google bigquery導入記
TRANSCRIPT

Google BigQuery導入記
自己紹介
@yamionp
gumi ってところでエンジニアやってます
Python歴約3年
サーバーさわりはじめて約10年

関わったもの

アジェンダ
ログについて
BigQueryに入れる
BigQueryを使う

ログ

いろんなログOSなどのシステムログ
DBのログ
nginxのアクセス/エラーログ
ルーターなどネットワークレイヤーのログ
pythonで発行するログ
ユーザーの行動ログ
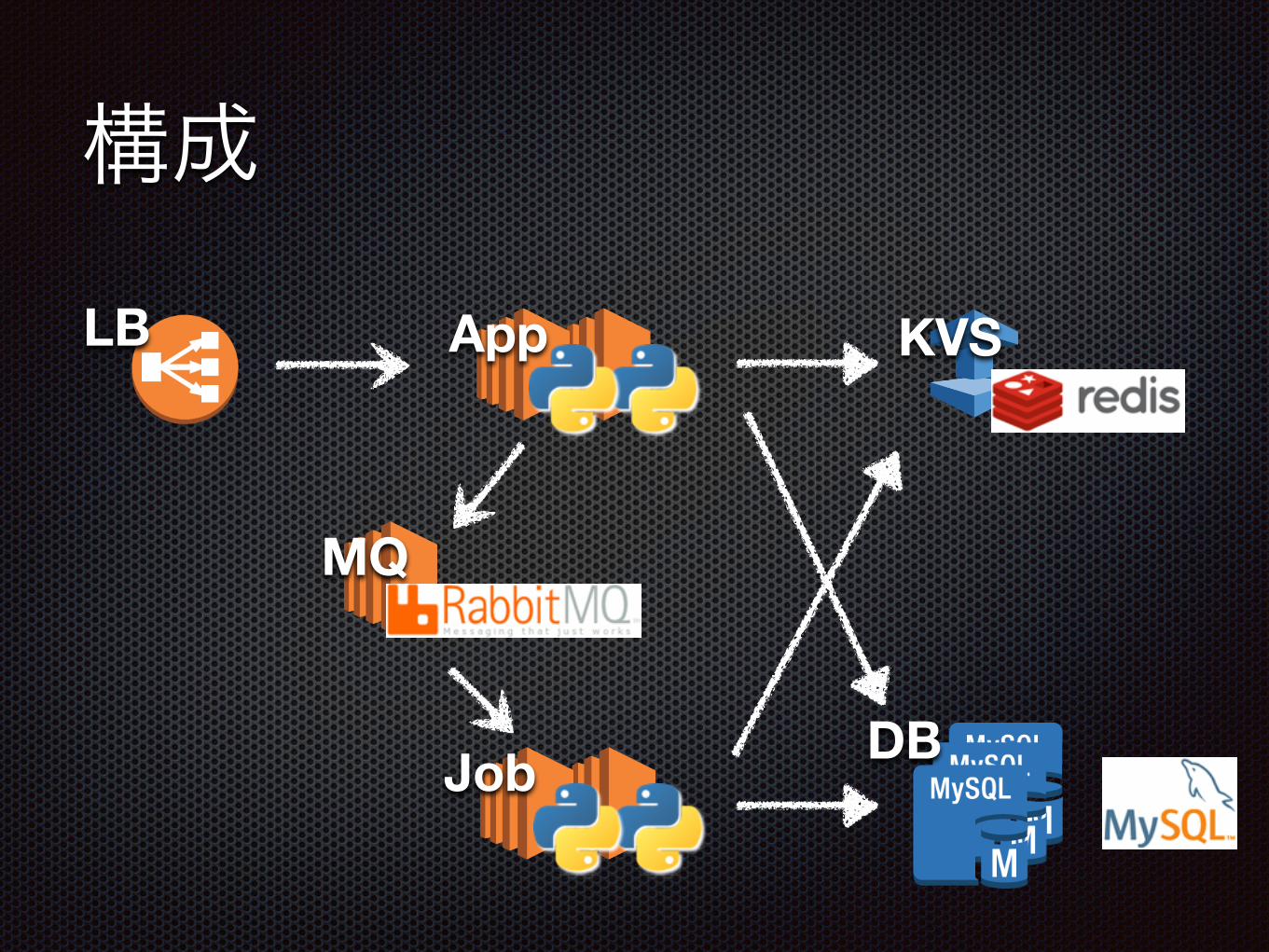
構成
DB
LB App KVS
MQ
Job

どこに保存してますか?

ログの保存先?
ファイル
RDB
S3
DWH
Elasticsearch

データが大きくなると…
検索をしたいが遅い
集計をしたいが終わらない/落ちる
保存先の特性(Elasticsearch/DWH等)にくわしくないと死ぬ
保存先の容量が足りなくなる。移動も大変

そこで


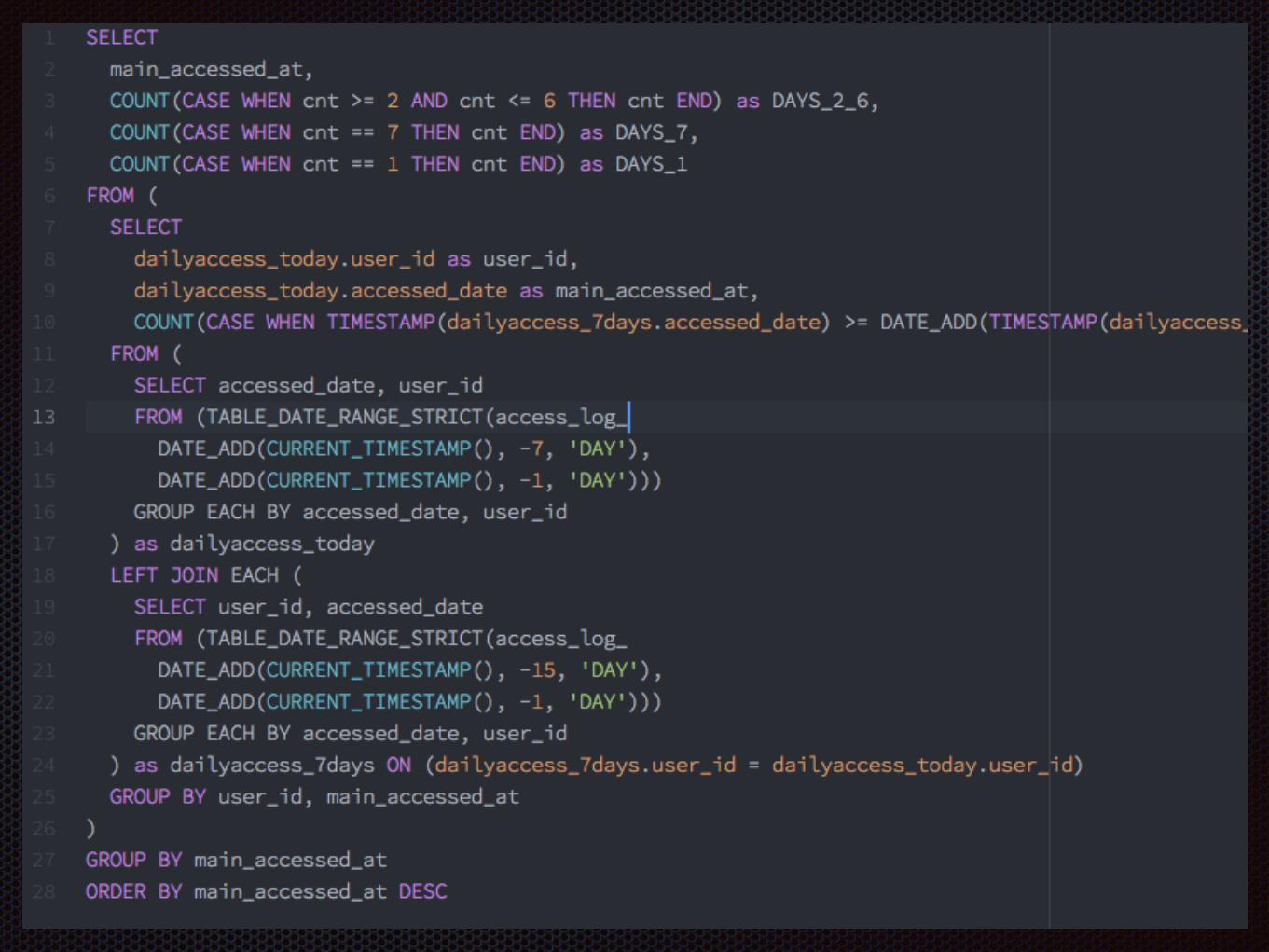
なにがすごいか120億行(414GB)のデータにクエリを投げても5秒(フルスキャン+正規表現によるフィルタ+集計)
データ操作にはSQLが使える
てきとーなSQLを書いても動く(賢いSQLでなくても使える)
JSONを入れられるのでスキーマレスに使える
しかも安い(無料枠もかなりある

