Download - Elasticsearch 簡介


內容• 本投影⽚片內容簡化於 Elasticsearch: The Definitive Guide 中 Getting Started 章節的:
• You know, for search…
• life inside a cluster
• Distributed Document Store
• Mapping and Analysis
• Index Management
• inside a shard
• 除此之外也介紹了三個 elasticsearch 的 rails gem

elasticsearch• 分散式叢集架構,具有⾼高擴充性,可隨時增加或移除節點,並確保資料正確
• 使⽤用 Apache Lucene 儲存 JSON ⽂文件,提供全⽂文搜索功能
• 所有操作均可透過 RESTful API 完成
• 跨平台,JAVA 撰寫⽽而成

有誰在使⽤用?
Github

⽤用來做什麼?
記錄
搜尋
分析

安裝
• 到官網下載 zip,解壓縮後直接運⾏行執⾏行檔即可,不需要額外設定。
• 除了 elasticsearch 本體,也可以安裝 Marvel 插件,它提供了 web 圖形化監控介⾯面。

與關聯資料庫有什麼不⼀一樣?
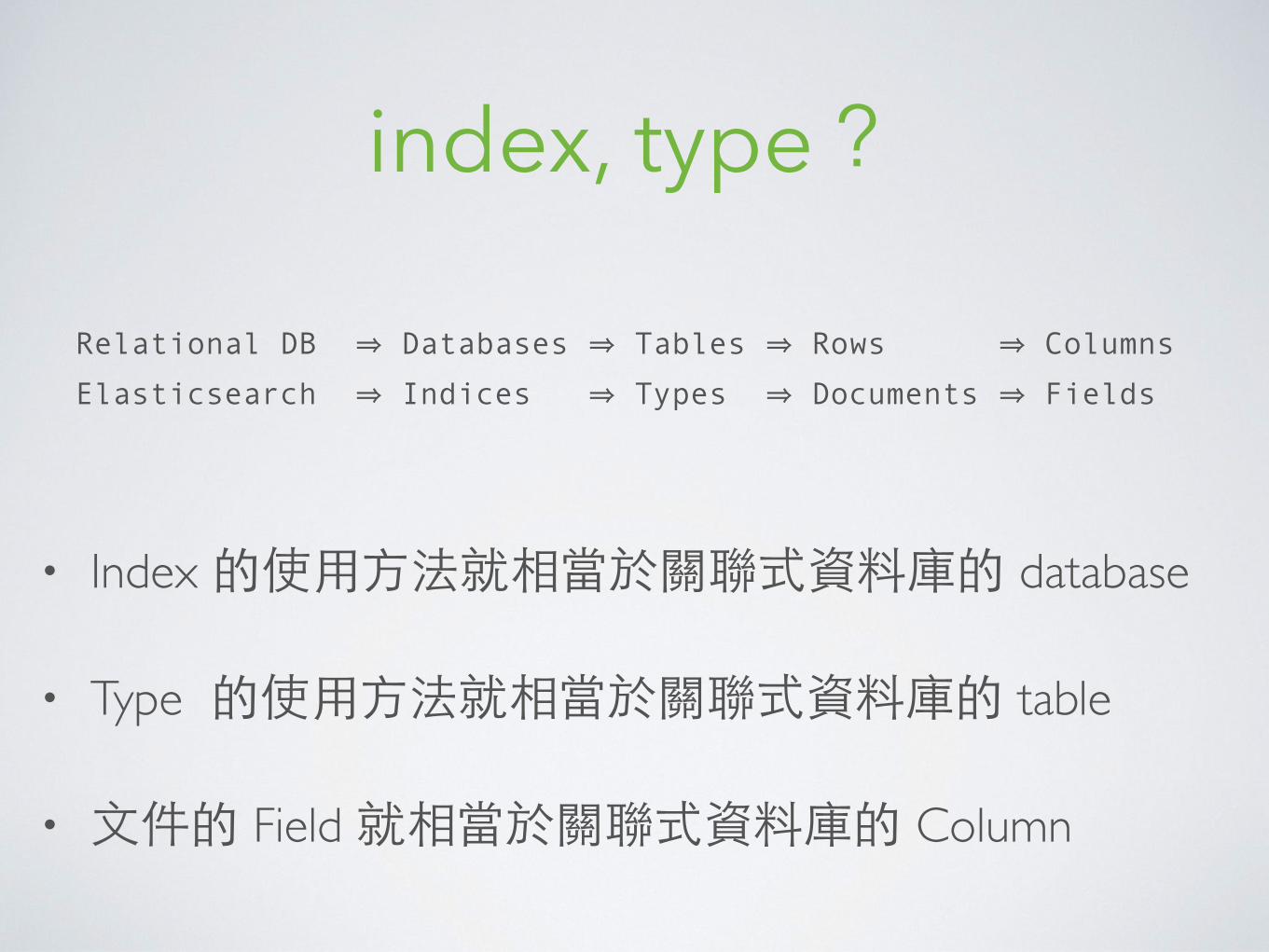
index, type?
Relational DB ⇒ Databases ⇒ Tables ⇒ Rows ⇒ Columns Elasticsearch ⇒ Indices ⇒ Types ⇒ Documents ⇒ Fields
• Index 的使⽤用⽅方法就相當於關聯式資料庫的 database
• Type 的使⽤用⽅方法就相當於關聯式資料庫的 table
• ⽂文件的 Field 就相當於關聯式資料庫的 Column

快速預覽⼀一下如何使⽤用

如何存⼊入資料?PUT /megacorp/employee/1 { “first_name": "John", "last_name" : "Smith", "age" : 25, "about" : "I am hero", "interests": [ "sports", "music" ] }
1. 創建 megacorp Index2. 在裡⾯面創建⼀一個 employee type3. 在裡⾯面建⽴立⼀一個 _id 是 1 的 JSON ⽂文件

如何取得資料?GET /megacorp/employee/1
or
GET /megacorp/employee/_search?q=music
or
GET /megacorp/_search?q=hero
or
……

回傳了什麼訊息?{ …… "took": 4, "hits": { "total": 1, "hits": [ { "_index": "megacorp", "_type": "employee", "_id": "1", "_score": 0.095891505, "_source": { "first_name": "John", …… } } ] } }

有個官⽅方的教學範例

Employee Directory Tutorial• Enable data to contain multi value tags, numbers, and full text.
• Retrieve the full details of any employee.
• Allow structured search, such as finding employees over the age of 30.
• Allow simple full-text search and more-complex phrase searches.
• Return highlighted search snippets from the text in the matching documents.
• Enable management to build analytic dashboards over the data.
• 詳細請看: http://www.elasticsearch.org/guide/en/elasticsearch/guide/current/_finding_your_feet.html

