generation of f 0 contours using a model-constrained data- driven method atsuhiro sakurai (texas...
TRANSCRIPT

Generation of F0 Contours Using a Model-Constrained Data-
Driven Method
Atsuhiro Sakurai (Texas Instruments Japan, Tsukuba R&D Center)Nobuaki Minematsu (Dep. of Comm. Eng., The Univ. of Tokyo, Japan)Keikichi Hirose (Dep. of Frontier Eng., The Univ. of Tokyo, Japan)

Corpus-Based Intonation Modeling
• Rule-based approach: ad-hoc rules derived from experience– Human-dependent, labor-expensive
• Corpus-based approach: mapping from linguistic to prosodic features statistically derived from a database– Automatic, potential to improve as larger corpora become av
ailable
– The F0 model : a parametric model that reduces degrees of freedom and improves learning efficiency

F0 Model
lnF0
(t) lnFmin
Api
Gpi
(t T )i 1
IA
aj{G
aj(t T
1j)
j 1
JGaj(t t
2j)}i
0
G tt
t
G tt
t
piit it
ajjt jt
( )exp( ) ( )
( )
( )min[ ( ) exp( ), ] ( )
( )
0
0 0
1 1 0
0 0

F0 Model
• Characteristics of the F0 Model:
– Direct representation of physical F0 contours
– Relatively good correspondence with syntactic structure
– Ability to express an F0 contour with a small number of parameters
Better training efficiency by reducing degrees of freedom

Prosodic Database
Training module
Intonation model
Linguistic features +
F0 model parameters
Intonation model
Linguistic features F0 model parameters
Training/Generation Mechanism1) Training Phase
2) Generation Phase

Parameter Prediction Using a Neural Network
• Neural networks are good for non-linear mappings• The generalizing ability of neural networks can deal wit
h imperfect or inconsistent databases (prosodic databases labeled by hand)
• Feedback loops can be used to capture the relation between accentual phrases (partial recurrent networks)

InputLayer
HiddenLayer
OutputLayer
ContextLayer
InputLayer
HiddenLayer
OutputLayer
StateLayer
(a) Elman network (b) Jordan network
InputLayer
HiddenLayer
OutputLayer
(c) Multi-layer perceptron(MLP)
Neural Network Structure

Input Features
Position of accentual phrase within utteranceNumber of morae in accentual phraseAccent type of accentual phraseNumber of words in accentual phrasePart-of-speech of first wordConjugation form of first wordPOS category of last wordConjugation form of last word
181598217217
Input Feature Max. value

Chiisana unagiyani nekkinoyoona monoga minagiru(小さな うなぎ屋に 熱気のような ものが みなぎる)
“unagiyani”Position of accentual phrase within utterance: 2No. of morae in accentual phrase: 5Accent type of accentual phrase: 0No. of words in accentual phrase: 2POS, conjugation type/category of first word: noun/0POS, conjugation type/category of last word: particle/0
Input Features - Example

t
Command
Ap
Aa
t0 t1 t2
tA tB tDtC
t
Waveform
Output FeaturesAccent nucleus
Phrase command magnitude (Ap)Accent command amplitude (Aa)Phrase command delay (t0 off = tA - t0)Delay of accent command onset (t1 off = tA - t1 or tB - t1)Delay of accent command reset (t2 off = tC - t2)Phrase command flag
Output Feature
tA, tB, tC, tD: mora boundariest0, t1, t2: F0 model parameters

• Background– Neural networks provide no additional information on the modeling
– Binary regression trees provide human interpretability
– The knowledge obtained from binary regression trees could be used as a feedback in other kinds of modeling
• Outline– Input and output features equal to the neural network case
– Tree-growing stop criterion: minimum number of examples per leaf node
Parameter Prediction Using Binary Regression Trees