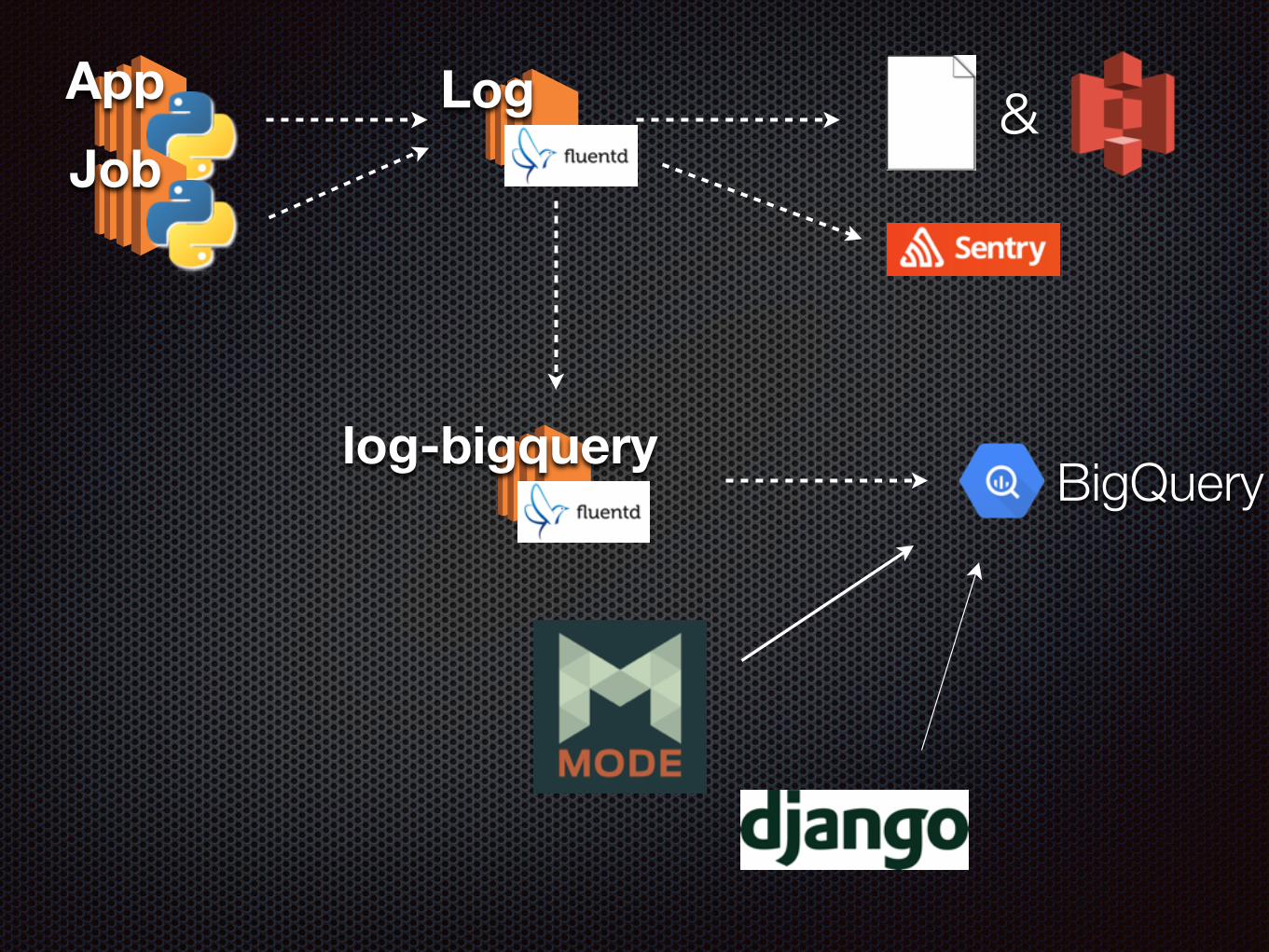
ログを集める

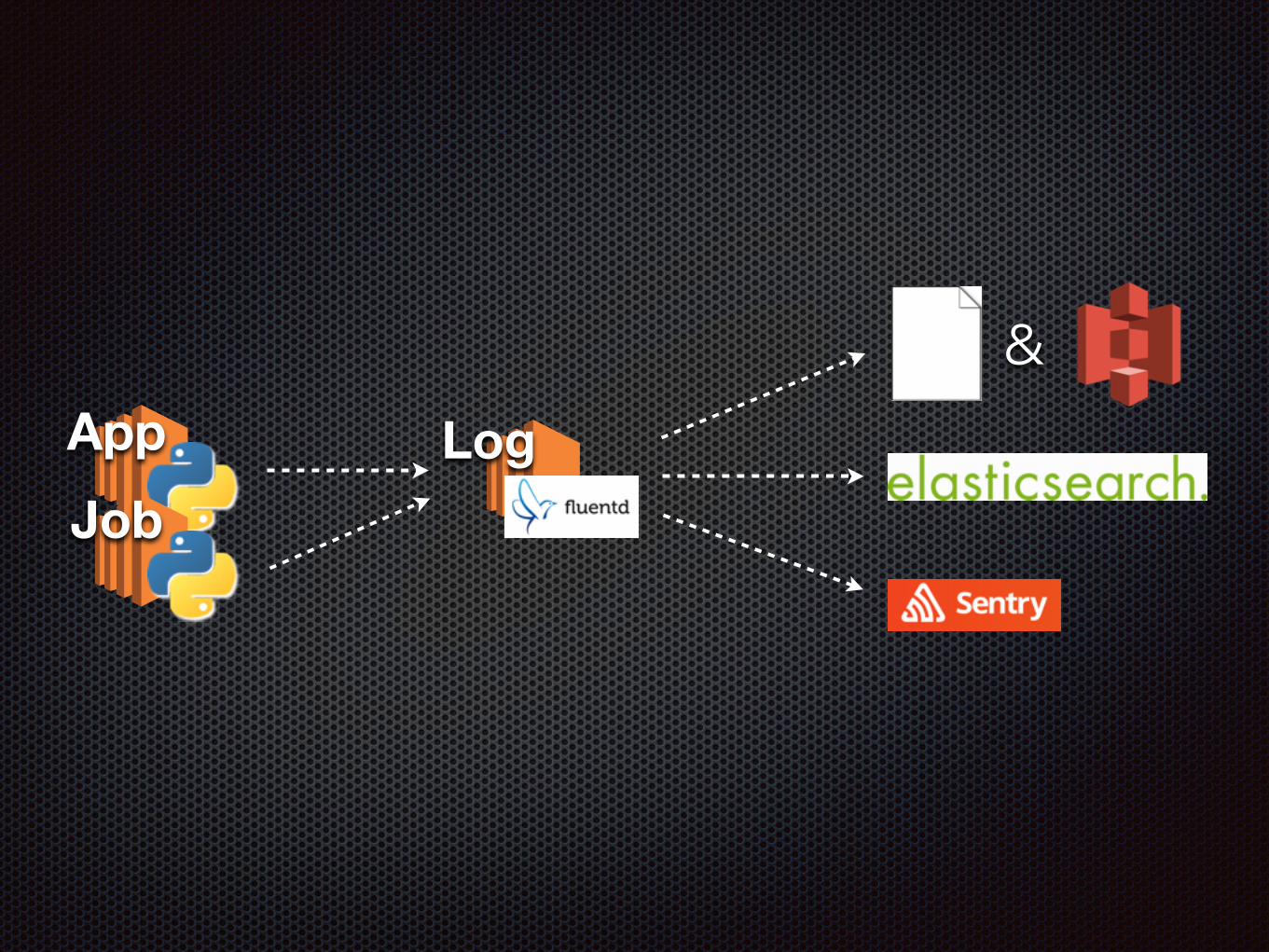
