biological databases overview • introduction • what is … · overview • introduction ......
TRANSCRIPT

Biological Databases Overview • Introduction • What is a database • What type of databases can we access • What roles do they play • What type of information can we get from them • How do we access these information

What is a database ? • Convenient method of vast amount of information • Allows for proper storing, searching &retrieving of data. • Before analyzing them we need to assemble them into central, shareable resources

Why databases ? • Means to handle and share large volumes
of biological data • Support large-scale analysis efforts • Make data access easy and updated • Link knowledge obtained from various
fields of biology and medicine

Different Database Types • depends on the nature of information stored
(sequences, 2D gel or 3D structure images) • manner of storage (flat files, tables in a relational
database, etc) • In this course we are concerned more about the
different types of databases rather than the particular storage

Features • Most of the databases have a web-
interface to search for data • Common mode to search is by Keywords • User can choose to view the data or save
to your computer • Cross-references help to navigate from
one database to another easily

Biological Databases (Effectively Electronic Filing Cabinets)
Type of databases Information they contain
Bibliographic databases Literature Taxonomic databases Classification Nucleic acid databases DNA information
Genomic databases Gene level information Protein databases Protein information Protein
families, domains and functional sites Classification of proteins and identifying domains
Enzymes/ metabolic pathways Metabolic pathways

Types Of Biological Databases Accessible There are many different types of database but
for routine sequence analysis, the following are initially the most important
Primary databases Secondary databases Tertiary databases Composite databases

Primary databases (amino acid and nucleic acid sequences stored
as linear alphabets in primary databases) • Contain sequence data such as nucleic acid
or protein • Example of primary databases include Nucleic Acid Databases Protein Databases
• EMBL • SWISS-PROT • Gen bank • TREMBL • DDBJ •PIR

Secondary databases (regions of local regularity like α – helices and β –
strands apparent as well conserved motifs stored as patterns so sometimes known as pattern databases)
• Contain results from the analysis of the sequences in the
primary databases • Example of secondary databases include : PROSITE Pfam BLOCKS PRINTS

Tertiary databases Packing of secondary databases elements
forming domains or modules stored as sets of atomic co-ordinates.
Examples of Tertiary databases PDB SCOP CATH

Composite databases • Combine different sources of primary
databases. • Make querying and searching efficient and
without the need to go to each of the primary databases.
• Example of composite databases include : NRDB –Non-Redundant DataBase OWL

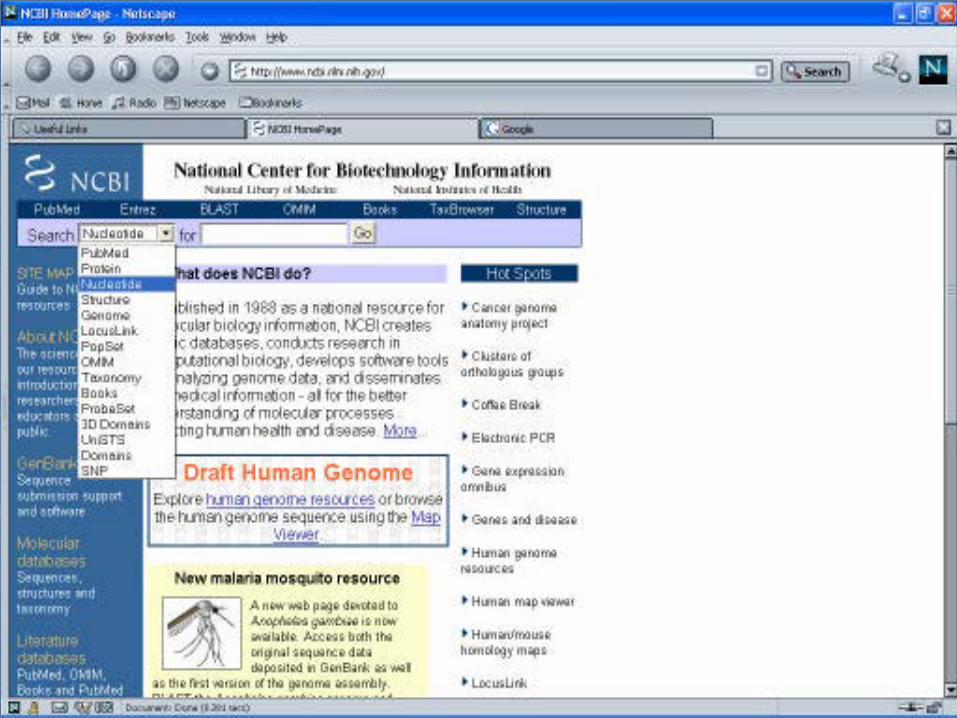
How to access them NCBI (American Information Provider, established in1988 ) : http://www.ncbi.nlm.nih.gov/ at the NIH campus, USA It provides timely and accurate processing and biological review of new entries and
updates to existing entries and is ready to assist authors who have new data to submit.
Its role is to develop new information technologies to aid our understanding of
molecular and genetic processes that underlie health and disease. It has developed www form called BankIt for convenient and quick submission of
sequence data. Its specific aims –
creation of automated systems for stoning and analyzing biological information. Development of advanced methods of computer based information processing Facilitation of user access to databases and software. Coordination of efforts to gather biotechnology information worldwide.

