amber: large-scale deep learning for intelligent computer system
TRANSCRIPT

微信模式识别中心
Amber: Large-Scale Deep Learning for Intelligent Computer System
白明
2016/09/12

products/areastext classificationsentiment analysistopic analysisconversation generationEvent detectionspam recognitionUser modelingroboticsimage understandingface recognitiononline advertisingspeech recognitionwechat searchOCRaugmented realitysecurity defense
…many others…
0
50
100
150
200
250
Direc
tories
Time
# of directories of containing model files
Use of Machine Learning at WeChat

Outline
Two generations of machine learning software systems
1st generation: Amber-Trex
2nd generation: Amber-Velo

Varied raw data
Text data: trillions of words of Chinese + other languages
Visual data: billions of images and videos
Audio: tens of thousands of hours of speech per day
User activity: post, comment, thumbs up, emotion icon, queries,
collection, transmit, ignore etc.
...
Applications @ image
Applications @ audio

Applications @ NLP

Applications @ User profiling

Applications @ User profiling

Applications @ User profiling

Stay true to the mission
To explore what is possible or better in perception, cognition and
language understanding
Datasets
LargeInsights
UniqueComputation
Efficient
New
Algorithms
ReasonableArchitecture
Imagination
Active

Open source projects about Deep Learning
Caffe: the first mainstream industrial grade DL tool;
Purine: composite graph;
TensorFlow: separation of op and its gradient, flexible, reproducibility,
portability;
MXNet: programming paradigm fusion, w/r dependent concurrency, memory reuse
in place, memory analysis in stages, subgraph optimization;
CNTK: automatic loop unwrapping, NDL, MEL, 1-bit SGD, adaptive minibatch;
Theano/Torch: many research ideas come from them, flexible graph/layer
description, github lautch earlier;
...

Train Large, Powerful Models Quickly
Data/model parallelism
Flexible resource management and scheduling
Compile the graphs
Best-effort concurrent operations
Limited memory reuse
Consistent data streaming
Kernels merge
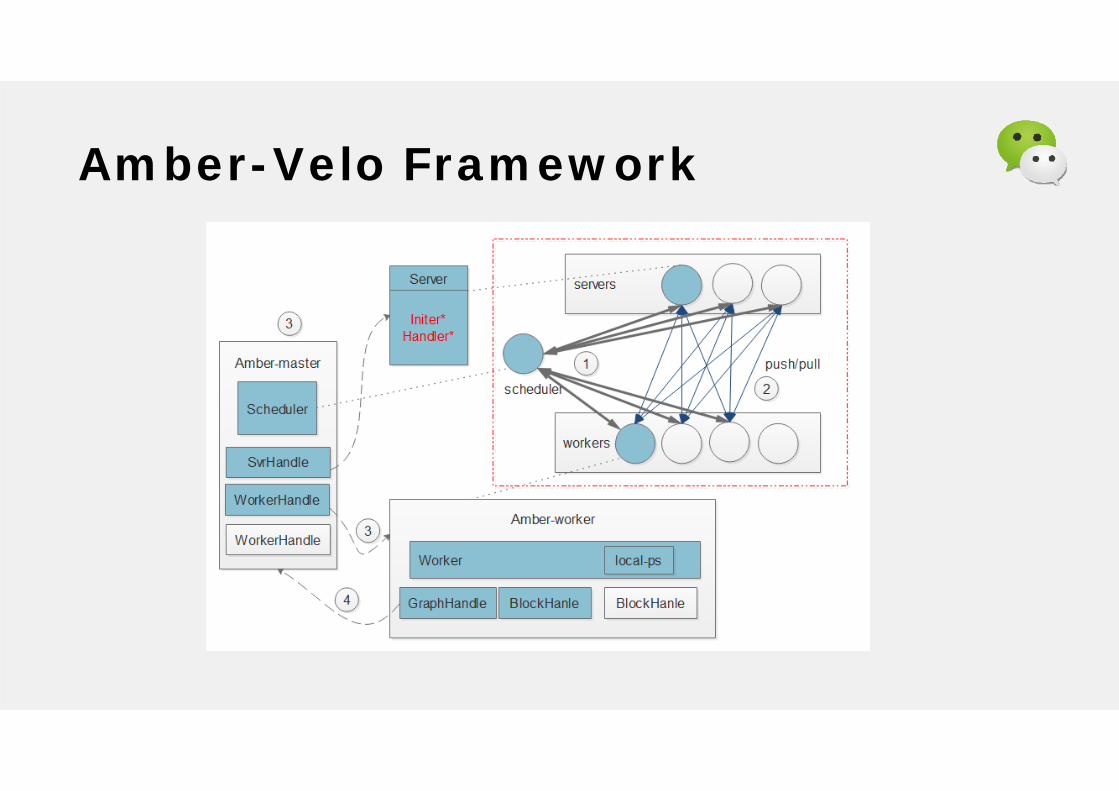
Amber-Velo Framework

