データ活用に必要なdmpはこう作る! ·...
TRANSCRIPT

データ活用に必要なDMPはこう作る!
2014/12/9 東京エレクトロンデバイス(株) CN事業統括本部 CN営業本部 コーポレートアカウント営業部
住友義典

当社のあゆみ
1965年 東京エレクトロンで電子部品ビジネスを開始
1998年 東京エレクトロンの電子部品事業(現:半導体及び電子デバイス事業)が分離・独立
2003年 東京証券取引所 市場第2部上場
2006年 東京エレクトロン からコンピュータネットワーク事業(現:コンピュータシステム関連事業)を承継
2010年 東京証券取引所 市場第1部上場
約半世紀にわたる歴史と経験
東京エレクトロングループから分離・独立
半導体製造装置メーカー 東京エレクトロン
東京エレクトロン デバイス
コンピュータシステム関連 (CN)事業
半導体及び電子デバイス (EC)事業
EC事業 CN 事業
1998年独立
2006年事業承継
2

コンピューター関連(CN事業)取扱い
ネットワーク
レイヤー
サーバーレイヤー
ストレージレイヤー
10Gb低遅延スイッチ
Application Delivery Controller
Firewall
DNS/DHCPアプライアンス VDX
(VCSファブリックテクノロジー) ネットワーク仮想化 ソフトウェア
OpenStack 大規模プライベートクラウド
ソフトウェア
L2/L3 スイッチ、Wireless Access Point
H/Wセキュリティー モジュール PCIeカードSSD DWH、Hadoop KVS In Memory DB
オールフラッシュ ストレージ
スケールアウト NAS
Unified&階層型 ストレージ
重複排除バックアップ NAS
オブジェクトストレージ
クラウド基盤
データプラットフォームソフトウェア
3
統合ネットワーク セキュリティー アプライアンス
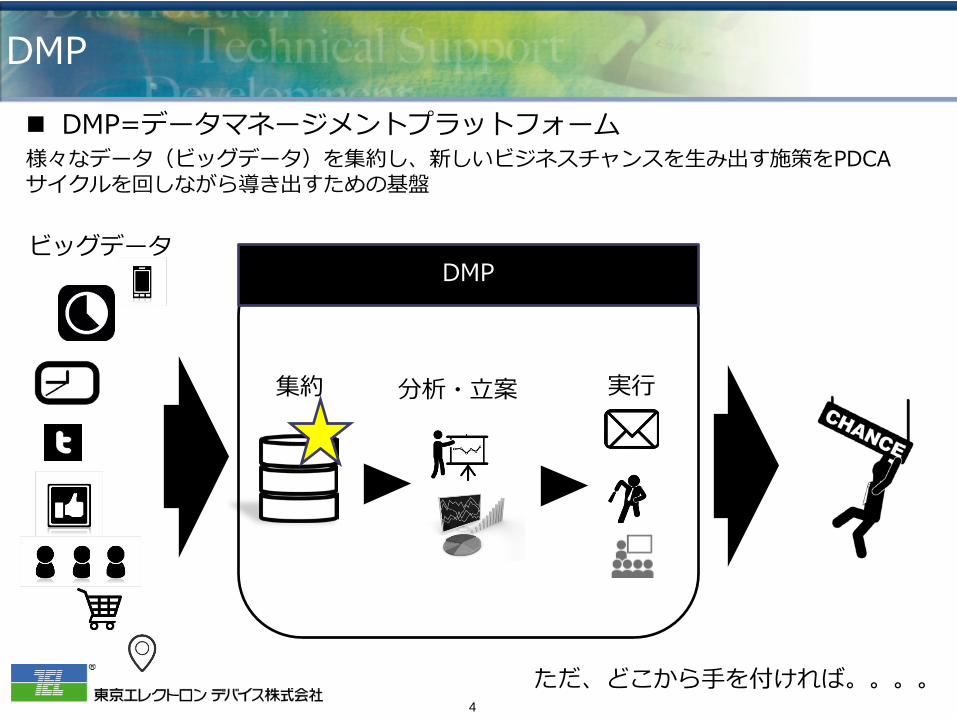
DMP
DMP=データマネージメントプラットフォーム 様々なデータ(ビッグデータ)を集約し、新しいビジネスチャンスを生み出す施策をPDCAサイクルを回しながら導き出すための基盤
DMP
集約 分析・立案 実行
ただ、どこから手を付ければ。。。。
ビッグデータ
4

