discriminatie in big data - scripties - bibliotheek
TRANSCRIPT

Discriminatie in Big Data Literatuur Review
Student: Eric Louwers Studentnummer: 11853751 Datum: 01-07-2020 Begeleider: Arjan Vreeken 2e Examinator: Imke Brummer Bachelorscriptie Informatiekunde Faculteit der Natuurwetenschappen, Wiskunde en Informatica Universiteit van Amsterdam
Abstract Discriminatie in big data is een probleem dat de wetenschap steeds meer bezighoudt. Favaretto et al hebben in 2019 een literatuur review geschreven op basis van literatuur over discriminatie in big data in de periode 2010 tot en met 2017. Deze literatuurreview vult de literatuur aan vanuit het jaar 2018. De centrale onderzoeksvraag van deze literatuur review is: “Wat zijn de nieuwste inzichten op het gebied van discriminatie in big data in het jaar 2018 en hoe verhouden deze zich tot de resultaten uit het onderzoek van Favaretto et al?” De literatuur van 2018 presenteert verschillende oorzaken, gevolgen, belemmeringen en oplossingen. De belangrijkste bevindingen zijn dat het internet of things een steeds grotere rol speelt in big data, transparantie de belangrijkste oplossing is om discriminatie te bestrijden, wetgeving rondom discriminatie in big data onvoldoende bescherming biedt en dat het anonimiseren van personen tot op heden onmogelijk blijkt. De inzichten benadrukken de complexiteit van het onderwerp en vormen geen voldoende oplossing voor de huidige en toekomstige uitdagingen. Er is dringend meer onderzoek nodig naar de bestrijding van discriminatie in big data.
Keywords: Discriminatie, Big Data, Data mining, Data Linkage, Transparantie

2
Inhoudsopgave
1. Inleiding .................................................................................................................................. 4
2. Theoretisch Kader .................................................................................................................. 5
2.1 Big data ......................................................................................................................................... 5
2.2 Discriminatie ................................................................................................................................. 7
3. Methodiek .............................................................................................................................. 9
3.1 Literatuur reviews ......................................................................................................................... 9
3.2 Selectie artikelen ......................................................................................................................... 10
3.3 Analyse artikelen ......................................................................................................................... 11
3.4 Beschrijving resultaten ................................................................................................................ 12
4. Resultaten Literatuuronderzoek .......................................................................................... 13
4.1 Literatuurselectie ........................................................................................................................ 13
4.2 Oorzaken ..................................................................................................................................... 14
4.2.1 Algoritmische fouten ........................................................................................................... 14
4.2.3 De Digitale kloof................................................................................................................... 14
4.2.4 Data linkage ......................................................................................................................... 15
4.2.5 Conclusies ............................................................................................................................ 15
4.3 Gevolgen ..................................................................................................................................... 16
4.3.1 Sociale marginalisatie en stigmatisering ............................................................................. 16
4.3.2 Verergeren van bestaande ongelijkheden........................................................................... 17
4.3.3 Economische discriminatie .................................................................................................. 17
4.3.4 Discriminatie op het gebied van gezondheidsvoorspelling ................................................. 18
4.3. Conclusies .............................................................................................................................. 18
4.4 Belemmeringen ........................................................................................................................... 19
4.4.1 Black box algoritmen ........................................................................................................... 19
4.4.2 Menselijke vooroordelen ..................................................................................................... 20
4.4.3 Conceptuele uitdagingen ..................................................................................................... 20
4.4.4 Wet- en regelgeving ............................................................................................................. 21
4.4.5 Conclusies ............................................................................................................................ 22
4.5 Oplossingen ................................................................................................................................. 23
4.5.1 Technische oplossingen ....................................................................................................... 23
4.5.2 Menselijke oplossingen ....................................................................................................... 24
4.5.3 Wet- en regelgeving ............................................................................................................. 25
4.5.4 Conclusies ............................................................................................................................ 25
5. Huidige staat van de literatuur ............................................................................................. 27

3
5.1 Focus van de literatuur ............................................................................................................... 27
5.1.1 Globale focus ....................................................................................................................... 27
5.1.2 Focus van oorzaken ............................................................................................................. 28
5.1.3 Focus van gevolgen .............................................................................................................. 28
5.1.5 Focus van de oplossingen .................................................................................................... 29
5.2 Uitdagingen uit de periode 2010 tot en met 2017 ..................................................................... 30
5.2.1 Gebrek aan een consensus van een werkbare definitie van discriminatie ......................... 30
5.2.2 Het tekort aan empirisch onderzoek ................................................................................... 31
5.2.3 Het gebrek aan het leggen van de relatie van big data vanuit de vier dimensies en discriminatie ................................................................................................................................. 32
5.2.4 De tragere snelheid van de ontwikkeling van de wetgeving ten opzichte van de ontwikkelingen van big data. ........................................................................................................ 32
5.2.5 Conclusies ............................................................................................................................ 32
5.3 Huidige Uitdagingen .................................................................................................................... 32
6. Conclusie en discussie .......................................................................................................... 33
6.1 Samenvatting van de resultaten ............................................................................................. 33
6.2 Belangrijkste resultaten .......................................................................................................... 34
6.3 Discussie.................................................................................................................................. 35
6.3.1 Limitaties en aanbevelingen ................................................................................................ 35
6.3.2 Reflectie op het onderzoeksproces ..................................................................................... 35
Referenties ............................................................................................................................... 37
Bijlage I: Geannoteerde bibliografie literatuuronderzoek ....................................................... 41

4
1. Inleiding Een van de populairste onderwerpen in de wetenschappelijke literatuur van de computerwetenschappen is ongetwijfeld big data. Big data wordt beschreven als “de kunst en wetenschap van het analyseren van enorme hoeveelheden informatie, die als doel hebben het identificeren van patronen, verkrijgen van nieuwe inzichten en het voorspellen van antwoorden op complexe problemen” (Crawford, 2013). Over de voordelen die big data onze samenleving biedt lijkt geen twijfel te bestaan. Big data wordt door velen als de drijfveer van technologische ontwikkelingen beschouwd en zou nadrukkelijk aanwezig zijn bij de ontwikkeling van de samenleving. Mayer-Schönberger en Kennedy Cukier (2013) schrijven in het boek “Big Data: A revolution that will transform how we live, work and think” dat de voordelen voor de gehele maatschappij immens zouden zijn en een deel van de oplossingen zouden zijn op globale problemen als klimaatverandering, geneeskunde en economische ontwikkeling. Naast deze voordelen brengt big data ook uitdagingen met zich mee. Voorbeelden hiervan zijn kwesties met betrekking tot privacy, veiligheid, geïnformeerde toestemming, identiteit en discriminatie (Granville, 2014, Favaretto et al., 2019 ). Het laatste is volgens Favaretto et al. (2019) onderbelicht ten opzichte van de andere uitdagingen. Favaretto et al. (2019) hebben een grootschalig literatuuronderzoek verricht dat alle artikelen met betrekking tot discriminatie en big data afkomstig uit zes grote databases heeft verzameld. De artikelen komen uit de periode van 2010 tot en met 2017. Op basis van alle relevante resultaten van deze artikelen is er geprobeerd om antwoord te geven op vragen in drie verschillende gebieden. Het eerste gebied heeft betrekking op het begrijpen van de oorzaken en gevolgen van discriminatie in big data. Het tweede gebied focust op het identificeren van de belemmeringen van eerlijke data mining en op het derde gebied staat het onderzoeken naar potentiële oplossingen voor deze belemmeringen centraal. In totaal zijn er 61 relevante onderzoeken gevonden waaruit de resultaten zijn opgenomen.
De literatuur review heeft een aantal belangrijke bevindingen opgeleverd. Ten eerste lijkt de belangrijkste humane oplossing van discriminatie in big data transparantie te zijn. Andere mogelijke oplossingen zijn vooral gericht op praktische algoritmische methoden. Verder benadrukken Favaretto et al (2019) de noodzaak voor empirische studies. Ook opmerkelijk is dat veel onderzoeken uit de periode focussen op de negatieve aspecten van big data op discriminatie, terwijl big data ook ingezet kan worden om discriminatie tegen te gaan.
In de discussie van de paper worden verschillende problemen beschreven. Allereerst zijn veel van de onderzoeken die in deze literatuur review opgenomen theoretisch van aard. Ook zijn er geen onderzoeken geweest die discriminatie volgens de traditionele dimensies onderzoeken. Bovendien is de absentie van een algemeen geaccepteerde definitie van discriminatie opmerkelijk. Veel onderzoeken behandelen de term discriminatie als duidelijk en voor zichzelf sprekend. Los van het feit dat er veel verschillende definities in verschillende gebieden voor discriminatie zijn, is dit volgens Favaretto et al. (2019) ook een probleem. Discriminatie heeft in praktijken als machine learning een heel andere betekenis dan in de volksmond. Technisch gezien komt hier veel meer bij kijken. Implementeren van ethisch verantwoorde algoritmen wordt onmogelijk zonder duidelijke definitie. Als laatste wordt het als problematisch genoemd dat de wetgeving achterloopt op de ontwikkeling, en dat deze kloof alleen maar groter dreigt te worden (Favaretto et al., 2019). Adequate oplossingen hierop zijn nog niet bekend, mede doordat mensen werkzaam in het juridische gebied vaak te weinig verstand hebben van de complexiteit van big data. Meer samenwerking op deze gebieden is vereist. Favaretto et al. (2019) laten zien dat veel problemen rondom big data en discriminatie nog niet fatsoenlijk zijn geadresseerd. Er is onvoldoende onderzoek geweest om hier adequaat een antwoord op te geven. Het is de vraag of er in de meest recente literatuur over het onderwerp discriminatie in big data aanvullingen zijn op de nu al bekende oorzaken, gevolgen, belemmeringen en oplossingen. Dit wordt in deze scriptie behandeld, waarbij de volgende centrale onderzoeksvraag wordt beantwoord: “Wat zijn de nieuwste inzichten op het gebied van discriminatie in big data in het jaar 2018 en hoe verhouden deze zich tot de resultaten uit het onderzoek van Favaretto et al. (2019)?” In deze literatuurscriptie zal informatie verzameld worden over discriminatie in big data van 2018 en vergeleken worden met de studie van Favaretto et al. (2019). Het gaat hierbij om de periode van 1 januari 2018 tot en met 31 december 2018. De deelvragen zijn geformuleerd als volgt:

5
1. Wat zijn de nieuwe inzichten rondom de oorzaken en gevolgen van discriminatie in big data en hoe verhouden deze zich tot de bevindingen van Favaretto et al. (2019)?
2. Wat zijn de nieuwe inzichten met betrekking tot belemmeringen die een eerlijke manier van het gebruik van big data hinderen en hoe verhouden deze zich tot de bevindingen van Favaretto et al (2019)?
3. Wat zijn nieuwe inzichten in mogelijke oplossingen voor deze belemmeringen en hoe verhouden deze zich tot de bevindingen van Favaretto et al. (2019)?
4. In hoeverre is de focus van het onderzoeksgebied verschoven ten opzichte van de periode 2010 tot en met 2017 vergeleken met de resultaten van deelvragen 1 tot en met 3?
5. In hoeverre zijn de problemen die aangehaald zijn in de discussie van Favaretto et al. (2019) geadresseerd? Deze deelvraag zal gesplitst worden in de volgende problemen: 5.1 Afwezigheid van een duidelijke definitie van discriminatie 5.2 Het tekort aan empirisch onderzoek 5.3 Het gebrek aan het benaderen van big data vanuit de vier dimensies, zijnde volume, snelheid,
verscheidenheid en waarheidsgetrouwheid. 5.4 De tragere snelheid van de ontwikkeling van de wetgeving ten opzichte van de ontwikkelingen
van big data. 6. Welke nieuwe uitdagingen worden geïdentificeerd in de literatuur van 2018?
In het theoretisch kader (hoofdstuk 2) wordt het onderzoek afgebakend. Hier zal big data en discriminatie uitgebreid behandeld worden. Vervolgens wordt de methodiek van het onderzoek beschreven in hoofdstuk 3. De databases worden behandeld, net als het proces van de selectie en analyse van de literatuur uit 2018. In paragraaf 4.1 worden de resultaten beschreven van de literatuurselectie.
Favaretto el al. (2019) onderzoeken drie kerngebieden. Het eerste gebied heeft betrekking op de oorzaken en gevolgen van discriminatie in big data (paragrafen 4.2 en 4.3). Het tweede onderdeel heeft betrekking op het identificeren van de belemmeringen van eerlijke data mining (paragraaf 4.4) en het derde onderdeel onderzoekt potentiële oplossingen om deze belemmeringen te verwijderen (paragraaf 4.5). Deze onderdelen vormen de basis voor de eerste drie deelvragen. In de vierde deelvraag (paragraaf 5.1) worden de resultaten van het onderzoek van Favaretto et al. (2019) vergeleken met de resultaten uit de eerste drie deelvragen, waarna er bepaald kan worden in hoeverre de focus verschoven is. Volgens Favaretto et al. (2019) ligt de focus vooral op het blootstellen van de gevaren van discriminatie in big data, verdeeld over vele toepassingen in big data. In deelvraag 5 (paragraaf 5.2) worden de problemen aangehaald die genoemd worden in de discussie. Als laatste worden er in paragraaf 5.3 nieuwe uitdagingen geïdentificeerd uit de literatuur (deelvraag 6).
2. Theoretisch Kader Het onderzoek van Favaretto et al. (2019) heeft twee kernbegrippen centraal staan. Dit zijn big data en discriminatie. Deze scriptie bouwt voort op dit onderzoek. De kernbegrippen zullen daarom overeenkomen. In dit hoofdstuk worden de kernbegrippen big data en discriminatie omschreven en toegelicht. Binnen het kader van deze omschrijvingen wordt het literatuuronderzoek uitgevoerd.
2.1 Big data
Centraal in het onderzoek staat de term big data. Crawford (2013) omschrijft, zoals in hoofdstuk 1 genoemd, big data als “de kunst en wetenschap van het analyseren van enorme hoeveelheden informatie, die als doel hebben het identificeren van patronen, verkrijgen van nieuwe inzichten en het voorspellen van antwoorden op complexe problemen”. Deze definitie is echter wat abstract en zal nader toegelicht worden in hoofdstuk 2.1.1. In essentie gaat big data over het gebruiken van de rekenkracht van computers om de exponentieel toenemende hoeveelheden informatie te verwerken en te analyseren (Wash, 2012). Hoe dit gebeurt wordt in hoofdstuk 2.1.2 behandeld. 2.1.1 Definities big data Zoals Favaretto et al (2019) aangeeft, heeft de term big data sinds haar bestaan verschillende betekenissen. Deze observatie wordt bevestigd door Ward en Baker (2013), die stellen dat de term “alomtegenwoordig” is, uiteenlopende definities heeft en dat er door verschillende belanghebbenden tegenstrijdige definities gebruikt worden.

6
De oorsprong van big data zou in eerste instantie gedefinieerd zijn door Laney (Ward en Baker, 2013) aan de hand van drie dimensies, zijnde volume, snelheid en verscheidenheid (Laney, 2001). Bij gebrek aan wetenschappelijke en gekwantificeerde onderbouwing is deze definitie herhaaldelijk herzien en is er uiteindelijk een vierde dimensie, waarheidsgetrouwheid, aan toegevoegd. In de internationale wetenschap worden deze dimensies overigens de 4 V’s genoemd, respectievelijk afgeleid van de woorden volume, velocity, variety en veracity. De dimensie volume is de omvang van data die een entiteit verzamelt of genereert (Lee, 2017). Om aan de eisen van big data te voldoen, is er een minimale drempel waaraan de omvang van de gegevens moet beantwoorden. Volgens Lee (2017) ligt deze drempel op 1 terabyte, oftewel 1000 gigabyte. Deze grens is tegenwoordig al snel bereikt. Volgens Hildebrand (2019) is de gemiddelde grootte van een uur video ongeveer 700 megabytes. Per minuut wordt er ongeveer 500 uur aan video’s geüpload op YouTube (Iqbal, 2020), wat neerkomt op 3,5 terabyte per minuut. Veel bedrijven maken dus al snel gebruik van big data. Snelheid is de tweede dimensie die genoemd wordt. Hiermee wordt de snelheid van het verwerken van de gegevens bedoeld (Lee, 2017). De snelheid van deze verwerking wordt in eerste instantie bepaald door de rekenkracht van een computer. In 1965 voorspelde Gordon Moore, medeoprichter van het bedrijf Intel, dat het aantal transistoren in een microchip elke twee jaar verdubbelt terwijl de kosten van computers gehalveerd worden (Tardi, 2019). De wet van Moore gaat dus uit van een exponentiële groei. Deze voorspelling heeft zich in de afgelopen vijftig jaar waargemaakt en wordt nu gezien als de gouden regel van technologische ontwikkeling (Mack, 2015). Omdat de rekenkracht van computers exponentieel groeit, geldt een soortgelijke ontwikkeling ook voor de snelheid van de verwerking van de gegevens. Deze dimensie kan gezien worden als de katalysator achter big data. De derde dimensie, variëteit, refereert naar het aantal verschillende gegevenstypes (Lee, 2017). Deze data types worden vervolgens geordend in drie verschillende categorieën: gestructureerde data, semi gestructureerde data en ongestructureerde data. De categorieën verwijzen naar de mate van overzichtelijkheid en ordelijkheid van de gegevens, waarbij gestructureerde data het overzichtelijkst geordend is en ongestructureerde data het minst overzichtelijk. In traditionele databases, die al enige tijd in gebruik zijn, wordt voornamelijk gestructureerde data gebruikt. Dankzij de technologische ontwikkelingen van de afgelopen jaren beschikken steeds meer computers over de mogelijkheid om semi gestructureerde data of zelfs ongestructureerde data te verwerken en te analyseren. Volgens Mayer-Schönberger en Cukier (2013) is ruim 95% van alle data semi gestructureerd of ongestructureerd. De groei van geschikte computers om dit soort ongestructureerde data te verwerken, analyseren en zelfs te produceren draagt bij aan de groei van big data. De vierde en meest recente algemeen aanvaarde dimensie is waarheidsgetrouwheid. Deze dimensie omvat de onzekerheid en onbetrouwbaarheid van data. Deze onzekerheid en onbetrouwbaarheid zou ontstaan door het incompleet registreren van gegevens, subjectiviteit omtrent de interpretatie van gegevens, latentie en het verwerken van gegevens (Lee, 2017). Verschillende statistische methoden zijn inmiddels ontwikkeld om met de waarheidsgetrouwheid in big data om te gaan. Naast de hierboven beschreven vier dimensies, zijn er door verschillende wetenschappers additionele dimensies geopperd. Volgens Gandomi en Haider (2015) geven de vier dimensies een onvoldoende beeld van de alomvattende definitie van big data. Zo stelt SAS (2012) variabiliteit en complexiteit als extra dimensies voor. Variabiliteit gaat hierbij om de notie dat informatiestromen niet constant zijn en met pieken en dalen verzameld moet worden (Gandomi en Haider, 2015). Complexiteit zou de bronnen van data omvatten. Hoe meer bronnen er tegelijkertijd geanalyseerd moeten worden, hoe complexer de gegevensstromen worden. Het databasemanagementsysteem Oracle noemt waarde als nog een extra dimensie van big data (Oracle, 2014). Met waarde wordt de economische waarde bedoeld, oftewel het deel van informatie dat bruikbaar is voor verwerking en analyse. Het zou de uitdaging van het bedrijf zijn om het onderscheid te zien tussen bruikbare en onbruikbare informatie. Omdat het steeds beter mogelijk is om ook ongestructureerde gegevens te analyseren, wordt een groot deel van onbruikbare informatie getransformeerd naar bruikbare informatie. Hoewel er nog steeds een verschil is in omvang van de waarde van bepaalde gegevens, zal de bruikbaarheid van gegevens alleen maar toenemen, en daarmee ook de economische waarde (Mayer-Schönberger en Cukier, 2013). Als laatste stelt Lee (2017) nog een dimensie voor, namelijk verval. Verval omvat het feit dat de waarde en bruikbaarheid van data na verloop van tijd vervalt. Tegelijk met de ontwikkeling van big data zal het verval van gegevens ook in een exponentiële functie uit te drukken zijn (Lee, 2017). 2.1.2 Gebruik van big data

7
In de inleiding wordt gesteld dat big data een steeds grotere rol inneemt in de samenleving. Tot voor kort was die invloed nog veel kleiner. Volgens Blauw (2018) maakt een mens al eeuwenlang gebruik van gegevens in de vorm van cijfers. Data is dus altijd al aanwezig geweest. Door de ontwikkeling van de middelen die gebruikt worden om gegevens op te vangen, zou er een toename van de invloed van deze gegevens ontstaan. Zo geven deze middelen meer betekenis aan de aanwezige gegevens (Blauw, 2018). Kijkend naar de dimensie snelheid, die mede bepaald wordt door de wet van Moore, zien we dat de omvang van onze bekwaamheid om met gegevens om te gaan exponentieel is toegenomen en dit nog steeds doet. Des te meer reden om aan te nemen dat big data in toenemende mate een centrale rol gaat spelen in de samenleving.
Volgens Mayer-Schönberger en Cukier (2013) zijn er drie verschuivingen in de manier van denken geweest. Deze verschuivingen hebben onze houding ten opzichte van gegevens veranderd en de mate van gebruik van big data beïnvloed. De eerste verschuiving heeft betrekking tot de mogelijkheid om enorme hoeveelheden informatie te kunnen analyseren en te gebruiken. Deze verschuiving houdt rechtstreeks verband met de dimensies volume en snelheid. Tot voor kort werd er vooral gebruik gemaakt van de aselecte steekproef. Een aselecte steekproef is een steekproef waarbij elk element dezelfde kans heeft om in een steekproef terecht te komen (Steekproef algemeen, 2015). Conclusies trekken op basis van een steekproef is een kenmerk van inductie (Hu, 2006). Big data doet een poging om de gehele populatie te meten, of zoals Mayer-Schönberger en Cukier (2013) het noemen: N is alles. Voorspellingen doen op basis van “N is alles” is deductie. Door het gebruik van big data vindt er een verschuiving plaats van inductie naar deductie. Er kan meer geanalyseerd worden, waardoor je mogelijk betere conclusies kan trekken. Blauw (2018) waarschuwt echter wel voor het feit dat er altijd meer data is dan dat er kan worden verwerkt, waardoor de uitspraken die gedaan worden nooit volledig deductief kunnen zijn. Omdat big data enkel correlaties geeft, en dus waarschijnlijkheidsverschijnselen, zul je nooit honderd procent accurate voorspellingen kunnen doen.
De tweede verschuiving is gebaseerd op het toelaten van rommeligheid in data. Dit staat in verband met de dimensie variëteit, waarin gestructureerde, semi gestructureerde en ongestructureerde data onderscheden wordt. Omdat 95% van alle data ongestructureerd is en big data analyses het mogelijk maken om deze ongestructureerde gegevens te gebruiken, komen we op een punt waarin vrijwel elke gegevensbron economische waarde heeft. Mayer-Schönberger en Cukier (2013) geven toe dat dit ten koste gaat van de waarheidsgetrouwheid van de gegevens, maar dat weegt volgens hen bij lange na niet op tegen de extra voordelen die het biedt om deze ongestructureerde data toch toe te laten tot de gegevensanalyses.
Als laatste wordt het toegenomen respect voor correlaties gezien als grote verschuiving in de manier waarop er tegen de gegevens wordt aangekeken. Vaak worden causale verbanden, oftewel oorzaak-gevolg relaties gezien als de beste manier om gegevens te interpreteren en te gebruiken. Er wordt hierbij gefocust op het “waarom” van de data. Big data zou zich echter niet bezighouden met de “waarom”, maar met de “wat” (Mayer-Schönberger & Cukier, 2013). Big data laat dus niet zien waarom er een verband is, maar dat er een verband is. Juist omdat de analyses steeds meer deductief van aard zijn, en dus alle beschikbare data worden meegenomen in de analyse, kun je ervan uitgaan dat de correlaties die gevonden worden optreden, ondanks de absentie van een logische verklaring. Hierdoor wordt het belang van correlaties dus groter ten opzichte van causale verbanden.
2.2 Discriminatie
Discriminatie kan gezien worden als een groot maatschappelijk probleem dat vandaag de dag veel aandacht krijgt. Het verbod op discriminatie is in artikel 1 van de Nederlandse grondwet opgenomen. Favaretto et al. (2019) merkten al op dat veel onderzochte artikelen de term discriminatie als vanzelfsprekend achtten, zonder enige definitie te geven. Vaak linkten zij discriminatie aan termen als ongelijkheid, exclusie en ongerechtigheid. In paragraaf 2.2.1 word de term discriminatie in de algemene vorm besproken. In paragraaf 2.2.2 wordt er besproken hoe discriminatie in combinatie met big data kan voorkomen. 2.2.1 Definities en toepassingen discriminatie Discriminatie lijkt al eeuwenlang in de maatschappij aanwezig te zijn. In de meest recente geschiedenis is dit op pijnlijke wijze tot uiting gekomen. Denk hierbij aan de slavernij in de zeventiende eeuw of de holocaust in de tweede wereldoorlog. De Britse socioloog Michael Banton deed een poging voor een definitie van discriminatie in 1994. Deze luidde als volgt: “Discriminatie is het maken van verboden onderscheid” (Tanja, 2019). Een definitie als deze roept echter grote vraagtekens op en is aan meerdere interpretaties onderhevig. De complexiteit van het begrip is groot. Juristen, wetgevers, sociale wetenschappers en zelfs politici hebben zich ingezet om een algemene standaarddefinitie te maken, maar zonder succes (Tanja, 2019). Ieder wetenschapsgebied werkt met anderedefinities. Wel zijn er gemeenschappelijke redeneringen die in vrijwel

