
Latent Semantic Transliteration
using Dirichlet Mixture
Masato Hagiwara, Satoshi Sekine
Rakuten Institute of Technology, New York
NEWS 2012, July 12 2012

2
Background
• Transliteration
– Phonetic translation between languages with
different writing systems
e.g., flextime / furekkusutaimu フレックスタイム
– Major way to import words to different languages
• Transliteration models
– Phonetic-based re-writing models
(Knight and Jonathan 1998)
– Spelling-based supervised models
(Li et al. 2004) (Finch and Sumita 2008)
3
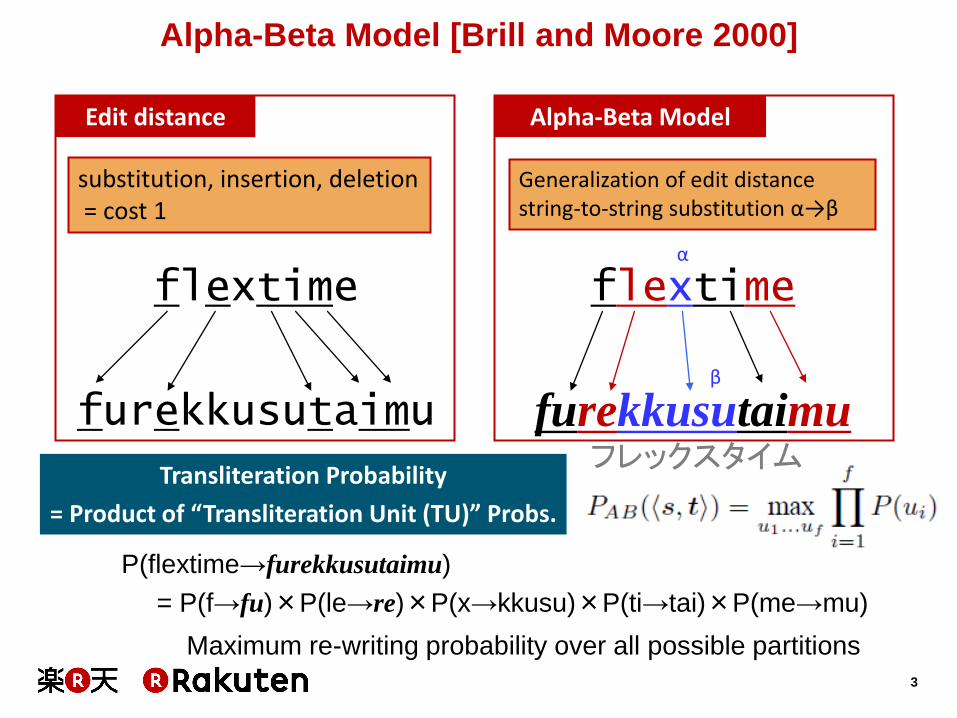
Alpha-Beta Model [Brill and Moore 2000]
Edit distance
substitution, insertion, deletion = cost 1
Alpha-Beta Model
flextime
furekkusutaimu
Generalization of edit distance string-to-string substitution α→β
P(flextime→furekkusutaimu)
= P(f→fu)×P(le→re)×P(x→kkusu)×P(ti→tai)×P(me→mu)
Transliteration Probability
= Product of “Transliteration Unit (TU)” Probs.
Maximum re-writing probability over all possible partitions
α
β
flextime
furekkusutaimu フレックスタイム
4
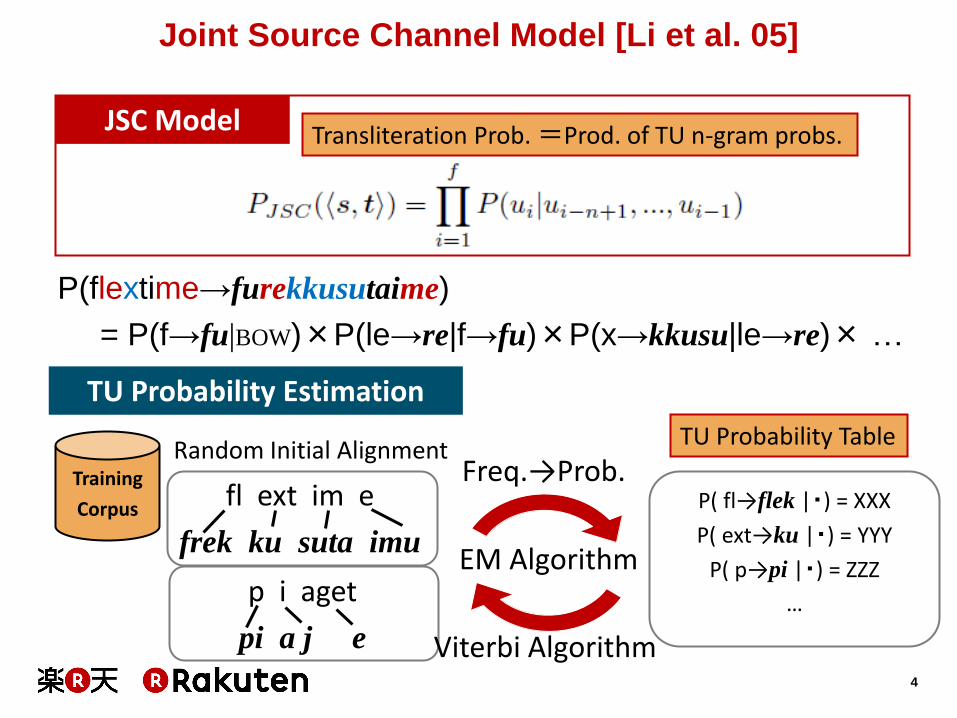
Joint Source Channel Model [Li et al. 05]
P(flextime→furekkusutaime)
= P(f→fu|BOW)×P(le→re|f→fu)×P(x→kkusu|le→re)× …
JSC Model
fl ext im e
frek ku suta imu
p i aget
pi a j e
Transliteration Prob. =Prod. of TU n-gram probs.
