alex krasheninnikov – hadoop high availability
TRANSCRIPT


О чем доклад?
✦Основные узлы и компоненты Hadoop✦Зачем обеспечивать высокую доступность
кластера✦Как постичь дзен Hadoop
High Availability (HA)✦Наш опыт внедрения HA

Что будет в докладе
5полезных
ссылок
2
72слайда
про Hadoop
2картиныЛожкина
5блок-схем
4
1КО
5классныхсоветов
историифакапов
sequencediagrams

Компоненты кластера

Hadoop "на пальцах"
Hadoop Distributed FileSystemФайловая система
● Иерархическая● Распределенная● С репликацией
Yet Another Resource NegotiatorВычислительные ресурсы кластера
● Набор нод● Ядра (vCores)● RAM
Программный комплекс

HDFS
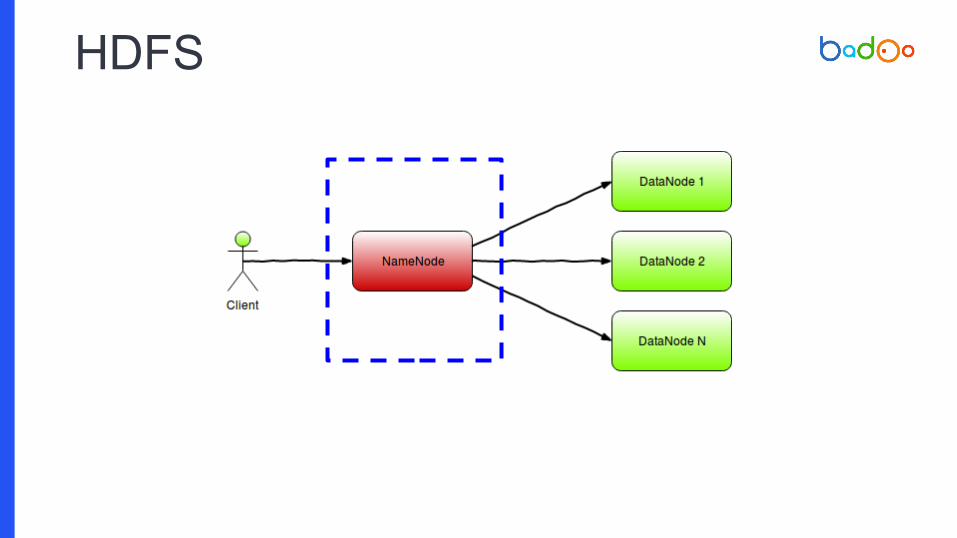
HDFS

HDFS: узлы и роли
NameNode
✦ Центральный узел кластера
✦ Хранит индекс FS
✦ Предоставляет API для манипуляций с ним
✦ Знает, где лежат данные

HDFS

HDFS: узлы и роли
DataNode
✦ Принимает read/write запросы к содержимому файлов HDFS
✦ Хранит содержимое файлов на своей дисковой подсистеме

HDFS: запрос с отказом DataNode

NameNode отправляет клиента на “живую” реплику файла

HDFS: запрос с отказом NameNode

HDFS: выводы
✦Выход из строя датанод не критичен, пока есть хотя бы одна, хранящая копию данных
✦Выход из строя неймноды ведёт к полной недоступности HDFS

YARN

YARN

YARN: узлы и роли
ResourceManager
✦ Запущен на одной машине кластера
✦ Принимает пользовательские запросы на запуск программ в кластере
✦ Делит ресурсы кластера между программами
✦ Просит ресурсы у конкретных NodeManager

YARN

YARN: узлы и роли
NodeManager
✦ Запущен на “рабочих” машинах кластера
✦ Принимает запросы на создание JVM с заданным размером HEAP и резервированием виртуальных ядер
✦ Исполняет пользовательский код в этих JVM

