
数学と実世界が出あうとき数学の祭典 MathPower
六本木ニコファーレ 2018年10月7日
渡辺 澄夫
東京工業大学
この講演では 中澤俊彦さん(ドワンゴ)に
お世話になりました。御礼を申し上げます。

このファイルについて
このファイルは2018年10月7日に数学の祭典 MathPower で講演したときのものです。
数学を愛する一般のみなさまに、数学の不思議さや広がりについて楽しんでいただく
目的で書かれています。
1 初めて人工知能や機械学習に出会ったかたは下記をご覧ください。
http://watanabe-www.math.dis.titech.ac.jp/users/swatanab/suzaka2016.pdf
2 統計学や機械学習のエンジニアのかたは、下記をご覧ください。
http://watanabe-www.math.dis.titech.ac.jp/users/swatanab/johotusin20180910.pdf

3 統計学および機械学習の研究者のかたは 「WAIC statistics」 で検索して
関係する研究の発展を調べてみてください。
このファイルについて(続き)
5 数学について、たとえば Resolution of singularities, Bernstein-Sato polynomial,
log canonical threshold, Birational geometry, D-module, Analytic space,
は素晴らしい数学のテーマであり、現在も多数の研究がなされつつあります。
4 代数統計学という研究分野に関心があるかたは「algebraic statistics」で
検索して関連する研究の発展を調べてみてください。

数学と実世界が出あうとき
このファイルは 数学を愛するみなさまに
数学の不思議さや広がりを楽しんでいただく
目的で書かれています。

数学と実世界が出あうとき
1 実世界=数学から最も遠い場所
2 迷宮
3 代数解析学
4 代数幾何学
5 数学と実世界が出あうとき

エピソード 1
実世界=数学から最も遠い場所

多様な実世界
人間は実世界を認識できる
人間
あれが数学の星です
しかし人間の認識は言葉で説明できない
人間
これは紅茶ですが、なぜ私が
紅茶だとわかるか説明できません
人工知能は人間を学習する
…
先生
学習さん
先生と同じになるには
りんご,みかん,ぶどう,でしょう
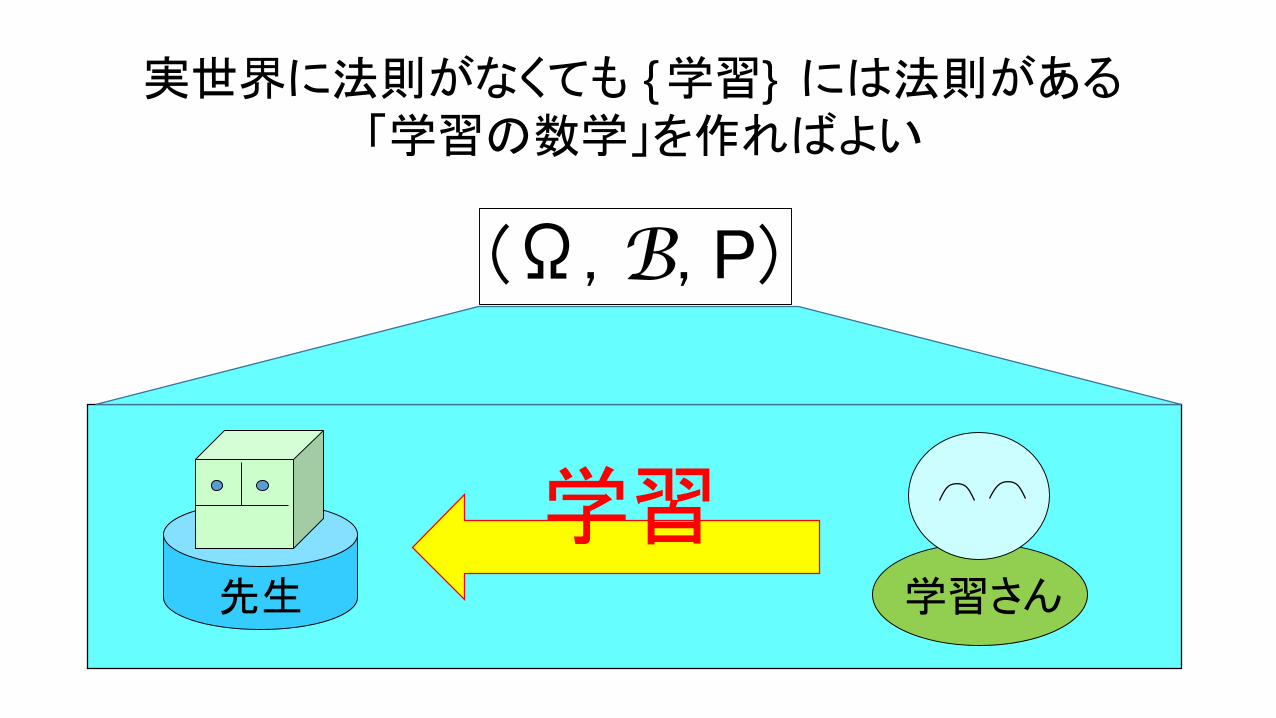
先生 学習さん
実世界に法則がなくても {学習} には法則がある「学習の数学」を作ればよい
(Ω, B, P)
学習
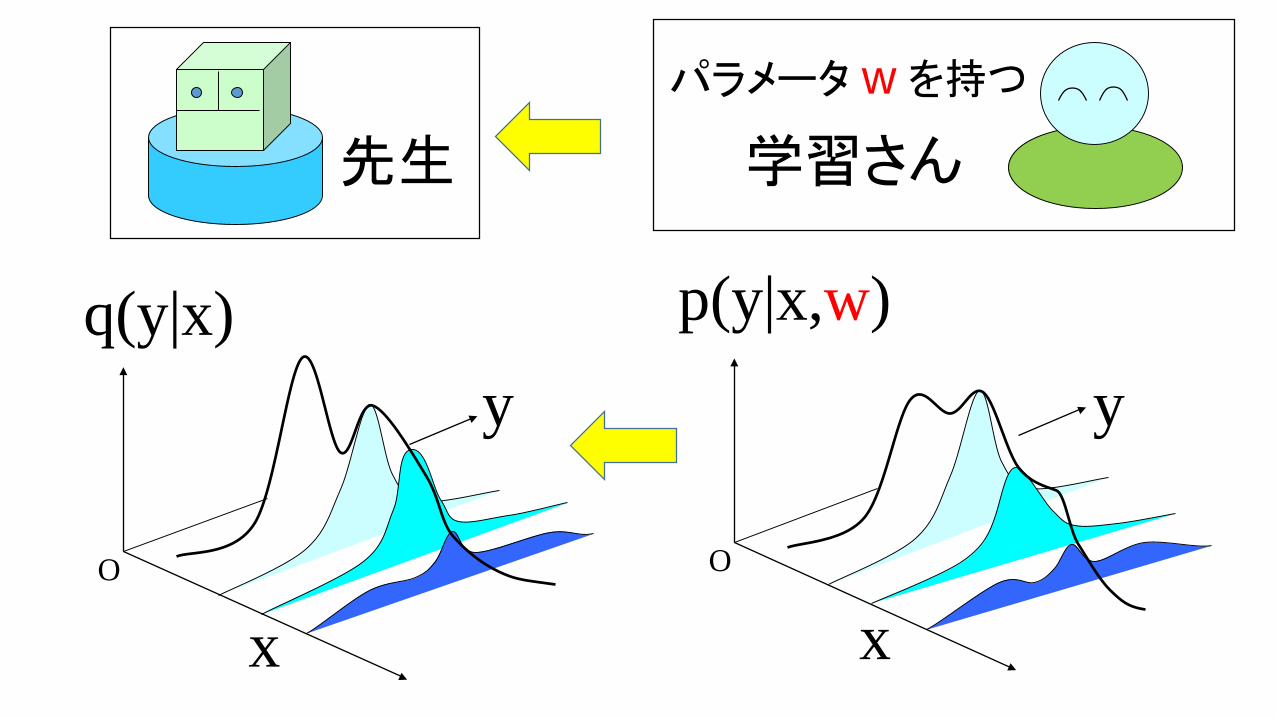
先生 学習さん
y
O
q(y|x)
x
y
O
p(y|x,w)
x
パラメータ w を持つ

先生 ← 学習さん
q(y|x) ← p(y|x,w)
q(x) q(y|x) ← q(x) p(y|x,w)
q(x) ← p(x|w)
(x,y) をあわせて一個の x で表すことにすると
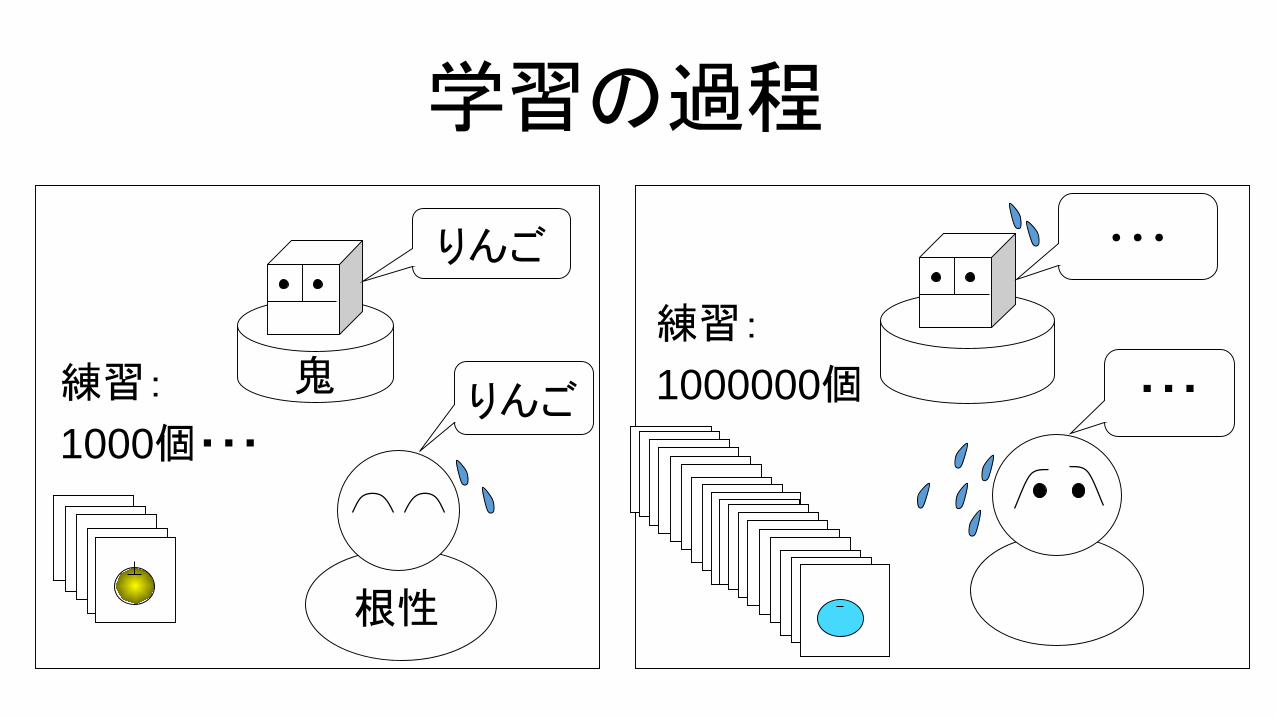
りんご
鬼練習:
1000個・・・りんご
根性
・・・
練習:
1000000個 ・・・
学習の過程

