elasticsearch a quick introduction
TRANSCRIPT

Elasticsearch
[email protected] - CTO
Federico Panini
CTO @ fazland.comemail : [email protected]
linkeIn : https://uk.linkedin.com/in/federicopaninislides : http://www.slideshare.net/FedericoPanini

Cos’è Elasticsearch ?
[email protected] - CTO
motore di ricerca full text
“Un motore di ricerca (in inglese search engine) è un sistema automatico che, su richiesta, analizza un insieme di dati (spesso da esso stesso raccolti) e restituisce un indice dei contenuti disponibili classificandoli in modo automatico in base a formule statistico-matematiche che ne indichino il grado di rilevanza data una determinata chiave di ricerca”.


Cos’è Elasticsearch ?
[email protected] - CTO
motore di ricerca full text
“It’s a distributed, scalable, and highly available Real-time search and analytics software.”

Cos’è Elasticsearch ?
[email protected] - CTO
caratteristiche
Dati disponibili real-time Analisi dei dati real-time Ambiente distribuito Alta disponibilità Ricerche full-text Document oriented DB Schemaless DB
RESTFul Api Persistenza per-operazione Open Source Costruito su Apache Lucene Optimistic version control

Apache Lucene #1
[email protected] - CTO
E’ il cuore pulsante di Elasticsearch
Lucene è il motore di ricerca di Elasticsearch

Apache Lucene #1
[email protected] - CTO
E’ scritto in Java
E’ un prodotto Apache foundation quindi open source

Elastic cosa ha in più di Lucene?
[email protected] - CTO
ricerche full text
horizontal scaling high availability Semplicità d’uso near real time

Architettura
[email protected] - CTO
requirements - CPU
Per sua natura elasticsearch non necessita di molte capacità “computazionali”. In generale l’utilizzo della CPU è molto limitato.
E’ consigliato utilizzare un modello di CPU di ultima generazione con più di un core.
In genere installazioni standard di ES utilizzano dai 2 agli 8 cores.

Architettura
[email protected] - CTO
requirements - Disco
L’utilizzo del disco è importante per tutte le tipologie di cluster, nel nostro caso è fondamentale.
E’ consigliato utilizzare dischi SSD.

Architettura
[email protected] - CTO
requirements - Disco - bonus slide …
Unico punto di attenzione è sullo scheduler in uso dal sistema operativo. Lo scheduler è lo strumento che i sistemi operativi *nix utilizzano per decidere quando i dati devono essere inviati al disco e con quale tipo di priorità. Normalmente le installazioni di unix utilizzano cfq, che è uno scheduler ottimizzato per i dischi classici a “piatti rotanti”. Se si implementano dischi SSD è consigliato utilizzare “noop” o “deadline”, scheduler ottimizzati per questa tipologia di hard disk.
Si riescono a raggiungere miglioramenti nelle prestazioni di 500x rispetto ad una errata configurazione del Sistema operativo.

Architettura
[email protected] - CTO
Sistema Operativo
Non ci sono particolari vincoli sul sistema operativo in quanto ES è sviluppato in Java, quindi potenzialmente multipiattaforma. Il consiglio è d i ut i l izzare l ’u l t ima versione disponibile della JDK.

Architettura
[email protected] - CTO
requirements - RAM
Elasticsearch è un divoratore di RAM !!!
https://www.elastic.co/guide/en/elasticsearch/guide/current/heap-sizing.html

Architettura
[email protected] - CTO
memory !?!?
max 64GB di ram max 32GB per Java consigliato l’uso in parallelo di macchine, configurate in cluster.

Architettura
[email protected] - CTO
installazione
curl -L -O http://download.elasticsearch.org/PATH/TO/VERSION.zip unzip elasticsearch-$VERSION.zip cd elasticsearch-$VERSION
sono disponibili distribuzioni Debian o RPM packages oltre a moduli chef e puppet.

Java based
[email protected] - CTO
elastic questo sconosciuto
Elasticsearch è sviluppato in Java
Robusto Scalabile Multipiattaforma

Comunicare con Elastic
[email protected] - CTO
clients Java #1
Per Java sono disponibili 2 client:
Node client: con questo tipo di approccio il client fa una join al cluster come “nodo non contenente dati”, il nodo in se non ha dati ma sa perfettamente su quale nodo del cluster si trovano i dati che sta cercando

Comunicare con Elastic
[email protected] - CTO
clients Java #2
Per Java sono disponibili 2 client:
Transport client : è molto più “snello” del precedente ed è lo strumento utilizzato per comunicare con cluster in remoto.

