cours 6 jalilboukhobza université de bretagne occidentale...
TRANSCRIPT

21/12/2017
1
Cours 6
Jalil Boukhobza
Université de Bretagne Occidentale – Lab-STICC
J.Boukhobza - Systèmes d'exploitation embarqués 1
Plan du cours1. Introduction
2. Espace noyau / utilisateur
3. Segmentation
4. Pagination
5. Mémoire virtuelle
6. Gestion de la mémoire sous Linux
7. Gestion de la mémoire du noyau
J.Boukhobza - Systèmes d'exploitation embarqués 2

21/12/2017
2
Introduction� Multitâches: plusieurs tâches qui partagent le même
espace mémoire:� L’OS a besoin d’un mécanisme de de gestion et de
sécurité pour protéger les espaces mémoires des tâches les uns des autres.
� L’OS se trouve aussi dans ce même espace mémoire:� Gestion de son propre code en mémoire
� Protection de son propre code de celui des tâches gérées.
J.Boukhobza - Systèmes d'exploitation embarqués 3
Les responsabilités du gestionnaire
de la mémoire� Gestion de la correspondance entre mémoire
logique/physique et les références mémoires des tâches� Déterminer quelle espace d’adressage (de processus)
charger dans l’espace mémoire disponible.� Allouer et désallouer la mémoire des processus qui
constituent le système� Supporter l’allocation et la désallocation dynamiques des
requêtes du code (au sein d’un processus) � exemple: malloc & free.
� Contrôler et gérer l’usage de la mémoire par les processus� Assurer la protection de l’espace d’adressage du processus
J.Boukhobza - Systèmes d'exploitation embarqués 4

21/12/2017
3
Espace noyau/utilisateur� Généralement 2 espaces mémoires:
� Espace noyau: contenant le code du noyau ainsi que les structures manipulées par ce dernier.� Blocs de contrôle des tâches.
� …
� Espace utilisateur: contenant le code des applications� Mémoire en mode noyau accédée via des appels système:
� IPC,
� caractéristiques d’un fichier,
� Contient les éléments mémoire (code, variables, etc.) permettant à un processus de s’exécuter
J.Boukhobza - Systèmes d'exploitation embarqués 5
Techniques de gestion de mémoire� Swapping: des portions de la mémoire sont rapatriées et envoyées vers l’espace
de stockage secondaire.� Permet d’exécuter plus de tâches / ou des tâches de taille plus importante
� Segmentation : subdivision des espaces d’adressage d’après leur fonctionnalité.� Permet une meilleure gestion de l’espace mémoire en terme de fonctionnalité
(exemple: sécurité, partage, extensibilité)
� Pagination : subdivision des espaces d’adressage des tâches en petites tranches de taille fixe � permet d’éviter que la fragmentation externe de la mémoire soit problématique
pour la création et l’exécution de tâche.
� … mais produit de la fragmentation interne.
� Mémoire virtuelle: création d’un espace d’adressage important incluant la mémoire physique et une partie de la mémoire secondaire (disque).� Permet à des tâches de très grande taille de pouvoir s’exécuter.
J.Boukhobza - Systèmes d'exploitation embarqués 6

21/12/2017
4
La segmentation� L’espace d’adressage d’un processus est constitué de
plusieurs unités logiques de mémoire de tailles variables contenant des informations différentes appelés segments.
� Un segment:� Contient plusieurs données du même type (exemple:
variables)� Commence à une adresse logique 0� Est numéroté (chaque segment à un numéro), c’est ce qui
indique son adresse, et un déplacement dans ce segment indique l’adresse en mémoire physique de la donnée.
� A une protection qui peut être différente des autres segments de la même tâche.
� A une taille différente des autres segments
J.Boukhobza - Systèmes d'exploitation embarqués 7
Les différents types de segments
de tâche� Généralement 5 types d’informations pour les segments
1. Segment texte (ou code): contient le code source à exécuter � segment statique
2. Segment de données: contient les variables initialisées dans le code source � segment statique
3. Segment bss (block started by symbol) ou segment de symboles: contient les variables non initialisées du programme� segment statique
4. Segment de pile (stack): espace mémoire en LIFO, utilisé pour stocker les variables locales, arguments, etc. Lors d’appel à des fonctions � segment dynamique
5. Segment de tas (heap): contient les espaces alloués dynamiquement (malloc).
J.Boukhobza - Systèmes d'exploitation embarqués 8

21/12/2017
5
L’exécutable� Le segment de texte, de données et de symboles sont
crées à partir de l’exécutable. � L’OS crée une correspondance entre l’image de la tâche
en mémoire et le fichier exécutable.� Plusieurs formats d’exécutable supportés par les OS
embarqués, exemple:� Format ELF (Executable and Linking Format): basé sur
UNIX� Class: byte code java� COFF (Common Object File Format); Microsoft
Portable Executable format
J.Boukhobza - Systèmes d'exploitation embarqués 9
Le format ELF� Constitué d’une entête ELF, table d’entêtes de programme,
table d’entêtes de section, sections ELF et les segments ELF.
� Format supporté par Linux et VxWorks.
J.Boukhobza - Systèmes d'exploitation embarqués 10
Entête ELF
Table d’entêtes du programme
Section 1
…
Section 2
…
…
Table d’entête de section
Entête ELF
Table d’entêtes du programme
Segment 1
Segment 2
…
…
Table d’entête de segment
Vu
e d
’éd
itio
n d
es l
ien
Vu
e d
’exéc
uti
on

21/12/2017
6
Le format ELF (2)� .init: instructions exécutables
qui contribuent au code d’initialisation du processus.
� .fini: instructions exécutables qui contribuent au code de terminaison du processus.
� .rodata: données en lecture seule.
� .strtab: chaînes de caractères
� …
J.Boukhobza - Systèmes d'exploitation embarqués 11
Le format class� Un fichier class décrit une classe java en détail sous la
forme d’un stream (flot) de 8bits (d’où le nom byte code).� Ce type de fichier contient la description de la classe ainsi
que la description de ses connexions avec d’autres classes. � Les principaux composants d’un tel fichier sont:
� Une table des symboles (avec les constantes)� Déclaration des champs� Implémentation des méthodes (code)� Références symboliques (références vers les autres classes)
� L’RTOS Jbed est un exemple du type de système supportant ce type d’exécutable.
J.Boukhobza - Systèmes d'exploitation embarqués 12

21/12/2017
7
Le format COFF� Format de fichier qui définit une image contenant les entêtes qui incluent une
signature de fichier, une entête COFF, une entête optionnelle ainsi que des fichiers objets ne contenant que des entêtes COFF.
� Initialement développé pour UNIX, il est actuellement utilisé, entre autre, par WinCE.
J.Boukhobza - Systèmes d'exploitation embarqués 13
Source: http://support.microsoft.com/kb/121460/fr
Segment de pile (stack)� Taille (non) fixée pendant la compilation mais évolue
dynamiquement pendant l’exécution
� Structurée en LIFO (Last In First Out, pile), 2 opérations possibles:� Empiler
� Dépiler
� Variables locales, passage de paramètres, adresse de retour.
� L’espace de données réservé dans la pile est contigu mais limité.
J.Boukhobza - Systèmes d'exploitation embarqués 14

