a brief introduction to regular expression with python 2.7.3 standard library
TRANSCRIPT

A Brief Introduction to Regular Expression
- with Python 2.7.3 Standard Library
Wen Liao

Disclaimer
● 投影片資料為作者整理資料及個人意見,沒有經過嚴謹確認,請讀者自行斟酌
● 只有簡介Regular Expression部份語法,省略很多細節
● API的用法不是本投影片重點,請自行參考手冊

Goal
● 以Python 2.7.3 Standard Library為範例簡介Regular Expression (簡稱為re/regex)
● 範例大部分使用re.match(),少部份用re.search(),更少部份使用re.sub()和re.findall()○ re.search()和re.findall()是只取得符合的部份。
■ print re.search(“test”, "test_whatever").group()test
■ print re.findall("test", "test54 test_2 test_whatever") ['test', 'test', 'test']

Outline
● 概論● 測試環境設定● 有效的字元● Qualifiers● Groups● Assertion● 總結● 參考資料● Q & A

Wen自認的Regular Expression
一種由字元組合而成的
字串描述方法

● 範例○ 身份證號碼:
■ 大寫英文字母開頭,之後連接九個數字○ 電子郵件信箱:
■ 由使用者和主機名稱組成,中間以@隔開■ 使用者名稱
● 可以由數字, 英文句號和英文組合● 使用者名稱最長為63 bytes● …
■ 主機名稱:● 以英文句號隔開的字串● 最後一個字元不得為英文句號● …

Regex和我有什麼關係?
● 有了描述方法後,可以○ 從大量文字中找出符合描述的字串
■ 取代■ 產生報表
○ 判斷字串是否合於規定?○ 切割字串
● 範例:○ 找出目錄中所有變數my_var被設定的檔案○ 把檔案中的巨集加上MY_DEF prefix○ 撈出百萬行訊息中發生錯誤的來源IP○ 判斷使用者輸入的email是否型式正確○ ...

字串描述方法?
到底是描述三小?

Wen自認的字串描述方法
● 有效的單獨字元
● 有效的單獨字元組合而成的順序● 目前有效的字元(組)出現的特定次數● 檢查目前字元位置是否符合描述的條件
● …● 上面描述的排列組合

有效的單獨字元
● 任何字元● 多選一
○ 範例: + - * / 其中一個
● 範圍○ 範例: 0到9, A到Z
● 排除○ 範例: 除了* 以外任何字元
● 單一特定字元○ 範例: A

有效的字元組合而成的順序
● 範例○ 單一特定位元組合字串
■ Linux■ Pork belly
○ 有效字元組合字串■ 任何字母 空白 = 空白 數字 數字;
● a = 10;● c = 66;
■ 五個英文字母後面接三個數字● abcde123● Linux769● Belly007

目前有效的字元(組)出現的特定次數
● 連續十個A● 連續八個Linux● 九到三十位數的數字

檢查目前字元位置是否符合描述的條件
● 每行開頭為A○ App○ Ace
● 每行結尾為!○ Bad!○ GG!
● 空白字元位置前面要是This○ This cat○ This one
● 空白字元位置後面要是over○ oh over○ game over

撒尿牛丸
● 以<a開頭 /a>結尾● 中間要name, =, 有一對””, “”中間有任意長度
的數字或英文字母● 並且=前後可以有任意個空白
○ < a name = “wen” /a>○ < a name = “regex” /a>

● 字串可以有哪些pattern● 字串不允許哪些pattern● 字串可以有哪些pattern或不允許哪些pattern● 字串可以有哪些pattern和不允許哪些pattern
字串描述方式分類

Outline
● 概論● 測試環境設定● 有效的字元● Qualifiers● Groups● Assertion● 總結● 參考資料● Q & A

$ ipythonPython 2.7.3 (default, Feb 27 2014, 19:58:35) ...
IPython 0.12.1 -- An enhanced Interactive Python.…
In [1]: import re

