bab ii tinjauan pustaka 2.1 pengertian kriptografi ii.pdfuntuk melakukan enkripsi dan dekripsi,...
TRANSCRIPT

1
BAB II
TINJAUAN PUSTAKA
2.1 Pengertian kriptografi
kriptografi adalah seni atau ilmu yang digunakan untuk menjaga keamanan
informasi atau pesan dengan mengubahnya menjadi suatu yang tidak memiliki
arti. Pada kriptografi terdapat enkripsi dan dekripsi, enkripsi adalah mengubah
pesan menjadi data yang tidak bisa dibaca atau di mengerti sedangkan dekripsi
adalah mengembalikan data seperti semula sehingga data dapat dibaca dengan
baik. Selain itu kriptografi juga dapat dibagi berdasarkan jenis kunci yaitu
algoritma simetris dan asimetris. Agoritma simetris adalah algortima yang
menggunakan kunci yang sama untuk melakukan enkripsi dan dekripsi,
sedangkan algoritma asimetris adalah algoritma yang menggunakan kunci berbeda
untuk melakukan enkripsi dan dekripsi, untuk eknripsi menggunakan kunci public
dan dekripsi menggunakan kunci private.
2.1.1 Kriptografi simetris
Algoritma simetris (symmetric algorithm) adalah algortima yang
menggunakan kunci yang sama untuk melakukan enkripsi dan dekripsi.
Gambar 2.1 Proses algoritma kriptografi simetris
(Sumber : Kristoforus, Aditya, 2012)
2.1.2 Algoritma AES
AES merupakan standar algoritma kriptografi terbaru yang dipublikasikan
oleh NIST ( National Institute of Standard and Technology ) sebagai pengganti
algoritma DES ( Data Encryption Standard ) yang sudah berakhir masa
penggunaannya. Algoritma AES adalah algoritma kriptografi yang dapat
mengenkripsi dan mendekripsi data dengan panjang kunci 128 bit, 192 bit, dan
256 bit. Pada algoritma AES (Yuniati dkk, 2009) perbedaan panjang kunci akan
mempengaruhi jumlah round yang akan diimplementasikan pada algoritma AES.
2
Tabel 2.1 Jumlah proses berdasarkan bit blok dan kunci
( Sumber : Yuniati dkk, 2009 )
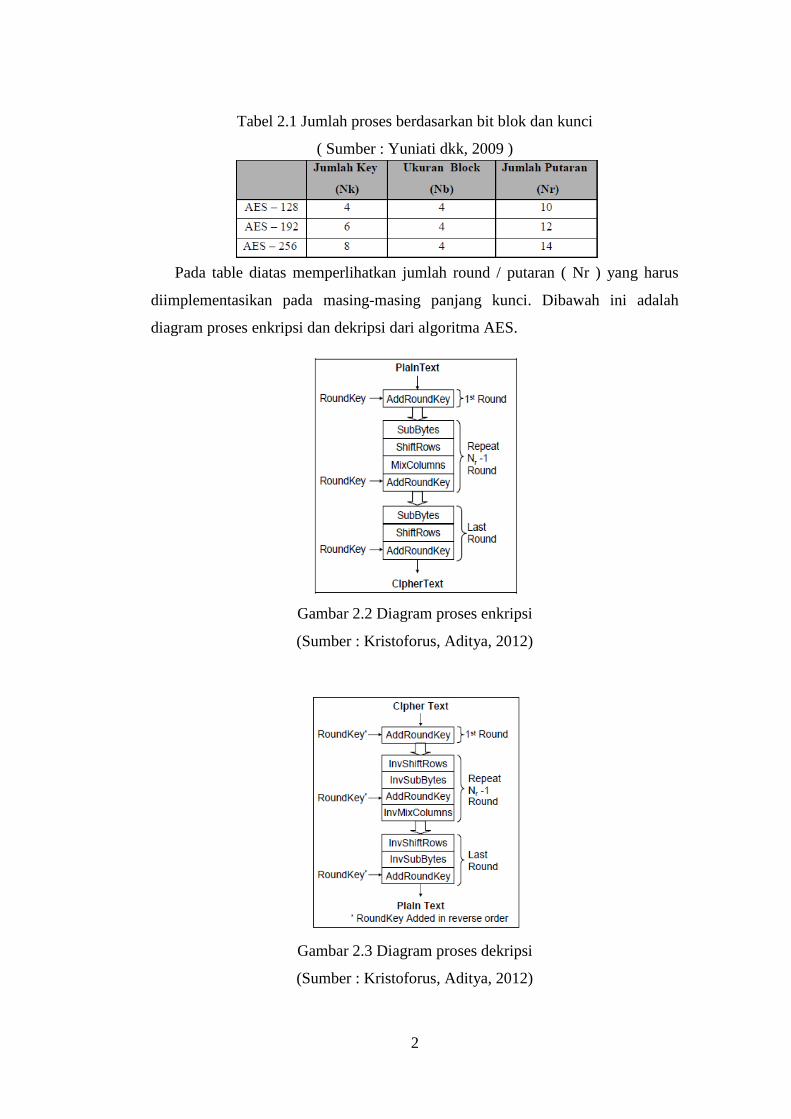
Pada table diatas memperlihatkan jumlah round / putaran ( Nr ) yang harus
diimplementasikan pada masing-masing panjang kunci. Dibawah ini adalah
diagram proses enkripsi dan dekripsi dari algoritma AES.
Gambar 2.2 Diagram proses enkripsi
(Sumber : Kristoforus, Aditya, 2012)
Gambar 2.3 Diagram proses dekripsi
(Sumber : Kristoforus, Aditya, 2012)