データ活用の要素と課題
5
活用基盤
データ
人材
社内データ(売上、顧客情報、生産管理など)のデータを使った集計・分析に加えて、外部データを含んだこれまで分析対象としてこなかったデータを対象とすることでビジネスチャンスが生まれると言われている
基幹システム・社内システム内でのデータ集計基盤や、集計されたデータを部門単位で活用できるシステムはあるものの、あらゆるデータを活用対象とできる分析基盤がデータ活用には必要と言われている
営業・財務経理・経営・マーケティング等の部門単位でのデータ活用ができるスキルセットだけでなく、統計学や数学的な手法を使いこなし、ビジネスマインドを持ったデータ活用部隊が必要と言われている
課題
課題
課題
そんな人材・組織…
どんなデータを…
どんなシステムを…
データサイエンティスト
オープンデータ
クラウドサービス
データウェアハウス
BI・データマイニング
データ分析・活用サービス
・・・・
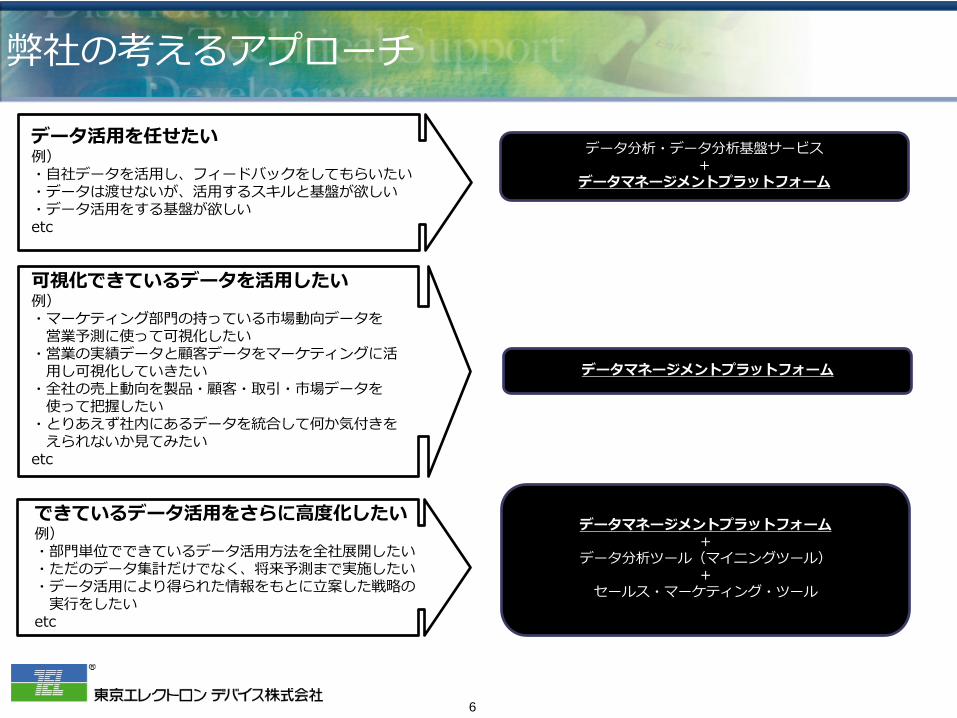
弊社の考えるアプローチ
6
データ活用を任せたい 例) ・自社データを活用し、フィードバックをしてもらいたい ・データは渡せないが、活用するスキルと基盤が欲しい ・データ活用をする基盤が欲しい etc
可視化できているデータを活用したい 例) ・マーケティング部門の持っている市場動向データを 営業予測に使って可視化したい ・営業の実績データと顧客データをマーケティングに活 用し可視化していきたい ・全社の売上動向を製品・顧客・取引・市場データを 使って把握したい ・とりあえず社内にあるデータを統合して何か気付きを えられないか見てみたい etc
できているデータ活用をさらに高度化したい 例) ・部門単位でできているデータ活用方法を全社展開したい ・ただのデータ集計だけでなく、将来予測まで実施したい ・データ活用により得られた情報をもとに立案した戦略の 実行をしたい etc
データ分析・データ分析基盤サービス +
データマネージメントプラットフォーム
データマネージメントプラットフォーム
データマネージメントプラットフォーム +
データ分析ツール(マイニングツール) +
セールス・マーケティング・ツール

データマネージメントプラットフォーム に求められる要素
1、大規模データ処理 - 大量データの処理 - 汎用性の高いデータアクセスI/F
2、構成面における柔軟性 - 拡張性の高い構成 - 柔軟H/Wサイジング
並列処理アーキテクチャー(MPP)
ソフトウェア
汎用H/W
SQLインターフェース
データ量・性能要件へ柔軟に対応することができるスケールアウトアーキテクチャー
ソフトウェア提供により、サーバー1台単位から拡張が可能
汎用H/Wの活用ができることにより、H/Wの最新テクノロジー恩恵を受けることが可能
独自アプリケーションのみならず、汎用的なBI・BAツールからのアクセスが可能
求められる要素
7
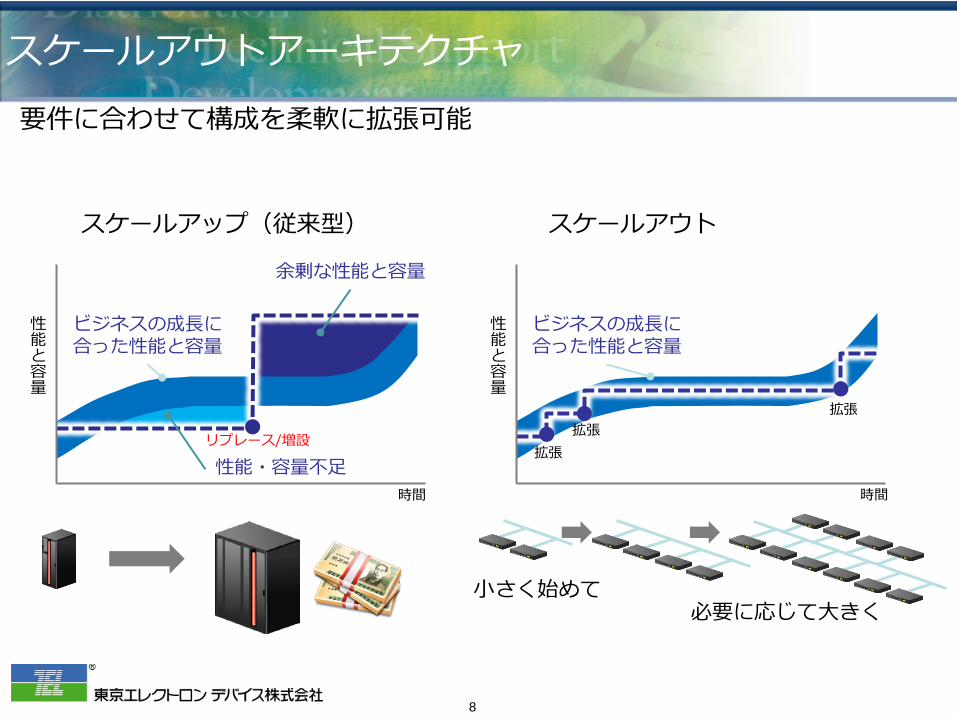
スケールアウトアーキテクチャ
小さく始めて 必要に応じて大きく
スケールアップ(従来型) スケールアウト
拡張 拡張
拡張
リプレース/増設
ビジネスの成長に 合った性能と容量
ビジネスの成長に 合った性能と容量
性能と容量
性能と容量
性能・容量不足
余剰な性能と容量
要件に合わせて構成を柔軟に拡張可能
時間 時間
8