Outline
● 概論● 測試環境設定● 有效的字元● Qualifiers● Groups● Assertion● 總結● 參考資料● Q & A

多選一
● [字元一字元二字元三...]○ [abcdefghijklmnopqurstuvwxyz]○ [0123456789]○ [-+*/]
● 範例
print re.match(r'[012345789]', "0").group()0
print re.match(r'[012345789]', "a")None
- 有特殊意義,做為一般字元請放第一位

範圍
● [起始字元(ASCII值小)-結束字元(ASCII值大)]○ [0-9]○ [a-z]○ [S-T]
● 範例
print re.match(r"[0-9]", "0").group()0
print re.match(r"[0-9]", "a")None

不允許字元出現
● [^字元一字元二字元三]
● 範例
print re.match(r'[^012345789]', "a").group()a
print re.match(r'[^012345789]', "0")None
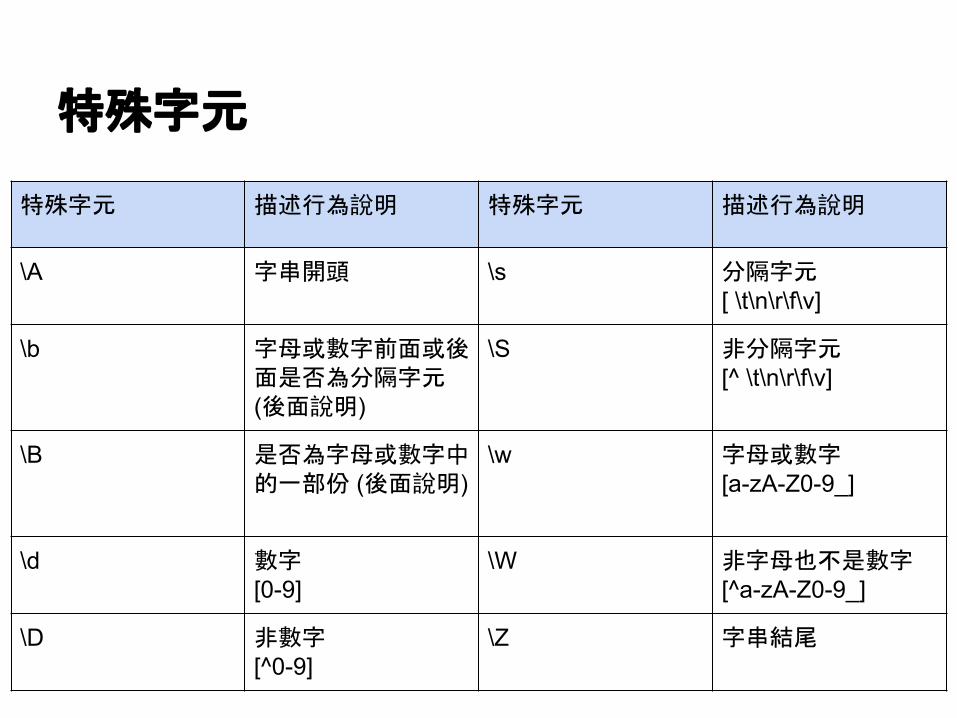
特殊字元
特殊字元 描述行為說明 特殊字元 描述行為說明
\A 字串開頭 \s 分隔字元[ \t\n\r\f\v]
\b 字母或數字前面或後面是否為分隔字元 (後面說明)
\S 非分隔字元[^ \t\n\r\f\v]
\B 是否為字母或數字中的一部份 (後面說明)
\w 字母或數字[a-zA-Z0-9_]
\d 數字[0-9]
\W 非字母也不是數字[^a-zA-Z0-9_]
\D 非數字[^0-9]
\Z 字串結尾

任意字元
● .○ 不包含跳行符號
● [\s\S]
print re.match(r".", "\n")None
print re.match(r"[\s\S]", "\n")<_sre.SRE_Match object at 0x132d920>