3
2.2 Proses Enkripsi Advanced Enryption Standard (AES)
Proses enkripsi algoritma AES terdiri dari 4 jenis transformasi bytes, yaitu
SubBytes, ShiftRows, Mixcolumns, dan AddRoundKey.
2.2.1 Sub bytes
Proses SubBytes adalah mengganti setiap byte state dengan byte pada
sebuah tabel yang dinamakan tabel S-Box. Sebuah tabel S-Box terdiri dari 16x16
baris dan kolom dengan masing-masing berukuran 1 byte.
Gambar 2.4 S-box
( Sumber : Yuniati dkk, 2009 )
Gambar 2.5 Proses sub bytes
( Sumber : Yuniati dkk, 2009 )
2.2.2 Shift Row
Shift rows adalah proses pergeseran bit, bit paling kiri akan dipindahkan
menjadi bit paling kanan ( rotasi bit ).
Gambar 2.6 Proses shift row
( Sumber : Yuniati dkk, 2009 )

4
2.2.3 Mix Columns
MixColumns mengoperasikan setiap elemen yang berada dalam satu kolom
pada state. lebih jelasnya bisa dilihat pada perkalian matriks dibawah ini :
Hasil dari perkalian matriks diatas dapat dilihat dibawah ini :
Berikut adalah contoh perhitungan MixColumns :
Input = D4 BF 5D 30
Output (0) = (D4*2) XOR (BF*3) XOR (5D*1) XOR (30*1)
= E(L(D4)+L(02)) XOR E(L(BF)+L(03)) XOR 5D XOR 30
= E(41+19) XOR E(9D+1) XOR 5D XOR 30
= E(5A) XOR E(9E) XOR 5D XOR 30
= B3 XOR DA XOR 5D XOR 30
= 04
Output (1) = (D4*1) XOR (BF*2) XOR (5D*3) XOR (30*1)
= D4 XOR E(L(BF)+L(02)) XOR E(L(5D)+L(03)) XOR 30
= D4 XOR E(9D+19) XOR E(88+01) XOR 30
= D4 XOR E(B6) XOR E(89) XOR 30
= D4 XOR 65 XOR E7 XOR 30
= 66
Output (2) = (D4*1) XOR (BF*1) XOR (5D*2) XOR (30*3)
= D4 XOR BF XOR E(L(5D)+L(02)) XOR E(L(30)+L(03))
= D4 XOR BF XOR E(88+19) XOR E(65+01)
= D4 XOR BF XOR E(A1) XOR E(66)

