aws meetup「apache spark on emr」
TRANSCRIPT

Apache Spark on EMR
Yuyang Lan
SmartNews Inc.

MOKUJI
• Intro
• Recent Spark
• How we use Spark in Smartnews
• Best Practices

Who am I
• @y2_lan
• Engineer at SmartNews Inc. (AD team)
• Hacker, Data Engineer, Beer Lover

何か要望・問題あったら @kaiseh :)

About Apache Spark
maybe
just skip?

About Apache Spark Quick catch up
RDD
action
transformations

Recent Spark at a glance
• Databricks Cloud goes public
• Spark 1.4.x
• Project Tungsten
• AWS adds support for Apache Spark on EMR
• …

Spark 1.4.x• SparkR
• DataFrame API
• ML Pipeline
• Streaming UI
• …

Spark at SmartNews
• AD CTR Prediction ( Logistic Regression )
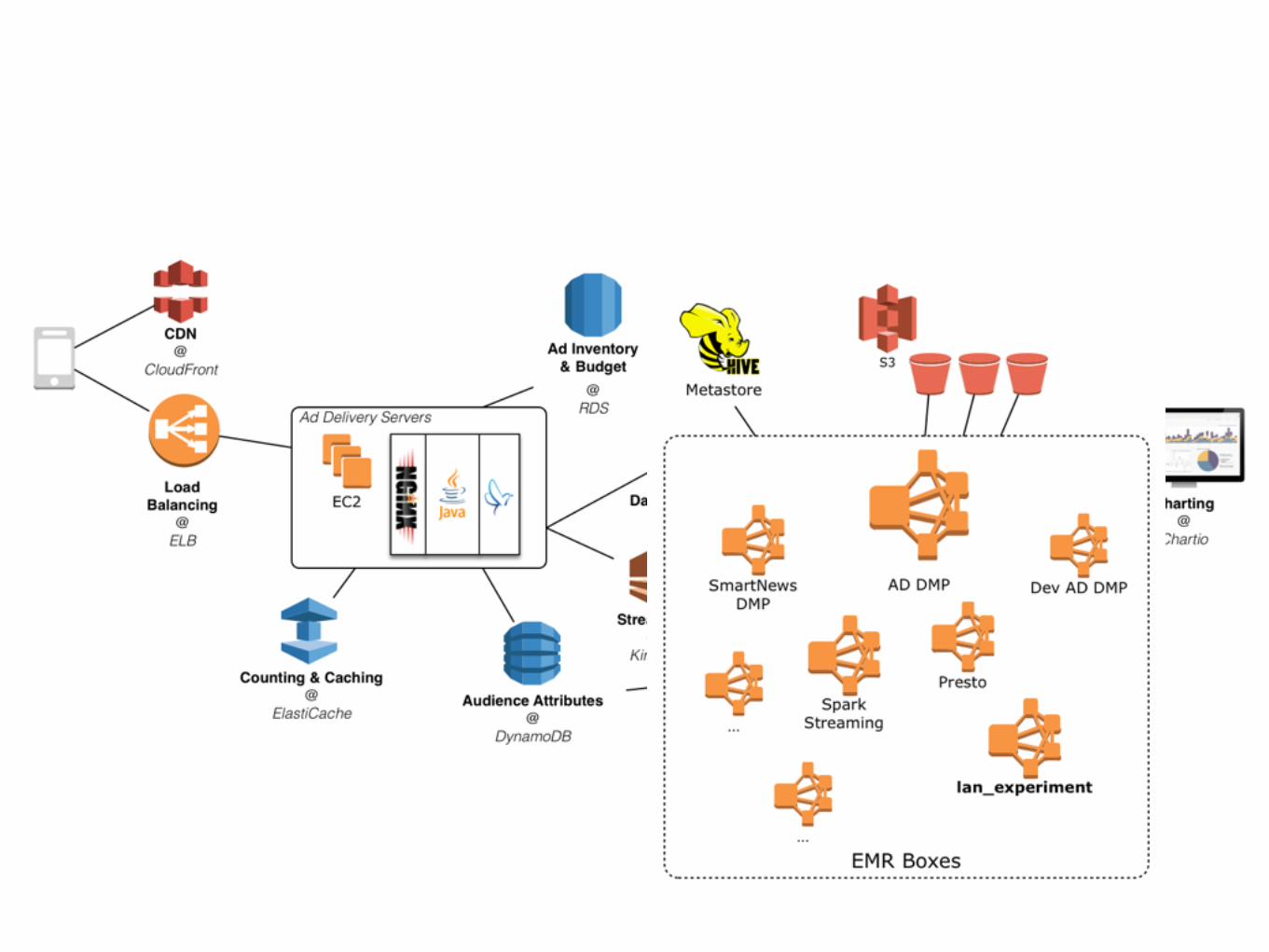

