boletim de anÁlise estatÍstico · fernanda cardoso romão freitas 1º semestre de 2017 são paulo...
TRANSCRIPT

PONTIFÍCIA UNIVERSIDADE CATÓLICA DE SÃO PAULO
Programas de Pós Graduação em
Economia e
Administração da
PUC-SP
BOLETIM DE ANÁLISE ESTATÍSTICOBASTA 2017
Vol. 1
IDHM ÍNDICE DE DESENVOLVIMENTO HUMANO MUNICIPAL ATLAS BRASIL
CLASSIFICAÇÃO: Da Visão Não Supervisionada a Supervisionada,
Utilizando 18 variáveis selecionadas do Atlas Brasil.
DISCIPLINA: MÉTODOS QUALITATIVOS E QUANTITATIVOS EM ADMINISTRAÇÃO PROF. ARNOLDO JOSÉ DE HOYOS GUEVARA
Fernanda Cardoso Romão Freitas
1º SEMESTRE DE 2017
São Paulo – SP
2017

2
SUMÁRIO
INTRODUÇÃO ........................................................................................................................... 3
CAPÍTULO I. ENTENDENDO OS DADOS .............................................................................. 3
1.1. Os Indivíduos ........................................................................................................................ 3
1.2. As Variáveis .......................................................................................................................... 3
1.3 A tabela de Dados .................................................................................................................. 6
1.4 Variáveis Categóricas ............................................................................................................. 7
1.5 Variável “Município” ............................................................................................................. 7
CAPÍTULO II. ANÁLISE DE CLUSTERS E DENDOGRAMA ................................................ 7
2.1 Mapa do Brasil com 7 Clusters ............................................................................................ 10
CAPÍTULO III. DENDOGRAMA COM 4 CLUSTERS – CLASSIFICAÇÃO
SUPERVISIONADA ................................................................................................................ 10
3.1 Mapa do Brasil com 4 Clusters ............................................................................................ 12
CAPÍTULO IV. ANOVA por região das variáveis ESPVIDA, MORT1, T_ANALF11á14 e
T_ANALF15M .......................................................................................................................... 12
CONSIDERAÇÕES FINAIS ..................................................................................................... 14
REFERÊNCIA............................... ............................................................................................15

3
INTRODUÇÃO
O Atlas Brasil do Desenvolvimento Humano é uma plataforma de consulta ao
Índice do Desenvolvimento Humano Municipal (IDHM). O Atlas traz o IDHM e mais
200 indicadores de desenvolvimento nas dimensões de demografia,
educação,renda,trabalho,habitação e vulnerabilidade através dos dados extraídos dos
censos demográficos.
Este trabalho tem por objetivo realizar uma análise exploratória na dimensão do
IDHM dos dados disponibilizados na plataforma Atlas. A Base de dados do Atlas Brasil
apresenta o Índice de Desenvolvimento Humano Municipal de 5.565 municípios, 27
unidades de Federação (UF) e 20 Regiões Metropolitanas.
Para iniciar a compreensão dos dados faremos a apresentação das variáveis
escolhidas incluindo suas definições, significados, unidade de medida e faremos a
apresentação da tabela de dados. Em seguida será apresentada a análise de cada uma das
variáveis. Para a análise contaremos com a o auxílio de gráficos e dados numéricos como
histograma, Box-plot, curva de densidade, teste de normalidade de Anderson
Darling,média,mediana,quartis,desvio padrão, variância e intervalo de confiança.
Por fim faremos uma análise sobre todas as variáveis estudadas. O Software
estatístico utilizado neste trabalho foi o MINITAB 17.
CAPÍTULO I. ENTENDENDO OS DADOS
1.1 Os Indivíduos
Os indivíduos estudados neste trabalho são os 5.565 municípios brasileiros que
serão analisados pela dimensão do Desenvolvimento Humano e seus indicadores,
presentes no relatório do Atlas Brasil 2013. Os dados analisados são do ano de 2010.
Quando a dimensão do Desenvolvimento Humano Municipal Brasileiro, este
considera as mesmas três dimensões do IDH- Global que são longevidade, educação e
renda.
