econometrie lineaire
DESCRIPTION
PROJET EN ECONOMETRIE LINEAIREREGRESSIONS SIMPLES ET REGRESSIONS MULTIPLESREGLES BAYNESIENTRANSCRIPT

1 | P a g e
Master 2 professionnel « TIDE »
Universite Paris 1 Pantheon Sorbonne
Projet de l’Econométrie Non Linéaire
Etude sur le Baromètre Politique
Français 2007
LARBAOUI Sonia
VIJA Radu-Ioan
Sous la direction de
M. Rynkiewicz
14 Juin 2013

2 | P a g e
SOMMAIRE
CONTEXTE DE L’ETUDE ................................................................................................................................. 3
1. PRESENTATION DE LA BASE ................................................................................................................ 4
1.1. STATISTIQUES DESCRIPTIVES SUR LES VARIALES SENSIBLES D’OPINION ....................... 6
1.2. STATISTIQUES DESCRIPTIVES SUR LES VARIALES SENSIBLES DE CONTEXTE ................. 9
2. DETERMINATION DU MEILLEUR MODELE CONTENANT 3 VARIABLES DE CONTEXTE
EXPLICATIVES ET 3 VARIABLES D’OPINION EXPLICATIVES .......................................................... 11
2.1. ANALYSE DES LIAISONS ENTRE LES VARIABLES EXPLICATIVES ET LA VARIABLE Q46D ....................... 11
2.2. TOUS LES MODELES POSSIBLES A SIX VARIABLES EXPLICATIVES .......................................................... 15
3. AJUSTEMENT DU MODELE DECOMPOSABLE LE PLUS ADAPTE AUX DONNEES. ............. 16
ANNEXES ........................................................................................................................................................... 20

3 | P a g e
CONTEXTE DE L’ETUDE
Notre étude est basée sur une enquête réalisée lors du tour de l’élection
présidentielle de 2007.Par cette enquête, 5650 personnes ont été choisies selon une méthode
de quotas. Nous disposons de 236 variables dans cette base.
Tableau numero1 : Présentation générale de la table
Nous nous intéresserons dans ce devoir au choix de vote des électeurs que nous
chercherons à expliquer grâce aux variables suivantes :
VARIABLES D’OPINION
Opinion sur les immigrés (Q17E)
Problèmes en France (Q12A et Q12B)
Chômage (Q14)
Délinquance (Q15)
Homosexualité (Q17B)
France en déclin (Q18)
TV (Q37 et Q38)
Mondialisation (Q44)
Peine de mort (Q17D)

4 | P a g e
VARIABLES DE CONTEXTE
Diplôme le plus élevé (RCRS2)
Profession (RCRS7)
Origine Parents (RCRS13)
Tranche d’âge (RAGE)
Sexe (SEXE)
Grande région (GR)
Situation professionnelle (RRS8)
Situation familiale (Q48)
Religion (RCRS15)
Afin d’expliquer le choix de vote des électeurs, nous allons en premier lieu sélectionner
le meilleur modèle avec 6 variables explicatives (3 variables de contexte et 3 variables
explicatives d’opinion) pour ensuite ajuster le modèle décomposable le plus adapté aux