Spark at SmartNews
• Scoring articles by Kinesis + Spark Streaming

Spark at SmartNews
• Ad-Hoc Analysis, Faster (& Hive-compatible) SQL

Spark at SmartNews
• Realtime Stats by Kinesis + Spark Streaming

Spark at SmartNews• ML experiments
• AD targeting
• User Clustering
• Recommendation
• …

Best Practices #1
• Should use the default Spark with EMR ?
• Yes Sure
• EMR 4.0 is great ! (Released today ?!)
• Hadoop 2.6 + Hive 1.0 + Spark 1.4.1

Best Practices #1
• Should use the default Spark with EMR ?
• But only if you need a custom-build Spark
• Cutting Edge Version
• Native netlib-java ( mvn -Pnetlib-lgpl )
• Custom dependency version
• …

Best Practices #1
• Should use the default Spark with EMR ?
• But only if you need a custom-build Spark
• --bootstrap-actions bootstrap.json

Best Practices #1
• Should use the default Spark with EMR ?
• But only if you need a custom-build Spark
• Remember to start SparkHistoryServer

Best Practices #2
• Run Spark on Yarn
• Use yarn-cluster mode to distribute Drivers
• specify jars and files to distribute necessary resources

Best Practices #3
• Tuning Memory
• CPU shortage only slow down your program, but short in memory make it crash
• you can even set --executor-cores bigger than your CPU num
• Cache-able heap != JVM’s Xmx
• (normally about 50%)
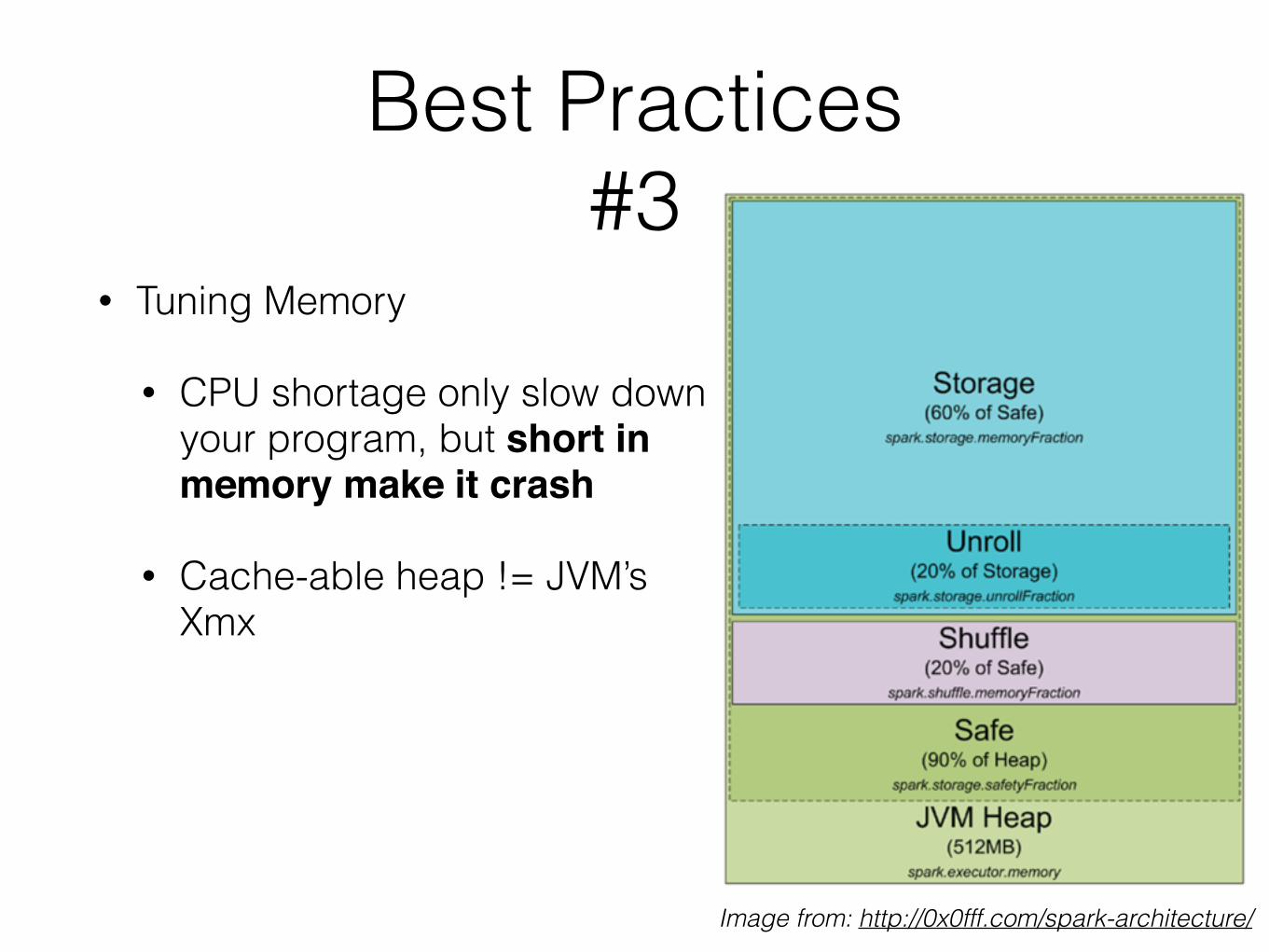
Best Practices #3
• Tuning Memory
• CPU shortage only slow down your program, but short in memory make it crash
• Cache-able heap != JVM’s Xmx
Image from: http://0x0fff.com/spark-architecture/