21/12/2017
8
Segment de tas (heap)� Emplacement mémoire alloué en bloc en cours d’exécution.
� Liste chaînée d’emplacements mémoire.
� L’OS doit implémenter des mécanismes d’allocation mémoire pour permettre, par exemple, l’utilisation des malloc (en C).
� Politiques d’allocation typiques:� FF (First fit): la liste est scannée depuis le début à la recherche du premier emplacement pouvant
contenir la donnée.
� NF (Next Fit): la liste est scannée depuis le dernier emplacement trouvé, à la recherche du premier emplacement pouvant contenir la donnée.
� BF (Best Fit): toute la liste est inspectée à la recherche du meilleure (plus petit) emplacement pouvant contenir la donnée.
� WF (Worst Fit): toute la liste est parcourue et la donnée est placée dans le plus grand emplacement.
� QF (Quick Fit): une liste d’emplacements libres est maintenue et l’allocation est faite à partir de là.
� Le buddy system: où les blocs sont alloués par puissance de 2. A chaque fois qu’un bloc est libéré, il est fusionné avec les blocs libres voisins.
� …
J.Boukhobza - Systèmes d'exploitation embarqués 15
Désallocation de la mémoire (tas)� 2 possibilités
� Explicite: le programmeur doit désallouer lui-même la mémoire dynamiquement allouée;
� Implicite: la désallocation est prise en charge par un ramasse miettes (garbage collector):� Algorithme de copie: le système copie toutes les références des objets utilisés et
efface le reste.
� La copie est une opération non-interruptible,
� L’espace mémoire requis pour cet algorithme est important.
� Algorithme mark & sweep: on marque les objets utilisés et on efface les autres
� Pb de fragmentation.
� Algorithme générationnel: sépare les objets en groupe (générations). Cet algorithme suppose que la plupart des objets crées « vivent » peu de temps. Les objets « vieux » ont donc moins de chance d’être effacés, les copier est, par conséquent, une perte de temps.
� …J.Boukhobza - Systèmes d'exploitation embarqués 16

21/12/2017
9
Gestion de la mémoire et
segmentation sous VxWorks� Après l’appel à taskSpawn()une image de la tâche fils est créée, contenant TCB, pile et
programme.
integer seconds;
integer minutes=5;
// tâche parent qui active le timer
void parentTask(void)
{
…
if sampleSoftware Clock NOT running {
//newSWClkId est une valeur d’entier unique assignée par le noyau lorsque la tâch est crée
newSWClkId = taskSpawn (“sampleSoftwareClock”, 255, VX_NO_STACK_FILL, 3000,(FUNCPTR) minuteClock, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0);
….
}
//fonction exécutée par la tâche fille Software Clock
void minuteClock (void) {
while (softwareClock is RUNNING) {
seconds = 0;
while (seconds < 60) {
seconds = seconds+1;
}
……
}
}
J.Boukhobza - Systèmes d'exploitation embarqués 17
pileSegment
de code
(texte)
Segment des
symboles
(Bss)
Segment de
données
Source: Embedded Systems Architecture: A comprehensive guide for engineers and
programmers, Elsiever ed, T. Noergaard, 2005
Allocation mémoire et Jbed� L’allocation se fait avec le mot
clé new.
� malloc peut être utilisé si la JNI (Java Native Interface) est supportée.
� Le ramasse miettes de Jbeds’occupe de désallouer la mémoire avec un algorithme mark & sweep, ce qui permet de faire du temps réel (car non bloquant).
public void CreateOneshotTask(){// caractéristiques pour l’ordonnacementfinal long DURATION = 100L; // temps d’exécution< 100usfinal long ALLOWANCE = 0L; // pas de gestion de
dépassement de duréefinal long DEADLINE = 1000L;// terminaison au bout de
1000usRunnable target; // code executable de la tâcheOneshotTimer taskType;Task task;// Création d’un objet exécutabletarget = new MyTask();// Création d’une tâche de type oneShot sans délaitaskType = new OneshotTimer( 0L );// Création de la tâchetry{task = new Task( target, DURATION, ALLOWANCE,
DEADLINE, taskType );
}catch( AdmissionFailure e ){System.out.println( “Echec de création de la tâche ” );return;}
J.Boukhobza - Systèmes d'exploitation embarqués 18
Source: Embedded Systems Architecture: A comprehensive guide for engineers and
programmers, Elsiever ed, T. Noergaard, 2005

21/12/2017
10
Pagination et mémoire virtuelle� Avec ou sans segmentation, les OS divisent la mémoire en partitions de
taille fixe appelées: blocs, cadres, pages ou une combinaison de ces derniers.
� Mémoire découpée en cadres (@: numéro de cadre + déplacement) �espace utilisateur (@: numéro de page + déplacement).
� Pagination: processus chargé en mémoire � liste de pages.� Table des pages: contient les informations entre la correspondance
page/cadre.
J.Boukhobza - Systèmes d'exploitation embarqués 19
Page 0
Page 1
Page 2
Page 3
Numérode page
Numéro de cadre
0 1
1 4
2 3
3 7
Page 0
Page 2
Page 1
Page 3
Mémoire
logique Table des pages
Mémoire
physique
0
1
2
3
4
5
6
7
Numéro de
cadre
Pagination à la demande� Dans un système paginé, les processus sont lancés sans qu’aucune de leurs
pages ne soit en mémoire :� Dès que le processeur essaie d’exécuter la première instruction, il se produit un
défaut de page, ce qui amène le système d’exploitation à charger la page correspondante en mémoire centrale.
� D’autres défauts de page apparaissent rapidement pour les variables globales ou la pile.
� C’est seulement au bout d’un certain temps que le processus dispose de la plupart de ses pages et que l’exécution peut se poursuivre avec relativement peu de défauts de page.
� Cette stratégie est appelée pagination à la demande car les pages sont chargées à la demande et non à l’avance
J.Boukhobza - Systèmes d'exploitation embarqués 20

21/12/2017
11
Ensemble de travail� Théorie de localité de références de Knuth: le système passe 90% du temps
à traiter 10% du code.
� Généralement, les processus font des références groupées, c’est-à-dire que pendant une certaine phase de leur exécution ils ne référencent qu’un nombre restreint de leurs pages.� Cet ensemble de pages utilisées pendant un certain temps par un processus
constitue l’ensemble de travail du processus.
� Si l’ensemble de travail est entièrement en mémoire, le processus s’exécute sans provoquer (beaucoup) de défauts de page.
� De nombreux systèmes de pagination mémorisent l’ensemble de travail de chaque processus et le chargent en mémoire avant de lancer le processus.� Cette approche est appelée “ Modèle de l’ensemble de travail ”.
� Le chargement des pages avant exécution est appelé le Préchargement ou la Prépagination .
J.Boukhobza - Systèmes d'exploitation embarqués 21
Swapping et algorithme
d’allocation� Mémoire physique pleine + besoin de mémoire => swapper des
pages sur une mémoire hiérarchiquement inférieure.� Différents algorithmes quant au choix de la page à décharger:
� Optimal: swapper les pages qui ne vont pas être utilisées dans un futur proche….inimplémentable.
� LRU (Least Recently Used): swapper la page qui a été utilisée le moins récemment.
� FIFO: swapper la page qui a été mise en mémoire la première.� Not Recently Used: swapper les pages qui n’ont pas été utilisées
pendant un certain temps.� Seconde chance: FIFO avec un bit de référence, si zéro � swapper
(ce bit est à 1 si la page est accédée, et remis à 0 après une vérification+ remise de la page en début de liste comme une page nouvellement accédée)
� …
J.Boukhobza - Systèmes d'exploitation embarqués 22