App LogJob
&
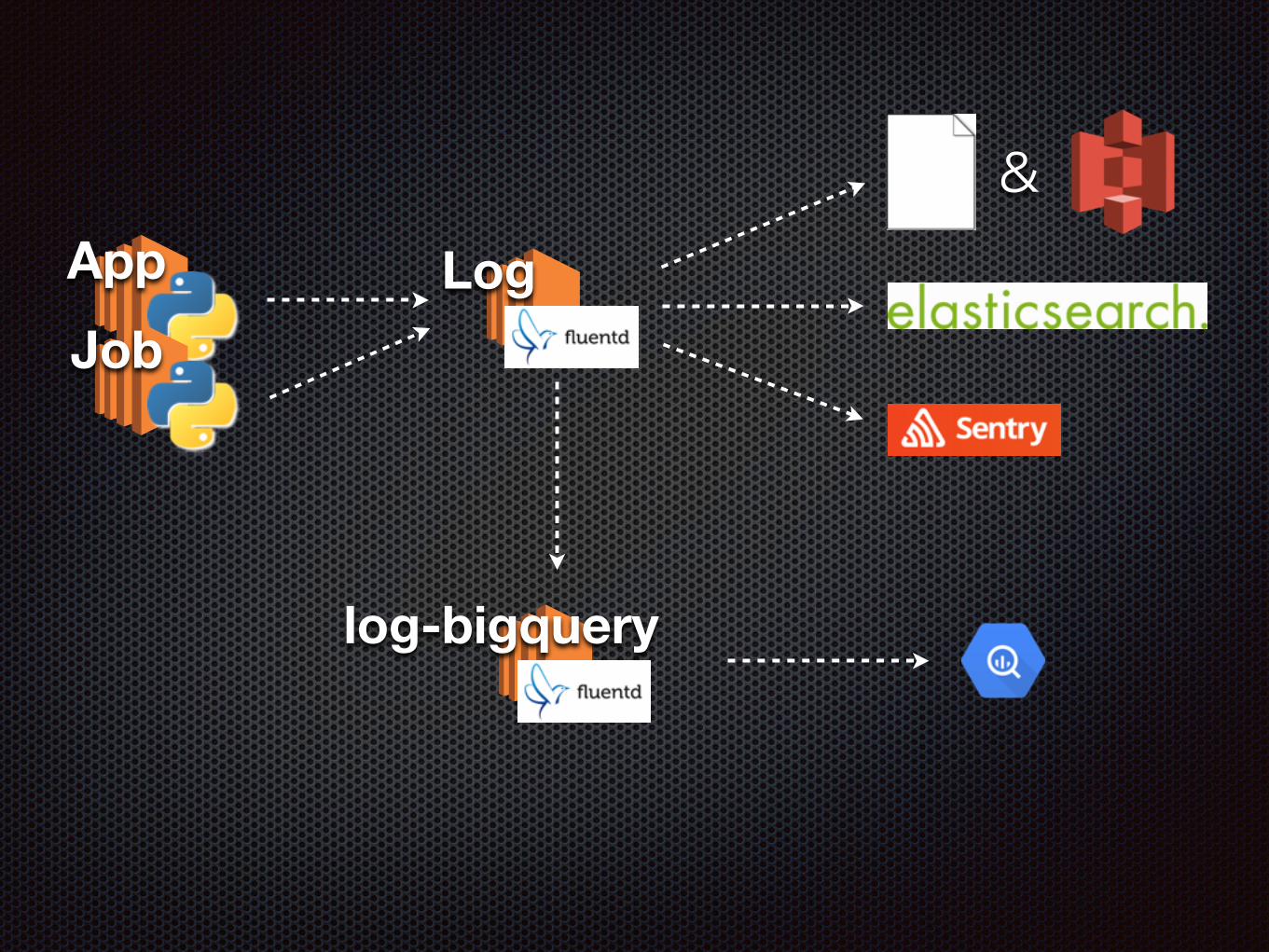
App LogJob
log-bigquery
&

