arquitetura e organiza ção de computadores ii arquitetura e organiza ção arquitetura de...
TRANSCRIPT

Arquitetura e OrganizaArquitetura e Organiza çção de ão de Computadores IIComputadores II
Universidade Estadual de MaringUniversidade Estadual de Maring ááDepartamento de InformDepartamento de Inform ááticatica
João Angelo MartiniJoão Angelo Martini

RoteiroRoteiro
o Professores da Área no DINo Área de Arquitetura de Computadoreso Linhas de Pesquisaso Projetos do Grupo GSE (Grupo de Sistemas
Embarcados)

Professores da Professores da ÁÁrea no DINrea no DIN
o Carlos Benedito Sica de Toledoo Elvio João Leonardoo João Angelo Martinio Linnyer Beatrys Ruizo Nardênio Almeida Martinso Paulo Cesar Gonçalveso Ronaldo Augusto de Lara Gonçalves

MotivaMotiva çção para estudar Arquitetura e ão para estudar Arquitetura e OrganizaOrganiza çção de Computadoresão de Computadores
Componentes DigitaisComponentes DigitaisComponentes Digitais
ProcessadorProcessadorProcessador
Por que estudar todos esses componentes?
Para atender a demanda por recursos humanos na área de Sistemas Embarcados
Por que estudar todos esses componentes?
Para atender a demanda por recursos humanos na área de Sistemas Embarcados
Sistemas Embarcados dominam o mercadoSistemas Embarcados dominam o mercado
Fonte: Tennenhouse, David L. “Proactive Computing”. Communications of the ACM. Vol.43, n. 5, 2000, pp. 43-50

MotivaMotiva çção para estudar Arquitetura e ão para estudar Arquitetura e OrganizaOrganiza çção de Computadoresão de Computadores

Conceito: Arquitetura e OrganizaConceito: Arquitetura e Organiza ççãoão
Arquitetura de Computadores:Arquitetura de Computadores:o Refere-se aos aspectos funcionaisdo Sistema Computacional que
são “visíveis” ao programador.o Exemplo:
– Conjunto de Instruções (Tipos de Instruções)– Tamanho dos Dados (Número de Bits)
OrganizaOrganizaçção de Computadores:ão de Computadores:o Refere-se aos aspectos estruturaisdo Sistema Computacional
que nãosão “visíveis” ao programador.o Exemplo:
– Sinais de Controle, Frequência de Clock– Multiplicação implementada por adições ou hardware
específico

ÁÁrea de Arquitetura de Computadoresrea de Arquitetura de ComputadoresArquitetura e Organização de Computadores
O que se estuda?
-Do que consiste um sistema de computador
-Como o computador trabalha
-Como ele é organizado internamente e quais são os compromissos de projeto
-Como consertar um computador
-Como construir meu próprio computador
-Como comprar um computador
Sim Não

ÁÁrea de Arquitetura de Computadoresrea de Arquitetura de ComputadoresArquitetura e Organização de Computadores
O que se estuda?
Sistemas de NumeraSistemas de Numeraççãoão Linguagem de MontagemLinguagem de Montagem
RepresentaRepresentaçção da Informaão da Informaççãoão
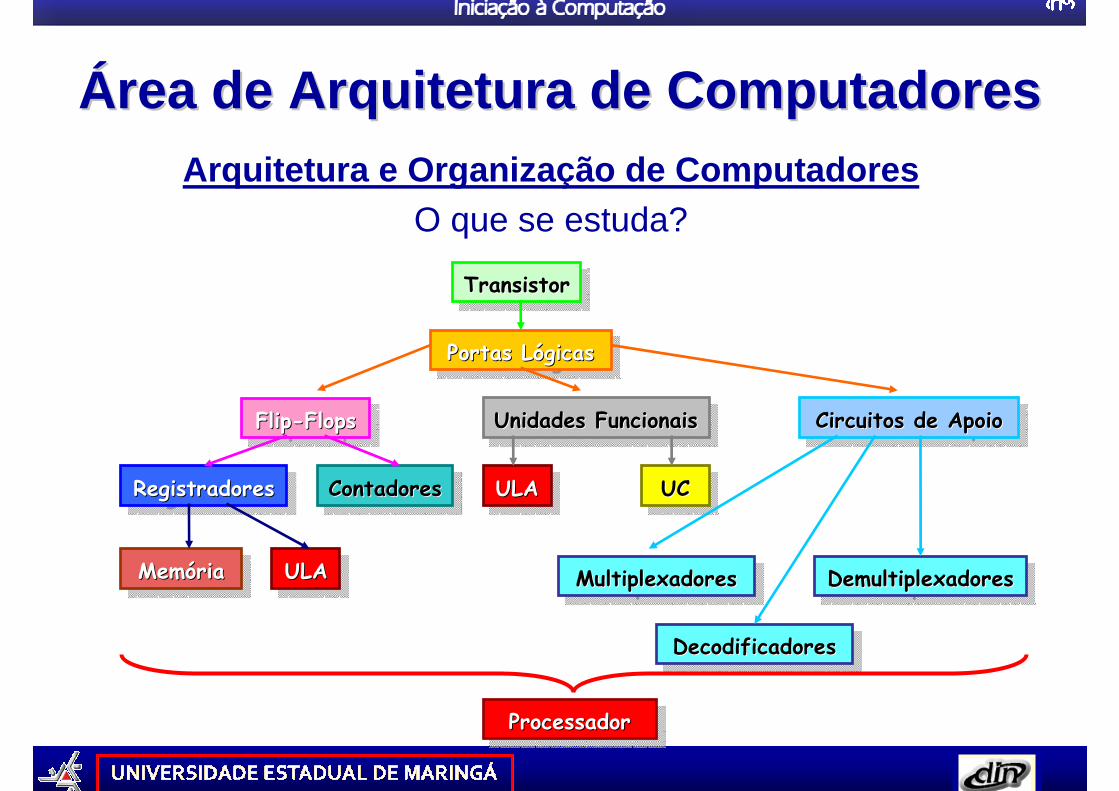
ÁÁrea de Arquitetura de Computadoresrea de Arquitetura de ComputadoresArquitetura e Organização de Computadores
O que se estuda?
TransistorTransistorTransistor
Portas LógicasPortas LPortas Lóógicasgicas
Flip-FlopsFlipFlip--FlopsFlops
ContadoresContadoresContadoresRegistradoresRegistradoresRegistradores
MemóriaMemMemóóriaria ULAULAULA
Unidades FuncionaisUnidades FuncionaisUnidades Funcionais
ULAULAULA UCUCUC
Circuitos de ApoioCircuitos de ApoioCircuitos de Apoio
MultiplexadoresMultiplexadoresMultiplexadores
DecodificadoresDecodificadoresDecodificadores
DemultiplexadoresDemultiplexadoresDemultiplexadores
ProcessadorProcessadorProcessador

