banco de dados cliente servidor.pdf
TRANSCRIPT

ENIO KILDER OLIVEIRA DA SILVA
UM ESTUDO SOBRE SISTEMAS DE BANCO DE DADOS CLIENTE/SERVIDOR
ASPER - ASSOCIAÇÃO PARAIBANA DE ENSINO RENOVADO FACULDADE PARAIBANA DE PROCESSAMENTO DE DADOS CURSO SUPERIOR DE TECNOLOGIA EM PROCESSAMENTO
DE DADOS
João Pessoa – PB 2001

UM ESTUDO SOBRE SISTEMAS DE BANCO DE DADOS CLIENTE/SERVIDOR

FICHA CATALOGRÁFICA
004.65 SILVA, Enio Kilder Oliveira S586u Um Estudo sobre Sistemas de Banco de Dados Cliente/Servidor. João Pessoa – PB, 2001 97p Monografia
1. Banco de Dados – Sistemas. 2. Cliente/Servidor – Arquitetura
I . Título ilus.

ENIO KILDER OLIVEIRA DA SILVA
UM ESTUDO SOBRE SISTEMAS DE BANCO DE DADOS CLIENTE/SERVIDOR
Orientad
ASPER - ASSOCIAÇÃO PARAIBANAFACULDADE PARAIBANA DE PROCCURSO SUPERIOR DE TECNOLOGI
DE DADOS
Monografia apresentada ao Curso
de Processamento de Dados da Faculdade Paraibana de Processamento de Dados, como um dos requisitos para a obtenção do título de Graduado em Processamento de Dados.or: Prof. Nilton Freire Santos .
DE ENSINO RENOVADO ESSAMENTO DE DADOS
A EM PROCESSAMENTO

ENIO KILDER OLIVEIRA DA SILVA
UM ESTUDO SOBRE SISTEMAS DE BANCO DE DADOS CLIENTE/SERVIDOR
Aprovada em _____/_____________/ 2001
BANCA EXAMINADORA
__________________________________ Orientador
__________________________________ Examinador (1)
__________________________________ Examinador (2)

Aos meus pais José de Arimatéa da Silva e Maria de Lourdes Oliveira da Silva e aos meus irmãos Nenê e Hercênio, DEDICO.

AGRADECIMENTOS
Primeiramente a Deus, por ter me dado vida, saúde e sabedoria necessária para
enfrentar os obstáculos.
Aos meus pais Arimatéa e Lourdes, pelo amor, carinho, educação e todo apoio necessário para minha formação.
Ao Prof. Nilton, por sua orientação para a conclusão deste trabalho, fica a minha
eterna gratidão.
À bibliotecária Cristiane Gaspar, pelo apoio técnico dado na organização deste trabalho.
À Jailma pela sua amizade, carinho e apoio, e também por ter me ajudado a
organizar o trabalho em cima da hora.

SUMÁRIO LISTA DE FIGURAS RESUMO CAPÍTULO 1 - APRESENTAÇÃO.............. ........................................................ ...... 10 1.1. Introdução........................................................................................................... ...... 10 1.2. Justificativa......................................................................................................... ...... 12 1.3. Objetivos............................................................................................................. ...... 14 1.3.1. Geral ................................................................................................................ ...... 14 1.3.2. Específicos....................................................................................................... ...... 14 1.4. Organização do Trabalho ................................................................................... ...... 15 CAPÍTULO 2 - REVISÃO BIBLIOGRÁFICA.................................................... ...... 16 2.1. Fundamentos sobre Sistemas de Banco de Dados.............................................. ...... 16 2.1.1. Retrospectiva Histórica ................................................................................... ...... 16 2.1.2. Teoria de Banco de Dados Multiusuário ......................................................... ...... 22 2.2. Fundamentos sobre a Arquitetura Cliente/Servidor ........................................... ...... 23 2.2.1. Aspectos Básicos da Arquitetura Cliente/Servidor ......................................... ...... 23 2.2.2. Tipos de Sistema Cliente/Servidor .................................................................. ...... 24 2.2.3. Principais Mecanismos.................................................................................... ...... 26 2.2.3.1. O Sistema Cliente ......................................................................................... ...... 26 2.2.3.2. O Sistema Servidor....................................................................................... ...... 28 2.2.3.3. A Rede de Comunicação de Dados .............................................................. ...... 30 2.2.4. Aplicações e Perspectivas................................................................................ ...... 32 CAPÍTULO 3 - SISTEMAS DE BANCO DE DADOS CLIENTE/SERVIDOR...... 33 3.1. Definições .......................................................................................................... ...... 33 3.1.1. O Sistema Cliente ............................................................................................ ...... 34 3.1.2. O Sistema Servidor.......................................................................................... ...... 35 3.2. Vantagens e Desvantagens ................................................................................. ...... 36 3.3. Componentes Principais ..................................................................................... ...... 38 3.3.1. O Sistema de Gerenciamento de Banco de Dados (SGBD) ............................ ...... 38 3.3.2. O Modelo de Representação de Dados............................................................ ...... 40 3.3.2.1. Modelo Relacional........................................................................................ ...... 41 3.3.2.2. Modelo Orientado a Objetos ........................................................................ ...... 43 3.3.2.3. Modelo Objeto-Relacional ........................................................................... ...... 46 3.3.3. A Linguagem SQL e seus Recursos ................................................................ ...... 47 3.3.3.1. Visões ........................................................................................................... ...... 50

3.3.3.2. Índices........................................................................................................... ...... 50 3.3.3.3. Transações .................................................................................................... ...... 51 3.3.3.4. Procedimentos Armazenados ....................................................................... ...... 51 3.3.3.5. Triggers......................................................................................................... ...... 52 3.3.4. Interfaces de Comunicação para Bancos de Dados......................................... ...... 52 3.3.4.1. ODBC ........................................................................................................... ...... 53 3.3.4.2. DBI ............................................................................................................... ...... 55 3.3.4.3. JDBC ............................................................................................................ ...... 57 3.3.4.4. BDE .............................................................................................................. ...... 59 3.3.5. Os Programas de Aplicação............................................................................. ...... 60 3.3.6. Gerência de Transações................................................................................... ...... 64 3.3.7. Controle de Concorrência................................................................................ ...... 67 3.3.8. Segurança e Administração ............................................................................. ...... 69 3.4. Principais Soluções da Indústria de Banco de Dados Cliente/Servidor............. ...... 72 3.4.1. Oracle .............................................................................................................. ...... 72 3.4.2. SQL Server...................................................................................................... ...... 74 3.4.3. Sybase SQL Server ......................................................................................... ...... 75 3.4.4. Informix........................................................................................................... ...... 76 3.4.5. C/A Ingres ....................................................................................................... ...... 78 3.4.6. IBM DB2......................................................................................................... ...... 79 3.4.7. Centura SQLBase............................................................................................ ...... 80 3.4.8. PostgreSQL ..................................................................................................... ...... 81 3.4.9. MySQL............................................................................................................ ...... 81 3.4.10. GemStone...................................................................................................... ...... 83 CAPÍTULO 4 - APLICAÇÕES DE BANCO DE DADOS CLIENTE/SERVIDOR 85 4.1. Aspectos Básicos................................................................................................ ...... 85 4.2. Processamento de Bancos de Dados Distribuídos ............................................. ...... 86 4.3. Internet e Intranets Organizacionais .................................................................. ...... 87 4.4. Sistemas de Informações Geográficas (GIS) ..................................................... ...... 89 4.5. Banco de Dados Multimídia............................................................................... ...... 91 4.6. Data Warehouses................................................................................................ ...... 92 CAPÍTULO 5 - CONCLUSÃO .............................................................................. ...... 93 5.1. Considerações Finais.......................................................................................... ...... 93 ABSTRACT .............................................................................................................. ...... 95 Referências Bibliográficas ...................................................................................... ...... 96

LISTA DE FIGURAS
FIGURA 1 - Representação de um sistema de banco de dados ................................ ...... 17 FIGURA 2 - Representação da arquitetura cliente/servidor ..................................... ...... 24 FIGURA 3 - Tipos de sistema cliente/servidor ......................................................... ...... 25 FIGURA 4 - Componentes de um sistema cliente .................................................... ...... 28 FIGURA 5 - Componentes de um sistema servidor .................................................. ...... 30 FIGURA 6 - Representação de um sistema de banco de dados cliente/servidor ...... ...... 35 FIGURA 7 - Estrutura de um SGBD......................................................................... ...... 39 FIGURA 8 - Modelo de banco de dados relacional .................................................. ...... 42 FIGURA 9 - Modelo de banco de dados orientado a objeto ..................................... ...... 44 FIGURA 10 - Exemplos de resultados obtidos através de instrução SQL ............... ...... 48 FIGURA 11 - A arquitetura ODBC........................................................................... ...... 55 FIGURA 12 - A arquitetura DBI............................................................................... ...... 56 FIGURA 13 - A arquitetura JDBC............................................................................ ...... 58 FIGURA 14 - A arquitetura do BDE......................................................................... ...... 59 FIGURA 15 - Interface de um programa de aplicação.............................................. ...... 61 FIGURA 16 - Estrutura de uma aplicação ................................................................ ...... 62 FIGURA 17 - Representação de um processo de transação...................................... ...... 66 FIGURA 18 - Conexão com SGBD cliente/servidor ................................................ ...... 70 FIGURA 19 - Definindo privilégios no SQL Server 6.5........................................... ...... 71 FIGURA 20 - Visão Geral do Oracle Enterprise Manager ....................................... ...... 73 FIGURA 21 - Visão geral do Microsoft SQL Server................................................ ...... 75 FIGURA 22 - Visão geral do Sybase SQL Server .................................................... ...... 76 FIGURA 23 - Visão geral do Command Center do Informix ................................... ...... 77 FIGURA 24 - Visão geral do Centro de Controle do DB2 ....................................... ...... 79 FIGURA 25 - Visão geral do MySQL para Windows .............................................. ...... 83 FIGURA 26 - Exemplo de aplicação web de comércio eletrônico ........................... ...... 88 FIGURA 27 - Exemplo de processamento de dados geográficos na Internet ........... ...... 90

RESUMO Esta pesquisa tem por objetivo, apresentar uma abordagem sobre os sistemas de banco de dados utilizados em ambientes de processamento cliente/servidor, descrevendo seus principais componentes e as tecnologias empregadas para integração entre bancos de dados e aplicações. Com base nesta análise são apontados os principais aspectos que levaram os sistemas de bancos de dados cliente/servidor a se tornarem as principais plataformas para gerenciamento de dados e suporte às novas aplicações.

CAPÍTULO 1 - APRESENTAÇÃO
1.1. INTRODUÇÃO
Segundo Hackathorn (1993, p.2), a última década do século XX ocasionou
uma profunda reavaliação sobre os fundamentos relativos aos sistemas de informação
utilizados nas empresas. Tal fato originou-se em virtude da discussão gerada em relação à
real efetividade de custo, desempenho e flexibilidade dos sistemas centralizados.
Com base na meta de reduzir custos operacionais e ao mesmo tempo
oferecer soluções de forma imediata aos seus clientes, as empresas apontaram como
alternativa, adotar um processo de modernização através do achatamento de suas estruturas
organizacionais. Tal processo visava integrar novas tecnologias às aplicações que
representam as regras de negócio da organização.

11
Paralelamente, mesmo com a mudança imposta pela adoção de novos
paradigmas empresariais, sempre houve a preocupação por manter dados pessoais e
gerenciais armazenados com segurança e ao mesmo tempo, gerenciados de forma rápida e
eficiente. Com a aquisição de novas soluções tecnológicas de tratamento de dados,
esperava-se atingir o objetivo esperado, que é a produção de informações operacionais,
necessárias para o processo de tomada de decisões.
De acordo com Date (1990, p.5), o propósito principal a ser alcançado pelos
sistemas de bancos de dados desde o seu surgimento, era o de oferecer recursos que visam
manter os dados organizacionais e torná-los disponíveis quando solicitados. Com a adoção
de sistemas de banco de dados, as empresas puderam dispor de uma ferramenta eficiente
para tratamento e disseminação de informações, superando assim todas as limitações
impostas pelos sistemas anteriores.
Hoje podemos afirmar que os sistemas de informação evoluíram
consideravelmente, contribuindo de forma significativa para o amadurecimento e o
crescente uso dos sistemas de banco de dados. Com o surgimento de novos modelos de
SGBDs, os sistemas de informação ganharam mais capacidade para armazenar e gerenciar
bancos de dados de forma simples e eficiente.
Já com a arquitetura cliente/servidor, os sistemas de banco de dados
ampliaram ainda mais a sua potencialidade e a sua importância para as empresas. Isso
impulsionou nos últimos anos o desenvolvimento de novas tecnologias capazes de prover
integração entre banco de dados e suporte a várias aplicações em diferentes plataformas
computacionais.