Client
Symbolic network declaration
All parallel (data/model) logic is
completed in a process
Only need to focus on logic of the
algorithm
Asynchronous and synchronous interface
Dynamic interaction with Master
C++ & python front ends
import amber as am
def alloc_vars():with am.Device("/ps:s0/device:CPU:0"):
w1 = am.Variable("fc1_w", shape=(128, 784))w2 = am.Variable("fc2_w", shape=(10, 128))return [w1,w2]
def get_mlp(w1, w2, input):with am.Device("/worker:w0/device:GPU:0"):
fc1 = am.symbol.FullyConnected(data=input[0], params=[w1])act1 = am.symbol.Activation(data=fc1, act_type="relu")
with am.Device("/worker:w1/device:GPU:1"):fc2 = am.symbol.FullyConnected(data=act1, params=[w2])mlp = am.symbol.SoftmaxOutput(data=[fc2, input[1]])return mlp
def train_net(input):[w1,w2] = alloc_vars()mlp = get_mlp(w1,w2,input)handler = am.GetMaster().Compile(mlp)for i in range(0,1000):
handler.run()if i%100 == 0:
print handler.GetBlob(mlp.GetId(0),is_train=True)

Master
Compiling optimization of graphs
Stale control, Monitoring status
Special optimization for sparse structure
Consanguinity in subgraphs
Server load balancing placement
Composite graph and its optimization
Memory initialization description and
reuse analysis
…

SchedulerYard
Self-developed resource management & schedule
Exception handling and recovery automatically
Resource dynamically scaling
Assignable processes exist in same machine
preferentially
Warm start and resume from breakpoint
Start run dependencies between jobs,
e.g.
AB
C D
E

Worker
Asynchronous data reader
Push & pull based on priorities
Best-effort concurrency
Decoupling computation and network
Multiple Ops write the same tensor
Read ahead /read caching
multiple parsers & user-defined parser
Automatic partition and shuffle
variable-length structure and auto-
completion

Parameter server
Decouple network and logic to facilitate integrate new technology
Asynchronous abstraction of localPs interface
Interactive data persistence
Tradeoff between full steam and merging with same priority
BSP/SSP/ASP and hybird

Debug & MonitoringFacilitate innovation and experiment
Examine symbolic description at any time
Batch or Ops granularity execution progress
Obtain the output of any Op or tensor interactively
Trend dynamic display
Interactive training to comprehend hyper-parameters
To find the relative degree of a parameter variation
To analyze which parameters or ops are critical and which are
redundant