Exemplo de AplicaExemplo de Aplica çção dos Estudosão dos Estudos
RIRI
UCUC
SomadorSomador
SubtratorSubtrator
ULA
CPU
ULA com 2 circuitos para efetuar a adição e a subtração

Circuito Digital da ULACircuito Digital da ULA

MatemMatem áática Discretatica DiscretaRepresentação do Circuito Somador em Tabela Verdade
A B Cin S Cout
0 0 0 0 0
0 0 1 1 0
0 1 0 1 0
0 1 1 0 1
1 0 0 1 0
1 0 1 0 1
1 1 0 0 1
1 1 1 1 1
Entradas Saídas
A B Cin
A B Cin
A B Cin
A B Cin
S = A B Cin + A B Cin + A B Cin + A B Cin

MatemMatem áática Discretatica DiscretaRepresentação do Circuito Somador em Tabela Verdade
A B Cin S Cout
0 0 0 0 0
0 0 1 1 0
0 1 0 1 0
0 1 1 0 1
1 0 0 1 0
1 0 1 0 1
1 1 0 0 1
1 1 1 1 1
Entradas Saídas
Cout = A B Cin + A B Cin + A B Cin + A B Cin
A B Cin
A B Cin
A B Cin
A B Cin

ÁÁlgebra de Boolelgebra de BooleSimplificação do Circuito Somador por Álgebra de Boole
S = A B Cin + A B Cin + A B Cin + A B Cin
Simplificando as expressõesSimplificando as expressões
S = A (B Cin + B Cin)+ A (B Cin + B Cin)
Fazendo X = B + Cin e X = B Cin
Como B + Cin = B Cin + B Cin e B Cin = B Cin + B Cin
S = A + X
S = A X+ A X
S = A + B + Cin
A e A em evidência
S = A (B + Cin)+ A (B Cin)

Sistemas de NumeraSistemas de Numera ççãoão
Exemplo de Adição:
7
(+5)
2
710=01112 1000
+ 1
1001
Complemento de 2 do valor -710
1001
0101
1110 =-210
1
510=01012
+
Cout=0
Cin=0
Cin=0
Cout=0Overflow=0
em Complemento de 2
0001
+ 1
0010
Complemento de 2 de -210
-
-
0
0
+
Uso de Representação em Complemento de 2 para implementar somador e subtrator binário
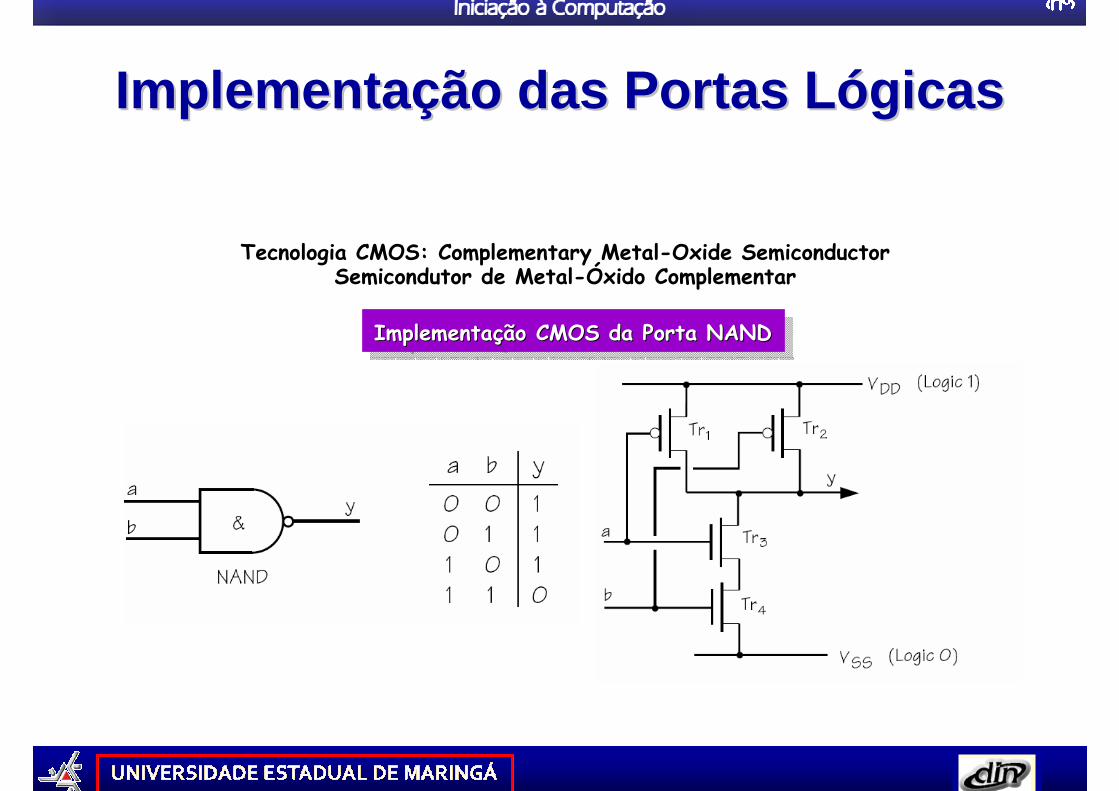
ImplementaImplementa çção das Portas Lão das Portas L óógicasgicas
Implementação CMOS da Porta NANDImplementaImplementaçção CMOS da Porta NANDão CMOS da Porta NAND
Tecnologia CMOS: Complementary Metal-Oxide SemiconductorSemicondutor de Metal-Óxido Complementar

