data structure 3
TRANSCRIPT

Author: chuong3a, nick yahoo: chuong3a
I) Danh sách liên kết đơn...............................................................................................31. Tổ chức danh sách đơn..............................................................................................3II. Các thao tác cơ bản trên danh sách đơn....................................................................41.Chèn một phần tử vào danh sách:..............................................................................52. Tìm một phần tử trong danh sách đơn.......................................................................63. Hủy một phần tử khỏi danh sách...............................................................................6Hủy phần tử đầu xâu:....................................................................................................6Hủy một phần tử đứng sau phần tử q............................................................................6Hủy 1 phần tử có khoá k................................................................................................74. Thăm các nút trên danh sách.....................................................................................7Thuật toán xử lý các nút trên danh sách:.......................................................................7Thuật toán hủy toàn bộ danh sách:................................................................................71. Chèn một phần tử vào danh sách:.............................................................................8Cách 1: Chèn vào đầu danh sách...................................................................................8Cách 2: Chèn vào cuối danh sách..................................................................................8Cách 3 : Chèn vào danh sách sau một phần tử q...........................................................8Cách 4 : Chèn vào danh sách trước một phần tử q........................................................8III. Ngăn xếp (stack)......................................................................................................9Biểu diễn Stack dùng mảng...........................................................................................9Biểu diễn Stack dùng danh sách liên kết đơn..............................................................10Ứng dụng của Stack:...................................................................................................10IV. Hàng đợi ( Queue).................................................................................................10Biểu diễn dùng mảng:..................................................................................................11Bài 2: Một số phương pháp sắp xếp............................................................................122. Thuật toán sắp xếp nhanh - Quick Sort...................................................................12II. Radix sort...............................................................................................................14III. Sắp xếp cây - Heap sort.........................................................................................171.Ý tưởng:....................................................................................................................172. Cấu trúc dữ liệu Heap..............................................................................................19Ðịnh nghĩa Heap:.........................................................................................................19Heap có các tính chất sau :..........................................................................................19Giải thuật Heapsort :....................................................................................................19Ðánh giá giải thuật.......................................................................................................21Bài 3: BẢNG BĂM (HASH TABLE).........................................................................21Các khái niệm chính trên cấu trúc bảng băm:.............................................................221. Phép Băm (Hash Function).....................................................................................22Một hàm băm tốt phải thỏa mãn các điều kiện sau:....................................................222. Bảng Băm (Hash Table - Direct-address table)......................................................23Phần này sẽ trình bày các vấn đề chính:......................................................................23a. Mô tả dữ liệu............................................................................................................23
1

b. Các phép toán trên bảng băm..................................................................................24Các Bảng băm thông dụng:.........................................................................................24Ưu điểm của các Bảng băm:........................................................................................243. Các phương pháp tránh xảy ra đụng độ...................................................................252.4.1. Bảng băm với phương pháp kết nối trực tiếp (Direct chaining Method)..........25Bài 4: CÂY, CÂY NHỊ PHÂN, CÂY NHỊ PHÂN TÌM KIẾM.................................251. Cấu trúc cây.............................................................................................................251.1. Định nghĩa 1:........................................................................................................251.2. Một số khái niệm cơ bản......................................................................................251.3. Một số ví dụ về đối tượng các cấu trúc dạng cây.................................................262. Cây nhị phân............................................................................................................272.1 Định nghĩa.............................................................................................................272.2. Một số tính chất của cây nhị phân:.......................................................................272.3. Biểu diễn cây nhị phân T......................................................................................282.4. Các thao tác trên cây nhị phân..............................................................................28Thăm các nút trên cây theo thứ tự trước (Node-Left-Right).......................................28Thăm các nút trên cây theo thứ tự giữa (Left- Node-Right).......................................28Thăm các nút trên cây theo thứ tự sau (Left-Right-Node)..........................................292.5. Biểu diễn cây tổng quát bằng cây nhị phân..........................................................302.6. Một cách biểu diễn cây nhị phân khác.................................................................303. Cây nhị phân tìm kiếm............................................................................................303.1. Định nghĩa:...........................................................................................................303.2. Các thao tác trên cây.............................................................................................313.2.1. Thăm các nút trên cây........................................................................................313.2.2. Tìm một phần tử x trong cây.............................................................................313.3.3. Thêm một phần tử x vào cây.............................................................................312.4. Hủy một phần tử có khóa x..................................................................................322.5. Đánh Giá...............................................................................................................331. Cây nhị phân cân bằng hoàn toàn............................................................................341.1. Định nghĩa............................................................................................................341.2. Đánh giá................................................................................................................342. Cây nhị phân cân bằng (AVL Tree)........................................................................342.1. Định nghĩa:...........................................................................................................342.2. Lịch sử cây cân bằng (AVL Tree)........................................................................352.3. Chiều cao của cây AVL........................................................................................352.4. Cấu trúc dữ liệu cho cây AVL..............................................................................362.5. Đánh giá cây AVL................................................................................................373. Các thao tác cơ ban trên cây AVL...........................................................................373.1. Các trường hợp mất cân bằng...............................................................................37Trường hợp 1: cây T lệch về bên trái (có 3 khả năng)................................................37Trường hợp 2: cây T lệch về bên phải.........................................................................38Sau đây, ta sẽ khảo sát và giải quyết từng trường hợp nêu trên..................................383.2. Thêm một phần tử trên cây AVL:........................................................................403.3. Hủy một phần tử trên cây AVL:...........................................................................40BÀI 6: CÂY ĐỎ ĐEN.................................................................................................40
2

1. Giới thiệu.................................................................................................................41Độ phức tạp:................................................................................................................412. Định nghĩa cây đỏ đen.............................................................................................41Khai báo cấu trúc:........................................................................................................42Bổ đề:...........................................................................................................................423. Phép quay................................................................................................................424. Thêm node mới........................................................................................................434.1 Các phép lật màu trên đường đi xuống..................................................................434.2. Các phép quay khi chèn node...............................................................................445. Loại bỏ node............................................................................................................486. Tính hiệu quả của cây đỏ đen..................................................................................48BÀI 7: CÂY 2-3-4.......................................................................................................481. Giới thiệu về cây 2-3-4............................................................................................482. Tổ chức cây 2-3-4....................................................................................................503. Tìm kiếm.................................................................................................................504. Thêm vào.................................................................................................................51Tách nút.......................................................................................................................52Tách node gốc..............................................................................................................53Tách theo hướng đi xuống...........................................................................................545. Biến đổi cây 2-3-4 sang cây Đỏ-Đen......................................................................55
Bài 1: Danh sách liên kếtI) Danh sách liên kết đơn
1. Tổ chức danh sách đơn Danh sách liên kết bao gồm các phần tử. Mỗi phần tử của danh sách đơn là một cấu trúc chứa 2 thông tin : - Thành phần dữ liệu: lưu trữ các thông tin về bản thân phần tử . - Thành phần mối liên kết: lưu trữ địa chỉ của phần tử kế tiếp trong danh sách, hoặc lưu trữ giá trị NULL nếu là phần tử cuối danh sách.
Ta có định nghĩa tổng quát
typedef struct tagNode { Data Info; // Data là kiểu đã định nghĩa trước
Struct tagNode* pNext; // con trỏ chỉ đến cấu trúc node }NODE;
Ví dụ : Ðịnh nghĩa danh sách đơn lưu trữ hồ sơ sinh viên:
3

typedef struct SinhVien //Data{ char Ten[30];
int MaSV; }SV;
typedef struct SinhvienNode { SV Info;
struct SinhvienNode* pNext; }SVNode;
Các phần tử trong danh sách sẽ được cấp phát động. Biết phần tử đầu tiên ta sẽ truy xuất được các phần tử tiếp theo. Thường sử dụng con trỏ Head để lưu trữ địa chỉ đầu tiên của danh sách.
Ta có khai báo: NODE *pHead;
Để quản lý địa chỉ cuối cùng trong danh sách ta dùng con trỏ TAIL. Khai báo như sau:
NODE *pTail;
VD:
II. Các thao tác cơ bản trên danh sách đơn Giả sử có các định nghĩa: typedef struct tagNode {
Data Info; struct tagNode* pNext;
}NODE; typedef struct tagList {
NODE* pHead; NODE* pTail;
}LIST;
NODE *new_ele // giữ địa chỉ của một phần tử mới được tạo Data x; // lưu thông tin về một phần tử sẽ được tạo LIST lst; // lưu trữ địa chỉ đầu, địa chỉ cuối của danh sách liên kết
4

1.Chèn một phần tử vào danh sách: Có 3 loại thao tác chèn new_ele vào xâu: Cách 1: Chèn vào đầu danh sách
Thuật toán : Bắt đầu: Nếu Danh sách rỗng Thì
B11 : pHead = new_ele; B12 : pTail = pHead;
Ngược lại B21 : new_ele ->pNext = pHead; B22 : pHead = new_ele ;
Cài đặt:
Cách 2: Chèn vào cuối danh sách
Thuật toán : Bắt đầu :Nếu Danh sách rỗng thì
B11 : pHead = new_elelment; B12 : pTail = pHead;
Ngược lại B21 : pTail ->pNext = new_ele; B22 : pTail = new_ele ;
Cách 3 : Chèn vào danh sách sau một phần tử q
Thuật toán : Bắt đầu :
5

Nếu ( q != NULL) thì B1 : new_ele -> pNext = q->pNext; B2 : q->pNext = new_ele ;
Cài đặt : 2. Tìm một phần tử trong danh sách đơn Thuật toán : Bước 1:
p = pHead; //Cho p trỏ đến phần tử đầu danh sách Bước 2:
Trong khi (p != NULL) và (p->Info != k ) thực hiện: p:=p->pNext;// Cho p trỏ tới phần tử kế
Bước 3:Nếu p != NULL thì p trỏ tới phần tử cần tìm Ngược lại: không có phần tử cần tìm.
Cài đặt :
3. Hủy một phần tử khỏi danh sách Hủy phần tử đầu xâu:
Thuật toán : Bắt đầu:
Nếu (pHead != NULL) thì B1: p = pHead; // p là phần tử cần hủy B2:
B21 : pHead = pHead->pNext; // tách p ra khỏi xâu B22 : free(p); // Hủy biến động do p trỏ đến
B3: Nếu pHead=NULL thì pTail = NULL; //Xâu rỗng
Hủy một phần tử đứng sau phần tử q
Thuật toán : Bắt đầu: Nếu (q!= NULL) thì B1: p = q->Next; // p là phần tử cần hủy B2: Nếu (p != NULL) thì // q không phải là cuối xâu
6

B21 : q->Next = p->Next; // tách p ra khỏi xâu B22 : free(p); // Hủy biến động do p trỏ đến
Hủy 1 phần tử có khoá k Thuật toán : Bước 1:
Tìm phần tử p có khóa k và phần tử q đứng trước nó Bước 2:
Nếu (p!= NULL) thì // tìm thấy k Hủy p ra khỏi xâu tương tự hủy phần tử sau q; Ngược lại Báo không có k;
4. Thăm các nút trên danh sách- Ðếm các phần tử của danh sách, - Tìm tất cả các phần tử thoả điều kiện, - Huỷ toàn bộ danh sách (và giải phóng bộ nhớ)
Thuật toán xử lý các nút trên danh sách: Bước 1: p = pHead; //Cho p trỏ đến phần tử đầu danh sách Bước 2: Trong khi (Danh sách chưa hết) thực hiện B21 : Xử lý phần tử p; B22 : p: = p -> pNext; // Cho p trỏ tới phần tử kế
Thuật toán hủy toàn bộ danh sách: Bước 1: Trong khi (Danh sách chưa hết) thực hiện B11: p = pHead; pHead: = pHead -> pNext; // Cho p trỏ tới phần tử kế B12: Hủy p; Bước 2: Tail = NULL; //Bảo đảm tính nhất quán khi xâu rỗng II. Danh sách liên kết kép
Là danh sách mà mỗi phần tử trong danh sách có kết nối với 1 phần tử đứng trước và 1 phần tử đứng sau nó.
7

Khai báo:typedef struct tagDNode { Data Info;struct tagDNode* pPre; // trỏ đến phần tử đứng trướcstruct tagDNode* pNext; // trỏ đến phần tử đứng sau}DNODE;
typedef struct tagDList{DNODE* pHead; // trỏ đến phần tử đầu danh sáchDNODE* pTail; // trỏ đến phần tử cuối danh sách}DLIST;
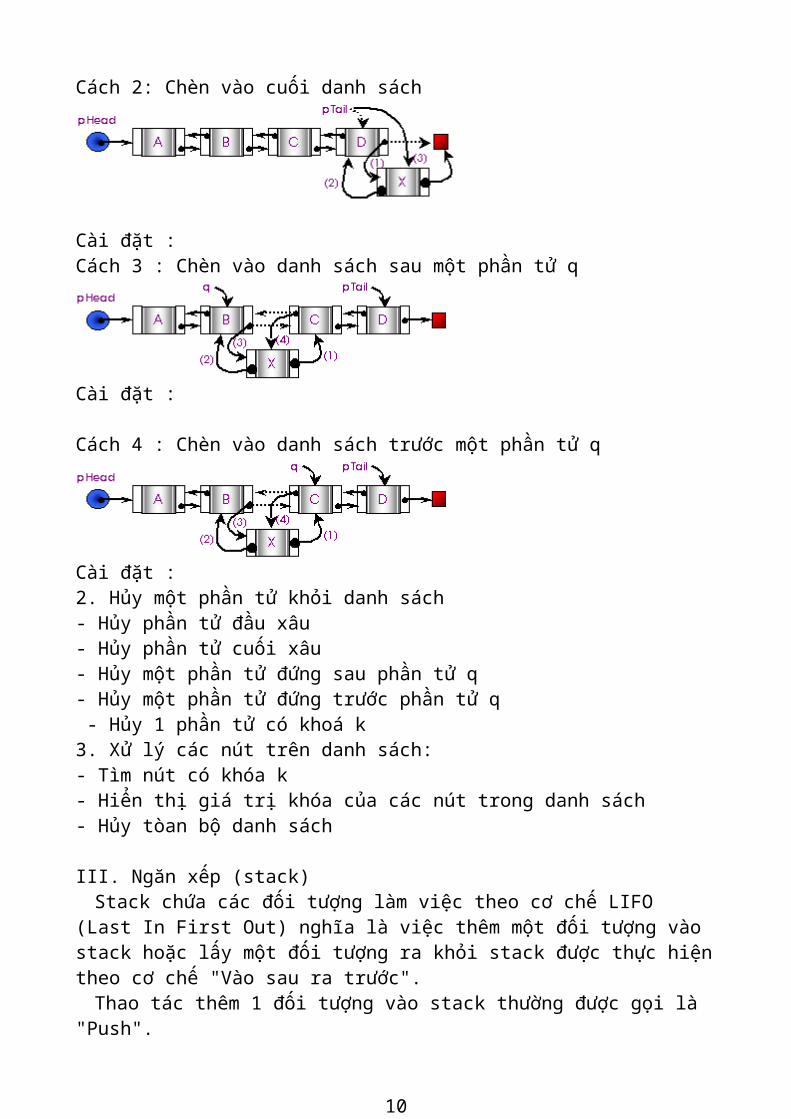
1. Chèn một phần tử vào danh sách:Có 4 loại thao tác chèn new_element vào danh sách:Cách 1: Chèn vào đầu danh sách
Cài đặt :Cách 2: Chèn vào cuối danh sách
Cài đặt : Cách 3 : Chèn vào danh sách sau một phần tử q
Cài đặt : Cách 4 : Chèn vào danh sách trước một phần tử q
8

Cài đặt : 2. Hủy một phần tử khỏi danh sách- Hủy phần tử đầu xâu- Hủy phần tử cuối xâu - Hủy một phần tử đứng sau phần tử q - Hủy một phần tử đứng trước phần tử q - Hủy 1 phần tử có khoá k 3. Xử lý các nút trên danh sách:- Tìm nút có khóa k- Hiển thị giá trị khóa của các nút trong danh sách- Hủy tòan bộ danh sách
III. Ngăn xếp (stack)Stack chứa các đối tượng làm việc theo cơ chế LIFO (Last In First Out) nghĩa là
việc thêm một đối tượng vào stack hoặc lấy một đối tượng ra khỏi stack được thực hiện theo cơ chế "Vào sau ra trước".
Thao tác thêm 1 đối tượng vào stack thường được gọi là "Push". Thao tác lấy 1 đối tượng ra khỏi stack gọi là "Pop".Trong tin học, CTDL stack có nhiều ứng dụng: khử đệ qui, lưu vết các quá trình
tìm kiếm theo chiều sâu và quay lui, ứng dụng trong các bài toán tính toán biểu thức, .
Một hình ảnh một stack
Các thao tác Push(o): Thêm đối tượng o vào đầu stackPop(): Lấy đối tượng ở đỉnh stack ra khỏi stack và trả về giá trị của nó. Nếu stack
rỗng thì lỗi sẽ xảy ra.isEmpty(): Kiểm tra xem stack có rỗng không.Top(): Trả về giá trị của phần tử nằm ở đầu stack mà không hủy nó khỏi stack.
Nếu stack rỗng thì lỗi sẽ xảy ra.
Biểu diễn Stack dùng mảng
9
Ta có thể tạo một stack bằng cách khai báo một mảng 1 chiều với kích thước tối đa là N (ví dụ, N có thể bằng 1000).
VD:
Tạo stack S và quản lý đỉnh stack bằng biến t – chỉ số của phần từ trên cùng trong stack:
Data S [N];int t;
Biểu diễn Stack dùng danh sách liên kết đơnVD:
LIST S;Các thao tác:Tạo Stack S rỗng (S.pHead=l.pTail= NULL sẽ tạo ra một Stack S rỗng)Kiểm tra stack rỗng: int IsEmpty(LIST &S)Thêm một phần tử p vào stack S:void Push(LIST &S, Data x)Trích huỷ phần tử ở đỉnh stack S: Data Pop(LIST &S)Xem thông tin của phần tử ở đỉnh stack S: Data Top(LIST &S)
Ứng dụng của Stack:Biến đổi biểu thức:
Dạng trung tốa+ba*ba*(b+c)-d/e
Dạng hậu tốab+ab*abc+*de-/
Tính giá trị của biểu thức ở dạng hậu tố.
IV. Hàng đợi ( Queue)Hàng đợi chứa các đối tượng làm việc theo cơ chế FIFO (First In First Out) nghĩa
là việc thêm một đối tượng vào hàng đợi hoặc lấy một đối tượng ra khỏi hàng đợi được thực hiện theo cơ chế "Vào trước ra trước".
Hàng đợi
Các thao tác:EnQueue(o): Thêm đối tượng o vào cuối hàng đợi
10

