convnetの歴史とresnet亜種、ベストプラクティス
TRANSCRIPT

ConvNetの歴史とResNet亜種、ベストプラクティス
Yusuke Uchida@DeNA
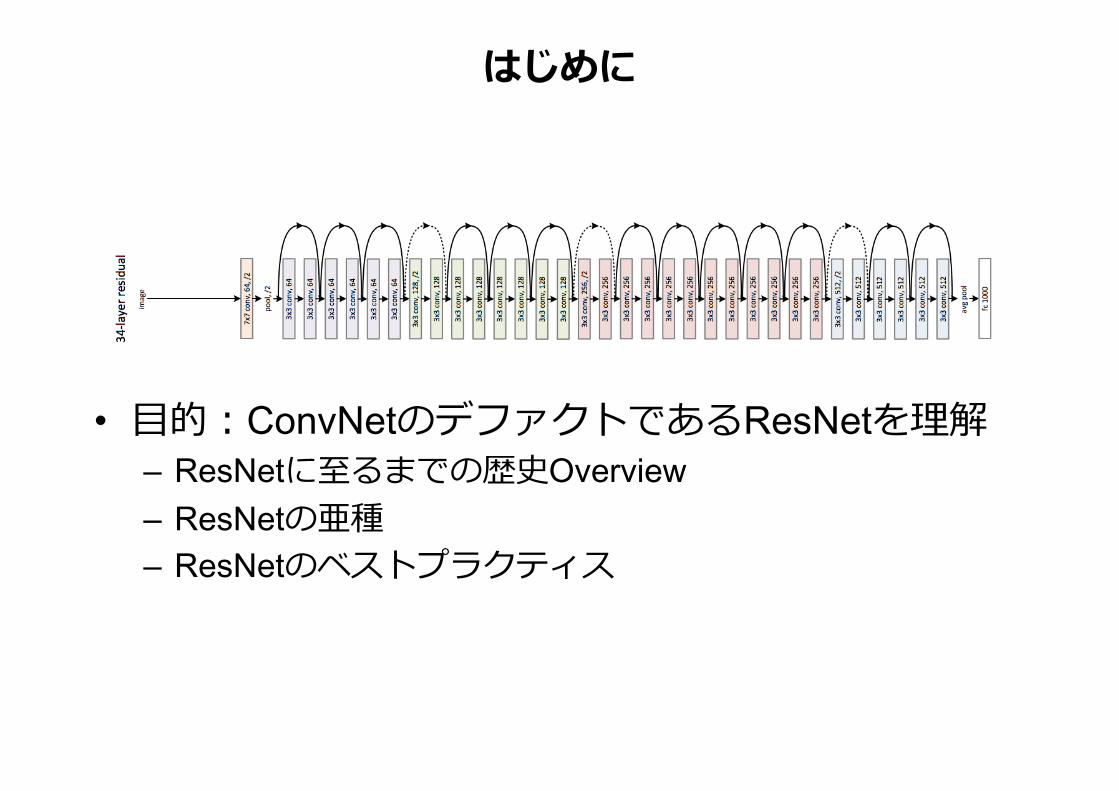
はじめに
• ⽬的:ConvNetのデファクトであるResNetを理解 – ResNetに⾄るまでの歴史Overview – ResNetの亜種 – ResNetのベストプラクティス

LeNet-5 [Lecun+’98]
conv5x5,6 conv2x2stride=(2,2)
conv5x5,16 conv2x2stride=(2,2)
Featuremap毎
• convにパディングなし、subsamplingが2x2のconv• 入力の全channelと結合していないconvがある

AlexNet [Krizhevsky+’12]
conv11x11,48stride=(4,4)
max-pool3x3stride=(2,2)
• conv11x11と大きいフィルタを利用• overlappingpooling• dropoutの利用• acBvaBonにReLUを利用• LocalResponseNormalizaBonの利用(BNでオワコン化)

