amazon athena 初心者向けハンズオン
TRANSCRIPT

© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Makoto Shimura, Data Science Solution ArchitectAmazon Web Services Japan, K. K.2017.10.25
Amazon Athena初⼼者向けハンズオン

⾃⼰紹介
所属:アマゾンウェブサービスジャパン株式会社
業務:ソリューションアーキテクト(データサイエンス領域)
経歴:Hadoopログ解析基盤の開発データ分析データマネジメントや組織のデータ活⽤
志村 誠 (Makoto Shimura)

ハンズオンの最中に質問を投げることができます
• Adobe Connect の Q&A ウィンドウから、質問を書き込んでください。(書き込んだ質問は、主催者にしか⾒えません)
• 今後のロードマップに関するご質問はお答えできませんのでご了承ください。
• Twitter へツイートする際はハッシュタグ #awsblackbelt をご利⽤ください。
Q&A ウインドウの右下のフォームに質問を書いてください
質問を書き終わったら吹き出しマークを押して送信してください

ハンズオン資料のダウンロード
画⾯右上のリンクからダウンロードできます
1. ダウンロードしたい資料を選択
2. 「参照先」をクリック

このハンズオンの⽬的
1. Amazon Athena がどのようなものかを理解する
2. 実際に Amazon Athena を使ってみて,AWS のマネジメントコンソールからクエリを投げたり,データの持ち⽅によるクエリ速度の違いを体感たりする

注意点
このハンズオンでは,ごくわずかですが,Amazon Athena の利⽤料⾦が発⽣します
Amazon Athena の料⾦は,スキャンしたデータ 1 TB につき 5 ドル(課⾦単位は MB で,最低 10 MB から)
詳細は以下の AWS の公式サイトをご確認くださいhttps://aws.amazon.com/jp/athena/pricing/

事前に準備すべきもの
AWS アカウント• AWS アカウント作成の流れとポイント
https://aws.amazon.com/jp/register-flow/
Web ブラウザ• Firefox または Chrome を推奨

注意事項• お客様の環境により、本ラボが実施できない場合がございます
• すべてのサポートは難しい点についてご了承ください• 本資料からコピーアンドペーストしないでください
• 不必要なスペース等が⼊る可能性があります• 複数の画⾯を表⽰するため、ディスプレイ表⽰を⼯夫してください
オンラインセミナー配信画⾯
ブラウザ(Chrome, Firefox)・資料(PDF)閲覧・AWS マネジメントコンソール・簡易アプリケーション・⼊⼒⽤テキストなど 任意のテキストエディタ
・コピーアンドペースト⽤に使⽤

Agenda
Amazon Athena 概要• Amazon Athena とは• Amazon Athena のデータ形式とパフォーマンス
ハンズオン• 前準備とデータの確認• サンプルデータを S3 にアップロードしてクエリ• ファイルフォーマットによるクエリ速度の違いを確認

© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Amazon Athena 概要

Amazon Athena とは
S3上のデータに対して,標準 SQL によるインタラクティブなクエリを投げて
データの分析を⾏うことができるサービス

Amazon Athena とは• re:Invent 2016 のキーノートにて発表された新サービス• バージニア北部,オレゴン,オハイオ,アイルランド,シンガポール,
東京の計 6 リージョンで展開• クエリエンジンとして Presto を使⽤
https://aws.amazon.com/jp/blogs/news/amazon-athena-interactive-sql-queries-for-data-in-amazon-s3/

Presto : ⾼速な分散クエリエンジン• Athenaで使⽤しているクエリエンジン• データをディスクに書き出さず,すべてメモリ上で処理• ノード故障やメモリ溢れの場合にはクエリ⾃体が失敗• インタラクティブクエリ向け
https://prestodb.io/overview.html
参考: Presto のアーキテクチャ