Comunicare con Elastic
[email protected] - CTO
clients Java #2
Per Java sono disponibili 2 client:
Tutti e due i tipi di client comunicano con il cluster sulla porta 9300, che tra l’altro la stessa porta con la quale comunicano i nodi stessi del cluster.

Comunicare con Elastic
[email protected] - CTO
client API RESTful
Tutti gli altri linguaggi possono comunicare con Elasticsearch utilizzando le API Rest disponibili sulla porta 9200.
Esistono client ufficiale per questi linguaggi : Groovy, JavaScript, .NET, PHP, Perl, Python, e Ruby

Elastic
[email protected] - CTO
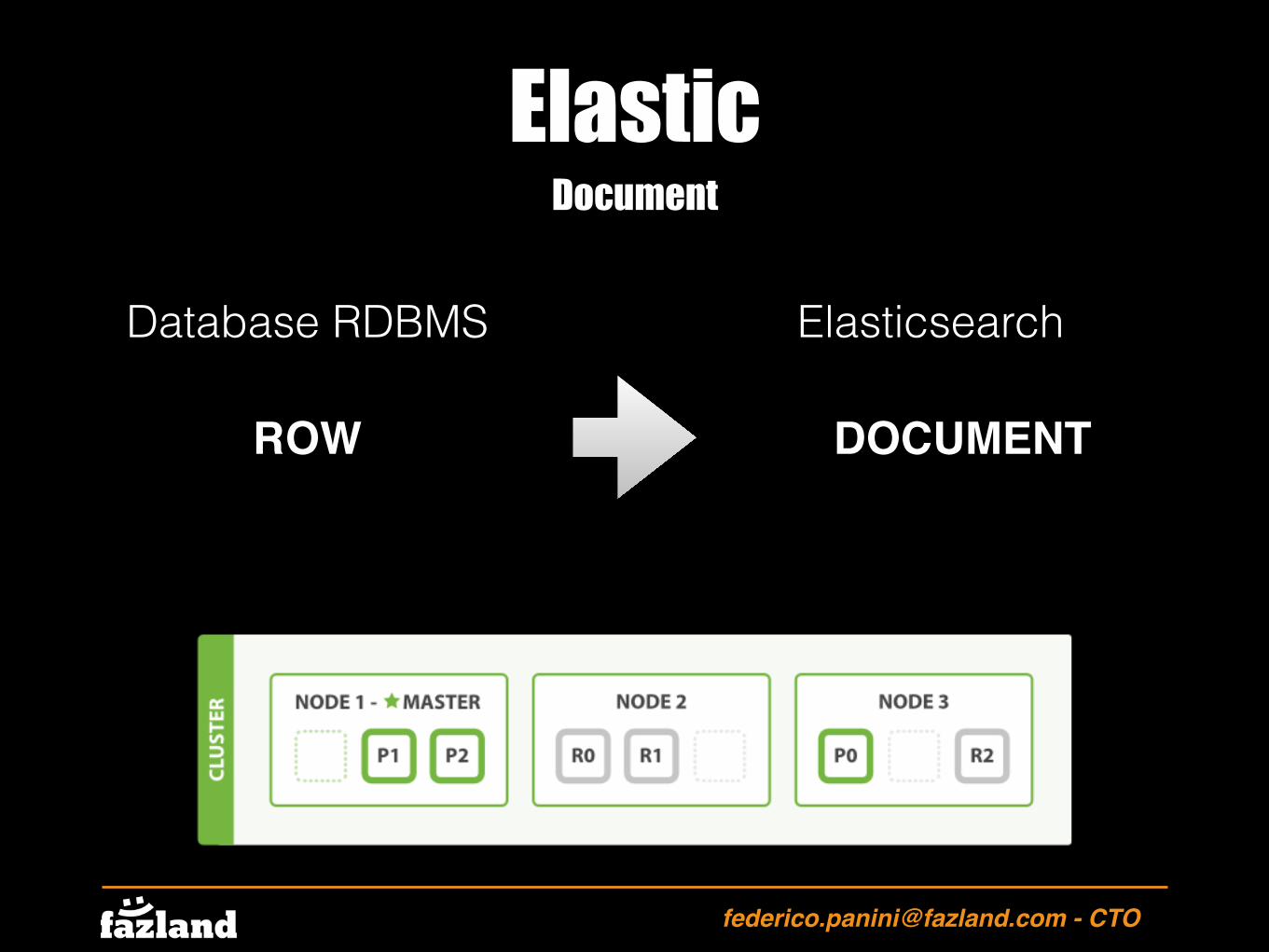
Document oriented
NoSql
Elasticsearch è un database document oriented. Questo significa che i dati inseriti non sono “costretti” a nessun tipo di forma tabellare ma è possibile i n s e r i re o g g e t t i o m e g l i o documenti direttamente.
A seguito del l ’ inserimento, Elasticsearch provvede anche ad indicizzare i dati appena inseriti.