Linhas de PesquisaLinhas de Pesquisa

MotivaMotiva çções para Pesquisas em ões para Pesquisas em Arquitetura de ComputadoresArquitetura de Computadores
A principal motivação para desenvolvimento de pesquisas em Arquitetura de Computadores tem como alvo a melhoria de desempenho
A principal motivação para desenvolvimento de pesquisas em Arquitetura de Computadores tem como alvo a melhoria de desempenho
Atualmente busca-se um balanço entre o desempenho e o consumo de potência
Atualmente busca-se um balanço entre o desempenho e o consumo de potência

Metodologias para Pesquisas em Metodologias para Pesquisas em Arquitetura de ComputadoresArquitetura de Computadores
Metodologias para melhorar desempenhoMetodologias para melhorar desempenho
oo Melhorar a Tecnologia de FabricaMelhorar a Tecnologia de Fabricaççãoãooo Melhorar a OrganizaMelhorar a Organizaçção do Processadorão do Processador
Tecnologia de FabricaTecnologia de Fabricaçção ão tem 2 limitantes:tem 2 limitantes:
-- Custo elevadoCusto elevado
-- Limite fLimite f íísico de redusico de reduçção ão do tamanho do transdo tamanho do transíístorstor
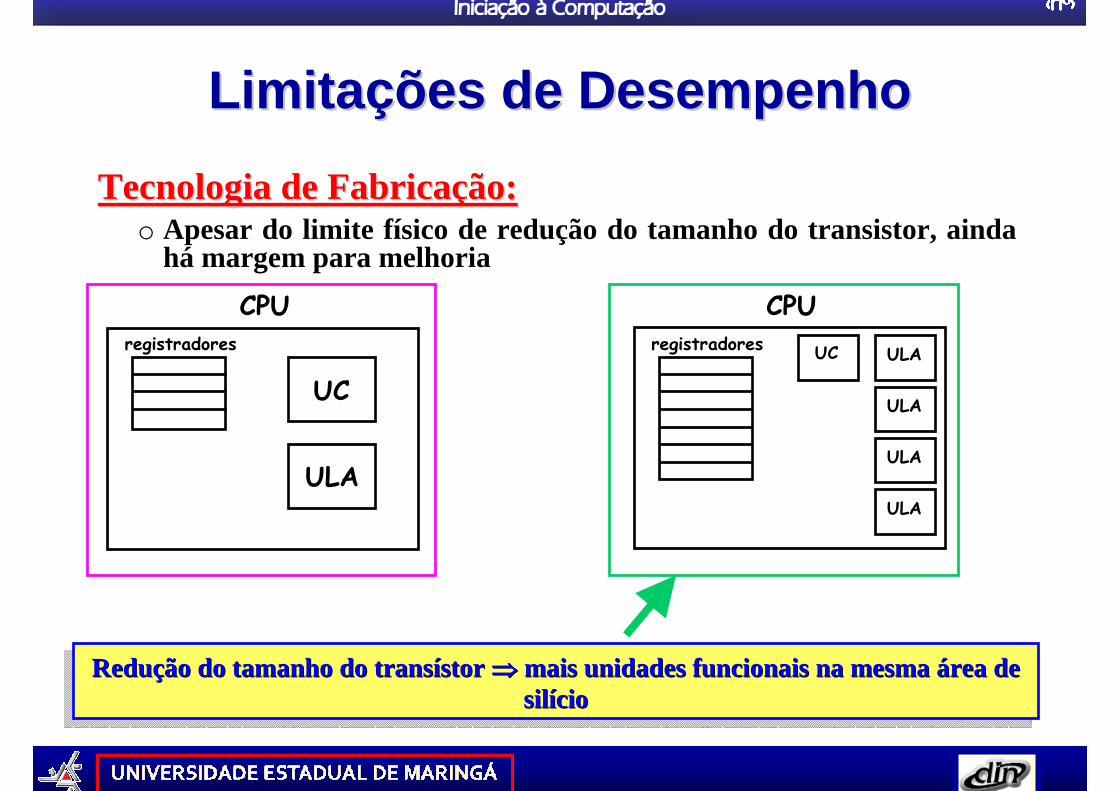
LimitaLimita çções de Desempenhoões de Desempenho
Tecnologia de FabricaTecnologia de Fabricaçção:ão:o Apesar do limite físico de redução do tamanho do transistor, ainda
há margem para melhoria
registradores
CPU
UC
ULA
registradores
CPU
ULA
ULA
ULA
ULAUC
Redução do tamanho do transístor ⇒⇒⇒⇒ mais unidades funcionais na mesma área de silício
ReduReduçção do tamanho do transão do tamanho do transíístor stor ⇒⇒⇒⇒⇒⇒⇒⇒ mais unidades funcionais na mesma mais unidades funcionais na mesma áárea de rea de silsilííciocio

LimitaLimita çções de Desempenhoões de DesempenhoEscorregamento de Clock Escorregamento de Clock –– Limite de VelocidadeLimite de Velocidade
Dispositivo 1Dispositivo 1
registrador
Dispositivo 2Dispositivo 2
registrador
tproptcomb
test
Escorregamento do clock:É a diferença de tempo entre os instantes em que os dois dispositivos “enxergam” o sinal de clock. Ocorre porque o sinal de clock percorre caminhos diferentes para se propagar até os dispositivos.
Num sistema realdeve-se considerar o tempo de escorregamento tescorreg. O período do clock precisa ser no mínimo tão grande quanto:Tclock=tprop+tcomb+test+tescorreg
clockclock
Circuito
Combinacional
Circuito
Combinacional

Pesquisas para Melhoria de Pesquisas para Melhoria de DesempenhoDesempenho
TTéécnicas para Melhoria de Desempenho:cnicas para Melhoria de Desempenho:o Tecnologias mais rápidaso Projeto mais eficiente da arquitetura:
• Múltiplos Registradores• Hierarquia de Memória (Cache)• Pipeline• Previsão de Desvios• Paralelismo em Nível de Instrução – Arquitetura Superescalar• Arquiteturas Paralelas

