ch6- 字元裝置驅動程式的進階操作
DESCRIPTION
Ch6- 字元裝置驅動程式的進階操作. Outline. Introduction 6.1ioctl6.2 推延式 I/O 6.3poll 與 select6.4 臨時通知 6.5 改變裝置的存取點 6.6 裝置檔的存取控制. 6-Introduction. 驅動程式除了 讀寫動作 之外,通常還需要提供 各種控制硬體的能力 ,而控制動作通常是透過 ioctl 作業方法來實施。 不過,並非所有的裝置都採用 ioctl 控制方式,有的驅動程式採用了另一種控制技術 ( 預先定義一組特殊序列來當成控制命令 ) ,例如: tty - PowerPoint PPT PresentationTRANSCRIPT

Ch6- 字元裝置驅動程式的進階操作

Outline
• Introduction
• 6.1 ioctl 6.2 推延式 I/O
• 6.3 poll 與 select 6.4 臨時通知• 6.5 改變裝置的存取點 6.6 裝置檔的存取控制

6-Introduction
• 驅動程式除了讀寫動作之外,通常還需要提供各種控制硬體的能力,而控制動作通常是透過 ioctl作業方法來實施。
• 不過,並非所有的裝置都採用 ioctl控制方式,有的驅動程式採用了另一種控制技術 (預先定義一組特殊序列來當成控制命令 ),例如: tty
• ioctl( )系統呼叫為驅動程式提供了一個下達“裝置特有的命令 (device-specific command)”的管道。這類命令的定義與功能是隨硬體裝置而定:– 設定暫存器的狀態– 進入或離開某作業某作業模式
• ioctl( )的作用:控制 I/O通道

6.1-ioctl• User-space的觀點來看, ioctl( )系統呼叫的函式原形如下:int ioctl (int fd, int cmd, …)fd : file descriptor,檔案描述單元cmd : 控制命令… : 並非代表不定量引數,而是一個可有可無的引數 -習慣上表示為 char *argp(為了通過編譯時期的型別檢查 type checking)
• ioctl作業方法會收到下列宣告的引數:int (*ioctl) (struct inode *inode, struct file *filp, unsigned int
cmd, unsigned long arg)inode指標指向對應到應用程式傳來的 fd…filp指標指向一個代表裝置節點的 file結構cmd的值等於 ioctl( )系統呼叫的第二引數如果應用程式發出的 ioctl( )系統呼叫有第三個引數,則 ioctl作業方法會收到一個 unsigned long型別的 arg引數,否則無意義

6.1-ioctl
• 由於編譯器無法檢查額外引數的型別,因此,當應用程式傳遞了一個無效引數給 ioctl( ),驅動程式也要到執行期才會知道錯誤。這項缺點是 ioctl系統定義使然,但卻是 ioctl( )為了提供通用功能性的必然代價。
• 大部份驅動程式實作出來的 ioctl作業方法都包含了一個 switch敘述,並依據 cmd引數來選擇正確的處理程序。
• 不同的命令 (cmd)有不同的代表值,通常在標頭檔裡定義一組符號來代表各個命令值 <ex : scull驅動程式就在 scull.h標頭檔裡宣告一組命令代號 >

6.1.1- 選擇 ioctl 指令編號• 編寫 ioctl 的具體程式之前,必須先為各個指令挑選對
應的編號。最簡單的選擇“從 1 開始逐一分配”是不好的。
• 系統上,每個命令的編號都必須是獨一無二的 :– 以免正確命令被下達到錯誤裝置所造成的災難。– 若沒有重複的 ioctl 命令編號,則搞錯對象的程式就會收到
EINVAL 錯誤。• 初版的 linux 採用 16bits 的編號 :
– 高八位元代表裝置個體的“魔數 (magic number)”
– 低八位元則是供裝置內部使用的“序號 (sequence number)”
– 同系統上,沒有相同魔數的裝置。同一裝置裡沒有重複的序號。 <clueless 說:這樣的劃分是他一時的無知 >#define SCULL_IOCTL1 0x6b01
#define SCULL_IOCTL2 0x6b02