CPU
メモリ
ディスクI/Oを分散して処理を高速化
ディスク
CPU
メモリ
ディスク
CPU
メモリ
ディスク
CPU
メモリ
ディスク
CPU
メモリ
ディスク
CPUを 使いきれない CPUを
使いきれる CPUを
使いきれる CPUを
使いきれる CPUを
使いきれる
ディスクI/Oがボトルネックとなり、 単一ノードでは処理の多重度に限界がある
並列処理することで、I/Oが分散され、 HW本来の性能を使い切ることができる
従来型RDB 使用率
使用率
並列分散処理型DB 使用率
使用率
使用率
9
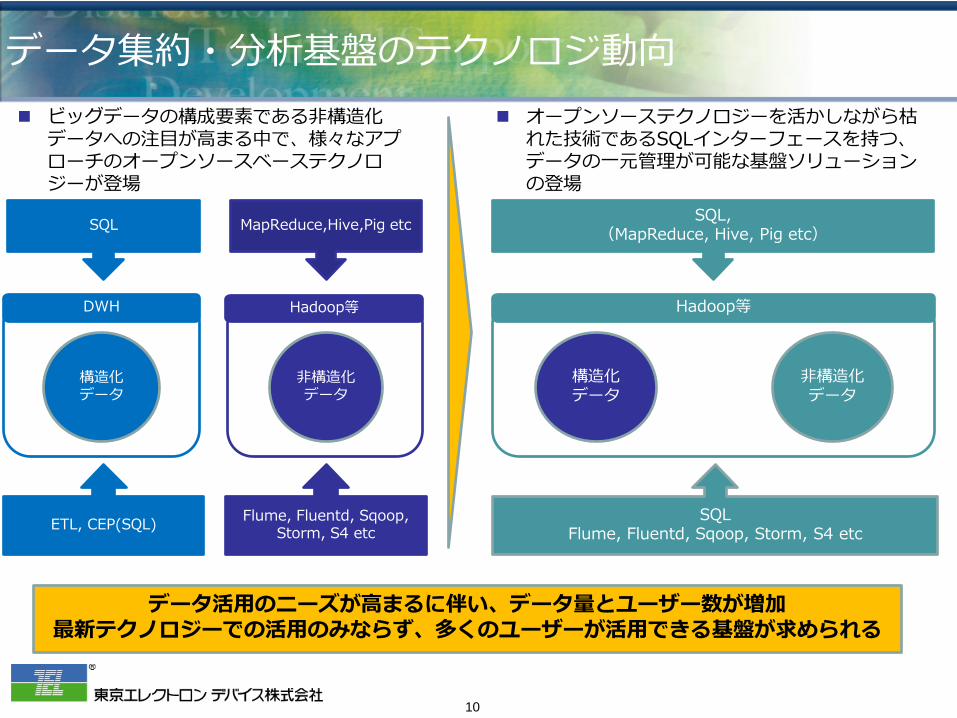
データ集約・分析基盤のテクノロジ動向
構造化 データ
非構造化 データ
SQL MapReduce,Hive,Pig etc
ETL, CEP(SQL) Flume, Fluentd, Sqoop, Storm, S4 etc
DWH Hadoop等
ビッグデータの構成要素である非構造化データへの注目が高まる中で、様々なアプローチのオープンソースベーステクノロジーが登場
構造化 データ
非構造化 データ
SQL, (MapReduce, Hive, Pig etc)
SQL Flume, Fluentd, Sqoop, Storm, S4 etc
Hadoop等
オープンソーステクノロジーを活かしながら枯れた技術であるSQLインターフェースを持つ、データの一元管理が可能な基盤ソリューションの登場
データ活用のニーズが高まるに伴い、データ量とユーザー数が増加 最新テクノロジーでの活用のみならず、多くのユーザーが活用できる基盤が求められる
10