「学習後の状態」を ρ(w) で定義した・・・
ϕ(w) p(X1|w) p(X2|w) ・・・p(Xn|w)ρ(w) =
データ X1,X2,・・・,Xn を学習した後の状態を
と定義した(事後分布という。ϕ(w) は事前分布)。
1Z

「予測」を ρ(w) の平均で定義した・・・
p(x|w) ρ(w) dwp*(x) =
学習した後の予測を
と定義した。
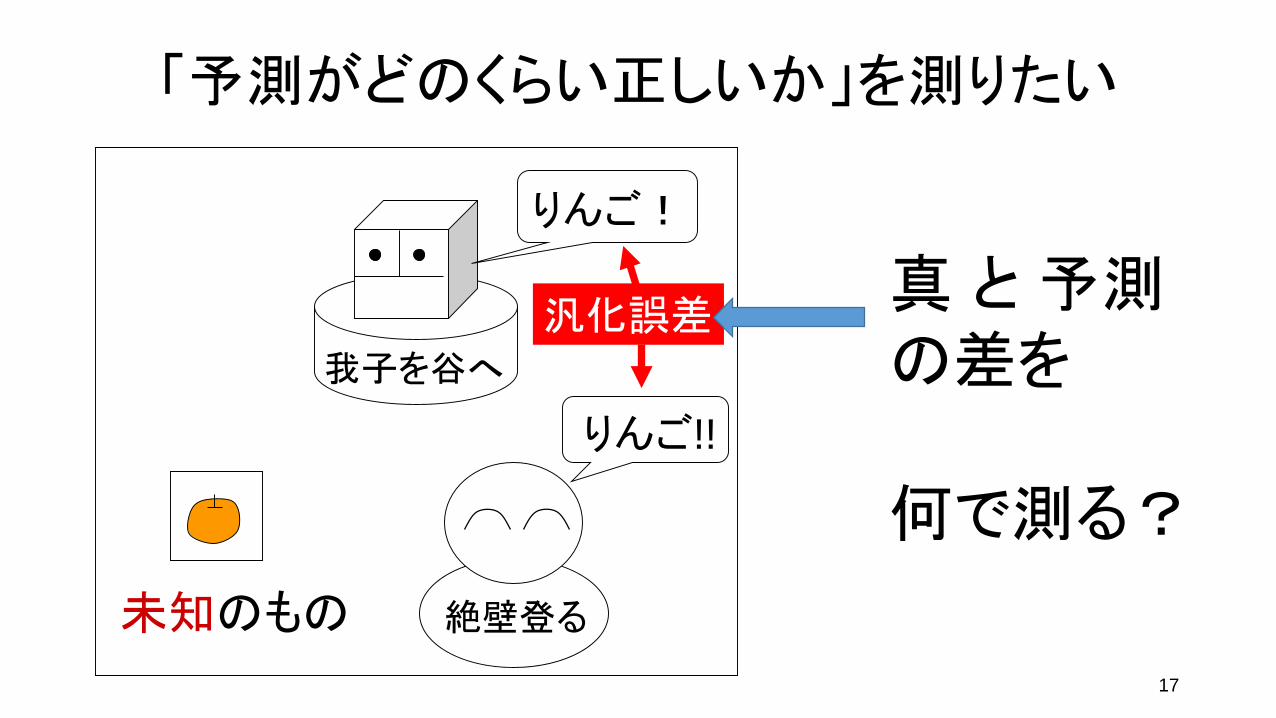
17
「予測がどのくらい正しいか」を測りたい
未知のもの
りんご!!
汎化誤差我子を谷へ
絶壁登る
真 と 予測の差を
何で測る?
りんご!

18
カルバック・ライブラ擬距離=相対エントロピー
K(w) = ∫ q(x) log ( q(x) / p (x|w) ) dx
G = ∫ q(x) log ( q(x) / p*(x) ) dx
真 と モデル の差を表す関数
「真 と 予測 の差=汎化誤差」の挙動を知りたい
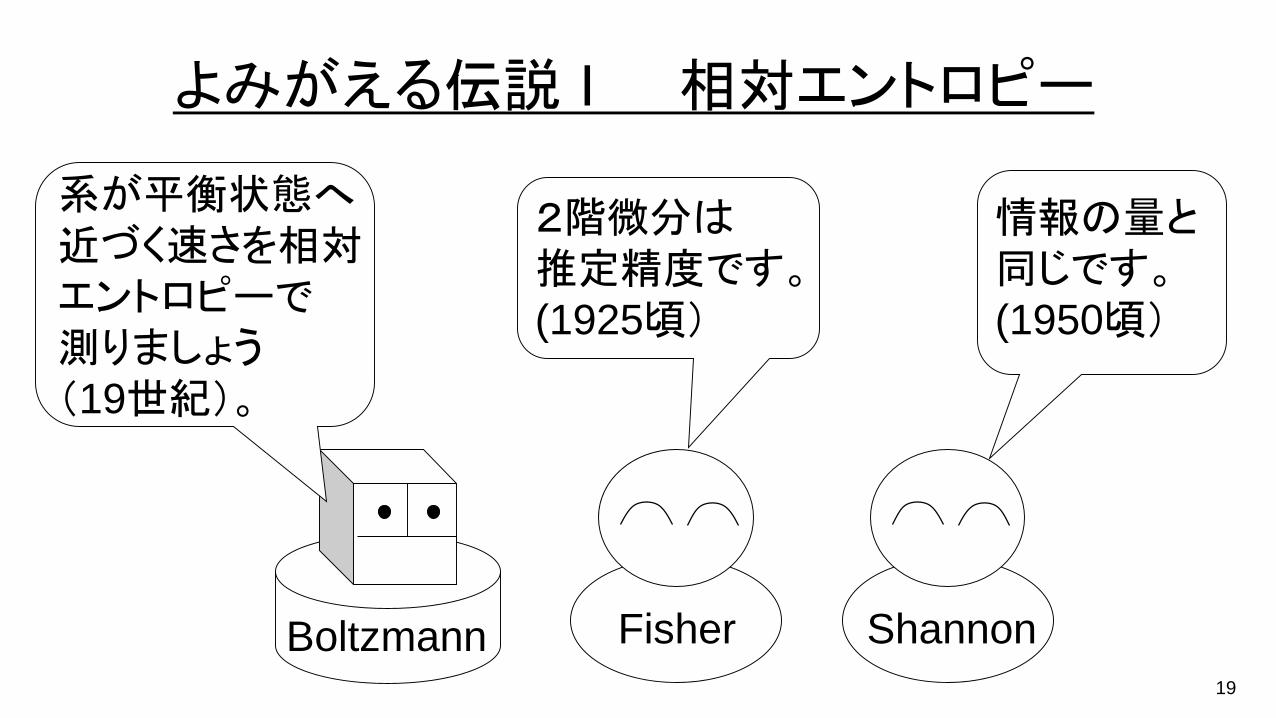
19
よみがえる伝説 I 相対エントロピー
Boltzmann
情報の量と同じです。(1950頃)
ShannonFisher
2階微分は推定精度です。(1925頃)
系が平衡状態へ近づく速さを相対エントロピーで測りましょう(19世紀)。
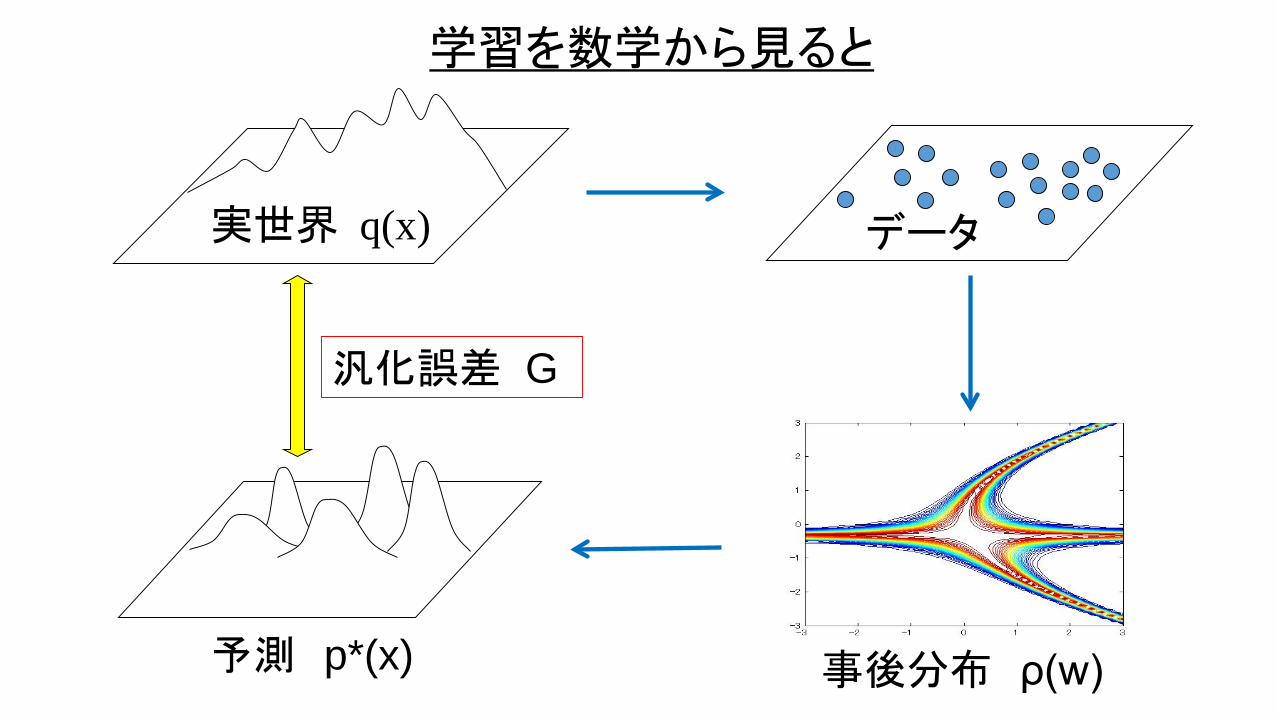
実世界 q(x) データ
汎化誤差 G
予測 p*(x) 事後分布 ρ(w)
学習を数学から見ると
21
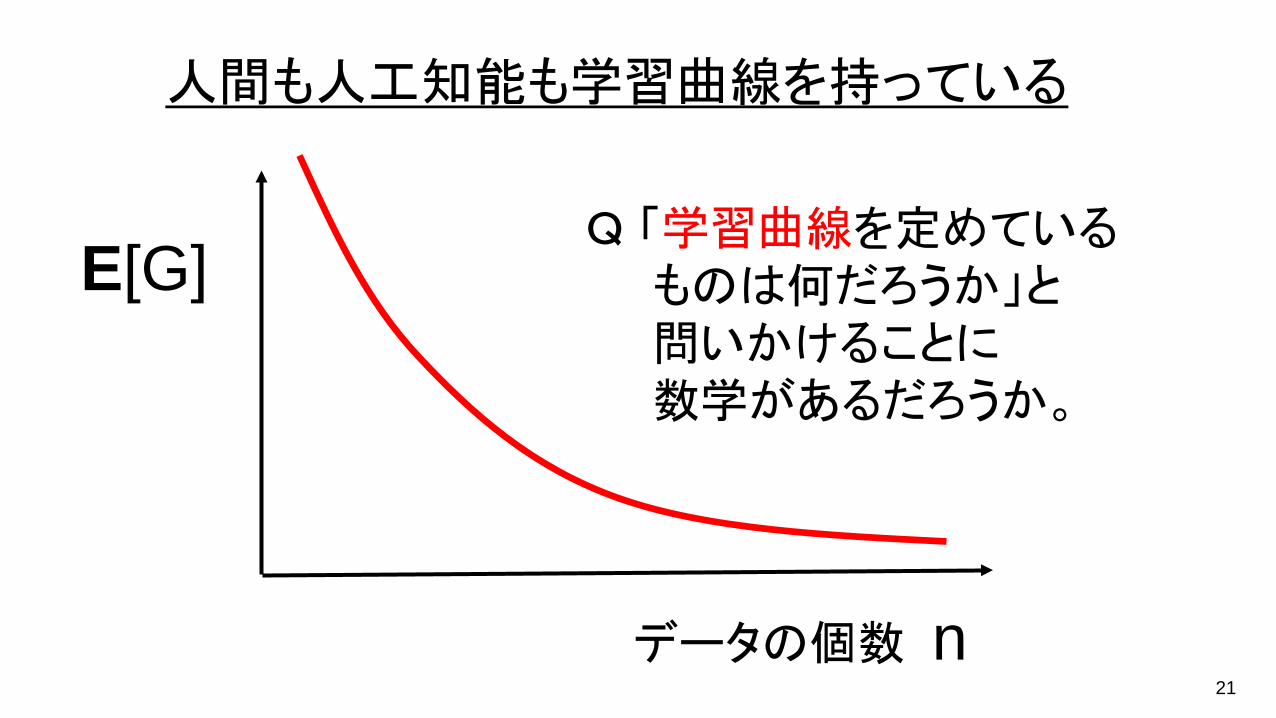
人間も人工知能も学習曲線を持っている
データの個数 n
E[G]Q 「学習曲線を定めている
ものは何だろうか」と問いかけることに数学があるだろうか。