EBI (Established in 1994) is an outstation of European Molecular Biology Laboratory
(EMBL). http://www.ebi.ac.uk/ An International research institute with its headquarters
in Heidelberg, Germany. Its central activity is development and distribution of
EMBL nucleotide sequence databases. Collaborative project with Genbank, NCBI and DDBJ
which ensures that all new and updated databases entries are shared between groups on daily basis.
Also collaborate with Swiss institute of Bioinformatics to
maintain and distribute Swiss Prot Protein sequence databases.

ExPASy http://www.expasy.org/ Expert Protein Analysis System
proteomics server of the Swiss Institute of Bioinformatics (SIB)
dedicated to the analysis of protein
sequences and structures
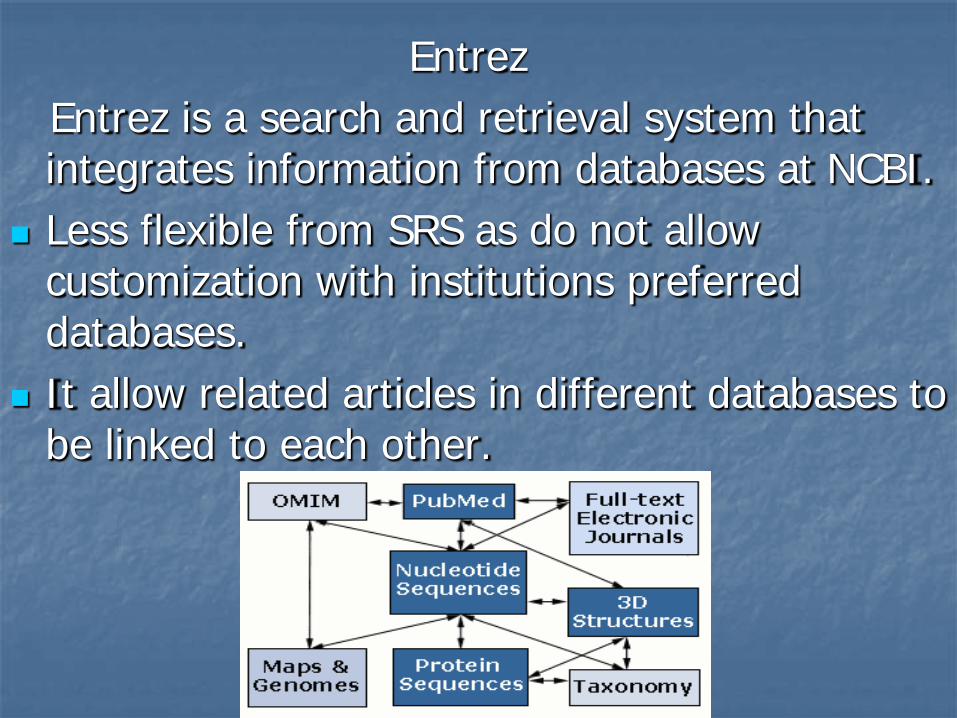
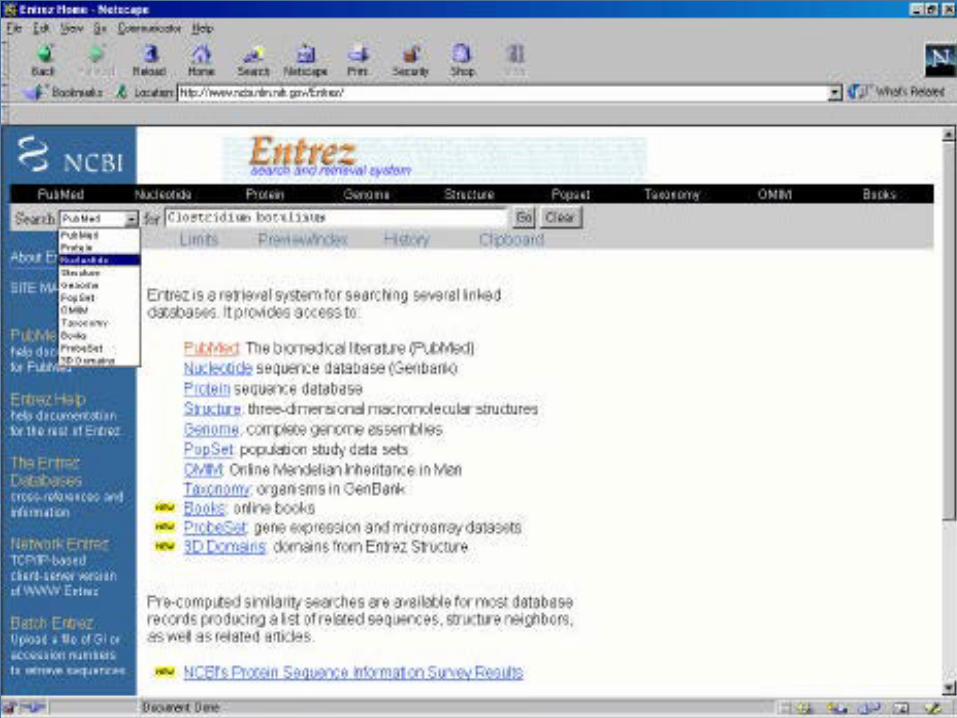
Entrez Entrez is a search and retrieval system that
integrates information from databases at NCBI. Less flexible from SRS as do not allow
customization with institutions preferred databases.
It allow related articles in different databases to be linked to each other.

SRS ( Sequence Retrieval System) It is a network browser for databases in
molecular biology or allows any flat file database to be indexed to any other.
It is a powerful tool allowing the users to
formulate queries across a range of different database types via a single interface.
Advantage of SRS derived indices may be rapidly searched,
allowing users to retrieve link and access entries from all interconnected resources.

EMBL- Nucleotide sequence database from EBI http://www.emblheidelberg.de/ (a) Includes sequences
Both from direct Author submissions and genome sequence groups.
From scientific literature and patent applications. (b) Database produced in collaboration with DDBJ and Gen
bank and all new and updated entries are exchange between them on daily basis.
(c) Rate of growth has an exponential trend, in 1998 – more then a million entries.
(d) Information can be retrieved from EMBL using SRS sequence retrieval system/or with query sequences via EBI’s web interfaces to BLAST and ClustalW programs. SRS link DNA and protein databases with motif, structure, mapping and other specialist databases. It also link to Medline facility.