données. Enfin nous en déduirons une description de la motivation du vote.
1. PRESENTATION DE LA BASE
Notre base contient 5650 observations et a 236 variables. Nous nous intéresserons à 20
d’entre elles (9 variables de contexte et 11 variables d’opinion) dans un premier temps, pour
ensuite en retenir 6 variables, 3 de chaque côte. Elles seront choisies de façon à expliquer le
mieux possible le choix de vote des électeurs.
Définissant tout d’abord les modalités de chaque variable et leur éventuel regroupement
ainsi que leur recodage. Notre variable à expliquer est le résultat des votes des élections
présidentielles de 2007 pour le candidat Buffet(Q46D).
5 | P a g e
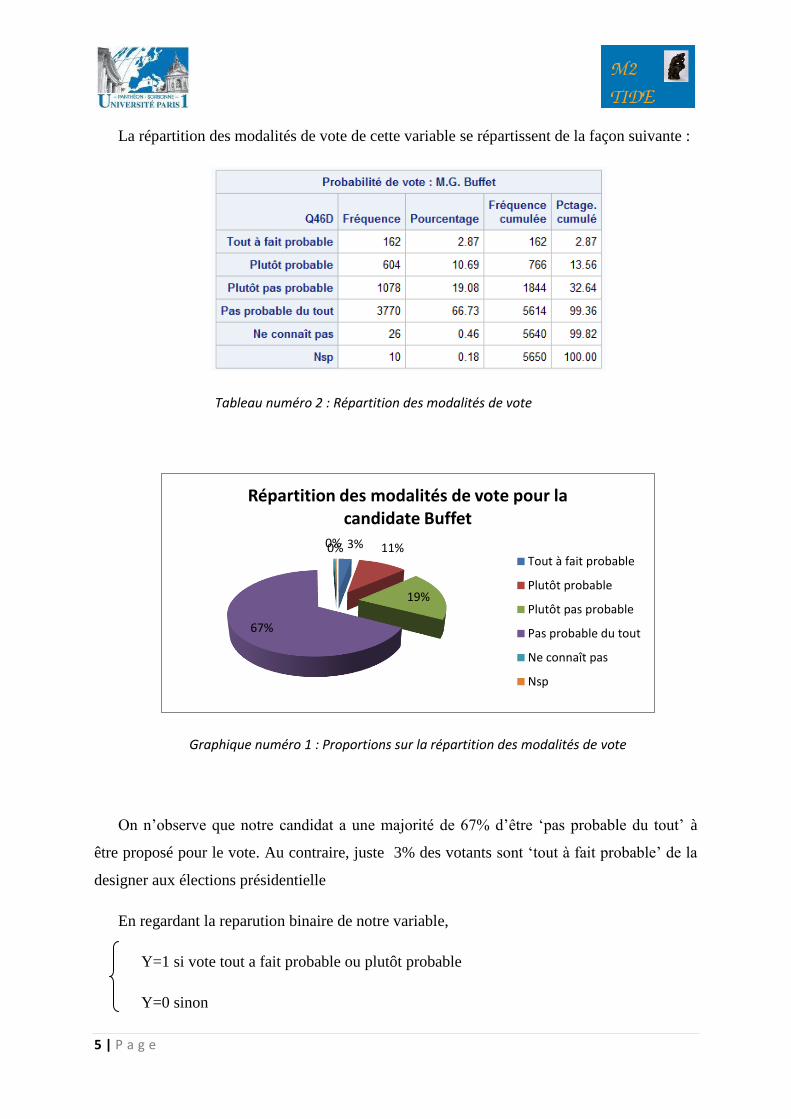
La répartition des modalités de vote de cette variable se répartissent de la façon suivante :
Tableau numéro 2 : Répartition des modalités de vote
Graphique numéro 1 : Proportions sur la répartition des modalités de vote
On n’observe que notre candidat a une majorité de 67% d’être ‘pas probable du tout’ à
être proposé pour le vote. Au contraire, juste 3% des votants sont ‘tout à fait probable’ de la
designer aux élections présidentielle
En regardant la reparution binaire de notre variable,
Y=1 si vote tout a fait probable ou plutôt probable
Y=0 sinon
3% 11%
19%
67%
0% 0%
Répartition des modalités de vote pour la candidate Buffet
Tout à fait probable
Plutôt probable
Plutôt pas probable
Pas probable du tout
Ne connaît pas
Nsp
6 | P a g e
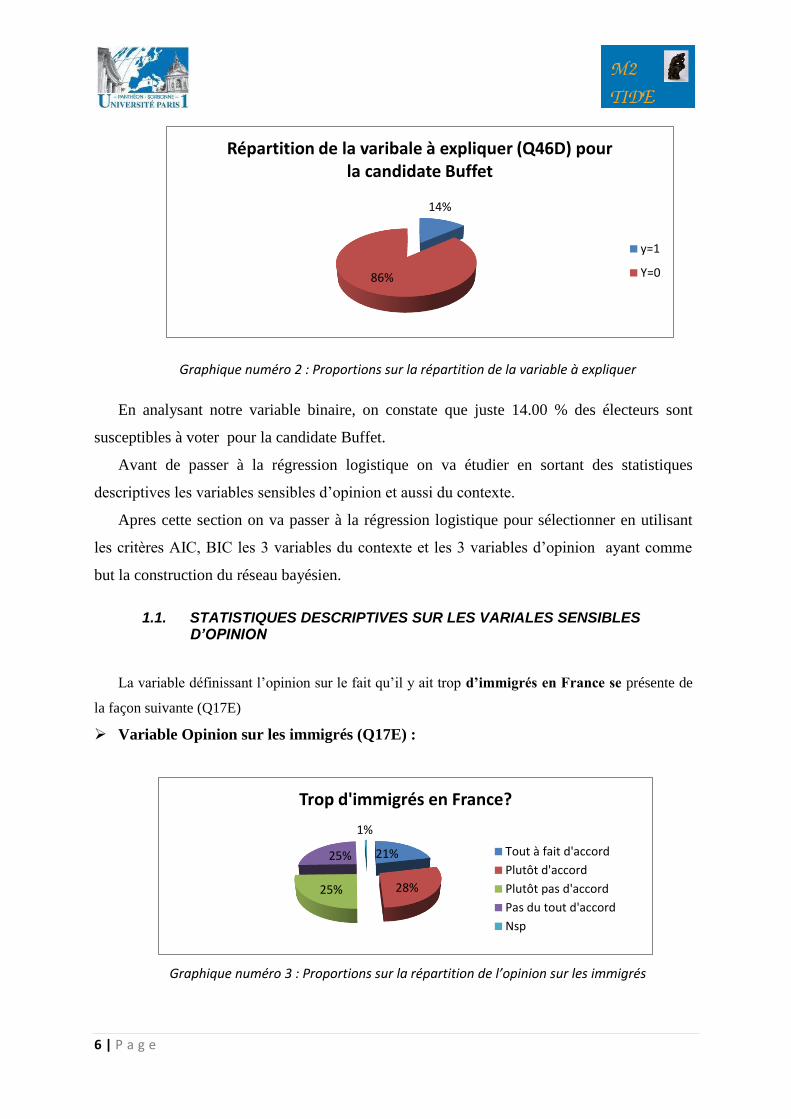
Graphique numéro 2 : Proportions sur la répartition de la variable à expliquer
En analysant notre variable binaire, on constate que juste 14.00 % des électeurs sont
susceptibles à voter pour la candidate Buffet.
Avant de passer à la régression logistique on va étudier en sortant des statistiques
descriptives les variables sensibles d’opinion et aussi du contexte.
Apres cette section on va passer à la régression logistique pour sélectionner en utilisant
les critères AIC, BIC les 3 variables du contexte et les 3 variables d’opinion ayant comme
but la construction du réseau bayésien.
1.1. STATISTIQUES DESCRIPTIVES SUR LES VARIALES SENSIBLES D’OPINION
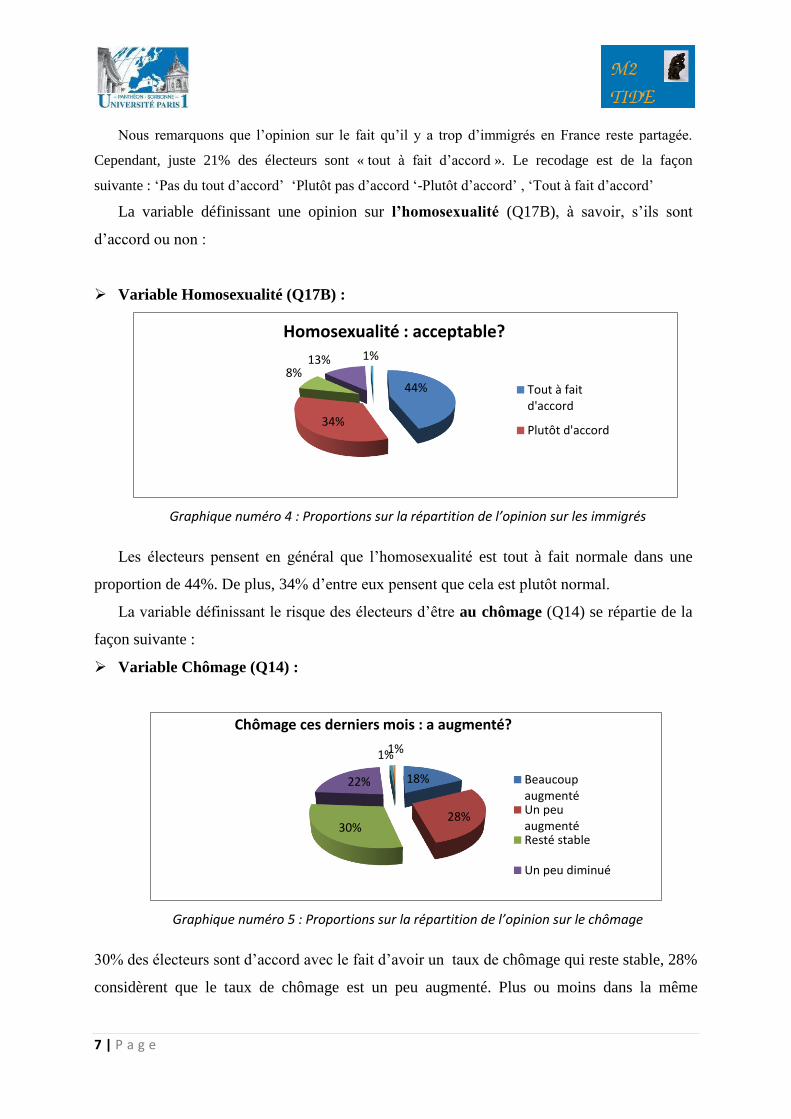
La variable définissant l’opinion sur le fait qu’il y ait trop d’immigrés en France se présente de
la façon suivante (Q17E)
Variable Opinion sur les immigrés (Q17E) :
Graphique numéro 3 : Proportions sur la répartition de l’opinion sur les immigrés
14%
86%
Répartition de la varibale à expliquer (Q46D) pour la candidate Buffet
y=1
Y=0
21%
28% 25%
25%
1%
Trop d'immigrés en France?
Tout à fait d'accord
Plutôt d'accord
Plutôt pas d'accord
Pas du tout d'accord
Nsp
7 | P a g e
Nous remarquons que l’opinion sur le fait qu’il y a trop d’immigrés en France reste partagée.