Outline
● 概論● 測試環境設定● 有效的字元● Qualifiers● Groups● Assertion● 總結● 參考資料● Q & A

Qualifiers
● 定義○ 描述出現字元(組)次數的方式
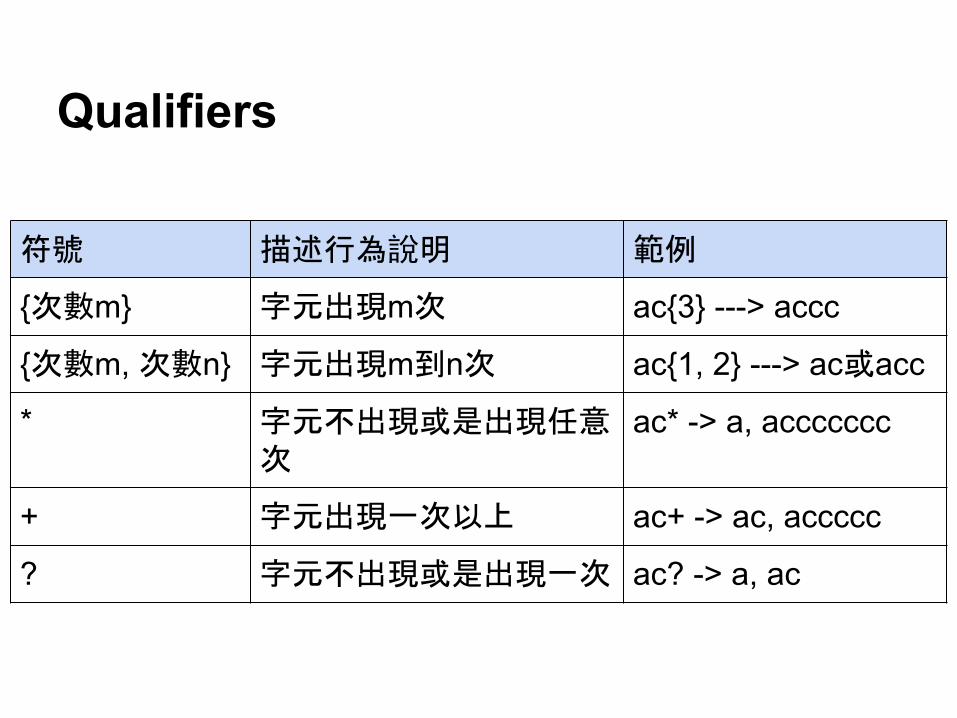
Qualifiers
符號 描述行為說明 範例
{次數m} 字元出現m次 ac{3} ---> accc
{次數m, 次數n} 字元出現m到n次 ac{1, 2} ---> ac或acc
* 字元不出現或是出現任意次
ac* -> a, accccccc
+ 字元出現一次以上 ac+ -> ac, accccc
? 字元不出現或是出現一次 ac? -> a, ac

● 找tags包起來的字串如<tags>
<.*>
Greedy Qualifier
>結束
<開始
任意字元 前面字元出現任意次數

print re.match(r'<.*>', "<tags>").group()<tags>
print re.match(r'<.*>', "<tags>>>").group()<tags>>>
測試一下
有找到,<( ̄︶ ̄)>
( ̄□ ̄|||)a 這三小!

Greedy Qualifier說明
● Regex engine遇到.*或.+會一直比對到字串結束的地方。
● 比對到字串結束的地方,會backtrack之前的字元,再比對後面的描述。○ regex: <.*> v.s. <tags>>> ○ <tags>>>
<.* 比對成立一路到底,backtrack一個字元,該值為>。
> 符合<.*>的最後預期字元的描述,所以字串符合regex的描述。
參考: http://www.perlmonks.org/?node_id=390117

Greedy Qualifier
範例2:.*suffix v.s. This_is_test_suffix
.* 比對成立一路到底,再backtrack比對suffix是否成立

怎麼辦?
● 在qualifier後面加?告訴regex engine不要用greedy qualifier
print re.match(r'<.*?>', "<tags>>>").group()<tags>
● <>中間不允許出現>字元
print re.search(r'<[^>]*>', "<tags>>>").group()<tags>