fluent-plugin-bigqueryを使用
バッファリングしながら指定Tableにログを流せる
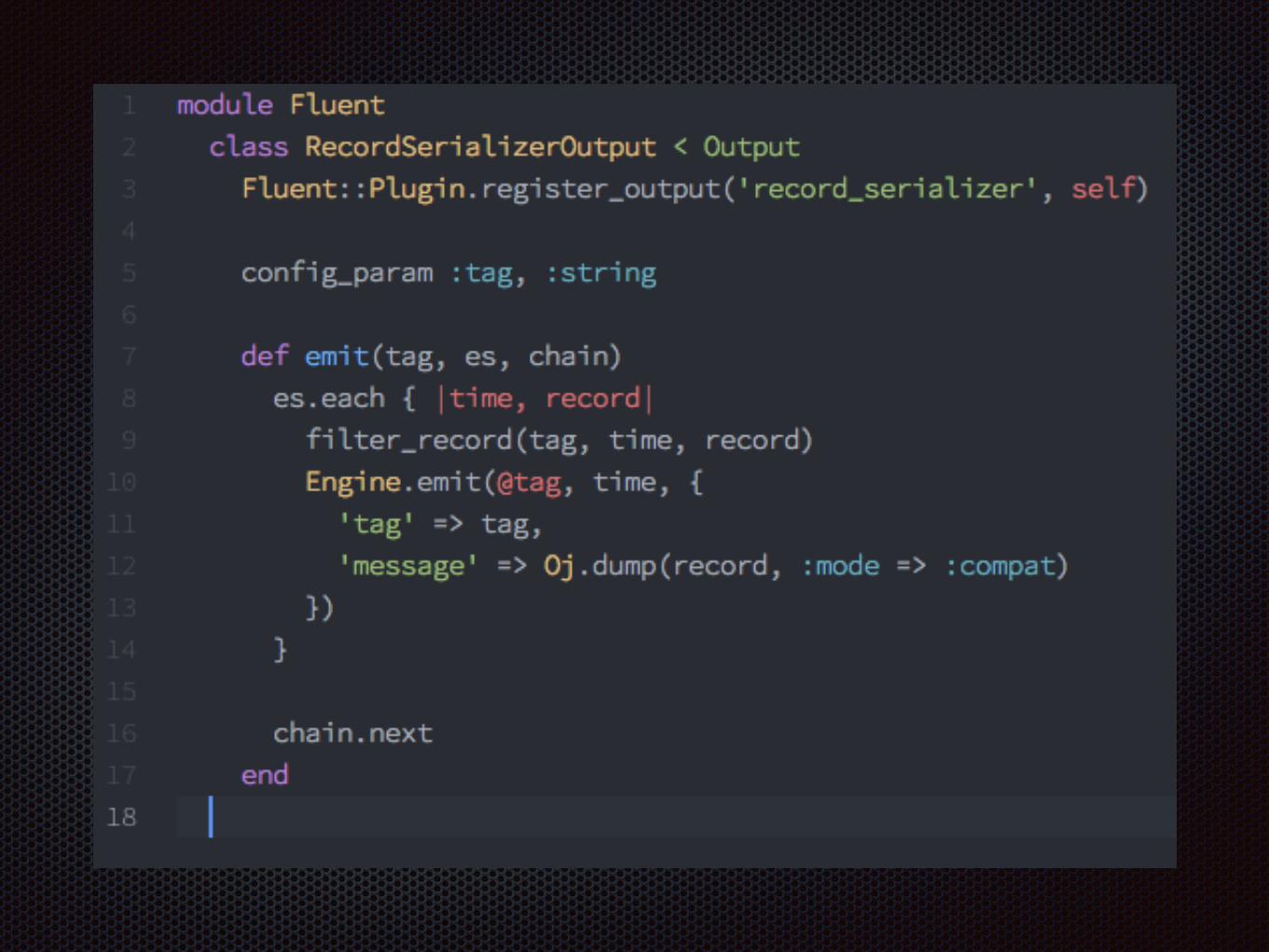
自作fluent pluginでjson化してフォーマットを揃える
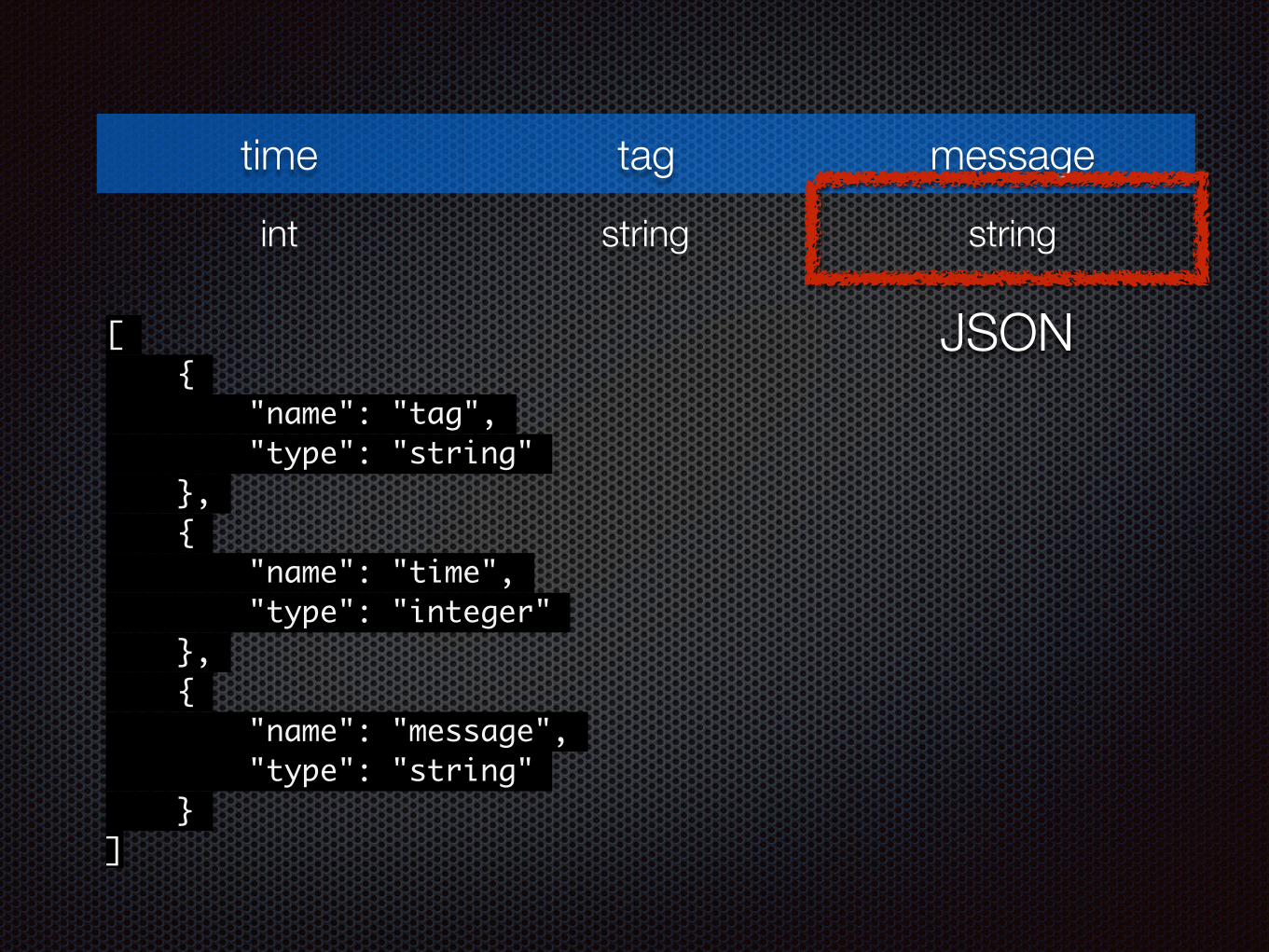
time tag message
int string string
