an introduction to inverted index
DESCRIPTION
TRANSCRIPT

An introduction to Inverted Index
倒排索引的介绍
邬 勇

引言倒排索引 (Inverted index) ,也常被称为反向索
引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。有两种不同的反向索引形式:
文档水平 (Document-level) 反向索引(或者反向档案索引)包含每个引用单词的文档的列表。
单词水平 (word-level) 反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置。
后者的形式提供了更多的兼容性(比如短语搜索),但是需要更多的时间和空间来创建。

主要内容
1. 倒排索引 (inverted index) 结构2. 倒排索引构造流程3. 倒排索引构造 (index construction)
4. 倒排索引压缩 (index compression)
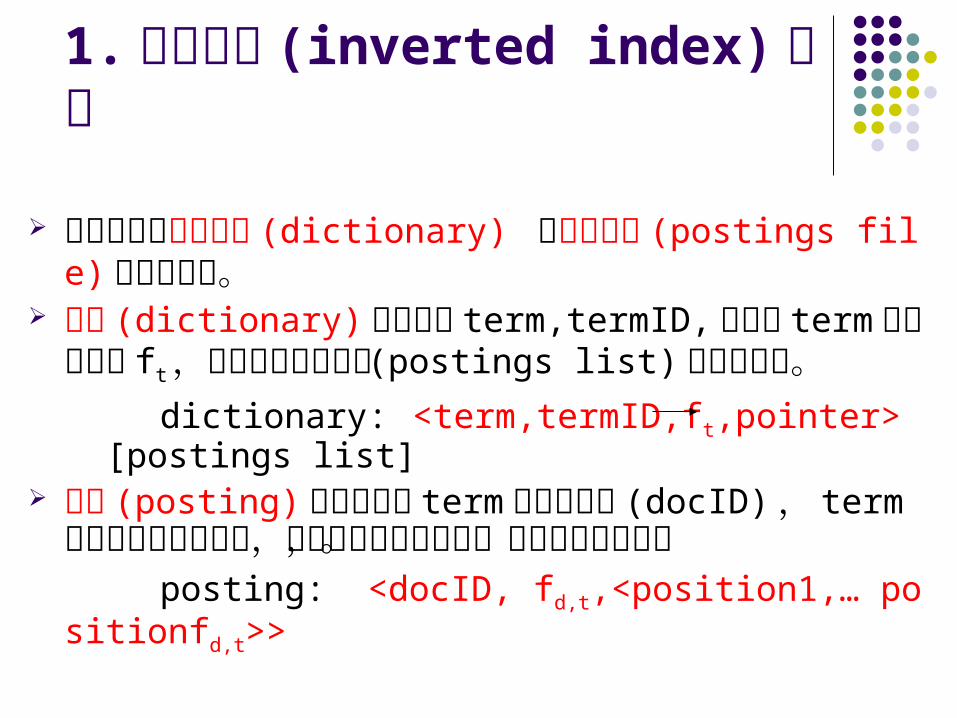
1. 倒排索引 (inverted index) 结构
倒排索引由字典文件 (dictionary) 和记录文件 (postings file) 两部分组成。
字典 (dictionary) 主要是由 term,termID, 包含该 term 的文档数目 ft ,以及指向该记录表 (postings list) 的指针组成。
dictionary: <term,termID,ft,pointer> [postings list]
记录 (posting) 主要是记录 term 所在的文档 (docID) , term 在文档中出现的次数,以及在文档中的位置,文档长度等信息。
posting: <docID, fd,t,<position1,… positionfd,t>>