Cependant, juste 21% des électeurs sont « tout à fait d’accord ». Le recodage est de la façon
suivante : ‘Pas du tout d’accord’ ‘Plutôt pas d’accord ‘-Plutôt d’accord’ , ‘Tout à fait d’accord’
La variable définissant une opinion sur l’homosexualité (Q17B), à savoir, s’ils sont
d’accord ou non :
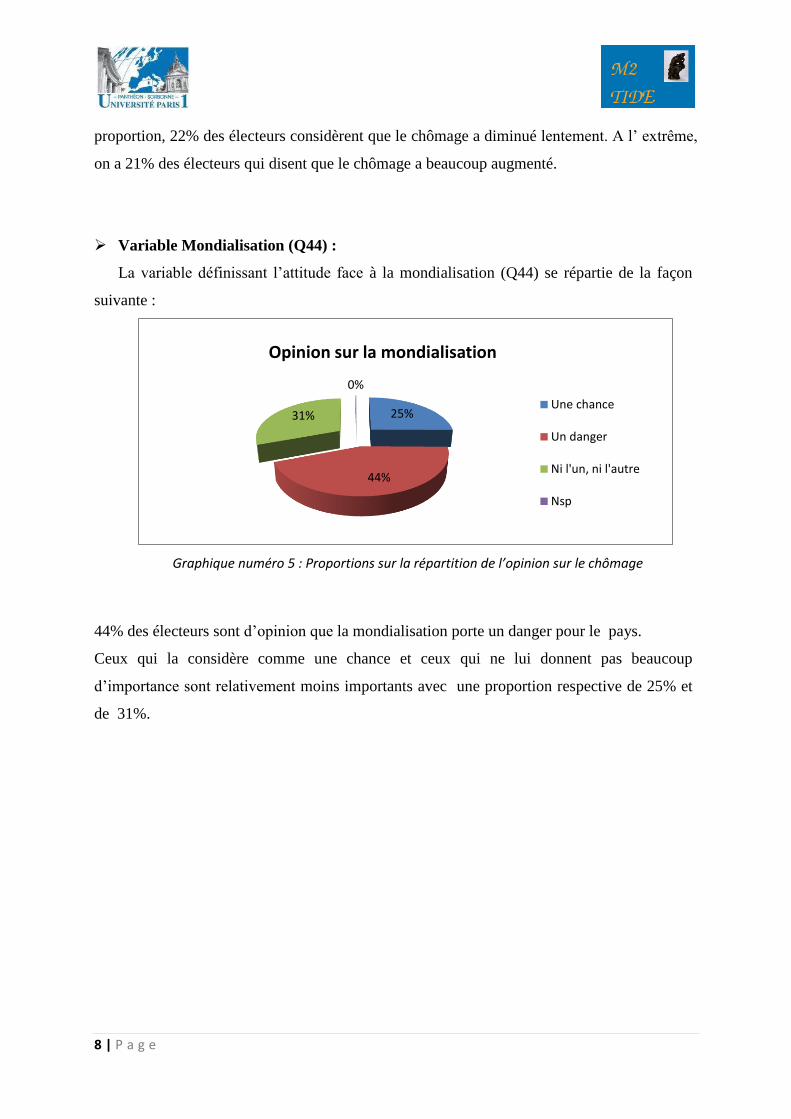
Variable Homosexualité (Q17B) :
Graphique numéro 4 : Proportions sur la répartition de l’opinion sur les immigrés
Les électeurs pensent en général que l’homosexualité est tout à fait normale dans une
proportion de 44%. De plus, 34% d’entre eux pensent que cela est plutôt normal.
La variable définissant le risque des électeurs d’être au chômage (Q14) se répartie de la
façon suivante :
Variable Chômage (Q14) :
Graphique numéro 5 : Proportions sur la répartition de l’opinion sur le chômage
30% des électeurs sont d’accord avec le fait d’avoir un taux de chômage qui reste stable, 28%
considèrent que le taux de chômage est un peu augmenté. Plus ou moins dans la même
44%
34%
8% 13% 1%
Homosexualité : acceptable?
Tout à faitd'accord
Plutôt d'accord
18%
28% 30%
22%
1% 1%
Chômage ces derniers mois : a augmenté?
BeaucoupaugmentéUn peuaugmentéResté stable
Un peu diminué
8 | P a g e
proportion, 22% des électeurs considèrent que le chômage a diminué lentement. A l’ extrême,
on a 21% des électeurs qui disent que le chômage a beaucoup augmenté.
Variable Mondialisation (Q44) :
La variable définissant l’attitude face à la mondialisation (Q44) se répartie de la façon
suivante :
Graphique numéro 5 : Proportions sur la répartition de l’opinion sur le chômage
44% des électeurs sont d’opinion que la mondialisation porte un danger pour le pays.
Ceux qui la considère comme une chance et ceux qui ne lui donnent pas beaucoup
d’importance sont relativement moins importants avec une proportion respective de 25% et
de 31%.
25%
44%
31%
0%
Opinion sur la mondialisation
Une chance
Un danger
Ni l'un, ni l'autre
Nsp
9 | P a g e
1.2. STATISTIQUES DESCRIPTIVES SUR LES VARIALES SENSIBLES DE CONTEXTE
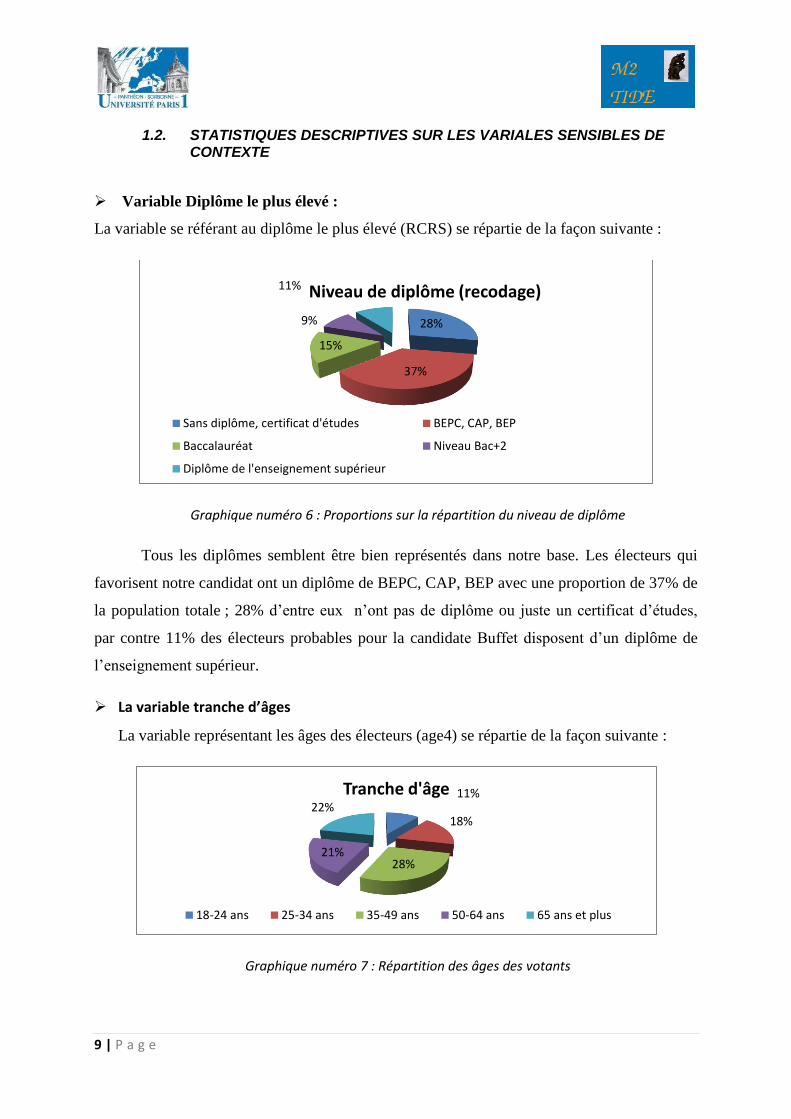
Variable Diplôme le plus élevé :
La variable se référant au diplôme le plus élevé (RCRS) se répartie de la façon suivante :
Graphique numéro 6 : Proportions sur la répartition du niveau de diplôme
Tous les diplômes semblent être bien représentés dans notre base. Les électeurs qui
favorisent notre candidat ont un diplôme de BEPC, CAP, BEP avec une proportion de 37% de
la population totale ; 28% d’entre eux n’ont pas de diplôme ou juste un certificat d’études,
par contre 11% des électeurs probables pour la candidate Buffet disposent d’un diplôme de
l’enseignement supérieur.