Best Practices #3
• Tuning Memory
• CPU shortage only slow down your program, but short in memory make it crash
• Cache-able heap != JVM’s Xmx
• spark.yarn.executor.memoryOverhead
• spark.executor.memory
• spark.storage.memoryFraction
• …
• Split your executors if HEAP_SIZE > 64GB (GC)
• -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps

Best Practices #4
• If your ML job is really CPU-bound
• Try using OpenBLAS + netlib.NativeSystemBLAS

Best Practices #4
• Try using OpenBLAS + netlib.NativeSystemBLAS
4~5 times FAST

Best Practices #5
• Minimize data shuffle
• Prefer reduceByKey over groupByKey+map
• RDD.repartition(NUM_OF_CORES) before cache
• Try to do filter early

Best Practices #5
• Minimize data shuffle

Best Practices #6
• Prefer DataFrame APIs over low level RDD APIs
• Better DAG Optimization
• Same interface & same performance

Best Practices #7
• Use Kryo serialization if possible
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer

Best Practices #8
• Pick up a notebook tool (iPython or Zeppelin or ?
• For memo, sharing, visualisation
• Convenient for non-engineer users

Best Practices #9
• Multiple small & task-driven EMR clusters

Best Practices #10
• use Dynamic scaling with Spark Streaming
• spark.dynamicAllocation.enabled = true
• spark.shuffle.service.enabled = true
• be careful if you use cached data

Best Practices #11
• Use Spot Instance
• Be more aggressive in bid price : p
• BID_PRICE != MONEY_TO_PAY
• Check Spot Instance Pricing History
• Find the instance type with relative stable price
• often Previous Generation Instance ?
• Prepare failure, don’t use them in critical missions

Further Reading
• To use Spark Streaming in Production
• http://www.slideshare.net/SparkSummit/recipes-for-running-spark-streaming-apploications-in-production-tathagata-daspptx

Further Reading
• If you’re interested in new ML pipelines
• http://www.slideshare.net/SparkSummit/building-debugging-and-tuning-spark-machine-leaning-pipelinesjoseph-bradley

Thanks!
We’re hiring!
http://about.smartnews.com/ja/careers/
iOSエンジニア / Androidエンジニア / Webアプリケーションエンジニア
/ プロダクティビティエンジニア / 機械学習 / 自然言語処理エンジニア
/ グロースハックエンジニア / サーバサイドエンジニア
/ 広告エンジニア…