1. 倒排索引 (inverted index) 结构
下图是简单的倒排索引结构例子。
5
Dictionary Postings list
Doc IDDoc ID
Brutus
Calpurnia
Caesar 1 2 4 5 6 16 57 132
1 2 4 11 31 45173
2 31
174
54101
TermTerm PointerPointer
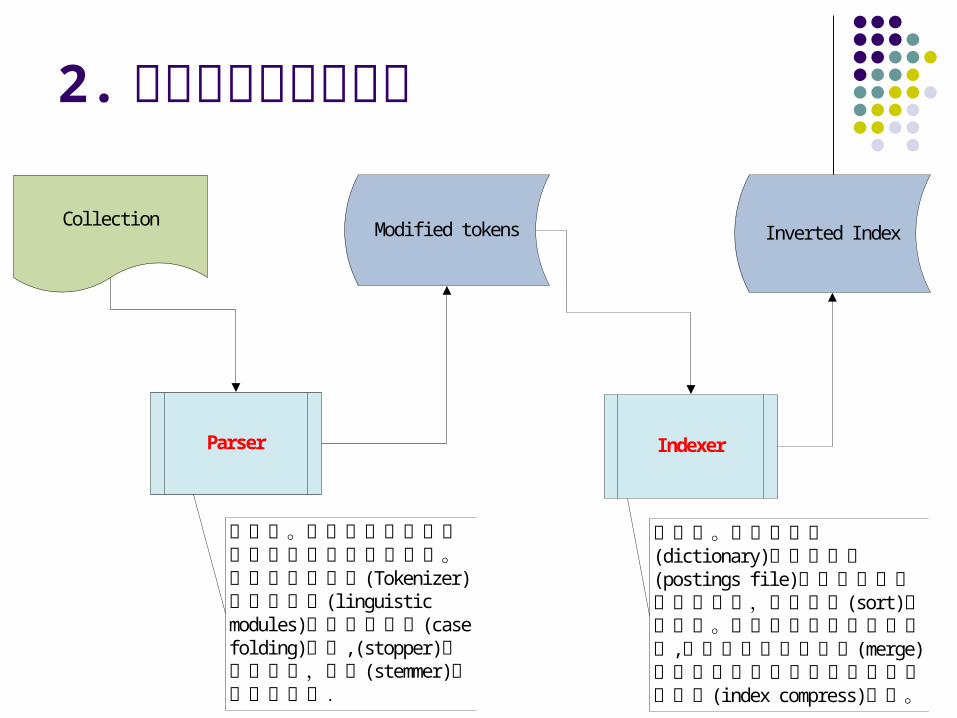
2. 倒排索引的构造过程
Col l ecti on
Parser
Modi fi ed tokens
Indexer
I nverted I ndex
解析器。根据不同的文档采用不同的解析器对其解析。其中包括分词器(Tokeni zer)和语言模块( l i ngui sti c modul es)如大小写折叠(case fol di ng)处理, (stopper)停用词处理,以及(stemmer)词根化处理等.
索引器。主要是生成(di cti onary)字典文件和(posti ngs fi l e)记录文件组成的倒排索引,其中包括(sort)排序操作。对于大规模的文档的处理,包括中间文件的合并(merge)操作以及对字典文件和记录文件的压缩( i ndex compress)操作。

2. 倒排索引的构造过程
I did enact JuliusCaesar I was killed i' the Capitol; Brutus killed me.
Doc 1
So let it be withCaesar. The nobleBrutus hath told youCaesar was ambitious
Doc 2
Term Doc #I 1did 1enact 1julius 1caesar 1I 1was 1killed 1i' 1the 1capitol 1brutus 1killed 1me 1so 2let 2it 2be 2with 2caesar 2the 2noble 2brutus 2hath 2told 2you 2caesar 2was 2ambitious 2
Term Doc #ambitious 2be 2brutus 1brutus 2capitol 1caesar 1caesar 2caesar 2did 1enact 1hath 1I 1I 1i' 1it 2julius 1killed 1killed 1let 2me 1noble 2so 2the 1the 2told 2you 2was 1was 2with 2
构造无词语位置信息倒排索引的简单示例:

3. 倒排索引的构造方法硬件基础回顾 :
2007 年系统的典型参数规格指标(寻道时间指磁头重一个位置到另一个位置的时间。每字节传输时间指数据从外存到内存的时间比例)
symbol statistic value
s 平均寻道时间 5 ms = 5 x 10−3 s
b 每字节传输时间 0.02 μs = 2 x10−8 s
处理器的时钟频率 109 s−1
p 低层次处理时间 0.01 μs = 10−8 s
(e.g., compare & swap a word)
主要内存大小 several GB
外存空间大小 1 TB or more