8
alle gebieden gebruikt worden om de essentie van discriminatie duidelijk maken. Deze redeneringen hebben betrekking op het ‘onderscheid maken’ of ‘ongelijk behandelen’ van een of meerdere personen (Tanja, 2019).
Discriminatie komt voor in verschillende vormen. Volgens het College voor de rechten van de mens (z.d.) komt discriminatie vooral voor op het gebied van godsdienst, levensovertuiging, politieke gezindheid, ras, geslacht, nationaliteit, seksuele gerichtheid, leeftijd, handicap en burgerlijke staat. Op de hiervoor genoemde vormen is het verboden om onderscheid te maken. Dit wordt goed duidelijk in de definitie van discriminatie van het wetboek van strafrecht: “elke vorm van onderscheid, elke uitsluiting, beperking of voorkeur, die ten doel heeft of ten gevolge kan hebben dat de erkenning, het genot of de uitoefening op voet van gelijkheid van de rechten van de mens en de fundamentele vrijheden op politiek, economisch, sociaal of cultureel terrein of op andere terreinen van het maatschappelijk leven, wordt tenietgedaan of aangetast” (Artikel1, z.d.).
Discriminatie wordt, over het algemeen, gezien als iets negatiefs. Het is verboden in de grondwet en veel definities hebben een negatieve ondertoon. Echter, discriminatie hoeft niet negatief van aard te zijn. Zoals eerder beschreven is discriminatie in eerste instantie gelinkt aan onderscheid maken en ongelijke behandeling. Tanja (2019) onderstreept dat met de opvatting dat het Latijnse begrip van discriminatie (discriminatio) vooral neutraal gebruikt werd en het vooral gedefinieerd werd als onderscheid. Onderscheid maken of ongelijke behandeling is niet verboden en wordt regelmatig gedaan in de maatschappij.
Discriminatie geeft dus niet aan dat een ongelijke behandeling nadelig hoeft te zijn voor de ongelijk behandelde groep. Toch wordt het in de volksmond wel zo aangenomen. Het omgekeerde bestaat echter ook, namelijk het opzettelijk bevoordelen van bepaalde groepen mensen. Dit wordt positieve discriminatie genoemd (Tanja, 2019). Positieve discriminatie heeft verschillende doeleinden, die Waldron (2001) rechtsvaardigheidsgronden noemen. De eerste rechtvaardigheidsgrond is het herstel voor historische onrechtvaardigheden. Hierbij kun je denken aan bijvoorbeeld het opzettelijk bevoordelen voor mensen met een donkere huidskleur omdat zij in door de geschiedenis een negatief stereotype hebben gekregen. De tweede rechtsvaardigheidsgrond is de compensatie van indirecte en structurele discriminatie. Dit is de vorm van discriminatie die “op het eerste gezicht neutraal lijkt, maar waarin mensen toch benadeeld worden” (Waldron, 2001). Een voorbeeld hiervan is de discriminatie die ontstaat wanneer de voorkeur wordt gegeven aan vrouwen tijdens de sollicitaties voor topposities. Ook wordt het bevorderen van diversiteit als rechtvaardigheidsgrond gezien.
In het vervolg van het onderzoek wordt het begrip ‘discriminatie’ opgevat als het benadelen van een groep door middel van ongelijke behandeling. Als het om het bevoordelen van een groep gaat, zal de term ‘positieve discriminatie’ gebruikt worden. 2.2.2 Discriminatie in big data In paragraaf 2.2.1 wordt het fundament van discriminatie toegelicht. Zoals eerder vermeld, gebruiken verschillende gebieden andere definities voor discriminatie en bestaat er weinig consensus over het begrip, los van de rode draad van ongelijke behandeling. Deze literatuur review gaat enkel in op discriminatie in combinatie met big data. Hieronder wordt discriminatie in big data nader bekeken. Waar discriminatie in sociale contexten gemakkelijk kan worden gedetecteerd, is dit in big data veel moeilijker. Leetaru (2016) geeft aan dat big data toepassingen als machine learning al dermate complex zijn, dat de ontwikkelaars van deze algoritmen zelf niet meer begrijpen hoe de big data worden ingezet en hoe de algoritmen tot een bepaalde conclusie komen. Dit zou komen door het zelflerend vermogen van algoritmen in big data toepassingen, wat de identificatie van mogelijke gevallen van discriminatie bemoeilijkt. Het zou zomaar jaren kunnen duren voordat dergelijke gevallen aan het licht komen. Aangezien men steeds meer vertrouwt op big data toepassingen om beslissingen te nemen en deze een toenemende invloed heeft op ieder individu, kan dergelijke discriminatie grote negatieve gevolgen hebben voor een individu zonder dat het wordt opgemerkt. Op juridisch gebied worden er vaak twee vormen van discriminatie gebruikt. Dit zijn directe discriminatie en indirecte discriminatie. Directe discriminatie treedt op wanneer individuen expliciet een minder gunstige behandeling krijgen, gebaseerd op de beschermde attributen, bijvoorbeeld een sollicitant die enkel is afgewezen vanwege geslacht (Zhang et al, 2016). Indirecte discriminatie verwijst naar de situatie waar de behandeling gebaseerd lijkt te zijn op neutrale niet-beschermde attributen, maar alsnog resulteert in ongerechtvaardigd onderscheid tegen individuen van de beschermde groep (Zhang et al, 2016). Een voorbeeld hiervan is dat inwoners die een hypotheek aanvragen beoordeeld worden op hun postcode. Beide vormen van discriminatie komen voor in big data, al is directe discriminatie veel gemakkelijker op te sporen dan indirecte discriminatie. Door de complexiteit van big data blijft indirecte discriminatie vaak verborgen en wordt daardoor pas opgemerkt als de discriminatie al is voorgekomen.

9
Er zijn diverse voorbeelden te noemen waarbij mensen zijn gediscrimineerd als gevolg van het gebruik van big data. Zo proberen bedrijven te voorspellen welke personen een verhoogd gezondheidsrisico lopen. Deze informatie verkopen zij dan weer aan derden, die op basis daarvan beslissingen kunnen nemen (Gumbus & Grodzinsky, 2016). Denk hierbij bijvoorbeeld aan het aannemen van werknemers. Een ander voorbeeld is het algoritme dat Amazon heeft ontwikkeld om bedrijven de helpen bij de sollicitatieprocedure en dat bevooroordeeld was tegen vrouwen (Hamilton, 2018). Het gebrek aan vaardigheden om het algoritme te begrijpen kan er dus voor zorgen dat discriminatie te laat opgemerkt wordt, maar het laat ook zien dat deze vorm van discriminatie vaak onbedoeld is. Zo stelt Taurinskas (2016) dat het gebruik van big data door marketingbedrijven zorgt voor onbedoelde discriminatie en dat marketeers vooral van deze algoritmen af moeten blijven. Het is aannemelijk om te bedenken dat dit voor vrijwel elke sector geldt. Draaien aan de knoppen, bijvoorbeeld door middel van het beïnvloeden van bepaalde variabelen om discriminatie tegen te gaan, kan in eerste instantie misschien de gewenste resultaten opleveren, maar dit kan op termijn juist leiden tot meer discriminatie. Omdat er in de laatste jaren steeds meer gevallen van discriminatie als gevolg van big data aan het licht zijn gekomen, heeft discriminatie in big data zich ontwikkeld tot een maatschappelijke kwestie. Overheden proberen de maatschappij hiertegen te beschermen door middel van wet en regelgeving omtrent big data. Regulering zou weinig effect hebben tegen deze vorm van discriminatie. In sommige gevallen zou dit zelfs averechts werken, blijkt uit de resultaten van het onderzoek van Favaretto et al. (2019). Daarnaast zou de wetgeving altijd achterlopen op de technologische ontwikkelingen op het gebied van big data, waardoor gepaste wetten simpelweg niet mogelijk zijn (Favaretto et al, 2019).
Discriminatie die voorkomt bij het gebruik van big data verschilt dus van discriminatie in het algemeen. Er kan gesteld worden dat discriminatie in big data een complexer probleem is, omdat het moeilijker te identificeren is, algoritmen te complex zijn en daarom ook de regelgeving achterloopt op de technologische ontwikkelingen. Door de toenemende rol van big data krijgen de ontwikkelaars van de algoritmen automatisch een grotere rol, omdat zij de keuzes moeten maken in ethische dilemma’s.
3. Methodiek In dit onderdeel wordt de methodiek van het onderzoek beschreven. Het onderzoek is een literatuur review. In de eerste paragraaf wordt term literatuur review besproken. Hier wordt ingegaan op de eigenschappen van de methode en waarom deze methode van belang is in de wetenschap. Vervolgens worden de databases die geselecteerd zijn voor de scriptie toegelicht. Ook de zoektermen die gebruikt worden in het onderzoek worden beschreven. Als laatste wordt het stappenplan besproken betreffende de uitvoering van het onderzoek.
3.1 Literatuur reviews
3.1.1 Definities literatuur review
Een literatuur review wordt door Marshall (2010) beschreven als “een systematische methode voor het identificeren, evalueren en het interpreteren van werk van onderzoekers, geleerden en wetenschappers”. Het is een belangrijke methode op elk wetenschapsgebied, omdat het handvaten en overzicht bieden van het wetenschapsgebied. Schryen et al. (2020) onderschrijven dat het bij een literatuur review niet enkel gaat om een samenvatting van de huidige stand van zaken, maar ook om de interpretatie ervan. Abrams (2012) beschrijft drie doelen die een literatuur review kan nastreven. In het eerste doel wil de onderzoeker laten zien wat er allemaal geschreven is over een bepaald onderwerp. Dit heeft vooral een informatieve functie. Ten tweede kan er geïllustreerd worden hoe de bestaande literatuur een bepaald probleemgebied aanpakt. Deze doelstelling wordt volgens Abrams (2012) vooral gebruikt om de huidige staat van de literatuur te beschrijven zonder dat hiervoor een centrale onderzoeksvraag voor gesteld is. Als laatste doelstelling beschrijft Abrams (2012) dat een literatuur review een uitstekend startpunt is voor een onderzoek in de betreffende discipline. Een literatuur review wordt hier gebruikt door onderzoekers om bekend te raken met het veld waarin zij zich begeven. Kortom, de literatuur review is belangrijk om een duidelijk overzicht te krijgen van de literatuur op een bepaald gebied en vormt een startpunt voor gedegen vervolgonderzoek. Volgens Baker (2016) vormt een goed uitgevoerde literatuur review een solide basis voor wetenschappelijke consensus. Deze scriptie bouwt voort op de literatuur review van Favaretto et al. (2019). Het gaat hierbij om de literatuur van dezelfde categorie, namelijk discriminatie in big data. Deze scriptie beschrijft en interpreteert de

10
huidige stand van zaken en legt ontwikkelingen en uitdagingen bloot. Ook wordt er aandacht besteed aan de probleemgebieden rondom het onderwerp, waardoor de aanpak van problemen ook geadresseerd worden. 3.1.2 Literatuur reviews in big data Favaretto et al. (2019) noemen dat de omvang van de literatuur op het gebied van in big data snel toeneemt, maar dat er een tekort is aan consensus en literatuur reviews of het gebied van big data. Schryen et al (2020) versterkt deze observatie door te stellen dat het overzicht op het gebied van informatiesystemen verdwenen is en dat er daardoor weinig vooruitgang is. Dit ondanks de enorme toename van onderzoek op het gebied. Ook zouden de meeste literatuur reviews betrekking hebben op de evaluatie en het gebruik van informatiesystemen. Zo zou er nog te weinig aandacht zijn aan de uitdagingen van deze systemen (Schryen et al, 2020). Favaretto et al. (2019) stellen dat van de onderzoeken die zijn gedaan op het gebied van de gevaren van informatiesystemen, er te weinig papers naar discriminatie in big data verwijzen. Zelfs met de toevoeging van hun onderzoek is discriminatie in big data nog ondergrepresenteerd. Deze scriptie is een toevoeging op de bestaande literatuur op het gebied van discriminatie in algoritmen.
3.2 Selectie artikelen
3.2.1 Databases De databases die gebruikt worden zijn PsychInfo, PhilPapers, Cinhal, Pubmed, SocIndex en Web of Science. Deze databases worden in eerste instantie gebruikt omdat ze ook gebruikt worden in het onderzoek van Favaretto et al. (2019). Het doel van dit literatuuronderzoek is om zo dicht mogelijk bij het onderzoek van Favaretto et al. (2019) te blijven. PsychInfo is een Amerikaanse database waar onderzoeken op staan rondom de discipline psychologie. Ook worden hier onderzoeken gepubliceerd van verwante gebieden, waaronder interdisciplinaire gebieden. Discriminatie in big data heeft raakvlakken met het type onderzoeken wat PsychInfo aanbiedt, wat het een geschikte database maakt. Philpapers is een internationale database die gepubliceerde tijdschriftartikelen aanbieden op het gebied van filosofie. Discriminatie en big data hebben ook filosofische aspecten, waardoor deze ook gebruikt kan worden in de review. Cinahl en Pubmed zijn databases met artikelen over de zorg, inclusief gezondheidszorg. Discriminatie valt hier ook onder. SocIndex is een database die artikelen aanbiedt op het gebied van sociologie. Deze database heeft veel raakvlakken met discriminatie, omdat hier veel studies gepubliceerd zijn over ras, ongelijkheid en sociale psychologie. Als laatste wordt Web of Science gebruikt als database voor dit onderzoek. Web of Science biedt artikelen aan uit disciplines van onder andere sociale wetenschappen en geesteswetenschappen. Web of Science wordt door officiële organisaties gebruikt, wat het een betrouwbare database maakt.
3.2.2 Zoektermen In het onderzoek wordt gezocht op diverse zoektermen in de databases die genoemd zijn in paragraaf 3.2 De belangrijkste zoektermen zijn “discrimination” en “big data”. Favaretto et al. (2019) noemen daarnaast nog de zoektermen “digital data”, “data mining”, “data linkage”, “equality”, “vulnerab*”, “justice”, “ethic” en “exclusion”. Deze zoektermen worden ook voor dit onderzoek gebruikt. Verder is gezocht op synoniemen van big data en discriminatie. Resulterend worden de zoektermen “favoratism”, “injustice”, “bigotry” toegevoegd aan de zoekopdrachten. Filters worden ingesteld op de periode 1 januari 2018 tot en met 31 december 2018. Daarnaast wordt er enkel gezocht op Engelstalige onderzoeken. Restricties op disciplines worden, net als in het originele literatuuronderzoek van Favaretto et al. (2019), niet gespecificeerd. Dit betekent dat elk onderzoek van discriminatie in big data wordt meegenomen in de selectie, en niet alleen onderzoeken in bepaalde disciplines. De reden hiervan is om zoveel mogelijk studies te omvatten die discriminatie in big data in zijn algemeenheid behandelen.
Er wordt gebruik gemaakt van de AND-operator om de termen big data en discriminatie te verbinden. Voor de verschillende termen van big data wordt de OR-operator gebruikt. Zo komen alle zoekwoorden die te maken hebben met big data in combinatie met alle zoekwoorden die betrekking hebben op discriminatie voor in de zoekresultaten. 3.2.3 Bepaling definitieve selectie De definitieve selectie van de artikelen wordt geselecteerd volgens de PRISMA flowchart methode. De PRSIMA flowchart is een methode die auteurs helpt met de verslaglegging van meta-analyses en literatuur reviews (Health Sciences Library, 2020). De flowchart kent vier opeenvolgende fases. Dit zijn identificatie, screening, verkiesbaarheid en definitieve selectie.

11
De identificatiefase bevatten alle resultaten die naar boven komen op basis van de in 3.2.2 geformuleerde zoekwoorden. De resultaten die hier verzameld worden zijn niet allemaal bruikbaar. De bruikbaarheid wordt in de volgende fases beoordeeld. De tweede fase is de screeningfase. Hier worden alle duplicaten verwijderd en genoteerd. De unieke artikelen gaan door naar de verkiesbaarheidsfase. In deze fase wordt de abstract gelezen en beoordeeld. De artikelen die niet bijdragen worden verwijderd uit de selectie.
Als laatste wordt definitieve selectie aan papers opgeslagen. De artikelen worden opgeslagen met de naam van de auteur, gevolgd door de titel van het artikel.
3.3 Analyse artikelen
Alle definitief geselecteerde artikelen worden inhoudelijk geanalyseerd. De analyse wordt uitgevoerd met Atlas TI. Dit is een softwareprogramma dat geschikt is voor het uitvoeren van kwalitatief onderzoek. Atlas TI bevat veel functies, maar niet elke functie is relevant voor het literatuuronderzoek. Om erachter te komen welke functies het meest effectief zijn, wordt er een pilot uitgevoerd met een klein aantal artikelen uit de definitieve selectie. In de pilot worden diverse functies getest op de artikelen. Op basis van de resultaten van de pilot wordt er een definitieve aanpak voor de analyse bepaald. 3.3.1 Opzet Pilot Voor de pilot worden vijf artikelen geanalyseerd afkomstig uit de definitieve selectie. Er worden diverse functies getest op basis van deze artikelen. De basisfuncties, zoals het maken van memo’s en annotaties, worden gebruikt. Ook worden er functies gebruikt die betrekking hebben op het coderen van de artikelen. Codes geven het onderwerp van de geselecteerde tekst aan en kunnen gemakkelijk worden teruggevonden bij de beschrijving van de resultaten. Ook is het mogelijk om codegroepen te definiëren. In tabel 3.1 staan de gemaakte codegroepen weergegeven. Normale codes worden aangegeven met een voorvoegsel. Een voorbeeld van een dergelijke code is: “oorzaak: kennis algoritmen”. Ook wordt er gebruik gemaakt van documentgroepen. Afzonderlijke documenten kunnen hierbij toegedeeld worden aan een groep. De documentgroepen zijn hetzelfde als de codegroepen.
De volgende functie die getest wordt is de code-document tabel. Dit is een toepassing die codes tegenover verschillende documenten zet, en daarmee descriptieve resultaten laat zien. Ook zal er gebruik worden gemaakt van netwerken. Atlas TI biedt de mogelijkheid om netwerken te creëren die codes, annotaties en documenten visueel kan weergeven. De pilot onderzoekt of een dergelijke visualisatie nuttig is.
In het onderzoek wordt er gebruik gemaakt van een geannoteerde bibliografie. Een geannoteerde bibliografie is een lijst met citaten, inclusief een korte samenvatting van ongeveer 150 woorden (Engle, 2020). Het gebruik van een geannoteerde bibliografie geeft de auteur de mogelijkheid om gemakkelijk te zoeken in de geselecteerde literatuur en geeft de lezer een naslagwerk in relatie met de beschrijving van de resultaten. De geannoteerde bibliografie kan ook worden bijgehouden in Atlas TI. Dit zal ook getest worden.
Als laatste worden de word Cloud functie en de auto coding functie toegepast. De word Cloud functie laat de meest voorkomende woorden van een document zien. Automatisch coderen is een functie die gemakkelijk te gebruiken is met de word Cloud functie. Deze functie zoekt in het document een opgegeven woord, bijvoorbeeld afkomstig uit de word Cloud, en navigeert naar elk woord, elke zin of elke paragraaf waarin het voorkomt. Deze kan automatisch een code toegewezen krijgen na een korte inspectie van de zin of alinea. Dit zou veel tijdwinst op kunnen leveren.
3.3.2 Resultaten pilot In de pilot zijn vijf geselecteerde artikelen inhoudelijk geanalyseerd door middel van Atlas TI. Alle functies, zoals besproken in paragraaf 3.3.1 zijn getest. De resultaten van de pilot worden hier besproken. Het automatisch coderen is geen functie die gebruikt gaat worden in het vervolg van het onderzoek. Er zitten veel irrelevante codevoorstellen in de artikelen, waardoor het teveel tijd kost om de functie te gebruiken. Daarnaast wordt er na het automatisch coderen nog afzonderlijk over het hele document
Code- en documentgroepen
Deelvraag 1: Oorzaken en Gevolgen
Deelvraag 2: Belemmeringen
Deelvaag 3: Oplossingen
Deelvraag 5: Problematiek Favaretto
Deelvraag 6: Nieuwe uitdagingen
Tabel 3.1: Code- en documentgroepen pilot

12
gecodeerd. Het kost teveel tijd om dit allebei te doen en de voordelen zijn minimaal. Wel is er veel gebruik gemaakt van de word Cloud functie. Niet als basis voor het automatisch coderen, maar om een globale indruk te krijgen over de inhoud en bruikbaarheid van het artikel. Als termen zoals discriminatie en data mining veel voorkomen, is de relevantie vaak hoger dan wanneer deze termen minder vaak voorkomen. Het coderen van de artikelen is erg nuttig gebleken. Met een consistente codering kun je in één oogopslag zien bij welke deelvraag de code hoort. Wel kan het aantal codes flink oplopen, wat ten koste kan gaan in het overzicht. Daarom is er besloten dat tekstdelen die betrekking hebben op de inhoud van het artikel, maar niet zozeer bijdragen aan de scriptie, met vrije annotaties vast te leggen. Ook het toewijzen van codes aan codegroepen blijkt nuttig te zijn. Enkele additionele codegroepen zijn toegevoegd, namelijk “Big data: algemeen” en “Discriminatie: algemeen”. Deze codes hebben betrekking op de algemene opvattingen van big data en discriminatie. Favaretto et al. (2019) merken op dat er weinig aandacht is over de definitie van big data en discriminatie. Door middel van deze code omvat je dit, waarna ze vergeleken kunnen worden met de observaties van Favaretto et al. (2019). Daarnaast is het gebruik van kleuren per codegroep overzichtelijk gebleken.
Het werken met documentgroepen die dezelfde naam hebben als de codegroepen is overbodig gebleken. Wel is er besloten om de documentgroepen de naam te geven van de discipline waarin het onderzoek zich bevindt. De documentgroepen die nu zijn geïdentificeerd zijn criminaliteit, financieel, medisch en sociaal. Daarnaast is er een algemene groep die alle artikelen omvat zonder specifieke discipline. Op deze manier kunnen er uitspraken gedaan worden over de verschillen in disciplines. Het bijhouden van een geannoteerde bibliografie is onbruikbaar. Atlas TI kan enkel referenties importeren met een XML-formaat. Het exporteren van referenties in XML-formaat vanuit de database werkt niet naar behoren, waardoor de hele functie onbruikbaar wordt. De geannoteerde bibliografie wordt in een apart Word document bijgehouden. Annotaties worden wel gemaakt in Atlas TI in de vorm van een opmerking bij het artikel. Daarnaast is de netwerkfunctie nuttig gebleken voor het onderzoek. Voor de pilot heeft de functie geholpen om codes en codegroepen op een overzichtelijke manier te illustreren, waardoor er gemakkelijk genavigeerd kan worden naar de plek van codering in het document. Daarmee zorgt het netwerk voor een beknopte samenvatting van de analyse. De code-document tabel is ook gebruikt. Deze zegt in de pilot nog niet veel, maar is veelbelovend voor het definitieve onderzoek. Er kan gemakkelijk geschakeld worden met codegroepen en documentgroepen, waardoor je snel kan zien welke artikelen of documentgroepen bijdragen aan de beantwoording van de centrale onderzoeksvraag. Daarnaast kost het gebruik van de functie weinig tijd.
3.4 Beschrijving resultaten
Na de analyse worden de resultaten beschreven. Allereerst zullen de oorzaken en gevolgen van discriminatie in big data besproken worden (deelvraag 1). Daarna worden de belemmeringen geïdentificeerd (deelvraag 2), gevolgd door de mogelijke oplossingen (deelvraag 3). Geïntegreerd in deze onderdelen is ook de vergelijking met de resultaten van het onderzoek van Favaretto et al. (2019). De tabellen die Favaretto et al. (2019) gebruiken om de oorzaken, gevolgen, obstakels en oplossingen samen te vatten worden hierbij aangevuld met de nieuwe inzichten uit de literatuur van 2018. Daarna worden de descriptieve resultaten van beide perioden vergeleken om te bepalen of de focus in de laatste jaren verschoven is (deelvraag 4). Dit gebeurt aan de hand van het vergelijken van de resultaten van deelvragen 1 tot en met 3 met de resultaten van Favaretto et al. (2019). Er worden conclusies getrokken over een eventuele verschuiving van de focus van het onderzoeksgebied. Als laatste wordt er een deel gewijd in hoeverre de problemen die zijn aangehaald in de discussie van het onderzoek van Favaretto et al. (2019) op adequate wijze zijn geadresseerd (deelvraag 5). De problemen die hier worden aangehaald zijn het gebruik van de definitie van discriminatie (5.1), het tekort aan empirisch onderzoek (5.2), het gebrek aan de benadering van big data aan de hand van de vier dimensies (5.3), en de snelheid van de ontwikkeling van de wetgeving op het gebied van big data ten opzichte van de technologische ontwikkeling van big data (5.4). De verschillende problemen worden als aparte onderdelen van de vijfde deelvraag beantwoord. Als laatste worden eventuele nieuwe uitdagingen geïdentificeerd die de literatuur aanhaalt (deelvraag 6).
De antwoorden van de deelvragen vormen het antwoord op de centrale onderzoeksvraag. Dit zal behandeld worden in de conclusie van de scriptie. Uiteraard zullen de beperkingen van het literatuuronderzoek aangehaald worden en wordt er een uitspraak gedaan over mogelijk toekomstig onderzoek op het gebied van discriminatie in big data. Ook wordt er gereflecteerd op het onderzoeksproces.

