gtc 2016 ディープラーニング最新情報
TRANSCRIPT

井﨑武士
GTC 2016 ディープラーニング最新情報
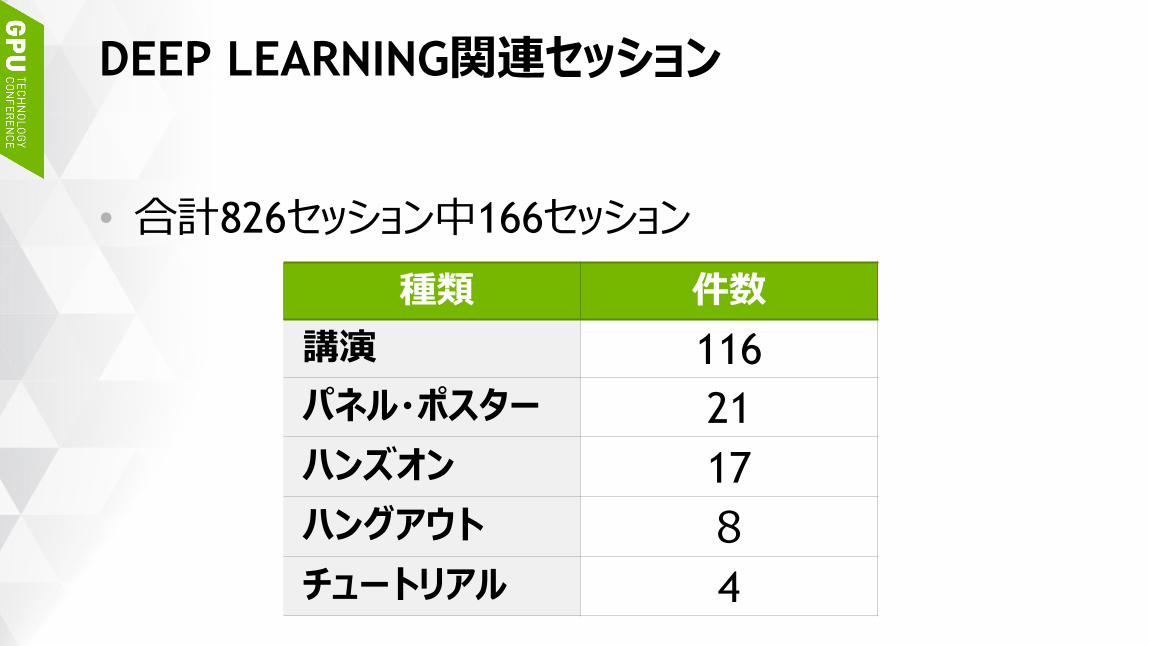
DEEP LEARNING関連セッション
• 合計826セッション中166セッション
種類 件数
講演 116
パネル・ポスター 21
ハンズオン 17
ハングアウト 8
チュートリアル 4
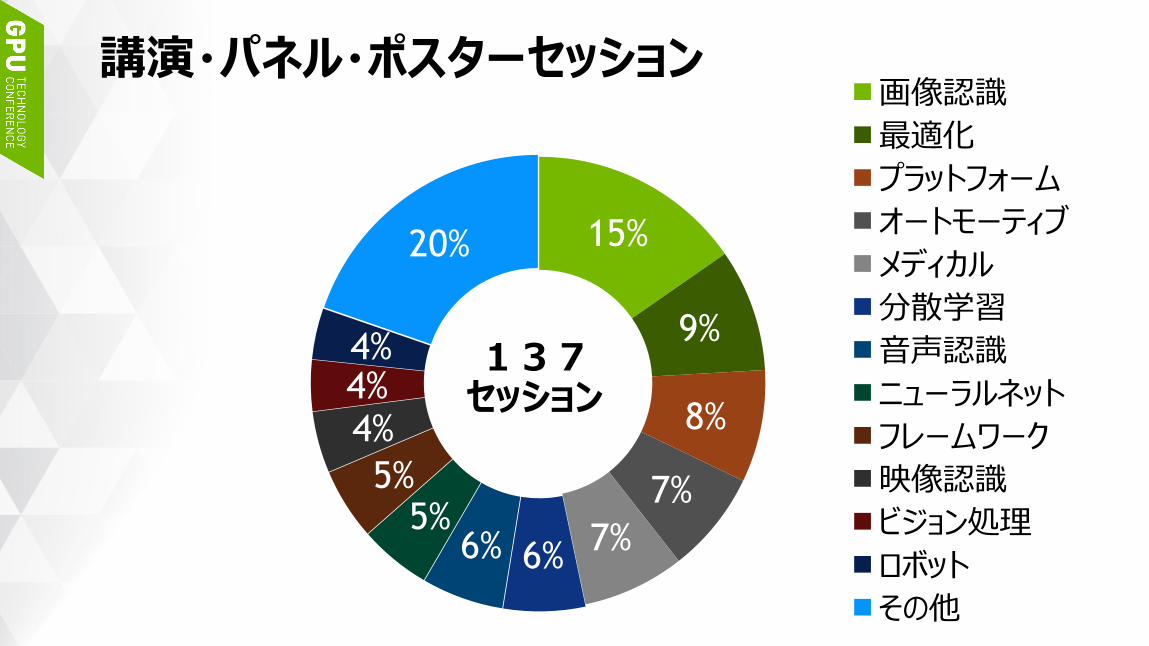
講演・パネル・ポスターセッション
15%
9%
8%
7%
7%6%6%
5%5%
4%4%4%
20%
画像認識
最適化
プラットフォーム
オートモーティブ
メディカル
分散学習
音声認識
ニューラルネット
フレームワーク
映像認識
ビジョン処理
ロボット
その他
137セッション

Xian-Sheng Hua Senior Director/Researcher, Alibaba Group
DEEP LEARNING IN REAL-WORLD LARGE-SCALE IMAGE SEARCH AND RECOGNITION
SESSION 1
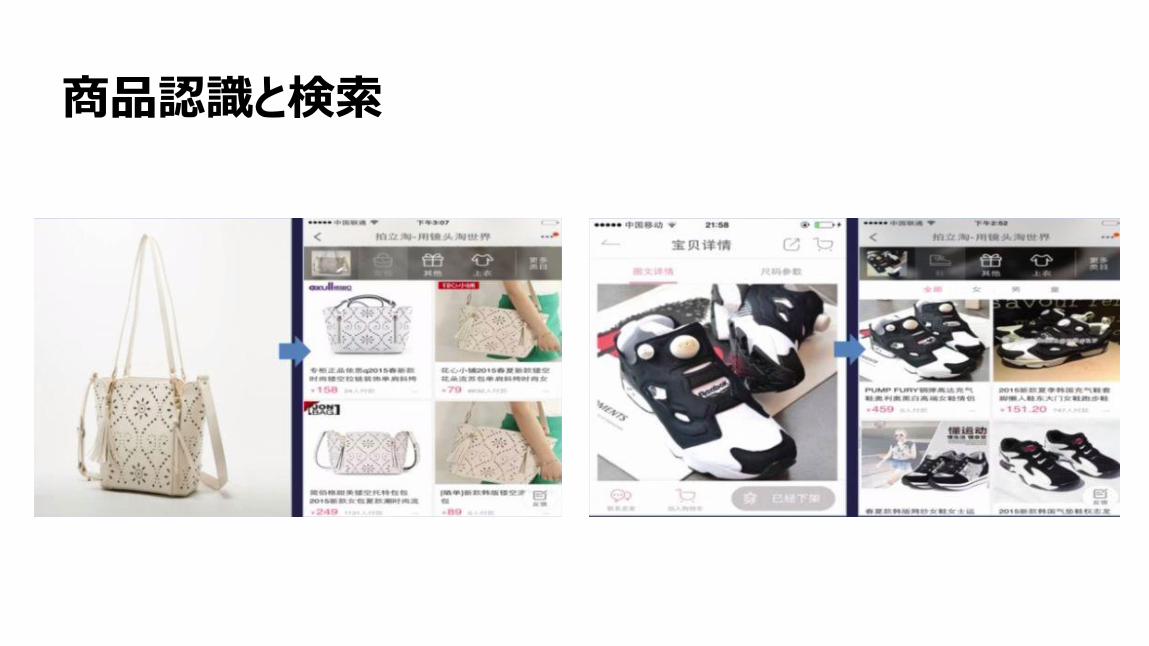
5
商品認識と検索

6
特徴抽出は難しい
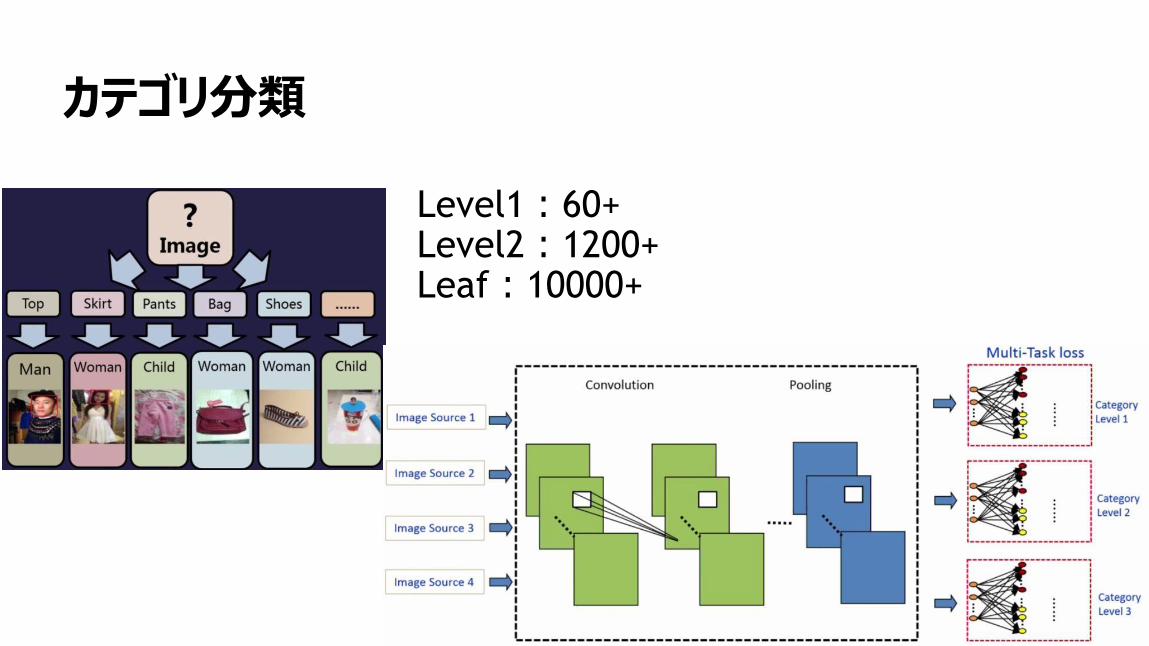
7
カテゴリ分類
Level1:60+Level2:1200+Leaf:10000+
8
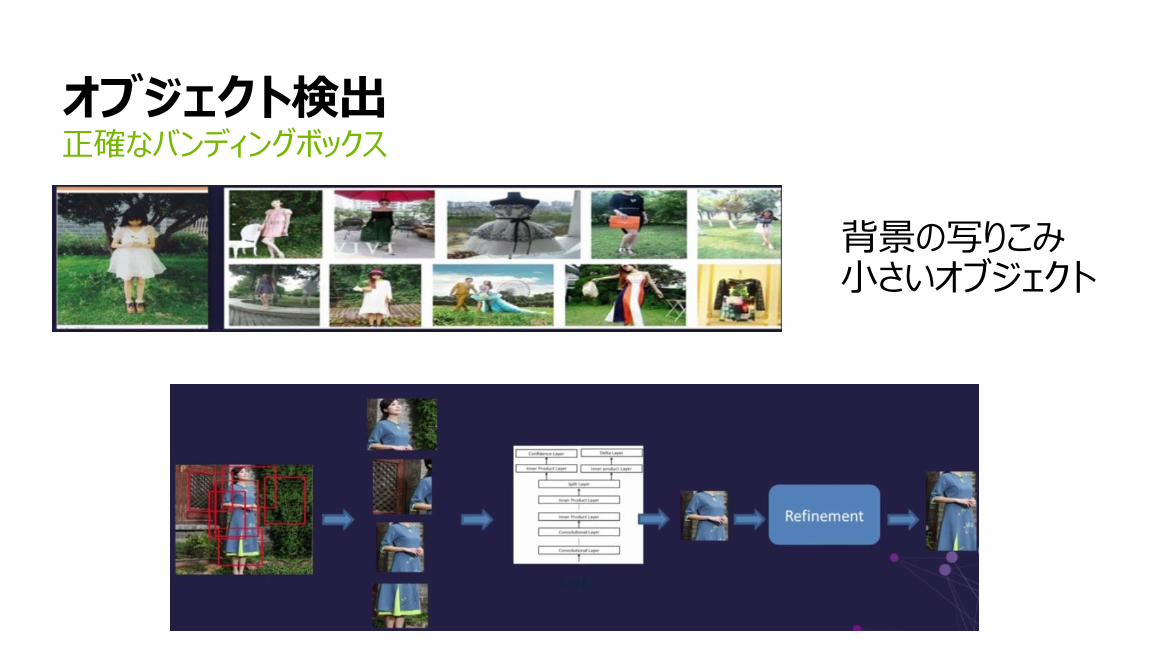
オブジェクト検出正確なバンディングボックス
背景の写りこみ小さいオブジェクト
9
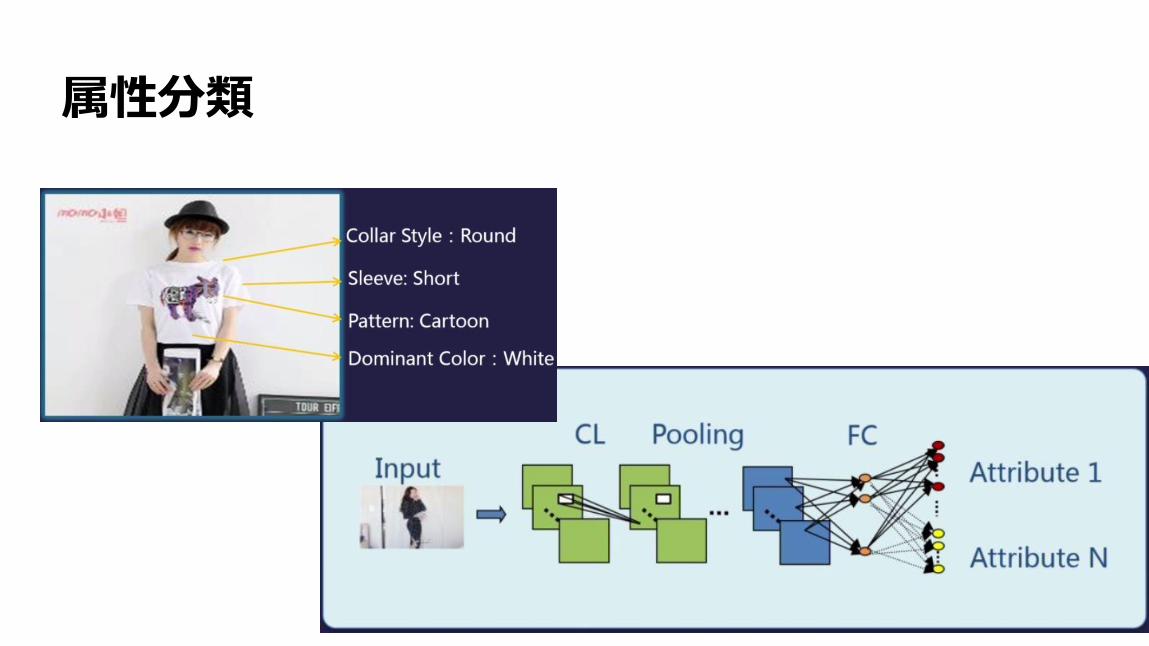
属性分類
10
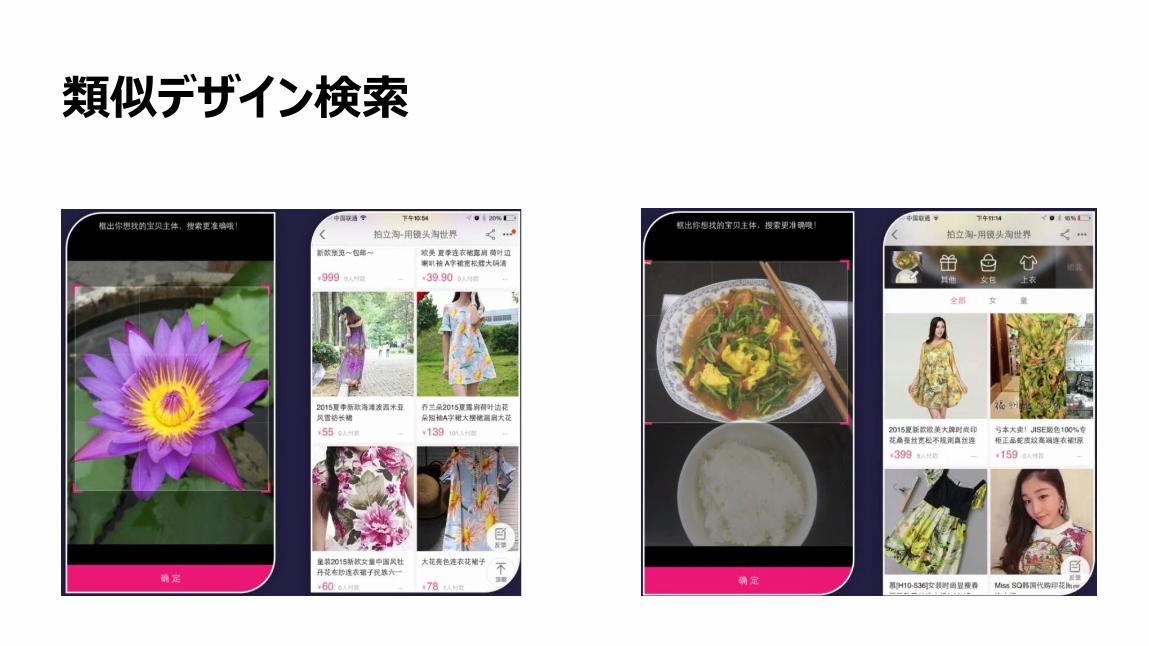
類似デザイン検索

11
同一商品、類似品検索

Chiyuan Zhang PhD Student, MIT
AUTOMATED GEOPHYSICAL FEATURE DETECTION WITH DEEP LEARNING
SESSION 2

