ch09epaper.gotop.com.tw/pdf/ael008000.pdf9-3 w 第九章 字串...
TRANSCRIPT

字 串
子曰:「質勝文則野,文勝質則史。文質彬彬,然後君子。」
《論語﹒雍也第六》
文字和數字是資料的兩大基礎元素。字串固然可以視為由「字元」構成的一維陣
列,標準的 C++ 提供了方便的程式庫,讓我們能將「字串」視為獨立的單元,
以進行各種存取和剪接的處理。本章將探討處理字串的相關技術。
9.1 字串的基本概念
9.2 字串的輸入與輸出
9.3 字串的處理
9.4 字串的指標陣列
9.5 字串處理在編碼上的應用
9.6 常犯的錯誤
9.7 本章重點
9.8 本章練習

9-2
C++程式設計(第二版)
9.1 字串的基本概念
字串 (string) 是由雙引號 " " 所包括起來的一串文字。例如:
"Hello!" "嗨! 您好!" "Good boy."
字串在記憶體內的儲存方式很特別,除了我們看到的文字部份外,其後又
多加了一個 ’\0’字元,亦即空字元 (NULL character);它的 ASCII 值為零,
做為字串的結束記號。上面兩個例子在記憶體內的儲存方式如下:
H e l l o ! \0
嗨 ! 您 好 ! \0
G o o d b o y . \0
在上圖中,英文字母、空隔和標點符號都佔有 1 個位元組 (8 bits),而每
個中文字佔了 2 個位元組。(注意,逗號和驚嘆號各有「,!」和「,!」兩種寫
法,前者為 ASCII 碼,各只佔 1 byte,後者為全型碼,佔 2 bytes。)
字串可以視為由字元 (character,資料型態為 char) 構成,並以 '\0' 作為
結尾的一維陣列。宣告字串的方式有下列三種:
char S1[20] = "Hello, 您好!"; // 陣列式的宣告 char S2[] = "Hello, 您好!"; // 自動設定字元陣列的長度為 13 char* pS2 = "Hello, 您好!"; // 指標式的宣告,C-style string
字串的存取可以透過指向第一個字元的指標,也可以經由陣列的名稱。由
於陣列的名稱本身也是一個指標 (詳見 8.1 節的說明),因此字串的資料型態為
「char *」。在 C++ 中一個字串的值 (value) 是第一個字元的位址。上述這
種字串的定義方式也適用於 C 語言,稱為 C-style string (C 風格的字串)。

9-3
第九章 字串
以一維陣列的方式逐一列舉字元定義字串
將字串視為一維 char 陣列時,也可以採用逐一列舉各字元的方式設定字串
的初始值,只是這種定義字串的方式太煩瑣,實際上很少使用。譬如下列二例
(某些編譯器會自動添加 '\0';使用下面所示 S4 的語法時要確定有足夠的陣
列長度):
char S3[] = {'T', 'h', 'e', ' ', 'b', 'o', 'y', '\0'}; char S4[10] = {'\n', 'G', 'o', '!', '\0'};
字元 (char) 可分為可以正常列印和顯示的各種英文字母和符號,以及以
反斜線開頭的指令字元 (例如 S4[10] 中的 '\n') 兩種,但不包括中文字。這
是因為每個 char 只佔一個 byte,而每個中文字需要 2 bytes。如果把中文字當
成字元,則只有前一個 byte 被處理,造成輸出結果被扭曲 (經常是亂碼)。因
此,當字串內含有中文時,不可以使用上述在大括號內逐一列舉字元的語法。
此外,空白處要以字元 ' ' 表示 (兩個單引號之間有空隔),如果不慎寫
成'' (兩個單引號之間沒有空隔),則為錯誤的語法,無法通過編譯。
以指標的方式定義字串
首先,我們觀察下列宣告:
char* pS2 = "嗨! 您好!";
這個敘述在執行時發生了兩件事情:
(1) 在記憶單元內存入字串 "嗨! 您好!"。
(2) 將此字串第一個字元的位址存入指標 pS2 裏面。
如下圖所示:
嗨 ! 您 好 ! \0
pS2