La variable tranche d’âges
La variable représentant les âges des électeurs (age4) se répartie de la façon suivante :
Graphique numéro 7 : Répartition des âges des votants
28%
37%
15%
9%
11% Niveau de diplôme (recodage)
Sans diplôme, certificat d'études BEPC, CAP, BEP
Baccalauréat Niveau Bac+2
Diplôme de l'enseignement supérieur
11%
18%
28% 21%
22%
Tranche d'âge
18-24 ans 25-34 ans 35-49 ans 50-64 ans 65 ans et plus
10 | P a g e
Toutes les tranches d’âge sont bien représentées dans notre base. La population 35-49 ans
est majoritaire avec une proportion de 28% de tous nos électeurs.
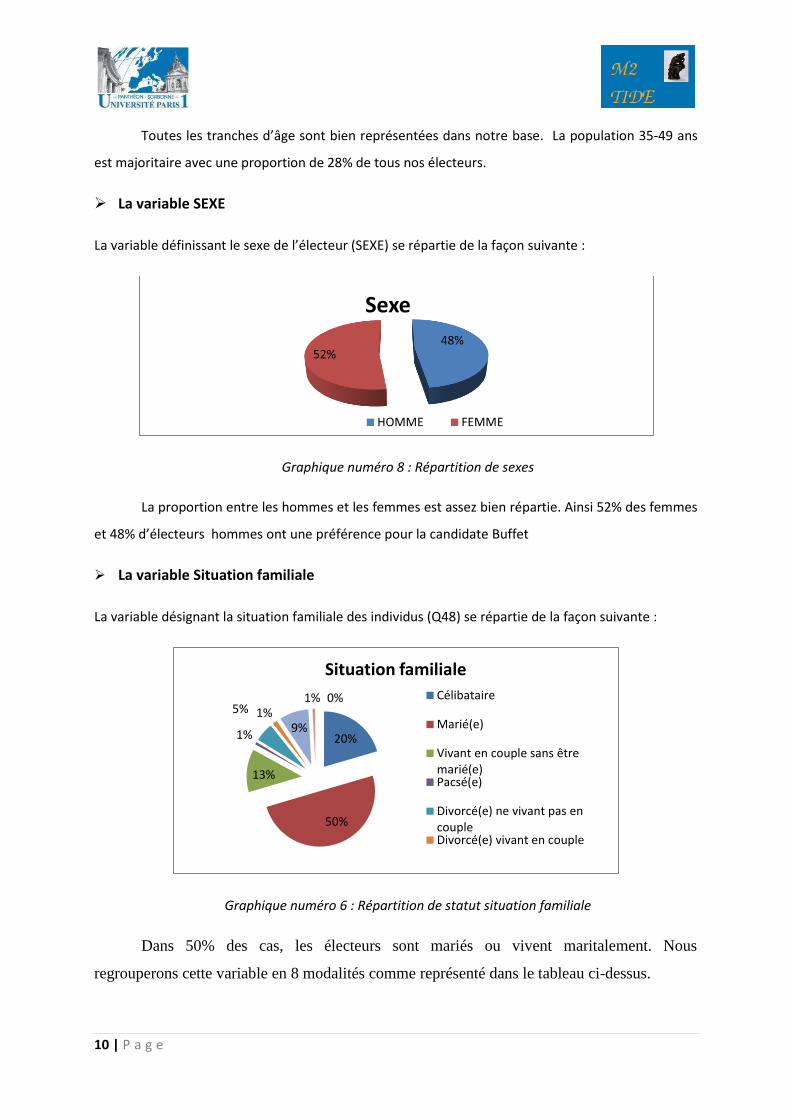
La variable SEXE
La variable définissant le sexe de l’électeur (SEXE) se répartie de la façon suivante :
Graphique numéro 8 : Répartition de sexes
La proportion entre les hommes et les femmes est assez bien répartie. Ainsi 52% des femmes
et 48% d’électeurs hommes ont une préférence pour la candidate Buffet
La variable Situation familiale
La variable désignant la situation familiale des individus (Q48) se répartie de la façon suivante :
Graphique numéro 6 : Répartition de statut situation familiale
Dans 50% des cas, les électeurs sont mariés ou vivent maritalement. Nous
regrouperons cette variable en 8 modalités comme représenté dans le tableau ci-dessus.
48% 52%
Sexe
HOMME FEMME
20%
50%
13%
1%
5% 1% 9%
1% 0%
Situation familiale
Célibataire
Marié(e)
Vivant en couple sans êtremarié(e)Pacsé(e)
Divorcé(e) ne vivant pas encoupleDivorcé(e) vivant en couple

11 | P a g e
2. Détermination du meilleur modèle contenant 3 variables de contexte explicatives et 3 variables d’opinion
explicatives
Notre variable à expliquer est de nature polytomique car elle est qualitative avec plus de 2
modalités. De plus, elle est ordonnée. Ainsi, nous allons utiliser la procédure LOGISTIC ou
CATMOD de SAS afin de déterminer le meilleur modèle contenant 6 variables explicatives
parmi les variables définies précédemment.
Cependant, avant de commencer une quelconque analyse, nous allons vérifier grâce à la
PROC FREQ de SAS et son option du Chi2 si les variables ont une liaison avec notre variable
à expliquer. Le programme est le suivant
proc freq data=enl.data;
table Q46D *(RCRS2 RCRS7 RCRS13 RAGE SEXE GR RRS8 Q48 RCRS15) / chisq
noprint;
run;
proc freq data=enl.data;
table Q46D *(Q17E Q12A Q12B Q14 Q15 Q17B Q18 Q37 Q38 Q44 Q17D) / chisq
noprint;
run;
2.1. Analyse des liaisons entre les variables explicatives et la variable Q46D
Avant de passer à la modélisation, nous vérifions d’abord par un test d’indépendance de
KHI2, et voir si les variables explicatives sont liées ou pas avec la variable expliquée
VOTE=1 ou 0 ( qui est recodé à travers la variable Q46D).