VGGNet [Simonyan+’14]
112x112
56x56
28x28
14x14
• 全て3x3のconv、2x2のmaxpooling、より深く• 半分にダウンサンプリングしてフィルタ数を2倍にする
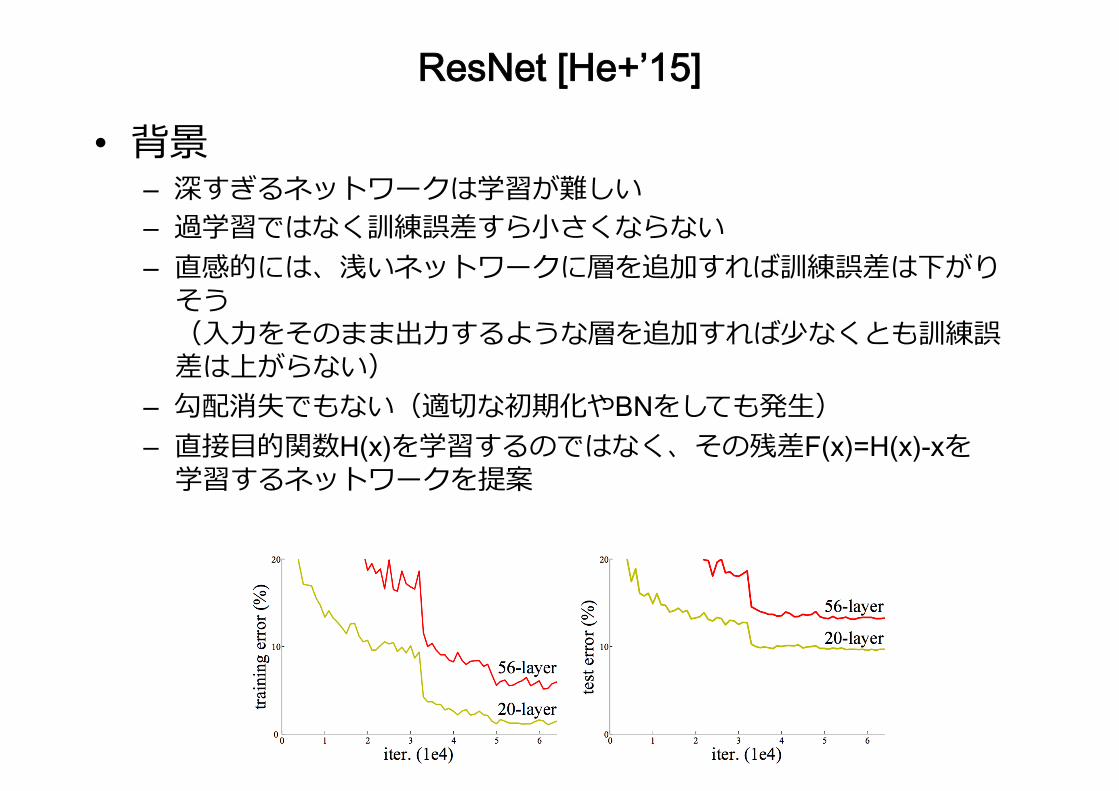
ResNet [He+’15]
• 背景 – 深すぎるネットワークは学習が難しい – 過学習ではなく訓練誤差すら⼩さくならない – 直感的には、浅いネットワークに層を追加すれば訓練誤差は下がりそう(⼊⼒をそのまま出⼒するような層を追加すれば少なくとも訓練誤差は上がらない)
– 勾配消失でもない(適切な初期化やBNをしても発⽣) – 直接⽬的関数H(x)を学習するのではなく、その残差F(x)=H(x)-xを学習するネットワークを提案
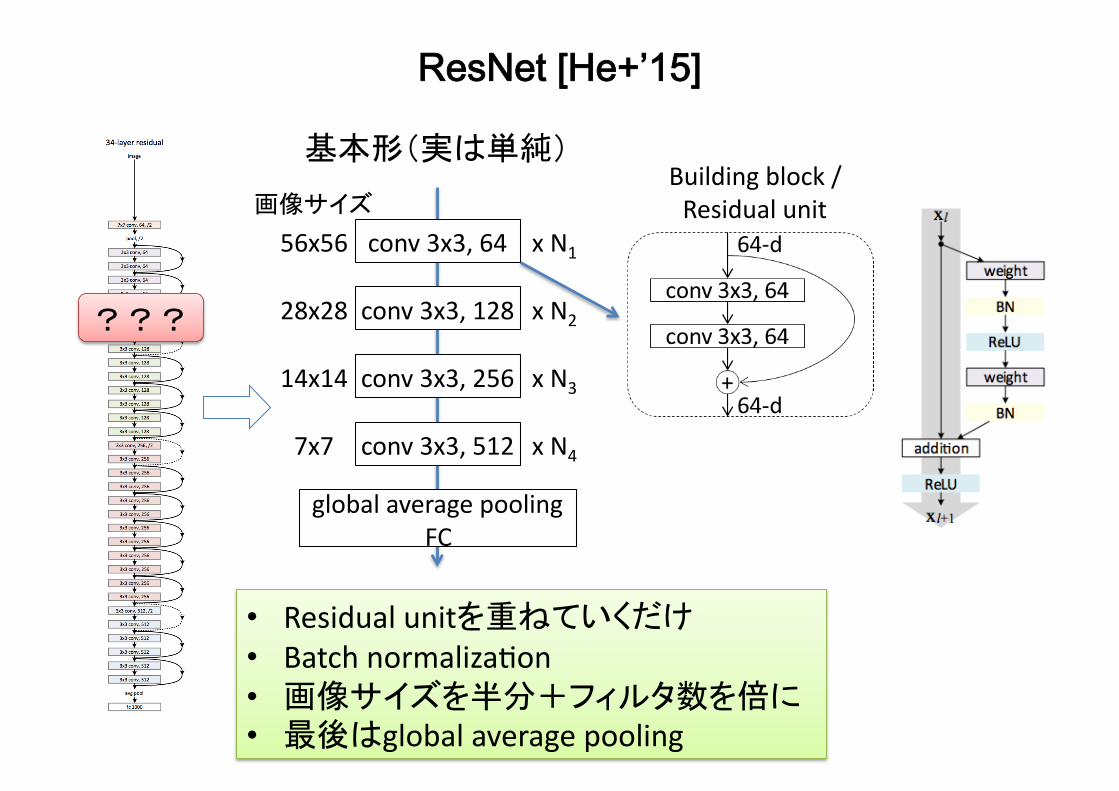
ResNet [He+’15]
基本形(実は単純)
???
conv3x3,64
conv3x3,128
conv3x3,256
conv3x3,512
globalaveragepoolingFC
xN1
xN2
xN3