Experiments
Run the experiments on the following configuration:
1. Tesla K40c, CUDA 7.0, CUDNN 4.0.0.7
2. FB Memory: 11519 MiB, Clocks Memory: 3004 MHz, Performance State: P0
3. Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz, 125GB memory
4. 10G Ethernet
5. MXNet 0.7.0; Tensorflow 0.10
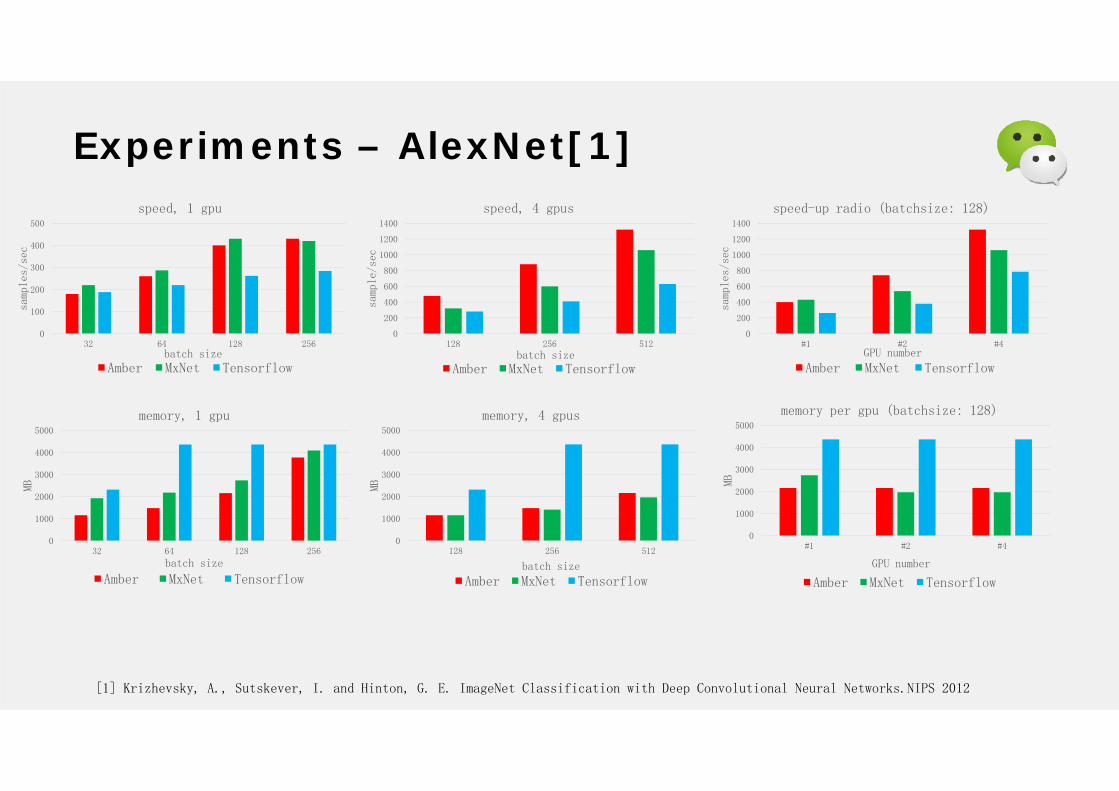
Experiments – AlexNet[1]
[1] Krizhevsky, A., Sutskever, I. and Hinton, G. E. ImageNet Classification with Deep Convolutional Neural Networks.NIPS 2012
0
100
200
300
400
500
32 64 128 256
samp
les/
sec
batch size
speed, 1 gpu
Amber MxNet Tensorflow
0
200
400
600
800
1000
1200
1400
#1 #2 #4
samp
les/
sec
GPU number
speed-up radio (batchsize: 128)
Amber MxNet Tensorflow
0
200
400
600
800
1000
1200
1400
128 256 512
samp
le/s
ec
batch size
speed, 4 gpus
Amber MxNet Tensorflow
0
1000
