Download - アルゴリズムとデータ構造

アルゴリズムとデータ構造アルゴリズムとデータ構造アルゴリズムとデータ構造アルゴリズムとデータ構造
20132013 年年 66 月月 1717 日日
酒居敬一酒居敬一 (([email protected]))
http://www.info.kochi-tech.ac.jp/k1sakai/Lecture/ALG/2013/index.html

連結リスト(29ページ)
• データをそれぞれの要素に格納• 要素どおし、つながってリストを形成
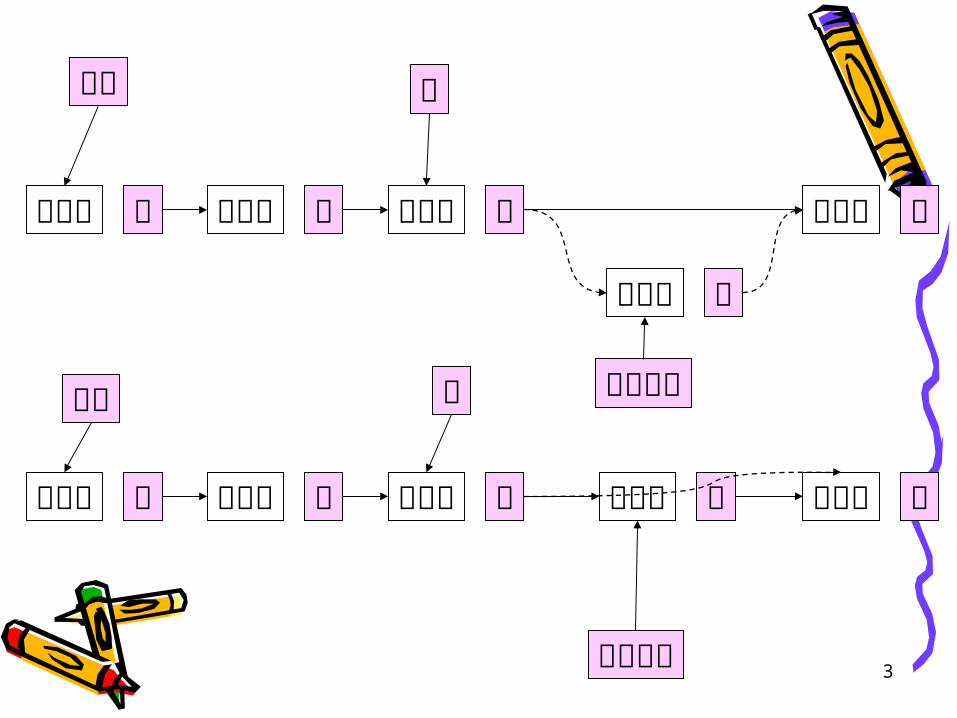
構造型データ
先頭 次次 次データ データ データ
次データ次データ
メモリ上に置かれた構造型データをアドレスで指す
2
先頭
次データ 次データ 次データ次データ次データ
次データ 次データ
次データ
次データ次データ
先頭 前
挿入対象前
削除対象 3

例:メモリ割り当て(37ページ)
空きの領域
最も簡単なメモリ割り当てアルゴリズム・リストで管理・データ領域を分断し、あらたなリスト要素として、挿入・リストのヘッダには空きか使用中かのフラグがある・割当てるデータ領域はリストのヘッダとヘッダの間
使用中空き使用中空き
使用状況を示すフラグ
次のヘッダを指すポインタ
ヘッダは左のような構造要素としては、フラグとポインタしかない
4
メモリの割り付け・開放を繰り返していくとメモリが分断するようになる・フラグメンテーションといい、大きな領域を割り当てできなくなる・そこで、ときおり、空き領域にはさまれたヘッダを削除する
使用中 空き空き 空き 使用中空き空き 空き
メモリ割付け技法•連続割付け
•単一連続割付け•分割割付け ( ゾーン割り付け )
•固定区画割付け•可変区画割付け
•非連続割付け•ページング•セグメンテーション
管理手法•線形リスト•ハッシュ表 5