TU Probability Estimation
Training
Corpus
TU Probability Table
P( fl→flek |・) = XXX
P( ext→ku |・) = YYY
P( p→pi |・) = ZZZ
…
EM Algorithm
Freq.→Prob. Random Initial Alignment
Viterbi Algorithm
5
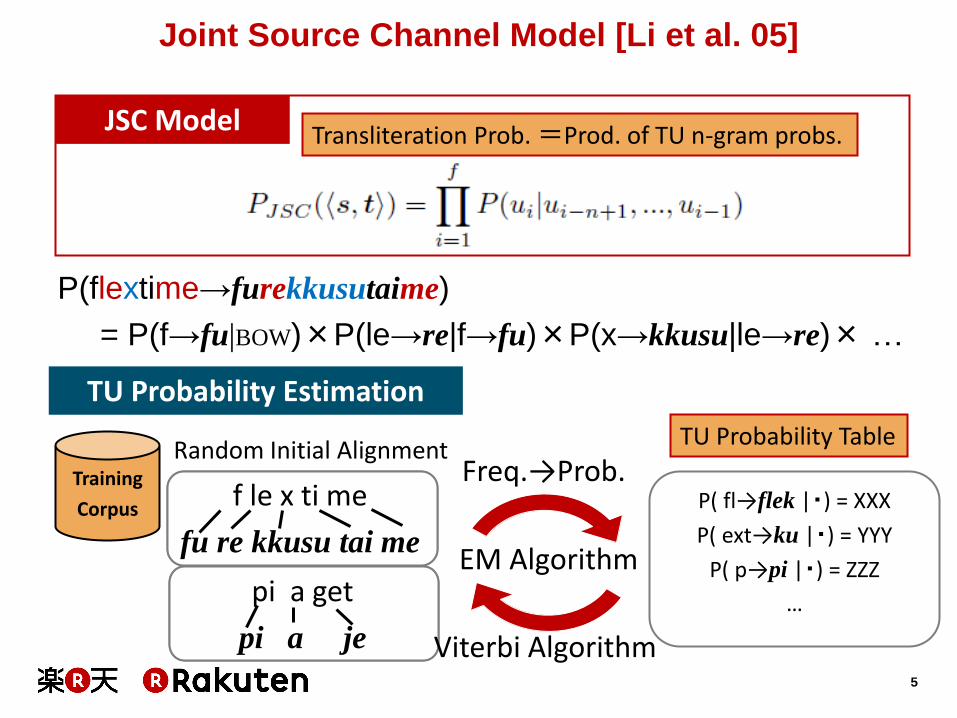
Joint Source Channel Model [Li et al. 05]
P(flextime→furekkusutaime)
= P(f→fu|BOW)×P(le→re|f→fu)×P(x→kkusu|le→re)× …
JSC Model
fl ext im e
frek ku suta imu
p i aget
pi a j e
Transliteration Prob. =Prod. of TU n-gram probs.
TU Probability Estimation
Training
Corpus
TU Probability Table
P( fl→flek |・) = XXX
P( ext→ku |・) = YYY
P( p→pi |・) = ZZZ
…
EM Algorithm
Freq.→Prob. f le x ti me
fu re kkusu tai me
pi a get
pi a je
Random Initial Alignment
Viterbi Algorithm
6
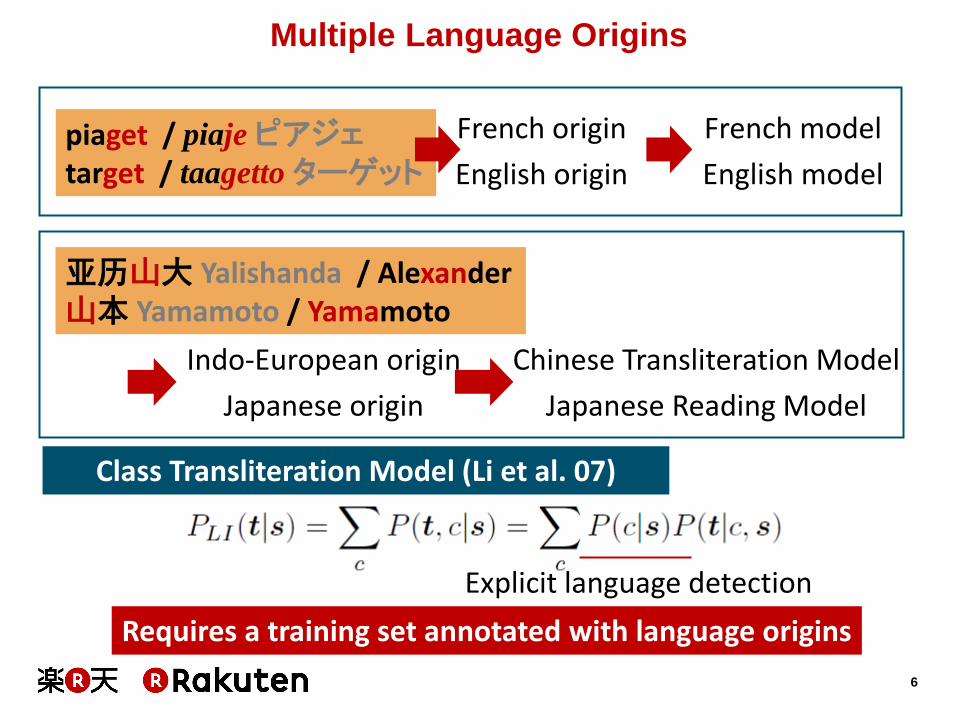
Multiple Language Origins
亚历山大 Yalishanda / Alexander 山本 Yamamoto / Yamamoto
Explicit language detection
Requires a training set annotated with language origins
piaget / piaje ピアジェ
target / taagetto ターゲット
French origin
English origin
French model
English model
Indo-European origin
Japanese origin
Chinese Transliteration Model
Japanese Reading Model
Class Transliteration Model (Li et al. 07)

7
Issues on Class Transliteration Model