xN4
56x56
28x28
14x14
7x7
画像サイズ
• Residualunitを重ねていくだけ• BatchnormalizaBon• 画像サイズを半分+フィルタ数を倍に• 最後はglobalaveragepooling
Buildingblock/Residualunit
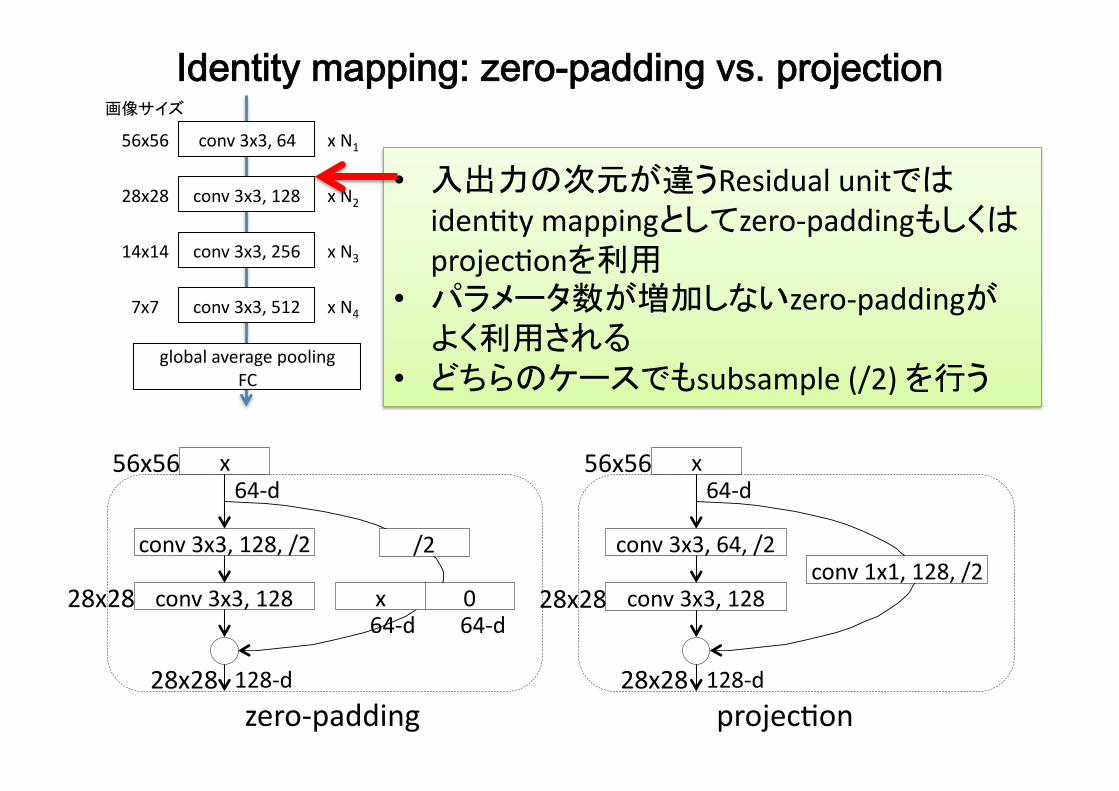
Identity mapping: zero-padding vs. projectionconv3x3,64
conv3x3,128
conv3x3,256
conv3x3,512
globalaveragepoolingFC
xN1
xN2
xN3
xN4
56x56
28x28
14x14
7x7
画像サイズ
conv3x3,128
conv3x3,128,/2
64-d
128-d
x
zero-padding
64-d0x64-d
conv3x3,128
conv3x3,64,/2
64-d
128-d
x
projecBon
conv1x1,128,/2
• 入出力の次元が違うResidualunitではidenBtymappingとしてzero-paddingもしくはprojecBonを利用
