deep learning - review - pennsylvania state … · deep learning - history, background &...
TRANSCRIPT

D E E P L E A R N I N G - R E V I E WYA N N L E C U N , YO S H U A B E N G I O & G E O F F R E Y H I N T O N .

O U T L I N E
• Deep Learning - History, Background & Applications.
• Recent Revival.
• Convolutional Neural Networks.
• Recurrent Neural Networks.
• Future.

W H A T I S D E E P L E A R N I N G ?
• A particular class of Learning Algorithms.
• Rebranded Neural Networks : With multiple layers.
• Inspired by the Neuronal architecture of the Brain.
• Renewed interest in the area due to a few recent breakthroughs.
• Learn parameters from data.
• Non Linear Classification.

S O M E C O N T E X T

H I S T O R Y
• 1943 - McCulloch & Pitts develop computational model for neural network.
Idea: neurons with a binary threshold activation function were analogous to first order logic sentences.
• 1949 - Donald Hebb proposes Hebb’s rule
Idea: Neurons that fire together, wire together!
• 1958 - Frank Rosenblatt creates the Perceptron.
• 1959 - Hubel and Wiesel elaborate cells in Visual Cortex.
• 1975 - Paul J. Werbos develops the Backpropagation Algorithm.
• 1980 - Neocognitron, a hierarchical multilayered ANN.
• 1990 - Convolutional Neural Networks.