A importância do IDHM se dá, pois sintetiza uma realidade complexa em um
único número e viabiliza a comparação entre os municípios ao longo do tempo. Ele
também populariza a visão do desenvolvimento voltado para pessoas e não apenas para o
progresso econômico. O Crescimento econômico seja transformado em outras conquistas
além da renda e da riqueza e que alcance a qualidade de vida de cada indivíduo.
1.2 As Variáveis
São 18 as variáveis desta pesquisa. As mesmas são melhores explicadas na tabela 1.
Ressalta-se que todos os dados desta pesquisa são referentes ao ano de 2010.
Tabela 1. As Variáveis
Variável Significado Tipo
Unidade
de
Medida
ESPVIDA
Número médio de anos que as
pessoas deverão viver a partir do
nascimento, se permanecerem
constantes ao longo da vida o nível
e o padrão de mortalidade por
idade prevalecentes no ano do
Censo.
Variável
Quantitativa Índice

4
MORT1
Número de crianças que não
deverão sobreviver ao primeiro ano
de vida em cada 1000 crianças
nascidas vivas.
Variável
Quantitativa Índice
T_ANALF11A14
Razão entre a população de 11 a 14
anos de idade que não sabe ler nem
escrever um bilhete simples e o
total de pessoas nesta faixa etária
multiplicado por 100.
Variável
Quantitativa Índice
T_ANALF15M
Razão entre a população de 15
anos ou mais de idade que não sabe
ler nem escrever um bilhete
simples e o total de pessoas nesta
faixa etária multiplicado por 100.
Variável
Quantitativa Índice
PIND
Proporção dos indivíduos com
renda domiciliar per capita igual
ou inferior a R$ 70,00 mensais, em
reais de agosto de 2010. O
universo de indivíduos é limitado
àqueles que vivem em domicílios
particulares permanentes.
Variável
Quantitativa Percentual
RIND
Média da renda domiciliar per
capita das pessoas com renda
domiciliar per capita igual ou
inferior a R$ 70,00 mensais, a
preços de agosto de 2010. O
universo de indivíduos é limitado
àqueles que vivem em domicílios
particulares permanentes.
Variável
Quantitativa Índice
REN3
Razão entre o número de pessoas
de 18 anos ou mais de idade
ocupadas e com rendimento
mensal de todos os trabalhos
inferior a 3 salários mínimos de
julho de 2010 e o número total de
pessoas ocupadas nessa faixa etária
multiplicado por 100.
Variável
Quantitativa Percentual
RENOCUP
Média dos rendimentos de todos os
trabalhos das pessoas ocupadas de
18 anos ou mais de idade. Valores
em reais de agosto de 2010.
Variável
Quantitativa Índice

5
T_AGUA
Razão entre a população que vive
em domicílios particulares
permanentes com água canalizada
para um ou mais cômodos e a
população total residente em
domicílios particulares
permanentes multiplicado por 100.
A água pode ser proveniente de
rede geral, de poço, de nascente ou
de reservatório abastecido por água
das chuvas ou carro-pipa.
Variável
Quantitativa Percentual
T_LIXO
Razão entre a população que vive
em domicílios com coleta de lixo e
a população total residente em
domicílios particulares
permanentes multiplicado por 100.
Estão incluídas as situações em que
a coleta de lixo realizada
diretamente por empresa pública
ou privada, ou o lixo é depositado
em caçamba, tanque ou depósito
fora do domicílio, para posterior
coleta pela prestadora do serviço.
São considerados apenas os
domicílios particulares
permanentes localizados em área
urbana.
Variável
Quantitativa Percentual
T_FORA6A14
Razão entre as crianças de 6 a 14
anos que não frequenta a escola e o
total de crianças nesta faixa etária
multiplicado por 100.
Variável
Quantitativa Percentual
T_M10A14CF
Razão entre as mulheres de 10 a 14
anos de idade que tiveram filhos e
o total de mulheres nesta faixa
etária multiplicado por 100.
