exploiting wikipedia as external knowledge for document clustering
DESCRIPTION
Exploiting Wikipedia as External Knowledge for Document Clustering. Xiaohua Hu, Xiaodan Zhang, Caimei Lu, E. K. Park, and Xiaohua Zhou Proceeding of International Conference on Knowledge Discovery and Data Mining, ACM SIGKDD, 2009. 報告人 : 吳建良. Outline. Motivation - PowerPoint PPT PresentationTRANSCRIPT

112/04/19 1
Exploiting Wikipedia as External Knowledge for Document Clustering
Xiaohua Hu, Xiaodan Zhang, Caimei Lu, E. K. Park, and Xiaohua Zhou
Proceeding of International Conference on Knowledge Discovery and Data Mining, ACM SIGKDD, 2009
報告人 : 吳建良

Outline Motivation Framework of Wikipedia-based clustering
Concept mapping schemes Category mapping Document clustering
Experiments Conclusions
2

Motivation Traditional text clustering algorithm
Based on BOW (Bag of Word) Ignore the semantic relationship among words
Synonym or semantically associated in other forms
One way to resolve this problem Use background knowledge to enrich document
representation Background knowledge is described by an ontology Ontology: concepts, attributes, relationships
3

Motivation (cont.)
Problem of this approach based on an ontology Difficult to find a comprehensive ontology to cover
all the concepts Previous works has adopted WordNet and Mesh
Replace original content with ontology term Information loss
Add ontology term to original document vector Bring data noise into the dataset
4

Goal Adopt more comprehensive ontology
Wikipedia Fully leverage ontology terms and relations
without introducing more noise Two matching methods
Exact-match Relatedness-match
5

Framework
6

Mapping Document to Wikipedia Concepts and Categories
Mapping process includes three steps:1. Build the connection between Wikipedia concepts
and categories
2. Map each document into a vector of Wikipedia concepts
3. Match each document to a set of Wikipedia categories
7

Figure of three steps
8
Step1
Step2
Step3

Concept-Category Matrix In Wikipedia, each topic is described by only one
article Title of the article preferred concept Each article (concept) has the corresponding categories Example:
Concept: Cluster Analysis Categories: Data mining | Data analysis | Cluster analysis |
Geostatistics | Machine learning | Multivariate statistics | Knowledge discovery in databases
9

Document-Concept Matrix Built matrix through two matching schemes
Exact-match Relatedness-match
Exact-match Issue: how to map synonymous phrases to the same concept Use redirect links in Wikipedia Example:
Preferred concept: cluster analysis Redirected concepts: data clustering,… are redirected to the same article
Use preferred and redirected concepts to construct a dictionary10

Exact-Match Scheme Each document is scanned to find concepts of dictionary Only preferred concepts are used to build the concept
vector for each document
Based on this frequency matrix Further calculate the document-concept TFIDF matrix
Efficient, but has low recall Product good results only when Wiki has good coverage
11
Preferred_concept1 Preferred_concept2
Doc1 Freq_pre_con1 + Freq_all_redi_con1 Freq_pre_con2 + Freq_all_redi_con2

Relatedness-Match Scheme Consist of two steps
1. First, create Wikipedia term-concept matrix from Wikipedia article collection
Each word token is represented by a concept vector Values of the vector are TFIDF scores For each word, only choose top k=5 concepts with highest TFIDF
scores
12

Relatedness-Match Scheme (cont.)
2. Use word-concept matrix as a bridge to associate documents with Wikipedia concepts
Calculate relatedness of a Wikipedia concept to a given document
: a document collection : all Wikipedia preferred concepts For each document, select top M=200 concepts with highest relatedness
score Concept relatedness score vector is normalized Especially useful when Wikipedia concepts have less coverage for a dataset
13

Category Mapping for Exact-Match Document-category frequency matrix
Derived from document-concept frequency matrix Replace each concept with its corresponding categories Calculate frequency of a category:
Further derive the document-category TFIDF matrix14
CAT1 CAT2
C1 1 0
C2 1 1
C1 C2
D1 9 2
D2 3 5
}CAT1 CAT2
D1 9+2 2
D2 3+5 5

Category Mapping for Relatedness-Match
Document-category matrix Derived from document-concept relatedness matrix Replace each concept with its corresponding categories Calculate relatedness score of a category:
15
CAT1 CAT2
C1 1 0
C2 1 1
C1 C2
D1 0.3 0.7
D2 0.63 0.37
}CAT1 CAT2
D1 0.3+0.7 0.7
D2 0.63+0.37 0.37

Document Clustering Agglomerative clustering algorithm
1. Initially, each document starts as a cluster
2. Repeatedly merge closest pair of clusters
3. Until only one cluster is formed covering all documents
Similarity measure
16