⼀一些基本⽤用語介紹

index, shard ?• 在 elasticsearch 中,index 這個詞不斷被使⽤用,他可能代表下⾯面幾個意思:
• index (名詞) - 類似於關聯式資料庫的 database
• index (動詞) - 儲存⽂文件這個動作
• inverted index - ⼀一種適合全⽂文搜索的索引結構
• elasticsearch index 由好幾個 shard 組成,shard 是⼀一個底層的⼯工作單元,負責實際上的⽂文件的儲存與搜尋

life inside a cluster

life inside a cluster• cluster 由⼀一個或以上具有相同 cluster.name 的 elasticsearch 節點所組成。當有節點加⼊入或移除時,cluster 會⾃自動平均分配資料。
• cluster 中會⾃自動選出⼀一個主節點負責 cluster 性的變動,例如新增節點或創建新 Index。
• 主節點可以不參與⽂文件操作或搜尋,因此只有⼀一個主節點不會導致瓶頸。
• 我們可以發送請求到任⼀一節點,它會清楚在 cluster 中該如何處理,並回傳給我們最終結果。

cluster 的健康狀態
• GREEN 所有的主要與複製的 shard 都是啟動的。
• YELLOW 所有的主要 shard 都是啟動的,但複製的沒有。
• RED 所有的主要與複製的 shard 都沒有啟動。
GET /_cluster/health

創建 indexPUT /blogs { "settings" : { "number_of_shards" : 3, "number_of_replicas" : 1 } }
創建⼀一個 blogs Index,並設定它有 3 個主要的 shard。每⼀一個主要的 shard 總共要有⼀一個複製的 shard 在其他機器。

⼀一個節點的時候
此時 cluster 健康狀態為 ⿈黃⾊色,因為沒有分配複製的 shard 到其他機器。此時 elasticsearch 可以正常運作,
但是資料若遭遇到硬體問題時無法復原。
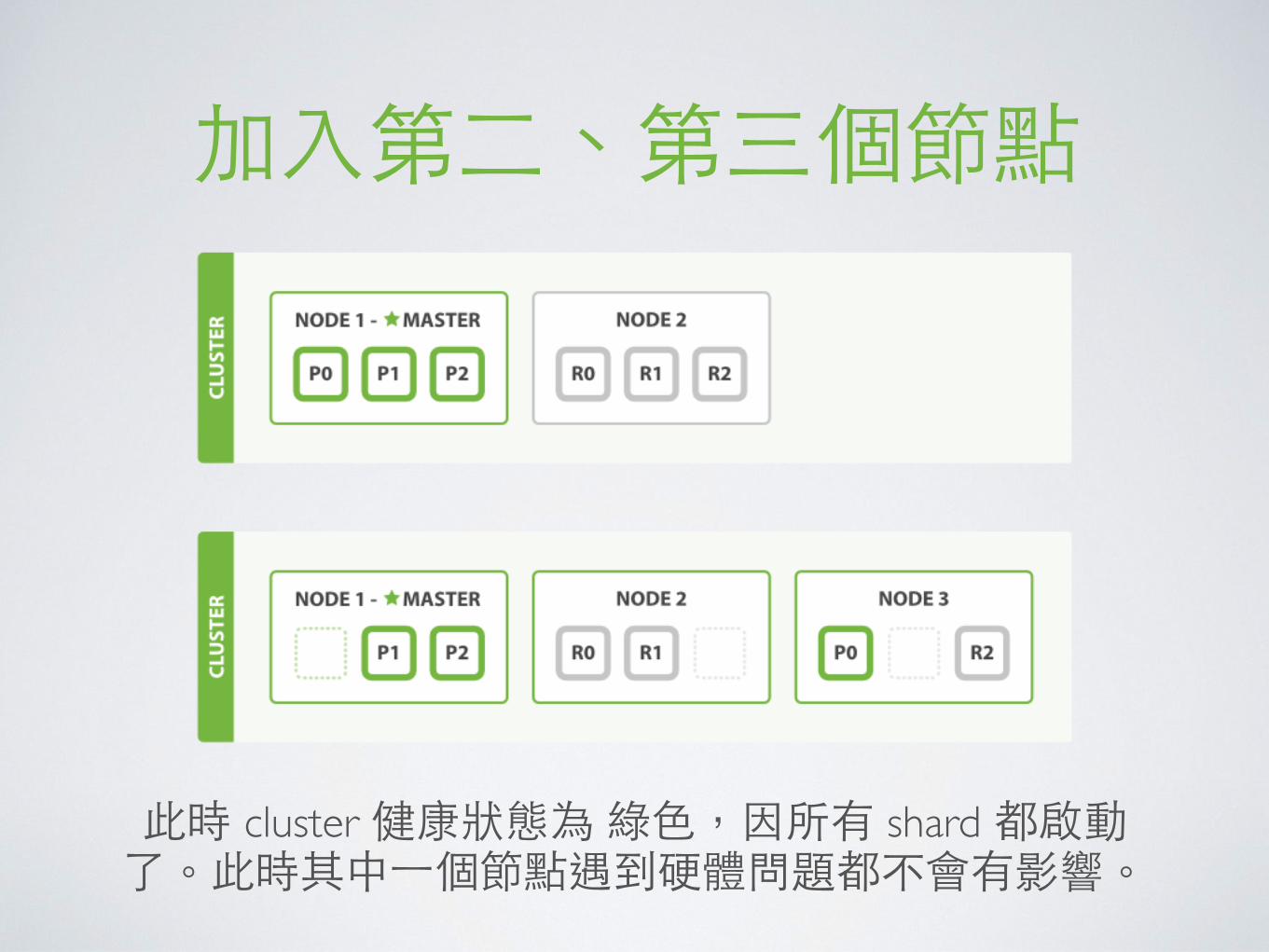
加⼊入第⼆二、第三個節點
此時 cluster 健康狀態為 綠⾊色,因所有 shard 都啟動了。此時其中⼀一個節點遇到硬體問題都不會有影響。