12
1.2. JUSTIFICATIVA
Os sistemas de banco de dados cliente/servidor passaram a ser adotados por
todas as empresas, devido às inúmeras vantagens apresentadas para prover suporte às
novas aplicações empresariais.
De acordo com Prado (1998, p.3), o que contribuiu de forma decisiva para
a disseminação do uso dos sistemas de bancos de dados cliente/servidor, foram os
inúmeros problemas encontrados em sistemas que utilizam o modelo de bancos de dados
centralizado. Apesar dos sistemas centralizados proporcionarem ganhos significativos de
produtividade, não ofereciam soluções para os seguintes problemas encontrados:
- Aumento de tráfego na rede, tendo como causa o acesso simultâneo dos usuários ao
banco de dados, gerando assim uma significativa degradação na performance do
sistema;
- Ausência de mecanismos que possibilitem restringir o acesso de usuários não
autorizados a determinadas informações do banco de dados;
- O grande volume de dados que eram processados em estações que, em muitos
casos, não possuíam capacidade de processamento adequada nem memória
suficiente.

13
A utilização da arquitetura cliente/servidor permitiu que os sistemas de
banco de dados atuais pudessem superar todas as limitações impostas pelos sistemas
centralizados, tornando o processo de gerência de banco de dados mais eficiente e com
maior grau de segurança. Além desses benefícios, a arquitetura cliente/servidor possibilitou
que os sistemas de informação pudessem evoluir, adotando novos recursos de hardware e
software, capazes de oferecer maior eficiência e performance aos sistemas de gerência de
banco de dados e suas aplicações.
Como justificativa para o tema proposto, podemos destacar que a
importância deste trabalho leva em conta que, os sistemas de banco de dados
cliente/servidor, são os principais recursos da tecnologia da informação empregados
atualmente nas empresas. A fim de ter-se um conhecimento amplo a respeito destes
sistemas, pretende-se com este trabalho fornecer uma fonte de informação abrangente a
respeito dos fundamentos e dos recursos tecnológicos empregados, de modo a contribuir
para desenvolvimento de novas aplicações cliente/servidor.
Vale lembrar que, a mudança do paradigma de “sistema centralizado” para o
paradigma de “sistema cliente/servidor”, acabou se tornando uma atitude a ser adotada
firmemente pelas organizações. Paralelamente, os sistemas de banco de dados, dentro deste
novo paradigma, continuarão em pleno processo de evolução de modo a expandir cada vez
mais a sua capacidade de forma a lidar com novos tipos de aplicações.

14
1.3. OBJETIVOS
1.3.1. GERAL
Apresentar um estudo sobre sistemas de banco de dados que usam a
arquitetura cliente/servidor, descrevendo os principais aspectos que contribuíram para
transforma-la na principal plataforma para desenvolvimento de novas soluções, voltadas ao
gerenciamento de dados empresariais.
1.3.2. ESPECÍFICOS
- Apresentar os principais componentes dos sistemas de banco de dados
cliente/servidor e sua aplicabilidade no processo de gerência de banco de dados;
- Identificar as principais ferramentas disponíveis e os processos utilizados no
gerenciamento de banco de dados multiusuário atuais;
- Descrever os principais benefícios dos modelos de banco de dados cliente/servidor
e suas aplicações.

15
1.4. ORGANIZAÇÃO DO TRABALHO
Os itens subseqüentes deste trabalho estão distribuídos da seguinte forma:
O Capítulo 2 aborda os conceitos fundamentais sobre os sistemas de banco
de dados e a arquitetura cliente/servidor. Descreve os aspectos históricos e técnicos destas
tecnologias, de modo a servir de base para compreensão a respeito da metodologia de
funcionamento dos sistemas de banco de dados cliente/servidor.
O Capítulo 3 relata uma visão geral sobre os conceitos fundamentais
referente aos sistemas de banco de dados cliente/servidor. São apresentadas as
características de seus componentes e os principais mecanismos utilizados no processo de
gerenciamento e segurança dos dados. Também serão abordados neste capítulo os
principais SGBDs cliente/servidor existentes no mercado, descrevendo algumas das
principais características empregadas nestes produtos.
O Capítulo 4 descreve as principais aplicações de banco de dados
clientes/servidor, analisando os principais aspectos funcionais e tecnológicos e empregados
nestas aplicações.
O Capítulo 5 apresenta a conclusão do trabalho realizado, expondo as
considerações finais do autor, sugestões e outras observações que poderão contribuir para
futuras pesquisas relacionadas o tema deste trabalho.

CAPÍTULO 2 - REVISÃO BIBLIOGRÁFICA
2.1. FUNDAMENTOS SOBRE SISTEMAS DE BANCO DE DADOS
2.1.1. Retrospectiva Histórica
Em meados dos anos 60 do Século XX, os paradigmas de armazenamento e
processamento de informações passaram por uma grande mudança com o surgimento da
tecnologia de armazenamento baseada em discos magnéticos. Isso fez com que dados e
aplicações de software, que antes formavam um único elemento, passaram a ser
independentes um do outro. Isso permitiu a criação de ferramentas capazes de gerenciar e
manipular estes dados da forma mais eficiente possível a fim de obter os resultados
esperados.
Os sistemas de banco de dados vieram a surgir na década de 60, com o
objetivo de fornecer recursos capazes de armazenar, organizar, manipular e recuperar
dados de forma segura, rápida e eficiente. Trata-se de uma solução que supera todas as

17
limitações da tecnologia baseada nos sistemas de arquivos tradicionais, que tinham uma
ampla dependência com relação à forma de organização da estrutura dos arquivos. Essa
dependência obrigava a alterar toda programação das funções de dados, sempre que
houvesse alterações em sua estrutura. Além disso, eles não apresentavam soluções para
problemas relativos à duplicação da informação, inconsistências e integridade.
Segundo Melo (1997, p.3), um sistema de banco de dados pode ser definido
como “um ambiente de hardware e software composto por dados armazenados em banco
de dados (BD), o software que gerencia o banco de dados (SGBD) e os programas de
aplicação”.
Pode-se dizer que esta modalidade de processamento de dados trouxe uma
série de vantagens, sendo que a mais significativa foi tornar os bancos de dados
independentes da aplicação. As aplicações, que antes acessavam os dados diretamente,
passaram a se comunicar com o SGBD, enviando apenas as requisições necessárias para
obter os resultados desejados.
Figura 1: Representação de um sistema de banco de dados

18
Para chegar aos modelos atuais, os sistemas de banco de dados passaram por
uma série de mudanças na sua arquitetura, de forma a se tornar compatível com as novas
tendências de tecnologia adotadas pelas organizações. Nos anos 70, quando o foco
principal era voltado exclusivamente aos programas de aplicação, os sistemas projetados
tinham a função de atender apenas as necessidades específicas da empresa. Isso resultou
em sistemas robustos, que dependiam diretamente da plataforma computacional na qual
eram projetados para operar.
Já nos anos 80, o avanço da tecnologia dos chips contribuiu de forma
significativa para diminuir o tamanho e o custo dos computadores. Juntamente com a
popularização do software e a disseminação das redes de computadores, criou-se uma nova
filosofia de desenvolvimento de aplicações de bancos de dados, cujo foco estaria
centralizado no usuário final. Com a difusão da computação distribuída, que levou a
aplicação a ser executada nas estações de trabalho, os requisitos de novas aplicações se
baseavam em oferecer recursos que tornassem a apresentação dos dados mais simples para
os usuários. Para complementar, as ferramentas de conectividade remotas adequadas,
fizeram com que os dados pusessem ser compartilhados por sistemas computacionais de
diferentes plataformas.
Atualmente os sistemas de banco de dados podem ser agrupados em
modelos, os quais representam claramente os diversos estágios de evolução até chegar aos
modelos atuais. Segundo Salemi (1994, p.7), os modelos de banco de dados possibilitaram
dividir os sistemas em várias categorias que serão apresentadas a seguir.

19
a) Sistema de Gerenciamento de Arquivos (FMS – File Management System): Foi a
primeira forma utilizada para armazenamento de dados em banco de dados. A
metodologia de funcionamento e baseia em armazenar os dados de forma
seqüencial em um único arquivo. Esse sistema tem como vantagem a simplicidade
na forma em que os dados são estruturados no arquivo. No entanto esse sistema não
apresenta relação entre os dados, nem mecanismos de busca, classificação e
recursos para evitar problemas de integridade.
b) Sistema de Banco de Dados Hierárquico (HDS – Hierarquical Database System):
Surgiu na década de 60 com a primeira linguagem de banco de dados conhecida
como a DL/I desenvolvida pela IBM e a North American Aviation. É um modelo
de banco de dados onde os dados armazenados são estruturados em forma de
árvore. Cada estrutura de dados se origina a partir de um nó raiz e se ramifica
criando relações pai-filho com outras classes de dados, criando assim relações de
um para vários elementos. A desvantagem estaria na rigidez da estrutura de dados,
que obrigaria refazer todo o banco de dados, caso a classe de dados principal ou a
classe que possuem classes dependentes fosse alterada. São exemplos de bancos de
dados hierárquicos o IMS (Information Management System) da IBM e TDMS
(Time-shared Database Management System) da System Development
Corporation.
c) Sistema de Banco de Dados em Rede (NDS - Network Database System): Esse
modelo surgiu entre a década de 60 e 70 como uma extensão do modelo
hierárquico, incorporando recursos para criar mais de uma relação pai-filho e
estabelecer relações entre os seus elementos. Esta metodologia torna a pesquisa

20
mais rápida e mais flexível, pois não depende de um único nó raiz como vetor de
inicialização de pesquisa. Entretanto apesar da flexibilidade, o modelo de rede
ainda apresenta os mesmos problemas com relação ao projeto de estrutura do
modelo hierárquico. Qualquer alteração feita em uma classe de dados implicaria na
criação de uma nova estrutura para suportar àquela alteração. Seus principais
representantes são o IDS da General Eletric e o Idms da Cullinet.
d) Modelo de Dados Relacional (RDM – Relational Data Model): Trata-se de um
modelo criado na década de 70 pelo pesquisador da IBM Dr. E. F. Codd, cujo
propósito era representar os dados de forma mais simples, através de um modelo
matemático de conjuntos de tabelas inter-relacionadas. Este modelo abandona por
completo os conceitos anteriores, tornando os bancos de dados mais flexíveis, tanto
na forma de representar as relações entre os dados, como na tarefa de modificação
de sua estrutura, sem ter que reconstruir todo o banco de dados. A única
peculiaridade com os modelos anteriores é que os detalhes sobre como os dados são
armazenados e acessados não são revelados ao usuário, o que torna necessário
projetar as aplicações de forma de acessem os dados baseados apenas no formato já
estabelecido pelo SGBD.
Com base nesta retrospectiva, podemos notar que os modelos de dados são
diretamente responsáveis pela evolução dos sistemas de banco de dados. Com o
surgimento de novos modelos, novas categorias de SGBDs puderam ser utilizadas ao longo
dos anos. Podemos citar como exemplo o ADABAS da Software A. G. que usa o modelo
de banco de dados baseados em listas invertidas1.
1 Trata-se de um tipo de banco de dados que se baseia em realizar pesquisas através de mecanismos derotas de acesso, diferente dos bancos de dados relacionais que se fundamentaram na álgebra relacional.

21
Os novos modelos de banco de dados com tecnologia de orientação a
objetos (OODBMS – Object-Oriented Database Management System)2 são considerados
uma forte tendência para estabelecimento de um modelo para novas tecnologias de banco
de dados. No entanto, devido à falta de um modelo padrão para construção de bancos de
dados OO puros, a baixa performance apresentada por eles, e a falta de recursos utilizados
atualmente em grande escala em aplicações empresariais, fizeram com que a demanda por
OODBMS diminuíssem.
Como alternativa, vários fabricantes de SGBD adotaram a medida de
incorporar características OO aos modelos relacionais, criando assim os modelos de banco
de dados objeto-relacionais (ORDBMS – Object-Relational Database Managenent
System).
Atualmente o modelo de dados Objeto-Relacional já está sendo
implementado na maioria dos produtos de SGBD. Acredita-se que o uso estes produtos
será cada vez mais difundido em relação aos ORDBMS devido ao sucesso dos já
consolidados bancos de dados relacionais.
2 Considera-se orientação a objetos como uma terminologia usada para desenvolvimento de sistemascom uso de recursos de modularidade e reusabilidade de componentes.

22
2.1.2. Teoria de Banco de Dados Multiusuário
Um banco de dados multiusuário, segundo Kroenke (1999, p.205), é um
tipo especial de banco de dados que pode ser manipulado por mais de um usuário ao
mesmo tempo. Este conceito surgiu com base na preocupação em fazer com que os
processos de um usuário não interferissem nos dos demais, garantindo assim a integridade
dos dados do sistema.
Atualmente, os bancos de dados multiusuário são utilizados em todos os
tipos de aplicações, onde os acessos são realizados simultaneamente por vários usuários.
Podemos ter como exemplo os sistemas de dados bancários, automação comercial, agência
de viagens, etc.
Com relação à arquitetura, os bancos de dados multiusuário, no princípio,
eram baseados nos modelos de sistemas onde todo o processamento era feito em um
computador central (mainframe ou minicomputador). Todas as requisições dos usuários
eram feitas através de terminais ou em computadores que emulavam esses terminais. Com
o surgimento dos microcomputadores e a interligação destes através de rede de
comunicação de dados, a exigência de bancos de dados com características de
processamento multiusuário tornou-se um requisito cada vez mais importante, devido às
inúmeras operações de transações que são realizadas pelas aplicações.