DeQueue(): Lấy đối tượng ở đầu queue ra khỏi hàng đợi và trả về giá trị của nó. Nếu hàng đợi rỗng thì lỗi sẽ xảy ra.
IsEmpty(): Kiểm tra xem hàng đợi có rỗng không.Front(): Trả về giá trị của phần tử nằm ở đầu hàng đợi mà không hủy nó. Nếu
hàng đợi rỗng thì lỗi sẽ xảy ra.
Biểu diễn dùng mảng:Ta có thể tạo một hàng đợi bằng cách sử dụng một mảng 1 chiều với kích thước tối
đa là N (ví dụ, N có thể bằng 1000) theo kiểu xoay vòng (coi phần tử an-1 kề với phần tử a0).
Ta ký hiệu nó là NULLDATA như ở những phần trước.
Trạng thái hàng đợi lúc bình thường:
Q – biến hàng đợi, f quản lý đầu hàng đợi, r quản lý phần tử cuối hàng đợi.Trạng thái hàng đợi lúc xoay vòng (mảng rỗng ở giữa):
Câu hỏi đặt ra: khi giá trị f = r cho ta điều gì ? Ta thấy rằng, lúc này hàng đợi chỉ có thể ở một trong hai trạng thái là rỗng hoặc đầy.
Hàng đợi có thể được khai báo cụ thể như sau:Data Q[N] ;int f, r;
Dùng danh sách liên kếtTa có thể tạo một hàng đợi bằng cách sử dụng một danh sách liên kết đơn.LIST Q;
Các thao tác:Tạo hàng đợi rỗng: Lệnh Q.pHead = Q.pTail = NULL sẽ tạo ra một hàng đợi rỗng.-Kiểm tra hàng đợi rỗng :
int IsEmpty(LIST Q)- Thêm một phần tử p vào cuối hàng đợi :
void EnQueue(LIST Q, Data x)- Trích/Hủy phần tử ở đầu hàng đợi:
Data DeQueue(LIST Q)- Xem thông tin của phần tử ở đầu hàng đợi :
11

Data Front(LIST Q)Ứng dụng của hàng đợi
- Bài toán quản lý tồn kho- Bài toán xử lý các lệnh trong máy tính điện tử.
Bài 2: Một số phương pháp sắp xếp
1. Thuật toán sắp xếp chọn – Selection Sort Algorithm
2. Thuật toán sắp xếp nhanh - Quick SortÝ tưởng:
Có dãy số: a1, a2, ..., an Giải thuật QuickSort làm việc như sau:
Chọn x là một phần tử làm biên: thường chọn là phần tử ở giữa dãy số.Phân hoạch dãy thành 3 dãy con
1. ak <= x , với k = 1..i 2. ak = x , với k = i..j 3. ak > =x , với k = j..N
Ak <= x Ak = x Ak >= x
Nếu số phần tử trong dãy con 1, 3 lớn hơn 1 thì ta tiếp tục phân hoạch dãy 1, 3 theo phương pháp trên. Ngược lại thì: dừng.
Giải thuật phân hoạch dãy am, am+1, ., an thành 2 dãy con: Step 1 : Chọn tùy ý một phần tử a[k] trong dãy là giá trị biên, m <= k <=n:
x = a[k]; i = m; j = n; Step 2 : Phát hiện và hiệu chỉnh cặp phần tử a[i], a[j] nằm sai vị trí:
Step 2a : While (a[i] < x) i++; Step 2b : While (a[j] > x) j--; Step 2c : If i <= j
// a[i] >= x; a[j] <= x mà a[j] đứng sau a[i] Hoán vị (a[i], a[j]); i++; j--;
Step 3: If i <= j: Return step 2. //chưa xét hết mảng Ngược lại: Dừng
Có thể phát biểu giải thuật sắp xếp QuickSort một cách đệ qui như sau : Bước 1 : Phân hoạch dãy am … an thành các dãy con :
- Dãy con 1:
12

- Dãy con 2: - Dãy con 3:
Bước 2 : Nếu ( m < j ) // dãy con 1 có nhiều hơn 1 phần tử Phân hoạch dãy am.. aj Nếu ( i < n ) // dãy con 3 có nhiều hơn 1 phần tử Phân hoạch dãy ai.. ar
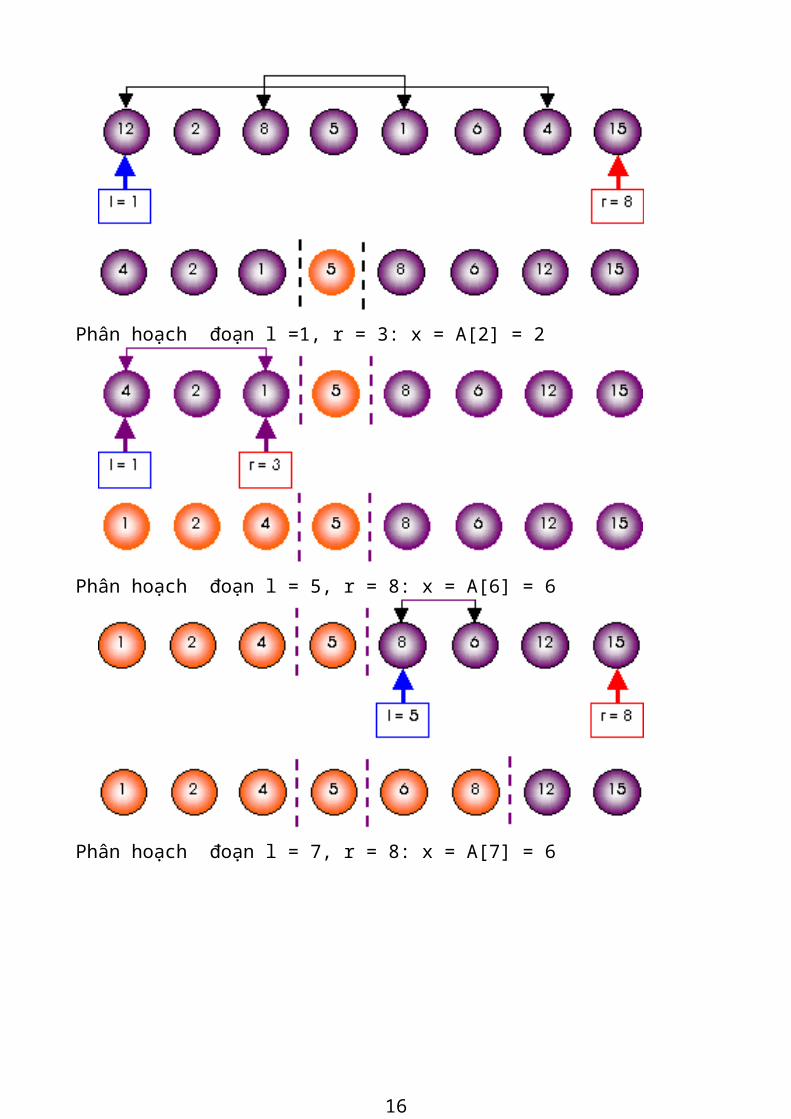
Ví dụ: Cho dãy số a:
12 2 8 5 1 6 4 15 Phân hoạch đoạn l = 1, r = 8: x = A[4] =5
Phân hoạch đoạn l =1, r = 3: x = A[2] = 2
Phân hoạch đoạn l = 5, r = 8: x = A[6] = 6
13

Phân hoạch đoạn l = 7, r = 8: x = A[7] = 6
Dừng. Cài đặt
Ðánh giá giải thuật Hiệu quả thực hiện của giải thuật QuickSort phụ thuộc vào việc chọn giá trị mốc. Trường hợp tốt nhất xảy ra nếu mỗi lần phân hoạch đều chọn được phần tử median
(phần tử lớn hơn (hay bằng) nửa số phần tử, và nhỏ hơn (hay bằng) nửa số phần tử còn lại) làm mốc, khi đó dãy được phân chia thành 2 phần bằng nhau và cần log2(n) bước phân hoạch thì sắp xếp xong.
Nhưng nếu mỗi bước phân hoạch phần tử được chọn có giá trị cực đại (hay cực tiểu) là mốc, dãy sẽ bị phân chia thành 2 phần không đều: một phần chỉ có 1 phần tử, phần còn lại gồm (n-1) phần tử, do vậy cần thực hiện n bước phân hoạch mới sắp xếp xong. Ta có bảng tổng kết
Trường hợp Ðộ phức tạp Tốt nhất n*log(n) Xấu nhất n2
II. Radix sort
Ý tưởng:
14

Khác với các thuật toán trước, Radix sort là một thuật toán tiếp cận theo một hướng hoàn toàn khác. Nếu như trong các thuật toán khác, cơ sở để sắp xếp luôn là việc so sánh giá trị của 2 phần tử thì Radix sort lại dựa trên nguyên tắc phân loại thư của bưu điện.
Ta biết rằng, để đưa một khối lượng thư lớn đến tay người nhận ở nhiều địa phương khác nhau, bưu điện thường tổ chức một hệ thống phân loại thư phân cấp:
Trước tiên, các thư đến cùng một tỉnh, thành phố sẽ được sắp chung vào một lô để gửi đến tỉnh thành tương ứng.
Bưu điện các tỉnh thành này lại thực hiện công việc tương tự. Các thư đến cùng một quận, huyện sẽ được xếp vào chung một lô và gửi đến quận, huyện tương ứng. Cứ như vậy, các bức thư sẽ được trao đến tay người nhận một cách có hệ thông mà công việc sằp xếp thư không quá nặng nhọc.
Mô phỏng lại qui trình trên, để sắp xếp dãy a1, a2, ..., an, giải thuật Radix Sort thực hiện như sau:
Trước tiên, ta có thể giả sử mỗi phần tử ai trong dãy: a1, a2, ..., an là một số nguyên có tối đa m chữ số.
Ta phân loại các phần tử lần lượt theo các chữ số hàng đơn vị, hàng chục, hàng trăm, . tương tự việc phân loại thư theo tỉnh thành, quận huyện, phường xã, ..
Các bước thực hiện thuật toán như sau: Bước 1 : // k cho biết chữ số dùng để phân loại hiện hành
k = 0; // k = 0: hàng đơn vị; k = 1:hàng chục; Bước 2 : //Tạo các lô chứa các loại phần tử khác nhau
Khởi tạo 10 lô B0, B1, ., B9 rỗng; Bước 3 :
For i = 1 .. n do Ðặt ai vào lô Bt với t = chữ số thứ k của ai;
Bước 4 : Nối B0, B1, ., B9 lại (theo đúng trình tự) thành a.
Bước 5 : k = k+1; Nếu k < m thì trở lại bước 2. Ngược lại: Dừng
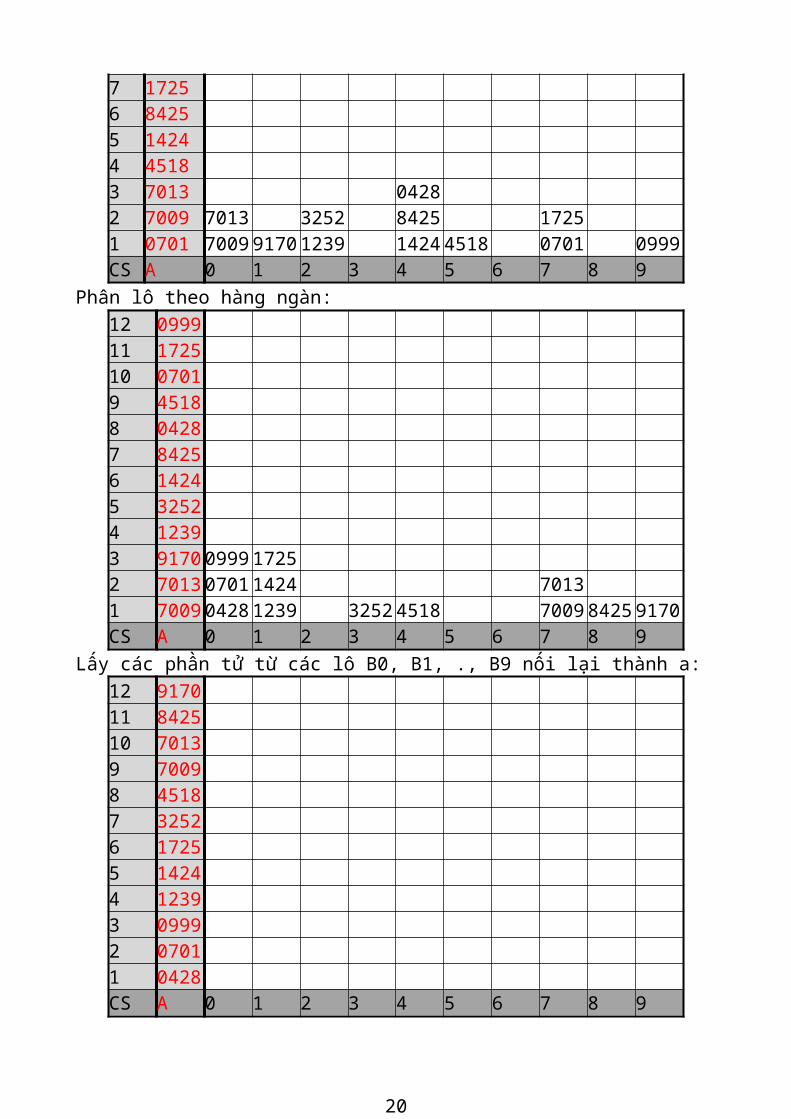
Ví dụ Cho dãy số a: 701 1725 999 9170 3252 4518 7009 1424 428 1239 8425 7013 Phân lô theo hàng đơn vị:
12 0701 11 1725 10 0999 9 9170 8 3252 7 4518
15
6 7009 5 1424 4 0428 3 1239 0999 2 8425 1725 4518 7009 1 7013 9170 0701 3252 7013 1424 8425 0428 1239 CS A 0 1 2 3 4 5 6 7 8 9 Các lô B dùng để phân loại
Phân lô theo hàng chục: 12 0999 11 7009 10 1239 9 4518 8 0428 7 1725 6 8425 5 1424 4 7013 0428 3 3252 1725 2 0701 7009 4518 8425 1 9170 0701 7013 1424 1239 3252 9170 0999 CS A 0 1 2 3 4 5 6 7 8 9
Phân lô theo hàng trăm: 12 0999 11 9170 10 3252 9 1239 8 0428 7 1725 6 8425 5 1424 4 4518 3 7013 0428 2 7009 7013 3252 8425 1725 1 0701 7009 9170 1239 1424 4518 0701 0999 CS A 0 1 2 3 4 5 6 7 8 9
Phân lô theo hàng ngàn: 12 0999 11 1725 10 0701 9 4518 8 0428
16

7 8425 6 1424 5 3252 4 1239 3 9170 0999 1725 2 7013 0701 1424 7013 1 7009 0428 1239 3252 4518 7009 8425 9170 CS A 0 1 2 3 4 5 6 7 8 9
Lấy các phần tử từ các lô B0, B1, ., B9 nối lại thành a: 12 9170 11 8425 10 7013 9 7009 8 4518 7 3252 6 1725 5 1424 4 1239 3 0999 2 0701 1 0428 CS A 0 1 2 3 4 5 6 7 8 9
Ðánh giá giải thuật Với một dãy n số, mỗi số có tối đa m chữ số, thuật toán thực hiện m lần các thao
tác phân lô và ghép lô. Trong thao tác phân lô, mỗi phần tử chỉ được xét đúng một lần, khi ghép cũng vậy. Như vậy, chi phí cho việc thực hiện thuật toán hiển nhiên là O(2mn) = O(n). NHẬN XÉT Thuật toán không có trường hợp xấu nhất và tốt nhất. Mọi dãy số đều được sắp với chi phí như nhau nếu chúng có cùng số phần tử và các khóa có cùng chiều dài. Thuật toán cài đặt thuận tiện với các mảng có khóa sắp xếp là chuỗi (ký tự hay số) hơn là khóa số như trong ví dụ do tránh được chi phí lấy các chữ số của từng số. Tuy nhiên, số lượng lô nhiều (10 khi dùng số thập phân, 26 khi dùng chuỗi ký tự tiếng anh, ...) nhưng tổng kích thước của tất cả các lô chỉ bằng dãy ban đầu nên ta không thể dùng mảng để biểu diễn B (B0->B9). Như vậy, phải dùng cấu trúc dữ liệu động để biểu diễn B => Radix sort rất thích hợp cho sắp xếp trên danh sách liên kết.
Khi sắp các dãy không nhiều phần tử, thuật toán Radix sort sẽ mất ưu thế so với các thuật toán khác.
III. Sắp xếp cây - Heap sort1.Ý tưởng:
Nhận xét: Khi tìm phần tử nhỏ nhất ở bước i, phương pháp sắp xếp chọn trực tiếp không tận dụng được các thông tin đã có được do các phép so sánh ở bước i-1.
17

