alen gri zoni ceprints.fri.uni-lj.si/984/1/grižonič_a._-un.pdf · zakulisje ne cesa, kar se mu...
TRANSCRIPT

UNIVERZA V LJUBLJANIFAKULTETA ZA RACUNALNISTVO IN INFORMATIKO
Alen Grizonic
Simulacija algoritmovza razvrscanje procesov
The Simulation of Process Scheduling Algorithms
DIPLOMSKO DELONA UNIVERZITETNEM STUDIJU
Mentor: prof. dr. Nikolaj Zimic
Ljubljana, 2009


Rezultati diplomskega dela so intelektualna lastninaFakultete za racunalnistvo in informatiko Univerze v Ljubljani.
Za objavljanje ali izkoriscanje rezultatov diplomskega dela je potrebnopisno soglasje Fakultete za racunalnistvo in informatiko ter mentorja.
Besedilo je oblikovano z urejevalnikom besedil LATEX.

Namesto te strani vstavite original izdane teme diplomskega dela s podpisommentorja in dekana ter zigom fakultete, ki ga diplomant dvigne v studentskemreferatu, preden odda izdelek v vezavo!


IZJAVA O AVTORSTVU
diplomskega dela
Spodaj podpisani Alen Grizonic,
z vpisno stevilko 63990195,
sem avtor diplomskega dela z naslovom:
Simulacija algoritmov za razvrscanje procesov
S svojim podpisom zagotavljam, da:
• sem diplomsko delo izdelal samostojno pod mentorstvom
prof. dr. Nikolaja Zimica
• so elektronska oblika diplomskega dela, naslov, povzetekter kljucne besede identicni s tiskano obliko diplomskega dela
• soglasam z javno objavo elektronske oblike diplomskega delav zbirki ”Dela FRI”.
V Ljubljani, dne 15.12.2009 Podpis avtorja:


Zahvala
Zahvalil bi se svojemu mentorju prof. dr. Nikolaju Zimicu za vso pomoc indobro voljo, predvsem pa za konstruktivno usmerjanje in neverjetno odzivnostmed izdelavo pricujocega dela. Zelo posebna zahvala gre tudi Ireni in Tjasi, kista sposobni lektorirati in z nasmehom prevajati tudi sredi noci, ko je najboljnujno. Najvecjo zahvalo pa bi rad namenil svojim starsem ter Simonu in Lukcu!Brez njihove podpore ne bi nikoli tako sprosceno pisal.
Posveceno vsem prijateljem!


Za vse, ki so me ta cas fino prenasali.


Kazalo
Povzetek 1
Abstract 3
1 Uvod 5
1.1 Opredelitev problema . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2 Struktura operacijskega sistema . . . . . . . . . . . . . . . . . . 5
1.3 Funkcije operacijskega sistema . . . . . . . . . . . . . . . . . . . 7
2 Procesi 9
2.1 Upravljanje s procesi . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 Zgradba procesa . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3 Razvrscanje procesov . . . . . . . . . . . . . . . . . . . . . . . . 12
2.4 Niti (Threads) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.5 Vecjedrno programiranje . . . . . . . . . . . . . . . . . . . . . . 15
3 Razvrscanje na procesorju 17
3.1 Algoritmi za razvrscanje . . . . . . . . . . . . . . . . . . . . . . 17
3.2 Merila kakovosti algoritmov . . . . . . . . . . . . . . . . . . . . 18
3.3 Primeri algoritmov . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.3.1 Algoritem FCFS . . . . . . . . . . . . . . . . . . . . . . 20
3.3.2 Algoritem Round Robin . . . . . . . . . . . . . . . . . . 21
3.3.3 Najkrajsi cas izvajanja prvi . . . . . . . . . . . . . . . . 22
3.3.4 Najkrajsi preostali cas izvajanja prvi . . . . . . . . . . . 22
3.4 Razvrscanje v realnem casu . . . . . . . . . . . . . . . . . . . . 24
3.5 Prednosti vecprocesorskega sistema . . . . . . . . . . . . . . . . 25
3.5.1 Procesorska afiniteta . . . . . . . . . . . . . . . . . . . . 25
3.5.2 Uravnotezena obremenitev . . . . . . . . . . . . . . . . . 26
3.5.3 Vecjedrni procesorji . . . . . . . . . . . . . . . . . . . . . 27

4 Linux 294.1 Razvojni cilji . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294.2 Zgradba Linux procesa . . . . . . . . . . . . . . . . . . . . . . . 30
4.2.1 Deskriptor procesa . . . . . . . . . . . . . . . . . . . . . 314.2.2 Stanja procesov . . . . . . . . . . . . . . . . . . . . . . . 324.2.3 Identifikacija procesov . . . . . . . . . . . . . . . . . . . 324.2.4 Cakalna vrsta . . . . . . . . . . . . . . . . . . . . . . . . 34
4.3 Delovanje algoritma . . . . . . . . . . . . . . . . . . . . . . . . . 344.3.1 Prioritetni razredi . . . . . . . . . . . . . . . . . . . . . . 374.3.2 Dinamicna prioriteta . . . . . . . . . . . . . . . . . . . . 384.3.3 Casovne rezine . . . . . . . . . . . . . . . . . . . . . . . 394.3.4 Metoda ponovne uvrstitve . . . . . . . . . . . . . . . . . 414.3.5 Vecjedrna obremenitev . . . . . . . . . . . . . . . . . . . 42
4.4 Razvrscanje v realnem casu . . . . . . . . . . . . . . . . . . . . 43
5 Windows 455.1 Arhitektura sistema . . . . . . . . . . . . . . . . . . . . . . . . . 455.2 Predstavitev procesov . . . . . . . . . . . . . . . . . . . . . . . . 465.3 Algoritem za razvrscanje . . . . . . . . . . . . . . . . . . . . . . 47
5.3.1 Razvrscanje po prioriteti . . . . . . . . . . . . . . . . . . 475.3.2 Prioritetno rekreditiranje . . . . . . . . . . . . . . . . . . 505.3.3 Prioritetna inverzija . . . . . . . . . . . . . . . . . . . . 51
5.4 Vecprocesorsko izvajanje . . . . . . . . . . . . . . . . . . . . . . 525.4.1 Procesorska afiniteta SMP sistema . . . . . . . . . . . . 535.4.2 Podpora za NUMA sisteme . . . . . . . . . . . . . . . . 535.4.3 Mnozica procesorjev . . . . . . . . . . . . . . . . . . . . 54
5.5 Multimedijski procesi . . . . . . . . . . . . . . . . . . . . . . . . 55
6 Realizacija simulacije 576.1 Primerjava algoritmov . . . . . . . . . . . . . . . . . . . . . . . 57
6.1.1 Algoritem Linux sistema . . . . . . . . . . . . . . . . . . 576.1.2 Razvrscevalnik Windows sistema . . . . . . . . . . . . . 59
6.2 Dolocitev bremena . . . . . . . . . . . . . . . . . . . . . . . . . 636.3 Implementacija delovanja . . . . . . . . . . . . . . . . . . . . . . 666.4 Interpretacija rezultatov . . . . . . . . . . . . . . . . . . . . . . 72
7 Zakljucek 79
Seznam slik 81
Literatura 83

Seznamuporabljenihkratic in simbolov
Oznaka Opis
CPE Centralno procesna enotaID Identifikator procesaNP Nedeterministicno polinomski (problem)OS Operacijski sistemPC Programski stevecPCB Programsko-nazorni blokPID Procesni identifikacijski deskriptorSMP Simetricno multiprocesiranjeV/I Vhodno/Izhodna (enota)
API Application Programming InterfaceDLL Dynamic Link LibraryFIFO First In, First OutHAL Hardware Abstraction LayerIEEE Institute of Electrical and Electronics EngineersMMCSS Multimedia Class Scheduler ServiceNUMA Non-Uniform Memory AccessPOSIX Portable Operating System InterfaceRAM Random-Access MemoryRR Round RobinSJF Shortest Job FirstUMS User-Mode Scheduling


Povzetek
Uporaba racunalniskega sistema postopoma vdira v zivljenje vse vecjega stevilaljudi, zato hitrejsi kot je tempo, bolj hitre in zmogljive so naprave, ki nasobdajajo. Potreba po hitri komunikaciji oziroma izvrsevanju od nas zahtevanihopravil nas postavi pred dejstvo, da je uporaba omenjenih sredstev skorajdaneizogibna in povsem smiselna. Vendar, ali smo se kdaj vprasali, kaj vse pritem dejansko zagotavlja optimalno izvedbo?
Ker racunalnik uporabljajo tako rekoc vsi, nam mnogi razvijalci ponujajo vsezmogljivejse operacijske sisteme, ki omogocajo izvedbo uporabniskih zahtev terpri tem delujejo kot vmesnik med posameznikom in strojno opremo. Vprasanjepa je, ali so algoritmi, ki jih uporabljajo razlicni (na trgu prisotni) operacijskisistemi, med seboj primerljivi in/ali je mogoce njihovo hitrost razvrscanja pro-cesov tudi izmeriti oziroma prilagoditi mnozici razlicnih vhodnih zahtev.
V ta namen sem realiziral simulacijo, ki prikazuje, kako do sedaj konkurencnaoperacijska sistema razpolagata s sistemskimi viri, na zasnovi vecprocesorskeracunalniske arhitekture. V prvem delu naloge sem bralcu predstavil, kako sov osnovi predstavljeni procesi znotraj sistema, kateri kriteriji se uporabijo zadolocitev zmogljivosti sistema ter kateri so najbolj osnovni principi razvrscanjaprocesov. Sledi opis pogosto uporabljenih algoritmov, pojem razvrscanja vrealnem casu, prednosti vecprocesorskega oziroma vecjedrnega sistema, in karje najbolj pomembno, podroben opis algoritmov za razvrscanje. V zadnjempoglavju predstavim se primerjavo posameznih korakov algoritmov ter celotnoimplementacijo simulacije, kjer v sklepnem delu, na podlagi vseh pridobljenihmeritev podam, pri kateri vrsti bremena se algoritma najbolje obneseta.
Kljucne besede:
algoritem za razvrscanje, operacijski sistem, simulacija, vecprocesorski sistem
1


Abstract
The use of computer systems is gradually entering lives of numerous people.The quicker as the speed of life is, faster and more efficient are the devices sur-rounding us. The need for quick communication and the execution of deman-ded tasks confront us with a fact that the use of the mentioned means is almostinevitable and completely sensible. The question, however, remains what givesan assurance of optimal realization.
Computers are so widely used that several developers offer more and moreefficient operating systems, which enable the execution of user requests, andact as user interfaces between the individual and computer hardware at thesame time. Whether algorithms used by different operating systems currentlypresent on the market are comparable, and/or their speed of process schedulingcan be measured and adapted to a great deal of different system demands, isquestionable.
For this purpose I carried out a simulation showing how two different up tonow competitive operating systems use their computer system resources basedon a multiprocessor computer architecture. The first part of the thesis presentsthe processes inside the system, the efficiency evaluation criteria used, and thebasic principals of process scheduling. In the second part I then concentrate onthe most commonly used algorithms, the notion of real-time scheduling, andthe advantages of the multiprocessor or multicore systems respectively. Whatfollows is a detailed description of the algorithms for process scheduling andthe most important, comparison and implementation of the simulation, which(with the use of the results acquired) helped me establish with which systemload the particular system or its algorithm proves the most effective.
Key words:
scheduling algorithm, operating system, simulation, multiprocessor system
3


Poglavje 1
Uvod
1.1 Opredelitev problema
V danasnjih dneh je uporaba operacijskega sistema nekaj vsakdanjega, zatobi bilo veliko bolje, ce bi uporabniki poznali vsaj osnove njegovega delovanja.Vendar, sistemi so postali relativno kompleksni, zato le malokdo rad pogleda vzakulisje necesa, kar se mu zdi prezahtevno. Tako nam novi operacijski sistemiponujajo veliko vec, kot so nam pred nekaj leti. Funkcij je resda veliko, osnovnipojmi in primarne naloge pa so zelo podobne tistim v predhodnih verzijah.Spreminja se graficna podoba, jedro pa temelji na osnovnih spoznanjih prvihgeneracij. Osnovni namen operacijskih sistemov se vedno ostaja komunikacijamed uporabnikom in strojno racunalnisko opremo.
Namen naloge ni predstaviti celotno delovanje operacijskih sistemov, zato semse v okviru diplomske naloge raje odlocil za nekoliko bolj natancen vpogledv razvrscanje procesorskega casa s strani dveh najbolj konkurencnih operaci-jskih sistemov. Osredotocil sem se na delovanje posameznih algoritmov terposkusil ugotoviti, kateri ponuja trenutno najbolj optimalno resitev - Windowsali Linux.
1.2 Struktura operacijskega sistema
Ker sta obravnavana operacijska sistema strukturno precej razlicna, je njunaprimerjava toliko bolj smiselna, ceprav pod drobnogledom zlahka opazimo, daveliko konceptov, na katerih temeljita, ostaja enakih. Res pa je tudi, da sistemase vedno sluzita kot uporabniski vmesnik, ki omogoca izvajanje programov.
5

6 Poglavje 1: Uvod
Da bi programi dobro izkoristili zmogljivost racunalnika, so razvijalci sistemovfunkcionalnost prilagajali racunalniski arhitekturi. Podobno se je zgodilo tuditakrat, ko so uporabniki, nezadovoljni z dolocenimi vidiki delovanja predlagalispremembe strojne opreme, kar je skozi cas privedlo do razlicnih resitev, takoz vidika operacijskih sistemov kot z vidika arhitekture racunalniskih sistemov.
Najbolj pomembna sprememba pri izrabi procesorskega casa je bila vpeljanaz novim algoritmom za razvrscanje opravil, ki uposteva dejstvo, da centralnoprocesna enota (CPE) v dolocenem trenutku izvaja le en sam proces. Tako seje porodila ideja o multiprogramiranju, kjer sistem v delovnem pomnilnikushranjuje procese, ki cakajo na izvrsitev. Ko se proces ne izvaja, ker caka naizvrsitev vhodno/izhodne zahteve, CPE ne stoji, temvec v izvrsevanje odposljenaslednji cakajoci proces.
Poleg tega moram omeniti, da multiprogramski sistemi, kljub ucinkovitemuizkoristku sistemskih virov, nikakor ne omogocajo uporabniske interakcije zracunalniskim sistemom. Kot resitev so se kasneje pojavili t.i. time sharing alivecopravilni (multitasking) operacijski sistemi, kjer CPE vse naloge izvajatako, da nenehoma ”preklaplja” med posameznimi procesi. Za uporabnika jeomenjeni sistem videti kot interaktivno orodje, s pomocjo katerega lahko vplivana izvrsevanje programov, za komunikacijo s programi ali sitemom pa uporabieno od V/I naprav. Kljub navidezno enostavni zamisli se tovrstna izmenjavapodatkov pogosto izkaze kot trd oreh pri zagotavljanju efektivnega delovanjasistema, ker uporabnik pricakuje odzivni cas, ki je krajsi od ene sekunde.
Ceprav vecina racunalnikov deluje na osnovi enega procesorja, so od nekdaj vuporabi vecprocesorski sistemi, ki jih relativno hitro nadomesca kompaktnejsaoblika vecjedrnih (multicore) procesorjev. Kljub temu so vecprocesorski sistemiuporabni in jih delimo na asimetricne vecprocesorske sisteme, kjer edenod procesorjev prevzame vlogo gospodarja, ter simetricne ali s kratico SMP(Symmetric Multi Processing) sisteme, pri katerih lahko vsaka procesna enotaizvrsi katerokoli nalogo operacijskega sistema, brez medsebojne relacije vrstegospodar-suzenj. Glavne prednosti tovrstnih sistemov so:
1. Povecan pretok. Pri vecjem stevilu procesorjev se povecan pretokpokaze kot vec opravljenega dela v krajsem casu. Pohitritev, ki jo lahkodosezemo z N procesorji, je vecinoma nizja od faktorja N , ker je mnozicoprocesov tezko enakomerno razporediti, saj si procesorji med seboj delijosistemske vire, kar povzroci istocasne dostope do pomnilnika in V/I enot.

1.3 Funkcije operacijskega sistema 7
2. Povecana zanesljivost. V primeru odpovedi enega ali vec procesorjevne pride do popolne zaustavitve sistema, ampak le do upocasnitve, kerpreostali del sistema prevzame delo izpadlega procesorja.
3. Ekonomicnost skalabilnosti. Stroski nakupa racunalniskega sistemaz vec procesorji so lahko bistveno nizji od stroska nabave vecjega stevilaracunalnikov, ki porazdeljeno izvajajo procesiranje nad skupno mnozicopodatkov. Ce kot primer vzamemo vecjederni racunalniski sistem, bomozlahka opazili, da si posamezna jedra med seboj delijo pomnilnik in ostaleperiferne enote (enako kot pri sistemu z vec procesorji), medtem ko vecjestevilo enoprocesorskih sistemov tega ne zmore.
1.3 Funkcije operacijskega sistema
Vse osnovne funkcije sistema so realizirane v okviru njegovega jedra (kernel).Strojna oprema je z jedrom povezana preko t.i. krmilnikov (handlers), medkrmilniki in jedrom pa so namesceni gonilniki (device drivers), ki prevzeteukaze predajajo krmilnikom.
Proces (na katerega lahko gledamo kot na program v izvajanju) predstavljamnozico ukazov, zato (za izvedbo) potrebuje vire, kot so CPE, pomnilnik invhodno/izhodne naprave. Tvori ga lahko tudi zbirka drugih procesov, pri tempa procesi operacijskega sistema izvajajo sistemsko kodo, za uporabniski delkode pa poskrbijo uporabniski procesi. Ko racunalnik zaposlimo, pravimo, dasmo mu izvedbo nekega procesa nalozili.
Vedeti pa moramo, da proces ne predstavlja le mnozice ukazov, temvec zajematudi trenutno aktivnost programa. Ker njegov pasivni del tvori le programskakoda, aktivni del sestoji iz vsebine registrov, programskega stevca ter sklada sparametri klicnih procedur. Ukazi procesne enote se izvajajo zaporedno, zatose v dolocenem trenutku izvrsuje le en proces, operacijski sistem pa je zadolzenza njegovo porazdelitev in sinhronizacijo.

8 Poglavje 1: Uvod

Poglavje 2
Procesi
2.1 Upravljanje s procesi
Procesi lahko izvirajo neposredno iz naloge (opravila), ki jo je uporabnik poslalv obdelavo, lahko pa nastanejo, ko se aktivirajo rutine operacijskega sistemaali drugih sistemskih programov. Procesi obicajno predstavljajo dele izvedljiveprogramske kode, ki se je predhodno nalozila v pomnilnik, med izvajanjem pavsak proces prehaja1 med razlicnimi stanji.
Enoprocesorski sistemi vseh opravil ne zmorejo izvajati vzporedno, temvec siprocesorski cas delijo (processor time sharing). Pri tem mora operacijski sistemposkrbeti, da se kapaciteta centralno procesne enote enakomerno porazdeli medvse aktivne uporabnike oziroma njihove procese, delitev procesorskega casa naenake casovne intervale ali casovne rezine pa ostaja osrednja tema pricujocegadela. Zanima nas torej, kako vecopravilni operacijski sistemi razvrscajo procesev primeru ene ali vec procesnih enot.
Procesi se porajajo v obliki zahtev (vhodnih procesov), zato potrebujejo prostostrezno enoto, ki je predstavljena s cakalno vrsto in streznikom. Ce je streznik(v nasem primeru procesor ali vhodno/izhodna naprava) zaseden, se zahtevezadrzujejo v cakalni vrsti, kjer cakajo, da se streznik sprosti. Poenostavljeno bilahko rekli, da procesi med seboj tekmujejo za pridobitev procesorskega casain ostalih sistemskih virov, za pravilno delovanje pa poskrbi temu namenjenasistemska rutina, ki ji pravimo razvrscevalnik procesov.
1Prehajanje med stanji je veliko bolj razvidno pri vecprogramskem (ali vecopravilnem)delovanju, kjer imamo obcutek, da je v dolocenem trenutku istocasno aktivnih vec procesov.
9

10 Poglavje 2: Procesi
2.2 Zgradba procesa
Razvrscevalnik spremlja proces od trenutka njegovega nastanka do zakljuckaizvajanja. Le-ta nastane kot manjsi del dolocene naloge (posla), lahko pa gaustvari drugi proces, kot svojega potomca. Razvrscevalnik vodi proces skozinaslednja tri stanja (prikazana na sliki 2.1):
1. aktivno stanje oziroma stanje pripravljenosti, ko je proces nalozenv pomnilniku in pripravljen (ready) na izvajanje
2. stanje, ko se proces izvaja (running) oziroma ko se na procesorjuizvajajo ukazi, ki ga sestavljajo
3. stanje, ko proces caka (waiting) na prosto vhodno/izhodno napravo
Slika 2.1: Stanja procesov.
Proces je v operacijskem sistemu predstavljen s pomocjo svojega nadzornegabloka PCB (Process Control Block), ki obicajno vsebuje:
• stanje procesa (caka, nov, pripravljen)
• vsebino programskega stevca (PC)
• vsebine ostalih CPE registrov
• identifikator procesa (ID)
• kazalec na svoje sinove
• podatke o stanju V/I naprav
• informacije o razvrscanju na procesorju
• podatke za obracunavanje procesorskega casa

2.2 Zgradba procesa 11
Ko proces vstopi v sistem, se postavi v cakalno vrsto. Procese, ki ze zasedajoprostor v glavnem pomnilniku in so pripravljeni na izvajanje, operacijski sistempremakne v vrsto pripravljenih procesov oziroma povezovalno strukturo, kjerglava vrste (header) vsebuje kazalca na prvi in zadnji PCB v seznamu.
Slika 2.2: Povezovalna struktura.
Kot vidimo, se bloki PCB med seboj povezujejo v razlicne cakalne vrste, zato jenjihova implementacija bistvenega pomena. Poleg tega moramo vedeti, da sotudi kontrolni bloki realizirani kot cakalne vrste, kar lahko terja veliko casa zanjihovo manipulacijo. Da bi ugotovitve ustrezale realnim sistemom, sem priprocesih svoje simulacije, s pomocjo podatkovnega razreda cPar razvojnegaorodja Omnet++, uporabil podobno podatkovno strukturo.