Elastic
[email protected] - CTO
Document oriented
JSONE l a s t i c s e a rc h s t e r i l i z z a i document i i nser i t i t rami te l’utilizzo di JSON.

Elastic
[email protected] - CTO
glossario
cluster nodes indexes shards replica segments in-memory buffers translog

Elastic
[email protected] - CTO
cluster
Un cluster è un insieme a cui appartiene uno o più nodi , che condiv idono la stessa propr ietà cluster.name. Il cluster server per bilanciare il carico delle richieste che provengono ad Elasticsearch. Un nodo può essere eliminato o aggiunto al cluster, questo sarà responsabile di riorganizzarsi.

Elastic
[email protected] - CTO
cluster
All’interno del cluster un nodo è eletto come Master. Questo nodo è responsabile di gestire operazioni sugli indici come la loro creazione o eliminazione, aggiungere o rimuovere un nodo dal cluster. Ogni nodo può essere Master.

Elastic
[email protected] - CTO
nodes
E’ l’elemento minimo che garantisce il funzionamento dell’istanza di Elasticsearch.
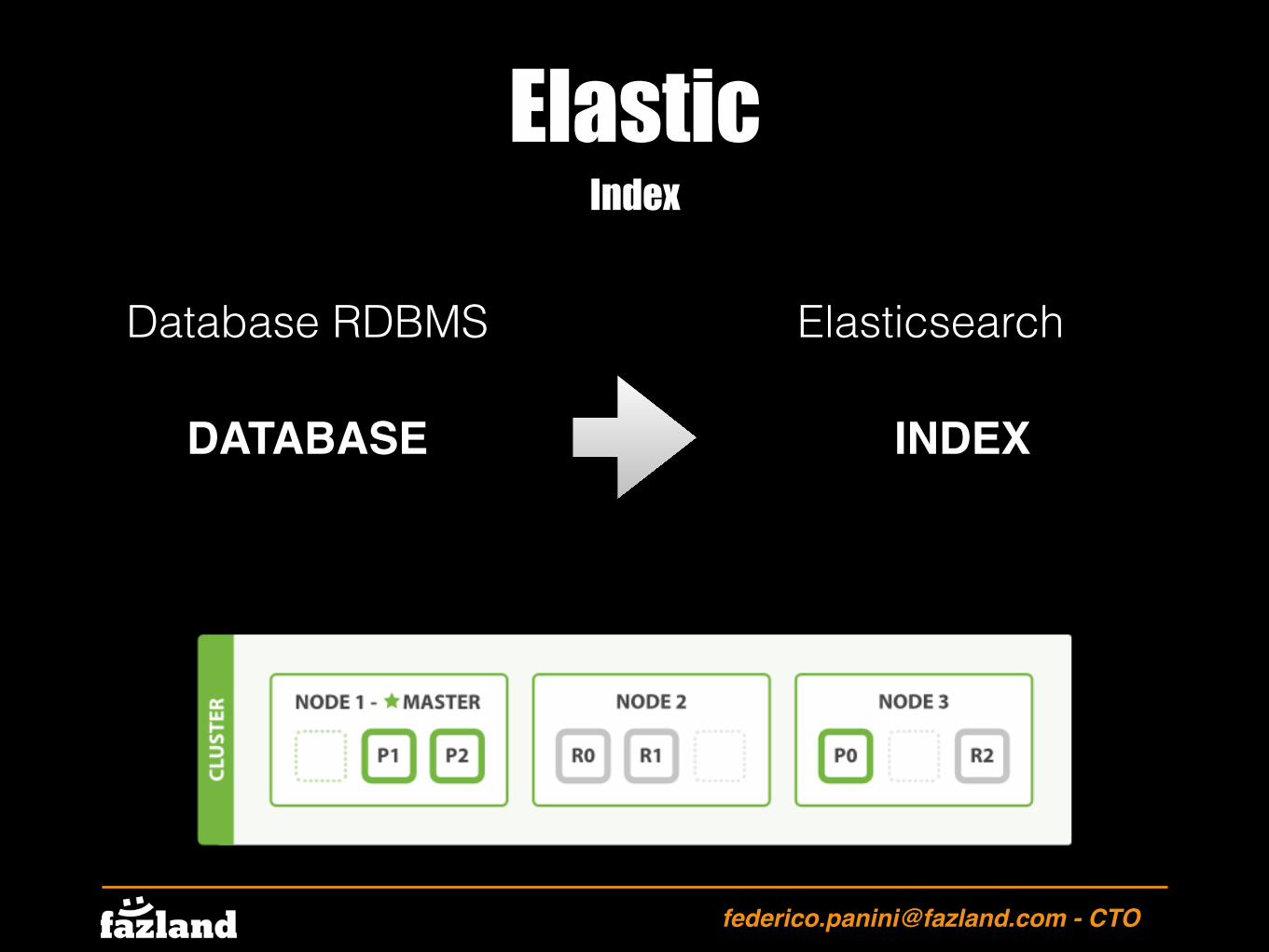
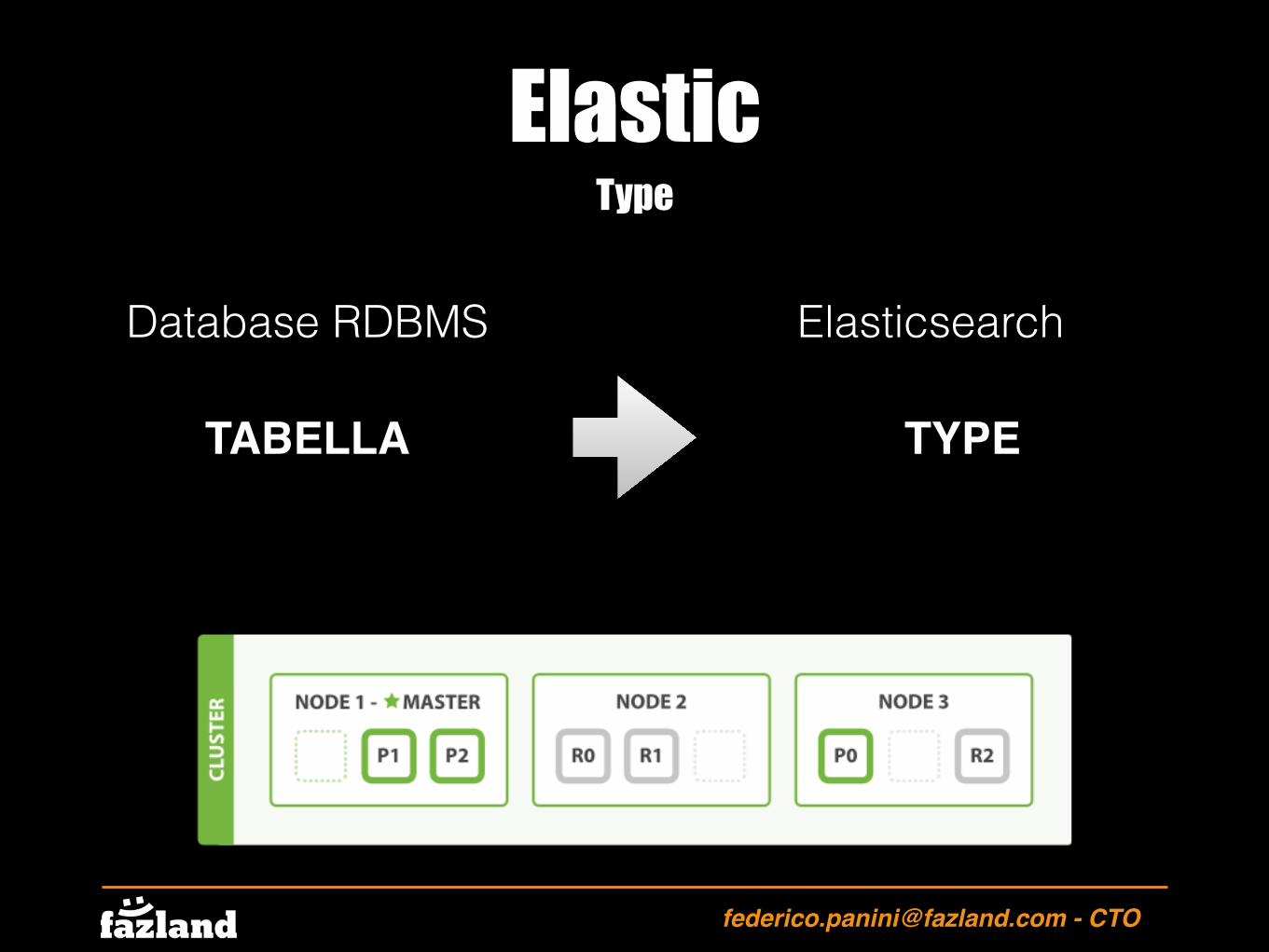
Elastic
[email protected] - CTO
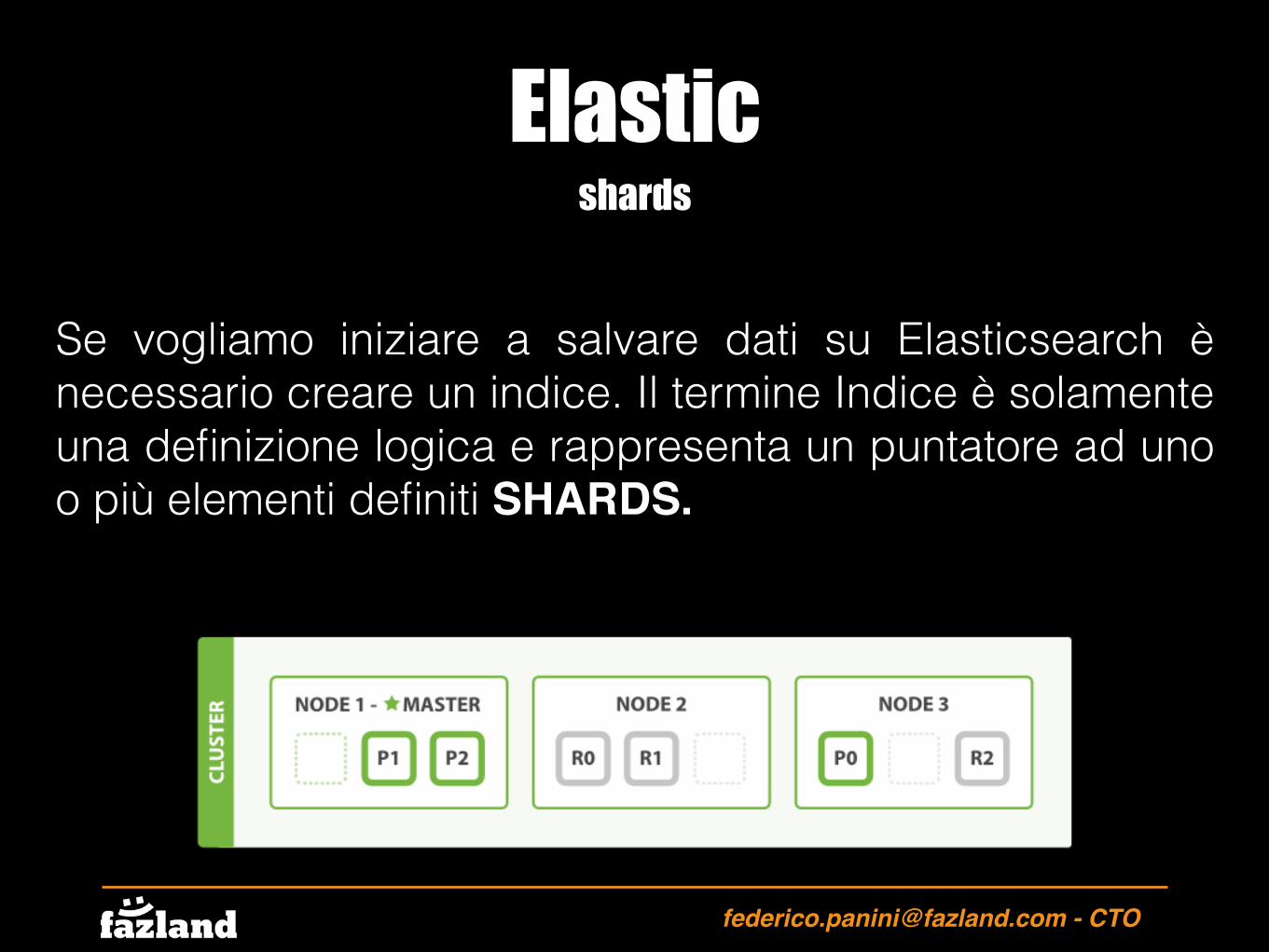
shards
Se vogliamo iniziare a salvare dati su Elasticsearch è necessario creare un indice. Il termine Indice è solamente una definizione logica e rappresenta un puntatore ad uno o più elementi definiti SHARDS.