YARN: запуск программы пользователя

YARN: отказ ResourceManager
Вспоминаем картинку про менеджера и разработчика

YARN: выводы
✦Выход из строя NodeManager’ов приводит к потере части ресурсов кластера
✦Выход из строя ResourceManager’а приводит к невозможности запуска чего-либо на кластере


Опыт Badoo по эксплуатации
Hadoop до HA

До HA: edit-logs && fsimageПри старте, NN производит combine своих edit-логов с транзакциями
○ если NN долго не перезапускалась, то restart мог достигать нескольких часов
Решение:○ перезапуск NN не реже чем раз в месяц○ ручное поэтапное подсовывание edit-логов○ использовать свежий Hadoop :)○ правильно настроить edit-logs

До HA: совсем грустноОднажды мы не смогли подняться из edit-логов1. Пропатчили код восстановления2. Сделали binary-патч одного jar-файла3. Скопировали все edit-логи на отдельную
машину4. Восстановились с патченным кодом5. Скопировали snapshot обратно6. …7. PROFIT!8. Downtime - почти сутки

В итоге, зачем нужен HA?

При HA Риски без HA✦Fault-tolerance
✦Низкий downtime
✦Не теряем $$$
✦Крепкий сон
✦HDFS => набор несвязных бинарей
✦Вместо вычислительного кластера - куча несвязных машин


Hadoop в Badoo
✦Инсталляция из 67 машин
✦Ёмкость HDFS ~ 850 Tb, 50M объектов
✦CPU: 2700 cores
✦RAM: 10 Tb

Hadoop в Badoo: ETL
✦ ETL-процессыЗагрузили много данных из внешних источников, посчитали свёртки, выгрузили в аналитическую БД
✦ > 700 заданий в сутки
✦ Десятки Tb на чтение

Hadoop в Badoo: Deep storage
✦ Deep storage для хранения исторических данных
✦ “Backup” данных из аналитической базы
✦ По некоторым источникам есть история за несколько лет
✦ > 600 Tb занятого дискового пространства
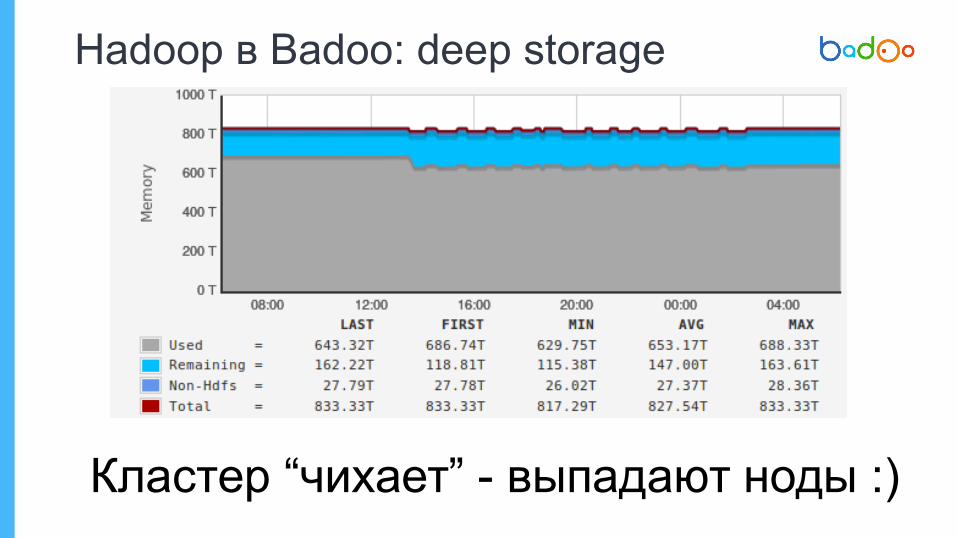
Hadoop в Badoo: deep storage
Кластер “чихает” - выпадают ноды :)

Hadoop в Badoo: realtime
✦Многие считают, что Hadoop и realtime - несовместимо
✦Но при правильных инструментах это не так :)
✦Keywords: Apache Spark, Storm, Samza

Hadoop в Badoo: realtime✦Потоковая агрегация событий
✦> 600 типов событий
✦Входная мощность: 350K событий/сек
✦Выходная мощность: 100К метрик/сек
✦Доклад

Цена downtime
✦Недоступность части данных для аналитиков к началу business time
✦Деградация графиков для realtime
✦Невозможность получения оперативной статистики

И что же делать?