• Requires training sets tagged with language origins
– Rare especially for proper nouns
• Language origins ≠ transliteration models
– e.g., spaghetti / supageti スパゲティ
Italian origins but can be found in English dictionaries
– e.g., Carl Laemmle / kaaru remuri カール・レムリ
German immigrant but listed as an “American” film
producer
→ An English transliteration model doesn’t work

8
Issues on Class Transliteration Model
• Requires training sets tagged with language origins
– Rare especially for proper nouns
• Language origins ≠ transliteration models
– e.g., spaghetti / supageti スパゲティ
Italian origins but can be found in English dictionaries
– e.g., Carl Laemmle / kaaru remuri カール・レムリ
German immigrant but listed as an “American” film
producer
→ An English transliteration model doesn’t work
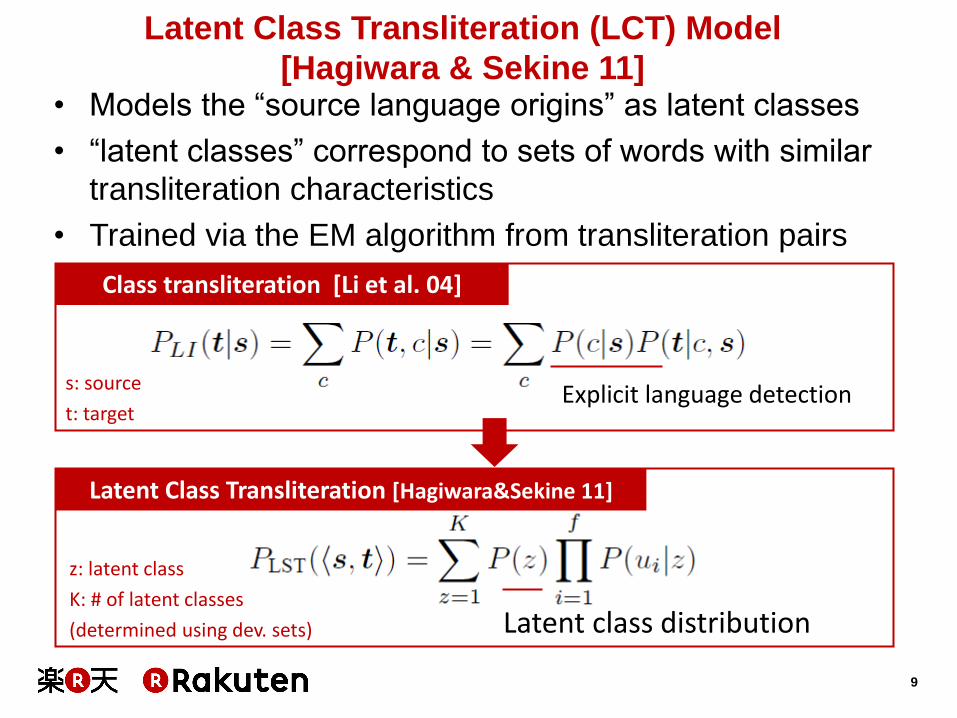
Model source language origins as latent classes
9
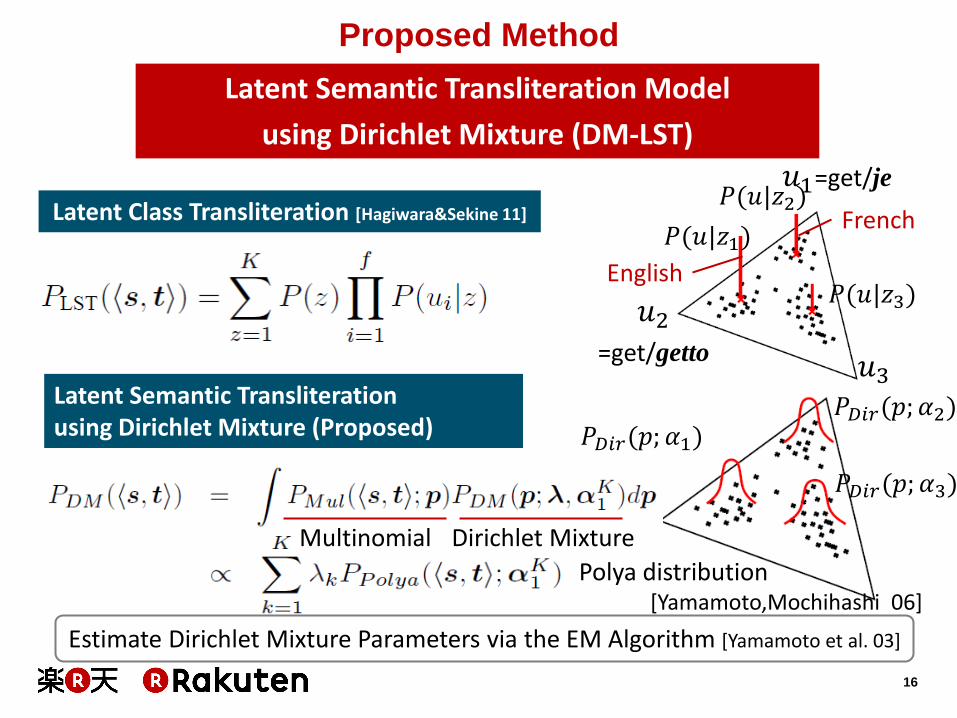
Latent Class Transliteration (LCT) Model
[Hagiwara & Sekine 11] • Models the “source language origins” as latent classes
• “latent classes” correspond to sets of words with similar
transliteration characteristics
• Trained via the EM algorithm from transliteration pairs