13
4. Resultaten Literatuuronderzoek In dit hoofdstuk worden de resultaten van het literatuuronderzoek besproken. De eerste paragraaf is gewijd aan de manier waarop artikelen verzameld zijn en welke artikelen uiteindelijk geanalyseerd zijn. In paragraaf 4.2 worden de oorzaken besproken uit de geanalyseerde literatuur van 2018. Paragraaf 4.3 richt zich op de gevolgen ervan. In deze paragraaf wordt de eerste deelvraag beantwoord. In paragraaf 4.4 worden de belemmeringen beschreven met betrekking tot discriminatie in big data en paragraaf 4.5 bespreekt de oplossingen ervan. In paragraaf 4.4 wordt de tweede deelvraag beantwoord en in paragraaf 4.5 wordt de derde deelvraag beantwoord.
4.1 Literatuurselectie In figuur 4.1 is de PRISMA Flowchart afgebeeld. Na het toepassen van de zoekwoorden en de filters hebben de databases gezamenlijk 2258 resultaten opgeleverd. Ruim de helft van de resultaten (1150 resultaten) zijn afkomstig van de database Web of Science. Meer dan de helft van de artikelen die uiteindelijk zijn geanalyseerd zijn afkomstig van deze database. PubMed produceerde 579 resultaten, gevolgd door 329 resultaten van CINAHL, 102 van SocIndex, 72 van PhilPapers en 26 van PsychInfo. Vervolgens zijn de artikelen beoordeeld op de titel, sleutelwoorden en abstract. 48 artikelen zijn in potentie bruikbaar voor het onderzoek en opgeslagen. Hier zitten geen duplicaten bij. Van de 48 artikelen zijn 23 artikelen uitgesloten voor geschiktheid. Twee van deze artikelen zijn duplicaten. Daarnaast vallen een aantal artikelen buiten het kader van het onderzoek. Deze onderzoeken komen vooral uit de geneeskunde, waarin toepassingen ontworpen zijn die juist op zoek gaan naar discriminatieve variabelen. In deze papers wordt dus positieve discriminatie als doel op zich gebruikt. Deze scriptie onderzoekt enkel discriminatie waarbij een groep benadeeld wordt, waardoor deze artikelen onbruikbaar zijn. Daarnaast gaan een aantal artikelen onvoldoende in op discriminatie, waardoor er weinig tot geen substantiële informatie voor deze scriptie is.
Figuur 4.1: PRISMA Flowchart literatuuronderzoek discriminatie in big data

14
Het uiteindelijke aantal artikelen dat geselecteerd is voor analyse bedraagt 25. De geannoteerde versie van de artikelen is terug te vinden in bijlage I. De artikelen zijn verwerkt in de volgende paragrafen van dit hoofdstuk.
4.2 Oorzaken Een aanzienlijk deel van de literatuur noemt oorzaken van discriminatie in big data. De oorzaken zijn opgedeeld in de categorieën algoritmische fouten, de digitale kloof en data linkage. In deze paragraaf worden de oorzaken en gevolgen uit de literatuur per categorie besproken. Referenties die met een categorie overeenkomen staan afgebeeld in tabel 4.2.1.
Oorzaken Referenties
Algoritmische fouten Onay & Öztürk, 2018; Kamiran et al, 2018; Illiadis, 2018; Moses & Chan, 2018; Bennet & Chen, 2018; Golinelli et al, 2018; Regan & Jesse, 2018; Paterson & McDonagh, 2018.
Digitale kloof Montiel, 2018; Onay & Öztürk, 2018;
Data linkage Wachter, 2018; Montgommery et al, 2018; Illiadis, 2018; Tschider, 2018; Schaefer et al, 2018; Berg, 2018.
Tabel 4.2.1: Oorzaken en referenties uit de literatuur van 2018
4.2.1 Algoritmische fouten
Veel risico’s op discriminatie in big data worden veroorzaakt door algoritmische fouten. Onay en Öztürk (2018) stellen in een literatuur review voor kredietscoresystemen dat er grote onenigheid is over de waarheidsgetrouwheid van kredietscoresystemen. Waar voorheen enkel de betalingsgeschiedenis van consument relevant was, heeft data uit onder andere sociale media nu ook invloed op de kredietscores (Onay & Öztürk, 2018). Door de toename van data laten algoritmen soms onverklaarbare resultaten zien. Het controleren van deze algoritmen is door de complexiteit vaak onmogelijk. Diverse artikelen waarschuwen dat een oorzaak van discriminatie in deze algoritmen zit (Onay & Özturk, 2018; Paterson & McDonagh, 2018; Regan & Jesse, 2018).
Algoritmen maken ook fouten die gemakkelijker te achterhalen zijn. In meerdere papers wordt het gebruik van bevooroordeelde historische data aangehaald als belangrijke oorzaak van discriminatie in big data. Kamiran et al. (2018) stellen dat discriminatie vaak optreedt als gevolg van algoritmen die getraind zijn op basis van historische gegevens. Dit gebeurt ondanks de toenemende bewustwording van de mogelijke gevolgen van deze algoritmen. Illiadis (2018) stelt dat door het gebruik van historische data de menselijke vooroordelen van vroeger gereflecteerd worden door algoritmen gebaseerd op historische gegevens. De ‘feedback loop’ die continu deze vooroordelen tonen ten koste van alternatieve observaties maken het lastig om ze in twijfel te trekken. Moses en Chan (2016) waarschuwen in de context van politiewerk voor een self fulfilling proficy die hieruit kan ontstaan, omdat er meer resultaten gevonden worden op plaatsen waar meer gezocht wordt. Het gebruik van historische data komt voort uit de aanname dat de toekomst hetzelfde is als het verleden (Bennet en Chan, 2018). Deze aanname wordt veel gedaan in voorspellende toepassingen van big data. Bennet en Chan (2018) waarschuwen dat dergelijke aannames niet op elke context van toepassing is. Dit wordt onderschreven door Golinelli et al. (2018), die de kwaliteit van herbruikbare data in twijfel trekken in medische analyses. Herhaaldelijk evalueren is volgens hen genoodzaakt om discriminatie te bestrijden.
4.2.3 De Digitale kloof
Sommige papers uit de literatuur van 2018 halen de digitale kloof aan als oorzaak van discriminatie in big data. Montiel (2018) stelt dat er verschillen in geslacht bestaan als het gaat om de toegang tot het internet. Deze kloof varieert per continent van 10 tot 43 procent. Dit komt onder andere doordat het vooral mannen zijn die inhoud op het internet produceren en dat vrouwen voor hun baan het internet minder nodig hebben. Dit verschil in toegang tot het internet kan een oorzaak zijn van discriminatie op basis van geslacht in big data analyses. Ook met betrekking tot kredietscores kan de digitale kloof discriminatie veroorzaken. Onay en Öztürk (2018) zien dat mensen uit welvarende landen een veel grotere kans hebben op het krijgen van een goede kredietscore. Mensen die afkomstig zijn uit ontwikkelingslanden hebben minder kans op een goede kredietscore. Volgens hen ligt de oorzaak zowel bij de geografische locatie als de toegankelijkheid tot het

15
internet. Mensen die al jarenlang online actief zijn, hebben meer informatie gegenereerd die kredietscoresystemen gebruiken bij de beoordeling (Onay & Öztürk, 2018).
4.2.4 Data linkage
Een aantal papers uit de literatuur van 2018 focust op het verzamelen en koppelen van data, ook wel data linkage genoemd. De koppelingen van gegevens zijn afkomstig uit meerdere bronnen. Door deze gegevens te combineren worden er profielen van gebruikers gecreëerd en bijgehouden. Volgens Wachter (2018) onthullen deze profielen veel informatie over individuele mensen. Inferenties die worden gedaan op basis van deze gegevens kunnen resulteren in discriminatie (Wachter, 2018, Montgommery et al., 2018, Illiadis, 2018, Tschider, 2018). Vooral door de groei van het internet of things is er veel nieuwe persoonlijke informatie beschikbaar gekomen.
Ook maken veel adverteerders gebruik van filters om bepaalde groepen mensen uit te sluiten of juist op te nemen in gepersonaliseerde marketing. Het gaat hierbij om bewuste opname of uitsluiting. Volgens Dalenberg (2018) is dit een risicovolle praktijk, waarbij de grens van discriminatie snel bereikt is. De selectie wordt gedaan op basis van filtervariabelen, waaronder locatie, geslacht, leeftijd en financiële status. Deze vorm van data linkage komt onder andere voor op het gebied van werkgelegenheid (Dalenberg, 2018), marketing (Illiadis, 2018), en nieuwsvoorziening (Illiadis, 2018; Berg, 2018). Fouten uit filtervariabelen komen mogelijk voort uit de ontologische basis die zij hebben (Illiadis, 2018). “Ontologieën helpen in het organiseren van data zodat er betekenis aan gegeven kan worden en is georganiseerd als een hiërarchie” (Illiadis, 2018). Volgens Illiadis (2018) gebruiken grote sociale mediabedrijven als Facebook ontologieën en presenteren zij deze als categorieën waarin gebruikers kunnen filteren. Het is niet zichtbaar op welke manier deze classificatie heeft plaatsgevonden in de metadata. Volgens Illiadis (2018) is het niet zeker of deze ontologieën op een correcte manier zijn opgebouwd en kunnen mogelijk discrimineren. Profilering wordt volgens Schaefer et al. (2018) ook toegepast op het afstemmen van individuele behandelingen in de geneeskunde. Big data wordt gebruikt voor praktijken zoals het ontdekken van biomarkers, het stellen van diagnoses en het bieden van preventieve zorg door middel van voorspellende software. De profielen die hier gemaakt worden kunnen fouten bevatten waardoor discriminatie veroorzaakt wordt (Schaefer et al, 2018).
4.2.5 Conclusies De mogelijke oorzaken van discriminatie zijn beschreven in de bovenstaande paragrafen. Uit tabel 4.2.1 is af te lezen dat er het meeste geschreven is over algoritmische fouten. Er wordt gesteld dat nieuwe soorten data gebruikt worden in de algoritmen waardoor de resultaten soms onverklaarbaar worden. Daarnaast wordt het gebruik van bevooroordeelde historische data aangehaald als mogelijke oorzaak van discriminatie. Er zijn twee papers die schrijven over de digitale kloof. Gesteld wordt dat de toegankelijkheid tot het internet een mogelijke oorzaak is van discriminatie op basis van geslacht of op basis van afkomst. Als laatste schrijven er vijf papers over data linkage als mogelijke oorzaak van discriminatie in big data. Profielen vanuit allerlei databronnen worden gecreëerd en daarop worden inferenties gemaakt. Vooral de ontwikkeling van het internet of things speelt hierin een grote rol. Daarnaast zouden filtervariabelen die gebruikt worden om specifieke mensen uit te sluiten of juist op te nemen in analyses een oorzaak van discriminatie in big data zijn. In tabel 4.2.2 worden de referenties die Favaretto et al. (2019) hebben gemaakt aangevuld met de referenties uit de literatuur van 2018. Net zoals in de periode 2010 tot en met 2017 worden fouten in algoritmen het meeste onderzocht. Opvallend is het lage aantal papers die de digitale kloof noemen als mogelijke oorzaak, terwijl papers over data linkage juist veel voorkomt. Inhoudelijk valt het op dat Favaretto et al. (2019) het internet of things nauwelijks noemen, terwijl deze in diverse papers uit de literatuur van 2018 (Montgomery et al, 2018; Tschider, 2018) juist als centraal onderwerp behandeld worden. De overige oorzaken die besproken worden in de literatuur van 2018 komen overeen met de oorzaken die Favaretto et al. (2019) behandelen in de literatuur review.
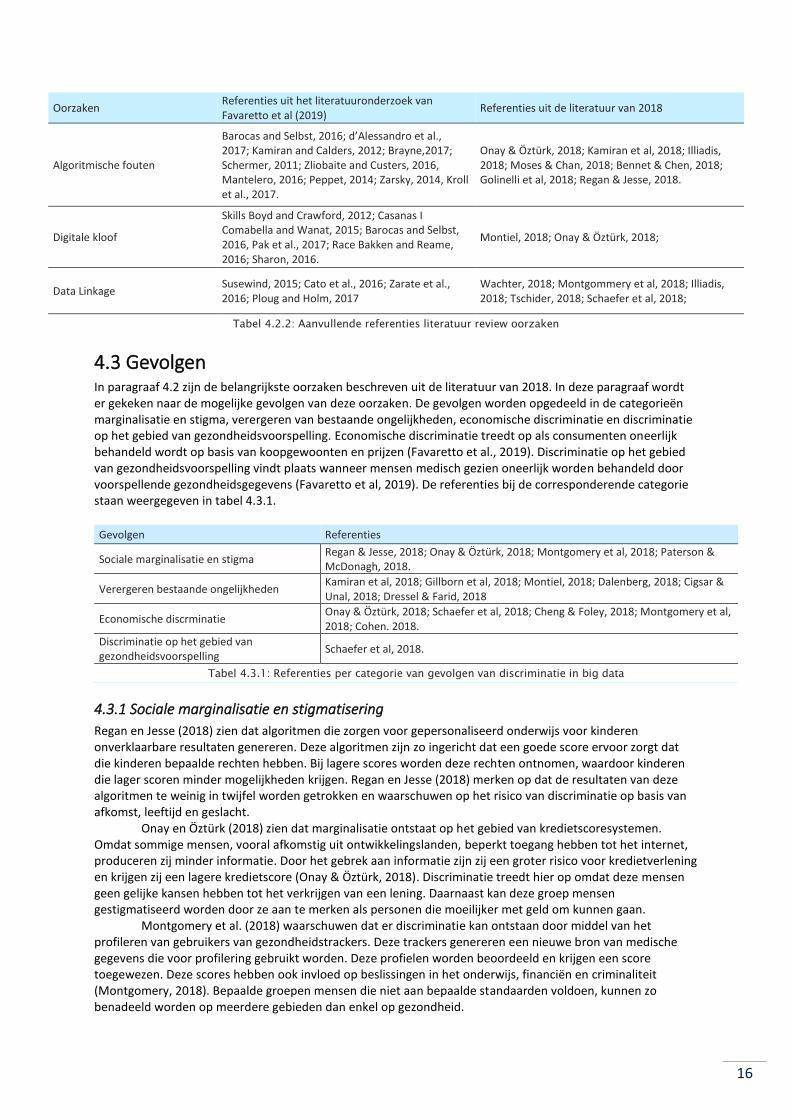
16
Oorzaken Referenties uit het literatuuronderzoek van Favaretto et al (2019)
Referenties uit de literatuur van 2018
Algoritmische fouten
Barocas and Selbst, 2016; d’Alessandro et al., 2017; Kamiran and Calders, 2012; Brayne,2017; Schermer, 2011; Zliobaite and Custers, 2016, Mantelero, 2016; Peppet, 2014; Zarsky, 2014, Kroll et al., 2017.
Onay & Öztürk, 2018; Kamiran et al, 2018; Illiadis, 2018; Moses & Chan, 2018; Bennet & Chen, 2018; Golinelli et al, 2018; Regan & Jesse, 2018.
Digitale kloof
Skills Boyd and Crawford, 2012; Casanas I Comabella and Wanat, 2015; Barocas and Selbst, 2016, Pak et al., 2017; Race Bakken and Reame, 2016; Sharon, 2016.
Montiel, 2018; Onay & Öztürk, 2018;
Data Linkage Susewind, 2015; Cato et al., 2016; Zarate et al., 2016; Ploug and Holm, 2017
Wachter, 2018; Montgommery et al, 2018; Illiadis, 2018; Tschider, 2018; Schaefer et al, 2018;
Tabel 4.2.2: Aanvullende referenties literatuur review oorzaken
4.3 Gevolgen In paragraaf 4.2 zijn de belangrijkste oorzaken beschreven uit de literatuur van 2018. In deze paragraaf wordt er gekeken naar de mogelijke gevolgen van deze oorzaken. De gevolgen worden opgedeeld in de categorieën marginalisatie en stigma, verergeren van bestaande ongelijkheden, economische discriminatie en discriminatie op het gebied van gezondheidsvoorspelling. Economische discriminatie treedt op als consumenten oneerlijk behandeld wordt op basis van koopgewoonten en prijzen (Favaretto et al., 2019). Discriminatie op het gebied van gezondheidsvoorspelling vindt plaats wanneer mensen medisch gezien oneerlijk worden behandeld door voorspellende gezondheidsgegevens (Favaretto et al, 2019). De referenties bij de corresponderende categorie staan weergegeven in tabel 4.3.1.
Gevolgen Referenties
Sociale marginalisatie en stigma Regan & Jesse, 2018; Onay & Öztürk, 2018; Montgomery et al, 2018; Paterson & McDonagh, 2018.
Verergeren bestaande ongelijkheden Kamiran et al, 2018; Gillborn et al, 2018; Montiel, 2018; Dalenberg, 2018; Cigsar & Unal, 2018; Dressel & Farid, 2018
Economische discrminatie Onay & Öztürk, 2018; Schaefer et al, 2018; Cheng & Foley, 2018; Montgomery et al, 2018; Cohen. 2018.
Discriminatie op het gebied van gezondheidsvoorspelling
Schaefer et al, 2018.
Tabel 4.3.1: Referenties per categorie van gevolgen van discriminatie in big data
4.3.1 Sociale marginalisatie en stigmatisering
Regan en Jesse (2018) zien dat algoritmen die zorgen voor gepersonaliseerd onderwijs voor kinderen onverklaarbare resultaten genereren. Deze algoritmen zijn zo ingericht dat een goede score ervoor zorgt dat die kinderen bepaalde rechten hebben. Bij lagere scores worden deze rechten ontnomen, waardoor kinderen die lager scoren minder mogelijkheden krijgen. Regan en Jesse (2018) merken op dat de resultaten van deze algoritmen te weinig in twijfel worden getrokken en waarschuwen op het risico van discriminatie op basis van afkomst, leeftijd en geslacht. Onay en Öztürk (2018) zien dat marginalisatie ontstaat op het gebied van kredietscoresystemen. Omdat sommige mensen, vooral afkomstig uit ontwikkelingslanden, beperkt toegang hebben tot het internet, produceren zij minder informatie. Door het gebrek aan informatie zijn zij een groter risico voor kredietverlening en krijgen zij een lagere kredietscore (Onay & Öztürk, 2018). Discriminatie treedt hier op omdat deze mensen geen gelijke kansen hebben tot het verkrijgen van een lening. Daarnaast kan deze groep mensen gestigmatiseerd worden door ze aan te merken als personen die moeilijker met geld om kunnen gaan.
Montgomery et al. (2018) waarschuwen dat er discriminatie kan ontstaan door middel van het profileren van gebruikers van gezondheidstrackers. Deze trackers genereren een nieuwe bron van medische gegevens die voor profilering gebruikt worden. Deze profielen worden beoordeeld en krijgen een score toegewezen. Deze scores hebben ook invloed op beslissingen in het onderwijs, financiën en criminaliteit (Montgomery, 2018). Bepaalde groepen mensen die niet aan bepaalde standaarden voldoen, kunnen zo benadeeld worden op meerdere gebieden dan enkel op gezondheid.

17
Paterson en McDonagh (2018) merken op dat gerichte marketing een belangrijke tool is om kwetsbaarheden van mensen uit te buiten. Volgens hen kan er gediscrimineerd worden in de informatievoorziening door gepersonaliseerde marketing. Het wordt ook wel het ultieme voorbeeld van asymmetrische informatie genoemd (Paterson & McDonagh, 2018). Los van de discriminatie die hierdoor kan optreden is dergelijke profilering ook onderhevig aan manipulatie van onder andere politici.
4.3.2 Verergeren van bestaande ongelijkheden
Fouten die gemaakt worden als gevolg van het gebruik van bevooroordeelde historische data kunnen bestaande vooroordelen verergeren. Volgens Kamiran et al., (2018) zijn het vooral vrouwen en etnische minderheden die benadeeld worden door deze fouten. Gillborn et al (2018) illustreren dat menselijke vooroordelen in algoritmen tot uiting komen. Zo zijn er bijvoorbeeld correlaties te vinden tussen ras en prestaties in de maatschappij. Veel mensen komen tot de conclusie dat bepaalde rassen minder goed functioneren in de maatschappij, maar Gillborn et al. (2018) stellen dat de gegevens gekleurd zijn door de manier waarop mensen met een ander ras behandeld zijn. Dit soort conclusies maken algoritmen ook. Gillborn et al. (2018) roepen op om te realiseren dat kwantitatieve data niet voor zichzelf spreekt en daarom altijd kritisch geëvalueerd moet worden. Zoals beschreven in paragraaf 4.2.3 hebben vrouwen minder toegang tot het internet en zijn er minder vrouwen werkzaam in de ICT (Montiel, 2018). Dit kan leiden tot het verergeren van bestaande ongelijkheden, omdat de belangen van vrouwen onvoldoende gerepresenteerd worden (Montiel, 2018). Juist omdat big data ons leven meer gaat beïnvloeden, is het belangrijk dat big data ingezet wordt om meer gelijkheid te realiseren. Dat er discriminatie optreedt op basis van geslacht, laat Dalenberg (2018) zien met het voorbeeld dat vacatures voor hoogbetaalde banen via het internet tot zes keer vaker aan mannen gepresenteerd worden dan aan vrouwen. Welke vacatures er worden gepresenteerd aan welke persoon wordt door middel van algoritmen bepaald. In dit geval discrimineert het algoritme dus op basis van geslacht. Deze oneerlijke behandeling ondermijnt het gelijkheidsbeginsel van de grondwet die stelt dat iedereen gelijke kansen moet hebben op werkgelegenheid (Dalenberg, 2018). Het omgekeerde komt ook voor. In de financiële sector worden juist mannen benadeeld op basis van hun profiel. Zo is het verkrijgen van krediet veel gemakkelijker voor vrouwen dan voor mannen, omdat vrouwen vaak een lager risicoprofiel hebben (Cigsar & Unal, 2018). Bestaande ongelijkheid kan ook verergerd worden in het opsporen van criminaliteit. Volgens Dressel en Farid (2018) kan software die voor dit doeleinde gebruikt wordt discrimineren, zelfs als variabelen als ras en afkomst uit de datasets worden gehaald. Zij concluderen dit naar aanleiding van de evaluatie van de commerciële risicobeoordelingssoftware COMPAS. Uit de evaluatie blijkt dat het gebruik van deze software geen eerlijkere resultaten oplevert dan de beoordeling van mensen zonder enige kennis op dit gebied. Dat is opmerkelijk, aangezien er een breed draagvlak is omtrent het gebruik van dergelijke software. Met een gemiddelde nauwkeurigheid van 65,2% legt de software het af tegen menselijke beoordelingen (Dressel & Farid, 2018).
4.3.3 Economische discriminatie
De stigmatisering die veroorzaakt wordt door de digitale kloof leidt ook tot economische discriminatie. Discriminatie die bij mensen uit ontwikkelingslanden optreedt zorgt ervoor dat deze groep weinig krediet kunnen krijgen. Omdat mensen uit ontwikkelde landen dit wel krijgen, wordt de gediscrimineerde groep benadeeld op het gebied van economische kansen (Onay & Öztürk, 2018). Schaefer et al. (2018) waarschuwen dat verzekeringsmaatschappijen hun premie gaan aanpassen op genetische profielen van hun klanten. Momenteel is dit in mindere mate al zichtbaar in de vorm van discriminatie op basis van leeftijd, rookgewoonten en familiegeschiedenis, waar premies al op afgestemd zijn. Schaefer et al. (2018) zien een groeiende discussie over de validiteit van nieuwe vormen van medische informatie die gegenereerd worden door de nieuwe technologie van onder andere het internet of things. Airbnb maakt het verhuurders mogelijk om te kiezen wie er in hun huis verblijft. Menselijke vooroordelen spelen dus een rol als verhuurders bepaalde groepen niet in hun huis laten verblijven. Indien Airbnb verhuurders verplicht om geen onderscheid te maken, bestaat de kans dat verhuurders geen gebruik meer gaan maken van het platform (Cheng & Foley, 2018). Dit kan weer leiden tot een andere vorm van discriminatie, namelijk dat verhuurders die geen gebruik maken van het platform benadeeld worden in de vindbaarheid op de website. In dat geval zullen verhuurders dus economisch gediscrimineerd worden. Montgomery et al. (2018) observeren dat bedrijven ook bewust discrimineren op basis van data die zij verkrijgen door middel van draagbare gezondheidstrackers. Dergelijke apparaten verzamelen gezondheidsinformatie van individuen die voorheen niet beschikbaar waren. Zo worden er scores toegewezen

18
aan individuen door middel van hun digitale lichaamstaal en worden ze gevangen in profielen (Montgomery et al, 2018). Walgreen heeft bijvoorbeeld een samenwerking met diverse aanbieders van draagbare gezondheidstrackers als Fitbit, MyFitness Pal en Google fit. Het bedrijf deelt beloningen uit aan individuen die bepaalde prestaties leveren, zoals sporten en het bereiken van een dagelijks stappendoel (Montgomery et al, 2018). Zo worden groepen die geen gebruik maken van deze diensten uitgesloten. Daarnaast waarschuwt Cohen (2018) voor prijsdiscriminatie die kan optreden bij het gebruik van big data. Studies hebben al uitgewezen dat er gepersonaliseerde prijzen worden toegepast op gebruikers, zonder dat zij weten dat het gebeurt. Op welke manier hun internetgedrag deze prijzen beïnvloeden is ook onbekend (Cohen, 2018).
4.3.4 Discriminatie op het gebied van gezondheidsvoorspelling
Profilering op medisch gebied is een betere manier voor de behandeling van patiënten dan een “one size fits all” behandeling (Schaefer et al., 2018). Behandelingen zouden meer effect hebben als ze volledig zijn afgestemd op de individu. Deze nieuwe methode kan echter ook een belangrijke oorzaak zijn voor discriminatie op het gebied van gezondheidsvoorspelling (Schaefer et al., 2018). “Gedragsmatige en levensstijlfactoren communiceren met genetische factoren die ziektes kunnen veroorzaken” (Schaefer et al, 2018). Beslissingen over diagnoses en preventieve zorg voor patiënten worden vrijwel altijd gebaseerd op data die voorspellingen maakt. Aan deze voorspellingen worden waarschijnlijkheden gekoppeld. Waarschijnlijkheden geven echter nooit een garantie, en profielen die gemaakt zijn op basis van deze waarschijnlijkheden zijn niet volledig accuraat. Schaefer et al., (2018) waarschuwt dat discriminatie op basis van gezondheidsvoorspelling het gevolg kan zijn van deze onvolledige profielen.
4.3. Conclusies
Discriminatie als gevolg van big data kunnen vier verschillende soorten gevolgen hebben. Allereerst kunnen ze sociale marginalisatie en stigmatisering veroorzaken. Algoritmen hebben de mogelijkheid om individuen in hokjes te plaatsen, dat er weer voor kan zorgen dat deze groepen moeilijker met elkaar om kunnen gaan. Dit gebeurt in bijvoorbeeld het onderwijs met gepersonaliseerde onderwijssystemen en in kredietscoresystemen. Ook zouden gegevens die gebruikt worden bij gezondheidstrackers hieraan bij kunnen dragen. Marginalisatie kan ook bestaande discriminatie verergeren. Vooral vrouwen en etnische minderheden worden hierdoor getroffen. Dit is te zien op het gebied van werkgelegenheid of bij de opsporing van criminaliteit. Economische discriminatie is een nieuw soort discriminatie, geïntroduceerd door Favaretto et al. (2019), waarbij mensen economisch benadeeld wordt. Papers uit de literatuur van 2018 noemen hierbij prijsdiscriminatie of het krijgen van ongelijke economische kansen. Als laatste kan discriminatie op het gebied van gezondheidsvoorspelling voorkomen, waar mensen verkeerde preventieve behandelingen kunnen krijgen omdat profielen onvoldoende accuraat zijn. In tabel 4.3.2 worden de referenties die Favaretto et al. (2019) hebben gemaakt aangevuld met de referenties uit de literatuur van 2018. Het valt op dat er in 2018 relatief minder wordt geschreven over sociale marginalisatie en stigma en er meer wordt geschreven over het verergeren van bestaande ongelijkheden en over economische discriminatie. Het feit dat er in één jaar meer is geschreven over economische discriminatie dan in de periode van 2010 tot en met 2017 geeft aan dat dit meer aandacht heeft gekregen. Anderzijds wordt er over discriminatie op het gebied van gezondheidsvoorspelling weinig onderzoek gedaan. De eerste deelvraag van deze literatuur review luidt: “Wat zijn de nieuwe inzichten rondom de oorzaken en gevolgen van discriminatie in big data en hoe verhouden deze zich tot de bevindingen van Favaretto et al. (2019)?” De ontwikkeling van het internet of things lijkt een grotere rol te spelen bij discriminatie in big data dan in de periode 2010 tot en met 2019. Het internet of things produceert nieuwe vormen van data, waarna algoritmen nieuwe soorten inferenties kunnen maken. Dit resulteert echter in moeilijker te doorgronden resultaten, waardoor er meer incidenten van discriminatie plaats kunnen vinden. Ook over economische discriminatie lijkt steeds meer geschreven te worden. Zo biedt het gebruik van gezondheidstrackers meer medische informatie die verzekeringsmaatschappijen kunnen gebruiken om premies aan te passen. Ook zijn er zorgen dat gepersonaliseerde prijzen al worden toegepast op gebruikers, zonder dat daar transparantie over is.