Vì lý do trên người ta tìm cách xây dựng một thuật toán sắp xếp có thể khắc phục nhược điểm này.
Mấu chôt để giải quyết vấn đề vừa nêu là phải tìm ra được một cấu trúc dữ liệu cho phép tích lũy các thông tin về sự so sánh giá trị các phần tử trong qua trình sắp xếp.
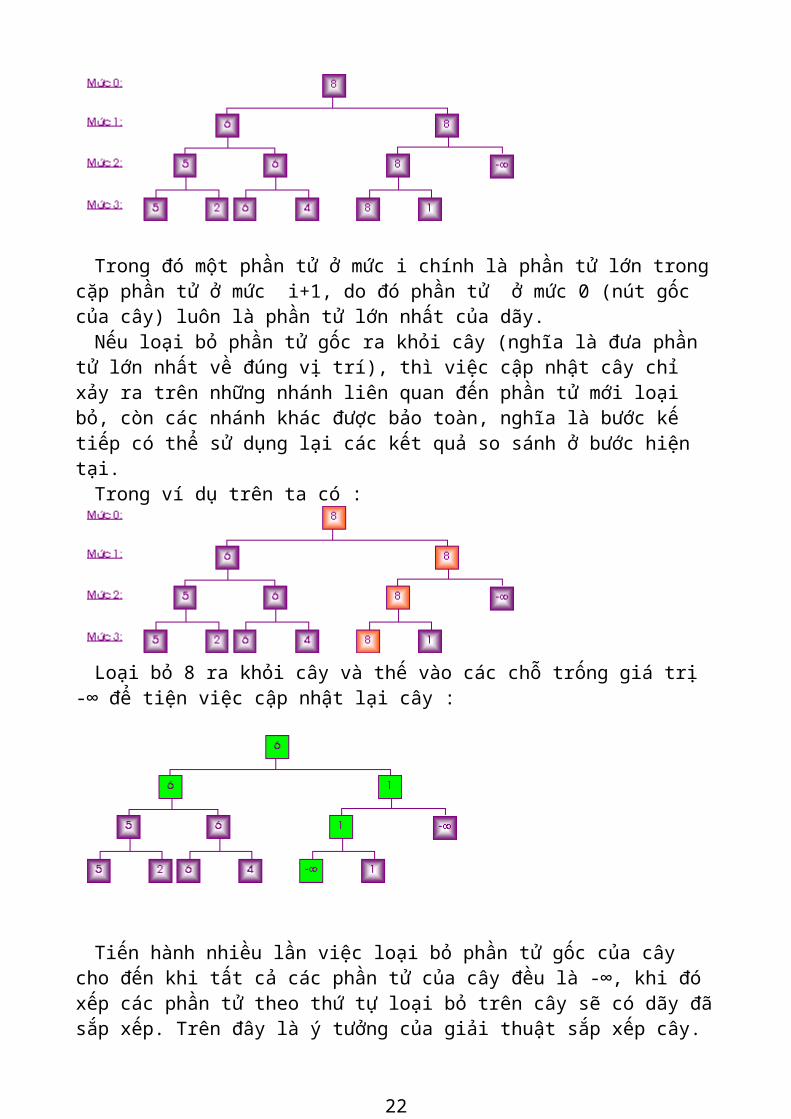
Giả sử dữ liệu cần sắp xếp là dãy số : 5 2 6 4 8 1 được bố trí theo quan hệ so sánh và tạo thành sơ đồ dạng cây như sau :
Trong đó một phần tử ở mức i chính là phần tử lớn trong cặp phần tử ở mức i+1, do đó phần tử ở mức 0 (nút gốc của cây) luôn là phần tử lớn nhất của dãy.
Nếu loại bỏ phần tử gốc ra khỏi cây (nghĩa là đưa phần tử lớn nhất về đúng vị trí), thì việc cập nhật cây chỉ xảy ra trên những nhánh liên quan đến phần tử mới loại bỏ, còn các nhánh khác được bảo toàn, nghĩa là bước kế tiếp có thể sử dụng lại các kết quả so sánh ở bước hiện tại.
Trong ví dụ trên ta có :
Loại bỏ 8 ra khỏi cây và thế vào các chỗ trống giá trị -∞ để tiện việc cập nhật lại
cây :
Tiến hành nhiều lần việc loại bỏ phần tử gốc của cây cho đến khi tất cả các phần tử của cây đều là -∞, khi đó xếp các phần tử theo thứ tự loại bỏ trên cây sẽ có dãy đã sắp xếp. Trên đây là ý tưởng của giải thuật sắp xếp cây.
18

2. Cấu trúc dữ liệu HeapTuy nhiên, để cài đặt thuật toán này một cách hiệu quả, cần phải tổ chức một cấu
trúc lưu trữ dữ liệu có khả năng thể hiện được quan hệ của các phần tử trong cây với n ô nhớ thay vì 2n-1 như trong ví dụ.
Khái niệm heap và phương pháp sắp xếp Heapsort do J.Williams đề xuất đã giải quyết được các khó khăn trên.Ðịnh nghĩa Heap:
Giả sử xét trường hợp sắp xếp tăng dần, khi đó Heap được định nghĩa là một dãy các phần tử ap, a2 ,... , aq thoả các quan hệ sau với mọi i thuộc [p, q]:1/. ai >= a2i
2/.ai >= a2i+1 {(ai , a2i), (ai ,a2i+1) là các cặp phần tử liên đới }
Heap có các tính chất sau :Tính chất 1 : Nếu ap , a2 ,... , aq là một heap thì khi cắt bỏ một số phần tử ở hai đầu
của heap, dãy con còn lại vẫn là một heap. Tính chất 2 : Nếu ap , a2 ,... , aq là một heap thì phần tử a1 (đầu heap) luôn là
phần tử lớn nhất trong heap. Tính chất 3 : Mọi dãy ap , a2 ,... , aq, dãy con aj, aj+1,…, ar tạo thành một heap với
j=(q div 2 +1).
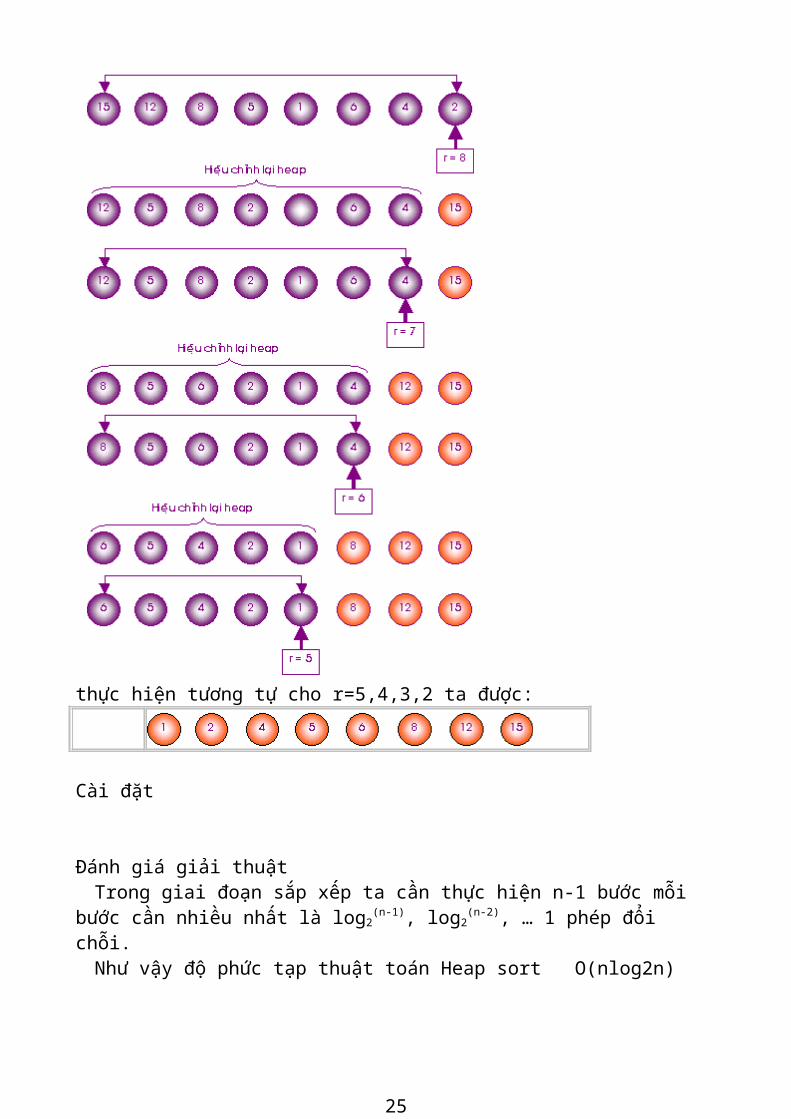
Giải thuật Heapsort :Giải thuật Heapsort trải qua 2 giai đoạn :Giai đoạn 1: Hiệu chỉnh dãy số ban đầu thành heap; Giai đoạn 2: Sắp xếp dãy số dựa trên heap:
Bước 1: Ðưa phần tử lớn nhất về vị trí đúng ở cuối dãy: r = n; Hoánvị (a1 , ar );
Bước 2: Loại bỏ phần tử lớn nhất ra khỏi heap: r = r-1; Hiệu chỉnh phần còn lại của dãy từ a1 , a2 ... ar thành một heap.
Bước 3: Nếu r > 1 (heap còn phần tử ): Lặp lại Bước 2Ngược lại : Dừng
Dựa trên tính chất 3, ta có thể thực hiện giai đoạn 1 bằng cách bắt đầu từ heap mặc nhiên an/2 + 1 , an/2 + 2 ... an, sau đó thêm dần các phần tử an/2, an/2-1, ., a1 ta sẽ nhân được heap theo mong muốn. Ví dụ Cho dãy số a:12 2 8 5 1 6 4 15Giai đoạn 1: hiệu chỉnh dãy ban đầu thành heap
19
Giai đoạn 2: Sắp xếp dãy số dựa trên heap :
20

thực hiện tương tự cho r=5,4,3,2 ta được:
Cài đặt
Ðánh giá giải thuật Trong giai đoạn sắp xếp ta cần thực hiện n-1 bước mỗi bước cần nhiều nhất là
log2(n-1), log2
(n-2), … 1 phép đổi chỗi.Như vậy độ phức tạp thuật toán Heap sort O(nlog2n)
Bài 3: BẢNG BĂM (HASH TABLE)
21
- Phép băm được đề xuất và hiện thực trên máy tính từ những năm 50 của thế kỷ 20. Nó dựa trên ý tưởng: biến đổi giá trị khóa thành một số (xử lý băm) và sử dụng số này để đánh chỉ số cho bảng dữ liệu.
- Các phép toán trên các cấu trúc dữ liệu như danh sách, cây nhị phân,… phần lớn được thực hiện bằng cách so sánh các phần tử của cấu trúc, do vậy thời gian truy xuất không nhanh và phụ thuộc vào kích thước của cấu trúc.
- Trong bài này chúng ta sẽ khảo sát một cấu trúc dữ liệu mới được gọi là bảng băm (hash table). Các phép toán trên bảng băm sẽ giúp hạn chế số lần so sánh, và vì vậy sẽ giảm thiểu được thời gian truy xuất. Độ phức tạp của các phép toán trên bảng băm thường có bậc là 0(1) và không phụ thuộc vào kích thước của bảng băm.
- Thông thường bảng băm được sử dụng khi cần xử lý các bài toán có dữ liệu lớn và được lưu trữ ở bộ nhớ ngoài.
1. Phép Băm (Hash Function)Định nghĩa:
- Trong hầu hết các ứng dụng, khoá được dùng như một phương thức để truy xuất dữ liệu. Hàm băm được dùng để ánh xạ giá trị khóa vào một dãy các địa chỉ của bảng băm.
- Khóa có thể là dạng số hay số dạng chuỗi. Giả sử có 2 khóa phân biệt ki và kj nếu h(ki) = h(kj) thì hàm băm bị đụng độ.Một hàm băm tốt phải thỏa mãn các điều kiện sau:
- Tính toán nhanh.- Các khoá được phân bố đều trong bảng.- Ít xảy ra đụng độ.- Xử lý được các loại khóa có kiểu dữ liệu khác nhau.
Hàm Băm sử dụng Phương pháp chiaDùng số dư: h(k) = k mod m
k là khoá, m là kích thước của bảng.Như vậy h(k) sẽ nhận: 0, 1, 2,…, m-1.Việc chọn m sẽ ảnh hưởng đến h(k).
- Nếu chọn m = 2p thì giá trị của h(k) sẽ là p bit cuối cùng của k trong biểu diễn nhị phân.
- Nếu chọn m = 10p thì giá trị của h(k) sẽ là p chữ số cuối cùng trong biểu diễn thập phân của k.
- Trong 2 ví dụ trên giá trị h(k) không phụ thuộc đầy đủ vào khóa k mà chỉ phụ thuộc vào p bít (p chữ số) cuối cùng trong khóa k. Tốt nhất ta nên chọn m sao cho h(k) phụ thuộc đầy đủ và khóa k. Thông thường chọn m là số nguyên tố.VD: Bảng băm có 4000 mục, chọn m = 4093Hàm Băm sử dụng Phương pháp nhân
h(k) = m*(k*A mod 1) k là khóa, m là kích thước bảng, A là hằng số: 0 < A < 1
Chọn m và ATheo Knuth thì chọn A bằng giá trị sau:A = ( -1)/2=0.6180339887…m thường chọn m = 2p
22

VD: k = 123456; m = 10000H(k) = 10000 (123456* 0.6180339887 mod 1) H(k) = 10000 (76300.0041089472 mod 1) H(k) = 10000 (0.0041089472) H(k) = 41Phép băm phổ quát (unisersal hashing) Việc chọn hàm băm không tốt có thể dẫn đến xác suất đụng độ cao.Giải pháp:
- Lựa chọn hàm băm h ngẫu nhiên.- Khởi tạo một tập các hàm băm H phổ quát và từ đó h được chọn ngẫu nhiên.Cho H là một tập hợp hữu hạn các hàm băm: ánh xạ các khóa k từ tập khóa U vào
miền giá trị { 0, 1, 2,…, m-1 }. Tập H là phổ quát nếu với mọi f H và 2 khoá phân biệt k1, k2 ta có xác suất: Pr{ f(k1) = f(k2) } <= 1/m
2. Bảng Băm (Hash Table - Direct-address table)Phần này sẽ trình bày các vấn đề chính:
- Mô tả cấu trúc bảng băm tổng quát (thông qua hàm băm, tập khóa, tập địa chỉ)- Các phép toán trên bảng băm như thêm phần tử (insert), loại bỏ (remove), tìm
kiếm (search), …Giả sử
· K: tập các khoá (set of keys)· M: tập các dịa chỉ (set of addresses).· h(k): hàm băm dùng để ánh xạ một khoá k từ tập các khoá K thành một địa chỉ
tương ứng trong tập M. Các phép toán trên bảng băm
· Khởi tạo (Initialize): Khởi tạo bảng băm, cấp phát vùng nhớ hay qui định số phần tử (kích thước) của bảng băm.
· Kiểm tra rỗng (Empty): kiểm tra bảng băm có rỗng hay không?· Lấy kích thước của bảng băm (Size): Cho biết số phần tử hiện có trong bảng
băm.· Tìm kiếm (Search): Tìm kiếm một phần tử trong bảng băm theo khoá k chỉ định
trước.· Thêm mới phần tử (Insert): Thêm một phần tử vào bảng băm. · Loại bỏ (Remove): Loại bỏ một phần tử ra khỏi bảng băm.· Sao chép (Copy): Tạo một bảng băm mới tử một bảng băm cũ đã có.· Xử lý các khóa trong bảng băm (Traverse): xử lý toàn bộ khóa trong bảng băm
theo thứ tự địa chỉ từ nhỏ đến lớn.Các Bảng băm thông dụng:
- Với mỗi loại bảng băm cần thiết phải xác định tập khóa K, xác định tập địa chỉ M và xây dựng hàm băm h cho phù hợp.
*) Bảng băm với phương pháp kết nối trực tiếp: mỗi địa chỉ của bảng băm tương ứng một danh sách liên kết. Các phần tử bị xung đột được kết nối với nhau trên một danh sách liên kết.
*) Bảng băm với phương pháp kết nối hợp nhất: bảng băm này được cài đặt bằng danh sách kề, mỗi phần tử có hai trường: trường key chứa khóa của phần tử và trường
23