Variável
Quantitativa Percentual
PESORUR População residente na área rural Variável
Quantitativa Índice
PESOURB População residente na área urbana Variável
Quantitativa Índice
IDHM
Índice de Desenvolvimento
Humano Municipal. Média
geométrica dos índices das
dimensões Renda, Educação e
Longevidade, com pesos iguais.
Variável
Quantitativa Índice

6
Fonte: Atlas Brasil 2013
1.3 A Tabela de Dados
Estatísticas Descritivas: ANO; UF; Codmun6; Codmun7; ESPVIDA; MORT1;
T_ANALF11A14; ... Variável N N* Média EP Média DesvPad Mínimo Q1 Mediana
Q3
ANO 5565 10 2010,0 0,000000 0,000000 2010,0 2010,0 2010,0
2010,0
UF 5565 10 32,372 0,132 9,830 11,000 25,000 31,000
41,000
Codmun6 5565 10 325305 1320 98452 110001 251209 314620
411905
Codmun7 5565 10 3253053 13198 984521 1100015 2512089 3146206
4119054
ESPVIDA 5575 0 72,968 0,0525 3,920 1,000 71,140 73,470
75,160
MORT1 5575 0 19,293 0,0966 7,213 8,490 13,800 17,000
23,900
T_ANALF11A14 5565 10 3,6888 0,0508 3,7925 0,0000 1,1900 2,0200
5,2400
T_ANALF15M 5565 10 16,159 0,132 9,840 0,950 8,080 13,120
24,320
PIND 5565 10 11,341 0,158 11,764 0,000 1,640 6,240
19,065
IDHM_ E
Índice sintético da dimensão
Educação que é um dos 3
componentes do IDHM. É obtido
através da média geométrica do
subíndice de frequência de crianças
e jovens à escola, com peso de 2/3,
e do subíndice de escolaridade da
população adulta, com peso de 1/3.
Variável
Quantitativa Índice
IDHM_L
Índice da dimensão Longevidade
que é um dos 3 componentes do
IDHM. É obtido a partir do
indicador Esperança de vida ao
nascer, através da fórmula: [(valor
observado do indicador) - (valor
mínimo)] / [(valor máximo) -
(valor mínimo)], onde os valores
mínimo e máximo são 25 e 85
anos, respectivamente.
Variável
Quantitativa Índice
IDHM_R
Índice da dimensão Renda que é
um dos 3 componentes do IDHM.
É obtido a partir do indicador
Renda per capita, através da
fórmula: [ln (valor observado do
indicador) - ln (valor mínimo)] /
[ln (valor máximo) - ln (valor
mínimo)], onde os valores mínimo
e máximo são R$ 8,00 e R$
4.033,00 (a preços de agosto de
2010).
Variável
Quantitativa Índice
7
RIND 5565 10 32,036 0,129 9,603 0,000 27,435 32,510
37,090
REN3 5565 10 90,932 0,0789 5,889 51,450 87,275 91,940
95,840
RENOCUP 5565 10 780,11 4,58 341,68 136,42 488,59 761,72
1008,08
T_AGUA 5565 10 85,598 0,197 14,721 0,150 79,635 90,280
96,260
T_LIXO 5565 10 94,047 0,148 11,050 0,000 93,720 98,030
99,490
T_FORA6A14 5565 10 2,8632 0,0357 2,6653 0,0000 1,5200 2,3800
3,4350
T_M10A14CF 5565 10 0,39929 0,00927 0,69120 0,00000 0,00000 0,00000
0,67000
pesoRUR 5565 10 5360 89,0 6642 0,0 1599 3233
6769
pesourb 5565 10 28917 2702 201551 174 2838 6263
15492
IDHM 5565 10 0,65916 0,000965 0,07200 0,41800 0,59900 0,66500
0,71800
IDHM_E 5565 10 0,55909 0,00125 0,09333 0,20700 0,49000 0,56000
0,63100
IDHM_L 5565 10 0,80156 0,000599 0,04468 0,67200 0,76900 0,80800
0,83600
IDHM_R 5565 10 0,64287 0,00108 0,08066 0,40000 0,57200 0,65400
0,70700
Para esta análise usaremos apenas as varáveis, ESPVIDA, MORT1,
T_ANALF15M e T_ANALF11A14.