23
2.2. FUNDAMENTOS SOBRE A ARQUITETURA CLIENTE/SERVIDOR
2.2.1. Aspectos Básicos da Arquitetura Cliente/Servidor
A arquitetura cliente/servidor é atualmente a principal plataforma
tecnológica da indústria tecnologia da informação. A sua popularização se deve aos vários
fatores oriundos do processo de achatamento das estruturas organizacionais, fazendo com
que muitos dos sistemas fossem descentralizados.
Segundo Renaud (1994, p.3) “cliente/servidor é um conceito lógico, mais
precisamente um paradigma, ou modelo para interação entre processos de software em
execução concorrente”. Isso significa dizer que a metodologia cliente/servidor foi criada
com o objetivo de possibilitar que vários tipos de aplicações, executadas em máquinas
distintas, se comuniquem entre si, sem que a execução de um processo interfira no do
outro.
Baseado neste conceito, a arquitetura cliente/servidor estabeleceu um novo
paradigma de processamento de dados, diversificando o processamento entre dois
processos de software distintos (cliente e servidor). Ao mesmo tempo a arquitetura visa
fornecer recursos que coordenem estes processos de forma que, a perda de sincronização,
não resulte em alterações ou perda de informações para o sistema.

24
Seu funcionamento se baseia no seguinte esquema: o usuário do sistema,
através do processo de software cliente, envia o pedido de requisição ao processo de
software servidor, que por sua vez devolve ao cliente os resultados solicitados. Todos os
processos de software rodam sobre o controle do Sistema Operacional que coordena todos
os recursos do sistema computacional utilizado.
Figura 2: Representação da arquitetura cliente/servidor
2.2.2. Tipos de Sistema Cliente/Servidor
Ainda segundo o autor, os sistemas cliente/servidor podem ser divididos em
vários tipos, dependendo da forma em que os processos cliente e servidor estão alocados.
Os tipos de sistema podem ser classificados nas seguintes categorias descritas a seguir.

25
a) Intra-sistema cliente/servidor: sistemas nos quais os processos cliente e servidor
residem no mesmo local. São exemplos típicos as estações de trabalho, isoladas ou
não da rede. O usuário ao fazer uso da aplicação local emite uma solicitação de
serviço ao processo servidor situado na mesma máquina onde o usuário está
operando;
b) Servidor Desktop: abrange os sistemas nos quais tanto o processo cliente quanto o
servidor residem na máquina servidora e os usuários, através de uma estação ou
terminal remoto, interagem com o processo cliente remotamente emitindo o pedido
e recebendo os resultados;
c) Cliente Desktop: nesse sistema o processo cliente é executado na estação de
trabalho do usuário na qual são enviadas as requisições à máquina servidora através
da rede. O servidor por sua vez recebe as requisições do cliente, efetua o
processamento e devolve os resultados.
Figura 3: Tipos de sistema cliente/servidor

26
Atualmente, mesmo possibilitando a execução dos processos tanto o cliente
quanto o servidor em uma única máquina, o que caracteriza realmente o fundamento da
arquitetura cliente/servidor hoje em dia é a divisão do poder de processamento. Os dois
processos são separados em máquinas distintas e ao mesmo tempo, são interligadas através
de uma rede de computadores local (LAN) ou remota (WAN), o que permite as estações de
trabalho processarem os dados armazenados no servidor, liberando o mesmo para a
execução de outras aplicações.
2.2.3. Principais Mecanismos
Os principais mecanismos da arquitetura estão divididos entre sistema
cliente, sistema servidor e a rede de comunicação de dados. Serão analisadas neste tópico
as principais características que complementam cada um destes mecanismos, visando um
melhor entendimento sobre a sua importância para o processamento das informações.
2.2.3.1. O Sistema Cliente
O sistema cliente é a parte responsável pela tarefa de requisição de pedidos
ao servidor e também por toda a parte relativa à interação com o usuário final.
Normalmente os sistemas cliente abstraem do usuário todas as funções de rede e do
servidor, fazendo parecer que todos os processos estão rodando em um mesmo local.

27
Para prover esta interação, o sistema cliente abrange um conjunto de
componentes básicos que auxiliam nas funcionalidades, tanto ao nível de aplicação como
de sistema. Estes componentes de acordo com Melo (1997, p.28) são agrupados em:
a) Hardware de estação: é formado pelos componentes básicos de um sistema de
computação, tais como unidade central de processamento (CPU), memória,
unidades de disco e dispositivos de entrada e saída de dados (periféricos);
b) Sistema operacional: é o software que possui o conjunto de instruções necessárias
para gerenciar os recursos de hardware e fornecer os meios necessários para que as
aplicações utilizem estes recursos de forma adequada;
c) Interface de conectividade: concentra o conjunto de instruções para permitir que os
processos cliente interajam com o processo servidor através da rede de
comunicação;
d) Os programas de aplicação: consiste em um conjunto de programas desenvolvidos
com a finalidade de realizar operações que atendam a uma necessidade específica
do usuário ou organização;
e) Interface Gráfica de Usuário (GUI): é o principal componente de interação de
interação com os usuários finais, pois é o que torna as aplicações serem utilizadas
de forma mais simples e intuitiva.

28
Figura 4: Componentes de um sistema cliente
2.2.3.2. O Sistema Servidor
O sistema servidor é a parte responsável de um sistema cliente/servidor que
tem a função de receber dos clientes as requisições, processa-las e devolve-las ao mesmo
os resultados. A grande vantagem desse sistema é que, por ser totalmente reativo, só é
disparado quando recebe alguma requisição do cliente. Isso faz com que o servidor não
procure interagir com outros servidores durante um pedido de requisição, o que torna o
processo de ativação uma tarefa a ser desempenhada apenas pelo cliente que o solicitou.

29
Da mesma forma que o sistema cliente, o sistema servidor possui um
conjunto de componentes básicos para prover as funcionalidades necessárias ao
processamento de informações através da rede. Estes componentes são divididos em:
a) Hardware de servidor: normalmente são compostos por sistemas de computação
que variam de microcomputadores de alto desempenho até computadores de grande
porte. Estes sistemas, para cumprir a função de servidor, devem possuir alta
capacidade de armazenamento e grande quantidade de memória para fornecer
melhor desempenho aos processos que estarão sempre rodando a espera de
requisições;
b) O sistema operacional de rede: consiste em um recurso de software que além de
gerenciar os componentes de hardware, fornecem recursos que possibilitam obter o
controle total da rede de comunicações através de componentes de controle de
acesso, compartilhamento de recursos, administração e gerência, além de outras
funções de rede necessárias;
c) Interface de conectividade: são caracterizados pelo uso de protocolos de
comunicação e de interfaces para acesso a bancos de dados;
d) O SGBD: é o componente do sistema de banco de dados responsável por todo o
gerenciamento e controle centralizado dos dados operacionais.

30
Figura 5: Componentes de um sistema servidor
2.2.3.3. A Rede de Comunicação de Dados
A rede de comunicação de dados consiste em um conjunto de componentes
de hardware e software, interligados de forma a oferecer interação entre os sistemas cliente
e servidor. As redes de computadores, as quais são formadas pela interconexão entre os
computadores de um sistema computacional, estabelecem um caminho físico para que os
processos cliente e servidor se comuniquem.

31
Segundo Melo (1997, p.41), “as ligações podem ser implementadas através
de linhas telefônicas públicas, linhas privadas de comunicação, canais de satélite ou de
rádio e outros meios que a tecnologia está disponibilizando, com a mesma função”. Com
base nesta observação, pode-se dizer que o avanço tecnológico contribuiu bastante para
disseminação e uso das redes e conseqüentemente para a expansão do uso dos recursos
computacionais em diversas áreas de aplicação.
Atualmente os tipos de rede são agrupados em três categorias distintas. Esta
classificação é feita de acordo com a distância em que os componentes de hardware estão
alocados. Estas redes podem ser:
a) Redes Locais (Local Area Networks - LANs): são redes que permitem a
interconexão de equipamentos de comunicação de dados e compartilhamento de
recursos numa área fisicamente próxima, tais como as propriedades privadas;
b) Redes Metropolitanas (Metropolitan Area Networks - MANs): são redes
que apresentam as mesmas características das redes locais, porém cobrem
distâncias maiores do que as LANs e operam em velocidades maiores;
c) Redes Geograficamente Distribuídas (Wide Area Networks - WANs): são redes
capazes de compartilhar recursos especializados por uma comunidade maior de
usuários geograficamente dispersos.

32
Outro fator importante com relação à comunicação é a questão de como as
estações de trabalho se comunicam através da rede, independente do tipo de rede utilizado.
Para que seja possível viabilizar esta comunicação, os sistemas cliente/servidor utilizam
protocolos de rede, que são elementos responsáveis pela interação entre sistemas de igual,
ou diferentes plataformas. Dentre os principais protocolos podemos destacar o TCP/IP,
Netware IPX/SPX, AppleTalk, NetBios e OSI (Open Systems Interconnection).
2.2.4. Aplicações e Perspectivas
Embora as aplicações destinadas ao acesso aos bancos de dados em rede sejam as
mais utilizadas nesta arquitetura, elas apenas representam apenas um tipo comum de
sistemas cliente/servidor. Existem várias outras aplicações entre as quais podemos citar a
própria Internet, que utiliza redes de comunicações para prover uma grande variedade de
serviços. Outras aplicações podem ser inseridas neste contexto, como por exemplo, os
sistemas de gerenciamento de backup, gerenciamento de impressão, aplicações multimídia
e comunicações.
Convém afirmar que a adoção desta arquitetura impulsionou o mercado a
desenvolver produtos cada vez mais poderosos, não só para oferecer interação com o
usuário, como também para aumentar a produtividade no campo de desenvolvimento de
aplicações, deixando de lado a filosofia de se desenvolver produtos voltados apenas ao
gerenciamento do banco de dados.

CAPÍTULO 3 - SISTEMAS DE BANCO DE DADOS CLIENTE/SERVIDOR
3.1. DEFINIÇÕES
Um sistema de banco de dados cliente/servidor pode ser definido como um
sistema cliente/servidor onde pelo menos uma máquina servidora é responsável por manter
e processar o banco de dados. Os dados armazenados ficam disponíveis aos usuários que
poderão manipula-los através das aplicações cliente, instaladas em suas estações de
trabalho individuais.
Os sistemas de banco de dados cliente/servidor são utilizados atualmente
pela maioria das organizações, devido à flexibilidade obtida com esta plataforma. Com a
arquitetura cliente/servidor, tornou-se possível criar um ambiente capaz de fornecer um
controle centralizado dos dados. Ao mesmo tempo, pode-se integrar novas tecnologias e
aplicações de banco de dados, independente do tipo de plataforma ou sistema operacional
utilizado. Isso reforça ainda mais a demanda por novas aplicações que não aderem a
padrões específicos de arquitetura (sistemas abertos).

34
Com base na filosofia cliente/servidor, os sistemas de banco de dados
dividem o processamento entre os dois sistemas distintos. Para execução de suas
respectivas tarefas, estes sistemas utilizam uma estrutura, que normalmente compõe um
servidor de banco de dados e as estações de trabalho, interligadas através da rede.
Os sistemas podem ser definidos em sistemas Cliente e Servidor, cujos
detalhes serão descritos a seguir.
3.1.1. O Sistema Cliente
Encarrega-se de executar nas estações cliente as aplicações responsáveis
pela manipulação dos dados armazenados no servidor de banco de dados. As aplicações
cliente/servidor, chamadas de aplicações “front-end”’, correspondem a um conjunto de
programas integrados desenvolvidos em alguma linguagem de programação1.
Essas aplicações são na sua grande maioria compostas de uma interface
gráfica de usuário (GUI – Graphical User Interface) e de funções que permitem realizar
tarefas de requisição de serviços ao servidor. Isso permite ao usuário interagir com o
SGBD sem ter que se preocupar com as complexidades da arquitetura, no que diz respeito
aos métodos utilizados para acesso aos dados armazenados, bem como na forma na qual
eles são atualizados.
1 Trata-se de um software que tem a capacidade de desenvolver novos programas de aplicação. Algumaslinguagens podem ser utilizadas para desenvolver até mesmo outras linguagens de programação.

35
3.1.2. O Sistema Servidor
Constitui na parte que concentra o banco de dados, o SGBD propriamente
dito a as demais aplicações, conhecidas como aplicações “back-end”. Estes componentes
têm a função realizar o processamento dos dados requisitados pelo cliente através da rede.
No que se refere à localização dos dados e do SGBD no servidor, tanto
podem estar armazenados em servidores que executam outras tarefas (como por exemplo,
um servidor de arquivos ou de comunicações), ou em um servidor dedicado (servidor de
banco de dados).
Figura 6: Representação de um sistema de banco de dados cliente/servidor

36
3.2. VANTAGENS E DESVANTAGENS
Com base na filosofia cliente/servidor voltada ao processamento de banco
de dados, existe uma série de vantagens significativas, dentre as quais podemos destacar:
- O aumento de desempenho, através da distribuição das tarefas de banco de dados
entre computadores clientes e servidores. Todo o processamento desempenhado
pelo SGBD passou a ser executado no lado do servidor, enquanto que as aplicações
que manipulam dados, passaram a ser executadas no lado do usuário nas estações
de trabalho, reduzindo drasticamente o tráfego da rede;
- A independência da estação de trabalho, que torna possível aos usuários
executarem aplicações de banco de dados em qualquer tipo de plataforma ou
sistema;
- A preservação da integridade dos dados, dando ao SGBD a capacidade de efetivar
controle de atualizações através de mecanismos de transações e controle de
concorrência, adequados ao processamento de banco de dados multiusuário;
- Segurança dos dados reforçada, através de mecanismos de backup e restauração de
banco de dados implementados nos produtos de SGBDs.