スタック( LIFO )
スタックポインタ
ポッププッシュ
スタックポインタスタックポインタ
6
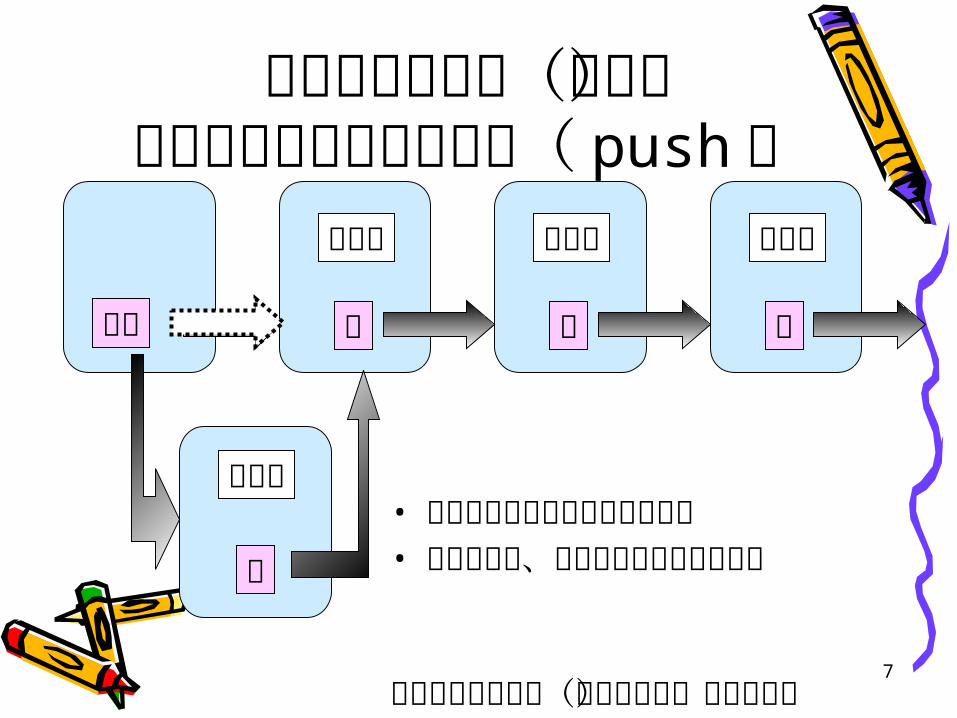
連結リスト操作(挿入)リストを使ったスタック
( push )
単純な連結リスト(線形リスト)データ挿入
先頭 次次 次
データ データ データ
次
データ• データをそれぞれの要素に格納• 要素どおし、つながってリストを形成
7

単純な連結リスト(線形リスト)データ削除
先頭 次次 次
データ データ データ
連結リスト操作(削除)リストを使ったスタック
( pop )
8

Postscript• プログラミング言語ではなくて、ページ記述言語• オペランドスタック、辞書スタックを持つ• オブジェクトはリテラル、エグゼキュータブル• A-WS で gs というコマンドで実行できる
• push/pop 以外のスタック処理がある• index 指定位置の内容をコピーして push• rotate 指定位置までのスタックを配列とみて回転• [] , {}, () スタックから配列オブジェクトを切り出せ
る
9

RPN (逆ポーランド記法)
普通は 1 + 2 と入力して 3 という答えを得ます同じ答えを得るために、 RPN で書くと 1 2 + となります。
普通の書き方の (1 + 2) × (3 + 4) を RPN にすると 1 2 + 3 4 + × となります。
ありがちなプログラミング言語では規則をもとに構文解析を行っている演算子には優先順位がある
括弧は優先度を変える
変わった言語、変わったプロセッサというものがありましてForth, PostScript といった言語、インテル x87 数値演算プロセッサ
これらはスタックを基本的なデータ構造としている
10

GS>1 2 add 3 4 add mul =21GS>1 2 add 3 4 add mul 5 6 mul 7 8 mul sub div =-0.807692GS>30 sin =0.5GS>45 cos =0.707107
(1 + 2) × (3 + 4) RPN では 1 2 + 3 4 +
(1 + 2) × (3 + 4) ÷(5×6 – 7×8)RPN では 1 2 + 3 4 + × 5 6 × 7 8 × - ÷
PostScript では、三角関数まで定義されている。
RPN で記述するとき、日本語で数式の動作を読み上げることにかなり近い順序になる
11