1.4 Variáveis Categóricas
Este tipo de variável indica que o foco de concentração deve ser a análise de
gráficos do tipo pie chart e barras.
1.5 Variável: “Município”
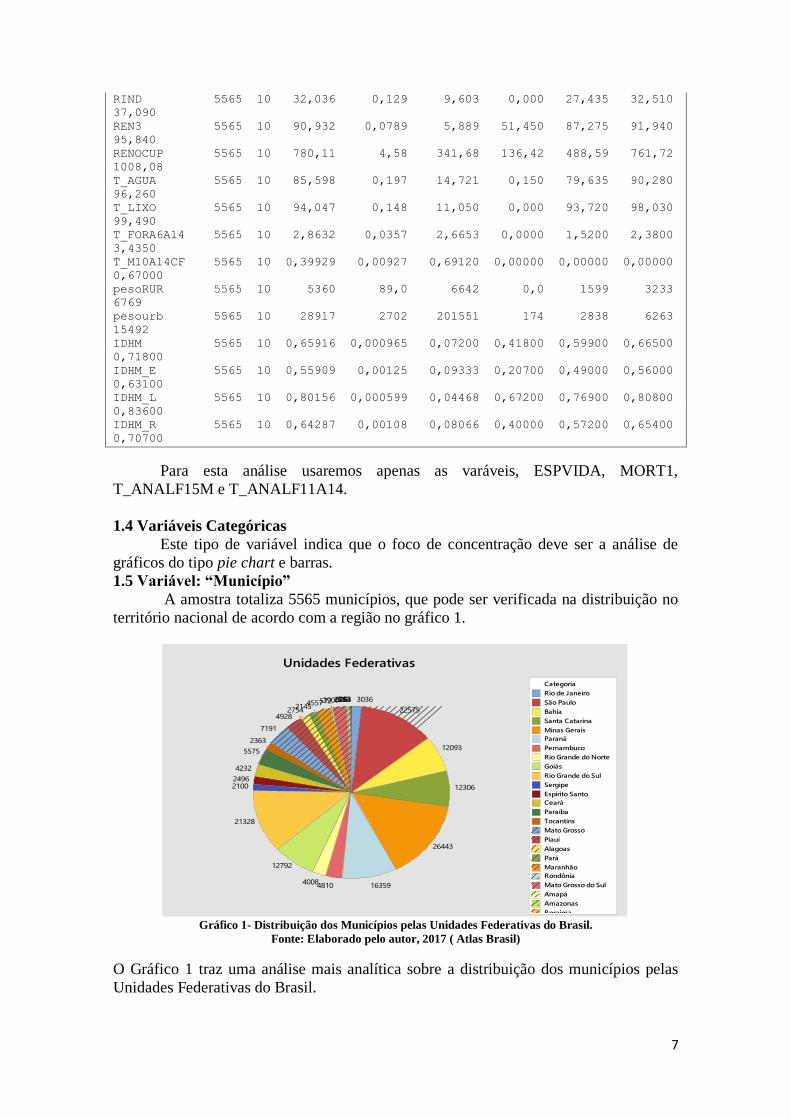
A amostra totaliza 5565 municípios, que pode ser verificada na distribuição no
território nacional de acordo com a região no gráfico 1.
Gráfico 1- Distribuição dos Municípios pelas Unidades Federativas do Brasil.
Fonte: Elaborado pelo autor, 2017 ( Atlas Brasil)
O Gráfico 1 traz uma análise mais analítica sobre a distribuição dos municípios pelas
Unidades Federativas do Brasil.
Rio Grande do Sul
Sergipe
Espírito Santo
Ceará
Paraíba
Tocantins
Mato Grosso
Piauí
Alagoas
Pará
Rio de Janeiro
Maranhão
Rondônia
Mato Grosso do Sul
Amapá
Amazonas
Roraima
São Paulo
Bahia
Santa Catarina
Minas Gerais
Paraná
Pernambuco
Rio Grande do Norte
Goiás
Categoria
53264210806256390057245572145
27544928
7191
2363
5575
4232
24962100
21328
12792
40084810 16359
26443
12306
12093
22575
3036
Unidades Federativas

8
Podemos observar que as Unidades Federativas com maior concentração de Municípios
são Minas Gerais, com 26443 municípios, seguido por São Paulo com 22575 municípios
e Rio Grande do Sul com 21328 Municípios.