3. 倒排索引的构造方法 基于分块排序索引 (BSBI:Blocked sort-based Indexing)
一遍式内存排序索引 (SPIMI: Single-pass in-memory indexing)

基于分块排序索引 (BSBI) 该方法主要包含以下步骤 :( 1 )将全部文档集合划分为若干相同大小的块,这个
块的大小一般和内存分配的大小正好相同。( 2 )在内存中对每个块的所有词语号和文档号构成的
值对 (termID - docID) 进行排序。( 3 )将这些排好序的中间结果存储到外存中。( 4 )对全部的中间结果进行合并,生成最终的倒
排索引。
基于分块排序索引(BSBI:Blocked sort-based Indexing)

基于分块排序索引(BSBI:Blocked sort-based Indexing)
Blocked sort-based indexing algorithm

基于分块排序索引(BSBI:Blocked sort-based Indexing)

基于分块排序索引(BSBI:Blocked sort-based Indexing)
Merging in blocked sort-based indexing(2 个块文件(待合并的记录表( postings list ))从外存加载到内存中。在内存中合并(合并好的记录
表)然后写回外存。为了方便理解,用词语 (term) 代替词语号( termID ) ).

一遍式内存排序索引 (SPIMI: Single-pass in-memory indexing)
基于分块排序索引方法虽然具有较好的可缩放性 (scaling properties) ,但是它要求一个数据结构存储所有的词语和映射的词语号 (map term to termID) 。对于大规模的文档集合而言,这个数据结构往往无法存储在内存中。
相对而言,一遍式内存排序( Single-pass in-memory indexing , SPIMI )方法既有较高的可缩放性,同时无需使用词语号,直接将每个字典数据块信息写到外存,在开始新的字典数据块的生成。所以,该方法可以索引任何大小规模的文档集合,只要外存空间足够。

一遍式内存排序索引 (SPIMI: Single-pass in-memory indexing)
Merging of blocks is analogous to BSBI.
Inversion of a block in single-pass in-memory indexing algorithm

一遍式内存排序索引 (SPIMI: Single-pass in-memory indexing)

基于分块排序索引与一遍式内存排序索引比较( BSBI vs SPIMI )
BSBI 的时间复杂度为 O( T×logT ),其中消耗时间最多的是对块的排序过程, T 是所要排序的数量上限,也就是所有值对的数量总和。这些时间是基本稳定的,实际索引的时间往往更易于受解析文档和最终的合并过程所影响。
SPIMI 的时间复杂度为 O(T) ,因为没有值对的排序要求,对于文档集的大小全部操作都是一遍式的处理 ;直接将记录添加到记录列表中。该方法不去首先获取全部的词语文档号的值对并对其排序,而把记录列表做成动态形式,也就是说,它的大小是可以动态调整的,并可以直接收集词语的记录信息。这样做有两个优点:一是由于没有额外的排序,所以速度很快;二是直接利用词语来得到相应的记录信息,无需使用词语号。所以该方法一次处理的数据块所包含的信息更多,相应的索引构造效率也就更高。

基于分块排序索引 (BSBI) 方法中各模块处理时间

一遍式内存排序索引 (SPIMI) 方法中各模块处理时间

相关资料:1. Efficient Single-Pass Index Construction for Text D
atabases Steen Heinz, Justin Zobel, 2003 。
2. Chapter 5 of《 Managing Gigabytes: Compressing and Indexing Documents and Images》 2nd
Morgan Kaufmann, San Francisco, California, 1999 。

分布式索引(Distributed indexing)
主要介绍分布式构造索引的过程,以及 Map-Reduce 方法。这部分由梁竹介绍。

动态索引(Dynamic indexing)
主要介绍在动态变化的文档集情况下,如何构造动态索引。这部分由蒋仁祥介绍。
4. 索引的压缩分为字典压缩 (Dictionary Compress) 和
记录压缩 (Posting Compress) 。以及 Heaps’ law 和 Zipf’s law 。

字典压缩 (Dictionary Compress)
主要介绍 Heaps’ law 以及几种字典压缩的编码方法。这部分由何泉昊介绍。

记录压缩 (Posting Compress)
主要介绍 Zipf’s law 以及几种记录压缩的编码方法。这部分由刘影介绍。

Thank you!