next chỉ phần tử kế bị xung đột. Các phần tử bị xung đột được kết nối nhau qua trường kết nối next.
*) Bảng băm với phương pháp dò tuần tự: Khi thêm phần tử vào bảng băm nếu bị đụng độ thì sẽ dò địa chỉ kế tiếp… cho đến khi gặp địa chỉ trống đầu tiên thì thêm phần tử vào địa chỉ này.
*) Bảng băm với phương pháp dò bậc hai: ví dụ khi thêm phần tử vào bảng băm này, nếu băm lần đầu bị xung đột thì sẽ dò đến địa chi mới, ở lần dò thứ i sẽ xét phần tử cách i2 cho đến khi gặp địa chỉ trống đầu tiên thì thêm phần tử vào địa chỉ này.
*) Bảng băm với phương pháp băm kép: bảng băm này dùng hai hàm băm khác nhau, băm lần đầu với hàm băm thứ nhất nếu bị xung đột thì xét địa chỉ khác bằng hàm băm thứ hai.
Ưu điểm của các Bảng băm:Bảng băm là một cấu trúc dung hòa giữa thời gian truy xuất và dung lượng bộ nhớ:
- Nếu không có sự giới hạn về bộ nhớ thì chúng ta có thể xây dựng bảng băm với mỗi khóa ứng với một địa chỉ với mong muốn thời gian truy xuất tức thời.
- Nếu dung lượng bộ nhớ có giới hạn thì tổ chức một số khóa có cùng địa chỉ, khi đó tốc độ truy xuất sẽ giảm.
- Bảng băm dược ứng dụng nhiều trong thực tế, rất thích hợp khi tổ chức dữ liệu có kích thước lớn và được lưu trữ ở bộ nhớ ngoài.
3. Các phương pháp tránh xảy ra đụng độ2.4.1. Bảng băm với phương pháp kết nối trực tiếp (Direct chaining Method)
- Bảng băm được cài đặt bằng các danh sách liên kết, các phần tử trên bảng băm được “băm” thành M danh sách liên kết (từ danh sách 0 đến danh sách M–1). Các phần tử bị xung đột tại địa chỉ i được kết nối trực tiếp với nhau qua danh sách liên kết i. Chẳng hạn, với M = 10, các phần tử có hàng đơn vị là 9 sẽ được băm vào danh sách liên kết i = 9.
- Khi thêm một phần tử có khóa k vào bảng băm, hàm băm f(k) sẽ xác định địa chỉ i trong khoảng từ 0 đến M-1 ứng với danh sách liên kết i mà phần tử này sẽ được thêm vào.
- Khi tìm một phần tử có khóa k vào bảng băm, hàm băm f(k) cũng sẽ xác định địa chỉ i trong khoảng từ 0 đến M-1 ứng với danh sách liên kết i có thể chứa phần tử này. Như vậy, việc tìm kiếm phần tử trên bảng băm sẽ được qui về bài toán tìm kiếm một phần tử trên danh sách liên kết. Để minh họa ta xét bảng băm có cấu trúc như sau:
- Tập khóa K: tập số tự nhiên- Tập địa chỉ M: gồm 10 địa chỉ M = { 0, 1, …, 9 } - Hàm băm h(key) = key % 10.
Bài 4: CÂY, CÂY NHỊ PHÂN, CÂY NHỊ PHÂN TÌM KIẾM
1. Cấu trúc cây1.1. Định nghĩa 1:
24
Cây là một tập hợp T các phần tử (nút trên cây) trong đó có 1 nút đặc biệt T0 được gọi là gốc, các nút còn khác được chia thành những tập rời nhau T1, T2 , ... , Tn theo quan hệ phân cấp trong đó Ti cũng là một cây. Nút ở cấp i sẽ quản lý một số nút ở cấp i+1. Quan hệ này người ta còn gọi là quan hệ cha-con. 1.2. Một số khái niệm cơ bản - Bậc của một nút: là số cây con của nút đó . - Bậc của một cây: là bậc lớn nhất của các nút trong cây. Cây có bậc n thì gọi là cây n-phân. - Nút gốc: nút không có nút cha. - Nút lá: nút có bậc bằng 0 . - Nút nhánh: nút có bậc khác 0 và không phải là gốc . - Mức của một nút: Mức (T0 ) = 1. Gọi T1, T2, T3, ... , Tn là các cây con của T0 Mức (T1) = Mức (T2) = ... = Mức (Tn) = Mức (T0) + 1. - Độ dài đường đi từ gốc đến nút x: là số nhánh cần đi qua kể từ gốc đến x. - Chiều cao h của cây: mức lớn nhất của các nút lá.
1.3. Một số ví dụ về đối tượng các cấu trúc dạng cây - Sơ đồ tổ chức của một doanh nghiệp- Sơ đồ tổ chức cây thư mục
25

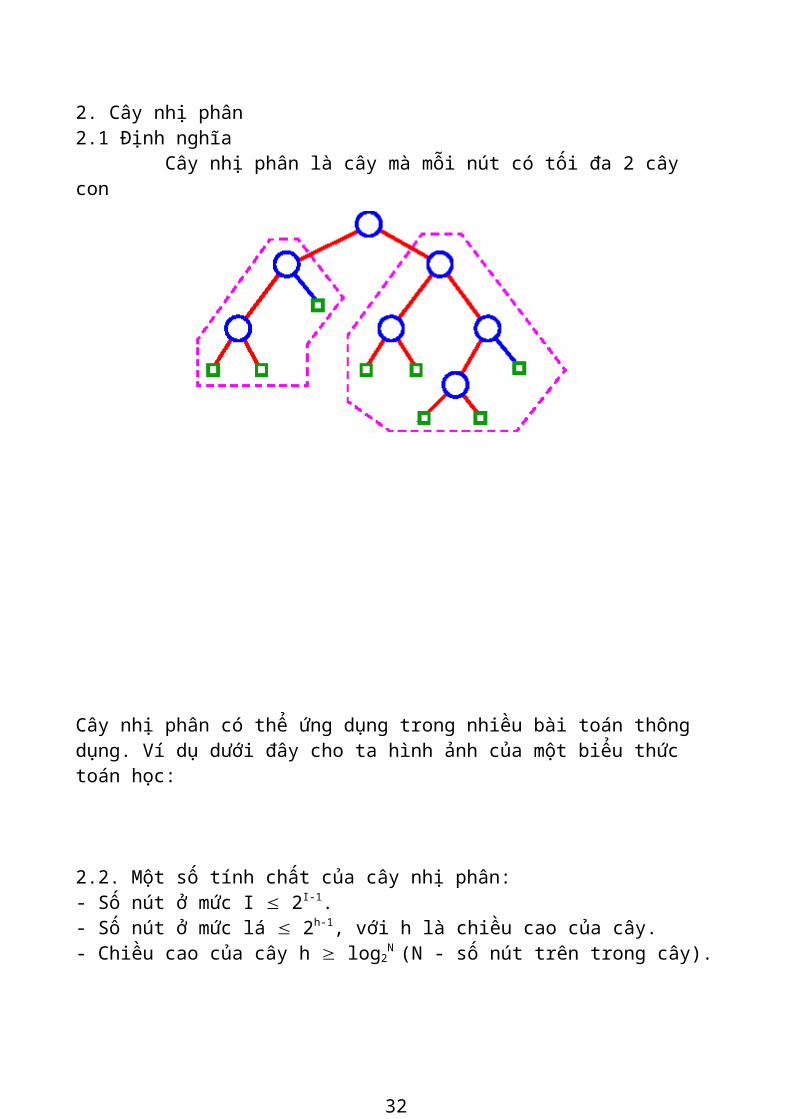
2. Cây nhị phân 2.1 Định nghĩa Cây nhị phân là cây mà mỗi nút có tối đa 2 cây con
Cây nhị phân có thể ứng dụng trong nhiều bài toán thông dụng. Ví dụ dưới đây cho ta hình ảnh của một biểu thức toán học:
2.2. Một số tính chất của cây nhị phân: - Số nút ở mức I £ 2I-1. - Số nút ở mức lá £ 2h-1, với h là chiều cao của cây. - Chiều cao của cây h ³ log2
N (N - số nút trên trong cây).
26

2.3. Biểu diễn cây nhị phân T Cây nhị phân là một cấu trúc bao gồm các phần tử (nút) được kết nối với nhau theo quan hệ “cha-con” với mỗi cha có tối đa 2 con. Để biểu diễn cây nhị phân ta chọn phương pháp cấp phát liên kết. Ứng với một nút, ta dùng một biến động lưu trữ các thông tin: + Thông tin lưu trữ tại nút. + Địa chỉ nút gốc của cây con trái trong bộ nhớ. + Địa chỉ nút gốc của cây con phải trong bộ nhớ. Khai báo như sau: typedef struct tagTNODE {
Data Key;//Data là kiểu dữ liệu ứng với thông tin lưu tại nút struct tagNODE *pLeft, *pRight;
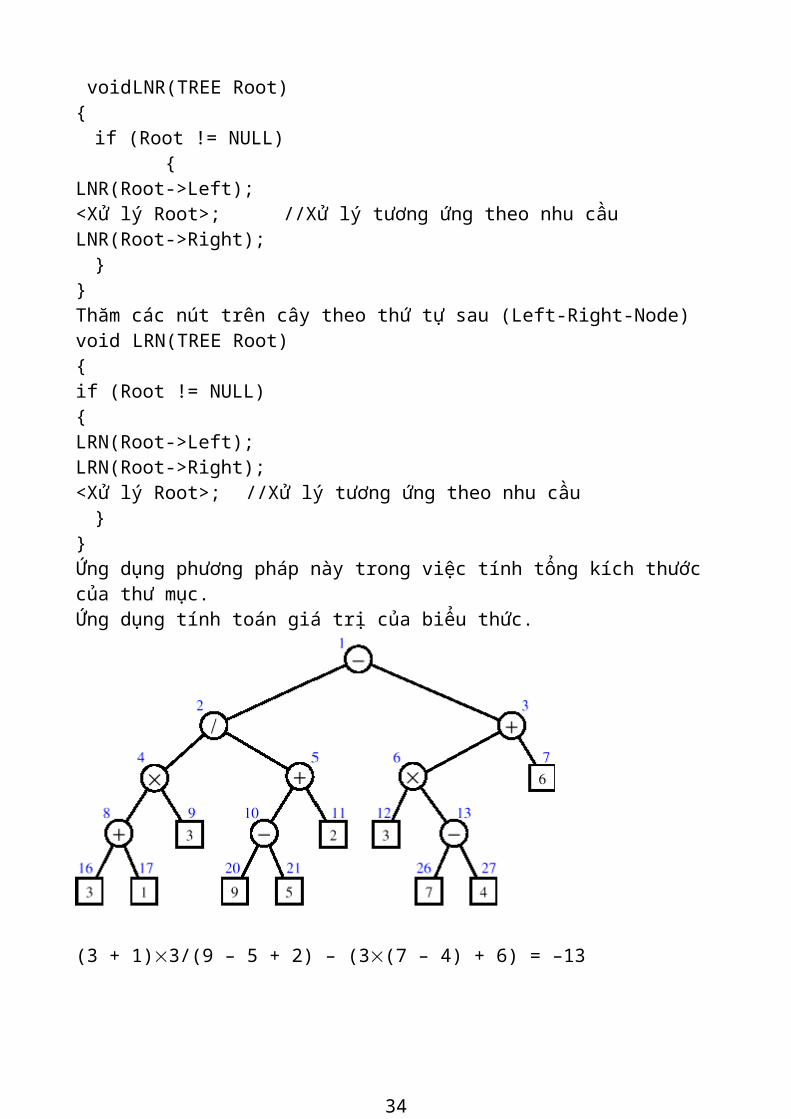
}TNODE; typedef TNODE *TREE; 2.4. Các thao tác trên cây nhị phânThăm các nút trên cây theo thứ tự trước (Node-Left-Right) void NLR(TREE Root) {
if (Root != NULL) { <Xử lý Root>; //Xử lý tương ứng theo nhu cầu NLR(Root->pLeft); NLR(Root->pRight);
} } Thăm các nút trên cây theo thứ tự giữa (Left- Node-Right) void LNR(TREE Root) {
if (Root != NULL) {LNR(Root->Left); <Xử lý Root>; //Xử lý tương ứng theo nhu cầu LNR(Root->Right);
}
27

} Thăm các nút trên cây theo thứ tự sau (Left-Right-Node) void LRN(TREE Root) { if (Root != NULL) { LRN(Root->Left); LRN(Root->Right); <Xử lý Root>; //Xử lý tương ứng theo nhu cầu
} } Ứng dụng phương pháp này trong việc tính tổng kích thước của thư mục.Ứng dụng tính toán giá trị của biểu thức.
(3 + 1)´3/(9 – 5 + 2) – (3´(7 – 4) + 6) = –13
28

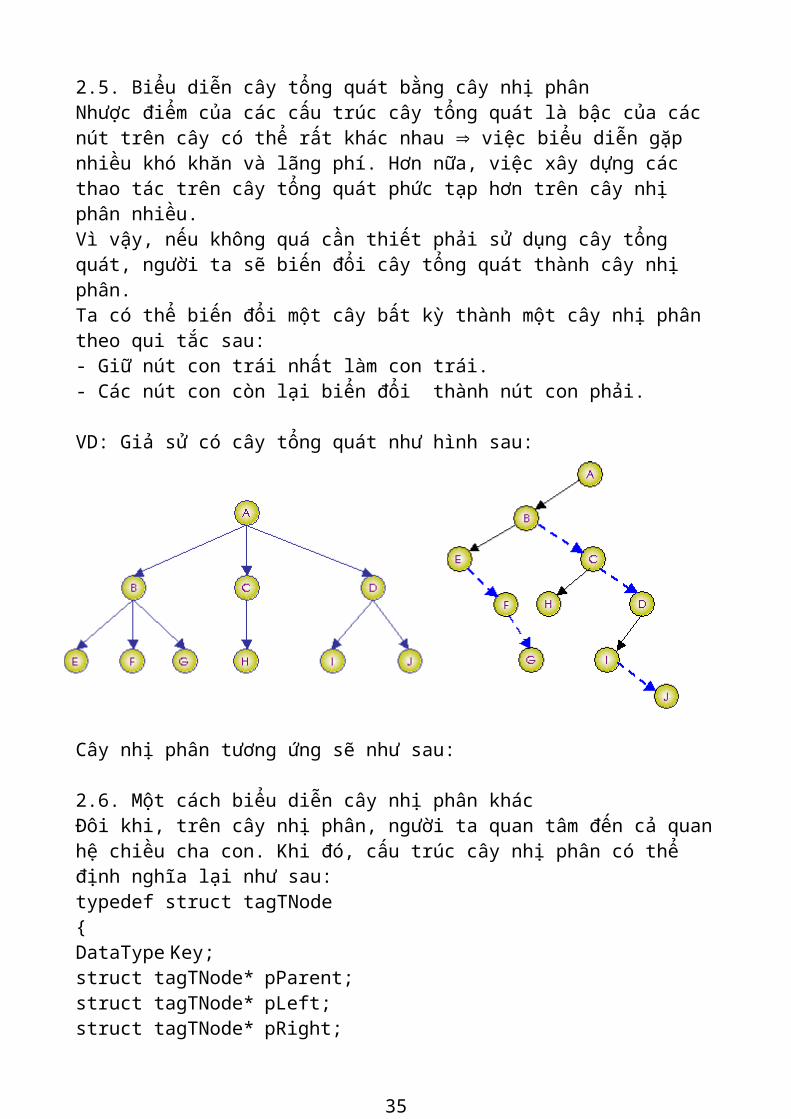
2.5. Biểu diễn cây tổng quát bằng cây nhị phân Nhược điểm của các cấu trúc cây tổng quát là bậc của các nút trên cây có thể rất khác nhau Þ việc biểu diễn gặp nhiều khó khăn và lãng phí. Hơn nữa, việc xây dựng các thao tác trên cây tổng quát phức tạp hơn trên cây nhị phân nhiều. Vì vậy, nếu không quá cần thiết phải sử dụng cây tổng quát, người ta sẽ biến đổi cây tổng quát thành cây nhị phân. Ta có thể biến đổi một cây bất kỳ thành một cây nhị phân theo qui tắc sau: - Giữ nút con trái nhất làm con trái. - Các nút con còn lại biển đổi thành nút con phải.
VD: Giả sử có cây tổng quát như hình sau:
Cây nhị phân tương ứng sẽ như sau:
2.6. Một cách biểu diễn cây nhị phân khác Đôi khi, trên cây nhị phân, người ta quan tâm đến cả quan hệ chiều cha con. Khi đó, cấu trúc cây nhị phân có thể định nghĩa lại như sau: typedef struct tagTNode { DataTypeKey; struct tagTNode* pParent; struct tagTNode* pLeft; struct tagTNode* pRight; }TNODE;typedef TNODE *TREE;
3. Cây nhị phân tìm kiếm3.1. Định nghĩa:
29