22
エピソード1 まとめ
実世界に法則がなくても 学習にはきっと法則がある。
学習曲線を定めている数学は何だろうか。

エピソード 2 迷宮
24
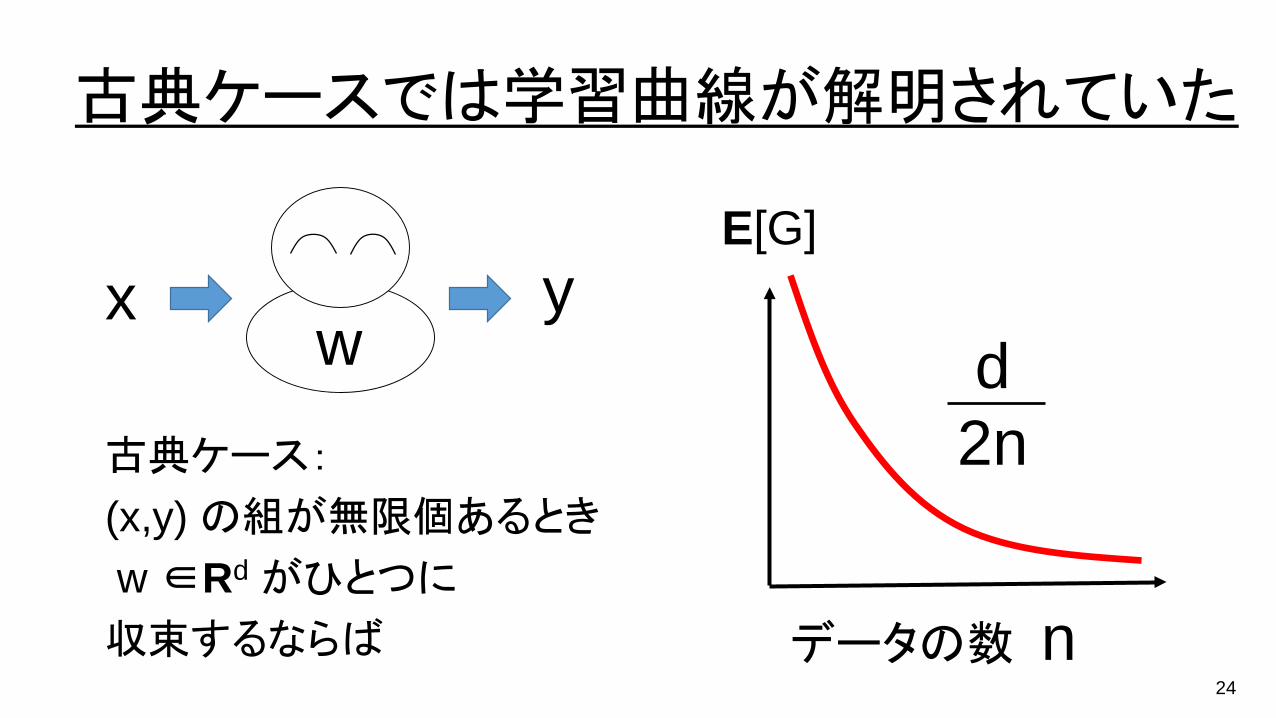
古典ケースでは学習曲線が解明されていた
wx y
データの数 n
d2n
E[G]
古典ケース:
(x,y) の組が無限個あるとき
w ∈Rd がひとつに
収束するならば
25
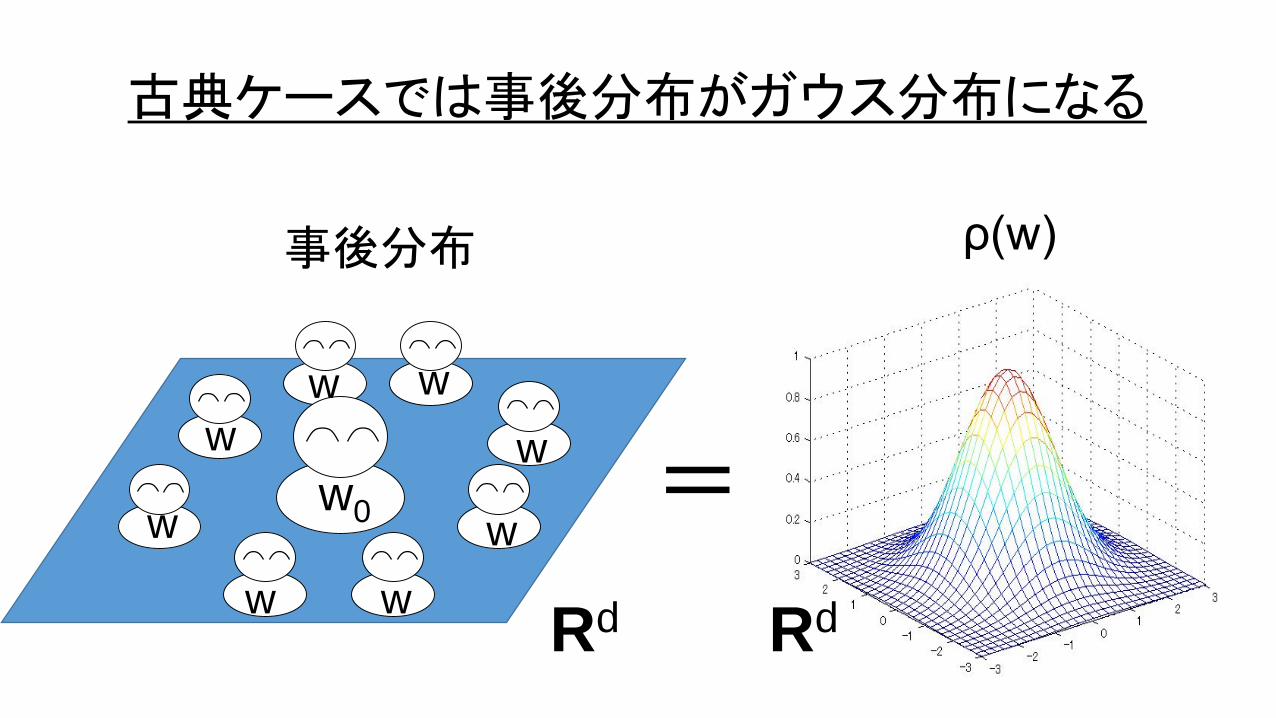
古典ケースでは事後分布がガウス分布になる
ρ(w)
w0 =
事後分布
ww
www
w
ww
Rd Rd