Athena のデータ形式 / 圧縮形式データ形式 圧縮形式
• CSV• TSV• Parquet• ORC• JSON• Regex• Avro• Cloudtrail• Grok
• Snappy• Zlib• GZIP• LZO
* https://aws.amazon.com/jp/blogs/big-data/aws-cloudtrail-and-amazon-athena-dive-deep-to-analyze-security-compliance-and-operational-activity/** https://aws.amazon.com/about-aws/whats-new/2017/08/amazon-athena-adds-support-for-querying-data-using-logstash-grok-filters/

データ設計に影響する Athena の特性
• Athena は読み込むデータ量を絞って,すべての処理をメモリ状で⾏うことで,⾼速に結果を返すことができる
• いかにして読み込むデータ量を減らすかが重要• パーティション• 列指向フォーマット• 圧縮
* Online Transactional Processing ** Online Analytical Processing

パーティション
• S3のオブジェクトキーの構成をテーブルに反映して,読み込むファイル数を減らす
• WHERE で読み込み範囲を絞るときに頻繁に使われるカラムを,キーに指定する
• 絞り込みの効果が⾼いものが向いている• ログデータの場合,⽇付が定番• “year/month/day” と階層で指定する
SELECTmonth, action_category, action_detail, COUNT(user_id)
FROMaction_log
WHEREyear = 2016AND month >= 4AND month < 7
GROUP BYmonth, action_category, action_detail
以下のS3パスだけが読み込まれるs3://athena-examples/action-log/year=2016/month=04/day=01/...s3://athena-examples/action-log/year=2016/month=07/day=31/

列指向フォーマット
指向 特徴
⾏指向• レコード単位でデータを保存• 1カラムのみ必要でも,レコード全
体を読み込む必要がある• TEXTFILE(CSV, TSV) など
列指向• カラムごとにデータをまとめて保存• 特定の列だけを扱う処理では,ファ
イル全体を読む必要がない• ORC, Parquet など
https://orc.apache.org/docs/spec-intro.html
1 2 3 4 5 6
1 2 3 4 5 6
列指向
⾏指向

1 2 3 4 5 6
列指向フォーマット & 圧縮
分析クエリを効率的に実⾏できる
たいていの分析クエリは,⼀度のクエリで⼀部のカラムしか使⽤しない単純な統計データなら,メタデータで完結する
1 2 3 4 5 6 1 2 3 4 5 6
列指向⾏指向
データ読み込みの効率があがる• 圧縮と同時に使うことで読み込み効率が向上• カラムごとに分けられてデータが並んでいる• 同じカラムは,似たような中⾝のデータが続く
ため,圧縮効率がよくなる
1 2 3 4 5 61 2 3 4 5 6
列指向⾏指向

料⾦体系
• クエリ単位の従量課⾦• S3 のデータスキャンに対して,$5 / 1TB の料⾦
• バイト数はメガバイト単位で切り上げられ,10MB 未満のクエリは 10MB と計算される(0.0055円/10MB; 1$=110円)
• スキャンデータ量は,圧縮状態のデータサイズで計算される
• 別リージョンからデータを読み込む場合には,別途S3のデータ転送料⾦がかかる
• DDL のクエリや,実⾏に失敗したクエリの料⾦は無料• キャンセルしたクエリは料⾦がかかる

© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
ハンズオン

© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
前準備

AWS マネジメントコンソールへサインイン
アカウントユーザー名,パスワードを⼊⼒してサインイン

⾔語設定を⽇本語にする
画⾯左下をクリック

使⽤リージョンをバージニア北部にする
「⽶国東部(バージニア北部)」を画⾯右上から選択

進捗確認ログインと環境設定まで終わりましたか?
1. ⼈型アイコン右の ▽ ボタンを クリックしてプルダウンを開く
2. 「賛成」をクリック(ボタンが「賛成の消去」に変わるので,そのまま待つ)
3. 確認が終わったら,「賛成を消去」をクリック

© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
ハンズオン(1)サンプルデータをS3 にアップロードしてクエリ

ハンズオン(1) の全体像
1. 新しいバケットを作成2. 新しいフォルダを作成3. データをアップロード
S3 Athena
4. データベースを作成5. テーブルを作成6. クエリを投げる