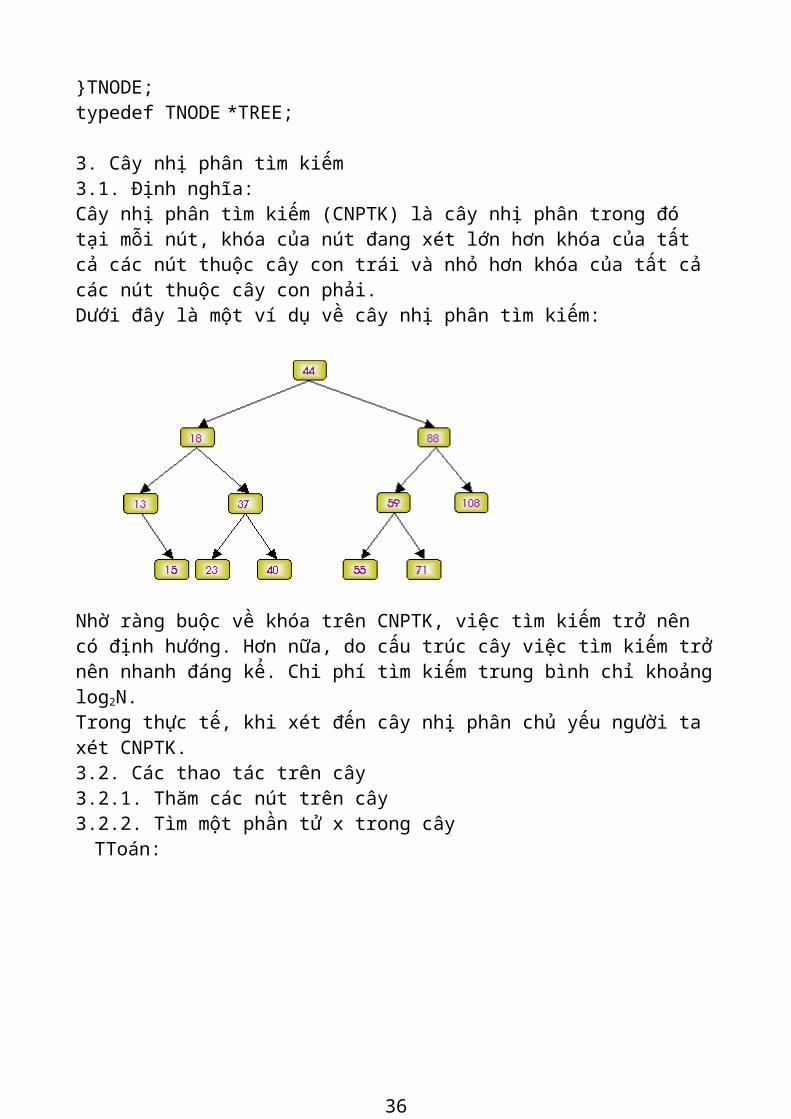
Cây nhị phân tìm kiếm (CNPTK) là cây nhị phân trong đó tại mỗi nút, khóa của nút đang xét lớn hơn khóa của tất cả các nút thuộc cây con trái và nhỏ hơn khóa của tất cả các nút thuộc cây con phải. Dưới đây là một ví dụ về cây nhị phân tìm kiếm:
Nhờ ràng buộc về khóa trên CNPTK, việc tìm kiếm trở nên có định hướng. Hơn nữa,
do cấu trúc cây việc tìm kiếm trở nên nhanh đáng kể. Chi phí tìm kiếm trung bình chỉ khoảng log2N. Trong thực tế, khi xét đến cây nhị phân chủ yếu người ta xét CNPTK. 3.2. Các thao tác trên cây3.2.1. Thăm các nút trên cây3.2.2. Tìm một phần tử x trong cây
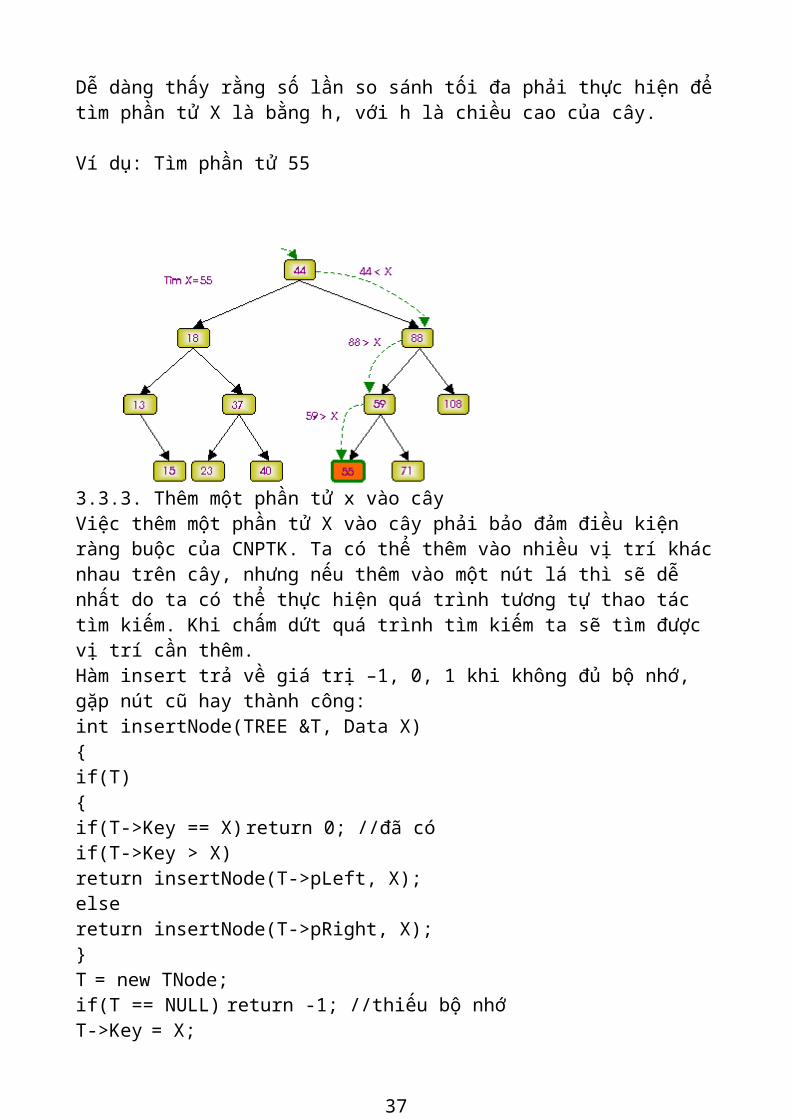
TToán:
Dễ dàng thấy rằng số lần so sánh tối đa phải thực hiện để tìm phần tử X là bằng h, với h là chiều cao của cây. Ví dụ: Tìm phần tử 55
3.3.3. Thêm một phần tử x vào cây
30

Việc thêm một phần tử X vào cây phải bảo đảm điều kiện ràng buộc của CNPTK. Ta có thể thêm vào nhiều vị trí khác nhau trên cây, nhưng nếu thêm vào một nút lá thì sẽ dễ nhất do ta có thể thực hiện quá trình tương tự thao tác tìm kiếm. Khi chấm dứt quá trình tìm kiếm ta sẽ tìm được vị trí cần thêm. Hàm insert trả về giá trị –1, 0, 1 khi không đủ bộ nhớ, gặp nút cũ hay thành công: int insertNode(TREE &T, Data X){if(T){if(T->Key == X) return 0; //đã cóif(T->Key > X)return insertNode(T->pLeft, X);elsereturn insertNode(T->pRight, X);}T = new TNode;if(T == NULL) return -1; //thiếu bộ nhớ T->Key = X;T->pLeft =T->pRight = NULL;return 1; //thêm vào thành công}
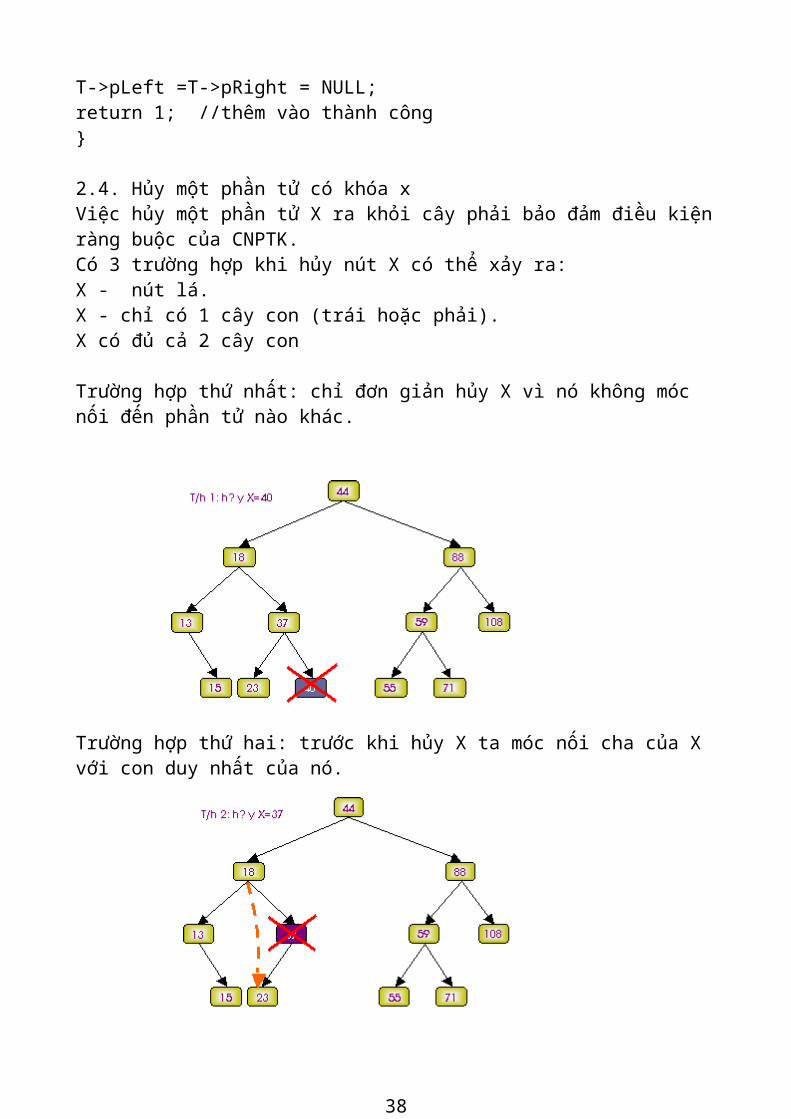
2.4. Hủy một phần tử có khóa x Việc hủy một phần tử X ra khỏi cây phải bảo đảm điều kiện ràng buộc của CNPTK. Có 3 trường hợp khi hủy nút X có thể xảy ra: X - nút lá. X - chỉ có 1 cây con (trái hoặc phải). X có đủ cả 2 cây con
Trường hợp thứ nhất: chỉ đơn giản hủy X vì nó không móc nối đến phần tử nào khác.
31
Trường hợp thứ hai: trước khi hủy X ta móc nối cha của X với con duy nhất của nó.
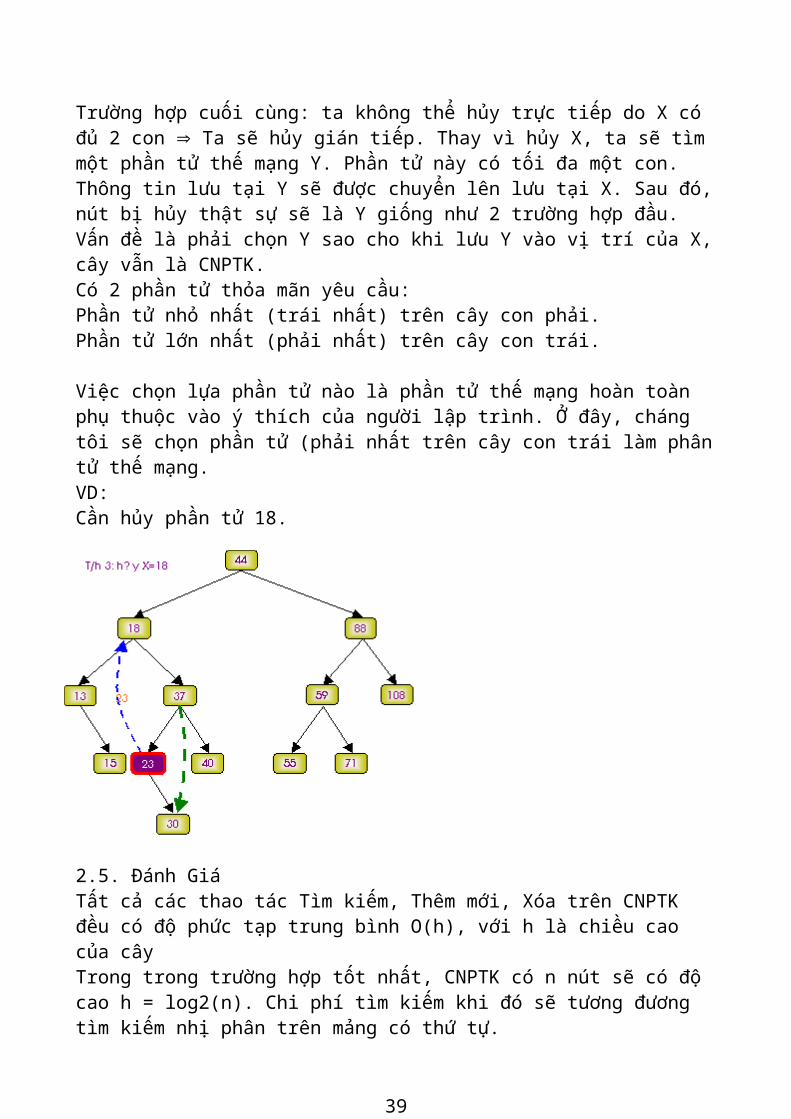
Trường hợp cuối cùng: ta không thể hủy trực tiếp do X có đủ 2 con Þ Ta sẽ hủy gián tiếp. Thay vì hủy X, ta sẽ tìm một phần tử thế mạng Y. Phần tử này có tối đa một con. Thông tin lưu tại Y sẽ được chuyển lên lưu tại X. Sau đó, nút bị hủy thật sự sẽ là Y giống như 2 trường hợp đầu. Vấn đề là phải chọn Y sao cho khi lưu Y vào vị trí của X, cây vẫn là CNPTK. Có 2 phần tử thỏa mãn yêu cầu: Phần tử nhỏ nhất (trái nhất) trên cây con phải. Phần tử lớn nhất (phải nhất) trên cây con trái.
Việc chọn lựa phần tử nào là phần tử thế mạng hoàn toàn phụ thuộc vào ý thích của người lập trình. Ở đây, cháng tôi sẽ chọn phần tử (phải nhất trên cây con trái làm phân tử thế mạng.
32