古典ケースの学習理論
定理. 正定値行列 J が存在し、ある w0 の近傍で
K(w) = (w-w0)・ J (w-w0) / 2
ならば
E[G] = + o( ).
ここで d は w の次元。
d2n
1n
23
27
しかし 現代の学習モデルでは
○ (x,y)の組が増えても
w ∈Rd はひとつに
収束しない。
○ 古典ケースだけを
考えても事実と合わず
新しい数学もできない。X
Y
w
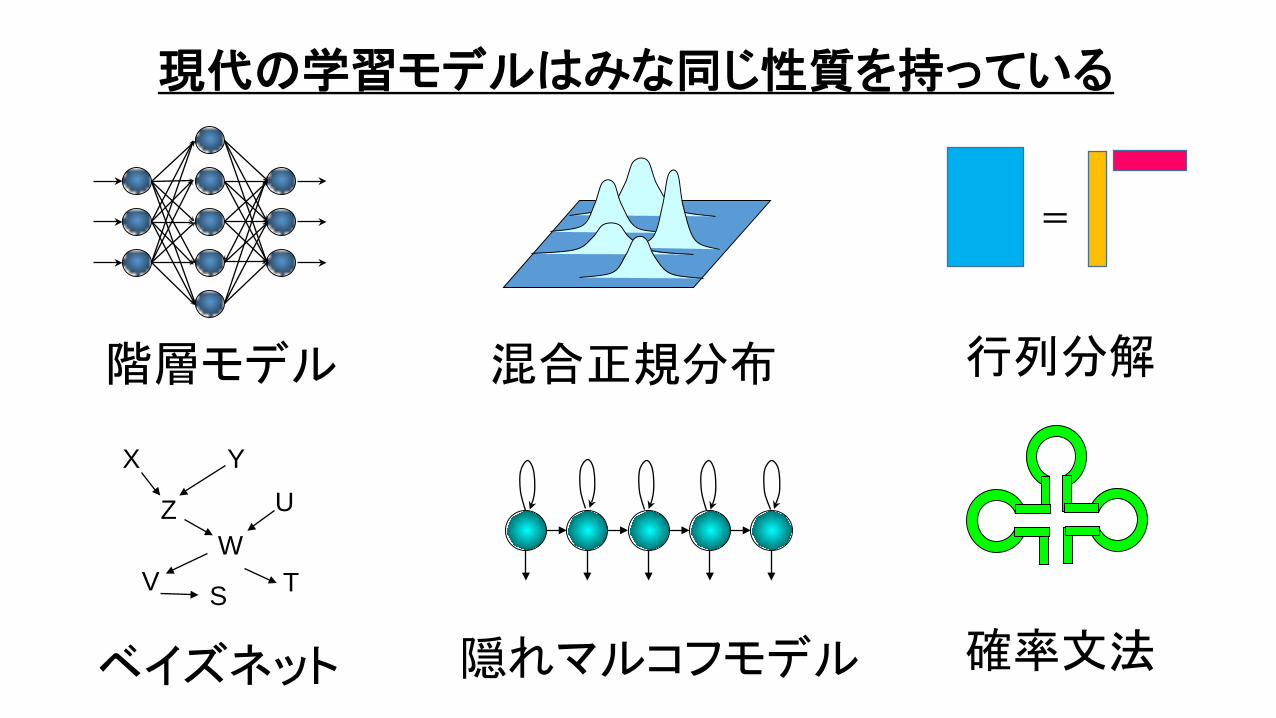
隠れマルコフモデル
混合正規分布
確率文法ベイズネット
階層モデル
X Y
ZW
U
V S T
=
行列分解
現代の学習モデルはみな同じ性質を持っている
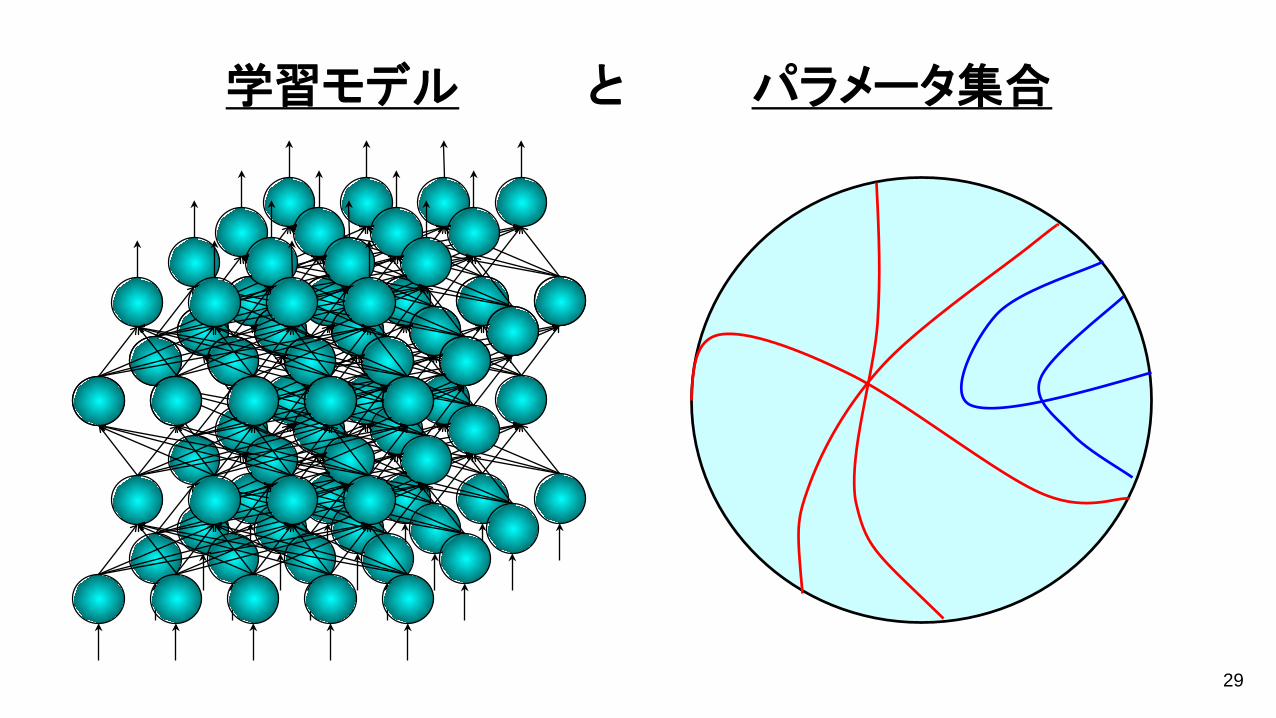
29
学習モデル と パラメータ集合
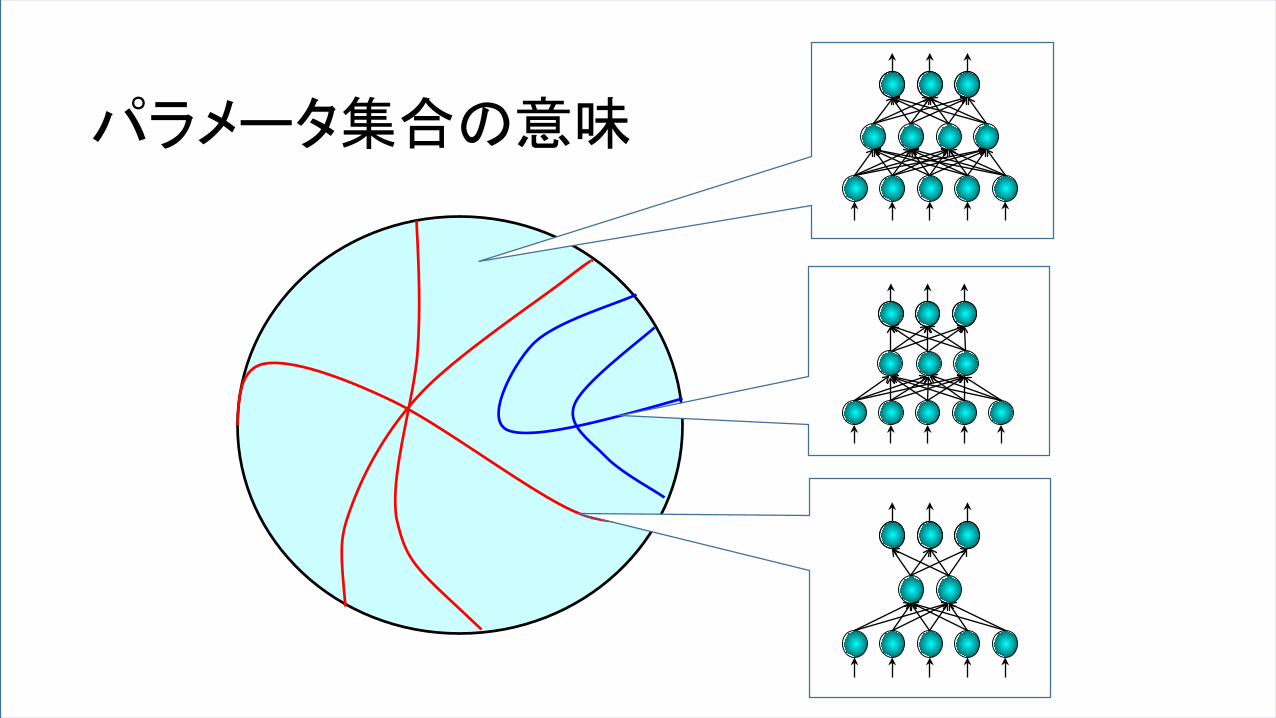
パラメータ集合の意味
特異点を含む解析的集合
31
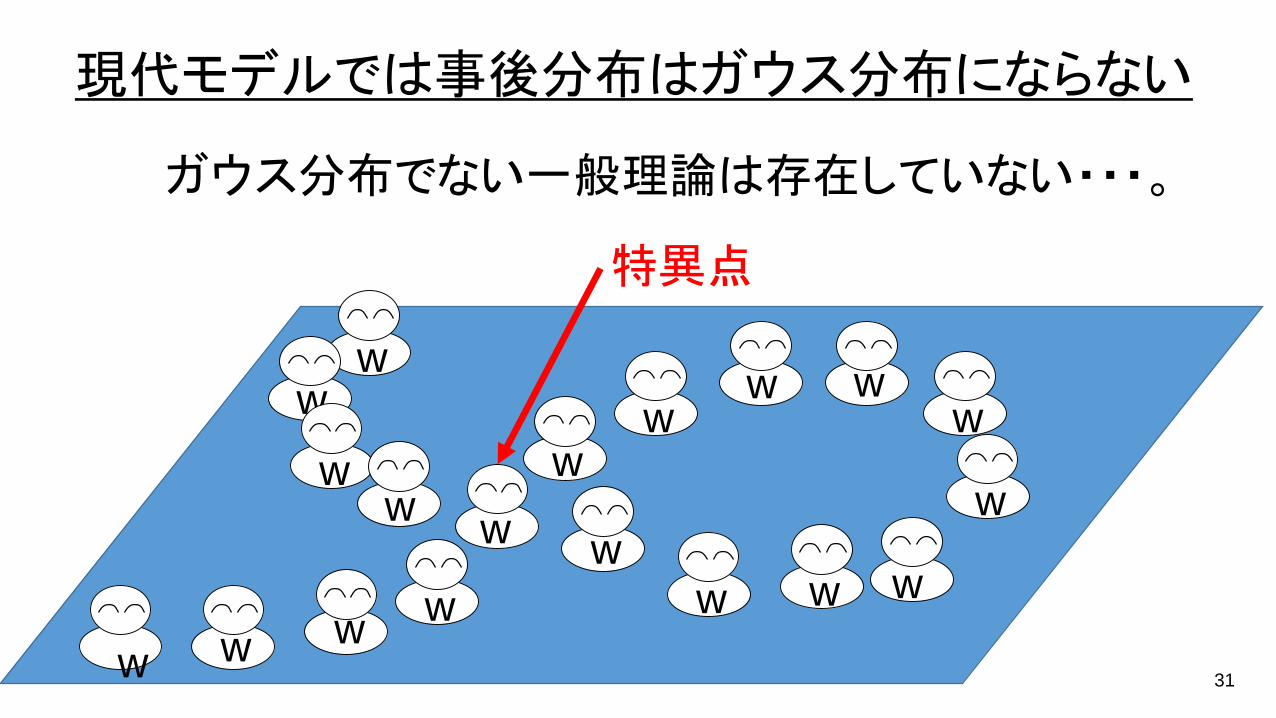
現代モデルでは事後分布はガウス分布にならない
www w
ww
w w ww w w
w
www
ww
ガウス分布でない一般理論は存在していない・・・。
ww
特異点
32
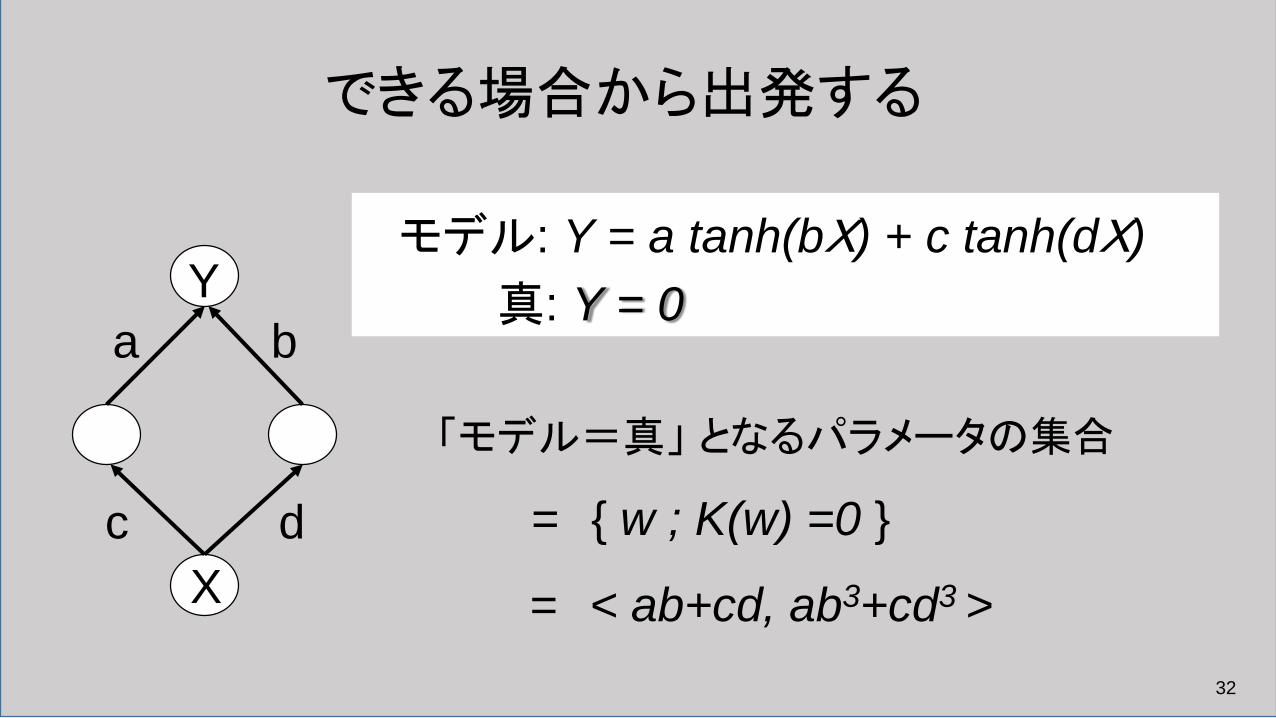
できる場合から出発する
モデル: Y = a tanh(bX) + c tanh(dX) 真: Y = 0
X
Ya b
c d
「モデル=真」 となるパラメータの集合
= { w ; K(w) =0 }
= < ab+cd, ab3+cd3 >