ダウンロードしたデータの確認
• ダウンロードデータ内の titanic.csv を開く• たとえば Excel であれば,以下のような表⽰になるはず

S3 のページを開く
画⾯左上の「サービス」をクリックして,サービス⼀覧から S3 を選択
1. 「サービス」をクリック
2. ⼀覧から S3 を選択

AWS アカウント ID を確認しておく
• 画⾯右上をクリックして,AWS アカウント ID をメモ• ハイフンは除いた 12 桁の数字でメモしてください
1. 画⾯右上のユーザー名をクリック
2. アカウントID をメモハイフンは無視

新しいバケットを作成する
画⾯左上の「バケットを作成する」をクリック
「バケットを作成する」をクリック

必要事項を⼊⼒してバケットを作成
1. バケット名を⼊⼒「アカウントID-20171025-titanic」
2. リージョンが「⽶国東部(バージニア北部)」であることを確認
3. 「作成」をクリック

作成したバケットに移動
作成したバケット名をクリックして,バケットの中に移動

作成したバケットにフォルダを作成
作成したバケットを選択して,フォルダを作成
1. 「+ フォルダの作成」をクリック
2. 「titanic」と⼊⼒して「保存」をクリック

作成したフォルダにファイルをアップロード
1. 「titanic」をクリック
2. アップロードボタンを押す
3. titanic.csv のファイルを追加
4. アップロード

ダウンロードしたクエリファイルの確認
• テキストエディタで,titanic.sql を開く• 16 ⾏⽬の S3 バケットを,先ほど作成したものに変更
バケット名を,先ほど作成した「アカウントID-20171025-titanic」に変更する

進捗確認クエリファイルの修正まで終わりましたか?
1. ⼈型アイコン右の ▽ ボタンをクリックしてプルダウンを開く
2. 「賛成」をクリック(ボタンが「賛成の消去」に変わるので,そのまま待つ)
3. 確認が終わったら,「賛成を消去」をクリック

Athena のページを開く
1. 「サービス」をクリック
2. ⼀覧から Athena を選択

使⽤リージョンがバージニア北部なのを確認
「⽶国東部(バージニア北部)」を画⾯右上から選択

Athena の開始画⾯
Athena を初めて使う場合には,この画⾯が表⽰されるので,
「Get Started」を押して先に進む
チュートリアルがハイライトされる場合には,× ボタンを押して,元の画⾯に戻る

Athena のマネジメントコンソール
DBテーブル⼀覧
クエリの結果表⽰欄
クエリエディタ
クエリ操作
この画⾯にならない場合は,画⾯左上の
「Query Editor」を押して移動する

データベースの作成
1. 「タイタニックデータベースの作成」のクエリをコピーして貼付
2. クエリの実⾏
3. 作成された DBの確認

テーブルの作成
1. 「タイタニックテーブルの作成」のクエリをコピーして貼付
2. クエリの実⾏
3. 作成された テーブルの確認

作成したテーブルのデータを確認
1. テーブルの右の をクリック「Preview table」を選択
…
2. SELECT クエリが実⾏され10 件のデータが表⽰される

進捗確認テーブルデータの確認まで終わりましたか?
1. ⼈型アイコン右の ▽ ボタンをクリックしてプルダウンを開く
2. 「賛成」をクリック(ボタンが「賛成の消去」に変わるので,そのまま待つ)
3. 確認が終わったら,「賛成を消去」をクリック

クエリの内容を確認
selectclass, sex, count(survived) as total_cnt, sum(survived) as survived_cnt
fromtitanic_db.titanic
group byclass, sex
order byclass
, sex;

クエリの内容を確認
selectclass, sex, count(survived) as total_cnt, sum(survived) as survived_cnt
fromtitanic_db.titanic
group byclass, sex
order byclass
, sex;
以下の 4 カラムを返す- 客室ランク,- 性別,- 全乗客数,- ⽣存者数(値が 1 のもの)
客室ランクと性別ごとに値を集約する
客室ランクと性別で,アルファベット順に並べる