High Availability в теории
✦Hot standby✦Round-robin request balancing✦Шардинг

High Availability в теории
✦Hot standby - используется в Hadoop для резервирования SPOF (NameNode, ResourceManager)
✦Шардинг - Federated NameNode

HA HDFS: общая схема

HA HDFS: общая схема
✦Пользовательские запросы по-прежнему обслуживает одна активная NN
✦Есть реплика, читающая журнал с транзакциями

HA HDFS: компоненты failover

HA HDFS: компоненты (Zookeeper)ZookeeperРаспределённая система с функционалом:
lock-service leader election иерархическое хранение конфигурацийВ рамках HDFS HA: выбирает активную NN предоставляет для неё лок оповещает об изменении статуса NN

HA HDFS: компоненты (ZKFC)ZKFailoverController (ZKFC)Вспомогательный сервис для автоматического failover’а
запускается на машинах NN мониторит живость локальной NN слушает уведомления от Zookeer производит failover

HA HDFS: компоненты (Journal Node)
✦ Реплика состояния NameNode
✦ Распределённость
✦ Отсутствие SPOF
✦ Запись в самую медленную реплику не тормозит общий процесс

Механизм failover
https://issues.apache.org/jira/browse/HDFS-2185

HDFS failover: summary
✦Активная NN держит лок в ZK✦Если лок пропал, то произвольный
ZKFC пытается сделать свою NN активной в ZK
✦Если удалось - переводит остальные NN в standby, а локальную делает active

HA YARN: общая схема

HA YARN: общая схема
✦ResourceManager’ы используют механизм leader-election, предоставляемый YARN
✦Для репликации состояния мастера используется хранилище Zookeeper
✦Контроллер failover’а встроен в сам демон RM, и не требует отдельного приложения

HA: внедрение
✦Research ~ 5 дней✦Инсталляция на dev-кластере: 2 дня✦Стрельбы/проверка
работоспособности – 2 дня✦Адаптация клиентов – 2 дня

HA: внедрение
✦С момента внедрения – не было даунтаймов дольше 10 секунд
✦Переключения между “мастерами” иногда случаются
✦Но не оказывают существенного влияния

С другой стороны баррикад
(настройка клиентов)

HDFS: клиентский API
✦ Native API
клиенты - в основном - JAVA
JAVA-клиенты знают про конфигурацию HA
✦ WebHDFS
HTTP-based, для любого языка
клиенты не знают, какая NN активная

WebHDFS: standby NNcurl http://stanbynn.domain:50070/webhdfs/v1/?op=LISTSTATUS
{ "RemoteException":
{"exception":"StandbyException","message":"Operation category READ is not supported in
state standby"}
}
Standby-нода не обслуживает клиентские запросы
http://$host:50070/jmx?qry=Hadoop:service=NameNode,name=NameNodeStatus
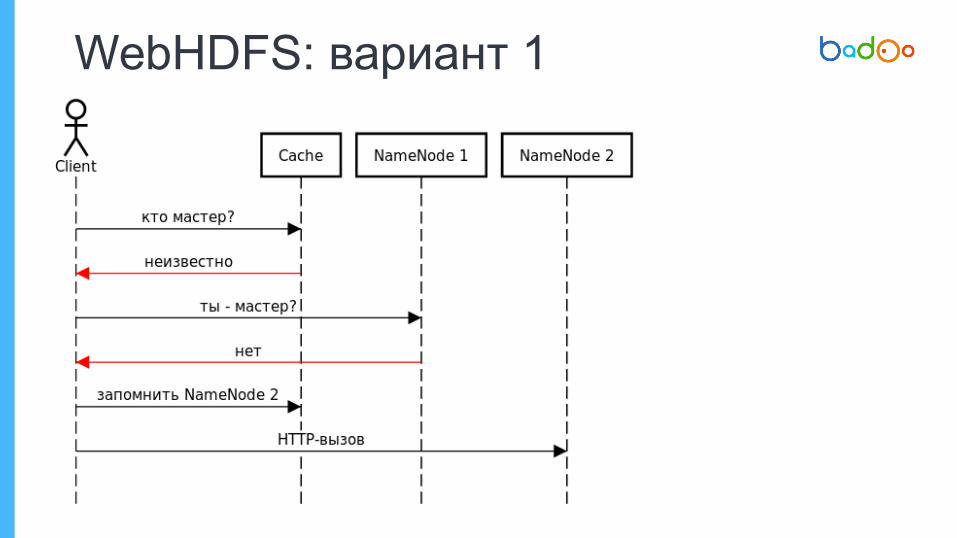
WebHDFS: вариант 1