Class transliteration [Li et al. 04]
Latent Class Transliteration [Hagiwara&Sekine 11]
Explicit language detection
Latent class distribution
s: source
t: target
z: latent class
K: # of latent classes
(determined using dev. sets)
10
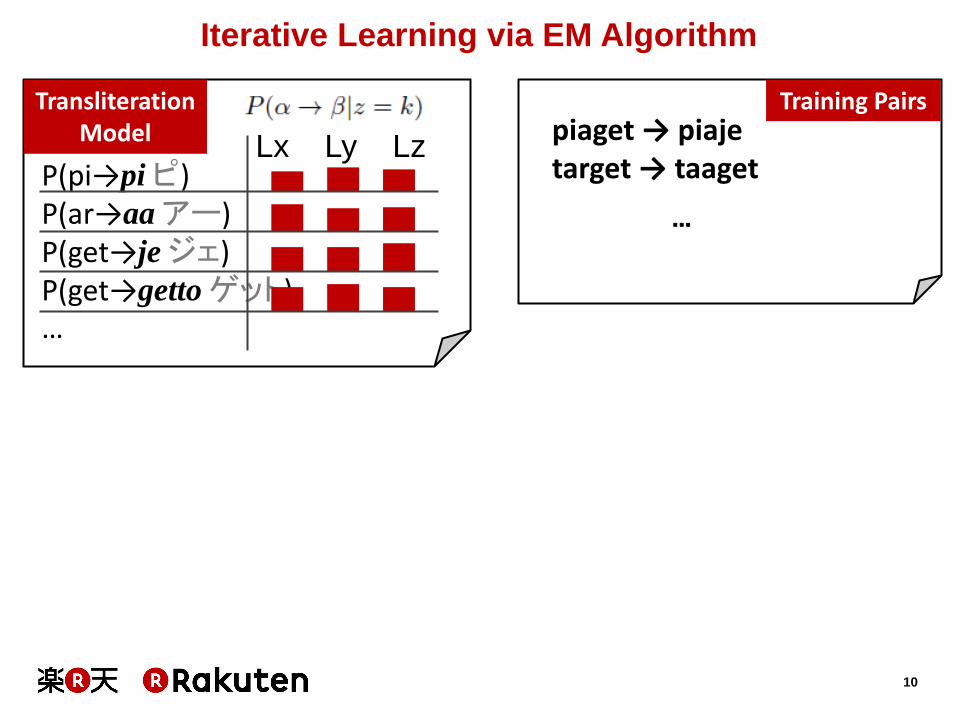
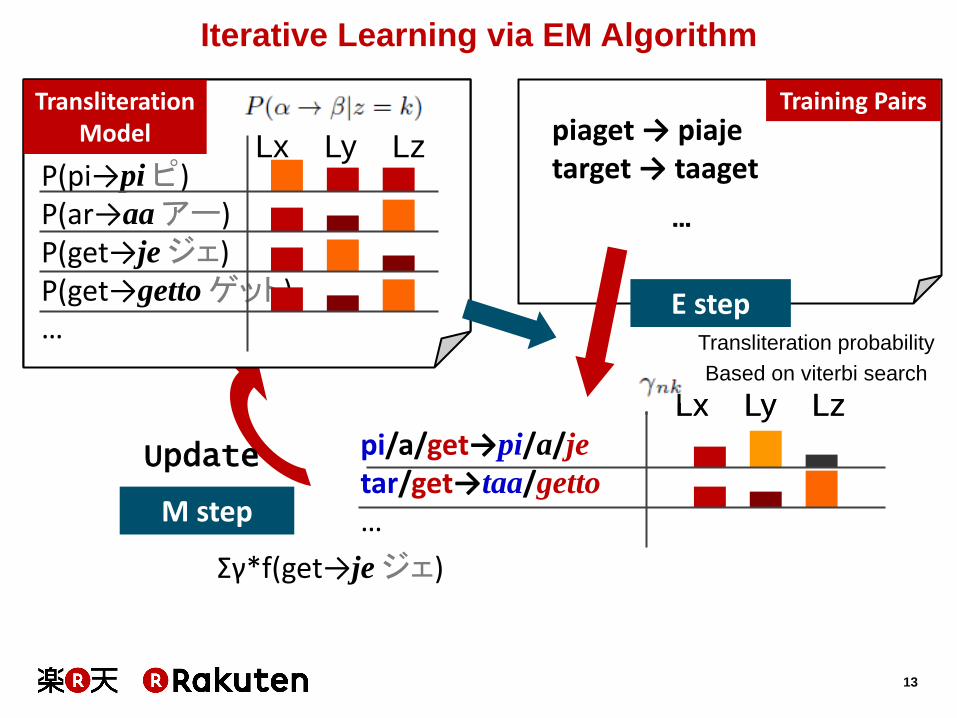
Iterative Learning via EM Algorithm
piaget → piaje target → taaget
…
Training Pairs
P(pi→pi ピ) P(ar→aa アー) P(get→je ジェ) P(get→getto ゲット) …
Transliteration Model
Lx Ly Lz
11
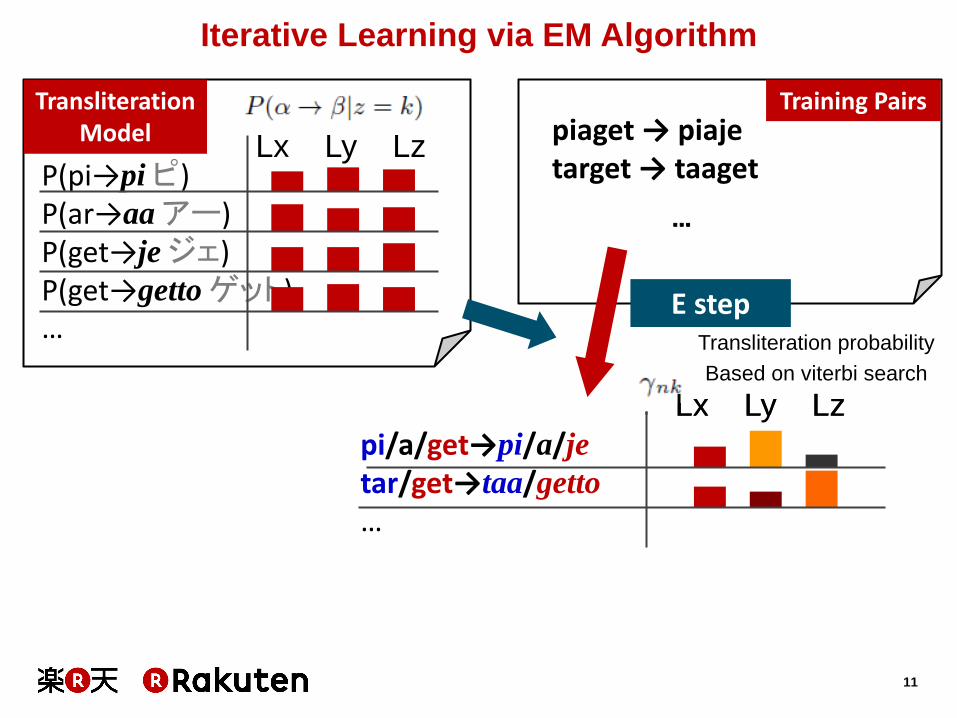
Iterative Learning via EM Algorithm
piaget → piaje target → taaget
…
p/i/a/get→pi/a/j/e
t/ar/get→taa/ge/tto
…
Lx Ly Lz
Training Pairs
P(pi→pi ピ) P(ar→aa アー) P(get→je ジェ) P(get→getto ゲット) …
Transliteration Model
Lx Ly Lz
pi/a/get→pi/a/je
tar/get→taa/getto
…
Lx Ly Lz
E step Transliteration probability
Based on viterbi search
12
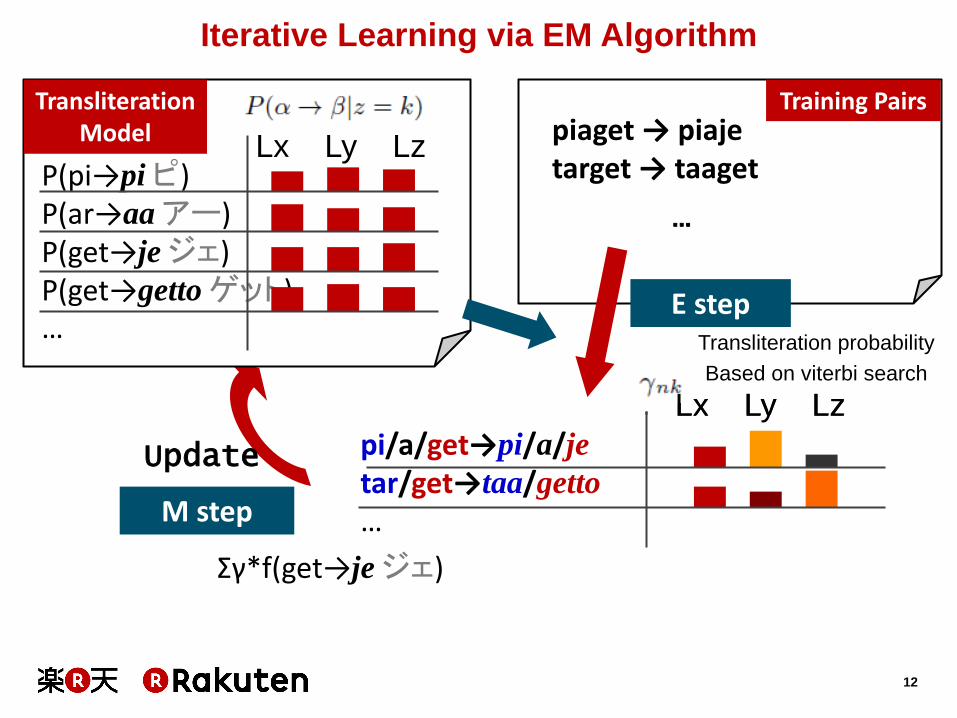
Iterative Learning via EM Algorithm
piaget → piaje target → taaget
…
p/i/a/get→pi/a/j/e
t/ar/get→taa/ge/tto
…
Lx Ly Lz
Update
M step
Σγ*f(get→je ジェ)
Training Pairs
P(pi→pi ピ) P(ar→aa アー) P(get→je ジェ) P(get→getto ゲット) …
Transliteration Model
Lx Ly Lz
pi/a/get→pi/a/je
tar/get→taa/getto
…
Lx Ly Lz