9-4
C++程式設計(第二版)
當電腦接著執行下列敘述時:
pS2 = "Good boy.";
其結果並不是把 pS2 原先所指向的記憶體內容更換,而是另外儲存新的字串,
並把 pS2 指向新字串的開頭字元,如下圖所示:
嗨 ! 您 好 ! \0
G o o d b o y . \0
pS2
兩個先後儲存的字串都各自佔有自己的記憶空間,而且除非我們先把原有
字串的起始位址存下來再改變 pS2 的指向目標,否則原有字串 (亦即“嗨! 您
好!”) 所佔用的空間在程式結束前再也無法存取!
只有字串的雙引號寫法才可以配合字串指標的初始化使用。例如,上述的
char* pS2 = "Good luck!";
也可以分開成兩個敘述:
char* pS2; pS2 = "Good luck!";
然而,下列則是錯誤的語法:
char* pS = { 'b', 'o', 'y'}; // 錯誤!
事實上,讓我們對照一下由 double 數字構成的一維陣列 V:
double V[3] = {48.4, 39.8, 40.5};
它可以在宣告時同時給定初始值;但是這種列舉式的敘述也不可使用指標:
double *pV = {48.4, 39.8, 40.5}; // 錯誤!

9-5
第九章 字串
9.2 字串的輸入與輸出 從鍵盤輸入或螢幕輸出資料的管道稱為資料流 (stream)。輸出入的管道係
由 <iostream> 程式庫所提供,它是 C++ 標準式庫的一部份。我們在先前的大
部份程式開頭的地方都有下列指令:
#include <iostream> using std::cin; using std::cout; using std::endl;
就是為了要使用由 <iostream> 程式庫所提供的輸出入的管道 cin 和 cout。
表 9.2.1 列出字元和字串的輸出入相關函數。在運用它們時,需要在程式
開頭的地方以下列指令加入相關的標頭檔 <iostream>:
#include <iostream>
表 9.2.1 C++ 字元和字串的輸出入相關函數及管道
iostream 標準函數或管道 功 能
cout 輸出資料流
cin 輸入資料流
cin.getline() 字串輸入函數
cin.get() 字元輸入函數
字串的輸出指令
cout 和 cin 分別要配合 << 和 >> 兩個運算子。在前述各章中,我們已經
有大量的使用經驗。一般而言,
cout << x << endl;
是把變數 x 的內容直接輸出。如果 x 是指標,則輸出的資料是其內存的位址。
但是,上述這個規則無法適用於字串指標 (string pointer)。

9-6
C++程式設計(第二版)
例如,在執行下列使用字串和字串指標的敘述後:
char S1[20] = "Hello,您好!";
char* pS = S1;
以下各種輸出敘述都得到同的字串,亦即 "Hello,您好!":
cout << S1; cout << pS; cout << &S1[0]; cout << &pS[0];
這是因為 cout 在遇到字串的指標或是字串的起始位址時,會自動將輸出改
為字串的內容,而不是將位址輸出。此外,由於字串都有明顯的 '\0' 做為結
尾,因此,只有 '\0' 之前的部份會輸出,其後的部份忽略不處理。
如果我們要輸出字串的位址,必須要使用下列特殊語法:
cout << (void *)S1; cout << (void *)pS;
字串的輸入指令
cin 可以做為字元或字串的標準輸入管道,但其輸入資料流在遇到空隔
(亦即鍵盤上的空白鍵),或新行 (下一行,new line) 符號 '\n' (亦即按下鍵
盤上的輸入鍵) 都會停止。因此,如果要輸入 "Hello,您好!" 的字串時,必須
分兩次擷取:
char S1[20], S2[20]; cin >> S1 >> S2;
為了避免這個限制,可以改用函數 cin.getline()。它的參數有三個:
cin.getline(字串名稱,最大字串長度,結束字元);
其中「結束字元」的預設值是 '\n',足以應付大部份的情況。以本例而言,只
要將敘述改成以下的形式即可完整輸入包括空白處的整個字串:
cin.getline(S1, 20); // 輸入字串並存入 S1