12 Poglavje 2: Procesi
2.3 Razvrscanje procesov
Primarna naloga razvrscevalnika je dobra razvrstitev procesov, upostevajoczahtevo, da v najvecji meri zaposli procesor. Kadarkoli se izvajanje trenutnegaprocesa prekine, mora operacijski sistem med preostalimi aktivnimi procesiizbrati kandidata, ki bo procesor prevzel. Pri tem je v PCB najprej potrebnoshraniti vse kljucne informacije o prekinjenem procesu, sele nato lahko sistemprebere podatke na novo izbranega procesa. Postopku pravimo zamenjava alipreklop okolja (context switch) in je pri danasnjih sistemih nekoliko krajsi od10 ms. Ker procesor med tem ne izvaja zelenih operacij, je potrebno zagotoviticim krajsi cas zamenjave, nanj pa vpliva:
• stevilo registrov, ki jih je potrebno shraniti
• hitrost pomnilnika, kamor se shranjujejo podatki
• obstoj posebnih ukazov za shranjevanje registrov
• operacijski sistem (algoritem za razvrscanje)
• arhitektura procesorja
Menjava okolja velja za ozko grlo v samem operacijskem sistemu, zato na tempodrocju potekajo mnoge raziskave na nivoju algoritmov in struktur.
Slika 2.3: Potek sistema prekinitev.

2.3 Razvrscanje procesov 13
Kratkorocno razvrscanje (short-term, CPU scheduler)
Izbere pripravljen proces in mu dodeli prost procesor. Ker je izbira pogosta,moramo imeti hiter razvrscevalni algoritem, ki v vrsti pripravljenih procesovtakoj najde ustreznega. Cas, ki ga ima razvrscevalnik na voljo, je tipicno krajsiod 10 ms, procese pa v povprecju menjuje vsakih 100 ms, kar pomeni, da se zarazvrscanje zapravi priblizno 10/(100 + 10) = 9 odstotkov procesorskega casa.
Dolgorocno razvrscanje (long-term, job scheduler)
Razvrscevalnik izbere posel, ki se caka, da bo sprejet v obdelavo, in se nahaja vzunanjem pomnilniku. Sistem zanj najprej ustvari proces tako, da v delovnempomnilniku rezervira prostor (za sistemske strukture, PCB, ...) in sele natoizvede izbiranje, ki je v tem primeru relativno redko, ker dolgorocno razvrscanjenadzira stopnjo multiprogramiranja. Procese se posledicno izbere le tedaj, kose drugi proces konca, zato je razvrscevalnik lahko pocasnejsi, vendar nekolikozahtevnejsi. Kljub temu so njegove odlocitve tehtnejse, saj pozornost posvetiuravnotezeni obremenitvi sistema (load balancing). Pri tem procese delimo na:
1. Procesorsko zahtevnejse (CPU-bound) procese,ki za dalj casa racunsko zaposlijo procesno enoto.
2. V/I zahtevnejse (I/O bound) procese,ki vecinoma dostopajo do V/I naprav.
Razvrscanje vzdrzuje ”dober nabor” obeh zato, da uravnotezeno obremeni vessistem, kar omogoca vecji pretok. Kljub temu se pri (time sharing) operacijskihsistemih, kot sta Linux in Windows, le redko ali zelo malo uporablja, ker lahkovpliva na stabilnost sistema. Le-ta je odvisna od fizicnih omejitev sistema, kotje stevilo razpolozljivih terminalov in najbolj pomemben dejavnik, cloveskanarava. Ce je odzivni cas operacij na vecopravilnem sistemu pocasen, bo njegovuporabnik nezadovoljen, zato se velikokrat uporablja tretja resitev, ki zajemadobre lastnosti obeh razlicic.
Srednjerocno razvrscanje (medium-term scheduler)
Izbere enega od pripravljenih (ali tudi blokiranih) procesov in ga prenese vzunanji pomnilnik, kar ga izloci iz tekme za osvojitev procesorja in posledicnozmanjsa stopnjo multiprogramiranja.

14 Poglavje 2: Procesi
Razvrscevalnik si nov proces priskrbi tako, da opravi (na sliki 2.4 prikazano)funkcijo zamenjave procesov (swapping), ki med drugim omogoca veliko boljsoobremenitev sistema.
Slika 2.4: Shema strezne enote.
2.4 Niti (Threads)
Niti niso nic drugega kot najbolj osnovne enote procesa, ki se lahko izvedejo naprocesorju, zato je njihovo stanje podano s programskim stevcem, enolicnimdeskriptorjem procesa (ID) ter vsebino registrov in sklada. Ker si niti procesadelijo razlicne vire, poznamo tuje niti, ki pripadajo le istemu programu, insorodne niti (peer threads), ki si delijo programsko kodo, podatkovni segment(data segment) in sistemske vire, kot so odprte datoteke (open files) in signali(signals), skupaj pa tvorijo opravilo (task) ali ogrodje (framework).
Obicajne procese predstavlja le ena nit (lightweight process), zato jim pravimokar enonitni (single-threaded) procesi. Znano pa je tudi, da so doloceni procesizgrajeni iz vec niti, kar pomeni, da je doloceno nalogo mogoce izvesti v oblikivecjega sevila manjsih paralelno izvedljivih opravil. Tedaj je tudi racunalniskiprogram realiziran kot vecnitna (multithreaded) aplikacija, kjer proces nadziravec svojih (podrejenih) niti.
Ce kot primer vzamemo aplikacijo za urejanje besedil (word processor), lahkoza vsako funkcijo uporabimo loceno nit - eno za graficni prikaz teksta, drugoza odziv na tipkovnico ali misko, tretjo pa za funkcijo, ki se izvaja v ozadju inopravi crkovanje ter slovnicni pregled teksta.

2.5 Vecjedrno programiranje 15
Prednosti uporabe vecnitnega programiranja (multithreaded programming):
1. Boljsa odzivnost. Vecnitnost omogoca neprekinjeno delovanje, tudi vprimeru, ko se del programa zacasno blokira ali predstavlja dolgotrajnooperacijo, ki je ni mogoce prekiniti.
2. Enostavna uporaba skupnih virov. Ker si niti istega procesa delijoiste podatke ter isto programsko kodo, dostopajo do enakega naslovnegaprostora, medtem ko je za locene procese rezerviran locen del pomnilnika.
3. Hitrejsa rezija procesov. Menjava okolja (context switch) je zaradiskupnih virov sorodnih niti hitrejsa kot menjava okolja med procesi, sajne zahteva dodatnega dela pri upravljanju s pomnilnikom. Posledicno jehitrejse tudi ustvarjanje in unicevanje niti.
4. Moznost izkoriscanja vecprocesorskih sistemov. Prednost takegasistema se pokaze pri vecprocesorski arhitekturi, kjer se posamezne nitiizvajajo vzporedno, na razlicnih procesnih enotah.
2.5 Vecjedrno programiranje
Kot sem ze omenil, je v danasnjih dneh teznja po paralelnem procesiranju, zvpeljavo vecjedrnih procesorjev, nekoliko izpodrinila uporabo vecprocesorskihracunalniskih sistemov. Ceprav vecjedrne CPE sestavlja vec procesnih jeder naenem samem cipu, so znotraj operacijskega sistema posamezna jedra videti kotloceni procesorji, ki omogocajo vzporedno izvajanje posameznih niti. Tovrstnatendenca vpliva tudi na pisanje izpopolnjenih aplikacij z boljsim izkoristkomvedno vecjega stevila jeder in, vec kot predvidljivo, tudi na implementacijoopisane simulacije.
Najvecji izziv se pokaze pri doseganju razvojnih ciljev, ki so podvrzeni stevilnimtehnicnim zahtevam, kot so delitev procesov aplikacij na paralelno izvajajocaopravila, iskanje uravnotezenih opravil, ki bodo enakomerno zaposlila vsajedra, delitev podatkov na tak nacin, da se lahko generirani procesi izvajajoparalelno, analiza soodvisnosti in sinhronizacija procesov, ki dostopajodo skupnih virov, ter testiranje in odstranjevanje napak, kar je zaradirazlicnih poti izvrsevanja vecinoma najbolj zahtevna naloga.

16 Poglavje 2: Procesi

Poglavje 3
Razvrscanje na procesorju
3.1 Algoritmi za razvrscanje
V dosedanji razlagi je bilo veliko povedanega o razvrscanju procesov, zato jeprav, da omenim se algoritme, ki so temu namenjeni. Kot vemo, racunalniskisistem deluje tako, da CPE v dolocenem trenutku izvaja le en proces. Znanoje tudi, da si procesi in ukazi sledijo po dolocenem vrstnem redu. Programi soposledicno taki, da zahteve po procesorju in ostalih vhodno/izhodih napravahgenerirajo izmenicno, zato stanju, kjer proces uporabi procesno enoto, pravimointerval nenadne aktivnosti (CPU burst). Ocitno pa je, da procesna enotalahko cas, ko trenutno izvajajoci proces caka na podatke V/I naprave, uporabiza prevzem procesa, ki je pripravljen na izvedbo. Aktivni (pripravljeni) procesiso tako povezani v kazalcni seznam, ki tvori aktivno vrsto. Algoritem naslednjiproces enostavno izbere tako, da se sprehodi po seznamu in prebere potrebneinformacije, ki so shranjene v ustreznih PCB.
Pri obravnavi posameznih algoritmov je potrebno ugotoviti, kaj najbolj vplivana izbiro algoritmov, zato si najprej oglejmo naslednje tipicne situacije:
• proces preide v stanje cakanja, ker je sprozil V/I zahtevo alije z izvajanjem koncal njegov proces-potomec (child process)
• proces se je izvedel do konca
Ker je proces v lasti centralno procesne enote vse do trenutka, ko se prenehaizvajati ali preide v cakajoce stanje, se pri prvih dveh primerih uporabi obicajnorazvrscanje brez prekinjanja (nonpreemptive scheduling).
17

18 Poglavje 3: Razvrscanje na procesorju
• proces preide iz stanja izvajanja v stanje pripravljenosti zaradi prekinitve
• proces preide iz cakalnega stanja v stanje pripravljenosti,ker se je izvedla njegova V/I zahteva
Slednji dve predstavljata razvrscanje s prekinjanjem, kjer trenutni procesne more vec nadaljevati z izvajanjem, ker je med pripravljenimi procesi prislodo spremembe. Prednost preemptive vrste razvrscanja tako predstavlja velikobolj fleksibilno in enostavno jedro sistema, kar pa ni izkljucno bolje, ker se lahkopojavijo problemi pri procesih, ki si delijo skupne vire. Branje podatkov, ki jihdrugi proces se ni azuriral, lahko privede do nekonsistentnosti, zato so vcasihpotrebni novi mehanizmi za usklajevanje (sinhronizacijo), kar posledicno vplivana delovanje in implementacijo operacijskega sistema. Novost je bila uvedenapri operacijskem sistemu Windows 95 in se uporablja se danes.
Ker uporabna novost vpliva na delovanje jedra operacijskega sistema, so se priizvedbi razvrstitve s prekinjanjem odlocili za dodatne ukrepe, ki preprecujejotovrsten problem, ko se izvaja eden od sistemskih klicev. V primeru prekinitveizvajanja takega procesa se lahko zaradi spremembe na strukturnem nivojusistem ”porusi”, zato sistemskih ukazov ni mogoce prekinjati!
3.2 Merila kakovosti algoritmov
Kakovost razvrscevalnih algoritmov lahko dolocimo na podlagi parametrov, kitako ali drugace izkazujejo naklonjenost posameznim vrstam procesov, zato sepri izbiri najboljse razlicice upostevajo lastnosti posameznega sistema. Najboljpogosti kriteriji, ki jih obicajno uporabimo, so naslednji:
1. Izkoriscenost procesorja (CPU utilization), kjer nam primarni ciljpredstavlja doseganje maksimalnega oziroma stoodstotnega izkoristkaprocesne enote, kar se v praksi izkaze kot skorajda neizvedljivo, zato se pritestiranju sistemov obicajno zadovoljimo s priblizno 40 % obremenitvijomanj zasedenih procesorjev ter kvecjemu 90 % obremenitvijo pri dobroizkoriscenih procesorjih.
2. Prepustnost sistema (throughput) prikazujemo s stevilom zakljucenihprocesov na casovno enoto. Ponovno lahko povem, da je dosezek mocnoodvisen od vrste procesa, ki ga izvajamo. Pri dolgotrajnih procesih lahkosistem doseze prepustnost, ki jo merimo kot stevilo zakljucenih procesovna uro, medtem ko se pri hitrem sistemu prepustnost meri na sekundo.

3.2 Merila kakovosti algoritmov 19
3. Cas obdelave (turnaround time) je z vidika samega procesa se nekolikobolj zanimiv podatek, saj nam podaja vrednost, ki nam pove, koliko casaje dolocen proces prebil znotraj sistema. Merimo ga od trenutka, ko smoproces generirali, do trenutka, ko se je zakljucil, kar vkljucuje tudi cas,ki ga je proces prebil v posameznih cakalnih vrstah, cas procesiranja, terdelo z vhodno/izhodnimi napravami.
4. Cakalni cas (waiting time) predstavlja vsoto celotnega neizkoriscenegacasa, ki ga je proces prebil v cakalnih vrstah. Na cas, ko proces zasedaV/I sistem, pa razvrscevalnik nima neposrednega vpliva, zato se v temprimeru ne uposteva.
5. Odzivni cas (response time) pride najbolj do izraza pri interaktivnihsistemih, kjer se cas obdelave zaradi prevelike odvisnosti od hitrosti V/Inaprave izkaze kot nezadovoljiv kriterij. Odzivni cas se posledicno meriod trenutka izstavitve zahteve do prvega odziva sistema, ko se proceszvrsti v obdelavo.
Nekatera merila so med seboj povezana, zato poleg izkoriscenosti procesorjaposkusamo maksimizirati se propustnost sistema, minimizirati pa cas obdelaveter cakalni in odzivni cas. Obicajno optimiziramo povprecne vrednosti, vendarje v nekaterih primerih priporocljivo optimizirati minimalne in maksimalnevrednosti. Pri interaktivnih sistemih je bolj pomembno minimizirati variancoodzivnega casa kot povprecen odzivni cas, saj je veliko bolj zazelen sistem spredvidljivim odzivnim casom kot sistem, ki je v povprecju hitrejsi, vendar jezelo spremenljiv.
Minimizacijo oziroma maksimizacijo, ki jo zelim izvesti, uvrscamo med splosneoptimizacijske probleme. Kot vemo, so obvladljivi le posebni primeri, kot stapovprecni cas obdelave in maksimizacija izkoriscenosti procesorja, medtem koso ostali vecinoma neobvladljivi. Pravimo jim NP-polni ali nedeterministicnopolinomski problemi, ker zanje v praksi ne obstaja algoritem, zato se resujejohevristicno. Pregleda se razmeroma majhna podmnozica resitev, za optimalnopa vzamemo ”najboljso” od razpolozljivih. V praksi je blizu optimalni, vendarzanjo nimamo empiricnega dokaza.

20 Poglavje 3: Razvrscanje na procesorju
3.3 Primeri algoritmov
3.3.1 Algoritem FCFS
Najbolj preprost algoritem za razvrscanje je zagotovo First Come, First Served(FCFS) oziroma ”kdor prvi pride, prvi melje”. Ker je zelo enostaven, se velikouporablja, vendar ni ravno najboljsi. Proces, ki prvi zahteva procesor, se tudiprvi zvrsti v obdelavo, zato ga najenostavneje implementiramo s t.i. FIFO(First In, First Out) vrsto, ceprav je njegov povprecni cakalni cas predolg invecinoma predstavlja vidno slabost.
Kot primer vzemimo podatke: procesi cas izvajanja na CPE
P1 24 msP2 3 msP3 3 ms
Ce procesi nastopijo vnaslednjem vrstnem redu: P1, P2, P3
P1 P2 P3
0 24 27 30
in so postrezeni po sistemu FCFS,dobimo povprecni cakalni cas enak: 0 + 24 + 27
3= 17 ms
Ce pa procesi nastopijo kot: P2, P3, P1
P2 P3 P1
0 3 6 30
bo povprecni cakalni cas enak: 0 + 3 + 6
3= 3 ms
Povprecen cakalni cas pri FCFS v splosnem ni minimalen in lahko zelo varira.Pojavlja se tudi problem ”konvoja”, ko vsi ostali procesi cakajo, da racunskoin vhodno/izhodno zahteven proces sprosti CPE, kar se izkaze za zelo slabopri razvrscanju procesov interaktivnih sistemov.

3.3 Primeri algoritmov 21
3.3.2 Algoritem Round Robin
Z enostavnim popravkom lahko FCFS spremenimo v priljubljeni Round Robin(RR) algoritem ali krozni seznam, kjer procesi zasedejo CPE le za (vnaprej)doloceno casovno rezino (time quantum). Kot bomo videli, je bil algoritemrazvit za interaktivne sisteme, casovna rezina pa tipicno traja od 10 do 100milisekund. Algoritma FCFS in RR uporabljata tudi obravnavana operacijskasistema, zato naj ju predstavim nekoliko podrobneje.
Za implementacijo razvrscanja uporabimo FIFO cakalno vrsto, kjer se procesivedno dodajo na konec vrste, jemljejo pa na zacetku. Ko trenutno izvajajocemuse procesu potece razpolozljivi cas, ga razvrscevalnik zamenja z naslednjim vvrsti, prekinjeni proces pa premakne na konec vrste, kjer pocaka na ponovnouvrstitev. Ce se proces ni izvedel do konca, mu algoritem dodeli novo casovnorezino, sicer ga po preteku le-te izloci iz vrste. Seveda obstaja tudi primer, koproces potrebuje bistveno krajsi cas od trenutno dodeljenega, zato lahko predpretekom casovne rezine procesor prostovoljno prepusti naslednjemu procesu.
Povprecni cas procesiranja se lahko tudi v primeru RR algoritma izkaze kotnekoliko predolg. Kot primer vzemimo vrednosti, ki smo jih pred tem uporabilipri algoritmu FCFS, kjer upostevamo dodatni parameter - 4ms dolgo casovnorezino. Procesi se izvedejo v naslednjem vrstnem redu: ceprav P1 prvi zasedeprocesor, zahteva dodatnih 20 ms procesiranja, zato ga razvrscevalnik po 4 msprekine in procesno enoto dodeli procesu P2. Ker slednji proces (za izvrsitev)potrebuje le 3 ms, bo z izvajanjem zakljucil pred pretekom casovne rezine invrsto prepustil procesu P3. Za njim se kot edini ponovno zvrsti proces P1.
Vrstni red izvajanja prikazuje Ganttov diagram:
P1 P2 P3 P1 P1 P1 P1 P1
0 4 7 10 14 18 22 26 30
Povprecni cakalni cas pa je enak: (10− 4) + 4 + 7
3= 5, 66 ms
Kakovost RR algoritma je mocno odvisna od dolzine predefinirane casovnerezine. Ce izberemo najdaljso vrednost, dobimo prejsnji FCFS algoritem, podrugi strani pa nam zelo kratek interval (recimo) 1 ms daje obcutek, da vsak odn izvajajocih se procesov izkorisca 1/n zmogljivosti uporabljenega procesorja.