21/12/2017
12
Mémoire virtuelle� Plus grand espace adressable (par rapport à la mémoire
physique)� Demande effectuée par segment de processus ou par processus
(globalement).� Table de page (Virt � Phys): utilisation de TLB (Translation
Lookaside Buffer)� Utilisation d’MMU pour la traduction d’adresse
J.Boukhobza - Systèmes d'exploitation embarqués 23
C P U
M M U
B u s
Ad re sse s v irtu e l le s
Ad re ss es ré e lle s
M ém o ire p h y s iq u e
P ér ip h é riq u e C ar te C P U
Disque
Quelques spécificités des OS
embarqués et temps réel� Gestion de mémoire rapide et déterministe: il est plus rapide de … ne pas avoir
à gérer du tout !!. Le programmeur gère tout (très petit EOS et RTOS). Sinon gestion basique: allocation et désallocation.
� Verrouillage des pages: évite d’avoir certaines pages sur stockage secondaire (accès non déterministe) pour les tâches temps réel.
� Allocation dynamique: pas sûr qu’il y a assez de place, et donc risque de swapping (si swap). Il faut faire attention.
� Mapping mémoire: différents registres des périphériques doivent être accédés par les applications, d’où le besoin de mapping en mémoire de ces derniers.
� Partage de mémoire (communication): allocation/désallocation
� RAM disk: utiliser la mémoire comme stockage secondaire pour avoir des temps déterministes (possibilité d’utiliser un disque flash) � utilisation d’un système de fichiers.
J.Boukhobza - Systèmes d'exploitation embarqués 24

21/12/2017
13
J.Boukhobza - Systèmes d'exploitation embarqués 25
Introduction� La tâche de la gestion de la mémoire physique n’incombe pas
seulement à l’OS.� Les microprocesseurs incluent un support matériel pour rendre
la gestion de la mémoire plus performante et plus sûre.� Etudié à travers l’exemple de Linux sur une plateforme x86
� La mémoire peut être adressée de 3 points de vue différents:� Point de vue processeur
� Comment se fait l’adressage de la mémoire physique ?
� Point de vue noyau� Comment le noyau gère la mémoire pour son propre usage ?
� Point de vue des processus� Comment la mémoire est allouée aux processus par le noyau ?
J.Boukhobza - Systèmes d'exploitation embarqués 26

21/12/2017
14
Adressage mémoire� Support matériel pour l’adressage� 3 formes d’adressage pour les CPUs x86
� Adressage logique� Spécifie l’adresse d’une opérande et/ou d’une instruction� Chaque adresse logique est constituée d’un numéro de segment et d’un
déplacement (offset)� Adressage linéaire (ou virtuelle)
� Un entier sur 32bits non signé permettant d’adresser n’importe quelle zone mémoire (4GOctets adressables)
� Adressage physique� Adresse la cellule mémoire sur les bonnes puces� Correspond aux signaux électriques
J.Boukhobza - Systèmes d'exploitation embarqués 27
Unité de segmentation
Unité de pagination
Adresse logique Adresse
linéaire/virtuelle
Adresse physique
Matériel pour la segmentation� 80286: µproc Intel effectue la traduction d’adresse en 2
modes: 1. Mode réel:
� Existe encore à des buts de compatibilité� Pas de protection mémoire� CPUs précédents n’avaient qu’un unique mode, équivalent à réel
2. Mode protégé:� Permet la gestion matérielle de la protection mémoire� Ajout d’un mécanisme de pagination dans le 80386� Introduit les niveaux de privilège ou rings
� 0 a tous les pouvoirs� 3 très limité
J.Boukhobza - Systèmes d'exploitation embarqués 28
21/12/2017
15
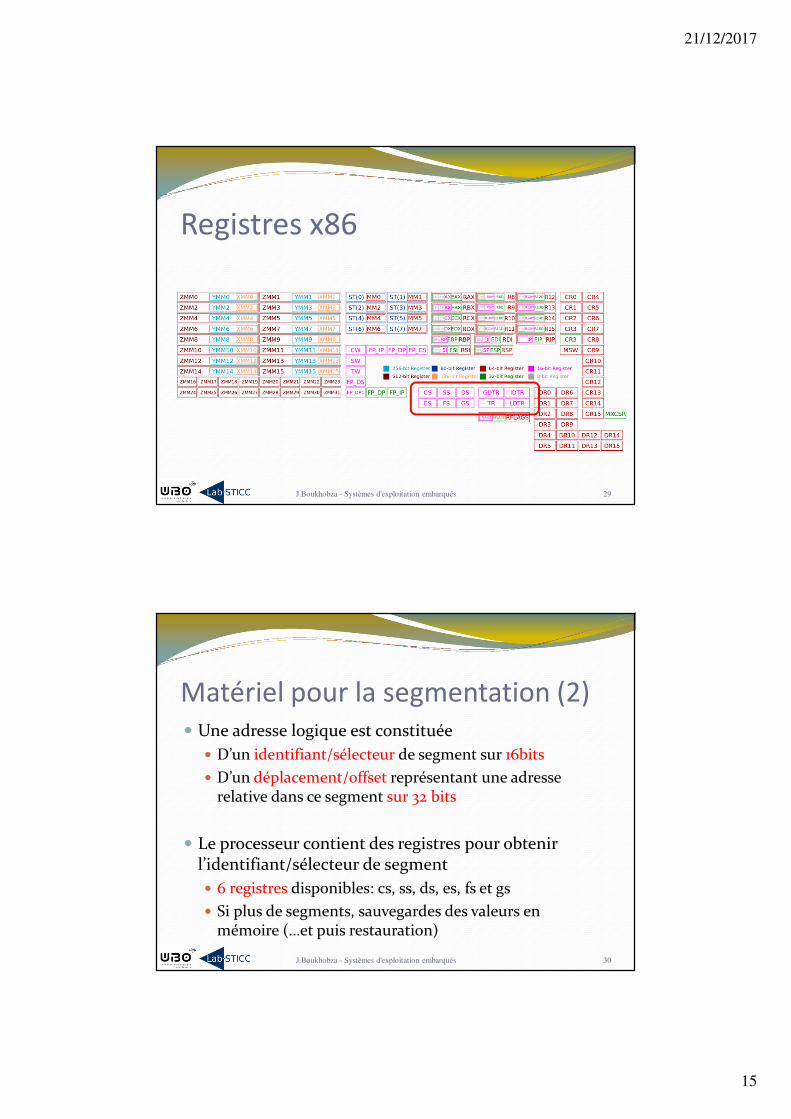
Registres x86
J.Boukhobza - Systèmes d'exploitation embarqués 29
Matériel pour la segmentation (2)
� Une adresse logique est constituée� D’un identifiant/sélecteur de segment sur 16bits
� D’un déplacement/offset représentant une adresse relative dans ce segment sur 32 bits
� Le processeur contient des registres pour obtenir l’identifiant/sélecteur de segment� 6 registres disponibles: cs, ss, ds, es, fs et gs
� Si plus de segments, sauvegardes des valeurs en mémoire (…et puis restauration)
J.Boukhobza - Systèmes d'exploitation embarqués 30

21/12/2017
16
Registres pour la segmentation� 3 registres ont un rôle spécifique� cs: Code Segment
� Pointe vers un segment contenant le code (segment texte)� Contient un champs de 2 bits qui indiquent le Current Privilege
Level (CPL):� 4 privilèges possibles sur les processeurs x86 Intel, Linux en utilise 2
(mode utilisateur et mode noyau)
� ss: Stack Segment� Pointe vers le segment contenant la pile courante du programme
� ds: Data Segment� Pointe vers le segment contenant les données statiques du
programme� Les 3 autres registres (es, fs, gs) peuvent faire référence à des
segments arbitraires
J.Boukhobza - Systèmes d'exploitation embarqués 31
Descripteurs de segment� Chaque segments est décrit par un descripteur de segment de 8 octets
� Stocké dans le LDT ou dans le GDT (Local/Global Descriptor Table)
� Un registre spécifique contient un pointeur vers le GDT (gdtr) et vers le LDT (ldtr)
� Champs du descripteur de segment� Base : 32 bits contenant l’adresse linéaire de début de segment
� G : granularité, si 0 la taille segment est exprimée en octets, sinon en multiples de 4Ko (taille d’une page)
� Limit : 20 bits indiquant la longueur du segment en octets
� S : (system flag) Si 0, segment contenant des données critiques pour le noyau, sinon code ou données normales (utilisateur)
� Type : 4 bits caractérisant le type du segment et ses droits d’accès
� DPL : Descriptor Privilege Level, 2 bits indiquant le niveau de privilège minimal pour accéder à ce segment
� P: Segment-Present, indique si le segment est en mémoire principale � sous linux toujours 1, un segment n’est jamais entièrement swappé sur le disque.
� D ou B: à 1 lorsque les déplacements dans le segment (offset) sont sur 32 bits et 0 si sur 16 bits.
J.Boukhobza - Systèmes d'exploitation embarqués 32