37
No que se refere às desvantagens, a utilização de banco de dados
cliente/servidor pode apresentar alguns inconvenientes, tais como:
- Aumento de custo com pessoal, o que obriga a investir em capacitação ou
contratação de profissional para administração e suporte para manutenção do banco
de dados;
- O aumento da quantidade de componentes de sistema pode contribuir para
aumentar a complexidade;
- A independência de aplicativos cliente/servidor pode aumentar a quantidade de
suporte de programação para estações de trabalho;
- A necessidade de se ter controle efetivo das operações de transação com dados.
Como as estações de trabalho tendem a acessar os dados de forma simultânea,
tornaria necessário então coordenar o processamento das aplicações para evitar
perda de atualização de dados na rede.

38
3.3. COMPONENTES PRINCIPAIS
3.3.1. O Sistema de Gerenciamento de Banco de Dados (SGBD)
Podemos caracterizar o SGBD como um recurso de software composto por
programas e utilitários destinados às tarefas voltadas para o completo gerenciamento de um
sistema de banco de dados. As principais tarefas a serem desempenhadas pelo SGBDs se
constituem no armazenamento, organização, atualização e restauração de banco de dados
de sistemas computacionais.
O SGBD é considerado o componente mais importante do sistema de banco
de dados, pois concentra todos recursos que definem o que um sistema computacional deve
possuir para gerenciar bases de informações, de modo a atender às necessidades de
integração, exigidas pelas novas tecnologias.
Sob o ponto de vista lógico, seu principal propósito era de estabelecer um
modelo que representasse o mundo real, capturando os dados e dando a eles conteúdo e
estrutura de forma a tornar possível ao banco de dados representar logicamente os aspectos
da vida real de cada elemento para um fim específico de um usuário ou grupo de usuários.

39
Na prática, além de cobrir estas necessidades, a utilização dos SGBDs
tornou a administração do banco de dados mais segura, fazendo com que as aplicações não
tenham acesso direto ao dados armazenados, como era o caso dos sistemas de arquivos
convencionais. Todas as requisições feitas pelas aplicações passaram a ser analisadas e
processadas pelo SGBD. Isso favoreceu a sua utilização como base de administração de
dados para diversos tipos de aplicações.
Figura 7: Estrutura de um SGBD
Em resumo, as principais características funcionais dos SGBDs, podem ser
definidas da seguinte maneira:
- Todas as operações em banco de dados solicitadas pelos clientes são realizadas
diretamente pelo SGBD no próprio servidor, devolvendo ao cliente apenas o
resultados;

40
- Utiliza esquemas de controle de acesso, que determinará quais usuários terão
acesso aos dados armazenados no banco de dados, assim como os privilégios
que cada um terá sobre eles;
- Utiliza-se de toda a potencialidade do servidor para a execução de operações de
validação de dados e execução de instruções mais complexas;
- Garante a segurança dos dados armazenados e as mantém ao mesmo tempo
rapidamente disponíveis aos usuários.
Com o passar dos anos, a evolução dos SGBDs vem contribuindo bastante
para o surgimento de produtos cada vez mais sofisticados. Muitas empresas produtoras de
software têm investido constantemente na criação e aprimoramento destes produtos. Um
dos fatores que tem contribuido bastante é o aprimoramento dos modelos de representação
de dados que são considerados o principal elemento responsável pela evolução dos
SGBDs.
3.3.2. O Modelo de Representação de Dados
O modelo de representação de dados é o elemento que está diretamente
relacionado à qualidade dos SGBDs, pois dá a eles a capacidade de traduzir ou modelar o
mundo real, descrevendo como os dados serão acessados e manipulados pelos usuários.

41
Com o passar dos anos, vários modelos surgiram gerando novas categorias
de banco de dados. Atualmente o modelo relacional é a principal base para o
desenvolvimento de produtos de SGBDs. Esse modelo, além de solucionar os problemas
encontrados nos modelos que o antecederam, ainda deu mais flexibilidade na organização
e manipulação de bancos de dados maiores e mais complexos. No entanto, com o avanço
da tecnologia, a demanda por sistemas capazes de gerenciar dados complexos tornou-se
um fator que impulsionou a elevação de esforços para criar novos modelos de tratamento
de dados.
Segue aqui um relato sobre os principais modelos de dados existentes e os
que poderão se tornar a plataforma principal para desenvolvimento de novos SGBDs
cliente/servidor.
3.3.2.1. Modelo Relacional
O modelo relacional foi criado por Codd em 1970 com o propósito de tornar
o mundo mais simples na visão dos usuários e dar aos SGBDs a capacidade de processar os
dados de forma mais eficiente. O modelo relacional se baseia em representar os dados em
forma de tabelas, que se relacionam através de um elemento comum que atenda às
restrições impostas pelo próprio modelo, garantindo a integridade dos dados.

42
Figura 8: Modelo de banco de dados relacional
O sucesso atual dos SGBDs que usam o modelo relacional fez com que
estes produtos dominassem cerca de 90% do mercado de bancos de dados corporativos.
Juntamente com a linguagem SQL e as interfaces de comunicação, este modelo facilitou a
implementação de vários processos disponíveis na vida dos usuários. Hoje é comum
encontrar aplicações de bancos de dados relacionais cliente/servidor em diversos ambientes
de sistemas empresariais, seja na Internet ou em ambientes corporativos mais restritos.
No entanto, a ampla utilização dos bancos de dados ao logo do tempo fez
com que houvesse uma demanda cada vez maior por modelos capazes de operar com
novos tipos de dados (como som, imagens, texto, etc.), cada vez mais comuns nas
aplicações empresariais atuais.

43
3.3.2.2. Modelo Orientado a Objetos
Analisando as aplicações atualmente existentes, podemos perceber que
existe uma grande variedade de novos tipos de dados os quais somos obrigados a lidar. A
necessidade de fazer com que dados não-convencionais, pudessem ser estruturados e
armazenados em banco de dados, tornou-se um motivo para que se desenvolvessem
modelos de dados mais complexos para atender a esses requisitos.
O modelo de banco de dados orientado a objetos (OO) é baseado nos
conceitos de orientação a objetos, já difundidos em linguagens de programação como o
SmallTalk e o C++. Seu objetivo principal é tratar os tipos de dados complexos como um
tipo abstrato (objeto), podendo ser definidos tanto à nível interno como pelo próprio
usuário.
Segundo Silberschatz (1999, p.269), a filosofia do modelo de dados OO
consiste em agrupar os dados e o código que manipula estes dados em um único objeto,
estruturando-os de forma que possam ser agrupados em classes. Isso significa que, baseado
nos conceitos OO, os objetos de banco de dados agrupados podem usar o mesmo
mecanismo de herança para definir superclasses e subclasses de objetos, criando assim
hierarquias.

44
Figura 9: Modelo de banco de dados orientado a objeto
Dentre as vantagens significativas proporcionadas pelos SGBD orientados a
objetos (SGBDOO), podemos destacar a capacidade de integração com linguagens de
programação OO. Esta integração permite que os métodos envolvidos no processo de
armazenamento e gerenciamento possam ser feitos de forma automática, desconsiderando
a necessidade de ter conhecimento da linguagem de programação utilizada.
Outra vantagem do modelo OO é a capacidade de permitir que os usuários
definam tipos de dados que serão gerenciados pelo SGBD. No modelo OO não existe
dependência de relacionamentos. Os tipos dados também não precisam ser incorporados
aos SGBDs, como ocorre nos modelos relacionais.

45
As desvantagens significativas, no entanto, estariam relacionadas às
exigências impostas pela linguagem de programação OO, além do alto custo de conversão
do banco de dados tradicional para o modelo OO. A ausência de ferramentas mais
eficientes para geração de consultas e relatórios também é um fator a ser considerado.
Podemos considerar ainda que não se tem uma informação precisa sobre o
desempenho dos SGBDOO em sistemas que lidem com grande volume de dados, o que
levanta a dúvida sobre se os SGBDOO são ou não melhores do que os SGBDs, utilizados
atualmente no processamento de dados convencionais. Acredita-se também que os
SGBDOO demandem recursos mais eficazes destinados ao processamento de transações e
controle de concorrência.
Para finalizar, é importante que se tenha uma definição de um padrão
específico para a construção de SGBDOO. Segundo Kroenke (1999, p.322), são
apresentadas duas soluções de padronização para incluir recursos de orientação a objetos
aos bancos de dados. Uma delas é o desenvolvimento do padrão SQL3 proposta pelos
comitês ISO e ANSI fundamentada na ampliação do padrão SQL92, usado nos modelos
relacionais.
A outra solução se origina de um consórcio entre fabricantes de banco de
dados de objetos com outros especialistas. Trata-se do modelo ODMG-93, que se baseia no
objeto como sua estrutura fundamental e os aspectos relacionados ao gerenciamento de
dados são tidos como um processo evolutivo.

46
O ODMG-93 é um modelo completamente diferente do padrão SQL3 que se
baseia na visão do banco de dados e evolui na visão do objeto. Ainda segundo o autor, não
se tem certeza de qual padrão será o mais utilizado, mas acredita-se que muitas empresas
produtoras de software poderão se apoiar em qualquer um destes padrões para construção
de SGBDOO cliente/servidor.
3.3.2.3. Modelo Objeto-Relacional
O Modelo Objeto-Relacional surgiu como uma alternativa de expandir o
modelo relacional para atender a demanda de construção de sistemas a lidar com dados
complexos não suportados pelo modelo relacional. O fator que obrigou o seu surgimento se
fundamentou nas questões relacionadas a real efetividade do modelo OO, no que diz
respeito ao desempenho e custos com a migração de bancos de dados relacionais para
bancos de dados OO. Como conseqüência, a migração ocasionaria uma brusca mudança
em praticamente todas as aplicações que completam o sistema computacional da
organização.
Este modelo se baseia na adoção de conceitos de orientação a objetos
integrados ao modelo relacional. Isso significa dizer que este modelo é capaz de incluir
características de orientação a objetos e ao mesmo tempo incorporar estruturas às
linguagens de consultas relacionais como a SQL.

47
Como principal benefício, esse modelo permite ampliar a capacidade dos
SGBDs para lidar com dados complexos, evitando que os produtores de software
desconsiderem os investimentos feitos na produção de SGBDs relacionais.
Entretanto, da mesma forma que o modelo OO, não existe um modelo
padrão padronizado para construção de SGBDs objeto-relacionais. Diferente dos SGBDs
relacionais, que são sustentados por um modelo formal já definido, os SGBDs objeto-
relacionais obtiveram sucesso comercial graças às iniciativas de implementações em
produtos comerciais já disponíveis no mercado como o Oracle 8.x da Oracle Corporation.
3.3.3. A Linguagem SQL e seus Recursos
A linguagem SQL (Structured Query Language), surgiu em meados os anos
70 com a finalidade de se tornar uma linguagem padrão para acessar um antigo banco de
dados relacional (o System R da IBM), que rodava em computadores de grande porte
(mainframes). Atualmente, esta linguagem garante seu sucesso no mercado de banco de
dados simplesmente porque está integrada em praticamente todos os produtos de SGBDs
Relacionais e Objeto-Relacionais.

48
Segundo Kroenke (1999, p.175), a linguagem SQL é tida como “uma
linguagem orientada a transformações que aceita uma ou mais relações como entrada e
produz uma relação única como saída”. Isso significa dizer que a linguagem SQL é capaz
de transformar em resultado, qualquer operação envolvendo uma ou mais tabelas dentro de
banco de dados. Cada um destes resultados gera uma nova tabela com linhas e colunas
conforme a definição estabelecida pelo modelo relacional.
Sua principal vantagem é a capacidade de facilitar e agilizar a consulta e
manipulação de dados, independente da plataforma que está sendo usada, ou em qual
linguagem o aplicativo que irá interagir com os dados tenha sido desenvolvido.
Figura 10: Exemplo de resultados obtidos através de instrução SQL.

49
Esta linguagem apresenta uma série de instruções (comandos) para definir e
manipular estruturas de banco de dados. No que diz respeito à definição de dados, a SQL
utiliza a chamada de DDL (Data Definition Language), que é composta pelos comandos
destinados a criação de banco de dados, tabelas e relações. Como exemplo de comandos da
classe DDL temos os comandos Create, Alter e Drop.
No que diz respeito à manipulação de dados, a SQL utiliza chamadas da
série DML (Data Manipulation Language), destinadas a operações de consulta, inclusão,
exclusão e alteração de registros das tabelas de uma banco de dados. Como exemplo de
comandos da classe DML temos os comandos Select, Insert, Update e Delete.
Devido a sua popularidade, a linguagem SQL fez com que muitos produtos
de banco de dados SQL fossem lançados no mercado. Cada um com características
próprias do vendedor. Isso fez com que o comitê de padronização ANSI (American
National Standard Institute) estabelecesse uma padronização para esta linguagem, que
resultou na criação de várias especificações.
Hoje o SQL2 ou SQL92 é tido como o padrão mais utilizado nos SGBDs
cliente/servidor comerciais, devido aos novos mecanismos introduzidos nesta linguagem
que serão apresentados a seguir.