22 Poglavje 3: Razvrscanje na procesorju
3.3.3 Najkrajsi cas izvajanja prvi
Ko je procesor prost, algoritem SJF (Shortest Job Frst) izbere proces, ki imatrenutno v pripravi najkrajsi cas izvajanja na CPE. Takrat, ko imamo na izbirodva ali vec procesov z enako (najkrajso) vrednostjo, naslednjega izberemo naosnovi algoritma FCFS.
Oglejmo si primer: procesi dolzina naslednjega racunskega dela
P1 6 msP2 8 msP3 7 msP4 3 ms
Ce pogledamo Ganttov diagram:
P4 P1 P3 P3
0 3 9 16 24
je povprecni cakalni cas enak: 0 + 3 + 9 + 16
4= 7 ms
Pri uporabi FCFS bi za enak primer dobili povprecen cakalni cas 10,25 ms, karprica o tem, da SJF zagotavlja minimalen povprecen cakalni cas, ampak lemed algoritmi, kjer ni prekinjanja. Tedaj je algoritem optimalen. Kljub temuima algoritem vidno slabost, ker je trajanje naslednjega procesa nemogocenapovedati. Vcasih je le smiselno poskusiti s priblizno napovedjo naslednjeganemotenega teka, ki se obicajno izracuna kot eksponentno povprecje dolzinpredhodnih procesov. Naj bo tn dolzina n - tega racunskega dela, medtem koτn+1 napovedana (ocenjena) dolzina naslednjega racunskega dela. Tedaj za α,0 ≤ α ≤ 1, velja:
τn+1 = α tn + (1− α) τn
3.3.4 Najkrajsi preostali cas izvajanja prvi
Ce nov proces vstopi v vrsto pripravljenih med izvajanjem nekega drugegaprocesa, se lahko zgodi, da ima nov proces krajsi ocenjeni cas od trenutnoizvajajocega. SJF s prekinjanjem ali SRTF (Shortest Remaining Time First)bo trenutni proces prekinil, SJF brez prekinjanja pa mu bo pustil, da se izvede.

3.3 Primeri algoritmov 23
Primer: procesi trenutek prihoda τ
P1 0 ms 8P2 1 ms 4P3 2 ms 9P4 3 ms 5
Predstavitev SJF s prekinjanjem s pomocjo Ganttovega diagrama:
P1 P2 P4 P1 se nadaljuje P3
0 1 5 10 17 24
Ob casu 0 je P1 edini proces v vrsti, zato pricne z izvajanjem. Ko ob casu 1nastopi se proces P2, je preostali cas procesa P1 daljsi od casa procesa P2, zatose P1 prekine in procesor dodeli procesu P2. Povprecni cakalni cas je enak:
(0− 0) + (1− 1) + (5− 3) + (10− 1) + (17− 2)
4= 6, 5 ms
Pri SRTF je cas krajsi kot pri SFJ, kar pomeni, da se prekinjanje splaca!
Rezultat SJF brez prekinjanja z uporabo Ganttovega diagrama:
P1 P2 P4 P3
0 8 12 17 26
Tudi tokrat je ob casu 0 proces P1 edini v vrsti. Ob casu 1 pa nastopi se procesP2, ki mora pocakati, da se P1 izvede do konca. Povprecni cakalni cas je enak:
(0− 0) + (8− 1) + (12− 3) + (17− 2)
4= 7, 75 ms
SJF je pogosto naveden kot poseben primer splosnega algoritma razvrscanjapo prioriteti, ki procesu dodeli staticno ali dinamicno prioriteto. Ko procespreide v vrsto pripravljenih, se njegova prioriteta primerja s prioriteto trenutnoizvajajocega se procesa. Ce je prioriteta novoprispelega procesa visja, bo sistemza razvrscanje proces, ki se trenutno izvaja, prekinilo. Razvrscanje po prioritetibrez prekinjanja pa bo nov proces postavilo na zacetek vrste, zato se bo zvrstilkot naslednji.

24 Poglavje 3: Razvrscanje na procesorju
Velik problem pri razvrscanju po prioriteti predstavlja stradanje (starvation),kjer procesi z nizko prioriteto cakajo neskoncno dolgo in se nikoli ne zvrstijona procesorju. Problem resujemo s staranjem (aging) - metodo, ki obcasnopovecuje prioritete procesom, ki cakajo ze dalj casa. Procesi na ta nacin dobijonajvisjo prioriteto in koncno stecejo.
3.4 Razvrscanje v realnem casu
Z razliko od ostalih vrst razvrscanja procesiranje v realnem casu upostevadodatno casovno komponento, kar pomeni, da odziv sistema ni odvisen le odnatancnosti posameznih operacij, temvec tudi od casa, ki ga sistem porabi zaprocesiranje in izstavitev koncnega rezultata. S pojmom t.i. realnega casa pamerjenje sistemskega casa povezujemo z zunanjim okoljem, katerega casovnipotek dogodkov dejansko vpliva na delovanje sistema. Hitrost tako ali drugaceizmerjenega casa sistema mora ustrezati hitrosti zunanjega (realnega) okolja.
Racunalniski sistemi vrste real-time pridejo v postev, ko je za izvrsitev dolocenenaloge (vnaprej) strogo dolocen skrajni rok izvrsitve (deadline period). Cepravsistem nudi natancen rezultat, dostava le-tega (po preteku casovne omejitve)predstavlja neuspeh oziroma napako sistema. V primeru nekega racunalniskovodenega vozila je povsem nesmiselno, ce krmilnik prejme podatek o razdaljioddaljenega predmeta po tem, ko se je vanj ze zaletelo.
Interakcija med procesorjem in zunanjim svetom mora biti predvidljiva in zelohitra, reakcija na spremembe pa predvsem pravocasna. Pri dolocenih fizikalnihin tehnoloskih pojavih je odzivni cas dolg nekaj tisocink sekunde, v primeruclovekove interakcije s sistemom pa le nekoliko daljsi, ceprav se vedno znosenin predvidljiv. Klasicni operacijski sistemi, ki programsko aplikacijo zacasnoprekinejo na racun drugih, niso primerni za delo v realnem casu. Sisteme zaprocesiranje v realnem casu delimo na:
I. Trde (Hard Real-Time) sisteme, ki zagotavljajo izvrsitev t.i. kriticnihopravil pred pretekom roka izvrsitve. Ce se tovrstni procesi ne izvedejov vnaprej dolocenem casu, je lahko dosezeni ucinek katastrofalen, zatomorajo biti vse te operacije casovno omejene, dolocljive in predvsempredvidljive. Zagotoviti tako strogo delovanje pri racunalniskih sistemihs sekundarnim ali virtualnim pomnilnikom je skorajda nemogoce, zatoreal-time sisteme tvori specializirana programska oprema, ki se izvrsujena strojni opremi, prilagojeni casovno kriticnim opravilom.

3.5 Prednosti vecprocesorskega sistema 25
II. Mehke (Soft Real-Time) sisteme dolocajo nekoliko manj dosledne ome-jitve pri izvrsevanju procesov, zato njihove funkcije obicajno dopolnjujejotime-sharing operacijske sisteme, ki podpirajo operacije posebne vrste, skaterimi razpolaga danasnja multimedijska programska oprema.
Implementacija soft real-time funkcij zahteva skrben razvoj celotnega operacij-skega sistema, ki omogoca razvrscanje po prioriteti, kjer se najvisja prioritetavedno dodeli real-time procesom. Novododane funkcije lahko vcasih povzrocijonekatere nezazelene ucinke, kot so neenakomerno dodeljevanje racunalniskihvirov ter daljsi odzivni casi nekaterih procesov, vendar je njihova vkljucitev pridoseganju splosnonamenskega operacijskega sistema neizogibna. Poleg tega seprioritete real-time procesov skozi cas ne spreminjajo, casovni zamik odzivasistema (latency) pa mora biti dovolj kratek, sicer posodobitev nima smisla.Manjsa kot je latenca, hitrejsi je zacetek izvrsevanja procesa.
3.5 Prednosti vecprocesorskega sistema
Do sedaj sem opis razvrscevanja procesov omejil na racunalniske sisteme zenim samim procesorjem, ampak glede na to, da danasnji racunalniki vecinomavsebujejo vecjedrne procesorje in temu prilagojene operacijske sisteme, je pred-stavitev slednjega vec kot smiselna.
Kot sem omenil v prvem poglavju, vecprocesorska arhitektura pozna dva os-novna principa delitve opravil na vec CPE. Omenjena vrsta asimetricnegamultiprocesiranja poskrbi, da vse odlocitve prevzame enota, ki je dolocenakot gospodar. Tu imam v mislih vse, od razvrscanja na procesorju do vhodno-izhodnega procesiranja. V osnovi je tovrstno dodeljevanje procesorskega casaenostavnejse, iz preprostega razloga, ker je dostop do sistemskih podatkovnihstruktur omejen le na gospodarja. Kljub temu je v uporabi nekoliko zahtevnej-se simetricno multiprocesiranje (SMP), kjer posamezna procesna enotasama poskrbi za razvrscanje procesov.
3.5.1 Procesorska afiniteta
Ko govorimo o delitvi opravil na posamezne procesorje, najprej pomislimo nato, kaj se dogaja pri dostopu do pomnilnika. Ker vsak procesor vodi svojocakalno vsto, se ukazi shranjujejo v posameznih predpomnilnikih, kar v osnovizadostuje za hitro izvrsevanje ukazov, vednar se v primeru, ko je potrebnoukaze preobremenjenih procesorjev seliti na prosto enoto, pojavi problem.

26 Poglavje 3: Razvrscanje na procesorju
Za pravilno delovanje je potrebno ukaze v (pred)pomnilniku razveljaviti inprenesti na pomnilnisko lokacijo novoizbranega procesorja, zato se SMP sistemiselitvi (migraciji) procesov izogibajo z uporabo metode procesorske afinitete(processor affnity). Slednja problem resi tako, da vsem procesom doloci stopnjonaklonjenosti do procesorja na katerem se trenutno izvajajo. Glede na izkazanodoslednost pri dodeljevanju procesov izbranim procesorjem locimo dve vrstiprocesorske afinitete. Pri ohlapni afiniteti (soft affinity) operacijski sistem leposkusa izvesti proces na dolocenem procesorju, medtem ko stroga afiniteta(hard affinity) vedno zagotovi izvrsitev procesa, brez kakrsnekoli migracije.
3.5.2 Uravnotezena obremenitev
Pri uporabi SMP sistemov je zelo pomembna uravnotezena obremenitev vsehrazpolozljivih procesnih enot, sicer ne dosezemo vidne prednosti v primerjavi zenoprocesorskim sistemom. Brez uravnotezene obremenitve lahko zagotovimole enako stopnjo ucinovitosti, ker procesi obicajno zaposlijo samo eno procesnoenoto, medtem ko ostale ostanejo neizrabljene. Zavedati pa se moramo, da jefunkcija za uravnotezeno obremenitev (load balancing) uporabna le takrat, koima vsak procesor svojo cakalno vrsto. V nasprotnem primeru bi razvrscevalnikprocese vedno jemal iz skupne vrste pripravljenih procesov ter jih posiljal leprostim enotam. Zaradi boljsega razumevanja naj predstavim se uporabljenimetodi za uravnotezeno obremenitev sistema:
I. Push migracija uporabi sistemsko funkcijo, ki periodicno pregledujezasedenost vseh procesnih enot. V primeru neenakomerne obremenitveprocesorja pripravljene procese razporedi tako, da jih s prezasedenegaprocesorja ”porine” na neuporabljene (idle) ali manj obremenjene enote.
II. Pull migracija pa se vrsi s strani neizrabljenega procesorja, ki cakajociproces ”povlece” iz vrste zasedenega.
V primeru Linux operacijskega sistema razvrscevalnik (scheduler) uporabljaobe tehniki, zato funkcijo push migration pozene vsakih 200 ms, medtem kose funkcija pull migration izvede vsakic, ko se sprosti eden od procesorjev.Kljub temu uravnotezena obremenitev deluje v nasprotju z omenjeno metodoprocesorske afinitete, saj ne izkorisca prednosti hitreje dostopnih podatkovpredpomnilnika. Odlocitev o tem, katera metoda se boljse obnese, je posledicnozelo tezka, zato nekateri operacijski sistemi procese vedno povlecejo iz cakalnihvrst prezasedenih procesorjev, ostali pa procesom dovolijo selitev (migracijo)le, ce neuravnotezenost prestopi vnaprej doloceno mejo.

3.5 Prednosti vecprocesorskega sistema 27
3.5.3 Vecjedrni procesorji
Medtem ko so tradicionalni SMP sistemi omogocali paralelno procesiranje navecjem stevilu fizicno locenih procesorjev, novejsi vecjedrni procesorji proceseizvrsujejo znotraj enega samega cipa. Pri tem ima vsako jedro svojo mnozicoregistrov, zato jih operacijski sistem zazna kot locene procesne enote. Polegtega so vecjedrni SMP sistemi hitrejsi in omogocajo nizjo porabo energije.
Pri omenjenih prednostih pa moramo upostevati tudi dejstvo, da vecjedrniprocesorji nekoliko zapletejo sistem razvrscanja. Problem se pojavi pri dostopudo pomnilnika, ki traja predolgo in nastane kot posledica pogostih zgresitevv (pred)pomnilniku, ker se podatki, ki jih procesor potrebuje, ne nahajajo nazeleni (pred)pomnilnisi lokaciji. Posledicno procesor vec kot 50 odstotkov casacaka na podatek, kar lahko privede do brezizhodnega stanja, ki mu pravimomemory stall. Da bi se izognili neugodni situaciji, so proizvajalci procesorjevrazvili vecnitna procesorska jedra (multithreaded processor cores), kjer sejim dodeli dve ali vec niti. Ko pride do zaustavitve (stall) enega procesorskegajedra, proces prevzame drugi. Tako se v primeru multithreading (dual thread)procesorja na vsakem jedru izvajata po dve niti, kjer se posamezni korakiizvrsevanja, podobno kot pri cevovodu, prekrivajo. S perspektive operacijskegasistema vsako vecnitno jedro deluje kot locen logicni procesor, ki lahko izvajaposamezno nit, kar pomeni, da je dual-core procesor z uporabljeno dual-threadtehnologijo za operacijski sistem videti kot 4 procesne enote. Boljsi izkoristekjeder omogocata naslednji dve tehniki:
I. Grobo zrnato (coarse-grained) vecnitno procesiranje, kjer se nitizvrsuje na procesorju, dokler ne pride do dogodka, ko lahko prevelikalatenca povzroci zaustavitev sistema. Prvi scenarij predstavlja omenjenimemory stall, kjer je procesor (zaradi predolgega zakasnitvenega casa)primoran zamenjati proces. V vsakem primeru je zamenjava procesov ledolgotrajno opravilo, ker prevzem novega procesa zahteva razveljavitevukazov v uporabljenih stopnjah cevovoda (pipeline flush).
II. Drobno zrnato (fine-grained, interleaved) vecnitno procesiranje panekoliko bolj natancno zamenjuje niti. Slednje obicajno izvede na koncuukaznega cikla, kar je mogoce s prilagojeno zgradbo procesne enote, kivkljucuje logiko za preklop med procesi (nitmi). Cas, ki ga prilagojeniprocesor za to porabi je, posledicno bistveno krajsi.

28 Poglavje 3: Razvrscanje na procesorju

Poglavje 4
Linux
4.1 Razvojni cilji
Pri razvoju Linux operacijskega sistema so si kot glavni cilj zastavili ucinkovitoin zmogljivo delovanje razvrscevalnika. Dejstvo pa je, da zmogljivosti ni vednolahko zagotoviti, ker nanjo vpliva veliko drugih odlocitev, ki so tesno povezane zucinkovitostjo. Pri nacrtovanju se velikokrat zagotavlja interaktivno delovanjesistema, kar lahko privede do pogoste zamenjave okolja (context switch).
Poleg tega je pojem interaktivnega delovanja tesno povezan z uporabo vsehV/I naprav, ki zahtevajo hiter odzivni cas. Pricakuje se zanesljivo delovanjesistema, ki preprecuje stradanje in omogoca prioritetno razlikovanje s postenoizbiro procesov in operacij, ceprav je za uporabnika velikokrat najbolj opaznahitra izvrsitev posameznih poslov in procesov. Ce kot primer navedem uporabograficnega okolja okenskega sistema (X Window System), nam je znano, da bouporabnik veliko bolj zadovoljen, ce bo sistem omogocal hiter preklop medprogrami in zadovoljiv odzivni cas pri uporabi perifernih naprav, kot hitroizvrsitev racunsko zahtevne operacije, ki se izvaja v ozadju.
Uporabnik pricakuje, da bo odziv sitema na pritisk tipke takojsnji, kar pa jemogoce le s hitro prekinitvijo trenutno izvajajocega procesa. Za hitro delovanjeje potrebno tovrstne pojave minimizirati, ker kratek odzivni cas zagotavljanavidezno hiter sistem, medtem ko ga mnozicno preklapljanje upocasnjuje.
29

30 Poglavje 4: Linux
Na resitve operacijskega sistema vpliva namen njegove uporabe, zato ima tudipojem zmogljivosti, recimo v primeru strezniskih sistemov, nekoliko drugacenpomen. Ker je pri streznikih delovanje osredotoceno na hitro izvajanje procesovin veliko manj na zamenjavo okolja, mora sistem zagotoviti ustrezno delovanjetudi v primeru, ko veliko stevilo odjemalcev pricakuje hiter prenos podatkov.Transparentnost delovanja je realizirana tako, da se procesorski cas deli nacasovne rezine, vendar preklop med procesi ne poteka tako hitro kot pri ostalihvecopravilnih sistemih. Kljub temu, da je odzivni cas takega sistema nekolikodaljsi, mora zadostovati pricakovanjem vsakega uporabnika-odjemalca, iz cesarje razvidno, da univerzalna izbira razvrscevalnega algoritma ne obstaja.
4.2 Zgradba Linux procesa
Preden preidem k natancnemu opisu algoritma za razvrscanje, bi rad najprejopisal, kako so procesi predstavljeni v Linux operacijskem sistemu. Sprva najomenim dejstvo, da Linux ne pozna razlike med nitmi (threads) in procesi(processes), pri tem pa avtor knjige [1] pravi, da niti predstavljajo le modernoprogramsko abstrakcijo, ki omogoca t.i. paralelno izvajanje posameznih delovprograma, pri cemer si niti delijo skupen naslovni prostor.
Ker Linux ne pozna koncepta niti, so slednje predstavljene na edinstven nacinv okviru obicajnih procesov (tasks), zato implementacija procesov oziroma nitinasprotuje staliscu tovrstne realizacije pri Windows operacijskih sistemih, kjerjedro nudi eksplicitno podporo lahkim (lightweight) procesom. Linux procesiso ze sami po sebi hitro izvrsljive enote, ki ne potrebujejo dodatne distinkcijena ”lazje” in ”tezje”, medtem ko ostali operacijski sistemi pojmujejo niti kotalternativo za uporabljene tezke (heavyweight) procese.
Ce kot primer vzamemo proces, ki je deljiv na stiri niti, bo sistem z eksplicitnopodporo za vecnitno procesiranje procesu dodelil en sam deskriptor1 s stirimikazalci na posamezne niti. Linux deluje nasprotno in v ta namen uporabi stirilocene procese in z njimi povezane task_struct podatkovne strukture, kjer siposamezni procesi med seboj delijo ostale vire. Operacije, za katere zelimo, dajih operacijski sistem izvaja le v ozadju, so pri Linux sistemu realizirane kotniti jedra (kernel threads) oziroma enostavni procesi, ki obstajajo le v jedruoperacijskega sistema.
1Deskriptor procesa je podatkovna struktura, ki nosi opis lastnosti in virov procesa.

4.2 Zgradba Linux procesa 31
4.2.1 Deskriptor procesa
Ce zelimo jedru sistema podati jasno sliko o tem, kaj proces pocne, moramodobro poznati njegovo strukturo. Dobro je vedeti, v katerem stanju se procesnahaja, kaksen je njegov prioritetni nivo, kateri naslovni prostor mu je bildodeljen ter do katerih datotek lahko proces dostopa. V ta namen se uporabljadeskriptor procesa (process descriptor), katerega posamezna polja vsebujejovse potrebne informacije o procesu. Deskriptor pocesa je znotraj operacijskegasistema predstavljen s task_struct podatkovno strukturo, ki poleg stevilnihlastnosti (atributov) vsebuje tudi kazalce na druge strukture, kar na videznekoliko zaplete zgradbo, prikazano na sliki 4.1.
Slika 4.1: Deskriptor Linux procesa [3].