9-7
第九章 字串
此外,函數 cin.get() 一次只能輸入一個字元,其使用方式如下:
char C1; cin.get(C1); // 輸入字元並存入 C1
程式 BasicString.cpp 將上述包括字串的宣告、初始化,和輸入、輸出等操
作寫成一個完整的程式。為了比較,我們在程式中另外加入了一個 int 向量 I,
以顯示一般不是字串的一維矩陣名稱與 cout 配合使用時,得到的是位址,而不
是陣列的內容。
範例程式 檔案 BasicString.cpp
// BasicString.cpp #include <iostream> using namespace std; // ---主程式------------------------ int main() { const int SLength = 30; char S1[SLength] = "Hello, 您好!"; int I[5]={1, 2, 4, 5, 6}; char* pS; int* pI=I; pS=S1; cout << "S1 is: " << S1 << endl; cout << "pS is: " << pS << endl; cout << "I is: " << I << endl; cout << "pI is: " << pI << endl; cout << "*S1 is: " << *S1 << endl; cout << "&S1[0] is: " << &S1[0] << endl; cout << "S1[0] is: " << S1[0] << endl; cout << "(void*)S1[0] is: << (void*)S1[0] << endl; cout << "(void*)S1 is: " << (void*)S1 << endl; cout << "\n請輸入 S1 的新值:\n"; cin.getline(S1,SLength); cout << "輸入新值後, S1 的值為: \n" << S1 << endl; system("PAUSE"); return 0; }

9-8
C++程式設計(第二版)
程式執行結果
S1 is: Hello, 您好! pS is: Hello, 您好! I is: 0012FF1C pI is: 0012FF1C *S1 is: H &S1[0] is: Hello, 您好! S1[0] is: H (void*)S1[0] is: 00000048 (void*)S1 is: 0012FF30
請輸入 S1 的新值: As seen by you.
輸入新值後, S1 的值為: As seen by you.
9.3 字串的處理 如果把字串看做「資料型態為 char 的一維陣列」,則其中的每個字元都可
以單獨使用下標或是指標代數的方式來存取。
例如,對於下列字串 S1 和字串指標 pS 兩個含有初始化敘述的定義:
const Length = 40; char S1[Length] = "Good luck!"; char* pS = S1;
字串 S1 的第 4 個字元 (亦即 'd') 可以使用下列四種寫法來存取:
S1[3] *(S1+3) pS[3] *(pS+3)
9-9
第九章 字串
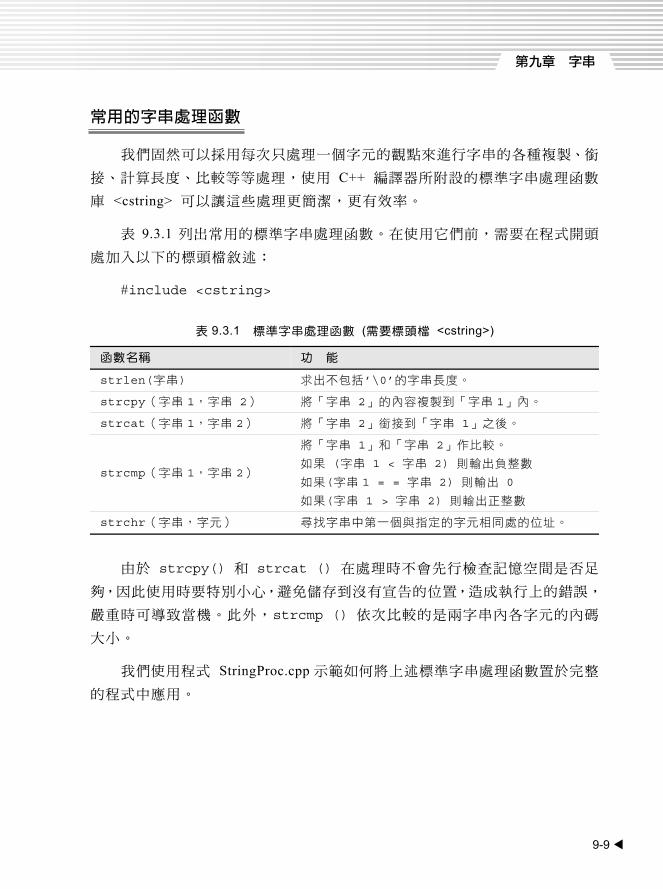
常用的字串處理函數
我們固然可以採用每次只處理一個字元的觀點來進行字串的各種複製、銜
接、計算長度、比較等等處理,使用 C++ 編譯器所附設的標準字串處理函數
庫 <cstring> 可以讓這些處理更簡潔,更有效率。
表 9.3.1 列出常用的標準字串處理函數。在使用它們前,需要在程式開頭
處加入以下的標頭檔敘述:
#include <cstring>
表 9.3.1 標準字串處理函數 (需要標頭檔 <cstring>)
函數名稱 功 能
strlen(字串) 求出不包括’\0’的字串長度。
strcpy(字串 1,字串 2) 將「字串 2」的內容複製到「字串 1」內。
strcat(字串 1,字串 2) 將「字串 2」銜接到「字串 1」之後。
strcmp(字串 1,字串 2)
將「字串 1」和「字串 2」作比較。
如果 (字串 1 < 字串 2) 則輸出負整數
如果(字串 1 = = 字串 2) 則輸出 0
如果(字串 1 > 字串 2) 則輸出正整數
strchr(字串,字元) 尋找字串中第一個與指定的字元相同處的位址。
由於 strcpy() 和 strcat () 在處理時不會先行檢查記憶空間是否足
夠,因此使用時要特別小心,避免儲存到沒有宣告的位置,造成執行上的錯誤,
嚴重時可導致當機。此外,strcmp () 依次比較的是兩字串內各字元的內碼
大小。
我們使用程式 StringProc.cpp 示範如何將上述標準字串處理函數置於完整
的程式中應用。