增加複製的 shard
如此⼀一來,壞掉兩個節點也不影響。
PUT /blogs/_settings { "number_of_replicas" : 2 }

資料如何分配到 shard?
當有⽂文件要儲存進⼊入 Index 時,elasticsearch 經過上⾯面的計算後決定要把該⽂文件儲存到哪⼀一個 shard。
routing 為任意的字串,預設為⽂文件上的 _id,可被改為其他的值。透過改變 routing 可以決定⽂文件要儲存
到哪個 shard。
shard = hash(routing) % number_of_primary_shards
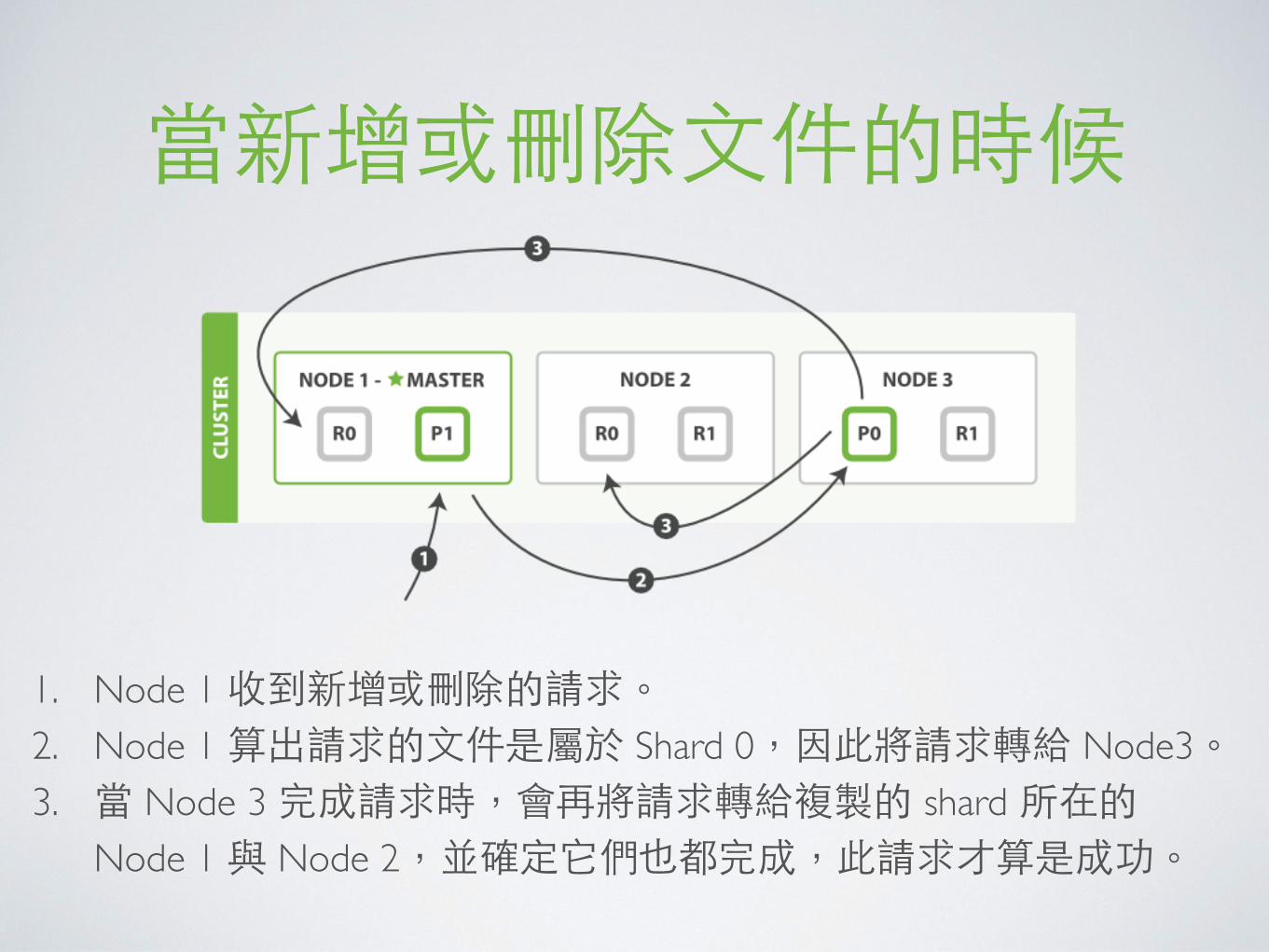
當新增或刪除⽂文件的時候
1. Node 1 收到新增或刪除的請求。2. Node 1 算出請求的⽂文件是屬於 Shard 0,因此將請求轉給 Node3。3. 當 Node 3 完成請求時,會再將請求轉給複製的 shard 所在的
Node 1 與 Node 2,並確定它們也都完成,此請求才算是成功。
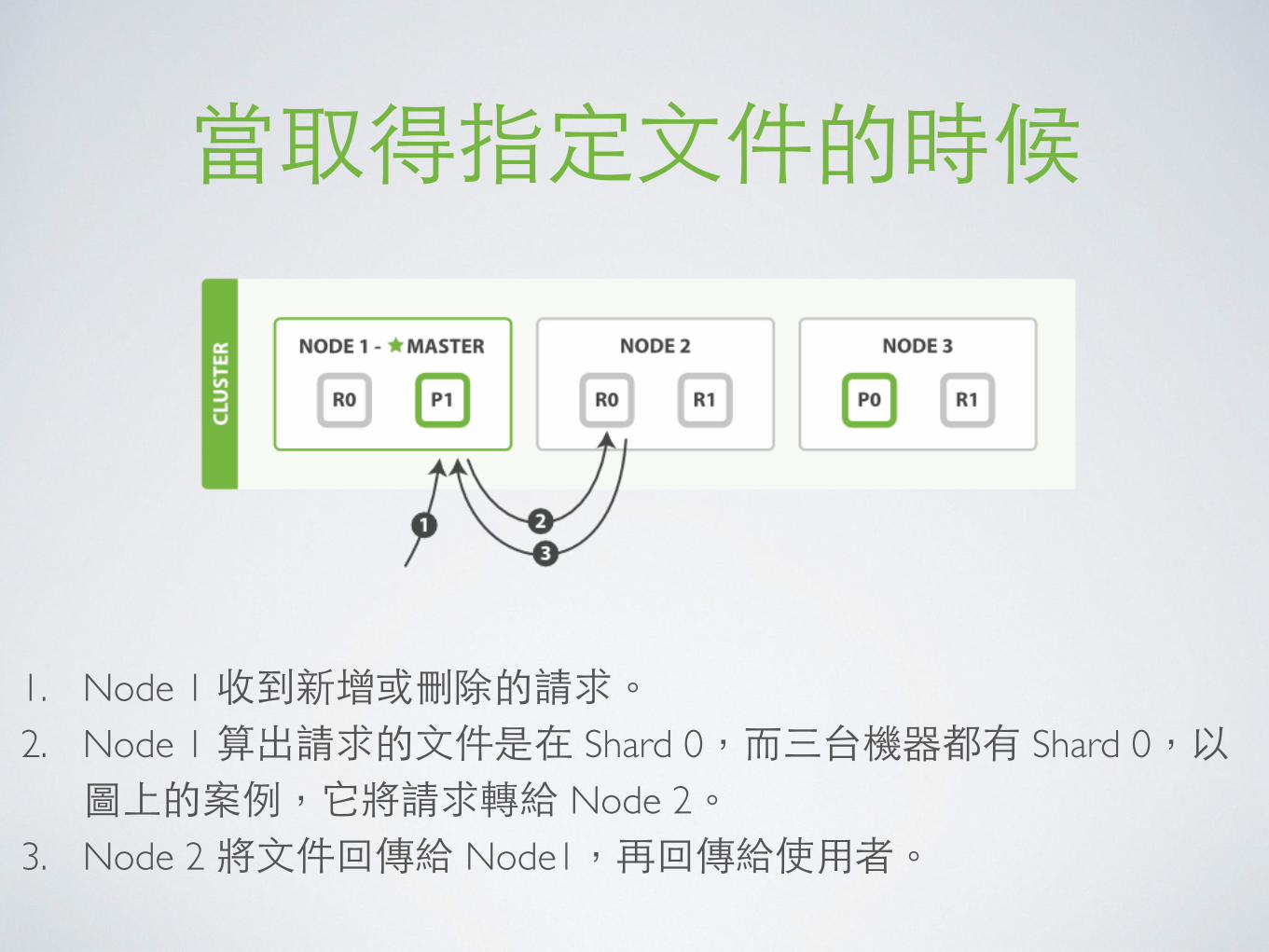
當取得指定⽂文件的時候
1. Node 1 收到新增或刪除的請求。2. Node 1 算出請求的⽂文件是在 Shard 0,⽽而三台機器都有 Shard 0,以圖上的案例,它將請求轉給 Node 2。
3. Node 2 將⽂文件回傳給 Node1,再回傳給使⽤用者。
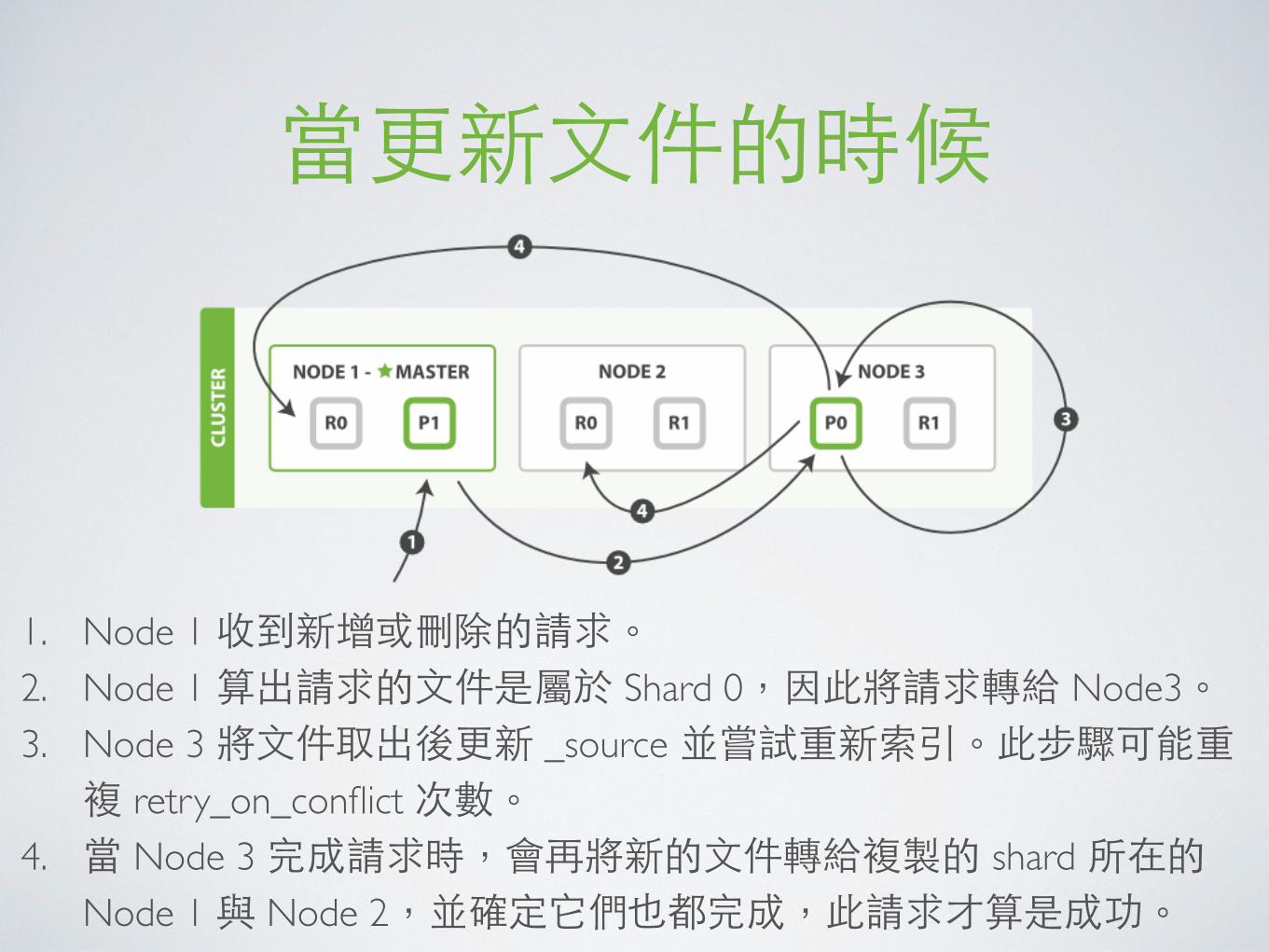
當更新⽂文件的時候
1. Node 1 收到新增或刪除的請求。2. Node 1 算出請求的⽂文件是屬於 Shard 0,因此將請求轉給 Node3。3. Node 3 將⽂文件取出後更新 _source 並嘗試重新索引。此步驟可能重複 retry_on_conflict 次數。
4. 當 Node 3 完成請求時,會再將新的⽂文件轉給複製的 shard 所在的 Node 1 與 Node 2,並確定它們也都完成,此請求才算是成功。