Outline
● 概論● 有效的字元● Qualifiers● Groups
○ Reference○ Alternation
● Assertion● 總結● 參考資料● Q & A

Group
● 以小括號組合有效字元提供regex engine 比對。
● 範例:○ regex: (I am ).*
■ I am Wen.■ I am whatsoever
print re.match(r'(I am ).*', "I am")None
print re.match(r'(I am ).*', "I am Wen.").group()I am Wen.
沒有空白

● 描述學生英文姓名及六位數學號
(\w+)\s(\w+):\s(\d{6})
更多範例
第1組:First name
第2組:Last name
第3組:六位數學號

驗證
print re.match(r'(\w+)\s(\w+):\s(\d{6})', "Wen Liao: 123456").group()
Wen Liao: 123456

驗證
print re.match(r'(\w+)\s(\w+):\s(\d{6})',
"Wen Liao: 123456").group(0)Wen Liao: 123456

驗證
print re.match(r'(\w+)\s(\w+):\s(\d{6})',
"Wen Liao: 123456").group(1)Wen

驗證
print re.match(r'(\w+)\s(\w+):\s(\d{6})',
"Wen Liao: 123456").group(2)Liao

驗證
print re.match(r'(\w+)\s(\w+):\s(\d{6})',
"Wen Liao: 123456").group(3)123456

觀察簡結
● Group以小括號將描述一組字元● regex允許多個group● regex會把group 編號,可以存取這些編號的
群組,而group 0表示全體match的字串。○ Keyword:
■ group reference■ capturing group

Outline
● 概論● 有效的字元● Qualifiers● Groups
○ Reference○ Alternation
● Assertion● 總結● 參考資料● Q & A

前情回顧
● Group以小括號將描述一組字元● regex允許多個group● regex會把group 編號,可以存取這些編號的
群組,而group 0表示全體match的字串。○ Keyword:
■ group reference■ capturing group

編號是什麼?可以吃嗎?

可以,而且很好吃 <3

把連續十位數電話號碼照4-3-3方式顯示
ex: 0123456789 變成0123-456-789
print re.sub(r'(\d{4})(\d{3})(\d{3})', r'\1-\2-\3', "0123456789")
0123-456-789
字串取代的API,用\1\2\3代表第1、第2、第3組group

姓名表示方式: 西方 v.s. 東方
ex: Wen Liao v.s. Liao, Wen
print re.sub(r'(\w+)\s(\w+)', r'\2, \1', "Wen Liao")Liao, Wen 字串取代的API,用
\1\2代表第1、第2組group

Outline
● 概論● 有效的字元● Qualifiers● Groups
○ Reference○ Alternation
● Assertion● 總結● 參考資料● Q & A

提供regex or的功能
● 把regex以|隔開,多選一,由左至右match。● (ab|cd).*
○ abdddddddddd○ cd10jasdfsadf○ cd○ ab○ ...

Outline
● 概論● 有效的字元● Qualifiers● Groups● Assertion
○ Anchor○ Lookahead Assertion和Lookbehind Assertion
● 總結● 參考資料● Q & A

Assertion
● Longman: assert○ to state firmly that something is true
■ http://www.ldoceonline.com/dictionary/assert○ 堅定地表達特定事物為真的事實
● 表達立場,所以要驗證是否唬爛○ 一種測試

Regex的Assertion
● 測試目前parse到的字元位置○ 前面是否符合特定條件,或是○ 後面是否符合特定條件
● parse位置不會移動○ 之前的「字串描述」,滿足條件regex engine會parse目
標字串的下一個字元。○ ex:
■ regex: linux■ string: linux
● 第一次l滿足,第二次比對l下一個字元是不是i

表示符號 描述行為說明 範例
\A 字串開頭 \Ahi.*
\Z 不包含跳行符號的字串結尾 .*over\n\Z , .*over\Z
^ 字串開頭 ^hi.*
$ 字串結尾,等於(\Z|\n\Z) .*over$
\b 字母或數字前面或後面是否為分隔字元 \bcon\b
\B 是否為字母或數字中的一部份 \Bcon\B
(?=regex) 目前字元位置後面是否滿足regex (?=over)
(?!regex) 目前字元位置後面是否不是regex (?!start)
(?<=regex) 目前字元位置前面是否滿足regex (?<=over)
(?<!regex) 目前字元位置前面是否不是regex (?<!start)
有哪些特定條件呢?