「データレイク」という考え方とKeyman
11

Pivotal DataLake
12
HDFS
Pivotal データプラットフォーム DataLake
インメモリオブジェクトサービス
アナリティック ワークロード
SQLサービス
オペレーショナル インテリジェンス
インメモリサービス
ランタイム アプリケーション
ストリーム インジェスチョン
ストリーミングサービス
GemFireXD GemFireXD
Data Lake : データ処理基盤の基盤要素となるHDFSにデータを蓄積 あらゆるデータ・要件に応じて処理エンジンを使い分ける
Software-Defined Datacenter
New Data-fabrics
...ETC
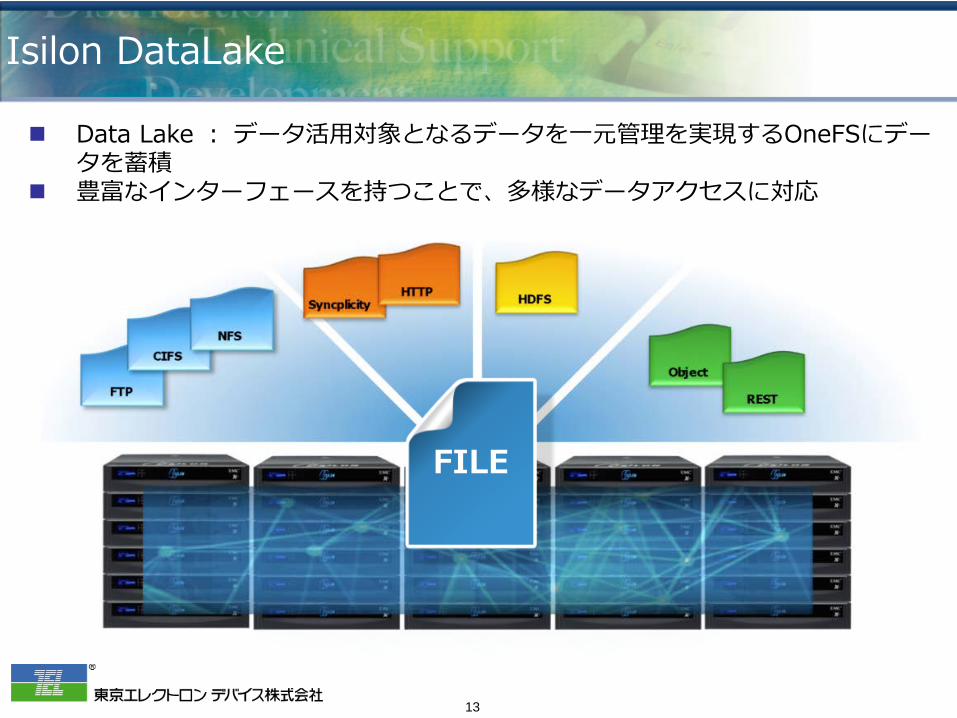
Isilon DataLake
13
FILE
Data Lake : データ活用対象となるデータを一元管理を実現するOneFSにデータを蓄積
豊富なインターフェースを持つことで、多様なデータアクセスに対応

2つのDataLakeの融合
14
Pivotal DataLake
インメモリオブジェクトサービス
アナリティック ワークロード
SQLサービス
オペレーショナル インテリジェンス
インメモリサービス
ランタイム アプリケーション
ストリーム インジェスチョン
ストリーミングサービス
GemFireXD GemFireXD
Isilon DataLake
HDFS
HDFSを介した大規模且つ利便性の高い、Hadoop基盤を実現
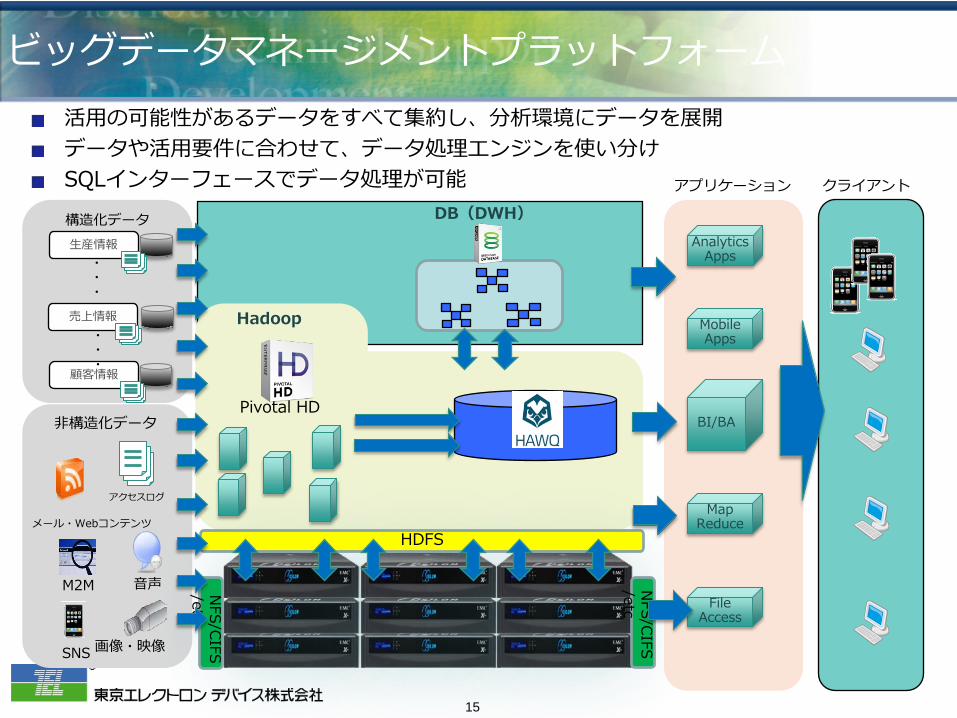
ビッグデータマネージメントプラットフォーム 活用の可能性があるデータをすべて集約し、分析環境にデータを展開 データや活用要件に合わせて、データ処理エンジンを使い分け SQLインターフェースでデータ処理が可能
15
売上情報
・・・
顧客情報
・・・
生産情報
構造化データ
アクセスログ
メール・Webコンテンツ
M2M 音声
画像・映像 SNS
非構造化データ
DB(DWH)
Hadoop
Pivotal HD
HDFS
Analytics Apps
Mobile Apps
BI/BA
アプリケーション クライアント
File Access
Map Reduce
NFS/CIFS
/etc
NFS/CIFS
/etc