A P P L I C A T I O N S
• Predict the activity of potential drug molecules.
• Reconstruct Brain circuits.
• Predict effects of mutation on non-coding regions of DNA.
• Speech/Image Recognition & Language translation
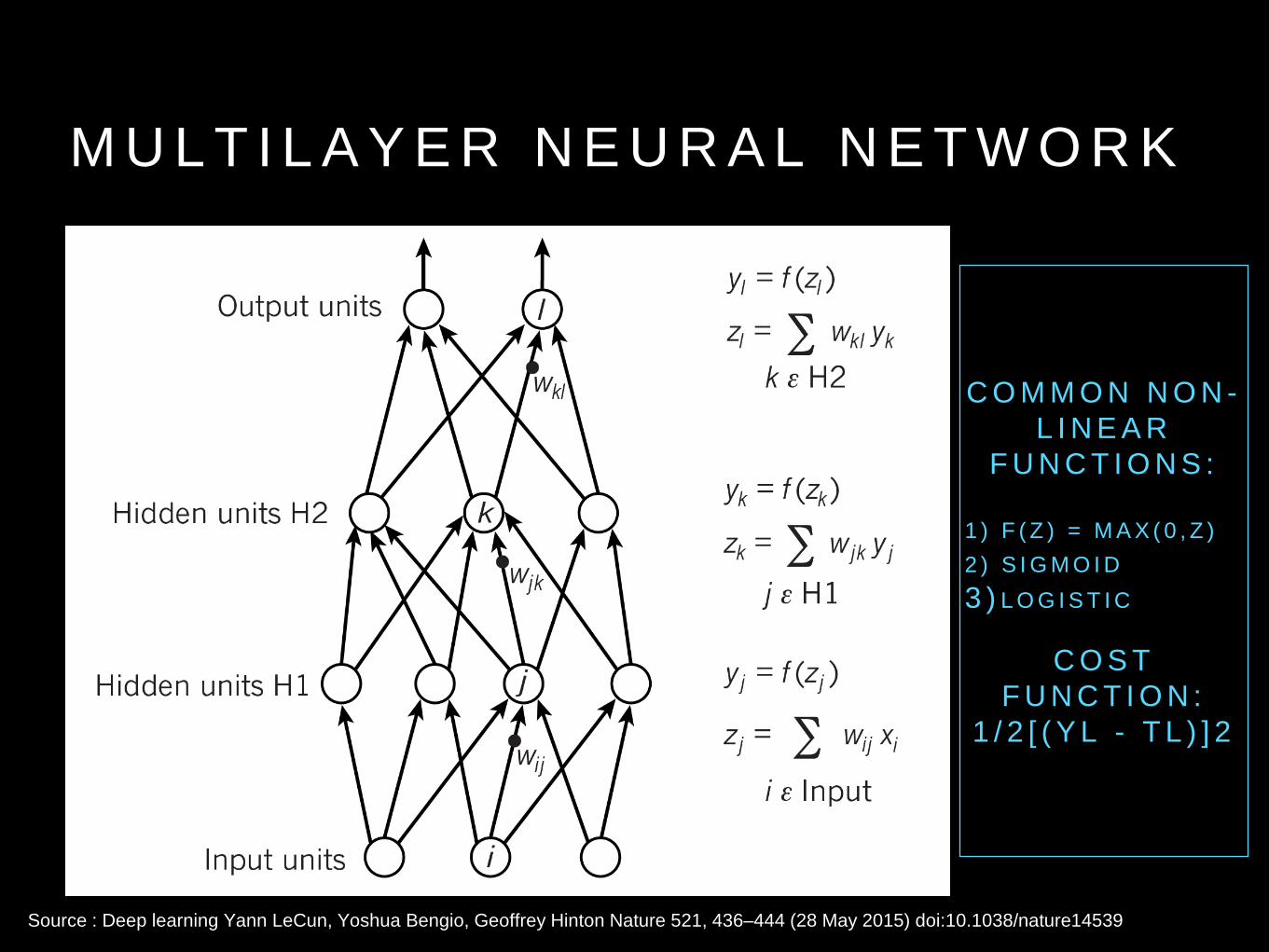
M U L T I L A Y E R N E U R A L N E T W O R K
C O M M O N N O N -L I N E A R
F U N C T I O N S :
1 ) F ( Z ) = M A X ( 0 , Z )2 ) S I G M O I D3 ) L O G I S T I C
C O S T F U N C T I O N :
1 / 2 [ ( Y L - T L ) ] 2
Source : Deep learning Yann LeCun, Yoshua Bengio, Geoffrey Hinton Nature 521, 436–444 (28 May 2015) doi:10.1038/nature14539
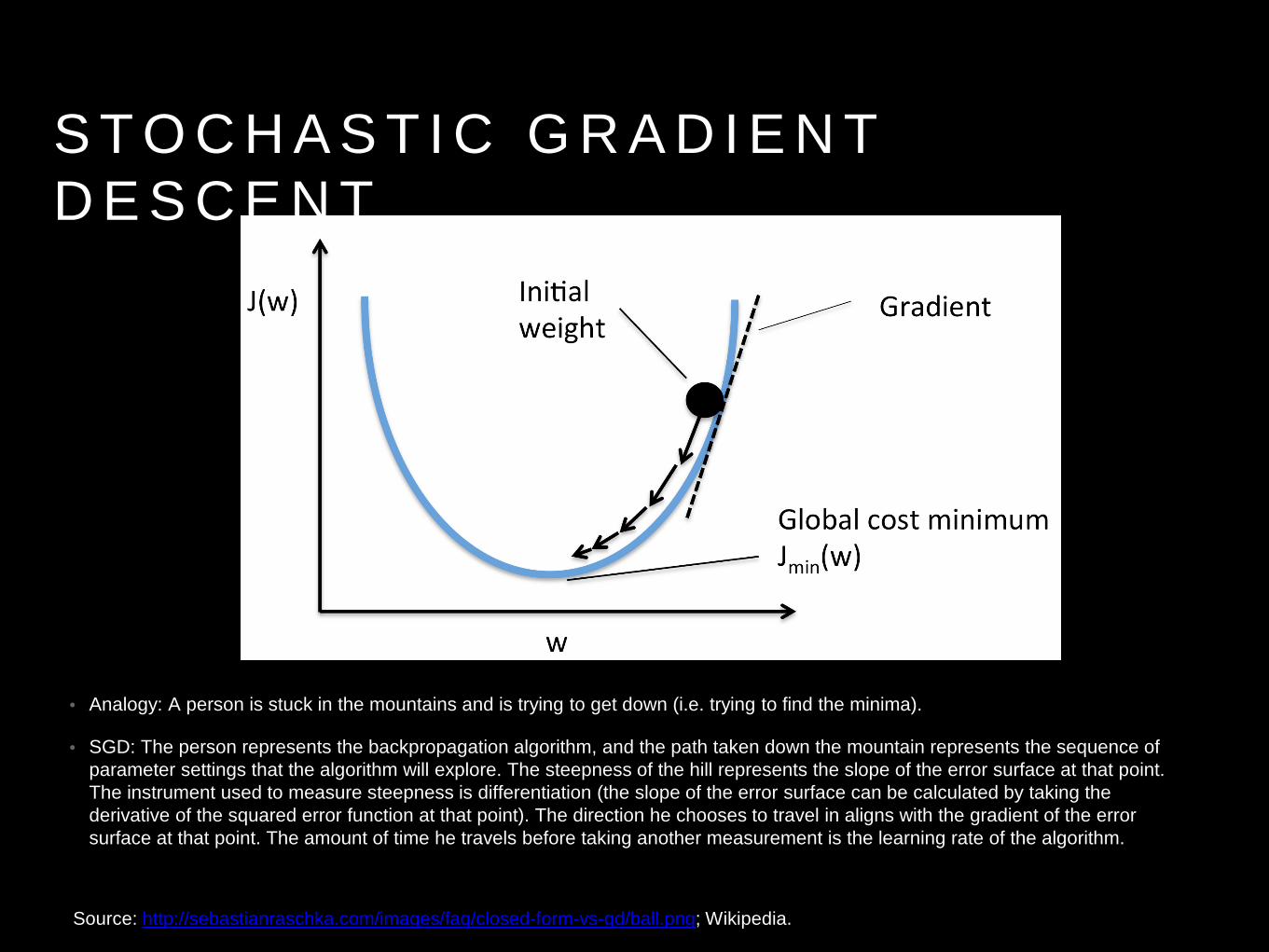
S T O C H A S T I C G R A D I E N T D E S C E N T
Source: http://sebastianraschka.com/images/faq/closed-form-vs-gd/ball.png; Wikipedia.
• Analogy: A person is stuck in the mountains and is trying to get down (i.e. trying to find the minima).