Closest Pair of Clusters Calculation
Single linkage
Complete linkage Adopted in this paper
Average linkage
17
C1 C2

Partitional Clustering
18
K-means clustering algorithm
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 100
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
K=2
Arbitrarily choose K object as initial cluster center
Assign each objects to most similar center
Update the cluster means
Update the cluster means
reassignreassign

Partitional Clustering (cont.)
Similarity measure
Clustering result is influenced by initial selection of cluster centroids Evaluation:
Run ten times with random initialization Take average as the final clustering result
19
Experiments Wikipedia data
Download from http://download.wikipedia.org 911,028 articles and 29,000 categories
Clustering dataset TDT2: 7,094 documents, 10 classes LA Times (from TREC): 18,547 documents from top
ten sections, 10 classes 20-newgroups (20NG): 19,997 documents, 20 classes
20

Experiments (cont.)
For each dataset, five small datasets are created Method:
For each small dataset, randomly pick 100 documents from each selected class of a given dataset
Merge them into a big pool Cluster each small dataset separately Average result is viewed as the clustering result for
whole dataset
21

Evaluation Metrics Purity
Average percentage of the dominant class label in each cluster
F-score Combine precision and recall to compute score
Normalized mutual information (NMI)
22
%1001
K
C
C
purity
K
ii
di
recallprecision
recallprecisionF
)(2
2/)log(log
);(),(
ck
YXIYXNMI
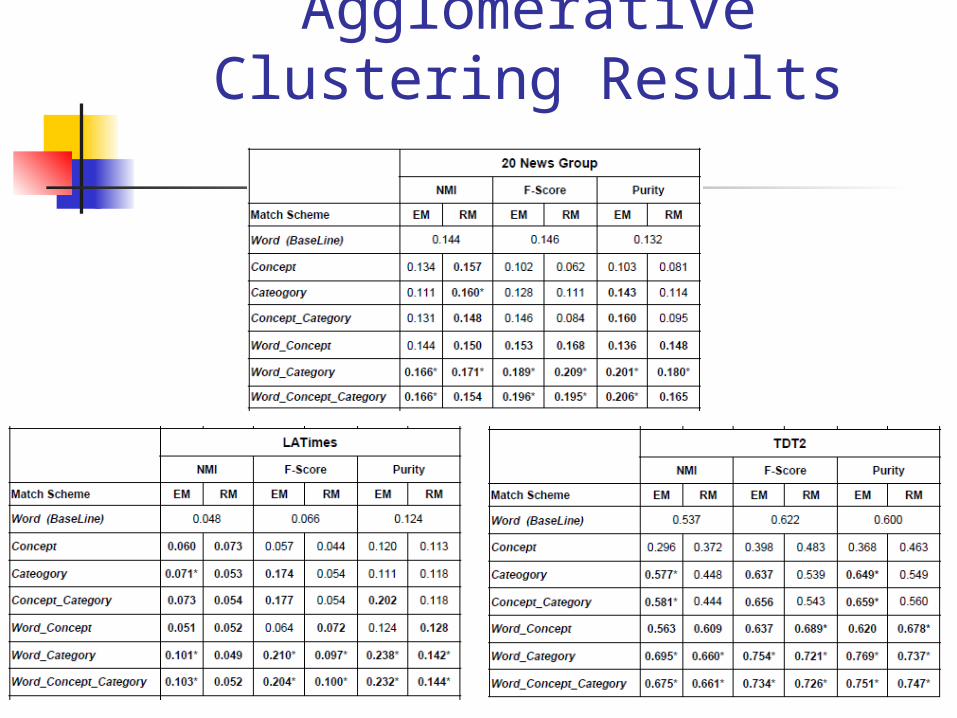
Agglomerative Clustering Results
23

Summary of this result Word_Category performs better than Word_Concept_Category Combining Word and Category significantly improve clustering
result Category information is more useful than concept information
Word_Concept improves clustering result, but not significant Clustering only based on Concept performs worse than the
baseline Still contain too much noise
Do not disambiguate concept senses during concept mapping process
24

Partitional Clustering Results
25

Summary of this result For 20 Newsgroup, Word_Category scheme still significantly
improve clustering result F-Score and Purity of Word_Concept_Category based clustering
are significantly improved For 20 Newsgroup , RM always produces better result than EM For LATimes and TDT2, EM always outperforms RM
26

Conclusion A framework
Leverage Wikipedia concept and category information to improve text clustering performance
Mapping Schemes Exact-Match and Relatedness-Match
Concept vector and Category vector Two clustering approaches on three datasets
Agglomerative and partitional clustering
27