Nous testons l’hypothèse :
H0 : il y a indépendance entre les variables
contre l’hypothèse alternative
H1 : les variables ne sont pas indépendantes
12 | P a g e
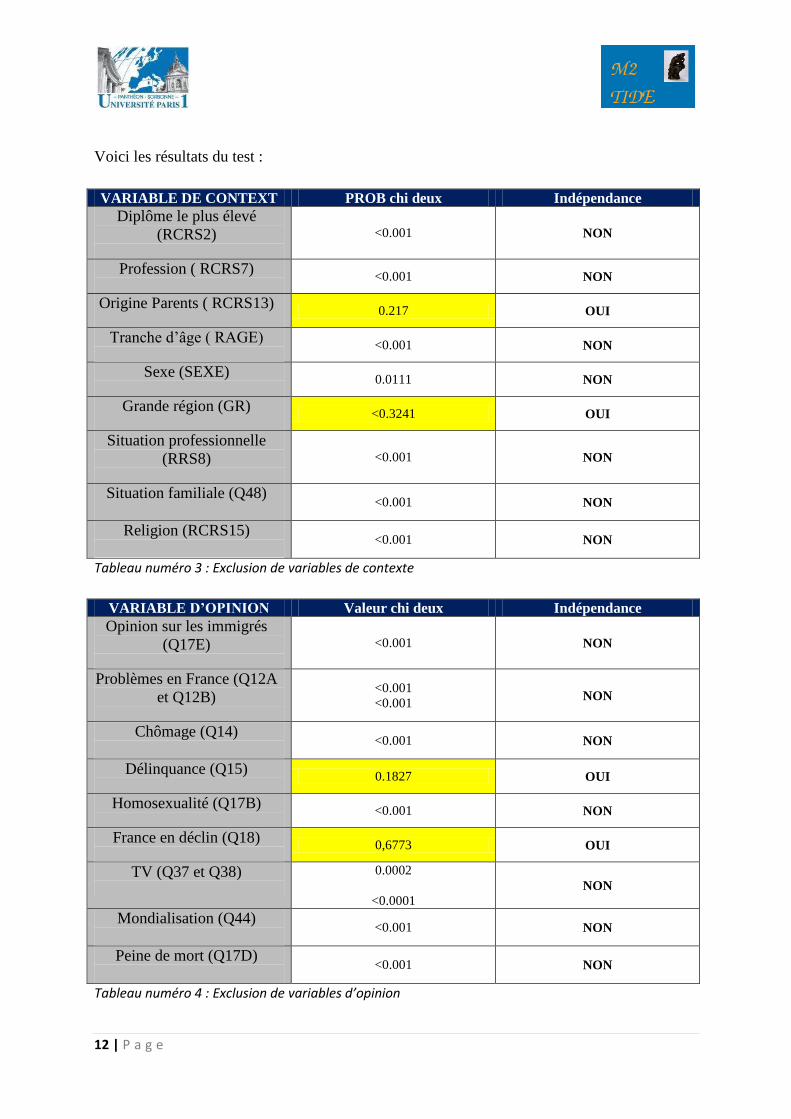
Voici les résultats du test :
VARIABLE DE CONTEXT PROB chi deux Indépendance
Diplôme le plus élevé
(RCRS2)
<0.001 NON
Profession ( RCRS7)
<0.001 NON
Origine Parents ( RCRS13)
0.217 OUI
Tranche d’âge ( RAGE)
<0.001 NON
Sexe (SEXE)
0.0111 NON
Grande région (GR)
<0.3241 OUI
Situation professionnelle
(RRS8)
<0.001 NON
Situation familiale (Q48)
<0.001 NON
Religion (RCRS15)
<0.001 NON
Tableau numéro 3 : Exclusion de variables de contexte
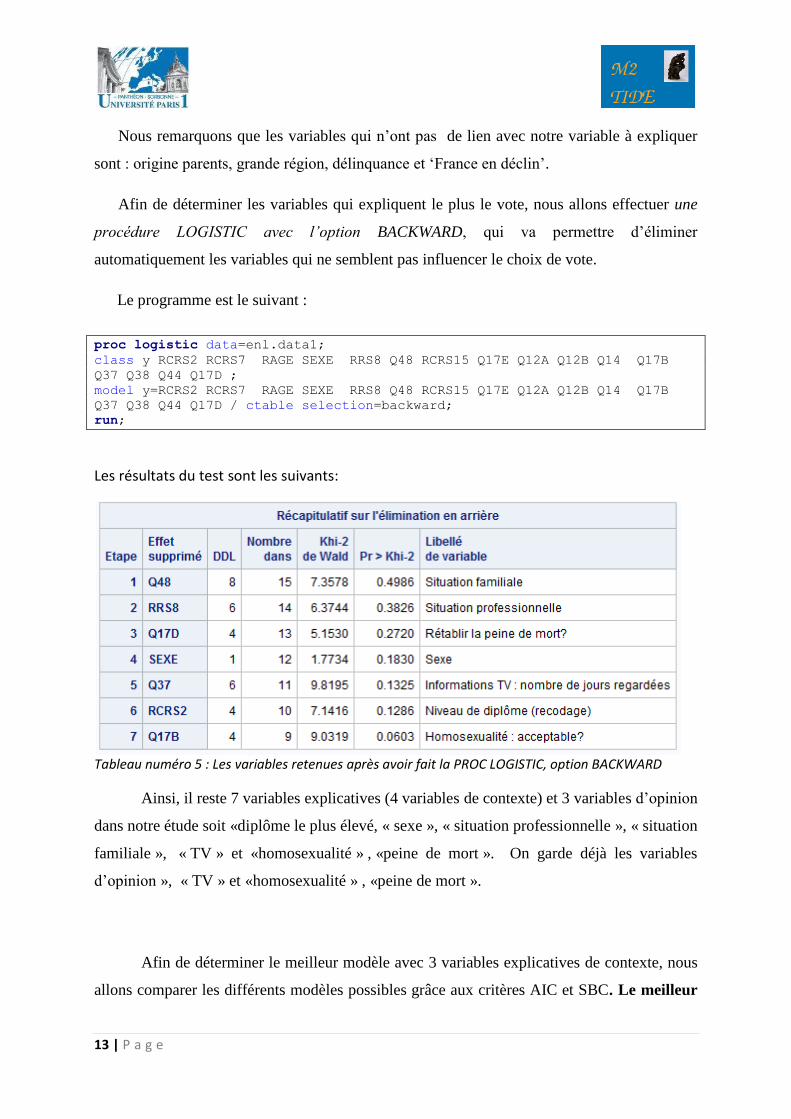
VARIABLE D’OPINION Valeur chi deux Indépendance
Opinion sur les immigrés
(Q17E)
<0.001 NON
Problèmes en France (Q12A
et Q12B)
<0.001
<0.001 NON
Chômage (Q14)
<0.001 NON
Délinquance (Q15)
0.1827 OUI
Homosexualité (Q17B)
<0.001 NON
France en déclin (Q18)
0,6773 OUI
TV (Q37 et Q38)
0.0002
<0.0001 NON
Mondialisation (Q44)
<0.001 NON
Peine de mort (Q17D)
<0.001 NON
Tableau numéro 4 : Exclusion de variables d’opinion
13 | P a g e
Nous remarquons que les variables qui n’ont pas de lien avec notre variable à expliquer
sont : origine parents, grande région, délinquance et ‘France en déclin’.
Afin de déterminer les variables qui expliquent le plus le vote, nous allons effectuer une
procédure LOGISTIC avec l’option BACKWARD, qui va permettre d’éliminer
automatiquement les variables qui ne semblent pas influencer le choix de vote.
Le programme est le suivant :
proc logistic data=enl.data1;
class y RCRS2 RCRS7 RAGE SEXE RRS8 Q48 RCRS15 Q17E Q12A Q12B Q14 Q17B
Q37 Q38 Q44 Q17D ;
model y=RCRS2 RCRS7 RAGE SEXE RRS8 Q48 RCRS15 Q17E Q12A Q12B Q14 Q17B
Q37 Q38 Q44 Q17D / ctable selection=backward;
run;
Les résultats du test sont les suivants:
Tableau numéro 5 : Les variables retenues après avoir fait la PROC LOGISTIC, option BACKWARD
Ainsi, il reste 7 variables explicatives (4 variables de contexte) et 3 variables d’opinion
dans notre étude soit «diplôme le plus élevé, « sexe », « situation professionnelle », « situation
familiale », « TV » et «homosexualité » , «peine de mort ». On garde déjà les variables
d’opinion », « TV » et «homosexualité » , «peine de mort ».