33
できる場合から出発する(続き)
X
Ya b
c d
b = b’ d
c = a b’ { (b’-1) c’ d – 1 }
とおくと E[G] = 2/3n +o(1/n) がわかる。
奇妙な変数変換
学習曲線は n に反比例し
係数は (2/3) ・・・・・古典ケースと違う

34
計算しても 計算しても 計算しても・・・
できる場合の一般化を求める
計算式は果てしなく複雑に・・・
現実の学習モデルは
難しい特異点を持っているX
Y
a c
d f
b
e

35
苦闘から 絶望へ
どんなに計算を進めても 数学は見えてこない
もしかしたら同じ場所をさまよっている・・・。
ここから先は
絶望の暗闇が続くだけだ・・・ 帰ろう・・・。
もう二度と 夢を見ることなんてない・・・。

36
エピソード2 まとめ
学習曲線を考えることに数学はない。
⇒ 研究がなかったのは 不可能だから。
⇒ 諦めて 引き返す勇気も大切だ。
⇒ さようなら、学習理論・・・。
・・・ 絶望 そして 長い時間が流れていった ・・・。

エピソード 3 代数解析学
絶望・・・・・ え?

ベルンシュタイン・佐藤のb関数
任意の多項式 f(x)∈R[x1,x2,…,xN] に対してある微分作用素 D と1変数多項式 b(z) が存在して 任意の z∈C について
D f(x)z+1 = b(z) f(x)z.佐藤(1970) Bernstein(1971) が独立に発見
39
b関数は代数的な世界に住んでいます。D加群を用いて証明されます。
佐藤先生Bernstein
よみがえる伝説 II b関数の住むところ

b関数の性質
☆ 最も次数が低く最高次の係数が1の b(z) はユニークである。
☆ 任意の解析関数 f(x) に対しても成立(Bjork)。
☆ b(z) の零点は負の有理数(柏原先生)。
☆ b(z) を求めるアルゴリズムを構成(大阿久先生)。
:

なぜ この例が 学習理論なのか
(∂a2+∂b
2+∂c2) (a2+b2+c2)z+1
= 4(z+1)(z+3/2) (a2+b2+c2)z
(∂a2∂b
3) (a2b3)z+1
= 36(z+1)2(z+1/3)(z+1/2)(z+2/3) (a2b3)z

学習理論のゼータ関数を考えてみた
カルバック・ライブラ情報量 K(w) と事前分布 φ(w) が与えられたとき、学習理論のゼータ関数を
ζ(z) = ∫ K(w)z φ(w) dw.
と定義すると Re(z)>0 で解析的である。

D の共役作用素を D* とすると
これを繰り返すと ζ(z) は複素平面全体に有理型関数としてユニークに解析接続できる。その極は b関数の零点集合に含まれる。
解析接続
ζ(z) = ∫ K(w)z+1 D*φ(w) dw.1 b(z)
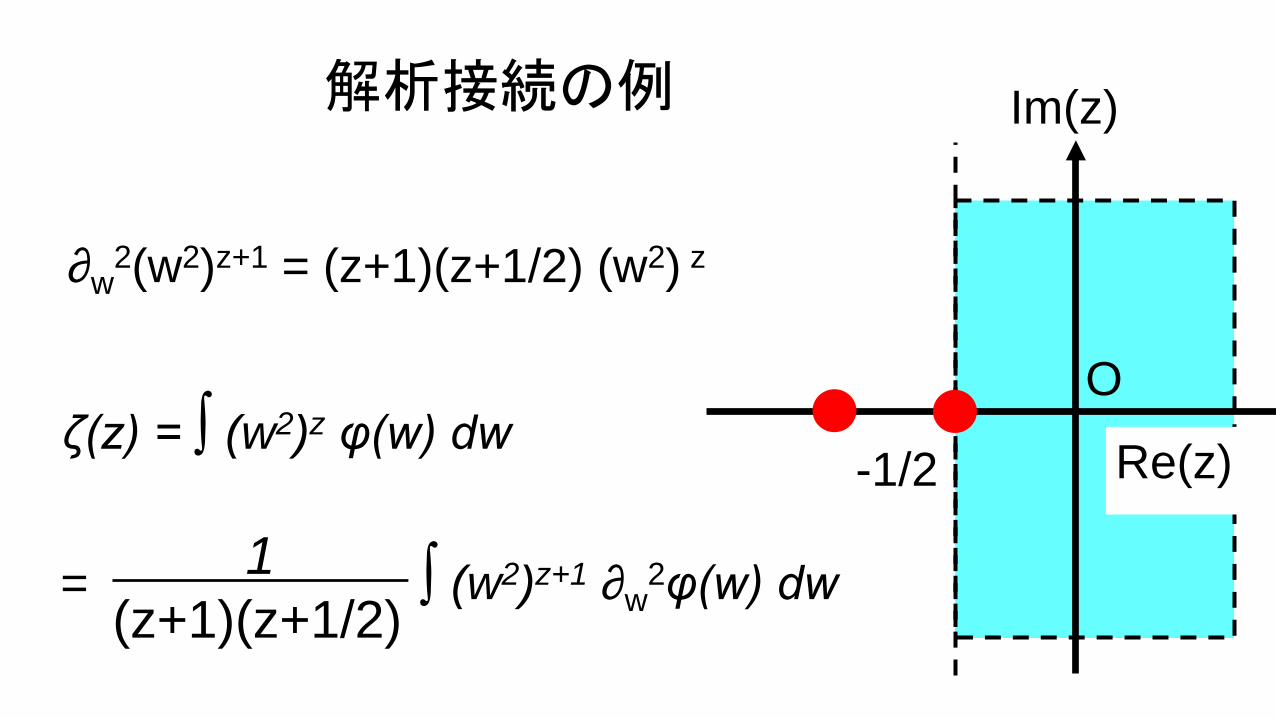
解析接続の例
ζ(z) = ∫ (w2)z φ(w) dw
Im(z)
Re(z)-1/2
∂w2(w2)z+1 = (z+1)(z+1/2) (w2) z
= ∫ (w2)z+1 ∂w2φ(w) dw1
(z+1)(z+1/2)
O

ゼータ関数から状態密度へ
v(t) = ∫ δ(t-K(w)) φ(w) dw.
状態密度関数は、ゼータ関数の逆メリン変換
学習理論のゼータ関数の最も原点に近い極を(-λ)としその位数を m とすれば t→+0 で
v(t) ∝ tλー1 (-log t)m-1 .