MMúúltiplos Registradoresltiplos Registradores
MM úúltiplos Registradores:ltiplos Registradores:o Aumenta velocidade de acesso aos dados
registradores
CPU
UC
ULA
memória
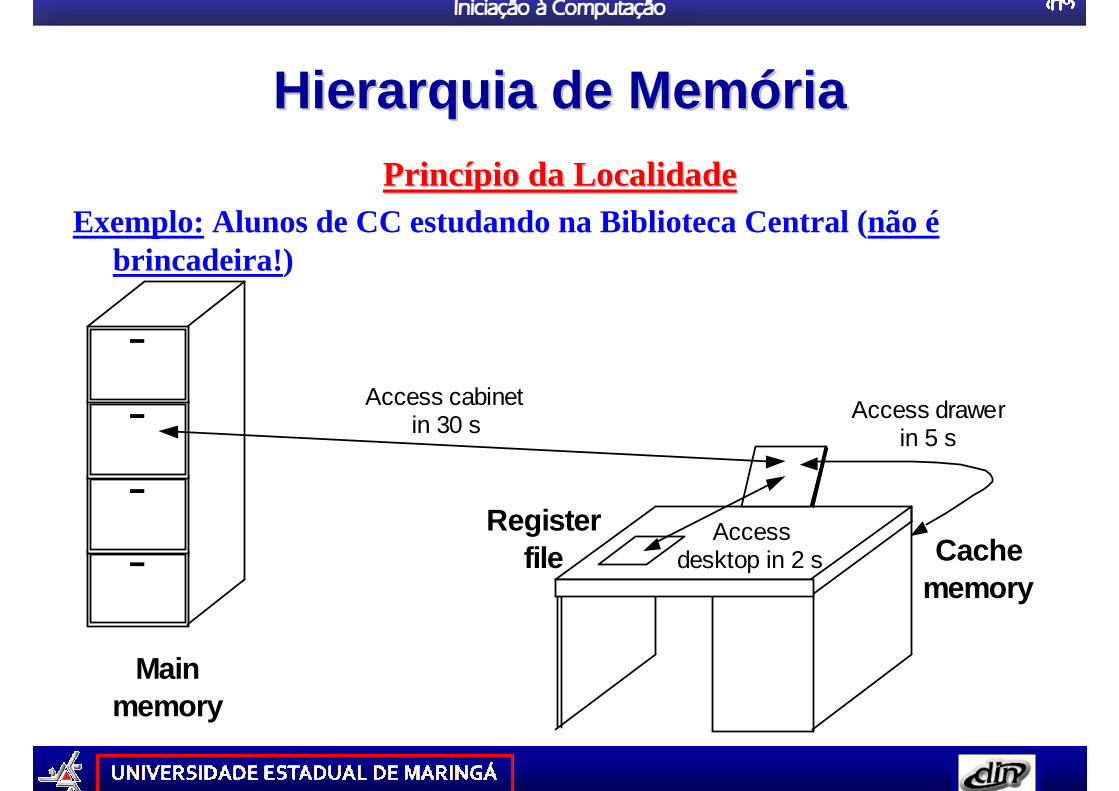
Hierarquia de MemHierarquia de Mem óóriariaPrincPrincíípio da Localidadepio da Localidade
Exemplo: Alunos de CC estudando na Biblioteca Central (não ébrincadeira! )
Main memory
Register file
Access cabinet in 30 s
Access desktop in 2 s
Access drawer in 5 s
Cache memory

Hierarquia de MemHierarquia de Mem óóriaria
CPUCPUregsregs
Cache
MemóriaMemória discodisco
tamanho:velocidade:$/Mbyte:
500 B0,25 ns
Registrador Cache Memória Disco64 KB/4MB1 ns$100/MB
512 MB100 ns$1.50/MB
100 GB5 ms$0.05/MB
maior capacidade, mais lento, mais barato
cache memória virtualPrincípio da LocalidadePrincPrincíípio da Localidadepio da Localidade

PipelinePipeline
Ideia:
o Dividir o processo em estágios independentes
o Mover objetos através dos estágios em sequência
o Em qualquer instante, múltiplos objetos estão sendo processados
Ideia:
o Dividir o processo em estágios independentes
o Mover objetos através dos estágios em sequência
o Em qualquer instante, múltiplos objetos estão sendo processados

Exemplo de PipelineExemplo de Pipeline
Exemplo da LavanderiaExemplo da LavanderiaYandre, João, Valéria, Luciana
cada um tem uma sacola de roupas para lavar, secar e passar
o Lavar consome 30 minutos
o Secar consome 40 minutos
o Passar consome 20 minutos
A B C D

Lavanderia sem PipelineLavanderia sem Pipeline
o Lavanderia Seqüencial gasta 6 horas para 4 sacolaso Se eles aprendessem sobre pipelining, quanto tempo gastariam?
A
B
C
D
30 40 20 30 40 20 30 40 20 30 40 20
6 PM 7 8 9 10 11 Meia Noite
Ordem
tarefas
Tempo

Lavanderia com PipelineLavanderia com Pipeline
o Lavanderia Pipelined gasta 3,5 horas para 4 sacolas
A
B
C
D
6 PM 7 8 9 10 11 Meia Noite
Orddem
Tarefas
Tempo
2030 40 40 40 40

Pipeline no ProcessadorPipeline no Processador
BIbusca instrução
DIdecodifica instrução
MEMacessa memória
EXexecuta instrução/calcula endereço
WBwrite back
BI DI EX ME WBBI DI EX ME WB
BI DI EX ME WB
INST1INST2INST3
Tempo
INST1INST2INST3
TempoSem Pipeline: Não pode iniciar uma nova instrução sem concluir a anterior
Com Pipeline: Pode iniciar uma nova instrução enquanto a anterior estásendo processada

Conflito no PipelineConflito no Pipeline
Conflito de Controle:o Instrução de desvio condicional que pode invalidar diversas buscas
de instruções
Instruções de Desvios:o Testam uma condição especificada pela instrução
o Se a condição é verdadeira, então o desvio é “tomado”o Se a condição é falsa, então o desvio é “não tomado”
o Quando o desvio é “tomado” a execução começa no endereço-alvo do desvio

Conflito no PipelineConflito no PipelineBI
busca instruçãoDI
decodifica instruçãoMEM
acessa memória
EXexecuta instrução/calcula endereço
WBwrite back
BI DI EX ME WBBI DI EX ME WB
BI DI EX ME WB
INST1INST2INST3
Tempo
Pipeline sem instruções de desvios
BI DI EX ME WBBI DI EX ME WB
BI DI EX ME WB
INST1INST2
INST3Tempo
Pipeline com instruções de desvios
InstruInstruçção ão de Desviode Desvio
Inst3 espera Inst3 espera decisão se o decisão se o desvio serdesvio seráátomadotomado

