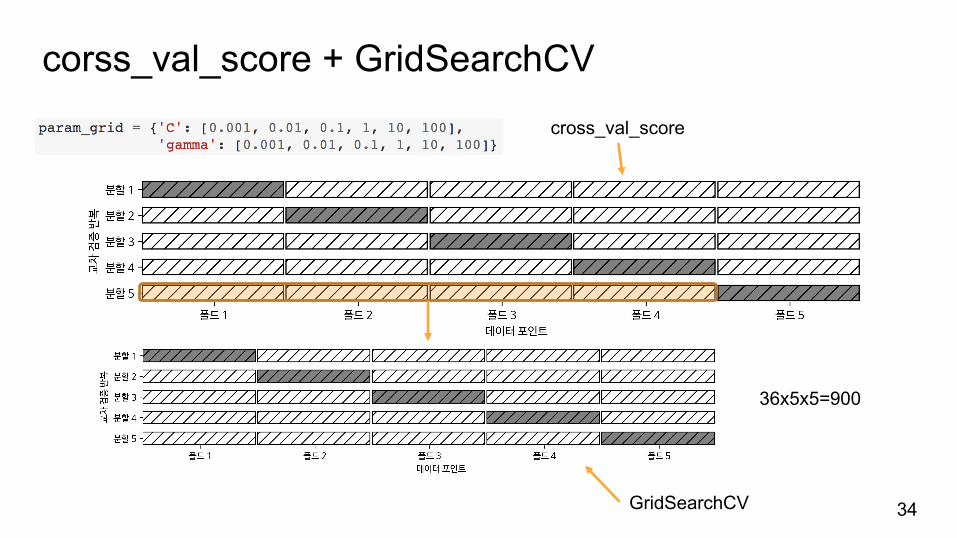
corss_val_score + GridSearchCV
34GridSearchCV
cross_val_score
36x5x5=900

병렬화
그리드서치는연산에비용이많이들지만매개변수조합마다쉽게병렬화가능
GridSearchCV와 cross_val_score의 n_jobs에사용할 CPU 코어수를지정할수습니다(기본 1, 최대 -1).
하지만 GridSearchCV와 RandomForestClassifier 같은모델이동시에 n_jobs옵션을사용할수없습니다(이중 fork로데몬프로세스가되는것을방지).
마찬가지로 cross_val_score와 GridSearchCV도동시에 n_jobs 옵션을사용할수없습니다.
35

평가지표와측정
36

평가지표
일반적으로회귀: R2, 분류: 정확도를사용합니다.
비즈니스임팩트를고려하여목표를설정합니다(교통사고회수, 입원환자수등)
비즈니스지표를얻으려면운영시스템에적용해야알수있는경우가많으므로대리할수있는평가지표를사용합니다(보행자이미지를사용한자율주행테스트)
시스템의목표에따라방문고객이 10% 늘어나는모델을찾을수있지만매출은15% 줄어들수있습니다(경우에따라고객이아니라매출을비즈니스지표로삼아야합니다).
37

이진분류
38

에러의종류
양성클래스(관심대상)와음성클래스로나뉩니다.
암진단: 암(양성테스트, 악성), 정상(음성테스트)
양성테스트(암)를양성클래스, 음성테스트(정상)을음성클래스라할때정상을양성클래스로분류(거짓양성false positive): 추가적인검사동반암을음성클래스로분류(거짓음성false negative): 건강을해침
거짓양성을타입 I 에러, 거짓음성을타입 II 에러라고도합니다.
거짓양성과거짓음성이비슷한경우는드물며오류를비용으로환산하여비즈니스적인판단을해야합니다.
39

불균형데이터셋
예) 광고노출수와클릭수: 99 vs 1 (현실에서는 0.1% 미만입니다)
무조건 ‘클릭아님’으로예측하면 99%의정확도를가진분류기가됩니다.
불균형한데이터셋에서는정확도만으로는모델이진짜좋은지모릅니다.
40
숫자 9는 1, 나머지는 0인타깃값