テーブルに対してクエリを実⾏ (1)1. 「データの集計 1」の
クエリをコピーして貼付
2. クエリの実⾏
3. 集計結果を確認客室ランクと性別ごとの乗客数と⽣存者数が算出

クエリの内容を確認selectclass, sex, total_cnt, survived_cnt, round(cast(survived_cnt as double)/cast(total_cnt as double), 2) as survival_rate
from (selectclass, sex, count(survived) as total_cnt, sum(survived) as survived_cnt
fromtitanic_db.titanic
whereclass != '*ʼ
group byclass, sex
)order bysurvival_rate desc;

クエリの内容を確認selectclass, sex, total_cnt, survived_cnt, round(cast(survived_cnt as double)/cast(total_cnt as double), 2) as survival_rate
from (selectclass, sex, count(survived) as total_cnt, sum(survived) as survived_cnt
fromtitanic_db.titanic
whereclass != '*ʼ
group byclass, sex
)order bysurvival_rate desc;
⽣存者数を⼈数で割って⽣存率を算出
先ほどのクエリをサブクエリとして実⾏して,その結果に対してさらに処理を⾏う

テーブルに対してクエリを実⾏ (2)1. 「データの集計 2」の
クエリをコピーして貼付
2. クエリの実⾏
3. 集計結果を確認先ほどの結果に加えて⽣存率が集計されている

クエリ結果のダウンロード
結果画⾯右上のアイコンをクリックcsvファイルがダウンロードされる

過去のクエリ結果の確認とダウンロード
1. History をクリック
2. クリックしてダウンロード
3. 実⾏時間やスキャンデータ量も確認可能

S3 上の結果を格納するバケットの確認 (1)
1. Settings をクリック
2. クエリ結果の配置場所を確認

S3 上の結果を格納するバケットの確認 (2)
画⾯左上の「サービス」をクリックして,サービス⼀覧から S3 を選択
1. 「サービス」をクリック
2. ⼀覧から S3 を選択

S3 上の結果を格納するバケットの確認 (3)
1. 先ほどのバケットを順に辿っていく
2. 結果ファイルの存在を確認

進捗確認クエリ結果の確認まで終わりましたか?
1. ⼈型アイコン右の ▽ ボタンをクリックしてプルダウンを開く
2. 「賛成」をクリック(ボタンが「賛成の消去」に変わるので,そのまま待つ)
3. 確認が終わったら,「賛成を消去」をクリック

© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
ハンズオン (2)ファイルフォーマットによるクエリ速度の違いを確認

ハンズオン(2) の全体像
別アカウントの S3 Athena
1. データベースを作成2. テーブルを作成3. パーティション認識4. クエリを投げる

対象データ: Swingbench
• ベンチマーク⽤のサンプルデータベース• その中の Sales テーブルを使⽤
データサイズ 約 90 GB
データサイズ(gzip圧縮時) 約 40 GB
行数 1,472,876,032行
期間 1995/01 – 2013/12

同⼀テーブルを 2 種類のデータ形式で読込
データ形式 圧縮形式 パーティション クエリ実⾏速度
tsv gzip なし• 遅い• すべてのカラムを読み込む
必要あり
parquet snappy年,⽉でパーティション作成
• 速い• クエリで必要なカラムのみ
読み込む• クエリで必要なパーティ
ションのみ読み込む

データの確認

データベースの作成swingbench.sql のクエリを順に実⾏する
1. 「Swingbench データベースの作成」のクエリをコピーして貼付
2. クエリの実⾏
3. 作成された DBの確認

テーブルの作成 (1)
1. 「 tsv + gzip 圧縮データに対するテーブルの作成 」
のクエリをコピーして貼付
2. クエリの実⾏3. 作成された テーブルの確認

テーブルの作成 (2)
1. 「 parquet + snappy 圧縮データに対するテーブルの作成 」
のクエリをコピーして貼付
2. クエリの実⾏3. 作成された テーブルの確認