CAPÍTULO II. ANÁLISE DE CLUSTER E DENDOGRAMA
A análise de variância (ANOVA) testa a hipótese de que as médias de duas ou
mais populações são iguais. Análises ANOVA testam a importância de um ou mais
fatores comparando as médias das variáveis de resposta em diferentes níveis dos fatores.
A hipótese nula afirma que todas as médias das populações (médias dos níveis dos
fatores) são iguais, enquanto a hipótese alternativa afirma que pelo menos uma é
diferente.
O objetivo do presente trabalho é através da ANOVA obter as médias por estado
de cada uma das quatro variáveis ESPVIDA, MORT1, T_ANALF11A14 e
T_ANALF15M para que posteriormente pudéssemos realizar uma análise de cluster das
médias por estado a fim de agrupar os munícipios e sintetizar os dados. Neste trabalho
faremos o agrupamento dos estados com maior similaridade em clusters.A princípio foi
realizada uma classificação não supervisionada com a formação de 7 clusters,
posteriormente fizemos uma classificação supervisionada com o propósito de reagrupar
os grupos de acordo com as distâncias centroides de cada grupo e chegamos a um novo
agrupamento de 4 clusters.
Dendograma com 7 clusters - Classificação não supervisionada
Análise de Agrupamentos de Observações: ESP VIDA M; MORT 1 M;
T_ANALF11á14 M; T_ANALF15M M
Distância Euclideana, Ligação Completa
Passos de Amalgamação
Número de
obs. no
Número de Nível de Nível de Agrupados Novo novo
Passo agrupados similaridade distância reunidos agrupado agrupado
1 25 97,4715 0,024019 7 8 7 2
2 24 96,8539 0,029885 22 23 22 2
3 23 95,9615 0,038362 15 24 15 2
4 22 94,3665 0,053513 10 12 10 2
5 21 93,5533 0,061238 7 17 7 3
6 20 92,8399 0,068014 6 19 6 2
7 19 92,2765 0,073366 22 25 22 3
8 18 92,1685 0,074392 14 16 14 2
9 17 91,8375 0,077536 6 15 6 4
10 16 90,7920 0,087468 10 11 10 3
11 15 89,9409 0,095552 5 6 5 5
12 14 89,7477 0,097387 4 20 4 2
13 13 88,2976 0,111162 3 13 3 2
14 12 86,1785 0,131292 7 18 7 4
15 11 85,4686 0,138035 2 9 2 2
16 10 85,1159 0,141385 7 10 7 7
17 9 83,9018 0,152918 1 5 1 6
18 8 83,4348 0,157354 4 26 4 3
19 7 79,1887 0,197688 1 14 1 8
20 6 77,9190 0,209749 3 21 3 3
21 5 75,3522 0,234131 7 22 7 10
22 4 68,8182 0,296198 1 2 1 10
23 3 65,0913 0,331600 3 4 3 6
24 2 36,8568 0,599802 3 7 3 16
25 1 0,0000 0,949907 1 3 1 26

9
Partição Final
Número de agrupados: 7
Dentro da
soma de
quadrados Distância Distância
Número de do média do máxima do
observações agrupado centróide centróide
Agrupado1 8 0,0453447 0,0679041 0,116947
Agrupado2 2 0,0095268 0,0690173 0,069017
Agrupado3 2 0,0061785 0,0555810 0,055581
Agrupado4 3 0,0175359 0,0752035 0,092354
Agrupado5 7 0,0279480 0,0604621 0,088042
Agrupado6 1 0,0000000 0,0000000 0,000000
Agrupado7 3 0,0033089 0,0318070 0,043683
Centróides do grupo
Variável Agrupado1 Agrupado2 Agrupado3 Agrupado4 Agrupado5
Agrupado6 Agrupado7
ESP VIDA M 0,389658 0,307295 0,441870 0,520600 0,673411
0,5685 0,761793
MORT 1 M 0,540655 0,394535 0,622795 0,703467 0,808444
0,7608 0,878320
T_ANALF11á14 M 0,815547 0,750175 0,757450 0,914383 0,954614
0,7615 0,968061
T_ANALF15M M 0,404392 0,337950 0,605750 0,695510 0,758554
0,5976 0,860750
Centróide
Variável global
ESP VIDA M 0,528660
MORT 1 M 0,674045