• SGD: The person represents the backpropagation algorithm, and the path taken down the mountain represents the sequence of parameter settings that the algorithm will explore. The steepness of the hill represents the slope of the error surface at that point. The instrument used to measure steepness is differentiation (the slope of the error surface can be calculated by taking the derivative of the squared error function at that point). The direction he chooses to travel in aligns with the gradient of the error surface at that point. The amount of time he travels before taking another measurement is the learning rate of the algorithm.
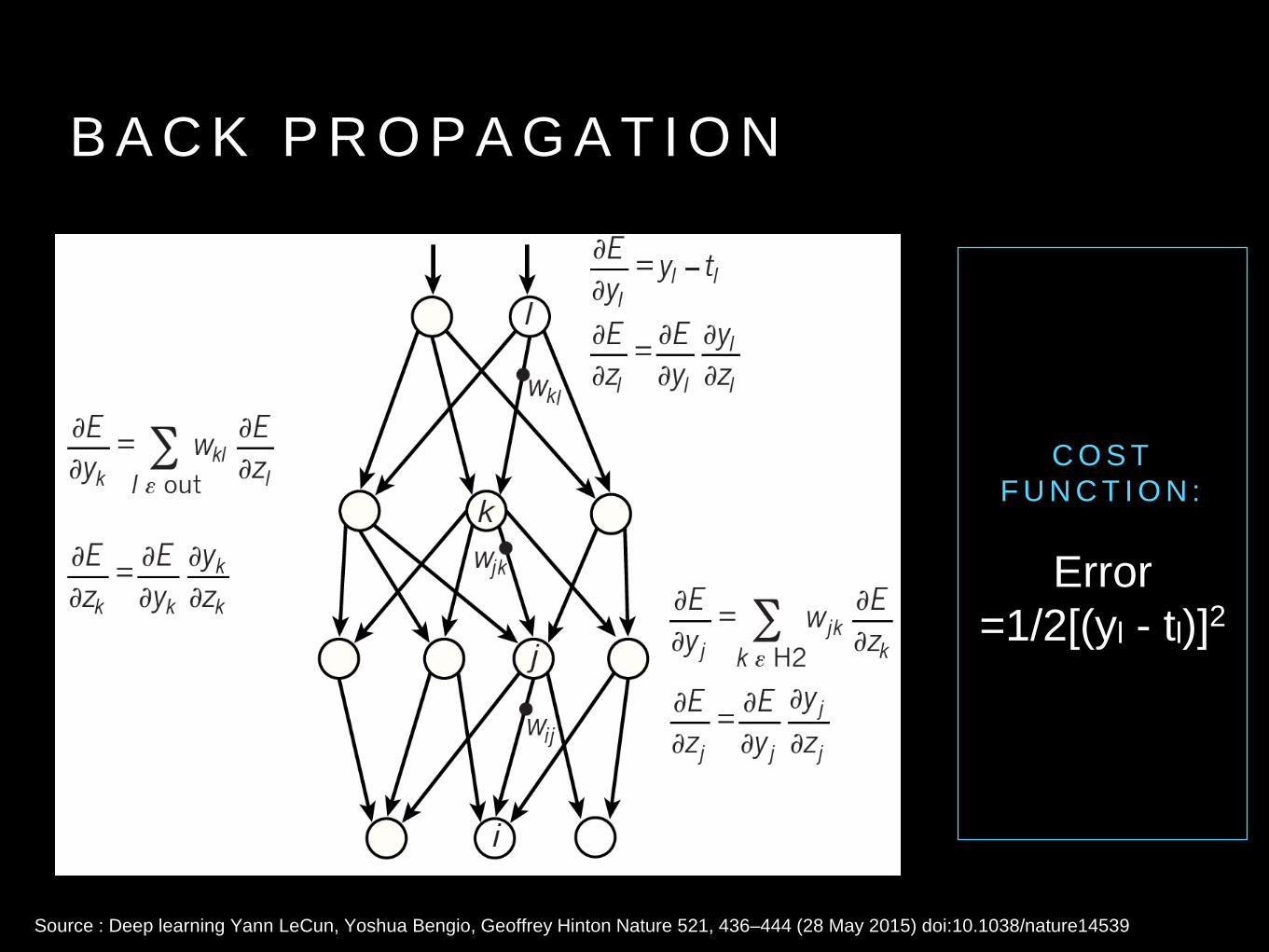
B A C K P R O P A G A T I O N
C O S T F U N C T I O N :
Error =1/2[(yl - tl)]2
Source : Deep learning Yann LeCun, Yoshua Bengio, Geoffrey Hinton Nature 521, 436–444 (28 May 2015) doi:10.1038/nature14539