Elastic
[email protected] - CTO
shards
Lo shard è considerato un elemento di basso livello nell’infrastruttura di ES. Lo shard contiene un subset di tutti i dati contenuti nell’indice.
Lo shard, fisicamente rappresenta una singola istanza di Apache Lucene.

Elastic
[email protected] - CTO
Replica shards
Gli shards di tipo replica sono delle copie esatte degli shards utilizzate per proteggere i nostri dati da errori hardware. Allo stesso modo degli shards “servono” richieste e ricerche sugli indici.

Elastic
[email protected] - CTO
shards immutability
IL numero di shards è prestabilito all’atto della creazione dell’indice ed è IMMUTABILE.

Elastic
[email protected] - CTO
shards immutability
curl -X http://localhost:9200/blogs -d ‘{ "settings" : { "number_of_shards" : 3, "number_of_replicas" : 1 } }’

Elastic
[email protected] - CTO
shards immutability
curl http://localhost:9200/_cluster/health“{ "cluster_name": "elasticsearch", "status": "yellow", "timed_out": false, "number_of_nodes": 1, "number_of_data_nodes": 1, "active_primary_shards": 3, "active_shards": 3, "relocating_shards": 0, "initializing_shards": 0, "unassigned_shards": 3 }”

Elastic
[email protected] - CTO
shards immutability
Shards di tipo replica sullo stesso nodo sono assolutamente inutili… perde di ogni significato il concetto di ridondanza per il quale sono stati creati. E’ necessario eseguire un nuovo nodo. In automatico il cluster si renderà responsabile di creare 3 replica shards per il nostro indice.

Elastic
[email protected] - CTO
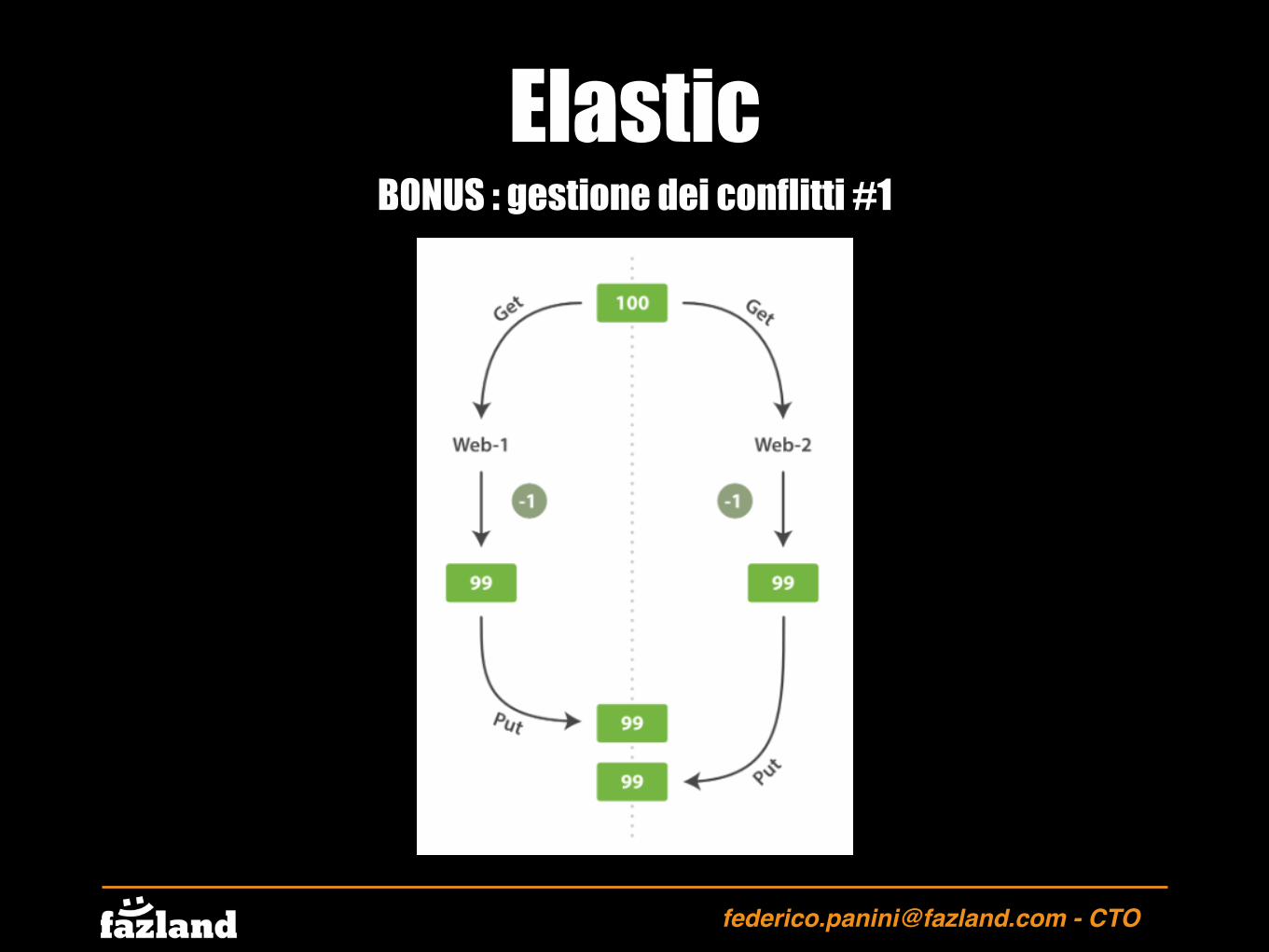
BONUS : gestione dei conflitti #2 : Pessimistic Concurrency Control
Gestito ed utilizzato normalmente nei RDBMS
Questo approccio parte dall’assunto che i conflitti possano avvenire di frequente e quindi per evitarli blocca la risorsa alla quale sta accedendo.
Il processo blocca l’accesso alla row prima di accedere ai suoi dati in lettura, avendo così la garanzia che solamente questo thread possa modificarla e nessun altro. Al termine dell’operazione rilascerà il LOCK.

