analiza korespondencji - coin.wne.uw.edu.plcoin.wne.uw.edu.pl/~jcieciel/coresp_v2.pdf · związane...
TRANSCRIPT

ANALIZA KORESPONDENCJI
opisowa i eksploracyjna technika analizy danych jakościowych
pozwala na graficzne przedstawienie zmiennych w
niskowymiarowej przestrzeni
stosunkowo łatwo interpretowalne wyniki
technika redukcji danych – przedstawienie danych w bardziej
przystępnej formie, kosztem utraty pewnej ilości informacji

ANALIZA KORESPONDENCJI
Analizę korespondencji w podstawowym zastosowaniu wykonuje się
dla przypadku dwóch zmiennych jakościowych.
Przykład.
Mamy zmienne ulubiony napój i przedział wiekowy.
Za pomocą analizy korespondencji można stwierdzić, napoje jakiej
marki wolą ludzie młodzi, a jakiej osoby starsze.

ANALIZA KORESPONDENCJI
Klasyczne zastosowanie jest jednak stosunkowo rzadko stosowane,
właśnie ze względu na konieczność ograniczenia się do dwóch
zmiennych.
Metoda ta pozwala jednak również na analizę bezpośrednio tablic
wielodzielnych.

ANALIZA KORESPONDENCJI
Przykład.
Analiza wizerunku marek produktów
Dysponując ocenami baterii stwierdzeń dla poszczególnych marek
można stworzyć sztuczną zmienną zawierającą średnie oceny marek
dla tych stwierdzeń – drugą zmienną będzie wtedy identyfikator
marki. Na bazie powstałej tablicy kontyngencji można otrzymać mapę
percepcji, która pozwala w jednym układzie współrzędnych
zaznaczyć marki i stwierdzenia. Wzajemne położenie marek i
stwierdzeń pozwala wnioskować, na ile poszczególne marki są
związane z każdym z nich oraz czym różnią się ich wizerunki.

ANALIZA KORESPONDENCJI
Jak zrobić to w praktyce?
Przykład zbioru danych: wizer_czynniki.sav banki.sav
konieczne jest utworzenie zmiennej systemowej rowcat_:
val lab rowcat_1 'NA SPECJALNE OKAZJE'2 'NATURALNE'3 'DOBRY MARKETING'4 'TRADYCYJNE'5 'NIEDROGIE'.exe.

ANALIZA KORESPONDENCJI
*Pierwsze wiersze.
CORRESPONDENCETABLE = all (5,3) /DIMENSIONS = 2/MEASURE = euclid/STANDARDIZE = RCMEAN/NORMALIZATION = SYMMETRICAL/PRINT = TABLE RPOINTS CPOINTS/PLOT = NDIM(1,MAX) BIPLOT(20) /OUTFILE=score('xxx.sav') /supplementary =row(4,5).
exe.
Liczba wierszy - stwierdzeń
Liczba kolumn - marek
Miara odległości – euclid (dla średnich) – chisq (dla odsetków)
Zmienne pasywne

ANALIZA KORESPONDENCJI
Zmienne pasywne:
nie wpływają na geometryczną orientację przestrzeni dzięki
temu możliwe jest umieszczenie dodatkowych zmiennych np.
demograficznych, które mogą być pomocne w interpretacji
wyników.
mogą też służyć do porównywania różnych grup
przypadku wystąpienia efektu dźwigni, kategorie rzadko
występujące mogą być potraktowane jako zmienne pasywne,
podobnie jak braki danych

ANALIZA KORESPONDENCJI
WYMIAR 2 (17%)
WY
MIA
R 1
(8
3%
)
NIEDROGIE
TRADYCYJNE
DOBRY MARKETING
NA SPECJALNE OKAZJE
NATURALNE
Marka C
Marka B
Marka A


HOMALS
Większe możliwości analizy daje również wielowymiarowa analiza
korespondencji, nazywana też analizą homogeniczności (HOMALS), będąca
rozszerzeniem analizy korespondencji na przypadek wielu zmiennych.
HOM ogeneity analysis via A lternating L east S quares => HOMALS

HOMALS
Analiza HOMALS pozwala zrzutować wielowymiarowy zbiór
danych na przestrzeń dwu- lub więcej wymiarową) w taki
sposób, aby zachować maksimum początkowej informacji
zawartej w zbiorze danych, mierzonej za pomocą statystyki
Chi-kwadrat (używanej też w teście niezależności). W
utworzonym układzie współrzędnych każdy obiekt –
respondent, kategoria – ma wówczas określone współrzędne.