W H Y A L L T H E B U Z Z ?
ImageNet:
• ~5M labeled high resolution images.
• Roughly 22K categories.
• Collected from web & labeled by Amazon Mechanical Turk
http://vision.stanford.edu/teaching/cs231b_spring1415/slides/alexnet_tugce_kyunghee.pdf
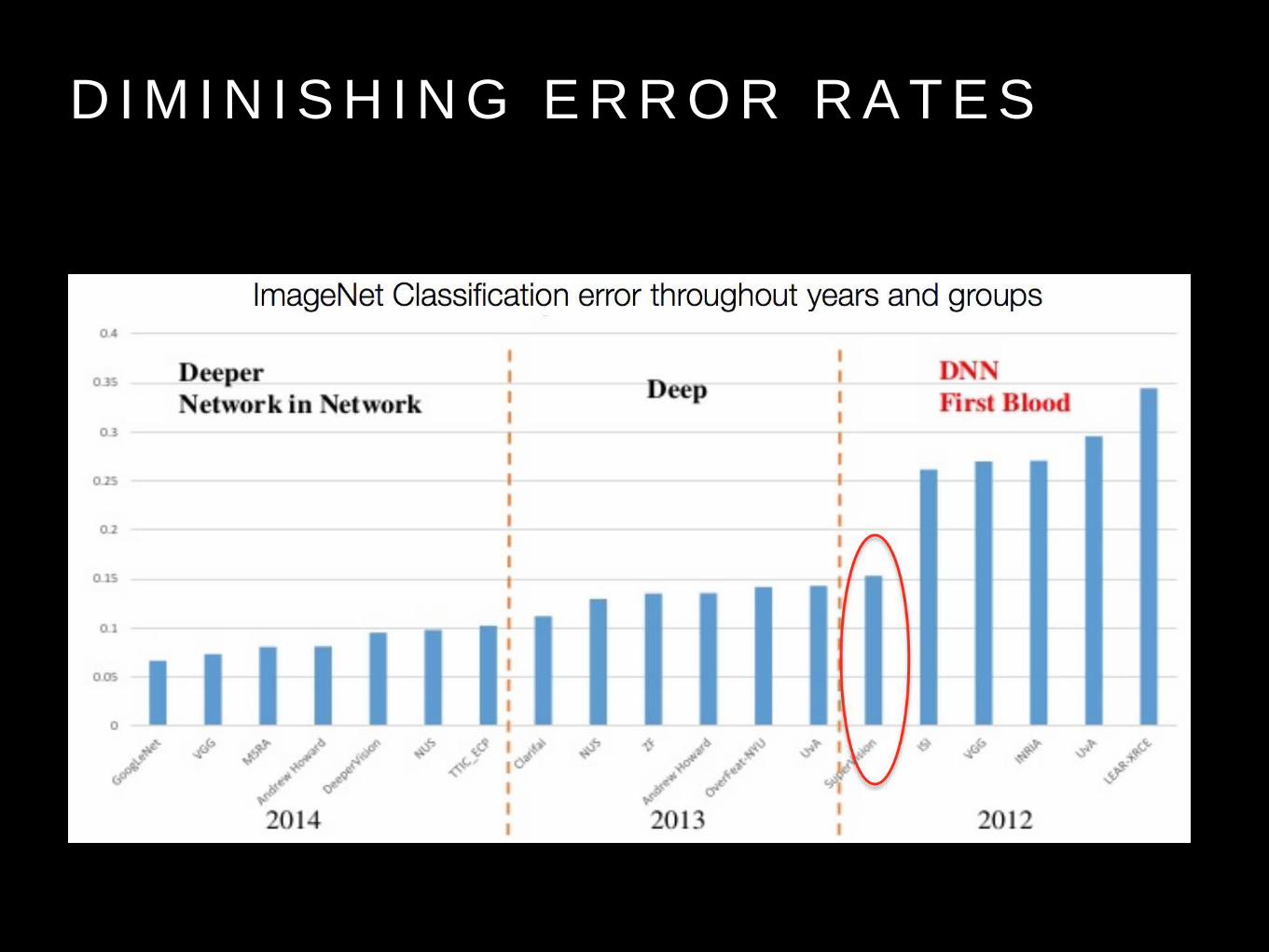
D I M I N I S H I N G E R R O R R A T E S