/* 可変長引数を持つ関数 */int printf(const char *fmt,…);
/* それの呼び出し */printf(“%d %f \n”, int_number, dbl_number);
C 言語では引数はスタックに積まれて、関数に渡される。呼び出し側の責任で引数を積んだり降ろしたりする。
呼ばれた関数のスタックフレーム
PC
fmt
dbl_number
int_number
呼んだ関数のスタックフレーム
← TOS
呼ばれた関数にわかっていること1. 呼ばれた関数のスタックフレームの大きさ2. 関数の戻り先 ( 呼び出し元 PC)3. 第 1 引数が const char *fmt であること
つまり fmt が読める→以降の引数がわかる
12

/* 可変長引数を持つ関数 */ int execl(const char *path, const char *arg, ...);
/* それの呼び出し */execl(“/bin/ls”, “ls”, “-l”, “/home/sakai”, NULL);
呼ばれた関数のスタックフレーム
PC
“/bin/ls”
“-l”
“ls”
呼んだ関数のスタックフレーム
← TOS呼ばれた関数にわかっていること1. 呼ばれた関数のスタックフレームの大きさ2. 関数の戻り先 ( 呼び出し元 PC)3. 第 1 引数が“/bin/ls”であること4. 第 2 引数が”ls”であること5. 最後の引数は必ず NULL であること
NULL
“/home/sakai”
スタックに何らかのマークを push し、TOS からマークまでをリストとして渡す
13

% PostScript における配列の切り出し% [1 2 3 4 5 6 7 8 9 10] という配列を定義
GS>[GS<1>1GS<2>2GS<3>3GS<4>4GS<5>5GS<6>6GS<7>7GS<8>8GS<9>9GS<10>10GS<11>]GS<1>==[1 2 3 4 5 6 7 8 9 10]GS>
PostScript では、配列が定義できる。スタック上の「マーク」と「マークまでを配列とする」オペレータを組み合わせて使う。このオペレータはマークまでをすべて pop し、配列オブジェクトとしてふたたび push する
[ オブジェクトの並び ] は通常の配列{ オブジェクトの並び } は実行可能な配列 ( 手続き )( 文字の並び ) は文字の配列(文字列)
いずれも配列の基本的な性質は継承している 14
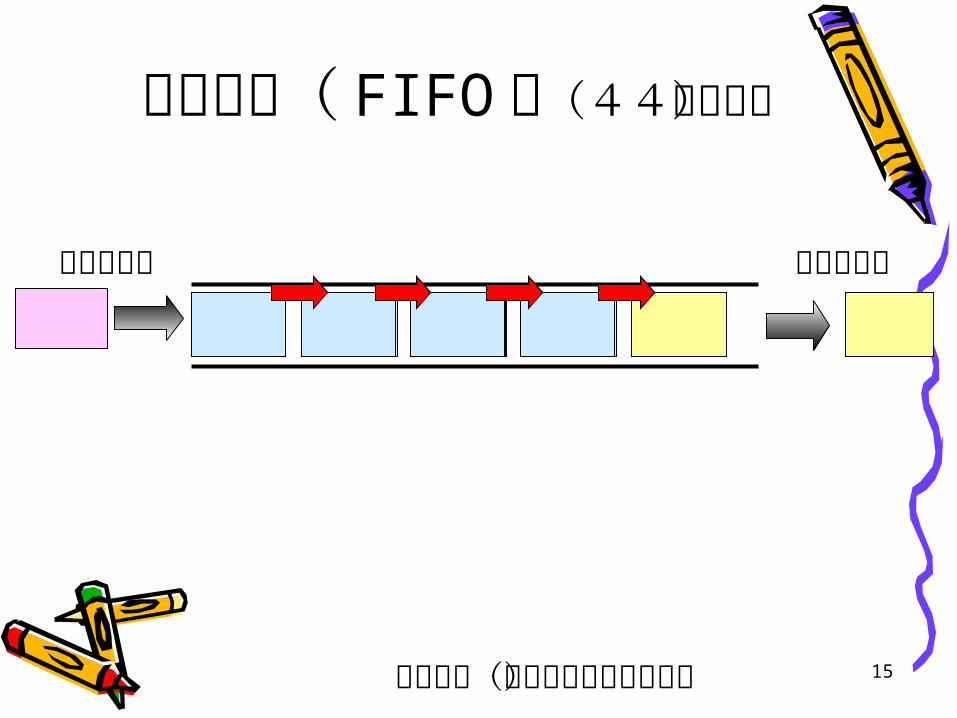
待ち行列( FIFO )(44ページ)
待ち行列(データの挿入・取得)
データ挿入 データ取得
15
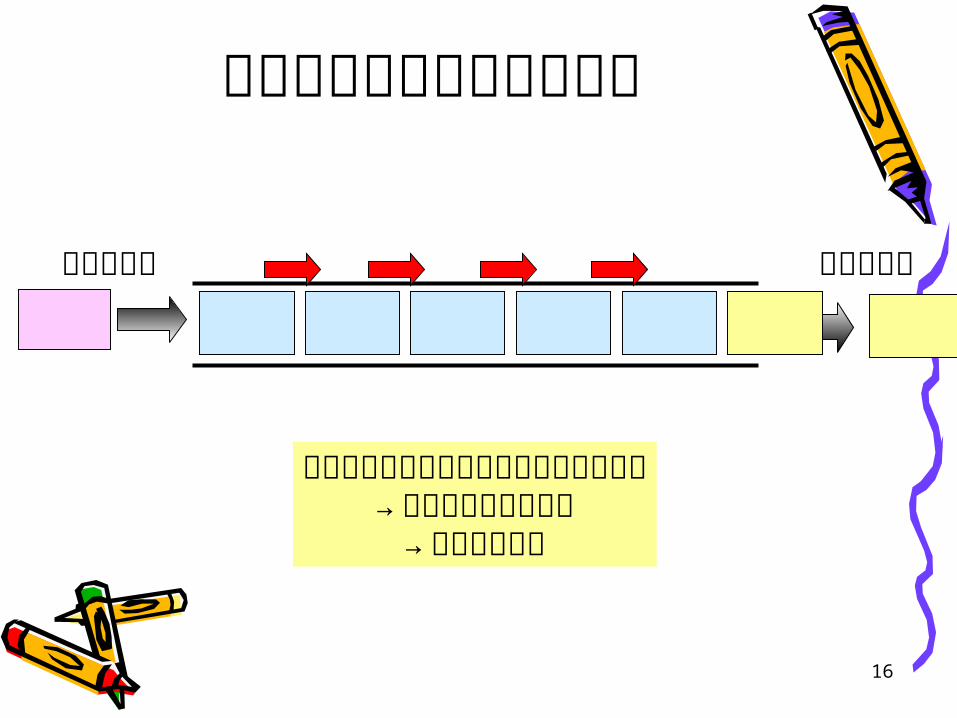
待ち行列の配列による実現
データ挿入 データ取得
新しい要素を入れようとすると入らない→右へコピーして移動
→隙間を空ける
16