• 新版的劃分法則:– 查閱 include/asm/ioctl.h( 定義所要使用的各個位元欄,包括:
類型 , 魔數 , 流水號 , 傳輸方向 )– 查閱 Documentation/ioctl-number.txt( 列出所有已經分配給核心
的魔術,及解釋了為何應該採用新法則 )
• 新的劃分法使用四個位元欄位 < 定義在 linux/ioctl.h>– type(magic number) : 自己挑選一個符合規定的數值,並用於
整個驅動程式。欄位長度為 _IOC_TYPEBITS(8-bits)– number(ordinal number) : 可稱為序號,此欄位的長度為
_IOC_NRBITS(8-bits)– direction : 傳輸方向,代表資料的流向。包括 (_IOC_NONE,
_IOC_READ, _IOC_WRITE, _IOC_READ | _IOC_WRITE) 。應站在應用程式的觀點來看。
– size : 使用者資料量。此欄位的寬度隨硬體平台而定。 (8-bits~14-bits) 建議在 8-bits 以下來保持可移植性。
6.1.1- 選擇 ioctl 指令編號

• _IO(type,number) 沒有引數的指令• _IOR(type,number,datatype) 從驅動程式
讀出資料的指令• _IOW(type,number,datatype) 傳輸資料到
驅動程式的指令• _IOWR(type,number,datatype) 雙向傳輸的
指令
6.1.1- 選擇 ioctl 指令編號

#define SCULL_IOC_MAGIC 'k'
#define SCULL_IOCRESET _IO(SCULL_IOC_MAGIC, 0)
/* Use 'k' as magic number */
#define SCULL_IOCSQUANTUM _IOW(SCULL_IOC_MAGIC, 1, int)
#define SCULL_IOCSQSET _IOW(SCULL_IOC_MAGIC, 2, int)
#define SCULL_IOCTQUANTUM _IO(SCULL_IOC_MAGIC, 3)
#define SCULL_IOCTQSET _IO(SCULL_IOC_MAGIC, 4)
#define SCULL_IOCGQUANTUM _IOR(SCULL_IOC_MAGIC, 5, int)
#define SCULL_IOCGQSET _IOR(SCULL_IOC_MAGIC, 6 int)
#define SCULL_IOCQQUANTUM _IO(SCULL_IOC_MAGIC, 7)
#define SCULL_IOCQQSET _IO(SCULL_IOC_MAGIC, 8)
#define SCULL_IOCXQUANTUM _IOWR(SCULL_IOC_MAGIC, 9, int)
#define SCULL_IOCXQSET _IOWR(SCULL_IOC_MAGIC,10 int)
#define SCULL_IOCHQUANTUM _IO(SCULL_IOC_MAGIC, 11)
#define SCULL_IOCHQSET _IO(SCULL_IOC_MAGIC, 12)
/*HARDRESET命令,可將模組的用量計次歸零 */

• 整數引數的傳遞方式有兩種,一是透過指標,二是直接給明確數值; ioctl( ) 的普遍慣例,應該採用指標來交換數值。
• 對於系統呼叫的回傳值有不成文的慣例:負值代表錯誤且被用來設定 user-space 的 errno 變數,正值的意義由系統呼叫自己決定。
• atomic( 在實務上,驅動程式偶爾會需要一口氣完成原本是分離的兩項動作,尤其是應用程式需要設定 , 或釋放 lock 時 ) :– X( 交換 )=G( 取得 )+S( 設定 ) H( 移位 )=T( 通知 )+Q( 查詢 )
/ * S means “Set” through a ptr,(設定 )
* T means “Tell” directly with the argument value(通知 )
* G means “Get”: reply by setting through a pointer(取得 )
* Q means “Query”: response is on the return value(查詢 )
* X means “eXchange”: G and S atomically(交換 )
* H means “sHift”: T and Q atomically(移位 ) */
6.1.1- 選擇 ioctl 指令編號

6.1.2-ioctl 的回傳值• ioctl 作業方法的具體內容,主要是用來分辨指令編號
(cmd 引數 ) 的 switch 敘述。• 如果 cmd 不符合任何命令編號,則 default 應做?
– 許多核心合適採取的行為是回傳 -EINVAL(Invalid Argument) ,這是合理的。
– 但, POSIX 標準卻規定回傳 -ENOTTY(Not a typewriter) 這不甚合理,但 libc6 已將訊息改成比較合理的“ Inappropriate ioctl for device”