Gen bank – DNA database from NCBI Incorporates sequences from publicly available sources,
primarily from direct author submissions and large scale sequencing projects.
Due to diversity of data sources available there was
increase in size of database so Gen bank divided into 17 small discrete divisions like PRI, ROD, MAM, VRT etc. as it facilitates fast specific searches by restricting queries to particular database subsets.
Information can be retrieved from Gen bank using
Entrez integrated system/ or with user query sequences by means of NCBI web interface to BLAST programs.Like SRS, entrez also link DNA and protein databases with motif, structure, mapping and other specialist databases. It also link to Medline facility.

DDBJ(DNA Data Bank of Japan from NIG) DDBJ began data bank activities in 1986 at NIG with the endorsement of
the Ministry of Education, Science, Sport and Culture. To operate DDBJ more efficiently, CIB; the Center for Information Biology was established in NIG in 1995.
DDBJ is organized by CIB-DDBJ; Center for Information Biology and
DNA Data Bank of Japan of NIG; National Institute of Genetics DNA Data Bank of Japan is the sole nucleotide sequence data bank in Asia,
which is officially certified to collect nucleotide sequences from researchers and to issue the internationally recognized accession number to data submitters.
DDBJ collects sequence data mainly from Japanese researchers, but of
course accepts data and issue the accession number to researchers in any other countries.
The principal purpose of DDBJ operations is to improve the quality of INSD, as public domains

Major Activities of DDBJ 1. One of the members of INSDC DDBJ is officially
certified to collect nucleotide sequences from researchers and to issue the internationally recognized accession number to data submitters
2. Bioinformatics databases management developing
tools for depositing and retrieving data eg.ARSA All-round Retrieval of Sequence and Annotation
3. Developing software tools for analyzing biological
data eg. Web API for Biology (WABI) 4. Holding a course to teach beginners: How to analyze
biological data

The International Sequence Database Collaboration • These databases have collaborated since 1982. Each
database collects and processes new sequence data and relevant biological information from scientists in their region e.g. EMBL collects from Europe, GenBank from the USA.
• These databases automatically update each other with
the new sequences collected from each region, every 24 hours. The result is that they contain exactly the same information, except for any sequences that have been added in the last 24 hours.
• This is an important consideration in your choice of
database. If you need accurate and up to date information, you must search an up to date database.