13
弾性波探査
探査段階:弾性波データは石油・ガス産業で非常に重要。深層にある石油を見つけるために使用され石油・ガス探査における様々なフェーズで初期および発掘時に現場の特徴づけに使用される
14
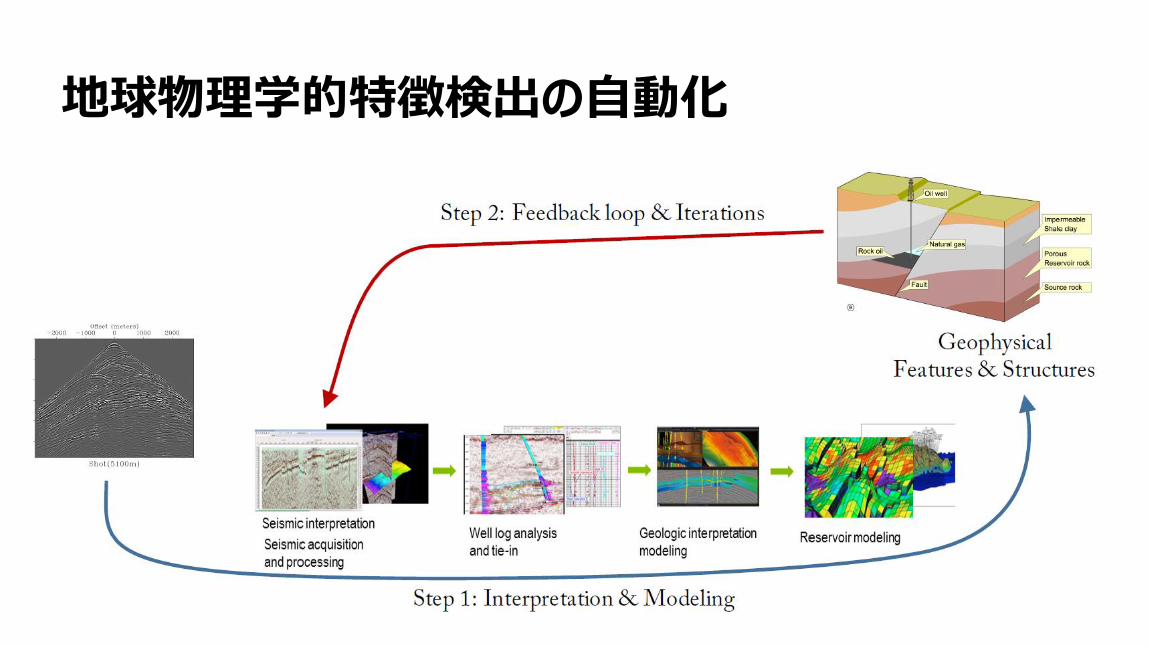
地球物理学的特徴検出の自動化
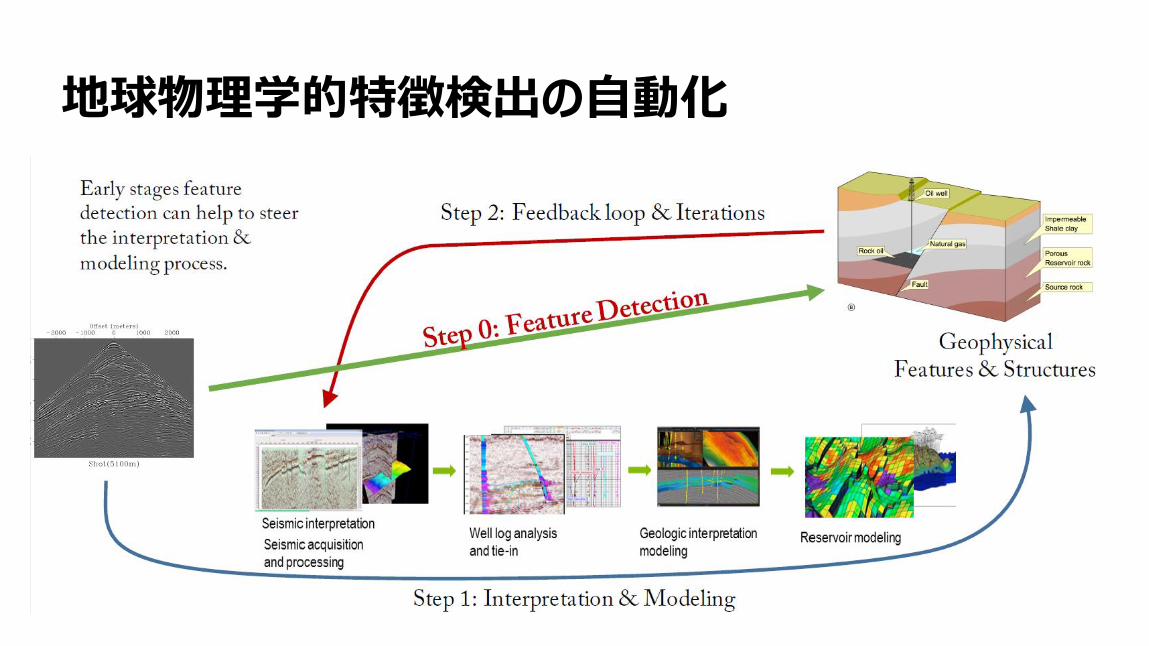
15
地球物理学的特徴検出の自動化
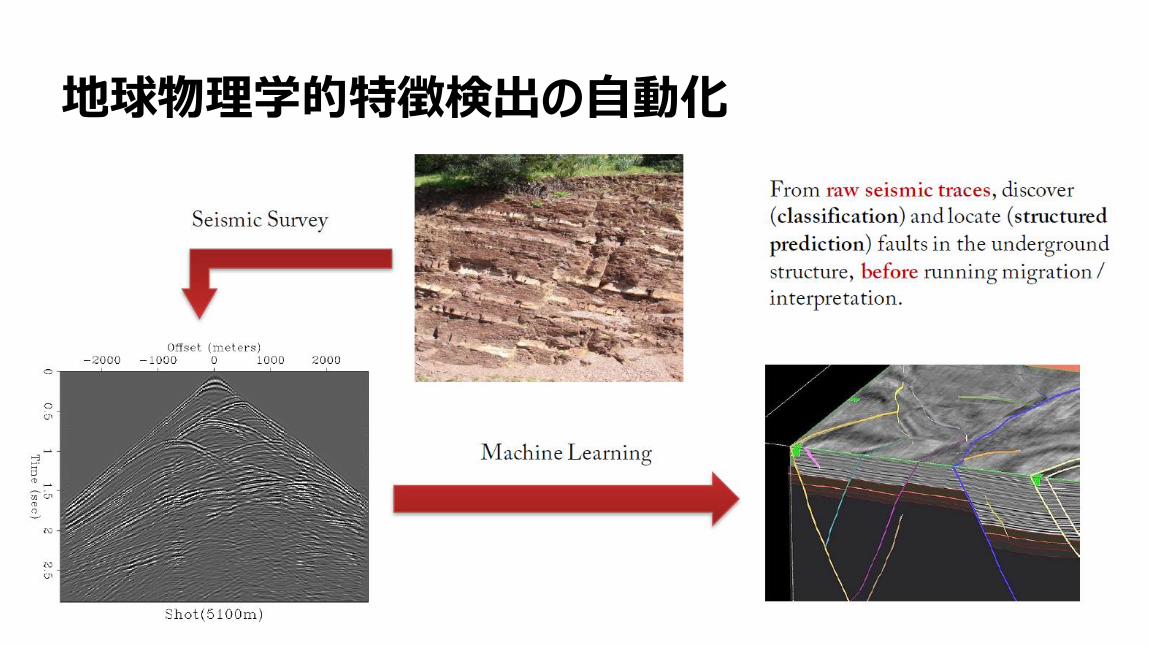
16
地球物理学的特徴検出の自動化
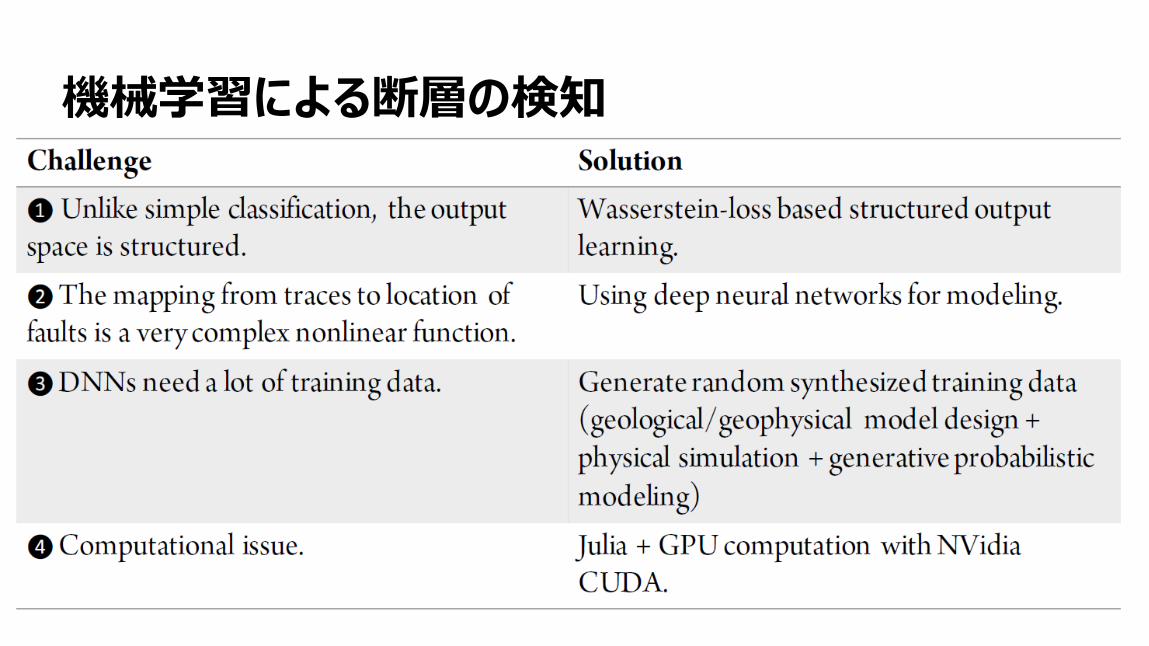
17
機械学習による断層の検知
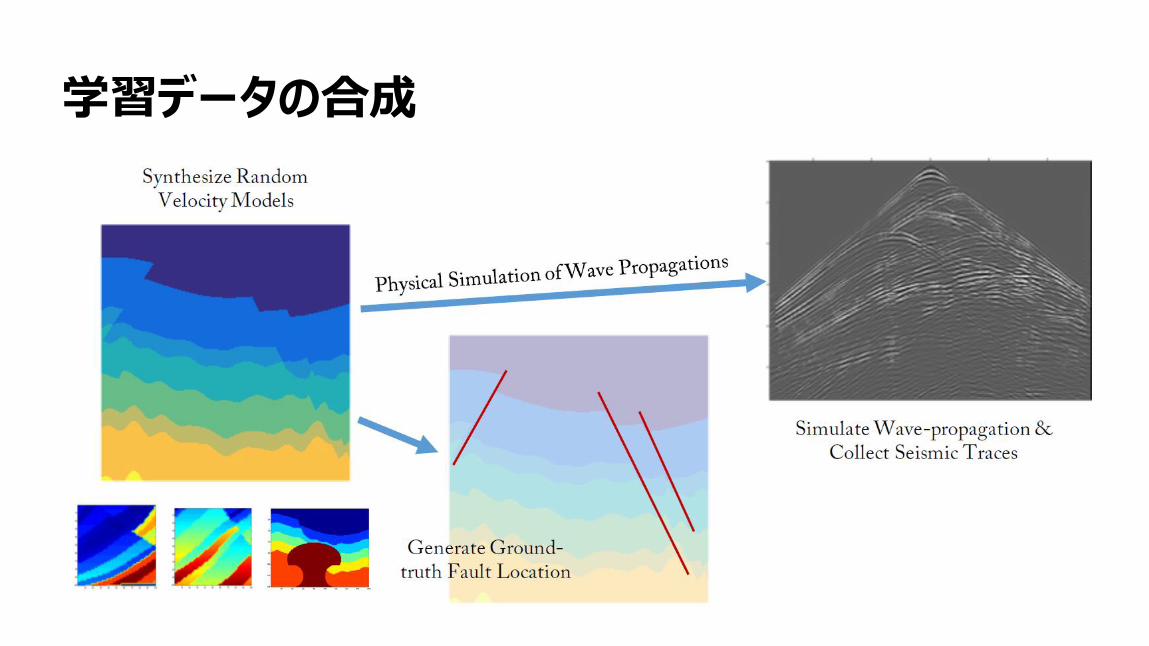
18
学習データの合成
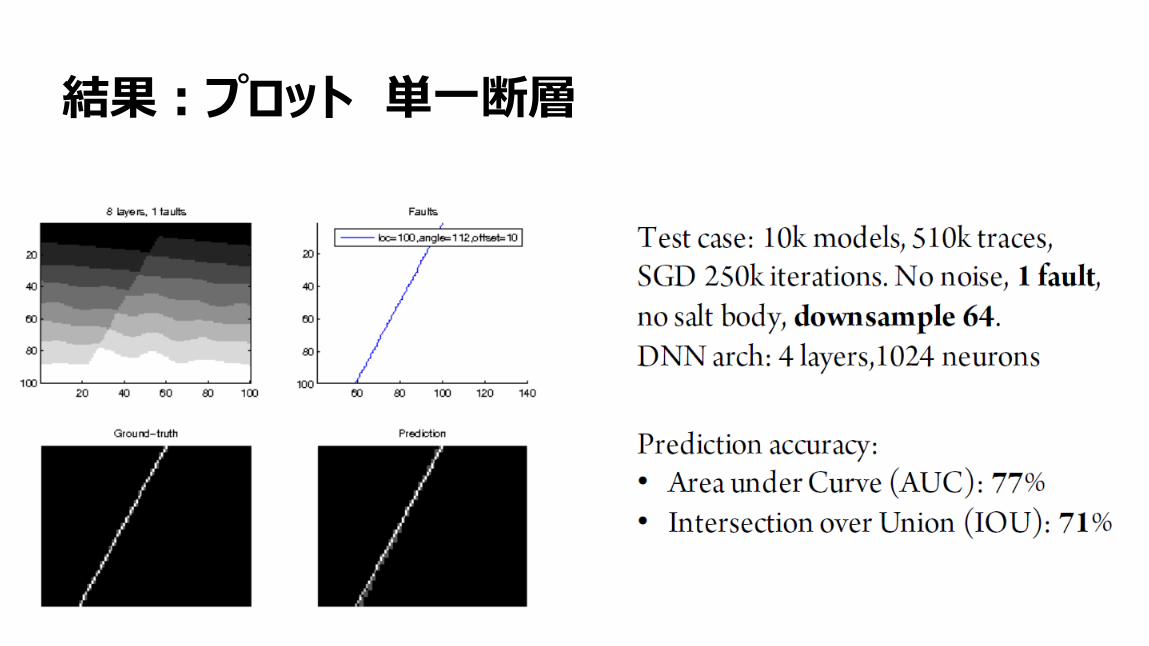
19
結果:プロット 単一断層
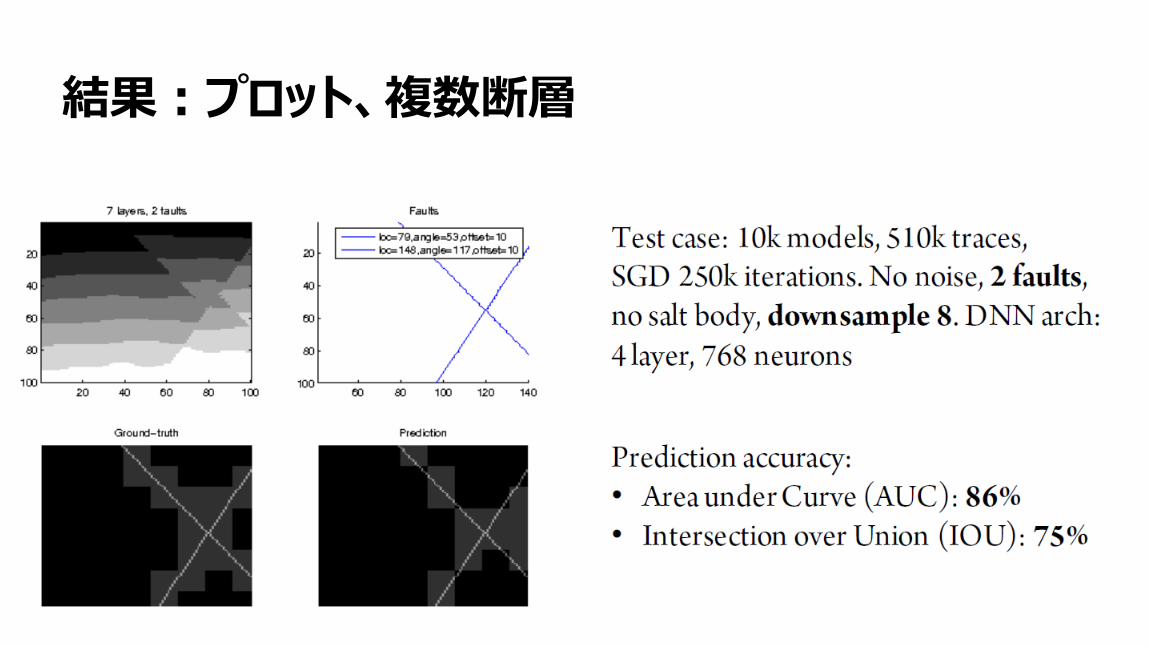
20
結果:プロット、複数断層

21
結果:プロット、岩塩

Konstantin Kiselev Data Scientist, Youth Laboratories
DEEP LEARNING ALGORITHMS FOR RECOGNIZING THE FEATURES OF FACIAL AGEING
SESSION 3

23
美容:肌年齢測定から肌ケアへ若く保つためのケア方法への探求
美容師皮膚科医その他の医師
部分的な意見バイアス
一貫性が無い時間+お金
自己評価(鏡) バイアス
周囲の人部分的な意見バイアス
一貫性が無い
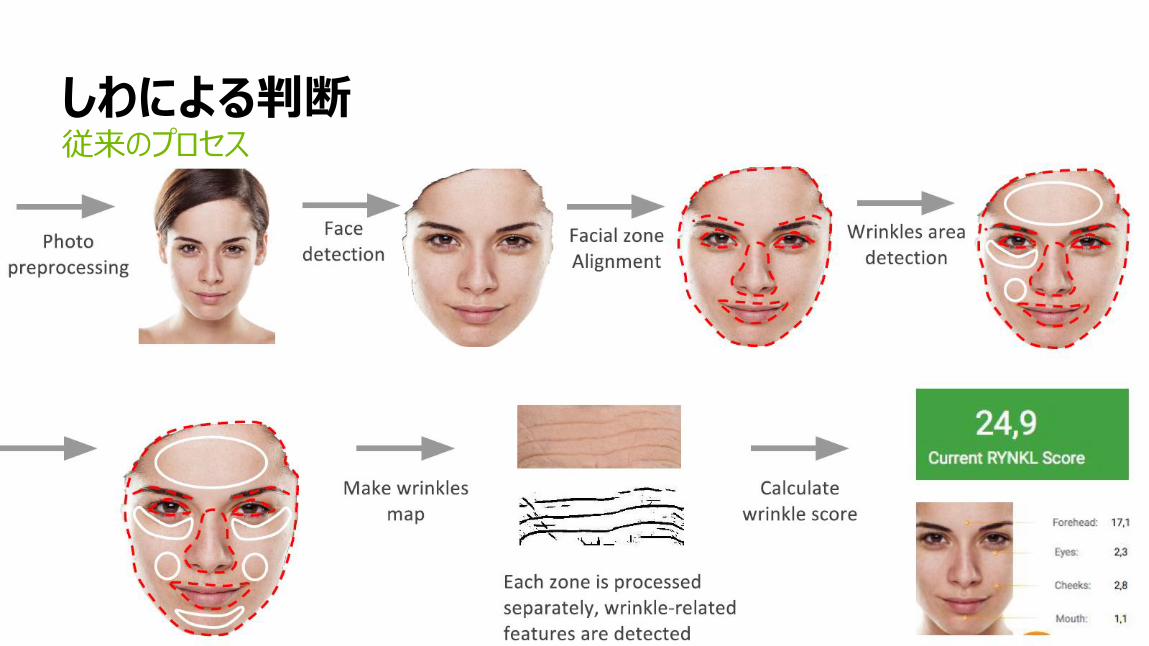
24
しわによる判断従来のプロセス
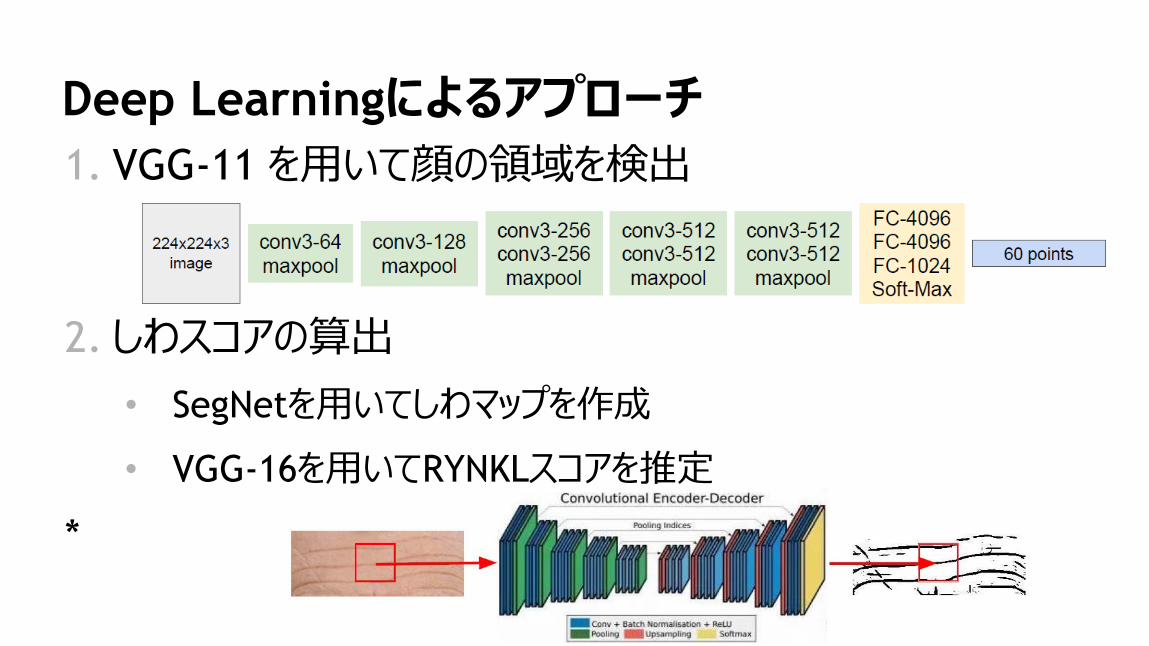
25
Deep Learningによるアプローチ
1. VGG-11 を用いて顔の領域を検出
2. しわスコアの算出
• SegNetを用いてしわマップを作成
• VGG-16を用いてRYNKLスコアを推定
*

26
データセットの集め方
AI判定による第1回目の国際ビューティコンテスト開催(2015年12月1日~2016年1月18日)
約3000に上る画像(解像度2K以上)+ 情報(体重、身長、年齢、性別、人種、国)
第2回目のコンテストを2016年5月1日~開催予定
結果
平均二乗誤差: 従来手法 0.39、 Deep Learning 0.32

Bryan Catanzaro Senior Researcher, Baidu Research
TRAINING AND DEPLOYING DEEP NEURAL NETWORKS FOR SPEECH RECOGNITION
SESSION 4
28
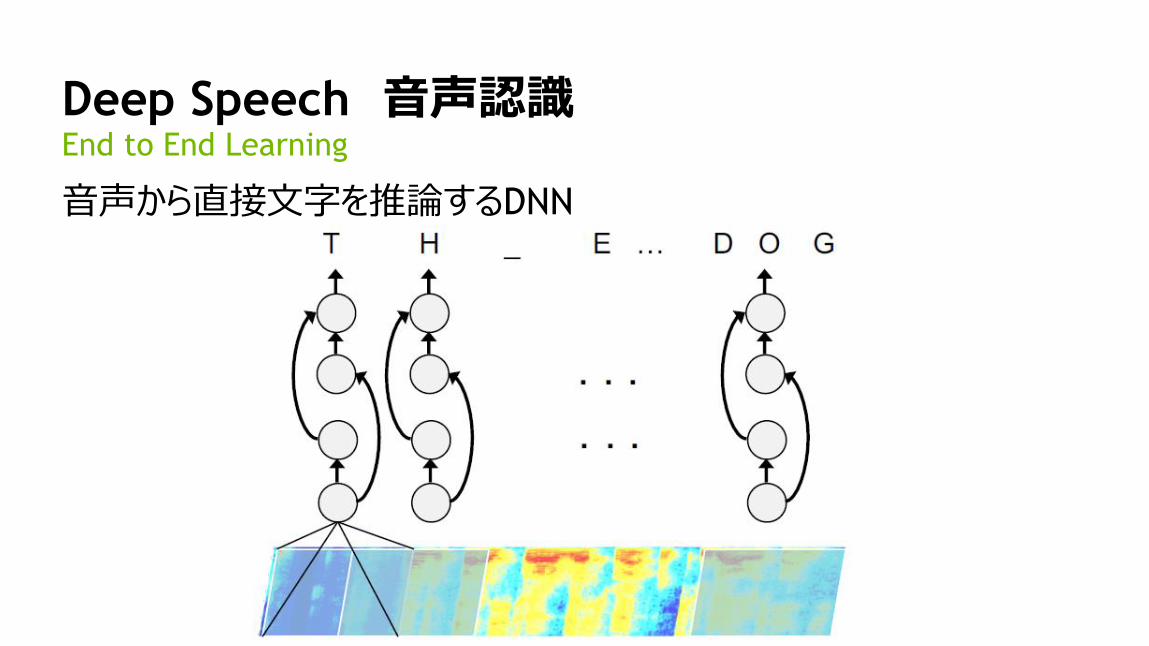
Deep Speech 音声認識End to End Learning
音声から直接文字を推論するDNN