5
= D4 XOR BF XOR BA XOR 5D
= 81
Output (3) = (D4*3) XOR (BF*1) XOR (5D*1) XOR (30*2)
= E(L(D4)+L(03)) XOR BF XOR 5D XOR E(L(30)+L(02))
= E(41+01) XOR BF XOR 5D XOR E(65+19)
= E(42) XOR BF XOR (5D) XOR (E(7E)
= 67 XOR BF XOR 5D XOR 60
= E5
Hasil dari MixColumns dicari dengan menggunakan tabel Galois Field
Multiplication. Cara yang dilakukan adalah mirip dengan mencari nilai
SubByte, tetapi tabel yang digunakan bukan tabel S-Box, melainkan E-Table
dan L-Table dari Galois Field Multiplication.
Gambar 2.7 E-Table dari Galois Field Multiplication
(Sumber : Barent, 2014)
Gambar 2.8 L-Table dari Galois Field Multiplication
(Sumber : Barent, 2014)

6
2.3 Proses Dekripsi Advanced Encryption Standard (AES)
Proses dekripsi algoritma AES berbeda dengan proses enkripsi, transformasi
cipher dapat dibalikkan dan diimplementasikan dalam arah yang berlawanan.
Transformasi byte yang digunakan pada invers cipher adalah InvShiftRows,
InvSubBytes, InvMixColumns, dan AddRoundKey.
2.3.1 InvShiftRows
InvShiftRows adalah berkebalikan dengan transformasi shiftrows pada
proses enkripsi. Pada transformasi InvShiftRows, dilakukan pergeseran bit ke
kanan.
Gambar 2.9 Transformasi InvShiftRows
( Sumber : Yuniati dkk, 2009 )
2.3.2 InvSubBytes
InvSubBytes adalah berkebalikan dengan transformasi SubBytes pada
proses enkripsi. Pada InvSubBytes, tiap elemen pada state dipetakan dengan
menggunakan table Inverse S-Box.
Gambar 2.10 Inverse S-Box
( Sumber : Yuniati dkk, 2009 )
2.3.3 InvMixColumns
Setiap kolom dalam state dikalikan dengan matrik perkalian dalam AES.
Perkalian dalam matrik dapat dilihat dibawah ini :

7
Hasil dari perkalian dalam matrik adalah
Untuk mencari hasil dari invers mixcolumn hampir sama dengan
perhitungan pada mixcolumn dengan menggunakan tabel E dan tabel L.
2.4 Add Round Key
Pada proses ini subkey digabungkan dengan state. Proses penggabungan ini
menggunakan operasi XOR untuk setiap byte dari subkey dengan byte yang
bersangkutan dari state. Untuk setiap tahap, subkey dibangkitkan dari kunci utama
dengan menggunakan proses key schedule. Setiap subkey berukuran sama dengan
state yang bersangkutan.
Gambar 2.11 Proses add round key
( Sumber : Surian, 2009 )
2.5 Key Schedule
Proses key schedule diperlukan untuk mendapatkan subkey-subkey dari kunci
utama agar dapat melakukan enkripsi dan dekripsi. Proses ini terdiri dari beberapa
operasi yaitu:
Operasi Rotate, yaitu operasi perputaran 8 bit pada 32 bit dari kunci.

8
Operasi SubBytes, pada operasi ini 8 bit dari subkey disubstitusikan
dengan nilai dari S-Box.
Operasi Rcon, operasi ini dapat diterjemahkan sebagai operasi pangkat
2 nilai tertentu dari user. Operasi ini menggunakan nilai-nilai dalam
Galois field. Nilai-nilai dari Rcon kemudian akan di-XOR dengan hasil
operasi SubBytes. Operasi XOR dengan w[i-Nk] yaitu word yang
berada pada Nk sebelumnya.
Tabel 2.2 Tabel Rcon
(Sumber : Stallings, 2010)
2.6 Gambar (Citra Digital)
Gambar adalah suatu representasi kemiripan atau imitasi dari suatu objek.
Sebuah citra digital dapat diwakili oleh sebuah matriks yang terdiri dari M kolom
dan N baris, dimana perpotongan antara kolom dan baris disebut piksel, yaitu
elemen terkecil dari sebuah citra. Citra bitmap menyimpan data kode citra secara
digital dan lengkap, salah satu contoh citra bitmap yaitu bmp (Kristoforus, Aditya,
2012). Format file bmp ini biasanya digunakan oleh aplikasi dan sistem operasi
Microsoft Windows dan merupakan kompresi tipe lossless. Format ini mampu
menyimpan informasi dengan kualitas tingkat 1 bit sampai 24 bit.
2.7 Kompresi Lossless
Metode Lossless adalah metode yang dapat memperkecil filenya sehingga
ukuran datanya menjadi kecil, namun dapat dikembalikan lagi seperti aslinya.
Proses kompresi dapat dilakukan dengan mengganti suatu data dengan kode yang
berukuran lebih ringkas, data yang diganti tersebut dapat dikembalikan seperti
semula dengan melakukan proses dekompresi. Tujuan utama dari metode lossless
(Wijaya, Widodo, 2010) adalah menghasilkan file yang kecil namun tanpa
sedikitpun mengurangi kualitas dari data tersebut. Hal ini sangat penting untuk