더미 vs 결정트리
41
무조건 9아님(0)으로예측을만듦

더미 vs 로지스틱회귀
42
strategy 기본값: stratified클래스비율(10%:1, 90%:0) 대로랜덤하게예측

오차행렬confusion matrix
43
타깃값, 예측결과
거짓양성
거짓음성

더미분류기의오차행렬
44
무조건 ‘9아님’으로예측(TN,FN)
비슷한 FP, FN

정확도accuracy, 정밀도precision, 재현율recall
정확도 =𝑇𝑃 + 𝑇𝑁
𝑇𝑃 + 𝑇𝑁 + 𝐹𝑃 + 𝐹𝑁
정밀도 =𝑇𝑃
𝑇𝑃 + 𝐹𝑃
재현율 =𝑇𝑃
𝑇𝑃 + 𝐹𝑁
45
양성으로예측된것중진짜양성의비율(양성예측도)ex) 신약의효과측정
진짜양성중양성으로예측된비율(민감도, 적중률, 진짜양성비율-TPR)ex) 암진단
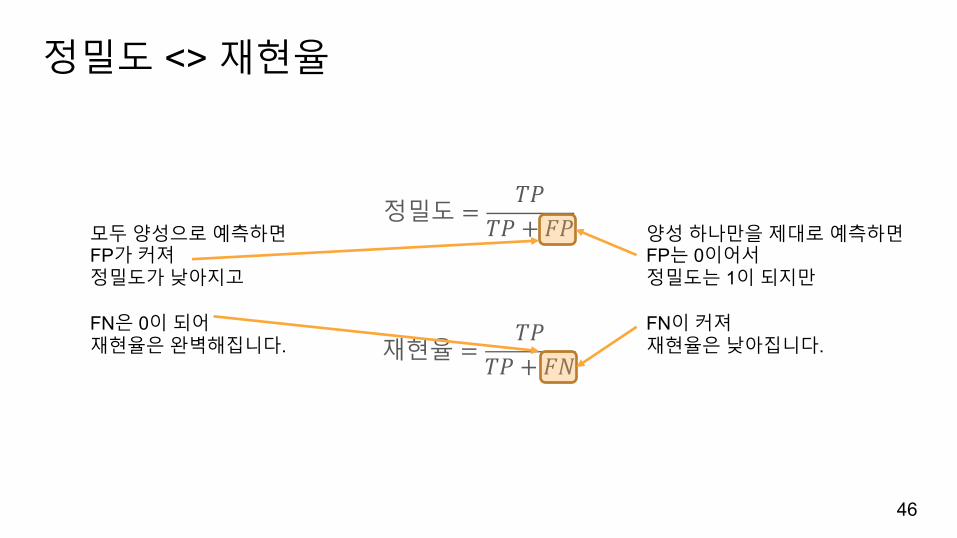
정밀도 <> 재현율
정밀도 =𝑇𝑃
𝑇𝑃 + 𝐹𝑃
재현율 =𝑇𝑃
𝑇𝑃 + 𝐹𝑁
46
모두양성으로예측하면FP가커져정밀도가낮아지고
FN은 0이되어재현율은완벽해집니다.
양성하나만을제대로예측하면FP는 0이어서정밀도는 1이되지만
FN이커져재현율은낮아집니다.

f-점수f-score
f1-점수라고도합니다.정밀도와재현율의조화평균으로불균형데이터셋에좋지만설명하기어렵습니다.
𝐹 = 2×정밀도×재현율
정밀도+재현율
47
f-점수의분모가 0이됨
정확도0.800.92

classification_report + pred_most_frequent
48
진짜타깃값
양성클래스를 ‘9아님’으로바꾸었을때점수
pred_most_frequent는모든데이터를 ‘9아님’으로예측하기때문에양성클래스를맞춘것이없음

classification_report + pred_dummy, pred_logreg
49
어떤클래스를양성클래스로선택하는지가중요

불확실성
decision_function()은선형판별식이 0보다크면양성으로,
predict_proba()는선형판별식에시그모이드함수를적용하여 0.5보다크면양성으로판단합니다.
이함수들의반환값이클수록예측에대한확신이높다고간주할수있습니다.
50

decision_function() > 0
51
악성
악성이양성클래스일경우모든악성을잡아내기위해재현율을높여야합니다.