9-10
C++程式設計(第二版)
範例程式 檔案 StringProc.cpp
// StringProc.cpp #include <iostream> #include <cstring> using namespace std; // ---主程式------------------------
int main() { const int SLength = 30; char S1[SLength] = "Hello, 您好!";
char S2[SLength] = "Good boy."; char *pS1, *pS2; pS1=S1; pS2=S2; cout << "\n" << "pS1 的值為 : " << pS1 << "\n" << "pS1 的長度為: " << strlen(pS1) << " 字元." << endl;
cout << "\n" << "S1 的值為 : " << S1 << "\n" << "S1 的長度為: " << strlen(S1) << " 字元." << endl;
cout << "\n" << "pS2 的值為 : " << pS2 << "\n" << "pS2 的長度為: " << strlen(pS2) << " 字元." << endl;
strcat(S1, S2); cout << "執行 strcat(S1, S2); 後," << "S1 的值為: \n"
<< S1 << endl; cout << "執行 strcmp(S1, S2); 的值為: "
<< strcmp(S1, S2) << endl; char* p = strchr(S1, 'l'); cout << "第 1個 'l' 位於 S1 的第 " << (p - pS1)+1 << " 個字元的位置" << endl; cout << "執行 strchr(S1, 'l'); 的值為: "
<< strchr(S1, 'l') << endl; strcpy(S1, S2); cout << "執行 strcpy(S1, S2); 後," << "S1 的值為: \n"
<< S1 << endl; system("PAUSE"); return 0; }