T_ANALF11á14 M 0,870414
T_ANALF15M M 0,603800
Distâncias Entre Centróides do Grupo
Agrupado1 Agrupado2 Agrupado3 Agrupado4 Agrupado5 Agrupado6
Agrupado7
Agrupado1 0,000000 0,191893 0,231070 0,371714 0,544975 0,347417
0,695719
Agrupado2 0,191893 0,000000 0,376806 0,543830 0,723924 0,519543
0,872589
Agrupado3 0,231070 0,376806 0,000000 0,213052 0,387685 0,187519
0,526333
Agrupado4 0,371714 0,543830 0,213052 0,000000 0,199912 0,196319
0,344867
Agrupado5 0,544975 0,723924 0,387685 0,199912 0,000000 0,276542
0,152705
Agrupado6 0,347417 0,519543 0,187519 0,196319 0,276542 0,000000
0,403842
Agrupado7 0,695719 0,872589 0,526333 0,344867 0,152705 0,403842
0,000000

10
Figura 1: Média por estados.
Notamos analisando o dendograma que podemos separar o Brasil em 7 grandes
grupos de estados com mesma similaridade de média destas variáveis. Os grupos cujos
estados são mais similares entre si são Grupo 5, sendo os estados mais similares ES e GO
e grupo 7 composto por RS, SC e SP, sendo os estados mais similares RS e SC.
Observamos através do relatório o que foi posteriormente confirmado pelo
dendograma que o grupo 6 , onde contém o estado RR , o grupo 2 com AL e MA e o
grupo com AM e PA por conta das distâncias entre os centroides do grupo , podem ser
reagrupados em um dos outros grupos já existentes como veremos na próxima etapa.
2.1 Mapa do Brasil com 7 clusters
SPSCRS
MS
MT
MGRJPRG
OESTOROAPRRPAA
MM
AALPIPBSEP
ERNC
EBAA
C
0,00
33,33
66,67
100,00
Observações
Sim
ilari
dad
e
Média por estados

11
CAPÍTULO III. DENDROGRAMA COM 4 CLUSTERS - CLASSIFICAÇÃO
SUPERVISIONADA
De acordo com a análise da distância dos centroides podemos extinguir 3 clusters
que por sua proximidade com outros clusters puderam ser agrupados a estes.
A classificação supervisionada foi realizada da seguinte forma: Número de
observações
Agrupado1 8
Agrupado2 2 ------------------------ foi para o grupo 1
Agrupado3 2 --------------------------- foi para o grupo 4
Agrupado4 3
Agrupado5 7
Agrupado6 1 -----------------------------foi para o grupo 4
Agrupado7 3
Recodificar
Sumário
Número
Valor Valor de
Original registrado Linhas
2 1 2
3 4 2
6 4 1
Coluna de dados de origem CLUSTER OBS 7
Coluna de dados registrada Recodificado CLUSTER OBS 7
Número de linhas inalteradas: 21
Análise Discriminante: Recodificado CLU versus ESP VIDA M; MORT 1 M; ...
Método Linear para Resposta: Recodificado CLUSTER OBS 7
Preditores: ESP VIDA M; MORT 1 M; T_ANALF11á14 M; T_ANALF15M M
Grupo 1 4 5 7
Contagem 10 6 7 3
Sumário de classificações
Alocado no Grupo Verdadeiro
Grupo 1 4 5 7
1 10 0 0 0
4 0 6 0 0
5 0 0 7 0
7 0 0 0 3
Total de N 10 6 7 3
N correto 10 6 7 3
Proporção 1,000 1,000 1,000 1,000
N = 26 N Correto = 26 Proporção Correta = 1,000
Distância Quadrática Entre Grupos
1 4 5 7
1 0,000 28,753 93,396 164,945
4 28,753 0,000 30,151 71,862
5 93,396 30,151 0,000 10,602
7 164,945 71,862 10,602 0,000
Função Discriminante Linear para Grupos
1 4 5 7
Constante -118,48 -151,50 -228,79 -275,09
ESP VIDA M 84,26 179,43 415,68 542,74
MORT 1 M 37,14 20,71 -81,35 -135,34
T_ANALF11á14 M 245,86 195,58 198,35 169,98
T_ANALF15M M -27,56 53,97 71,27 105,78

12
Figura 2: Média por estados.