19
4.4 Belemmeringen De literatuur van 2018 laat zien dat er veel problemen zijn rondom het gebruik van big data. Deze paragraaf gaat in op de belemmeringen die verantwoord gebruik van big data in de weg staan. Deze belemmeringen zijn ingedeeld in de categorieën black box algoritmen, menselijke vooroordelen, conceptuele uitdagingen en het wet- en regelgeving. Tabel 4.4.1 laat per categorie zien welke literatuur erover schrijft.
Belemmeringen Referenties
Black Box Algoritmen Montgomery et al., 2018; Regan & Jesse, 2018; Tschider, 2018; Vayena & Blasimme, 2018; Kamiran et al, 2018; Wachter, 2018; Wang et al, 2018; Deliversky & Deliverska, 2018; Paterson & McDonagh, 2018; Dalenberg, 2018.
Menselijke vooroordelen Dressel & Farid, 2018; Bennet & Chan, 2018; Kamiran et al, 2018; Gillborn & Demack, 2018; Cheng & Foley, 2018; Wachter, 2018.
Conceptuele uitdagingen Bennet & Chan, 2018; Vayena & Blasimme, 2018; Montiel, 2018; Tschider, 2018; Cohen, 2018.
Wet- en regelgeving Boris & Bouchagiar; Veliz, 2018; Schaefer et al, 2018; Montgomery et al, 2018; Cuquet & Fensel, 2018; Paterson & McDonagh, 2018.
Tabel 4.4.1: Referenties per categorie van belemmeringen van discriminatie in big data
4.4.1 Black box algoritmen
Zoals besproken in paragraaf 4.2, kunnen algoritmen onverklaarbare resultaten laten zien. Deze black box algoritmen vormen een belangrijke belemmering voor verantwoorde big data analyses. Het zijn niet de resultaten van de analyses die een gevaar vormen, maar juist het gebrek aan transparantie die black box algoritmen hebben (Montgomery et al., 2018). Algoritmen zijn in staat om veel grotere aantallen gegevens te analyseren dan dat de mens ooit zou kunnen. Zelfs vreemde en onverklaarbare resultaten kunnen valide zijn. Volgens Montgomery et al. (2018) is het gevaarlijk om deze resultaten te snel als waarheid aan te zien omdat de procedure te complex is om te controleren. Volgens Regan en Jesse (2018) is het cruciaal om de mogelijkheid te hebben om algoritmen te kunnen onderzoeken en beoordelen. Het probleem is dat dit bij veel big data praktijken onmogelijk is. De complexiteit van dergelijke algoritmen komen voort uit het feit dat er veel meer gegevens verzameld en verwerkt kunnen worden voor analyse. Volgens Tschider (2018) en Wachter (2018) speelt de ontwikkeling van het internet of things hierin een grote rol, omdat zij real time big data gebruiken om onder andere nieuwe data te creëren. De infrastructuur van deze data is nog niet ingericht om deze hoeveelheden informatie te kunnen analyseren. Wang et al. (2018) geven ook aan dat er in de data die gebruikt wordt voor big data analyses teveel overtollige informatie aanwezig is. Deze informatie kan verkeerde resultaten opleveren. De ruis die aanwezig is kan leiden tot kwaliteitsvermindering.
Daarnaast zorgen de ontwikkelingen van big data voor leermodellen zonder toezicht. Dergelijke modellen zijn typen algoritmen waarbij geen menselijke betrokkenheid meer is. “Deze algoritmen zullen een eigen taal ontwikkelen, die het voor mensen onmogelijk maakt om te begrijpen” (Tschider, 2018). De
Gevolgen Referenties uit het literatuuronderzoek van Favaretto et al (2019)
Referenties uit de literatuur van 2018
Sociale marginalisatie en stigma
Lerman, 2013; Casanas I Comabellaand Wanat, 2015; Kennedyand Moss, 2015; Lupton, 2015; Susewind, 2015; Barocas and Selbst, 2016; Sharon, 2016; Francis and Francis, 2017; Pak et al., 2017; Ploug andHolm, 2017; Taylor, 2017.
Schaefer et al, 2018; Onay & Öztürk, 2018; Montgomery et al, 2018; Paterson & McDonagh, 2018.
Verergeren bestaande ongelijkheden
Timmis et al., 2016; Brannon, 2017; Brayne, 2017; Paket al., 2017; Taylor, 2017; Voigt, 2017.
Kamiran et al, 2018; Gillborn et al, 2018; Montiel, 2018; Dalenberg, 2018; Cigsar & Unal, 2018; Dressel & Farid, 2018
Economische discrminatie Hildebrandt and Koops, 2010; Peppet, 2014; Turow et al., 2015.
Onay & Öztürk, 2018; Schaefer et al, 2018; Cheng & Foley, 2018; Montgomery et al, 2018.
Discriminatie op het gebied van gezondheidsvoorspelling
Hoffman, 2010; Cohen et al., 2014; Ajunwa et al. 2016;, Hoffman, 2017.
Schaefer et al, 2018.
Tabel 4.3.2 Aanvullende referenties literatuur review oorzaken

20
procedures kunnen niet achterhaald en gecommuniceerd worden naar het publiek, waardoor transparantie onmogelijk wordt. Ook Vayena en Blassime (2018) merken op dat de black box algoritmen die op medisch gebied gebruikt worden direct ingaat tegen de transparantiestandaarden die zijn opgesteld om evidence-based medicine te waarborgen. Dit is een belangrijke methode in de geneeskunde die ervan uitgaat dat er altijd voldoende wetenschappelijk bewijs nodig is om een bepaalde behandeling te rechtvaardigen (Vayena & Blassime, 2018). Transparantie is vooral belangrijk in gevallen waar er gewerkt wordt met grote datasets, een hoge technische complexiteit en veel betrokkenen, omdat dit de betrokkenen weerhoudt om concreet te begrijpen wat er gebeurt met hun data (Deliverski & Deliverska, 2018). Black box algoritmen hebben bijna altijd grote datasets, hoge technische complexiteit en veel betrokkenen.
Discriminatie in black box algoritmen zijn vaak lastig te detecteren. Dit geldt voor directe discriminatie, maar het detecteren van indirecte discriminatie is nog lastiger (Dalenberg, 2018 ) Volgens Kamiran et al. (2018) zijn er nog geen technische hulpmiddelen die helpen om indirecte discriminatie op te sporen, waardoor discriminatieve resultaten in complexe algoritmen te makkelijk aangenomen worden (Kamiran et al, 2018). Paterson & McDonagh (2018) stellen zelfs dat het gebrek aan transparantie een voorwaarde is om een black box effect te genereren.
4.4.2 Menselijke vooroordelen
Hoewel big data veel onze capaciteiten heeft uitgebreid, blijft de menselijke factor aanwezig in de interpretatie van de resultaten. Hiermee staat de interpretatie van de resultaten direct in verbinding met beslissingen die de mens moet nemen. Deze menselijke factor is verre van perfect, waardoor menselijke vooroordelen alsnog een belemmering vormen voor verantwoorde big data analyses. Menselijke vooroordelen kunnen op verschillende manieren tot uiting komen in het gebruik van big data algoritmen. Dressel en Farid (2018) stellen dat er vaak een misvatting bestaat omtrent de effectiviteit van big data toepassingen. Ook als een algoritme foute resultaten produceert, kunnen ze alsnog voor waarheid aangezien worden. Dit komt omdat het vertrouwen in big data (Gillborn et al., 2018, Dressel & Farid, 2018). Voorstanders van het gebruik van geavanceerde machine learning geven vaak als argument dat big data veel nauwkeuriger is en minder bevooroordeeld dan menselijke beslissingen (Dressel & Farid, 2018). De resultaten van risicobeoordelingssoftware COMPAS laten echter zien dat de nauwkeurigheid van de algoritmen met een kleine 60% lager is dan menselijke beslissingen. Het denken dat de resultaten uit big data analyses superieur zijn zorgt voor onterechte aannames (Dressel & Farid, 2018). Ook de gedeelde platformeconomie heeft te kampen met menselijke vooroordelen die doorwerken in algoritmen. Het grote huizenverhuurplatform Airbnb wordt herhaaldelijk in verband gebracht met digitale discriminatie. Alvorens werd er gedacht dat getrainde algoritmen deze discriminatie veroorzaken door historische gegevens te gebruiken, maar Cheng en Foley (2018) merken op dat er op het platform direct gediscrimineerd wordt door verhuurders. Deze vooroordelen worden gereflecteerd in de algoritmen. Bennet en Chan (2018) stellen dat het handelen naar de resultaten uit big data invloed heeft op de werking van de algoritmen. Als een algoritme bijvoorbeeld stelt dat er meer gepatrouilleerd moet worden in een gebied wat een hoog risicoprofiel heeft, dan zorgt deze extra mankracht voor meer input voor toekomstige risicobeoordeling van het algoritme. Als dit keer op keer gebeurt, kunnen resultaten voor overrepresentatie zorgen, waardoor men risico’s hoger inschat dan daadwerkelijk het geval is. Het probleem ligt hier bij de data die men verzamelt en aan het algoritme voedt. Zoals in paragraaf 4.2 is besproken, is historische, bevooroordeelde data vaak een oorzaak van discriminatie (Kamiran et al, 2018). Gebaseerd op de assumptie dat de toekomst hetzelfde is als het verleden (Bennet & Chan, 2018), worden menselijke vooroordelen in stand gehouden door algoritmen. Wachter (2018) stelt dat deze vooroordelen zelfs versterkt kunnen worden door algoritmen. Zolang deze vooroordelen niet worden opgemerkt, blijft het gebruik van historische data een groot risico. De verantwoordelijkheid voor het ontdekken van de vooroordelen ligt bij de ontwerpers van de algoritmen. Volgens Kamiran et al. (2018) is het voor een mens te lastig om discriminerende data te ontdekken, waardoor het risico op discriminatie blijft bestaan. Gillborn et al. (2018) zeggen dat er nog altijd teveel onterechte causaliteit wordt gezien in correlaties. Big data zegt enkel iets over correlaties, maar dat wil nog niet betekenen dat er een oorzaak-gevolg relatie in zit. In kwantitatieve data analyses is er altijd een gevaar op deze menselijke denkfout (Gillborn et al., 2018).
4.4.3 Conceptuele uitdagingen
Bennet en Chan (2018) merken op dat software die gebruikt wordt om criminaliteit op te sporen veel lof krijgt. Verschillende media rapporteren succesvolle resultaten door het gebruik van deze software. Echter, er is onvoldoende bewijs dat resultaten hieraan te danken zijn. Volgens Bennet en Chan (2018) en Cohen (2018)

21
wordt dergelijke software te weinig geëvalueerd. De bestaande evaluaties zijn niet altijd onafhankelijk en peer reviewed. De positieve berichten die de software krijgt vanuit de media en daarmee het vertrouwen schept in de toepassingen zijn niet gerechtvaardigd. Vayena en Blasimme (2018) stellen dat zelfs als er adequaat geëvalueerd wordt, mogelijke discriminatie nog niet altijd voorkomen kan worden. Verder roepen veel papers op om big data toepassingen meer te evalueren om discriminatie uit te sluiten.
Montiel (2018) zegt dat de infrastructuur van het internet vrouwonvriendelijk is ingericht. De meeste gebruikers van big data toepassingen zouden bedrijven zijn die gedomineerd zijn door mannen. Daarnaast zijn vrouwen in de ICT ondervertegenwoordigd en daarmee ook hun belangen (Montiel, 2018). Door de digitale kloof tussen vrouwen en mannen zou big data ongelijkheid op basis van geslacht kunnen versterken. Het gebrek aan een duidelijke definitie van discriminatie in de context van big data vormt ook een belemmering voor verantwoorde big data analyses (Tschider, 2018) Momenteel zou er nog teveel vertrouwd worden op algemene eerlijkheidsbeginselen. Alleen als er een duidelijke definitie van discriminatie ontwikkeld wordt, kunnen er duidelijke richtlijnen opgesteld worden om big data op een verantwoorde manier te gebruiken (Tschider, 2018).
4.4.4 Wet- en regelgeving
Er zijn meerdere instanties die zich bezighouden met de wet- en regelgeving omtrent big data analyse. Veel artikelen merken op dat consumenten steeds meer gegevens afstaan aan bedrijven, met onder andere hun internetgebruik en het gebruik van het internet of things (Boris & Bouchagiar, 2018; Montgomery et al, 2018; Veliz, 2018, Cuquet en Fensel, 2018). De General Data Production Regulation (GDPR) van de EU is een set nieuwe wetten die zijn opgesteld om de risico’s voor consumenten die data afgeven te minimaliseren. Elke vorm van data wordt gereguleerd door de GDPR. Boris en Bouchagiar (2018) onderzoeken de rechtmatigheid van de GDPR, en concluderen dat de bescherming voor de consumenten onvolledig is. Volgens Wachter (2018) zijn teveel termen van de GDPR te vaag omschreven of zorgen ze enkel voor zeer gelimiteerde toepassingen. Cuquet en Fensel (2018) stellen dat het beleid onvoldoende voorbereid is op de gevaren van big data en er niet tegen opgewassen zijn. Een van de fundamentele principes van de gegevensbeschermingswet, zoals die is opgesteld door de GDPR, is het waarborgen van de persoonlijke autonomie (Boris & Bouchagiar, 2018). Dit wil zeggen dat de gebruiker altijd mag bepalen wat er gebeurt met zijn of haar gegevens. Bedrijven zouden zich hieraan houden door altijd toestemming te vragen voor het verzamelen en analyseren van data. Volgens artikel 6 van de GDPR is het analyseren van persoonlijke gegevens gerechtvaardigd als er toestemming voor gegeven is. Bottis & Bouchagiar (2018) merken op dat het onmogelijk is om volledig te weten wat er met je gegevens gebeurt door een simpele muisklik. Dit ondermijnt het principe van autonomie over je gegevens. Daarnaast kan er geen gebruik worden gemaakt van een dienst als de gebruiker geen toestemming geeft aan de dienst, waardoor er eigenlijk geen keuze is. Discriminatie kan dus ook optreden als er geen toestemming gegeven wordt. In de GDPR staat dat als de gegevens geanonimiseerd zijn, ze vrij verhandeld mogen worden met derden (Boris & Buchegiar, 2018). Deze derde partijen mogen er vervolgens mee doen wat ze willen. Als de identiteit achterhaald kan worden, kunnen er inferenties worden gemaakt ten koste van een individu of een groep. Volgens Wachter (2018) is er ernstige bezorgdheid dat als het anonimiseren niet mogelijk is. Data linkage ervoor zorgt dat veel mensen benadeeld worden op elk gebied waarin big data wordt ingezet. Het is dus belangrijk dat het anonimiseren van gegevens correct gebeurt. Er zijn op dit moment echter geen tools beschikbaar die gebruikt kunnen worden om anonimisering te kunnen garanderen (Veliz, 2018; Wachter, 2018; Onay & Öztürk, 2018). Door de exponentiële groei van data en daarmee ook persoonlijke gegevens, wordt er getwijfeld of het anonimiseren van data ooit nog mogelijk zal zijn. Paterson en McDonagh (2018) stellen als voorbeeld dat de-individualisering slechts één aspect is van anonimisering, en dat variabelen als leeftijd, locatie en geslacht ook tot de identiteit van de gebruiker kan leiden. Door de talloze inferenties die gemaakt kunnen worden, kunnen gegevens over personen vrijwel altijd terug te vinden zijn (Boris & Buchagiar, 2018). Ook in de geneeskunde is het anonimiseren van gegevens bijna onmogelijk. Elk genoom in het lichaam is uniek voor elk persoon (Schaefer et al., 2018, Veliz, 2018) . Daarnaast is er uitgewezen dat een genomisch profiel altijd te herleiden is als deze wordt geanalyseerd in publieke genetische databases (Schaefer et al, 2018). Bij zorg op individueel niveau kan er dus geen garantie gegeven worden dat de anonimiteit gewaarborgd blijft. Ook Montgomery et al. (2018) stellen dat de wet- en regelgeving onvoldoende bescherming biedt tegen discriminatie. Consumenten zouden moeten vertrouwen op een zelfregulerende markt. Met de opmerking dat het lastig is te achterhalen wat er met je gegevens gebeurt en je daarom wel toestemming moet geven (Boris & Buchegiar, 2018), is het een groot offer om je gegevens af te staan. Veel beleidsmatige richtlijnen erkennen dat gevoelige informatie beschermd zou moeten worden, maar dit concept is te losjes

22
gedefinieerd (Montgomery et al, 2018). Er zou nog minder in de wet staan omtrent het combineren van gevoelige gegevens die tot discriminatie kunnen leiden (Montgomery et al., 2018). De wetgeving is ook onvolledig over het hergebruiken van gegevens. Volgens Veliz (2018) is het niet ondenkbaar dat data die verzameld is voor medische doeleinden naar verloop van tijd gebruikt wordt voor andere doeleinden. Momenteel is er geen wetgeving die dit verbiedt, waardoor zelfs de gevoeligste informatie geanalyseerd kan worden door derden. Het is juridisch zelfs toegestaan om individuen die in geanonimiseerde databases zijn opgenomen te heridentificeren (Montgomery et al., 2018).
4.4.5 Conclusies
Opmerkelijk aan de literatuur van zowel Favaretto et al. (2019) en de literatuur van 2018 is het grote aantal papers die over belemmeringen schrijft die verantwoorde big data analyses mogelijk maken. Zo schrijven er tien papers over black box algoritmen, zes over menselijke vooroordelen, vier over conceptuele uitdagingen en vijf over wet- en regelgeving. Black box algoritmen worden vooral als belemmering genoemd omdat deze algoritmen transparantie onmogelijk maken. Onverklaarbare resultaten kunnen niet gecontroleerd worden op discriminatie. Menselijke vooroordelen betrekken zich tot het gebruik van bevooroordeelde data die voor waarheid worden aangezien. Ook de resultaten van algoritmen worden voor waarheid aangezien. Conceptueel gezien is het een probleem dat veel systemen niet geëvalueerd worden of kunnen worden door de black box algoritmen. Daarnaast zou de manier waarop big data analyses zijn ingericht nadelig zijn voor vrouwen. Ook de afwezigheid van een duidelijke definitie van discriminatie wordt gezien als een belemmering van eerlijke data mining. Als laatste vormt de wet- en regelgeving grote problemen rondom big data. Favaretto et al. (2019) noemen dat de wet- en regelgeving onvolledig was in de periode 2010 tot en met 2017. In 2018 zijn er papers die deze ingestelde wetgeving van de GDPR evalueren. Zij komen tot de conclusie dat de wetgeving de gebruiker alsnog niet geheel behoedt voor discriminatie in big data. De belemmering is dus nog niet opgelost. Daarbij houden diverse papers zich bezig met het probleem dat data niet te anonimiseren is, terwijl dit een voorwaarde is van de wet- en regelgeving. Als data niet geanonimiseerd is, kan er veel gemakkelijker discriminatie optreden. De aanvulling uit de literatuur staat weergegeven in tabel 4.4.2 De tweede deelvraag luidt als volgt: “Wat zijn de nieuwe inzichten met betrekking tot belemmeringen die een eerlijke manier van het gebruik van big data hinderen en hoe verhouden deze zich tot de bevindingen van Favaretto et al. (2019)?” Allereerst zijn er nieuwe inzichten op het gebied van de wet- en regelgeving, specifiek de wetgeving die is ingevoerd in 2018 door de GDPR. Deze wetgeving, die gebruikers moet beschermen tegen de negatieve gevolgen van big data, waaronder discriminatie, is onvoldoende gebleken. Verder zijn er nieuwe inzichten met betrekking tot het anonimiseren van gegevens, namelijk dat het anonimiseren van gegevens een grote en complexe uitdaging is. Ook is de onmogelijkheid tot transparantie in black box algoritmen een grote belemmering.
Belemmeringen Referenties uit het literatuuronderzoek van Favaretto et al (2019)
Referenties uit de literatuur van 2018
Black Box Algoritmen
Hildebrandt and Koops, 2010; Ruggieri et al., 2010; Schermer, 2011; Berendt and Preibusch, 2014; Citron and Pasquale, 2014; Cohen et al., 2014; Leese, 2014; Zarsky, 2014; Kennedy andMoss, 2015; Newell and Marabelli, 2015; McGuigan et al., 2015; Mantelero, 2016; Zarsky, 2016; Brannon, 2017; Brayne, 2017; d’Alessandro et al., 2017; Kroll et al., 2017; Taylor, 2017.
Montgomery et al., 2018; Regan & Jesse, 2018; Tschider, 2018; Vayena & Blasimme, 2018; Kamiran et al, 2018; Wachter, 2018; Wang et al, 2018; Deliversky & Deliverska, 2018; Paterson & McDonagh, 2018; Dalenberg, 2018.
Menselijke vooroordelen
Human bias Boyd and Crawford, 2012; Kamiran and Calders, 2012; Citron and Pasquale, 2014; Zarsky, 2014; Ajana, 2015; Ajunwa et al., 2016; Barocas and Selbst, 2016; Berendt and Preibusch, 2017; Brayne, 2017;, d’Alessandro et al., 2017; Veale and Binns, 2017; Voigt, 2017.
Dressel & Farid, 2018; Bennet & Chan, 2018; Kamiran et al, 2018; Gillborn & Demack, 2018; Cheng & Foley, 2018; Wachter, 2018.