• パラメータ数が増加しないzero-paddingがよく利用される
• どちらのケースでもsubsample(/2)を行う
/2
56x56
28x28 28x28
56x56
28x28 28x28
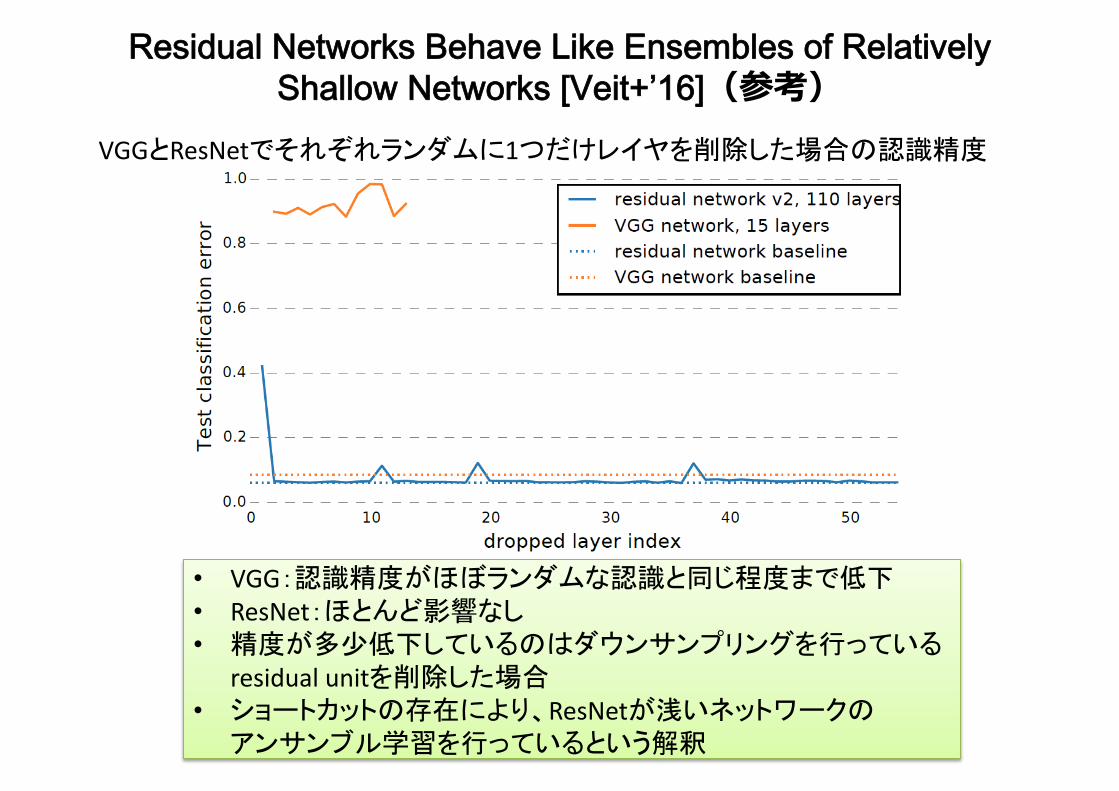
Residual Networks Behave Like Ensembles of Relatively Shallow Networks [Veit+’16](参考)
• VGG:認識精度がほぼランダムな認識と同じ程度まで低下• ResNet:ほとんど影響なし• 精度が多少低下しているのはダウンサンプリングを行っている
residualunitを削除した場合• ショートカットの存在により、ResNetが浅いネットワークのアンサンブル学習を行っているという解釈
VGGとResNetでそれぞれランダムに1つだけレイヤを削除した場合の認識精度

Residual Networks Behave Like Ensembles of Relatively Shallow Networks [Veit+’16](参考)
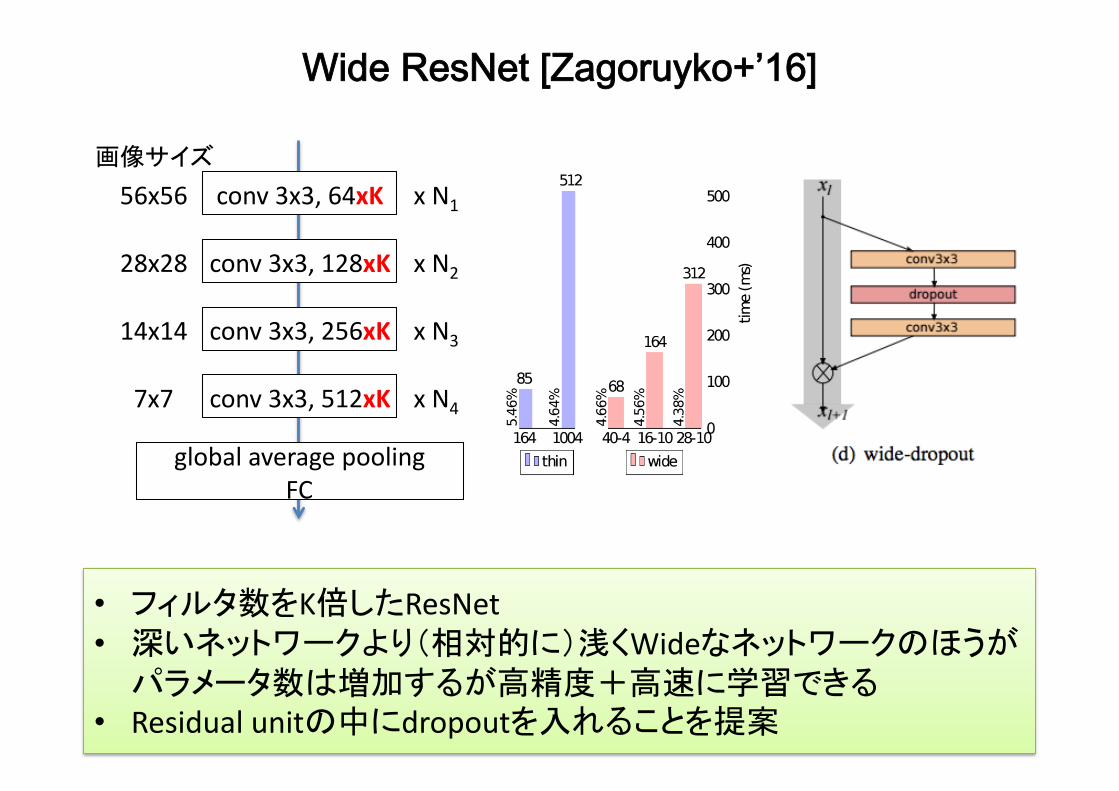
Wide ResNet [Zagoruyko+’16]
conv3x3,64xK
conv3x3,128xK
conv3x3,256xK
conv3x3,512xK
globalaveragepoolingFC
xN1
xN2
xN3
xN4
56x56
28x28
14x14
7x7
画像サイズ
• フィルタ数をK倍したResNet• 深いネットワークより(相対的に)浅くWideなネットワークのほうがパラメータ数は増加するが高精度+高速に学習できる
• Residualunitの中にdropoutを入れることを提案

PyramidNet [Han+’16]
• ResNetはランダムに層を削除しても精度がほとんど低下しない• ダウンサンプリング層(フィルタ数を2倍にしているところ)は唯一精度が低下• この層への依存が強く、アンサンブル学習としては望ましくない
→全てのresidualunitで少しずつフィルタ数を増加させる• 増加のさせ方として、単調増加させるaddiBvePyramidNetと指数的に増加させるmulBplicaBvePyramidNetを提案→addiBveのほうが高精度
• Residualと相関の低い特徴をちょっとずつ抽出しているイメージ?