9-11
第九章 字串
程式執行結果
pS1 的值為 : Hello, 您好! pS1 的長度為: 12 字元. S1 的值為 : Hello, 您好! S1 的長度為: 12 字元.
pS2 的值為 : Good boy. pS2 的長度為: 9 字元.
執行 strcat(S1, S2); 後,S1 的值為: Hello, 您好!Good boy.
執行 strcmp(S1, S2); 的值為: 1 第 1個 'l' 位於 S1 的第 3 個字元的位置
執行 strchr(S1, 'l'); 的值為: llo, 您好!Good boy.
執行 strcpy(S1, S2); 後, S1 的值為: Good boy.
1. 在本程式中,我們分別示範了 strlen(),strcat(),strcmp(),strchr(),
和 strcpy() 5 個函數的用法。
2. 函數 strlen() 的參數可以用字串 S1 或字串指標 pS1。其他字串處理函數
也都具有相同的特性。
3. 執行
strcmp(S1, S2);
的值為 1,因為 S1 的第一個字母 'H' 比 S2 的第一個字母 'G' 在 ASCII 表中
的次序較後面,值比較大。
4. 函數 strchr() 可以找到字串中第一個與指定的字元相同處的位址。但因為
字串位址直接從 cout 輸出時,得到的是從這個位址之後的字串,例如程式
對於 strchr(S1, 'l') 的輸出是
llo, 您好!Good boy.
因此要與字串開頭處的位址 (例如程式中的 pS1) 相減,才可得到相對的位
置。

9-12
C++程式設計(第二版)
字串與數字的轉換(conversion between strings and numbers)
字串內容的資料是以 ASCII 或 Unicode 的方式儲存的,而數字則是以二進
位的方式儲存,因此
"365" 和 365
所代表的意義完全不同。數字可以進行數學運算,但字串不可以。如果要將字
串與數字互相轉換,可以使用 C++ 編譯器所附設的標準字串轉換函數庫。
表 9.3.2 列出常用的三種標準字串轉換函數。在使用它們前,需要在程式
開頭處加入以下的標頭檔敘述:
#include <cstdlib>
表 9.3.2 標準字串轉換函數 (需要標頭檔 <cstdlib>)
函數名稱 功 能
atoi(字串) 將字串轉成整數,遇到非數字字元時,停止轉換。
atof(字串 1,字串 2) 將字串轉 double 數字,遇到非數字或小數點字元時,
停止轉換。
itoa(整數,字串,基底) 將整數轉成以基底為進位數的 ASCII 字串。例如基底為
10 表示十進位數字。
在程式 St2Num.cpp 中,我們分別示範了 atoi()、atof()和 itoa()共 3
個函數的用法。
範例程式 檔案 St2Num.cpp
// St2Num.cpp #include <iostream> #include <cstdlib> using namespace std; // ---主程式------------------------ int main() { const int SLength = 20; char S1[SLength] = " 320"; char S2[SLength] = " 60.5"; char *pS1, *pS2;

9-13
第九章 字串
int Num = 365; pS1=S1; pS2=S2; cout << "\n320 + 5 的值為 : " << atoi(pS1)+5 << endl; cout << "\n60.5 + 5 的值為: " << atof(pS2)+5 << endl; itoa(Num, S2, 10); cout << "\nS2 的值 (十進位) 為 : " << S2 << endl; itoa(Num, S2, 16); cout << "\nS2 的值 (十六進位) 為 : 0x" << S2 << endl; itoa(Num, S2, 2); cout << "\nS2 的值 (二進位) 為 : " << S2 << endl; system("PAUSE"); return 0; }
程式執行結果
320 + 5 的值為 : 325 60.5 + 5 的值為: 65.5 S2 的值 (十進位) 為 : 365 S2 的值 (十六進位) 為 : 0x16d S2 的值 (二進位) 為 : 101101101
字元的檢查與大小寫轉換
有時為了將某份檔案中的文字進行特殊的轉換和編排的工作,譬如:
進行大小寫的轉換
將數據中的逗點「,」去除
將所有的文字對齊
將所有的非數字符號去除
將所有的段落符號去除
等等這類的工作都需要逐一進行字元的檢查或是轉換。
這類的功能可以呼叫 C++ 的標準字元函數庫 <cctype>,詳列在表 9.3.3
中。這些函數輸出部份的資料型態都是 int,在功能說明中「否」表示「0」,