リングバッファ (46 ページ )
配列の最初と最後を接続して環にしたもの2つのポインタでデータの出し入れを管理
データの先頭を指すポインタhead, front
データの最後尾を指すポインタtail, rear
2つのポインタが重なったらデータは空領域の大きさを n としたらポインタの位置は n とお
りデータの数が 0から n まで n+1 とおりあるポインタが重なったら、空か満杯の状態が重なる…
17
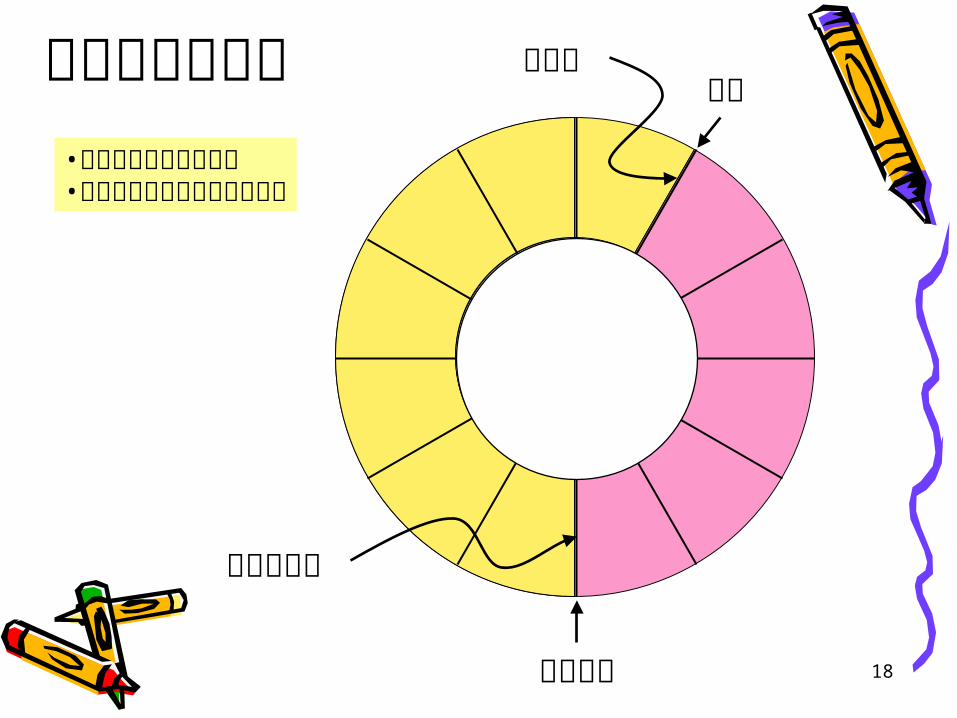
リングバッファリア
フロント
挿入口
取り出し口
•環状のデータ格納領域•データの存在を示すポインタ
18