Neste segundo os dados dos estados foram divididos em quatro grandes grupos, o
que é perfeitamente possível de acordo com a similaridade dos dados.
Abaixo vemos a distribuição dos estados de acordo com a similaridade.
3.1 Mapa do Brasil com 4 clusters
CAPÍTULO IV. ANOVA por região das variáveis ESPVIDA, MORT1,
T_ANALF11á14 e T_ANALF15M
ANOVA com um fator: ESP VIDA M versus Recodificado CLUSTER OBS 7 Método
SPSCRSRJPRM
TM
SM
GGOESRRPATOROA
PPIM
AALSEP
EPBRNC
EBA
AMA
C
0,00
33,33
66,67
100,00
Observações
Sim
ilari
dad
eMédia por estados

13
Hipótese nula Todas as médias são iguais
Hipótese alternativa No mínimo uma média é diferente
Nível de significância α = 0,05
Assumiu-se igualdade de variâncias para a análise
Informações dos Fatores
Fator Níveis Valores
Recodificado CLUSTER OBS 7 4 1; 2; 3; 4
Análise de Variância
Fonte GL SQ (Aj.) QM (Aj.) Valor F Valor-P
Recodificado CLUSTER OBS 7 3 0,55785 0,185950 138,81 0,000
Erro 22 0,02947 0,001340
Total 25 0,58732
Sumário do Modelo
S R2 R2(aj) R2(pred)
0,0366011 94,98% 94,30% 93,22%
Médias
Recodificado
CLUSTER OBS 7 N Média DesvPad IC de 95%
1 8 0,39860 0,01987 (0,37177; 0,42544)
2 3 0,3215 0,0248 ( 0,2777; 0,3654)
3 5 0,5185 0,0390 ( 0,4845; 0,5524)
4 10 0,6999 0,0464 ( 0,6759; 0,7239)
DesvPad Combinado = 0,0366011
ANOVA com um fator: MORT 1 M versus Recodificado CLUSTER OBS 7 Método
Hipótese nula Todas as médias são iguais
Hipótese alternativa No mínimo uma média é diferente
Nível de significância α = 0,05
Assumiu-se igualdade de variâncias para a análise
Informações dos Fatores
Fator Níveis Valores
Recodificado CLUSTER OBS 7 4 1; 2; 3; 4
Análise de Variância
Fonte GL SQ (Aj.) QM (Aj.) Valor F Valor-P
Recodificado CLUSTER OBS 7 3 0,53977 0,179923 80,62 0,000
Erro 22 0,04910 0,002232
Total 25 0,58887
Sumário do Modelo
S R2 R2(aj) R2(pred)
0,0472425 91,66% 90,52% 88,13%
Médias
Recodificado
CLUSTER OBS 7 N Média DesvPad IC de 95%
1 8 0,5576 0,0335 (0,5230; 0,5922)
2 3 0,4246 0,0523 (0,3680; 0,4811)
3 5 0,6993 0,0492 (0,6555; 0,7431)
4 10 0,8294 0,0538 (0,7984; 0,8604)
DesvPad Combinado = 0,0472425

14
ANOVA com um fator: T_ANALF11á14 M versus Recodificado CLUSTER
OBS 7 Método
Hipótese nula Todas as médias são iguais
Hipótese alternativa No mínimo uma média é diferente
Nível de significância α = 0,05
Assumiu-se igualdade de variâncias para a análise
Informações dos Fatores
Fator Níveis Valores
Recodificado CLUSTER OBS 7 4 1; 2; 3; 4
Análise de Variância
Fonte GL SQ (Aj.) QM (Aj.) Valor F Valor-P
Recodificado CLUSTER OBS 7 3 0,14569 0,048562 20,93 0,000
Erro 22 0,05106 0,002321
Total 25 0,19674
Sumário do Modelo
S R2 R2(aj) R2(pred)
0,0481741 74,05% 70,51% 61,78%
Médias
Recodificado
CLUSTER OBS 7 N Média DesvPad IC de 95%