E step Transliteration probability
Based on viterbi search
13
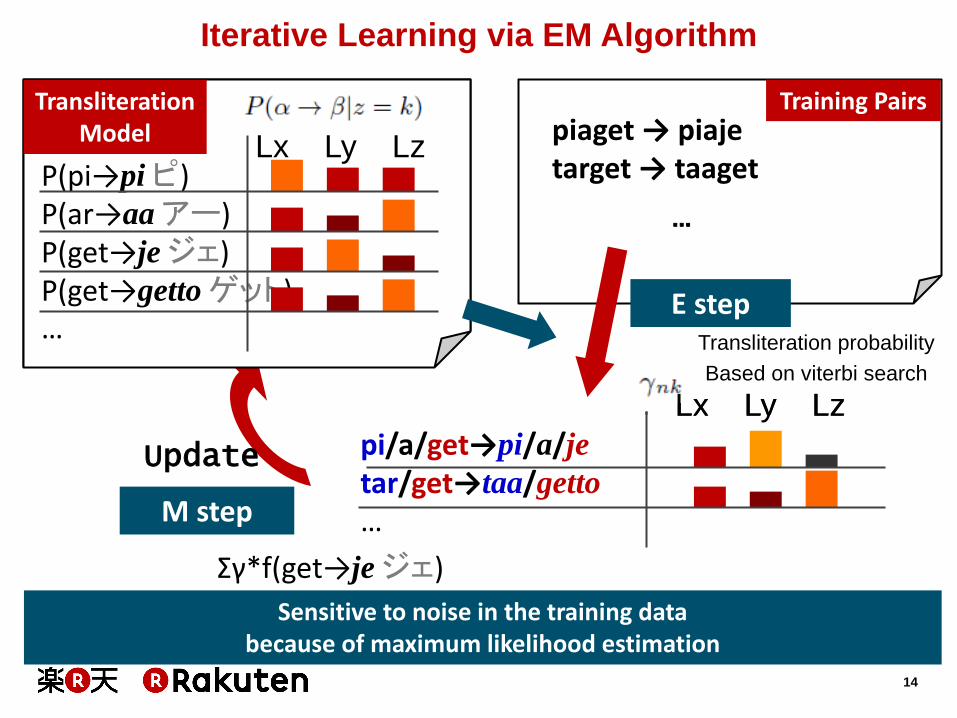
Iterative Learning via EM Algorithm
piaget → piaje target → taaget
…
p/i/a/get→pi/a/j/e
t/ar/get→taa/ge/tto
…
Lx Ly Lz
Update
M step
Σγ*f(get→je ジェ)
Training Pairs
P(pi→pi ピ) P(ar→aa アー) P(get→je ジェ) P(get→getto ゲット) …
Transliteration Model
Lx Ly Lz P(pi→pi ピ) P(ar→aa アー) P(get→je ジェ) P(get→getto ゲット) …
TransliterationModel
Lx Ly Lz
pi/a/get→pi/a/je
tar/get→taa/getto
…
Lx Ly Lz
E step Transliteration probability
Based on viterbi search
14
Iterative Learning via EM Algorithm
piaget → piaje target → taaget
…
p/i/a/get→pi/a/j/e
t/ar/get→taa/ge/tto
…
Lx Ly Lz
Update
M step
Σγ*f(get→je ジェ)
Training Pairs
P(pi→pi ピ) P(ar→aa アー) P(get→je ジェ) P(get→getto ゲット) …
Transliteration Model
Lx Ly Lz P(pi→pi ピ) P(ar→aa アー) P(get→je ジェ) P(get→getto ゲット) …
TransliterationModel
Lx Ly Lz
pi/a/get→pi/a/je
tar/get→taa/getto
…
Lx Ly Lz
E step Transliteration probability
Based on viterbi search
Sensitive to noise in the training data because of maximum likelihood estimation

15
Transliteration Models vs Topic Models
Transliteration Models Document Topic Models
Transliteration Unit (Atomic units of substitution )