フロントリア リア
満杯になったとき、リアとフロントのポインタが
重なってしまって空と区別が付かない
19

配列を使用したリングバッファ
配列には始まりと終わりがあるポインタが終わりまで移動したら先頭へ戻
る(フロント-リア)の演算でも境界を考慮
ラップラウンド処理
ラップラウンド処理条件文で判定配列の大きさを 2 のべき乗にする
配列のインデックスをビットごとの AND 処理20

public class Queue{ private Queue() { } public Queue(int aMaxSize) { int realSize = aMaxSize + 1; this.maxSize = realSize; this.queueArray = new Object[realSize]; this.front = 0; this.rear = 0; }
private int front; private int maxSize; private Object[] queueArray; private int rear;}
•データのおき場所は配列•front, rear というポインタで管理•キューの容量は maxSize で管理
21

public Object dequeue() { if(this.isEmpty()){ System.err.println("待ち行列は空です "); return null; }
Object dequedObject = this.queueArray[this.front]; this.queueArray[this.front] = null; ++this.front; if(this.maxSize == this.front){ this.front = 0; } return dequedObject; } public boolean isEmpty() { return (this.rear == this.front); }
•front の指すところがキューの先頭•先頭と最後尾が同じ場合は空•条件文でラップラウンド処理
22

public boolean enqueue(Object aTarget) { if(this.isFull()){ System.err.println("待ち行列はいっぱいです "); return false; } this.queueArray[this.rear] = aTarget; ++this.rear; if(this.maxSize == this.rear){ this.rear = 0; } return true; }
public boolean isFull() { return ((this.rear + 1) == this.front); }
•rear の指すところがキューの最後尾•先頭と最後尾が同じ場合は空
•そうならないようにする判定が必須•条件文でラップラウンド処理
23

public void printAll() { System.out.println("待ち行列の内容 "); if(this.isEmpty()){ System.out.println(); return; } int count = 1; int position = this.front; int limit = (this.front > this.rear)? this.maxSize: this.rear; while(position < limit){ System.out.println(count +"\t" + this.queueArray[position]); ++count; ++position; } position = 0; limit = (this.front > this.rear)? this.rear: 0; while(position < limit){ System.out.println(count +"\t" + this.queueArray[position]); ++count; ++position; } System.out.println(); }
•場合分けしてラップラウンド処理•front から配列終わりまでの表示•配列先頭から rear までの表示
24