[ { "name": "tag", "type": "string" }, { "name": "time", "type": "integer" }, { "name": "message", "type": "string" }]
JSON
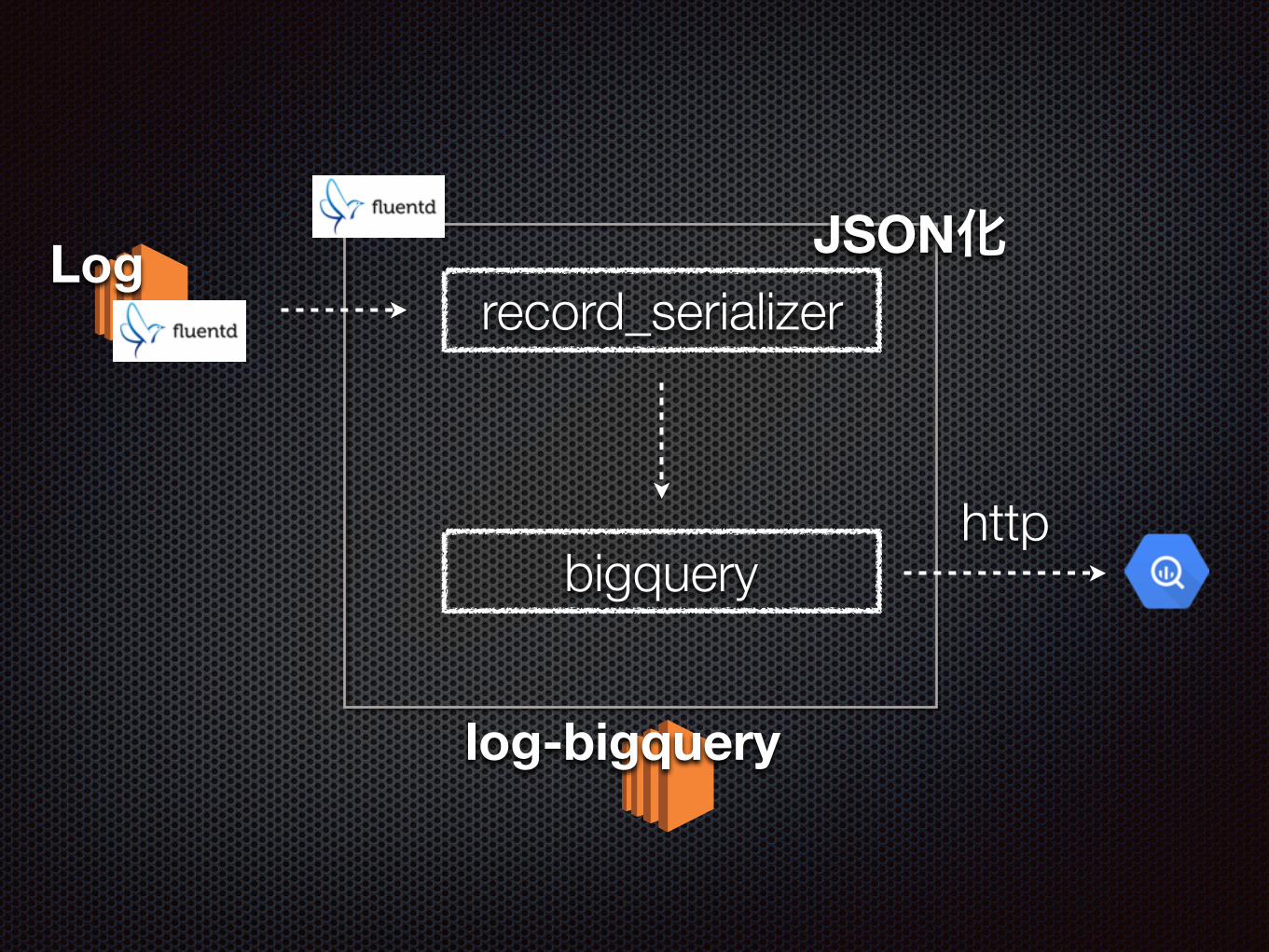
Log
log-bigquery
http
record_serializer
bigquery
JSON化