VD: Cần hủy phần tử 18.
2.5. Đánh Giá Tất cả các thao tác Tìm kiếm, Thêm mới, Xóa trên CNPTK đều có độ phức tạp trung bình O(h), với h là chiều cao của cây Trong trong trường hợp tốt nhất, CNPTK có n nút sẽ có độ cao h = log2(n). Chi phí tìm kiếm khi đó sẽ tương đương tìm kiếm nhị phân trên mảng có thứ tự. Tuy nhiên, trong trường hợp xấu nhất, cây có thể bị suy biến thành 1 DSLK. Lúc đó các thao tác trên sẽ có độ phức tạp O(n). Vì vậy cần có cải tiến cấu trúc của CNPTK để đạt được chi phí cho các thao tác là log2(n).
CÂY CÂN BẰNG
1. Cây nhị phân cân bằng hoàn toàn1.1. Định nghĩa Cây cân bằng hoàn toàn là cây nhị phân tìm kiếm mà tại mỗi nút của nó, số nút của cây con trái chênh lệch không quá một so với số nút của cây con phải.1.2. Đánh giá Một cây rất khó đạt được trạng thái cân bằng hoàn toàn và cũng rất dễ mất cân bằng vì khi thêm hay hủy các nút trên cây có thể làm cây mất cân bằng, chi phí cân bằng lại cây cao vì phải thao tác trên toàn bộ cây.
Đối với cây cân bằng hoàn toàn, trong trường hợp xấu nhất ta chỉ phải tìm qua log2N
phần tử (N là số nút trên cây).
33
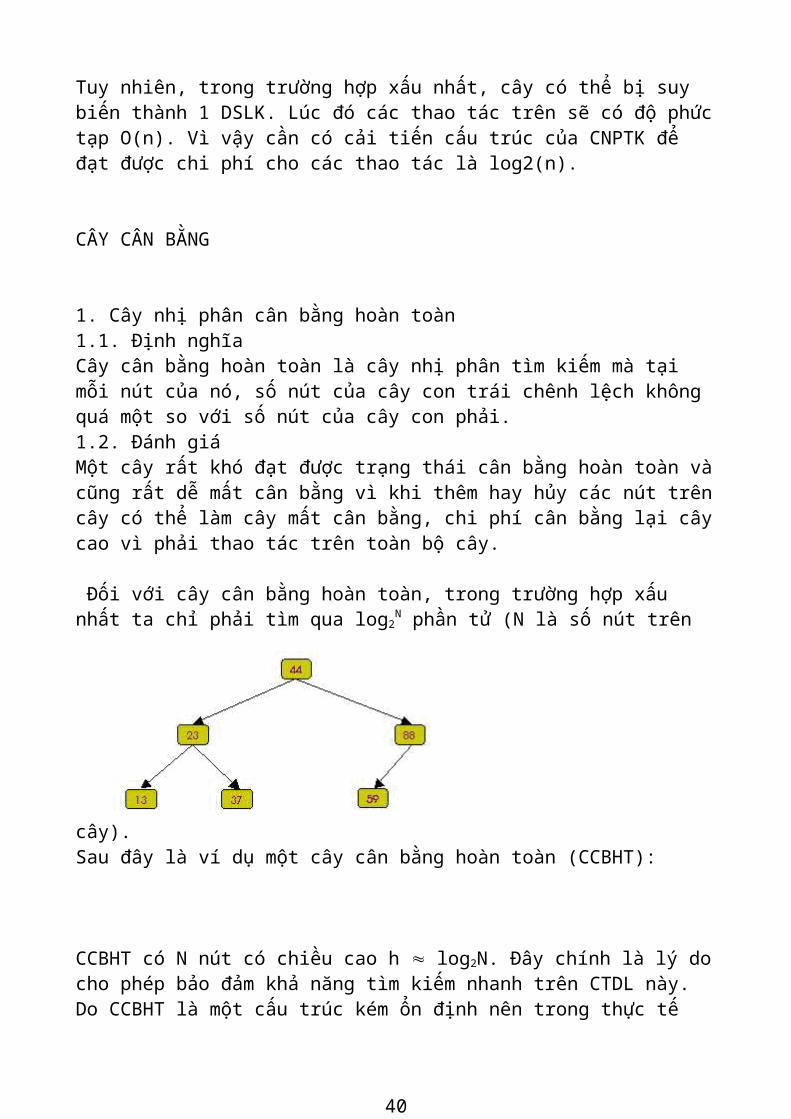
Sau đây là ví dụ một cây cân bằng hoàn toàn (CCBHT):
CCBHT có N nút có chiều cao h log2N. Đây chính là lý do cho phép bảo đảm khả năng tìm kiếm nhanh trên CTDL này. Do CCBHT là một cấu trúc kém ổn định nên trong thực tế không thể sử dụng. Nhưng ưu điểm của nó lại rất quan trọng. Vì vậy, cần đưa ra một CTDL khác có đặc tính giống CCBHT nhưng ổn định hơn.
2. Cây nhị phân cân bằng (AVL Tree)2.1. Định nghĩa: Cây nhị phân tìm kiếm cân bằng là cây mà tại mỗi nút của nó độ cao của cây con trái và của cây con phải chênh lệch không quá một.
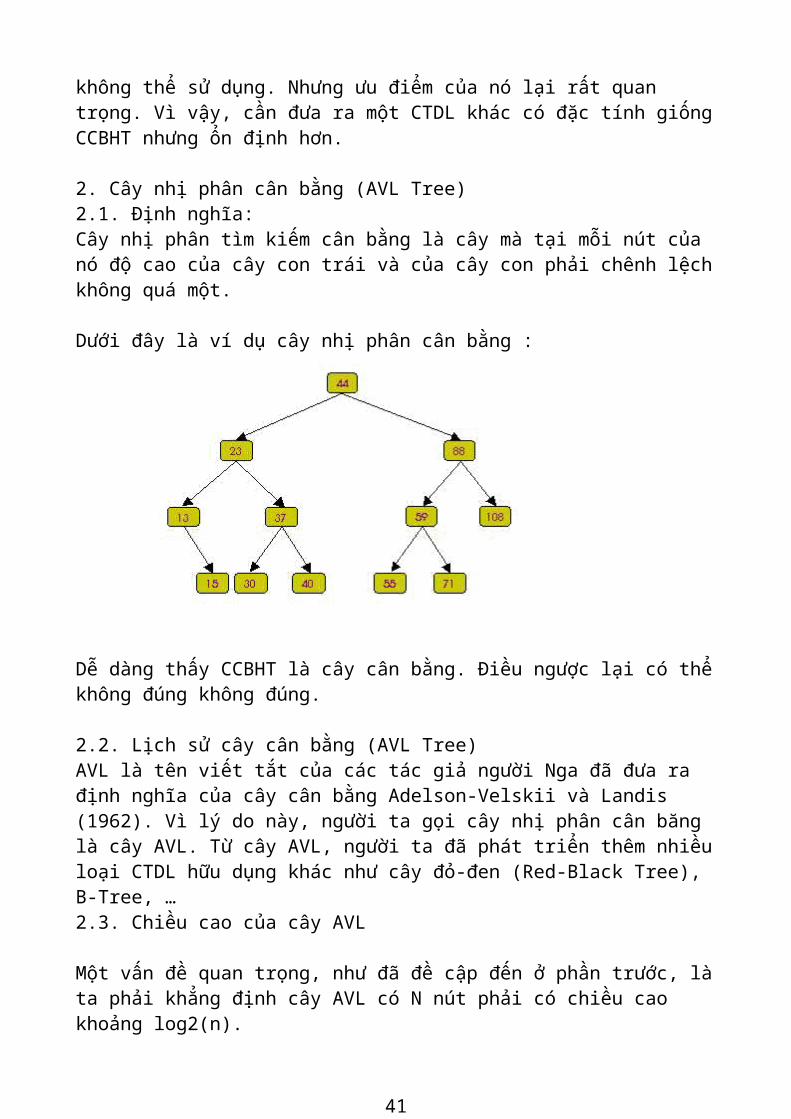
Dưới đây là ví dụ cây nhị phân cân bằng :
Dễ dàng thấy CCBHT là cây cân bằng. Điều ngược lại có thể không đúng không đúng.
2.2. Lịch sử cây cân bằng (AVL Tree)AVL là tên viết tắt của các tác giả người Nga đã đưa ra định nghĩa của cây cân bằng Adelson-Velskii và Landis (1962). Vì lý do này, người ta gọi cây nhị phân cân băng là cây AVL. Từ cây AVL, người ta đã phát triển thêm nhiều loại CTDL hữu dụng khác như cây đỏ-đen (Red-Black Tree), B-Tree, … 2.3. Chiều cao của cây AVL
Một vấn đề quan trọng, như đã đề cập đến ở phần trước, là ta phải khẳng định cây AVL có N nút phải có chiều cao khoảng log2(n).
Để đánh giá chính xác về chiều cao của cây AVL, ta xét bài toán: cây AVL có chiều cao h sẽ phải có tối thiểu bao nhiêu nút ?
34
Gọi N(h) là số nút tối thiểu của cây AVL có chiều cao h.
Ta có N(0) = 0, N(1) = 1 và N(2) = 2.
Cây AVL có chiều cao h sẽ có 1 cây con AVL chiều cao h-1 và 1 cây con AVL chiều cao h-2. Như vậy:
N(h) = 1 + N(h-1) + N(h-2) (1)
Ta lại có: N(h-1) > N(h-2)Nên từ (1) suy ra:N(h) > 2N(h-2)N(h) > 22N(h-4)…N(h) > 2iN(h-2i)i =h/2 N(h)>2h/2
h < 2log2(N(h)) Như vậy, cây AVL có chiều cao O(log2(n)).
Ví dụ: cây AVL tối thiểu có chiều cao h=4
2.4. Cấu trúc dữ liệu cho cây AVL
Chỉ số cân bằng của một nút: Chỉ số cân bằng của một nút là hiệu của chiều cao cây con phải và cây con trái của nó.
Đối với một cây cân bằng, chỉ số cân bằng (CSCB) của mỗi nút chỉ có thể nhận một trong ba giá trị sau đây:
CSCB(p) = 0 <=> Độ cao cây trái (p) = Độ cao cây phải (p)CSCB(p) = 1 <=> Độ cao cây trái (p) < Độ cao cây phải (p)CSCB(p) =-1 <=> Độ cao cây trái (p) > Độ cao cây phải (p)
Xét nút P, ta dùng các ký hiệu sau:
35
P->balFactor = CSCB(P);Độ cao cây trái P ký hiệu là hleft
Độ cao cây phải P ký hiệu là hright
Để khảo sát cây cân bằng, ta cần lưu thêm thông tin về chỉ số cân bằng tại mỗi nút. Lúc đó, cây cân bằng có thể được khai báo như sau:
typedef struct tagAVLNode {
char balFactor; //Chỉ số cân bằngData key;struct tagAVLNode* pLeft;struct tagAVLNode* pRight;
}AVLNode;
typedef AVLNode *AVLTree;
Để tiện cho việc trình bày, ta định nghĩa một số hăng số sau:#define LH -1 //Cây con trái cao hơn#define EH -0 //Hai cây con bằng nhau#define RH 1 //Cây con phải cao hơn 2.5. Đánh giá cây AVLCây cân bằng là CTDL ổn định hơn CCBHT vì khi thêm, hủy làm cây thay đổi chiều cao các trường hợp mất cân bằng mới có khả năng xảy ra. Cây AVL với chiều cao được khống chế sẽ cho phép thực thi các thao tác tìm, thêm, hủy với chi phí O (log2(n)) và bảo đảm không suy biến thành O(n).
3. Các thao tác cơ ban trên cây AVLTa nhận thấy trường hợp thêm hay hủy một phần tử trên cây có thể làm cây tăng hay giảm chiều cao, khi đó phải cân bằng lại cây. Việc cân bằng lại một cây sẽ phải thực hiện sao cho chỉ ảnh hưởng tối thiểu đến cây nhằm giảm thiểu chi phí cân bằng. Như đã nói ở trên, cây cân bằng cho phép việc cân bằng lại chỉ xảy ra trong giới hạn cục bộ nên chúng ta có thể thực hiện được mục tiêu vừa nêu.Như vậy, ngoài các thao tác bình thường như trên CNPTK, các thao tác đặc trưng của cây AVL gồm:Thêm một phần tử vào cây AVL.Hủy một phần tử trên cây AVL.Cân bằng lại một cây vừa bị mất cân bằng.
3.1. Các trường hợp mất cân bằng
36
Ta sẽ không khảo sát tính cân bằng của 1 cây nhị phân bất kỳ mà chỉ quan tâm đến các khả năng mất cân bằng xảy ra khi thêm hoặc hủy một nút trên cây AVL.Như vậy, khi mất cân bằng, độ lệch chiều cao giữa 2 cây con sẽ là 2. Ta có 6 khả năng sau:Trường hợp 1: cây T lệch về bên trái (có 3 khả năng)
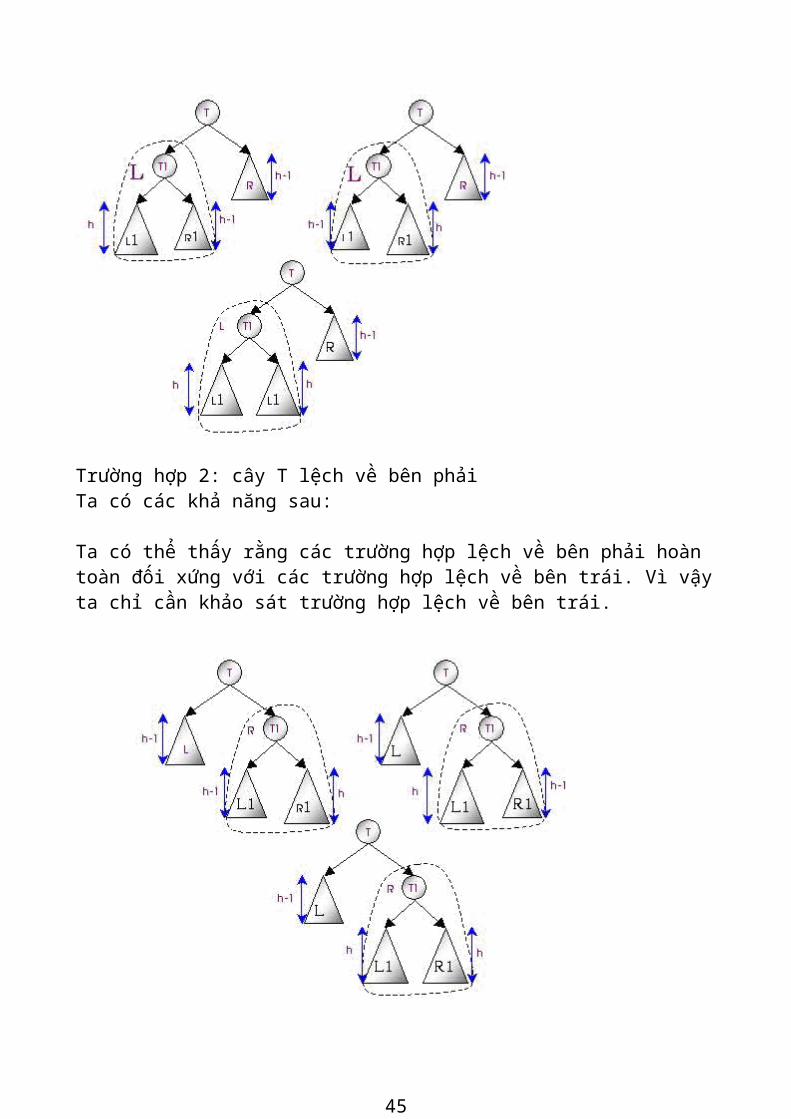
Trường hợp 2: cây T lệch về bên phải Ta có các khả năng sau:
Ta có thể thấy rằng các trường hợp lệch về bên phải hoàn toàn đối xứng với các
trường hợp lệch về bên trái. Vì vậy ta chỉ cần khảo sát trường hợp lệch về bên trái.
37
Trong 3 trường hợp lệch về bên trái, trường hợp T1 lệch phải là phức tạp nhất. Các trường hợp còn lại giải quyết rất đơn giản.Sau đây, ta sẽ khảo sát và giải quyết từng trường hợp nêu trênT/h 1.1: cây T1 lệch về bên trái. Ta thực hiện phép quay đơn Left-Left
T/h 1.2: cây T1 không lệch. Ta thực hiện phép quay đơn Left-Left
38
Ttoán quay đơn Left-Left:B1: T là gốc; T1 = T->pLeft;
T->pLeft = T1->pRight; T1->pRight = T;B2:// đặt lại chỉ số cân bằngNếu T1->balFactor = LH thì:
T->balFactor = EH; T1->balFactor = EH; break;
Nếu T1->balFactor = EH thì: T->balFactor = LH;T1->balFactor = RH; break;
B3:// T trỏ đến gốc mớiT = T1;
T/h 1.3: cây T1 lệch về bên phải. Ta thực hiện phép quay kép Left-Right
Do T1 lệch về bên phải ta không thể áp dụng phép quay đơn đã áp dụng trong 2 trường hợp trên vì khi đó cây T sẽ từ trạng thái mất cân bằng do lệch trái thành mất cân bằng do lệch phải.Hình vẽ dưới đây minh họa phép quay kép áp dụng cho trường hợp này:
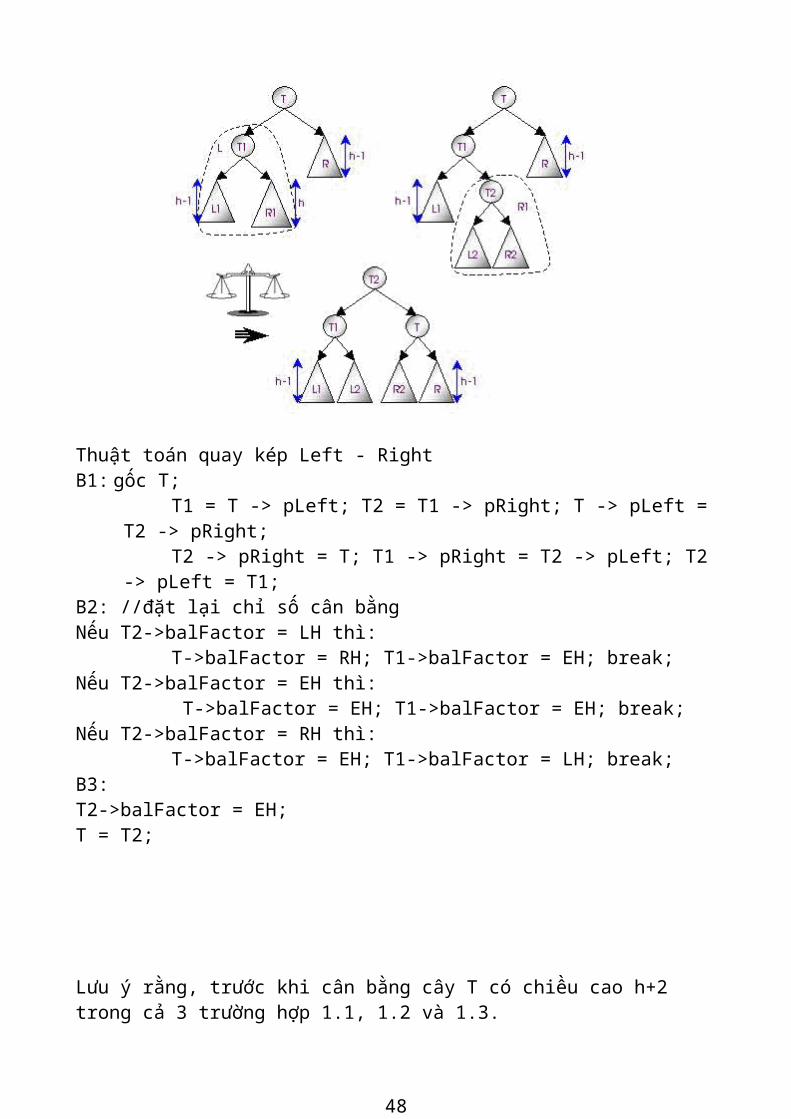
Thuật toán quay kép Left - RightB1: gốc T;
T1 = T -> pLeft; T2 = T1 -> pRight; T -> pLeft = T2 -> pRight;T2 -> pRight = T; T1 -> pRight = T2 -> pLeft; T2 -> pLeft = T1;
39
B2: //đặt lại chỉ số cân bằngNếu T2->balFactor = LH thì:
T->balFactor = RH; T1->balFactor = EH; break;Nếu T2->balFactor = EH thì:
T->balFactor = EH; T1->balFactor = EH; break;Nếu T2->balFactor = RH thì:
T->balFactor = EH; T1->balFactor = LH; break;B3: T2->balFactor = EH;T = T2;
Lưu ý rằng, trước khi cân bằng cây T có chiều cao h+2 trong cả 3 trường hợp 1.1, 1.2 và 1.3.Sau khi cân bằng, trong 2 trường hợp 1.1 và 1.3 cây có chiều cao h+1; còn ở trường hợp 1.2 cây vẫn có chiều cao h+2. Và trường hợp này cũng là trường hợp duy nhất sau khi cân bằng nút T cũ có chỉ số cân bằng khác 0.
Thao tác cân bằng lại trong tất cả các trường hợp đều có độ phức tạp O(1).Với những xem xét trên, xét tương tự cho trường hợp cây T lệch về bên phải, ta có thể xây dựng 2 hàm quay đơn và 2 hàm quay kép sau:
3.2. Thêm một phần tử trên cây AVL:Việc thêm một phần tử vào cây AVL diễn ra tương tự như trên CNPTK. Tuy nhiên, sau khi thêm xong, nếu chiều cao của cây thay đổi, từ vị trí thêm vào, ta phải tìm ngược lên gốc để kiểm tra các nút bị mất cân bằng không. Nếu có, ta phải cân bằng lại ở nút này.
TToán: Giả sử cần thêm vào một nút mang thông tin X.1. Tìm kiếm vị trí thích hợp để thêm nút X (đưa ra thông báo nếu đã có nút X rồi)2. Thêm nút X vào cây3. Cân bằng lại cây.
3.3. Hủy một phần tử trên cây AVL:Cũng giống như thao tác thêm một nút, việc hủy một phần tử X ra khỏi cây AVL thực hiện giống như trên CNPTK. Chỉ sau khi hủy, nếu tính cân bằng của cây bị vi phạm ta sẽ thực hiện việc cân bằng lại. Tuy nhiên việc cân bằng lại trong thao tác hủy sẽ phức tạp hơn.
BÀI 6: CÂY ĐỎ ĐEN
40
1. Giới thiệuCây tìm kiếm nhị phân là một cấu trúc lưu trữ dữ liệu tốt với tốc độ tìm kiếm nhanh.Tuy nhiên trong một số trường hợp cây tìm kiếm nhị phân có một số hạn chế. Nó hoạt động tốt nếu dữ liệu được chèn vào cây theo thứ tự ngẫu nhiên. Tuy nhiên, nếu dữ liệu được chèn vào theo thứ tự đã đuợc sắp xếp sẽ không hiệu quả. Khi các trị số cần chèn đã đuợc sắp xếp thì cây nhị phân trở nên không cân bằng. Khi cây không cân bằng, nó mất đi khả năng tìm kiếm nhanh (hoặc chèn hoặc xóa) một phần tử đã cho.Chúng ta khảo sát một cách giải quyết vấn đề của cây không cân bằng: đó là cây đỏ đen, là cây tìm kiếm nhị phân có thêm một vài đặc điểm .Có nhiều cách tiếp cận khác để bảo đảm cho cây cân bằng: chẳng hạn cây 2-3-4. Tuy vậy, trong phần lớn trường hợp, cây đỏ đen là cây cân bằng hiệu quả nhất, ít ra thì khi dữ liệu được lưu trữ trong bộ nhớ chứ không phải trong những tập tin.Trước khi khảo sát cây đỏ đen, hãy xem lại cây không cân bằng được tạo ra như thế nào.
Hình 1. Các node được chèn theo thứ tự tăng dầnNhững node này tự sắp xếp thành một đường không phân nhánh. Bởi vì mỗi node lớn hơn node đã được chèn vào trước đó, mỗi node là con phải của nút trước đó. Khi ấy, cây bị mất cân bằng hoàn toàn. Độ phức tạp:Khi cây một nhánh, sẽ trở thành một danh sách liên kết, dữ liệu sẽ là một chiều thay vì hai chiều. Trong trường hợp này, thời gian truy xuất giảm về O(N), thay vì O(log2N) đối với cây cân bằng. Để bảo đảm thời gian truy xuất nhanh của cây, chúng ta cần phải bảo đảm cây luôn luôn cân bằng (ít ra cũng là cây gần cân bằng). Điều này có nghĩa là mỗi node trên cây phải có xấp xỉ số node con bên phải bằng số node con bên trái.
2. Định nghĩa cây đỏ đenCây đỏ đen là một cây nhị phân tìm kiếm (BST) tuân thủ các quy tắc sau: (hình 2)(1) Mọi node phải là đỏ hoặc đen.(2) Node gốc và các node lá (NIL) phải luôn luôn đen.(3) Nếu một node là đỏ, những node con của nó phải đen.(4) Mọi đường dẫn từ gốc đến một lá phải có cùng số lượng node đen.Khi chèn (hay xóa) một node mới, cần phải tuân thủ các quy tắc trên -gọi là quy tắc đỏ đen. Nếu được tuân thủ, cây sẽ được cân bằng.
41