29
Warp-CTC
BaiduのOpen source化されたCTC実装
CPUとGPUの並列化に効果的
他の実装に比べ100~400倍高速
Apacheライセンス、Cインターフェイス

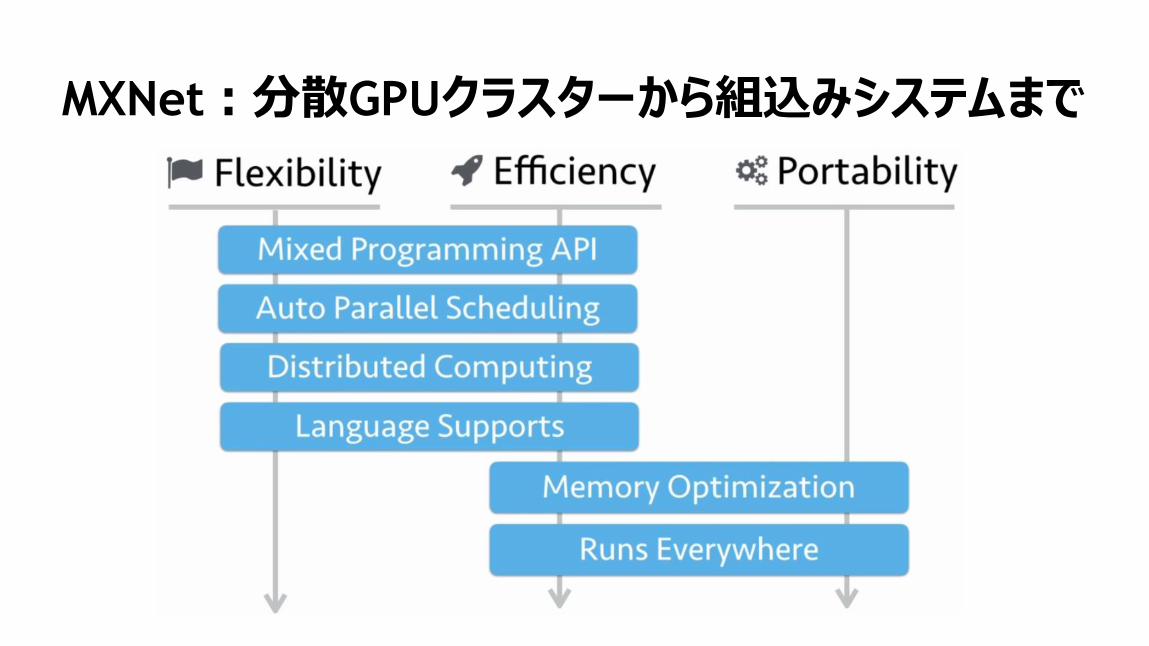
30
Deep Speech2
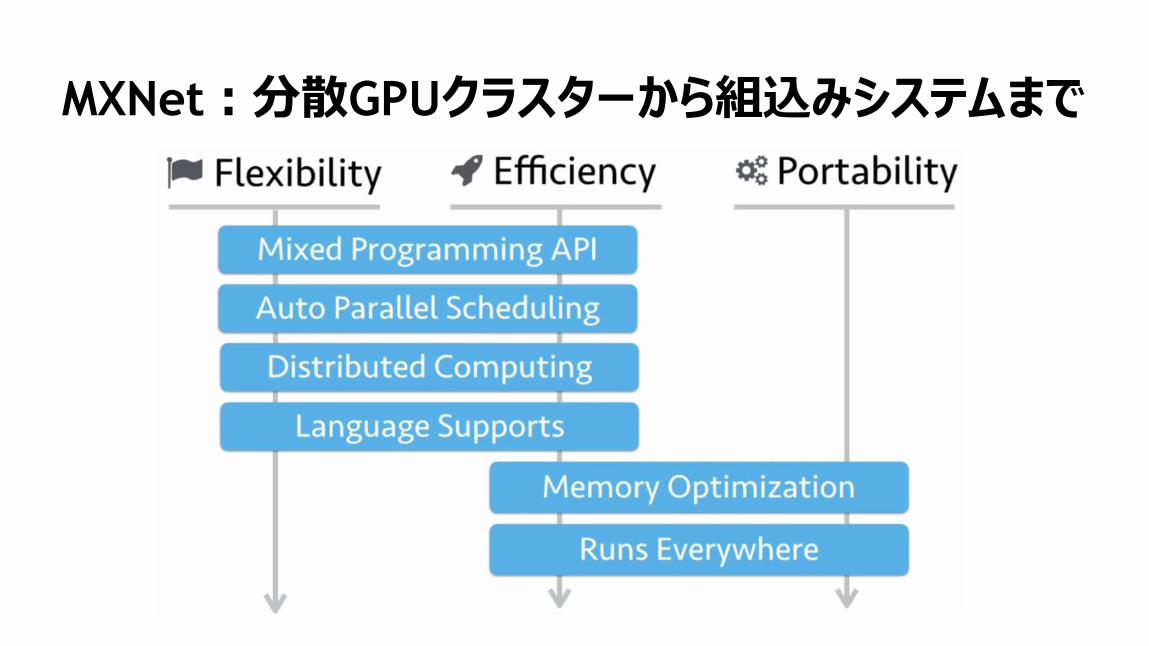
Batch Norm
トレーニングデータ:1年半の蓄積データ(英語と北京語)
31
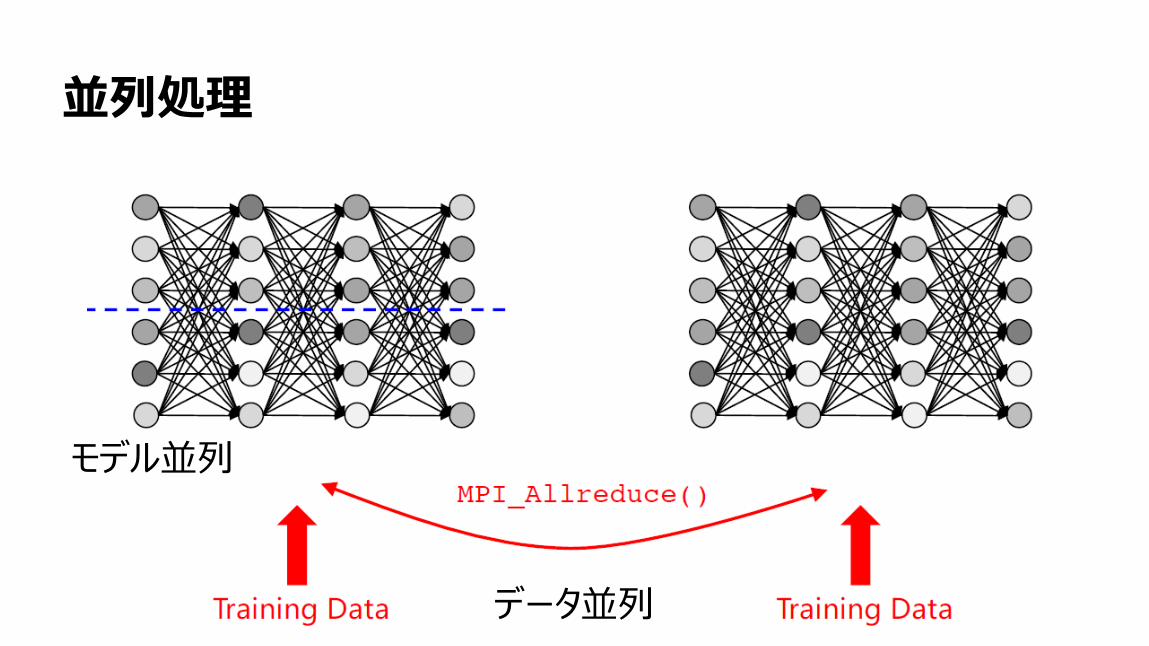
並列処理
モデル並列
データ並列
32
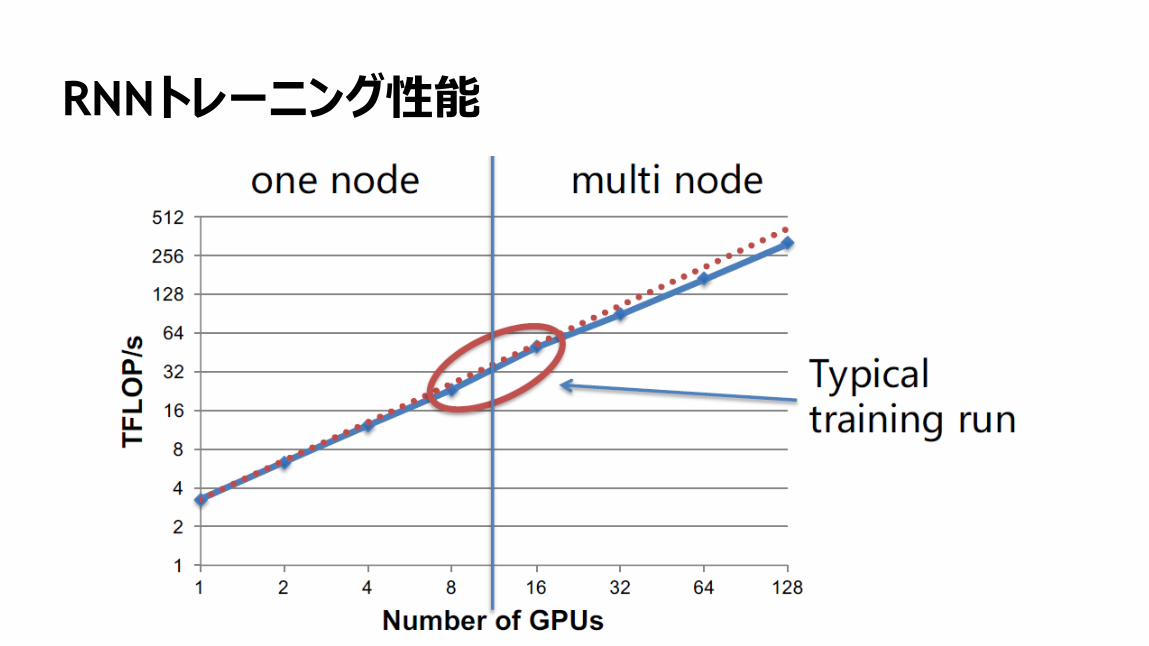
RNNトレーニング性能
33
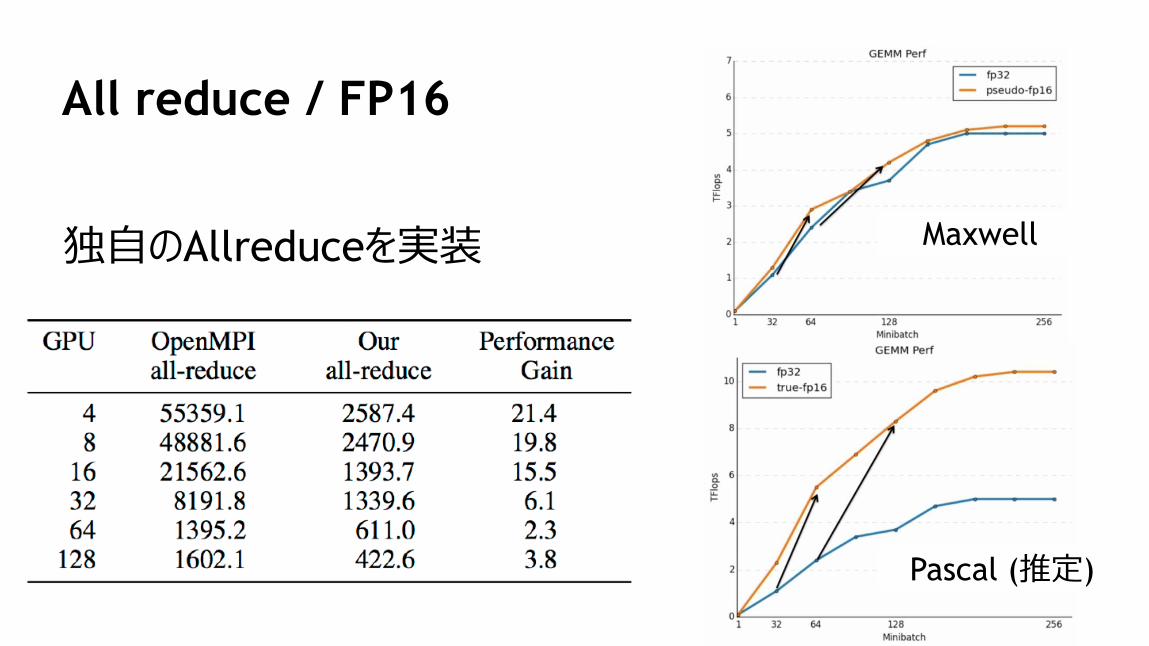
All reduce / FP16
独自のAllreduceを実装 Maxwell
Pascal (推定)

Nigel Cannings Chief Technical Officer, Intelligent Voice Limited
DEEP CONVOLUTIONAL NEURAL NETWORKS FOR SPOKEN DIALECT CLASSIFICATION OF SPECTROGRAM IMAGES USING DIGITS
SESSION 5

35
CNNを用いた方言分類NIST LRE Competition
6言語、20方言
アラビア語(エジプト、イラク、レバノン、マグレビ、標準語)
中国語(広東、北京、上海、台湾)
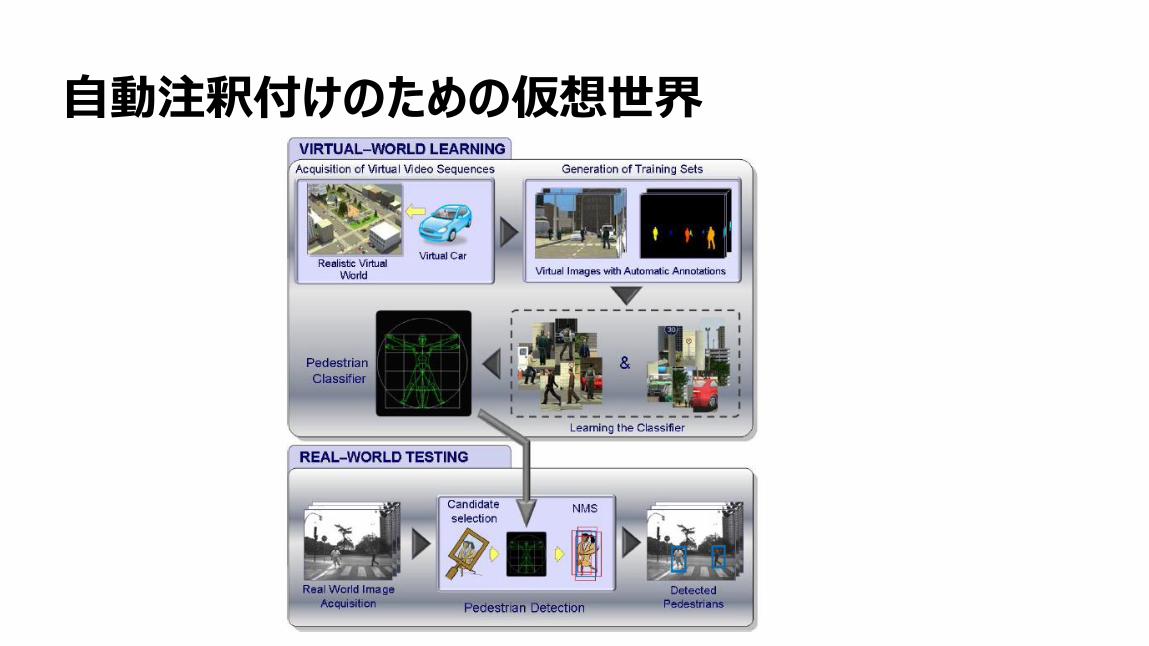
英語(英国、米国、インド)
フランス語(西アフリカ、ハイチ)
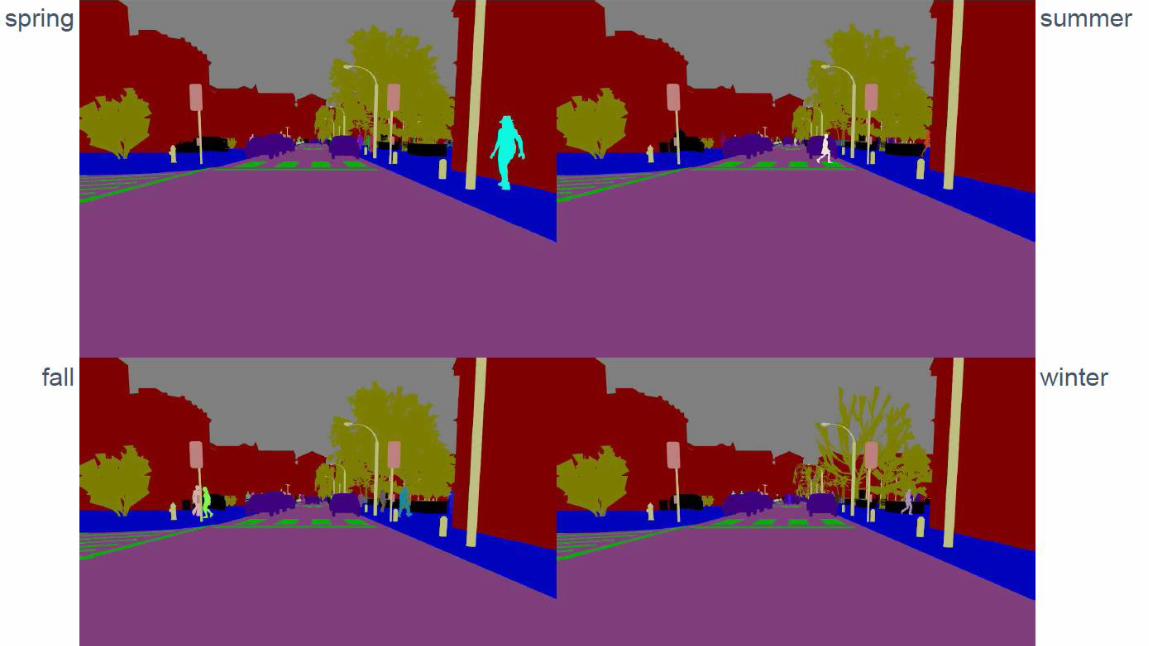
リベリア語(カリブスペイン、ヨーロッパスペインラテンアメリカスペイン、ブラジルポルトガル)
スラブ語(ポーランド、ロシア)
500時間以上のスピーチデータ

36
スペクトログラム+CNN
環境:NVIDIA DIGITS GoogLeNet
会話データを256x256のスペクトログラムに変換
異なるスペクトル表現やコーディングを試行

37
GoogLeNetでの処理
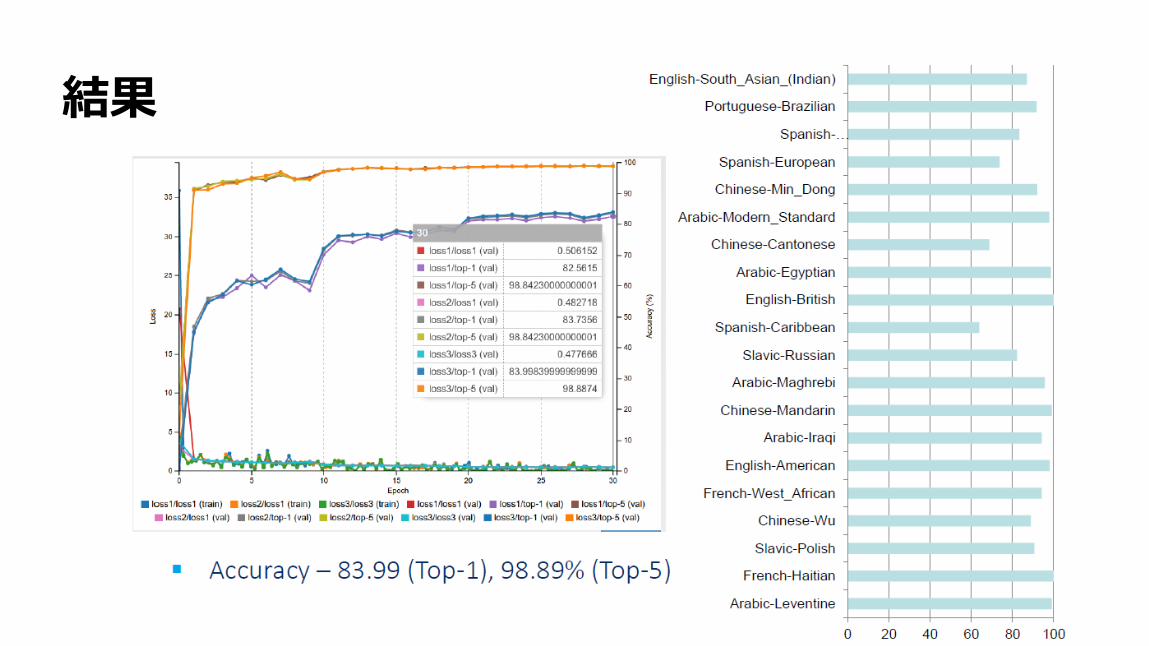
38
結果

Jianxiong Xiao Assistant Professor, Princeton University
3D DEEP LEARNING
SESSION 6

40
ロボットのための3次元 Deep Learning 認識
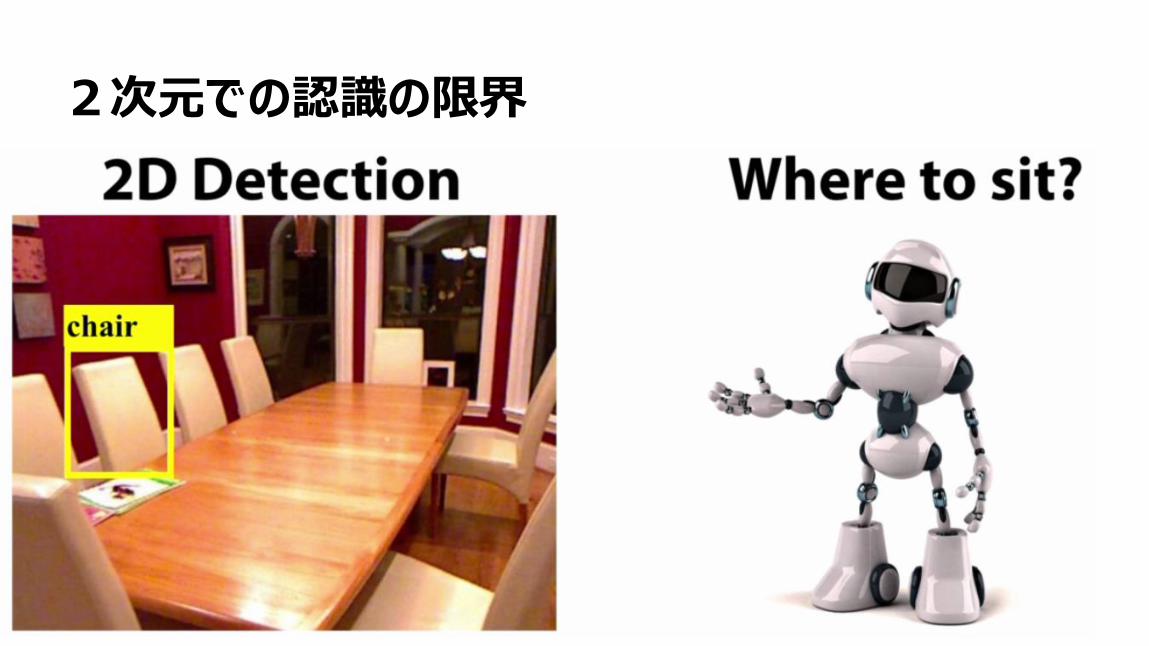
41
2次元での認識の限界

42
3次元での認識
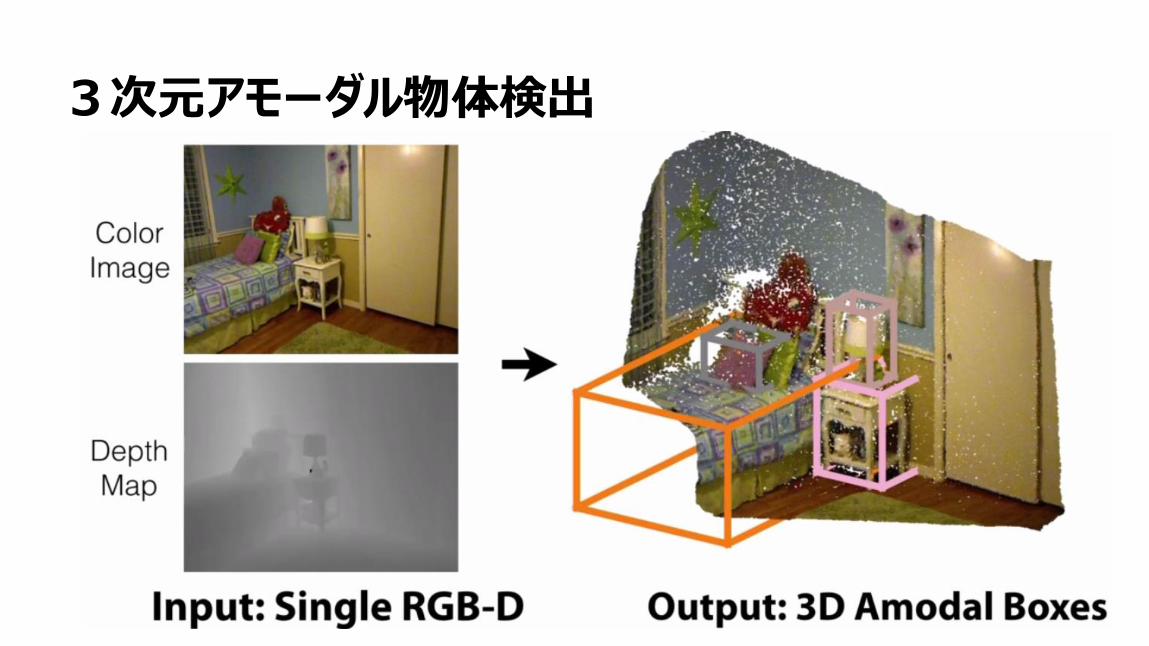
43
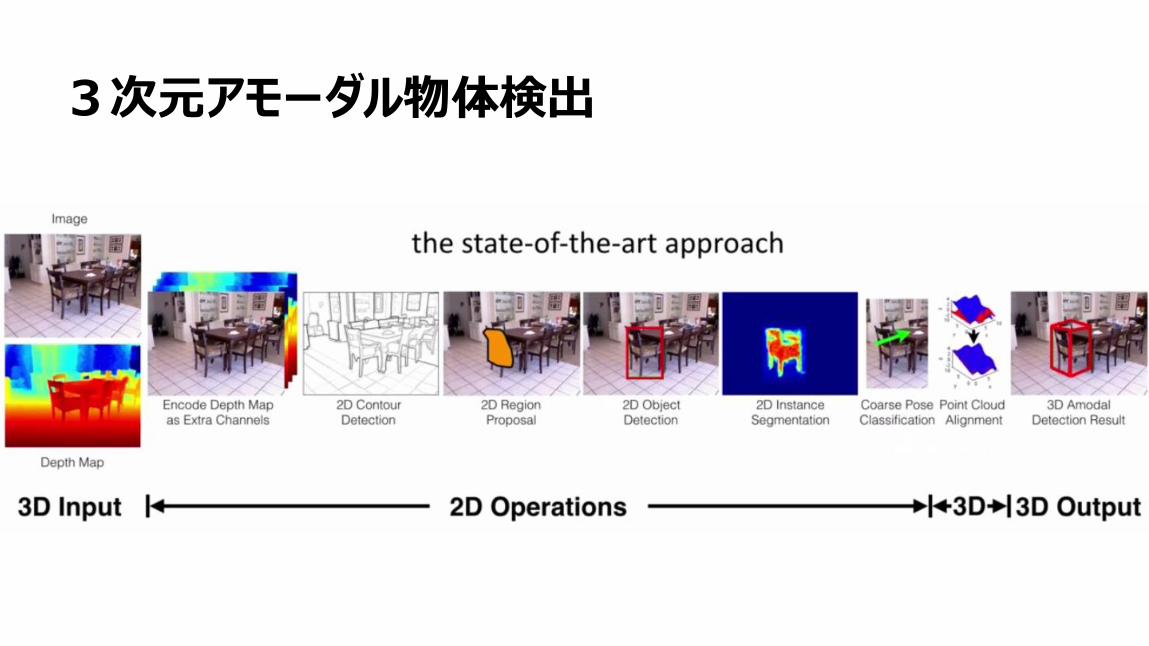
3次元アモーダル物体検出