2000
3000
4000
5000
32 64 128 256
MB
batch size
memory, 1 gpu
Amber MxNet Tensorflow
0
1000
2000
3000
4000
5000
128 256 512
MB
batch size
memory, 4 gpus
Amber MxNet Tensorflow
0
1000
2000
3000
4000
5000
#1 #2 #4
MB
GPU number
memory per gpu (batchsize: 128)
Amber MxNet Tensorflow
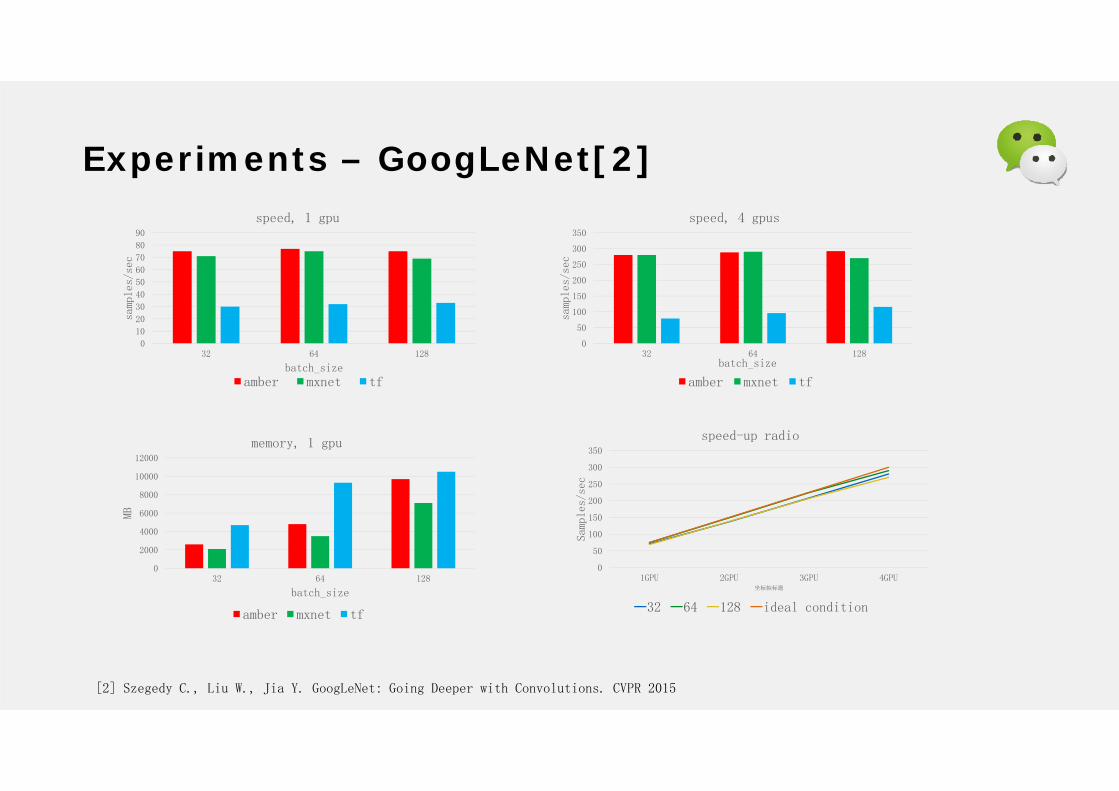
Experiments – GoogLeNet[2]
[2] Szegedy C., Liu W., Jia Y. GoogLeNet: Going Deeper with Convolutions. CVPR 2015
0
10
20
30
40
50
60
70
80
90
32 64 128
samp
les/
sec
batch_size
speed, 1 gpu
amber mxnet tf
0
50
100
150
200
250
300
350
32 64 128
samp
les/
sec
batch_size
speed, 4 gpus
amber mxnet tf
0
2000
4000
6000
8000
10000
12000
32 64 128
MB
batch_size
memory, 1 gpu
amber mxnet tf
0
50
100
150
200
250
300
350
1GPU 2GPU 3GPU 4GPUSa
mple
s/se
c坐标轴标题
speed-up radio
32 64 128 ideal condition