Afin de déterminer le meilleur modèle avec 3 variables explicatives de contexte, nous
allons comparer les différents modèles possibles grâce aux critères AIC et SBC. Le meilleur

14 | P a g e
modèle est celui qui a ces critères les plus faibles. La macro suivante nous permet de définir
les 4 modèles possibles :
%macro logist(var1,var2,var3,var4,var5,var6);
proc logistic data=enl.data1;
class y &var1 &var2 &var3 &var4 &var5 &var6;
model y=&var1 &var2 &var3 &var4 &var5 &var6 / ctable;
run;
quit;
%mend;
Modèle1 : %logist( diplôme, sexe, profession, TV homosexualité peine de mort );
Modèle2 : %logist( diplôme, sexe, famille, TV , homosexualité , peine de mort );
Modèle3 : %logist(diplôme, profession, famille, TV ,homosexualité, peine de mort );
Modèle4 : %logist(sexe, profession, famille, TV ,homosexualité, peine de mort );
Nous allons tenter une autre méthode pour déterminer clairement le meilleur modèle à
six variables explicatives.
15 | P a g e
2.2. Tous les modèles possibles à six variables explicatives
Comparaison des modèles en utilisant les critères AIC et SBC :
Modèle AIC SC -2log
1 4463.36 4642.768 4409.542
2 4467.010 4659.512 4409.010
3 4469.728 4695.440 4401.728
4 4478.741 4684.519 4416.741
Tableau numéro 6 : Comparaison des modèles
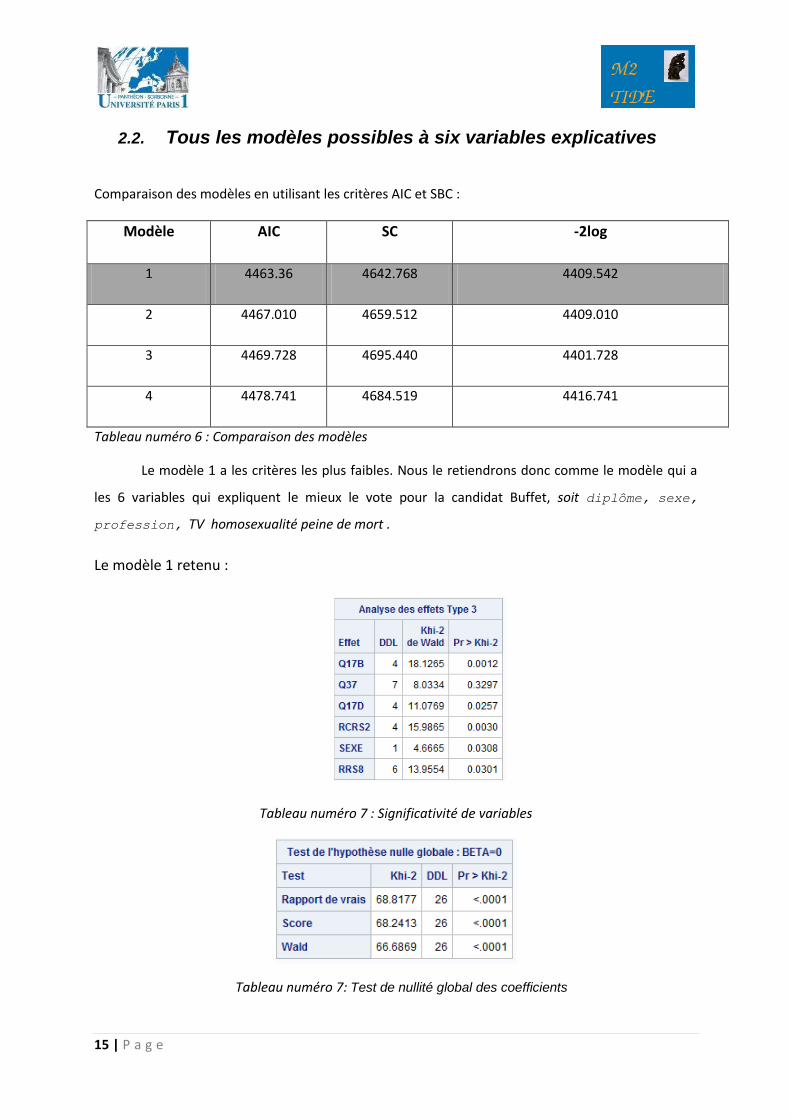
Le modèle 1 a les critères les plus faibles. Nous le retiendrons donc comme le modèle qui a
les 6 variables qui expliquent le mieux le vote pour la candidat Buffet, soit diplôme, sexe,
profession, TV homosexualité peine de mort .
Le modèle 1 retenu :
Tableau numéro 7 : Significativité de variables
Tableau numéro 7: Test de nullité global des coefficients

16 | P a g e
3. Ajustement du modèle décomposable le plus adapté aux données.
Les modèles décomposables sont des modèles graphiques (sous-ensemble des
modèles hiérarchiques, déterminés uniquement par l’annulation d’interaction d’ordre 2) ne
contenant pas de cycle supérieur ou égal à quatre, non triangularisable.
Le principe est que nous partons d’un modèle saturé, c’est à dire, un modèle qui
contient toutes les interactions possibles, et nous enlevons au fur et à mesure toutes les
interactions qui ne sont pas significatives au seuil de 5% pour lesquelles aucune interaction
d’ordre supérieure les contenant n’est significative au même seuil. Ensuite, il faut vérifier que
le modèle obtenu est mieux que le modèle saturé à l’aide du ratio de la vraisemblance.
Grâce à la macro suivante, nous allons pouvoir estimer les modèles décomposables :
%let a=y;
%let b=RCRS2;
%let c=SEXE ;
%let d=RRS8 ;
%macro decomposable (m,n,o,p,q,r,s,t);
proc catmod data=enl.data1;
model y*RCRS2*SEXE*RRS8=_response_ / noresponse noparm itprint;
loglin &m|&n|&o &p|&q|&r;
title ''&m*&n*&o &p*&q*&r sans &s*&t'';
run;
quit;
%mend decomposable;
Les résultats des significativités des modèles sont résumés dans le tableau suivant
grâce au Likehood Ratio :
17 | P a g e
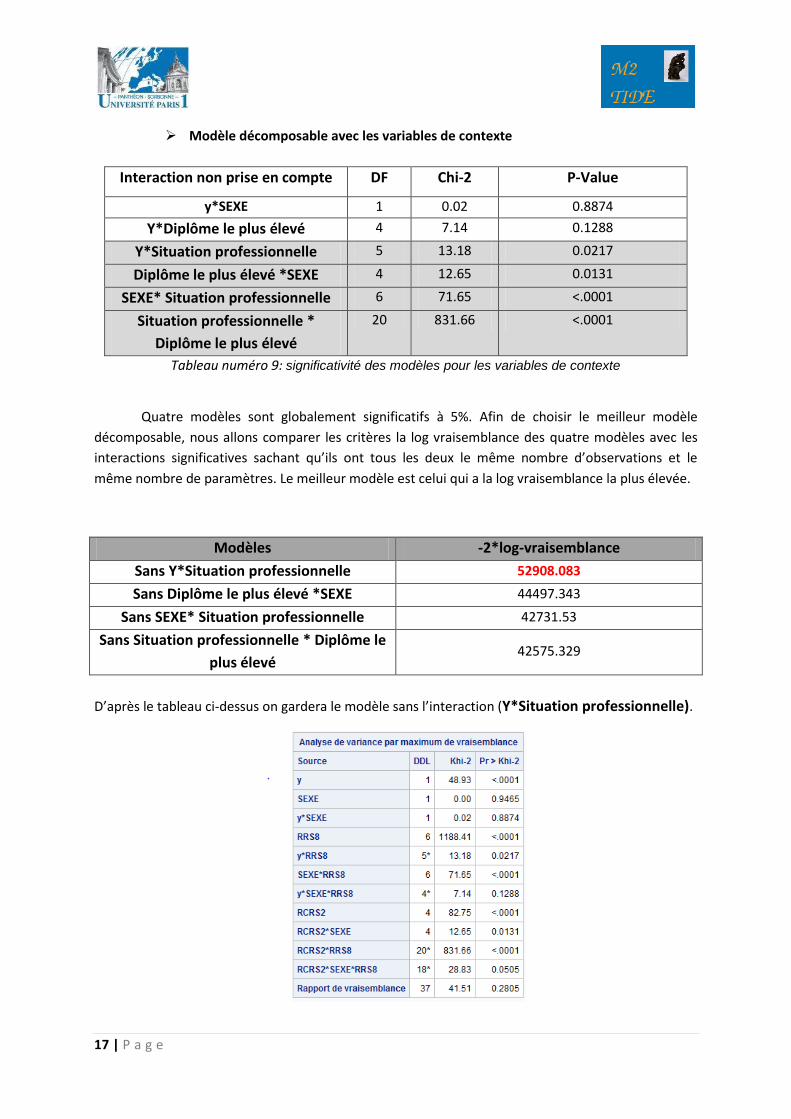
Modèle décomposable avec les variables de contexte
Interaction non prise en compte DF Chi-2 P-Value
y*SEXE 1 0.02 0.8874
Y*Diplôme le plus élevé 4 7.14 0.1288
Y*Situation professionnelle 5 13.18 0.0217
Diplôme le plus élevé *SEXE 4 12.65 0.0131
SEXE* Situation professionnelle 6 71.65 <.0001
Situation professionnelle *
Diplôme le plus élevé
20 831.66 <.0001
Tableau numéro 9: significativité des modèles pour les variables de contexte
Quatre modèles sont globalement significatifs à 5%. Afin de choisir le meilleur modèle
décomposable, nous allons comparer les critères la log vraisemblance des quatre modèles avec les
interactions significatives sachant qu’ils ont tous les deux le même nombre d’observations et le
même nombre de paramètres. Le meilleur modèle est celui qui a la log vraisemblance la plus élevée.
