big data visualization frameworks and applications at...
TRANSCRIPT

Dr. Marcus D. Hanwell [email protected]
@mhanwell www.kitware.com
27 March, 2014 South Bay Meetup
Big Data Visualization Frameworks and Applications at Kitware
!"

#"
About Kitware

Kitware, Inc. • Founded in 1998 by five former GE Research employees
• 118 current employees; 39 with PhDs
• Privately held, profitable from creation, no debt
• Rapidly Growing: >30% in 2011, 7M web-visitors/quarter
• Offices – Clifton Park, NY
– Carrboro, NC
– Santa Fe, NM
– Lyon, France
• 2011 Small Business Administration’s Tibbetts Award
• HPCWire Readers and Editor’s Choice
• Inc’s 5000 List since 2008

Kitware’s customers & collaborators Over 75 academic institutions including! • Harvard • MIT • University of California,
Berkeley • Stanford University • California Institute of
Technology • Imperial College London • Johns Hopkins University • Cornell University • Columbia University • Robarts Research Institute • University of Pennsylvania • Rensselaer Polytechnic
Institute • University of Utah • University of North Carolina
Over 50 government agencies and labs including! • National Institutes of Health
(NIH) • National Science Foundation
(NSF) • National Library of Medicine
(NLM) • Department of Defense (DOD) • Department of Energy (DOE) • Defense Advanced Research
Projects Agency (DARPA) • Army Research Lab (ARL) • Air Force Research Lab
(AFRL) • Sandia (SNL) • Los Alamos National Labs
(LANL) • Argonne (ANL) • Oak Ridge (ORNL) • Lawrence Livermore (LLNL)
Over 100 commercial companies in fields including! • Automotive • Aircraft • Defense • Energy technology • Environmental sciences • Finance • Industrial inspection • Oil & gas • Pharmaceuticals • Publishing • 3D Mapping • Medical devices • Security • Simulation

Kitware: Core Technologies
$"
CMake
CDash

Business Model: Open Source
• Open-source Software – Normally BSD-licensed – Collaboration platforms
• Collaborative Research and Development • Technology Integration • Services and Support • Consulting • Training and webinars
%"

&"
Data at Scale

What is “Big Data”?
• We deal with two primary types – Small number of very large data elements
• Computational fluid dynamics simulations • Cosmological simulations covering billions of years
– Large number of (usually smaller) elements • Social media data, financial data, geospatial data • Over 3M compounds, 40M quantum calculations
• Different types of data differ in structure • Very different strategies are needed!
'"

Many Small Versus Few Big
• Many small “records” – Major challenge lies in indexing, searching – Once found we can generally send to browser – Aggregation and/or summarization important
• Few big “records” – Major challenge lies in data reduction – Must work hard to do all work near the data – Can still deliver reduced data to web clients
("

Considerations for Data at Scale
• Key areas to be addressed: – Storage – Metadata extraction – Index – Search – Visualization – Interaction – Further calculations, simulations, etc.
!)"

Data Storage at Scale • How much data do you have? • Must all data be stored in the same place? • Existing metadata extraction techniques? • Uniform data layout/schema? • Existing index/search techniques?
– Algorithmic challenges – Open implementations that scale – Interaction with the database
!!"

What Does a Result Look Like? • Once you are done searching:
– What does a typical result look like? – How big is the resulting data? – How should the data be presented? – Is all data in the database referenced?
• Is a simple ordered list useful? • What about multidimensional result sets?
!#"

Challenges with Big Data • Storage for petabytes of data is tough
– Moving it is even harder – Extracting metadata is a challenge – Backing up and restoring isn’t any easier – Even individual results can be very large
• Mostly done in central facilities – Specialized file systems – Power, backup, redundancy, staff
!*"

!+"
Frameworks

The Visualization Toolkit (VTK)
• Collection of C++ libraries – Leveraged by many applications – Divided into logical areas, e.g.
• Filtering – data processing in visualization pipeline • InfoVis – informatics visualization • Widgets – 3D interaction widgets • VolumeRendering – 3D volume rendering
• Cross platform, using OpenGL • Wrapped in Python, Tcl and Java
http://www.vtk.org/