21/12/2017
17
Accès au descripteur de segments� Sélecteur/identifiant de segment (16 bits) contient:
� Un indice qui identifie le descripteur de segment contenu dans la GDT ou LDT (13 bits).
� Un indicateur de table: pour dire si le descripteur se trouve dans le LDT ou GDT (1 bit).
� RPL (Request privilege Level): spécifie le niveau de privilège du CPU lorsque le sélecteur de segment est chargé (2 bits).
� Pour accéder au segment: accéder d’abord au registre contenant le sélecteur puis en mémoire (descripteur) �lent !� Solution: pour chaque registre de segment, il existe un
registre non programmable (8 octets) qui chargera le contenu du descripteur, cela évite de passer par la mémoire.
J.Boukhobza - Systèmes d'exploitation embarqués 33
Traduction d’adresse� Adresse logique � adresse linéaire (virtuelle)� L’unité de segmentation réalise les opérations suivantes:
� Examine le bit d’indicateur de table de sélecteur de segment pour savoir si le descripteur est dans la GDT ou LDT:� l’unité de segmentation prend le contenu du registre gdtr comme adresse linéaire de base ou celle du
registre ldtr� Trouve l’adresse du descripteur de segment grâce au champ indice *8 octets (taille d’un
descripteur de segment).� additionne l’offset/déplacement de l’adresse logique à l’adresse de base extraite du
descripteur.
J.Boukhobza - Systèmes d'exploitation embarqués 34
indice IT déplacement
*8
+
gdtr
ou ldtr
descripteur
+Adresse linéaire/virtuelle
Adresse logique
16 bits 32 bits
@ début de
segment
Taille du
descripteur
en octets

21/12/2017
18
Segmentation sous Linux� Linux préfère la pagination à la segmentation (si l’on peut opposer ces 2
concepts…):� L’un des objectifs de Linux est la portabilité: plusieurs processeurs RISC ont un
support limité pour la segmentation.
� Tous les processus Linux s’exécutant en mode utilisateur partagent la même pair de segments: code et données (user code segment et user data segment)
� Tous les processus Linux s’exécutant en mode noyau partagent la même pair de segments: code et données (kernel code segment et kernel data segment).
J.Boukhobza - Systèmes d'exploitation embarqués 35
Pagination matérielle� L’unité de pagination traduit/transforme les adresses linéaires/virtuelles en
adresses physiques� Pour des raisons d’efficacité, les adresses linéaires sont groupées en intervalles
de taille fixe: des pages� Des adresses contigües dans une page se traduisent (généralement) par des
adresses physiques contigües� Différence entre Page manipulée par l’OS et Page physique (page frame/cadre
ou page physique)� Une Page peut au cours de l’exécution changer de cadre (en mémoire ou sur le
disque)� Les structures de données assurant la conversion des adresses sont des tables
de pages� Stockées en mémoire (ou en partie dans le TLB …)� Doivent être initialisées par le noyau
� Les processeurs Intel peuvent fonctionner sans pagination� Registre pour activation de la pagination(drapeau PG du registre cr0)� Si désactivé, adresses linéaire sont interprétées comme physiques
J.Boukhobza - Systèmes d'exploitation embarqués 36
21/12/2017
19
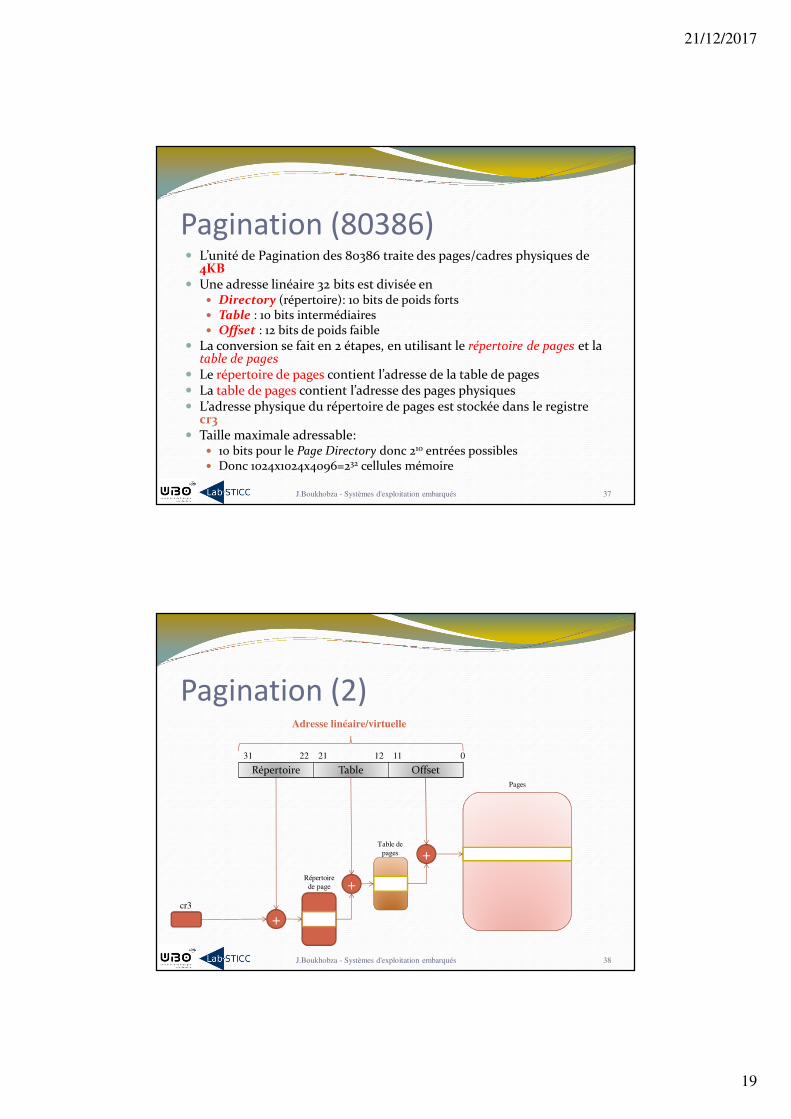
Pagination (80386)� L’unité de Pagination des 80386 traite des pages/cadres physiques de
4KB� Une adresse linéaire 32 bits est divisée en
� Directory (répertoire): 10 bits de poids forts� Table : 10 bits intermédiaires� Offset : 12 bits de poids faible
� La conversion se fait en 2 étapes, en utilisant le répertoire de pages et la table de pages
� Le répertoire de pages contient l’adresse de la table de pages� La table de pages contient l’adresse des pages physiques� L’adresse physique du répertoire de pages est stockée dans le registre
cr3� Taille maximale adressable:
� 10 bits pour le Page Directory donc 210 entrées possibles� Donc 1024x1024x4096=232 cellules mémoire
J.Boukhobza - Systèmes d'exploitation embarqués 37
Pagination (2)
J.Boukhobza - Systèmes d'exploitation embarqués 38
Répertoire Table Offset
Adresse linéaire/virtuelle
01112212231
cr3
+
+
+Répertoire
de page
Table de
pages
Pages