9-14
C++程式設計(第二版)
而「是」表示任意非零的整數,通常為「1」。使用前要記得在程式開頭加入
以下的敘述:
#include <cctype>
表 9.3.3 標準字元檢查與轉換函數 (需要標頭檔 <cctype>)
函 數 功 能(假設 ch 是個 char 資料)
isalpha(Ch) 判斷 Ch 是否為英文字母
isupper(Ch) 判斷 Ch 是否為大寫英文字母
islower(Ch) 判斷 Ch 是否為小寫英文字母
isdigit(Ch) 判斷 Ch 是否為 0 至 9 的數字
isascii(Ch) 判斷 Ch 是否為 ASCII 字元
isspace(Ch) 判斷 Ch 是否為空白間隔
isprint(Ch) 判斷 Ch 是否為可以印出來或看得見的字元
iscntrl(Ch) 判斷 Ch 是否為控制字元
ispucnt(Ch) 判斷 Ch 是否為標點符號字元
toupper(Ch) 如果 Ch 為小寫,則將其轉為大寫英文字母
tolower(Ch) 如果 Ch 為大寫,則將其轉為小寫英文字母
在程式 CharConv.cpp 中,我們示範了兩個字元的大小寫轉換和判斷的函數
toupper() 和 isalpha() 的使用方式:
範例程式 檔案 CharConv.cpp
// CharConv.cpp #include <iostream> #include <cctype> using namespace std; // ---主程式------------------------ int main() { const int SLength = 60; char S1[SLength], Ch; cout << "請輸入一句英文:" << endl; cin.getline(S1,SLength); for (int i=0; S1[i]!='\0';i++) S1[i] = toupper(S1[i]); cout << "此句英文轉成大寫後是:\n" << S1 << endl;

9-15
第九章 字串
cout << "請輸入一個字元:" << endl; Ch = cin.get(); if (isalpha (Ch)) cout << "您輸入了一個英文字母" << endl; else cout << "您輸入的不是英文字母" << endl; system("PAUSE"); return 0; }
程式執行結果
請輸入一句英文: How I love you!
此句英文轉成大寫後是: HOW I LOVE YOU!
請輸入一個字元: g 您輸入了一個英文字母
1. 在本程式中,我們分別示範了 isalpha()和 toupper()兩個函數的用法。
為了使用這兩個函數,我們在程式前加入了以下兩個 using 宣告: using std::toupper; using std::isalpha;
用來說明即將用到的標準函數名稱。我們也可以用 using 指令 using namespace std;
來取代這兩個 using 宣告。我們將在第 16 章「名稱空間」中詳細討論 using 指令和 using 宣告的用法。
2. 字串的各種處理都有 C++ 標準函數庫的支援,在使用時必須在程式前加上
適當的標頭檔含入指令。例如:
#include <iostream> #include <cstring> #include <cstdlib> #include <cctype>
這些標頭檔名稱的第一個字母 c 示繼承自 C 程式語言。C++ 本身有一個專
屬的字串處理標頭檔,使用下述標頭檔含入指令: #include <string>
不過,它是以物件導向的方式使用,在 23.4 節有相關的討論及範例。我們在
第 18 章以後才會仔細介紹物件導向的語法。

9-16
C++程式設計(第二版)
9.4 字串的指標陣列 如果把具有相同特質的一群字串以指標陣列 (pointer array) 來代表,常常
可以讓字串的處理更加方便。例如,我們可以將某個班的同學姓名以指標陣列
的方式宣告:
const Number = 5; char* Classmates[Number] = {"丁乾耀", "林昱為", "張喬安",
"林昱嘉", "張楚安"};
則使用 Classmates[i] 很方便地就可以取用第 i 個成員的姓名。
例如:
cout << "班上同學的名單是:\n"; for (int i=0; i<Number; i++) cout << Classmates[i] << ‘\n’;
我們在程式 StringPArray.cpp 中使用指標陣列改寫 4.5 節的程式 Seasons.
cpp,讓程式更簡潔。這個程式的功能是將使用者輸入的月份經由處理後,將
其所屬的季節顯示出來。
範例程式 檔案 StringPArray.cpp
// StringPArray.cpp #include <iostream> using namespace std; // --- 函數 FindSeason()的宣告 --------------- char* FindSeason(int); // --- 主程式 ------------------------------- int main() { int Num; cout << "\n請輸入一個月份 : " << endl; cin >> Num; cout << "\n" << Num << "月是" << FindSeason(Num) << endl; system("PAUSE"); return 0; } // --- 函數 FindSeason() 的定義 -------------- char* FindSeason(int Month) {