6.1.3-預先定義的 ioctl 命令• 雖然 ioctl( ) 系統呼叫的主要作用對象是硬體裝置,但
是核心本身仍能辨認少數幾個命令 (預設命令 ) 。因此,當你挑選的 ioctl 命令編號剛好與預定命令相同,則你寫出來的 ioctl 作業方法將永遠收不到該命令,而應用程式也會因為發出衝突的 ioctl 命令而遭遇到意外。
• 預定命令分為三大類:– 可作用於任何檔案 ( 正常檔 , 裝置檔 , FTFO 或 socket) 的命令– 只對正常檔案有作用的命令– 只能用於特定檔案系統類型的命令

6.1.3-預先定義的 ioctl 命令• 以下是核心內建的 ioctl 命令,可作用於任何檔案:– FIOCLEX :設立 close-on-exec旗標。當某行程開始執行 ( 使用 exec 系統呼叫 ) ,有被設立本旗標都會關閉
– FIONCLEX :撤銷 close-on-exec旗標– FIOASYNC :設立或撤銷檔案的“臨時通知”– FIOQSIZE :傳回一個檔案或目錄大小– FIONBIO :” File IOctl Nonblock I/O” 此命令會修改
filp->f_flags 裡的 O_NONBLOCK旗標。要下達此命令的應用程式,必須在 ioctl( ) 的第三引數註明他到底想要執行“設立”或“撤銷”的動作。

6.1.4-ioctl 的額外引數之用法• 在開始研究 scull 如何實作 ioctl 作業方法之前,有必要
先搞清楚如何使用它的額外引數 (第三引數 ) 。– 若該引數為整數時,那就直接拿來用。– 如果是指標,就必須多費點心。– 若指標指向 user-space 的位址,必須先確定該位址是有效的,
而且其對應的記憶頁目前已經映射 (mapped) 到系統記憶體(RAM) 。若核心程式試圖存取一個超出範圍的位址,處理器會主動觸發一次異常 (exception) 。
– 核驗位址合法性的工作,交由 access_ok( )函式來進行,此函式定義在 <asm/uaccess.h> 。
– int access_ok(int type , const void *)
– access_ok( ) 回傳值: 1 代表成功 ( 可存取 ) , 0 代表失敗 ( 不能存取 ) 。

6.1.4-ioctl 的額外引數之用法
• access_ok( )函式:– type 必須是 VERIFY_READ 或 VERIFY_WRITE 的其中之一
( 取決於想對 user-space 進行的動作是讀入或寫出 )
– addr 引數是要檢查的 user-space 位址– size 是檢查範圍 ( 以 byte 為計算單位 )
• access_ok( ) 值得注意的地方:– access_ok( ) 並非徹底檢驗指定範圍內的每一個位址,而是檢驗受查記憶區是否在行程的合理存取範圍 ( 不屬 kernel-space)
– 大部份的驅動程式並不需要刻意呼叫 access_ok( )(記憶體存取程序會幫忙處理 )
int access_ok (int type, const void *addr, unsigned long size);

6.1.5-機能管制• 使用者能否存取裝置,需借助作業系統的權限控管機
制 (限制對象為人 ) 。• 對於限制對象是操作項目而言,驅動程式自己必須作
一些額外檢查判斷使用者是否有權操作要求機能。– Ex: 任何人都能讀寫磁帶機,但並非人人都有權改變磁帶區塊
的預設大小。• 能力分權 (capabilities) ,不再只分成“特權”與“非特權”,而是細分成更多類細目:– 可將某種機能的使用權開放給某特定程式,而不必將無關的
其他權力也一並交出。– 在 user-space 下分權觀念還不是很廣泛,但是在核心內部則是
高度依賴。