44
2次元物体検出
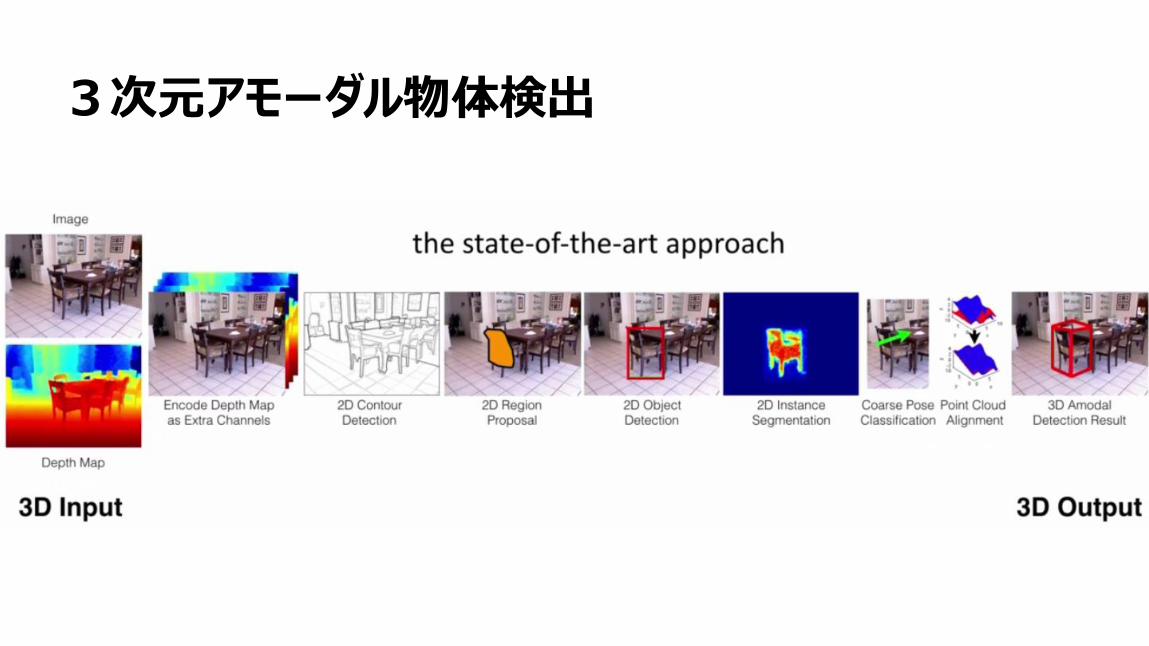
45
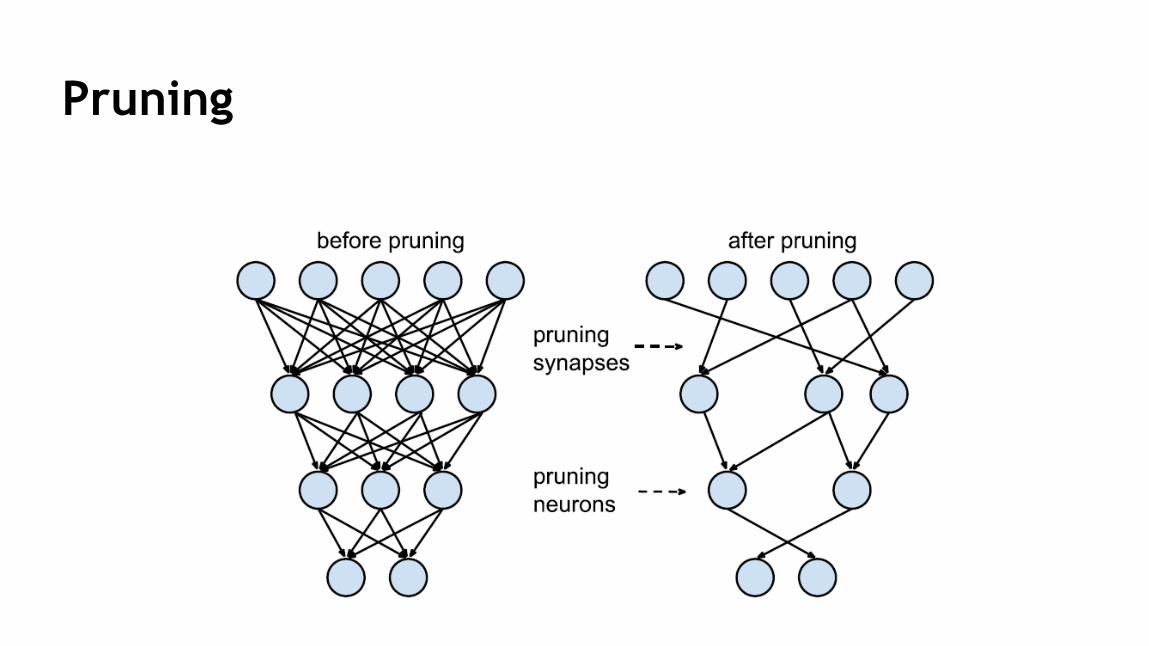
3次元アモーダル物体検出
46
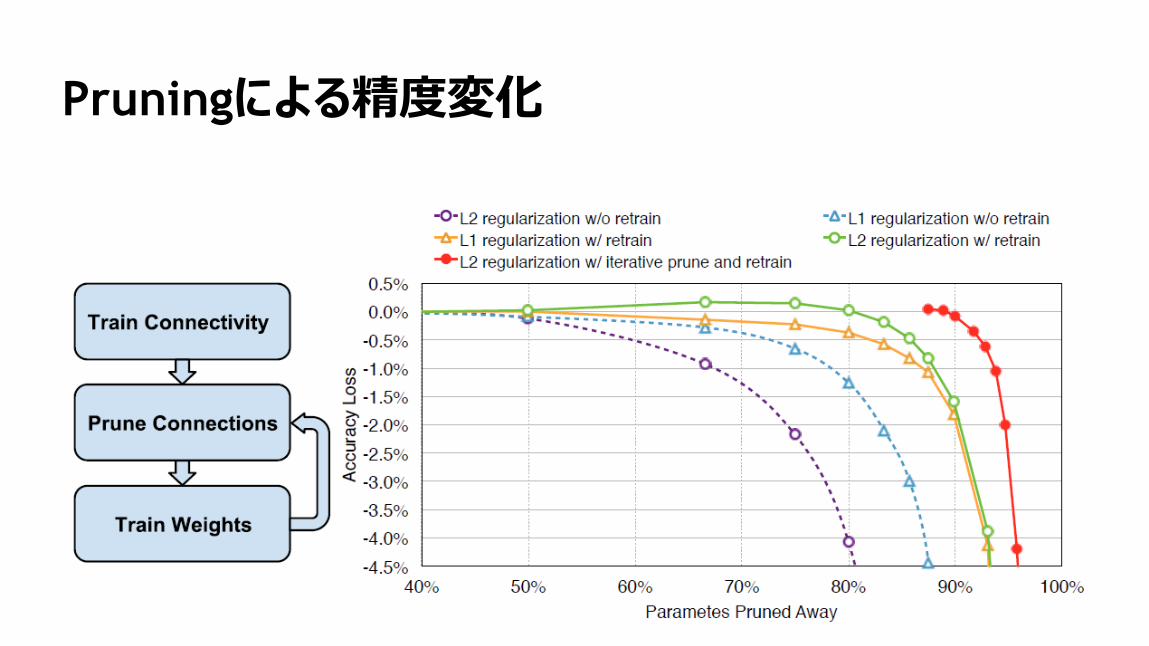
3次元アモーダル物体検出

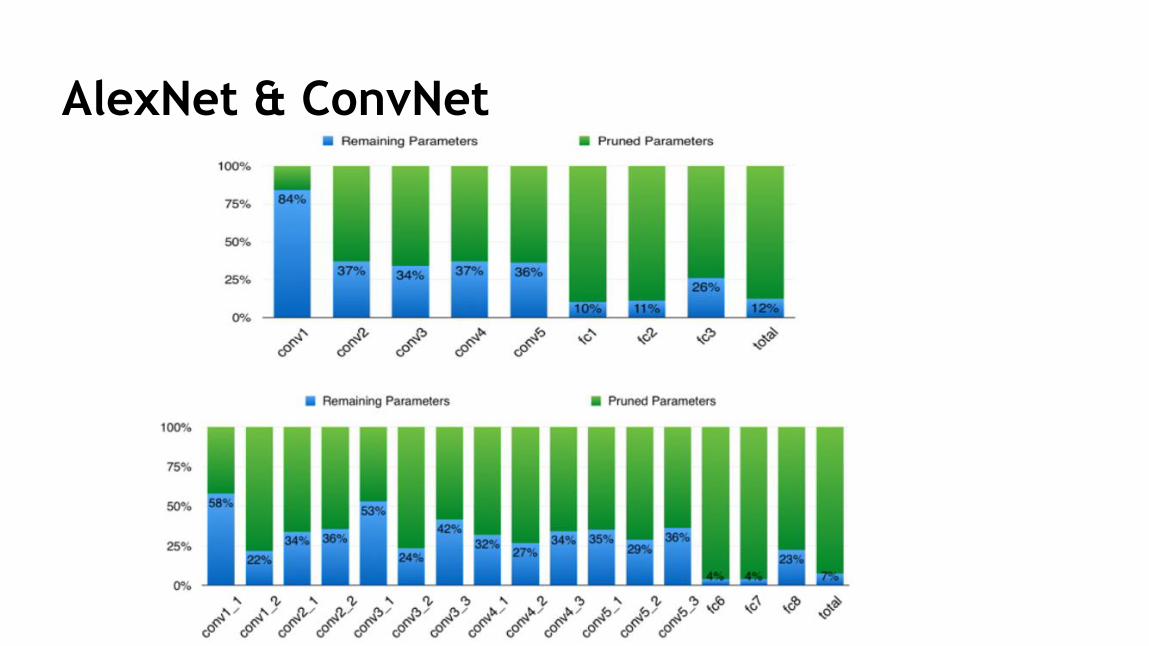
47
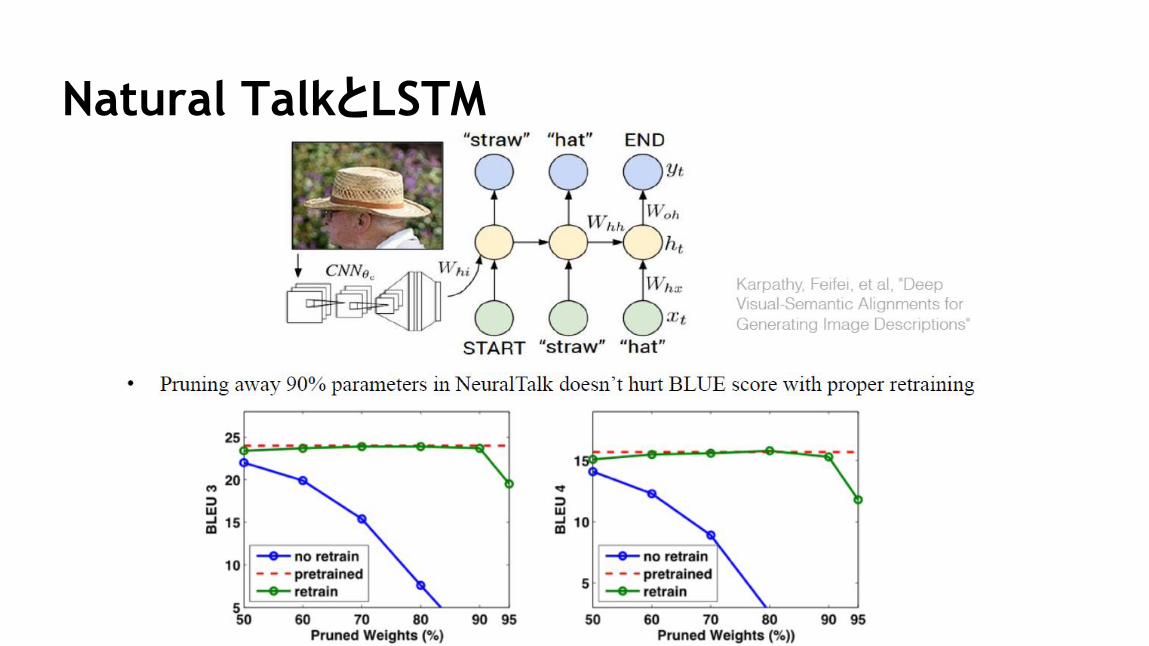
3次元アモーダル物体検出
48
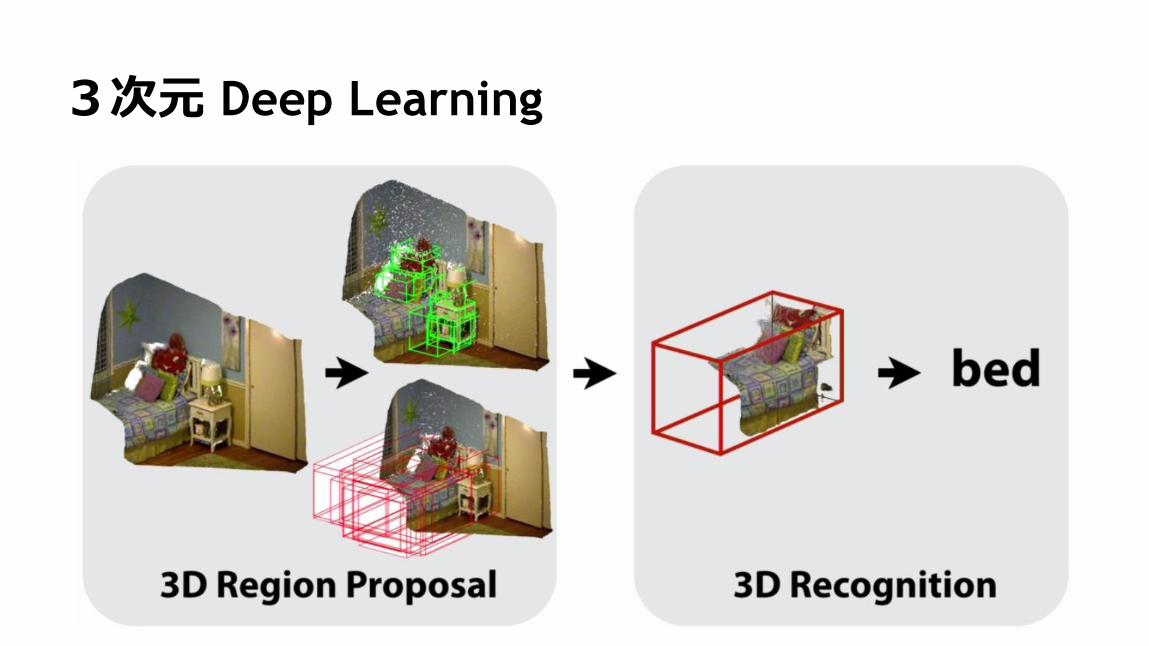
3次元 Deep Learning
49
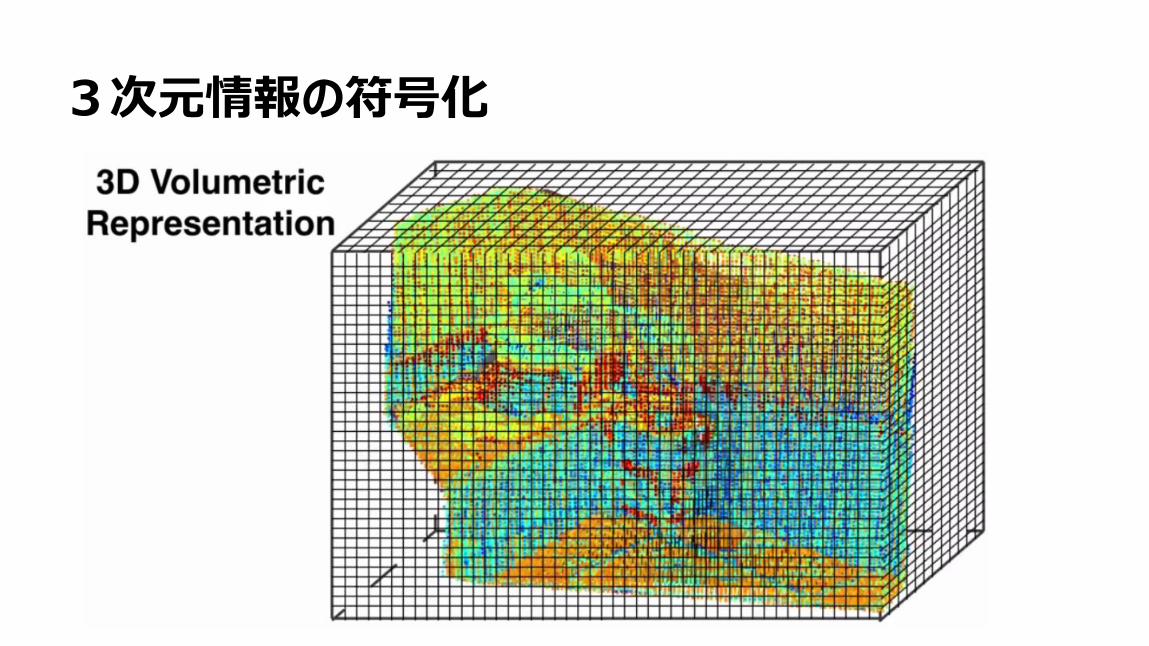
3次元情報の符号化
50
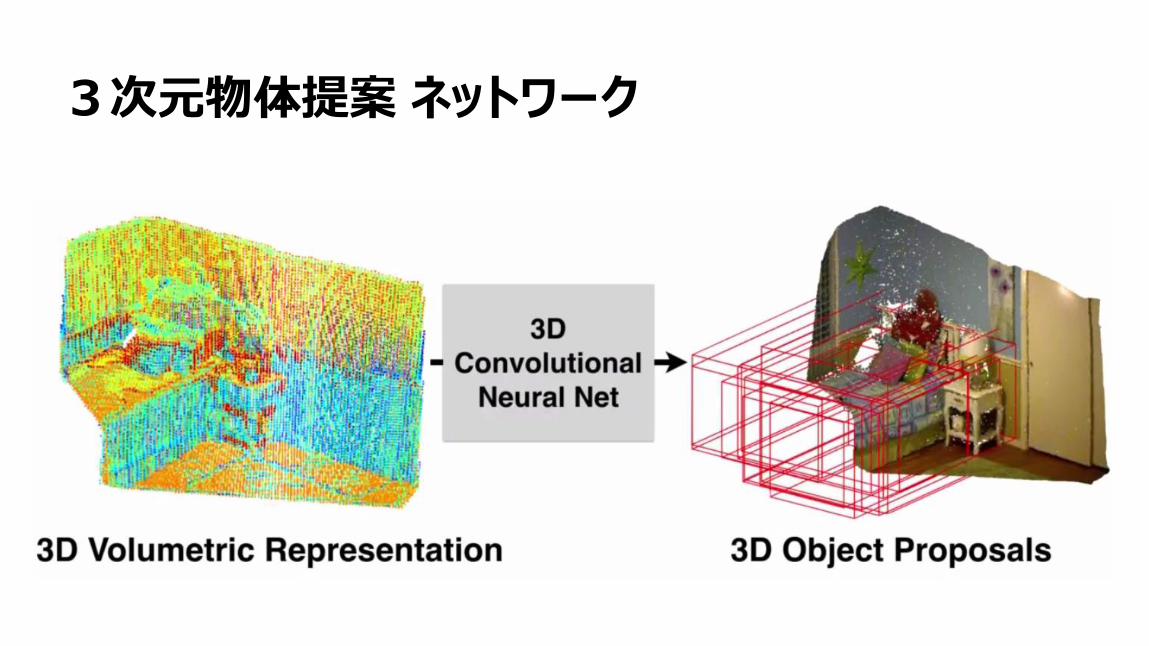
3次元物体提案 ネットワーク