32 Poglavje 4: Linux
4.2.2 Stanja procesov
Pozoren bralec je verjetno opazil, da prvo polje deskriptorja procesa na sliki4.1 nosi oznako state_flags. Omenjeno polje vsebuje podatek o trenutnemstanju procesa, zato je predstavljeno s seznamom zastavic (flags), kjer vsakadoloca natanko eno od spodaj navedenih moznosti. Ker se proces v dolocenemtrenutku nahaja le v enem stanju, so zastavice medsebojno izkljucujoce, karpomeni, da ostanejo pobrisane. Mozna stanja so naslednja:
• TASK_RUNNING ⇒ proces je pripravljen na izvrsitev oziroma se ze izvaja.
• TASK_INTERRUPTIBLE⇒ proces je bil prekinjen, zato caka na dogodek, kobodo izpolnjeni pogoji za ponovno uvrstitev med TASK_RUNNING procese.
• TASK_UNINTERRUPTIBLE ⇒ stanje procesa je podobno prejsnjemu, ven-dar procesa ni mogoce obuditi, dokler ne docaka izvrsitve dolocene ope-racije, ki je ni mogoce prekiniti.
• TASK_ZOMBIE⇒ proces se je dokoncno izvedel, vendar njegov deskriptorostane zapisan v drevesni strukturi, dokler nadrejeni oce (parent process)ne uporabi sistemskega klica, s katerim ga sam razveljavi. Jedro ne smezavreci podatkov o procesu, dokler jih oce procesa se potrebuje.
• TASK_STOPPED⇒ proces je bil blokiran s SIGSTOP, SIGTSTP, SIGTTIN aliSIGTTOU prekinitvenim signalom, zato se ne bo vec izvedel.
4.2.3 Identifikacija procesov
Ce zelimo razvrscati procese, moramo najprej zagotoviti sistem, po kateremjih lahko med seboj locujemo, zato Linux za identifikacijo procesov uporabljaenoznacne procesne identifikacijske deskriptorje ali PID, ki so shranjeniv pid polju deskriptorja procesa.
V praksi so PID (Process ID) navadna stevila, ki se procesom dodeljujejo gledena zaporedje njihovega nastanka. Vsak novonastali proces tako dobi vrednost,ki je za 1 visja od predhodno generiranega procesa (PID = PID−1 + 1).
Kljub temu se je s strani programerjev pojavila zahteva po novi identifikacijivseh lahkih procesov, ki skupaj predstavljajo vecnitno aplikacijo. Tako so zjedrom 2.4 vpeljali pojem skupine niti (thread group), ki omogoca tovrstnoidentifikacijo v skladu s POSIX 1003.1 standardom.

4.2 Zgradba Linux procesa 33
Deskriptorji lahkih procesov, ki so del iste skupine niti, skupaj tvorijo seznampovezanih struktur ali process list, prikazan na sliki 4.2. Vpleteni procesi sidelijo skupni PID, ki je zapisan v tgid polju deskriptorjev procesa, medtemko so podatkovne strukture, ki predstavljajo deskriptor, med seboj povezanepreko thread_group polja. Programerju, ki zeli pridobiti ID procesa s klicemfunkcije getpid(), operacijski sistem ne vrne vec PID vrednosti, definiranekot current->pid, temvec current->tgid vrednost, ker sta nova pid in tgid
vedno enaka, ne glede na vrsto procesa (navaden ali lahek). Stevilne seznamepovezanih podatkovnih struktur, ki so implementirani znotraj jedra, sistemuporabi, ker bistveno olajsajo iskanje dolocenega procesa. V primeru seznamana sliki 4.2 se tako uporabita kazalca prev_task na prejsnji in next_task
na naslednji generirani posel (task), kjer je prednik vseh generiranih procesovprikazani init_task (swapper). Kot lahko vidimo, njegov prev_task kazaleckaze na proces, ki je bil generiran kot zadnji.
Slika 4.2: Seznam povezanih procesov [3].
V dolocenih primerih se mora jedro sistema dokopati do deskriptorja procesana podlagi njegove PID vrednosti, ceprav se iskanje s sprehodom po seznamuizkaze kot neucinkovito. Slednje so pospesili z dodatno pidhash tabelo, ki zavsak PID vsebuje kazalce na iskane deskriptorje.
Slika 4.3: Tabela kazalcev na deskriptorje [3].

34 Poglavje 4: Linux
4.2.4 Cakalna vrsta
Ker lahko procese med izvajanjem tudi prekinemo, je uporaba cakalnih vrstnujno potrebna. Namrec, procesi ki so zaradi razlicnih razlogov, kot je dostopdo diska, primorani zapustiti procesno enoto, preidejo v stanje, kjer cakajo, dajih jedro sistema ponovno ”prebudi”. Cakalna vrsta tako predstavlja mnozicoprocesov, ki so neaktivni do trenutka, ko je ponovno izpolnjen dolocen pogoj.Struktura vrste je implementirana s pomocjo seznama povezanih procesov,kjer vsak element seznama vsebuje kazalec na svoj deskriptor, medtem ko jeidentifikacija posameznih cakalnih vrst omogocena s podatkovno strukturo tipawait queue head. Procese v cakalni vrsti locimo glede na prioriteto dostopa doposameznih virov sistema, zato poznamo procese z izkljucnim ali rezerviranimdostopom do posameznega vira (exclusive) in procese, ki do virov dostopajo zenako prioriteto kot vsi ostali (nonexclusive). Istocasno upravljanje cakalnihvrst je onemogoceno s pomocjo zascite, ki preprecuje nezazelena stanja sistema.
Slika 4.4: Dodajanje elementov v cakalni vrsti [3].
4.3 Delovanje algoritma
Pri razvoju jedra 2.5, so najvecji poudarek namenili ravno razvrscevalnemualgoritmu. Kljub temu, da je bilo delovanje jedra predhodne 2.4 razlicice zelozanesljivo, so bile pomanjkljivosti zadosten pogoj za nove spremembe. Slabostje predstavljala casovna zahtevnost algoritma, ki je za izvajanje razvrscevalneschedule() procedure znasala O(n), medtem ko razvrscevalnik razlicice 2.5nosi oznako O(1). Poleg tega je predhodni razvrscevalni algoritem procesomdodelil casovno rezino, ki je v povprecju merila 200ms, kar je za danasnje caseveliko, ce vemo, da jim kernel 2.6 v povprecju nameni le 100ms. Nenazadnjeima novo jedro povecano podporo za simetricno multiprocesiranje (SMP), ki jevkljucno s funkcijo za procesorsko afiniteto (processor affnity) in uravnotezenoobremenitvijo procesorja (load balancing) nujno potrebna.

4.3 Delovanje algoritma 35
Kot sem ze omenil, je bil razvoj novega algoritma kljucnega pomena, saj jezelo pohitril delovanje, ki je linearno narascalo s stevilom procesov v sistemu.Sedaj je algoritem izvedljiv v koncem casu in omogoca izvrsitev vseh funkcijv okviru casovne zahtevnosti O(1), kar jamci konstanten cas izvedbe, ne gledena stevilo vhodnih procesov. Temelj izboljsanega delovanja tako predstavljatanovi podatkovni strukturi - vrsta pripravljenih procesov (runqueue) in znjo povezana prioritetna vrsta (priority array).
Slika 4.5: Prioritetni vrsti.
Vrsta pripravljenih procesov jepredstavljena kot najbolj osnovenelement strukture za razvrscanje.Dopolnjujeta jo prioritetni vrsti,prikazani na sliki 4.5, kjer jedrosistema vhodne procese najprejpostavi v vrsto aktivnih (active)procesov, od koder jih premaknev krozne sezname, razporejene poprioriteti. Ko posamezni procesipotrosijo celoten cas, ki ga imajona razpolago, pa jih sistem preseliv vrsto neaktivnih (expired).
Slika 4.6: Zamenjava vrst.
Med vsakim tovrstnim premikom jedrosistema neaktivnemu procesu preracunanov cas procesiranja, ki ga bo uporabilpri naslednjem izvrsevanju. Ko se vrstaaktivnih procesov izprazni, jo algoritempreprosto zamenja z vrsto neaktivnih, pricemer si pomaga s prikazano nr_active
spremenljivko, ki podaja stevilo trenutnoaktivnih procesov izbrane vrste, medtemko knjiznica kernel/sched.c vsebuje ledefinicijo njene strukture. Algoritem vseprocese izbere po prioriteti, kar omogocaopisana struktura kroznih seznamov, kjerse naslednji proces izbere po sistemu round robin. Ko je krozni seznam pro-cesov z doloceno prioriteto prazen, se nov proces izbere iz seznama z nizjoprioriteto, kar omogoca zamenjavo procesov v konstantnem casu O(n).

36 Poglavje 4: Linux
Menjava prioritetnih vrst poteka v okviru casovnih epoh (epochs), katerihdolzina je vnaprej dolocena, na zacetku dolocene epohe pa se v izvajanje vednoposljejo procesi aktivne vrste. Po preteku casovne epohe ima operacijski sistemna razpolago procese v neaktivni vrsti, kar povzroci njuno zamenjavo.
Dodatno izboljsavo pri uporabi prioritetnih vrst predstavlja se sistematizacijaprocesov, ki z bitmap strukturo pripomore k hitrejsemu iskanju pripravljenegaprocesa z najvisjo prioriteto. Podatkovna struktura deluje kot bitna ravninas podatkom o prioritetnih razredih, ki razpolagajo z aktivnimi procesi.
⇒ V zacetni fazi je bitna ravnina prazna,zato so vse njene bitmap[] vrednosti enake 0.
⇒ Ko v vrsto pripravljenih (runnable) procesov vstopi nov proces, se vn-to polje bitne ravnine, kjer stevilo n predstavlja enega od prioritetnihrazredov, vpise vrednost 1.
⇒ Linux find first set algoritem s sprehodom po bitmap[] seznamu poisceprvi bit z vrednostjo 1, iz cesar takoj ugotovi, kateremu prioritetnemurazredu pripada proces, ki se bo prvi odposlal v izvajanje. Zahtevnostiskanja, zaradi nespremenljivega stevila prioritetni razredov, ostaja redaO(1) in se uporablja skupaj z omenjenimi kroznimi seznami, ki vsebujejopripravljene procese iskane prioritete.
Slika 4.7: Razvrscanje Linux procesov.

4.3 Delovanje algoritma 37
4.3.1 Prioritetni razredi
Navedel sem, da algoritem vedno izbere proces z najvisjo prioriteto, zato vokviru posamezne prioritetne vrste operira s procesi niza kroznih seznamov posistemu round robin. Opisana funkcija nosi ime sched_find_first_bit() inse uporablja skladno s strukturo 140-ih prioritetnih razredov, ki si sledijo pozaporedju, kjer vecje stevilo predstavlja nizjo prioriteto.
Linux temelji na ideji dinamicnega (dynamic priority-based) razvrscanja, kjerse procesom najprej dodeli staticna prioriteta (static priority), ki je odvisnaod vrste procesa. Literatura navaja dve kljucni klasifikaciji. Prva procese locina vhodno/izhodne ter procesorsko zahtevnejse, zato sem del drugega poglavjanamenil prav njim. Ce slednje na kratko povzamem, naj poudarim dejstvo, darazvrscevalnik daje vecjo prednost V/I oziroma interaktivnim (I/O - bound)procesom, ker zanje velja, da vecino casa cakajo na V/I naprave, za procesnooziroma procesorsko zahtevnejse (CPU - bound) procese pa vemo, da vecinomaizvajajo programsko kodo.
V predhodnih poglavjih sem veckrat omenil, kako pomemben je hiter odzivnicas sistema. Linux ga zagotavlja s favoriziranjem interaktivnih procesov, kjeralgoritem za razvrscanje vhodno/izhodnim procesom zvisuje prioriteto. S temzagotavlja bolj pogosto izvrsevanje interaktivnih procesov, vendar za krajsicas. Nasprotno zahtevnejsim procesom z nizjo prioriteto dodeli daljse casovnerezine, ker med izvrsevanjem ne blokirajo sistema s cakanjem na V/I napravo.Izvrsujejo se, dokler jih ne prekine proces z visjo prioriteto oziroma V/I procesz zahtevo po hitrem odzivnem casu, ki ga sistem mora zagotoviti. Poleg tegase kot ustrezno merilo uposteva pojem prepustnosti sistema v prid procesomz nizjo prioriteto, katerih nikakor ne gre zanemariti.
Druga vrsta kategorizacije razlikuje:
1. Interaktivne procese, katerih casovna zakasnitev (delay) pri odzivu naV/I prekinitev lahko v povprecju meri le od 50 do 150 ms.
2. Batch procese, ki se vecinoma izvajajo v ozadju in/ali ne potrebujejohitrega odzivnega casa, zato jim sistem dodeli nizko prioriteto.
3. Real-Time procese podvrzene strogim casovnim omejitvam, ki jih ostaliprocesi ne smejo prekiniti, sicer ne bodo izvrseni v predpisanem casu.

38 Poglavje 4: Linux
Na podlagi opisane kategorizacije se 140 prioritetih razredov deli na:
1. Staticno prioriteto procesov v realnem casu, ki je nespremenljivater zaseda prioritetne razrede na intervalu od 0 do 99. Z vrednostjo 0 jepredstavljena najvisja prioriteta, zato velja, da imajo procesi za delo vrealnem casu (real-time processes) visjo prioriteto od obicajnih procesov.
2. Dinamicno prioriteto obicajnih procesov, ki se med razvrscanjemspreminja. Omenil sem, da algoritem procesom najprej dodeli staticnoprioriteto z vrednostjo 0, kar na lestvici od 0 do 139 enacimo s 120-imprioritetnim razredom. Nato lahko uporabnik zacetno prioriteto procesaspremeni s klicem sistemske nice() funkcije, ki prioriteti pristeje oziromaodsteje nice value vrednost z intervala med -20 in 19. Kljub temu namfunkcija getpriority() vrne pozitivno vrednost oziroma pricakovanoprioriteto procesa, z vrednostjo med 100 in 139. S pozitivnim pristevkomenostavno zagotovimo, da bo izbrani proces nekoliko bolj ”prijazen” doostalih procesov, saj mu znizamo staticno prioriteto, ki je shranjena vspremenljivki static_prio in je razvrscevalnik ne spremeninja. Cepravostane staticna priorieta nespremenjena, jo dodatna funkcija uporabi zaizracun dinamicne prioritete.
4.3.2 Dinamicna prioriteta
Ker se Linux nagiba k podpori V/I procesov, staticni prioriteti dodaja oziromaodvzema tocke z effective_prio() funkcijo za izracun dinamicne prioriteteprocesov. Metoda interaktivne procese nagradi z nizanjem zacetne nice valuevrednosti, medtem ko se procesorsko zahtevnejsim vrednost poveca. Pri temnagrada (ali kazen) ne presega meje 5-ih tock in se doloci v skladu s stopnjointeraktivnosti procesa. Kot primer vzemimo V/I proces, ki je imel na samemzacetku staticno vrednost enako 0. S klicem nice() funkcije smo se odlocili zaprijazen proces in vrednost povecali za 10 tock. Kljub temu lahko V/I procesponovno pridobi na prioriteti tako, da mu funkcija effective_prio() zatemodsteje nekaj tock. Vendar, kako naj algoritem prepozna interaktiven proces?
Resitev je bila izbrana na osnovi rezulatov, pridobljenih s pomocjo hevristicnihmetod, ki navajajo da V/I procesi vecino casa dobesedno prespijo, ker cakajona proste V/I enote. Algoritem cas enostavno izmeri in na podlagi pridobljenevrednosti proces uvrsti v enega od predefiniranih interaktivnih razredov.

4.3 Delovanje algoritma 39
Ko se proces prebudi, se izmerjeni cas takoj pristeje spremenljivki sleep_avg, zvrednostjo omejeno na interval med 0 in MAX_SLEEP_AVG. Slednja v osnovi merile 10 ms in preprecuje zlorabo metode s strani procesov, ki zelo dolgo cakajona prosto enoto. Avtor clanka [2] kot najboljso lastnost metode navaja njenopresenetljivo natancnost, saj hevristika ne uposteva le casa spanja, temvectudi cas, ki ga je proces porabil za procesiranje. V trenutku, ko proces zapustiprocesor, se omenjeni cas spremenljivki odsteje, kar pomeni, da sistem grobokaznuje le procese s predolgim casom procesiranja, pri tem pa specim procesoms periodicno dobrim izkoristkom procesorja ne podeli prevec nagradnih tock.
4.3.3 Casovne rezine
Casovna rezina (timeslice)2 se procesom dodeli na osnovi njihove prioritete inpredstavlja najdaljsi cas izvajanja procesa, preden ga razvrscevalnik zamenja znaslednjim. Ceprav je predpisani cas procesiranja posameznega prioritetnegarazreda vedno enak, je dolocitev le-tega zahtevnejse, kot bi pricakovali. Predolgizbrani cas lahko povzroci neucinkovito interaktivno delovanje sistema, ker namprepocasna izmenjava procesov ne daje vec obcutka t.i. navidezno - paralelnega(multitasking) delovanja. Po drugi strani pa nas izbira prekratke casovne rezinepripelje do potratnega delovanja operacijskega sistema, ker procesor vecinosistemskega casa zapravi za preklop med procesi.
Slika 4.8: Dolzina casovne rezine.
Iz opisa in sheme je razvidno, da algoritem interaktivnim procesom oziromaprocesom z visjo prioriteto dodeli daljso casovno rezino. Vendar, ali slednje nenasprotuje definiciji, ki pravi, da algoritem vhodno/izhodne procese favoriziraz bolj pogostim izvrsevanjem in krajsim casom izvajanja?
2Pri drugih operacijskih sistemih se uporabljata izraza time quantum in processor slice.

40 Poglavje 4: Linux
Nasprotno, procesno zahtevnejsi posli potrebujejo daljso casovno rezino, karse ponovno izkaze kot konflikt med interesi nasprotujocih si procesov. Metodanam posledicno daje obcutek neoptimalnega interaktivnega delovanja, zatonekateri operacijski sistemi procesom dodelijo krajse casovne rezine, ki v osnovimerijo le 20 ms. Kljub temu razvijalci jedra zaupajo dejstvu, da Linux vednoizvaja procese z najvisjo prioriteto, zato je povprecna casovna rezina relativnodolga, kar omogoca daljse in bolj pogosto izvajanje interaktivnih procesov.Vedeti pa moramo, da procesi niso dolzni porabiti celotnega casa, ki ga imajona razpolago. Ceprav jim sistem v povprecju nameni le 100 ms, lahko casovnorezino porabijo kot vsoto krajsih, naprimer 20 ms dolgih casovnih izsekov, karovraca navidezno slabost algoritma in V/I procesom omogoca, da ostanejouvrsceni med hitro izvedljivimi oziroma pripravljenimi procesi.
Vsakic, ko procesu potece celoten cas, namenjen procesiranju, preide v stanjeoziroma vrsto neaktivnih procesov, kjer caka na konec epohe. Znano pa je, daneaktivnih procesov ni mogoce ponovno izvesti, vsaj do trenutka, ko cas potecese ostalim procesom aktivne vrste. Tedaj je epohe konec, zato algoritem vrstiaktivnih in neaktivih procesov zamenja. Vcasih je algoritem na koncu epoheopravil se izracun novih casovnih rezin, kar se je izkazalo kot zelo zahtevno incasovno potratno, zato novejse jedro slednje opravi loceno. Ko proces potrosisvojo casovno rezino, mu algoritem najprej izracuna novo, nato ga premaknemed neaktivne. Na koncu epohe algoritmu preostane le zamenjava kazalcev naprioritetni vrsti, s cimer ohrani optimalno hitrost delovanja, zahtevnosti O(1).
Izbira casovne rezine predstavlja relativno enostavno opravilo, saj temelji napredhodno izracunani prioriteti procesa, ki jo sistem pridobi na osnovi stopnjeinteraktivnosti. Linux nove procese tvori3 s funkcijo fork(), zato si novonastaliprocesi zacetno rezino delijo s svojim starsem. Ko proces - potomec omenjenopolovico casovne rezine porabi, dobi novo na podlagi dinamicne prioritete. Pritem se posluzi funkcije task_timeslice(), ki nove rezine ne izracuna, temvecle razbere z lestvice, kjer je procesom z najvisjo prioriteto namenjenih 200 msprocesorskega casa, medtem ko imajo procesi z najnizjo prioriteto na voljo leminimalnih 10 ms oziroma 100 ms v primeru obicajnih procesov, brez dodatnihkazenskih oziroma nagradnih tock.
Slabost opisanega predstavlja le stanje, pri katerem lahko interaktivni procesiobticijo v vrsti neaktivnih, ker ostali procesi niso se porabili svoje casovnerezine. Vendar tudi za to obstaja resitev.
3Podrobnejsi opis tvorbe Linux procesov si lahko preberete v tretjem poglavju knjige [3].

4.3 Delovanje algoritma 41
4.3.4 Metoda ponovne uvrstitve
Ceprav smo bili doslej vajeni, da se procese s pretecenim casom procesiranjavedno premakne med neaktivne, nam nova metoda daje moznost, da stradanjeinteraktivnih procesov odpravimo s postopkom, kjer jih ponovno uvrstimomed aktivne. Ko procesu potece casovna rezina, algoritem s pomocjo funkcijeTASK_INTERACTIVE() najprej preveri njegovo stopnjo interaktivnosti, zato jeponovna uvrstitev med aktivne procese mogoca le pri tistih procesih, ki jihoperacijski sistem pojmuje kot ”dovolj interaktivne”.
Ker je interaktivna lastnost procesa tesno povezana s prioriteto, ima funkcijatrivialno nalogo. Ponovno uvrstitev namrec izvede le pri najbolj interaktivnihprocesih oziroma tistih z najvisjo prioriteto. Stanje procesa se zelo preprostopreveri z branjem vrednosti parametra nice value, iz cesar ugotovimo, da seupostevajo le procesi, katerih vrednost ne presega stevila nic. Za enostavnejsoponazoritev si oglejmo sledeco programsko kodo:
struct task_struct *task;
struct runqueue *rq;
task = current;
rq = this_rq();
if (!--task->time_slice)
{
if (!TASK_INTERACTIVE(task) || EXPIRED_STARVING(rq))
enqueue_task(task, rq->expired);
else
enqueue_task(task, rq->active);
}
Kot lahko vidimo, metodo dopolnjuje funkcija, ki preprecuje stradanje ostalihprocesov, ker navidezno popolna metoda ponovne vkljucitve skriva neopaznoslabost. Ce se interaktivni procesi nenehno vkljucujejo med aktivne, dosezemoneizogiben polozaj, ko pricnejo stradati se ostali procesi, ki so ze bili vkljuceni vprioritetno vrsto neaktivnih procesov. Problem so pri algoritmu Linux sistemaresili tako, da funkcija EXPIRED_STARVING() periodicno pregleduje neaktivneprocese, iz cesar takoj ugotovi, koliko procesov strada, ker algoritem se vednocaka na menjavo prioritetnih vrst. V primeru predolgega stradanja bo metodaponovne uvrstitve svojo funkcijo zacasno prekinila, proces pa na obicajen nacinpremaknila v vrsto neaktivnih.