21/12/2017
20
Entrées des tablesLes entrées dans les répertoires et tables de pages ont les mêmes structures:
� Present : la page ou la table de pages est présente en mémoire
� 20 bits les plus significatifs (poids fort) de l’adresse physique de la page
� Les pages sont des multiples de 4096
� Les 12 bits les moins significatifs sont toujours 0
� Accessed : Mis à 1 quand l’unité de pagination accède à la page. Remis à 0 par l’OS
� Dirty : Applicable seulement aux entrées de la table de pages (et donc les pages).
� Mis à 1 lors de l’écriture sur un cadre. Remis à 0 par l’OS
� Read/Write : Droits de lecture ou lecture/écriture
� User/Supervisor : Privilège requis pour accéder à la page ou à la table de pages
� PCD et PWT : contrôle le cache matériel (méthode de gestion)
� Page Size : applicable seulement aux entrées du répertoire. Si mis, l’entrée correspond à une page physique de 4MB (ou 2 si Physical Address Extension est actif)
J.Boukhobza - Systèmes d'exploitation embarqués 39
Pagination étendue� Les pentiums ont introduit la notion de pagination
étendue� Permet des pages physiques dont la taille est de 4KB ou 4MB
� Dans ce cas, l’adresse linéaire/virtuelle est divisée en 2 champs� Répertoire: 10 bits les plus significatifs� Déplacement : les 22 bits restants
� Entrées dans le répertoire� Drapeau Page Size mis à 1� Les 10 bits de poids fort seulement sont nécessaires (multiples
de 4MB)� Les deux paginations peuvent cohabiter� Utilisés pour gérer des gros blocs de mémoire contigus
J.Boukhobza - Systèmes d'exploitation embarqués 40
21/12/2017
21
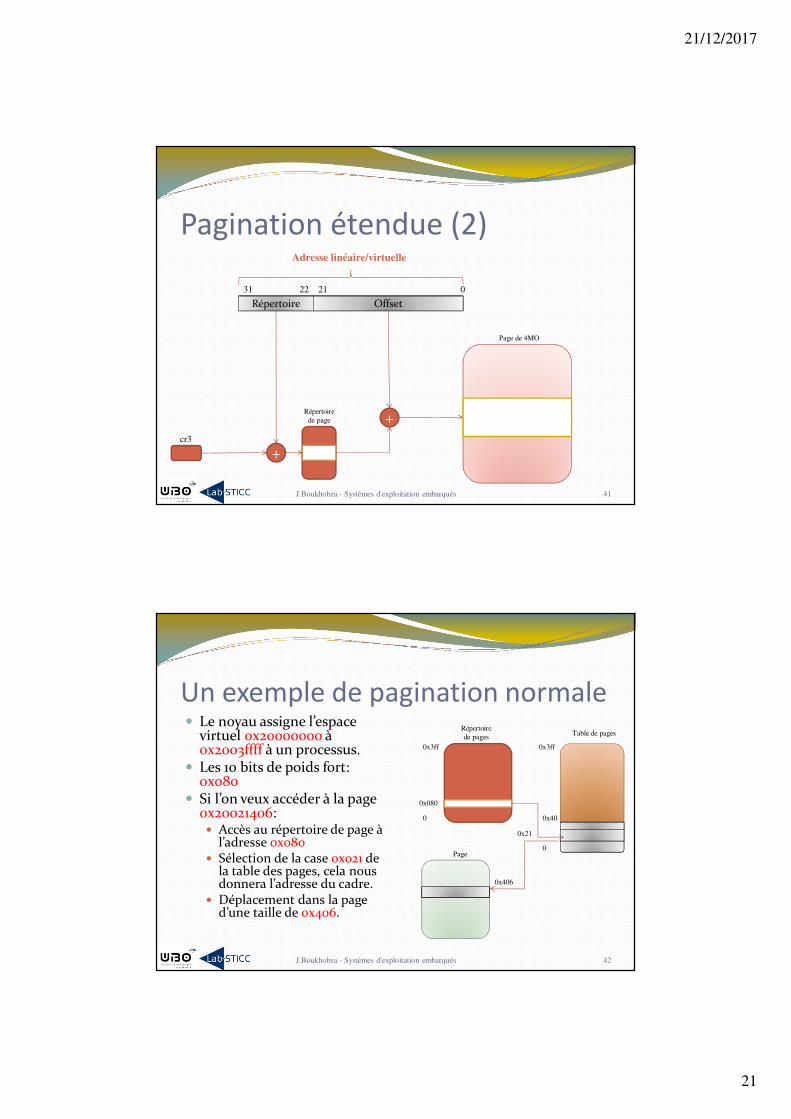
Pagination étendue (2)
J.Boukhobza - Systèmes d'exploitation embarqués 41
Répertoire Offset 0212231
cr3
+
+Répertoire
de page
Page de 4MO
Adresse linéaire/virtuelle
Répertoire
de pagesTable de pages
0x080
0x3ff
0
0
0x40
0x3ff
Un exemple de pagination normale� Le noyau assigne l’espace
virtuel 0x20000000 à 0x2003ffff à un processus.
� Les 10 bits de poids fort: 0x080
� Si l’on veux accéder à la page 0x20021406:� Accès au répertoire de page à
l’adresse 0x080� Sélection de la case 0x021 de
la table des pages, cela nous donnera l’adresse du cadre.
� Déplacement dans la page d’une taille de 0x406.
J.Boukhobza - Systèmes d'exploitation embarqués 42
0x21
0x406
Page

21/12/2017
22
Le cache matériel� Tous les processeurs modernes ont un ou plusieurs (niveaux de) caches
� L’unité de gestion de cache est située entre l’unité de pagination et la mémoire physique
� Le cache peut être:� Direct mapped : chaque ligne en mémoire est mise à la même adresse dans le cache
� Complètement associatif: chaque ligne en mémoire peut être stockée n’importe ou dans le cache.� N-way set associative: chaque ligne de mémoire peut être stockée dans N lignes différentes.
� 2 possibilités lors d’un accès:� Cache hit: données présentes dans le cache
� Lecture: données transférées vers les registres du CPU (gain de performance)
� Écriture: 2 possibilités:
� Write through: écriture dans le cache ET dans la mémoire (immédiatement)
� Write back (ou lazy write): écriture dans le cache (et écriture retardée dans la mémoire)
� Cache miss: données absentes du cache, la ligne de cache est écrite en mémoire au besoin et les données sont chargées à partir de la mémoire.
J.Boukhobza - Systèmes d'exploitation embarqués 43
Le cache matériel (2)
� Plusieurs niveaux de cache: L1, L2, L3 … la cohérence entre les différents niveaux est implémentée matériellement.� Linux ignore le détail des implémentations et suppose qu’il n’y a qu’un seul cache.
� Sur les x86, le cache peut être globalement désactivé ou activé� Drapeau CD du registre cr0 pour activation/désactivation
� Drapeau NW pour Write-through ou Write-back
� Possibilité d’associer une politique de cache pour chaque cadre mémoire (entrée dans la table)� PCD (Page Cache Disable) cache activé/désactivé
� PWT (Page Write through) Write-through ou Write-back
� Linux mets tous les drapeaux à 0 pour toutes les pages� Cache activé avec write-back pour toutes les pages
� Un cache spécifique pour la pagination (table de page) est disponible� Translation Lookaside Buffer (TLB)
� Garde en cache les adresses linéaires récemment transformées
� Il y en à 1 par CPU
J.Boukhobza - Systèmes d'exploitation embarqués 44