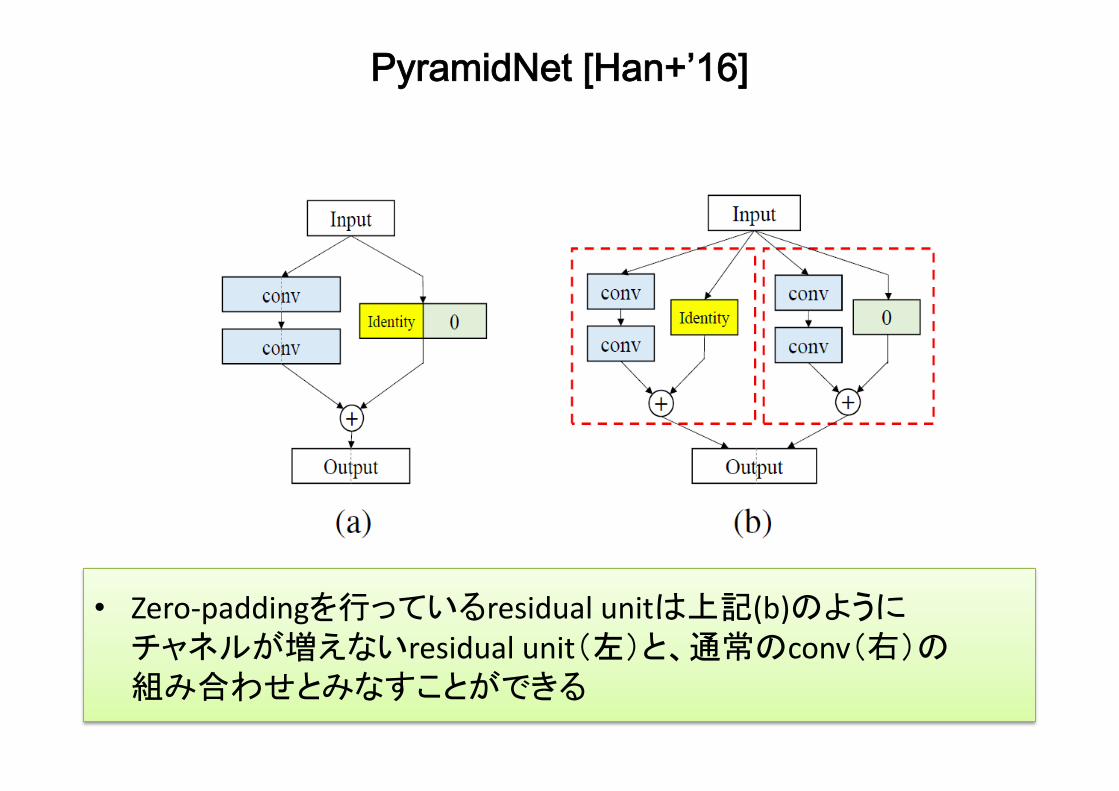
PyramidNet [Han+’16]
• Zero-paddingを行っているresidualunitは上記(b)のようにチャネルが増えないresidualunit(左)と、通常のconv(右)の組み合わせとみなすことができる
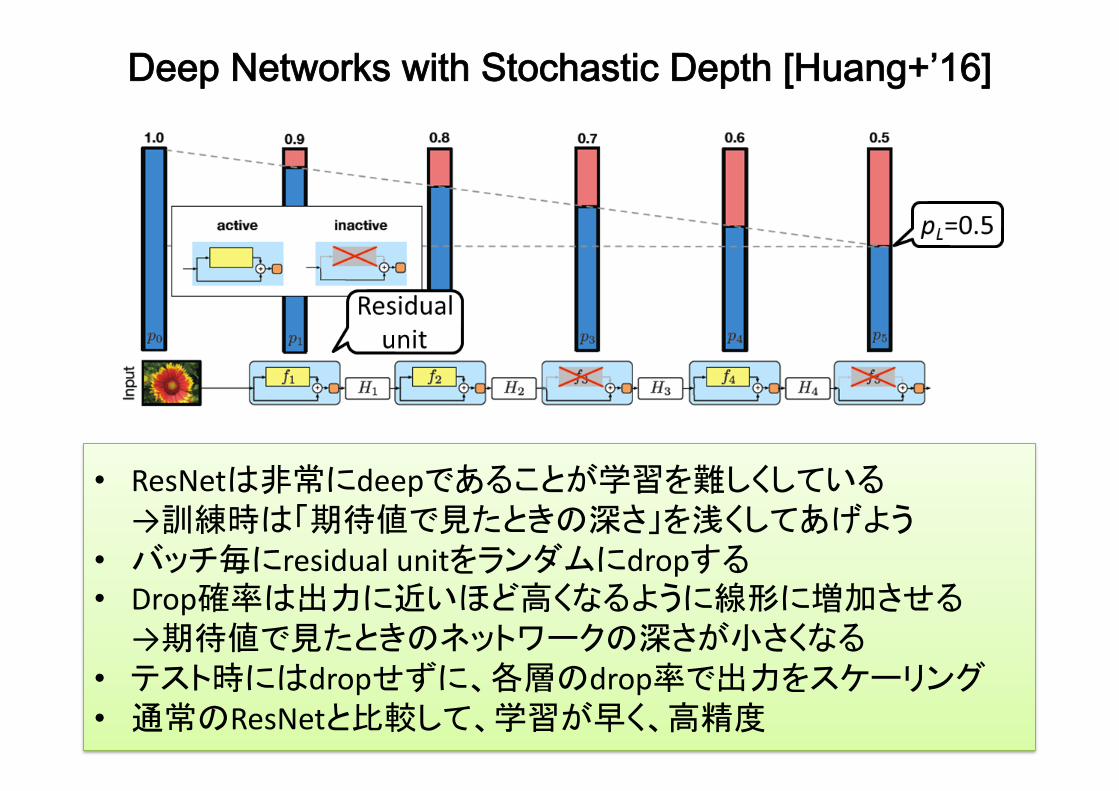
Deep Networks with Stochastic Depth [Huang+’16]
• ResNetは非常にdeepであることが学習を難しくしている→訓練時は「期待値で見たときの深さ」を浅くしてあげよう
• バッチ毎にresidualunitをランダムにdropする• Drop確率は出力に近いほど高くなるように線形に増加させる
→期待値で見たときのネットワークの深さが小さくなる• テスト時にはdropせずに、各層のdrop率で出力をスケーリング• 通常のResNetと比較して、学習が早く、高精度

PyramidSepDrop [Yamada+’16]