23
Conceptuele uitdagingen
de Vries, 2010; Hoffman, 2010; Lerman, 2013; Leese, 2014; Zarsky, 2014; Ajana, 2015; Hirsch, 2015; MacDonnell, 2015; Barocas and Selbst, 2016; Kuempel, 2016; Mantelero, 2016; Francis and Francis, 2017; Hoffman, 2017; Kroll et al., 2017; Taylor, 2017.
Bennet & Chan, 2018; Vayena & Blasimme, 2018; Montiel, 2018; Tschider, 2018; Cohen, 2018.
Wet- en regelgeving
Hildebrandt and Koops, 2010; Hoffman, 2010; Ruggieri et al., 2010; Lerman, 2013; Citron and Pasquale, 2014; Peppet, 2014; Barocas and Selbst, 2016; Kuempel, 2016; Zliobaite and Custers, 2016; Hoffman, 2017; Zliobaite, 2017.
Boris & Bouchagiar; Veliz, 2018; Schaefer et al, 2018; Montgomery et al, 2018; Cuquet & Fensel, 2018; Paterson & McDonagh, 2018.
Tabel 4.4.2 Aanvullende referenties literatuur review belemmeringen
4.5 Oplossingen Discriminatie in big data is een complex probleem met veel obstakels. In de literatuur van 2018 worden diverse voorstellen gedaan om deze obstakels te overwinnen. Deze voorstellen zijn in de delen in drie categorieën. Dit zijn technische oplossingen, menselijke interventies en wet- en regelgeving. In deze paragraaf worden deze oplossingen per categorie besproken. In tabel 4.5.1 staan de referenties per categorie.
Oplossingen Referenties
Technische oplossingen Montiel, 2018; Dalenberg, 2018; Kamiran et al, 2018; Wang et al, 2018; Cohen, 2018.
Menselijke oplossingen Wachter, 2018; Tschider, 2018; Montgomery, 2018; Berg, 2018; Deliversky & Deliverska, 2018; Veliz, 2018; Vayena & Blasimme, 2018; Goldkind et al, 2018; Gillborn et al, 2018; Onay & Özürk, 2018.
Wet- en regelgeving Golinelli et al, 2018; Cheng & Foley, 2018; Schaefer et al, 2018; Vayena & Blasimme, 2018; Wachter, 2018.
Tabel 4.5.1 Oplossingen en referenties vanuit de literatuur van 2018
4.5.1 Technische oplossingen
Een aantal artikelen zet in op het ontwikkelen van software die mogelijke discriminatie detecteert in datamining. Zo stelt Montiel (2018) voor om vooruitgang in gendergelijkheid te realiseren door middel van meerdere indicatoren die algoritmen monitoren. Voorbeelden hiervan zijn risico indicatoren, invloedindicatoren, procesindicatoren, prestatie indicatoren en resultatenindicatoren (Montiel, 2018). Hoe deze indicatoren geïmplementeerd dienen te worden, blijft abstract.
Ook Dalenberg (2018) zet in op technische oplossingen om discriminatie in algoritmen te bestrijden. Hij geeft hierbij meerdere opties. De eerste optie is om gevoelige variabelen volledig uit de dataset te laten. Algoritmen kunnen zo niet discrimineren op basis van die variabelen. De keerzijde is echter dat er veel tijd verloren gaat aan pre-processing, wat veel geld kost (Dalenberg, 2018). Daarnaast bestaat er alsnog de kans dat algoritmen zelf de inferentie kunnen maken als er veel gelijkenissen in de data voorkomen. Zo worden de resultaten onverklaarbaar, net als in black box algoritmen. De tweede optie die gesuggereerd wordt door Dalenberg (2018) is het weghalen van de beschermende variabelen uit algoritmische modellen. Op deze manier wordt er door het algoritme een blinde vlek gecreëerd waardoor beschermde groepen niet anders worden behandeld. Het manipuleren van een algoritme op deze manier kan wel tot directe discriminatie leiden en is daarom geen ideale oplossing. Een derde oplossing is het combineren van machine learning en regelinductie door mensen. Op deze manier zou het algoritme gegevens observeren die bewerkt zijn door mensen en zo discriminatie eruit kunnen halen. Het algoritme leert gaandeweg en kan dit gebruiken in toekomstige voorspellingen (Dalenberg, 2018). Indirecte discriminatie is lastiger te detecteren. Dalenberg (2018) stelt hier voor om bepaalde variabelen op een groene lijst te zetten, nadat deze als volledig neutraal zijn beoordeeld. Deze variabelen wegen dan zwaarder in analyses, zodat het risico op discriminatie verkleind wordt. Daarnaast pleit Dalenberg (2018) voor de Seymour Smith’s rule. Deze regel houdt in dat de invloed van een variabele geen relatief verschil van meer dan 12,3% mag hebben. Is dit verschil groter, dan mag deze variabele niet gebruikt worden in de analyse (Dalenberg, 2018). Kamiran et al. (2018) stellen een model voor die machine learning gebruikt voor classificatievariabelen die zeer onzeker of dubbelzinnig zijn. Het model geeft eerst een objectieve score aan een individu zonder te

24
kijken naar gevoelige variabelen. Vervolgens worden de gevoelige variabelen geanalyseerd die een individu positief of negatief beïnvloedt. Als de resultaten van de objectieve score en de analyses van de gevoelige variabelen teveel van elkaar afwijken, is de variabele mogelijk discriminerend. Na het model geëvalueerd te hebben concluderen Kamiran et al. (2018) dat het risico op discriminatie verkleind wordt en de nauwkeurigheid nauwelijks wordt aangetast. Ook Cohen (2018) roept om algoritmes te trainen zodat zij mogelijk discriminatieve resultaten kunnen detecteren. Wang et al. (2018) zetten in op software die in beginsel minder variabelen meeneemt in de analyse. Zij hebben een algoritme ontwikkeld die de selectie van variabelen analyseert in de pre-processing fase. Dit algoritme lijkt superieur te zijn aan vergelijkbare algoritmen, terwijl er minder variabelen worden meegenomen (Wang et al., 2018).
4.5.2 Menselijke oplossingen
Transparantie Veel papers focussen op het realiseren van voldoende transparantie in algoritmen en datasets, zodat het duidelijk wordt wat er precies met de data van individuen gebeurt. Zo stelt Wachter (2018) dat transparantie noodzakelijk is om te weten wat er met verzamelde gegevens gebeurt. Voldoende transparantie is te realiseren als partijen zich aan bepaalde stappen houden. Deze stappen zijn 1) het verstrekken van informatie over de beoogde dataverzameling, 2) het geven van een overzicht welke data er gebruikt wordt en voor welk doeleinde, 3) het verlenen van online toegang om data in te zien en 4) het in kaart brengen van de risico’s die de dataverzameling met zich meebrengt (Wachter, 2018).
Transparantie kan ook gerealiseerd worden door het publiek te betrekken in geautomatiseerde beslissingen. Consumenten zouden ten alle tijden informatie moeten kunnen opvragen over de variabelen en de mogelijkheid moeten hebben om resultaten te corrigeren die een negatieve impact kunnen hebben (Tschider, 2018). Op deze manier kunnen deze algoritmen gecontroleerd worden door iedereen die hier behoefte aan heeft. Montgomery et al. (2018) beweren dat volledige transparantie verder gaat dan enkel de servicevoorwaarden en het geven van toestemming. Zij vragen om algoritmische transparantie, die ervoor moet zorgen dat black box algoritmen beter uitgelegd worden.
Toestemming en bewustwording Veel papers stellen dat er een gebrek is aan bewustzijn van de risico’s van big data. Berg (2018) noemt een eed een mogelijke oplossing om meer bewustzijn te creëren. Deze eed lijkt op de eed van Hippocratis, en houdt in dat wetenschappers bewust zijn van de risico’s en hier op een verantwoordelijke manier mee om zullen gaan. Volgens Deliversky en Deliverska (2018) zijn veel gebruikers niet op de hoogte van de gevaren van het verstrekken van hun data. Er dient meer bewustwording gecreëerd te worden over de gevaren en mensen dienen beter geïnformeerd te worden over de rechten die zij hebben met betrekking tot hun data. Ook het gebruik van derde partijen is een oplossing. Volgens Veliz (2018) kunnen derde partijen een middel zijn om de toestemmingsvoorwaarden te onderzoeken namens gebruikers. Derde partijen zouden zo de rechten van gebruikers kunnen beschermen en communiceren naar gebruikers (Veliz, 2018; Regan & Jesse, 2018).
Vayena en Blasimme (2018) stellen voor om duidelijkere en concretere richtlijnen op te stellen met betrekking tot het toestemming geven over het verzamelen van data. Veliz (2018) merkt op dat het geven van toestemming een update moet krijgen, zodat men volledig op de hoogte is van de big data context. Veliz (2018) stelt het concept van “tiered consent” voor. Deze vorm van het verlenen van toestemming houdt in dat gebruikers zelf kunnen aanvinken waar ze toestemming voor geven en waarvoor niet. Dit maakt het gebruikers mogelijk om slechts een deel van hun informatie prijs te geven, terwijl zij toch gebruik kunnen maken van gewenste diensten. Overige menselijke interventies Goldkind et al. (2018) stellen voor om als tegenbeweging van big data het begrip “small data” te introduceren. De kenmerken zijn dat small data 1) enkel op de individu gefocust moet zijn, 2) heterogene informatie is en elke bron anders is, 3) in de context geïnterpreteerd moet worden, 4) de herkomst van de gegevens altijd terug te vinden moet zijn en 5) gegarandeerd voordelige effecten voor de individu moeten hebben (Gillborn et al., 2018). Als er goed met de principes van small data omgegaan wordt, zouden kwetsbare groepen beter beschermd zijn tegen discriminatie. Onay en Öztürk (2018) denken dat het verkleinen van de digitale kloof oplossingen biedt voor een eerlijkere kredietboordeling. Zij stellen dat financiële inclusie de beste manier is voor benadeelde groepen uitzicht te geven op een goede kredietscore. Een manier om dit te doen in de context van kredietscoresystemen is om de kosten te verlagen, resulterend in een gemakkelijkere toetreding tot online

25
financiële middelen. Hierdoor is er meer informatie voor kredietscoresystemen om te beoordelen, en kunnen ook zij gemakkelijker aan krediet komen. Daarnaast zou informatie die niet financieel gerelateerd is helpen om een betere kredietscore te krijgen (Onay & Öztürk, 2018). Dit lost echter het probleem van de black box algoritmen niet op.
Omdat veel kwantitatieve data historische vooroordelen bevatten, zetten veel wetenschappers vraagtekens bij de validiteit van deze vorm van data (Gillborn & Demack, 2018). Een oplossing die voorgesteld wordt door Gillorn & Demack (2018) is het opnemen en analyseren van meer kwalitatieve data omtrent ervaringen en perspectieven op discriminatie. Deze zouden beter geschikt zijn om racisme te belichten. Daarnaast worden er vijf principes voorgesteld die gevolgd moeten worden als er statistische analyses gemaakt worden omtrent rassen. Deze principes zijn 1) centrale behandeling van racisme in kwantitatieve data, 2) erkennen dat cijfers niet neutraal zijn, 3) erkennen dat categorieën nooit neutraal zijn, 4) erkennen dat cijfers nooit voor zichzelf spreken en 5) het gebruik van cijfers alleen gebruikt worden om sociale gerechtigheid te realiseren (Gillborn & Demack, 2018). Door deze principes in acht te nemen, kan big data gebruikt worden om discriminatie te detecteren en te bestrijden.
4.5.3 Wet- en regelgeving
Vooral medische informatie is gevoelig. Golinelli et al. (2018) onderzochten het wettelijk kader omtrent de verstrekking van medische gegevens aan derden en de rol van nationale gezondheidsdiensten hierop. Hierin staat dat data die aan derden verstrekt wordt altijd transparant moet zijn en niet mag discrimineren. Golinelli et al (2018) beweren dat nationale gezondheidsdiensten een belangrijke rol mogen spelen in het voorkomen van twijfelachtige en niet transparante data. Zij stellen voor dat nationale gezondheidsdiensten hun beleid aan kunnen passen binnen de mogelijkheden van het wettelijke kader om individuen te behoede van twijfelachtige partijken van derden. Om digitale discriminatie tegen te gaan op platforms zoals Airbnb, stellen Cheng & Foley (2018) voor om handhavingsmaatregelen op te nemen in de wetgeving voor de individuele gebruikers van de platformdienst. Individuen die zich dus schuldig maken aan discriminatie worden zo juridisch gestraft. Zij observeren namelijk dat platforms wel iets willen doen aan discriminatie, maar ze de consequenties niet financieel kunnen dragen. Op deze manier worden zij niet benadeeld, omdat dezelfde regel ook voor andere platformen geldt.
Schaefer (2018) stelt voor om een aantal richtlijnen aan te houden die gevolgd moeten worden om genoomgegevens te delen. Omdat het ziekenhuis hier geen rol in speelt, is er enige regulering nodig. Zo moet ervoor gezorgd worden dat elke partij die gebruik maakt van deze gegevens betrokken is en de gevaren erkent en daar naar handelt. Vervolgens dienen alle partijen volledig transparant te zijn en zodat alle betrokken personen op ieder moment in kunnen grijpen. Als laatste dienen big data analyses zich snel aan te kunnen passen indien de wetgeving omtrent gegevensbescherming verandert (Schaefer et al, 2018). Deze richtlijnen lijken op de systematische toezichtsaanpak die Vayena en Blasimme (2018) voorstellen. In deze aanpak wordt de focus vooral gelegd op het aanpassingsvermogen van de big datapraktijken als er problemen geïdentificeerd worden. Wachter (2018) legt de verantwoordelijkheid bij de GDPR. De standaarden die in de GDPR zijn opgesteld beschermen bij de individu onvoldoende voor misbruik van hun gegevens. De GDPR dient zo snel mogelijk herzien en geïmplementeerd te worden op de meest risicovolle big datapraktijken (Wachter, 2018). Daarnaast dienen er concrete wetten te komen die transparantie mogelijk maken.
4.5.4 Conclusies
In de literatuur van 2018 zijn er veel papers die oplossingen voorstellen om de belemmeringen op te lossen die big data heeft. 21 van de 26 papers bieden oplossingen variërend van technische oplossingen, menselijke oplossingen en oplossingen in de wet- en regelgeving. Technisch gezien zijn er diverse papers die inzetten op indicatoren die discriminatie detecteren en onder de aandacht brengen van mensen die moeten werken met de resultaten. Dalenberg (2018) stelt de seymour smith’s rule voor, die zegt dat er maximaal 12,3% verschil mag zitten tussen groepen bij het toevoegen van variabelen. Andere papers zoeken naar manieren om het aantal variabelen te verkleinen, omdat het opnemen van meer variabelen kan leiden tot een afname van de waarheidsgetrouwheid van gegevens. Veel papers schrijven ook over menselijke oplossingen. Zo worden procedures voorgesteld om transparantie of bewustwording te garanderen en wordt er geopperd om meer kwalitatieve data op te nemen in big data analyses. Ook wordt het begrip small data geïntroduceerd die analyses vereist op een kleinschaliger niveau, waardoor discriminatie van groepen mensen voorkomen kunnen worden. Als laatste worden een aantal oplossingen voorgesteld met betrekking tot de wet- en regelgeving. In