e.g., pia / pia ピア get / je ジェ Word
Transliteration Pair (Sequence of transliteration units)
e.g., pia get / pia je ピア ジェ Document
Alpha-Beta Model Word Unigram Language Model
Joint Source Channel Model Word n-gram Language Model
Class Transliteration Model [Li et al. 04] Classification + Switch LMs
Latent Class Transliteration Model [Hagiwara&Sekine 11]
Unigram Mixture [Nigam et al. 00]
Proposed Dirichlet Mixture
[Yamamoto & Sadamitsu 03]
Introduce a Dirichlet mixture prior to alleviate overfitting
16
Polya distribution [Yamamoto,Mochihashi 06]
Proposed Method
Latent Semantic Transliteration Model
using Dirichlet Mixture (DM-LST)
𝑃(𝑢|𝑧1)
𝑃𝐷𝑖𝑟(𝑝; 𝛼1) 𝑃𝐷𝑖𝑟(𝑝; 𝛼2)
𝑃𝐷𝑖𝑟(𝑝; 𝛼3)
𝑢1=get/je
Latent Class Transliteration [Hagiwara&Sekine 11] 𝑃(𝑢|𝑧2)
𝑃(𝑢|𝑧3) 𝑢2 =get/getto
Latent Semantic Transliteration using Dirichlet Mixture (Proposed)
Estimate Dirichlet Mixture Parameters via the EM Algorithm [Yamamoto et al. 03]
𝑢3
French
English
Multinomial Dirichlet Mixture
17
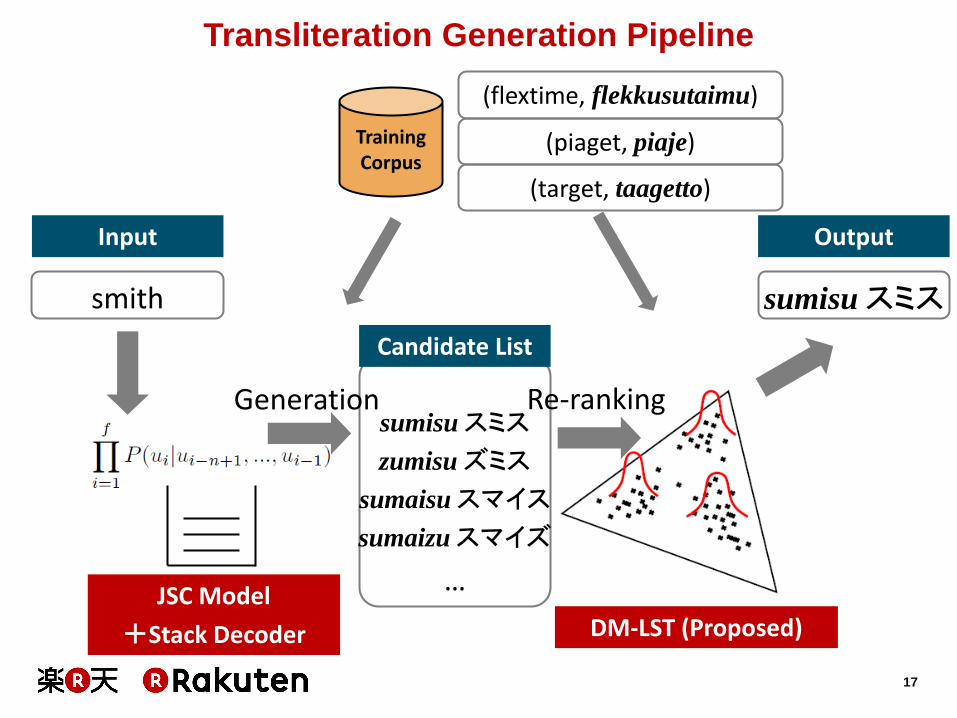
Transliteration Generation Pipeline
Training Corpus
(flextime, flekkusutaimu)
(piaget, piaje)
DM-LST (Proposed)
smith
Input
JSC Model
+Stack Decoder
sumisu スミス