学習曲線は
現代の学習モデルでも学習曲線は解明できる。
E[G] = λ/n +o(1/n). 定数 λ のことを実対数閾値という(双有理不変量)。
「学習曲線の解明」 「ゼータ関数が解析接続できる」

代数解析学とは何ですか
解析学の構造を 代数的な視点・方法に基づいて発見・開拓・証明する数学。
代数解析学は 自然科学に対して決定的な役割を果たすことがある。
(例:超関数、非線型可解モデル、特異摂動・・・。)

(参考) リーマンのゼータ関数
ζ(z) = Σn=1∞
= ∫0∞
dx1 Γ(z)
1 nz
xz-1
ex-1
学習理論 ζ(z) = ∫ K(w)z φ(w) dw.

未来への問題
規則を持つ関数列の b 関数の列は法則を持ちますか?
f1=(ab)2
f2=(ab+cd)2+(ab3+cd3)2
f3=(ab+cd+ef)2+(ab3+cd3+ef3)2+(ab5+cd5+ef5)2
無限極限での漸近特性は?⇒もしわかれば巨大な学習モデルが解明できる。

エピソード3 まとめ
学習曲線は
ゼータ関数の最大極で定まる。

エピソード4 代数幾何学
双有理の海・・・
52
学習理論は実世界で使えるのか
関数 K(w) は真の分布を
必要としている
実世界では真の分布は不明・・・。
まだまだじゃ ぐぬぬ
53
実世界を希求する
実世界を知るためには
真の分布が不明でも成り立つ恒等式が必要か・・・。
もっと数学を
54
よみがえる伝説 III ゼータ関数の解析接続
広中の定理を用いればできます。(1970)
Gel’fand Atiyah
最初に問題を見つけた先生
f(x)z
は複素平面全体に有理型に解析接続できるはず・・・ (1954)
55
よみがえる伝説 IV b関数の有理性
「b関数の零点はすべて有理数」は特異点解消定理に基づいて証明できます(1976)。
柏原先生
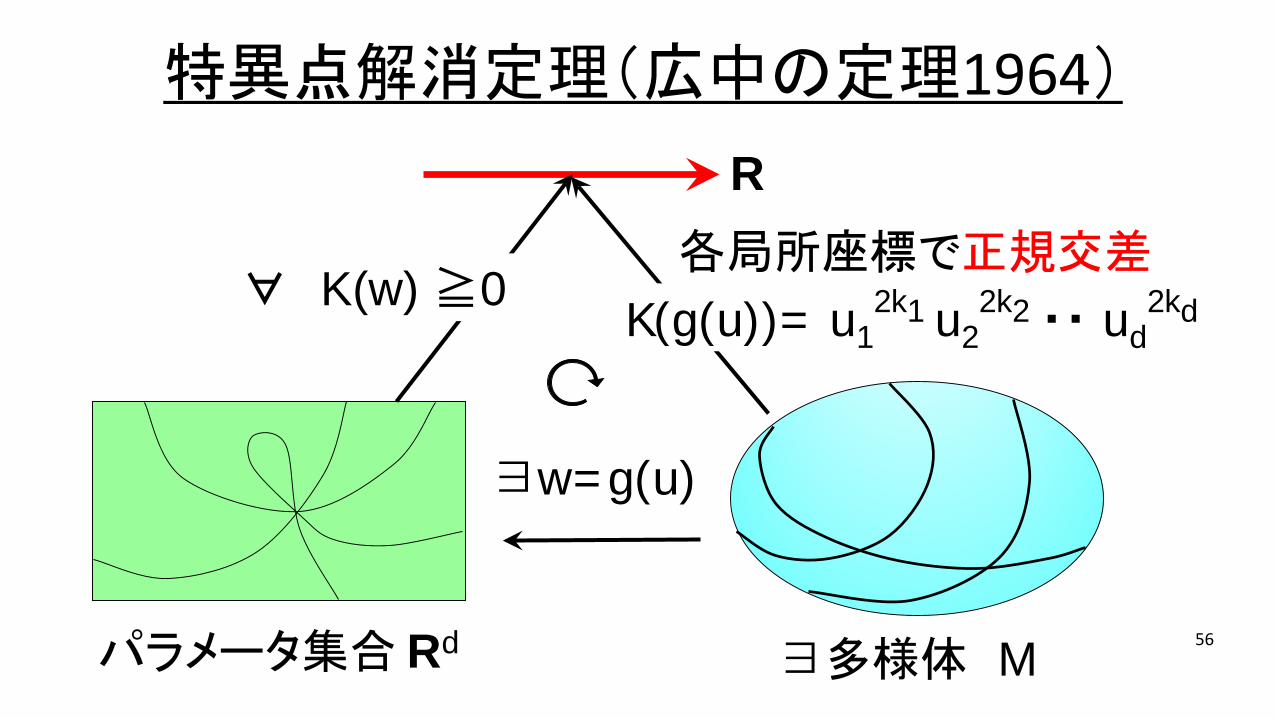
56
R
Rd
各局所座標で正規交差
∃w=g(u)
K(g(u))= u12k1 u2
2k2 ・・ ud2kd
∃多様体 M
∀ K(w) ≧0
パラメータ集合
特異点解消定理(広中の定理1964)
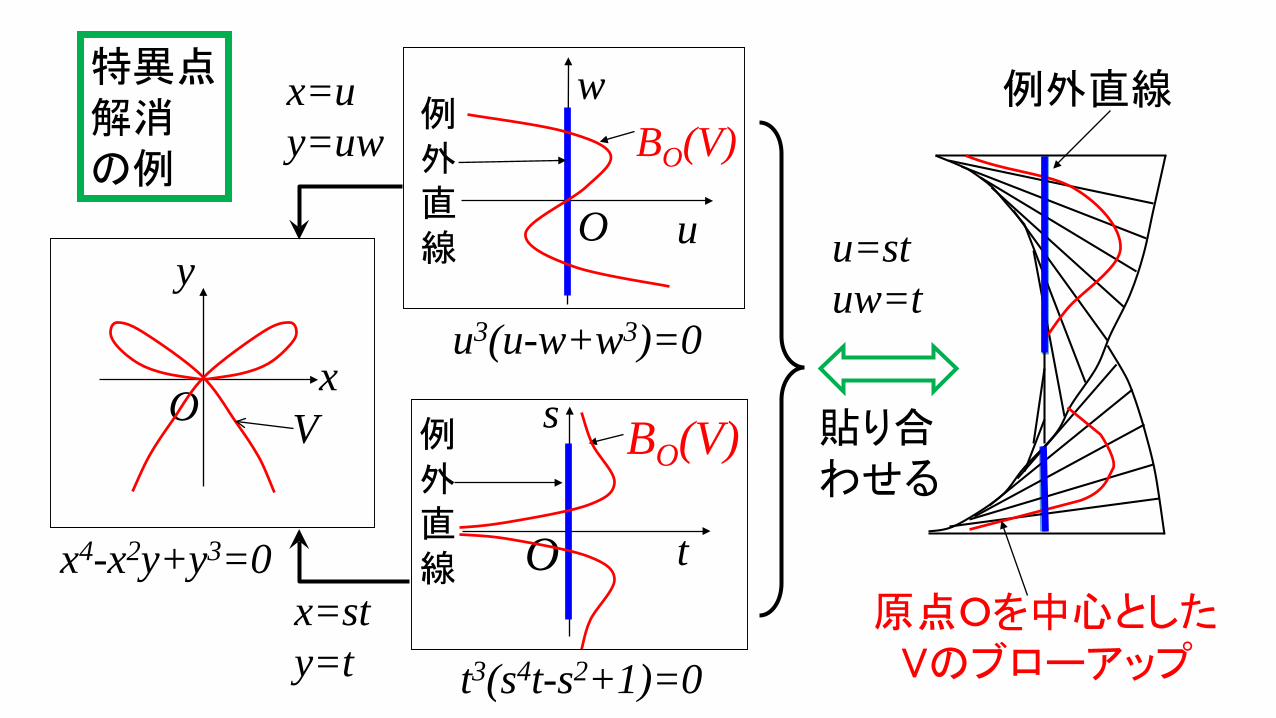
特異点解消の例
x4-x2y+y3=0
y
xO
x=uy=uw
x=sty=t
BO(V)
u3(u-w+w3)=0
s
t3(s4t-s2+1)=0
tO
例外直線
BO(V)
u
w
O
例外直線
V 貼り合わせる
u=stuw=t
例外直線
原点Oを中心としたVのブローアップ

58
広中の定理(続き)
代数多様体の特異点は、特異点集合に含まれる非特異集合のブローアップの有限回の合成により解消される。
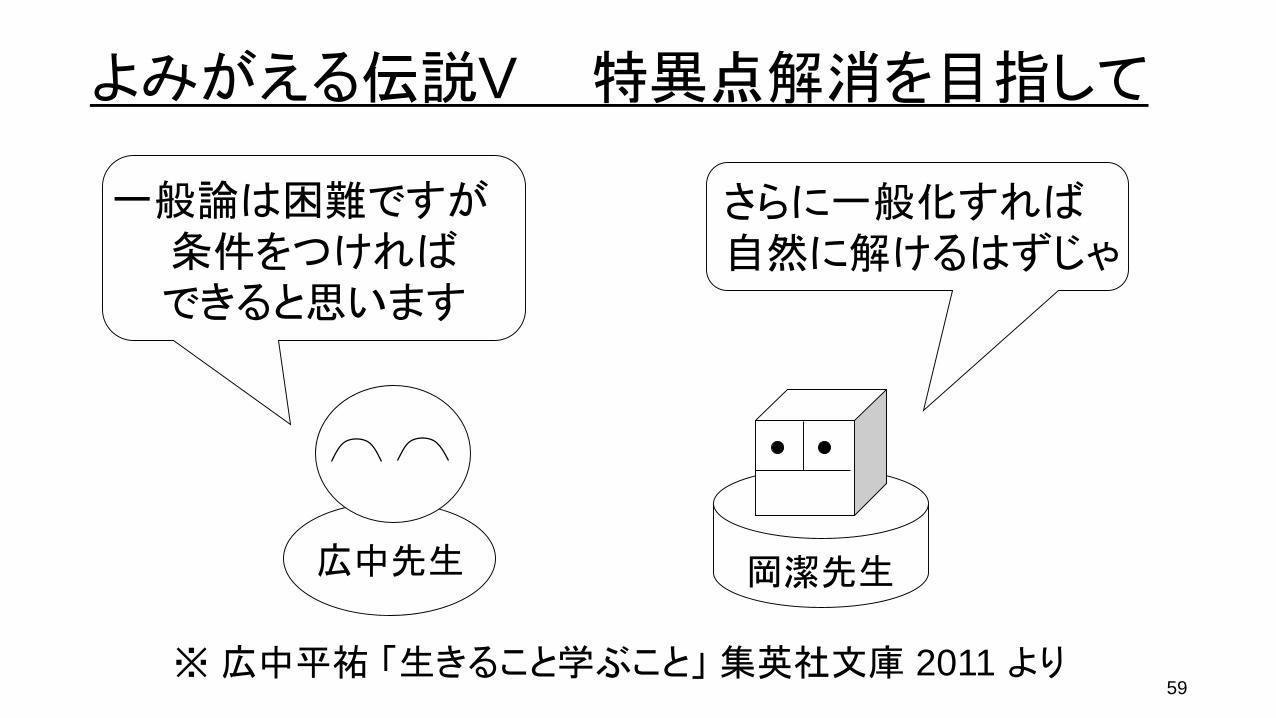
59
一般論は困難ですが条件をつければできると思います
さらに一般化すれば自然に解けるはずじゃ
岡潔先生広中先生
よみがえる伝説V 特異点解消を目指して
※ 広中平祐 「生きること学ぶこと」 集英社文庫 2011 より