它是如何製作搜尋索引?

• 假如有 12 筆 date 是 2014-xx-xx 的⽂文件。但只有⼀一個⽂文件的 date 是 2014-09-15。那我們發送以下請求:
GET /_search?q=2014 # 12 results GET /_search?q=2014-09-15 # 12 results ! GET /_search?q=date:2014-09-15 # 1 result GET /_search?q=date:2014 # 0 results !
怎麼結果會這麼奇怪呢?

跨欄位搜尋• 當儲存⽂文件時,elasticsearch 預設會另外儲存⼀一個 _all 欄位。該欄位預設由所有的欄位串接⽽而成,並使⽤用 inverted index 製作索引提供全⽂文搜索。例如:
{ "tweet": "However did I manage before Elasticsearch?", "date": "2014-09-14", "name": "Mary Jones", "user_id": 1 }
"However did I manage before Elasticsearch? 2014-09-14 Mary Jones 1"
該⽂文件的 _all 欄位如下
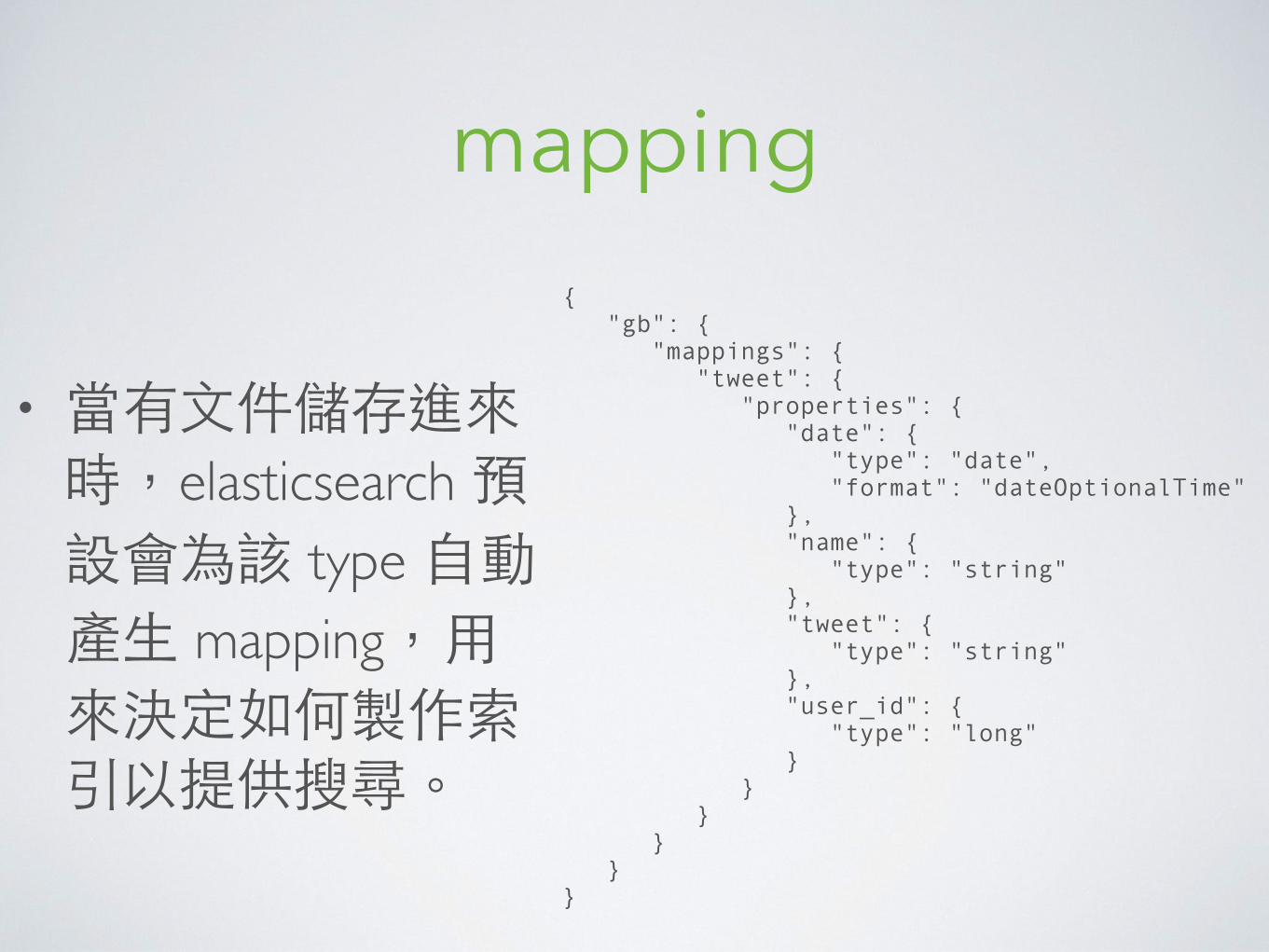
mapping
• 當有⽂文件儲存進來時,elasticsearch 預設會為該 type ⾃自動產⽣生 mapping,⽤用來決定如何製作索引以提供搜尋。
{ "gb": { "mappings": { "tweet": { "properties": { "date": { "type": "date", "format": "dateOptionalTime" }, "name": { "type": "string" }, "tweet": { "type": "string" }, "user_id": { "type": "long" } } } } } }