6.1.5-機能管制• 機能分類,紀錄在 <linux/capability.h>
– CAP_DAC_OVERRIDE :改變檔案或目錄之存取權限的能力。– CAP_NET_ADMIN :執行網路控管工作的能力 ( 包括會影響網路介面的動作 ) 。
– CAP_SYS_MODULE :將模組載入 , 移出核心的能力。– CAP_SYS_RAWIO :執行“原始 I/O(raw I/O)” 作業能力。 Ex: 存取裝置的 I/O port ,直接與 USB 裝置通訊。
– CAP_SYS_ADMIN :一種無所不能的能力,提供系統管理作業所需的一切存取能力。
– CAP_SYS_TTY_CONFIG :設定 tty組態的能力。• 驅動程式應先以 capable( )函式檢查 calling process 是否具備適當的能力 <sys/sched.h>– int capable (int capability);

6.1.6- 不需要 ioctl 的裝置控制法
• 這種控制方式稱為“指令導向式控制法 (command-oriented)” :– 優點:簡便,使用者只要寫入特殊資料 ( 命令 ) 就能控制裝置,
而不需要使用額外的工具程式 (ex : tty 驅動程式 , )– 缺點:在操作策略上有所限制,容易造成驅動程式將一般資料當成控制命令來處理 (“ 控制命令”與“平常資料”共用同一個傳輸管道 )
• 對於不會傳輸資料,只會對命令作出回應的裝置 ( 例如 :機械手臂 ) ,命令導向式控制法就肯定是最理想的選擇。
• 如果目標裝置適合使用命令導向式的控制法,驅動程式自然不必提供 ioctl ,而是一段能解讀控制命令的程式(interpreter) 。

6.2-Blocking I/O
• read( ) 可能遭遇的狀況“資料還沒結束 ( 到達 EOF) ,只是尚未到達而已”?
• 答案是,先去睡一覺等資料到期在說。• 本節宗旨:
– 如何對行程進行催眠?– 如何喚醒行程?– 如何能夠事先主動查詢資料是否存在,而非盲目的發出 read( )
系統呼叫之後叫不自覺的睡著… .
• 同樣的觀念也應用到 write( ) 上

6.2.1-Going to Sleep and Awakening
• Linux提供了多種處理催眠與喚醒的做法,方法雖然不同,但是所需的基本資料型別卻是相同的:一個待命佇列 (wait queue) ,即 wait queue head( 一個待命佇列紀錄了正在等待同一事件的行程 ) 。
• 以靜態方式宣告的待命佇列可以在編譯期就予以初始化:
• 忘了對待命佇列初始化是常見錯誤,通常會導致意料外的後果。
wait_queue_head_t my_queue; /*待命佇列的宣告
init_waitqueue_head (&my_queue); /*初始化程序
DECLARE_WAIT_QUEUE_HEAD (my_queue);

簡易休眠• wait_event(queue , condition)
• wait_event_interruptible(queue , condition)
• wait_event_timeout(queue , condition , timeout)
• wait_event_interruptible_timeout (queue , condition , timeout)

6.2.1-Going to Sleep and Awakening
• 休眠只是問題的一半,在某處一定還要有某樣東西於未來的某時間點喚醒行程。一般來說,驅動程式通常是在interrupt handler 收到新資料時,才喚醒其休眠行程。
• 如同催眠,喚醒的方式也不只一種手法,核心提供的高階喚醒函式如下:– void wake_up(wait_queue_head_t *queue); 喚醒在 queue 裡所有
行程– void wake_up_interruptible (wait_queue_head_t *queue);只喚醒當
初表示願意因中斷事件而甦醒的行程• wake_up() 應該配合 wake_event() ,
wake_up_interruptible() 應該配合wake_event_interruptible ()

遲滯作業與非遲滯作業• 在某些情況下,即使無法完成工作,也
不容許休眠。由於休眠會阻礙行程的運作發展,所以允許休眠的作業模式稱為遲滯作業,反之,完全不允許休眠的作業模式稱為非遲滯作業
• Filp ->f_flags 的 O_NONBLOCK 旗標

遲滯作業模式• O_NONBLOCK 旗標的預設值是 0( 代表
遲滯模式 )
• Read 作業方法 : 當輸入緩衝區 NULL ,沒有資料可以給 user-space 時,必須讓行程休眠,當資料抵達,必需立刻喚醒行程
• Write 作業方法 : 當緩衝區沒有空間必須休眠,當輸出緩衝區挪出空間 ( 可能有部分資料寫入硬體 ) ,必須立刻喚醒行程
• 前提 : 驅動程式得自備 I/O 緩衝區