26
de geneeskunde kunnen nationale gezondheidsorganisaties meer invloed hebben, omdat dit binnen het wettelijke kader valt van gegevensbescherming. Ook worden nationale overheden opgeroepen om meer richtlijnen op te stellen voor partijen die big data gebruiken bij hun bedrijfsvoering. Deze richtlijnen zouden vooral de gebruiker beter moeten betrekken en snelle aanpassingen mogelijk moeten maken. Als laatste wordt er voorgesteld dat de GDPR haar standaarden omtrent gegevensbescherming aan te scherpen om consumenten beter te beschermen. Als laatste dient er wetgeving te komen die transparantie verplicht stelt.
De derde deelvraag van deze scriptie is als volgt: “Wat zijn nieuwe inzichten in mogelijke oplossingen voor deze belemmeringen en hoe verhouden deze zich tot de bevindingen van Favaretto et al. (2019)?“ Enerzijds zijn er veel overeenkomsten in de voorgestelde oplossingen uit de periode 2010 tot en met 2017 en de literatuur van 2018. In de wet- en regelgeving wordt er vaak een beroep gedaan op beleidsontwikkeling van nationale autoriteiten. Menselijke oplossingen betreffen in beide perioden vooral procedures en toezicht. Technische oplossingen gaan veel in op het detecteren van discriminatie in big data. Er zijn wel diverse aanvullingen op het literatuuronderzoek van Favaretto et al. (2019). Zo zijn er tegenstrijdige adviezen over de omgang van gevoelige variabelen. Waar diverse papers voorstellen om zoveel mogelijk gevoelige variabelen op te nemen en in te zetten in analyses om discriminatie te bestrijden, zegt Dalenberg (2018) dat dit alsnog voor directe discriminatie kan leiden. In plaats daarvan roept Dalenberg (2018) op om juist de bewezen neutrale variabelen extra aandacht te geven in analyses om zo de invloed van gevoelige variabelen te verkleinen. Wang et al., (2018) hebben een algoritme ontwikkeld die het aantal te analyseren variabelen minimaliseert. Daarnaast wordt er met small data een nieuw begrip geïntroduceerd, dat vooral de nadruk legt op de individu. Volgens Goldkind et al., (2018) worden mensen dan beter beschermd tegen discriminatie. Een belangrijke voorwaarde van het gebruik van small data is het betrekken van de gebruiker in de analyses. Favaretto et al., (2019) geven ook aan dat het betrekken van gebruikers belangrijk is. Veliz (2018) stelt voor dat de betrokkenheid toe kan nemen door het gebruik van tiered consent, waarbij gebruikers per onderdeel toestemming kunnen geven voor het delen van hun data.
Oplossingen Referenties uit het literatuuronderzoek van Favaretto et al (2019)
Referenties uit de literatuur van 2018
Technische oplossingen
Kamiran and Calders, 2012; Hajian and Domingo-Ferrer, 2013; Kamiran et al., 2013; Hajian et al., 2014; Calders and Verwer, 2010; Pope and Sydnor, 2011; Zliobaite and Custers, 2016; Kroll et al., 2017; d’Alessandro et al., 2017; Hldebrandt and Koops, 2010; Schermer, 2011; Citronand Pasquale, 2014; Veale and Binns, 2017.
Montiel, 2018; Dalenberg, 2018; Kamiran et al, 2018; Wang et al, 2018; Cohen, 2018.
Menselijke oplossingen Hildebrandt and Koops, 2010; Hoffman, 2010; Citronand Pasquale, 2014; Peppet, 2014; Hirsch, 2015; Kuempel, 2016; Hoffman, 2017
Wachter, 2018; Tschider, 2018; Montgomery, 2018; Berg, 2018; Deliversky & Deliverska, 2018; Veliz, 2018; Vayena & Blasimme, 2018; Goldkind et al, 2018; Gillborn et al, 2018; Onay & Özürk, 2018.
Wet- en regelgeving
Zarsky, 2014; Berendt and Preibusch, 2017; d’Alessandro et al., 2017; Mantelero, 2016; Veale and Binns, 2017; Cohen et al., 2014; Taylor, 2016; Taylor, 2017; Hoffman, 2010.
Golinelli et al, 2018; Cheng & Foley, 2018; Schaefer et al, 2018; Vayena & Blasimme, 2018; Wachter, 2018.
Tabel 4.5.2 Aanvullende referenties literatuur review oplossingen
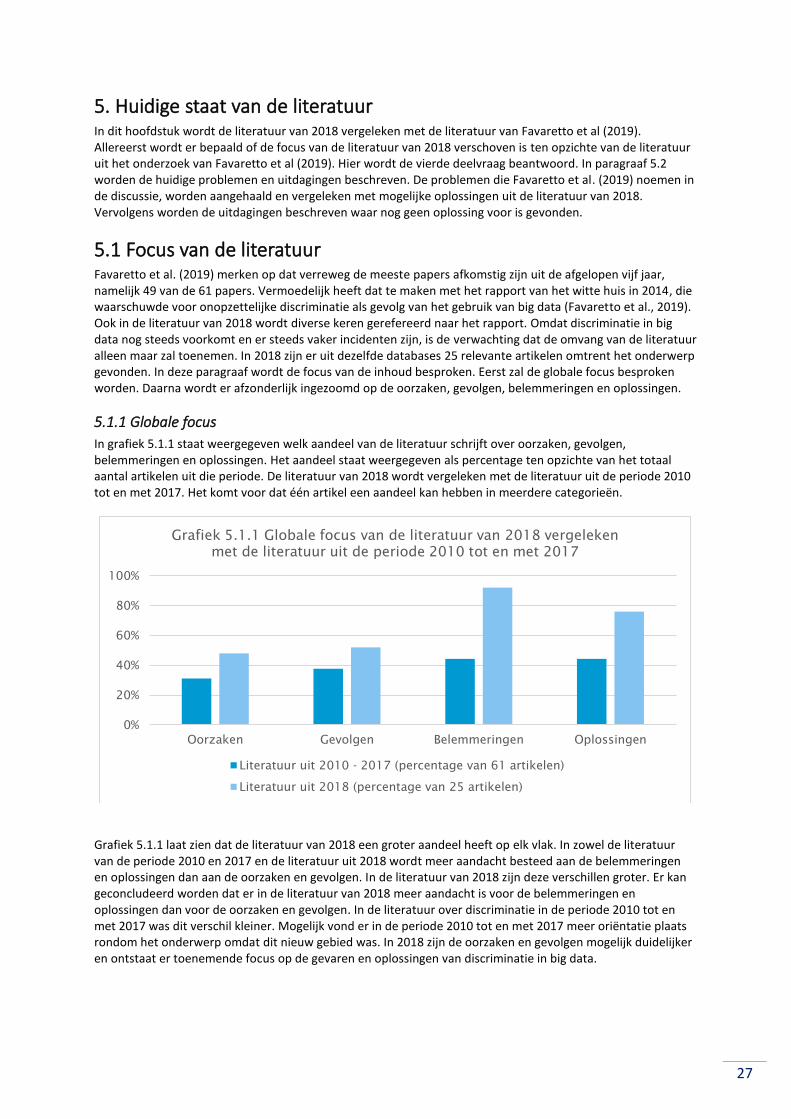
27
5. Huidige staat van de literatuur In dit hoofdstuk wordt de literatuur van 2018 vergeleken met de literatuur van Favaretto et al (2019). Allereerst wordt er bepaald of de focus van de literatuur van 2018 verschoven is ten opzichte van de literatuur uit het onderzoek van Favaretto et al (2019). Hier wordt de vierde deelvraag beantwoord. In paragraaf 5.2 worden de huidige problemen en uitdagingen beschreven. De problemen die Favaretto et al. (2019) noemen in de discussie, worden aangehaald en vergeleken met mogelijke oplossingen uit de literatuur van 2018. Vervolgens worden de uitdagingen beschreven waar nog geen oplossing voor is gevonden.
5.1 Focus van de literatuur Favaretto et al. (2019) merken op dat verreweg de meeste papers afkomstig zijn uit de afgelopen vijf jaar, namelijk 49 van de 61 papers. Vermoedelijk heeft dat te maken met het rapport van het witte huis in 2014, die waarschuwde voor onopzettelijke discriminatie als gevolg van het gebruik van big data (Favaretto et al., 2019). Ook in de literatuur van 2018 wordt diverse keren gerefereerd naar het rapport. Omdat discriminatie in big data nog steeds voorkomt en er steeds vaker incidenten zijn, is de verwachting dat de omvang van de literatuur alleen maar zal toenemen. In 2018 zijn er uit dezelfde databases 25 relevante artikelen omtrent het onderwerp gevonden. In deze paragraaf wordt de focus van de inhoud besproken. Eerst zal de globale focus besproken worden. Daarna wordt er afzonderlijk ingezoomd op de oorzaken, gevolgen, belemmeringen en oplossingen.
5.1.1 Globale focus
In grafiek 5.1.1 staat weergegeven welk aandeel van de literatuur schrijft over oorzaken, gevolgen, belemmeringen en oplossingen. Het aandeel staat weergegeven als percentage ten opzichte van het totaal aantal artikelen uit die periode. De literatuur van 2018 wordt vergeleken met de literatuur uit de periode 2010 tot en met 2017. Het komt voor dat één artikel een aandeel kan hebben in meerdere categorieën.
Grafiek 5.1.1 laat zien dat de literatuur van 2018 een groter aandeel heeft op elk vlak. In zowel de literatuur van de periode 2010 en 2017 en de literatuur uit 2018 wordt meer aandacht besteed aan de belemmeringen en oplossingen dan aan de oorzaken en gevolgen. In de literatuur van 2018 zijn deze verschillen groter. Er kan geconcludeerd worden dat er in de literatuur van 2018 meer aandacht is voor de belemmeringen en oplossingen dan voor de oorzaken en gevolgen. In de literatuur over discriminatie in de periode 2010 tot en met 2017 was dit verschil kleiner. Mogelijk vond er in de periode 2010 tot en met 2017 meer oriëntatie plaats rondom het onderwerp omdat dit nieuw gebied was. In 2018 zijn de oorzaken en gevolgen mogelijk duidelijker en ontstaat er toenemende focus op de gevaren en oplossingen van discriminatie in big data.
0%
20%
40%
60%
80%
100%
Oorzaken Gevolgen Belemmeringen Oplossingen
Grafiek 5.1.1 Globale focus van de literatuur van 2018 vergeleken
met de literatuur uit de periode 2010 tot en met 2017
Literatuur uit 2010 - 2017 (percentage van 61 artikelen)
Literatuur uit 2018 (percentage van 25 artikelen)
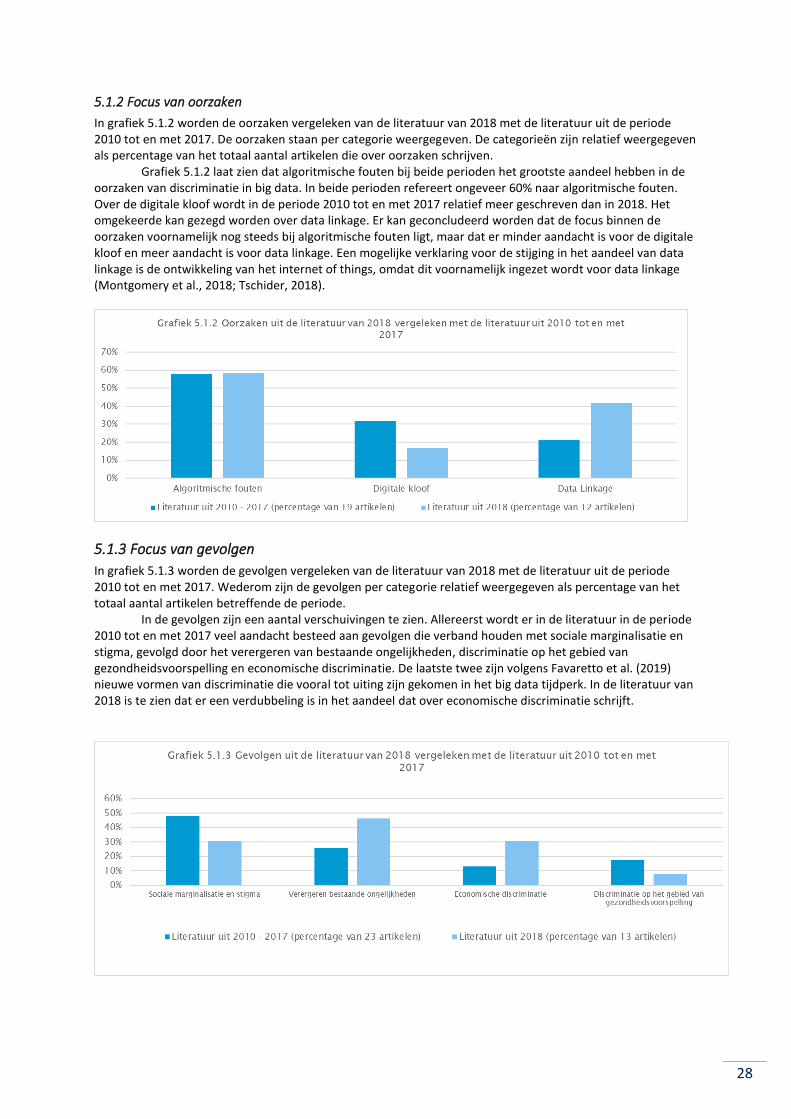
28
5.1.2 Focus van oorzaken
In grafiek 5.1.2 worden de oorzaken vergeleken van de literatuur van 2018 met de literatuur uit de periode 2010 tot en met 2017. De oorzaken staan per categorie weergegeven. De categorieën zijn relatief weergegeven als percentage van het totaal aantal artikelen die over oorzaken schrijven. Grafiek 5.1.2 laat zien dat algoritmische fouten bij beide perioden het grootste aandeel hebben in de oorzaken van discriminatie in big data. In beide perioden refereert ongeveer 60% naar algoritmische fouten. Over de digitale kloof wordt in de periode 2010 tot en met 2017 relatief meer geschreven dan in 2018. Het omgekeerde kan gezegd worden over data linkage. Er kan geconcludeerd worden dat de focus binnen de oorzaken voornamelijk nog steeds bij algoritmische fouten ligt, maar dat er minder aandacht is voor de digitale kloof en meer aandacht is voor data linkage. Een mogelijke verklaring voor de stijging in het aandeel van data linkage is de ontwikkeling van het internet of things, omdat dit voornamelijk ingezet wordt voor data linkage (Montgomery et al., 2018; Tschider, 2018).
5.1.3 Focus van gevolgen
In grafiek 5.1.3 worden de gevolgen vergeleken van de literatuur van 2018 met de literatuur uit de periode 2010 tot en met 2017. Wederom zijn de gevolgen per categorie relatief weergegeven als percentage van het totaal aantal artikelen betreffende de periode. In de gevolgen zijn een aantal verschuivingen te zien. Allereerst wordt er in de literatuur in de periode 2010 tot en met 2017 veel aandacht besteed aan gevolgen die verband houden met sociale marginalisatie en stigma, gevolgd door het verergeren van bestaande ongelijkheden, discriminatie op het gebied van gezondheidsvoorspelling en economische discriminatie. De laatste twee zijn volgens Favaretto et al. (2019) nieuwe vormen van discriminatie die vooral tot uiting zijn gekomen in het big data tijdperk. In de literatuur van 2018 is te zien dat er een verdubbeling is in het aandeel dat over economische discriminatie schrijft.
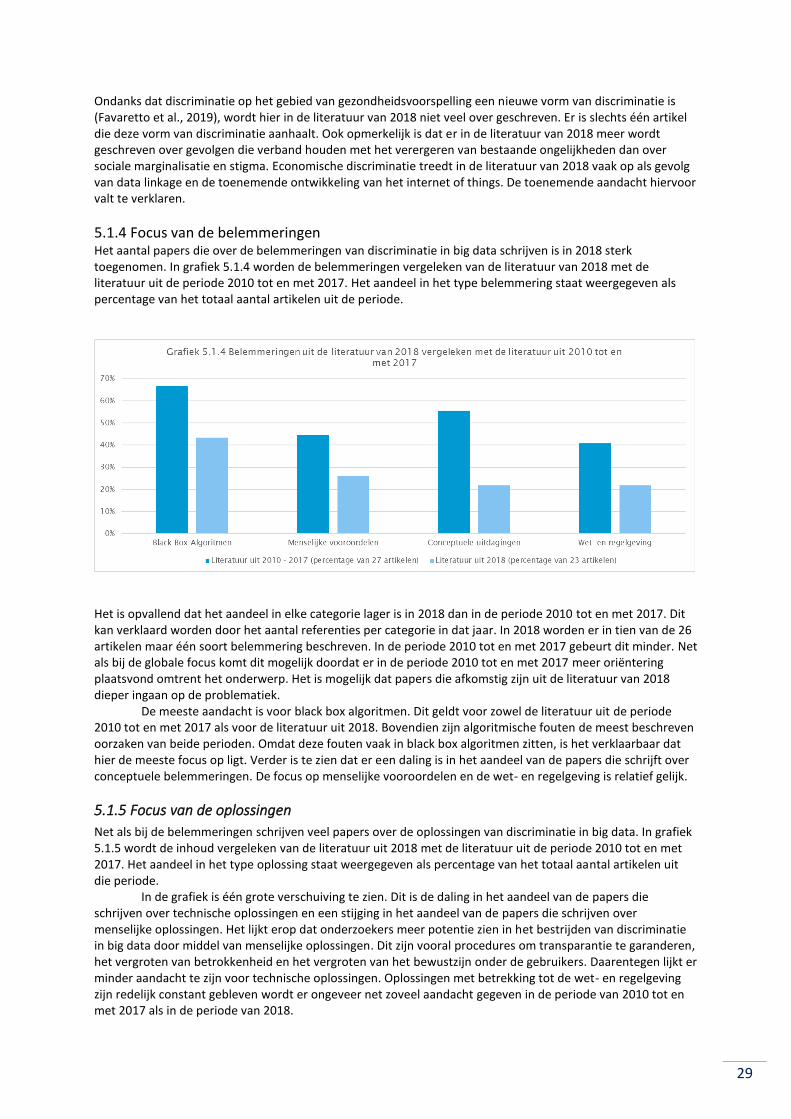
29
Ondanks dat discriminatie op het gebied van gezondheidsvoorspelling een nieuwe vorm van discriminatie is (Favaretto et al., 2019), wordt hier in de literatuur van 2018 niet veel over geschreven. Er is slechts één artikel die deze vorm van discriminatie aanhaalt. Ook opmerkelijk is dat er in de literatuur van 2018 meer wordt geschreven over gevolgen die verband houden met het verergeren van bestaande ongelijkheden dan over sociale marginalisatie en stigma. Economische discriminatie treedt in de literatuur van 2018 vaak op als gevolg van data linkage en de toenemende ontwikkeling van het internet of things. De toenemende aandacht hiervoor valt te verklaren.
5.1.4 Focus van de belemmeringen Het aantal papers die over de belemmeringen van discriminatie in big data schrijven is in 2018 sterk toegenomen. In grafiek 5.1.4 worden de belemmeringen vergeleken van de literatuur van 2018 met de literatuur uit de periode 2010 tot en met 2017. Het aandeel in het type belemmering staat weergegeven als percentage van het totaal aantal artikelen uit de periode.
Het is opvallend dat het aandeel in elke categorie lager is in 2018 dan in de periode 2010 tot en met 2017. Dit kan verklaard worden door het aantal referenties per categorie in dat jaar. In 2018 worden er in tien van de 26 artikelen maar één soort belemmering beschreven. In de periode 2010 tot en met 2017 gebeurt dit minder. Net als bij de globale focus komt dit mogelijk doordat er in de periode 2010 tot en met 2017 meer oriëntering plaatsvond omtrent het onderwerp. Het is mogelijk dat papers die afkomstig zijn uit de literatuur van 2018 dieper ingaan op de problematiek.
De meeste aandacht is voor black box algoritmen. Dit geldt voor zowel de literatuur uit de periode 2010 tot en met 2017 als voor de literatuur uit 2018. Bovendien zijn algoritmische fouten de meest beschreven oorzaken van beide perioden. Omdat deze fouten vaak in black box algoritmen zitten, is het verklaarbaar dat hier de meeste focus op ligt. Verder is te zien dat er een daling is in het aandeel van de papers die schrijft over conceptuele belemmeringen. De focus op menselijke vooroordelen en de wet- en regelgeving is relatief gelijk.
5.1.5 Focus van de oplossingen
Net als bij de belemmeringen schrijven veel papers over de oplossingen van discriminatie in big data. In grafiek 5.1.5 wordt de inhoud vergeleken van de literatuur uit 2018 met de literatuur uit de periode 2010 tot en met 2017. Het aandeel in het type oplossing staat weergegeven als percentage van het totaal aantal artikelen uit die periode. In de grafiek is één grote verschuiving te zien. Dit is de daling in het aandeel van de papers die schrijven over technische oplossingen en een stijging in het aandeel van de papers die schrijven over menselijke oplossingen. Het lijkt erop dat onderzoekers meer potentie zien in het bestrijden van discriminatie in big data door middel van menselijke oplossingen. Dit zijn vooral procedures om transparantie te garanderen, het vergroten van betrokkenheid en het vergroten van het bewustzijn onder de gebruikers. Daarentegen lijkt er minder aandacht te zijn voor technische oplossingen. Oplossingen met betrekking tot de wet- en regelgeving zijn redelijk constant gebleven wordt er ongeveer net zoveel aandacht gegeven in de periode van 2010 tot en met 2017 als in de periode van 2018.
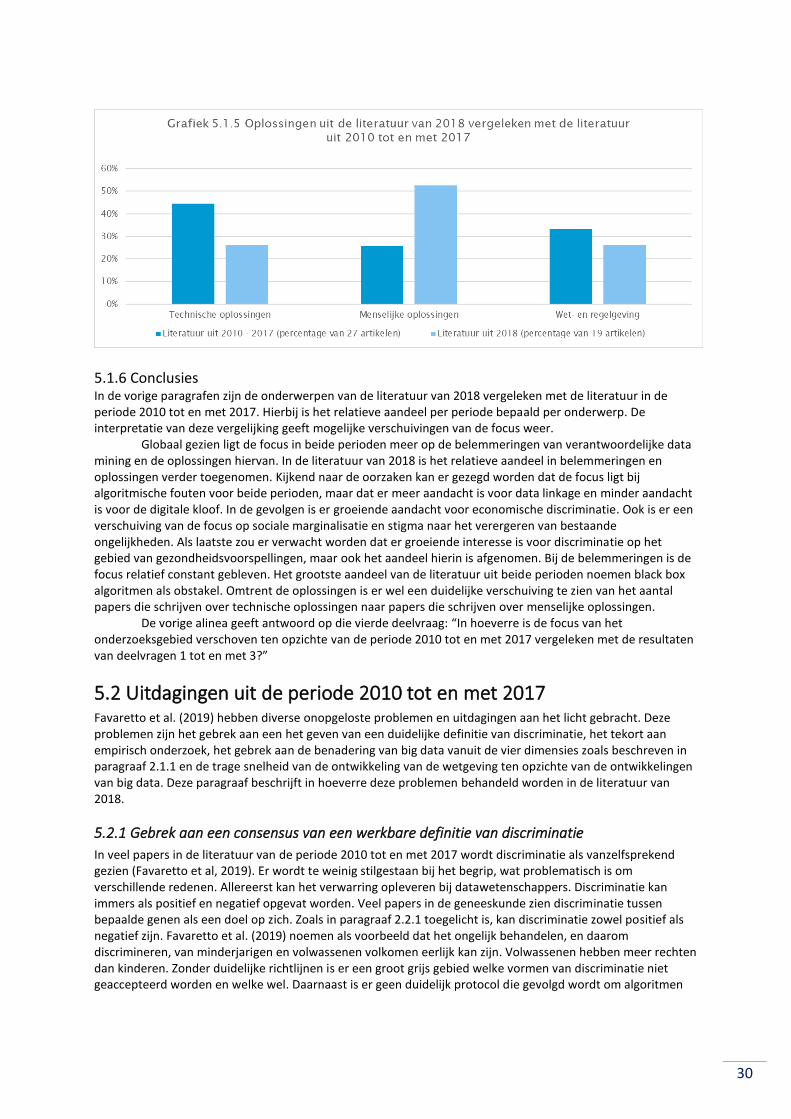
30
5.1.6 Conclusies In de vorige paragrafen zijn de onderwerpen van de literatuur van 2018 vergeleken met de literatuur in de periode 2010 tot en met 2017. Hierbij is het relatieve aandeel per periode bepaald per onderwerp. De interpretatie van deze vergelijking geeft mogelijke verschuivingen van de focus weer. Globaal gezien ligt de focus in beide perioden meer op de belemmeringen van verantwoordelijke data mining en de oplossingen hiervan. In de literatuur van 2018 is het relatieve aandeel in belemmeringen en oplossingen verder toegenomen. Kijkend naar de oorzaken kan er gezegd worden dat de focus ligt bij algoritmische fouten voor beide perioden, maar dat er meer aandacht is voor data linkage en minder aandacht is voor de digitale kloof. In de gevolgen is er groeiende aandacht voor economische discriminatie. Ook is er een verschuiving van de focus op sociale marginalisatie en stigma naar het verergeren van bestaande ongelijkheden. Als laatste zou er verwacht worden dat er groeiende interesse is voor discriminatie op het gebied van gezondheidsvoorspellingen, maar ook het aandeel hierin is afgenomen. Bij de belemmeringen is de focus relatief constant gebleven. Het grootste aandeel van de literatuur uit beide perioden noemen black box algoritmen als obstakel. Omtrent de oplossingen is er wel een duidelijke verschuiving te zien van het aantal papers die schrijven over technische oplossingen naar papers die schrijven over menselijke oplossingen. De vorige alinea geeft antwoord op die vierde deelvraag: “In hoeverre is de focus van het onderzoeksgebied verschoven ten opzichte van de periode 2010 tot en met 2017 vergeleken met de resultaten van deelvragen 1 tot en met 3?”
5.2 Uitdagingen uit de periode 2010 tot en met 2017 Favaretto et al. (2019) hebben diverse onopgeloste problemen en uitdagingen aan het licht gebracht. Deze problemen zijn het gebrek aan een het geven van een duidelijke definitie van discriminatie, het tekort aan empirisch onderzoek, het gebrek aan de benadering van big data vanuit de vier dimensies zoals beschreven in paragraaf 2.1.1 en de trage snelheid van de ontwikkeling van de wetgeving ten opzichte van de ontwikkelingen van big data. Deze paragraaf beschrijft in hoeverre deze problemen behandeld worden in de literatuur van 2018.
5.2.1 Gebrek aan een consensus van een werkbare definitie van discriminatie
In veel papers in de literatuur van de periode 2010 tot en met 2017 wordt discriminatie als vanzelfsprekend gezien (Favaretto et al, 2019). Er wordt te weinig stilgestaan bij het begrip, wat problematisch is om verschillende redenen. Allereerst kan het verwarring opleveren bij datawetenschappers. Discriminatie kan immers als positief en negatief opgevat worden. Veel papers in de geneeskunde zien discriminatie tussen bepaalde genen als een doel op zich. Zoals in paragraaf 2.2.1 toegelicht is, kan discriminatie zowel positief als negatief zijn. Favaretto et al. (2019) noemen als voorbeeld dat het ongelijk behandelen, en daarom discrimineren, van minderjarigen en volwassenen volkomen eerlijk kan zijn. Volwassenen hebben meer rechten dan kinderen. Zonder duidelijke richtlijnen is er een groot grijs gebied welke vormen van discriminatie niet geaccepteerd worden en welke wel. Daarnaast is er geen duidelijk protocol die gevolgd wordt om algoritmen

31
niet te laten discrimineren. Doordat er geen duidelijke definitie is, wordt er veel aan interpretatie overgelaten voor de ontwerpers van de algoritmen. Dit is een te grote verantwoordelijkheid om bij hen neer te leggen.
Ook in de literatuur van 2018 wordt discriminatie weinig toegelicht met een definitie. Er zijn maar twee papers die discriminatie aan de hand van een definitie expliciet behandelen. Kamiran et al. (2018) noemen dat “sociale discriminatie voorkomt als er een beslissing wordt gemaakt ten gunste van of tegen een persoon op basis van de groep, klasse of categorie waar deze zich in bevindt in plaats van op basis van verdienste”. Bennet en Chan (2018) hebben een soortgelijke definitie, maar focussen op digitale discriminatie. Deze definities dekken niet de gehele lading van discriminatie, kijkend naar de definitie in het wetboek van strafrecht, zoals beschreven in paragraaf 2.2.1. Andere papers noemen discriminatie als voor zichzelf sprekend zonder een definitie te geven. Dat is verwarrend, want waar Schaefer (2018) discriminatie als positief ziet in de geneeskunde, behandelt de meerderheid van de literatuur van 2018 discriminatie als negatief. Discriminatie is contextafhankelijk en breed. Gillborn et al., (2018) laten zien dat discriminatie veel complexer is dan dat er door veel papers wordt vernomen. Zij stellen dat het hebben van een bepaald ras vaak onbewust als factor gezien wordt, en vrijwel elke beslissing die daarop genomen wordt invloed heeft op de behandeling van de individu die tot die groep behoort. Het begrip behandelen als voor zichzelf sprekend is te ongenuanceerd en vereist vaak verduidelijking.
Daarnaast wordt discriminatie in sommige papers als probleem op zich gezien (Montgomery et al, 2018; Kamiran et al, 2018; Bottis & Buchagiar, 2018; Tschider, 2018), terwijl andere papers discriminatie als onderdeel van privacy behandelen. Zo stellen Regan en Jesse (2018) dat privacy op te delen is in zes ethische belangen, waar discriminatie er één van is. Ook Veliz (2018) noemt discriminatie als onderdeel van privacy. Wachter (2018) stelt juist dat discriminatie een gevolg is van het gebrek aan privacy. Sommige papers koppelen discriminatie aan privacy, terwijl anderen dat niet doen. Het koppelen van discriminatie en privacy brengt ook een risico met zich mee. Discriminatie gaat over meer dan alleen privacy. Privacy betreft volgens de Camebridge Dictionary (2020) het recht om persoonlijke informatie geheim te houden, terwijl discriminatie het recht op gelijke behandeling betreft. Naast discriminatie is ook privacy een complex en breed begrip. Het is dus goed om discriminatie los te zien van privacy.
Favaretto et al. (2019) zijn niet de enige die de noodzaak van een duidelijke definitie inzien. Tschider (2018) stelt dat de definitie van discriminatie, zoals die in de volksmond gebruikt wordt, verouderd is. Met name de ontwikkeling van het internet of things laat zien dat discriminatie in big data complex is en dat de huidige definitie aan herziening toe is.
5.2.2 Het tekort aan empirisch onderzoek
Favaretto et al. (2019) prijzen het feit dat discussie over discriminatie in big data eindelijk in opkomst is, maar dat empirische studies grotendeels ontbreken. Dit wordt als problematisch ervaren gezien de groei in het gebruik van big data analyses. Voorbeelden waarin big data discriminatie kan veroorzaken laten zien dat het gebruik van deze complexe praktijken nog een “work in progress” is. Hoewel de ontwikkeling steeds verder gaat en op een steeds bredere schaal wordt ingezet en daarmee steeds grotere gevolgen gaat hebben voor de individu (Cuquet & Fensle, 2018), blijft empirisch onderzoek uit. Ook in de literatuur van 2018 is empirisch onderzoek ondergerepresenteerd. Net als in de periode 2010 tot en met 2017 worden er vooral theoretische discussies gehouden over discriminatie in big data. Het valt op dat de meeste papers wijzen op de mogelijke discriminatieve resultaten en daar aanbevelingen op geven in plaats van het leveren van bewezen observaties.
Uiteindelijk worden er in vier van de 25 papers empirische resultaten geleverd op het gebied van discriminatie in big data. Dressel en Farid (2018) observeren in de evaluatie van software die ondersteunt bij het opsporen van criminaliteit dat slechts in iets meer dan de helft van alle gevallen correcte adviezen geeft. Discriminatie treedt op in ongeveer 47% van elke case. Cigsar en Unal (2018) observeren dat mannen benadeeld worden in het krijgen van krediet ten opzichte van vrouwen. Jesse en Regan (2018) zien in algoritmen voor gepersonaliseerd onderwijs voor kinderen dat discriminatie optreedt waarbij bepaalde groepen kinderen meer rechten tot hun beschikking hebben dan andere groepen, zonder dat hier een plausibele verklaring voor is. Het laatste empirische onderzoek naar discriminatie in big data is de case study van Airbnb door Cheng en Foley (2018). Zij laten zien op welke manier het platform bijdraagt aan directe discriminatie door verhuurders het recht te laten behouden om te kiezen welke groepen er op hun locatie mogen verblijven en welke niet.
De belangrijkste reden waarom meer empirisch onderzoek nodig is heeft te maken met het gebrek aan het bewustzijn en erkenning over discriminatie in big data (Favaretto et al., 2019). Ook evaluaties van systemen vallen hieronder. Als er geen empirisch bewijs is voor het probleem, dan zullen de gevolgen grotendeels

32
verborgen blijven. Cuquet & Fensel (2018) stellen ook dat er veel meer onderzoek gedaan moet worden naar de werking van deze algoritmen en dat evaluaties te weinig voorkomen. Het beoogde doel is hierbij ook het vergroten van het begrip over discriminatie in big data.
5.2.3 Het gebrek aan het leggen van de relatie van big data vanuit de vier dimensies en discriminatie
Opvallend in de literatuur van de periode 2010 tot en met 2017 is het feit dat geen enkele paper de link legt tussen discriminatie en de vier V’s van big data (Favaretto et al., 2019). In de literatuur van 2018 wordt deze link ook in geen enkele paper gelegd. In plaats daarvan wordt het paraplubegrip big data gebruikt, waardoor het onduidelijk blijft welke dimensies van big data discriminatie oplevert. Een aantal papers lijken impliciet het verband te leggen, bijvoorbeeld door de opmerking van Tschider (2018) dat de exponentiële groei van big data bijdraagt aan discriminatie. Hoewel het niet expliciet gezegd wordt, is het duidelijk dat het over de volume van big data gaat. Daarnaast zeggen Wang et al. (2018) dat er in de grote hoeveelheid data veel ruis zit, wat de waarheidsgetrouwheid (veracity) van data impliceert. De link kan soms dus gemaakt worden, maar het wordt niet voldoende expliciet gemaakt in de literatuur van 2018. Daarnaast wordt er in de literatuur van 2018 het begrip big data zelden duidelijk gedefinieerd aan de hand van de vier dimensies. Er zijn 3 van de 25 papers die de dimensies noemen (Montgomery et al, 2018; Onay & Öztürk, 2018; Goldkind et al, 2018). Dit is onvoldoende, waardoor het probleem blijft bestaan.
5.2.4 De tragere snelheid van de ontwikkeling van de wetgeving ten opzichte van de ontwikkelingen van big data.
Favaretto et al. (2019) noemen in de literatuur review dat de wetgeving die opgesteld is in de GDPR in de loop van 2018 ingaat. Ze stellen al vraagtekens bij de werking van deze nieuwe wetgeving. Dit wordt in de literatuur van 2018 bevestigd door Bottis en Bouchagiar (2018). Zij stellen dat gegevensbescherming volledig in handen is van de GDPR en consumenten weinig controle hebben op hun gegevens.
In Artikel 4 van de GDPR staat dat het verzamelen en gebruiken van data geoorloofd is als de gebruiker toestemming hiervoor heeft gegeven, onder de voorwaarde dat het geven van toestemming een vrije, geïnformeerde en weloverwogen keuze moet zijn. Bottis en Buchagiar (2018) merken op dat deze voorwaarden niet opgaan door simpelweg een vakje aan de kruisen. Artikel 32 van de GDPR staat echter toe dat websites het aankruisen van een vakje voldoende is voor het krijgen van toestemming. Daarnaast stelt de GDPR in artikel 26 dat persoonlijke data geanonimiseerd moet worden op zo’n manier dat de identiteit van de individu te achterhalen is. Echter, in paragraaf 4.4.4 is er opgemerkt dat het niet mogelijk is om data te anonimiseren. In de wetgeving staan echter geen concrete procedures om deze praktijken tegen te houden (Bottis & Buchagiar, 2018), waardoor artikel 26 overbodig is. Bovenstaande voorbeelden bevestigen de opmerking van Wachter (2018), die stelt dat veel artikelen in de wetgeving te vaag omschreven zijn en achterlopen op de ontwikkeling van big data. In paragraaf 4.5.3 worden enkele oplossingen beschreven met betrekking tot de wet- en regelgeving. Er worden bijvoorbeeld richtlijnen genoemd en aanbevelingen gedaan op het implementeren van transparantie en aanpassingsvermogen in de wet. Zij erkennen echter de complexiteit hiervan en zien de implementatie als een grote uitdaging. De kloof tussen de wetgeving en de ontwikkeling van big data is nog niet gedicht en lijkt alleen maar verder uit te lopen.
5.2.5 Conclusies
De vijfde deelvraag gaat over de uitdagingen die Favaretto et al. (2019) aanhalen op het gebied van discriminatie in big data. Deze uitdagingen zijn gesplitst in paragrafen 5.2.1 tot en met 5.2.4. Terugkijkend op de paragrafen kan er gesteld worden dat deze problemen nog niet opgelost zijn. In paragrafen 5.2.1 tot en met 5.2.4 worden de uitdagingen wel bevestigd.
5.3 Huidige Uitdagingen Cuquet en Fensel (2018) hebben voor Europa een stappenplan ontwikkeld die ervoor moet zorgen dat big data analyses op een verantwoordelijke manier uitgevoerd en ontwikkelt worden. In het stappenplan zijn ook ethische vraagstukken geïntegreerd, waardoor men gedwongen wordt om mogelijke gevaren van big data te voorkomen. Deze ethische vraagstukken hebben het doel om discriminatie te bestrijden en worden gepresenteerd als uitdagingen.