Previsão de DesviosPrevisão de DesviosInstruInstruçção de Desvioão de DesvioLinguagem Alto NLinguagem Alto Níívelvela = c-d;if (a==0){b=1;
}else{b=0;
}
InstruInstruçção de Desvioão de DesvioAssemblyAssembly
sub r1,r2,r3jz
b_recebe_1mvi b,0jmp salta_b
b_recebe_1: mvi b,1salta_b: nop

TTéécnicas de Previsão de Desvioscnicas de Previsão de Desvios
EstratEstratéégias de Previsão de Desviosgias de Previsão de Desvios
Previsões Estáticas:o Fazem a mesma previsão sempre, sem considerar o histórico dos
desvios
Previsões Dinâmicas:o Baseiam as previsões na história passada dos desvios(usam
tabelas de histórico)

TTéécnicas de Previsão de Desvioscnicas de Previsão de Desvios
Previsões EstPrevisões Estááticasticas
1. Prever que todos os desvios sempre serão tomados:o Precisão de 50% ou maiso Simples de implementar
2. Prever que todos os desvios nunca serão tomados:o Precisão de 50% ou maiso Simples de implementar
3. Prever desvio baseado no OP CODE da instrução de desvio:o Prevê que para alguns OP CODEs o desvio será sempre tomado –
ex. jz end-alvo (sempre tomado) e jnz end-alvo (nunca tomado)o Estudos mostram taxa de acerto de +-75%

TTéécnicas de Previsão de Desvioscnicas de Previsão de DesviosPrevisões DinâmicasPrevisões Dinâmicas
o Prever que o desvio será decidido de acordo com o histórico dos desvios anteriores:
1
01
program counter
1
01
BHT (Branch History Table)BHT (Branch History Table)
Obs.: Com 1 bit conta apenas a história do último desvio
Obs.: Com 1 bit conta apenas a história do último desvio

TTéécnicas de Previsão de Desvioscnicas de Previsão de Desvios
111
000110
program counter
Esses bits ‘110’ significam que:•Na antepenúltima vez o desvio foi “tomado”•Na penúltima vez o desvio foi “tomado”•Na última vez o desvio foi “não-tomado”
Esses bits ‘110’ significam que:•Na antepenúltima vez o desvio foi “tomado”•Na penúltima vez o desvio foi “tomado”•Na última vez o desvio foi “não-tomado”
100
000001
Branch History TableBranch History Tableantepenúltimapenúltima
última
Usa-se um algoritmo para decidir se o desvio será ou não tomado, com base nos 3 últimos históricos
Usa-se um algoritmo para decidir se o desvio será ou não tomado, com base nos 3 últimos históricos

Arquitetura SuperescalarArquitetura Superescalar
Tecnologia de Fabricação + Tecnologia RISC = Redução do Tamanho do Transistor + Redução da UC ⇒⇒⇒⇒ Sobra espaço no Chip
registradores
CPU
UC
ULA
registradores
CPU
UF2
UF3
UF4
UF1UC
Redução do tamanho do transistor + Redução da UC⇒⇒⇒⇒mais unidades funcionais na mesma área de silício
ReduReduçção do tamanho do transistor + Reduão do tamanho do transistor + Reduçção da UCão da UC⇒⇒⇒⇒⇒⇒⇒⇒mais unidades funcionais na mesma mais unidades funcionais na mesma áárea de silrea de silííciocio

Arquitetura SuperescalarArquitetura Superescalar
Arquitetura SuperescalarArquitetura Superescalaro Múltiplas Unidades Funcionaiso Explora Paralelismo em Nível de Instruções
InstruInstruçções Independentesões IndependentesCiclo 1: add r1,r2,r3Ciclo 2: sub r4,r5,r6Ciclo 3: mul r7,r8,r9Ciclo 4: div r10,r11,r12Processador seqüencial executa 1 instrução por ciclo
Execução em paralelo
Ciclo 1: add r1,r2,r3 sub r4,r5,r6 mul r7,r8,r9 div r10,r11,r12
Processador poderia executar as quatro instruções simultaneamente num único ciclo
ExecuExecuçção em paraleloão em paralelo
Ciclo 1: add r1,r2,r3 sub r4,r5,r6 mul r7,r8,r9 div r10,r11,r12
Processador poderia executar as quatro instruções simultaneamente num único ciclo