1 8 0,8060 0,0560 ( 0,7707; 0,8413)
2 3 0,7637 0,0315 ( 0,7060; 0,8214)
3 5 0,8611 0,0809 ( 0,8164; 0,9058)
4 10 0,95865 0,01043 (0,92705; 0,99024)
DesvPad Combinado = 0,0481741
ANOVA com um fator: T_ANALF15M M versus Recodificado CLUSTER OBS
7 Método
Hipótese nula Todas as médias são iguais
Hipótese alternativa No mínimo uma média é diferente
Nível de significância α = 0,05
Assumiu-se igualdade de variâncias para a análise
Informações dos Fatores
Fator Níveis Valores
Recodificado CLUSTER OBS 7 4 1; 2; 3; 4
Análise de Variância
Fonte GL SQ (Aj.) QM (Aj.) Valor F Valor-P
Recodificado CLUSTER OBS 7 3 0,80729 0,269098 59,66 0,000
Erro 22 0,09923 0,004510
Total 25 0,90652
Sumário do Modelo
S R2 R2(aj) R2(pred)
0,0671586 89,05% 87,56% 84,46%
Médias
Recodificado
CLUSTER OBS 7 N Média DesvPad IC de 95%
1 8 0,4368 0,0714 (0,3875; 0,4860)

15
2 3 0,3315 0,0664 (0,2511; 0,4119)
3 5 0,6636 0,0723 (0,6013; 0,7259)
4 10 0,7892 0,0613 (0,7452; 0,8333)
DesvPad Combinado = 0,0671586
ESPVIDA MORT1 T_ANALF11A14 T_ANALF15M
1 0,39860 0,5576 0,8060 0,4368
2 0,3215 0,4246 0,7637 0,3315
3 0,5185 0,6993 0,8611 0,6636
4 0,6999 0,8294 0,95865 0,7892
Valor de F 138,81 80,62 20,93 59,66 Fonte: Elaborado pela autora
CONSIDERAÇÕES FINAIS
Dada a similaridade dos dados entre alguns estados foi possível realizar o
agrupamento das vinte e seis unidades federativas do Brasil a princípio em 7 grandes
grupos. Posteriormente, analisando o cluster com 7grupos foi possível sintetizar ainda
mais os dados dividindo o país em quatro grupos com alto grau de similaridade conforme
demonstrado no segundo mapa acima através da classificação supervisionada.
Através da formação destes clusters foi possível a sintetização dos dados de 5.565
municípios em estados e grupos mostrando a grande diferença de realidade nos diferentes
estados e regiões do Brasil conforme demonstramos através do mapa acima. Esta análise
apenas corroborou a ideia de termos “mais de um Brasil” já antes mencionadas em
trabalhos anteriores.
Por último realizamos a ANOVA que possibilita a comparação das variáveis entre
os 4 novos grupos criados e como cada variável contribui em cada nova região.
REFERÊNCIA
ANDERSON, David R.; SWEENEY, Dennis J.; WILLIAMS, Thomas A. Estatística aplicada à administração e economia. 2. ed. São Paulo: Thomson Learning, 2007.
ATLAS DO DESENVOLVIMENTO HUMANO NO BRASIL. Disponível em: <http://www.atlasbrasil.org.br/2013/>. Acessado em: 17 mar. 2017.
IBGE, Instituto Brasileiro de Geografia e Estatística. Séries Históricas e Estatísticas. Disponível em: <http://seriesestatisticas.ibge.gov.br/apresentacao.aspx>. Acessado em: 30 mar. 2017.
LAS CASAS A., DE HOYOS A. Pesquisa de Marketing