HOMALS
Dane wejściowe:
nominalne, ewentualnie porządkowe z ograniczoną liczbą poziomów
Cele
Odkrycie kluczowych, ukrytych cech respondentów
Wskazanie współwystępujących grup kategorii
Identyfikacja związków przyczynowo-skutkowych
Stworzenie mapy percepcyjnej
Identyfikacja jednorodnych grup respondentów

HOMALS
Obiekty o podobnych profilach są blisko siebie
Kategorie o podobnej zawartości są blisko siebie
Homogeniczność danej grupy zmiennych jest mierzona przez:
obliczenie sumy kwadratów odchyleń dla każdego obiektu
(OSS)
oraz sumy kwadratów odchyleń pomiędzy obiektami (TSS)
Miarą homogeniczności jest stosunek OSS i TSS
homogeniczność jest doskonała gdy OSS=0
Celem jest optymalne skwantyfikowanie zmiennych (przypisanie
ich kategoriom wartości liczbowych), w ten sposób, by
zmaksymalizować homogeniczność

HOMALS
Przygotowanie danych dla SPSS:
kodowanie kategorii liczbami naturalnymi, zaczynając od 1
nie ma kategorii pasywnych – każda kategoria musi być
kodowana kolejną liczbą naturalną
unikać kategorii rzadko występujących (<10% próby) – w
szczególności takie kategorie mogą mieć tak wysoki wkład w
całkowitą zmienność zbioru, że wyznaczą jeden z wymiarów,
choć nie będzie on odpowiadał żadnej kategorii latentnej

HOMALS
HOMALS może być zastosowany do konstruowania syntetycznych
skal mierzących cechy latentne (ukryte). Wówczas analizuje się
wartości punktów w układzie współrzędnych jako wartości do
konstrukcji skali (podobnie jak w PCA)

HOMALS
HOMALS kwantyfikuje nie tylko kategorie zmiennych ale też każdą
obserwację.
Współrzędne punktu na każdym wymiarze są wyliczone tak, aby
punkt reprezentujący każdą obserwację był środkiem ciężkości dla
skwantyfikowanych kategorii do których należy
W SPSS w opcjach możemy utworzyć nowe zmienne ze
współrzędnymi

HOMALS
*Tworzenie skali: (pliki stw.sav stw.sps )
HOMALS
/VARIABLES=p2(7) p3(2) p4(3)
/ANALYSIS=p2 p3 p4
/DIMENSION=1
/PRINT FREQ EIGEN DISCRIM QUANT
/PLOT QUANT OBJECT NDIM(ALL,MAX)
/SAVE = (1)
/MAXITER = 100
/CONVERGENCE = .00001 .
TYLKO jeden wymiar
zachowuje jeden wymiar - jako skalę

HOMALS
Jakość analizy
• liczbę iteracji – nie powinna być bardzo duża, normą jest kilkadziesiąt iteracji
• wartości własne – bardzo mała wartość drugiej w porównaniu z pierwszą (kilkakrotnie mniejsza) oznacza, że w zasadzie można ograniczyć się do jednego wymiaru
• miary dyskryminacji – sytuacja, gdy w danym wymiarze tylko jedna zmienna ma wysoką miarę dyskryminacji, zaś pozostałe zmienne mają miary dyskryminacji poniżej 0.1, oznacza, że zmienna latentna, którą oddaje ten wymiar dokładnie odpowiada zmiennej mierzalnej
• samotne kategorie na krańcach wykresu kategorii – zwykle są to właśnie kategorie o zbyt niskiej liczebności, zaburzające proces znajdowania właściwej płaszczyzny odwzorowania. W takim przypadku najlepiej wyeliminować te kategorie i powtórzyć analizę.

HOMALS
Jakość analizy
• wyraźnie rozdzielne grupy respondentów na wykresie respondentów –jeżeli ich występowanie wynika z założonych filtrów lub innych znanych i zmierzonych powodów, należy wówczas grupy te analizować oddzielnie
• wyizolowani respondenci na wykresie respondentów – nietypowe obserwacje, które należałoby wykluczyć z analizy

HOMALS
Interpretacja wyników
• Wykres kategorii
• Miary dyskryminacji
• Wartości własne -
• Wykres respondentów -
Interpretacja wyłonionych wymiarów
Ocena relatywnego wkładu obu wymiarów w całkowitą zmienność respondentów
Ocena jednorodności respondentów (czy można wyodrębnić jakieś jednorodne grupy)