Hadoopとは?
16
HDFS (Hadoop Distributed File System) 分散ファイルシステム
MapReduce 大規模分散処理フレームワーク
データをブロックに分割して複数のサーバに分散配置/3つのレプリカを作成
Map/Reduceというシンプルな処理の組み合わせで、HDFS上にあるデータの分散処理を行う汎用的なフレームワーク
データをためる データを加工する
2つの分散アーキテクチャーを持つコンポーネントで構成させる

Hadoopでの悩みと解決方法
17
HDFS (Hadoop Distributed File System) 分散ファイルシステム
MapReduce 大規模分散処理フレームワーク
分散アーキテクチャメリットを残しつつ、データ搭載効率を高め、更に可用性も担
保するシステム
分散アーキテクチャメリットを使いこなし、業界標準SQLに準拠したSQLイン
ターフェース +
EMC ISILON
1、3つレプリカを作成することにより、1ノードにおけ るデータ搭載効率が悪くなる 2、容量要件・性能要件を満たすためのサイジ ングが難しいことがある 容量vs性能の観点で必要ノード数がマッチ しない etc
1、データ処理言語(MapReduce)がHDFS専用 言語であるため、 ・ 分析ツールからのアクセスが難しい ・ MapReduceエンジニアが少ない 2、枯れたデータ処理言語の一つであるSQLライクな処理言語(Hive、Pig等)も存在するが、 ・ 汎用SQLと同等レベルでない ・ 性能を含めた処理安定性に不安あり etc

Pivotal HD+HAWQ
18
Pivotal HD – Apache Hadoop 2.2.0 ベース
– 処理全体のデータスループット効率化:YARN – 運用・管理性: スナップショット/HDFS Federation/NFS v3によるデータアクセス
– Advanced Database Services(HAWQ) – 性能:HDFSに対する標準SQLによる高速クエリ処理 – 連携:Hive, Hbase, Avro等 Hadoop データとの連携
– 仮想化・エンタープライズストレージ対応 – Hadoop構成の VMWare 上での最適化や Isilonとの連携
HDFS
HBase Pig, Hive, Mahout
Map Reduce
Sqoop Flume
リソース管理 & ワークフロー
Yarn
Zookeeper
Apache
Oozie
Pivotal HD 追加機能
Command Center
コンフィグ デプロイ モニター 管理
HVE
Pivotal HD Enterprise
Xtension フレームワーク
カタログ サービス
クエリ オプティマイザ
ダイナミック・パイプライニング
ANSI SQL + アナリティクス
HAWQ アドバンスド
データベースサービス