非遲滯作業模式• 主要是讓應用程式可以 POLL DATA ,也
就是試探裝置的讀寫狀態• 若 read() 無法即時提供資料 ( 輸入緩衝區是
空的 ) 或 write() 的輸出動作會造成休眠 (輸出緩衝區全滿 ) ,則必須傳回 -EAGAIN要求行程下次再試,而不可使行程休眠
• 只有 read 、 write 、 open 這三種檔案操作,才會受到 O_NONBLOCK 旗標影響

遲滯式 I/O : scullpipe
• scull_pipe
• scull_p_read
• https://github.com/martinezjavier/ldd3/blob/master/scull/pipe.c

6.2.2-A Deeper Look at Wait Queues- 行程如何休眠
• 待命佇列 (wait queue) 是什麼?– wait_queue_head_t 型別 ( 定義於 <linux/wait.h>) 是一個相當簡
單的結構,由 spinlock 以及 linked list構成。串列上的每個節點,各是一個 [待命佇列項目 ] ,型別宣告為 wait_queue_t
– wait_queue_t結構包含有關於行程休眠的資訊,以及在怎樣的條件下被喚醒。
– 第一步 : 配置並且初始化 wait_queue_t結構– 第二步 : 將行程狀態設定為 [即將入眠 ](being sleep)
• <linux/sched.h> 定義多種狀態。例 : TASK_RUNNUNG
• 可以呼叫 schedule( ) 使行程立即重新排程• 在呼叫 schedule( ) 之前,要先檢查休眠條件
– If(!condition){schedule()}

• 第一步是建立並初始化一個待命佇列,通常以DEFINE_WAIT(my_wqentry) 巨集完成
• my_wqentry 可以看成以下 2 個等效步驟 : wait_queue_t my_wqentry;
init_wait(my_wqentry);
• void prepare_to_wait(wait_queue_head_t *queue, wait_queue_t *my_wqentry,int state)
• void finish_wait(wait_queue_head_t *queue, wait_queue_t *my_wqentry)
6.2.2-A Deeper Look at Wait Queues-手動休眠

6.2.2-A Deeper Look at Wait Queues - 獨家等待
• 多個行程等待同一事件時,當 wake_up( ) 被呼叫時,它是喚醒所有正在等待該事件的行程。如果要等待的事件,是收到一段必須獨占存取的資料,所以只有一個行程能順利爭取該段資料,而其餘剛才被喚醒的行程,則因為沒有資料可讀,又回復到休眠狀態。這種現在被稱為“驚蛰問題 (thundering herd problem)” 在講究高效率的環境,驚蛰問題會浪費掉大量的系統資源。
• 對於驚蛰問題, KERNEL 開發者的解決之道是 [ 獨家等待 ](exclusive)

• “獨家等待”跟”一般休眠”方式相似,不過多了以下 2 點差異
1.對於有設立 WQ_FLAG_EXCLUSIVE 旗標的待命佇列項目,它們會被加到待命佇列的末端。相對地,沒此旗標的項目,則是被放到佇列的開頭。
2.當 wake_up( ) 在處理待命佇列時,若遇到有設立 WQ_FLAG_EXCLUSIVE 旗標的項目,就停止不再處理後續的項目
6.2.2-A Deeper Look at Wait Queues - 獨家等待

• 對驅動程式而言,若下列 2 項條件成立,可以考慮獨家等待
1.資源有限,競爭嚴重2.喚醒一個行程會消耗所有資源
6.2.2-A Deeper Look at Wait Queues - 獨家等待

喚醒程序的細節• wake_up(wait_queue_head_t *queue)
• wake_up_interruptible(wait_queue_head_t *queue)
• wake_up_nr(wait_queue_head_t *queue)
• wake_up_interruptible_nr(wait_queue_head_t *queue)
• wake_up_all(wait_queue_head_t *queue)
• wake_up_interruptible_all(wait_queue_head_t *queue)