Modèles -2*log-vraisemblance
Sans Y*Situation professionnelle 52908.083
Sans Diplôme le plus élevé *SEXE 44497.343
Sans SEXE* Situation professionnelle 42731.53
Sans Situation professionnelle * Diplôme le
plus élevé 42575.329
D’après le tableau ci-dessus on gardera le modèle sans l’interaction (Y*Situation professionnelle).
18 | P a g e
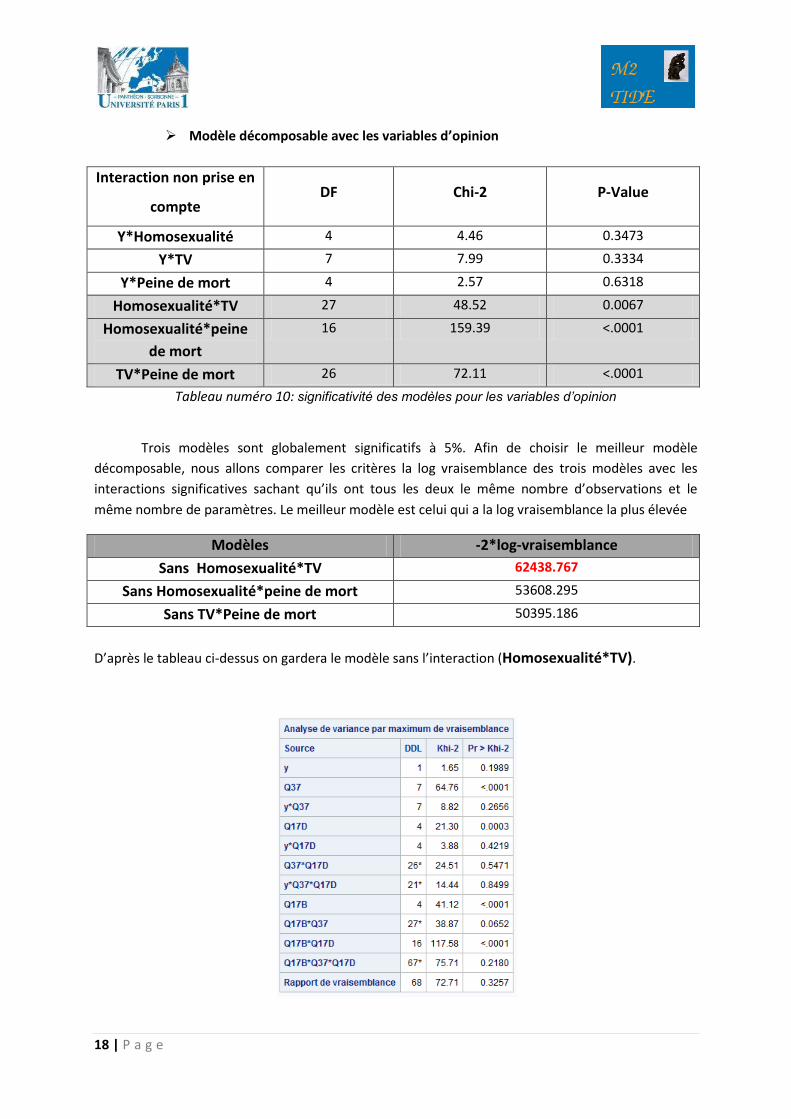
Modèle décomposable avec les variables d’opinion
Interaction non prise en
compte DF Chi-2 P-Value
Y*Homosexualité 4 4.46 0.3473
Y*TV 7 7.99 0.3334
Y*Peine de mort 4 2.57 0.6318
Homosexualité*TV 27 48.52 0.0067
Homosexualité*peine
de mort
16 159.39 <.0001
TV*Peine de mort 26 72.11 <.0001
Tableau numéro 10: significativité des modèles pour les variables d’opinion
Trois modèles sont globalement significatifs à 5%. Afin de choisir le meilleur modèle
décomposable, nous allons comparer les critères la log vraisemblance des trois modèles avec les
interactions significatives sachant qu’ils ont tous les deux le même nombre d’observations et le
même nombre de paramètres. Le meilleur modèle est celui qui a la log vraisemblance la plus élevée
Modèles -2*log-vraisemblance
Sans Homosexualité*TV 62438.767
Sans Homosexualité*peine de mort 53608.295
Sans TV*Peine de mort 50395.186
D’après le tableau ci-dessus on gardera le modèle sans l’interaction (Homosexualité*TV).