Outline
● 概論● 有效的字元● Qualifiers● Groups● Assertion
○ Anchor○ Lookahead Assertion和Lookbehind Assertion
● 總結● 參考資料● Q & A

Anchor
表示符號 描述行為說明 範例
\A 字串開頭 \Ahi.*
\Z 不包含跳行符號的字串結尾 .*over\n\Z , .*over\Z
^ 字串開頭 ^hi.*
$ 字串結尾,等於(\Z|\n\Z) .*over$
\b 字母或數字前面或後面是否為分隔字元 \bcon\b
\B 是否為字母或數字中的一部份 \Bcon\B
(?=regex) 目前字元位置後面是否滿足regex 稍候再談
(?!regex) 目前字元位置後面是否不是regex 稍候再談
(?<=regex) 目前字元位置前面是否滿足regex 稍候再談
(?<!regex) 目前字元位置前面是否不是regex 稍候再談

Anchor
● 描述目前有效字元位置資訊○ 字串開頭?○ 字串結尾?
○ 前方會或是後方是否為字母、數字和_以外的字元(即分隔字元,如空白\t等)?

$: 範例
print re.search(r'test.*over$', "test over123\n")None
print re.search(r'test.*over', "test over123\n").group()test over
字串結束字元為跳行符號\n
不包含跳行符號的字串結束位置

\Z: 範例
print re.search(r'test.*over\Z', "test over\n")None
print re.search(r'test.*over\n\Z', "test over\n").group()test over
字串結束字元為跳行符號\n
包含跳行符號的字串結束位置
必須要明確指定\n

\Z和$的差別
# 預設的單行模式只差在\n是否算是字串結尾字元
print re.findall(r'test.*over\n\Z', "test over\ntest is over\n")['test is over\n']
print re.findall(r'test.*over$', "test over\ntest is over\n")['test is over']

\Z和$的差別
# 多行模式下$還可以提供多次搜尋而\Z仍然是字串結尾
print re.findall(r'(?m)test.*over$', "test over\ntest is over\n")['test over', 'test is over']
print re.findall(r'(?m)test.*over\n\Z', "test over\ntest is over\n")['test is over\n']
多行模式,請自行參考手冊

^: 範例
print re.search(r'^test', "my_test")None
print re.search(r'test', "my_test").group()test
字串起始位置
字串開頭不是t

\A和^的差別
# 多行模式下^還可以提供多次搜尋而\A仍然是字串開頭
print re.findall(r'(?m)^test.*', "test_1\ntest_2")['test_1', 'test_2']
print re.findall(r'(?m)\Atest.*', "test_1\ntest_2")['test_1']
字串起始位置
字串起始位置
跳行符號
跳行符號多行模式,請自行參考手冊

\b範例 (b for boundary)
# 用來區別是否是一個wordprint re.findall(r'\btest\b', "test test_whatever")['test']
print re.findall(r'test\b', "test test_whatever")['test']
print re.findall(r'\btest', "test test_whatever")['test', 'test']

\B: 前面或後面不得有分隔字元
print re.findall(r'\Btest\B', "my_test_whatever")['test']
print re.findall(r'\Btest', "my_test")['test']
print re.findall(r'test\B', "test_whatever")['test']