decision_function() > -0.8
52
악성
실전에서는테스트세트를사용해서는안됩니다!
model.predict_proba(X_test) > 0.45
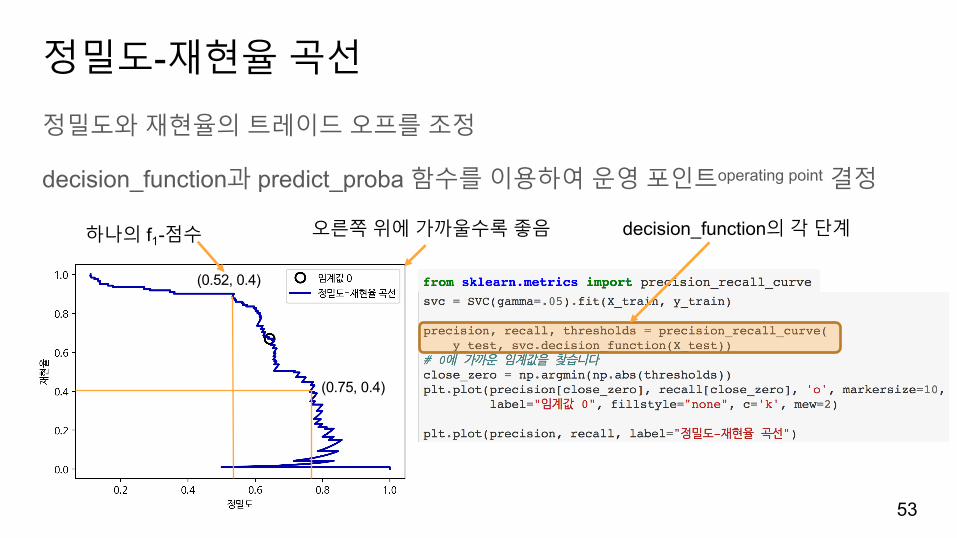
정밀도-재현율곡선
정밀도와재현율의트레이드오프를조정
decision_function과 predict_proba 함수를이용하여운영포인트operating point 결정
53
decision_function의각단계
(0.75, 0.4)
(0.52, 0.4)
하나의 f1-점수 오른쪽위에가까울수록좋음

RandomForestClassifier vs SVC
54
predict_proba의결과중양성클래스(배열인덱스 1)에대한확률값을전달합니다.
재현율이나정밀도가극단일경우랜덤포레스트가더낫습니다.

평균정밀도average precision
정밀도-재현율곡선의아랫부분면적을나타냅니다.
55
평균정밀도는거의비슷한수준
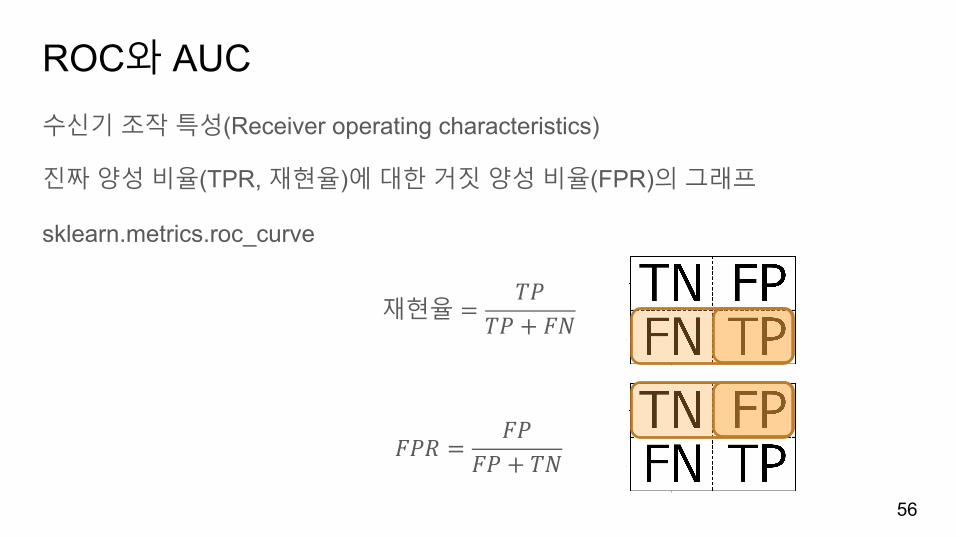
ROC와 AUC수신기조작특성(Receiver operating characteristics)
진짜양성비율(TPR, 재현율)에대한거짓양성비율(FPR)의그래프
sklearn.metrics.roc_curve
재현율 =𝑇𝑃
𝑇𝑃 + 𝐹𝑁
𝐹𝑃𝑅 =𝐹𝑃
𝐹𝑃 + 𝑇𝑁
56
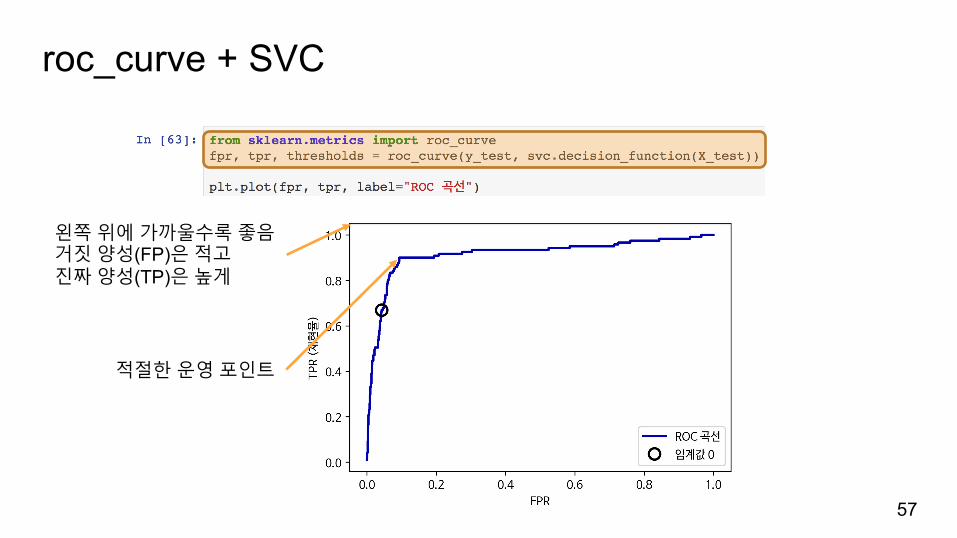
roc_curve + SVC
57
왼쪽위에가까울수록좋음거짓양성(FP)은적고진짜양성(TP)은높게
적절한운영포인트