MCA – alternatywy
MCA – macierz znaczników
MCA – macierz Burta

MCA – macierz znaczników
Macierz znaczników tworzy się
kodując zmienne w postaci zero-
jedynkowej. Jedynka oznacza
wystąpienie danej kategorii.
Następnie postępujemy tak, jak w
przypadku zwykłej analizy
korespondencji.
wiek
……………
10004
00013
00012
00101
51-6041-5031-4021-30
nr
rsp

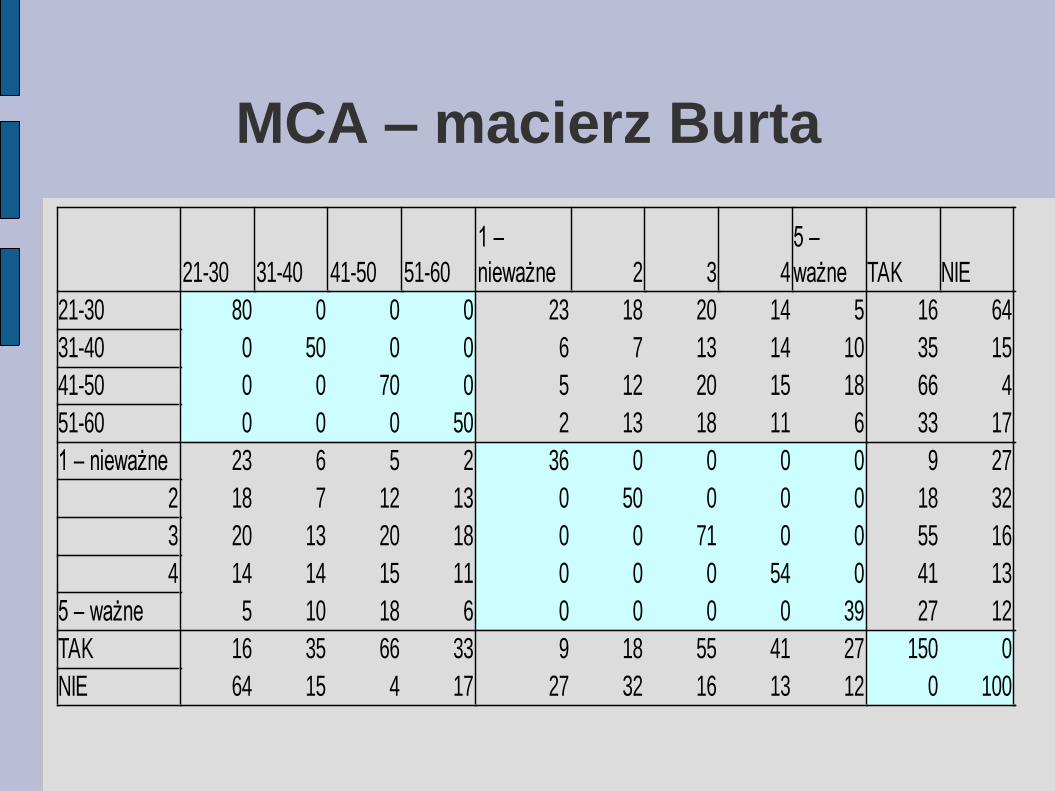
MCA – macierz Burta
Macierz Burta jest to symetryczna macierz blokowa, na
której przekątnej znajdują się macierze diagonalne z
liczebnościami poszczególnych kategorii na przekątnej.
Tworzą one bloki diagonalne. Bloki pozadiagonalne są
tablicami kontygencji między parami zmiennych.
Dalej ponownie postępujemy analogicznie jak w przypadku
zwykłej analizy korespondencji.
MCA – macierz Burta
21-30 31-40 41-50 51-60 2 3 4 TAK NIE
21-30 80 0 0 0 23 18 20 14 5 16 64
31-40 0 50 0 0 6 7 13 14 10 35 15
41-50 0 0 70 0 5 12 20 15 18 66 4
51-60 0 0 0 50 2 13 18 11 6 33 17
1 – nieważne 23 6 5 2 36 0 0 0 0 9 27
2 18 7 12 13 0 50 0 0 0 18 32
3 20 13 20 18 0 0 71 0 0 55 16
4 14 14 15 11 0 0 0 54 0 41 13
5 – ważne 5 10 18 6 0 0 0 0 39 27 12
TAK 16 35 66 33 9 18 55 41 27 150 0
NIE 64 15 4 17 27 32 16 13 12 0 100
1 –
nieważne
5 –
ważne