C O N V O L U T I O N N E U R A L N E T W O R K S - C O R E I D E A
• Color Image - 32 x 32 pixels on 3 color palettes.
• Pixel Intensity - 0 - 255.
• Image Representation : 32 * 32 * 3 array of numbers with each pixel ranging between 0 and 255.
• Idea : Feed the numerical array to a ConvNet and obtain probabilities for each class of objects as an N dimensional vector, where N is the number of classes.

C O N V O L U T I O N A L N E U R A L N E T S
• Multi stage Neural Nets that model V1,V2,V3 areas of the visual cortex.
• (Convolutional Layer + NL Layer + Pooling Layer)^n + Fully Connected Layer.
• Highly correlated local values are easily detected.
• Ideal for volumetric data that come in multiple arrays. e.g., Color images.
• Learn the ‘essence' of images well.
• Applications in Computer Vision

I N I T I A L W O R K - Y A N L E C U N
• Primitive recognition without hand coded features.
• Adaptive, yet constrained architecture.
• Hand written digit recognition served as a simple and powerful model.
• Training Sample : 9298 zip codes on mails passing through Buffalo, NY.
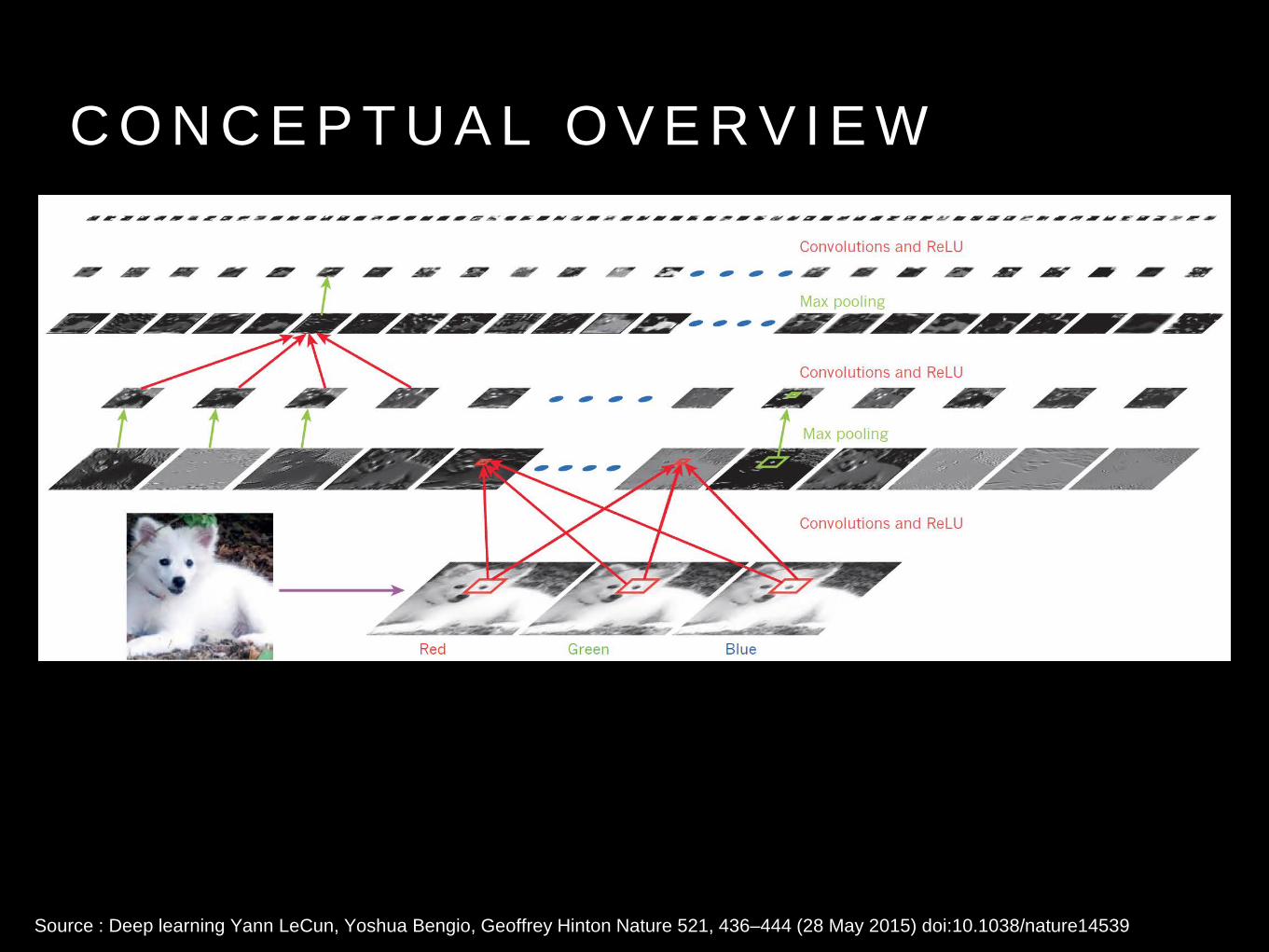
C O N C E P T U A L O V E R V I E W
Source : Deep learning Yann LeCun, Yoshua Bengio, Geoffrey Hinton Nature 521, 436–444 (28 May 2015) doi:10.1038/nature14539

W H A T I S A C O N V O L U T I O N ?
• Several meanings depending on the area of application.
• Convolution - Operation of applying filters/kernels through overlapping regions of the image.
• Stride - Extent of overlap during convolution.
• Each filter has the same set of weights and biases. This minimizes the number of parameters.
Sources: http://ufldl.stanford.edu/http://www.kdnuggets.com/2016/09/beginners-guide-understanding-convolutional-neural-networks-part-1.html

F I L T E R S / K E R N E L S
• Filters - Carefully designed feature detectors (matrices) to detect edges, curves, colors etc.
• Receptive field - Area covered by a single filter.
• 3*3 and 5*5 are the common sizes.
• Alexnet used 96 Kernels on the input layer.
http://web.pdx.edu/~jduh/courses/Archive/geog481w07/Students/Ludwig_ImageConvolution.pdf