作成したテーブルのパーティションを認識1.「 parquet + snappy テーブルの
パーティションを認識 」のクエリをコピーして貼付
2. クエリの実⾏
3. しばらく待つと,Results に認識されたパーティションの⼀覧が表⽰される

作成したテーブルのパーティションを確認
1.「 作成したパーティションの確認」のクエリをコピーして貼付
2. クエリの実⾏
3. しばらく待つと,Results に認識されたパーティションの⼀覧が表⽰される

進捗確認パーティションの確認まで終わりましたか?
1. ⼈型アイコン右の ▽ ボタンをクリックしてプルダウンを開く
2. 「賛成」をクリック(ボタンが「賛成の消去」に変わるので,そのまま待つ)
3. 確認が終わったら,「賛成を消去」をクリック

tsv + gzip テーブルに対するクエリの実⾏ (1)
selectprod_id, count(1) as deal_conut, avg(quantity_sold) as average_sold_num, sum(quantity_sold*amount_sold) as total_sales
fromswingbench_db.sales_gz
whereyear(time_id) = 2013and month(time_id) = 4
group byprod_id
order bytotal_sales desc
limit 20;

tsv + gzip テーブルに対するクエリの実⾏ (2)
selectprod_id, count(1) as deal_conut, avg(quantity_sold) as average_sold_num, sum(quantity_sold*amount_sold) as total_sales
fromswingbench_db.sales_gz
whereyear(time_id) = 2013and month(time_id) = 4
group byprod_id
order bytotal_sales desc
limit 20;
gz テーブルに対するクエリ
timestamp を年⽉に変換

tsv + gzip テーブルに対するクエリの実⾏ (3)
1.「 tsv テーブルに対してクエリ」のクエリをコピーして貼付
2. クエリの実⾏
3. 実⾏時間とスキャンデータ量を確認する
4. 結果を確認
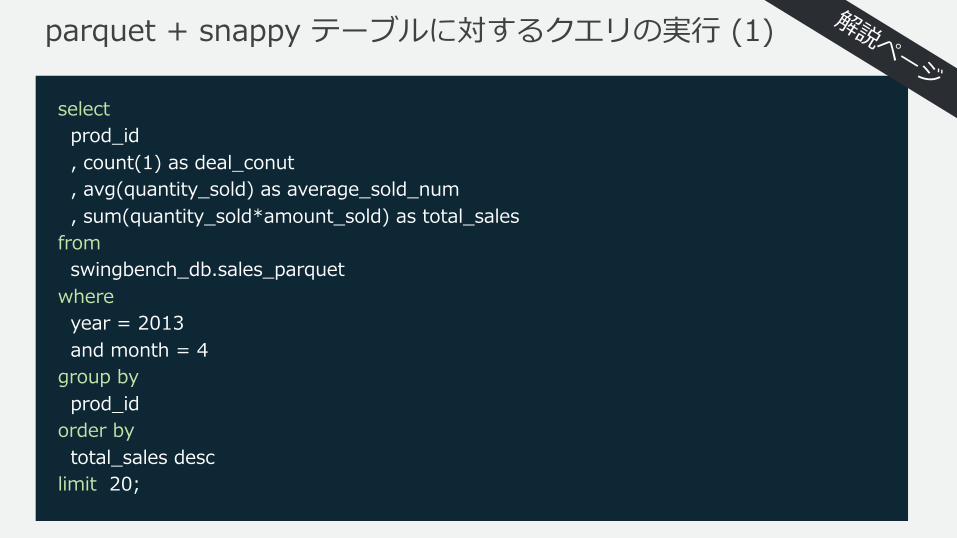
parquet + snappy テーブルに対するクエリの実⾏ (1)
selectprod_id, count(1) as deal_conut, avg(quantity_sold) as average_sold_num, sum(quantity_sold*amount_sold) as total_sales
fromswingbench_db.sales_parquet
whereyear = 2013and month = 4
group byprod_id
order bytotal_sales desc
limit 20;