Hình 2. Một ví dụ về cây đỏ đenSố lượng node đen trên một đường dẫn từ gốc đến lá được gọi là chiều cao đen (black height). Ta có thể phát biểu quy tắc (4) theo một cách khác là mọi đường dẫn từ gốc đến lá phải có cùng chiều cao đen.Khai báo cấu trúc:typedef int Data; /* Kiểu dữ liệu khoá */typedef enum { BLACK, RED } nodeColor;typedef struct NodeTag {nodeColor color; /* Màu node (BLACK, RED) */Data info; /* Khoá sử dụng tìm kiếm */struct NodeTag *left; /* Con trái */struct NodeTag *right; /* Con phải */struct NodeTag *parent; /* Cha */} NodeType;typedef NodeType *iterator;Bổ đề: Một cây đỏ đen n-node có chiều cao h <= 2 log2(n+1)
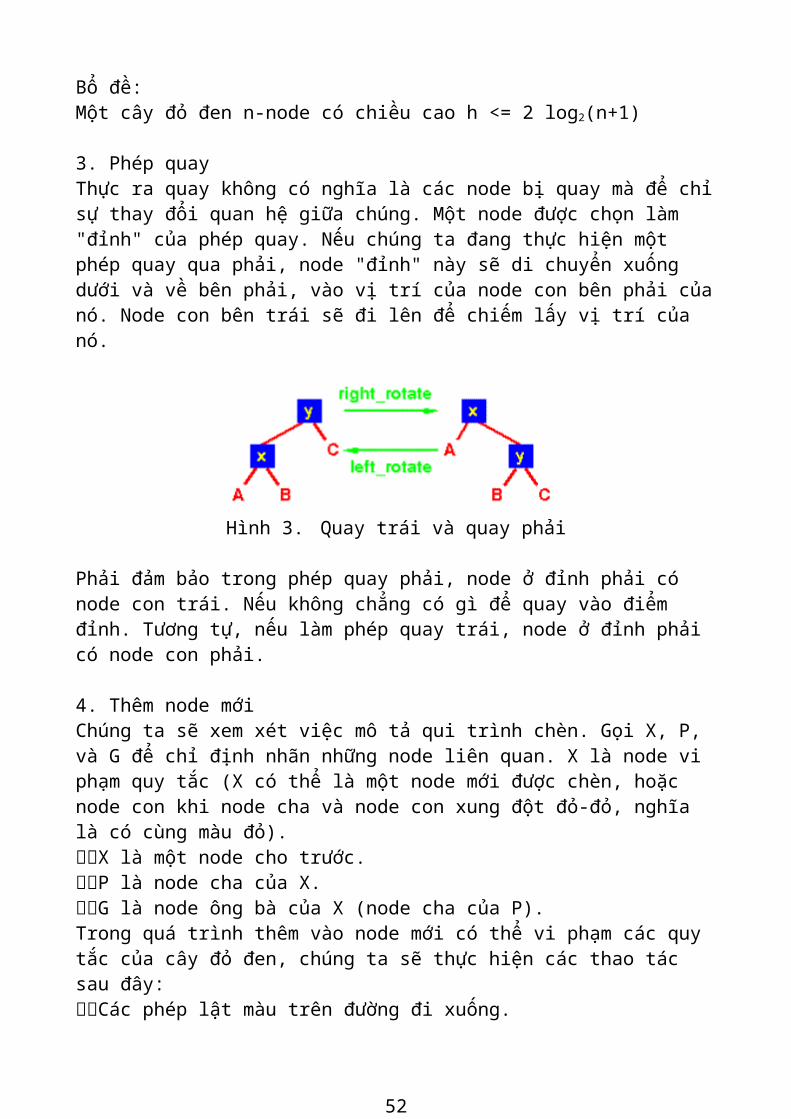
3. Phép quayThực ra quay không có nghĩa là các node bị quay mà để chỉ sự thay đổi quan hệ giữa chúng. Một node được chọn làm "đỉnh" của phép quay. Nếu chúng ta đang thực hiện một phép quay qua phải, node "đỉnh" này sẽ di chuyển xuống dưới và về bên phải, vào vị trí của node con bên phải của nó. Node con bên trái sẽ đi lên để chiếm lấy vị trí của nó.
Hình 3. Quay trái và quay phải
Phải đảm bảo trong phép quay phải, node ở đỉnh phải có node con trái. Nếu không chẳng có gì để quay vào điểm đỉnh. Tương tự, nếu làm phép quay trái, node ở đỉnh phải có node con phải.
42

4. Thêm node mớiChúng ta sẽ xem xét việc mô tả qui trình chèn. Gọi X, P, và G để chỉ định nhãn những node liên quan. X là node vi phạm quy tắc (X có thể là một node mới được chèn, hoặc node con khi node cha và node con xung đột đỏ-đỏ, nghĩa là có cùng màu đỏ).X là một node cho trước.P là node cha của X.G là node ông bà của X (node cha của P).Trong quá trình thêm vào node mới có thể vi phạm các quy tắc của cây đỏ đen, chúng ta sẽ thực hiện các thao tác sau đây:Các phép lật màu trên đường đi xuống.Các phép quay khi node đã được chèn.Các phép quay trên đường đi xuống. 4.1 Các phép lật màu trên đường đi xuốngPhép thêm vào trong cây đỏ đen bắt đầu như trên cây tìm kiếm nhị phân thông thường: đi theo một đường dẫn từ node gốc đến vị trí cần chèn, đi qua phải hay trái tùy vào giá trị của khóa node và khóa tìm kiếm.Tuy nhiên, trong cây đỏ đen, đến được điểm chèn là phức tạp bởi các phép lật màu và quay. Để bảo đảm không vi phạm các quy tắc màu, cần phải tiến hành các phép lật màu khi cần theo quy tắc như sau: Nếu phép thêm vào làm xuất hiện tình trạng một node đen có hai node con đỏ, chúng ta đổi các node con thành đen và node cha thành đỏ (trừ khi node cha là node gốc, nó vẫn vẫn giữ màu là đen).Một phép lật màu ảnh hưởng đến các quy tắc đỏ-đen ra sao? chúng ta gọi node ở đỉnh tam giác, node có màu đen trước phép lật là P (P thay cho node cha). Chúng ta gọi hai node con trái và phải của P là X1 và X2. Xem hình 4a.
Hình 4. Lật màu
Hình 4a. trước khi lật màu, Hình 4b sau khi lật màu.Chúng ta nhận thấy sau khi lật màu chiếu cao đen của cây không đổi. Như vậy phép lật màu không vi phạm quy tắc (4).
43

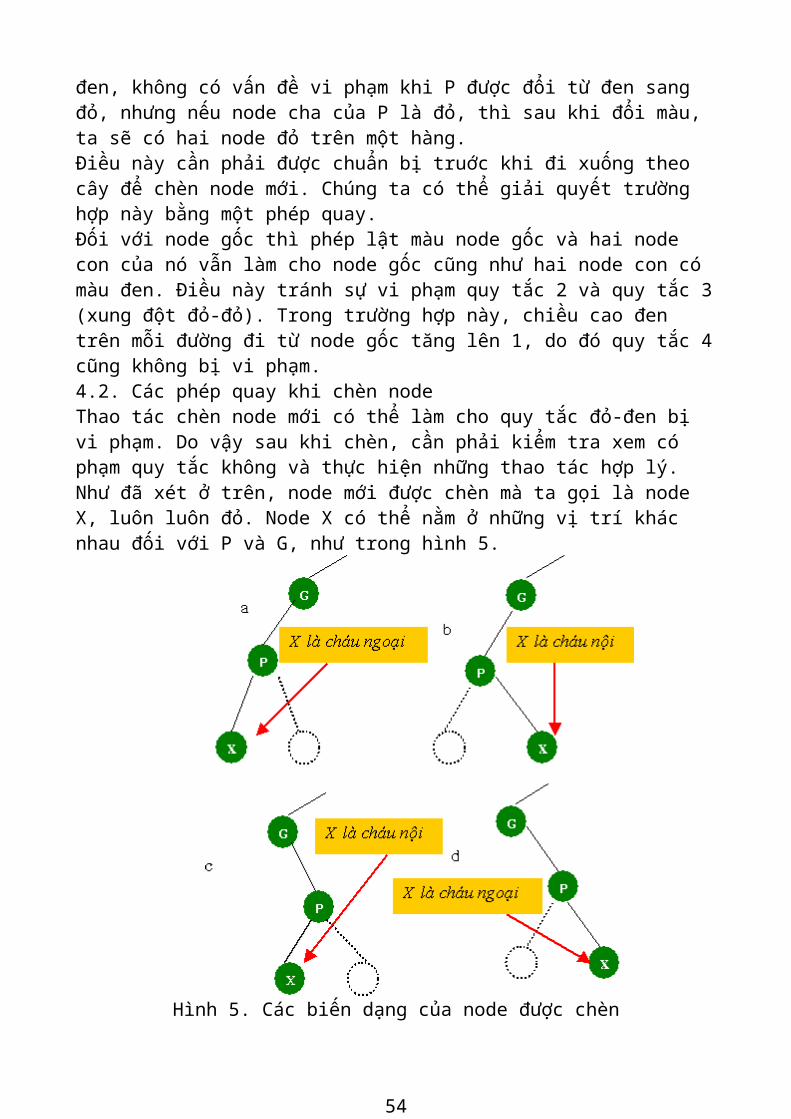
Mặc dù quy tắc (4) không bị vi phạm qua phép lật, nhưng quy tắc 3 (một node con và node cha không thể đồng màu đỏ) lại có khả năng bị vi phạm. Nếu node cha của P là đen, không có vấn đề vi phạm khi P được đổi từ đen sang đỏ, nhưng nếu node cha của P là đỏ, thì sau khi đổi màu, ta sẽ có hai node đỏ trên một hàng.Điều này cần phải được chuẩn bị truớc khi đi xuống theo cây để chèn node mới. Chúng ta có thể giải quyết trường hợp này bằng một phép quay.Đối với node gốc thì phép lật màu node gốc và hai node con của nó vẫn làm cho node gốc cũng như hai node con có màu đen. Điều này tránh sự vi phạm quy tắc 2 và quy tắc 3 (xung đột đỏ-đỏ). Trong trường hợp này, chiều cao đen trên mỗi đường đi từ node gốc tăng lên 1, do đó quy tắc 4 cũng không bị vi phạm.4.2. Các phép quay khi chèn nodeThao tác chèn node mới có thể làm cho quy tắc đỏ-đen bị vi phạm. Do vậy sau khi chèn, cần phải kiểm tra xem có phạm quy tắc không và thực hiện những thao tác hợp lý.Như đã xét ở trên, node mới được chèn mà ta gọi là node X, luôn luôn đỏ. Node X có thể nằm ở những vị trí khác nhau đối với P và G, như trong hình 5.
Hình 5. Các biến dạng của node được chèn
X là một node cháu ngoại nếu nó nằm cùng bên node cha P và P cùng bên node cha G. Điều này có nghĩa là, X là node cháu ngoại nếu hoặc nó là node con trái của P và P là node con trái của G, hoặc nó là node con phải của P và node P là node con phải của G. Ngược lại, X là một node cháu nội.
44
Nếu X là node cháu ngoại, nó có thể hoặc bên trái hoặc bên phải của P, tùy vào việc node P ở bên trái hay bên phải node G. Có hai khả năng tương tự nếu X là một node cháu nội. Bốn trường hợp này được trình bày trong hình 5. Thao tác phục hồi quy tắc đỏ-đen được xác định bởi các màu và cấu hình của node X và những bà con của nó. Có 3 khả năng xảy ra được xem xét như sau:(hình 6)
Hình 6. Ba khả năng sau khi chèn núti) Khả năng 1: P đenii) Khả năng 2: P đỏ và X là cháu ngoại của Giii) Khả năng 3: P đỏ và X là cháu nội của G
Chúng ta sẽ xét các khả năng trên một cách cụ thể như sau:i) Khả năng 1: P đenP đen là trường hợp đơn giản. Node thêm vào luôn đỏ. Nếu node cha đen, không có xung khắc đỏ-đỏ (quy tắc 3), và không có việc cộng thêm vào số node đen (quy tắc 4). Do vậy, không bị vi phạm quy tắc về màu. Thao tác chèn đã hoàn tất.ii) Khả năng 2: P đỏ và X là cháu ngoại của GNếu node P đỏ và X là node cháu ngoại, ta cần một phép quay đơn giản và một vài thay đổi về màu. Bắt đầu với giá trị 50 tại node gốc, và chèn các node 25, 75 và 12. Ta cần phải làm một phép lật màu trước khi chèn node 12.Bây giờ, chèn node mới X là 6. (hình 7a. )xuất hiện lỗi: cha và con đều đỏ, vì vậy cần phải có các thao tác như sau: (hình 7)Trong trường hợp này, ta có thể áp dụng ba bước để phục hồi tính đỏ-đen và làm cho cân bằng cây. Sau đây là các bước ấy:
-Đổi màu node G - node ông bà của node X (trong thí dụ này là node 25).-Đổi màu node P - node cha của node X (node 12)-Quay với node G (25) ở vị trí đỉnh, theo huớng làm nâng node X lên (6). Đây là một phép quay phải.
45