50
3.3.3.1. Visões
Uma visão em SQL consiste em uma forma que a linguagem utiliza para
gerar uma tabela virtual com resultados oriundos de outras tabelas fisicamente existentes
no banco de dados.
Trata-se de um recurso que pode ser bastante utilizado em casos onde
aplicação necessite acessar informações que geralmente já são resultados de outra operação
de consulta. Como exemplo temos o Create View que é o principal comando SQL utilizado
definição de visões.
3.3.3.2. Índices
Os índices são caracterizados como um meio utilizado para melhorar o
desempenho das aplicações de banco de dados. Trata-se de um método que possibilita criar
uma tabela auxiliar, contendo uma seqüência de registros indexados por uma ou mais
colunas, freqüentemente utilizadas como critérios de pesquisa em uma tabela. A definição
para criação de índices é feita através do comando Create Index.

51
3.3.3.3. Transações
Para realizar transações, que são uma das tarefas mais importantes dos
SGBDs cliente/servidor, a linguagem SQL utiliza instruções que permitem realizar com
sucesso as transações, garantindo a integridade para as informações. Também permite
desfaze-las antes de realizar as alterações no banco de dados. A SQL utiliza os comandos
Commit e Rollback que, respectivamente, efetiva e desfaz as transações.
3.3.3.4. Procedimentos Armazenados
Os procedimentos armazenados são objetos de banco de dados que ficam
localizados no servidor, tendo como finalidade armazenar um conjunto de instruções SQL
que poderão ser executadas em qualquer momento pelas aplicações.
Outra característica dos procedimentos armazenados é a capacidade de
receber parâmetros e retornar valores quando necessário, agilizando assim trabalho das
aplicações. A criação de procedimentos armazenados no SGBD é feita através do comando
Create Procedure.

52
3.3.3.5. Triggers
Da mesma forma que os procedimentos armazenados, os triggers contém
conjuntos de instruções SQL que ficam armazenadas no servidor, porém eles não podem
receber parâmetros nem retornar valores.
Em um banco de dados cliente/servidor, os triggers permitem especificar
regras de negócio que são chamadas pelo próprio banco de dados no momento em que
ocorre um determinado evento, reforçando ainda mais as restrições de integridade do
banco de dados. A definição para a criação de triggers no banco de dados é feita com o
comando Create Trigger.
3.3.4. Interfaces de Comunicação com Banco de Dados
Vimos que a arquitetura cliente/servidor proporcionou aos sistemas de
computação distribuir os processos cliente e servidor através da rede, levando a
funcionalidade da aplicação para o lado do usuário. Com esta distribuição, os SGBDs
puderam seguir seu padrão, concentrando as atividades de gerência de banco de dados
apenas no lado do servidor, limitando as aplicações apenas ao processo de atualização dos
dados através das estações cliente.

53
No entanto, a grande variedade de bancos de dados de diferentes
fabricantes, além da própria separação dos sistemas em front-end e back-end, ocasionou a
demanda por padrões e mecanismos que possibilitassem às aplicações cliente/servidor
interagirem com bancos de dados, independente da plataforma ou sistema operacional.
Com isso, vários fabricantes de software se uniram formando o SQL Access
Group (SAG), com o objetivo de produzir especificações de acesso a dados para produtos
de SGBDs que usam o padrão SQL. Estes mecanismos, conhecidos como interfaces de
comunicação com banco e dados, concentram um conjunto de instruções que permitem às
aplicações se comunicarem com o SGBD e estabelecer um meio compatível de
transferência de dados através da rede.
Com o desenvolvimento das novas tecnologias, surgiram vários modelos de
interface de banco de dados para diversas plataformas. Dentre os modelos existentes,
podemos destacar nos tópicos subseqüentes, algumas das principais interfaces de
comunicação para bancos de dados comumente usadas.
3.3.4.1. ODBC
O padrão ODBC (open database connectivity) foi desenvolvido pela
Microsoft e acabou se tornando o padrão dominante no mercado de interfaces comum para
acesso a bases de dados. Sua arquitetura em camadas permite aos aplicativos acessarem
uma grande variedade de banco de dados utilizando a linguagem SQL.

54
Segundo Melo (1997, p.205) a arquitetura ODBC é composta por quatro
componentes básicos: a aplicação, o gerente de driver (driver manager), o driver e a fonte
de dados (data source).
A aplicação consiste em um recurso de software que tem a função de
processar as chamadas das funções ODBC que cria meios padronizados para estabelecer
uma conexão com o banco de dados, de modo que torne possível emitir instruções SQL ao
SGBD.
O gerente de drivers é a parte intermediária da arquitetura, responsável pelo
recebimento das requisições emitidas pelas aplicações e pela determinação de qual driver
será carregado para fazer a conexão com o SGBD apropriado. Uma vantagem significativa
do gerente de driver é a capacidade de permitir que múltiplos drivers estejam ativos
simultaneamente utilizando o nome da fonte de dados fornecido pela aplicação.
O driver2 por sua vez consiste em uma biblioteca de funções que processam
as solicitações ODBC enviando instruções SQL especificas para cada fonte de dados.
Quando uma aplicação faz uma requisição, o driver ODBC traduz a requisição para o
formato apropriado do SGBD, servindo assim como um mediador entre os dois elementos.
A fonte de dados contém a definição de um driver ODBC utilizado pela
aplicação para acessar um SGBD específico. Trata-se dos dados propriamente ditos na
abordagem ODBC e cada fonte de dados deve possuir um driver apropriado para que a
intermediação possa ser estabelecida.
2 O driver corresponde a um conjunto de informações que fornece as instruções necessárias para que osistema operacional possa se comunicar com componentes de hardware específicos.

55
Figura 11: A arquitetura ODBC
3.3.4.2. DBI
A DBI (Database Interface) é uma interface de programação de aplicações
(API) desenvolvida para a linguagem Perl3. Sua arquitetura foi projetada com o intuito de
oferecer um conjunto de funções, variáveis e convenções que possam prover um
mecanismo de comunicação de banco de dados consistente e independente da plataforma
computacional utilizada pelo SGBD.
3 PERL (Practical Extraction and Report Language) é uma linguagem criada por Larry Wall,inicialmente para sistemas Unix, e hoje roda em vários outros sistemas como Windows, Amiga, VMS,etc.

56
Essa interface (Descartes, 2000, p.1), se divide em dois grupos onde, o
primeiro, corresponde a própria arquitetura DBI, que implementa todas as funções de
chamada de drivers, enquanto que o segundo, corresponde aos drivers responsáveis pela
conexão ao seu SGBD específico.
Figura 12: A arquitetura DBI
Esta separação permite que a DBI suporte uma grande variedade de bancos
de dados para utilização em ambientes de computação distribuída. Com isso a DBI é capaz
de fornecer acesso múltiplo a diferentes tipos de bancos de dados, de uma forma
transparente para os usuários. Com ela pode-se estabelecer conexões com bancos de dados
Oracle, Informix, mSQL, Sybase, ou qualquer outra base de dados compatível, sem a
necessidade de conhecer o mecanismo utilizado para efetuar esta tarefa.
Como benefício principal, a DBI dá às aplicações capacidade de conectar
duas bases de dados de fabricantes diferentes, fazendo com que elas se comuniquem
através do mesmo código-fonte escrito na linguagem Perl. Isso dá à aplicação capacidade
de atualizar bases de dados através de uma forma bastante simples, facilitando assim o
trabalho do programador.

57
3.3.4.3. JDBC
O JDBC (Java Database Conectivity) é uma interface desenvolvida pela Sun
Corporation com a finalidade de estabelecer conexão entre bancos de dados SQL e
aplicações desenvolvidas através da linguagem Java4. Com a JDBC os programadores
podem criar aplicações Java capazes de acessar dados corporativos, independente da
plataforma onde a aplicação está sendo executada.
A sua arquitetura, de acordo com Hamilton (1997, p.8) é composta por um
conjunto de interfaces abstratas que permite ao programador estabelecer conexões a um
determinado banco de dados, manipula-los através de instruções SQL e processar os
resultados. Estas interfaces podem ser resumidas em quatro classes principais, a saber:
- java.sql.DriverManager: gerencia o carregamento de drivers para criar novas
conexões de banco de dados;
- java.sql.Connection: representa uma conexão de um banco de dados específico;
- java.sql.Statement: funciona como um container para declaração ou execução
de comandos SQL;
- java.sql.ResultSet: controla o acesso aos resultados das requisições.
4 A linguagem Java foi desenvolvida para ser uma linguagem independente de plataforma tornando-seuma boa opção para criação de aplicações de acesso remoto a banco de dados.

58
Figura 13: A arquitetura JDBC
Com base nesta arquitetura, podemos perceber que a principal característica
da JDBC é permitir um acesso genérico a banco de dados através de SQL. Ao mesmo
tempo, a JDBC oferece uma interface padronizada para diferentes fontes de dados,
cabendo ao programador apenas construir uma interface de usuário para facilitar a
interação com o banco de dados.
Os tipos de drives suportados pela JDBC podem fornecer interfaces para
SGBDs, tais como o Oracle, Sybase, Informix, além de outros que utilizam protocolos de
acesso a banco de dados específicos, independentes ou não de protocolos de rede. Além
desses, a JDBC, fornece conectividade para drivers ODBC.

59
3.3.4.4. BDE
O Borland Database Engine (BDE) é uma interface de acesso a banco de
dados que contém um conjunto de funções e drivers que possibilitam às aplicações se
comunicarem com uma variedade de sistemas de banco de Dados local ou remotamente.
Sua arquitetura fornece uma forma única e transparente para a aplicação acessar os
diferentes tipos de SGBDs.
Segundo Rudraraju (1995, p.1) o BDE utiliza drivers SQL IDAPI nativos
para fornecer conectividade aos diferente servidores de bancos de dados. Através da IDAPI
(Integrated Database Application Program Interface), pode-se estabelecer conexões para
SGBDs cliente/servidor Interbase, Oracle, Sybase, Informix, DB2 e SQL Server. Através
desta interface, pode-se executar vários tipos de operações, tais como: criação de sessões,
bancos de dados, tabelas, índices, campos, consultas, procedimentos e filtros.
Figura 14: A arquitetura do BDE

60
Para concluir, o BDE se constitui em uma solução desenvolvida pela
Borland Corporation para ser executada em plataformas Windows 9x/2000/ME e Windows
NT. O BDE provê suporte a base de dados para aplicações desenvolvidas através de
ambientes de desenvolvimento integrados, tais como o Delphi e C++ Builder.
3.3.5. Os Programas de Aplicação
Vimos que a arquitetura cliente/servidor divide o poder de processamento
de um sistema computacional em sistemas cliente e servidor. Neste sentido, cada
componente tem seu papel específico. A aplicação cliente fica encarregada de fazer a
interface com o usuário, capturando os dados e exibindo informações, enquanto que a
aplicação servidora, fornece recursos necessários para as aplicações clientes.
O programa de aplicação é o principal recurso que dá ao usuário a
possibilidade de interagir com os sistemas de computação, principalmente nas tarefas que
envolvem o acesso à banco de dados. Para prover esta funcionalidade, principalmente em
sistemas cliente/servidor, as aplicações devem conter um conjunto de funções que
possibilitem interação entre dois ou vários processos distribuídos em diferentes
plataformas, de forma a cooperarem entre si para produzir os resultados desejados.

61
Para Melo (1997, p.60), “uma aplicação possui funções que podem ser
agrupadas em componentes para o processamento da lógica da interface do usuário, para o
processamento da lógica de negócios, para a manipulação de dados e para os serviços de
acesso aos dados”.
Figura 15: Interface de um programa de aplicação
As funções de interface de usuário correspondem a todas as atividades de
interação entre o usuário e a máquina. Concentra recursos de controle de dispositivos de
entrada e saída de dados, formatação de tela de apresentação, além de outras funções
avançadas como verificação e validação de dados. As funções da lógica do negócio são
aquelas que definem o verdadeiro propósito da aplicação, pois compreende toda a regra de

62
negócio e os processos administrativos de uma organização. As funções de gerência dos
dados processam todas as operações de acesso e manipulação de dados fornecidos pelo
usuário. Por fim, as funções de acesso a dados encarregam-se de fornecer recursos para
acesso físico aos dados armazenados em um banco de dados.
Figura 16: Estrutura de uma aplicação
Com isso podemos perceber que um programa de aplicação tem uma
estrutura claramente definida e que cada um de seus componentes cooperam entre si para
executar a tarefa desejada pelo usuário. No que se refere à sua alocação, quando se tratava
de ambientes centralizados, eles eram alocados em um único local. No entanto, a
arquitetura cliente/servidor permitiu distribuir as funções entre os servidores e clientes da
rede de forma a aumentar o desempenho dos sistemas de informação.