51
2次元コンボリューショナル・ニューラル・ネットワーク
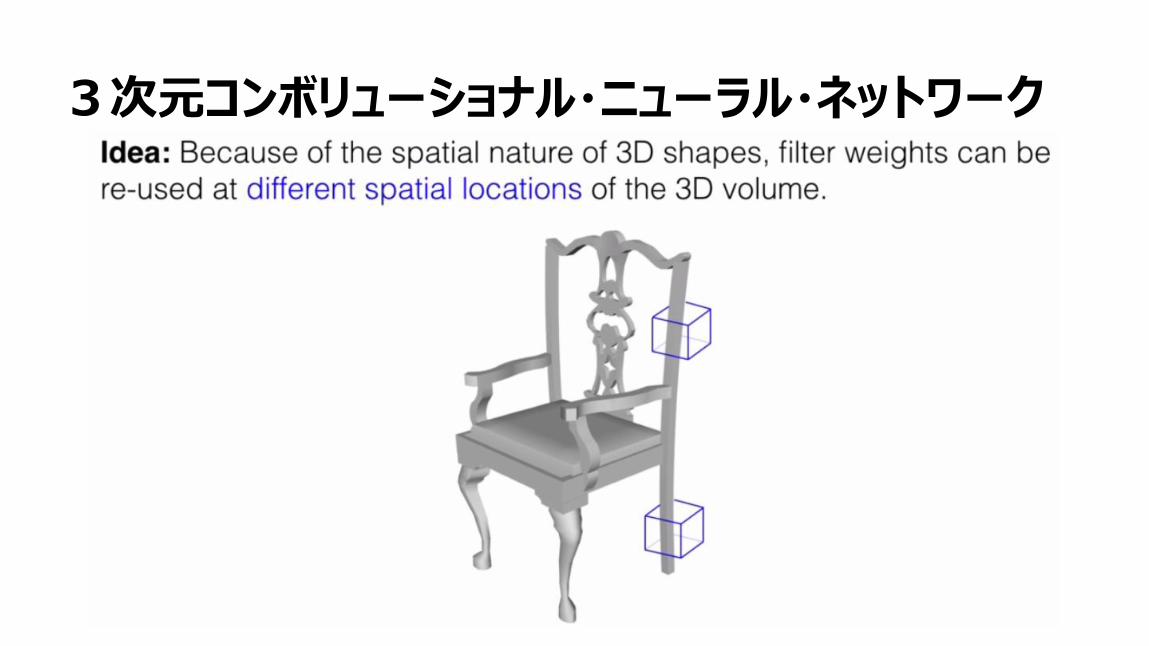
52
3次元コンボリューショナル・ニューラル・ネットワーク
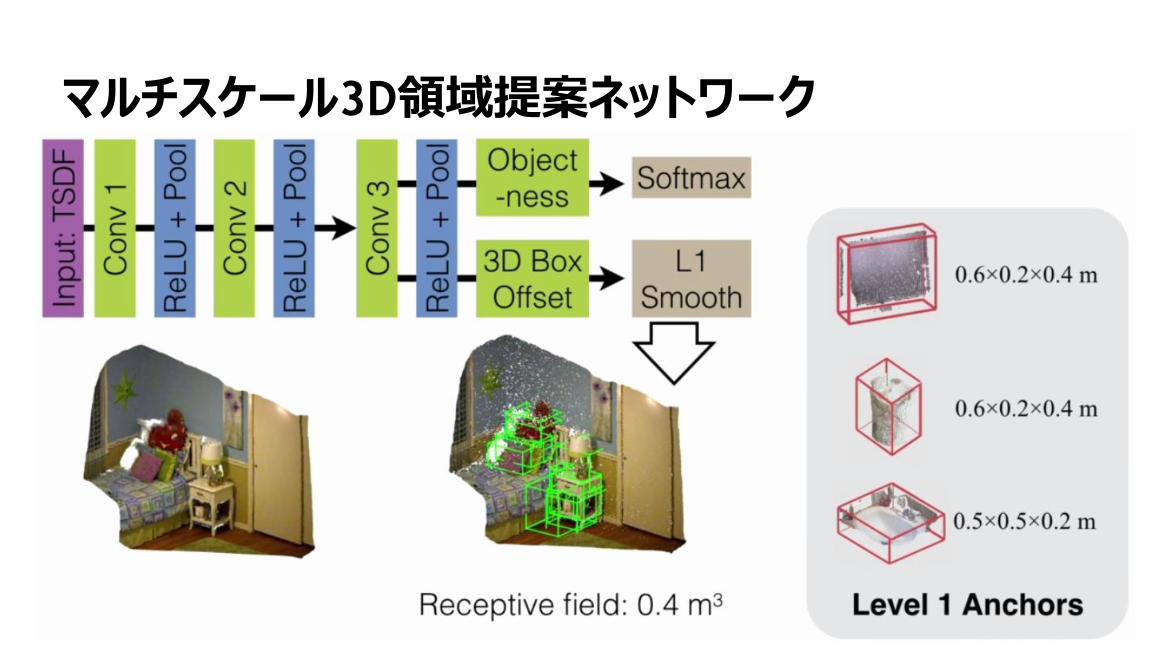
53
マルチスケール3D領域提案ネットワーク
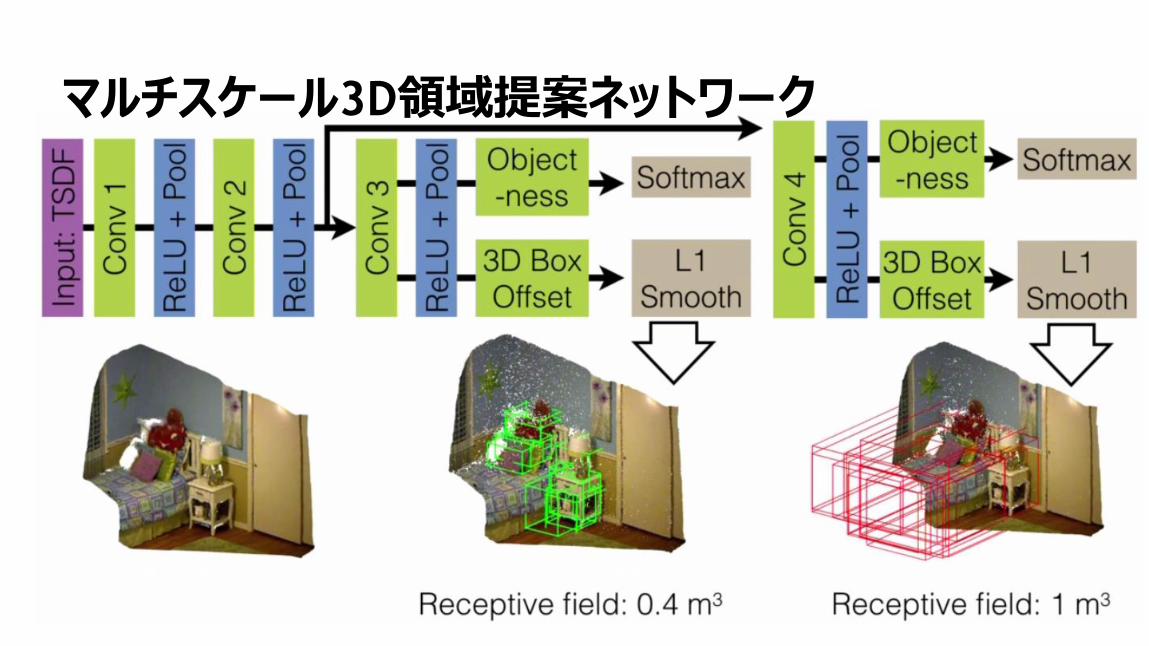
54
マルチスケール3D領域提案ネットワーク
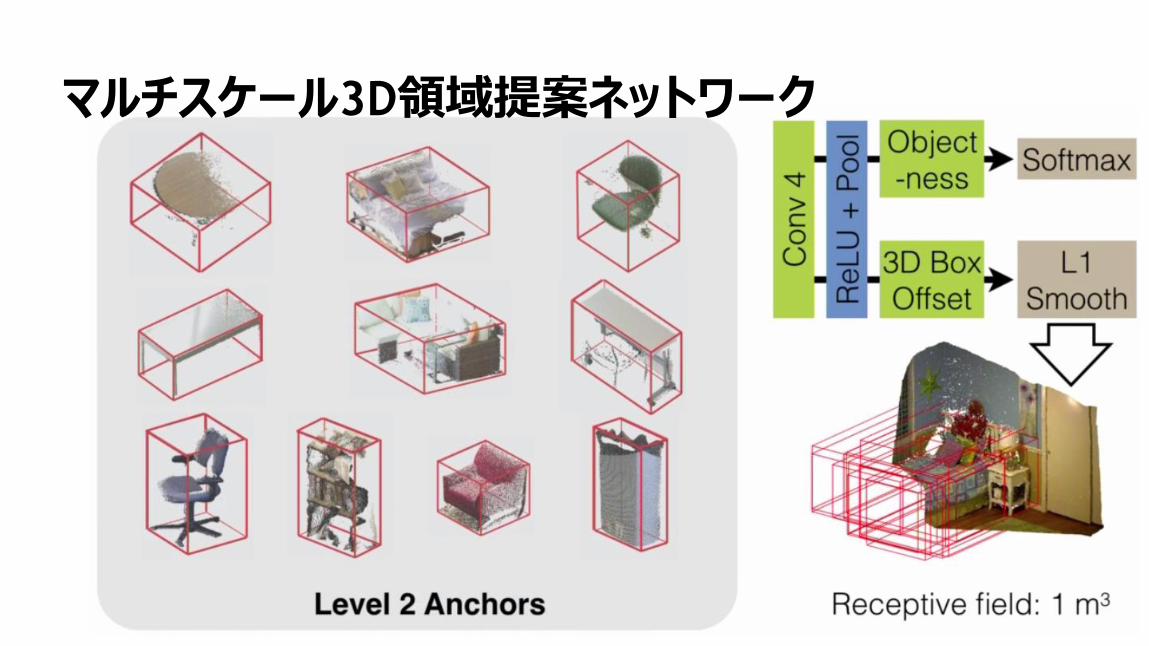
55
マルチスケール3D領域提案ネットワーク
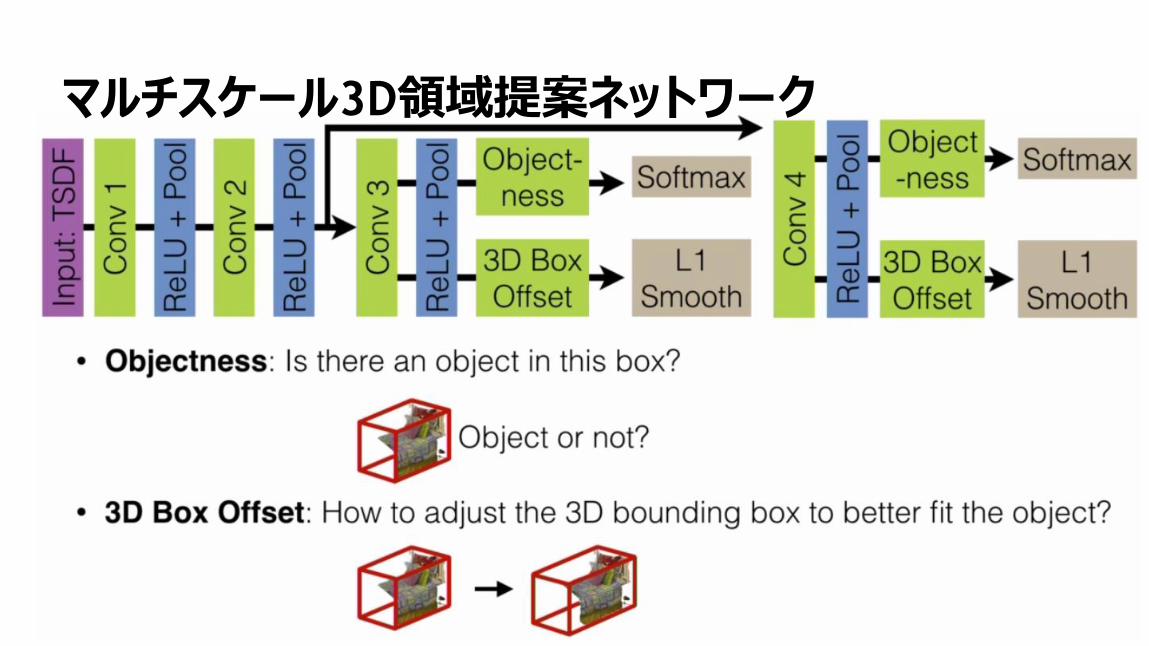
56
マルチスケール3D領域提案ネットワーク
57
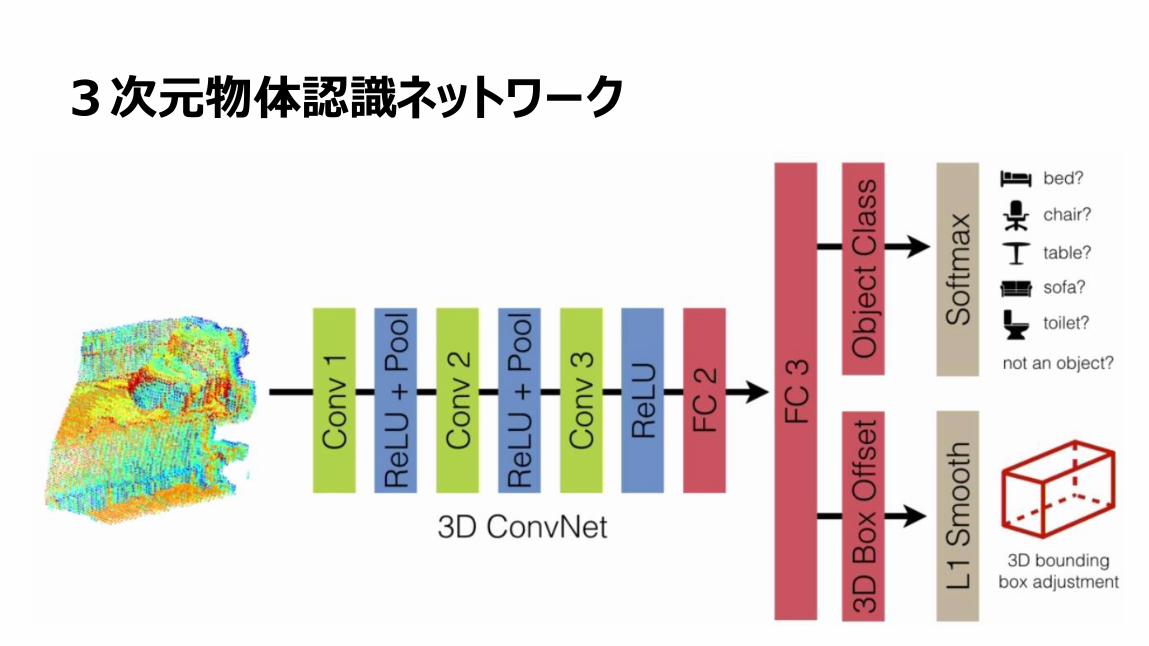
3次元物体認識ネットワーク

58
3次元物体認識例
59
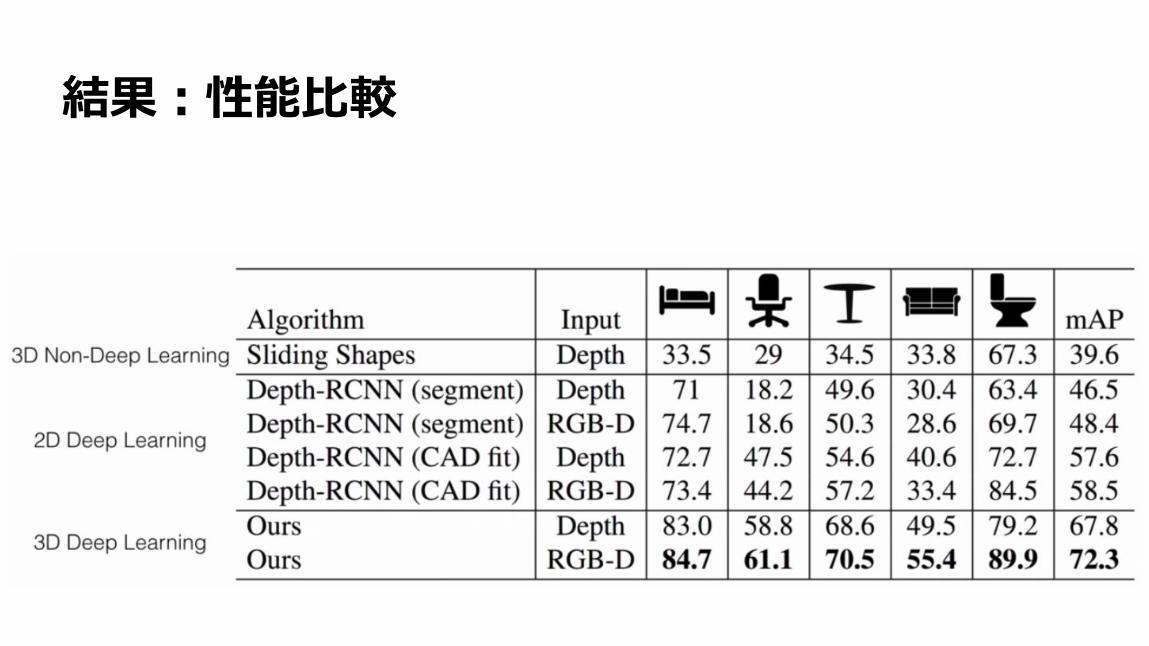
結果:性能比較
60
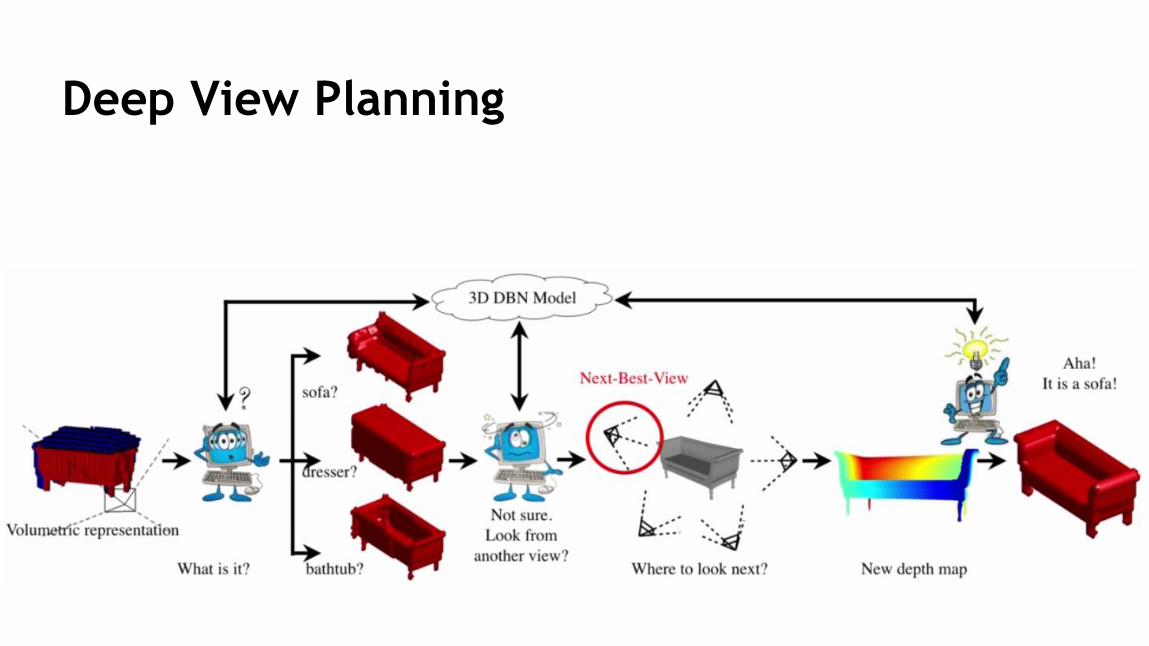
Deep View Planning

Pavlo Molchanov Research Scientist, NVIDIA
HAND GESTURE RECOGNITION WITH 3D CONVOLUTIONAL NEURAL NETWORKS
SESSION 7