19 | P a g e
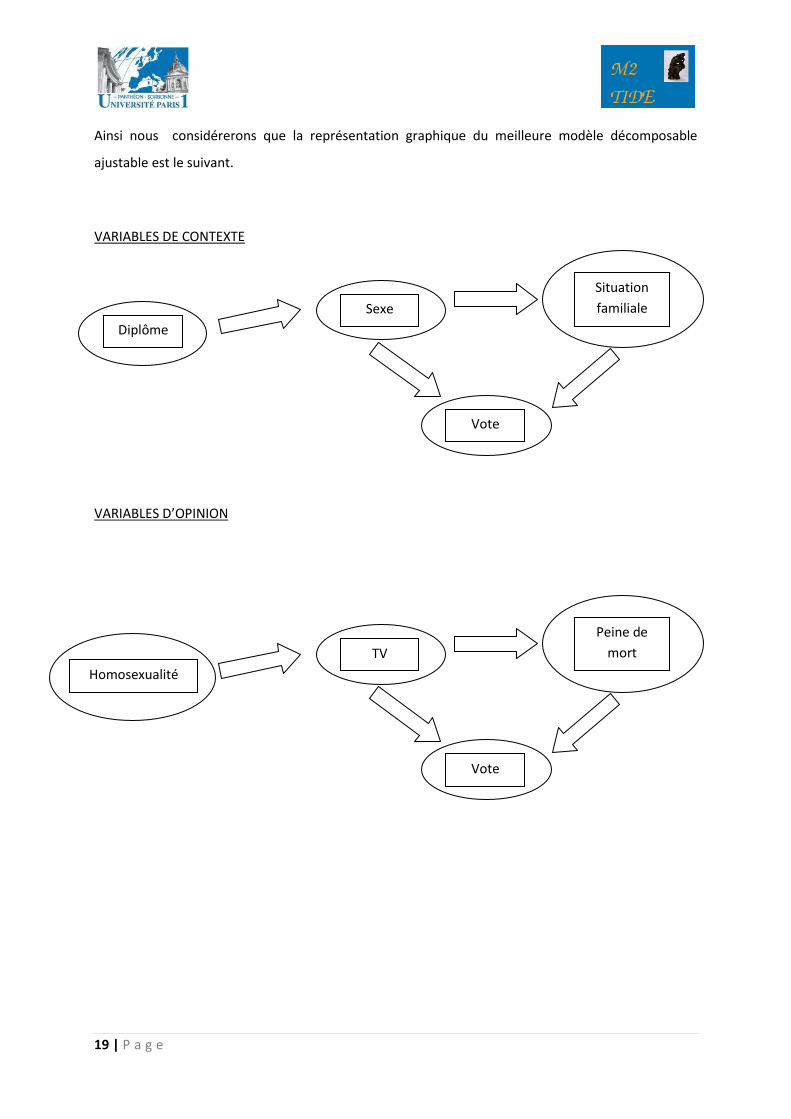
Ainsi nous considérerons que la représentation graphique du meilleure modèle décomposable
ajustable est le suivant.
VARIABLES DE CONTEXTE
VARIABLES D’OPINION
Diplôme
Sexe
Situation
familiale
Vote
Homosexualité
TV
Peine de
mort
Vote
20 | P a g e
ANNEXES
libname ENL 'C:\Users\e0g411l028o\Desktop\ENL';
proc contents data=enl.data;
run;
proc freq data=enl.data;
table Q46D;
run;
data enl.data1;
set enl.data;
vote=put(Q46D,best12.);
run;
proc sql;
select distinct vote, Q46D from enl.data1;
quit;
/*la variable binaire à expliquer (Y)*/
data enl.data1;
set enl.data1;
if vote in (1,2) then y=1;
else y=0;
run;
/* la variable à expliquer*/
proc freq data=enl.data1;
table y;
run;
/*1. VARIABLES d'OPINION*/
/*opinion sur les immigrés*/
proc freq data=enl.data;
table Q17E;
run;
/* Chomage */
proc freq data=enl.data;
table Q14;
run;
/* Homosexualité*/
proc freq data=enl.data;
table Q17B;
run;
/*mondialisation*/
proc freq data=enl.data;
table Q44;
run;

21 | P a g e
/* 2. VARIABLES DE CONTEXET*/
/* le diplome de plus elevé*/
proc freq data=enl.data;
table RCRS2;
run;
/*Tranche d'age*/
proc freq data=enl.data;
table RAGE;
run;
/*SEXE*/
proc freq data=enl.data;
table SEXE;
run;
/*situation familiale*/
proc freq data=enl.data;
table Q48;
run;
/* Test d'indepandance de chi-2*/
proc freq data=enl.data;
table Q46D *(RCRS2 RCRS7 RCRS13 RAGE SEXE GR RRS8 Q48 RCRS15) / chisq
noprint;
run;
proc freq data=enl.data;
table Q46D *(Q17E Q12A Q12B Q14 Q15 Q17B Q18 Q37 Q38 Q44 Q17D) / chisq
noprint;
run;
/* On suprime les variables RCRS13 GR Q15 Q18 car elles sont indépandentes
avec la variable à expliquer */
/* La regression logistique avec l'option "backward"*/
proc logistic data=enl.data1;
class y RCRS2 RCRS7 RAGE SEXE RRS8 Q48 RCRS15 Q17E Q12A Q12B Q14 Q17B
Q37 Q38 Q44 Q17D ;
model y=RCRS2 RCRS7 RAGE SEXE RRS8 Q48 RCRS15 Q17E Q12A Q12B Q14 Q17B
Q37 Q38 Q44 Q17D / ctable selection=backward;
run;
%macro logist(var1,var2,var3,var4,var5,var6);
proc logistic data=enl.data1;
class y &var1 &var2 &var3 &var4 &var5 &var6;
model y=&var1 &var2 &var3 &var4 &var5 &var6 / ctable;
run;
quit;
%mend;
/*Les modeles*/
/*Modèle 1*/
%logist(Q17B,Q37,Q17D ,RCRS2 ,SEXE ,RRS8);
/* Modèle 2*/

22 | P a g e
%logist(Q17B,Q37,Q17D ,RCRS2 ,SEXE,Q48);
/* Modèle 3*/
%logist(Q17B,Q37,Q17D ,RCRS2 ,RRS8,Q48);
/* Modèle 4*/
%logist(Q17B,Q37,Q17D ,SEXE ,RRS8 Q48);
/* on garde le premier modéle qui a un BIC et SBC minimum*/
/*Création de la macro cat pour estimer les modèles décomposables*/
/*1. Modele decomposable avec les variables de contexte*/
%let a=y;
%let b=RCRS2;
%let c=SEXE ;
%let d=RRS8 ;
%macro decomposable (m,n,o,p,q,r,s,t);
proc catmod data=enl.data1;
model y*RCRS2*SEXE*RRS8=_response_ / noresponse noparm itprint;
loglin &m|&n|&o &p|&q|&r;
title ''&m*&n*&o &p*&q*&r sans &s*&t'';
run;
quit;
%mend decomposable;
/*Retrait de l'interaction (a*b)*/
%decomposable (&a,&c,&d,&b,&c,&d,&a,&b);
/*Retrait de l'interaction (a*c)*/
%decomposable (&a,&c,&d,&b,&c,&d,&a,&c);
/*Retrait de l'interaction (a*d)*/
%decomposable (&a,&c,&d,&b,&c,&d,&a,&d);
/*Retrait de l'interaction (b*c)*/
%decomposable (&a,&c,&d,&b,&c,&d,&b,&c);
/*Retrait de l'interaction (b*d)*/
%decomposable (&a,&c,&d,&b,&c,&d,&b,&d);
/*Retrait de l'interaction (c*d)*/
%decomposable (&a,&c,&d,&b,&c,&d,&c,&d);
/*2. Modele decomposable avec les variables d'opinion*/
%let e=y;
%let f=Q17B;
%let g=Q37 ;
%let h=Q17D ;
%macro decomposable2 (m,n,o,p,q,r,s,t);
proc catmod data=enl.data1;
model y*Q17B*Q37*Q17D=_response_ / noresponse noparm itprint;
loglin &m|&n|&o &p|&q|&r;
title ''&m*&n*&o &p*&q*&r sans &s*&t'';
run;
quit;
%mend decomposable2;
/*Retrait de l'interaction (e*f)*/
%decomposable2 (&e,&g,&h,&f,&g,&h,&e,&f);
/*Retrait de l'interaction (e*g)*/
%decomposable2 (&e,&f,&h,&f,&g,&h,&e,&g);
/*Retrait de l'interaction (e*h)*/
%decomposable2 (&e,&f,&g,&f,&g,&h,&e,&h);
/*Retrait de l'interaction (f*g)*/

23 | P a g e
%decomposable2 (&e,&f,&h,&e,&g,&h,&f,&g);
/*Retrait de l'interaction (g*h)*/
%decomposable2 (&e,&f,&h,&e,&f,&g,&g,&h);
/*Retrait de l'interaction (f*h)*/
%decomposable2 (&e,&f,&g,&e,&g,&h,&f,&h);