Arquitetura Superescalar: Falsas Arquitetura Superescalar: Falsas DependênciasDependências
ADD R1,R2,R3
SUB R4,R5,R3Instruções lêem R3
RAR - Read after Read - Não há dependência
Instruções lêem R3
RAR - Read after Read - Não há dependência
ADD R1,R2,R3
SUB R4,R5,R1
SUB lê R1
RAW - Read after Write
Dependência de dados – inserir bolhas no pipeline
SUB lê R1
RAW - Read after Write
Dependência de dados – inserir bolhas no pipeline
ADD R1,R2,R3
SUB R2,R5,R6
SUB escreve em R2 que é lido por ADD
WAR - Write after Read – SUB não pode escrever em R2 antes de ADD ler R2 – Falsa dependência
SUB escreve em R2 que é lido por ADD
WAR - Write after Read – SUB não pode escrever em R2 antes de ADD ler R2 – Falsa dependência
ADD R1,R2,R3
SUB R1,R5,R6
SUB escreve no mesmo registrador que ADD (R1)
WAW - Write after Write – SUB não pode escrever em R1 antes de ADD escrever em R1 –Falsa dependência
SUB escreve no mesmo registrador que ADD (R1)
WAW - Write after Write – SUB não pode escrever em R1 antes de ADD escrever em R1 –Falsa dependência
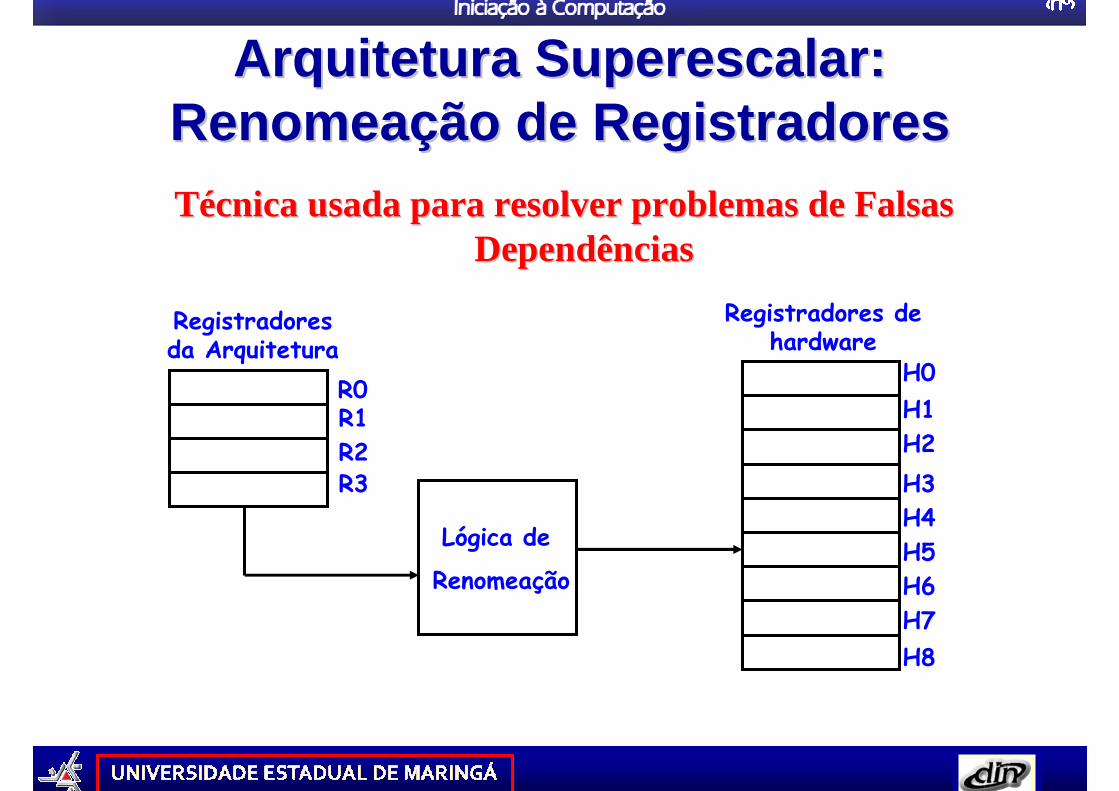
Arquitetura Superescalar: Arquitetura Superescalar: RenomeaRenomea çção de Registradoresão de RegistradoresTTéécnica usada para resolver problemas de Falsas cnica usada para resolver problemas de Falsas
DependênciasDependências
Registradores da Arquitetura
Lógica de
Renomeação
Registradores de hardware
R0
R2R1
R3
H0
H2H1
H3H4
H6H5
H7H8

Arquitetura Superescalar: Arquitetura Superescalar: RenomeaRenomea çção de Registradoresão de RegistradoresAntes da Antes da RenomeaRenomeaççãoão
T1: ADD R3,R4,R5T2: LDA R7,(R3)T3: SUB R3,R12,R11T4: STA (R15),R3
Depois da RenomeaDepois da RenomeaççãoãoT1: ADD H3,H4,H5 SUB H20,H12,H11T2: LDA H7,(H3) STA (H15),H20
Antes:Falsa dependência entre LDA e SUB
Antes:Antes:Falsa dependência entre LDA Falsa dependência entre LDA e SUBe SUB
Depois:-Renomeação elimina falsa dependência-LDA e SUB podem ser executadas em paralelo
Depois:Depois:--RenomeaRenomeaçção elimina falsa dependênciaão elimina falsa dependência--LDA e SUB podem ser executadas em LDA e SUB podem ser executadas em paraleloparalelo

Arquitetura Superescalar: Diagrama Arquitetura Superescalar: Diagrama de Blocosde Blocos
I-Cache
BUSCA
I-FILA
DECODIFICAÇÃO REMESSA
EST-RES
CONCLUSÃO
FILA-REORD
EXEC
D-Cache
REGs

Arquitetura de Alto DesempenhoArquitetura de Alto Desempenho
Por quê investigar Arquiteturas de Alto Desempenho?Por quê investigar Arquiteturas de Alto Desempenho?
Cada vez mais as aplicações demandam mais poder computacional:o Simulação de dinâmica molecularo Simulação de reação nuclearo Previsão de tempoo Previsão para mercado financeiroo Indústria de entretenimento

Arquitetura de Alto DesempenhoArquitetura de Alto Desempenho
P PP
MM M
RI
M=Módulo de Memória
P=Processador
RI=Rede de Interconexão

Arquitetura de Alto DesempenhoArquitetura de Alto Desempenho
P PP
MM M
RI
M=Módulo de Memória
P=Processador
RI=Rede de Interconexão

Arquitetura de Alto DesempenhoArquitetura de Alto Desempenho
Imagine uma super máquina com motor V12, de 6.0 litros, 660 cavalos, e velocidade máxima de 350 Km/h, partindo do tédio à emoção em 3,65 s.
Uma super máquina precisa de uma super rodovia. Isso leva ao projeto das Redes de Interconexão.

Arquitetura de Alto DesempenhoArquitetura de Alto DesempenhoVocê usaria sua super máquina numa estrada de pista simples com asfalto cheio de buracos, como esta?????
Ou usaria este veículo?