63
Com base nesta distribuição, a arquitetura cliente/servidor permitiu criar
várias categorias de arquitetura, dividindo-a em camadas para tratar com diferentes
configurações de seus componentes de aplicação. As principais arquiteturas abrangem dois
tipos de modelos, a saber:
a) modelo de duas camadas: modelo no qual as aplicações cliente/servidor
normalmente concentram as funções de interface de usuário e da lógica de negócio
em um único componente. Esse componente fica alocado no cliente, enquanto que
os dados e as funções de acesso a dados se concentram no servidor;
b) modelo de três camadas: neste modelo os dados e suas funções de acesso se
concentram no servidor, enquanto que as regras de negócio e as aplicações são
separadas em camadas distintas. Neste modelo as operações de acesso e
manipulação de dados são executadas pela aplicação. O servidor só irá processa-los
obedecendo às regras de negócio, que podem estar alocadas, ou na máquina
servidora, ou na máquina cliente, ou em ambas as máquinas.
Através da arquitetura cliente/servidor, podemos perceber que a divisão das
tarefas em camadas distintas resulta em um grande benefício para as aplicações. A
distribuição de suas funções aproveitando de todos os recursos existentes, resulta em um
melhor aproveitamento e um considerável ganho de performance, sem comprometer a
integridade dos dados armazenados.

64
Para o desenvolvimento das aplicações, podemos encontrar atualmente uma
grande variedade de ferramentas, ou linguagens, capazes de produzir aplicativos. Estas
linguagens dispõem de todas as funções necessárias para criação de interfaces e
implementação de funções de controle e de manipulação de dados. As ferramentas de
desenvolvimento mais utilizadas atualmente são as linguagens orientadas a objetos e
dirigidas por eventos, tendo como exemplo Java, Delphi, Powerbuilder, Visual Basic, SQL
Windows, SmallTalk e Kylix.
3.3.6. Gerência de Transações
Um SGBD cliente/servidor implementa mecanismos de gerência de
transações como um método destinado a assegurar que o banco de dados não sofra algum
tipo de alteração que resulte em perda de dados ou resultados indesejados. O uso de
transações em ambientes de banco de dados cliente/servidor se deve ao fato de que, muitos
ambientes corporativos, em seus processos diários de trabalho, executam uma seqüência
complexa de atividades que dependem constantemente da atualização dos seus dados para
gerar resultados imediatos ao usuário da aplicação.
Segundo Silberschatz (1999, p.441) “uma transação é uma unidade lógica
de execução que acessa e, possivelmente, atualiza itens de dados”. Pode-se dizer que uma
transação consiste em elemento importante para os SGBDs cliente/servidor, pois trata-se
de um mecanismo que possibilita as aplicações em execução simultânea, atualizarem os
dados de um banco de dados, sem comprometer a sua integridade.

65
Esse benefício só pôde ser obtido graças a um conjunto de operações,
originadas de um estudo baseado em quatro regras fundamentais para gerenciamento de
dados em ambientes multiusuário. Estas regras conhecidas como propriedades ACID,
correspondem respectivamente a:
a) Atomicidade: define se todas as ações que representam a transação em um banco de
dados serão aplicadas, ou caso contrário nenhuma delas será;
b) Consistência: assegura que um banco de dados ao sofrer uma alteração, mova seu
estado de consistência de forma a garantir que os dados afetados não violem as
regras de integridade;
c) Isolamento: define que uma transação não poderá ser afetada por outra, mesmo
quando ambas são executadas simultâneamente;
d) Durabilidade: implica que os resultados de um processo de transação sejam
permanentes, caso sejam concluídas com sucesso.
Um exemplo mais comum de um processo de transação (Hackathorn 1993,
p.61) é a transferência de fundos entre contas bancárias. Uma transação só deverá ser
completada se existirem fundos suficientes na conta original, verificando sempre se houve
alguma alteração no banco de dados antes que ocorra a transferência. Se isto acontecer, a
transação deverá ser abortada, evitando que o banco de dados seja alterado.

66
Figura 17: Representação de um processo de transação
Os SGBDs cliente/servidor realizam as transações através de comandos
introduzidos na própria linguagem SQL conhecidos como Commit e Rollback. Estes
comandos definem se as alterações serão concluídas com sucesso ou desfeitas quando há
risco de inconsistência. Uma vez concluída a transação (através do comando commit), o
SGBD muda o estado do banco de dados, tornando as alterações imediatamente visíveis
para outros processos de transações. Caso o processo de transação não puder ser
completado, a transação pode ser desfeita (através do comando rollback), fazendo que
banco de dados retorne ao seu estado original.
Normalmente estas instruções são executadas através da aplicação, de
acordo com o critério de processamento estabelecido pela lógica do negócio, ficando o
SGBD responsável por toda à parte de gerência, podendo ou não utilizar mecanismos de
controle, que muitas vezes são necessários em ambientes em que haja a execução de
transações concorrentes.

67
3.3.7. Controle de Concorrência
Vimos que em um sistema de banco de dados cliente/servidor, ocorrerá
situações em que vários itens de dados estarão sendo manipulados pelos usuários e quase
que ao mesmo tempo. Isso significa dizer que, todas as atividades que ocorrem no banco
de dados, estão em pleno processo de concorrência, podendo acontecer naquela mesma
unidade de tempo, porém em fatias de tempo definidas.
O sistema de gerência de transações de um SGBD oferece mecanismos que
torna possível realizar tarefas no banco de dados de forma isolada. No entanto, não
poderão garantir a confiabilidade dos dados se o SGBD, não possuir meios para controlar o
sincronismo entre as operações.
Segundo Kroenke (1999, p. 210), “o controle de concorrência consiste em
medidas que são tomadas para evitar que o trabalho do usuário não interfira no do outro”.
Isso significa dizer que, se um SGBD cliente/servidor tiver que gerenciar atualizações em
seu banco de dados, ele deverá possuir meios que garantam ao usuário, que o resultado se
seu trabalho seja o mesmo, como se ele estivesse trabalhando isoladamente.
Existem atualmente dois mecanismos básicos de controle de concorrência
utilizados pelos SGBDs. Estes mecanismos são baseados em princípios de bloqueios
(deadlocks) ou de ordenação, de acordo com um critério estabelecido para a efetivação das
ações de atualização de dados. Estes mecanismos são conhecidos como:

68
a) Controle de Concorrência Pessimista: funciona de maneira a bloquear o item
de dado impedindo que outras transações executem atualizações no item
bloqueado. Trata-se de um método que trabalha sempre na premissa de que
sempre haverá possibilidade de conflito entre operações de transação, fazendo
com que uma operação interfira na execução da atual. Com o método de
bloqueio, torna-se possível garantir o isolamento, que é a principal propriedade
das operações de transação. A desvantagem significativa estaria relacionada aos
consideráveis atrasos que podem ocorrer, e que às vezes podem ser até
desnecessários;
b) Controle de Concorrência Otimista: trata-se de uma técnica que se concentra
em realizar alterações, baseados na premissa da não-existência de conflitos.
Cada processo de transação age sem comprometer a execução de outra. Neste
mecanismo toda a avaliação é feita no momento em que o item de dado está
sendo atualizado. Neste período, é feita a verificação das demais transações
para ver se algum dado foi alterado no período em que a transação foi iniciada.
Este mecanismo evita a possibilidade de usar métodos de bloqueio durante o
processo. A desvantagem desta técnica é que, em algum caso de falha, toda a
operação de transação deverá reinicializada para assegurar a integridade dos
dados.

69
3.3.8. Segurança e Administração
Segundo Silberschatz (1999, p.13), “uma das principais razões que
motivaram o uso de SGBDs é o controle centralizado, tanto dos dados, quanto dos
programas de acesso a esses dados”. Isso convêm afirmar que o controle centralizado de
um sistema de banco de dados, em um ambiente cliente/servidor, consiste em um grande
benefício para a segurança das informações. No entanto, ao fazer uma analogia com os
sistemas de informação atuais, observamos que as empresas disponibilizam seus dados a
vários tipos de usuários, dentro ou fora do seu ambiente físico.
Por essa razão tem-se por definido que, para garantir a segurança do próprio
banco de dados da empresa, não se deve levar em conta apenas o uso das ferramentas de
administração incorporadas nos SGBDs. Deve-se considerar também o fator humano, que
determina qual pessoa tem o perfil necessário para administrar os recursos primários
(banco de dados) e secundários (SGBD e ferramentas relacionadas) do sistema.
O Administrador de Banco de Dados (DBA), é a pessoa que possui a
competência técnica para gerenciar todo o sistema de banco de dados de uma organização.
Suas principais funções envolvem um conjunto de atividades que partem, desde a
definição da estrutura e do conteúdo do banco de dados, até atividades relacionadas à
administração dos componentes principais do sistema. Dentre esses componentes são
mencionados os servidores, estruturas de armazenamento e métodos de acesso,
mecanismos de medição de desempenho, backup e recuperação de dados, administração de
usuários e restrições de integridade.

70
Outra tarefa importante do DBA é também servir de elo de ligação entre os
bancos de dados e os usuários. O DBA define os critérios de autorização através de
mecanismos que permitam criar contas de usuário, implementando o critério de segurança
apropriado. Além disso, o DBA pode fornecer aos analistas e programadores, todas as
informações necessárias para viabilizar o desenvolvimento de aplicações de banco de
dados específicas, que serão utilizadas pelos usuários finais.
Com relação à tecnologia utilizada para resolver as questões de segurança
ao nível de usuário, o DBA pode através do SGBD, implementar mecanismos de
segurança baseados em esquemas de login e senha, e também em níveis de privilégios.
Os mecanismos de controle de acesso baseados em login e senha, permitem
aos SGBDs, não só garantir ou restringir o acesso dos usuários, como também registrar
todas as operações a partir do período em que o usuário acessa o banco de dados até o
momento em que ele encerra suas atividades.
Figura 18: Conexão com SGBD cliente/servidor

71
Os níveis de privilégios por sua vez, permitem restringir o acesso a
determinado banco de dados a um grupo restrito de usuários. Uma vez definido qual banco
de dados poderá ser acessado, poderemos também definir quais tipos de operações poderão
ser realizadas pelos usuários sobre seus objetos. Vários produtos de SGBD que utilizam
SQL implementam métodos conhecidos como GRANT e REVOKE para garantia e a
revogação dos níveis de privilégios dos usuários.
Figura 19: Definindo privilégios no SQL Server 6.5
Em um ambiente cliente/servidor, pudemos observar que as tecnologias de
SGBDs são capazes de garantir a segurança dos dados contra usuários não autorizados. No
que se refere às questões de hardware e software, o controle centralizado dos dados
também torna possível reforçar os níveis de segurança. O DBA pode em caso de pane ou
perda de dados durante alguma operação complexa, utilizar mecanismos de backup e
recuperação adequados para garantir a restauração do banco de dados.

72
3.4. PRINCIPAIS SOLUÇÕES DA INDÚSTRIA DE BANCO DE DADOS
CLIENTE/SERVIDOR
Nos últimos anos, os SGBDs cliente/servidor evoluíram dando origem a
produtos cada vez mais poderosos, capazes de gerenciar bancos de dados de forma mais
eficiente, dando ao mesmo tempo mais simplicidade nas operações. Atualmente podemos
encontrar no mercado diversos produtos de SGBD cliente/servidor, projetados para vários
tipos de plataformas e sistemas operacionais. A seguir serão apresentadas características de
alguns dos produtos atualmente disponíveis.
3.4.1. Oracle
O Oracle é um SGBD cliente/servidor objeto-relacional (ORDBMS) de alta
performance produzido pela Oracle Corporation. Foi projetado para ser executado em
plataformas UNIX, Linux e Microsoft Windows NT. Sua tecnologia integra recursos,
capazes de gerenciar grande volume de dados em ambientes multi-usuário. Isso garante o
acesso simultâneo dos usuários ao banco de dados, sem comprometer o desempenho do
sistema.
Como linguagem SQL nativa o Oracle utiliza a PL/SQL, que implementa
vários recursos ativos, tais como triggers e procedimentos armazenados. Além disso, o
Oracle fornece um potente mecanismo de integridade referencial.

73
Para prover facilidade na administração dos recursos, as versões mais
recentes o Oracle dispõem de uma ferramenta conhecida como Oracle Enterprise
Manager. Essa ferramenta integra vários utilitários de administração e manipulação de
elementos de banco de dados.
Outro mecanismo importante a ser destacado é o Data Manager, que
oferece recursos que permitem importar e exportar objetos de um banco de dados para
outro, facilitando as tarefas de migração e atualização.
Figura 20: Visão geral do Oracle Enterprise Manager.