6.3-poll and select
• nonblocking I/O 應用程式,通常會使用 select( )poll( )與 epoll( ) 系統呼叫 =>讓行程判斷下次的 I/O 動作會不會遲滯。– select( ) 是 BSD Unix提出的構想– poll( ) 是 System V 的解決方案
• 當應用程式對裝置檔發出 poll( ) 或 select( ) 系統呼叫,就會觸發該裝置檔驅動程式的 poll 作業方法,而此作業方法必須執行以下兩個步驟:– 呼叫一次或多次 poll_wait( ) ,將一個或多個可能改變輪詢狀態的待命佇列放入 poll table
– 傳回一個位元遮罩,描述些操作項目可立即執行而不會遲滯
unsigned int (*poll) (struct file *filp, poll_table *pt);

6.3-poll and select
• poll_table結構– 宣告在 <linux/poll.h>
– 每個驅動程式都應該引入此標頭檔
• poll.h預先定義了一系列常數的各種可能的輪詢狀態– POLLIN : 裝置可被 READ 而不遲滯– POLLOUT 裝置可被寫入而不遲滯– POLLRDNORM : 資料已準備好可被讀取– POLLWRNORM : 資料已準備好可被寫入– POLLPRI, POLLHUP, POLLER
void poll_wait(struct file *filp, wait_queue_head_t *sync, poll_table *pt);

6.3.1-Interaction with read , write and poll
• poll( ) 與 select( ) 最重要的使命 =>讓應用程式同時等待多個資料串流
• 從裝置讀出資料 (Read)– 如果資料已經在輸入緩衝區裡– 如果輸入緩衝區是空的– 如果遇到檔尾 (EOF)
• 從裝置寫入資料 (Write)– 如果緩衝區上有空間– 如果緩衝區是滿的– 絕對不要讓 write( ) 系統呼叫等待資料傳輸 (即使沒設立
O_NONBLOCK)
• 通則,適當的依照每種裝置修改某些規則是容許的,甚至是必要的。

6.3.1-Interaction with Read and Write
• 出清延宕資料 (POLL)– 光靠 write 作業方法本身,並不能滿足“徹底輸出所有資料”
的需求。以 fsync 作業方法來彌補此一缺憾。– int (*fsync) (struct file *file , struct dentry *dentry , int datasync);
– 驅動程式只要有部分應用程式需要確認資料是否如實寫出到裝置上,驅動程式本身就必須提供 fsync 作業方法。
– 不管當初是否以 O_NONBLOCK模式開啟裝置,在發出fsync( ) 系統呼叫之後,等到返回之時,就可認定先前用write( ) 寫出的資料,已經全數出清 (flush) 到裝置上。
– Fsync 作業方法沒有不尋常的特性,呼叫者擺明了就是願意等待。一般而言, char drive :將 fops 指標指向 NULL 。而block driver :以通用的 block_fsync 來完成任務。