HAWQ≒GreenplumDB
19
標準 SQL 対応 堅牢なクエリオプティマイザ ローストア・カラムストア両方への対応 圧縮 分散格納 マルチレベルパーティショニング パラレルーロード・アンロード 高速データ再分散
SELECT INSERT JOIN 統計解析関数(MADlib) ビュー 外部表 リソースマネジメント セキュリティ 認証 管理・監視 ODBC/JDBC対応
HAWQ: Pivotal社が10年にわたり開発をしてきたGreenplumDBをHadoop用に改良 GreenplumDBの大半の機能が利用可能
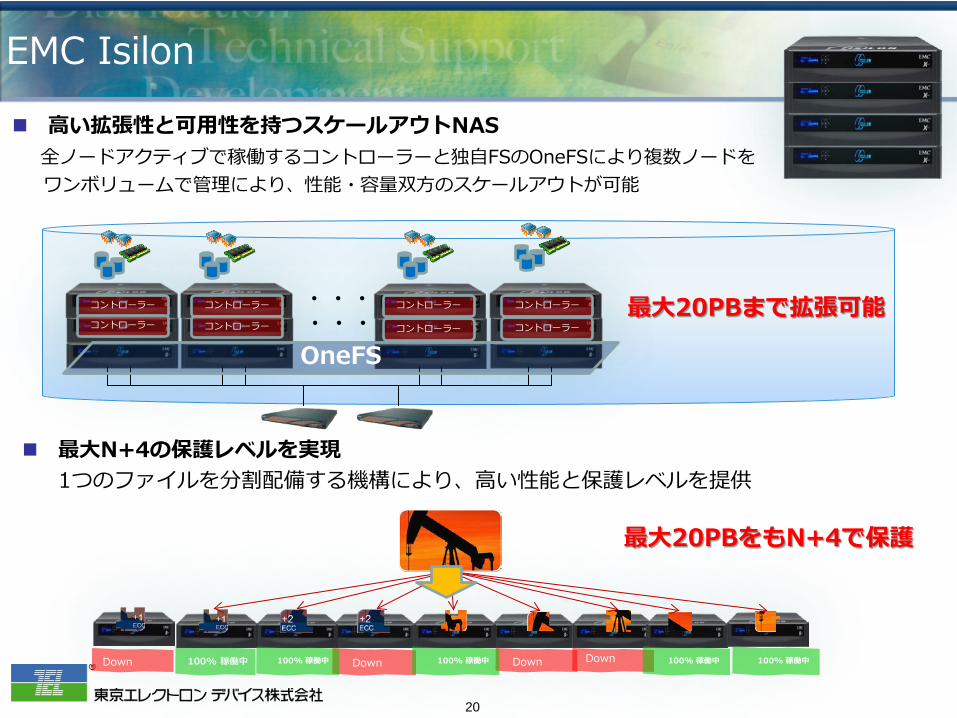
EMC Isilon
高い拡張性と可用性を持つスケールアウトNAS 全ノードアクティブで稼働するコントローラーと独自FSのOneFSにより複数ノードを ワンボリュームで管理により、性能・容量双方のスケールアウトが可能
・・・ ・・・
OneFS
コントローラー コントローラー
コントローラー コントローラー
コントローラー
コントローラー
コントローラー
コントローラー 最大20PBまで拡張可能
100% 稼働中 Down Down Down Down 100% 稼働中 100% 稼働中 100% 稼働中 100% 稼働中
最大N+4の保護レベルを実現 1つのファイルを分割配備する機構により、高い性能と保護レベルを提供
最大20PBをもN+4で保護
20
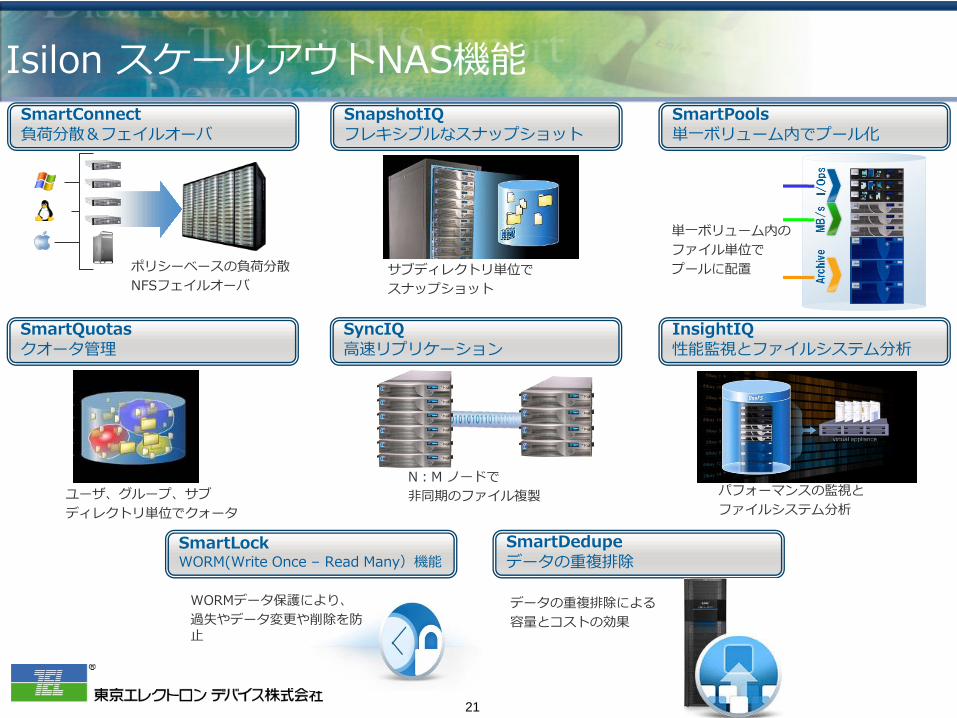
Isilon スケールアウトNAS機能
InsightIQ 性能監視とファイルシステム分析
SmartPools 単一ボリューム内でプール化
単一ボリューム内の ファイル単位で プールに配置
SyncIQ 高速リプリケーション
SnapshotIQ フレキシブルなスナップショット
サブディレクトリ単位で スナップショット
SmartConnect 負荷分散&フェイルオーバ
SmartQuotas クオータ管理
ポリシーベースの負荷分散 NFSフェイルオーバ
N:M ノードで 非同期のファイル複製 ユーザ、グループ、サブ
ディレクトリ単位でクォータ パフォーマンスの監視と ファイルシステム分析
SmartLock WORM(Write Once – Read Many)機能
SmartDedupe データの重複排除
データの重複排除による 容量とコストの効果
WORMデータ保護により、 過失やデータ変更や削除を防止
21

通常のHadoopアーキテクチャー
22
Data Node + Compute Node Data Node + Compute Node Data Node + Compute Node
Data Node + Compute Node Data Node + Compute Node Data Node + Compute Node
Name Node
R(RHIPE) NameNode
2nd NameNode Job Tracker Task Tracker DataNode
Pig Mahout Hive HBase
多くの処理プロセスと実データが分散配置 メタデータ(NameNode)は冗長化のみ
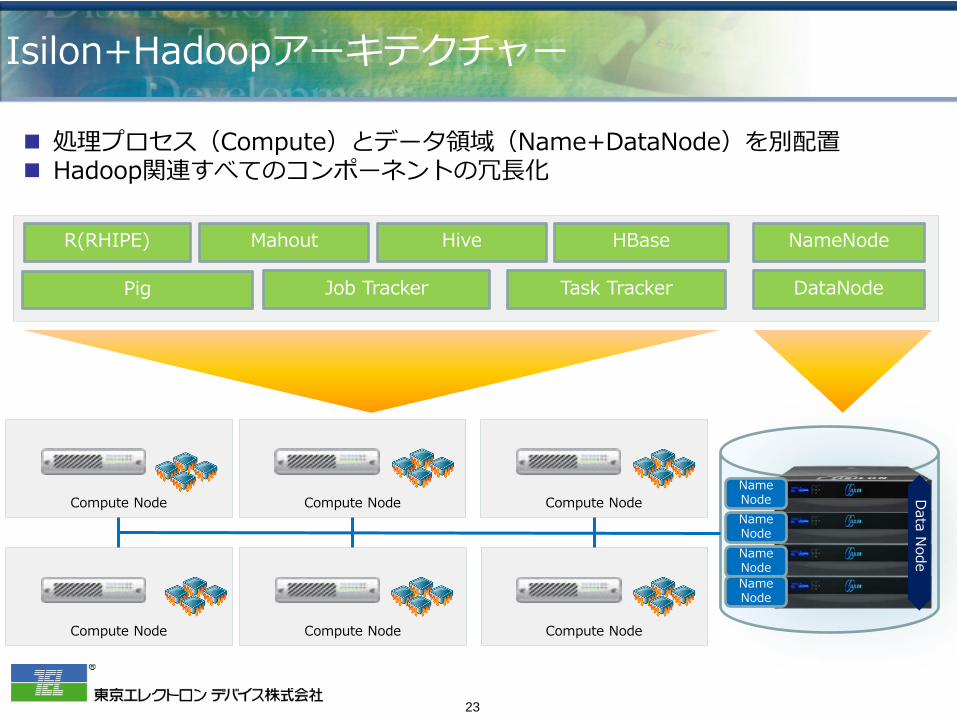
Isilon+Hadoopアーキテクチャー
23
Compute Node Compute Node Compute Node
Compute Node Compute Node Compute Node
R(RHIPE) NameNode
Job Tracker Task Tracker DataNode Pig
Mahout Hive HBase
Name Node Name Node Name Node Name Node
Data N
ode
処理プロセス(Compute)とデータ領域(Name+DataNode)を別配置 Hadoop関連すべてのコンポーネントの冗長化