74
3.4.2. SQL Server
O SQL Server (Soukup, 1999, p.30) é um SGBD cliente/servidor relacional
(RDBMS), projetado para oferecer alto desempenho e suporte a processamento de alto
volume de dados. Sua plataforma é baseada em sistemas operacionais Windows NT Server
ou Workstation, Windows 95/98/ME e em plataformas Windows 2000. Tem como
linguagem SQL nativa a Transact-SQL, que incorpora vários recursos como otimização de
consultas, construção de programação e procedimentos armazenados.
Na sua versão 7, o SQL Server possui um ambiente integrado de
desenvolvimento, conhecido como Enterprise Manager, onde permite administrar todos os
recursos de qualquer servidor de banco de dados SQL acessível. Trata-se de uma interface
que apresenta uma estrutura de árvore, onde é possível visualizar todos os detalhes de um
servidor de banco de dados, incluindo, além dos bancos de dados, todas as ferramentas de
gerência necessárias.
Outra ferramenta importante é o Query Analyzer, que permite executar
instruções SQL e visualizar os resultados através de uma interface simples. A principal
vantagem dessa ferramenta é admitir que várias janelas sejam abertas ao mesmo tempo,
possibilitando realizar conexões simultâneas a bancos de dados diferentes.

75
Figura 21: Visão geral do Microsoft SQL Server.
3.4.3. Sybase SQL Server
O Sybase SQL Server, na sua versão 11 (Freeman 1996, p.1), foi
desenvolvido de acordo com o processo de certificação ISO 9000 para ser um dos mais
avançados SGBDs do mercado.
Sua arquitetura inclui um conjunto ferramentas baseadas em ambiente
gráfico Windows. Dentre essas ferramentas, inclui o Server Manager, que permite
gerenciar todo o processo de manipulação de banco de dados e de seus objetos, além de
fornecer um utilitário para gerar scripts SQL.

76
Figura 22: Visão geral do Sybase SQL Server.
Dentre os outros recursos do Sybase SQL Server, também podemos destacar
o Service Manager, que oferece recursos para carregar e interromper servidores de banco
de dados Sybase. Outra ferramenta, o Server Config, permite configurar servidores a um
nível mais alto, envolvendo tarefas de ajuste de controles, parâmetros de linha de comando,
conexões de rede, segurança e registro de erros.
3.4.4. Informix
O Informix, desenvolvido pela Informix Corporation, é um SGBD
multiusuário que possui como núcleo principal o Command Center, que concentra
ferramentas usadas na administração de servidores de banco de dados.

77
Além do Command Center, o Informix possui outras ferramentas
administrativas voltados para as seguintes finalidades: gerenciamento de espaço de
armazenamento de banco de dados (Space Explorer), criação e manipulação de objetos de
banco de dados (Database Explorer), execução de instruções SQL (SQL Editor). Além
destas ferramentas, o Informix também possui o Dbschema, que permite criar arquivos de
scripts para serem executados em outros bancos de dados.
Figura 23: Visão geral do Command Center do Informix
Os bancos de dados Informix podem escalar e rodar em qualquer plataforma
de sistema operacional, que pode variar desde o Windows NT até sistemas baseados em
Linux ou Unix.

78
3.4.5. C/A Ingres
O C/A Ingres é um SGBD relacional que teve seu início nas plataformas
Unix, DEC e VAX, onde a maioria das ferramentas tinha interfaces orientadas a caracter.
Na suas versões 1.1 e 1.2, o Ingres traz um subsistema de gerenciamento de
objetos baseado em ambiente gráfico Windows (CA-Visual/DBA), além de outros
utilitários importantes, dentre os quais destaca-se o CBF (Configuration by Forms), usado
para configurar diversos tipos de servidores, incluindo os de SGBDs e de banco de dados
distribuído.
Atualmente a versão do Ingres, conhecida como Ingres II é tida como a
solução mais completa de sua categoria para aplicações de múltiplas camadas e
gerenciamento de informação. O Ingres II está disponível em duas versões, conhecidas
como Workgroup e Enterprise. A versão Workgroup, roda em plataforma Windows NT e
permite conexões de até 25 usuários simultâneos. Já a versão Enterprise permite conexão
de um número ilimitado de usuários e pode ser utilizado em qualquer ambiente
multiplataforma.

79
3.4.6. IBM DB2
O DB2 Universal Database é um SGBD relacional da IBM Corporation,
projetado para ser um banco de dados capaz de oferecer um suporte relacional de
gerenciamento de dados rápido, seguro e eficiente. Sua tecnologia é derivada do conceito
de Banco de Dados Universal, que visa ampliar as capacidades da tecnologia de banco de
dados, permitindo manipular tipos de dados não-convencionais, tais como: informações
armazenadas em documentos, planilhas e objetos multimídia. Hoje as versões mais
recentes oferecem suporte a vários tipos de aplicações cliente/servidor disponíveis,
incluindo a internet.
Figura 24: Visão geral do Centro de Controle do DB2.

80
O DB2 na sua versão 7.1, possui várias ferramentas de administração que podem
ser gerenciadas através do Centro de Controle (Control Center), que é seu ambiente
principal. Trata-se de um ambiente que permite ao DBA, através de uma interface gráfica
de usuário (GUI), gerenciar de forma simples e transparente, todos os bancos de dados
DB2 alocados em diferentes tipos de plataformas ou sistemas operacionais.
3.4.7. Centura SQLBase
O Centura SQLBase é um SGBD relacional multiusuário desenvolvido para
plataformas Windows e Novell Netware. Na sua versão 6.00, o SQLBase integra
ferramentas GUI baseadas no estilo Windows, dando ao DBA a capacidade de administrar
os recursos de forma mais simples.
Uma das principais ferramentas do SQLBase é o SQL Console, que permite
gerenciar servidores de banco de dados, dando a possibilidade de carregar, criar, modificar
e excluir bancos de dados ou objetos de banco de dados. Possui também um utilitário onde
o DBA pode executar backups e outros serviços de manutenção.

81
3.4.8. PostgreSQL
O PostgreSQL é um SGBD objeto-relacional (ORDBMS) de código-fonte
aberto, desenvolvido para plataformas Linux e Windows. Segundo Vasudevan (2000,
p.1), o PostgreSQL é um aperfeiçoamento do antigo SGBD Postgres. Sua arquitetura foi
projetada para se tornar 100% de acordo com o padrão ANSI/ISO SQL, e ao mesmo
tempo, a principal base de dados de livre distribuição no mundo.
Dentre as principais vantagens é a capacidade de permitir herança entre
tabelas, além de prover suporte a qualquer tipo de aplicação, que pode variar desde páginas
web simples até um sistema administrativo completo. Outros benefícios a serem
destacados são: o excelente desempenho, suporte a transações e integridade referencial.
3.4.9. MySQL
O MySQL é um sistema de banco de dados relacional de código aberto,
projetado oferecer um suporte a banco de dados cliente/servidor, oferecendo rapidez e
flexibilidade. Pode ser capaz de rodar em qualquer servidor e suportar diferentes
aplicações cliente, além de prover interação com diferentes ferramentas de administração e
interfaces de programação, tais como C, C++, Eiffel, Java, Perl, PHP, Python e Tcl.

82
Dentre os componentes principais do MySQL destaca-se o MySqlAdmin,
que pode ser utilizado para uma variedade de tarefas tais como: criação e exclusão de
banco de dados, controle de conexões em memória, controle de contas de usuário e
monitoramento de servidor.
O MySqlDump é outro utilitário importante, pois através dele, pode-se
gravar em um arquivo texto, todos os comandos SQL necessários para criar uma cópia de
um banco de dados, inteiro ou em parte. Para execução de instruções SQL, o MySQL
dispõe o cliente MySQL, onde é possível criar e manipular banco de dados e seus
respectivos objetos.
Existem atualmente versões do MySQL disponíveis para plataformas,
incluindo todas as variedades de sistema operacional Linux, AIX, FreeBSD, Irix e
Windows 95/98/NT.
Na versão Windows, foi incorporado o WinMySqlAdmin, que permite
através de uma interface gráfica, visualizar e alterar as configurações do MySQL, além de
criar novos bancos de dados. Outro utilitário, o MySQLManager, permite executar
instruções SQL nos bancos de dados criados pelo MySQL.

83
Figura 25: Visão geral do MySQL para Windows.
3.4.10. GemStone
O GemStone é um SGBDOO comercial disponível pela GemStone Systems.
Foi projetado para combinar os conceitos de linguagem de programação orientada a
objetos Smalltalk, com funções de sistema de gerenciamento de banco de dados. Sua
tecnologia apresenta robustez suficiente para manipular grande quantidade de dados a uma
baixa taxa de erros, além de possibilitar a recuperação de falhas sem comprometer a
disponibilidade dos dados.

84
Suas linguagens de manipulação (DML) e definição de dados (DDL) são
derivadas do Smalltalk, tendo como base os objetos, mensagens e métodos para tratamento
de dados. Os objetos têm uma interface e um estado, e se comunicam uns com os outros
através de mensagens. O suporte a transmissão de mensagens, encapsulamento, hierarquia
de classe, herança e identidade de objetos, são amplamente suportados pelas DML e DDL
do GemStone. Em comparação com a linguagem SQL, a DML do GemStone é bem
completa no aspecto de linguagem de programação.
O GemStone tem como componente básico o Gem Server, que concentra
todos os objetos que são executados pela DML do GemStone, inclusive a avaliação das
consultas. Outro componente principal é o Stone Monitor que aloca novos identificadores
de objetos e coordena a execução de transações.

CAPÍTULO 4 - APLICAÇÕES DE BANCO DE DADOS CLIENTE/SERVIDOR
4.1. ASPECTOS BÁSICOS
Podemos afirmar que os sistemas de banco de dados cliente/servidor são
utilizados hoje em dia em uma grande variedade de aplicações, sendo que a maioria delas,
são e vão continuar sendo voltadas ao uso comercial pelas organizações. No entanto, novas
aplicações surgiram nos últimos anos, contribuindo de maneira que tornasse possível às
empresas expandirem seus limites de atuação no mercado, dispondo ao mesmo tempo de
novos recursos de gerência de dados para seu negócio. Estes novos recursos permitem que
as aplicações possam lidar com informações não-convencionais, podendo ainda ser
acessadas e manipuladas em diferentes locais.
Com base nestas novas aplicações, as produtoras de software puderam
incorporar novos mecanismos de gerenciamento de dados em seus produtos de SGBDs.
Isso fez com que as aplicações de banco de dados também pudessem participar deste
processo evolutivo, de forma a poder lidar com tipos de informações, que antes era
inimagináveis pelos sistemas do passado.

86
Neste contexto relacionamos algumas das novas aplicações de banco de
dados que nos últimos anos, se tornaram cada vez mais importantes para as organizações.
4.2. PROCESSAMENTO DE BANCOS DE DADOS DISTRIBUÍDOS
Segundo Ceri e Pelagatti citado por Melo et al. (1997, p.165), “um sistema
de banco de dados distribuído é uma coleção de dados que é distribuída por diferentes
computadores, possivelmente em diferentes locais. Os computadores são conectados por
uma rede de comunicação. O sistema deve suportar aplicações locais em cada computador,
bem como aplicações globais nas quais mais de um computador esteja envolvido”.
Na verdade, um sistema de banco de dados distribuído, é considerado como
uma modalidade de processamento de banco de dados cliente/servidor, que integra a
filosofia dos bancos de dados como resolução dos problemas apresentados pelos sistemas
gerenciamento de arquivos. Um banco de dados distribuído também se fundamenta na
distribuição dos processos, que leva para o lado do usuário as tecnologias utilizadas para
manipular dados através da rede. Todos esses requisitos resultam em oferecer aos usuários
um sistema integrado para troca de informações, porém distribuídos no que se refere ao
local onde os bancos de dados serão alocados.
Em um banco de dados distribuído, o requisito fundamental é fazer com que
os bancos de dados, dispersos nos diversos locais, sejam vistos pelas aplicações como um
único banco de dados centralizado. Para isso, o SGBD cliente/servidor disponibiliza várias

87
funções que tornam os bancos de dados independentes uns dos outros. Ao mesmo tempo,
esses recursos visam a transparência na distribuição e na fragmentação, de forma que os
usuários vejam os dados de forma única, sem se preocupar com a sua localização física. No
que se refere aos requisitos de desempenho e disponibilidade dos dados, os SGBDs
utilizam técnicas de replicação que cria cópias locais de um banco de dados inteiro ou
parte dele.
4.3. INTERNET E INTRANETS ORGANIZACIONAIS
A Internet pode ser considerada atualmente como o ambiente
cliente/servidor mais utilizado para transações comerciais e disseminação de informações
empresariais de diferentes áreas de atuação. Trata-se de uma rede pública, que surgiu a
partir de um projeto conhecido como ARPANET, que tinha a finalidade de interligar
grandes centros de informações militares americanos. Quando os militares se retiraram do
projeto para a formação da MILNET, a ARPANET passou a ser conhecida como Internet,
se popularizando entre centros de pesquisa, empresas e universidades.

88
Com a sua liberação para uso comercial nos Estados Unidos, várias
empresas viram neste novo ambiente a possibilidade de expandir as suas fronteiras
comerciais, disponibilizando produtos e serviços aos seus clientes em qualquer parte do
mundo. Hoje podemos afirmar que o comércio eletrônico pôde se tornar uma realidade,
graças ao surgimento de interfaces que permitiram que bancos de dados pudessem ser
interligados ao ambiente Web1.
A integração de banco de dados na web também possibilitou que inúmeras
outras aplicações empresariais pudessem rodar neste novo ambiente. Como exemplo
prático, podemos destacar os próprios sistemas de transações bancárias pela Internet, que
nos últimos anos têm apresentado um nível de utilização bastante acima das previsões.
Figura 26: Exemplo de Aplicação web de comércio eletrônico.
1 Um acrônimo para World Wide Web (WWW). Corresponde a uma grande rede de informações queconcentra todos os sistemas de informação disponíveis na Internet.