exact value 與 full text
• elasticsearch 把值分成兩類:exact value 與 full text
• 當針對 exact value 的欄位搜尋時,使⽤用布林判斷,例如:Foo != foo
• 當針對 full text 的欄位搜尋時,則是計算相關程度,例如:UK 與 United Kingdom 相關、jumping 與 leap 也相關

inverted Index
• elasticsearch ⽤用 inverted index 建⽴立索引,提供全⽂文搜索。考慮以下兩份⽂文件:
• The quick brown fox jumped over the lazy dog
• Quick brown foxes leap over lazy dogs in summer

inverted Index
• 建⽴立出來的 inverted index 看起來⼤大概像是左邊的表。
• 搜尋 ”quick brown” 的結果如下表。
Term Doc_1 Doc_2 ------------------------- Quick | | X The | X | brown | X | X dog | X | dogs | | X fox | X | foxes | | X in | | X jumped | X | lazy | X | X leap | | X over | X | X quick | X | summer | | X the | X | ------------------------
Term Doc_1 Doc_2 ------------------------- brown | X | X quick | X | ------------------------ Total | 2 | 1

inverted Index• 此表還可以再優化,例如:
• Quick 可以變成 quick
• foxes, dogs 可以變成 fox 與 dog
• jumped, leap 可以變成 jump
• 這種分詞(tokenization)、正規化(normalization)過程叫做 analysis
Term Doc_1 Doc_2 ------------------------- Quick | | X The | X | brown | X | X dog | X | dogs | | X fox | X | foxes | | X in | | X jumped | X | lazy | X | X leap | | X over | X | X quick | X | summer | | X the | X | ------------------------
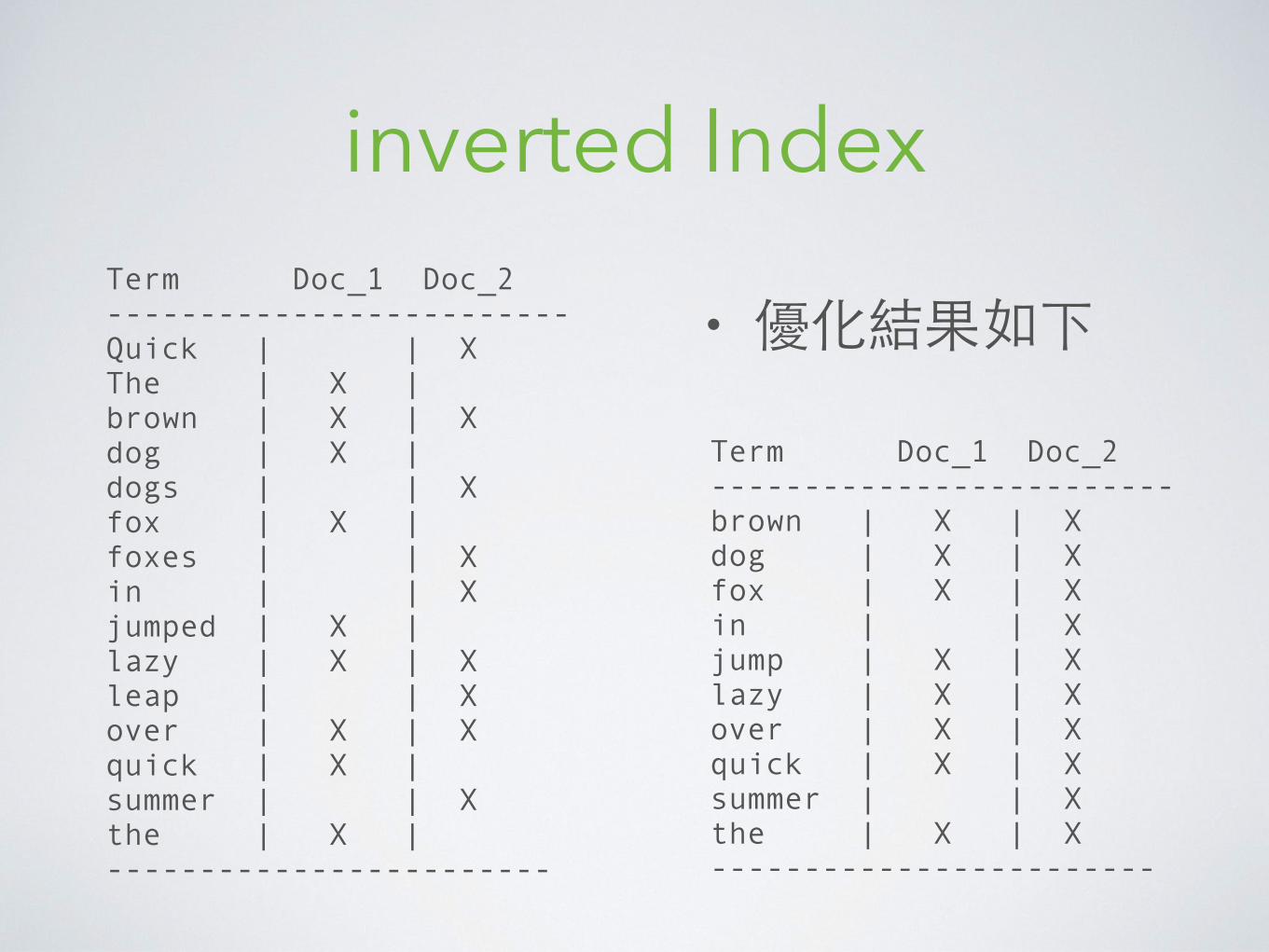
inverted Index
• 優化結果如下Term Doc_1 Doc_2 ------------------------- Quick | | X The | X | brown | X | X dog | X | dogs | | X fox | X | foxes | | X in | | X jumped | X | lazy | X | X leap | | X over | X | X quick | X | summer | | X the | X | ------------------------
Term Doc_1 Doc_2 ------------------------- brown | X | X dog | X | X fox | X | X in | | X jump | X | X lazy | X | X over | X | X quick | X | X summer | | X the | X | X ------------------------