33
De eerste uitdaging betrekt zich tot de wet en regelgeving. Volgens Cuquet en Fensel (2018) heeft onderzoek naar de wet- en regelgeving hoge prioriteit. Zij onderkennen het probleem zoals beschreven in paragraaf 5.2.4 en stellen dat er niet alleen aanpassingen moeten komen van de huidige wetgeving (Wachter, 2018), maar ook dat er duidelijke procedures moeten komen om discriminerende praktijken in big data aan te pakken (Cuquet & Fensel, 2018; Wachter, 2018).
Een andere uitdaging volgens Cuquet en Fensel (2018) is, net zoals beschreven in paragraaf 5.2.2, het tekort aan empirisch onderzoek. Naast het gebrek aan evaluaties is er ook een gebrek aan algoritmen die controleren, terwijl dit erg belangrijk is. Het evalueren van algoritmen en het ontwikkelen van big data toepassingen die algoritmen controleren op discriminatie zou het vertrouwen in big data moeten doen toenemen, maar het realiseren ervan is complex. Een andere belangrijke uitdaging is het vergroten van de transparantie in algoritmen. Zoals beschreven in paragraaf 4.4.1, is het realiseren van transparantie nu soms al onmogelijk. Vooralsnog zijn hier geen adequate oplossingen voor gevonden. Tschider (2018) stelt dat het aantal algoritmen die geen toezicht hebben de komende jaren gaat toenemen, waardoor de controle op deze algoritmen alleen maar complexer wordt. Het is daarom niet alleen een grote uitdaging om transparantie te realiseren in huidige big data praktijken, maar ook in de toekomstige complexere algoritmen. Tschider (2018) noemt met de de-identificatie van data een ander aandachtspunt in de literatuur. In paragraaf 4.4.4 staat beschreven dat het onmogelijk is gebleken om gegevens volledig te anonimiseren, waardoor er discriminatie op kan treden. Omdat de wet- en regelgeving hier geen uitkomst in kan bieden (Bottis & Buchagiar, 2018), is het anonimiseren van gegevens een uitdaging op zich geworden. De noodzaak hiervoor wordt alleen maar groter als er strengere wetten worden aangenomen die dergelijke praktijken harder aanpakken. Samenvattend staan de uitdagingen afgebeeld in tabel 5.3.1. Hierin staan de onopgeloste uitdagingen die afkomstig zijn uit de literatuur review van Favaretto et al. (2019), aangevuld met de uitdagingen die zijn geïdentificeerd in te literatuur van 2018. Dit laatste vormt het antwoord op deelvraag 6.
Uitdagingen uit de literatuur van 2010 tot en met 2017
Aandacht voor de definitie van discriminatie
Meer empirisch onderzoek uitvoeren
Betere behandeling van big data vanuit de vier dimensies
Snellere ontwikkeling van de wetgeving
Nieuwe uitdagingen uit de literatuur van 2018
Vergroten van transparantie in big data
Succesvol anonimiseren van persoonlijke gegevens
Tabel 5.3.1: Huidige uitdagingen discriminatie in big data
6. Conclusie en discussie De hoofdvraag van het onderzoek luidt: “Wat zijn de nieuwste inzichten op het gebied van discriminatie in big data in het jaar 2018 en hoe verhouden deze zich tot de resultaten uit het onderzoek van Favaretto et al. (2019)?” In dit hoofdstuk wordt deze vraag beantwoord. Allereerst worden de resultaten samengevat in paragraaf 6.1. In paragraaf 6.2 wordt er gereflecteerd op de resultaten en worden de belangrijkste conclusies besproken. De belangrijkste conclusies vormen het antwoord op de centrale onderzoeksvraag. In paragraaf 6.3.1 worden de limitaties van het onderzoek beschreven en worden er aanbevelingen gedaan. In paragraaf 6.3.2 wordt er gereflecteerd op het onderzoeksproces en worden persoonlijke uitdagingen beschreven die de kwaliteit van het onderzoek kunnen beïnvloeden.
6.1 Samenvatting van de resultaten
Betreffende de oorzaken van discriminatie in big data is er geconcludeerd dat er in 2018 het meeste geschreven is over algoritmische fouten, gevolgd door oorzaken die liggen in data linkage en de digitale kloof. De discriminatie die hieruit voort kan komen heeft betrekking op verschillende vormen van discriminatie. Dit zijn sociale marginalisatie en stigma, het verergeren van bestaande ongelijkheden, economische discriminatie en discriminatie op het gebied van gezondheidsvoorspelling. In 2018 is er het meeste geschreven over gevolgen die bestaande ongelijkheden verergeren, gevolgd door economische discriminatie, sociale marginalisatie en stigma en als laatste discriminatie op het gebied van gezondheidsvoorspelling. De literatuur van 2018 laat weinig nieuwe inzichten zien in de oorzaken en gevolgen vergeleken met de literatuur review van Favaretto et

34
al. (2019). Wel wordt er meer aandacht gegeven aan het aandeel van het internet of things in discriminatie. Deze bron levert nieuwe soorten gegevens, waardoor resultaten complexer en moeilijker te doorgronden zijn. Daarnaast wordt er meer aandacht gegeven aan economische discriminatie in de vorm van het aanbieden van verschillende prijzen voor dezelfde producten. Een groot aantal artikelen schrijft over belemmeringen die verantwoorde big data analyses in de weg staat. Black box algoritmen worden het meest aangehaald als belemmering, gevolgd door menselijke vooroordelen, wet- en regelgeving en conceptuele uitdagingen. Betreffende de belemmeringen zijn er nieuwe inzichten op het gebied van wet- en regelgeving, zoals die is ingevoerd met de GDPR. Deze wetgeving blijkt onvoldoende bescherming te bieden. Verder zijn er nieuwe inzichten met betrekking tot het anonimiseren van gegevens, namelijk dat dit tot op heden nog niet gelukt is. In de oplossingen wordt het meeste gezocht in menselijke oplossingen, zoals procedures om transparantie en flexibiliteit te vergroten. Technisch gezien wordt er vooral ingezet op software die discriminatie kan detecteren. In de wet- en regelgeving wordt er geopperd voor een aanscherping in de wetgeving, omdat deze niet voldoende bescherming biedt. Wat betreft de focus van de literatuur van 2018 ten opzichte van de literatuur van de periode 2010 tot en met 2017 hebben er ook een aantal verschuivingen plaatsgevonden. Globaal gezien wordt er meer aandacht besteed aan belemmeringen en oplossingen. In de oorzaken blijft de aandacht gericht op black box algoritmen en vindt er een verschuiving plaats van aandacht voor de digitale kloof naar aandacht voor data linkage. Met betrekking tot de gevolgen wordt er in de literatuur van 2018 relatief meer geschreven over het verergeren van bestaande ongelijkheden en is er groeiende aandacht voor economische discriminatie. De meeste aandacht betreffende de belemmeringen gaat in beide perioden naar black box algoritmen, gevolgd door menselijke vooroordelen, conceptuele uitdagingen en de wet- en regelgeving. De focus is weinig verschoven ten opzichte van de periode 2010 tot en met 2017. In de focus op de oplossingen heeft er een verschuiving plaatsgevonden van technische oplossingen naar menselijke oplossingen. Deze oplossingen verhouden zich vooral tot het vergroten van transparantie en de flexibiliteit van big data analyses. Favaretto et al. (2019) noemen een aantal uitdagingen in de discussie van hun paper die nog niet zijn opgelost. Deze problemen zijn 1) het geven van meer aandacht aan de definitie van discriminatie, 2) het gebrek aan empirisch onderzoek, 3) het gebrek aan het behandelen van big data aan de hand van de 4 v’s en 4) de trage ontwikkeling van de wet- en regelgeving ten opzichte van de ontwikkeling van big data. In 2018 zijn deze problemen nog niet opgelost, maar wel bevestigd. Het oplossen van deze problemen zijn uitdagingen voor de toekomst. Daarnaast worden er in de literatuur van 2018 twee extra uitdagingen genoemd, namelijk het vergroten van transparantie in big data en het succesvol anonimiseren van persoonlijke gegevens.
6.2 Belangrijkste resultaten
De resultaten uit de literatuur van 2018 laten een aantal belangrijke punten zien. Allereerst drukt de ontwikkeling van het internet of things een stempel op de resultaten. Tschider (2018) stelt dat de groei van het internet of things problemen rondom de complexiteit van het probleem goed weergeeft. Door deze groei zijn er grote hoeveelheden persoonlijke informatie vrijgekomen die eerst niet beschikbaar waren. Hierdoor kunnen algoritmen meer inferenties maken zonder dat hier een verklaring voor is (Tschider, 2018; Wachter, 2018). De groei van het internet of things wordt in de literatuur gereflecteerd door de aandacht voor black box algoritmen, data linkage en de onderzoeken naar economische discriminatie. Het bestaan van black box algoritmen lijkt het voornaamste gevaar te zijn voor discriminatie in big data. Daarnaast is de roep om meer transparantie nadrukkelijk aanwezig in de resultaten uit 2018. Het realiseren van transparantie is de voornaamste manier om black box algoritmen te doorgronden, wat aansluit op de aandacht voor deze black box algoritmen. Favaretto et al. (2019) stellen in de literatuur van de periode 2010 tot en met 2017 transparantie de belangrijkste menselijke oplossing is. In 2018 is dit niet anders. Oplossingen omtrent transparantie worden vooral in de wetgeving en het beleid gezocht. Verder zijn er enkele papers die implementatie van transparantie in software onderzoeken. Als derde beroepen veel papers in de literatuur van 2018 zich op het feit dat het anonimiseren van gegevens onmogelijk is (Wachter, 2018; Onay & Öztürk, 2018; Veliz, 2018). Dit is een probleem omdat met name data linkage kan leiden tot discriminatie. Omdat anonimisering niet mogelijk is en er in toenemende mate gebruikt wordt gemaakt van data linkage, heeft onderzoek op dit gebied prioriteit. Als laatste is er veel discussie over de wet- en regelgeving van eerlijke data mining. Favaretto et al. (2019) merken al op dat er een kloof is tussen de ontwikkeling van big data en de wet- en regelgeving daarop, en dat het een uitdaging is om deze kloof te overbruggen. De literatuur van 2018 bevestigt dit, door

35
herhaaldelijk te stellen dat de wetgeving van de GDPR onvoldoende is om de consument te beschermen. Veel papers opperen daarom om de GDPR regelgeving zo snel mogelijk aan te scherpen. Bovenstaande punten vormen de belangrijkste resultaten op de centrale onderzoeksvraag: “Wat zijn de nieuwste inzichten op het gebied van discriminatie in big data in het jaar 2018 en hoe verhouden deze zich tot de resultaten uit het onderzoek van Favaretto et al?” De resultaten laten zien dat problemen en uitdagingen rondom discriminatie in big data onvoldoende oplossing bieden en dat er dringend meer onderzoek nodig is rondom het onderwerp.
6.3 Discussie
In deze paragraaf wordt er gereflecteerd op het onderzoeksproces. In paragraaf 6.3.1 worden de limitaties van het onderzoek besproken en worden er aanbevelingen gedaan. In paragraaf 6.3.2 wordt er teruggeblikt op het onderzoeksproces. Hierin wordt beschreven welke obstakels er waren en hoe daarmee omgegaan is.
6.3.1 Limitaties en aanbevelingen
De eerste en grootste limitatie is de tijd gebleken. Aanvankelijk wilde ik niet alleen literatuur verzamelen uit het jaar 2018, maar ook uit 2019 en de eerste helft van 2020. Het afstudeertraject ging in februari van start en eindigt in juli. Dit betekent dat er vijf maanden beschikbaar waren voor de scriptie. De omvang van de literatuur is sterk toegenomen de afgelopen jaren. Favaretto et al. (2019) merken al op dat 49 van de 61 artikelen afkomstig zijn uit de periode 2014 tot en met 2017. Uit de literatuur van 2018 kwamen hier nog eens 25 artikelen bij. Het duurde alleen al 5 maanden om deze artikelen te verwerken in deze literatuur review, waardoor er geen tijd meer was om de overige jaren te onderzoeken. Een van de gevolgen hiervan is dat er uitspraken gedaan zijn over onder andere de focus van de literatuur waarbij er één jaar vergeleken wordt met een periode van zeven jaar. Als de literatuur van 2019 en de eerste helft van 2020 hieraan toegevoegd zou zijn, zou dit waarschijnlijk hebben geleid tot betere vergelijkingen. Daarnaast is een literatuur review completer als er langere perioden meegenomen worden in de analyse. Er wordt aanbevolen om de literatuur verder aan te vullen. Gezien de stijging van het aantal onderzoeken over de afgelopen jaren, is hier steeds meer tijd voor nodig.
Een andere beperking is het mogelijke verschil in interpretatie van de artikelen tussen Favaretto et al. (2019) en mezelf. Een voorbeeld hiervan is de opmerking van Favaretto et al. (2019) dat artikelen die onderzoek doen naar privacy, het geven van toestemming en het anonimiseren van gegevens niet zijn opgenomen in de literatuur review. In deze literatuur review zijn deze wel opgenomen, met de reden dat de problemen rondom privacy een belangrijke trigger kunnen zijn voor discriminatie. Zo stelt Wachter (2018) dat het niet kunnen anonimiseren tot discriminatie kan leiden. Bottis en Buchagiar (2018) stellen dat toegang tot bepaalde diensten geweigerd kunnen worden als er geen toestemming gegeven wordt voor het verstrekken van gegevens. Dit ondermijnt het recht op gelijke behandeling en is dus discriminerend. Favaretto et al. (2019) hebben dergelijke onderzoeken niet opgenomen, waardoor er verschillen zijn in de resultaten van beide onderzoeken. Het gebruik van zes databases is ook een mogelijke beperking. In deze literatuur review, en de literatuur review van Favaretto et al. (2019), zijn de zes databases gebruikt die beschreven zijn paragraaf 3.2.1. Mogelijk zijn er meerdere bronnen die relevante resultaten opleveren op het gebied van discriminatie in big data. Juist omdat het een populair onderzoeksgebied is, wordt er aanbevolen om meerdere bronnen te betrekken in het maken van een literatuur review.
6.3.2 Reflectie op het onderzoeksproces
Het uitvoeren van een literatuur review is iets wat ik nog nooit eerder heb gedaan. Er moest veel informatie opgezocht worden over deze onderzoeksmethode. Door mijn onervarenheid op dit gebied zijn er enkele uitdagingen op mijn pad gekomen waar ik mee om moest gaan. De eerste uitdaging trad vrij vroeg in het onderzoek al op. Dit was het zoeken in verschillende databases voor input. Van het bestaan van universele wildcards wist ik af, maar ik heb het zelden toegepast. Daarnaast is de manier waarop er gezocht wordt verschillend per database. Bij bijvoorbeeld Web of Science was het proces duidelijk en inzichtelijk, maar bij Cinahl was het verplicht om aparte onderzoeksgebieden aan te vinken die voor mij onduidelijk waren. Om hier goed mee overweg te kunnen is er veel tijd gestoken in het oriënteren op het zoekproces. Meerdere zoekopdrachten zijn gebruikt en verschillende onderzoeksgebieden zijn uitgetest. Door te sorteren op relevantie ben ik er uiteindelijk achter gekomen welke instellingen de

36
meeste relevante resultaten opleveren met de in paragraaf 3.2.2 beschreven zoekwoorden. Hoewel deze methode goede resultaten hebben opgeleverd, kunnen relevante artikelen onbedoeld uitgesloten zijn. Een andere uitdaging in het proces kwam naar voren bij de selectie van de artikelen. Bij de selectie werden de titels en keywords bestudeerd en de abstracts gelezen. Verreweg de meeste artikelen zijn niet relevant gebleken. In figuur 4.1 is te zien dat er in totaal 2258 resultaten waren, maar dat hiervan maar 25 artikelen geselecteerd zijn voor analyse. Ik betrapte me erop dat ik soms te snel een artikel afwees, omdat ik in eerste instantie geen relevantie kon vinden. Dit gebeurde vooral als ik al enkele uren bezig was met de selectie. Ik heb dit opgelost door in kleinere tijdsblokken te werken in het zoeken naar relevante artikelen. In plaats van twee uur zorgde ik ervoor dat ik niet langer dan drie kwartier aaneensluitend zocht. Daarnaast voerde ik niet meer dan drie blokken per dag uit. In de tussentijd werkte ik aan andere onderdelen in mijn scriptie. Desalniettemin blijft er enig risico dat artikelen te snel afgewezen worden, wat de validiteit kan schaden. Toen de selectie eenmaal opgemaakt was, begon ik met het lezen van de papers. Ik moest 48 papers lezen, en tijdens de analyse bleek de ene paper veel relevanter dan de andere. In eerste instantie wilde ik niet veel papers uitsluiten vanwege het gebrek aan relevantie, dus merkte ik dat ik daarnaar ging zoeken. Toen ik verschillende papers na het analyseren nogmaals las, was de relevantie in een aantal papers te vergezocht of zelfs niet aanwezig. Uiteindelijk heb ik besloten deze papers alsnog uit te sluiten, waardoor ik 23 van de 48 papers niet heb opgenomen in de literatuur review. Dit heeft veel tijd gekost, maar de beslissing om bijna de helft van de papers niet op te nemen waarborgt naar mijn mening te kwaliteit. Tijdens het analyseren werkte ik met de software Atlas TI. Ook hier ben ik onervaren mee. De codes die gebruikt zijn boden goed overzicht. Het navigeren was gemakkelijk. Tijdens het schrijven merkte ik echter dat oorzaken en belemmeringen soms door elkaar zijn gehaald. Dit zorgde ervoor dat ik bij elke code die een oorzaak of belemmering betrof goed na moest gaan wat het precies was. Dit kostte veel tijd in zowel het schrijfproces als in de hercodering. Achteraf gezien had ik meer tijd kunnen steken in het beoordelen van de codes.

37
Referenties Abrams, S. E. (2012). Purpose, Insight, and the Review of Literature. Public Health Nursing, 29(3), 189–190. https://doi.org/10.1111/j.1525-1446.2012.01025.x
Artikel1. (n.d.). Wat is discriminatie? | Art.1 MN. Geraadpleegd op 21 februari 2020, van https://www.art1middennederland.nl/over-discriminatie/wat-is-discriminatie/
Baker, J. D. (2016). The Purpose, Process, and Methods of Writing a Literature Review. AORN Journal, 103(3), 265–269. https://doi.org/10.1016/j.aorn.2016.01.016 Bennet Moses, L., & Chan, J. (2016). Algorithmic prediction in policing: assumptions, evaluation, and accountability. Policing and Society, 28(7), 806–822. https://doi.org/10.1080/10439463.2016.1253695 Blauw, S. (2018). Het bestverkochte boek ooit (met deze titel) (1st ed.). Amsterdam, Nederland: de Correspondent. Bottis, M., & Bouchagiar, G. (2018). Personal Data v. Big Data in the EU: Control Lost, Discrimination Found. Open Journal of Philosophy, 08(03), 192–205. https://doi.org/10.4236/ojpp.2018.83014 Cambridge Dictionary. (2020, 24 juni). Privacy. Geraadpleegd op 28 juni 2020, van https://dictionary.cambridge.org/dictionary/english/privacy Cheng, M., & Foley, C. (2018). The sharing economy and digital discrimination: The case of Airbnb. International Journal of Hospitality Management, 70, 95–98. https://doi.org/10.1016/j.ijhm.2017.11.002 Cohen, M. C. (2018). Big Data and Service Operations. Production and Operations Management, 27(9), 1709–1723. https://doi.org/10.1111/poms.12832 Crawford, K. (2013, May 10). Think Again: Big Data. Geraadpleegd op 27 februari 2020, van https://foreignpolicy.com/2013/05/10/think-again-big-data/ Cigsar, B., Unal, D. (2018). The Effect of Gender and Gender-Dependent Factors on the Default Risk. Revista de Cercetare si Interventie Sociala, 63, 28-41. Cuquet, M., & fessel, A. (2018). The societal impact of big data: A research roadmap for Europe. Technology in Society, 54, 74–86. https://doi.org/10.1016/j.techsoc.2018.03.005 Dalenberg, D. J. (2018). Preventing discrimination in the automated targeting of job advertisements. Computer Law & Security Review, 34(3), 615–627. https://doi.org/10.1016/j.clsr.2017.11.009 Deliversky, J., & Deliverska, M. (2018). Ethical and Legal Considerations in Biometric Data Usage—Bulgarian Perspective. Frontiers in Public Health, 6, 1–5. https://doi.org/10.3389/fpubh.2018.00025 Dressel, J., & Farid, H. (2018). The accuracy, fairness, and limits of predicting recidivism. Science Advances, 4(1), eaao5580. https://doi.org/10.1126/sciadv.aao5580 Engle, M. (2020, February 24). LibGuides: How to Prepare an Annotated Bibliography: The Annotated Bibliography. Geraadpleegd op 13 mei 2020, van https://guides.library.cornell.edu/annotatedbibliography Favaretto, M., De Clercq, E., & Elger, B. S. (2019). Big Data and discrimination: perils, promises and solutions. A systematic review. Journal of Big Data, 6(1). https://doi.org/10.1186/s40537-019-0177-4 College voor de Rechten voor de Mens. (n.d.). Discriminatie uitgelegd. Geraadpleegd op 3 april 2020 van https://www.mensenrechten.nl/nl/discriminatie-uitgelegd

38
Gandomi, A., & Haider, M. (2015). Beyond the hype: Big data concepts, methods, and analytics. International Journal of Information Management, 35(2), 137–144. https://doi.org/10.1016/j.ijinfomgt.2014.10.007
Gumbus, A., & Grodzinsky, F. (2016). Era of big data. ACM SIGCAS Computers and Society, 45(3), 118–125. https://doi.org/10.1145/2874239.2874256 Gillborn, D., Warmington, P., & Demack, S. (2018). QuantCrit: education, policy, ‘Big Data’ and principles for a critical race theory of statistics. Race Ethnicity and Education, 21(2), 158–179. https://doi.org/10.1080/13613324.2017.1377417 Goldkind, L., Thinyane, M., & Choi, M. (2018). Small Data, Big Justice: The Intersection of Data Science, Social Good, and Social Services. Journal of Technology in Human Services, 36(4), 175–178. https://doi.org/10.1080/15228835.2018.1539369 Golinelli, D., Toscano, F., Bucci, A., & Carullo, G. (2018). Transferring big data within the European Legal Framework: What rol for national healthcare services? Journal of law and medicine, 26, 488–493. Geraadpleegd van https://www.researchgate.net/publication/329935708_Transferring_Health _Big_Data_within_the_European_Legal_Framework_What_Role_for_National_Healthcare_Services Granville, V. (2016, September 14). Why is Big Data so Dangerous? Geraadpleegd op 21 februari 2020, van https://www.datasciencecentral.com/profiles/blogs/why-is-big-data-so-dangerous
Hamilton, I. A. (2018, October 14). Amazon built an AI tool to hire people but had to shut it down because it was discriminating against women. Geraadpleegd op 2 mei 2020, van https://www.businessinsider.nl/amazon-built-ai-to-hire-people-discriminated-against-women-2018-10?international=true&r=US
Health Sciences Library. (2020, May 4). LibGuides: Systematic Reviews: Creating a PRISMA flow diagram. Geraadpleegd op 14 mei 2020, van https://guides.lib.unc.edu/systematic-reviews/prisma
Hildenbrand, J. (2019, March 25). How much mobile data does streaming media use? Geraadpleegd op 30 maart 2020, van https://www.androidcentral.com/how-much-data-does-streaming-media-use Hu, C. (2006). Abduction, Deduction, and Induction: Their implications to quantitative methods. Geraadpleegd van https://canvas.uva.nl/courses/10498/files/2395474/download?wrap=1 Iliadis, A. (2018). Algorithms, ontology, and social progress. Global Media and Communication, 14(2), 219–230. https://doi.org/10.1177/1742766518776688 Iqbal, M. (2020, March 24). YouTube Revenue and Usage Statistics (2020). Geraadpleegd op 30 maart 2020, van https://www.businessofapps.com/data/youtube-statistics/ Kamiran, F., Mansha, S., Karim, A., & Zhang, X. (2018). Exploiting reject option in classification for social discrimination control. Information Sciences, 425, 18–33. https://doi.org/10.1016/j.ins.2017.09.064 Laney, D. (2001, February 1). 3D Data Management: Controlling Data Volume, Velocity, and Variety. Geraadpleegd op 30 maart 2020, van https://www.bibsonomy.org/bibtex/742811cb00b303261f79a98e9b80bf49
Lubin, G. (2012, March 16). The Incredible Story Of How Target Exposed A Teen Girl’s Pregnancy. Geraadpleegd op 1 mei 2020, van https://www.businessinsider.com/the-incredible-story-of-how-target-exposed-a-teen-girls-pregnancy-2012-2?international=true&r=US&IR=T
Lee, I. (2017). Big data: Dimensions, evolution, impacts, and challenges. Business Horizons, 60(3), 293–303. https://doi.org/10.1016/j.bushor.2017.01.004 Leetaru, K. (2016, January 4). In Machines We Trust: Algorithms Are Getting Too Complex To Understand. Geraadpleegd op 8 april 2020, van https://www.forbes.com/sites/kalevleetaru/2016/01/04/in-machines-we-trust-algorithms-are-getting-too-complex-to-understand/