21/12/2017
23
Pagination sous Linux� 4 niveaux / types de tables (Indispensable pour les machines 64 bits)
� Page Global Directory
� Page Upper Directory
� Page Middle Directory
� Page Table
� Pour les architectures 32 bits: les 2 répertoires intermédiaires sont éliminées (sans extension d’adresse physique sinon 3 répertoires)
� Sinon l’adresse linéaire est découpée en 4 parties (64 bits).
� Chaque processus a son propre Page Global Directory et ses propres tables de pages
� Quand un changement de processus intervient, Linux sauvegarde le contenu de cr3 (adresse du PGD) et charge la nouvelle valeur� L’unité de pagination utilise les bonnes tables
� Si Linux tourne sur un processeur qui n’a pas 4 niveaux de paginations (Pentium…), le nombre d’entrées de la Page Middle Directory est mis à 1.
J.Boukhobza - Systèmes d'exploitation embarqués 45
Pagination sous Linux (2)
J.Boukhobza - Systèmes d'exploitation embarqués 46
Global Dir Upper Dir Middle Dir
Adresse linéaire/virtuelle
0
cr3
+
+
+Répertoire
global de
page
Haut
répertoire
de pages
Page
Offset Table
+
Répertoire
de pages
moyen +
Table de
pages

21/12/2017
24
Organisation physique de la
mémoire� Pendant l’initialisation, le noyau « cartographie » la mémoire.
� Quels intervalles d’adresses physiques sont utilisables par le noyau et lesquels ne le sont pas (utilisés par des périph. ou par le BIOS).
� Ensemble de cadres réservés (jamais swappés sur le disque):� Les cadres indisponibles (pour le noyau)
� Les cadres contenant le code et les données initialisées du noyau
� Le noyau linux est installé à partir de l’adresse 0x00100000 (2ème méga octet) pour quelques mégas.
� Quelques particularités de l’architecture PC:� Le cadre 0 est utilisé par le BIOS pour stocker la configuration matérielle de
la machine.
� Adresses physiques de 0x000a0000 à 0x000fffff 640KO à 1MO: réservées pour les routines du BIOS et pour mapper la mémoire interne des cartes graphiques ISA.
J.Boukhobza - Systèmes d'exploitation embarqués 47
Linux, mémoire physique et
pagination� Le noyau fait un usage important du système de pagination
� Plus répandu que les segments sur les processeurs (RISC)� Le code du noyau et de ses structures sont dans des pages physiques (cadres)
réservées� Les pages de ces cadres ne peuvent jamais être swapées
� Habituellement, le noyau est en RAM à partir de l’adresse 0x00100000
� Nombre total de pages: dépend de la configuration� Pourquoi pas à l’adresse 0?
� A cause de l’architecture PC; BIOS et autre !
J.Boukhobza - Systèmes d'exploitation embarqués 48
Réservé matériel Espace réservé
noyau
0x10000

21/12/2017
25
Petite conclusion� Segmentation et pagination sont 2 mécanismes pouvant
permettre d’atteindre le même objectif (parmi d’autres):� Séparer les espaces d’adressage physique des processus
� La segmentation assigne un espace linéaire/virtuel différent à chaque processus (plusieurs dimensions)
� La pagination permet d’associer un espace linéaire/virtuel à différents espaces physiques
� Linux préfère la pagination� La gestion des processus est plus facile sur un unique espace
linéaire/virtuel� La segmentation n’est pas disponible sur tous les processeurs
(RISC)
J.Boukhobza - Systèmes d'exploitation embarqués 49
J.Boukhobza - Systèmes d'exploitation embarqués 50

21/12/2017
26
Descripteurs de page� La mémoire physique est un ensemble de cadres� Le noyau doit connaître l’état de chaque cadre mémoire stocké dans mem_map
� Distinguer entre cadre pour processus, pour le code du noyau ou contenant les données du noyau
� Libre ou pas
� Information sur un cadre mémoire représentée dans un descripteur de page (32 octets):� flags: tableau de drapeaux (voir tranparent suivant). Encode également le numéro de
zone à laquelle la page appartient.� _count: compteur de références au cadre.� _mapcount: nombre d’entrées dans la table des pages qui référencent ce cadre.� private: utilisé à des buts différents d’après l’état du drapeau (flags) plus haut.� mapping: structure utilisée lorsque la page est dans le cache des pages ou lorsqu’elle
appartient à une région anonyme.� index: utilisée par plusieurs composants du noyau à des buts différents (e.g. swap)� Lru: contient les pointeurs vers la liste doublement chaînée des pages les moins
récemment utilisées.::
J.Boukhobza - Systèmes d'exploitation embarqués 51
Descripteurs de page (suite)� _count: Compteur d’utilisation
� mis à -1 si la page est libre� tout autre valeur ≥0 si utilisée par un processus ou le noyau
� flags: jusqu’à 32 drapeaux décrivant l’état du cadre� PG_error : erreur d’E/S pendant le transfert des données de ce
cadre� PG_locked : le cadre est verrouillé � PG_slab : le cadre est dans un slab (voir plus loin)� PG_referenced: cadre récemment accédé.� PG_reserved: cadre mémoire réservé pour le noyau ou
inutilisable.� PG_dirty� …
J.Boukhobza - Systèmes d'exploitation embarqués 52

21/12/2017
27
Zones mémoire� Dans l’idéal, un cadre mémoire peut être utilisé pour stocker
n’importe quel type d’information.� … mais il existe des contraintes matérielles:
� Ex: les processeurs DMA ne peuvent adresser que les 16 premiers MO de la RAM
� Linux 2.6 partitionne la mémoire physique en 3 zones:� ZONE_DMA: de 0 à 16MO� ZONE_NORMAL: de 16MO à 896MO� ZONE_HIGHMEM: plus de 896 MO
� Chaque zone à son propre descripteur:� Nombre de pages libres� Verrou protégeant le descripteur� Nom de la zone� …
J.Boukhobza - Systèmes d'exploitation embarqués 53
Les allocations mémoire� Différents type d’allocation:
� Blocs contigus
� Très petites structures
� Blocs non-contigus
J.Boukhobza - Systèmes d'exploitation embarqués 54

21/12/2017
28
Allocation de blocs contigus� Le noyau alloue des groupes de cadres contigus� Pb de fragmentation externe� 2 façons d’éviter ce problème:
1. Utiliser le circuit de pagination du cpu pour mapper des adresses linéaires contigües vers des cadres non contigus
2. Maintenir une liste de blocs de cadres contigus libres et éviter de « casser » de gros blocs pour de petites allocations
� Linux utilise la 2ème approche car:� recourir au circuit de pagination n’est pas toujours possible (DMA:
accès direct au bus d’adresse) � cadres contigus nécessaires� meilleure gestion des TLB (cache associatif contenant la table des
pages) si cadres consécutifs �� Tables des pages non modifiées pour des cadres contigus� Possibilité d’utiliser des pages/cadres de 4MO
J.Boukhobza - Systèmes d'exploitation embarqués 55
Algorithme Buddy system� Tous les cadres libres sont mis dans des groupes (11) de tailles
différentes� 1, 2, 4, 8, 16, 32, 64, 128, 256, 512 et 1024 (4MO) cadres contigus
� Ces groupes sont maintenus dans des listes: une par taille de groupe� L’adresse physique du premier cadre du bloc est un multiple de la taille
du groupe� Ex: l’adresse initiale d’un bloc de 16 cadres est un multiple de 16x212
(taille page = 212 octets)� Algorithme
� Une demande est faite pour n cadres consécutifs� Si n a une liste correspondante, on l’utilise
� Sinon, utilisation de la liste supérieure la plus proche� Allocation des cadres nécessaires
� Les cadres restants sont mis dans la liste correspondante
J.Boukhobza - Systèmes d'exploitation embarqués 56