zumisu ズミス
sumaisu スマイス
sumaizu スマイズ
…
Candidate List
sumisu スミス
Output
Generation Re-ranking
(target, taagetto)

18
Experiments
• Alpha-Beta Model (AB)
• Joint Source Channel (JSC)
• Latent Class Transliteration (LST)
• Latent Semantic Transliteration using Dirichlet Mixture
(DM-LST; Proposed)
19
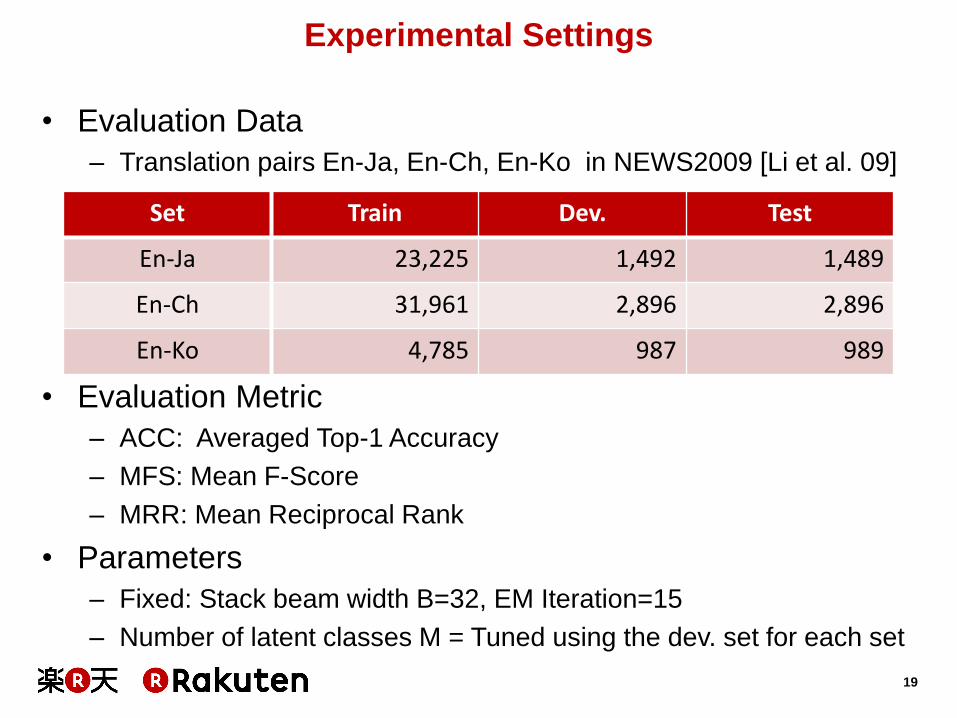
Experimental Settings
• Evaluation Data
– Translation pairs En-Ja, En-Ch, En-Ko in NEWS2009 [Li et al. 09]
• Evaluation Metric
– ACC: Averaged Top-1 Accuracy
– MFS: Mean F-Score
– MRR: Mean Reciprocal Rank
• Parameters
– Fixed: Stack beam width B=32, EM Iteration=15
– Number of latent classes M = Tuned using the dev. set for each set
Set Train Dev. Test
En-Ja 23,225 1,492 1,489
En-Ch 31,961 2,896 2,896
En-Ko 4,785 987 989
20
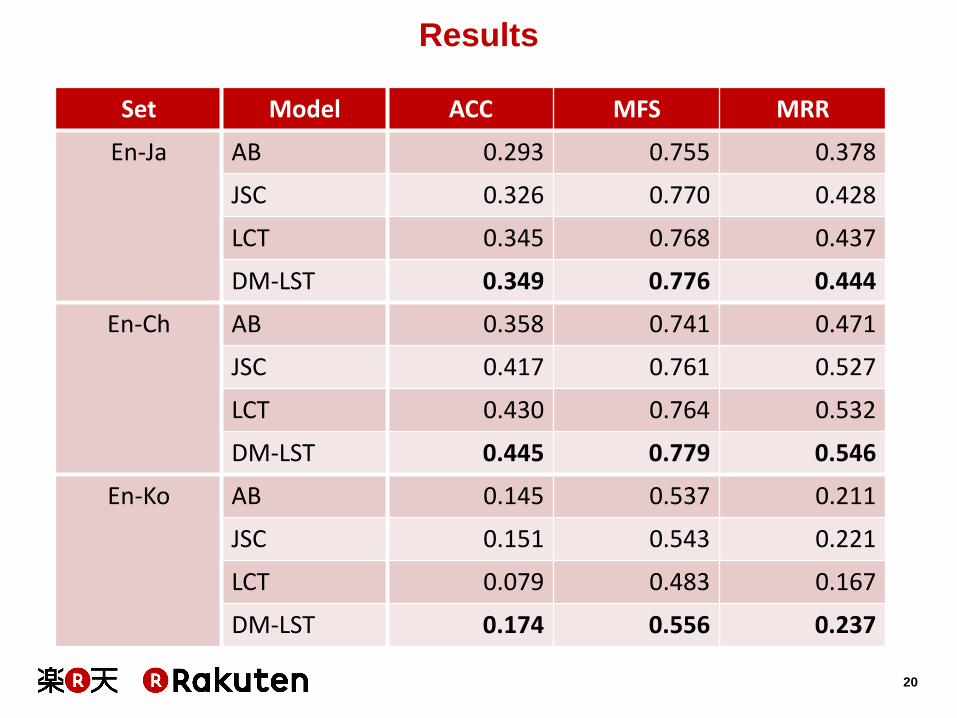
Results
Set Model ACC MFS MRR
En-Ja AB 0.293 0.755 0.378
JSC 0.326 0.770 0.428
LCT 0.345 0.768 0.437
DM-LST 0.349 0.776 0.444
En-Ch AB 0.358 0.741 0.471
JSC 0.417 0.761 0.527
LCT 0.430 0.764 0.532
DM-LST 0.445 0.779 0.546
En-Ko AB 0.145 0.537 0.211
JSC 0.151 0.543 0.221
LCT 0.079 0.483 0.167
DM-LST 0.174 0.556 0.237
21
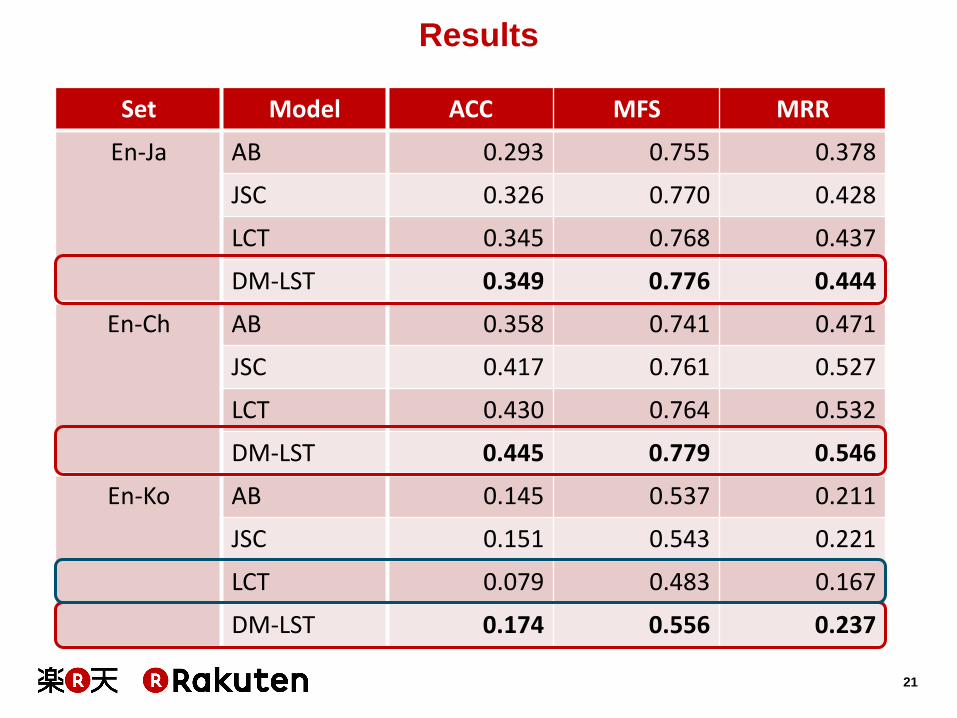
Results
Set Model ACC MFS MRR