42 Poglavje 4: Linux
4.3.5 Vecjedrna obremenitev
Dodatno prednost pri razvrscanju procesorskega casa dosezemo z uporabovecjedrnega racunalniskega sistema, zato velja poudariti, da razvrscevalnik zavsako procesno enoto zagotavlja loceno vrsto pripravljenih procesov. Zanimanas torej, v cem se skriva bistvena prednost uporabe globalnega razvrscanja, cevsaka procesna enota izvaja svoj (edinstveni) sistem za razvrscanje procesov?
Resitev predstavlja uravnotezena obremenitev sistema, ki v osnovi poskrbi, daso vse vrste pripravljenih procesov enako zalozene. Logika torej deluje tako, dadoloceno vrsto najprej primerja z ostalimi. Ce pri tem ugotovi, da obravnavanavrsta trenutno vsebuje najmanj pripravljenih procesov, sprozi funkcijo, ki novproces ”potegne” iz najbolj zasedene in ga vstavi v svojo. Pri tem je pomembnovedeti, da obstajata dva primera, ko sistem sprozi funkcijo load_balance().V prvem ga pozene funkcija schedule(), ko ugotovi, da je vrsta pripravljenihprocesov prazna, v drugem pa casovnik. Ko je sistem nezaposlen, se funkcijaza uravnotezeno obremenitev sprozi vsako milisekundo, v nasprotnem primerupa jo casovnik klice le vsakih 200 milisekund. Kljub temu se load_balance()
uporablja le pri vecprocesorskih oziroma vecjedrnih sistemih, medtem ko gasistem z enim procesorjem in enim jedrom ne potrebuje. Pa poglejmo, kako selogika obnasa pod drobnogledom:
• Funkcija load_balance() najprej poklice drugo, find_busiest_queue()funkcijo, s katero poisce trenutno najbolj zasedeno vrsto pripravljenihprocesov. Ce funkcija za iskanje ne najde cakalne vrste, ki bi vsebovalaza vec kot 25 % pripravljenih procesov, vrne vrednost NULL, v nasprotnemprimeru pa kazalec na zasedeno vrsto.
• Ko load_balance() prejme kazalec, opravi se izbiro prioritetne vrste.Pri tem vedno daje prednost vrsti neaktivnih procesov, saj najdlje cakajona izvrsitev. Vrsta aktivnih procesov pride v postev le takrat, ko je vrstaneaktivnih popolnoma prazna.
• V naslednjem koraku funkciji preostane le dokoncna izbira procesa, kjerga logika ”potegne” iz seznama z najvisjo prioriteto. Kljub temu je predtem potrebno preveriti stanje procesa, saj se lahko zgodi, da je izbraniproces ze v fazi izvedbe oziroma v zaklenjenem stanju, ker mu metodaprocesorske afinitete4 preprecuje selitev. Ce so pogoji izpolnjeni, logikaproces prenese s klicem funkcije pull_task().
4Metoda procesorske afinitete je nekoliko bolj podrobno opisana na strani 25.

4.4 Razvrscanje v realnem casu 43
4.4 Razvrscanje v realnem casu
V okviru vecopravilnega delovanja jedro operacijskega sistema omogoca tudirazvrscanje v realnem casu, vendar dokumentacija navaja, da Linux podpirale t.i. ”mehko” oziroma soft real-time razvrscanje, kar z drugimi besedami po-meni, da sistem izvaja vse procese, ki imajo strogo dolocene casovne omejitve,vendar ne zagotavlja omejitvam podvrzene izvrsitve.
Ker se tovrstno razvrscanje vseeno uporablja, moramo vedeti, da lahko privededo dolocenih tezav. Pri odzivu sistema na prekinitveno zahtevo Linux preide vkernel mode nacin delovanja, zato onemogoci prekinitve s strani uporabniskihprocesov. Ce se med servisiranjem prekinitvene zahteve v vrsti pripravljenihprocesov nenadoma pojavi nov proces, ki zahteva takojsnji prevzem oziromarazvrscanje v realnem casu, ga sistem ni sposoben takoj izvesti. Ceprav gre zazakasnitev, ki traja le nekaj milisekund, jo proces tipa real-time obravnava kotnesprejemljivo, saj ne izpolnjuje zahteve po hitrem in predvidljivem odzivnemcasu, kot to pocnejo ”pravi” hard real-time sistemi.
Kljub temu Linux pozna 140 prioritetnih razredov, kjer jih veliko vecino zasedaprav mnozica real-time procesov z vrednostmi med 0 in 99. Njihova prioritetaje najvisja, zato lahko vedno prekinejo ostale vrste procesov, ceprav zanje veljarazlicen tip razvrscanja. Do tedaj opisani algoritem so pri jedru Linux sistemaoznacili z SCHED_NORMAL, za razvrscanje v realnem casu pa sistem uporabljaSCHED_FIFO ter izpopolnjeni SCHED_RR algoritem.
Prvi se zgleduje po opisanem FIFO (First In, First Out) algoritmu, zato gaobravnavamo kot skrajno enostavnega. Kot bomo videli, Linux svoje proceseza delo v realnem casu izvaja glede na vhodno zaporedje, zato lahko trenutnegaprekine le real-time proces z visjo prioriteto. V nasprotnem primeru se procesizvaja, dokler zeli, saj metoda ne pozna casovnih rezin, s katerimi bi omejilacas procesiranja. Nasprotno pa SCHED_RR casovne rezine uporablja, saj proceseposameznih prioritetnih razredov razvrsca s pomocjo algoritma Round Robin.

44 Poglavje 4: Linux

Poglavje 5
Windows
5.1 Arhitektura sistema
Operacijski sistem je bil zasnovan za delo z 32-bitnimi mikroprocesorji z idejoproznega vecplastnega sistema, zato so osnovne funkcije realizirane v okviruizvrsitvene plasti, nad katero potekajo procesi uporabniskega nivoja. Tovrstnavecnivojska struktura omogoca enostavno dodajanje sistemskih funkcij, karizpolnjuje prvo od stevilnih zahtev, zastavljenih pri Microsoft-u.
Pomemben razvojni cilj predstavlja tudi prenosljivost sistema, zato je bilo jedrospisano v C in C++ programskem jeziku, kjer je programska koda za neposrednokomunikacijo s procesorjem locena od preostalih delov sistema. Zapisana je vDLL (Dynamic Link Library) knjiznicah strojne plasti, ki so jo poimenovaliHAL (Hardware Abstraction Layer).
Zanesljivost sistema je zagotovljena s strojno zascito navideznega pomnilnika(virtual memory) ter loceno programsko zascito za sistemske vire, zdruzljivostsistema s programsko opremo pa zagotovlja prevajanje programov v okviruIEEE 1003.1 (POSIX) standarda (brez spreminjanja izvorne kode). Poleg vsehmeril, ki v danasnjih dneh omogocajo zanesljivo delovanje, nikakor ne smemospregledati ucinkovitosti delovanja, cesar se zavedajo tudi mozje, ki skrbijo zarazvoj Windows vmesnika. Pri tem navajajo, da sistemski procesi med sebojkomunicirajo s posiljanjem visokozmogljivih (high-performance) sporocil, kiomogocajo hitrejsi odziv na zunanje prekinitve.
45

46 Poglavje 5: Windows
5.2 Predstavitev procesov
Procesi operacijskemu sistemu priskrbijo vse vire, ki so potrebni za izvrsitevdolocenega programa, zato jih sestavljajo elementi, kot so navidezni naslovniprostor (virtual address), izvrsljiva programska koda (executable code), vpletenespremenljivke (environment variables), deklarirane velikosti delovne mnozice(working set sizes), prioriteta razvrscanja (priority class), identifikator procesa(process identifier) ter najmanj ena izvrsitvena nit (thread of execution). Vsakproces se namrec najprej pozene kot ena sama nit, ki ji pravimo primarna aliosnovna (primary thread), nakar procesi iz svojih niti tvorijo nove.
Omenjene niti obravnavamo kot entitete, ki omogocajo izvajanje in razvrscanjeprocesov, zato si med seboj delijo njihove vire. Pri tem niti ohranijo le dolocenelastnosti, ki jih sistem ob zamenjavi okolja shrani v mnozico registrov, sklad ternaslovni prostor obravnavanega procesa. Operacijski sistem Windows podpiravecopravilno razvrscanje procesov, zato nam prekinjanje kot oblika zamenjaveokolja daje obcutek vzporednega izvajanja stevilnih opravil. Poleg tega se posli(opravila) obravnavajo kot enote, s katerimi operacijski sistem lazje upravljain sciti atribute procesov, ki so z njimi povezani. Tako se operacija dolocenegaopravila izvede tudi na podmnozici povezanih procesov.
Vedeti pa moramo, da Windows svoje procese oziroma niti deli na se manjseenote, ki jim pravijo vlakna1 (fibers). Zanje skrbijo aplikacije in niti tako, dajih generirajo in razvrscajo same. Kljub temu delitev ne predstavlja resnicnovidne prednosti v primerjavi z dobro nacrtovanimi vecnitnimi aplikacijami, kerjih operacijski sistem uporablja zgolj za posebne vrste aplikacij, ki razvrscanjeprocesov oziroma niti izvedejo v lastni reziji. Z vidika racunalniskega sistema bilahko rekli, da vlakna prevzamejo njihovo identiteto, saj zasedejo enak naslovniprostor. Dejstvo pa je, da stanja posameznih vlaken ne opisuje enaka kolicinainformacij kot niti, ker njihovo stanje hrani le poseben sklad in podmnozicaregistrov, kjer se razvrscanje izvaja brez prekinitev.
Ker operacijski sistem loci vec vrst procesov, mu razvijalci pogosto dodajonove nacine razvrscanja. Tako ima nova razlicica Windows 7 moznost uporabemehanizma, ki so ga poimenovali UMS (User-Mode Scheduling) in aplikacijamomogoca nadzor nad razvrscanjem lastnih procesov, brez vpletanja sistemskegarazvrscevalnika. Proizvajalec seveda navaja, da mehanizem dosega le nekolikovisjo zmogljivost, vendar za to potrebujemo zahtevnejse aplikacije.
1Podrobnejsi opis o delovanju vlaken si lahko preberete na spletnem naslovu [11].

5.3 Algoritem za razvrscanje 47
5.3 Algoritem za razvrscanje
Ker sem v prejsnjih poglavjih ze opisal vecino funkcij, ki zagotavljajo hitrorazvrscanje procesov, bom tokrat najprej predstavil prioritetne razrede, ki jihuporablja Windows operacijski sistem. Microsoft se posluzuje zelo podobnegapristopa, kot smo ga spoznali pri Linux-u, zato ponovno govorimo o algoritmuna osnovi prioritetnega kreditiranja, kjer imajo vedno prednost procesi z visjoprioriteto. Njihovo izvedbo omogoca razvrscanje s prekinjanjem, medtem koistoimenska funkcija nosi ime dispatcher. Slednja omogoca nemoteno izvajanjeprocesov, dokler ne pride do:
• porabe casovne rezine trenutno izvajajocega procesa,
• prekinitve s strani procesa z visjo prioriteto,
• dokoncne izvedbe trenutnega procesa ali
• nove zahteve po V/I napravi.
Kot sem omenil, gre za zagotavljanje izvedbe procesov z najvisjo razpolozljivoprioriteto, zato naj predstavim temu primerno delitev.
5.3.1 Razvrscanje po prioriteti
Ker se razvrscanje procesov izvaja glede na prioriteto posameznega procesa, sele-ta dodeli po metodi, kjer vsaki niti pripada ena od 32-ih vnaprej predpisanihvrednosti. Osnovna prioriteta (base priority) je posledicno definirana kot nekevrste kombinacija med prioritetnim razredom procesa in prioritetnim nivojemposamezne niti. Ceprav je moznosti veliko, se procesi oziroma niti delijo nadva osnovna razreda, in sicer spremenljivi razred (variable class) s procesi nizjeprioritete in vrednostmi od 1 do 15 ter razred sistemskih oziroma real-timeprocesov (real-time class), s prioritetnimi vrednostmi med 16 in 31. Kot lahkovidimo, smo pri kategorizaciji izpustili vrednost 0, ker jo sistem uporablja zaposebne procese, ki skrbijo za upravljanje s pomnilnikom.
Izbira naslednjega izvedljivega procesa se vedno pricne na vrhu lestvice, kjerlezijo procesi z najvisjo prioriteto (slika 5.1). Ce algoritem med iskanjem naletina seznam ali prioritetni nivo, ki vsebuje vecje stevilo procesov, se zamenjavaprocesov izvede po sistemu round robin, v nasprotnem primeru pa se naslednjiproces izbere tako, da pregleda en nivo nize. Ko so vsi seznami prazni oziromabrez zahtev, algoritem procesorju izroci t.i. ”prazen”(idle) proces, s katerim ganavidezno zaposli.

48 Poglavje 5: Windows
Slika 5.1: Prioritetna delitev procesov.
Prioriteto niti v osnovi doloca prioritetni razred procesa, ki obicajno pripadarazredu NORMAL_PRIORITY_CLASS. Ko nit poleg ostalih atributov podeduje tudinjegovo prioritetno vrednost, jo algoritem uporabi za izracun koncne prioritetena podlagi spodaj nastetih vrednosti:
• REALTIME_PRIORITY_CLASS (24)
• HIGH_PRIORITY_CLASS (13)
• ABOVE_NORMAL_PRIORITY_CLASS (10)
• NORMAL_PRIORITY_CLASS (8)
• BELOW_NORMAL_PRIORITY_CLASS (6)
• IDLE_PRIORITY_CLASS (4)
Vse nastete moznosti (razen REALTIME_PRIORITY_CLASS) spadajo v kategorijospremenljivega tipa, kjer so najnizje relativne prioritete delezni procesi razredaIDLE_PRIORITY_CLASS. Slednji je uporaben predvsem za procese aplikacij, kiperiodicno osvezujejo zaslon, saj tovrstni procesi ne smejo vplivati na izvajanjeostalih procesov z visjo prioriteto. Pri tem pa moramo paziti, da uporabniskimprocesom skrbno dodelimo status HIGH_PRIORITY_CLASS razreda, sicer lahkos predolgim izvrsevanjem za dalj casa onesposobijo izvajanje ostalih procesovv sistemu. Poleg tega Microsoft odsvetuje dodeljevanje najvisje prioritete vsevecjemu stevilu procesov, ker se izkaze kot zelo neucinkovito.

5.3 Algoritem za razvrscanje 49
Razred HIGH_PRIORITY_CLASS naj bi programerji uporabili le pri procesih, kizahtevajo pravocasen odziv na casovno kriticne dogodke, zato nam razvijalcipredlagajo obcasno uporabo funkcije SetPriorityClass. Procesi bodo deleznivisje prioritete, vendar le za kratko dobo izvrsitve problema, saj si ne zelimo, dabi se izvajali predolgo. Zavedati pa se moramo, da je najbolj strogih omejitevdelezna uporaba razreda REALTIME_PRIORITY_CLASS. Nepravilno poseganje poprocesiranju v realnem casu privede do prekinitve procesov za komunikacijo zvhodno/izhodnimi napravami. Odzivni cas postane predolg, delovanje sistemapa skrajno nezadovoljivo. Kljub temu razred uporabimo za aplikacije, katerihprocesi komunicirajo s strojno opremo, oziroma za kratka opravila, ki jih ostaliposli ne smejo prekiniti.
Drugemu dejavniku, ki vpliva na prioriteto posamezne procesne niti, pravimoprioritetni nivo in ta doloca vrednost, ki jo sistem pristeje relativni prioritetiuporabljenega prioritetnega razreda. Ko proces generira nit, slednja prioritetopodeduje, kar pomeni, da se relativni prioriteti najprej pristeje vrednost 0, kiustreza nivoju THREAD_PRIORITY_NORMAL. Prioriteto posamezne niti je mogocekasneje spremeniti le z uporabo enostavne funkcije SetThreadPriority, kivrednost priredi na osnovi naslednjih vrednosti:
• THREAD_PRIORITY_TIME_CRITICAL
• THREAD_PRIORITY_HIGHEST (+2)
• THREAD_PRIORITY_ABOVE_NORMAL (+1)
• THREAD_PRIORITY_NORMAL (+0)
• THREAD_PRIORITY_BELOW_NORMAL (-1)
• THREAD_PRIORITY_LOWEST (-2)
• THREAD_PRIORITY_IDLE
Prioritetni vrednosti, ki smo jo dobili kot vsoto obeh elementov niti, pravimoosnovna prioriteta (base priority). Vendar dva nivoja v zgornjem seznamunimata podanega podatka o tem, za koliko se spremeni prioriteta v primeruTHREAD_PRIORITY_TIME_CRITICAL in nizje lezecega THREAD_PRIORITY_IDLE
prioritetnega nivoja. Pri slednjih se le-ta doloci nekoliko drugace. Ker gre zakriticne vrednosti, so niti spremenljivega razreda s prioritetnim nivojem vrsteTIME_CRITICAL vedno delezne vrednosti 15. Podobno velja za niti tipa IDLE,le da je prioritetna vrednost enaka 1. Ko razpolagamo z nitmi real-time nivoja,pa sta vrednosti 31 (za casovno kriticne) in 16 (za prazne procese).

50 Poglavje 5: Windows
Razvrscevalnik za vsako od 32-ih prioritetnih stopenj, prikazanih v tabeli 5.1vzdrzuje loceno vrsto pripravljenih procesov. V trenutku, ko se katerakoli odenot za procesiranje sprosti (postane razpolozljiva), sistem opravi zamenjavookolja2, kjer izvede naslednje korake:
• Shrani stanje pravkar izvedenega procesa.
• Proces premakne na konec vrste predpisane prioritetne stopnje.
• Poisce vrsto pripravljenih procesov z najvisjo prioriteto.
• Iz vrste prevzame prvi proces, ga nalozi in izvede.
5.3.2 Prioritetno rekreditiranje
Sistem poleg osnovne prioritete pozna se dinamicno prioriteto, ki jo uporabi zaprocese spremenljivega razreda. Ker prioriteto niti (v osnovi) doloca prioritetnirazred procesa, algoritem prevzame funkcijo naknadne spremembe omenjenegarazreda. Pri nadaljnjem razvrscanju se tako posluzi nove metode prioritetnegarekreditiranja procesov (priority boost), ki z enostavnim visanjem in nizanjemprioritete sistemu omogoca, da sam izbere, kateri proces se bo izvedel.
Ker operacijski sistem modificira le prioriteto spremenljivega razreda, se posegizvaja izkljucno pri procesih z vrednostjo med 1 in 15. Tako algoritem poskrbiza bolj odziven sistem ter nizjo verjetnost nezazelenega stradanja procesov prinaslednjih vnaprej predvidenih stanjih:
• Ko v ospredje priklicemo okno aplikacije, katere proces pripada razreduNORMAL_PRIORITY_CLASS, sistem poskrbi, da se prioritetni razred procesazamenja. Nova vrednost je posledicno visja od prioritetnih razredov, kijih zasedajo ostali pripravljeni procesi. Ob kasnejsi zamenjavi procesa sevrednost prioritetnega razreda povrne v zacetno stanje.
• Kot drugo moznost literatura navaja dogodek, kjer proces koncno docakaizvrsitev vhodno/izhodne operacije in tako preide v naslednje stanje. Kerje verjetnost, da bo proces ponovno dolgo cakal na prosto procesno enotoprevisoka, mu algoritem prioriteto dvigne.
• Ce pa zelimo ohraniti se hiter odzivni cas sistema, bodo visje prioritetedelezni tudi procesi oken, ki v dolocenem trenutku prejmejo sporocilo sstrani vhodno/izhodne naprave.
2Razloge, zakaj pride do zamenjave okolja, sem navedel na strani 47.