21/12/2017
29
Algorithme Buddy system; un
exemple� Une demande de 256 cadres est effectuée� Le système regarde dans la liste des 256, si non vide, c’est
bon� Sinon, utilisation de la liste des 512
� Si non vide, allocation des 256� Ajout d’un nouveau bloc de 256 restant à la liste 256.
� Sinon utilisation de la liste des 1024� Si non vide, allocation des 256� Ajout d’un bloc de 256 et d’un bloc de 512 dans la bonne liste
� Sinon, pas assez de cadres libres� Arrêt de l’algorithme� Retour d’une erreur
J.Boukhobza - Systèmes d'exploitation embarqués 57
Algorithme de restitution des
cadres� Le nom de l’algorithme vient de la façon dont la libération
des cadres est effectuée� L’algorithme essaie de fusionner des pairs de blocs
«copains» (buddy) libres� 2 blocs de taille b deviennent un bloc de taille 2b
� 2 blocs sont « copains» si� Ils sont de même taille� Ils sont à des adresses physiques contigües� L’adresse physique du premier cadre du premier bloc est
multiple de 2b x 212
� Algorithme itératif� Si la fusion a réussi avec des blocs de taille b, on continue avec
2b
J.Boukhobza - Systèmes d'exploitation embarqués 58

21/12/2017
30
Gestion de l’espace mémoire� Un espace mémoire est un nombre arbitraire de cellules
mémoires ayant des adresses physiques contigües� Pas forcément un nombre exact de cadres
� Le buddy permet de gérer les demandes importantes (plusieurs pages)
� Mais comment gérer des demandes de quelques (dizaines ou centaines) d’octets?
� Ajout d’une structure pour gérer l’allocation dans un cadre?� Mais si demande de n octets, alors nécessite k octets dans les
meta-structures pour gérer allocation� Fragmentation interne
� Solution non satisfaisante
J.Boukhobza - Systèmes d'exploitation embarqués 59
Le slab (pavé, tablette) allocatorInventé en 1994 pour Solaris 2.4Basé sur plusieurs constatations:� Le type de données stockées peut affecter la façon dont l’allocation est effectuée
(get_zeroed_page remplit le cadre de 0 � pour la zone utilisateur)� Les espaces mémoire peuvent être vus comme des objets, avec des
constructeurs et des destructeurs� Quand un espace est libéré, l’objet le représentant est gardé pour être
éventuellement réutilisé� Le noyau a tendance a fréquemment demander des espaces mémoire du
même type� Ex: création d’un processus nécessite des tables d’une taille fixe� Lorsqu’un processus se termine, son espace est réutilisé
� Évite de perdre du temps à désallouer et réallouer. � Slab allocator les sauvegarde dans un cache.
� Les demandes peuvent être classées suivant leur fréquence� Les requêtes fréquentes de taille donnée peuvent être gérées en créant des
ensembles d’objets de la bonne taille
J.Boukhobza - Systèmes d'exploitation embarqués 60

21/12/2017
31
Le slab allocator (2)� Le slab allocator groupe tous les objets dans des caches� Chaque cache contient des collections d’objets de même type
� Libres ou utilisés ou partiellement utilisé (slab)� Chaque collection est un slab� Un slab: généralement un cadre mémoire
� La liste des caches est visible dans /proc/slabinfo� Le slab allocator utilise le buddy allocator pour obtenir des cadres� Et il ne rend pas les cadres spontanément sauf si:
� Demande explicite du noyau� le buddy ne peut satisfaire une demande
J.Boukhobza - Systèmes d'exploitation embarqués 61
Source: Understanding the Linux kernel 3rd edition, O’Reilly ed, D.P. Bovet, M.Cesati
Allocation non contigües� Il est préférable d’allouer la mémoire de façon contigüe
� Meilleure utilisation du cache � Mais on peut aussi avoir un espace linéaire contigu, et des cadres
non contigus� Limite la fragmentation externe
� La taille d’un espace non contigu doit être multiple de 4Ko� Les informations d’allocation sont maintenues dans une liste
simple de type struct vm_struct contenant� L’adresse linéaire de la première cellule mémoire� La taille de la zone� Pointeur vers suivant
� vmalloc et vfree…� Peu utilisés en pratique
J.Boukhobza - Systèmes d'exploitation embarqués 62

21/12/2017
32
Espace d’adressage d’un processus� La gestion de la mémoire par le noyau est simple:
� Demande de pages au buddy pour les zones contigües� Demande d’objets au slab allocator pour les petites zones� vmalloc pour des zones non contigües
� Fonctionne car:� Le noyau est le composant le plus important, donc ses demandes sont
traitées en priorité� Le noyau « se fait confiance », il y a peu/pas? d’erreurs à gérer �
pas/peu de protections� Mais les processus utilisateurs …
� Ne sont pas prioritaires/urgents� Un processus qui réclame beaucoup de mémoire ne va, sans doute, pas l’utiliser
immédiatement� Donc on peut différer l’allocation
� Ne sont pas fiables� Plusieurs erreurs à gérer … n’est ce pas !
J.Boukhobza - Systèmes d'exploitation embarqués 63
Espace d’adressage d’un processus
(2)� L’espace d’adressage d’un processus est l’ensemble des adresses linéaires qu’il
peut utiliser� Un ensemble d’adresses linéaires est représenté par
� une région de mémoire� Adresse linéaire initiale� Une taille� Des droits d’accès
� L’adresse et la taille sont des multiples de 4Ko
� Un processus obtient une nouvelle région mémoire� Lors de sa création (fork…) � ex: shell� Lors du changement de programme (exec…)� Accès à un fichier (mapping) en mémoire� Remplissage de sa pile� IPC� malloc()
J.Boukhobza - Systèmes d'exploitation embarqués 64

21/12/2017
33
Descripteur de mémoire� Toutes les informations concernant l’espace d’adressage d’un processus sont dans une
structure mm_struct (voir task_struct)
� Quelques champs:� mmap: pointeur sur la tête de la liste des objets de la région mémoire� mmap_cache: pointeur vers la dernière région utilisée� mmap_count : nombre de régions� mm_count: compteur d’utilisation� start_code et end_code: adresse de début et fin du segment de code du processus� start_data et end_data: adresse de début et fin du segment de données du processus� start_brk et brk: adresse de début et adresse courante du tas� start_stack : adresse de début de la pile� Pgd : adresses du répertoire global des pages� rss : nombre de cadres alloués au processus� total_vm : taille de l’espace en nombre de pages� locked_vm : nombre de pages ne pouvant être mises en swap� …
� L’ensemble des descripteurs sont stockés dans une liste doublement chainées.� Ces structures sont stockées dans un slab
J.Boukhobza - Systèmes d'exploitation embarqués 65
Les régions mémoire� Une région mémoire est décrite par une structure ; vm_area_struct
� Quelques champs� vm_mm : pointeur vers la mm_struct décrivant la mémoire du
processus� vm_start : première adresse linéaire� vm_end : première adresse linéaire hors de la région� vm_next: pointeur vers la région suivante� vm_page_prot: autorisation d’accès pour les cadres de la région� vm_file: pointeur vers l’objet de fichier mappé (s’il y en a un)� vm_private_data: pointeur sur les données privées de la région� …
� Les régions d’un processus ne se recouvrent pas� Le noyau essaie de fusionner des régions contigües
J.Boukhobza - Systèmes d'exploitation embarqués 66