Visualization
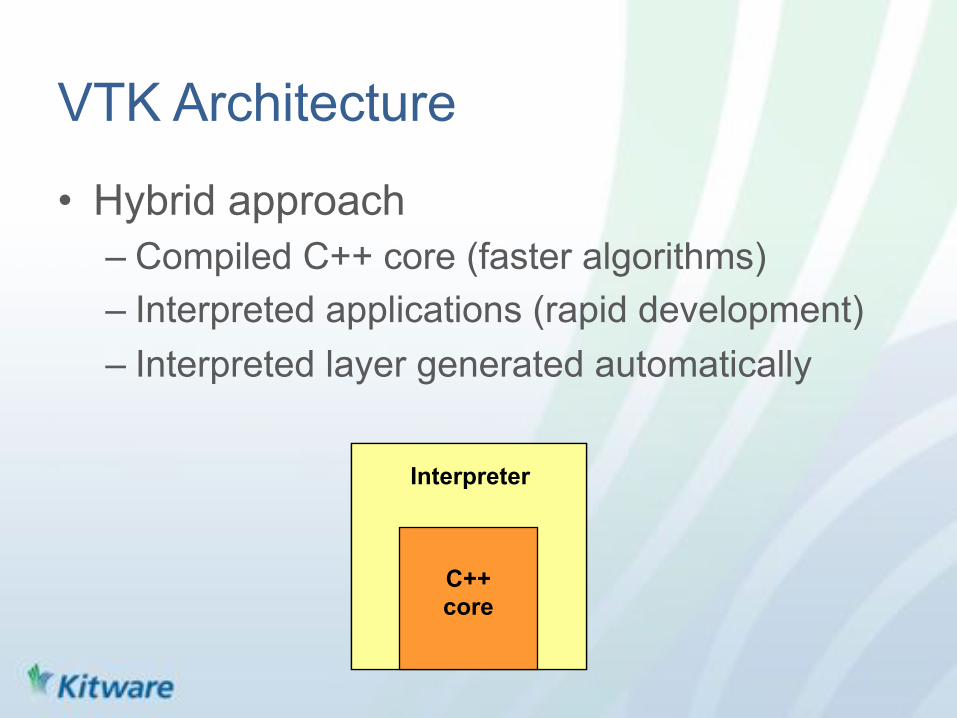
VTK Architecture
• Hybrid approach – Compiled C++ core (faster algorithms) – Interpreted applications (rapid development) – Interpreted layer generated automatically
C++ core
Interpreter
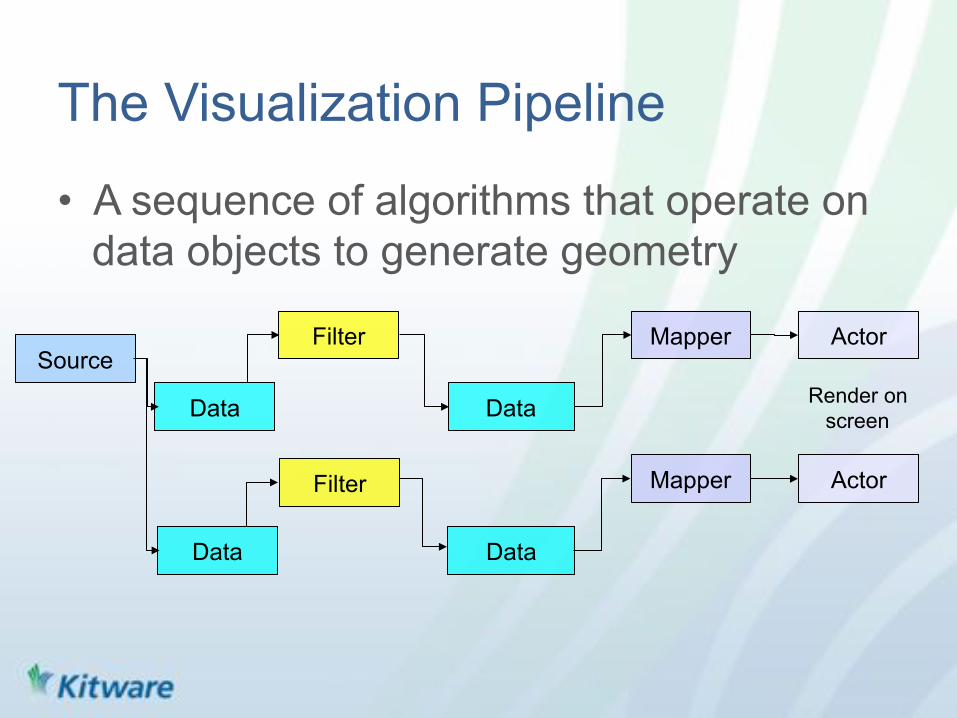
The Visualization Pipeline
• A sequence of algorithms that operate on data objects to generate geometry
Source
Data
Data
Filter
Filter
Data
Data
Mapper
Mapper Actor
Actor
Render on screen