Elastic
[email protected] - CTO
BONUS : gestione dei conflitti #3 : Optimistic Concurrency Control
Elasticsearch utilizza questo approccio
Al contrario l’assunzione, è che i conflitti avvengano poco di frequente. E quindi il DB non blocca la risorsa quando vi accede.
La responsabilità è applicativa : quando i dati sono modificati tra una lettura ed una scrittura allora l’aggiornamento fallisce. In questo caso è necessario recuperare il dato “fresco” e rifarne l’update.

Elastic
[email protected] - CTO
BONUS : gestione dei conflitti #4 : Optimistic Concurrency Control
Elasticsearch è per sua natura distribuito, concorrente ed asincrono. Quando un documento è creato/aggiornato/eliminato è necessario che questa informazine sia replicata su tutti i nodi del cluster.
Ogni informazione è inviata ai vari nodi in parallelo e può succedere che un dato arrivi a destinazione già scaduto.

Elastic
[email protected] - CTO
BONUS : gestione dei conflitti #5 : Optimistic Concurrency Control
E’ necessario che Elasticsearch abbia un modo per non aggiornare un dato più “aggiornato”.

Elastic
[email protected] - CTO
BONUS : gestione dei conflitti #6 : Optimistic Concurrency Control
VERSIONING

Elastic
[email protected] - CTO
BONUS : gestione dei conflitti #7 : Optimistic Concurrency Control
In ogni documento è presente un campo :
_version
Questo campo è incrementato ogni volta che un operazione sul documento è avvenuta con successo. In questo modo un aggiornamento della versione 3 non andrà mai ad aggiornare un document che è già alla versione 4.

Elastic
[email protected] - CTO
BONUS : gestione dei conflitti #8 : Optimistic Concurrency Control
Attenzione la responsabilità di implementare questa soluzione è tutta APPLICATIVA! quindi nostra. Se vogliamo essere assolutamente sicuri di non avere perdite di dati dobbiamo effettuare scritture utilizzando il version number del documento che vogliamo aggiornare!

Elastic
[email protected] - CTO
BONUS : gestione dei conflitti #9 : Optimistic Concurrency Control
http://www.jillesvangurp.com/2014/12/03/optimistic-locking-for-updates-in-elasticsearch/ h t tps : / / aphy r.com/pos ts /317 -ca l l -me-maybe-elasticsearch https://www.elastic.co/guide/en/elasticsearch/resiliency/current/index.html


Elastic
[email protected] - CTO
Simple searches - CREATE AN INDEX
curl -XPUT http://fazlab.fazland.com:9200/fazlab-d "{ "settings" :
{ "number_of_shards" : 3, "number_of_replicas" : 1
} }"

Elastic
[email protected] - CTO
Simple searches - INDEX A DOCUMENT
curl -XPUThttp://fazlab.fazland.com:9200/fazlab/categories/1?pretty -d '{
nome: "Federico"}'

Elastic
[email protected] - CTO
Simple searches - GET A DOCUMENT
curl http://fazlab.fazland.com:9200/fazlab/categories/1?pretty

Elastic
[email protected] - CTO
Simple searches - DELETE A DOCUMENT
curl -XDELETE http://fazlab.fazland.com:9200/fazlab/categories/2?pretty



Elastic
[email protected] - CTO
mapping and analysis
EXACT MATCH vs FULL TEXT
Exact match Full Text
where name = ‘Federico’
and user_id = 2
and date > “2014-09-15”
“Federico è andato al
mare”
Federico / FEDERICO /
federico

Elastic
[email protected] - CTO
mapping and analysis
EXACT MATCH vs FULL TEXT
Exact match
Full Text
binario : il documento contiene questi valori ?
Quanto è rilevante il documento per la query
digitata ?