62
ジェスチャー認識
63
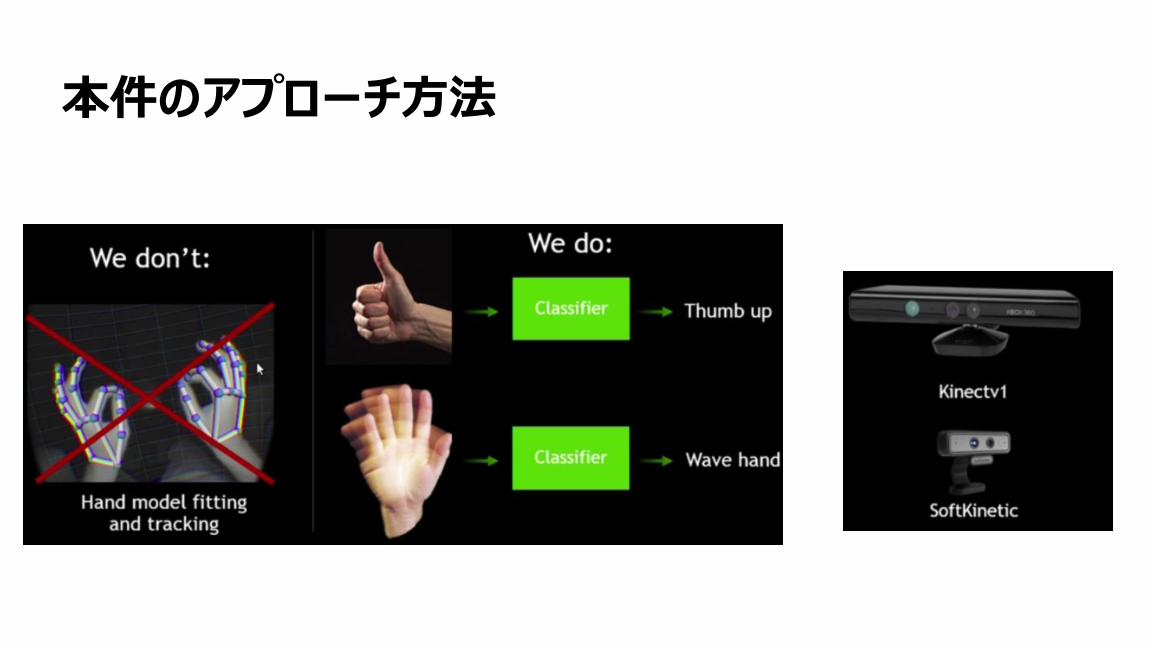
本件のアプローチ方法

64
最良の分類器の選択VIVA CHALLENGE 2015 UCLA
http://cvrr.ucsd.edu/vivachallenge/index.php/hands/hand-gestures/
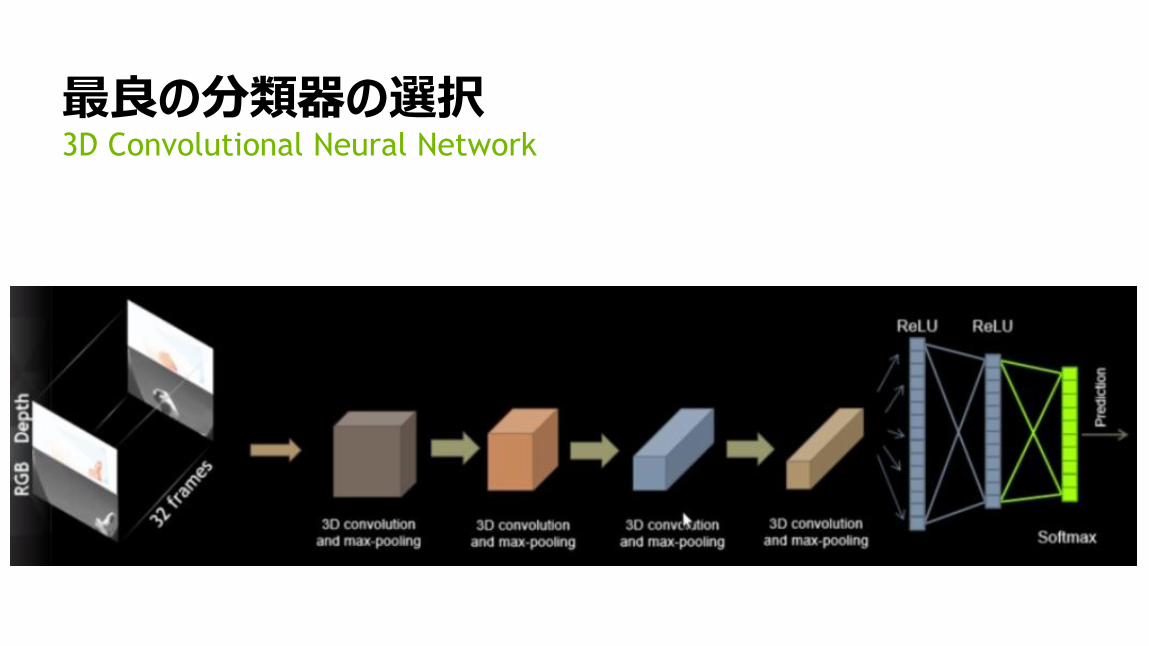
65
最良の分類器の選択3D Convolutional Neural Network
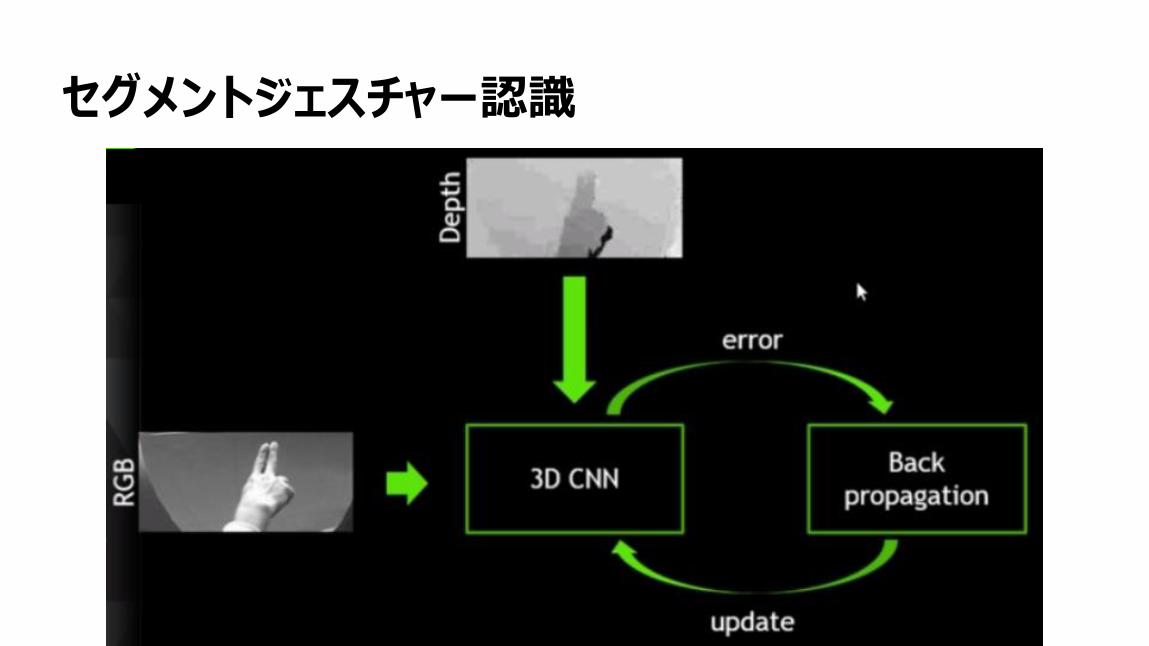
66
セグメントジェスチャー認識
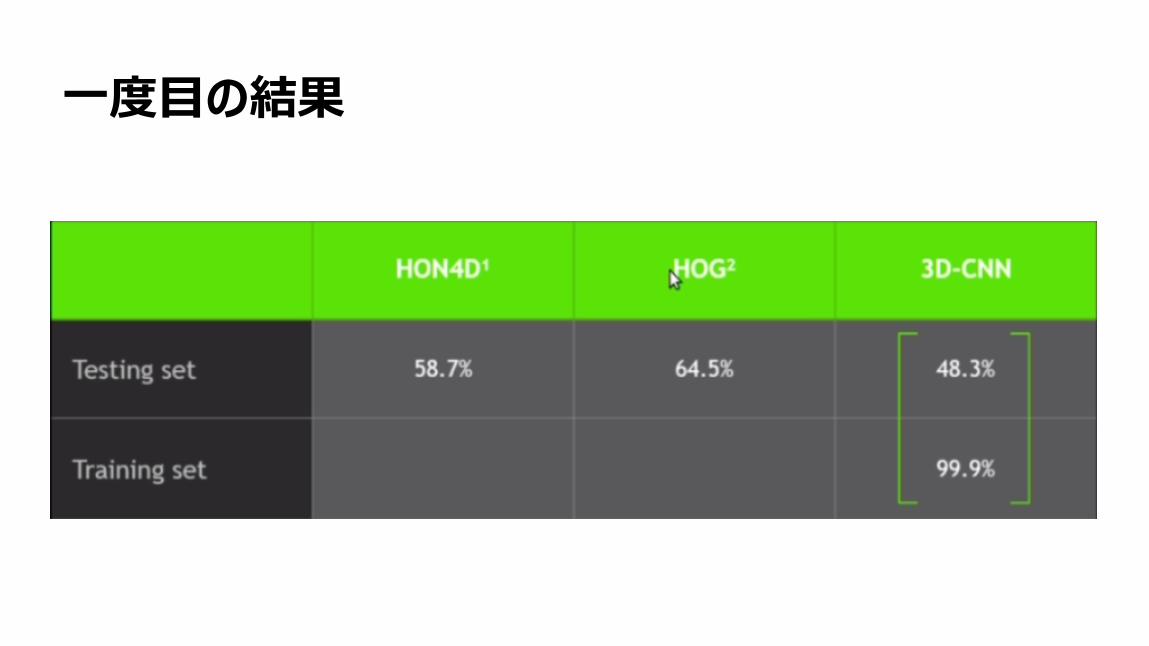
67
一度目の結果
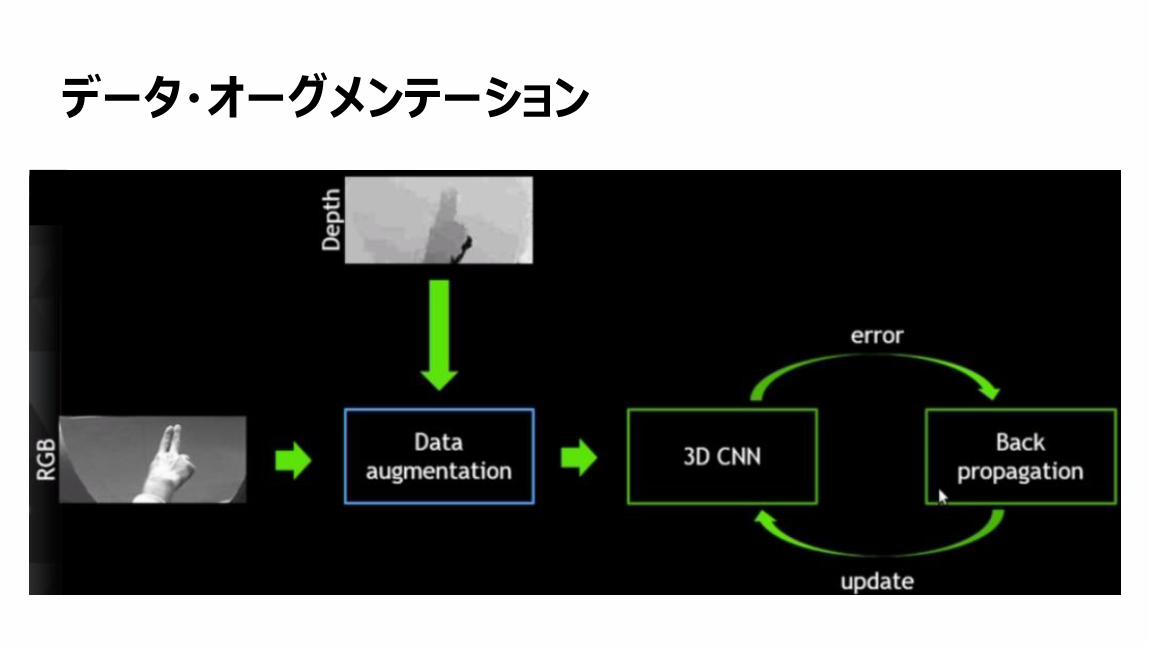
68
データ・オーグメンテーション

69
データ・オーグメンテーションSpatial geometric Transformation
元データ
拡大
縮小
左回転
右回転
左右移動
上下移動

70
データ・オーグメンテーションTemporal augmentation/Generating new training data
時間方向にフレームをずらす フリップ
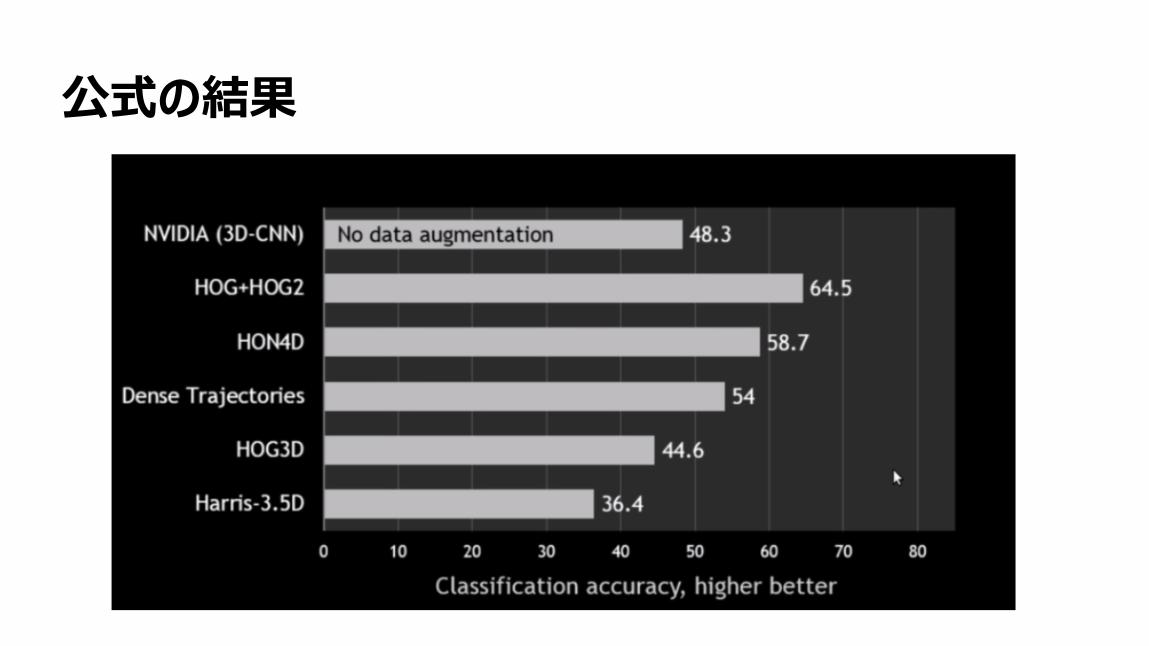
71
公式の結果
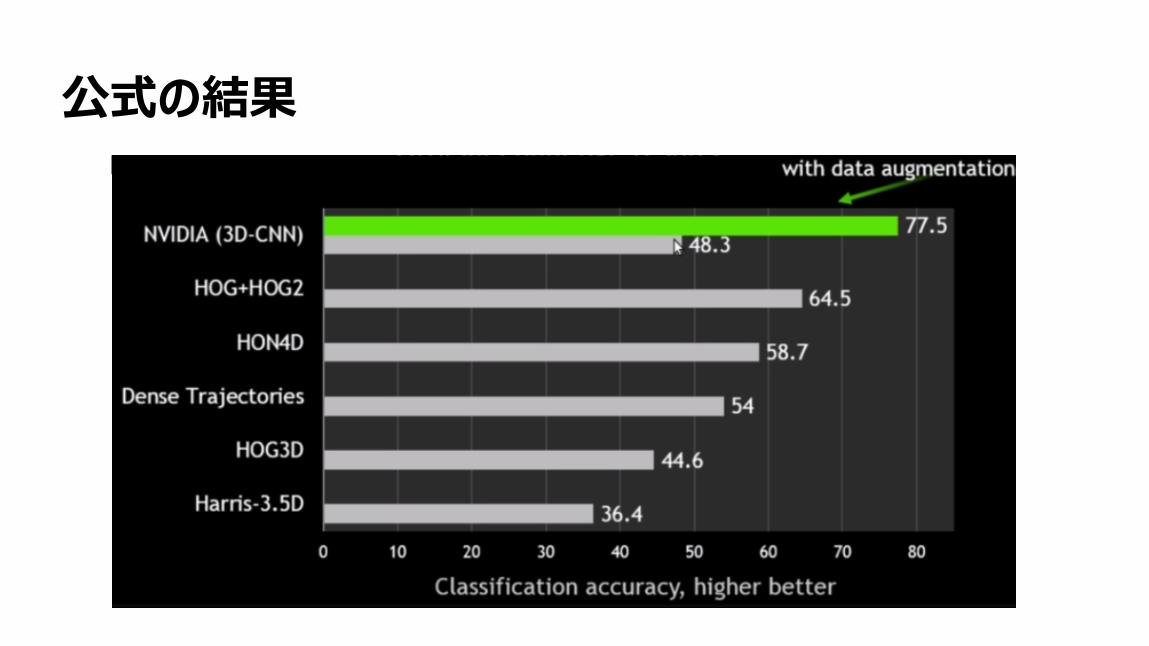
72
公式の結果
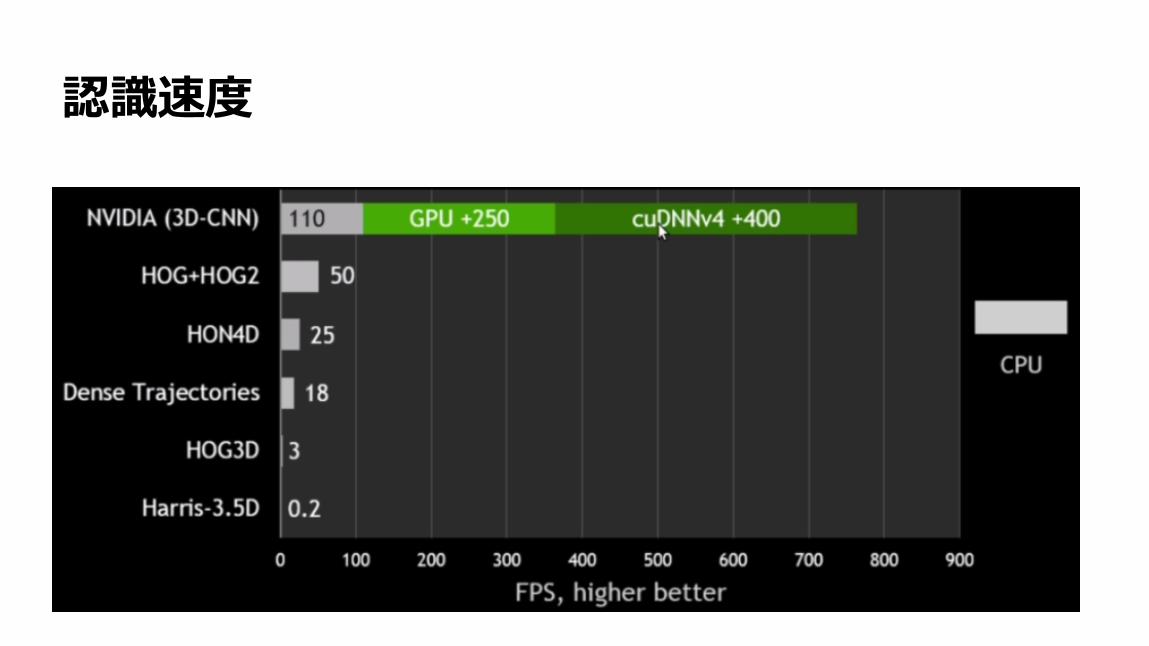
73
認識速度
74
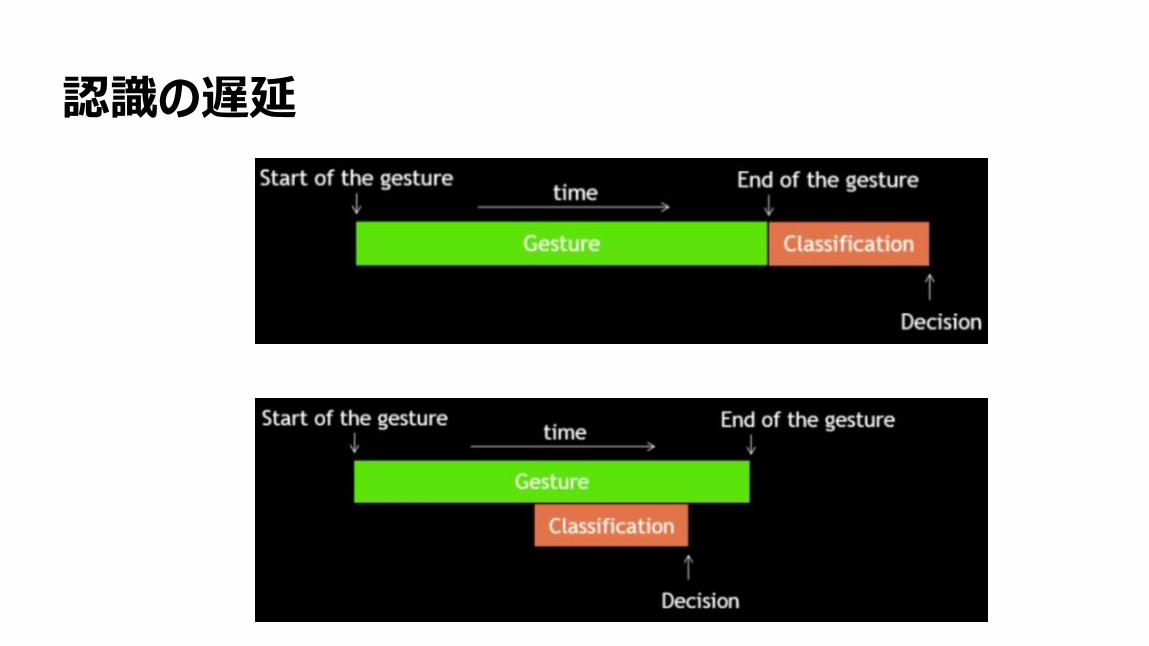
認識の遅延
75
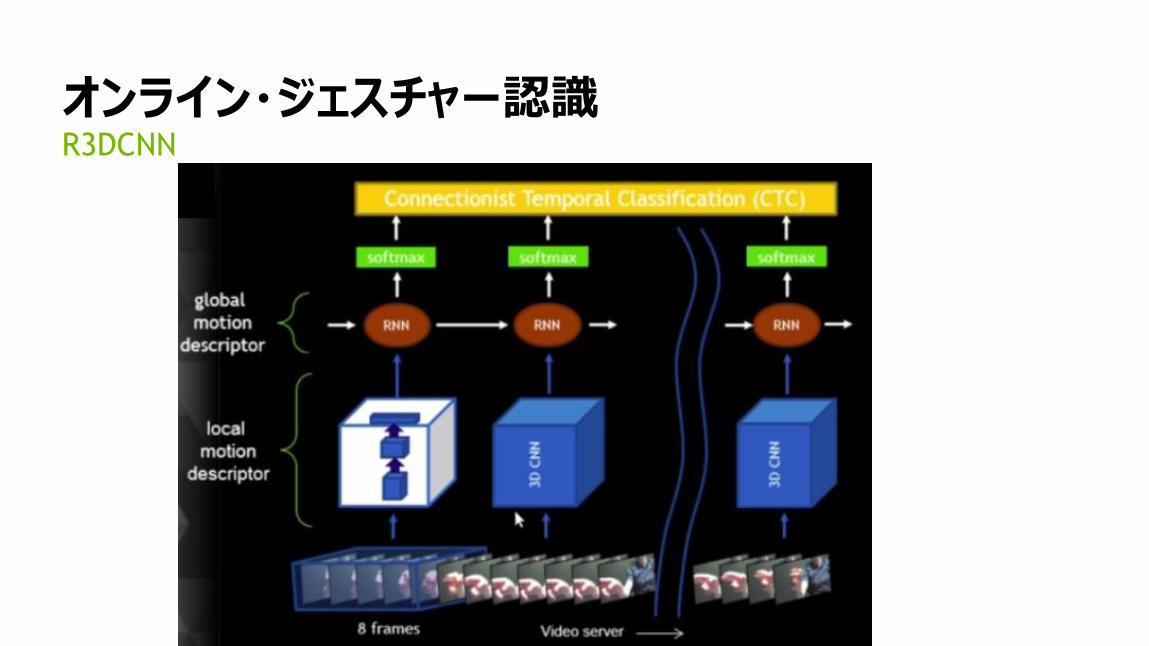
オンライン・ジェスチャー認識R3DCNN

Shiliang Pu Executive Vice President, Hikvision Research Institute
INTELLIGENT VIDEO ANALYSIS SYSTEM BASED ON GPU AND DISTRIBUTED ARCHITECTURE
SESSION 8

77
監視カメラが抱える問題
高解像度化 VS ストレージ
複雑さ VS 精度
大量のデータ VS 効率
複雑さを増す環境で、より高精細な認識精度を求められる
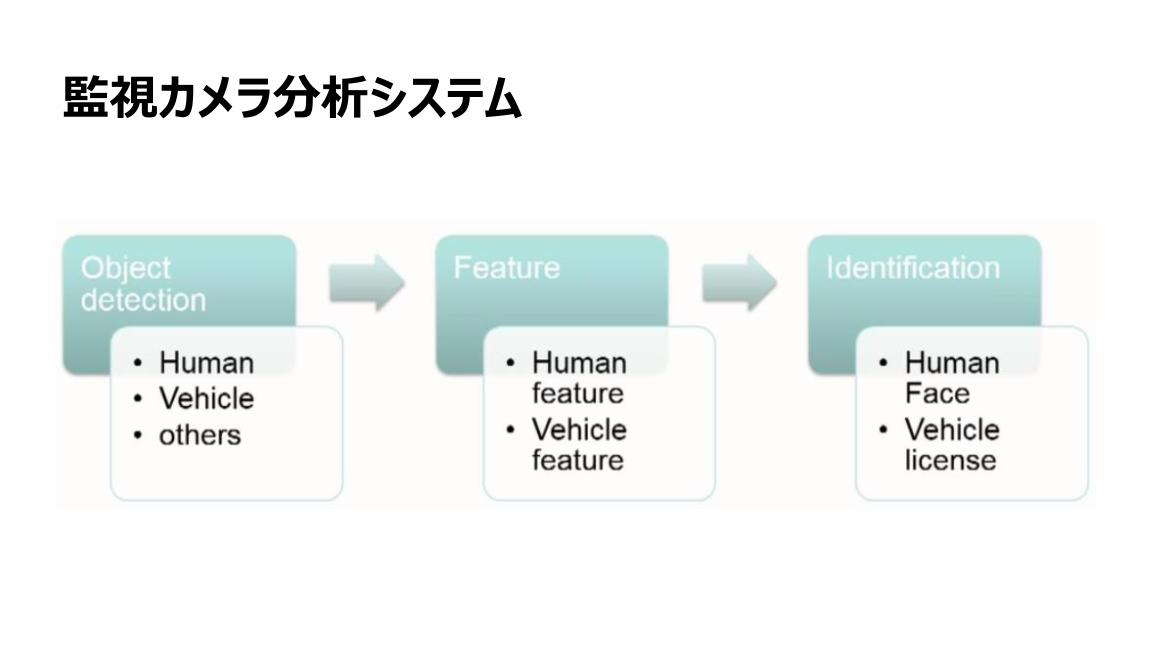
78
監視カメラ分析システム

79
認識例

80
複雑なシーンコンテンツは従来のアルゴリズムでは難しい
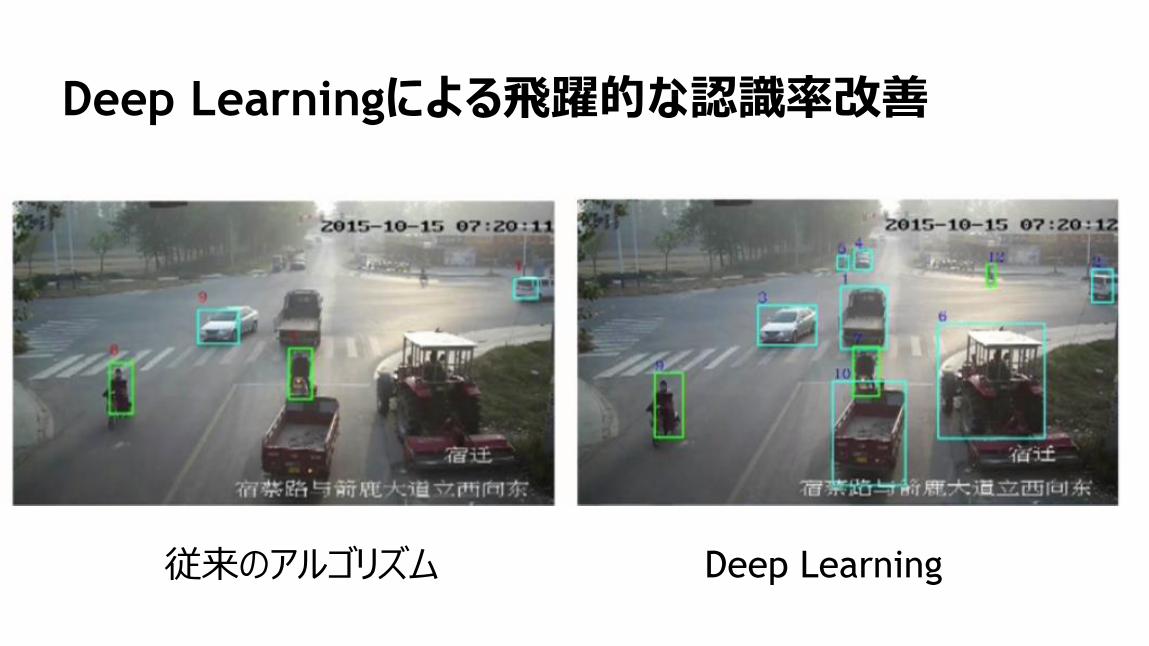
81
Deep Learningによる飛躍的な認識率改善
従来のアルゴリズム Deep Learning
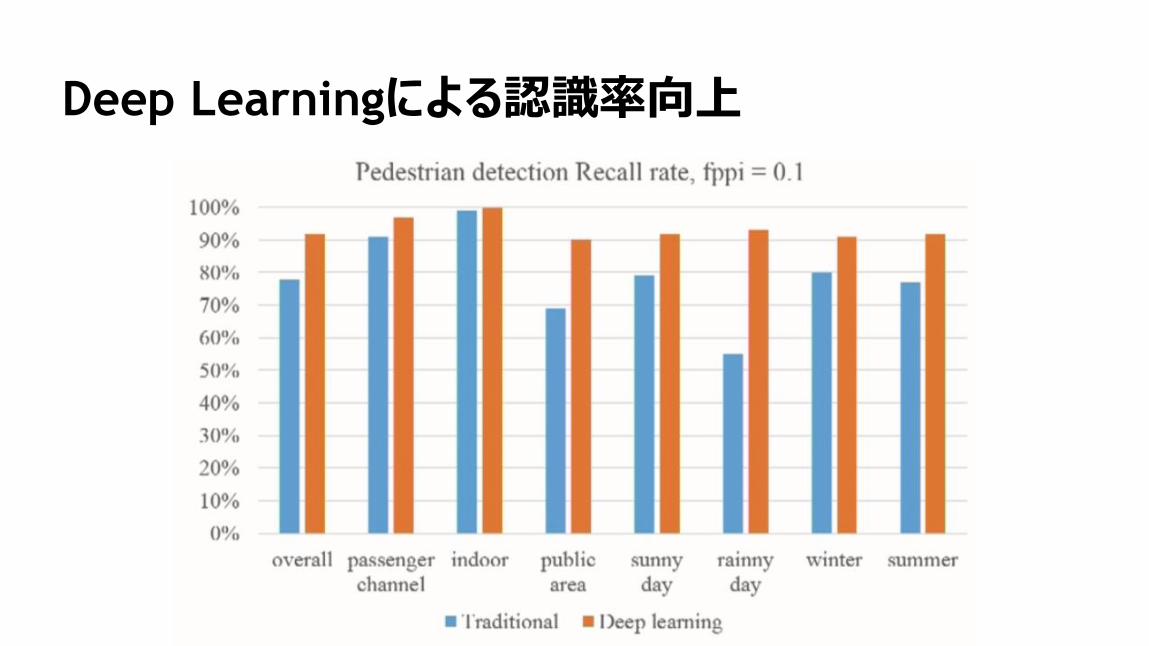
82
Deep Learningによる認識率向上