RandomForestClassifier vs SVC
58
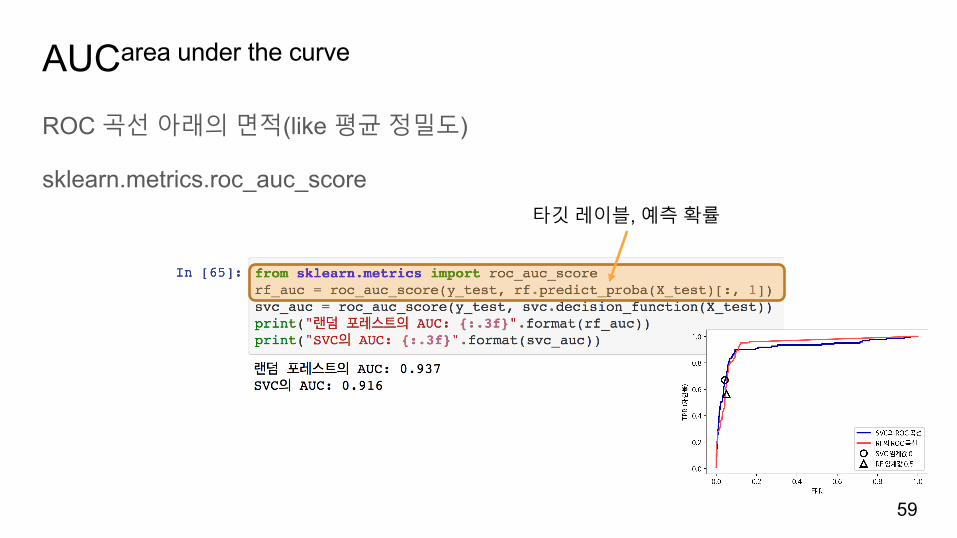
AUCarea under the curve
ROC 곡선아래의면적(like 평균정밀도)
sklearn.metrics.roc_auc_score
59
타깃레이블, 예측확률
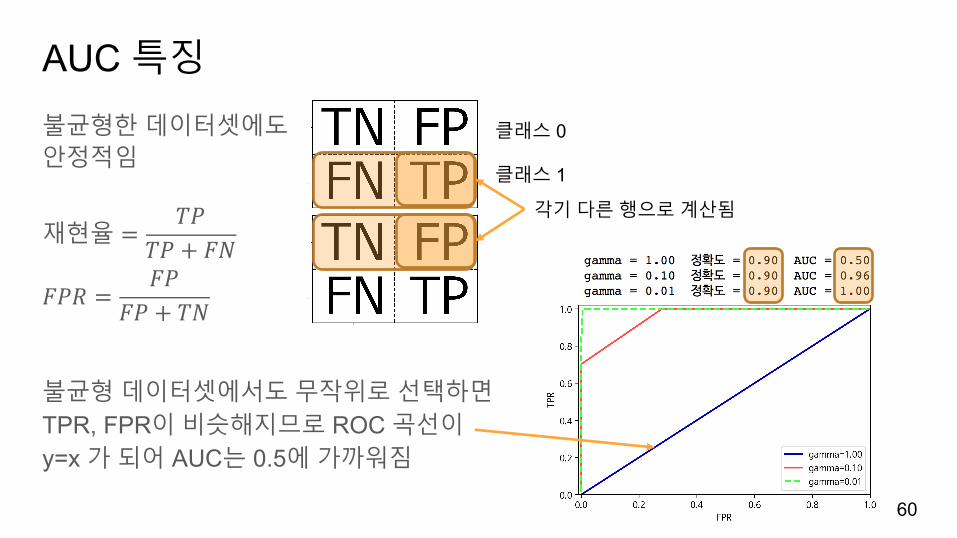
AUC 특징
불균형한데이터셋에도안정적임
재현율 =𝑇𝑃
𝑇𝑃 + 𝐹𝑁
𝐹𝑃𝑅 =𝐹𝑃
𝐹𝑃 + 𝑇𝑁
불균형데이터셋에서도무작위로선택하면TPR, FPR이비슷해지므로 ROC 곡선이y=x 가되어 AUC는 0.5에가까워짐
60
각기다른행으로계산됨
클래스 0
클래스 1