Elastic
[email protected] - CTO
mapping and analysis
Elasticsearch per facilitare la ricerca full-text analizza il testo ed utilizza il risultato di questa analisi per costruire un inverted index.
Inverted Index Analyzer

Elastic
[email protected] - CTO
Inverted Index
1. The quick brown fox jumped over the lazy dog
2. Quick brown foxes leap over lazy dogs in summer

Elastic
[email protected] - CTO
Inverted Index
Se dobbiamo cercare la parola “quick” e “brown” prendiamo i documenti dove sono presenti
entrambe i termini
1. The quick brown fox jumped over the lazy dog
2. Quick brown foxes leap over lazy dogs in summer

Elastic
[email protected] - CTO
Inverted Index
E’ stato portato tutto in lowercase, stemmer, e synonyms (leap)
1. The quick brown fox jumped over the lazy dog
2. Quick brown foxes leap over lazy dogs in summer

Elastic
[email protected] - CTO
ANALYZERS
Un Analyzer è un elemento che include 3 funzioni:
Character filters
Tokenizer
Token Filters

Elastic
[email protected] - CTO
ANALYZERS - Character Filters
Il primo step è passare ogni stringa ad un character filter il quale è responsabile di ripulire / riordinare le string prima della fase di Tokenizing.
in questa fase vengono eliminati i caratteri HTML o “&” è convertito in “and”.

Elastic
[email protected] - CTO
ANALYZERS - Tokenizer
Successivamente la stringa è suddivisa in singoli termini in funzione del Tokenizer selezionato.

Elastic
[email protected] - CTO
ANALYZERS - Token Filters
Successivamente alla fase di Tokenizzazione delle stringhe in singoli termini (terms), i filtri (selezionati) sono applicati in sequenza. Per esempio :
- lowercase di tutto il testo - rimuovi le stop words - aggiungi termini come sinonimi

Elastic
[email protected] - CTO
Standard Analyzer
“Set the shape to semi-transparent by calling set_trans(5)”
Lo standard analyzer è l’analyzer di default di Elasticsearch. Separa il testo in singole parole e rimuove buona parte della punteggiatura.
“set, the, shape, to, semi, transparent, by, calling, set_trans, 5”

Elastic
[email protected] - CTO
Simple Analyzer
“Set the shape to semi-transparent by calling set_trans(5)”
Il simple analyzer rimuove tutti i caratteri che non sono lettere e mette tutto il testo in minuscolo.
“set, the, shape, to, semi, transparent, by, calling, set, trans”

Elastic
[email protected] - CTO
Whitespace Analyzer
“Set the shape to semi-transparent by calling set_trans(5)”
Tokenizza utilizzando gli spazi e non forze le stringhe in minuscolo.
“Set, the, shape, to, semi, transparent, by, calling, set_trans(5)”

Elastic
[email protected] - CTO
Language Analyzer
“Set the shape to semi-transparent by calling set_trans(5)”
Questo analyzer utilizza le specificità del linguaggio naturale. Può eliminare le stop words e fare stemming.
“set, shape, semi, transpar, call, set_tran, 5”

Elastic
[email protected] - CTO
Language Analyzer
arabic, armenian, basque, brazilian, bulgarian, catalan, chinese, cjk, czech, danish, dutch, english, finnish, french, galician, german, greek, hindi, hungarian, indonesian, irish, italian, latvian, norwegian, persian, portuguese, romanian, russian, sorani, spanish, swedish, turkish, thai.

Elastic
[email protected] - CTO
Pre-built Analyzers
Standard Analyzer Simple Analyzer
Whitespace Analyzer Stop Analyzer
Keyword Analyzer Pattern Analyzer
Language Analyzers Snowball Analyzer Custom Analyzer

Elastic
[email protected] - CTO
Tokenizer
Standard Tokenizer Edge NGram Tokenizer
Keyword Tokenizer Letter Tokenizer
Lowercase Tokenizer NGram Tokenizer
Whitespace Tokenizer Pattern Tokenizer
UAX Email URL Tokenizer Path Hierarchy Tokenizer

Elastic
[email protected] - CTO
Token Filters
Standard Token Filter ASCII Folding Token Filter
Length Token Filter Lowercase Token Filter
NGram Token Filter Edge NGram Token Filter Porter Stem Token Filter
Shingle Token Filter Stop Token Filter
… circa 32 Filters


References• Elasticsearch : The Definitive Guide• https://en.wikipedia.org/wiki/Full_text_search• https://www.elastic.co/guide/en/elasticsearch/guide/current/
hardware.html• https://www.elastic.co/guide/en/elasticsearch/guide/current/
heap-sizing.html• https://mtalavera.wordpress.com/2015/02/16/monitoring-with-
collectd-and-kibana/• Fuzzy search : https://www.found.no/foundation/fuzzy-search/• Phonetic-plugin : https://github.com/elastic/elasticsearch-
analysis-phonetic
[email protected] - CTO