5.3 Algoritem za razvrscanje 51
Ko proces koncno prevzame nadzor nad procesorjem, se ob vsaki porabljenicasovni rezini vrednost zmanjsa za en nivo, vendar dinamicna prioriteta nedoseze vrednosti, ki je kakorkoli nizja od osnovne prioritete procesa.
Tabela 5.1: Prioritetna vrednost procesov.
5.3.3 Prioritetna inverzija
Metoda prioritetne inverzije (priority inversion) pride v postev, ko algoritemza razvrscanje doseze sporno stanje, kjer se vecje stevilo procesov z razlicnimiprioritetami (hkrati) poteguje za izvrsitev na procesorju. Naj navedem primertreh enostavnih procesov, kjer velja:
vrsta procesov z visoko prioriteto⇒ ... P1
vrsta procesov z nizko prioriteto⇒ ... P2 ⇒ procesor
vrsta procesov s srednjo prioriteto⇒ ... P3
P1 je definiran kot proces z visoko prioriteto, ki je pravkar postal pripravljenna izvrsitev, proces P2 ima nizko osnovno prioriteto, vendar trenutno izvajadel programske kode iz kriticne sekcije, proces P3 (s srednjo prioriteto) pa cakana procesor. Ker proces P1 pricakuje sprostitev skupnih virov, ki si jih deli sprocesom P2, se razvrscevalnik odloci, da bo procesorski cas dodelil procesuP3, vendar stanje privede do tezave.

52 Poglavje 5: Windows
Namrec, P2 zaradi kriticne sekcije3 noce zapustiti procesorja, ker se zaveda, damu nizka prioriteta preprecuje hiter (ponoven) prevzem procesorja. Algoritemza razvrscanje problem resi tako, da z visanjem prioritete procesov, katerihniti (v tem primeru proces z nizko prioriteto) zadrzujejo vire, ki jih potrebujejoostali procesi. Proces P2 se izvaja, dokler ne izvede svoje kriticne sekcije, nakarprocesor zasede proces z najvisjo prioriteto.
5.4 Vecprocesorsko izvajanje
Ce racunalnik vsebuje vecje stevilo procesnih enot, je praviloma nacrtovan naosnovi omenjene SMP ali NUMA (Non-Uniform Memory Access) racunalniskearhitekture. Za razliko od SMP sistemov (predstavljenih na straneh 24-26) imaNUMA racunalnik svoje procesorje postavljene tako, da lezijo blizje nekaterimdelom pomnilnika. Nekoliko spremenjena fizicna postavitev jim tako omogocahitrejsi dostop, zato algoritem najprej poskusi izstaviti procese, ki so shranjeniv neposredni blizini prostega procesorja.
Pri SMP racunalnikih je arhitektura sistema realizirana bolj obicajno, saj jevec enakih procesnih enot ali jeder procesorja povezanih na skupen pomnilniskimodul (kot je prikazano na sliki 5.2). Razlika je v tem, da razvrscevalnik lahkokaterikoli proces oziroma nit dodeli poljubni procesni enoti, zato je tovrstnorazvrscanje na las podobno razvrscanju na enoprocesorskem sistemu.
Slika 5.2: Dostop dopomnilnika pri SMParhitekturi sistema.
3Kriticna sekcija je segment programske kode, kjer proces spreminja vrednost skupnihspremenljivk, nadgrajuje tabele, pise v datoteke itd. Dobro zasnovani operacijski sistemiistocasno izvajanje kriticnih sekcij preprecujejo s sinhronizacijo procesov [4, str. 191].

5.4 Vecprocesorsko izvajanje 53
Kakorkoli gledamo, pa moramo vedeti, da skoraj vsak danasnji racunalniskisistem vsebuje vecjedrni mikroprocesor, ki mu omogoca vzporedno izvajanjeprocesov. Razvrscanje se vedno pogojuje prioriteta, vendar nanjo lahko zlahkavplivamo s poseganjem v nastavitve procesorske afinitete.
5.4.1 Procesorska afiniteta SMP sistema
Procesorska afiniteta proces ali nit prisili, da se izvede na doloceni podmnoziciprocesorjev, zato se ne uporablja prav pogosto. Ceprav se metoda vcasih izkazekot koristna, lahko vpliva na sposobnost efektivnega razvrscanja procesov, sajnezmoznost uporabe vseh razpolozljivih procesnih enot zmanjsa ucinek, ki smoga pridobili z vzporednim procesiranjem.
Predstavitev procesorske afinitete je znotraj operacijskega sistema realizirana spomocjo bitne maske, ki ji pravijo kar processor affinity mask. Dolzino pri temuporabljenega niza definira stevilo vseh procesnih enot sistema, kjer oznacenibiti dolocajo izbrano podmnozico procesorjev. Branje posamezne vrednosti inprogramsko spremembo maske omogocata funkciji GetProcessAffinityMaskin SetProcessAffinityMask, kjer najprej dolocimo, na katerih procesorjih selahko izvede proces, s funkcijo SetThreadAffinityMask pa na podoben nacinizberemo se enote posamezne niti.
Operacijski sistem poleg obicajne procesorske afinitete omogoca tudi dodatnoizbiro t.i. idealnega procesorja, kjer s funkcijo SetThreadIdealProcessor
vnaprej dolocimo procesno enoto na kateri se lahko nit izvaja. Vendar, zavedatise moramo, da razvrscevalnik ne zagotavlja stoodstotne izvedbe na izbranemprocesorju, zato idealni procesor nit izvede le, ko je to res mozno, sicer sistemza razvrscanje podatek o izbrani enoti kasneje uporabi kot koristen namig.
5.4.2 Podpora za NUMA sisteme
Ceprav se pri vecprocesorskih sistemih vecinoma uporablja SMP model, imataoba operacijska sistema (tudi Linux) realizirano podporo za neenotni dostopdo pomnilnika (NUMA). Slabost SMP sistemov se pokaze, ko zelimo uporabitivse vecje stevilo procesorjev, ker je vodilo, ki povezuje mnozico procesorjev inglavni pomnilnik, fizicno omejeno (predstavlja ozko grlo sistema). Nacrtovanjesistema potemtakem zahteva uporabo NUMA arhitekture, kjer je visja hitrostprocesorja zagotovljena s hitrejsim (locenim) dostopom do pomnilnika, ki nepovzroca dodatne obremenitve vodila.

54 Poglavje 5: Windows
Kot sem ze omenil, je prednost NUMA arhitekture odvisna od tega, kateremudelu pomnilnika je posamezni procesor fizicno blizji. Pri lokacijah, ki so velikobolj oddaljene od procesorja, je dostopni cas nekoliko daljsi, zato so procesneenote med seboj povezane v manjse sisteme, ki jim pravijo kar vozlisca sistema(nodes). Vsako vozlisce je predstavljeno kot vec procesnih enot z dostopom dolastnega pomnilnika, med seboj pa so povezana preko vodila, ki zagotavlja t.i.skladnost predpomnilnika. Operacijski sistem posledicno uporablja metodo zarazvrscanje, ki optimalno delovanje zagotavlja tako, da niti odposilja tistimvozliscem, katerih procesorji omogocajo veliko hitrejsi dostop do uporabljenihpomnilniskih lokacij.
Kljub temu sistem pozna dve manjsi tezavi. Prva je podobna problemu izbireidealnega procesorja, kjer razvrscevalnik ne zagotavlja stoodstotne izvrsitve nazeleni procesni enoti oziroma vozliscu, druga pa prica o tem, da je sistem, enakokot pri SMP, omejen na koncno stevilo 64-ih procesorjev. Prvo tezavo resimoz enostavno uporabo ostalih vozlisc, drugo pa z vpeljavo mnozice procesorjev.
Poleg tega nam Microsoft ponuja se API (Application Programming Interface)oziroma vmesnik za programiranje aplikacij, s katerim razvijalcem omogocauporabo specificne topologije racunalniskega sistema. Pri razvoju aplikacij jetako mogoce dodatno optimizirati razvrscanje in dodeljevanje pomnilnika zuporabo posebnih NUMA funkcij.
5.4.3 Mnozica procesorjev
Pri novejsih razlicicah Windows operacijskega sistema se je nenadoma pojavilapotreba po podpori veliko vecjega stevila t.i. logicnih4 procesorjev, ki jo danespremoreta le 64-bitni verziji sistema z oznako Windows 7 ter Windows Server2008 R2 (32-bitne razlicice Windows OS je ne poznajo).
Racunalniske sisteme, ki premorejo vecje stevilo fizicno locenih procesorjev (in)ali procesor(je) z vecjim stevilom procesnih jeder, operacijski sistem obravnavakot naprave z vecjim stevilom logicnih procesorjev. Po definiciji lahko slednjerazumemo kot locene (logicne) procesne enote, ki so del posameznega jedraprocesorja, le-ta pa je lahko zgrajen iz vec jeder. Podpora sistemom z velikimstevilom logicnih procesorjev deluje na osnovi pojma mnozice, ki predstavljaskupino do 64 skupaj povezanih logicnih procesnih enot, kjer se vsaka skupina(mnozica) v fazi razvrscanja obravnava kot enojna (locena) entiteta.
4O logicnih procesorjih je bilo govora ze v podpoglavju o vecjedrnih procesorjih [str. 27]

5.5 Multimedijski procesi 55
V trenutku, ko se racunalniski sistem zazene, operacijski sistem najprej ustvarinove mnozice, katerim dodeli logicne procesorje. Ce sistem podpira dodajanjeprocesorjev med samim delovanjem, se v nekaterih mnozicah pusti predvidenostevilo prostih mest za procesne enote, ki jih bo prikljucil kasneje, ko sistem zedeluje. V vsakem primeru pa operacijski sitem poskrbi za minimizacijo stevilamnozic, kjer 128 procesorjev vedno razporedi v dve mnozici po 64 in nikakorne v stiri mnozice z 32-imi logicnimi procesorji. Poleg tega operacijski sistemucinkovito delovanje zagotavlja z grupiranjem procesorjev na osnovi principalokalnosti pomnilniskih dostopov5, kjer so vse procesne enote jedra in vsa jedratega istega procesorja dodeljena isti mnnozici. Na podoben nacin so za skupnomnozico izbrani procesorji, ki lezijo v neposredni blizini, razen v primeru, kovsota integriranih logicnih procesorjev presega najvisje dovoljeno stevilo.
5.5 Multimedijski procesi
Microsoft pri svojih operacijskih sistemih skrbi predvsem za podporo razredamultimedijskih procesov, zato so v okviru razvrscanja razvili funkcije MMCSS(Multimedia Class Scheduler Service), s katerimi multimedijskim aplikacijamzagotovijo bolj pogost dostop do virov CPE. Za prepoznavanje tovrstnih nitiin visanje prioritete njihovih procesov MMCSS uporabi podatke, ki jih slednjihranijo v registrih. Ko nit zeli izvesti operacijo multimedijske narave, s klicemfunkcije AvSetMmThreadCharacteristics najprej o tem obvesti MMCSS. Kersistem ne zeli, da bi mu aplikacija ”pozrla” vse razpolozljive vire, ima v registruSystemResponsiveness zapisano, koliksen del procesorskega casa naj prihraniprocesom z nizjo prioriteto. Procese multimedijskega tipa delimo na razrede znaslednjimi prioritetnimi vrednostmi:
• Visoka [23-26] - nizja le od prioritete nekaterih sistemskih procesov.Nacrtovana je za procese, ki upravljajo (na primer) z zvokom zelo visokekakovosti, zato lahko CPE (teoreticno) zasedejo po potrebi.
• Srednja [16-22] - za vse multimedijske procese, ki se izvajajo v ospredju.
• Nizka [8-15] - za procese z rezerviranim delezem procesorskega casa, kizadosca izvrsitvi. Vrednosti [1-7] so rezervirane za tiste procese, katerihcasovni delez je ze bil izkoriscen, in ponovno cakajo na prosto enoto.
5Lokalnost pomnilniskih dostopov opisuje pojav, ko programi pogosto uporabijo tisteukaze in operande, ki so v pomnilniku blizu trenutno uporabljenim. Posledica tega je, da senekateri pomnilniski naslovi v nekem casovnem intervalu pojavijo pogosteje kot drugi, kervon Neumannov racunalnik, ce ni skoka, jemlje ukaze enega za drugim [10, str. 59].

56 Poglavje 5: Windows

Poglavje 6
Realizacija simulacije
6.1 Primerjava algoritmov
V predhodnih poglavjih sem podrobno opisal vecji del sistema za razvrscanjeposameznih operacijskih sistemov, zato bom tokrat najprej opravil krajso innekoliko bolj nazorno primerjavo algoritmov obravnavanih jeder.
6.1.1 Algoritem Linux sistema
Preden preidem k posameznim korakom izvrsevanja, naj omenim, da Linuxuporablja dva locena algoritma za razvrscanje. Prvi sluzi t.i. ”posteni” delitviprocesorskega casa z uporabo prekinitev, drugi pa zagotavlja izvrsitev real-timeprocesov, kjer je veliko bolj pomembna absolutna prioriteta. Potek dogodkovlahko enostavno povzamemo v naslednjih korakih:
• Linux za vsak procesor uporabi loceno vrsto pripravljenih procesov, zatose razvrscanje procesov izvaja v okviru posamezne domene ali podrocjadelovanja. V primeru NUMA sistema algoritem najprej poskrbi za delitevopravila na procese posameznih vozlisc, pri podrejeni domeni dolocenegavozlisca procese razporedi na procesorje, medtem ko pri najnizji domeniposkrbi za delitev procesov na jedra posameznega procesorja. Algoritemskrbi le za uravnotezenost znotraj posamezne domene, zato je migracijaprocesov dovoljena le med jedri dolocenega procesorja ali med procesorjidolocenega vozlisca.
Novoprispeli proces se doloceni vrsti pripravljenih procesov dodeli gledena obremenitev procesnih enot domene, zato algoritem najprej preverivrednost temu namenjene spremenljivke cpu_load posamezne vrste.
57

58 Poglavje 6: Realizacija simulacije
Ob zagonu sistema se vrednosti spremenljivk postavijo na nic, spremenijopa ob vsakem klicu funkcije rebalance_tick(), ki novo vrednost pridobiz izracunom povprecne obremenitve vseh procesnih enot domene. Slednjepreprosto pomeni, da algoritem obremenitev procesnih enot pregledujein uravnava sproti.
• V naslednjem koraku algoritem poskrbi, da se proces usmeri v aktivno(active) oziroma neaktivno (expired) prioritetno vrsto glede na to, kolikocasovne rezine mu je se ostalo. Ker se pravkar nastalim procesom dodelinovo rezino, jih algoritem postavi v vrsto aktivnih, tiste, ki so ze porabilisvoj delez procesorskega casa, pa med neaktivne. Ko aktivna vrsta ostanebrez procesov, jo algoritem preprosto zamenja z neaktivno:
struct prio_array *array = rq->active;
if (!array->nr_active)
{
rq->active = rq->expired;
rq->expired = array;
}
• Ker operacijski sistem podpira simetricno multiprocesiranje (SMP), jeodposiljanje procesov loceno na paralelno delujoce enote, ki so realiziranev okviru posameznih vrst pripravljenih procesov. Tako je vsak procesordelezen procesa z najvisjo razpolozljivo prioriteto posamezne vrste, kjerse proces izbere iz kroznega seznama prioritetnega razreda.
Pri kroznih seznamih z vecjim stevilom procesov se vsak naslednji procesizbere po sistemu round robin, zato so procesi delezni casovne rezine, kidoloca koliko casa se lahko izvaja. Pravilo velja za obicajne procese, zatosistem pri real-time procesih obicajno uporabi FIFO algoritem, s katerimnajprej izvede proces, ki je cakal najdlje.
• Ko procesu potece casovna rezina, je potrebno opraviti hitro zamenjavookolja, zato se lahko zgodi, da je vrsta s pripravljenimi procesi trenutnoprazna. Tedaj je moznih vec scenarijev:
a) Naslednji proces se izbere s funkcijo za uravnotezeno obremenitev.
b) Aktivna prioritetna vrsta se zamenja z neaktivno.
c) Uporabi se t.i. ”prazen”(idle) proces.

6.1 Primerjava algoritmov 59
• Po zamenjavi algoritem izlocenemu procesu na novo preracuna casovnorezino, pri tem pa nagradi tisti proces, ki je vecino svojega casa cakal naodziv V/I enote. Pravilo velja le za procese z dinamicno prioriteto, saj zareal-time procese vemo, da se jim staticna prioriteta med delovanjem nespreminja. Nova prioriteta in casovna rezina se potemtakem izracunataglede na vrednost parametra nice ter sestevek sistemskega casa, ki ga jeproces med cakanjem na V/I enoto prespal. Interaktivne procese sistemnagradi tako, da jim odsteje do 5 kreditnih tock. Zmanjsa se prioritetnavrednost nice, povisa pa dejanska prioriteta. Procesom, ki so vecino casaporabili za procesiranje, sistem tocke pristeje.
Ponoven izracun se izvede, preden izloceni proces preide med pripravljeneprocese, pri tem pa operacijski sistem uposteva tudi cas, ki ga je procesprebil v cakalni vrsti po tem, ko je ze zapustil procesor. Ceprav je procesnajverjetneje ze porabil celoten cas, ki ga je imel na razpolago, lahko napodlagi ponovne uvrstitve obide vrsto neaktivnih procesov in se ponovnouvrsti med aktivne. Poleg tega obstaja moznost, da proces se ni porabilsvoje casovne rezine, ker ga je izpodrinil proces z visjo prioriteto. Tedajga algoritem uvrsti med aktivne, kjer pocaka na ponovno uvrstitev.
• Linux poleg izbire procesorja omogoca tudi izbiro jedra, na katerem se boizvedel dolocen proces. V ta namen operacijski sistem uporabi periodicnofunkcijo rebalance_tick() s katero preveri obremenitev cakalnih vrstprocesnih jeder. Ce taista funkcija ugotovi, da procesor ni uravnotezenoobremenjen, pozene funkcijo load_balance(), ki izvede pull migracijoprocesov. Prazna vrsta proces ”povlece” iz najbolj zasedene.
6.1.2 Razvrscevalnik Windows sistema
Windows operacijski sistem (podobno kot Linux) zagotavlja gotovo izvedboprocesov z najvisjo prioriteto, zato uporablja razvrscanje s prekinitvami, kjerso novogenerirani procesi takoj delezni prioritetne klasifikacije. Sistem procesenajprej porazdeli v locene vrste, od koder prevzame najbolj ustreznega, korakicelotnega postopka pa so naslednji:
• Izbira se vedno pricne na vrhu lestvice, kjer lezi vrsta s procesi najvisjeprioritete. Ce je vrsta prazna, algoritem preveri naslednjo, vse dokler nenaleti na prvi razpolozljivi proces. Kljub temu lahko vrsta vsebuje vecjestevilo procesov, zato algoritem najprej izvede prvega v vrsti, ostale paciklicno, vse dokler se ne pojavi proces z visjo prioriteto.

60 Poglavje 6: Realizacija simulacije
V skrajnem primeru, ko so vse vrste prazne, algoritem procesorju izrociprazen (idle) proces, kar ga navidezno zaposli. Klub temu, da algoritemWindows operacijskega sistema razvrsca niti, bom zaradi lazje primerjavealgoritmov odslej uporabljal le pojem procesa. Vedeti pa moramo, da nitiprioriteto podedujejo, zato je uvrstitev med pripravljene procese odvisnaod obeh - prioritetnega razreda procesa in prioritetnega nivoja niti.
O prioriteti procesov je veliko napisanega v prejsnjem poglavju, zato bomtokratno primerjavo omejil le na bistvene lastnosti in ostale podrobnostiizpostavil pri obravnavi in realizaciji simulacije1.
• Ko algoritem med pripravljenimi procesi izbere naslednjega, CPE pricnez izvajanjem njegovih ukazov. Po preteku casovne rezine se izbrani proceszamenja z naslednjim, vendar do zamenjave lahko pride tudi med samimizvajanjem, ko se v vrsti pripravljenih procesov pojavi nov proces z visjoprioriteto, oziroma takrat, ko izvajajoci proces sprozi zahtevo za dostopdo vhodno/izhodne ali druge naprave.
• Ce proces potrosi svojo casovno rezino, ga sistem postavi na konec vrstein v izvajanje odposlje proces, ki je na njenem zacetku. Algoritem lahkoprocesom spremenljivega razreda prioriteto tudi zniza, kar jih uvrsti medprocese nizjega nivoja, novega pa izbere v vrsti visjega nivoja.
Naslednje stanje dobimo, ko proces prostovoljno zapusti procesor, ker seje odlocil, da bo izvedel doloceno (recimo V/I) funkcijo. Tedaj preide vcakajoce stanje, procesno enoto pa prevzame proces s trenutno najvisjorazpolozljivo prioriteto. Prioritetna vrednost izlocenega procesa se v temprimeru ne spremeni.
Tretji primer predstavlja zamenjava, ko se v vrsti pripravljenih procesovpojavi proces z visjo prioriteto. Ceprav algoritem trenutni proces prekinein enoto dodeli novemu, izloceni proces ponovno zasede prvo mesto vvrsti pripravljenih procesov, od koder najhitreje prevzame procesor. Kose proces dokoncno izvrsi, preide iz trenutnega stanja izvajanja v stanjezakljucenih (terminated) procesov, od koder ga sistem po dolocenem casurazresi in pobrise iz seznama procesov ter podatkovnih struktur.
1Simulacija ali simulator je naprava (v nasem primeru aplikacija), s katero se umetnoustvarijo delovni pogoji, kakrsni so pri opravljanju dolocenih nalog v resnici [SSKJ].