use_ite 1434249466 {“count”:”1","uid":"userxxxx","success":"True","event_id":"None","item_id":"12","item_type":"ITEM","user_level":"None","device":"SP_iPhone","id":"xxxxxx"}
use_item 1434249604 {“count”:”1","uid":"userxxxx","success":"True","event_id":"None","item_id":"12","item_type":"ITEM","user_level":"None","device":"SP_iPhone","id":"yyyyy"}
use_item 1434249951 {“count”:”1","uid":"userxxxx","success":"True","event_id":"None","item_id":"12","item_type":"ITEM","user_level":"None","device":"SP_iPhone","id":"zzzzz"}

使い方
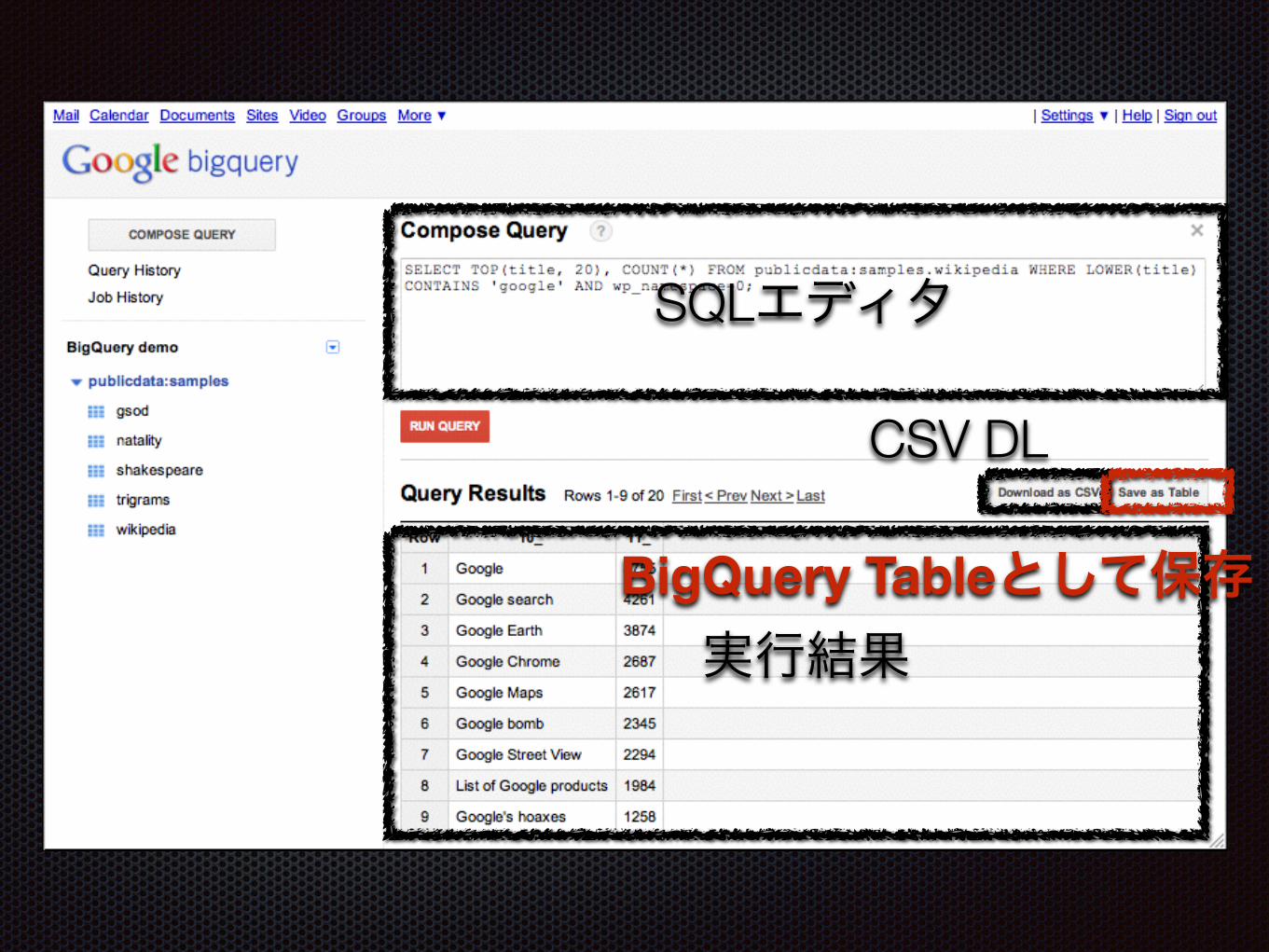
実行結果
SQLエディタ
CSV DL
BigQuery Tableとして保存

SELECT JSON_EXTRACT_SCALAR(message, "$.uid") as user_id, JSON_EXTRACT_SCALAR(message, "$.item_id") as item_id, DATE_ADD(STRFTIME_UTC_USEC(time*1000000, "%Y-%m-%d %H:00"), 9, "HOUR") as timestampFROM (TABLE_DATE_RANGE_STRICT( use_item_, DATE_ADD(CURRENT_TIMESTAMP(), -7, "DAY"), DATE_ADD(CURRENT_TIMESTAMP(), -1, "DAY")))
JSON Path風に指定
Datetimeに変換 &TimeZone補正
間近1週間分のTableから取得

料金のかかり方ストレージ $0.020 / GB
転送量 $0.01 / 100,000 row
8/12から $0.01 / 200 MB
クエリ課金 $5 / TB
100Gだと$0.05

クエリ課金の節約術
Tableは日付で分ける
複数TableをつなげてFROMに指定する関数がある
種類ごとにもTableを分ける
同じスキーマで良い。またがって取得したい場合はUNIONなどで繋げられる。

Table分割
BigQueryにはTableあたりのInsert速度の制限がある
別Tableなら問題ない
fluent-plugin-bigqueryはこのTable分割に対応している
InsertにTableがなければ指定したスキーマで自動生成

なにがすごいか120億行(414GB)のデータにクエリを投げても5秒(フルスキャン+正規表現によるフィルタ+集計)
データ操作にはSQLが使える
てきとーなSQLを書いても動く(賢いSQLでなくても使える)
JSONを入れられるのでスキーマレスに使える
しかも安い(無料枠もかなりある