Outline
● 概論● 有效的字元● Qualifiers● Groups● Assertion
○ Anchor○ Lookahead Assertion和Lookbehind Assertion
● 總結● 參考資料● Q & A
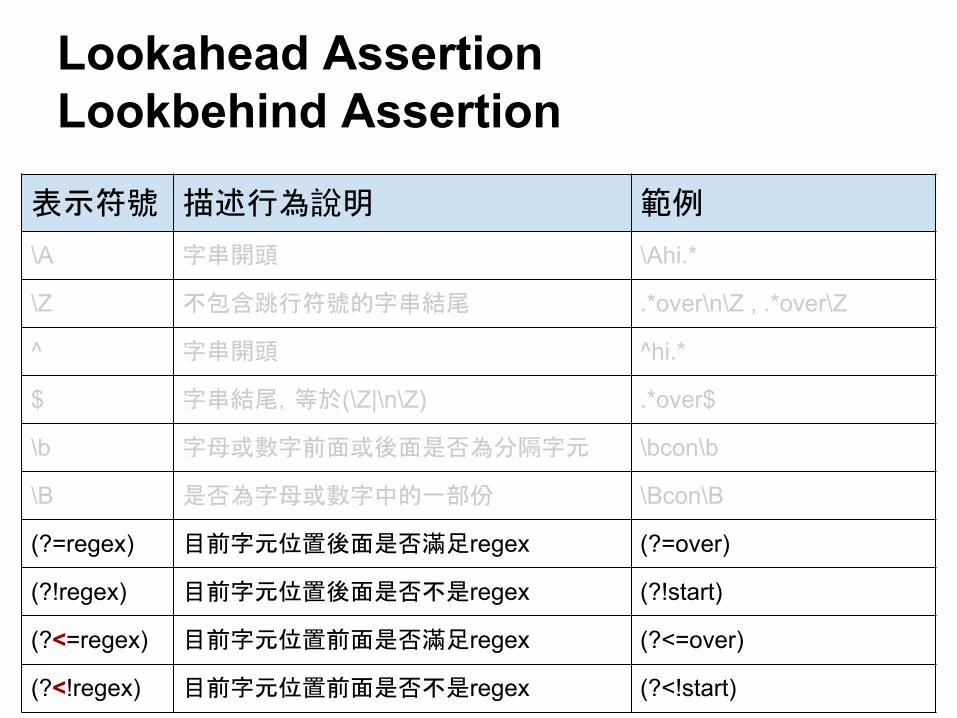
表示符號 描述行為說明 範例
\A 字串開頭 \Ahi.*
\Z 不包含跳行符號的字串結尾 .*over\n\Z , .*over\Z
^ 字串開頭 ^hi.*
$ 字串結尾,等於(\Z|\n\Z) .*over$
\b 字母或數字前面或後面是否為分隔字元 \bcon\b
\B 是否為字母或數字中的一部份 \Bcon\B
(?=regex) 目前字元位置後面是否滿足regex (?=over)
(?!regex) 目前字元位置後面是否不是regex (?!start)
(?<=regex) 目前字元位置前面是否滿足regex (?<=over)
(?<!regex) 目前字元位置前面是否不是regex (?<!start)
Lookahead AssertionLookbehind Assertion

Lookahead Assertion
● 目前字元後面是否符合特定條件○ 後面條件成立才繼續比對
■ (?=成立條件描述)○ 後面條件不成立才繼續比對
■ (?!不成立條件描述)
● 範例○ 字串前面必須要有file
■ unittest_file, src_file, ...○ 字串後面不得出現test

(?=) 範例
# 多個good-開頭的字串
# 只把good-dog換成bad-dogre.sub(r'good-(?=dog)', r'bad-', "good-man good-dog good-bye")
'good-man bad-dog good-bye'

(?!) 範例
# 多個good-開頭的字串
# 除了good-bye以外把good-換成bad-re.sub(r'good-(?!bye)', r'bad-', "good-man good-dog good-bye")
'bad-man bad-dog good-bye'

Lookbehind Assertion
● 目前字元前面是否符合特定條件○ 前面條件成立才繼續比對
■ (?<=成立條件描述)○ 前面條件不成立才繼續比對
■ (?<!不成立條件描述)
● 範例○ 字串前面必須要有unittest
■ unittest_file1, unittest_cases, ...○ 字串前面不得出現fake

(?<=)例子
# file前面必須是4個x
print re.match(r'(?<=x{4})file', "xxxxfile")None ( ̄□ ̄|||)a 那A阿捏?