9-17
第九章 字串
int N; char* Seasons[]={"冬季","春季","夏季","秋季"}; if (Month < 1 || Month >12) return "(您輸入的月份沒有意義)"; N =(Month%12)/3; return Seasons[N]; }
程式執行結果
請輸入一個月份 : 9 9月是秋季
9.5 字串處理在編碼上的應用
編碼 (encoding) 在以前的諜報工作中和現代的網路安全應用上,都是一
個常用的技巧。藉由編碼,可以讓文字依某個對照表轉換成無法直接閱讀的字
串,只有使用原來的對照表才能將此字串還原。
在程式 EncodeText.cpp 中,我們將編碼的工作寫成一個函數 Encode(),
在其中含有編碼對照表 Codes[]。本程式可以將英文字母 (不管大小寫) 依對
照表轉換後輸出,對於其他不是英文字母的符號則以空白取代。
範例程式 檔案 EncodeText.cpp
// EncodeText.cpp #include <iostream> #include <cstring> using namespace std; // --- 函數 Encode() 的宣告 ------------------------- void Encode(char* ); // --- 主程式 -------------------------------------- int main() { const MaxLength=40; char InputString[MaxLength]; cout << "Please input your original code:\n"; cin.getline(InputString, MaxLength);

9-18
C++程式設計(第二版)
Encode(InputString); cout << "The answer is:\n"; cout << InputString; system("PAUSE"); return 0; } // --- 函數 Encode() 的定義 ------------------------- void Encode(char* String) { char Codes[28]="DOJKZCTMYPAWHUQNBVGSRFXLIE "; char ABC[28] ="ABCDEFGHIJKLMNOPQRSTUVWXYZ "; char abc[28] ="abcdefghijklmnopqrstuvwxyz "; int i, j, Size = strlen(String); for(i=0; i<Size;i++) { j=0; while (String[i]!=ABC[j] && String[i]!=abc[j] && j<26) j++; String[i]=Codes[j]; } return; }
程式執行結果
Please input your original code: I love you The answer is: Y WQFZ IQR
為了達到編碼的功能,我們在 while 的判斷式中分別比對大小寫字母,並累計已
比對的數量,以忽略不在編碼表內的字母。

9-19
第九章 字串
9.6 常犯的錯誤 1. 計算字串長度時,沒有把結尾的空字元 '\0' 算在內。
2. 使用 strcpy() 進行字串間的複製,或使用 strcat() 進行字串間的銜
接時,沒有考慮到空間是否足夠。
3. 使用標準函數庫時,沒有使用適當的標頭檔含入指令。
4. 沒有正確區別「陣列」和「指標」的不同。例如
char* p1, *p2; p1 = "A string."; strcpy (p2, p1);
是錯誤的,因為 p2 是一指標,且未曾指向任何字串。只要在上列最後一
行的敘述「strcpy (p2, p1);」之前加上
p2 = " ";
或
p2 = new char [strlen(p1)+1];
的敘述,以備妥適當的記憶空間,即可解決這個問題。
9.7 本章重點 1. 字串是由雙引號 " " 所包括起來的一串文字。
2. 字串在記憶體內佔用的空間,除了文字和空白部份外,每個字串的後面
都有一個空字元 '0' 以標誌字串的結束。每個中文字佔用 2 bytes。
3. 字串可視為「由 char組成的一維陣列」,其宣告可以使用標準陣列的方
式,也可使用指標,例如: char S1[50] = "Boy! 好耶!"; char* pS = S1;