ある日

今日のデータが見れないという報告
調べると特定日以降のTableが作られていない
特に環境の変更はしていない
とくにBigQueryのアナウンスもない
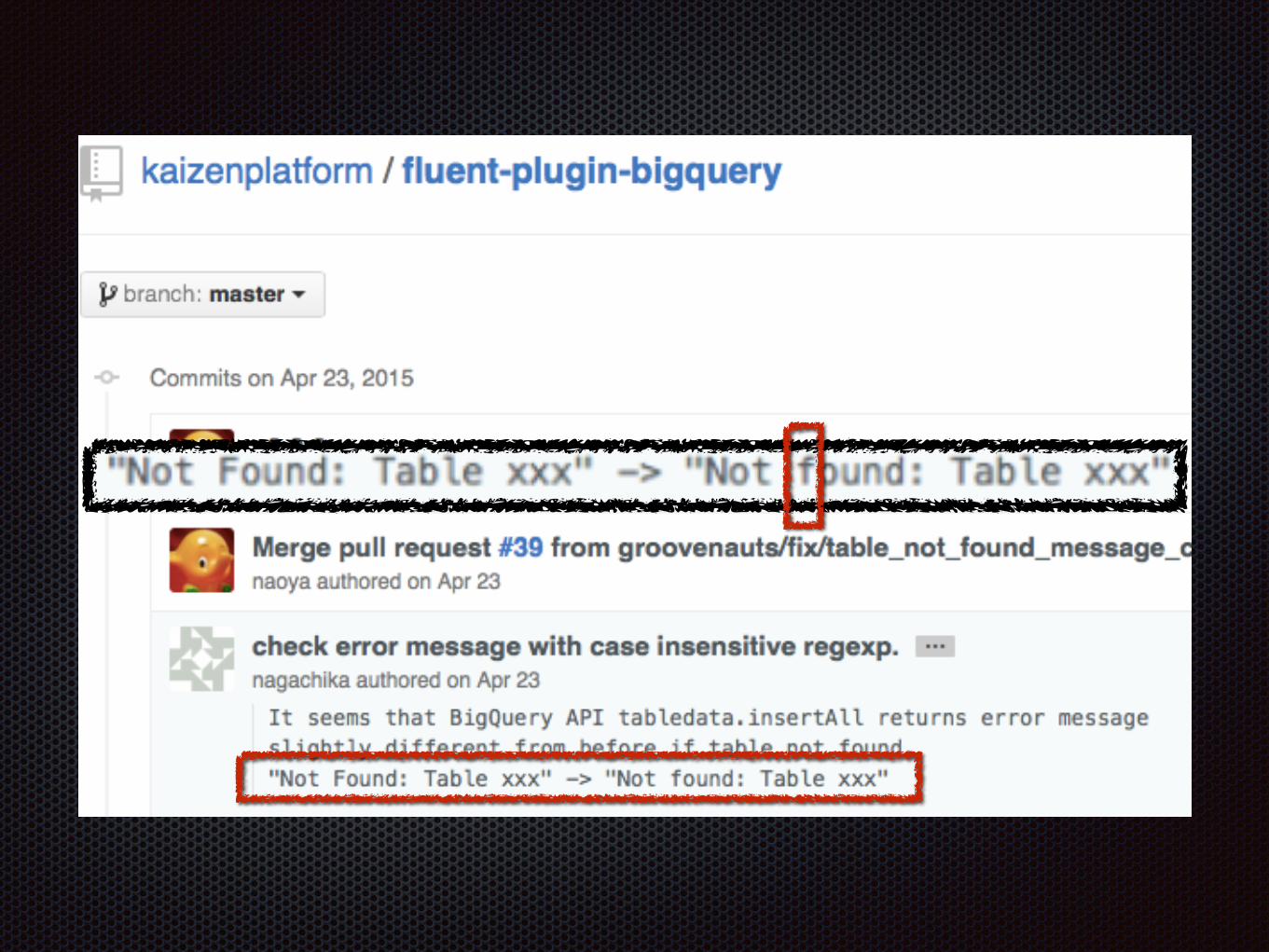
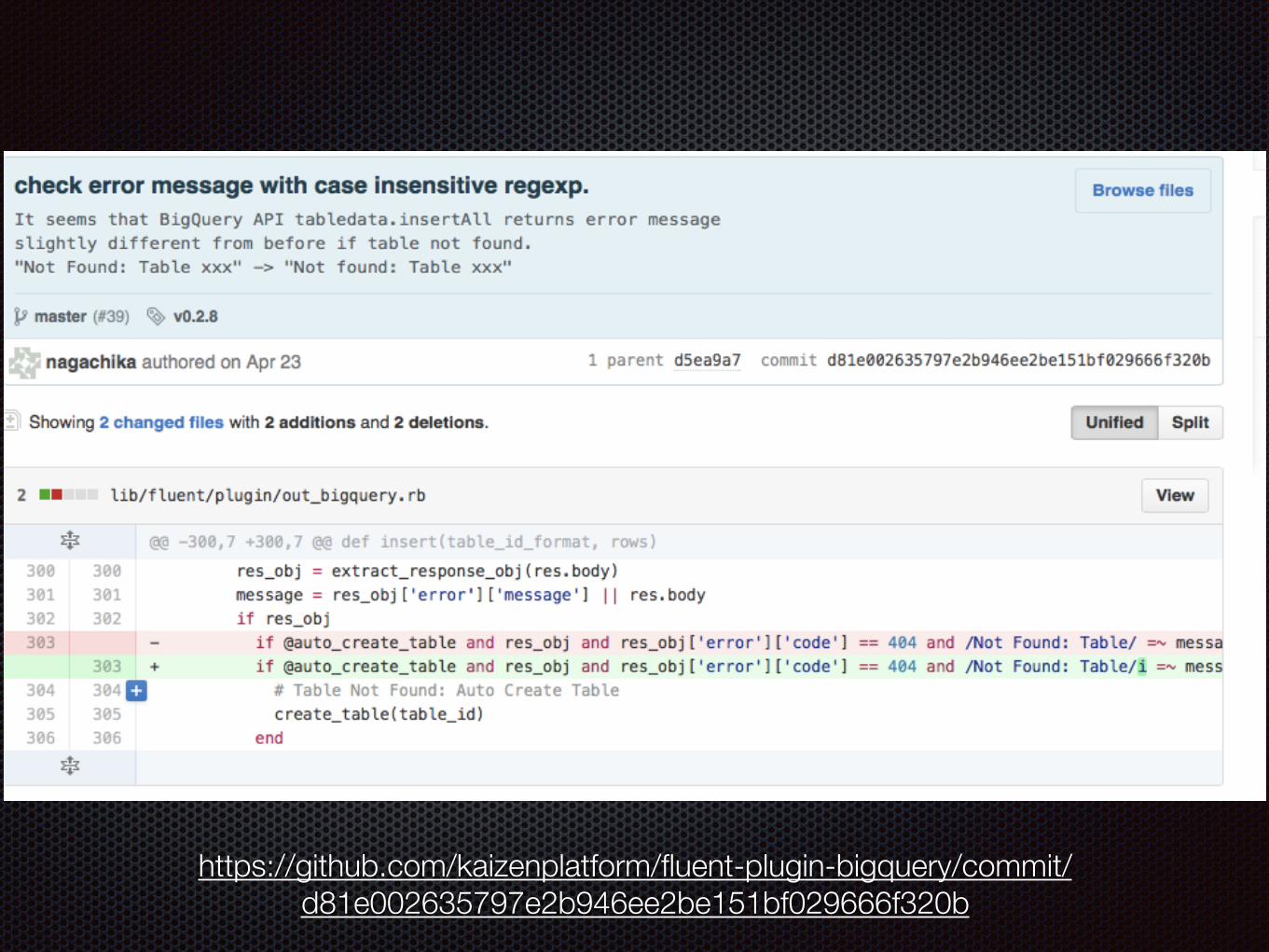
https://github.com/kaizenplatform/fluent-plugin-bigquery/commit/d81e002635797e2b946ee2be151bf029666f320b