Arquitetura de Alto Desempenho: Arquitetura de Alto Desempenho: Redes de InterconexãoRedes de Interconexão
Rede Totalmente ConectadaRede Ideal:
– Conecta todos os nós– Permite comunicações
simultâneas– Custo elevado

Arquitetura de Alto Desempenho: Arquitetura de Alto Desempenho: Redes de InterconexãoRedes de Interconexão
Rede Crossbar
P
P
P
MM M
M=Módulo de Memória
P=Processador

Arquitetura de Alto Desempenho: Arquitetura de Alto Desempenho: Redes de InterconexãoRedes de InterconexãoRede de Barramento Compartilhado
PP P
MM M
M=Módulo de Memória
P=Processador
Barramento Compartilhado

Rede Multi-Estágio Delta
0
1
3
2
4
5
6
7
000
010
001
011
100
101
110
111SE3
SE1
SE0
SE2
SE5
SE6
SE4
SE9
SE7
SE8
SE11
SE10
Arquitetura de Alto Desempenho: Arquitetura de Alto Desempenho: Redes de InterconexãoRedes de Interconexão

LimitaLimita çções das Redes de Interconexãoões das Redes de Interconexão
LimitaLimita çções das Redes Eletrônicas:ões das Redes Eletrônicas:o Taxa de transferênciao Conflitoso Complexidade de roteamento

Redes de InterconexãoRedes de Interconexão
Tecnologia WDM (Tecnologia WDM (WavelengthWavelengthDivision MultiplexingDivision Multiplexing ))
Tx
Rx...EP
PSC
Tx
Rx
... EP
Tx
Rx
...EP
Tx
Rx
... EP
EP=Elemento de Processamento
Rx=Receptor
Tx=Transmissor
PSC=Acoplador Estrela Passivo

Redes de InterconexãoRedes de Interconexão
Mul
tiple
xado
r
λ1
λ2
λ3
λ4
λΝ
C1
C2
C3
C4
CN
...
λΝλ1 λ2 λ3 λ4
...
Aco
plad
or E
stre
la P
assi
va
Fibra Óptica
λΝλ1 λ2 λ3 λ4
...
...
C1
C2
C3
C4
CN
Receptorλ1
λ2
λ3
λ4
λΝ
Receptor
Receptor
Receptor
Receptor
FiltrosSintonizáves
λΝλ1 λ2 λ3 λ4
...
Transmissor
Transmissor
Transmissor
Transmissor
Transmissor
Tecnologia WDM (Tecnologia WDM (WavelengthWavelengthDivision MultiplexingDivision Multiplexing ))

MMááquina de Alto Desempenhoquina de Alto DesempenhoConfiguração do Roadrunner:o 12.960 Processadores IBMo 6.480 Processadores AMDo Memória 103,6 TBo Performance 1,7 PETAFLOPSo 1º Lugar no TOP 500o Objetivos: Simular problemas extremamente complexos, como por exemplo, simular funções do cérebro, previsão do clima, exploração de petróleo o Ocupa área de 3 quadras de têniso Peso: 227 ton.o Custo: US $133 mi
Exemplo de capacidade de processamento: Se 6,7 bilhões de habitantes da Terra usassem uma calculadora 24 horas por dia, levariam 46 anos para concluir uma conta que o Roadrunner executa em um dia!

MMááquina de Alto Desempenhoquina de Alto Desempenho
Características do Netunoo Sediado na UFRJo Ocupa a 138ª posição no ranking do TOP 500o Performance 16,24 TFLOPS (2% da performance do Roadrunner)o Executa previsão de chuva para 10 dias em 1 hora (num PC levaria 40 dias)o Objetivos: Simular exploração de petróleo o Custo: US $5 mi

Sistemas EmbarcadosSistemas Embarcados

DefiniDefini çção de Sistemas Embarcadosão de Sistemas Embarcados


– Por exemplo:• Olho Artificial:
– Pesquisa de William Dobelle. [http://www.seeingwithsound.com]
ÁÁreasreas de de AplicaAplica ççãoão
Sistemas MédicosSistemas MSistemas Méédicosdicos
Aplicações MilitaresAplicaAplicaçções Militaresões Militares
Uso de redes de sensores sem fio para detectar movimento de tropa inimiga: substitui minas terrestres
Uso de redes de sensores sem fio para detectar movimento de tropa inimiga: substitui minas terrestres
ÁÁreasreas de de AplicaAplica ççãoão

ÁÁreasreas de de AplicaAplica ççãoão
Eletrônica de ConsumoEletrônica de ConsumoEletrônica de Consumo

Automação IndustrialAutomaAutomaçção Industrialão Industrial
ÁÁreasreas de de AplicaAplica ççãoão
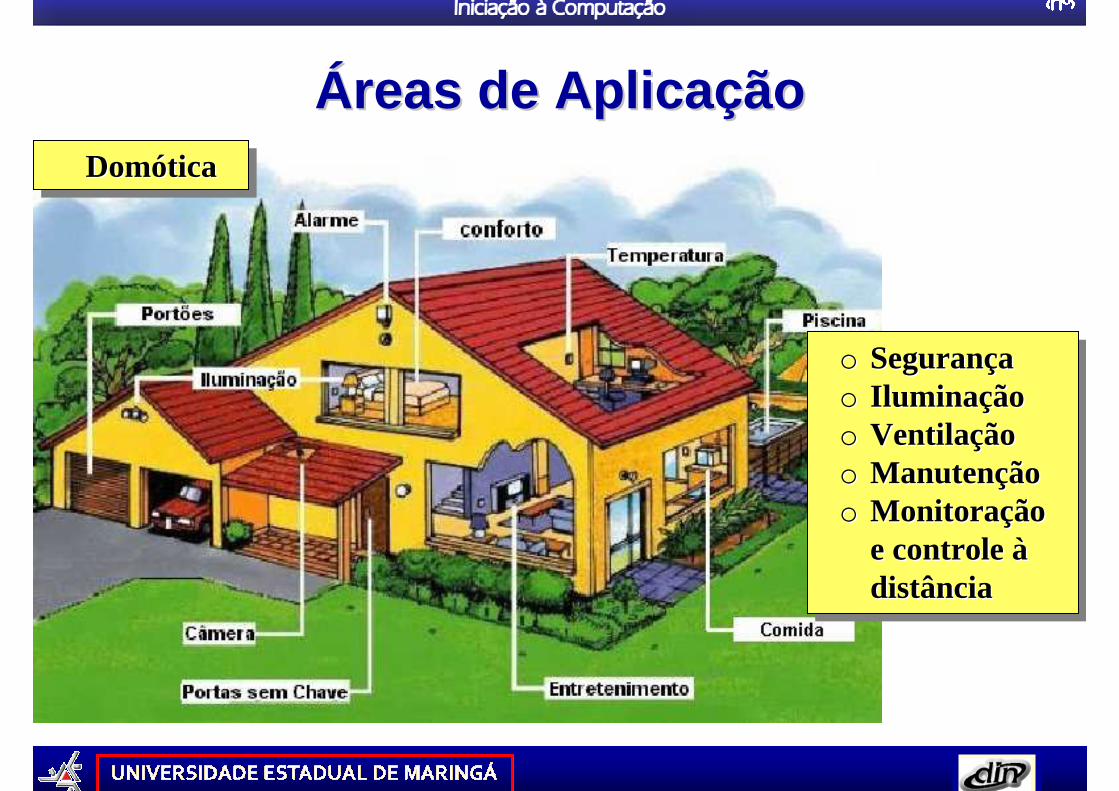
ÁÁreasreas de de AplicaAplica ççãoãoDomóticaDomDomóóticatica
o Segurançao Iluminaçãoo Ventilaçãoo Manutençãoo Monitoração
e controle àdistância
oo SeguranSeguranççaaoo IluminaIlumina ççãoãooo VentilaVentilaççãoãooo ManutenManutenççãoãooo MonitoraMonitora çção ão
e controle e controle ààdistânciadistância