In 2005, DDBJ, EMBL-Bank and GenBank agreed to call their collaboration "INSDC; International Nucleotide Sequence Database Collaboration"; and to call the unified nucleotide sequence database "INSD; the International Nucleotide Sequence Database". The agreement was approved by IAC in May 2005.
In 2009, INSDC added a coraborative meeting to deal with mass sequence data produced by the "next" generation sequencers (Sequence Read Archive) and traces produced by traditional sequencers (Trace Archive).
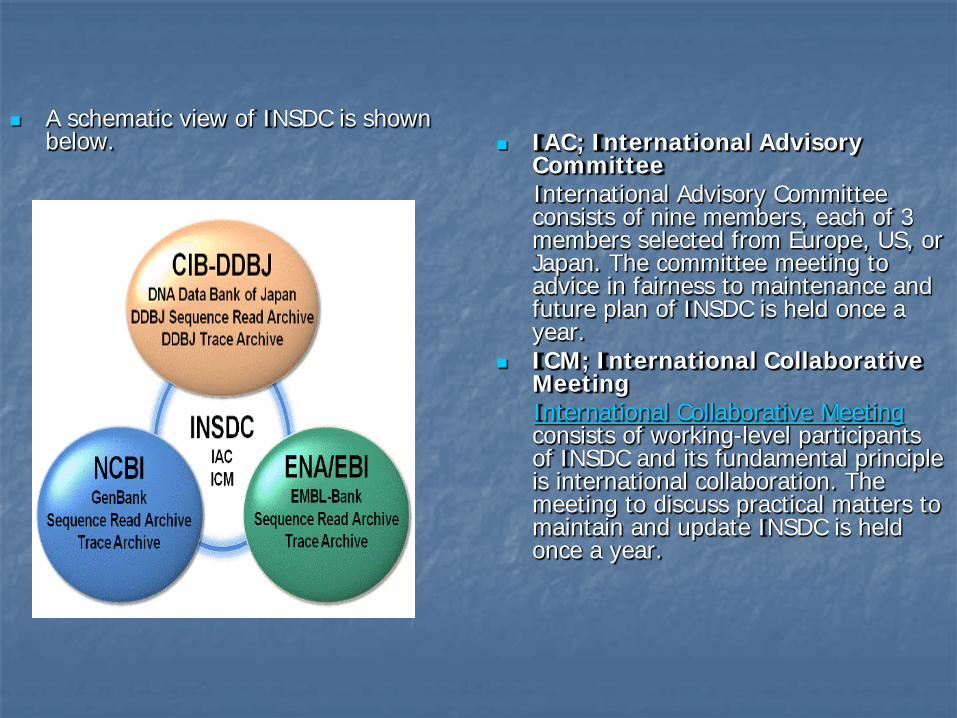
A schematic view of INSDC is shown below. IAC; International Advisory
Committee International Advisory Committee
consists of nine members, each of 3 members selected from Europe, US, or Japan. The committee meeting to advice in fairness to maintenance and future plan of INSDC is held once a year.
ICM; International Collaborative Meeting
International Collaborative Meeting consists of working-level participants of INSDC and its fundamental principle is international collaboration. The meeting to discuss practical matters to maintain and update INSDC is held once a year.

Literature Databases
Pubmed is free resource providing access to MEDLINE
database citations, abstracts and some full text articles on life sciences and biomedical topics.
It is available on entrez retrieval system. It was developed by NCBI at NLM.

In addition to Medline citations, it also contains • citations that precede the date that a journal was selected for
MEDLINE indexing.
• Some old Medline citations that have not yet been updated with current vocabulary
• Citations to articles that are out of scope from Medline Journal
• In process citations which provide a record for an article before it is indexed with MeSH and added to MEDLINE.
• Some life science journals that submit full text to Pubmed
central and may not yet have recommended for inclusion in Medline although they have undergone a review by NLM.

It has been available free on the internet since the mid 1990s.
Quick, simple telegram style search formulations can
be used and they generally produce acceptable results.
A special feature of Pubmed is the clinical queries
and systematic review option which can be used to identify more relevant studies by automatically applying quality filters to each search.
It links to related articles for a selected citation.

It links to many sites providing full text articles and other related sources
A strong feature of pubmed is its ability to automatically link to
MeSH and subheadings e.g.. Bad breath- Halitosis Breast cancer- breast neoplasms Search field tags can be used for searching Pubmed like au-author dp-date published, ip-issue, part or supplement, la-language, Pg-first
page no. article, pmid-pubmed ID, Pt-publication type like review, ti-journal title, vl–volume
Articles appearing in Pubmed will have only a PMID
It links to Pubchem, NCBI sequence and other molecular biology
databases.
It includes a spell checker feature.

MEDLINE (Medical literature analysis and retrieval system online)
It is the largest component of PubMed.
It is the freely accessible online database of biomedical
journal citations and abstracts created by US (NLM) It contains over 16 million reference to journal articles. A distinctive feature of Medline is that records are indexed
with NLM’s controlled vocabulary and MeSH.

The great majority of journals are selected for Medline based on recommendation of LSTRC (Literature selection technical review committee) an NIH chartered committee that review NIH grant applications.
Medline may also be searched by NLM Gateway. Articles appearing in Medline will have both PMID and
MUID(Medline unique identifier)