ParaView
• Parallel visualization application • Open source, BSD licensed • Turn-key application wrapper around VTK • Parallel data processing and rendering
http://www.paraview.org/

ParaView is for Extremely Large Data
1 billion cell asteroid detonation simulation
! billion cell weather simulation
source: Sandia National Lab

,-./-0"
1234250"
6784-"92:"
,-./-0"
1234250"
6784-"92:"
;<=">?@""A9" >?@"A9"
@"B2CD23-34"E.4."<.0.FF-F8GC"H20">"A9I4-"
J"
,-3/-0"K-0L-0",-3/-0"K-0L-0",-3/-0"K-0L-0",-3/-0"K-0L-0"
1F8-34"E.4."K-0L-0"E.4."K-0L-0"E.4."K-0L-0"E.4."K-0L-0"E.4."K-0L-0"E.4."K-0L-0"
Depth Composite
Tile Display
Control, Display and Rendering
of Small Data

• Python web framework built on CherryPy • Flexible HTML5 web server architecture • Developed with a clean separation
– Application in HTML, JavaScript, CSS – Service in pure Python (+ wrapped C/C++)
• Packages several other frameworks too – Bootstrap, D3, Vega, MongoDB
• Making web apps easier to develop/deploy
##"http://tangelo.kitware.com/

• Python for server side, native web clients • Easily add new services (single .py file)
– Use RESTful API – JSON delivery of data – Full power of Python
• Rapid prototyping
#*"
Browser Tangelo
web service “foo”
index.html index.js
styles.css foo.py

ParaViewWeb – Web Enabled
• Bring 3D visualization to a web page – Targeting HPC web portal – Simple usage with basic/rigid workflow – Framework to develop 3D web applications – Must work now (no WebGL) – Support collaboration with multiple clients sharing
the same visualization
• The goal was NOT to – Redo another generic ParaView client
#+

Tangelo Powering ParaViewWeb
• We need a web front end to – Start processes – Forward communications
#$

#%"
Simple Tangelo Examples

Visualizing Flickr Metadata • Uses Google maps • Flickr data in MongoDB • Python service retrieves
data using PyMongo • D3 layer over maps
– Geolocation – Day of the week – Photo (mouse hover)
#&"

Enron Email Network Visualization • enron.py retrieves emails
– Computes graph structure
• D3 force layout for viz • Controls to:
– Slice email by time – Change email originator – Set number of hops
• Tool targeted at investigating social network behavior
#'"
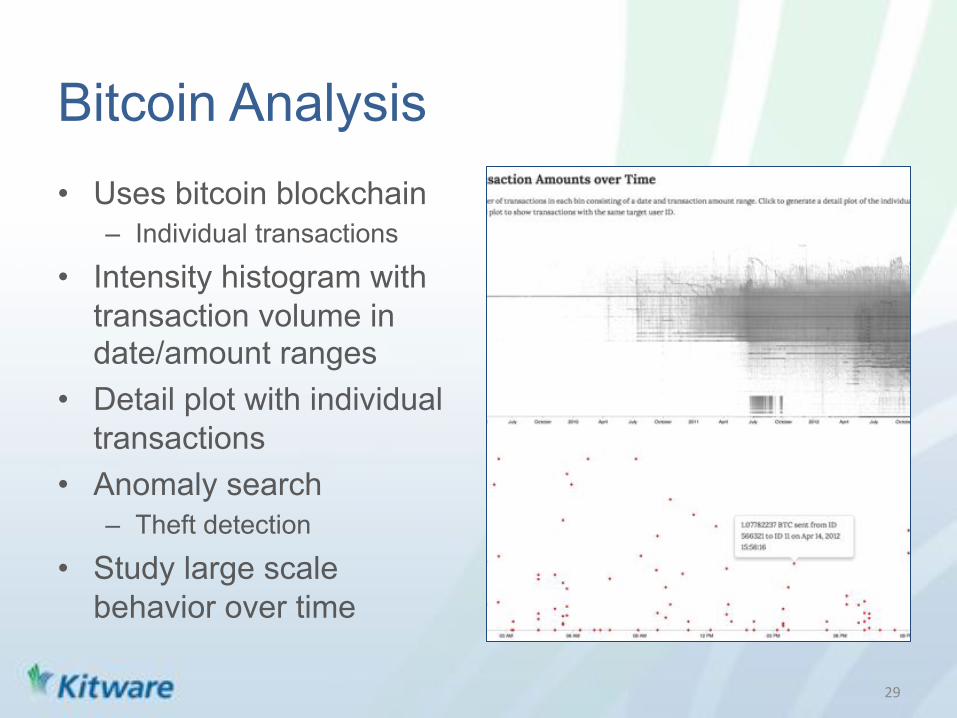
Bitcoin Analysis • Uses bitcoin blockchain
– Individual transactions
• Intensity histogram with transaction volume in date/amount ranges
• Detail plot with individual transactions
• Anomaly search – Theft detection
• Study large scale behavior over time
#("