parquet + snappy テーブルに対するクエリの実⾏ (2)
selectprod_id, count(1) as deal_conut, avg(quantity_sold) as average_sold_num, sum(quantity_sold*amount_sold) as total_sales
fromswingbench_db.sales_parquet
whereyear = 2013and month = 4
group byprod_id
order bytotal_sales desc
limit 20;
parquet テーブルに対するクエリ
パーティション情報を利⽤

parquet + snappy テーブルに対するクエリの実⾏ (3)
1.「 parquet テーブルに対してクエリ 」のクエリをコピーして
貼付
2. クエリの実⾏
3. 実⾏時間とスキャンデータ量を確認する
4. 結果が先ほどと同じなのを確認

進捗確認クエリの実⾏まで終わりましたか?
1. ⼈型アイコン右の ▽ ボタンをクリックしてプルダウンを開く
2. 「賛成」をクリック(ボタンが「賛成の消去」に変わるので,そのまま待つ)
3. 確認が終わったら,「賛成を消去」をクリック

© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
ハンズオン (3)複数のユーザで Athena を利⽤

ハンズオン(3) の全体像
2. 権限がないのでバケットを作成できないことを確認
S3 Athena
3. クエリを実⾏できることを確認
1. 新しいユーザーの作成
IAM

Amazon Athena ⽤の IAM ロールの作成
• IAM は,Identity and Access Management という,AWS 上での権限管理を⾏うためのサービスです
• Athena を使⽤するためには,以下の権限が必要です• Amazon Athena へのフルアクセス権限• Amazon S3 オブジェクトへの Read/Write/List 権限• AWS Glue のデータカタログの主要 API へのアクセス権限

IAM のページを開く
画⾯左上の「サービス」をクリックして,サービス⼀覧から IAM を選択
1. 「サービス」をクリック
2. ⼀覧から IAM を選択

IAM ユーザーを追加
IAM ユーザーから「ユーザーの追加」を選択
1.「ユーザー」をクリック 2. 「ユーザーを追加」をクリック

IAM ユーザーを新規に作成
1. ユーザー名に「athena_user」と⼊⼒する
2. 「awsマネジメントコンソールへのアクセス」にチェック
3. パスワードのリセットが必要のチェックを外す
4. 「次のステップ」を押す

アクセス権限の追加
「既存のポリシーを直接アタッチ」を選択

ポリシーのアタッチ (1)
検索窓に「athena」と⼊⼒して「AmazonAthenaFullAccess」と「AWSQuickSightAthenaAccess」にチェックを⼊れる

ポリシーのアタッチ (2)
1. 検索窓に「s3」と⼊⼒して「AmazonS3ReadOnlyAccess」にチェックを⼊れる
2.「次のステップ: 確認」をクリック

ユーザーの作成
「ユーザーの作成」をクリック

ユーザー追加の成功を確認
この画⾯が表⽰されたところで,いったんストップ

進捗確認ユーザーの作成まで終わりましたか?
1. ⼈型アイコン右の ▽ ボタンをクリックしてプルダウンを開く
2. 「賛成」をクリック(ボタンが「賛成の消去」に変わるので,そのまま待つ)
3. 確認が終わったら,「賛成を消去」をクリック

作成したユーザでサインイン
1. パスワードを表⽰してコピー
2. サインインリンクをクリック(⾃動でログアウトします)

AWS マネジメントコンソールへサインイン
先ほど作成したユーザであらためてログインし直す

S3 のページを開く
画⾯左上の「サービス」をクリックして,サービス⼀覧から S3 を選択
1. 「サービス」をクリック
2. ⼀覧から S3 を選択

新しいバケットを作成する
画⾯左上の「バケットを作成する」をクリック
「バケットを作成する」をクリック

バケットが作成できないことを確認
1. バケット名を⼊⼒「アカウントID-20171025-titanic」
2. リージョンが「⽶国東部(バージニア北部)」であることを確認
3. 「作成」をクリック