Experiments – VGG[3]
[3] Simonyan K., Zisserman A. Very deep convolutional networks for large-scale image recognition.ICLR 2015
0
5
10
15
20
25
30
35
40
32 64 96
samp
les/
sec
batch size
speed, 1 gpu
amber mxnet tensorflow
0
2000
4000
6000
8000
10000
12000
14000
32 64 96
MB
batch size
memory, 1 gpu
amber mxnet tensorflow
0
20
40
60
80
100
120
140
160
32 64 96
samp
les/
sec
batch size
speed, 4 gpus
amber mxnet tensorflow
0
2000
4000
6000
8000
10000
12000
32 64 96
MB
batch size
memory, 4 gpus
amber mxnet tensorflow
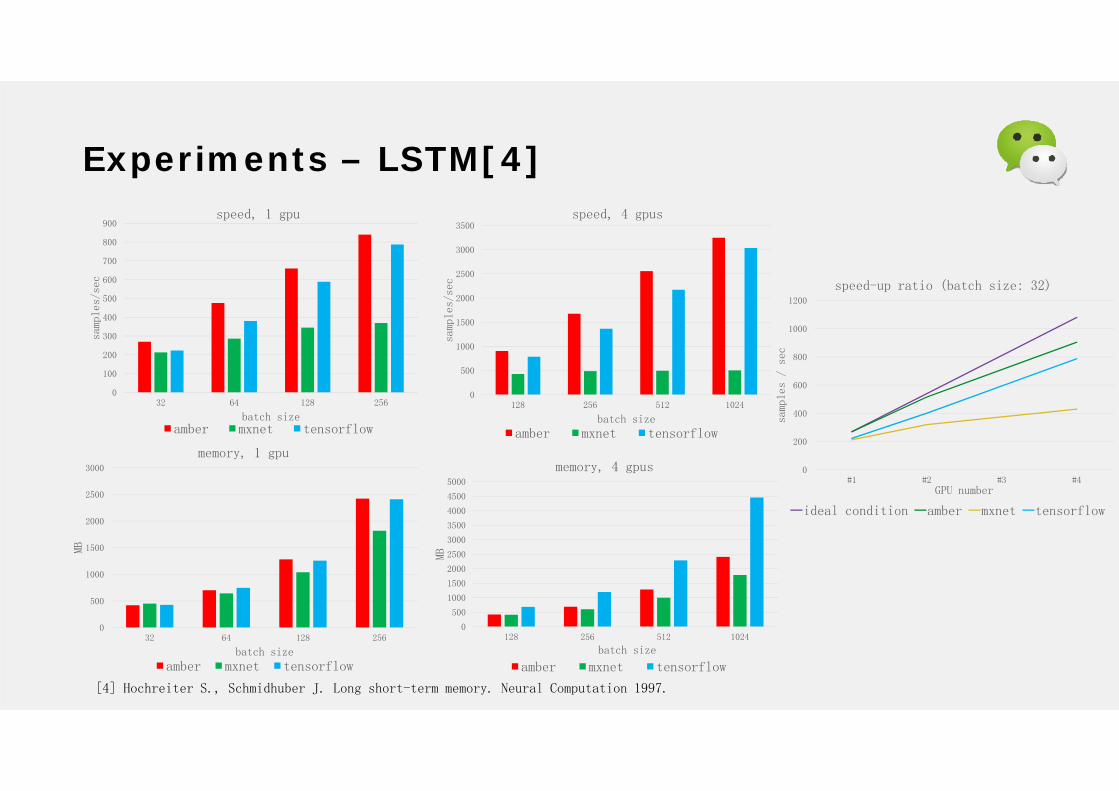
Experiments – LSTM[4]
[4] Hochreiter S., Schmidhuber J. Long short-term memory. Neural Computation 1997.
0
100
200
300
400
500
600
700
800
900
32 64 128 256
samp
les/
sec
batch size
speed, 1 gpu
amber mxnet tensorflow
0
500
1000
1500
2000
2500
3000
32 64 128 256
MB
batch size
memory, 1 gpu
amber mxnet tensorflow
0
200
400
600
800
1000
1200
#1 #2 #3 #4
samp
les
/ se
c
GPU number
speed-up ratio (batch size: 32)
ideal condition amber mxnet tensorflow
0
500
1000
1500
2000
2500
3000
3500
128 256 512 1024
samp
les/
sec
batch size
speed, 4 gpus
amber mxnet tensorflow
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
128 256 512 1024
MB
batch size
memory, 4 gpus
amber mxnet tensorflow

Thank you