*)"
Larger Projects

Informatics Software Stack
*!"
MNO"
PD-3M8-Q"
<.0.M8-Q6-R"
M8G2C8BG"
SN;T?U.L.GB08D4"
E*?M-V."
6-R"WDDG"E-GX42D"WDDG"
S2GD84.F"12G4G" YF8BX0" 17.084I@-4"
<I4723"
N.3V-F2"
," ;.4F.R" @TNO" S./22D" ;23V2" =CD.F." KZT" 1KM?UKP@"
W3.FIG8G"W/.D4-0G" E.4."W/.D4-0G"
J" J"

Digital Pathology
• MongoDB used for image tiles – Store once, using multiple times – Metadata, processing status, results – Browser-based application/interaction
*#"https://slide-atlas.org/

Arbor is an NSF-funded project to enable evolutionary biological research by making it easy for biologists to • create, • test, • and visualize algorithms on the Tree of Life. Below is the evolutionary tree for Heliconia (Lobster Claw) plants coupled to a character matrix of observational data such as color, feature measurements, and range.

Cosmology Data Management
*+"
Supercomputer DISC LSST
K8C5F.[23"
12GC2N22FG"Y0.C-Q20X"
!"#"$%&#'
K8C5F.[23"=3D54"/-BX"
12GC2N22FG"123\V50.[23"
(")"*+,-'.,)/,)'
(")"*+,-'!$+,0#'
<.0.M8-Q6-R"
1,2'3)4-&,)'
K50L-IG"
Advanced User/Developer/ Scientist
E.4."=34-3G8L-"KB.F.RF-"12CD]"
Database
Scientist
Experimentalist
Database

*$"
$+2!4&54644$&7"'
Voronoi Tesselation
FOF HaloFinder
Stream Counter
CosmoTools ParaView Plugins
Caustics
• ANL: Salman Habib, Katrin Heitmann, Tom Peterka, Adrian Pope, Hal Finkel
• LANL: Jim Ahrens, Jon Woodring, Pat Fasel • Kitware: George Zagaris, Berk Geveci, Casey
Goodlett, Zach Mullen

UV-CDAT for Climate Visualization
• Ultrascale Visualization and Climate Data Analysis Toolkit – Collaborative effort led by LLNL – Integrate DOE’s climate modeling/measures
• Integrates a large number of tools/libs – CDAT, VTK, R, ParaView, DV3D
• Current data sets at about 3.5 petabytes – Growing to 350 petabytes to ~3 exabytes
*%"

Climate Data Visualization
*&"

*'"
Open Chemistry

Applications Being Developed • Three independent applications • Communication handled with local sockets • Avogadro 2: Structure editing, input generation,
output viewing, and analysis • MoleQueue: Running local and remote jobs in
standalone programs, and management • MongoChem: Storage of data, searching, entry,
and annotation • Supporting frameworks (AvogadroLibs & VTK)
*("http://www.openchemistry.org/