Pivotal HD&HAWQ+Isilon
24
HAWQ HAWQ HAWQ
HAWQ HAWQ HAWQ
Name Node Name Node Name Node Name Node
Data N
ode
EMC ISILON
R(RHIPE) NameNode
Job Tracker Task Tracker DataNode Pig
Mahout Hive HAWQ
分散処理データベース 分散ファイルシステム
大規模且つ性能・容量に最適化された利便性の高いHadoop環境を実現
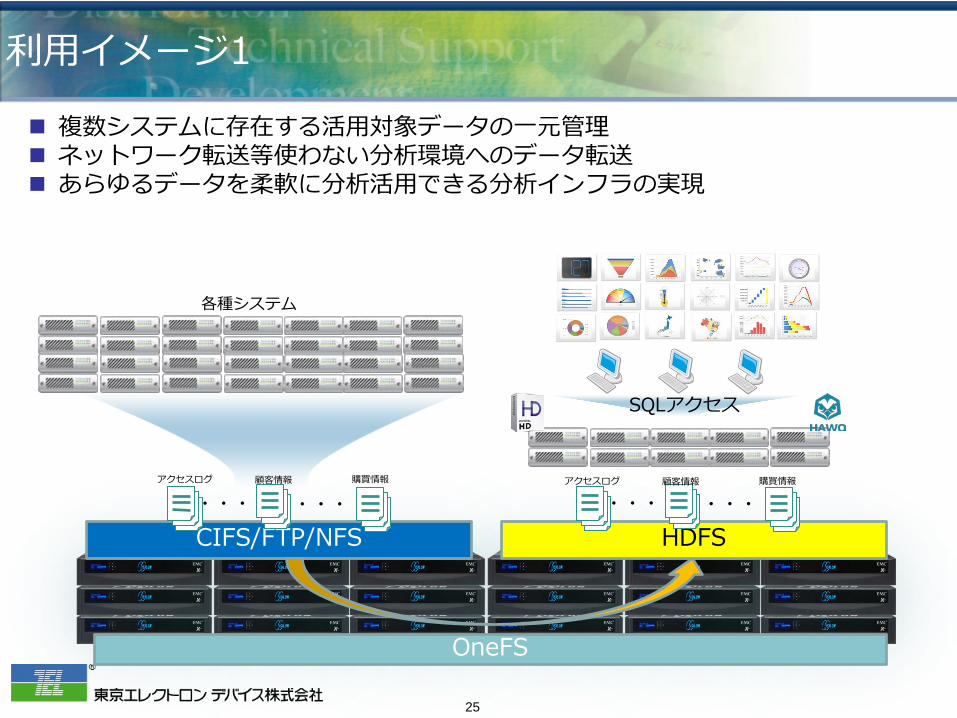
利用イメージ1
25
OneFS
CIFS/FTP/NFS HDFS
アクセスログ 顧客情報 購買情報
・・・ ・・・ ・・・ ・・・ アクセスログ 顧客情報 購買情報
複数システムに存在する活用対象データの一元管理 ネットワーク転送等使わない分析環境へのデータ転送 あらゆるデータを柔軟に分析活用できる分析インフラの実現
SQLアクセス
各種システム