ファイルから流し込みなおして対応orz

教訓
バックアップは常に用意する
どこかで何かあってもS3に上がっているという安心
エラーメッセージに依存した実装の危険性

可視化

ModeAnalytics

ModeAnalyticsとは
イカした感じの解析ツール
Webベース
SQLを登録する → グラフになる シンプル!
編集者あたり $249/m 閲覧ユーザーは無料
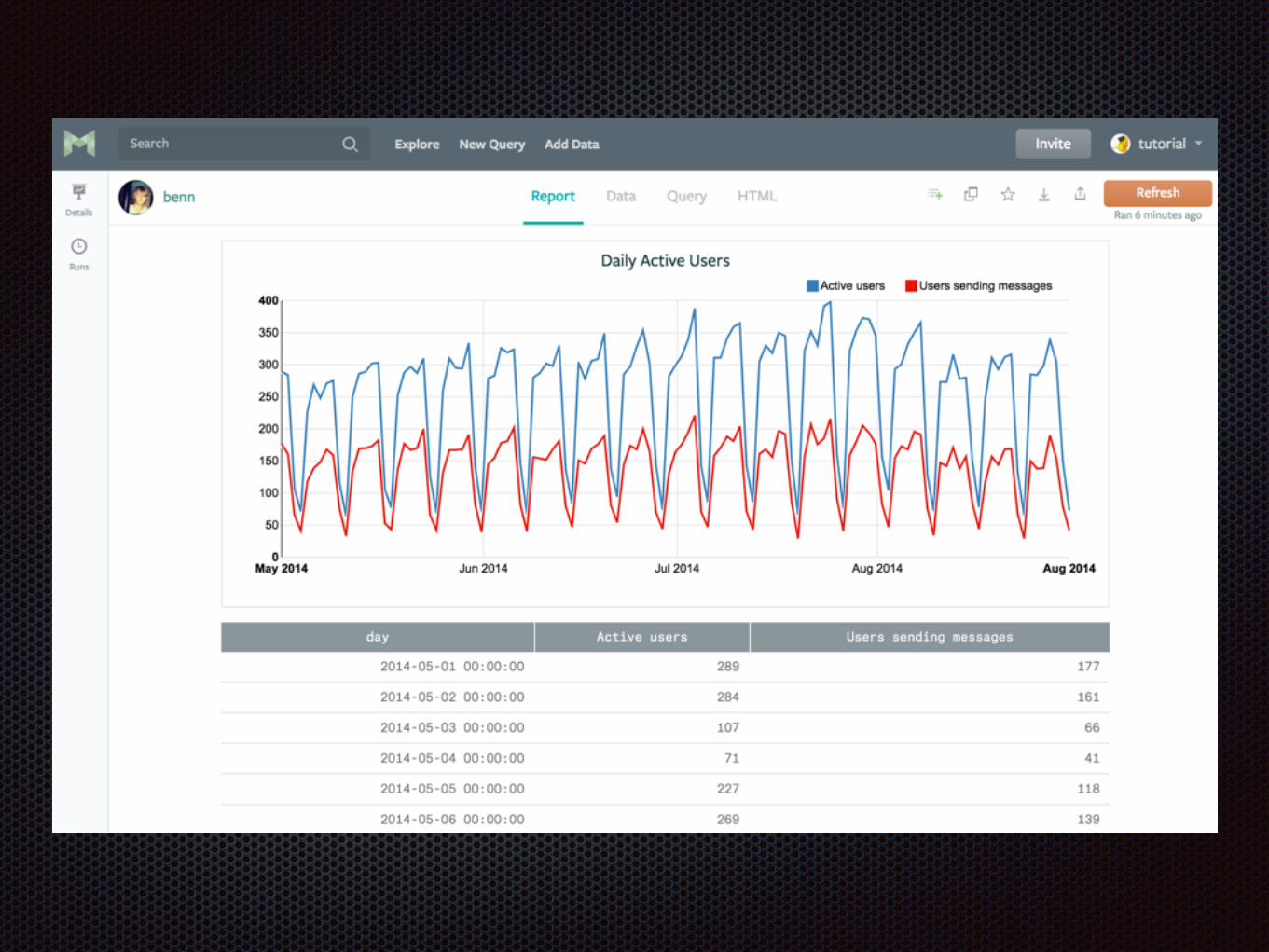
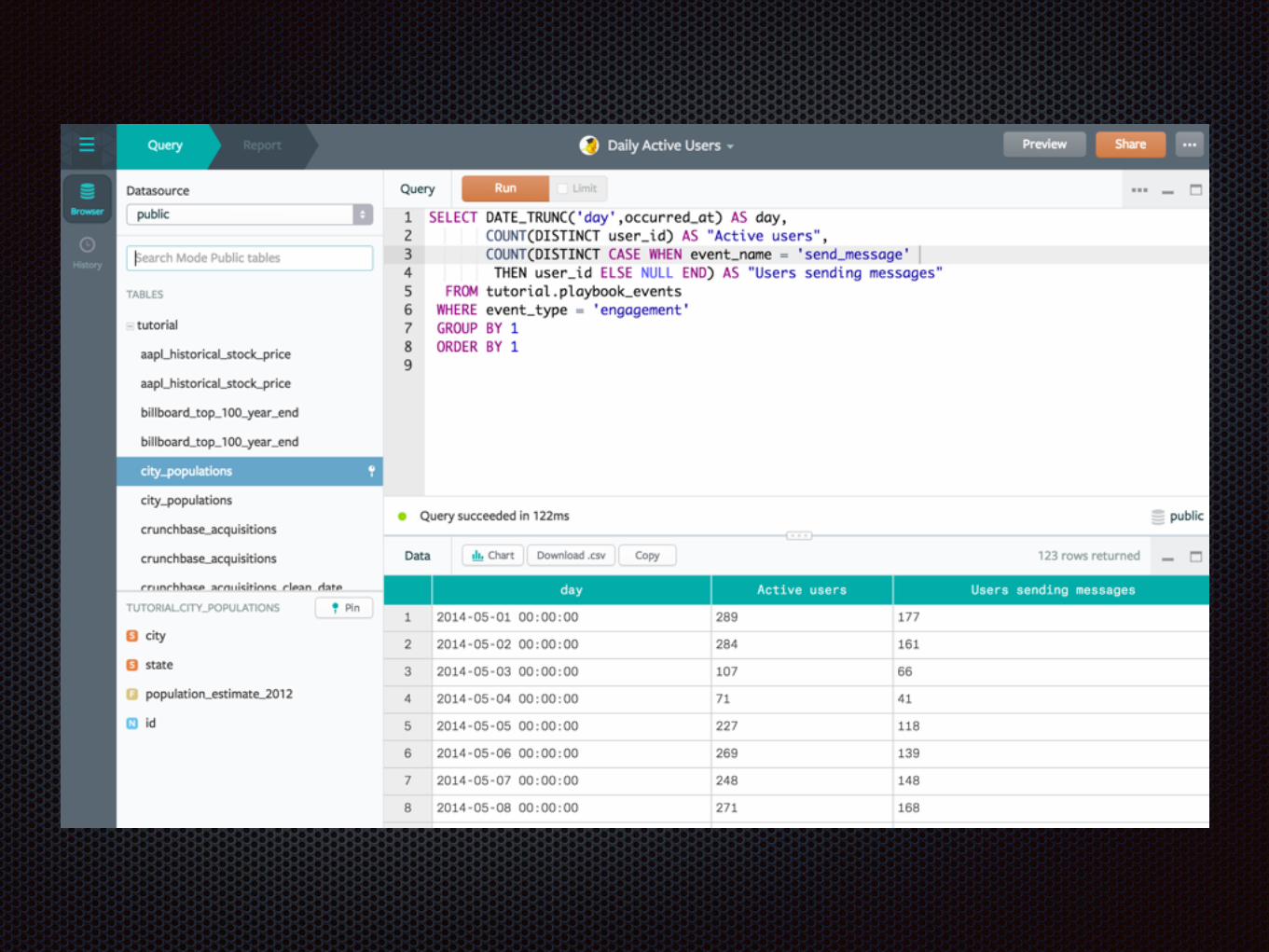

できます
スケジュール実行
実行結果の保存
レポートの加工(HTML風)
複数クエリの結果を複合したレポートの作成
App LogJob
log-bigquery
&
BigQuery

まとめ
BigQueryは簡単なSQLさえあればすぐに使える
JSONで突っ込むことでスキーマレスに運用可能
Tableはたくさん。スキーマは一つ。
バックアップとしてのファイル保存は残した方が良い

ご静聴ありがとうございました