// リストのデータ構造// Java 言語でアクセッサありpublic class Element1{ public Element1(Object aData) { this.data = aData; } public Object getData() { return this.data; } public Element1 getNextElement() { return this.next; } public void setNextElement(Element1 anNextElement) { this.next = anNextElement; } private Object data; // 参照型 private Element1 next;}
/* リストのデータ構造 *//* C 言語版その1 */union Object { int Integer; double Double;};struct Element1 { union Object data; struct Element1 *next;};
// リストのデータ構造// Java 言語でアクセッサなしpublic class Element2{ public Element2() { } public Object data; public Element2 next;}
/* リストのデータ構造 *//* C 言語版その2 */struct Element2 { void *data; struct Element2 *next;};
25
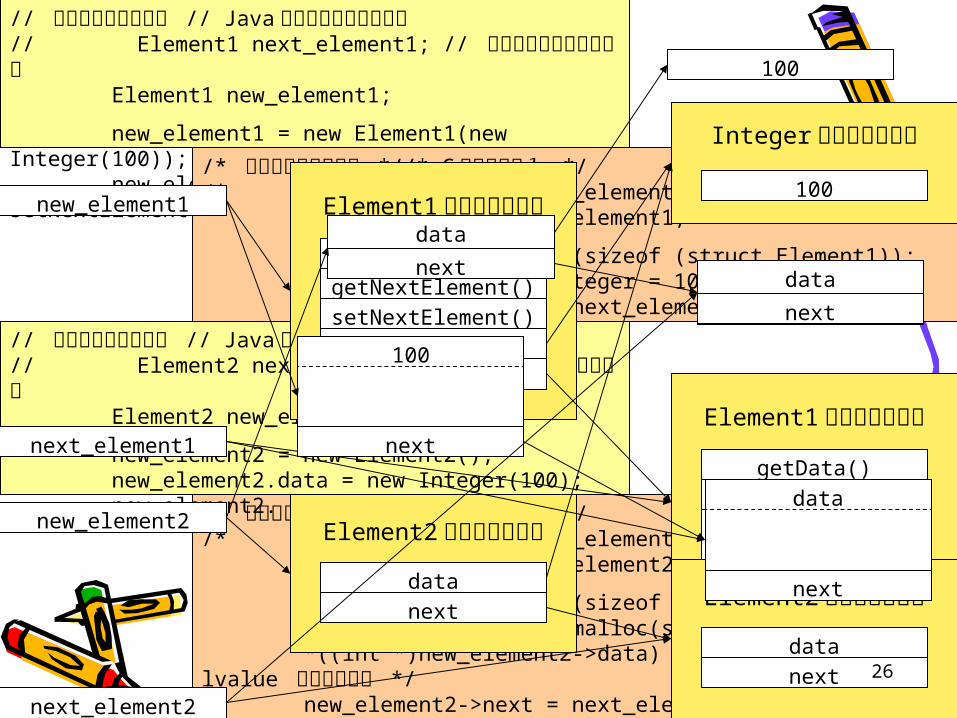
// リストのデータ構造 // Java 言語でアクセッサあり// Element1 next_element1; // どこかで与えられている Element1 new_element1;
new_element1 = new Element1(new Integer(100)); new_element1. setNextElement(next_element1);/* リストのデータ構造 *//* C 言語版その1 */
/* struct Element1 *next_element1: /* どこかで与えられている */ struct Element1 *new_element1;
new_element1 = malloc(sizeof (struct Element1)); new_element1->data.Integer = 100; new_element1->next = next_element1;
/* リストのデータ構造 *//* C 言語版その2 *//* struct Element2 *next_element2: /* どこかで与えられている */ struct Element2 *new_element2;
new_element2 = malloc(sizeof (struct Element2)); new_element2->data = malloc(sizeof (int)); *((int *)new_element2->data) = 100; /* cast as lvalue で行儀が悪い */ new_element2->next = next_element2;
// リストのデータ構造 // Java 言語でアクセッサなし// Element2 next_element2; // どこかで与えられている Element2 new_element2;
new_element2 = new Element2(); new_element2.data = new Integer(100); new_element2. next = next_element2;
Element1 のインスタンス
getData()getNextElement()setNextElement()
datanext
Element2 のインスタンス
datanext
Integer のインスタンス
100
Element1 のインスタンス
getData()getNextElement()setNextElement()
datanext
new_element1
next_element1
new_element2
next_element2
Element2 のインスタンス
datanext
100
data
next
next_element1
next
100
next_element1
next
data
data
next
26