Use Cases for Open Chemistry • Researchers interested in molecules
– Various sources of starting structure
• Perform studies using various codes – Some performed locally – Others using high-performance computing – Different calculations produce different data
• How do these results get stored, analyzed? – How can previous work be indexed, reused?
+)"

MongoChem Overview • A desktop cheminformatics tool
– Chemical data exploration and analysis – Interactive, editable, and searchable database
• Leverages several open-source projects – Qt, VTK, MongoDB, Avogadro 2, Open Babel
• Designed to look at many molecules • Spots patterns, outliers; runs many jobs • Scales to studies with ~3 million structures

Architecture Overview • Native, cross-platform C++ application built with Qt and Avogadro 2 • Stores chemical data in a NoSQL MongoDB database • Uses VTK for 2D and 3D dataset visualization
+#"

Moving MongoChem to the Web • Increasingly important to share data • MongoDB not suitable for web directly
– Developing RESTful APIs – Building on VTKWeb and Tangelo – Can do more processing close to the data
• Can we develop a platform for chemists? – Could this address materials and other areas? – Deposition of data, curation, client-server
processing, web interface and APIs
+*"

VTKWeb, Tangelo and MongoChem
• Uses VTK’s web architecture • Performs interactive 3D rendering • Runs in any modern web browser • Same MongoDB server as MongoChem • Moves more to the client JavaScript code • Using a simple, Python-based server
– Easy to add new APIs – Easy to deploy/integrate into other solutions
++"

MongoChemWeb Demo
+$"http://data.openchemistry.org/

Why MongoDB? • SQL vs NoSQL approaches • MongoDB is implemented in C++
– Scales well by adding extra shards (nodes) – Core constructs written in C++ – Access to JavaScript in map-reduce – Memory-mapped database files – GridFS for storing large files – Clients in many languages – C, C++, Python – Large, established open-source project
+%"

JSON, BSON and NoSQL • JSON: JavaScript Object Notation • BSON: Binary JSON
– Binary-encoded serialization of JSON-like documents
• MongoDB stores BSON documents – Collections are memory-mapped BSON – Clients work directly with BSON on-the-wire
• BSON written by client can be used by server • Very little overhead reading/writing documents
+&"

Nature of Data • Many documents for molecules
– Individual results are usually MBs – Small molecules, electronic structure, MD, etc.
• Materials tend to be different – Less documents, larger results – Less existing identifiers/search techniques
• Institutions maintain big disks – Move to referencing data, client-server, etc.
+'"

+("
Clean Energy Project

Clean Energy Project: Introduction • Searching for organic photovoltaics
– IBM World Community Grid – High-throughput, in-silico study – Partnered with experimental groups
• Synthesize most promising candidates
• Many views of the data – Simple numbers for many properties – 2D graphs and 3D chemical structures – 3D structures with quantum calculation output
$)"http://cleanenergy.molecularspace.org/

Clean Energy Project: Big Data • Overall size and scope of the data:
– 2.3 million unique molecules • 22 million conformers • 150 million DFT calculations • 400TB+ of raw output data • 80GB of metadata
– Growing at just under 1TB a day – ~2.8 million unique molecules
• ~27M conformers and 185M DFT calculations • 0.5PB of raw data in the latest result set
$!"

Clean Energy Project: Open Data • Part of the Materials Genome Initiative • Data released under CC-BY-SA license • Amazing opportunity for Open Chemistry
– Very large dataset pushing current limits – Openly-licensed, allowing us to experiment – Opportunity to improve the state-of-the-art – Molecules fit our model
• Less than 1024 atoms • DFT calculations with metadata extraction
$#"

Building Community • Community around projects • Using Kitware software process
– Ensuring quality with continuous testing
– Code contributions on the web – Public mailing lists, bug trackers,
and code review • Promoting projects and
participation – Publication – Conferences – Workshops – Social media
$*"
Software Repository
Build, Test & Package
Community Review
Developers & Users

Conclusions • Shared frameworks needed to work with data • Domain specific approaches are essential
– One size fits all rarely works well – The right frameworks can be extended/customized
• Storing, sharing, publishing, and analyzing data • Data scales increasing, client-server can help • Semantic data is an important aspect too • Questions?
$+"