6.3.2- poll table Structure
• poll_table結構的作用:– poll_table 本身是一個由 poll_table_entry結構所組成的陣列,
每個 poll_table_entry結構都是核心在收到 poll( ) 或 select( ) 系統呼叫時,特地為該次呼叫所配置的。
– 如果被調查的驅動程式中,沒有任何一個表示能立即執行 I/O而不遲滯,則 poll( ) 會休眠,直到它所處的待命佇列之一甦醒為止。
– 在 poll( ) 系統呼叫完成任務之後, poll_table結構就被釋放掉了,而先前被加到 poll_table 的所有待命佇列項目也會被移出輪詢表。
– <linux/poll.h> 及 fs/select.c
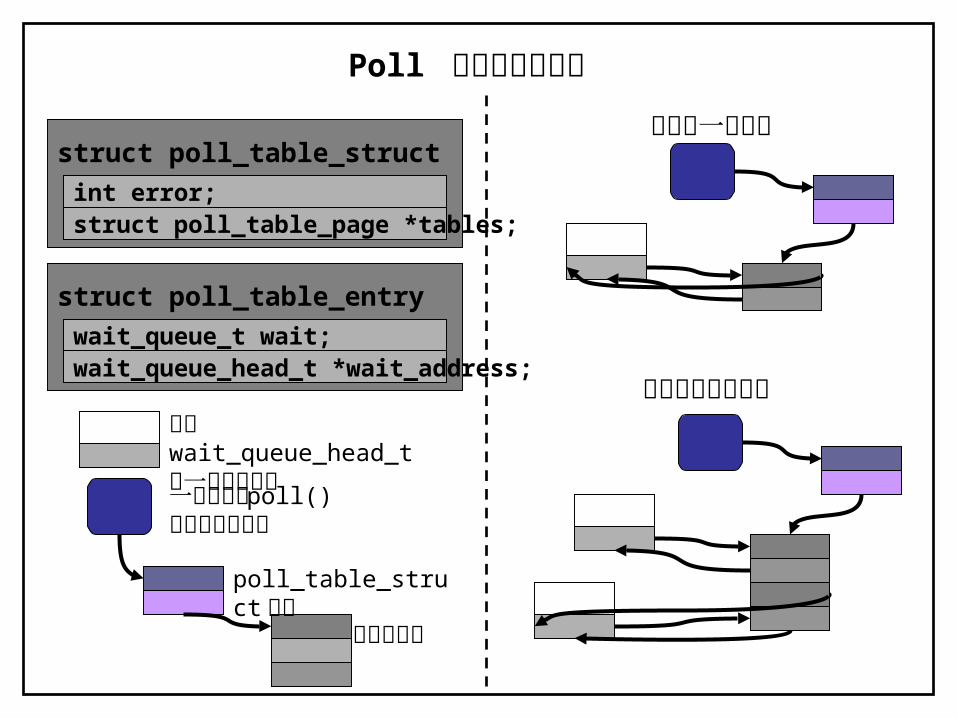
struct poll_table_struct
int error;struct poll_table_page *tables;
struct poll_table_entry
wait_queue_t wait;wait_queue_head_t *wait_address;
只調查一個裝置
Poll 所用的資料結構
自備 wait_queue_head_t的一般裝置結構
正在輪詢兩個裝置
一個觸發了 poll()系統呼叫的行程
poll_table_struct結構
輪詢表項目

6.4-Asynchronous Notification
• blocking/nonblocking 操作與 poll 作業方法的組合,通常已經足以應付狀態查詢的需求,但仍有些情況以目前所知道技術還不足以有效解決。
• 臨時通知,應用程式必須執行兩個步驟,才能得到輸入檔的臨時通知:– 1.讓自己成為檔案的“擁有者”,當行程使用 fcntl( ) 系統呼
叫發出 F_SETOWN 指令時,擁有者的 PID便會被存入 filp->f_owner ,以便往後使用。 =>讓核心知道通知對象是誰。– 2. 使用 fcntl( ) 系統呼叫發出 F_SETFL 命令,設定裝置的
FASYNC旗標。 => 實際讓臨時通知生效。

• signal (SIGIO , &input_handler);fcntl (STDIN_FILENO , F_SETOWN , getpid());oflags = fcntl (STDIN_FILENO , F_GETFL);fcntl (STDIN_FILENO , F_SETFL , oflags | FASYNC);
• 執行過這兩次 fcntl( ) 系統呼叫之後,就可要求輸入檔的驅動程式在每次收到新資料時,就發出 SIGIO信號。此信號會被送到 filp->owner 所指的行程。
6.4-Asynchronous Notification

6.4-Asynchronous Notification
• 並非所有裝置都支援非同步通知,一般而言,應用程式只有面對 socket 與 tty 時,才會假定它們支援非同步通知。
• 非同步通知的盲點:收到信號的行程,無法直接判別信號的來源。若行程有多個輸入來源,當收到 SIGIO信號時,就會搞混是哪個輸入檔要提供新資料,這時就必須借助 select( ) 或 poll( )才能查明到底出了什麼狀況。

6.4.1- 驅動程式對於臨時通知的支援
• 驅動程式如何支援此機制:– 收到 fcntl( ) 系統呼叫的 F_SETOWN 命令時,只會將目前行
程的 PID 設定給 filp->f_owner 。– 收到 fcntl( ) 系統呼叫的 F_SETFL 指令時,則設定裝置檔 filp-
>f_owner 的 FASYNC旗標,然後呼叫驅動程式 fasync 作業方法。
– 當資料到達,所有曾經註冊過要求收到非同步通知到行程,都必須收到 SIGIO 的信號。
– 對驅動程式而言,第一步其實沒有什麼事可做,由核心自己搞定。不過,後續的步驟就較為棘手,因為必須維護一個動態的結構,以登記哪些行程正在等待妳的通知。還好,由於此結構址只與行程有關,與硬體裝置無關,所以你不必自己定義,直接使用核心提供的通用結構即可。