9-20
C++程式設計(第二版)
4. 中文字無法以字元的形式表達。例如 '好' 是錯誤的語法,即使只有一
個中文字也需使用字串,例如 "好"。
5. 字串指標可以在宣告時初始化其內容。例如
char* pS = "容易多了!";
這個語法對於其他非 char的資料型態並不適用。
6. 將字串的指標配合 cout使用時,得到的不是位址,而是字串內容。例如,
延用上述第 3 點 S1和 pS的定義: cout << S1; cout << pS;
都會得到字串的內容。如果要輸出位址,需要改寫為 cout << (void *) S1; cout << (void *) pS;
7. 指令 char* pS2; pS2 = S1;
並不是把字串 S1的內容複製到 pS2所指的字串內,而是另行儲存一份內
容一樣的字串,並把 pS2 指向此字串。如果要進行真正的複製動作,需
要寫成以下的敘述: strcpy (pS2, S1);
8. 字串的各種處理都有 C++ 標準函數庫的支援,在使用時必須在程式前加
上適當的標頭檔含入指令。例如:
#include <iostream> #include <cstring> #include <cstdlib> #include <cctype>
這些標頭檔名稱第一個字 c 表示繼承自 C 程式語言。
C++ 本身有一個專屬的字串處理標頭檔,使用下述標頭檔含入指令:
#include <string>

9-21
第九章 字串
不過,它是以物件導向的方式使用,在 23.4 節有相關的討論及範例。我
們在第 18 章以後才會仔細介紹物件導向的語法。
9. 以指標陣列 (pointer array) 的方式取用一群有共同特性的字串,可以增
進程式的效率和簡化程式的撰寫。
9.8 本章練習 1. 下敘述有何錯誤?
int Length = 20; char S[Length];
Length 必須是常數。
2. 給定下列宣告:
char* pS = "Hello,您好!";
則 pS[2] 和 pS[7] 各是什麼?
字串的長度為何?
1. pS[2] 是 'l',pS[7] 是中文字「您」的後半段。
2. 12 bytes。(注意,逗號和驚嘆號各有「,!」和「,!」兩種寫法),前者
為 ASCII 碼,只佔 1 byte,後者為全型碼,佔 2 bytes。)
3. 寫出一個函數 Trim(),以便用來將字串前後的空白都去掉。
本題主要架構和 9.5 節的範例程式 EncodeText.cpp 很像,由於 Trim() 所產生的結果只可能縮短或不變,每個字元只會前移或留在原處,因此不需另
建新字串把處理後的內容存入。可使用 <cctype> 的 isspace() 和
isascii() 等函數來判斷字串內容。

9-22
C++程式設計(第二版)
4. 使用指標完成一個函數 AppendChar() 以便在字串之後加上一個任意指
定的字元。
首先將該字元轉成字串,再利用 <cstring> 中的函數 strcat() 將兩字串銜
接起來。
5. 寫一個函數 Reverse(),以便將任何輸入字串的前後次序顛倒過來。
將字串元素以下標分別取出,配合 for 迴圈即可完成。
6. 完成一個函數 CountDigit(),用來計算任何輸字串中的數字數量。
使用 <cstring> 中的函數 isdigit() 協助判斷。
7. 完成一個函數 CountChar(),以便用來計算字串中任一指定字元的數量。
使用 <cstring> 中的函數 strchr() 協助尋找。
8. 完成一個程式,可以將任何從 0 到 6 的輸入數字,以英文的對應星期順
序輸出。例如,以 Wednesday 對應 3,表示星期三,以 Sunday 對應 0。
使用字串的指標陣列 (pointer array)。
9. 延伸 9.5 節中的程式,寫出一個函數 Decode(),用來將已編碼過後的字
串還原。
仔細研讀原來的程式,只要把編碼表的對象顛倒即可。解答在隨書所附的光
碟中,詳見程式 Decode.cpp。