• PyramidDrop:PyramidNetにstochasBcdepthを適用したもの• PyramidSepDrop:PyramidDropにおいて、入力xと
zero-paddingに対応するチャネルに独立にstochasBcdepthを適用• PyramidSepDrop>PyramidNet>PyramidDrop• 前述のPyramidNetにおけるresidualunitと通常のconvの組み合わせという観点ではSepDropのほうが自然に見える
• CIFAR-10/100でSOTA

個⼈的なベストプラクティス
• ネットワーク:Wide Residual Networkがお⼿軽 • Residual unit:pre-act
– BN-ReLU-Conv-BN-ReLU-Conv • 初期化:He+(MSRA)
– Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
• 最適化:SGD+NesterovのMomentum+学習率⼿動スケジューリング(ロスがサチるEpochで1/5に)

闇IdenBtyMappingsinDeepResidualNetworks
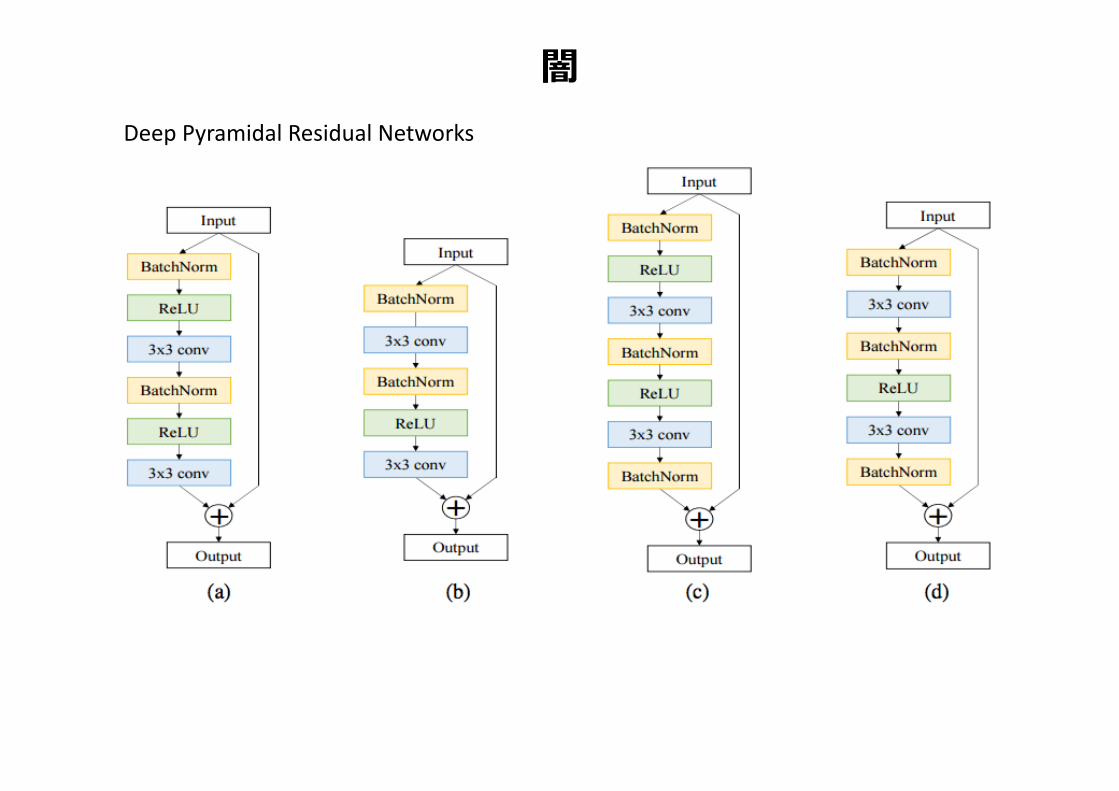
闇DeepPyramidalResidualNetworks
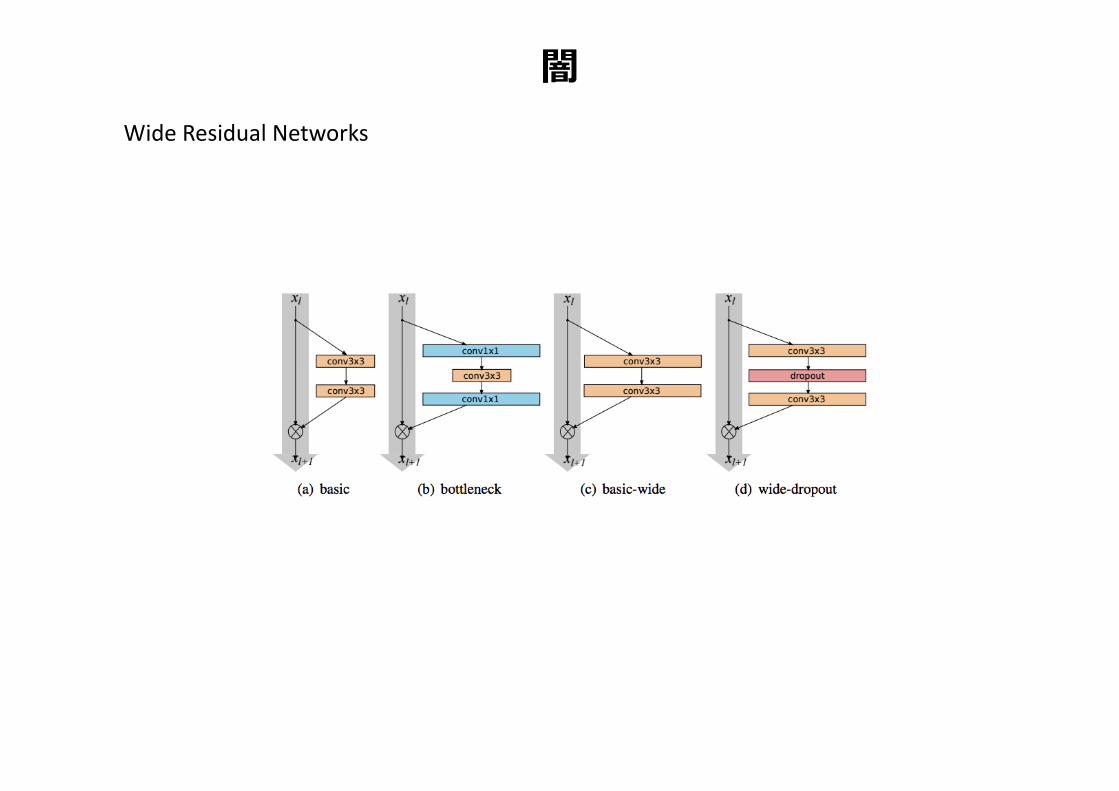
闇WideResidualNetworks

闇AggregatedResidualTransformaBonsforDeepNeuralNetworks
ResNetの亜種でも…FractalNet、DenseNet、Highwaynetworks、PolyNet、ResidualNetworksofResidualNetworks…

参考資料
• 元ネタ – http://qiita.com/yu4u/items/4a35b47d5cab8463a4cb
• ⾊々なChainer実装 – http://qiita.com/aiskoaskosd/items/59c49f2e2a6d76d62798
• より広範な資料 – http://slazebni.cs.illinois.edu/spring17/lec04_advanced_cnn.pdf