6.1 Primerjava algoritmov 61
• Prioriteta procesov se lahko tudi povisa, zato obstaja vec moznosti, kakodo tega pride. Sprva nanjo vplivamo s spremembo t.i. osnovne prioriteteprocesa, kasneje pa nanjo pod dolocenimi pogoji vpliva tudi algoritemza razvrscanje. Ceprav slednji lahko preoblikuje le dinamicno prioritetospremenljivega razreda, poznamo nekaj najbolj tipicnih stanj, pri katerihpride do dodelitve nove vrednosti.
Kot prvo naj omenim stanje, ko se prioritetno rekreditiranje izvede takojpo izvrsitvi pricakovane vhodno/izhodne operacije. Proces, ki je ze daljcasa cakal na V/I napravo, bo s pomocjo povisane dinamicne prioriteteveliko hitreje ponovno prevzel procesor, pristevek k trenutni prioritetnivrednosti pa predlaga gonilnik naprave. Moznosti so naslednje:
1. Pri dostopu do diska ali CD-ROM enote se prioriteta poveca zaeno prioritetno enoto. Enako velja za procese video operacij.
2. Pri dostopu do omrezne naprave za dve enoti.
3. Komunikacija s tipkovnico prioriteto povisa za sest enot.
4. Upravljanje z zvokom pa za osem.
Naslednjo zanimivost Windows sistema predstavlja rekreditacija tistihprocesov, ki so povezani z aktivnim oknom dolocene aplikacije. Pravkarpovedano enostavno pomeni, da algoritem povisa prioritetno vrednostprocesov, katerih okno je med cakanjem na izvedbo dolocene funkcije vospredju. Avtor knjige [6] navaja, da v tem primeru rekreditacija povecapredvsem odzivnost interaktivnih aplikacij, ker procesu omogoca hitrejsiprevzem procesorja pred ostalimi programi, ki svoje procese izvajajo lev ozadju in (trenutno) ne sodelujejo z uporabnikom.
Klju temu, da je podobnih primerov se veliko, naj v primerjavi z Linuxsistemom omenim le najbolj sodobnega. Znano je, da razvijalci Windowssistema veliko pozornosti posvecajo multimedijskim procesom, zato zanjeuporablja posebne funkcije pod imenom MMCSS. Ker te skrbijo, da pritovrstnih procesih ne pride do stradanja, si algoritem pomaga s posebnoprioritetno delitvijo (predstavljeno na strani 55), s katero jim zagotavljaneprekinjeno izvajanje.
• Ceprav nekoliko okrnjeno, tudi Windows spreminja dolzino predefiniranecasovne rezine. Le-ta v osnovi meri 20 ms, vendar jo pri procesih, katerihokna preidejo v ospredje, pomnozi s tri. Tako imajo tudi procesi, ki nisoprocesno zahtevnejsega tipa, moznost daljsega procesiranja.

62 Poglavje 6: Realizacija simulacije
• Najbolj presenetljivo je, da literatura o Windows operacijskih sistemih nenavaja neposredne podpore za uravnotezeno obremenitev pod imenomload balancing. Kljub temu lahko ponekod zasledimo, da algoritem izbiroprocesorja izvaja, vendar le na globalnem nivoju. Ko proces prispe medpripravljene, ga najprej dodeli eni od razpolozljivih enot. Kot vidimo nasliki 6.1, operacijski sistem za vsak procesor vsebuje dodatno mnozicoprioritetnih vrst. Po eno vrsto za vsako prioritetno stopnjo. Ker sistemskrbi za najkrajsi cas izvedbe procesov, uporablja (podobno kot Linux)32-bitno iskalno masko, s katero v konstantnem casu O(1) poisce procesz najvisjo prioriteto (ne glede na vhodno mnozico).
Bitna maska nosi ime ready summary in jo algoritem uporablja skupajz dvema dodatnima maskama, ki skupaj belezita trenutno obremenitevprocesnih enot v sistemu. Prva maska active proccessor oznacuje, kolikouporabnih (fizicnih) procesorjev nudi racunalniski sistem, medtem komaska idle summary pove, katere enote so trenutno proste. Ko se procespojavi v vrsti pripravljenih, ga sistem sprva poskusi dodeliti idealnemuprocesorju, sicer med prostimi (idle) procesorji poskusi izbrati tistega zdoloceno (visjo) afiniteto.
Slika 6.1: Locene vrste pripravljenih procesov.

6.2 Dolocitev bremena 63
6.2 Dolocitev bremena
Prvi korak pri realizaciji simulacije predstavlja smiselno dolocitev zacetnegabremena, ki ga bo le-ta generirala. Ker operacijska sistema uporabljata razlicniklasifikaciji procesov, je tehtna izbira toliko bolj potrebna, zato sem proceselocil na stiri osnovne razrede, z namenom priblizati se realnemu bremenu, kiga generira vsakdanji racunalniski sistem. Na koncni izid vpliva tudi moznostnaknadne prilagoditve bremena specificni situaciji, kar nam, pod razlicnimipogoji, omogoca boljsi vpogled v delovanje in posledicno odpravljanje napaksimulacijskega programa.
Po zgledu obeh operacijskih sistemov sem za procese svoje simulacije uporabilnaslednjo osnovno klasifikacijo:
• procesi za delo v realnem casu (real-time)
• sistemski procesi (system)
• uporabniski procesi (user)
• multimedijski procesi (multimedia)
Ce navedene moznosti primerjamo z realnim bremenom, zlahka ugotovimo, daomenjenih pet razredov v osnovi predstavlja dokaj stvarno sliko vseh dejanskihmoznosti. Kljub temu minimalne razlike obstajajo zato jih bom v nadaljevanjutudi predstavil. Kot prvo lastnost realnega operacijskega sistema naj navedemdelitev opravil na procese oziroma niti in vlakna. Ker je razvrscevalnik Linuxsistema ne uporablja, sem se odlocil simulirati le osnovne procesne enote, kinajbolje predstavljajo oba raziskana algoritma. Kot smo videli, Windows svojaopravila oziroma procese razvrsca na osnovi prioritetnih razredov, vendar kotvemo, oba sistema uporabljata delitev procesov na obicajne in real-time, zatosem podoben model uporabil tudi sam, pri tem pa uposteval se vse potrebnelastnosti procesov.
Ceprav se prioriteta procesov med delovanjem spreminja, je najprej potrebnodefinirati njeno osnovno vrednost. Vseh moznosti je resda veliko, vendar namrealizacija simulacije enostavno vsili uporabo manjse mnozice podatkov, sicerle-ta postane neobvladljiva. Kljub temu nam stevilo poenostavljenih vrednostizadostuje, saj sem pri posplositvi Windows sistema izpustil le najvisji razredHIGH_PRIORITY_CLASS. Kot bomo videli kasneje, poenostavitev zadostuje tudipri obravnavi multimedijskih procesov, pri Linux sistemu pa jo zlahka upora-bimo za osnovno predstavitev vrednosti nice in njenih robnih pogojev.

64 Poglavje 6: Realizacija simulacije
Prioriteto procesov lahko pri realnih operacijskih sistemih spreminjajo tudivsi uporabniki, ker pa vsak operacijski sistem slednje dopusca na svojevrstennacin, je omejitev vec kot smiselna, sicer modelirana simulacija ne daje povsemprimerljivih rezultatov. Sprememba prioritete je kljub temu mogoca v primerusimulacije, kjer imata operacijska sistema na voljo naslednje, povsem zadostneprioritetne razrede, ki omogocajo omenjeno delitev:
• REALTIME_PROCESS
• ABOVE_NORMAL_PROCESS
• NORMAL_PROCESS
• BELOW_NORMAL_PROCESS
Za obicajne procese lahko oba operacijska sistema izrabita moznost naknadnedelitve in spremembe parametrov, kjer ima Linux nadzor nad nice vrednostjoprocesov, Windows operacijski sistem pa jim naknadno spreminja dinamicnoprioriteto. V ta namen sem pri prvem modulu za generiranje procesov definirallastnosti, ki jih podaja primer sledece programske kode:
if (memoryFree == true)
{
cMessage *system = new cMessage("system");
system->addPar("processingTime") = 0.01s;
system->addPar("processed") = false;
system->addPar("processID");
system->setLength(250kB);
send(system, "out");
}
Dejanska sprememba prioritetne vrednosti se vrsi kasneje, zato sem funkcijorealiziral v sledecih si programskih modulih, kjer jedro operacijskega sistema popotrebi generira tudi ”prazne” procese razreda IDLE_PRIORITY_CLASS. Ker sealgoritma znotraj simulacije izvrsujeta neodvisno, lahko za prioriteto procesovuporabimo realne vrednosti. Ce slednje povzamem v stevilih, naj omenim, daje pri Windows razvrscevalniku mogoce dodeliti vrednosti, ki so zapisane nastrani 48, pri Linux-u pa tiste na strani 38. Kljub temu je potrebno ponovnopoudariti, da minimalna omejitev obstaja.

6.2 Dolocitev bremena 65
Osnovna prioriteta Windows procesa je resda dolocljiva na podlagi omenjenihsestih prioritetnih razredov, vendar nanjo vpliva se prioritetni nivo posamezneniti. Pri vpeljavi prve posplositve sem tako predpostavil, da jedro simuliranegasistema operira le s procesi, saj niti v realnem sistemu prioriteto podedejujood procesa, zato se relativni prioriteti pristeje vrednost nic, ki ustreza nivojuTHREAD_PRIORITY_NORMAL. Podobno naj velja za procese simuliranega Linuxsistema. Ceprav se slednji delijo na 140 razlicnih prioritetnih razredov, lahkoprivzamemo, da je zacetna (staticna) prioriteta obicajnih procesov pravilomavedno enaka nic, pristeta nice vrednost pa variira glede na vrsto generiranegaprocesa. Pri tem nekoliko strozja omejitev velja le za real-time procese, kjerje mnozica stotih razredov omejena le na enega, z moznostjo razvrscanja napodlagi algoritma FIFO.
Preden preidem k obravnavi vseh ostalih lastnosti, ki omogocajo reprodukcijodelovanja, naj omenim, da na efektivno analizo opazovanega sistema vplivametoda, s katero zelimo pridobiti ustrezne rezultate. V knjigi [8, str. 25] avtorpoudarja, da je analiza racunalniskega sistema mogoca le, ce ga znamo tudimodelirati, simulirati in meriti, vendar kot pravi v nadaljevanju, lahko analizoopravimo tudi s pomocjo ene same metode ali vec moznosti hkrati. Sedaj, kovemo, katere vrste procesov je smiselno generirati, moramo na podlagi izbranemetode ter performancnih kriterijev dolociti se vse potrebne parametre, ki jihza simulacijo potrebujemo.
Ker sta izbrana sistema realna ter izjemno spremenljiva, se brez specializiraneprogramske in strojne opreme pojavi tezava, ko zelimo te vrednosti dejanskoizmeriti. V ta namen sem se odlocil za uporabo spremenljivk, s katerimi lahkozacetne pogoje po zelji spremenimo tako, da v koncni fazi predstavljajo kar seda enostavno breme, ki je povsem podobno realnemu. Ce do sedaj povedanopovzamem, naj navedem vrednosti, ki jih je mogoce pred zagonom simulacijepovsem spremeniti:
• zacetna prioriteta procesa
• osnovna dolzina casovne rezine
• afiniteta procesa za dolocen procesor
• delez (generiranih) procesov dolocene vrste
• zahtevani cas procesiranja posameznega procesa

66 Poglavje 6: Realizacija simulacije
6.3 Implementacija delovanja
Na osnovi spoznanj o streznih procesih zlahka ugotovimo, da je za simulacijorealnega sistema, pri katerem se vhodne zahteve porajajo nakljucno, potrebnouporabiti primerno verjetnostno porazdelitev. Ceprav jih teorija modeliranjain simulacijsko orodje ponujata veliko, nam avtor v gradivu [9] priporoca t.i.Poissonov proces, ki je zanimiv zaradi dveh osnovnih lastnosti. Zadovoljivoopisuje vecino verjetnostnih porazdelitev ter ima lepe matematicne znacilnosti.
Breme oziroma vhodno mnozico ustvari enota Generator, kjer se vsi procesigenerirajo s pomocjo funkcije za eksponentno verjetnostno porazdelitev, kipodaja cas med dogodki Poissonove verjetnostne porazdelitve. Vhodne zahtevese porajajo z intenzivnostjo λ = 1 zahteve/sekundo, z izvedbo funkcije:
scheduleAt(simTime() + exponential(1.0), generateMessageEvent);
Procesi generiranega bremena se nato usmerijo v dva popolnoma neodvisnodelujoca modula. Prvi predstavlja vrsto pripravljenih procesov Windows, drugipa Linux operacijskega sistema. Ko posamezni modul tipa Queue ugotovi vrstoin izvor posameznega procesa, ga vstavi v definirano prioritetno vrsto in dodelipreostale vnaprej dolocene vrednosti:
if (msg->kind() == 5)
{
realtimeQueue.insert(msg);
msg->addPar("baseTimeQuantum") = 0.12s;
msg->setPriority(24);
...
}
Kot vidimo, proces vstopi v vrsto realtimeQueue, zato mu algoritem Windowsoperacijskega sistema dodeli obicajno real-time prioriteto z vrednostjo 24. Kergre za proces, ki omogoca navidezno procesiranje v realnem casu, se izvedepred ostalimi, ceprav obstaja velika verjetnost, da ne bo izpolnil predpisanecasovne omejitve. Podobno velja za procese, ki vstopajo v cakalno vrsto Linuxsistema. Ce gre za procesiranje v realnem casu, se procesi zvrstijo po sistemuFIFO, kjer vsak proces zavzame procesno enoto vse dokler se ne izvede dokonca. Sele tedaj lahko procesor oziroma eno od jeder upodobljenega sistemauporabi naslednji proces, ki ga algoritem prevzame v naslednji (nizje lezeci)prioritetni vrsti (seveda, ce je vrsta z real-time procesi trenutno prazna).

6.3 Implementacija delovanja 67
V vsakem primeru pa Linux proces sprva zasede aktivno prioritetno vrsto. Konato potrosi cas, ki mu ga je algoritem namenil za izvajanje na procesorju, paga modul LinuxQueue postavi v vrsto neaktivnih. Vemo pa, da Linux za vsakprocesor uporabi loceno vrsto pipravljenih procesov, zato pred izbiro samegaprocesa opravi se izbiro procesorja. Pri tem si pomaga s funkcijo, ki omogocauravnotezeno obremenitev in deluje podobno kot pri realnem operacijskemsistemu. Slika 6.2 prikazuje, kako je slednje realizirano z graficnim vmesnikomorodja Omnet++, ki za loceni vrsti pipravljenih procesov uporabi istoimenskamodula runqueue_one in runqueue_two, pri katerih je delovanje doloceno sprogramsko kodo.
Slika 6.2: Dodelitev procesorja pri Linux sistemu.
Windows operacijski sistem opravi izbiro procesorja v naslednjem koraku, kosprejete procese odposlje lokalnemu nivoju dveh (novih) mnozic prioritetnihvrst. Ceprav je prikaz delovanja na videz podobnem tistemu pri Linux sistemu(slika 6.3), med njima obstaja bistvena razlika, ki prica o tem, da se Linuxnajprej odloci za izbiro procesorja in sele nato procese klasificira ter vstavi vvrsti pripravljenih procesov, medtem ko algoritem Windows sistema delitevopravi drugace.
Slika 6.3: Delitev procesov pri Windows sistemu.

68 Poglavje 6: Realizacija simulacije
Razliko predstavlja klasifikacija procesov, ki se pri Windows sistemu opravi kardvakrat oziroma na dveh nivojih. Algoritem vhodno mnozico najprej razporediv stiri prioritetne vrste (opredeljene na strani 63), in ko se nato odloci kateremuprocesorju bo zahtevo tudi poslal, proces ponovno razporedi v novo prioritetnovrsto, tokrat na nivoju procesorja. Delovanje obeh simuliranih modulov lahkonekoliko bolj nazorno predstavimo z odsekom programske kode, ki predstavljaodposiljanje pri izbiri procesa z obicajno (uporabnisko) prioriteto:
if (!normalQueue.empty())
{
cMessage *tail = (cMessage *) normalQueue.tail();
tailLength = tail->length();
sentName = tail->name();
memoryUsed = memoryUsed - tailLength;
cMessage *pop = (cMessage *) normalQueue.pop();
idealProcessor = pop->par("idealProcessor");
if (readyOne == readyTwo)
{
send(pop, "out", idealProcessor);
windowsLastCpu = idealProcessor;
}
else if (readyOne > readyTwo)
{
send(pop, "out", 1);
windowsLastCpu = 2;
}
else
{
send(pop, "out", 0);
windowsLastCpu = 1;
}
}
Ceprav algoritem procesom dodeli t.i. idealni procesor, se v primeru zasedeneenote odloci drugace in proces odposlje vrsti, ki vsebuje manj procesov, karpomeni, da izvaja poenostavljeno obliko uravnotezene obremenitve.

6.3 Implementacija delovanja 69
Celotno strukturo delovanja oziroma odposiljanja procesov prikazuje slika 6.4.Pri tem vsaka ikona predstavlja dolocen modul, ki deluje povsem neodvisno inje z ostalimi povezan s pomocjo prikazanih povezav, katere lahko v obliki locenened datoteke tudi programiramo. Posamezne enote modeliranega sistema soposledicno opisane s programskim jezikom C++, kjer vsako napravo ali segmentposameznega operacijskega sistema doloca modul, ki je definiran s strukturocSimpleModule.
Slika 6.4: Shema simulacijskega prikaza delovanja sistema.
Ceprav sem delovanje posameznih segmentov operacijskih sistemov vecinomaze opisal, nam vseeno ostane nekaj pomembnih podrobnosti, ki zaznamujejofunkcionalnost realizirane simulacije. Kot vidimo na sliki, moduloma Runqueue
in Ready sledita po dva procesorja, kjer vsak med njimi vsebuje po dve procesnijedri ter dva predpomnilniska nivoja. Podobno kot doslej opisane enote, tudielemente procesorja doloca programska koda, zato bom nadaljevanje izkoristilza opis njihovih simulacijskih funkcij. Ko namrec dolocen proces vstopi v enotoza procesiranje, mu posamezna enota nameni svoj del izvedbe in ga takoj uvrstiv modul tipa LinuxCacheL2, ki predstavlja predpomnilnik drugega nivoja. Kersem pri realizaciji simulacijskega modela poskrbel za razmeroma realen modeldelovanja, sem predpomnilniku podaril kapaciteto danasnjih 512 KB.

70 Poglavje 6: Realizacija simulacije
Ko proces izstopi iz modula ready_one ali ready_two, predstavlja opraviloWindows operacijskega sistema, zato ga algoritem takoj odposlje primerljivemumodulu WindowsCacheL2 s povsem enako kapaciteto, kot jo ima predpomnilnikLinux sistema. Kljub navidezno podobni strukturi, sistema delujeta povsemdrugace, saj Windows ne omogoca uravnotezene obremenitve procesorjev nanivoju posameznih jeder. Implementirano dvonivojsko pomnilnisko strukturoprikazuje slika 6.1, modula Core_1 in Core_2 pa delujeta kot procesni jedri zaizvedbo simuliranih procesov.
Slika 6.5: Pomnilniska strukturasimulacijskega procesorja.
Ceprav simulacija uprizarja razvrscanja procesov na tipicnem racunalniskemsistemu, kjer uporabnik sprozi generiranje procesov s strani enega ali drugegaoperacijskega sistema, moram poudariti, da je posnemanje celotnega delovanjatako strojne kot programske opreme skorajda nemogoce. Kljub temu sem okvirraziskave nekoliko razsiril in uporabil realne podatke oziroma meritve, kot soverjetnost zgresitve pri dostopu do (pred)pomnilnika, predpisana zgresitvenakazen ter dostopni casi pri vhodno/izhodnih napravah, vendar o tem nekolikokasneje, v podpoglavju na temo interpretacije pridobljenih rezultatov.
Naslednje, kar velja omeniti, sem definiral kot modul tipa System in predstavljamnozico prej omenjenih vhodno/izhodni enot, ki so prikazane na sliki 6.6, kjersem kot zgled vzel enote pri katerih Windows operacijski sistem nagrajuje svojeprocese. System s pomocjo funkcije podrejenega modula win_input vhodnezahteve dodeli V/I enotam glede na vrsto procesa. V primeru najbolj obicajnihinteraktivnih aplikacij, kjer procesi zahtevajo hiter odzivni cas, program vsezahteve odposlje modulu win_user, ki simulira tipicne casovne zakasnitve priuporabniski interakciji s sistemom z uporabo perifernih enot, kot sta miska intipkovnica.