前情提要:Regex的Assertion
● 測試目前parse到的字元位置○ 前面是否符合特定條件,或是○ 後面是否符合特定條件
● parse位置不會移動○ 之前的「字串描述」,滿足條件regex engine會parse目
標字串的下一個字元。○ ex:
■ regex: linux■ string: linux
● 第一次l滿足,第二次比對l下一個字元是不是i

多測試
print re.match(r'.{4}(?<=x{4})file', "xxxxfile").group()xxxxfile
print re.match(r’.{4}(?<=x{4})file', "asdffile")None
讓regex engine match後吃掉四個字元

小結
● Assert parse位置不會移動不是喊假的● 難道下lookahead assertion都要算前面吃幾
個字元?○ match()需要○ search(), sub(), findall()不用
■ re.search(pattern, string, flags=0)● Scan through string looking for the first location where the
regular expression pattern produces a match
● 窮舉檢視字串所有字元,直到找到第一個符合Regex的結果為
止。
https://docs.python.org/2/library/re.html

(?<=)例子
# 多個-driven的字串中
# 只有test-driven改成test-basedre.sub(r'(?<=test)-driven', r'-based',
"test-driven boss-driven customer-driven")
'test-based boss-driven customer-driven

(?<!)例子
# 多個-driven的字串中
# 只要不是test-driven的字串都改成test-basedre.sub(r'(?<!test)-driven', r'-based',
"test-driven boss-driven customer-driven")
'test-driven boss-based customer-based

Outline
● 概論● 測試環境設定● 有效的字元● Qualifiers● Groups● Assertion● 總結● 參考資料● Q & A

回顧:Wen自認的Regex描述方法
● 有效的單獨字元
● 有效的單獨字元組合而成的順序● 目前有效的字元(組)出現的特定次數● 檢查目前字元位置是否符合描述的條件
● …● 上面描述的排列組合

有效的單獨字元
● a● [!@#$]● [0-9]● [^A-Z]

有效的單獨字元組合而成的順序
● Linux● 20[0-9][0-9]
○ 2000~2099● [SRT]ing
○ Sing, Ring, Ting● Profile-[0-9]
○ Profile-0 ~ Profile-9

目前有效的字元(組)出現的特定次數
● (Linux){8}○ LinuxLinuxLinuxLinuxLinuxLinuxLinuxLinux
● .*\.test\.tw○ abc.test.tw, test.test.tw
● [A-Z]\d{9}○ A123456789, Q129840030
● (\d{4})-(\d{2})-(\d{2})○ 2011-11-11○ 9999-91-39

檢查目前字元位置是否符合描述的條件
● <\s*a\s*name\s*="\w+"\s*(?=/a>)○ <a name = “ test” /a>
● ^Linux$● (<=\w)\d{9}
○ A123456789, Q129840030

上面描述的排列組合
● \ADear[\s\S]*\nBest regards,\nWen Liao\Z
Dear Sir,\nFirst at all, I would like to ..(下略500字)\nBest regards,\nWen Liao
. 不包含換行符號!

這只是簡介,還有興趣的可以去了解
● NFA● Regex modes● Re APIs (re.comple()...etc)● Unicode和Regex的關係● 描述方式和效率的關係
○ Disable capturing group○ 安全問題: ReDoS
● 流派○ PCRE○ POSIX: BRE, ERE, SRE
● ...

Outline
● 概論● 測試環境設定● 有效的字元● Qualifiers● Groups● Assertion● 總結● 參考資料● Q & A

參考資料
● The Python Standard Library: re○ https://docs.python.org/2/library/re.html
● Regular Expression HOWTO○ https://docs.python.org/2/howto/regex.html
● PHP: Assertions - Manual○ http://php.net/manual/en/regexp.reference.
assertions.php● 處理大數據的必備美工刀 - 全支援中文的正規
表示法精解○ http://www.grandtech.info/02-shop-detail-53-824.
html

Outline
● 概論● 測試環境設定● 有效的字元● Qualifiers● Groups● Assertion● 總結● 參考資料● Q & A