89
No ambiente corporativo, a infra-estrutura de comunicação de dados usada
na internet também é usada para criação de redes privadas, conhecidas como Intranets.
Trata-se de uma rede restrita apenas ao ambiente da empresa e que normalmente é utilizada
para compartilhamento de informações empresariais.
Da mesma forma que a internet, o uso de aplicações de banco de dados
permitiu expandir a funcionalidade das Intranets, dando a possibilidade de criar aplicações
para diversos fins.
4.4. SISTEMAS DE INFORMAÇÕES GEOGRÁFICAS (GIS)
Um Sistema de Infomações Geográfica (GIS – Geographic Information
System) consiste em uma modalidade não-convencional de aplicação de banco de dados,
que tem como características principais o armazenamento de informações baseadas em
dados geofísicos e a integração de ferramentas voltadas para processamento de imagens
geográficas. Seu funcionamento (Davis, 2001, p.2) é baseado na utilização de
componentes organizados em uma estrutura hierárquica que inclui: interface com o
usuário, entrada e integração de dados, consulta e análise espacial, visualização/plotagem,
funções de processamento gráfico de imagens e funções de gerência de dados baseada em
bancos de dados geográficos.
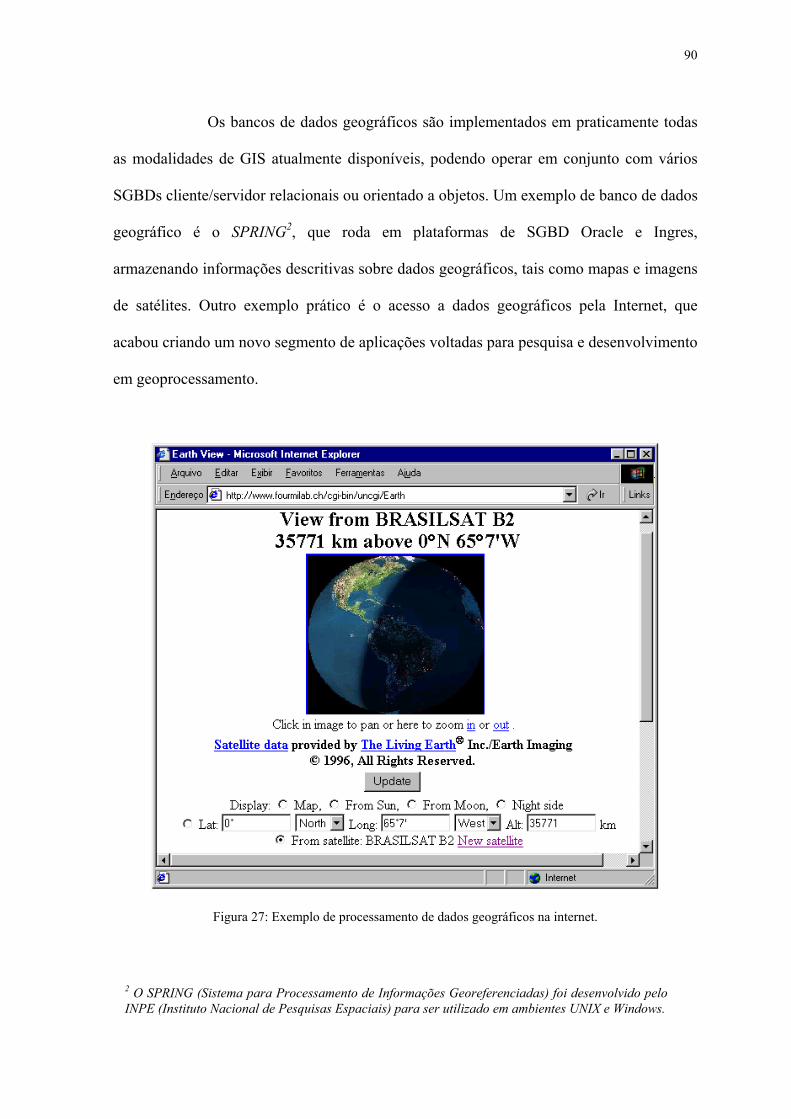
90
Os bancos de dados geográficos são implementados em praticamente todas
as modalidades de GIS atualmente disponíveis, podendo operar em conjunto com vários
SGBDs cliente/servidor relacionais ou orientado a objetos. Um exemplo de banco de dados
geográfico é o SPRING2, que roda em plataformas de SGBD Oracle e Ingres,
armazenando informações descritivas sobre dados geográficos, tais como mapas e imagens
de satélites. Outro exemplo prático é o acesso a dados geográficos pela Internet, que
acabou criando um novo segmento de aplicações voltadas para pesquisa e desenvolvimento
em geoprocessamento.
Figura 27: Exemplo de processamento de dados geográficos na internet.
2 O SPRING (Sistema para Processamento de Informações Georeferenciadas) foi desenvolvido peloINPE (Instituto Nacional de Pesquisas Espaciais) para ser utilizado em ambientes UNIX e Windows.

91
4.5. BANCO DE DADOS MULTIMÍDIA
Os bancos de dados multimídia passaram a ganhar interesse nos últimos
anos devido aos novos tipos de informação que passaram a estar presente em vários
segmentos de aplicações.
Tipos de dados como textos com livres formatos, documentos web, gráficos
estruturados, imagens estáticas ou com animação, voz e sons, se tornaram cada vez mais
comuns no ambiente corporativo. Hoje já é possível pensar em sistemas capazes de operar
com tipos de dados que possam representar imagens de impressões digitais,
eletrocardiogramas, ressonância magnética e radiografias, freqüentemente utilizados em
hospitais ou órgãos especializados.
Os SGBDs cliente/servidor relacionais e objeto-relacionais implementam
recursos destinados ao armazenamento de elementos gráficos e de texto em grandes
objetos binários, conhecidos como BLOB3. No entanto, devido às limitações para operar
outros novos tipos de dados, como vídeos e sons, os ORDBMS podem ser vistos como a
alternativa mais eficaz entre os dois modelos para gerenciar novos tipos de informação e
dar suporte mais adequado às novas aplicações.
3 BLOB (Binary Large Objects) consiste em um bloco de dados em formato binário que éarmazenado fisicamente, separado do registro principal. A sua localização normalmente é feitaatravés do uso de ponteiros sempre que o registro correspondente é referenciado.

92
4.6. DATA WAREHOUSES
Um Data Warehouse (Kroenke, 1999, p.280) é um depósito de dados
corporativo cuja estrutura inclui recursos destinados a facilitar o acesso a determinados
tipos de dados para tomada de decisões. Seu objetivo principal é aumentar o valor
patrimonial dos dados da empresa, armazenando dados de diversos clientes para geração
de informações integradas futuras.
O ambiente Data Warehouse agrega várias tecnologias para oferecer a
integração necessária aos bancos de dados de uma organização. Além da própria
arquitetura cliente/servidor aliada aos recursos dos SGBDs, são utilizadas interfaces de
usuários e ferramentas adequadas para análise e consulta de dados de modo a fornecer uma
interface única para gerar consultas de suporte à decisão.
De forma a viabilizar a implementação de Data Warehouses nos sistemas de
informação das empresas, várias produtoras de SGBDs já implementam em seus produtos
um conjunto de recursos, dentre os quais se destacam as ferramentas de processamento
analítico on-line (OLAP), que facilitam o compartilhamento de metadados (dados
referentes a dados) com outros bancos de dados e demais aplicações, de modo a fornecer
acesso e análise desses dados de forma simples para o usuário-final.

CAPÍTULO 5 - CONCLUSÃO
5.1. CONSIDERAÇÕES FINAIS
Conclui-se que, o ambiente de computação cliente/servidor é uma área que
está em plena evolução no que diz respeito ao segmento de novas aplicações de banco de
dados e tecnologias de integração. Paralelamente, os sistemas de banco de dados
cliente/servidor podem hoje ser também considerados como parte indispensável em
qualquer sistema computacional multi-plataforma.
A contribuição deste trabalho para compreensão dos principais aspectos dos
sistemas de banco de dados cliente/servidor foi uma abordagem genérica, que delimitou o
estudo dos principais elementos envolvidos no processamento de banco de dados para os
diversos segmentos de aplicações empresariais que lidam com tipos de informações, tanto
convencionais, como não-convencionais.

94
Com base nesse estudo, pode-se afirmar que a abordagem apresentada sobre
os aspectos tecnológicos e funcionais, empregados na arquitetura cliente/servidor para
banco de dados, serviu para mostrar que esse ambiente conseguiu superar os problemas
apresentados pelos sistemas centralizados, principalmente no que se refere às questões
relativas à redução de custos operacionais e implementação de novos recursos tecnológicos
para oferecer soluções imediatas para tomada de decisões. Ao mesmo tempo, os sistemas
de banco de dados no ambiente cliente/servidor puderam ainda estabelecer nas empresas
um novo padrão de comportamento, incentivando o estudo de novas soluções corporativas
e adotando estratégias para prover melhor organização e controle de todo o seu sistema de
informação, contribuindo ainda para dar amplo suporte às novas aplicações que poderão
ser adotadas ao longo do tempo.
Como sugestão para novos trabalhos, pode ser feita uma pesquisa sobre as
principais soluções de mercado que utilizam ORDBMS cliente/servidor, a fim de ter uma
idéia mais precisa sobre a real efetividade das aplicações OO cliente/servidor existentes
para processamento de dados não-convencionais.
Para finalizar, deve-se ter conhecimento sobre quais componentes poderão
ser considerados mais adequados para determinado tipo de aplicação cliente/servidor de
banco de dados. Apesar da arquitetura cliente/servidor oferecer independência de
plataforma e sistema operacional para comunicação entre processos, o melhor conjunto de
recursos pode fazer a diferença em termos de desempenho e produtividade.

ABSTRACT This research has for objective to present a boarding about database systems used in client/server processing environments, describing its main components and the technologies used for integration between databases and the applications. Based in this analysis will be pointed the main aspects that had taken the client/server database systems to become the main plataforms for data management and support to the new applications.

Referências Bibliográficas
DATE, C.J. Introdução a Sistemas de Bancos de Dados. 9. ed. Rio de Janeiro: Editora Campus, 1990. DAVIS, Clodoveu; CÂMARA, Gilberto. Fundamentos de Geoprocessamento – Arquitetura de Sistemas de Informação Geográfica. 04 Junho 2001. Disponível em: <http://www.dpi.inpe.br/gilberto/livro/introd/cap3-arquitetura.pdf> Acesso em 30 de julho de 2001 DESCARTES, Alligator: Programming the Perl DBI, 1ª Ed, 2000. Disponível em: <http://www.oreilly.com/catalog/perldbi/chapter/ch04.html> Acesso em 07 de maio de 2001 FREEMAN, Miller. Sybase SQL Server 11. DBMS and Internet Systems, 1996. Disponível em: <http://www.dbmsmag.com/9611d54.html> Acesso em 26 de junho de 2001 HACKATHORN, Richard D. Conectividade de Bancos de Dados Empresariais. Rio de Janeiro: Infobook, 1993. HAMILTON, Graham; CATTELI, Rick. JDBC – A Java SQL API. Sun Microsystems Inc. 1997. Disponível em: < ftp://ftp.java.sun.com/pub/jdbc/953287-12/jdbc-spec-0120.pdf> Arquivo capturado em 13 de junho de 2001 KROENKE, David M. Banco de Dados: Fundamentos, Projeto e Implementação. 6ª. Ed. Rio de Janeiro: LTC, 1999. MELO, Rubens N.; SILVA, Sidney D.; TANAKA, Asterio K. Banco de Dados em Aplicações Cliente/Servidor. Rio de Janeiro: Infobook, 1997. PRADO, Juano A. Nunez del. Acessando SQL Server com Visual Basic 5. Santa Catarina: Advanced Editora, 1998. RENAUD, Paul E. Introdução aos Sistemas Cliente/Servidor: Guia Prático para Profissionais de Sistemas. Rio de Janeiro: Infobook, 1994. RUDRARAJU, Pandu. Borland Database Engine and IDAPI - A Technology Overview. Borland Software Corporation, 1995. Disponível em: <http://www.borland.com/bde/papers/idapi/> Acesso em 18 de junho de 2001

SALEMI, Joe. Guia para Banco de Dados Cliente/Servidor. 2. ed. Rio de Janeiro: Infobook, 1995. SILBERSCHATZ. Abrahan; KORTH, Henry F. e SUDARSHAN, S. Sistema de Banco de Dados. 3. ed. São Paulo: Makron Books, 1999. SOUKUP, Ron. Desvendando o SQL Server 7.0. Rio de Janeiro: Campus, 1999. VASUDEVAN, Alavoor. Database-SQL-RDBMS HOW-TO - document for Linux (PostgreSQL Object Relational Database System). v40.0, 09 dez. 2000. Disponível em: <http://www.cybersite.com.au/HOWTO/PostgreSQL-HOWTO.html> Acesso em 05 de junho de 2001.