バケット作成に失敗
エラーが出てバケット作成に失敗

Athena のページを開く
1. 「サービス」をクリック
2. ⼀覧から Athena を選択

クエリが実⾏できることを確認
1. テーブルの右の をクリック「Preview table」を選択
…
2. SELECT クエリが実⾏され10 件のデータが表⽰される

管理者ユーザーで改めてサインイン
1. 画⾯右上のユーザ名をクリック
2. サインアウトをクリック
3. 管理者ユーザでサインイン

進捗確認管理者ユーザーでのサインインまで終わりましたか?
1. ⼈型アイコン右の ▽ ボタンをクリックしてプルダウンを開く
2. 「賛成」をクリック(ボタンが「賛成の消去」に変わるので,そのまま待つ)
3. 確認が終わったら,「賛成を消去」をクリック

© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
後⽚付け

S3 のページを開く
画⾯左上の「サービス」をクリックして,サービス⼀覧から S3 を選択
1. 「サービス」をクリック
2. ⼀覧から S3 を選択

S3 のバケットを削除 (1)1. 先ほど作成したバケットの
⾏をクリック
2. 「Delete bucket」を押す

S3 のバケットを削除 (2)
1. 削除するバケット名を⼊⼒
2. 「Confirm」を押す

Athena のページを開く
1. 「サービス」をクリック
2. ⼀覧から Athena を選択

Athena のテーブルとデータベースを削除
1. athena_cleanup.sql の中のクエリをについて,最初の 1 ⾏を貼り付ける
2. クエリを実⾏
3. 上記の 1-2 を,残りのクエリのぶんだけ繰り返す

IAM のページを開く
画⾯左上の「サービス」をクリックして,サービス⼀覧から IAM を選択
1. 「サービス」をクリック
2. ⼀覧から IAM を選択

IAM ユーザの削除
1.「ユーザー」をクリック2.「athena_user」を
チェック
3.「ユーザーの削除」を押して,ポップアップから削除を実⾏


© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Appendix

© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
ハンズオン (4)AWS QuickSight から Athena に接続

ハンズオン(4) の全体像
別アカウントの S3 Athena
1. セットアップを実施2. データセットを作成3. 分析を作成
QuickSight

QuickSight のページを開く
1. 「サービス」をクリック2. ⼀覧から QuickSight を選択
(別ウインドウが開きます)

QuickSight のエディション選択
1.「Standard edition」を選択
2.「Continue」をクリック

QuickSight の初期設定 1. 「Quicksight account name」に適当な名前を⼊⼒
2. 「Notification email address」に⾃分の AWS アカウントで使⽤しているメールアドレスを⼊⼒
3. 「region」はUS East (N. Virginia) を選択
4. チェックボックスはすべて選択
5. 「Finish」を押す

リージョンの変更
右上メニューから,リージョンをUS East (N. Virginia) に変更

新しいデータセットの作成
1. 「Manage data」を押す 2. 「New data set」を押す

データソースとして Athena を選択
1.「Athena」を選択2.「Data source name」に
適当な名前を⼊⼒
3.「Create data source」を押す

データベースとテーブルを選択1.「titanic_db」を選択 2.「titanic」を選択
3.「Select」を選択

データの格納場所を選択
1.「Import to SPICE」を選択
2.「Visualize」を選択

ダッシュボード作成画⾯
グラフ編集タブ
フィルタタブ
グラフ詳細
ディメンジョンカラム
ファクトカラムグラフ種類⼀覧
グラフ名

© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
後⽚付け

QuickSight のページを開く
1. 「サービス」をクリック2. ⼀覧から QuickSight を選択
(別ウインドウが開きます)

分析を削除1. 削除したい分析の右下の
をクリック
…
2. 「Delete」をクリック
3. 再度「Delete」をクリック

データセットの削除
1. 「Manage data」を押す
2. 削除したいデータを選択ポップアップから「Deletedata set」を選んで削除