// リストのデータ構造// Java 言語でアクセッサありpublic class Element1{ public Element1(int aData) { this.data = aData; } public int getData() { return this.data; } public Element1 getNextElement() { return this.next; } public void setNextElement(Element1 anNextElement) { this.next = anNextElement; } private int data; // 値型 private Element1 next;}
/* リストのデータ構造 *//* C 言語版その1 */struct Element1 { int data; struct Element1 *next;};
// リストのデータ構造// Java 言語でアクセッサなしpublic class Element2{ public Element2() { } public int data; public Element2 next;}
/* リストのデータ構造 *//* C 言語版その2 */struct Element2 { int *data; struct Element2 *next;};
27
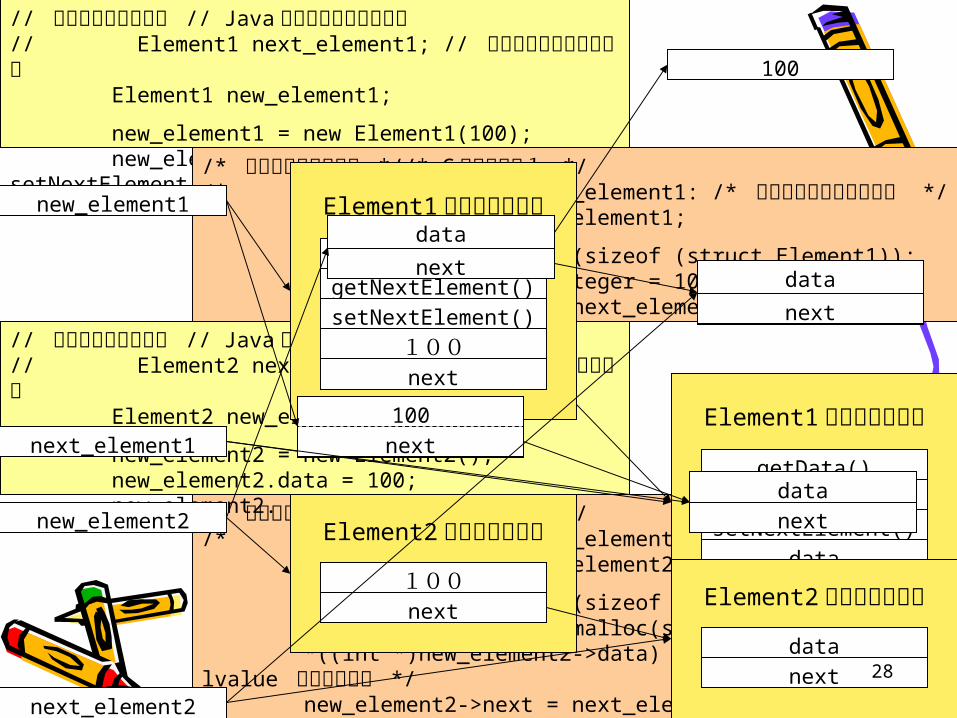
// リストのデータ構造 // Java 言語でアクセッサあり// Element1 next_element1; // どこかで与えられている Element1 new_element1;
new_element1 = new Element1(100); new_element1. setNextElement(next_element1);/* リストのデータ構造 *//* C 言語版その1 */
/* struct Element1 *next_element1: /* どこかで与えられている */ struct Element1 *new_element1;
new_element1 = malloc(sizeof (struct Element1)); new_element1->data.Integer = 100; new_element1->next = next_element1;
/* リストのデータ構造 *//* C 言語版その2 *//* struct Element2 *next_element2: /* どこかで与えられている */ struct Element2 *new_element2;
new_element2 = malloc(sizeof (struct Element2)); new_element2->data = malloc(sizeof (int)); *((int *)new_element2->data) = 100; /* cast as lvalue で行儀が悪い */ new_element2->next = next_element2;
// リストのデータ構造 // Java 言語でアクセッサなし// Element2 next_element2; // どこかで与えられている Element2 new_element2;
new_element2 = new Element2(); new_element2.data = 100; new_element2. next = next_element2;
Element2 のインスタンス
100next
Element1 のインスタンス
getData()getNextElement()setNextElement()
datanext
new_element1
next_element1
new_element2
next_element2
Element2 のインスタンス
datanext
100
data
next
Element1 のインスタンス
getData()getNextElement()setNextElement()
100next
next100
nextdata
data
next
28

自己再構成リスト• LRU の実装などに使える
次データ 次データ 次データ 次データ次データ
先頭 前
探索対象
次データ 次データ 次データ 次データ次データ
先頭 前
探索対象
探索対象を先頭に寄せる29