analysis 與 analyzersAnalysis 程序由 analyzer 完成,analyzer 由下⾯面三個功能組成:
1. Character filters⾸首先,字串先依序經過 character filters 處理過,再進⾏行分詞。例如可能先將 html 標籤移除,或將 & 轉換為 and。
2. Tokenizer分詞器就是將字串切為許多有意義的單詞。
3. Token filters每個單詞再依序經過 token filters 做最後處理。例如可能將 Quick 變成 quick、把 leap 換成 jump。

中⽂文分詞• 中⽂文做全⽂文搜索困難的地⽅方在於不好分詞。
• elasticsearch 內建的中⽂文 analyzer 效果有限。
• 建議使⽤用其他中⽂文分詞器,例如 ik 分詞器或 mmseg 分詞器
• https://github.com/medcl/elasticsearch-analysis-ik
• https://github.com/medcl/elasticsearch-analysis-mmseg
• 或是安裝容易的 Lucene Smart Chinese analysis 模組
• https://github.com/elasticsearch/elasticsearch-analysis-smartcn
• 其他可以參考 http://www.sitepoint.com/efficient-chinese-search-elasticsearch/

• 假如有 12 筆 date 是 2014-xx-xx 的⽂文件。但只有⼀一個⽂文件的 date 是 2014-09-15。那我們發送以下請求:
GET /_search?q=2014 # 12 results GET /_search?q=2014-09-15 # 12 results ! GET /_search?q=date:2014-09-15 # 1 result GET /_search?q=date:2014 # 0 results !
1. ⽤用 2014 去全⽂文搜尋 _all 欄位2. 2014-09-15 經過分析後變成使⽤用 2014, 09, 15 去全⽂文搜尋 _all 欄位,由於每份⽂文件都有 2014 所以全部都相關。
3. 針對 date 欄位搜尋 exact value4. 針對 date 欄位搜尋 exact value,沒有⽂文件的 date 是 2014