R E L U & P O O L I N G L A Y E R S
• RELU - Applies non-linear activation function MAX(0,x) to every pixel. Other common functions include tanh and sigmoid.
• RELU - Addresses the ‘vanishing gradient problem’.
• Pooling - Reduces the spatial size and minimizes overfitting.
• MAX 2x2 is the most common pooling operation.
• Dropout - Random elimination of neurons to minimize overfitting.
• Pooling Vs. Larger Strides.
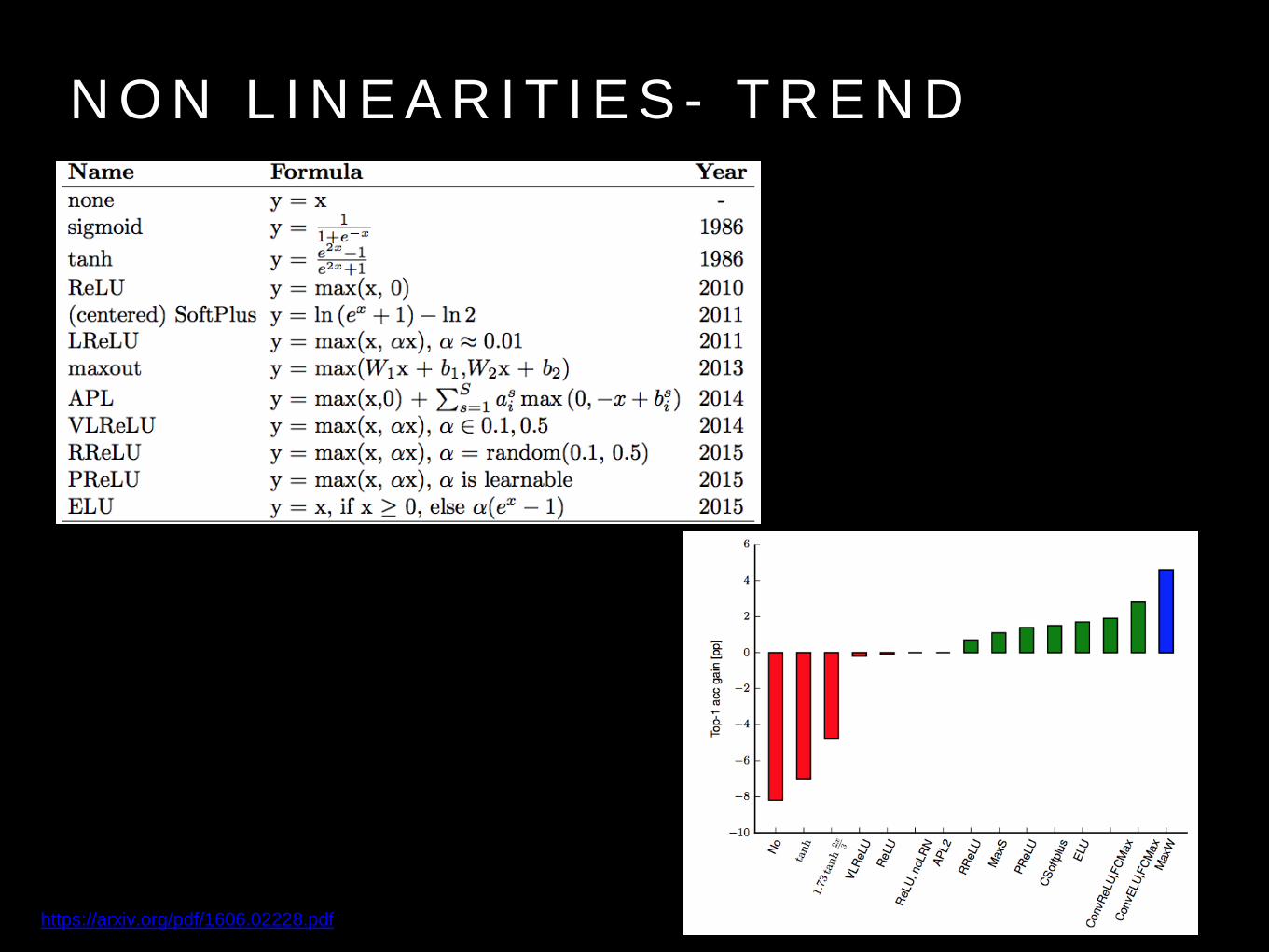
N O N L I N E A R I T I E S - T R E N D
https://arxiv.org/pdf/1606.02228.pdf
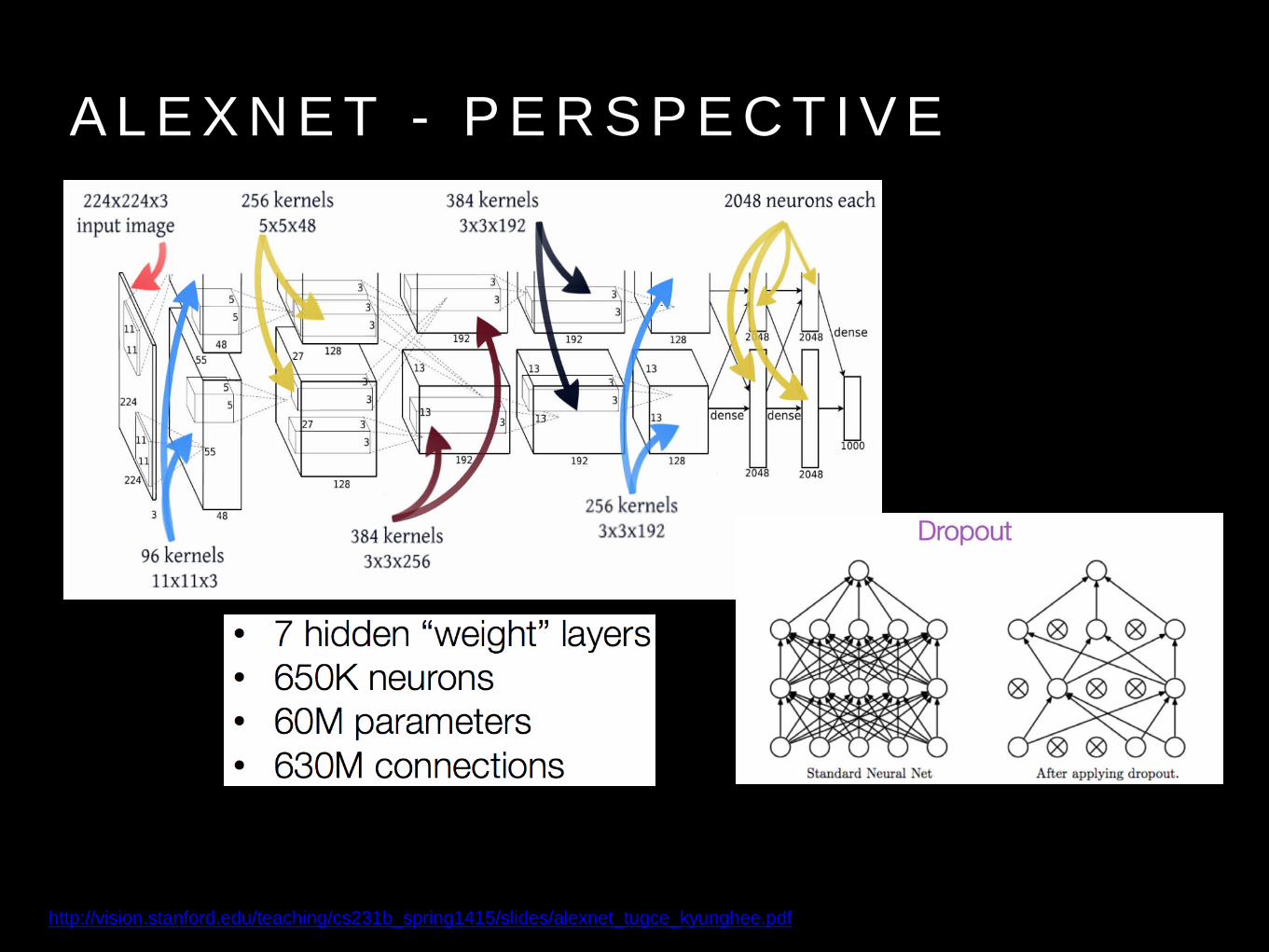
A L E X N E T - P E R S P E C T I V E
http://vision.stanford.edu/teaching/cs231b_spring1415/slides/alexnet_tugce_kyunghee.pdf