• <linux/fs.h>
• int fasync_helper (int fd , struct file *filp , int mode , struct fasync_struct **fa)
• void kill_fasync (struct fasync_struct **fa , int sig , int band)
6.4.1- 驅動程式對於臨時通知的支援

6.5-Seeking a Device
改變裝置的存取點:• lseek( ) 與 llseek( ) 系統呼叫的具體動作,是由驅動程式的
lseek 作業方法負責完成。• 若驅動程式沒提供 llseek 作業方法,則核心可帶為修改
flip->f_pos 來完成“相對於檔頭”以及“相對於目前位置‘的移位操作。
• 為了使 lseek( ) 系統呼叫能移位的正確位置, read 和 write作業方法都必須配合修正從引數得到的位移項。
• https://github.com/martinezjavier/ldd3/blob/master/scull/main.c
• Int nonseekable_open (struct inode *inode , struct file *filp) ,讓核心知道裝置不支援 lseek

• 提供存取控制能力,是確保裝置節點可靠性的關鍵。
• 除了限制使用者身分之外,還包括同時的使用人數。
6.6-Access Control on a Device File

6.6-Access Control on a Device File
• 單一行程獨占– 最強勢的存取管制措施,就是一次只容許一個行程開啟裝置,
在行程關閉裝置檔之前,拒絕其他行程的開啟嘗試。• 引發相競狀況的另一種成因
– 在 SMP 的世界裡,兩個處理器上剛好各有一個行程嘗試要開啟裝置時… ( 可用 semaphore 來避免,不過代價頗高因為可能造成 calling process休眠,對於“檢查狀態變數”顯得大器小用。可使用 spinlock( ) , spinlock( ) 不會催眠行程,只會一再重試 ) 。
• 單人獨占– 容許一位使用者以多個行程來開啟同一個裝置,但一次只允
許一位使用者。

6.6-Access Control on a Device File
• 延滯開啟代替 EBUSY– 當裝置無法被存取時,傳回 -EBUSY算是最合理的手法,但
是對於某些狀況,使用者會寧願等待。 (ex: 如果有人使用crontab 定期透過某個通訊管道來傳資料,在平常期間,該通訊管道也開放給其他人使用,如果剛好有人到了應該定期傳送資料的時間仍在佔用通訊裝置,這時候我們寧願多等待一會,而不會願意收到 -EBUSY)
• 開啟時產生分身– 再不同行程開裝置時,產生一個專屬於行程的裝置副本。正常的硬體裝置不可能採用這種策略,除非是類似的 scull 這種以“軟體”模擬出來的裝置。對於驅動程式以軟體技術模擬出來的分身裝置,這種方法習慣尚稱之為“虛擬裝置”。

DEMO - 1
• 範例 misc-modules/sleepy.c
1.make
2.insmod ./sleepy.ko
3.cat /proc/devices | grep sleepy
4.mknod /dev/sleepy c 250 0
5.cat /dev/sleepy &( 讀取動作 ==read)
6.echo trash > /dev/sleepy( 寫入動作 ==write)

DEMO - 2
1. tail -f /var/log/kernlog 觀察 cat 與 echo 會造成 Process 怎樣的結果
2. cat /dev/sleepy &
– Process 3066 去睡覺3. echo trash > /dev/sleepy
• Process 3066 被喚醒

1. 嘗試一次輸入 3 個 cat /dev/sleepy &
– 3 個 Process 去睡覺2. 輸入一次 echo trash > /dev/sleepy
– 只有 1 個 Process 被喚醒,而且是最後睡的被喚醒
DEMO - 3

DEMO - 4 ( 改變 )
• 將圖中 flag = 0 ; 這項敘述拿掉並再次觀察結果

1. 嘗試一次輸入 3 個 cat /dev/sleepy &
– 3 個 Process 去睡覺2. 輸入一次 echo trash > /dev/sleepy
– 3 個 Process 一次被喚醒3. 得到的結論是剛剛註解掉的那個 flag 是用來擋住
行程,不讓他一次被喚醒。
DEMO - 5 ( 改變 )