83
認識が難しい対象物
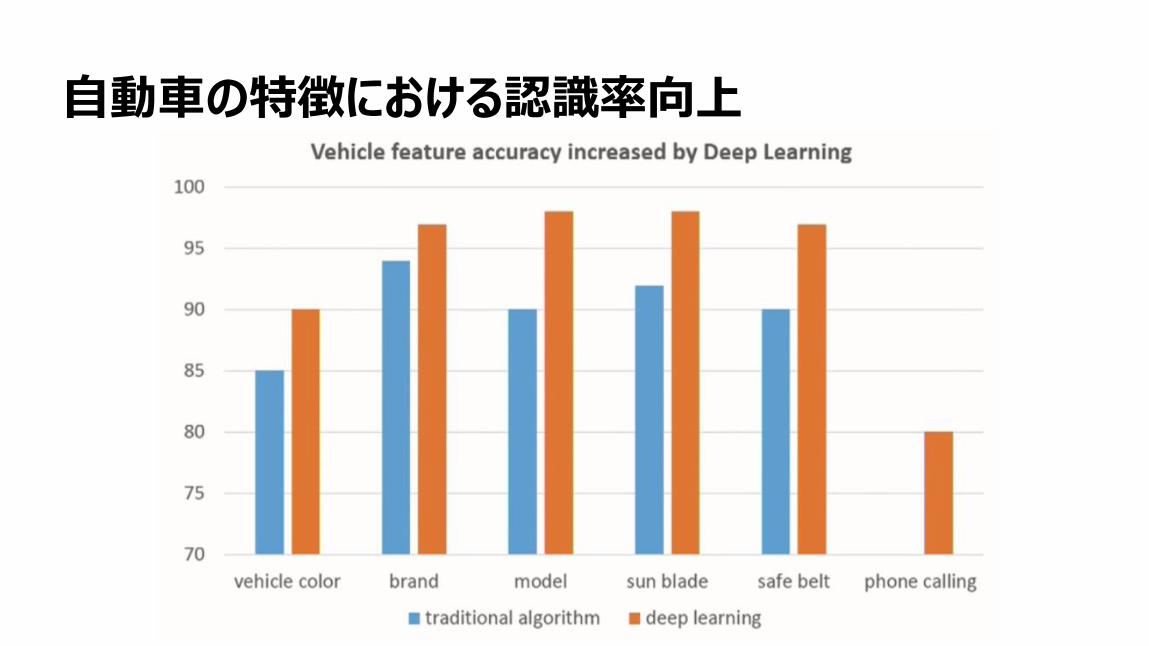
84
自動車の特徴における認識率向上

85
対象車両の特定

Stephen McGough Lecturer, Durham University
ANOMALY DETECTION AND CATEGORIZATION USING UNSUPERVISED DEEP LEARNING
SESSION 9

87
異常検知
• テロリストの活動監視
• 船/飛行機のデータ監視
• 警察犯罪データベース
• 好ましくない情報のリーク
• 機器の異常
• ソーシャルメディアの監視
• セキュリティカメラでの監視
• 不正なファイナンス取引
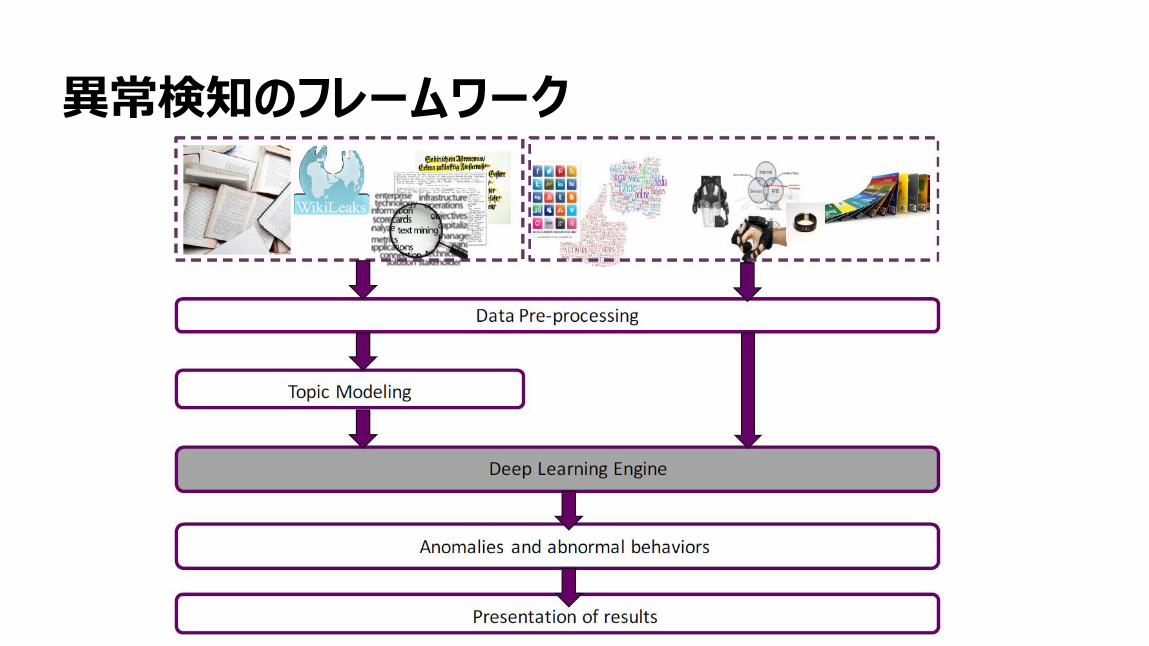
88
異常検知のフレームワーク
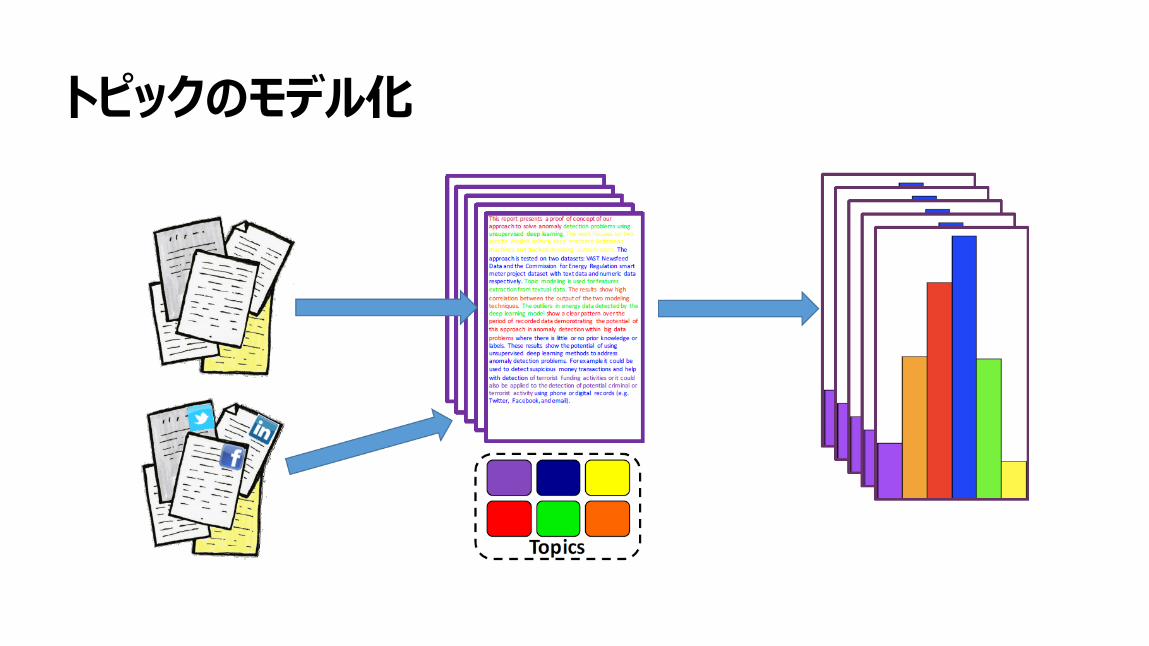
89
トピックのモデル化
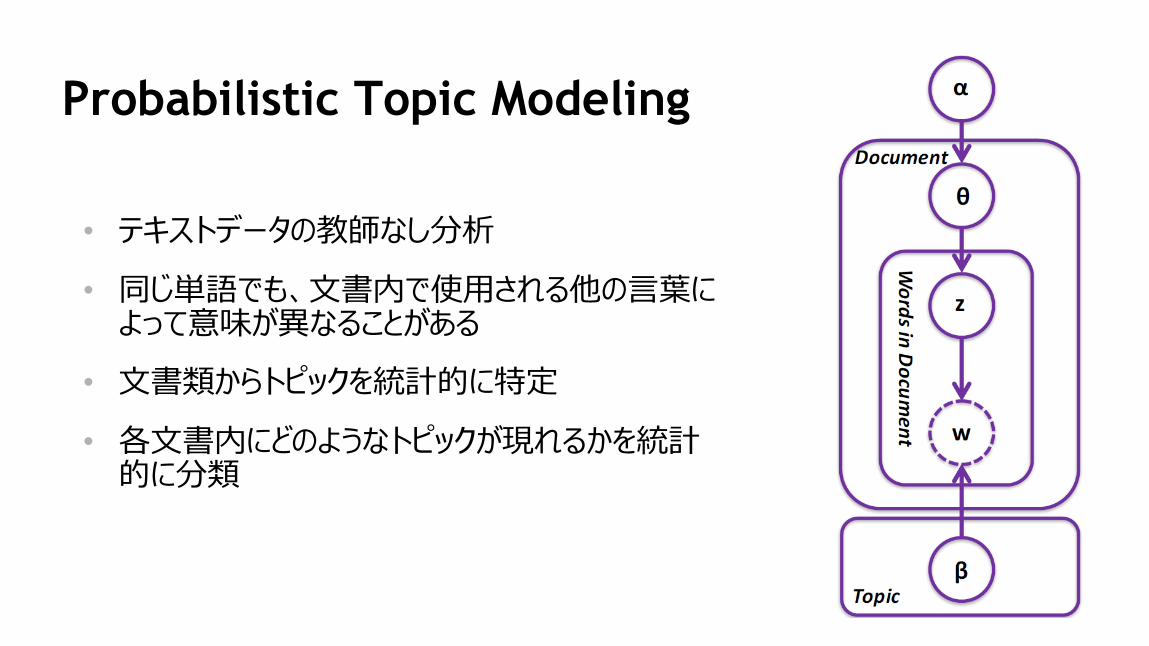
90
Probabilistic Topic Modeling
• テキストデータの教師なし分析
• 同じ単語でも、文書内で使用される他の言葉によって意味が異なることがある
• 文書類からトピックを統計的に特定
• 各文書内にどのようなトピックが現れるかを統計的に分類
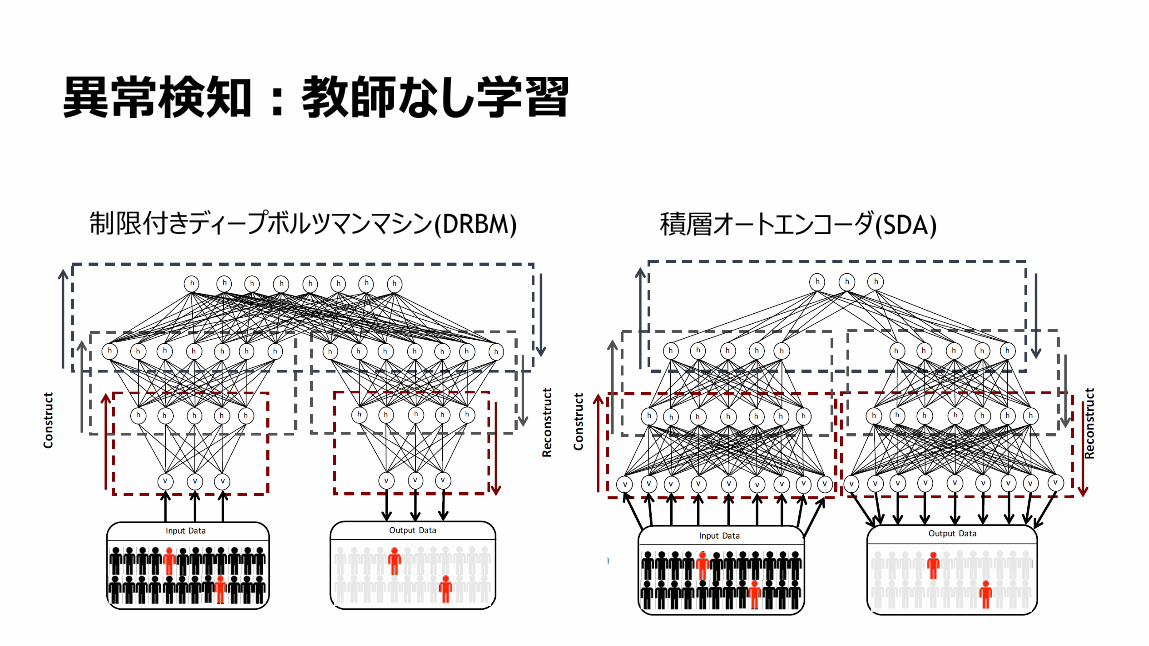
91
異常検知:教師なし学習
制限付きディープボルツマンマシン(DRBM) 積層オートエンコーダ(SDA)
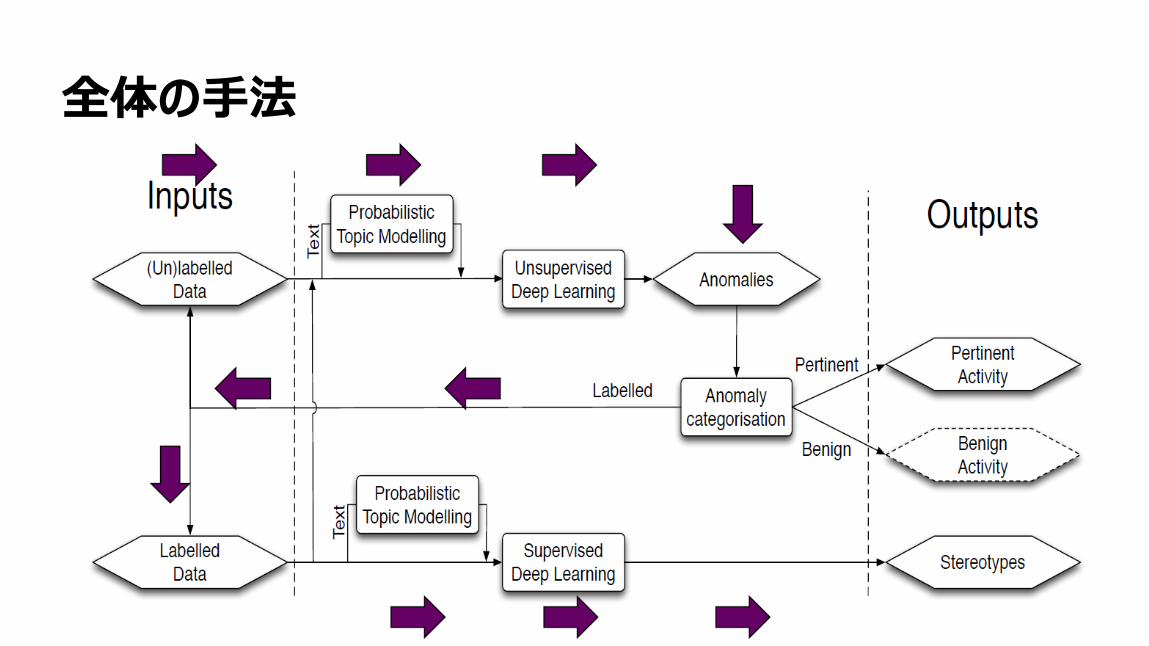
92
全体の手法
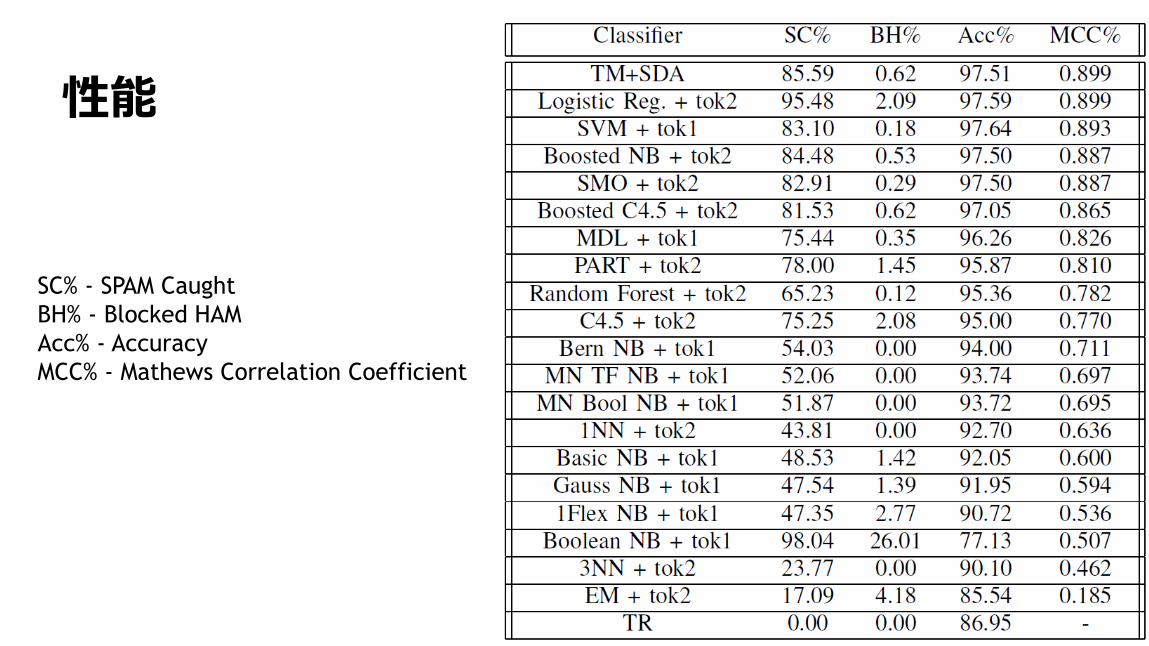
93
性能
SC% - SPAM Caught
BH% - Blocked HAM
Acc% - Accuracy
MCC% - Mathews Correlation Coefficient

Natalia Vassilieva Research Group Manager, Hewlett Packard Labs
SENSE MAKING IN AN IOT WORLD: SENSOR DATA ANALYSIS WITH DEEP LEARNING
SESSION 10

95
なぜディープラーニング+センサーデータか?ディープラーニングは:
• 大量の学習データ(ラベル有無)
• 自明でない(空間・時間的)多次元や複雑なデータ
• 人手で行っていたものが教師無し特徴学習に取って代わられている
• クロスモーダルな特徴学習
センサーデーター:
• 大量のデータ(ほとんどがラベル無)
• 自明でない複雑なデータ(ほぼ時間的)
• データ再現、特徴抽出の精査が困難
• マルチモーダル
スピーチでも活用 ほとんどのデータが時系列
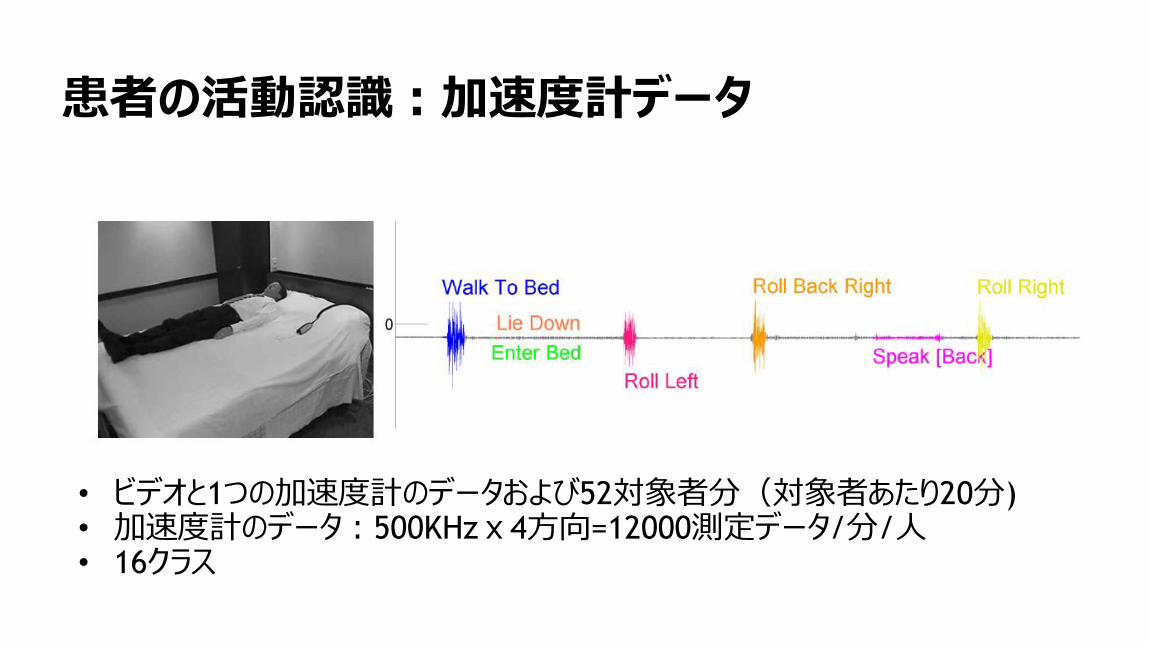
96
患者の活動認識:加速度計データ
• ビデオと1つの加速度計のデータおよび52対象者分(対象者あたり20分)• 加速度計のデータ:500KHzx4方向=12000測定データ/分/人• 16クラス

97
アプローチベースライン評価
- ZeroR (メジャーなクラス予測器)- サポートベクターマシン- 決定木(C50を実装)- 浅いニューラルネットワーク(FANNライブラリ)- 特徴:手作業
Deep Neural Networks- 全結合隠れ層+Softmax- 時間遅延層- リカレント層- DNN+CRF(条件付確率場)- マルチメターパラメータ設定- 特徴:振幅スペクトル