9
data-data yang memerlukan keakuratan yang tinggi. Contoh teknik kompresi
lossless diantaranya adalah Huffman dan Lempel-Ziv-Welch, Dynamic Markov
Compression.
2.7.1 Algoritma Huffman
Algoritma Huffman ini pertama kali diterbitkan pada tahun 1952 oleh D.A.
Huffman dalam paper-nya yang berjudul “A Method for the Construction of
Minimum Redundancy Codes”. Secara umum, algoritma ini dapat memberikan
penghematan sebesar 20%- 30%. Prinsip kerja dari Algoritma Huffman
(Adrisatria, 2006) adalah mengodekan setiap karakter ke dalam representasi bit.
Representasi bit untuk setiap karakter akan berbeda dari segi panjangnya. Hal ini
disebut sebagai variable-length code. Panjang pendek bit yang dihasilkan
ditentukan dengan sering atau tidak karakter tersebut muncul, jika sering maka
bitnya pendek sedangkan jika jarang maka bitnya makin panjang. Untuk cabang
kiri pada pohon biner diberikan label 0, sedangkan pada cabang kanan diberikan
label 1.
Kompresi Huffman adalah metode paling efisien dari metode lain yang
sejenis karena pemetaan lain menghasilkan simbol dari sumber data menjadi
string unik dan menghasilkan file output yang lebih kecil. Algoritma huffman
merupakan algoritma yang paling sederhana dibandingkan dengan algoritma
pengompresian lainnya karena Algoritma Huffman Statis hanya membutuhkan 2
langkah dalam pengompresian hal ini membuatnya begitu cepat, yaitu encoding
dan decoding karena peta kode akan selalu sama (Soendoro,2009). Algoritma
huffman ini dibagi menjadi dua yaitu statis dan dinamis. Algoritma huffman
dinamis lebih sering dipakai dalam proses transfer data (streaming) dan Algoritma
huffman statis dipakai dalam proses pengompresian internal (Soendoro,2009).
Kode Huffman pada dasarnya ( Putra dkk, 2013) adalah himpunan yang
berisi sekumpulan kode biner yang direpresentasikan dari pohon biner yang
diberikan nilai atau label. Untuk cabang kiri diberikan label 0, sedangkan pada
cabang kanan diberikan label 1. Pohon biner ini biasa disebut pohon Huffman
(Huffman tree). Langkah-langkah pembentukannya sebagai berikut :

10
Gambar 2.12 Diagram alir pengkodean Huffman
(Sumber : Zulen, 2009)
Setelah mendapatkan pohon biner, data asli dapat digantikan dengan kode
bit berdasarkan pohon biner, proses ini dinamakan encoding. Encoding
merupakan sebuah cara dalam menyusun susunan (string) biner dari data yang
ada. Proses encoding dilakukan setelah kita memperoleh pohon Huffman
(Soendoro, 2009) yaitu terlebih dahulu melihat akar baru kemudian akar kiri
kemudian kanan. Penyusunan pohon Huffman harus yang kemunculan lebih
besar di kiri, karena pohon kiri akan diperiksa terlebih dahulu daripada pohon
kanan. Metode Huffman termasuk metode lossless compression.
Pengkodean citra berdasarkan pada derajat keabuan (gray level) atau
tingkat warna dari piksel-piksel dalam keseluruhan image. Dengan kata
lain, metode Huffman termasuk dalam pendekatan statistikal (statistical
compression) dalam kompresi citra (Zulen, 2009). Derajat keabuan yang
sering muncul pada citra akan dikodekan dengan jumlah bit lebih sedikit