WebHDFS: вариант 1Pro:
1. Просто, как валенок
Cons:2. Лишний HTTP-вызов3. Имплементация под
каждый ЯП(у нас их много :)

WebHDFS: вариант 2Программный балансировщик
прокси перед NN проверяет апстримы через URL http://$host:50070/jmx?qry=Hadoop:service=NameNode,name=NameNodeStatus
Более одного варианта: Nginx HAProxy ваш любимый


WebHDFS: вариант 3 (hardware balancer)
✦ В Badoo - на входе в каждый ДЦ
✦ Маршрутизирует весь трафик
✦ Имеет функции и возможности тюнинга, превосходящие программный балансер
✦ Умеем его готовить
✦ Применили для WebHDFS

Советы из опыта эксплуатации

HDFS: rock your NameNode
✦ Простое правило:1М файлов = 1 Gb heap size для NN
✦ В противном случае наблюдается деградация
✦ Не влезли в RAM одного хоста - добро пожаловать в Federated HDFS (мы пока не доросли до него)

HDFS: rock your NameNode
✦ Вдохновлялись статьей от Hortonworks
✦ Асинхронное логирование операций с HDFS (у нас их > 3K RPS)
✦ Достаточное число потоков для обработки API запросов
✦ Выключили atime (как и в обычных FS на наших серверах)

YARN: tune NodeManager
✦ Увеличили HEAP size
✦ В мирное время не требуется, но у нас приложения Spark используют его для обмена промежуточными данными

HDFS: datanode
✦ Т.к. репликация программная, то нет большого смысла использовать RAID
✦ JBOD - наш друг: сила в шпинделях!

HDFS: выбор диска для блоков

HDFS: выбор диска для блоков
✦ By default - Round Robin
✦ Но на первом диске - OS => он заведомо меньше
✦ Всегда образуется перекос
✦ Решение 1: настройка для датанодыAvailableSpaceVolumeChoosingPolicy
✦ Решение 2: Hadoop 3 + междисковый балансер

Человек против машины
Может ли один аналитик уложить кластер?

Нет ничего невозможного!
✦ Пишет 4-х этажный SQL
✦ Запускаем, ждём 5 минут
✦ Забиваем IN/OUT eth на датанодах
✦ Забиваем свитч
✦ Залезаем в iowait
✦ PROFIT!

How to avoid
✦ На датанодах - 10Gb eth
или:
✦ Стараемся уважать data-locality(работаем с данными по месту их физического хранения)

Что вы узнали
✦ Из каких базовых сервисов состоит Hadoop
✦ Какие там существуют SPOF
✦ С помощью каких средств они устраняются
✦ Какие действия предпринять для адаптации клиентов кластера к HA

Полезные материалы
✦ https://tech.badoo.com
✦ Доклад Badoo про использование Hadoop
✦ Инструкции по настройке HA
✦ Тюнинг NameNode

Кажется, я обещал 2 картины?