60
特異点解消できると応用上うれしいこと
| f(w) | ≦ K(w) でもf(w) は K(w)で割り切れるとは限らない。
| f(g(u)) | ≦ K(g(u)) ならばf(g(u)) は K(g(u))で割り切れる。
K(g(u))が正規交差 因数定理が成り立つ

61
ここでは 「割り切れる⇔商が解析関数」
(1) xy は x2+y2 で割り切れないが
x=uy=uw
u2w は u2(1+w2 )で割り切れる
(2) とおくと

62
R
学習理論つくりやすい
学習理論つくりにくい
学習理論は双有理同値
双有理写像
u12k1 u2
2k2 ・・ ud2kdK(w)

対数尤度関数の標準形
L(w) = ー Σ log p(Xi|w)
L(w)-L(w0) = nK(g(u)) - nK(g(u)) ξn(u)
n
i=1
対数尤度関数は元空間では扱いにくい
特異点解消した空間では well-defined な関数 ξn(u) が存在して

繰り込み可能
確率過程 ξ(u) について関数空間上の部分積分を適用すると
次ページの定理が得られる。
L(w)-L(w0) ⇒ nK(g(u)) - nK(g(u)) ξ(u)
確率過程 ξn(u) は正規確率過程 ξ(u) に分布収束する。
特異点を解消した空間では、データ数 n とともに増大する項
と確率的に揺らぐ項を分離できた(繰り込み可能)。

汎化と学習の関係式
汎化損失 G =- ∫ q(x) log p*(x) dx
学習損失 T =-(1/n) Σ log p*(Xi) n
i=1
定理. いつでも E[G] = E[ T ] + E[ V ]
V =(1/n) Σ Vw[ log p(Xi|w) ]n
i=1汎関数分散

数学と実世界がつながった
定理. いつでも E[G] = E[ T ] + E[ V ]
実世界では G を直接に知ることはできないが
T と V を計算することはできる。
汎化損失と学習損失の差は、事後分布の揺らぎに等しい。
証明に必要となる数学は透明になり 結果には現れない。

代数幾何学とは何ですか
{多項式=0}で表される図形の性質を代数的な方法で研究する数学。双有理写像で不変な図形の性質を調べる数学は双有理幾何学と呼ばれる。
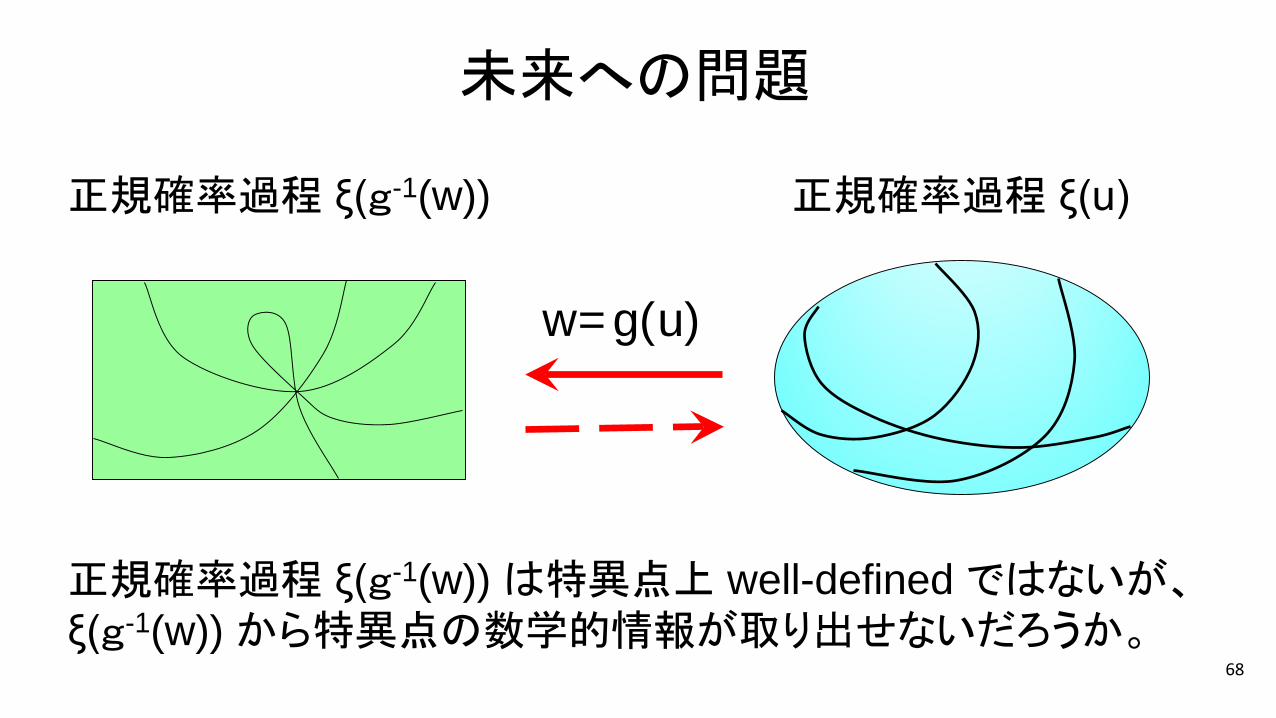
68
w=g(u)
未来への問題
正規確率過程 ξ(u)正規確率過程 ξ(g-1(w))
正規確率過程 ξ(g-1(w)) は特異点上 well-defined ではないが、ξ(g-1(w)) から特異点の数学的情報が取り出せないだろうか。

エピソード4 まとめ
特異点解消定理に基づいて
学習の恒等式が得られた。

エピソード 5
数学と実世界が出あうとき
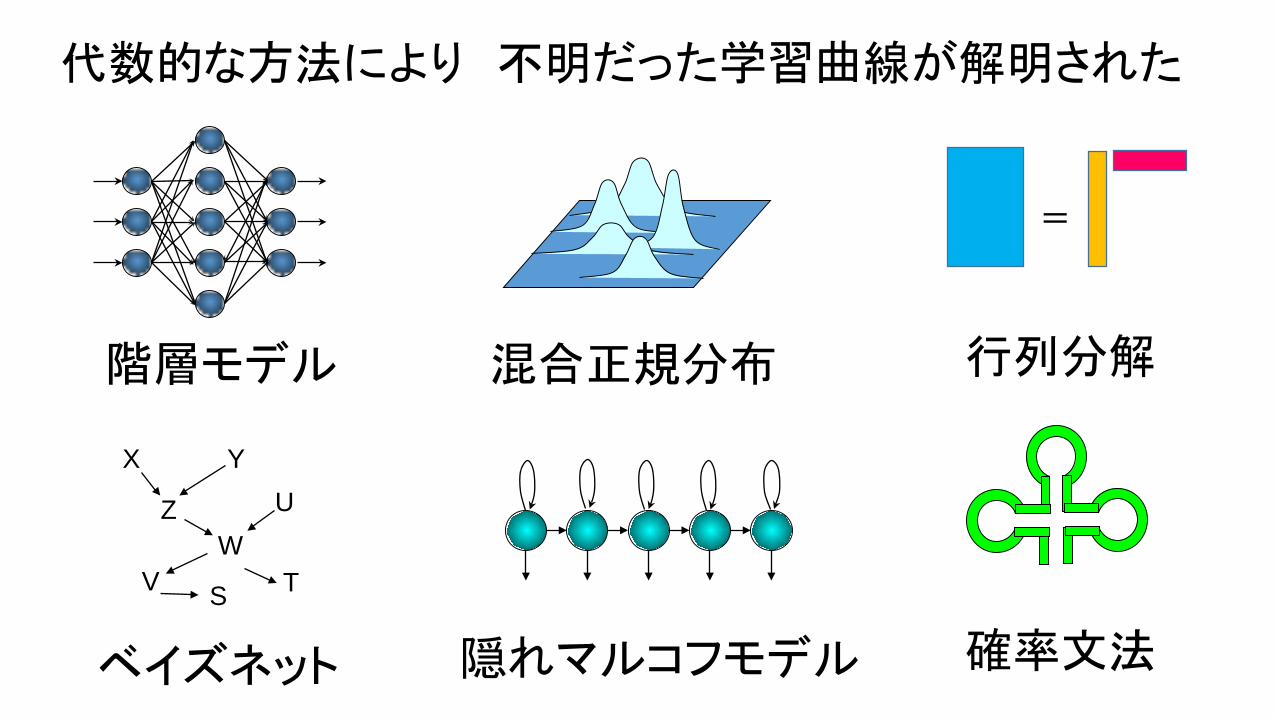
隠れマルコフモデル
混合正規分布
確率文法ベイズネット
階層モデル
X Y
ZW
U
V S T
=
行列分解
代数的な方法により 不明だった学習曲線が解明された

Special Thanks 機械学習モデルの性質解明(敬称略)
山崎啓介 混合正規分布隠れマルコフモデルベイズネット
青柳美輝 縮小ランク回帰階層型神経回路
永田賢二 レプリカ交換率山田耕史 擬正則モデル林 直輝 非負値行列分解佐藤件一郎 混合ポアソン
渡辺一帆 平均場近似星野 力 文脈自由文法中島伸一 平均場汎化損失西山 悠 ベーテ近似梶 大介 混合ベルヌーイ松田 健 混合多項分布藤原香織 検定統計量中村文士 ハイパパラメータ幸島匡宏 行列分解相転移