다중분류
61

다중분류의평가지표
이진분류평가지표에서유도한것으로모든클래스에대해평균을냅니다.
다중분류에서도불균형한데이터셋에서는정확도가좋은지표가아닙니다.
손글씨숫자 10개에대한오차행렬
62

다중분류의오차행렬
63
숫자 0은거짓음성(FN) 없음
클래스 0은거짓양성(FP) 없음

다중분류리포트
64

다중분류 f1-점수
다중분류용 f1-점수는한클래스를양성클래스로두고나머지를음성으로간주하여각클래스마다 f1-점수를계산합니다.
f1_score(y_test, pred, average=“...”)
• “macro”: 가중치없이평균을냅니다.• “weighted”: 클래스별샘플수로가중치를두어평균을냅니다.(분류리포트)• “micro”: 모든클래스의 FP, FN, TP를합하여 f1-점수를계산합니다.• “binary”: 이진분류에해당, 기본값.
65

회귀의평가지표
66

R2
회귀는연속된값을예측하므로 R2만으로충분합니다.
가끔평균제곱에러나평균절댓값에러를사용하기도합니다.
67

모델선택과평가지표
68

cross_val_scorescoring 매개변수에원하는평가지표를지정할수있습니다. 기본값은모델의score() 메소드입니다.
69
roc_auc_score() 함수를의미
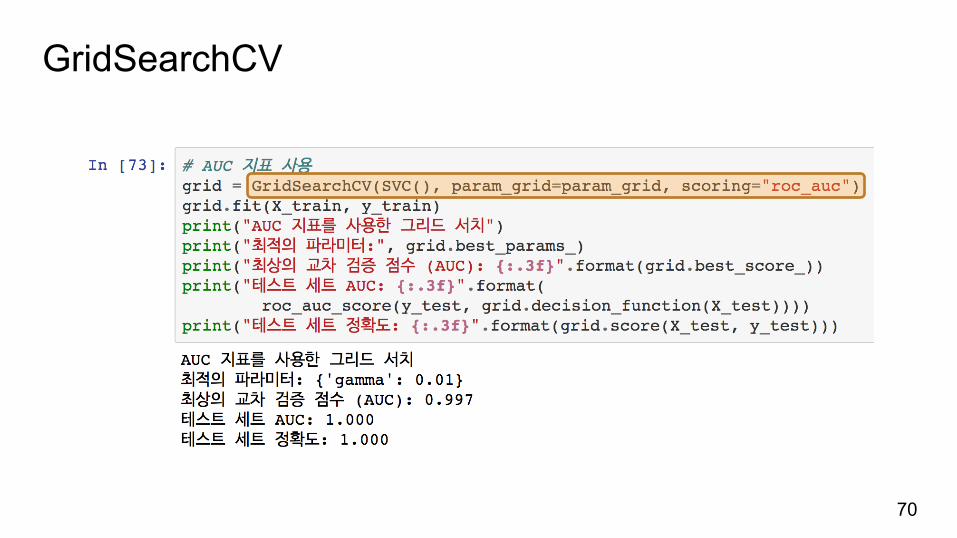
GridSearchCV
70

scoring 옵션
분류: accuracy(기본값)roc_auc(ROC 곡선아래면적)average_precision(정확도-재현율곡선아래면적)f1_macro, f1_micro, f1_weighted
회귀: r2(R2)mean_square_error(평균제곱오차)mean_absolute_error(평균절댓값오차)
71

요약및정리
72

중요한주의사항
교차검증을해야합니다.
훈련데이터: 모델학습
검증데이터: 모델과매개변수선택
테스트데이터: 모델평가
모델선택과평가에적절한지표를사용합니다.
높은정확도를가진모델à비즈니스목표에맞는모델
현실에서는불균형한데이터셋이아주많음
거짓양성(FP)과거짓음성(FN)이많은영향을미침
73