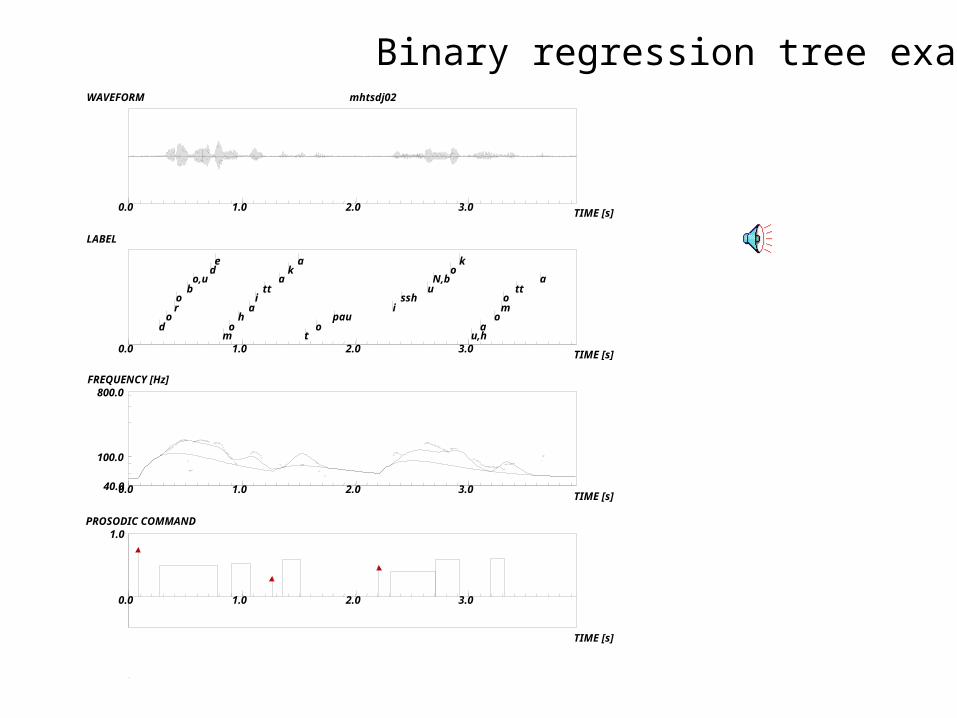
0.0 1.0 2.0 3.0 TIME [s]
WAVEFORM mhtsdj02
dorobo,u
de
mohaitt
aka
to
pauissh
uN,b
ok
u,ha
omo
tta
TIME [s]
LABEL
0.0 1.0 2.0 3.0
40.0
100.0
800.0
0.0 1.0 2.0 3.0TIME [s]
FREQUENCY [Hz]
1.0
0.0 1.0 2.0 3.0
TIME [s]
PROSODIC COMMAND
Neural network example
0.0 1.0 2.0 3.0 TIME [s]
WAVEFORM mhtsdj02
dorobo,u
de
mohaitt
aka
to
pauissh
uN,b
ok
u,ha
omo
tta
TIME [s]
LABEL
0.0 1.0 2.0 3.0
40.0
100.0
800.0
0.0 1.0 2.0 3.0TIME [s]
FREQUENCY [Hz]
1.0
0.0 1.0 2.0 3.0
TIME [s]
PROSODIC COMMAND
Binary regression tree example

)]log()[log(1
1
2'00
N
iii FF
NMSE
Experimental Results (1): MSE Error for Neural Networks
Neural net #Elements in Mean squareconfiguration hidden layer error
MLP 10 0.218MLP 20 0.217Jordan 10 0.220Jordan 20 0.215Elman 10 0.214Elman 20 0.232
elman-10

)]log()[log(1
1
2'00
N
iii FF
NMSE
Experimental Results (2): MSE Error for Binary Regression Trees
Stop Mean squarecriterion error
10 0.21520 0.22230 0.21040 0.22050 0.21750 0.220
stop-30

Method MSE
Experimental Results (3): Comparison with Rule-Based Parameter
Prediction
Neural network (elman-10) 0.214Binary regression tree (stop-30) 0.210Rule set I 0.221Rule set II 0.193
Rule set I: Phrase and accent commands derived from rules (including phrase command flag)Rule set II: Phrase and accent commands derived from rules (excluding phrase command flag)

Experimental Results (4): Listening Tests
Number of listeners: 8Number of sentencees
Neural network Binary regression trees Rule-based
Preference 28 39 13

Conclusions
• Advantages of data-driven intonation modeling:– No need of ad-hoc expertise
– Fast and straightforward learning
• Difficulties:– Prediction errors
– Difficulty in finding cause-effect relations for prediction errors
• For now on:– To explore other learning methods
– To deal with the data scarcity problem