39
Mack, C. (2015). The Multiple Lives of Moore’s Law. IEEE Spectrum, 52(4), 31. https://doi.org/10.1109/mspec.2015.7065415 Marshall G. (2010), Writing.a literature review. Synergy: Imaging & Therapy Practice ;20-23. Geraadpleegd op 18 april 2020, van https://www.tamuc.edu/academics/graduateSchool/documents/Writing...%20a%20literature%20review%20by%20Gill%20Marshall.pdf. Mayer-Schönberger, V., & Cukier, K. (2013). Big Data: A Revolution That Will Transform How We Live, Work, and Think (1st ed.). New York, United States: Houghton Mifflin Hartcour Publishing. Montgomery, K., Chester, J., & Kopp, K. (2018). Health Wearables: Ensuring Fairness, Preventing Discrimination, and Promoting Equity in an Emerging Internet-of-Things Environment. Journal of Involmation Policy, 8, 37–77. Geraadpleegd van https://www.jstor.org/stable/10.5325/jinfopoli.8.2018.0034#metadata_info_tab_contents Montiel, A. (2018). Gender equality and big data in the context of the sustainable development growth. The open journal of sociopolitical studies, 6, 544–556. https://doi.org/10.1285/i20356609v11i2p544 Onay, C., & Öztürk, E. (2018). A review of credit scoring research in the age of Big Data. Journal of Financial Regulation and Compliance, 26(3), 382–405. https://doi.org/10.1108/jfrc-06-2017-0054 Oracle. (2014, September 1). Oracle: Big Data for Enterprise. Geraadpleegd op 30 maart 2020, van https://www.oracle.com/assets/wp-bigdatawithoracle-1453236.pdf Paterson, M., & McDonagh, M. (2018). Data protection in an era of big data: The challenges posed by big personal data. Monash University Law Review, 44(1), 1–20. Geraadpleegd van https://www.monash.edu/__data/assets/pdf_file/0009/1593630/Paterson-and-McDonagh.pdf Regan, P. M., & Jesse, J. (2018). Ethical challenges of edtech, big data and personalized learning: twenty-first century student sorting and tracking. Ethics and Information Technology, 21(3), 167–179. https://doi.org/10.1007/s10676-018-9492-2 Schaefer, G. O., Tai, E. S., & Sun, S. (2019). Precision Medicine and Big Data. Asian Bioethics Review, 11(3), 275–288. https://doi.org/10.1007/s41649-019-00094-2 Schryen, G., Wagner, G., Benlian, A., & Paré, G. (2020). A Knowledge Development Perspective on Literature Reviews: Validation of a new Typology in the IS Field. Communications of the Association for Information Systems, 134–186. https://doi.org/10.17705/1cais.04607 Steekproef algemeen | Steekproef aselect. (2015, March 17). Geraadpleegd op 1 april 2020, van https://www.allesovermarktonderzoek.nl/steekproef-algemeen/steekproef-aselect/ Tanja, J., & Anne Frank Stichting (Amsterdam). (2019). Discriminatie. Amsterdam, Nederland: Athenaeum-Polak & van Gennep. Tardi, C. (2019, September 5). Moore’s Law. Geraadpleegd op 30 maart 2020, van https://www.investopedia.com/terms/m/mooreslaw.asp Taurinskas, B. T. (2016, August 11). Digital Discrimination: What Every Marketer Should Know To Stay Out Of Hot Water. Geraadpleegd op 8 april 2020, van https://www.aimclear.com/digital-discrimination-what-every-marketer-should-know-to-stay-out-of-hot-water/ Tschider, C. A. (2018). Regulating the internet of things: Discrimination, privacy, and cybersecurity in the artificial intelligence age. Denver Law Review, 96(1), 87-144.

40
Tusinski Berg, K. (2018). Big Data, Equality, Privacy, and Digital Ethics. Journal of Media Ethics, 33(1), 44–46. https://doi.org/10.1080/23736992.2018.1407189 Vayena, E., & Blasimme, A. (2018). Health Research with Big Data: Time for Systemic Oversight. The Journal of Law, Medicine & Ethics, 46(1), 119–129. https://doi.org/10.1177/1073110518766026 Wachter, S. (2018). Normative challenges of identification in the Internet of Things: Privacy, profiling, discrimination, and the GDPR. Computer Law & Security Review, 34(3), 436–449. https://doi.org/10.1016/j.clsr.2018.02.002 Ward, J. S. (2013, September 20). Undefined By Data: A Survey of Big Data Definitions. Geraadpleegd op 30 maart 2020, van https://arxiv.org/abs/1309.5821 Waldron, J. (2000, December 1). “Affirmative action”: efficiënt actiemiddel of tweesnijdend zwaard? Geraadpleegd op 8 april 2020, van https://www.mo.be/artikel/affirmative-action-efficient-actiemiddel-tweesnijdend-zwaard Wang, C., Hu, Q., Wang, X., Chen, D., Qian, Y., & Dong, Z. (2017). Feature Selection Based on Neighborhood Discrimination Index. IEEE Transactions on Neural Networks and Learning Systems, 1–14. https://doi.org/10.1109/tnnls.2017.2710422 Wash, R. (2014, October 23). The Big Bang: How the Big Data Explosion Is Changing the World. Geraadpleegd op 30 maart 2020, van https://news.microsoft.com/2013/02/11/the-big-bang-how-the-big-data-explosion-is-changing-the-world/
Zhang, L., Wu, Y., & Wu, X. (2016, November 22). A Causal Framework for Discovering and Removing Direct and Indirect Discrimination. Geraadpleegd op 9 mei 2020, van https://arxiv.org/pdf/1611.07509.pdf

41
Bijlage I: Geannoteerde bibliografie literatuuronderzoek 1. Bennet Moses, L., & Chan, J. (2016). Algorithmic prediction in policing: assumptions, evaluation, and accountability. Policing and Society, 28(7), 806–822. https://doi.org/10.1080/10439463.2016.1253695
In dit artikel wordt software onderzocht die de politie gebruikt voor het bestrijden van criminaliteit. Hoewel veel softwarepakketten beter ondersteuning bieden dan analoge alternatieven, werken veel toepassingen niet optimaal. Hierdoor is er een risico op discriminatie. Dit komt doordat er 1) te weinig begrip is van de software, 2) te weinig wordt geëvalueerd en 3) scheve resultaten zijn door een self-fulfilling proficy. Daarnaast is er veel vertrouwen in de software, waardoor veel beslissingen op basis van dergelijke software te weinig in twijfel worden getrokken.
2. Bottis, M., & Bouchagiar, G. (2018). Personal Data v. Big Data in the EU: Control Lost, Discrimination Found. Open Journal of Philosophy, 08(03), 192–205. https://doi.org/10.4236/ojpp.2018.83014
In dit artikel worden ethische kanten van persoonlijke en big data in Europa behandeld. Er wordt onderzocht of de regelgeving van de GDPR voldoende bescherming biedt met betrekking tot privacy en discriminatie. Ze onderzoekers concluderen dat dit niet het geval is en dat grondwettelijke rechten geschonden worden. Big data maakt het mogelijk om te discrimineren binnen de grenzen van de wet. Bottis en Bouchagiar roepen op om de regels van de GDPR aan te scherpen.
3. Cheng, M., & Foley, C. (2018). The sharing economy and digital discrimination: The case of Airbnb. International Journal of Hospitality Management, 70, 95–98. https://doi.org/10.1016/j.ijhm.2017.11.002
Dit is een case study waar de rol van Airbnb onderzocht wordt met betrekking tot digitale discriminatie. Airbnb is herhaaldelijk in verband gebracht met digitale discriminatie. Cheng & Foley merken op dat het lastig is voor Airbnb om digitale discriminatie te bestrijden. Het bedrijf vindt dat verhuurders altijd het recht moeten behouden om te kiezen wie er in hun huis verblijft. Chen & Foley merken op dat de complexiteit dermate groot is, dat interventies het probleem nooit helemaal oplossen. Deze paper kan gezien worden als startpunt voor de bestrijding van digitale discriminatie in de gedeelde economie.
4. Cohen, M. C. (2018). Big Data and Service Operations. Production and Operations Management, 27(9), 1709–1723. https://doi.org/10.1111/poms.12832
In dit onderzoek wordt er gekeken naar de mate waarin big data de service industrie beïnvloedt. Het artikel illustreert hoe de grote toename van Het artikel laat zien op welke manieren dit gebeurt en welke problemen en uitdagingen er zijn. Een van die uitdagingen is discriminatie die voortkomt uit de big data analyses. Cohen merkt op dat discriminatie vooral optreed in verborgen data. Als oplossing wordt er gepleit voor een technische toepassing die mogelijke discriminatie detecteert, zodat er ingegrepen kan worden.
5. Cigsar, B., Unal, D. (2018). The Effect of Gender and Gender-Dependent Factors on the Default Risk. Revista de Cercetare si Interventie Sociala, 63, 28-41.
Cisgsar & Unal passen in dit onderzoek big data toe om te onderzoeken of geslacht een rol speelt bij het bepalen van de credit score. Er is aanleiding om te denken dat als er een vrouw betrokken is bij de credit scores, deze beter zal zijn dan wanneer enkel mannen zijn betrokken. Deze studie bewijst het voordeel dat vrouwen hebben over mannen met betrekking tot het krijgen van een betere credit score. De reden hiervoor is dat vrouwen betrouwbaarder zijn in het terugbetalen van krediet en minder vaak schulden hebben.
6. Cuquet, M., & fessel, A. (2018). The societal impact of big data: A research roadmap for Europe. Technology in Society, 54, 74–86. https://doi.org/10.1016/j.techsoc.2018.03.005
Cuquet en Fensel onderkennen het gevaar van het gebruik van big data in de samenleving. Zij leggen een stappenplan voor, waarbij verantwoord analyseren met big data centraal staat. Dit stappenplan omvat uitdagingen als privacy en veiligheid, maar ook discrminatie. Transparantie is de belangrijkste aanbeveling die gedaan wordt om discriminatie in big data tegen te gaan. Verder wordt er gepleit voor anti-discriminerende ontwerpen als basis voor big data analyse.

42
7. Dalenberg, D. J. (2018). Preventing discrimination in the automated targeting of job advertisements. Computer Law & Security Review, 34(3), 615–627. https://doi.org/10.1016/j.clsr.2017.11.009
In dit onderzoek wordt discriminatie door kunstmatige intelligentie in sollicitatieprocedures onderzocht. Er worden diverse voorbeelden gegeven over hoe algoritmen hier kunnen discrimineren. Vervolgens worden er oplossingen gegeven waardoor algoritmen minder discrimineren. Voorbeelden hiervan zijn het buitensluiten van bepaalde variabelen, correlaties testen tegen een drempel en het gebruik van kunstmatige intelligentie om discriminatie te detecteren.
8. Deliversky, J., & Deliverska, M. (2018). Ethical and Legal Considerations in Biometric Data Usage—Bulgarian Perspective. Frontiers in Public Health, 6, 1–5. https://doi.org/10.3389/fpubh.2018.00025
Dit artikel focust zich op biometrische dataverzameling. Deliversky en Daliverska merken op dat er een serieus risico op discriminatie bestaat als gevolg van data linkage en profilering. Ook merken ze op dat er een gebrek is aan transparantie in de analyse, waardoor het moeilijk is om discriminatie te detecteren. Transparantie zou een belangrijke voorwaarde moeten zijn voor dergelijke analyses. Daarnaast wordt er gepleit voor meer bewustwording van de risico’s, wat kan leiden op zorgvuldigere procedures.
9. Dressel, J., & Farid, H. (2018). The accuracy, fairness, and limits of predicting recidivism. Science Advances, 4(1), eaao5580. https://doi.org/10.1126/sciadv.aao5580
In deze paper worden algoritmes die criminaliteit voorspellen onderzocht. Er zou een misvatting bestaan over de superioriteit van dergelijke algoritmen in het opsporen van criminaliteit ten opzichte van menselijke beslissingen. Voorstanders van dergelijke algoritmen gebruiken dit vaak als argument in ethische discussies. In het onderzoek wordt er echter geconcludeerd dat algoritmen niet beter presteren dan mensen. Algoritmen hebben een precisie van 65.2%, terwijl menselijke beslissingen een nauwkeurigheid hebben van ruim 67%.
10. Gillborn, D., Warmington, P., & Demack, S. (2018). QuantCrit: education, policy, ‘Big Data’ and principles for a critical race theory of statistics. Race Ethnicity and Education, 21(2), 158–179. https://doi.org/10.1080/13613324.2017.1377417
Deze paper behandelt het onderwerp van en discriminatie in het onderwijs als gevolg van big data. Algoritmen die gebruikt worden in het onderwijs maken vaak gebruik van historische kwantitatieve gegevens. Deze gegevens kunnen bevooroordeeld zijn, waardoor er een groot risico op discriminatie is. Volgens Gilborn en Demack ligt te oplossing bij het integreren van meer kwalitatieve data. Zo zouden er minder bevooroordeelde gegevens worden meegenomen in de analyses, wat het risico op discriminatie verkleint.
11. Goldkind, L., Thinyane, M., & Choi, M. (2018). Small Data, Big Justice: The Intersection of Data Science, Social Good, and Social Services. Journal of Technology in Human Services, 36(4), 175–178. https://doi.org/10.1080/15228835.2018.1539369
Big data wordt steeds meer ingezet in de samenleving. Deze paper benadrukt dat het gebruik van big data niet zonder gevaar is, en kijken kritisch naar het gebruik van big data. Er wordt een nieuw concept geïntroduceerd, genaamd small data, die een einde moet maken aan de onpersoonlijke manier waarop big data individuele gegevens gebruikt. Small data is de tegenhanger van big data die, in tegenstelling tot big data, enkel naar de individu kijkt. Dit zou manipulatie en discriminatie tegen moeten gaan.
12. Golinelli, D., Toscano, F., Bucci, A., & Carullo, G. (2018). Transferring big data within the European Legal Framework: What rol for national healthcare services? Journal of law and medicine, 26, 488–493. Geraadpleegd van https://www.researchgate.net/publication/329935708_Transferring_Health _Big_Data_within_the_European_Legal_Framework_What_Role_for_National_Healthcare_Services
Dit artikel geeft een juridische kijk op de rol van nationale gezondheidsdiensten en de toenemende invloed van big data op medisch gebied. Gezondheidsgegevens zijn erg gevoelig, en momenteel zou er te weinig gedaan worden om deze gegevens te beschermen. Hierdoor ontstaan er risico’s voor privacy en discriminatie. Een oplossing die gegeven wordt is het mogelijk maken van derde partijen die toezicht houden op instanties die deze gegevens gebruiken voor analyse. Het zou aan de nationale gezondheidsdiensten zijn om dit op te zetten.
13. Iliadis, A. (2018). Algorithms, ontology, and social progress. Global Media and Communication, 14(2), 219–230. https://doi.org/10.1177/1742766518776688

43
Semantische technologieën en ontologieën worden vaak gebruikt als basis voor algoritmen. Deze toepassingen worden gebruikt door onder andere Facebook. Volgens Illiadis zijn ontologieën en semantische technologieën niet adequaat geëvalueerd. Dit kan leiden tot classificatiefouten en uiteindelijk tot discriminatie. Er zou te weinig aandacht voor zijn. Verder worden er twee voorbeelden geïllustreerd waarbij ontologieën en semantische technologieën sociale processen beïnvloeden.
14. Kamiran, F., Mansha, S., Karim, A., & Zhang, X. (2018). Exploiting reject option in classification for social discrimination control. Information Sciences, 425, 18–33. https://doi.org/10.1016/j.ins.2017.09.064
Dit onderzoek richt zich op het discriminatieprobleem in de juridische wereld. Er wordt gesteld dat de huidige tools die het bewustzijn van discriminatie aan het licht brengt kwalitatief onvoldoende zijn. Er is een raamwerk gemaakt die het bewustzijn van discriminatie in juridische beslissingen aan het licht brengt. Dit raamwerk heeft vooral betrekking op de selectie van de variabelen die in big data analyses gebruikt worden.
15. Montgomery, K., Chester, J., & Kopp, K. (2018). Health Wearables: Ensuring Fairness, Preventing Discrimination, and Promoting Equity in an Emerging Internet-of-Things Environment. Journal of Involmation Policy, 8, 37–77. Geraadpleegd van https://www.jstor.org/stable/10.5325/jinfopoli.8.2018.0034#metadata_info_tab_contents
Door het toenemende gebruik van draagbare apparaten zoals sporthorloges en draagbare bloeddrukmeters, neemt het risico op privacyschending en discriminatie toe. De grootste belemmering is het gebrek aan wet en regelgeving op dit gebied. In dit onderzoek worden er door middel van kwalitatief onderzoek adviezen gegeven aan beleidsmakers. Negen verschillende adviezen worden gegeven om een veilig gebruik van het internet of things te waarborgen.
16, Montiel, A. (2018). Gender equality and big data in the context of the sustainable development growth. The open journal of sociopolitical studies, 6, 544–556. https://doi.org/10.1285/i20356609v11i2p544
Montiel haalt het probleem van discriminatie onder vrouwen aan. Ze stelt dat het tijdperk van big data de genderongelijkheid alleen maar doet toenemen. De oorzaak hiervan is enerzijds de digitale kloof die aanwezig is. Zo hebben vrouwen in bijna elk gebied in de wereld tien tot veertig procent minder toegang tot het internet, waardoor er minder vrouwelijke data gegenereerd wordt. Daarnaast zijn het vooral mannen die werkzaam zijn in de ICT, waardoor de belangen van vrouwen mogelijk ondermijnd worden. Het is een uitdaging om naar meer gelijkheid te streven in het tijdperk van big data.
17. Onay, C., & Öztürk, E. (2018). A review of credit scoring research in the age of Big Data. Journal of Financial Regulation and Compliance, 26(3), 382–405. https://doi.org/10.1108/jfrc-06-2017-0054
Deze paper is een literatuur review die kredietscoresystemen onderzoekt. Er is literatuur verzameld van de afgelopen 42 jaar. Kredietscoresystemen komen steeds vaker voor in de samenleving, maar ze brengen uitdagingen met zich mee in de vorm van privacy en discriminatie. Mensen in ontwikkelingslanden hebben vaak een lagere kredietscore omdat zij vaak minder toegang hebben tot het internet. Er worden minder gegevens over hen verzameld, wat resulteert in een hoger risico. China probeert deze digitale kloof te overbruggen door gediscrimineerde bevolkingsgroepen voordelen te bieden zodat het ook voor hen mogelijk maakt om betere kredietscores te krijgen.
18. Paterson, M., & McDonagh, M. (2018). Data protection in an era of big data: The challenges posed by big personal data. Monash University Law Review, 44(1), 1–20. Geraadpleegd van https://www.monash.edu/__data/assets/pdf_file/0009/1593630/Paterson-and-McDonagh.pdf
Paterson & McDonagh onderzoeken de uitdagingen omtrent het gebruik van personal data door bedrijven. Ze noemen enkele voorbeelden dat er wordt gediscrimineerd met persoonlijke gegevens in de vorm van oneerlijke marketing en ongelijke behandelingen. In de wet staat dat dit verboden is. Echter, de regelgeving van de GDPR is onvolledig, waardoor er aansluitende wetten gemaakt zouden moeten worden door overheden. Tot op heden gebeurt dit niet.
19. Regan, P. M., & Jesse, J. (2018). Ethical challenges of edtech, big data and personalized learning: twenty-first century student sorting and tracking. Ethics and Information Technology, 21(3), 167–179. https://doi.org/10.1007/s10676-018-9492-2

44
In dit artikel worden algoritmen die gebruikt worden voor gepersonaliseerd onderwijs behandeld. Discriminatie in het onderwijs is een probleem dat zich al voordoet sinds de vorige eeuw. Regan en Jesse zijn bang dat deze historische data ook invloed heeft op de resultaten die algoritmen nu gebruiken om kinderen te beoordelen. Ze merken op dat de variabelen die gebruikt worden in dergelijke algoritmen discriminatie niet kunnen voorkomen. Er is wet en regelgeving op dit gebied, maar ook dat is niet voldoende. Overheden leggen de verantwoordelijkheid bij de aanbieders van het onderwijs, maar zij hebben niet genoeg kennis om discriminatie te voorkomen.
20. Schaefer, G. O., Tai, E. S., & Sun, S. (2019). Precision Medicine and Big Data. Asian Bioethics Review, 11(3), 275–288. https://doi.org/10.1007/s41649-019-00094-2
In dit artikel wordt Genetische discriminatie behandeld in de medische wereld. Hoewel het een betere aanpak is dan de “one size fits all” procedure, zijn er ook gevaren. Een van die gevaren is het risico op discriminatie. Er worden diverse adviezen gegeven over het opstellen van een procedure die nagelopen zou moeten worden om de risico’s te minimaliseren. Deze adviezen betreffen ook de manier waarop er met gevoelige informatie omgegaan moet worden. Transparantie wordt gezien als belangrijkste aspect.
21. Tschider, C. A. (2018). Regulating the internet of things: Discrimination, privacy, and cybersecurity in the artificial intelligence age. Denver Law Review, 96(1), 87-144.
In dit artikel worden uitdagingen betreffende het Internet of Things onderzocht. Ze presenteren alle uitdagingen die erbij komen kijken met betrekking tot privacy en discriminatie, en waarom huidige wet- en regelgeving niet werkt. Ook presenteren ze enkele oplossingen, zoals transparantie en mid-level data classification. Deze classificatie zou ervoor moeten zorgen dat gegevens minder goed te herleiden zijn naar de identiteit van een persoon.
22. Tusinski Berg, K. (2018). Big Data, Equality, Privacy, and Digital Ethics. Journal of Media Ethics, 33(1), 44–46. https://doi.org/10.1080/23736992.2018.1407189
Deze paper schijnt haar licht op een aantal belangrijke ethische aspecten omtrent het gebruik van big data. De paper beoordeeld een paar populair wetenschappelijke boeken die zich met de ethiek van big data bezighouden. Er wordt geconcludeerd dat elke datawetenschapper een eed zou moeten afleggen die vergelijkbaar is met de eed die advocaten moeten afleggen. In deze eed zouden wetenschappers de gevaren en uitdagingen van big data moeten erkennen en hier ethisch verantwoord mee om moeten gaan.
23. Vayena, E., & Blasimme, A. (2018). Health Research with Big Data: Time for Systemic Oversight. The Journal of Law, Medicine & Ethics, 46(1), 119–129. https://doi.org/10.1177/1073110518766026
Dit artikel legt de focus op big data analyses op medisch gebied. De analyses die worden gedaan met deze gevoelige data zouden niet veilig genoeg zijn en zijn ook niet bestand tegen discriminatie. Als oplossing pleiten Vayena en Blasimme voor een “Systematic Oversight Approach”, waarbij transparantie centraal staat. Ook moeten individuen beter geïnformeerd worden over de doeleinden van hun data, zodat zij betere beslissingen kunnen nemen.
24. Wachter, S. (2018). Normative challenges of identification in the Internet of Things: Privacy, profiling, discrimination, and the GDPR. Computer Law & Security Review, 34(3), 436–449. https://doi.org/10.1016/j.clsr.2018.02.002
Dit artikel focust zich op de uitdagingen die zich voordoen bij het gebruik van internet of things. Vier uitdagingen worden behandeld, zijnde profiling, identity, consent en transparantie. Er wordt gekeken in hoeverre de GDPR helpt in het overkomen van deze obstakels. Concluderend helpen de GDPR regels in zekere zin, maar dit is nog lang niet voldoende om de gebruiker volledig te beschermen. Er wordt geopperd om meer onderzoek te doen naar wet- en regelgeving die gebruikers wel voldoende kan beschermen.
25. Wang, C., Hu, Q., Wang, X., Chen, D., Qian, Y., & Dong, Z. (2017). Feature Selection Based on Neighborhood Discrimination Index. IEEE Transactions on Neural Networks and Learning Systems, 1–14. https://doi.org/10.1109/tnnls.2017.2710422
Wang et al hebben een verbeterde versie gemaakt voor de selectie van variabelen in algoritmen. Het probleem is dat algoritmen teveel irrelevante variabelen meenemen, wat voor foute resultaten kan zorgen. Deze machine

45
learning toepassing maakt gebruik gemaakt de entropietheorie van Shannon. De toepassing wordt de discrimination index genoemd. De resultaten laten een betere nauwkeurigheid zien en een kleinere looptijd. Door deze methode te gebruiken kunnen algoritmen beter presteren en kunnen ze leiden tot minder discriminatie.