直接探索 線形探索
配列上の探索
添え字を用いて直接アクセス
先頭から順に調べる
30

public class Array{ public Array(int aMaxSize) { this.array = new String[aMaxSize];
this.number = 0; } public int search(String aTarget) { for(int count = 0; count < this.number; count++){ if(aTarget.equals(this.array[count])){ return count + 1; } } return -1; } private String[] array; private int number;}
配列の要素が尽きたかどうかの判定目的のデータであるかどうかの判定
1つのデータを探すのに 2 回も判定
31

番兵•計算量は減らないが、実行時間は減る• アルゴリズムではなくテクニックのひとつ• 線形探索では番兵を最後尾に置く
– 線形探索における番兵では、探索したいデータと等しい値のデータを用いることが多い
– 探索は目的のデータか番兵いずれかの発見で終了– 探索対象が無くなったかどうかの判定が不要にな
る•番兵は最も後に探索され、そして必ず一致する
32

public class Array{ public Array(int aMaxSize) { this.array = new String[aMaxSize+1];
this.number = 0; } public int search(String aTarget) { int count=0; this.array[this.number] = aTarget; while( !aTarget.equals(this.array[count]) ){ count++; } if(count != this.number){ return count + 1; } return -1; } private String[] array; private int number;}
配列の要素が尽きたかどうかの判定目的のデータであるかどうかの判定
配列の要素が尽きたかどうかの判定を最後に 1 回だけにした
これが番兵
33
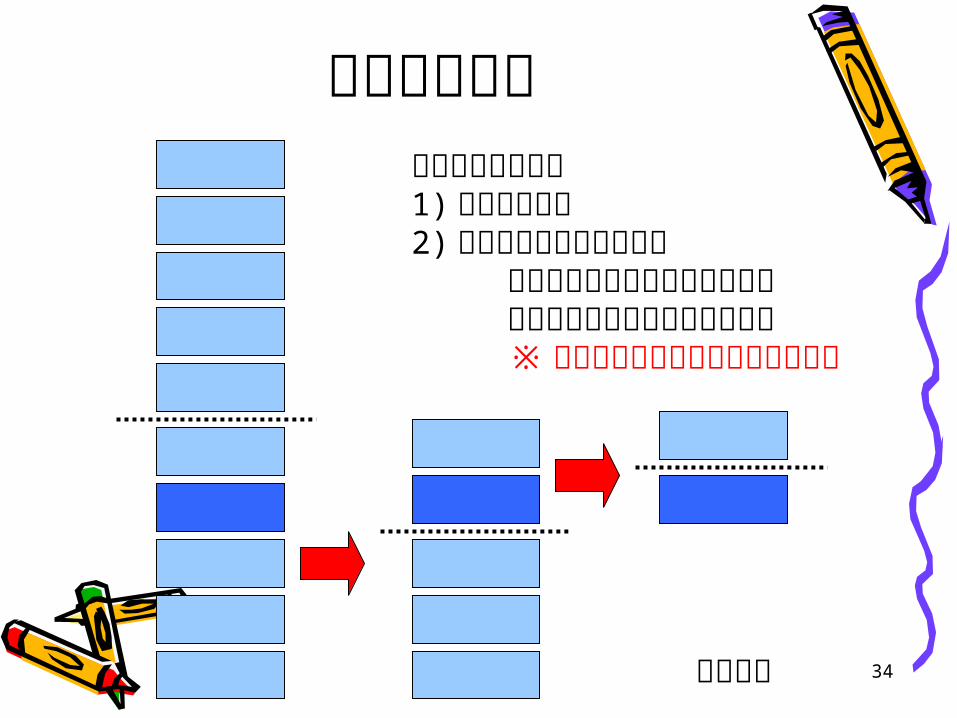
配列上の探索半分ずつ調べます1)半分に分ける2) 前半に存在するか調べる
前半にあれば前半について探索後半にあれば後半について探索※探索のためにデータの整列が必要
34二分探索

ルートノード
末端ノード
エッジ
ノード
木構造ルートとそれ以外のノードにちょうど1つだけの経路しか存在しない
35

まとめ• データ構造
– 配列・リスト・スタック・待ち行列・木• プログラムへの変換
– 参照型と値型の違い・利害得失• メモリのイメージ
– 抽象的なデータ構造との対応• プログラミング言語による違い
– Java にもポインタは存在する• ただし、ポインタ演算はない。
– Java と異なり、Cの構造型は値型である• Java のほうが参照を多用するけど、表立って見えな
い
36