11
sedangkan derajat keabuan yang sedikit muncul akan dikodekan dengan
jumlah yang lebih panjang. Algoritma Huffman untuk kompresi citra yaitu:
1. Buat data citra yang berupa matriks tersebut menjadi vektor.
2. Tentukan frekuensi kemunculan tiap warna atau derajat keabuan.
3. Urutkan secara menaik warna atau nilai keabuan berdasarkan frekuensi
kemunculannya atau peluang kemunculan piksel dalam citra Setiap nilai
dinyatakan sebagai pohon bersimpul tunggal dan setiap simpul di-
assign dengan frekuensi kemunculan nilai tersebut.
4. Gabungkan 2 buah pohon yang mempunyai frekuensi kemunculan
paling kecil pada sebuah akar. Akar mempunyai frekuensi yang
merupakan jumlah dari frekuensi dua pohon penyusunnya. Frekuensi
dengan nilai lebih kecil diletakkan di sisi kiri dan diberi bobot 0
sedangkan sisi kanan diberi bobot 1.
5. Ulangi langkah 4 sampai tersisa 1 pohon biner.
6. Telusuri pohon biner dari akar ke daun. Barisan bobot sisi dari akar
ke daun menyatakan kode Huffman untuk derajat keabuan atau warna yang
bersesuaian.
7. Mengganti data dengan kode Huffman yang bersesuaian
8. Menyimpan data lebar citra, tinggi citra, kode bit untuk tiap nilai, data
warna yang terdapat di dalam citra, dan data citra yang sudah dikodekan
ke dalam file hasil kompresi.
Berikut ini adalah langkah-langkah untuk mengembalikan data citra yang
sudah dikodekan menjadi data citra semula :
1. Baca file hasil kompresi dan data-datanya dimasukkan ke variabel yang
sesuai yaitu variabel ukuran citra, variabel kode bit data,dan variabel
warna
2. Baca data kode bit per bit dari kiri ke kanan dan dicocokkan dengan kode
Huffman dari data warna yang didapat.Demikian seterusnya konversi
dilakukan hingga data terakhir.
3. Rekonstruksi citra dengan menggunakan data ukuran citra, berarti data
pixel berbentuk 1D dipenggal baris dan kolom sesuai ukuran citra.

12
2.7.2 Rasio Kompresi
Rasio kompresi data adalah menghitung pengurangan ukuran representasi
data yang dihasilkan oleh algoritma kompresi data (Zulen, 2009). Untuk
menghitung persentase kompresi dengan cara :
……………….(1)
Sedangkan untuk menghitung rasio kompresi dengan cara :
……………….(2)
2.8 Algoritma SHA (Secure Hash Algorithm)
SHA adalah fungsi hash satu-arah yang dibuat oleh NIST dan digunakan
bersama DSS (Digital Signature Standard). Oleh NSA, SHA dinyatakan sebagai
standard fungsi hash satu-arah. Pada tahun 2002 dipublikasikan empat variasi
lainnya, yaitu SHA-224, SHA-256, SHA-384, dan SHA-512, keempatnya disebut
sebagai SHA-2 (Sutanto, 2011).
Algoritma hash menghitung suatu representasi digital dengan panjang yang
telah ditentukan (message digest) dari suatu masukkan data yang panjangnya
berbeda-beda atau bermacam-macam. SHA-1 menerima masukan berupa pesan
dengan ukuran maksimum 264 bit (2.147.483.648 gigabyte) dan menghasilkan
message digest yang panjangnya 160 bit, lebih panjang dari message digest yang
dihasilkan oleh MD5 yang hanya 128 bit. Algoritma utama SHA-1 terdiri dari
enam proses utama berikut.
1. Inisialisasi variabel kunci
2. Penambahan bit 1
3. Pemecahan pesan ke dalam kelompok berukuran 512-bit
4. Ekstensi pesan
5. Iterasi utama
6. Pembangkitan hash value.