En-Ja AB 0.293 0.755 0.378
JSC 0.326 0.770 0.428
LCT 0.345 0.768 0.437
DM-LST 0.349 0.776 0.444
En-Ch AB 0.358 0.741 0.471
JSC 0.417 0.761 0.527
LCT 0.430 0.764 0.532
DM-LST 0.445 0.779 0.546
En-Ko AB 0.145 0.537 0.211
JSC 0.151 0.543 0.221
LCT 0.079 0.483 0.167
DM-LST 0.174 0.556 0.237
22
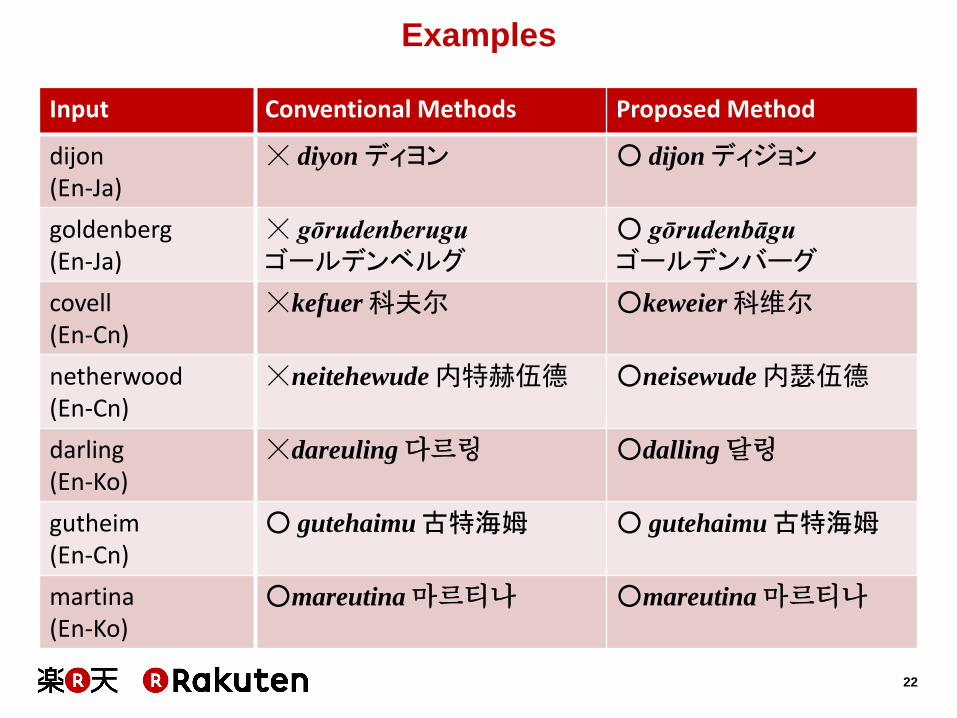
Examples
Input Conventional Methods Proposed Method
dijon (En-Ja)
☓ diyon ディヨン ○ dijon ディジョン
goldenberg (En-Ja)
☓ gōrudenberugu ゴールデンベルグ
○ gōrudenbāgu ゴールデンバーグ
covell (En-Cn)
☓kefuer 科夫尔 ○keweier 科维尔
netherwood (En-Cn)
☓neitehewude 内特赫伍德 ○neisewude 内瑟伍德
darling (En-Ko)
☓dareuling 다르링 ○dalling 달링
gutheim (En-Cn)
○ gutehaimu 古特海姆 ○ gutehaimu 古特海姆
martina (En-Ko)
○mareutina 마르티나 ○mareutina 마르티나

23
Conclusion
• Proposed Latent Semantic Transliteration
based on Dirichlet Mixture (DM-LST)
– Formalized conventional transliteration models
by document topic models
– Introduced a Dirichlet Mixture prior to alleviate
overfitting
– Superior transliteration performance
to the conventional methods
• Future Works
– Deal with transliteration unit N-grams (N≧2)
– Context-dependent transliteration • e.g., Charles → チャールズ chāruzu or シャルル sharuru