C O N V N E T S - T H E B I G P I C T U R E
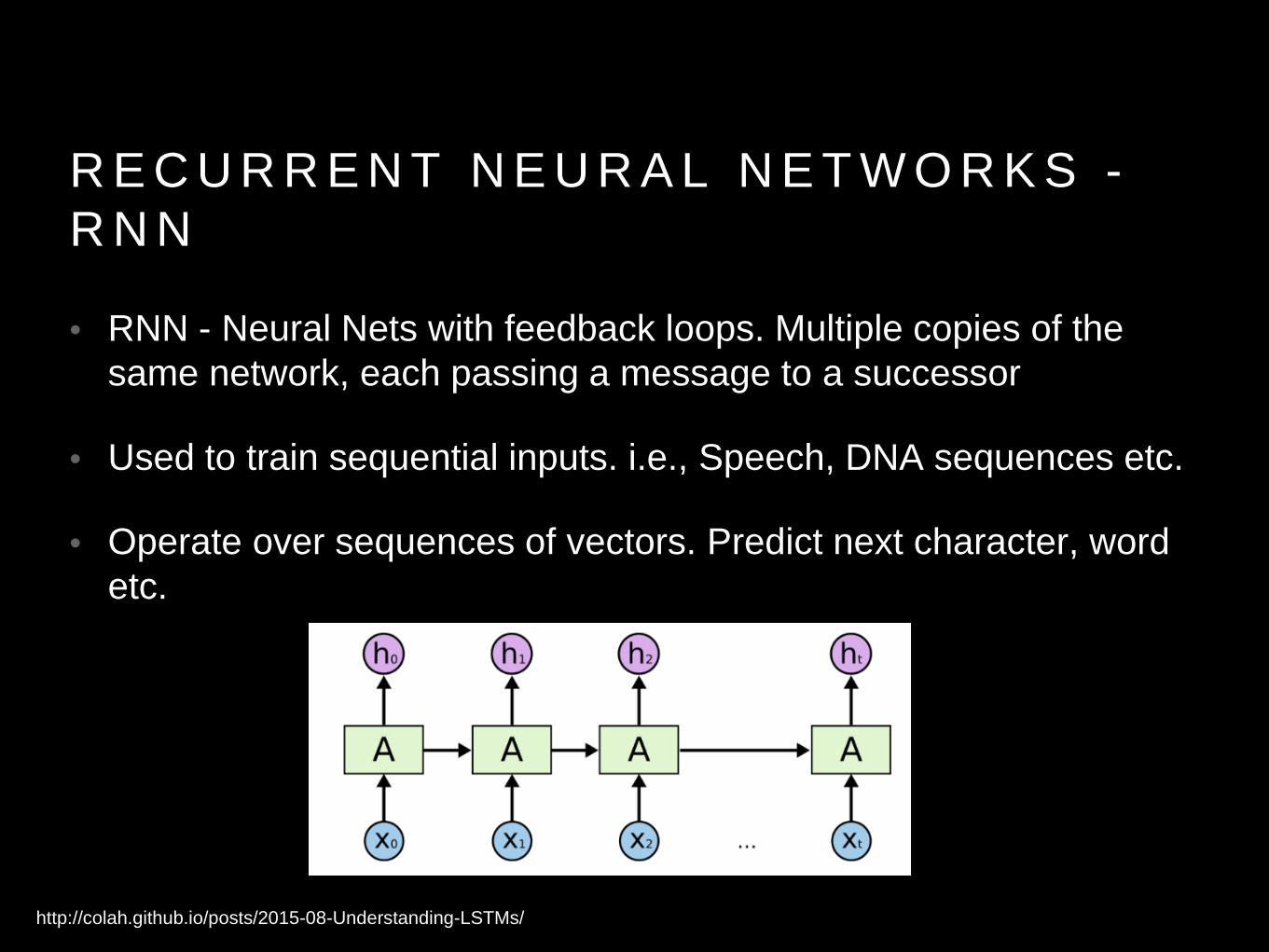
R E C U R R E N T N E U R A L N E T W O R K S -R N N
• RNN - Neural Nets with feedback loops. Multiple copies of the same network, each passing a message to a successor
• Used to train sequential inputs. i.e., Speech, DNA sequences etc.
• Operate over sequences of vectors. Predict next character, word etc.
http://colah.github.io/posts/2015-08-Understanding-LSTMs/