6.3 Implementacija delovanja 71
Pri multimedijskih procesih, ki poleg procesorskega casa potrebujejo tudi velikopodatkov z diska, simulacija uporabi modul win_disk, medtem ko pri izvedbiaplikacije, kot je brskalnik, proces izmenicno oziroma nakljucno odposlje vsemtrem razpolozljivim enotam.
Slika 6.6: Modul V/I sistema.
Ko posamezni proces zapusti simulirano V/I enoto, mu oba operacijska sistemaspremenita tako prioriteto kot dolzino casovne rezine. Ker sem vse podrobnostiglede delovanja opisal v cetrtem in petem poglavju, bom tokrat pozornost rajeposvetil dolocenim funkcijam win_output oziroma linux_output modula, kislednje tudi izvaja. Na strani sestdeset sem zapisal, da razvrscevalni algoritemWindows sistema svoje procese nagrajuje tako, da jim glede na uporabljenovhodno/izhodno enoto povisa prioritetno vrednost za doloceno stevilo. Enakopocne tudi Linux-ov algoritem, le da procese tudi kaznuje, ko ugotovi, da soprocesno prevec potratni. Kot primer bom navedel kar ustrezno programskokodo, ki podaja del funkcije modula linux_disk:
cMessage *access = receive();
diskQueue.insert(access);
waitAndEnqueue(0.005s + normal(0,1)/1000, &diskQueue);
if (!diskQueue.empty())
used = (cMessage *) diskQueue.pop();
if (used->kind() != 5)
used->priority() = currentPriority - 1;
else
used->priority() = currentPriority + 5;

72 Poglavje 6: Realizacija simulacije
Dolzina casovne rezine se pri Linux-u spremeni glede na prioriteto procesa, inkar je najbolj pomembno - cas, ki ga je proces prespal med cakanjem na V/Ienoto. Pri Windows operacijskem sistemu se casovna rezina procesa spremenile, ko se okno njegove aplikacije priklice v ospredje. Tedaj algoritem vrednostcasovne rezine pomnozi s tri.
Po izhodu iz modula System se procesi ponovno uvrstijo v prioritetni vrsti tipaQueue, kjer jih Linux v primeru porabljene casovne rezine postavi v neaktivnoprioritetno vrsto, medtem ko pri Windows sistemu zasedejo zadnje mesto vvrsti dosezene prioritete.
6.4 Interpretacija rezultatov
Po zgledu podatkov in meritev, izvedenih na realnih operacijskih sistemih, semtudi sam (pri izvajanju simulacije) najprej uporabil najbolj obicajne nastavitveparametrov, kot so dolzina casovne rezine, zacetna prioriteta procesa in delezgeneriranih procesov dolocene vrste. Ceprav je pri pogonu simulacije moznospremeniti veliko vrednosti, sem se odlocil, da kljub omenjeni moznosti naimplementirani sistem ne bom vplival na nacin, ki bi lahko omajal njegovonavidezno - realno izvajanje.
Zacetne vrednosti, ki sem jih potemtakem uporabil, sem povzel v naslednjitabeli:
procesi delez Linux cas. rezina Windows cas. rezina
real-time 20 % 100 ms 120 mssistemski 25 % 100 ms 60 ms
uporabniski 30 % 100 ms 40 msmultimedijski 25 % 100 ms 20 ms
Tabela 6.1: Zacetne simulacijske vrednosti.
Kot lahko vidimo, Linux svojim procesom dodeli zacetno vrednost 100-tihmilisekund, medtem ko Windows operacijski sistem uporabi razlicne zacetnevrednosti. Pri tem modul Generator, v predvidenih casovih intervalih, ustvariin odposlje prikazane stiri vrste procesov, ki si sledijo po nakljucnem vrstnemredu. Meritve, ki jih tako dobimo, prikazuje slika 6.7.

6.4 Interpretacija rezultatov 73
Slika 6.7: Primerjava stevila izvedenih procesov pri obeh algoritmih simuliranihoperacijskih sistemov, kjer sem za casovno rezino uporabil obicajne vrednosti.
Vrednosti, ki jih dobimo, so povsem primerljive, odstopanje pa lahko opazimole pri izvedbi multimedijskih procesov, kjer Linux uporabi veliko daljso casovnorezino, zato proces (razumljivo) dokonca v krajsem casu. Sedaj je le potrebnopreveriti, kaj se zgodi, ce vrednosti casovnih rezin spremenimo. Ker vemo, daLinux prednost pridobi z daljso casovno rezino, poglejmo, ce Windows lahkonadoknadi s spremembo svoje zacetne vrednosti pri procesih, ki predstavljajomultimedijske vhodne zahteve. Kot vidimo na sliki 6.8, Windows pridobi primultimedijskih procesih, vendar slednje vpliva na uporabniske procese, saj jimtakorekoc ukrade del razpolozljivega procesorskega casa.
Slika 6.8: Primerjava stevila izvedenih procesov s spremenjenimi vrednostmi.
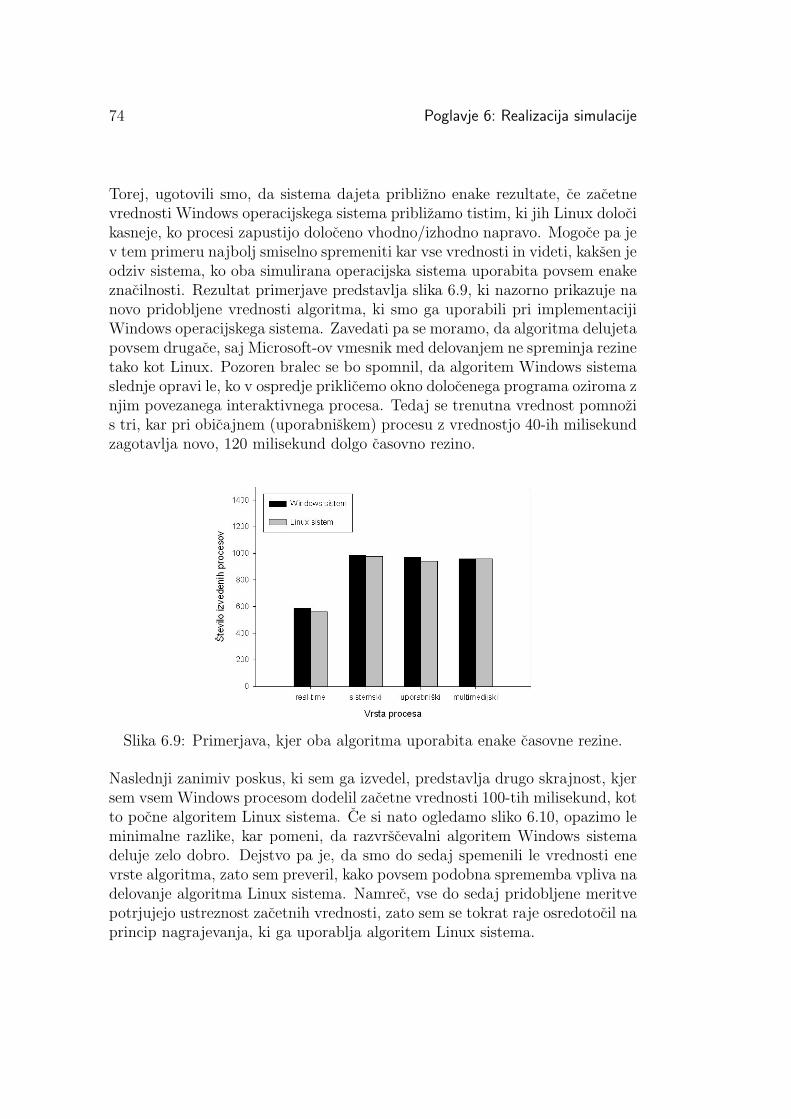
74 Poglavje 6: Realizacija simulacije
Torej, ugotovili smo, da sistema dajeta priblizno enake rezultate, ce zacetnevrednosti Windows operacijskega sistema priblizamo tistim, ki jih Linux dolocikasneje, ko procesi zapustijo doloceno vhodno/izhodno napravo. Mogoce pa jev tem primeru najbolj smiselno spremeniti kar vse vrednosti in videti, kaksen jeodziv sistema, ko oba simulirana operacijska sistema uporabita povsem enakeznacilnosti. Rezultat primerjave predstavlja slika 6.9, ki nazorno prikazuje nanovo pridobljene vrednosti algoritma, ki smo ga uporabili pri implementacijiWindows operacijskega sistema. Zavedati pa se moramo, da algoritma delujetapovsem drugace, saj Microsoft-ov vmesnik med delovanjem ne spreminja rezinetako kot Linux. Pozoren bralec se bo spomnil, da algoritem Windows sistemaslednje opravi le, ko v ospredje priklicemo okno dolocenega programa oziroma znjim povezanega interaktivnega procesa. Tedaj se trenutna vrednost pomnozis tri, kar pri obicajnem (uporabniskem) procesu z vrednostjo 40-ih milisekundzagotavlja novo, 120 milisekund dolgo casovno rezino.
Slika 6.9: Primerjava, kjer oba algoritma uporabita enake casovne rezine.
Naslednji zanimiv poskus, ki sem ga izvedel, predstavlja drugo skrajnost, kjersem vsem Windows procesom dodelil zacetne vrednosti 100-tih milisekund, kotto pocne algoritem Linux sistema. Ce si nato ogledamo sliko 6.10, opazimo leminimalne razlike, kar pomeni, da razvrscevalni algoritem Windows sistemadeluje zelo dobro. Dejstvo pa je, da smo do sedaj spemenili le vrednosti enevrste algoritma, zato sem preveril, kako povsem podobna sprememba vpliva nadelovanje algoritma Linux sistema. Namrec, vse do sedaj pridobljene meritvepotrjujejo ustreznost zacetnih vrednosti, zato sem se tokrat raje osredotocil naprincip nagrajevanja, ki ga uporablja algoritem Linux sistema.
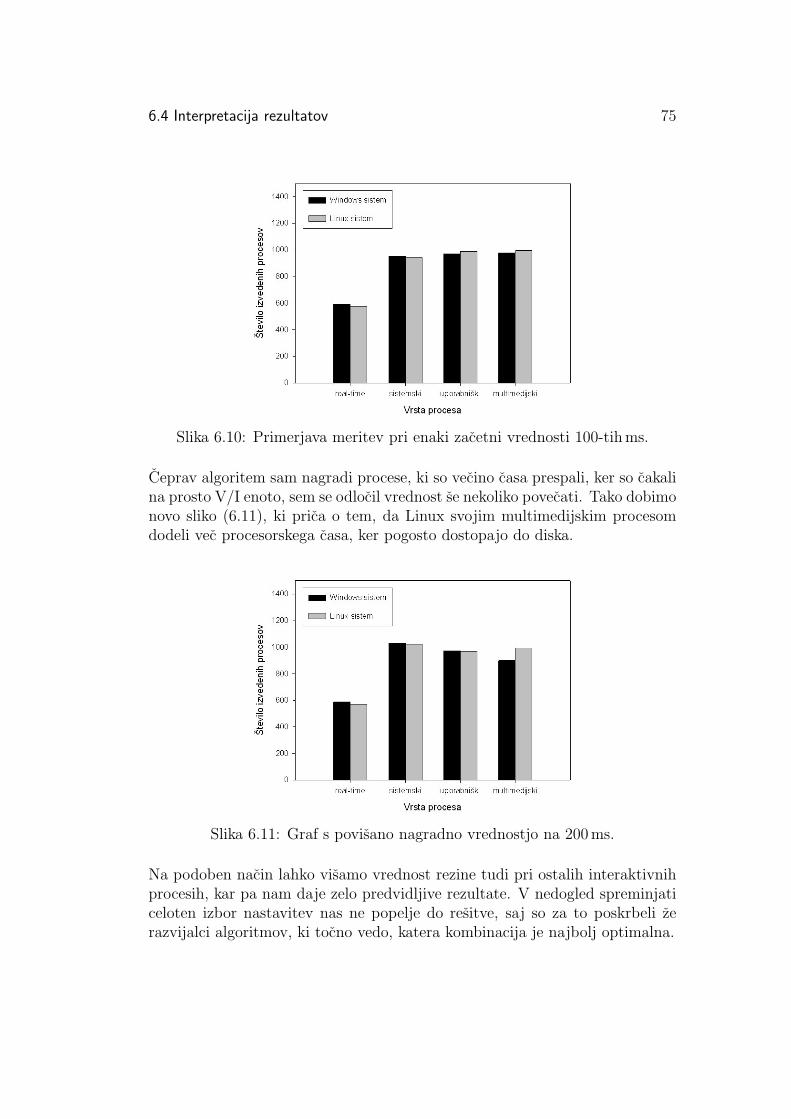
6.4 Interpretacija rezultatov 75
Slika 6.10: Primerjava meritev pri enaki zacetni vrednosti 100-tih ms.
Ceprav algoritem sam nagradi procese, ki so vecino casa prespali, ker so cakalina prosto V/I enoto, sem se odlocil vrednost se nekoliko povecati. Tako dobimonovo sliko (6.11), ki prica o tem, da Linux svojim multimedijskim procesomdodeli vec procesorskega casa, ker pogosto dostopajo do diska.
Slika 6.11: Graf s povisano nagradno vrednostjo na 200 ms.
Na podoben nacin lahko visamo vrednost rezine tudi pri ostalih interaktivnihprocesih, kar pa nam daje zelo predvidljive rezultate. V nedogled spreminjaticeloten izbor nastavitev nas ne popelje do resitve, saj so za to poskrbeli zerazvijalci algoritmov, ki tocno vedo, katera kombinacija je najbolj optimalna.

76 Poglavje 6: Realizacija simulacije
Windows operacijski sistem celo uporablja razlicne nastavitve pri racunalniskihsistemih z eno ali vec procesnimi enotami, poiskati novo optimalno porazdelitevpa predstavlja potratno opravilo. Kar pa nas dejansko pritegne, je spremenljivicas procesiranja posameznih procesov in delez procesov dolocene vrste. Polegtega sem pri vseh predstavljenih meritvah uporabil vrednost, ki ponazarjarealen cas priblizno ene ure, zato je prav, da simulacijo pozenem za dolocencas, ki je razlicen od do sedaj simuliranega.
Vrednosti, ki sem jih dobil, so popolnoma primerljive s prejsnjimi, le nekolikobolj izrazite, zato je veliko bolj zanimivo simulirati racunalniski sistem, kjerglavno vlogo igra dobro generirano breme. Ceprav pri obravnavanih algoritmihlahko pricakujemo popolnoma uravnotezeno vlogo, se optimizirano razvrscanjeprocesov vseeno prevesi na eno ali drugo stran. Slednje sem zelel tudi dokazatiob dolocenih predpostavkah, kjer sem na primer sklenil, da uporabnik obicajnouporablja srednje zmogljiv racunalnik, ki operacijskega sistema ne izrablja zaizvajanje zahtevnih procesov v realnem casu, zato predstavljajo le vzorec.
I. Ker Windows sistem uporablja algoritem, s katerim najvec pozornostiposveti interaktivnim procesom, sem pri razlicnih pogojih veckrat dosegelrahlo, vcasih skoraj neopazno prednost pri procesih, ki sem jih uvrstilmed uporabniske. Ceprav oba algoritma podpirata hiter odzivni cas, jefunkcija, ki jo uporablja Windows sistem, le nekoliko bolj ucinkovita priprocesih, ki predstavljajo interakcijo z uporabnikom, ker jim sunkovitopovisa prioriteto in se bolj opazno spremeni casovno rezino. Slednje sepokaze tudi pri meritvah, ki ustrezajo spodnji sliki.
Slika 6.12: Tipicen primer simulacije s poudarkom na uporabniskih procesih.

6.4 Interpretacija rezultatov 77
II. Kljub temu lahko generiramo neprimerno breme, kjer s poudarkom namultimedijskih procesih sprozimo nekoliko vecjo predanost s strani Linuxsistema, kar vcasih toliko poveca casovno rezino, da malenkost zanemariostale procese. V tem primeru se multimedijski procesi izvedejo nekolikohitreje, vendar bistveno prevec zavzamejo procesno enoto.
Slika 6.13: Primer neuravnotezenega bremena, kjer Linuxuporabi daljso casovno rezino pri multimedijskih procesih.
Tipicen primer s prejsnje strani nazorno prikazuje naslednja tabela:
vrsta procesov stevilo Windows procesov stevilo Linux procesov
real-time 589 575sistemski 956 956
uporabniski 964 958multimedijski 1010 1014

78 Poglavje 6: Realizacija simulacije

Poglavje 7
Zakljucek
Po nesteto poskusih simuliranja in prav toliko tehtnih spremembah dolocljivihparametrov sem ugotovil, da sta oba algoritma zelo dobro premisljena, zatose pri simulaciji izkaze, da ne gre toliko za to, koliko procesov dolocene vrstelahko posamezni operacijski sistem izvede v primerjavi z drugim, temvec zarazmerje med izvrsenimi procesi znotraj posameznega sistema.
Ceprav sem s spreminjanjem casovne rezine in ostalih parametrov vedno dosegelminimalne razlike med obema operacijskima sistemoma, sem pri tem opazilpomembno vsebinsko razliko, ki doloca, koliksen je lahko odzivni cas celotnegasistema pri razlicnih vhodnih zahtevah. Odlocitev o tem, katere procese bomopostavili v ospredje, pa v veliki meri vpliva na celotno delovanje racunalnika.
Ceprav je zelo tezko dolociti, kateri algoritem se je izkazal kot boljsi, sem sena podlagi principa razvrscanja procesov naucil veliko koristnega o strukturiracunalniskega sistema in vecnitnih procesorskih zasnovah.
Kako bom razpolagal z novim znanjem in kako razvrscal vsakodnevne procesepa prepuscam zapletenemu algoritmu svojih misli ...
79


Slike
2.1 Stanja procesov . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.2 Povezovalna struktura . . . . . . . . . . . . . . . . . . . . . . . 112.3 Potek sistema prekinitev . . . . . . . . . . . . . . . . . . . . . . 122.4 Shema strezne enote . . . . . . . . . . . . . . . . . . . . . . . . 14
4.1 Deskriptor Linux procesa . . . . . . . . . . . . . . . . . . . . . . 314.2 Seznam povezanih procesov . . . . . . . . . . . . . . . . . . . . 334.3 Tabela kazalcev na deskriptorje . . . . . . . . . . . . . . . . . . 334.4 Cakalna vrsta sistema . . . . . . . . . . . . . . . . . . . . . . . 344.5 Prioritetni vrsti Linux sistema . . . . . . . . . . . . . . . . . . . 354.6 Zamenjava prioritetnih vrst . . . . . . . . . . . . . . . . . . . . 354.7 Razvrscanje Linux procesov . . . . . . . . . . . . . . . . . . . . 364.8 Dolzina casovne rezine . . . . . . . . . . . . . . . . . . . . . . . 39
5.1 Prioritetna delitev Windows procesov . . . . . . . . . . . . . . . 485.2 Dostop do pomnilnika pri SMP sistemih . . . . . . . . . . . . . 52
6.1 Locene vrste pripravljenih procesov . . . . . . . . . . . . . . . . 626.2 Dodelitev procesorja pri Linux sistemu . . . . . . . . . . . . . . 676.3 Delitev procesov pri Windows sistemu . . . . . . . . . . . . . . 676.4 Simulacijski prikaz delovanja sistema . . . . . . . . . . . . . . . 696.5 Struktura simulacijskega procesorja . . . . . . . . . . . . . . . . 706.6 Modul vhodno/izhodnega sistema . . . . . . . . . . . . . . . . . 716.7 Graf zacetne simulacije . . . . . . . . . . . . . . . . . . . . . . . 736.8 Primerjava stevila izvedenih procesov . . . . . . . . . . . . . . . 736.9 Prikaz meritev pri enakih casovnih rezinah . . . . . . . . . . . . 746.10 Graf algoritmov z enako zacetno vrednostjo . . . . . . . . . . . 756.11 Graf s povisano nagradno vrednostjo . . . . . . . . . . . . . . . 756.12 Primer tipicnega rezultata simulacije. . . . . . . . . . . . . . . . 766.13 Primer neuravnotezenega bremena . . . . . . . . . . . . . . . . 77
81


Literatura
[1] R. Love, Linux Kernel Development,Sams Publishing, 2004.
[2] J. Aas, Understanding the Linux 2.6.8.1 CPU Scheduler,Silicon Graphics, 2005.
[3] D. P. Bovet, M. Cesati, Understanding the Linux Kernel,Second Edition, O’Reilly, 2002.
[4] A. Silberschatz, P. B. Galvil, G. Gagne, Operating System Concepts,Eight Edition, John Wiley & Sons, 2009.
[5] A. S. Tanenbaum, Modern Operating Systems,Third Edition, Pearson Prentice Hall, 2009.
[6] M. E. Russinovich, D. A. Solomon, A. Ionescu, Windows Internals,Fifth Edition, Microsoft Press, 2009.
[7] G. C. Buttazzo, Sistemi in Tempo Reale,Seconda edizione, Pitagora Editrice Bologna, 2001.
[8] J. Virant, Modeliranje in simuliranje racunalniskih sistemov,Didakta, 1991.
[9] N. Zimic, Modeliranje in simulacija,Predloge s predavanj, 2009.
[10] D. Kodek, Arhitektura racunalniskih sistemov,2. popravljena in razsirjena izdaja, BI-TIM, 2000.
[11] (2009) Microsoft Developer Network, Process and Thread Functions.http://msdn.microsoft.com/en-us/library/ms682659(VS.85).aspx
83