実世界の多様性を知ること
74
モデルを作り実世界に挑む
実世界をモデルで解明する不可能に挑戦する・・・
実世界から得られる膨大なデータ
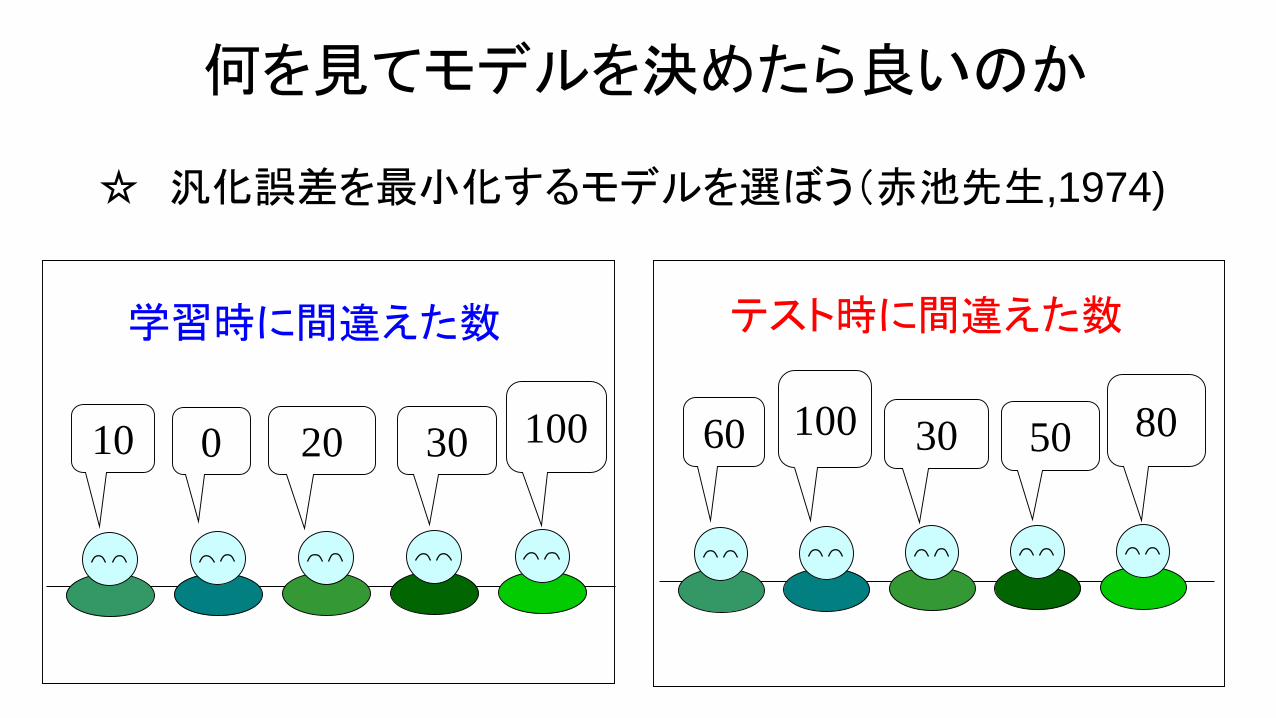
10 0 20 30 100
学習時に間違えた数
60 100 30 50 80
テスト時に間違えた数
何を見てモデルを決めたら良いのか
☆ 汎化誤差を最小化するモデルを選ぼう(赤池先生,1974)
76
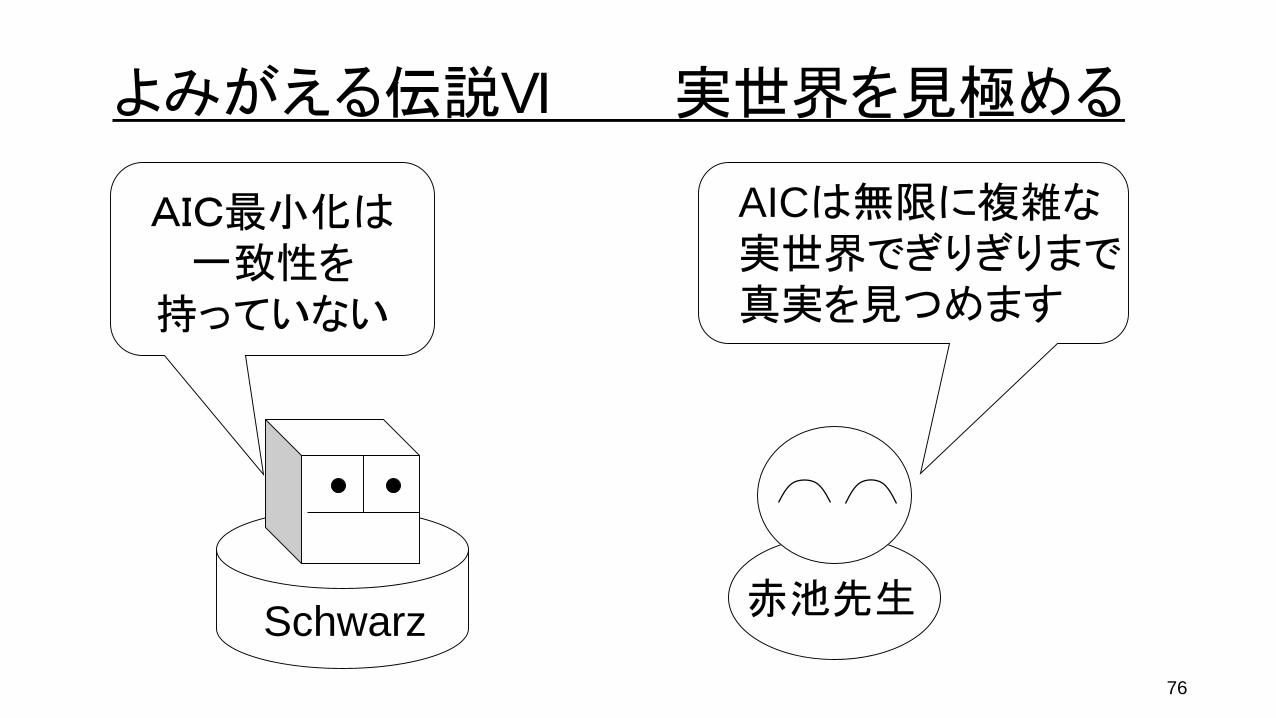
AIC最小化は一致性を
持っていない
AICは無限に複雑な実世界でぎりぎりまで真実を見つめます
Schwarz 赤池先生
よみがえる伝説VI 実世界を見極める

77
AICは無限に複雑な世界で実力を発揮する。
AICでモデルを決めたとき、真の分布と一致するものの中で最もパラメータ次元の小さいものが選ばれる確率はデータ数が無限大に近づく極限でも1には近づきません(Schwarz)。
しかしながら、真の分布が有限のモデル集合の中にないとき、AICによって選ばれるモデルはデータ数の増加とともに複雑になることで、平均的に最も真の分布に近いモデルを見つけることができます(赤池先生)。

78
古典的なケース
赤池情報量規準(1974) AIC= T+d/n とおくと
E[G] = E[ AIC]
データが独立であるとき AIC はクロスバリデーションと
漸近等価である(1977,Stone)。
AICは極めて多くのモデリングをサポート。

79
現代のモデルでも
広く使える情報量規準(2010) WAIC=T+V とおくと
E[G] = E[ WAIC ]
データが独立であるとき WAIC はクロスバリデーションと
漸近等価である。
数年前から 広く使われるようになってきました。
80
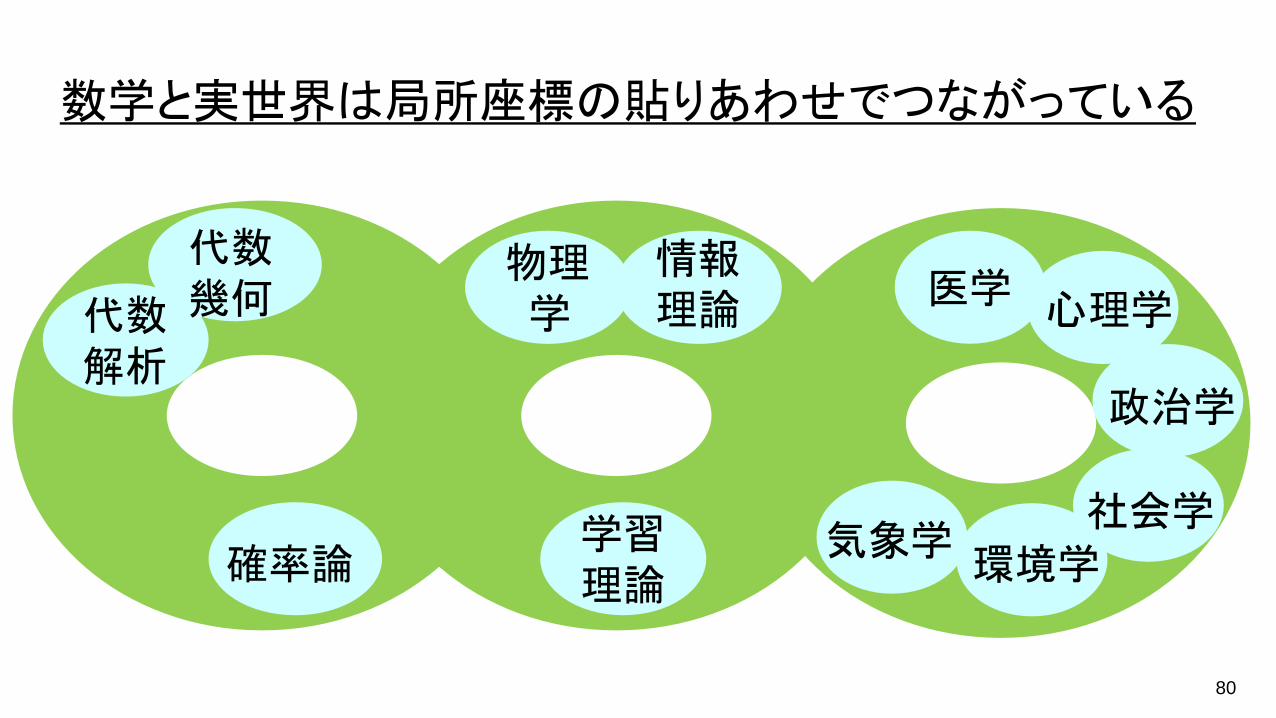
数学と実世界は局所座標の貼りあわせでつながっている
代数幾何代数
解析
学習理論
医学心理学
政治学
環境学社会学
物理学
確率論気象学
情報理論

81
透明な法則が数学と実世界をつないでいる
WAIC
数学
数学 実世界
エピソード5まとめ
数学と実世界は透明な法則でつながれている

結論
数学と実世界が出あう例を紹介しました