L O N G S H O R T T E R M M E M O R Y ( L S T M )• Sequences have long term dependencies.
Why? “the clouds are in the sky” vs. “I grew up in France… I speak fluent French.”
• Problem: Hard to store information for very long.
• Solution: LTSTM
http://colah.github.io/posts/2015-08-Understanding-LSTMs/

E X A M P L E B Y A N D R E J K A R P A T H Y
• Source : 474MB of C code from Github
• Multiple 3-layer LSTMs;
• Few days of training on GPUs
• Parameters - 10 Million.
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
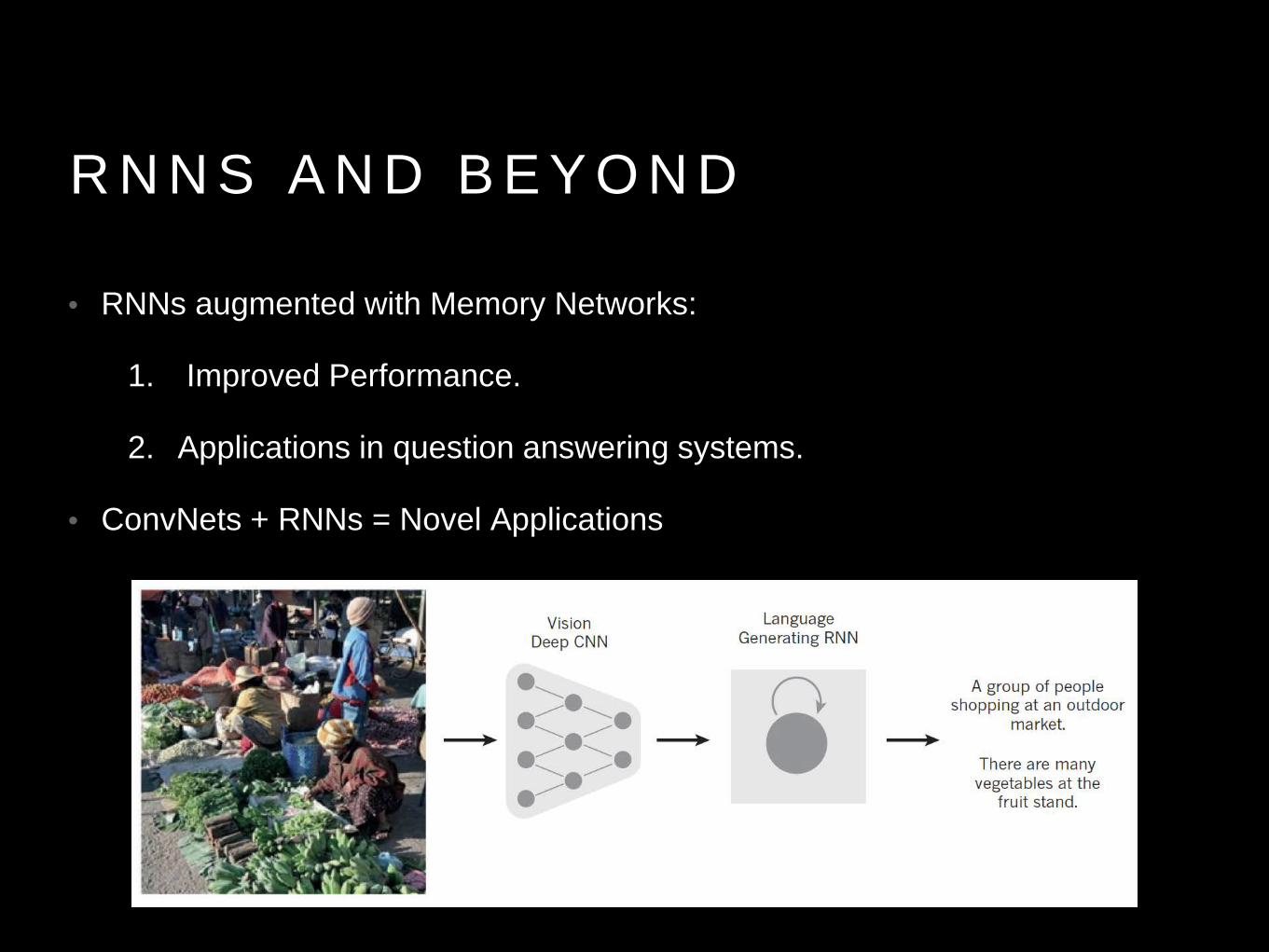
R N N S A N D B E Y O N D
• RNNs augmented with Memory Networks:
1. Improved Performance.
2. Applications in question answering systems.
• ConvNets + RNNs = Novel Applications

F U T U R E - D E E P L E A R N I N G
• Extension of recent successes from to Unsupervised Learning.
• End to End Integration :Reinforcement + Convnets + RNNs
• Natural language understanding.
• Complex systems that combine learning, memory and reasoning.
Source: https://developer.amazon.com/alexaprize

R E F E R E N C E S
• Andrej Karpathy’s Course: http://cs231n.stanford.edu/
• DeepLearning.tv : https://www.youtube.com/channel/UC9OeZkIwhzfv-_Cb7fCikLQ
• Wikipedia!