利用イメージ2
26
Before
After
低SpecマシンでSmallStartしたHadoop環境の大規模化 - 分析データの大量化に伴い、性能要件以上のサーバー台数のシステムに - システム効率化の観点でオーバーヘッドが多数存在 - MapReduce、Hiveが使えるエンジニアが必ず必要
PivotalHD&HAWQ+Isilonにて、効率化の図られた利便性能高いHadoop環境を実現 - ComputeNodeとデータ領域の役割分担により、システム効率化を実現 - 要件に合わせた拡張が可能 - 汎用SQLの活用が可能なため、BI/BAツールにてアクセスも可能
+
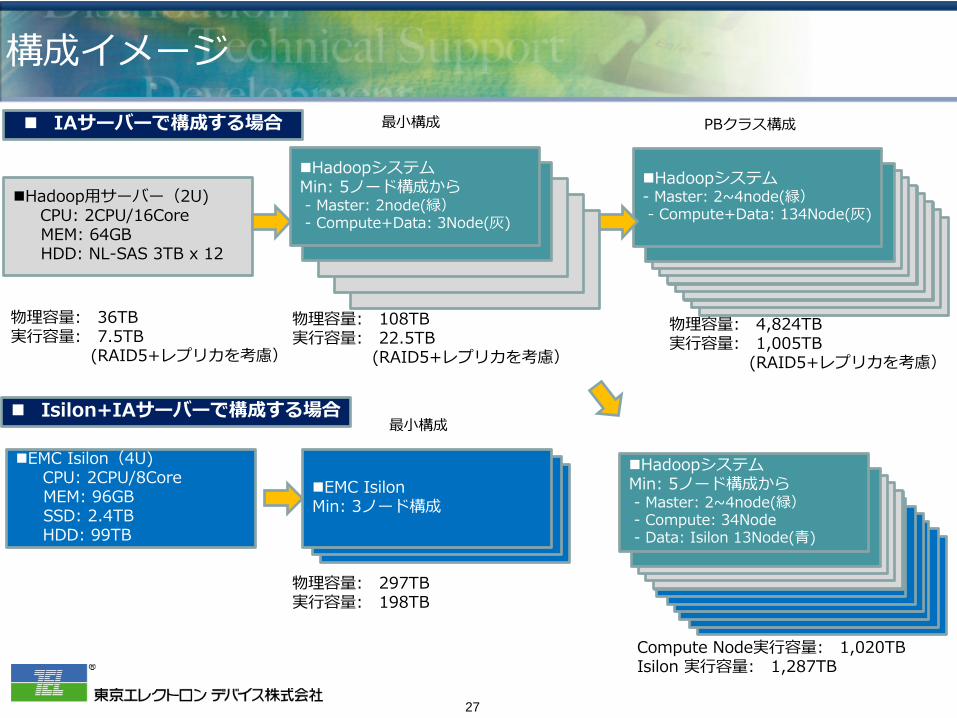
構成イメージ
27
Hadoop用サーバー(2U) CPU: 2CPU/16Core MEM: 64GB HDD: NL-SAS 3TB x 12
Hadoopシステム Min: 5ノード構成から - Master: 2node(緑) - Compute+Data: 3Node(灰)
物理容量: 36TB 実行容量: 7.5TB (RAID5+レプリカを考慮)
最小構成 PBクラス構成
Hadoopシステム - Master: 2~4node(緑) - Compute+Data: 134Node(灰)
物理容量: 4,824TB 実行容量: 1,005TB (RAID5+レプリカを考慮)
EMC Isilon(4U) CPU: 2CPU/8Core MEM: 96GB SSD: 2.4TB HDD: 99TB
最小構成
EMC Isilon Min: 3ノード構成
物理容量: 297TB 実行容量: 198TB
EMC Isilon Min: 3ノード構成
EMC Isilon Min: 3ノード構成
Hadoopシステム Min: 5ノード構成から - Master: 2~4node(緑) - Compute: 34Node - Data: Isilon 13Node(青)
Compute Node実行容量: 1,020TB Isilon 実行容量: 1,287TB
IAサーバーで構成する場合
Isilon+IAサーバーで構成する場合
物理容量: 108TB 実行容量: 22.5TB (RAID5+レプリカを考慮)

構成比較
28
実行容量 10TB 50TB 100TB 250TB 500TB 750TB 1000TB
IAサーバーで構築する場合
Compute+DataNode台数(IAサーバー) 3 7 13 33 67 100 133
ラックユニット数(Cpmpute+DataNode) 6 14 26 66 133 200 267
ラック数 1 1 1 2 4 5 7
Isilon+IAサーバーで構築する場合
ComputeNode台数 (IAサーバー) 3 3 3 9 17 25 34
DataNode台数(Isilon) 3 3 3 4 6 8 13 ラックユニット数(Cpmpute+DataNode) 18 18 18 34 58 82 120
ラック数 1 1 1 1 2 3 4

ビッグデータ+ファストデータ マネージメントプラットフォーム
29
売上情報
・・・
顧客情報
・・・
生産情報 構造化データ
アクセスログ
メール・Webコンテンツ
M2M 音声
画像・映像 SNS
非構造化データ
DB(DWH)
Hadoop
Pivotal HD
HDFS
Analytics Apps
Mobile Apps
BI/BA
アプリケーション クライアント
File Access
Map Reduce
NFS/CIF
S/etc
NFS/CIF
S/etc
GemFireXD
非構造化データ
Online Apps
M2Mに代表される大量トラフィックデータのサービスおよび分析活用を実現

PivotalHD+Isilon 東京エレクトロンデバイス(株)
Pivotal製品: 2008年10月より取扱い
30
Isilon製品: 2004年10月より取扱い
Pivotal+Isilon: 2014年6月ソリューション開始
PivotalHD+HAWQ単体検証からIsilonを使った統合検証環境
PivotalHD+HAWQ構成に必要なNWスイッチを含めた構成の提案
ソリューションカットでのワンストップサポート体制構築
POCセンターでの性能・機能検証
ソフトウェア、IAサーバーとのパッケージ、アプライアンスとお客様ニーズに合わせた製品提供、構築
24x365サポート提供
貸出機を含めた検証支援
お客様ご要件に合わせたモデル選定・製品提供・構築
24x365サポート提供(全国オンサイト体制)

31
もっと使えるHadoopを!
東京エレクトロンデバイス(株) CN事業統括本部 CN営業本部 コーポレートアカウント営業部
住友義典 Tel: 03-5908-1977
E-mail: [email protected]