21/12/2017
34
Structures de données des régions
mémoire� Toutes les régions mémoire d’un processus sont dans une liste chaînée
� Ordre croissant d’adresse linéaire
� Le descripteur de mémoire d’un processus possède un champs mmap qui pointe vers la première région
� Le noyau doit fréquemment trouver la région correspondant à une adresse linéaire� Rapide avec une liste courte
� Mais quand même du O(n)
� Solution : utiliser des structures plus rapides, arbre red-black tree
� Arbres binaires de recherches
� Opérations en O(log(n))
J.Boukhobza - Systèmes d'exploitation embarqués 67
Source: Understanding the Linux kernel 3rd edition, O’Reilly ed, D.P. Bovet, M.Cesati
Les erreurs de page� Au niveau OS, la mémoire est gérée grâce à des pages
� Le contenu des pages peut être en mémoire physique (dans un cadre)
� Ou ailleurs (swap: ex disque)
� Quand un programme essaie d’utiliser une page non associée à un cadre, le CPU génère une erreur de page (Page FaultException)� Le contrôle est passé à l’OS qui doit gérer le problème
� Raisons possibles pour une erreur de page:� Le cadre a été swappé� Le programme essaie d’accéder à une page qui devrait lui appartenir
mais qui n’a pas été allouée (à cause d’une allocation différée)� Erreur de programmation, l’accès est interdit
J.Boukhobza - Systèmes d'exploitation embarqués 68

21/12/2017
35
Gestionnaire des défauts de page
J.Boukhobza - Systèmes d'exploitation embarqués 69
L’adresse appartient-t-
elle à l’espace
d’adressage du
processus?
Le type d’accès
correspond-t-il
aux autorisations
de la région
mémoire
L’exception a-t-
elle eu lieu en
mode utilisateur ?
Accès légal,
allocation d’un
nouveau cadre
Accès illégal,
envoi d’un signal
SIGSEGV
Bug noyau, tuer
le processus
Allocation différée� Linux pratique l’allocation différée� Les cadres ne sont alloués à un processus que lorsqu’il en a
vraiment besoin, pas quand il les demande� Motivations
� Un processus n’utilise jamais toutes les adresses mémoire dés le début
� Et parfois ne les utilise jamais toutes� Avec l’allocation différée: meilleure gestion de la RAM� Mais � latences !
� Génération (et donc gestion) d’erreurs de pages pour des adresses valides
� Mais pas trop: � principe de localité : les adresses référencées sont souvent proches,
donc peu de cadres sont effectivement utilisées en même temps
J.Boukhobza - Systèmes d'exploitation embarqués 70

21/12/2017
36
Allocation différée (2)� Et quand il n’y a plus de mémoire (ni RAM, ni swap…):
� Solution brutale : le noyau tue le processus qui fait la demande
� Solution moins brutale (pour le processus demandeur): on tue un autre processus…, mais lequel?
� Le choix est fait par OOM Killer (mm/oom_kill.c) ou Out Of Memory Killer
� Calcul d’un score pour chaque processus pour décider lequel éliminer
� Buts� Perdre le minimum de travail (mauvaise idée de tuer un processus batch qui a tourné
pendant 4h!)
� Récupérer une grande quantité de mémoire
� Ne pas tuer un processus important� Tournant en mode noyau
� Le processus 0 et 1 par exemple !!
� Priorité statique basse
� Tuer un minimum de processus (un seul!?)
J.Boukhobza - Systèmes d'exploitation embarqués 71
OOM killer� Informations disponibles
� /proc/<pid>/oom_adj
� Contrôle le comportement du OOM-Killer pour ce processus� Valeurs [-16:15] : valeur élevée augmente la probabilité d’être choisi … pour être tué!� Valeur -17 spéciale pour l’immunité
� /proc/<pid>/oom_score
� Score actuel du processus� Calcul du score
� Commence par la taille mémoire du processus (mm->total_vm)� La taille mémoire de chacun des fils est ajoutée� Plus le nice � plus le score �� Les processus super-utilisateurs ont leur score diminué� Une opération binaire est effectuée sur le score avec oom_adj
� Conclusion� On choisit un processus non privilégié, qui avec ses fils prend beaucoup de
mémoire et a été assez … gentil (nice)
J.Boukhobza - Systèmes d'exploitation embarqués 72

21/12/2017
37
Copy On Write (COW)� Implémentation naïve du fork()� ancienne versions de Linux
� Un fork provoque la création d’un nouveau processus fils� Avec un espace mémoire différent de celui du père:
� Allocation de nouveaux cadres pour les pages du fils� Initialisation de la table des pages du fils� Copie du contenu des pages du père dans celles du fils
� Très coûteux� Cycles CPUs� Pollution du cache
� Et souvent totalement inutile…. (pourquoi?)� Meilleure solution:
� Les cadres sont partagés par le père et le fils et interdits en écriture� Si tentative d’écriture, alors erreur de page, le noyau duplique le cadre� Utilisation du champs _count du descripteur de page (nb de proc
accédant à la page)
J.Boukhobza - Systèmes d'exploitation embarqués 73
Le swapping (va et vient)� L’OS utilise le disque comme extension de la mémoire� But
� Augmenter l’espace adressable par un processus� Avoir plus de RAM pour charger des processus
� Échange d’espace contre temps� 2 opérations
� Page Swap-Out : une page en mémoire est écrite sur le disque� Page Swap-In : une page sur le disque est ramenée en
mémoire physique� Transparent pour le programmeur/utilisateur� Les premiers Unix avaient du swap …
� Déplacement de l’espace complet d’un processus
J.Boukhobza - Systèmes d'exploitation embarqués 74

21/12/2017
38
Swapping sous Linux� Dans les Linux actuels, le swapping se fait au niveau de la
page� Utilisation de l’unité de pagination (drapeau Present dans
table des pages/ LRU)
� Pages devant être gérées par le swap :� Pages appartenant à de la mémoire « anonyme » (données,
pile ou tas en mode utilisateur) d’un processus� Page modifiée (dirty) utilisée dans un mapping privé de
processus� Pages appartenant à une mémoire partagée IPC
� Les autres pages sont soit au noyau (conception plus simple) soit pour un mapping de fichier non modifié
J.Boukhobza - Systèmes d'exploitation embarqués 75
Swapping sous Linux (2)� Distribution des pages dans la zone de swap
� La zone de swap (partition ou fichier) est divisée en slots (4ko)
� Le noyau essaie d’y mettre les pages consécutivement pour améliorer les performances
� Si plusieurs zones de swap, utilisation de priorités� Valeur entre 0 et 32 (priorité croissante)
� Recherche d’une zone de swap� Parcours des zones de la plus haute à la plus basse priorité� Dès qu’une zone est non pleine, utilisation� Si zones de même priorité � rotation (pour ne pas surcharger
une même zone)
J.Boukhobza - Systèmes d'exploitation embarqués 76

21/12/2017
39
Swapping sous Linux (3)� Utilisation d’un algorithme d’éviction de page
� Utilisation du drapeau Accessed des entrées de la table des pages
� Mise à 1 par le matériel x86 (remis à 0 par l’OS)� Quand mettre une page dans le swap ?
� Le noyau garde toujours quelques pages libres pour son propre usage� Évite les crash « bêtes» (l’algorithme de swap ne peut pas tourner par
manque de mémoire…)� Un thread noyau, kswapd, est activé quand le nombre de
cadres libres descend en dessous d’une certaine limite� Du swapping peut aussi démarrer quand le buddy ne peut
satisfaire une requête
J.Boukhobza - Systèmes d'exploitation embarqués 77
Choix d’un slot� Il faut essayer de stocker les pages contigus dans des slots
contigus� Algorithme:
� Toujours commencer au premier slot et avancer� Mais risque de swap-out lent
� Commencer au dernier slot alloué� Mais swap-in lent si la zone est globalement vide
� Linux a une approche hybride� Commence toujours au dernier slot alloué� Sauf si:
� Fin de la zone de swap� SWAPFILE_CLUSTER (=256) slots ont été alloués au début de la
zone depuis la dernière reprise � revenir au début
J.Boukhobza - Systèmes d'exploitation embarqués 78