Khi ta hoàn tất ba buớc trên sẽ bảo toàn cây đỏ đen. Xem hình 7b.Trong thí dụ này, node X là node cháu ngoại của một node con trái. Có một trường hợp đối xứng khi node X là node cháu ngoài nhưng của một node con phải. Thử làm điều này bằng cách tạo nên cây 50, 25, 75, 87, 93 (với phép lật màu khi cần). Chỉnh sửa cây bằng cách đổi màu node 75 và 87, và quay trái với node 75 là node đỉnh. Một lần nữa cây lại được cân bằng.
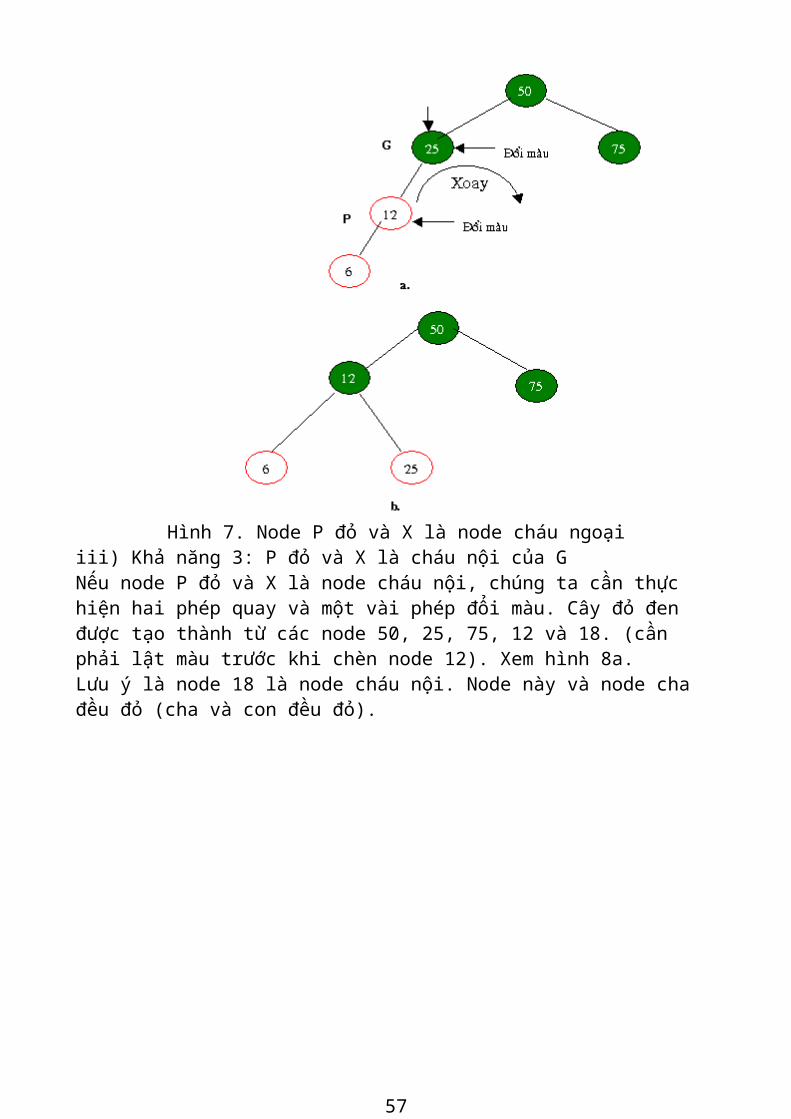
Hình 7. Node P đỏ và X là node cháu ngoạiiii) Khả năng 3: P đỏ và X là cháu nội của GNếu node P đỏ và X là node cháu nội, chúng ta cần thực hiện hai phép quay và một vài phép đổi màu. Cây đỏ đen được tạo thành từ các node 50, 25, 75, 12 và 18. (cần phải lật màu trước khi chèn node 12). Xem hình 8a.Lưu ý là node 18 là node cháu nội. Node này và node cha đều đỏ (cha và con đều đỏ).
46

hình 8.cHình 8. Khả năng 3: P đỏ và X là node cháu nội
Chỉnh lại sự sắp xếp này cũng khá rắc rối hơn. Nếu ta cố quay phải node ông bà G (25) ở đỉnh, như ta đã làm trong khả năng 2, node cháu trong X (18) đi ngang hơn là đi lên, như thế cây sẽ không còn cân bằng như trước. (Thử làm điều này, rồi quay trở lại, với node 12 ở đỉnh, để phục hồi cây nhu cũ). Phải cần một giải pháp khác. Thủ thuật cần dùng khi X là node cháu nội là tiến hành hai phép quay hơn là một phép. Phép quay đầu biến X từ một node cháu nội thành node cháu ngoại, như trong hình 8b. Bây giờ, trường hợp là tương tự như khả năng 1, và ta có thể áp dụng cùng một phép quay, với node ông bà ở đỉnh, như đã làm trước đây. Kết quả như trong hình 8c.Chúng ta cũng cần tô màu lại các nút. Ta làm điều này trước khi làm bất cứ phép quay nào (thứ tự không quan trọng, nhưng nếu ta đợi đến khi sau khi quay mới tô màu lại node thì khó mà biết phải gọi chúng như thế nào). Các bước là:
47
- Đổi màu node ông bà của node X ( node 25).- Đổi màu node X ( node X đây là node 18).- Quay trái với node P - node cha của X - ở đỉnh ( node cha đây là 12).- Quay lần nữa với node ông bà của X (25) ở đỉnh, về hướng nâng X lên (quay phải).
5. Loại bỏ nodeTrong cây BST chúng ta thấy rằng phép loại bỏ phức tạp hơn so với phép thêm vào. Trong cây đỏ đen phép loại bỏ càng phức tạp hơn rất nhiều so với phép thêm vào vì yêu cầu đảm bảo quy tắc đỏ đen. Chúng ta có thể tham khảo trong phần cài đặt.
Nếu xóa một nút đỏ thì chiều cao đen của cây không đổi Nếu xóa một nút đen thì chúng ta phải cân bằng lại cây.
6. Tính hiệu quả của cây đỏ đenGiống như cây tìm kiếm nhị phân thông thường, cây đỏ đen có thể cho phép việc tìm kiếm, chèn và xóa trong thời gian O(log2N). Thời gian tìm kiếm là gần như bằng nhau đối với hai loại cây, vì những đặc điểm của cây đỏ đen không sử dụng trong quá trình tìm kiếm. Điều bất lợi là việc lưu trữ cần cho mỗi node tăng chút ít để điều tiết màu đỏ-đen (một biến boolean).Đặc thù hơn, theo Sedgewick, trong thực tế tìm kiếm trên cây đỏ đen mất khoảng log2N phép so sánh, và có thể chứng minh rằng nó không cần hơn 2*log2N phép so sánh.Thời gian chèn và xóa tăng dần bởi một hằng số vì việc phải thực thi phép lật màu và quay trên đường đi xuống và tại những điểm chèn. Trung bình một phép chèn cần khoảng chừng một phép quay. Do đó, chèn hày còn chiếm O(log2N) thời gian, nhưng lại chậm hơn phép chèn trong cây nhị phân thường.Bởi vì trong hầu hết các ứng dụng, có nhiều thao tác tìm kiếm hơn là chèn và xóa, có lẽ không có nhiều bất lợi về thời gian khi dùng cây đỏ đen thay vì cây nhị phân thuờng. Dĩ nhiên, điều thuận lợi là trong cây đỏ đen, dữ liệu đã sắp xếp không làm giảm hiệu suất O(N).Một trở ngại trong cây đỏ đen là việc cài đặt các phép toán phức tạp hơn so với cây BST. Chúng ta có thể tham khảo các phép toán thêm vào và loại bỏ trong phần cài đặt.
BÀI 7: CÂY 2-3-4
1. Giới thiệu về cây 2-3-4Chúng ta sẽ xem xét các đặc tính của cây 2-3-4 và mối quan hệ khá gần gũi giữa cây 2-3-4 và cây đỏ-đen.Hình 1 trình bày một cây 2-3-4 đơn giản. Mỗi node có thể lưu trữ 1, 2 hoặc 3 mục dữ liệu.
48

Hình 1 cây 2-3-4Các số 2, 3 và 4 trong cụm từ cây 2-3-4 có ý nghĩa là khả năng có bao nhiêu liên kết đến các node con có thể có được trong một node cho trước. Đối với các node không phải là lá, có thể có 3 cách sắp xếp sau:Một node với một mục dữ liệu thì luôn luôn có 2 con.Một node với hai mục dữ liệu thì luôn luôn có 3 con.Một node với ba mục dữ liệu thì luôn luôn có 4 con.
Như vậy, một node không phải là lá phải luôn luôn có số node con nhiều hơn 1 so với số mục dữ liệu của nó. Nói cách khác, đối với mọi node với số con là k và số mục dữ
liệu là d, thì : k = d + 1
Hình 2. các trường hợp của cây 2-3-4Với mọi node lá thì không có node con nhưng có thể chứa 1, 2 hoặc 3 mục dữ liệu, không có node rỗng.Một cây 2-3-4 có thể có đến 4 cây con nên được gọi là cây nhiều nhánh bậc 4. Trong cây 2-3-4 mỗi node có ít nhất là 2 liên kết, trừ node lá (node không có liên kết nào).
49

Hình 2 trình bày các trường hợp của cây 2-3-4. Một node với 2 liên kết gọi là một 2-node, một node với 3 liên kết gọi là một 3-node, và một node với 4 liên kết gọi là một 4-node, nhưng ở đây không có node là 1-node.
2. Tổ chức cây 2-3-4Các mục dữ liệu trong mỗi node được sắp xếp theo thứ tự tăng dần từ trái sang phải (sắp xếp từ thấp đến cao).
Trong cây tìm kiếm nhị phân, tất cả node của cây con bên trái có khoá nhỏ hơn khóa của node đang xét và tất cả node của cây con bên phải có khoá lớn hơn hoặc bằng khóa của node đang xét. Trong cây 2-3-4 thì nguyên tắc cũng giống như trên, nhưng có thêm một số điểm sau:
Tất cả các node con của cây con có gốc tại node con thứ 0 thì có các giá trị khoá nhỏ hơn khoá 0.Tất cả các node con của cây con có gốc tại node con thứ 1 thì có các giá
trị khoá lớn hơn khoá 0 và nhỏ hơn khoá 1.Tất cả các node con của cây con có gốc tại node con thứ 2 thì có các giá
trị khoá lớn hơn khoá 1 và nhỏ hơn khoá 2.Tất cả các node con của cây con có gốc tại node con thứ 3 thì có các giá
trị khoá lớn hơn khoá 2.
Trong cây 2-3-4, các nút lá đều nằm trên cùng một mức. Các node ở mức trên thường không đầy đủ, nghĩa là chúng có thể chứa chỉ 1 hoặc 2 mục dữ liệu thay vì 3 mục.Lưu ý rằng cây 2-3-4 là cây cân bằng. Nó vẫn giữ được sự cân bằng khi thêm vào các phần tử có thứ tự (tăng dần hoặc giảm dần).
3. Tìm kiếmThao tác tìm kiếm trong cây 2-3-4 tương tự như thủ tục tìm kiếm trong cây nhị phân. việc tìm kiếm bắt đầu từ node gốc và chọn liên kết dẫn đến cây con với phạm vi giá trị phù hợp.Ví dụ, để tìm kiếm mục dữ liệu với khoá là 64 trên cây ở hình 1, bạn bắt đầu từ gốc. Tại node gốc không tìm thấy mục khoá này. Bởi vì 64 lớn 50, chúng ta đi đến node con 1, (60/70/80)(lưu ý node con 1 nằm bên phải, bởi vì việc đánh số của các node con và các liên kết bắt đầu tại 0 từ bên trái). Tại vị trí này vẫn không tìm thấy mục dữ liệu, vì thế phải đi đến node con tiếp theo. Tại đây bởi vì 64 lớn hơn 60 nhưng nhỏ hơn 70 nên đi tiếp đến node con 1. Tại thời điểm chúng ta tìm được mục dữ liệu đã cho với liên kết là 62/64/66.
50

4. Thêm vàoCác mục dữ liệu mới luôn luôn được chèn vào tại các node lá . Nếu mục dữ liệu được thêm vào node mà có node con, thì số lượng của các node con cần thiết phải được biến đổi để duy trì cấu trúc cho cây, đây là lý do tại sao phải có số node con nhiều hơn 1 so với các mục dữ liệu trong một nút. Việc thêm vào cây 2-3-4 trong bất cứ trường hợp nào thì quá trình cũng bắt đầu bằng cách tìm kiếm node lá phù hợp.Nếu không có node đầy nào (node có đủ 3 mục dữ liệu) được bắt gặp trong quá trình tìm kiếm, việc chèn vào khá là dễ dàng. Khi node lá phù hợp được tìm thấy, mục dữ liệu mới đơn giản là thêm vào nó. Hình 3 trình bày một mục dữ liệu với khoá 18 được thêm vào cây 2-3-4. Việc chèn vào có thể dẫn đến phải thay đổi vị trí của một hoặc hai mục dữ liệu trong node vì thế các khoá sẽ nằm với trật tự đúng sau khi mục dữ liệu mới được thêm vào. Trong ví dụ này số 23 phải được đẩy sang phải để nhường chỗ cho 18.
51
Hình 3 Chèn vào không làm tách cây(i) trước khi chèn vào(ii) sau khi chèn vào
Tách nútViệc thêm vào sẽ trở nên phức tạp hơn nếu gặp phải một node đầy (node có số mục dữ liệu đầy đủ) trên nhánh dẫn đến điểm thêm vào. Khi điều này xảy ra, node này cần thiết phải được tách ra. Quá trình tách nhằm giữ cho cây cân bằng. Loại cây 2-3-4 mà chúng ta đề cập ở đây thường được gọi là cây 2-3-4 top-down bởi vì các node được tách ra theo hướng đi xuống điểm chèn.Giả sử ta đặt tên các mục dữ liệu trên node bị phân chia là A, B và C. Sau đây là tiến trình tách (chúng ta giả sử rằng node bị tách không phải là node gốc; chúng ta sẽ kiểm tra việc tách node gốc sau này):
Một node mới (rỗng) được tạo. Nó là anh em với node sẽ được tách và được đưa vào bên phải của nó.Mục dữ liệu C được đưa vào node mới.Mục dữ liệu B được đưa vào node cha của node được tách.Mục dữ liệu A không thay đổi.Hai node con bên phải nhất bị hủy kết nối từ node được tách và kết nối
đến node mới.( Một cách khác để mô tả sự tách node là một 4-node được tách thành hai 2-nút)
Một ví dụ về việc tách node trình bày trên hình 4.
52

Hình 4: Tách một nút(i ) Trước khi chèn vào(ii) Sau khi chèn vào
Tách node gốcKhi gặp phải node gốc đầy tại thời điểm bắt đầu tìm kiếm điểm chèn, kết quả của việc tách thực hiện như sau:
Node mới được tạo ra để trở thành gốc mới và là cha của node được tách.Node mới thứ hai được tạo ra để trở thành anh em với node được tách.Mục dữ liệu C được dịch đưa sang node anh em mới.Mục dữ liệu B được dịch đưa sang node gốc mới.Mục dữ liệu A vẫn không đổi.Hai node con bên phải nhất của node được phân chia bị hủy kết nối
khỏi nó và kết nối đến node mới bên phải.
53
Hình 4.5 Tách node gốci) Trước khi thêm vàoii) Sau khi thêm vào
Hình 5 chỉ ra việc tách node gốc. Tiến trình này tạo ra một node gốc mới ở mức cao hơn mức của node gốc cũ. Kết quả là chiều cao tổng thể của cây được tăng lên 1.Đi theo node được tách này, việc tìm kiếm điểm chèn tiếp tục đi xuống phía dưới của cây. Trong hình 5 mục dữ liệu với khoá 41 được thêm vào lá phù hợp.
Tách theo hướng đi xuống Chú ý rằng, bởi vì tất cả các node đầy được tách trên đường đi xuống nên việc tách node không gây ảnh hưởng gì khi phải đi ngược lên trên của cây. Node cha của bất cứ node nào bị tách phải đảm bảo rằng không phải là node đầy, để đảm bảo node cha này có thể chấp nhận mục dữ liệu B mà không cần thiết nó phải tách ra. Tất nhiên nếu node cha này đã có hai con thì khi node con bị tách, nó sẽ trở thành node đầy. Tuy nhiên điều này chỉ có nghĩa là nó có thể sẽ bị tách ra khi lần tìm kiếm kế tiếp gặp nó.Hình 6 trình bày một loạt các thao tác chèn vào một cây rỗng. Có 4 node được tách, 2 node gốc và 2 node lá.
Thêm vào 70, 30, 50
Thêm 40
54
30, 50, 70

Thêm vào 20, 80
Thêm vào 25, 90
Thêm vào 75
Thêm vào 10
Hình 6 Minh họa thêm một node vào cây 2-3-4
5. Biến đổi cây 2-3-4 sang cây Đỏ-ĐenMột cây 2-3-4 có thể được biến đổi sang cây đỏ-đen bằng cách áp dụng các luật sau:
Biến đổi bất kỳ 2-node ở cây 2-3-4 sang node đen ở cây đỏ-đen.Biến đổi bất kỳ 3-node sang node con C (với hai con của chính nó) và
node cha P (với các node con C và node con khác). Không có vấn đề gì ở đây khi một mục trở thành node con và mục khác thành node cha. C được tô màu đỏ và P được tô màu đen.
55

Biến đổi bất kỳ 4-node sang node cha P và cả hai node con C1, C2 màu đỏ.
Hình 4.7 trình bày các chuyển đổi này. Các node con trong các cây con được tô màu đỏ; tất cả các node khác được tô màu đen.
Hình 7 Chuyển đổi từ cây 2-3-4 sang cây đỏ-đen
Hình 4.8 trình bày cây 2-3-4 và cây đỏ-đen tương ứng với nó bằng cách áp dụng các chuyển đổi này. Các đường chấm xung quanh các cây con được tạo ra từ 3-node và 4-nút. Các luật của cây đỏ-đen tự động thoả mãn với sự chuyển đổi này. Kiểm tra rằng:
56
Hai node đỏ không bao giờ được kết nối, và số lượng các node đen là như nhau ở mọi đường dẫn từ gốc đến lá (hoặc node con null).
Hình 4.8 Cây 2-3-4 và cây đỏ-đen tương ứng
Tài liệu tham khảo: 1) Data Structures, Algorithms, and Object-Oriented Programming. NXB McGraw Hill; Tác giả Gregory Heilleman -1996 2) Advanced Data Structures. NXB McGraw Hill - 1990; Tác giả Thomas H. C., Charles E.L., and Ronald L.R. 3) Giáo trình thuật toán. NXB Thống kế 2002. Nhóm Ngọc Anh Thư dịch 4) Algorithms and Data Structures in C++; Tác giả Alan Parker
Bài tập:
57