ÁÁreasreas de de AplicaAplica ççãoão
Eletrônica Automotiva
Eletrônica Automotiva

RobóticaRobRobóóticatica
Robô “Johnnie“
ÁÁreasreas de de AplicaAplica ççãoão


SEs x PCsSEs x PCs
Sistemas Embarcados são dedicados a tarefas específicas X
PCs são plataformas de computação de uso geral
Sistemas Embarcados são dedicados a tarefas específicas X
PCs são plataformas de computação de uso geral

SEs x PCsSEs x PCs
Sistemas Embarcados são suportados por uma ampla gama de processadores e arquiteturas
Há mais de 140 microprocessadores diferentes fabricados por mais de 40 fabricantes
Sistemas Embarcados são suportados por uma ampla gama de processadores e arquiteturas
Há mais de 140 microprocessadores diferentes fabricados por mais de 40 fabricantes

SEs x PCsSEs x PCs
Sistemas Embarcados são normalmente sensíveis ao custo Sistemas Embarcados são normalmente sensíveis ao custo
Projeto Mars Rover: Certamente a NASA não estava preocupada com o custo

SEs x PCsSEs x PCs
Sistemas Embarcados são normalmente sensíveis ao custoSistemas Embarcados são normalmente sensíveis ao custo
Indústria Automobilística:Se você economiza R$0,10 num Sistema Embarcado, você será o herói da empresa
Indústria Automobilística:Se você economiza R$0,10 num Sistema Embarcado, você será o herói da empresa

SEs x PCsSEs x PCs
Sistemas Embarcados têm restrições de tempo-realSistemas Embarcados têm restrições de tempo-real
No desktop as tarefas, em geral, não são sensíveis ao tempo
No desktop as tarefas, em geral, não são sensíveis ao tempo
Por exemplo, o PC pode parar as tarefas para fazer back up
Por exemplo, o PC pode parar as tarefas para fazer back up

SEs x PCsSEs x PCs
Sistemas Embarcados têm restrições de tempo-realSistemas Embarcados têm restrições de tempo-real
o Não dá para suspender uma tarefa de controle de segurança num sistema que tem restrições de tempo real.
o Seria desastroso. Literalmente!!
o Não dá para suspender uma tarefa de controle de segurança num sistema que tem restrições de tempo real.
o Seria desastroso. Literalmente!!

SEs x PCsSEs x PCs
SE é menos tolerante a falhas que desktop PCSE é menos tolerante a falhas que desktop PC
Vixi: Tela Azul!

SEs x PCsSEs x PCs
SE é menos tolerante a falhas que desktop PCSE é menos tolerante a falhas que desktop PC
Sistema Embarcado usa Watchdog TimerSistema Embarcado usa Watchdog Timer

SEs x PCsSEs x PCs
Sistemas Embarcados têm restrições de potênciaSistemas Embarcados têm restrições de potência
Bateria
Impatcos:o SE deve funcionar por longo tempo com pequeno conjunto de bateriaso SE deve operar em “sleep mode” para economizar energiao Afeta na escolha do processador, na sua velocidade e na arquitetura de memória
Impatcos:o SE deve funcionar por longo tempo com pequeno conjunto de bateriaso SE deve operar em “sleep mode” para economizar energiao Afeta na escolha do processador, na sua velocidade e na arquitetura de memória

Grupos de PesquisasGrupos de Pesquisas
o HPPCA – High Performance and Parallel Computer Architecture Group
o GSE – Grupo de Sistemas Embarcadoso Manna – Management Architecture for Wireless
Sensor Networks

Pesquisas do Grupo HPPCAPesquisas do Grupo HPPCA
HPPCA-DIN
o Paralelização de Aplicaçõeso Desenvolvimento de Ferramentas de Monitoramentoo Simulação de Arquiteturas de Alto Desempenho


Sistema Embarcado para auxSistema Embarcado para aux íílio a lio a Agricultura FamiliarAgricultura Familiar
Estação coletora de dados:o Sensores de umidade, temperatura, radiação, velocidade do vento, direção do ventoo Microcontrolador ATMELo Coleta dos dados: Celular, Infrared, USB, ZigBee
Estação coletora de dados:o Sensores de umidade, temperatura, radiação, velocidade do vento, direção do ventoo Microcontrolador ATMELo Coleta dos dados: Celular, Infrared, USB, ZigBee

Sistema Embarcado com Aeronave Sistema Embarcado com Aeronave Não TripuladaNão Tripulada
Estação coletora de dados:o coleta de dados e transmissão pelo avião não tripulado
Estação coletora de dados:o coleta de dados e transmissão pelo avião não tripulado
Cooperação: ICMC/USP-DIN/UEM
Cooperação: ICMC/USP-DIN/UEM

Sistema Embarcado com Aeronave Sistema Embarcado com Aeronave Não TripuladaNão Tripulada
Cooperação: ICMC/USP-DIN/UEM
Cooperação: ICMC/USP-DIN/UEM
Estação coletora de dados:o coleta de dados e transmissão pelo avião não tripulado
Estação coletora de dados:o coleta de dados e transmissão pelo avião não tripulado

FerramentasFerramentas
o Simuladores– SimpleScalar
– Watch
o Linguagens de Descrição de Hardware– VHDL
– SystemC
o Kits de Programação– ATMEL