搜尋時要注意資料是分散的

分散式搜尋• elasticsearch 將搜尋分成兩個階段,來完成在分散式系統中的搜尋與排序:query 與 fetch
• 排序的其中⼀一個⺫⽬目的是為了分⾴頁,考慮以下搜尋請求:
GET /_search { "from": 90, "size": 10 }
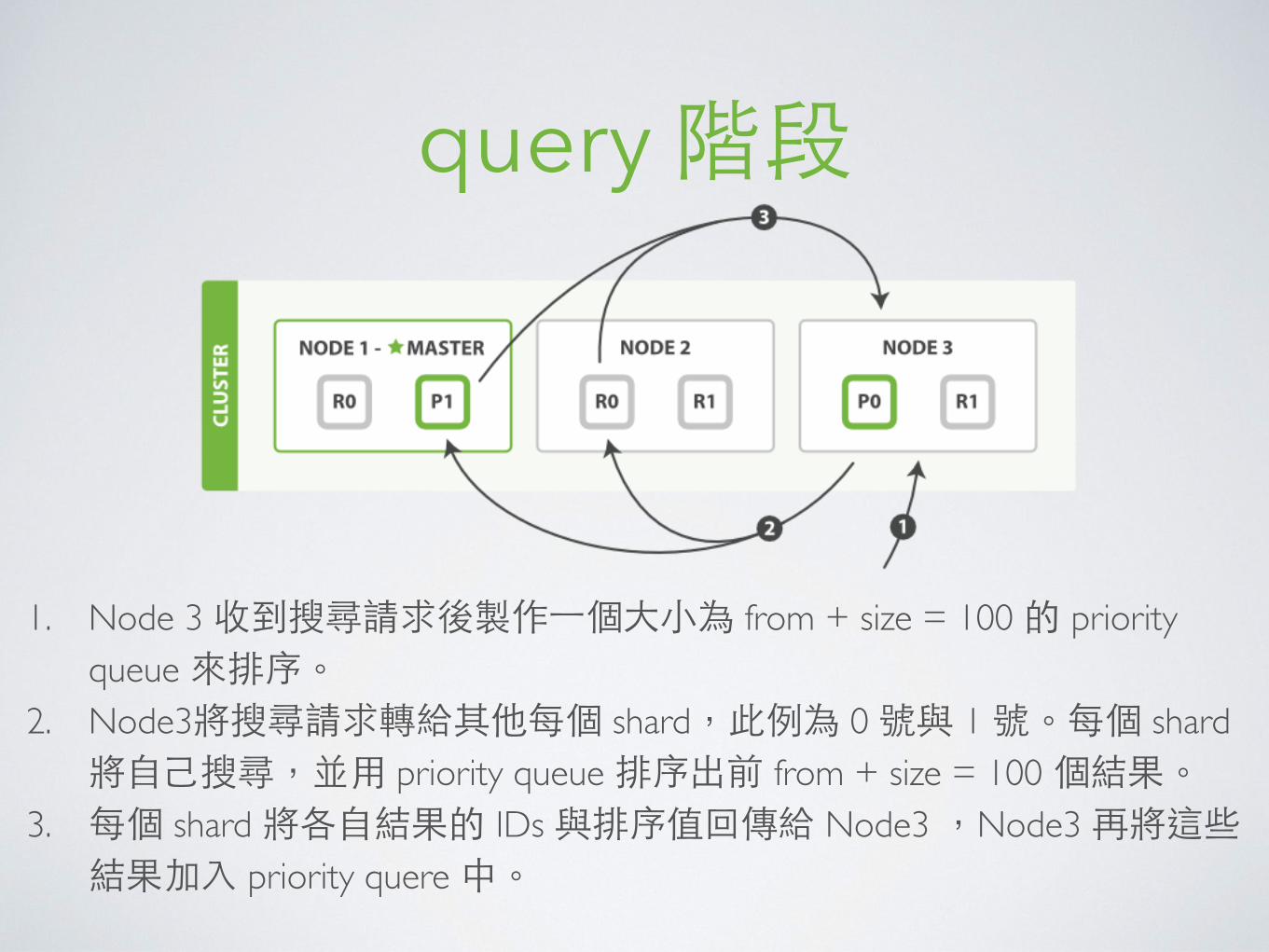
query 階段
1. Node 3 收到搜尋請求後製作⼀一個⼤大⼩小為 from + size = 100 的 priority queue 來排序。
2. Node3將搜尋請求轉給其他每個 shard,此例為 0 號與 1 號。每個 shard 將⾃自⼰己搜尋,並⽤用 priority queue 排序出前 from + size = 100 個結果。
3. 每個 shard 將各⾃自結果的 IDs 與排序值回傳給 Node3 ,Node3 再將這些結果加⼊入 priority quere 中。
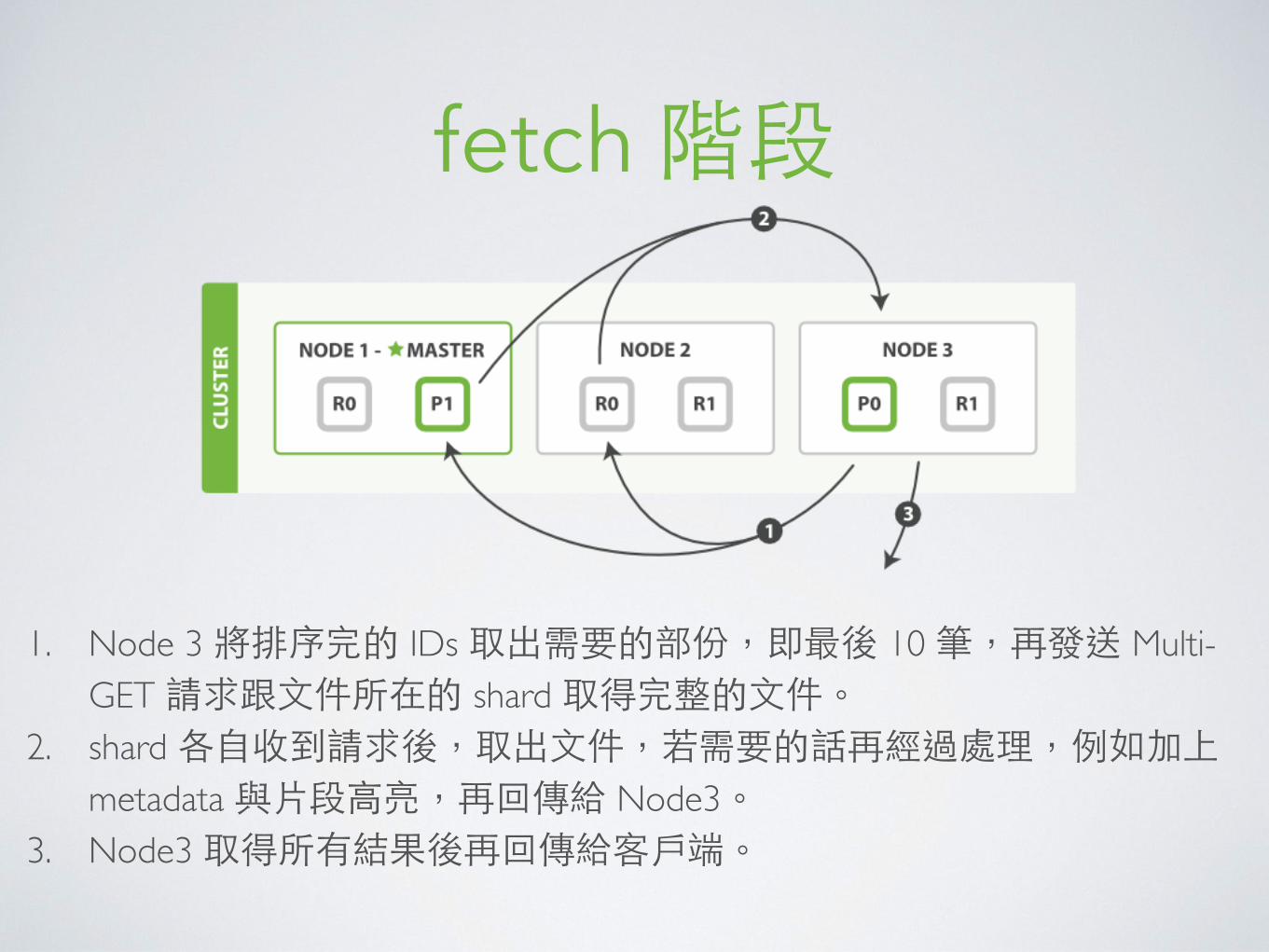
fetch 階段
1. Node 3 將排序完的 IDs 取出需要的部份,即最後 10 筆,再發送 Multi-GET 請求跟⽂文件所在的 shard 取得完整的⽂文件。
2. shard 各⾃自收到請求後,取出⽂文件,若需要的話再經過處理,例如加上 metadata 與⽚片段⾼高亮,再回傳給 Node3。
3. Node3 取得所有結果後再回傳給客⼾戶端。

在分散式系統中的排序與分⾴頁• elasticsearch 搜尋結果預設只會回傳 10 個經過 _score 排序的⽂文件。
• 我們可以透過 size 與 from 參數,取得其他分⾴頁的結果。例如 GET /_search?size=10&from=10000
• 但是在分散式系統中分⾴頁的成本⾮非常⾼高。預設⼀一個 Index 有五個 shard,若要取出第1000⾴頁的內容的話,必須從每個 shard 取出前 10010 個⽂文件。再將總共 50050 個結果重新排序取出 10 個 (10001 - 10010 )。因此若要取出⼤大量資料,不建議使⽤用排序與分⾴頁的功能。

scan 與 scroll
• 設定 search_type=scan,這樣⼀一來 elasticsearch 不會對結果進⾏行排序。
• 設定 scroll=1m,將會對這個搜尋建⽴立快照,並維持⼀一分鐘。根據回傳的 _scroll_id 可以取得下⼀一批的結果。經由 size 參數可以設定⼀一個 shard ⼀一批最多取多少⽂文件,因此每⼀一批取得的數量最多為 size * number_of_primary_shards
• 透過 scan 與 scroll,我們可以批次取得⼤大量的⽂文件,⽽而且不會有分⾴頁成本。若有需要重新索引整個 index 時,可以使⽤用此⽅方法完成。
GET /old_index/_search?search_type=scan&scroll=1m { "query": { "match_all": {}}, "size": 1000 }

最佳化 index

index 設定• 雖然 elasticsearch 在存⼊入⽂文件的時候就會⾃自動創建 index,但使⽤用預設設定可能不是個好主意。例如:
• 主要的 shard 數量不能夠被修改
• ⾃自動 mapping 可能會猜錯
• 使⽤用不符需求的 Analyzer
• 這些設定都需要在儲存資料之前設定完成,否則將會需要重新索引整個 index。
• 除了⼿手動設定 index 之外,也可以使⽤用 index template ⾃自動套⽤用設定。
• mapping 的部分則可以設定 dynamic_templates ⾃自動套⽤用。

index 別名與 reindex
• 若想要改變已經既有欄位的索引⽅方式,例如改變 Analyzer。將需要重新索引整個 index,否則既有的資料與新索引的不⼀一致。
• 利⽤用 Index 別名,可以做到 zero downtime 的重新索引。

index 別名與 reindex
• 應⽤用程式請求的 index 叫做 my_index。實際上 my_index 是個別名,指到的是 my_index_v1。
• 若要重新索引,則創建新的 my_index_v2,並套⽤用新的設定。再透過 scan 與 scroll 將⽂文件從 my_index_v1 放⼊入 my_index_v2。
• 最後將 my_index 別名導向 my_index_v2 即可。

inside a shard

inside a shard
• shard 是⼀一個低階的⼯工作單元,事實上是⼀一個 Lucene 實例,負責⽂文件的儲存與搜尋。
• inverted index 由 shard 創建,並寫⼊入硬碟,⽽而且建⽴立好的 inverted index 不會被更改。

不會被修改的 inverted index
• inverted index 的不變性帶來了許多好處,如:
• 當多個 processes 來讀取時,不需要鎖定
• ⼀一旦被讀⼊入系統的 cache,將會⼀一直留在 cache 中,如此⼀一來便不⽤用再讀取硬碟

更新 inverted index• Lucene 帶來了 per-segment search 的概念,segment 就是⼀一個
inverted index。既有的 segment 不被改變,因此當有新⽂文件存⼊入的時候,就建⽴立新的 segment;若更新或刪除⽂文件時,則另外將舊⽂文件標記於.del檔案。⽽而搜尋時,就依序對各個 segment 搜尋。
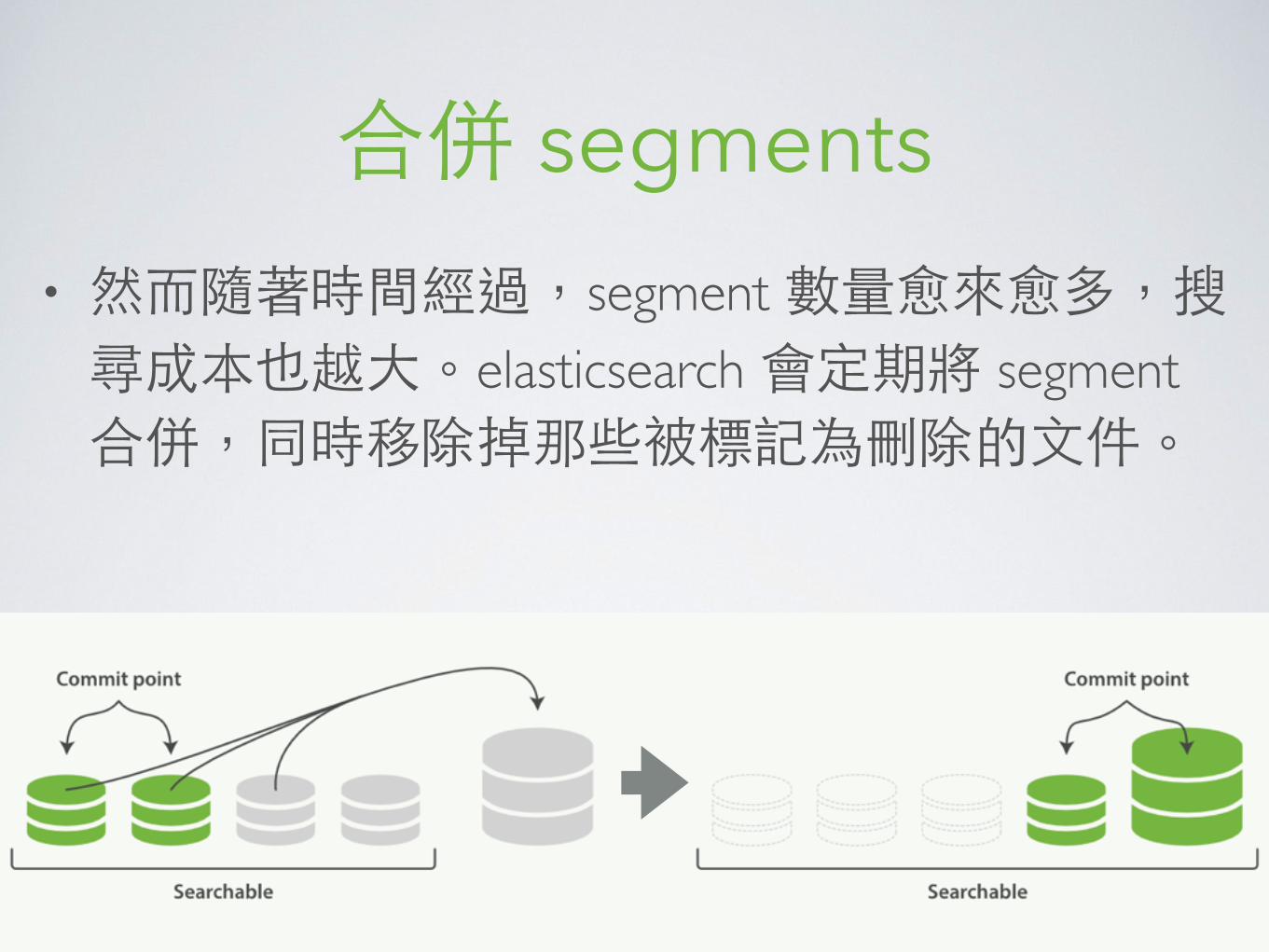
合併 segments• 然⽽而隨著時間經過,segment 數量愈來愈多,搜尋成本也越⼤大。elasticsearch 會定期將 segment 合併,同時移除掉那些被標記為刪除的⽂文件。

繼續學習• 以上內容簡化於 elasticsearch: the definitive guide 的
getting started 章節,並略過搜尋相關內容,如:
• searching - the basic tools
• full-body search
• 繼續學習搜尋相關技巧,請繼續閱讀 search in depth、aggregations 等章節。

Logstash, Kibana, Shield, Marvel, Hadoop
• elasticsearch 有需多衍⽣生產品:
• logstash - 集中收集系統 log 到 elasticsearch。
• kibana - 分析與視覺化 elasticsearch 中的資料。
• shield - 為 elasticsearch 提供⾝身份認證與傳輸加密。
• Marvel - 圖形化的 elasticsearch 監控介⾯面。
• elasticsearch 也提供 Hadoop 深度 API 整合。

elasticsearch + rails
• ⺫⽬目前有許多 gem 可以⽅方便與 rails 整合:
• chewy
• searchkick
• elasticsearch-rails

searchkick• 相當⾼高階的 elasticsearch 整合,已經完成了許多功能:
• SQL like query DSL
• zero downtime reindex
• 根據使⽤用者與搜尋紀錄動態調整搜尋結果
• 地理位置相關搜尋
• ⾃自動完成
• “Did you mean” 建議
• 但是 searchkick ⺫⽬目前以 Model 為單位做成 elasticsearch index,跨 Model 的搜尋還在 Roadmap 中,值得關注。

elasticsearch-rails
• elasticsearch 官⽅方的 rails 整合,功能沒有像 searchkick 那麼豐富。elasticsearch index 也是直接跟 Model 掛勾,要製作跨 Model 搜尋⽐比較不容易。

Chewy• 沒有 searchkick 那麼多⾼高階應⽤用功能,但是 index 跟
model 是獨⽴立的,要製作跨 model 的搜尋相當容易。其他特⾊色:
• zero downtime reindex
• AR-style query DSL
• 缺點是⺫⽬目前 Async reindexing 還在 Roadmap 中,需要靠⾮非官⽅方的 chewy_kiqqer gem。

references• elasticsearch.org
• elasticsearch: the definitive guide
• elasticsearch: reference
• searchkick
• elasticsearch-rails
• chewy
• chewy-kiqqer