98
アプローチベースライン評価
- ZeroR (メジャーなクラス予測器)- サポートベクターマシン- 決定木(C50を実装)- 浅いニューラルネットワーク(FANNライブラリ)- 特徴:手作業
Deep Neural Networks- 全結合隠れ層+Softmax- 時間遅延層- リカレント層- DNN+CRF(条件付確率場)- マルチメターパラメータ設定- 特徴:振幅スペクトル
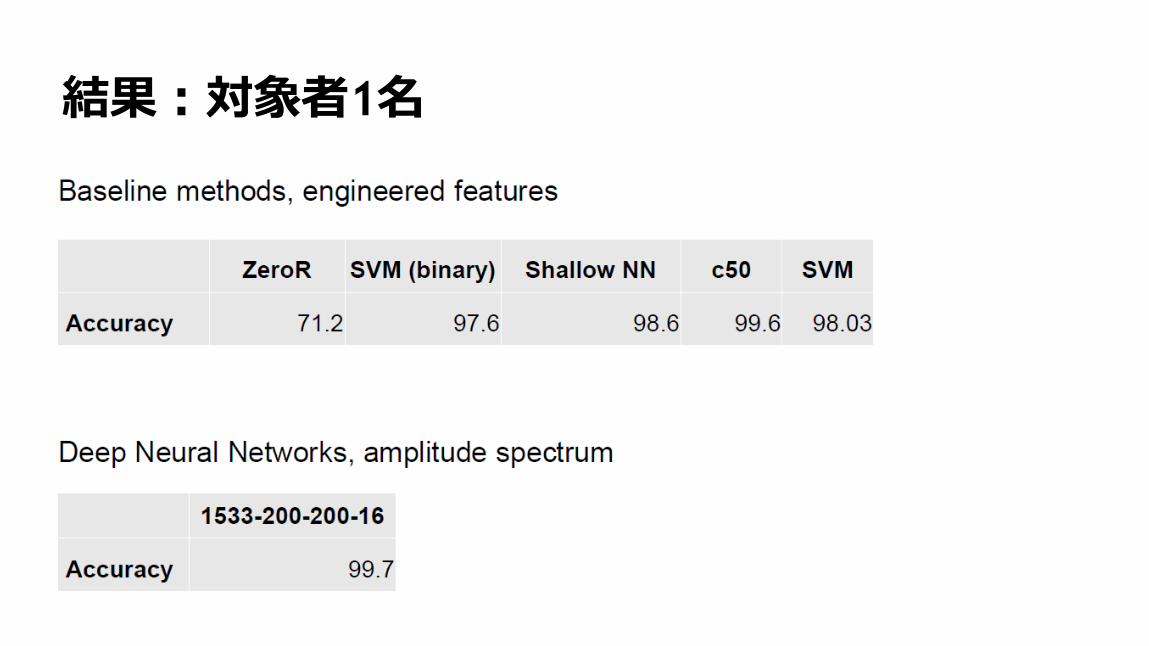
99
結果:対象者1名
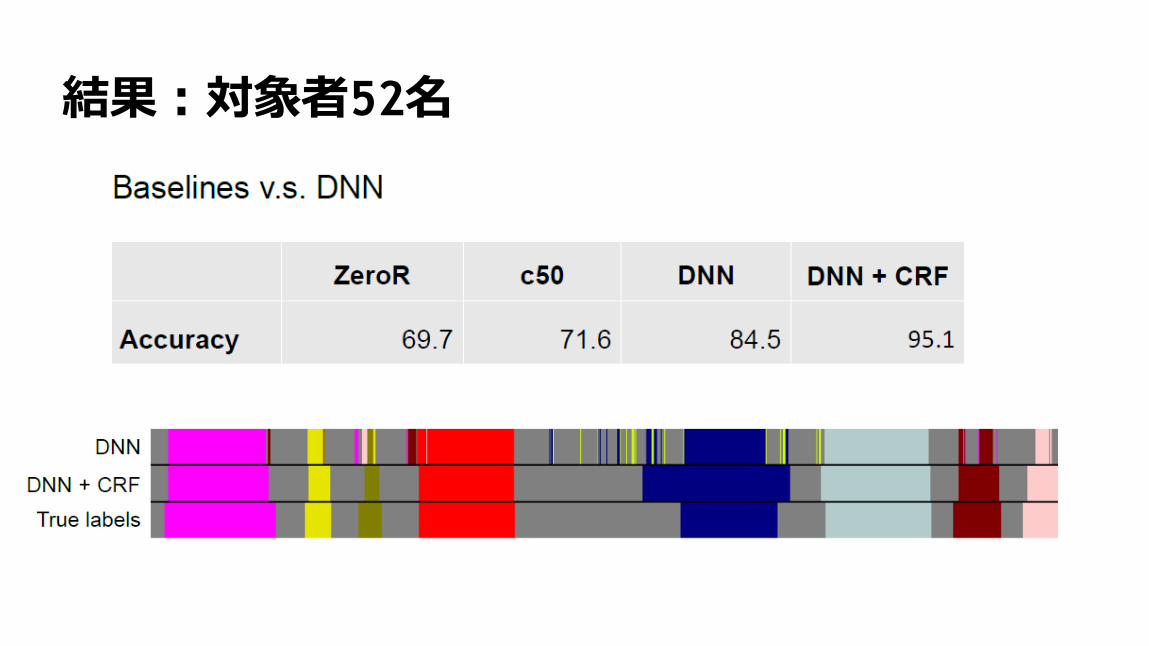
100
結果:対象者52名

Aishwarya Agrawal Ph.D. Student, Virginia Tech
VQA: VISUAL QUESTION ANSWERING
SESSION 11

102
VQA
静止画について自然言語の自由回答質問を与え、自然言語の回答を生成する
Visual Answering Questions

103
使用用途
視覚障害者の補助
通りを渡っても安全ですか?
監視カメラ赤いシャツを着た男性が乗り去った車の種類は?
ロボットとの会話ノートPCは2階の寝室
にある?
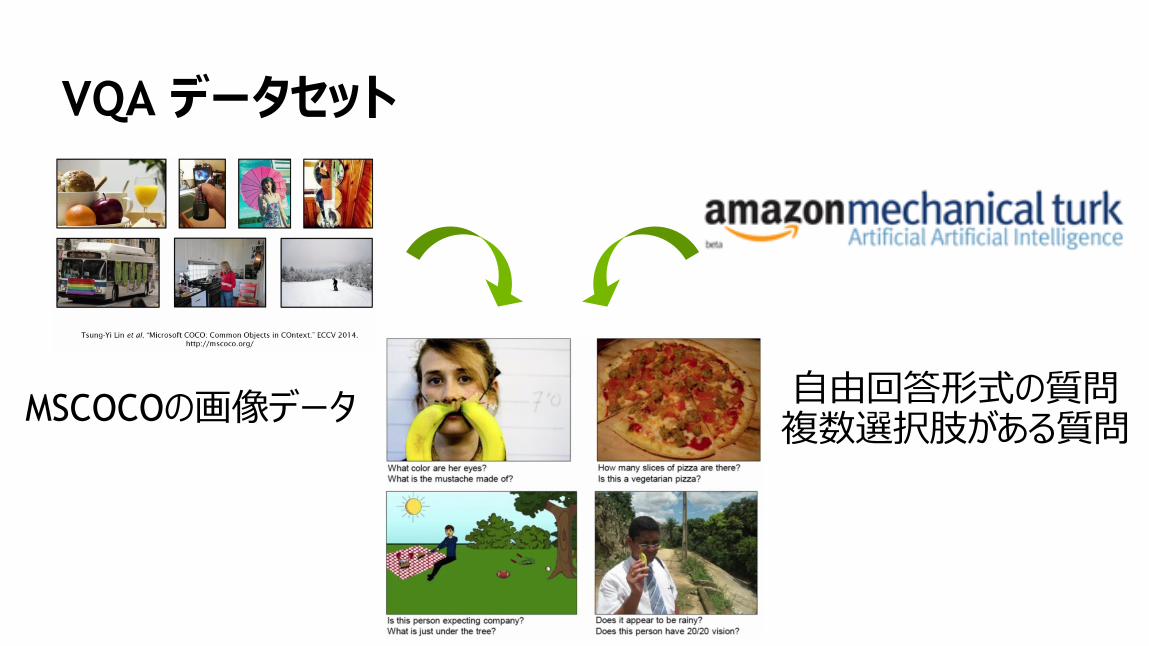
104
VQA データセット
MSCOCOの画像データ自由回答形式の質問複数選択肢がある質問

105
VQA データセット
25万点以上のイメージデータ(MSCOCO+5万のイラストデータ)
75万の質問(3質問/イメージ)
1000万の回答
データセットはこちら
http://www.visualqa.org/
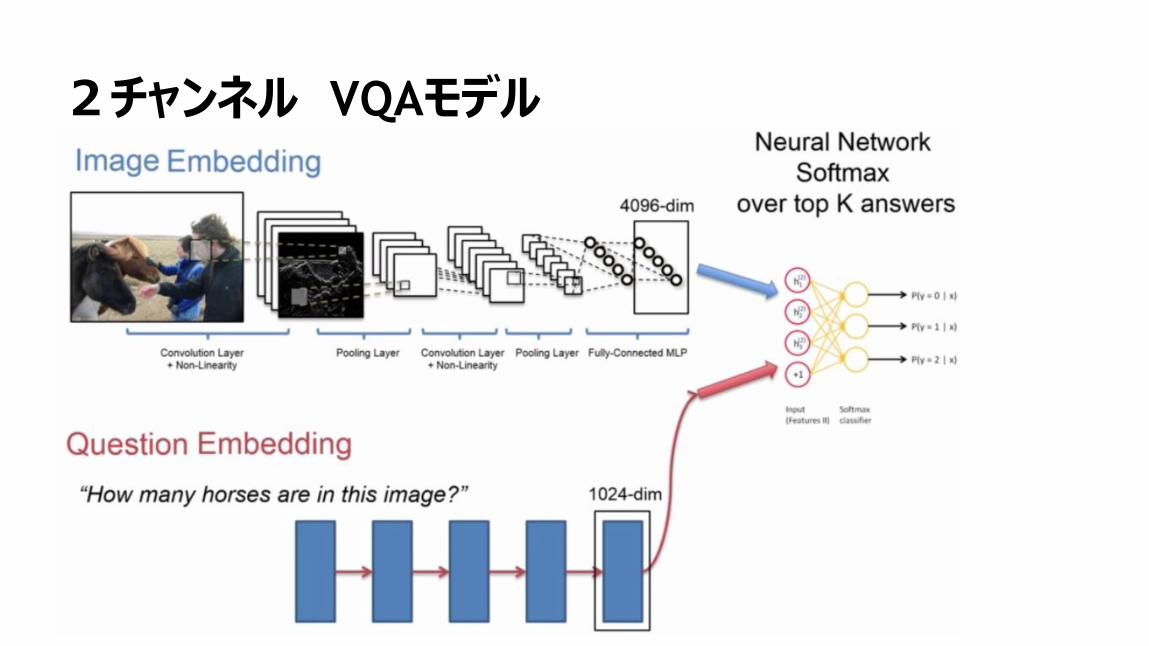
106
2チャンネル VQAモデル

107
精度の指標

108
自由回答形式の質問問題の精度

Ian Goodfellow Senior Research Scientist, OpenAI
GENERATIVE ADVERSARIAL NETWORKS
SESSION 12
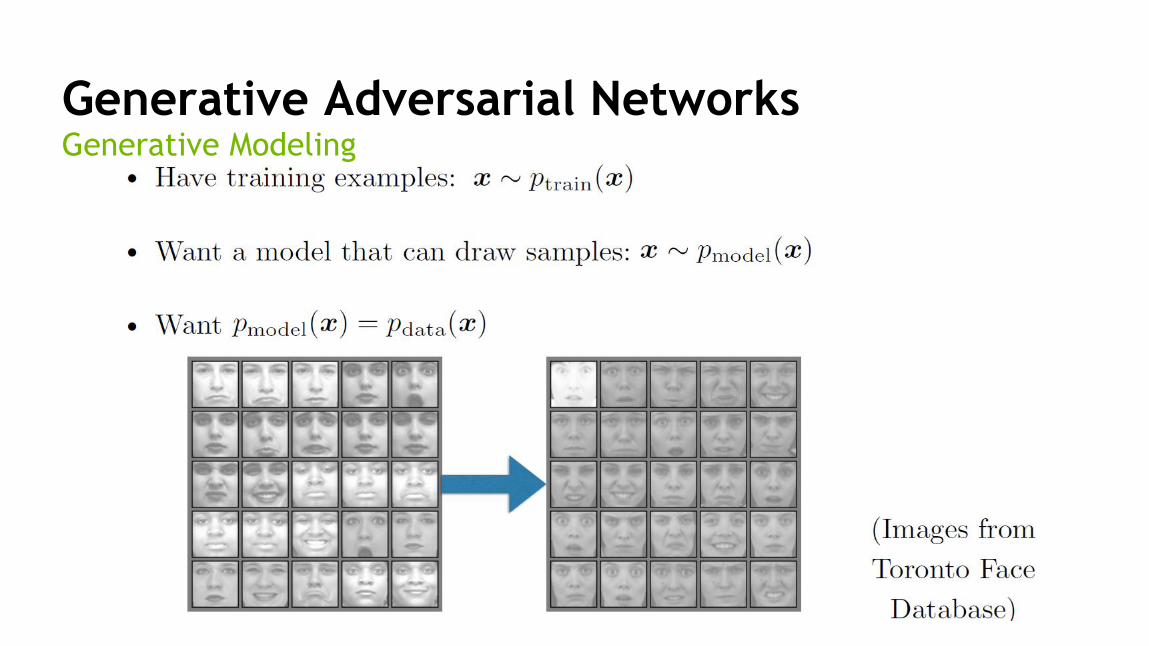
110
Generative Adversarial NetworksGenerative Modeling
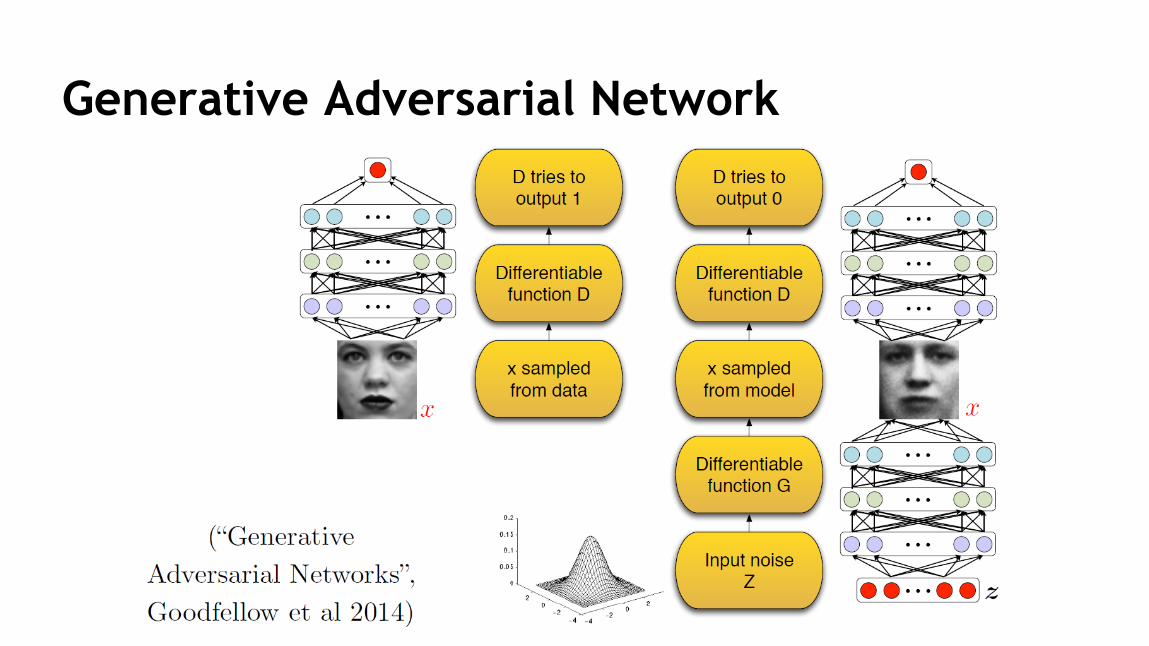
111
Generative Adversarial Network

112
LAPGAN/DCGAN

113
DCGANのベクトル演算性

Mu Li Ph.D. Student, Carnegie Mellon University
Tianqi Chen Ph.D. Student, University of Washington
MXNET: FLEXIBLE DEEP LEARNING FRAMEWORK FROM DISTRIBUTED GPU CLUSTERS TO EMBEDDED SYSTEMS
SESSION 13
115
MXNet:分散GPUクラスターから組込みシステムまで
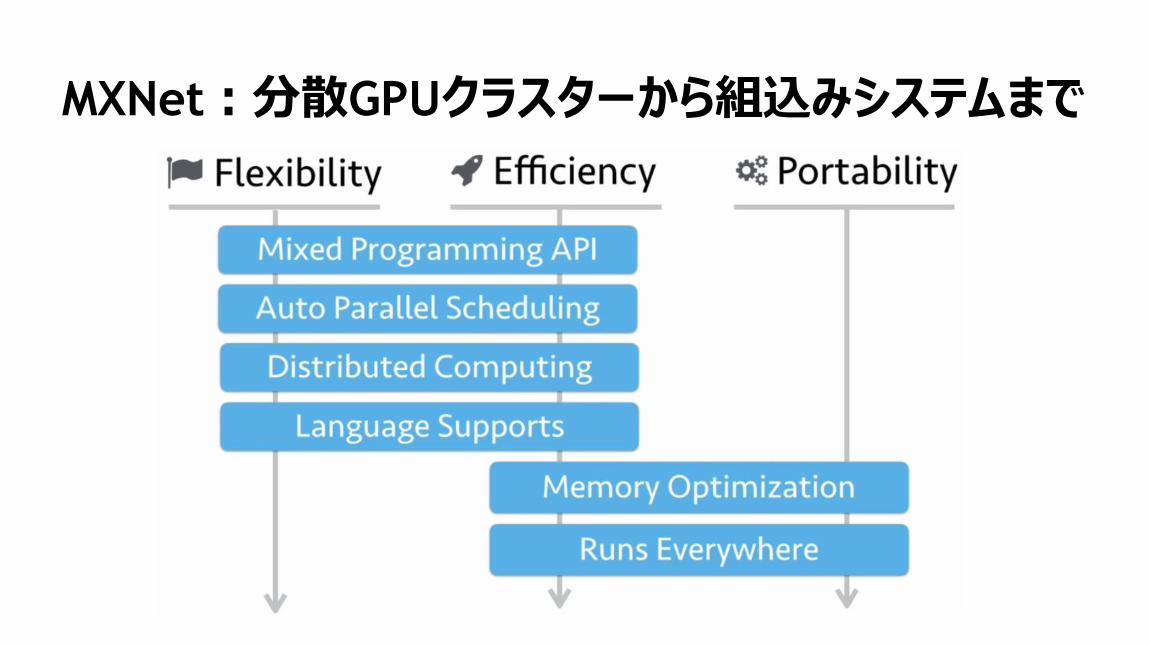
116
MXNet:分散GPUクラスターから組込みシステムまで
117
ミックス プログラミング API

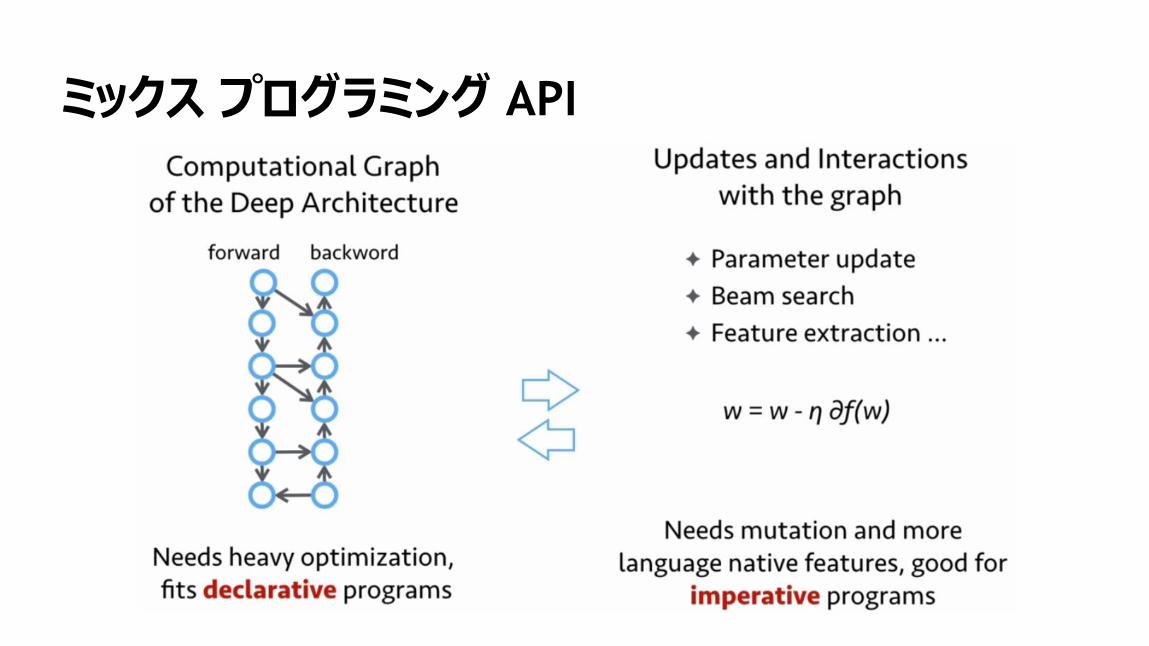
118
MXNet:両方の実装が可能
119
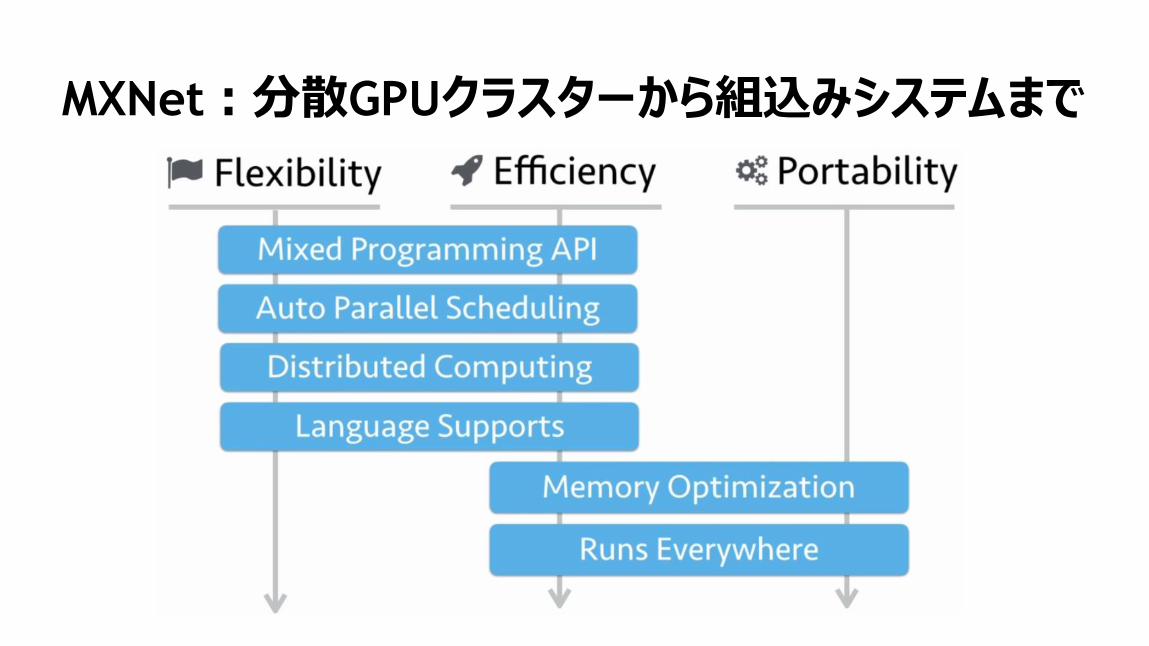
MXNet:分散GPUクラスターから組込みシステムまで
120
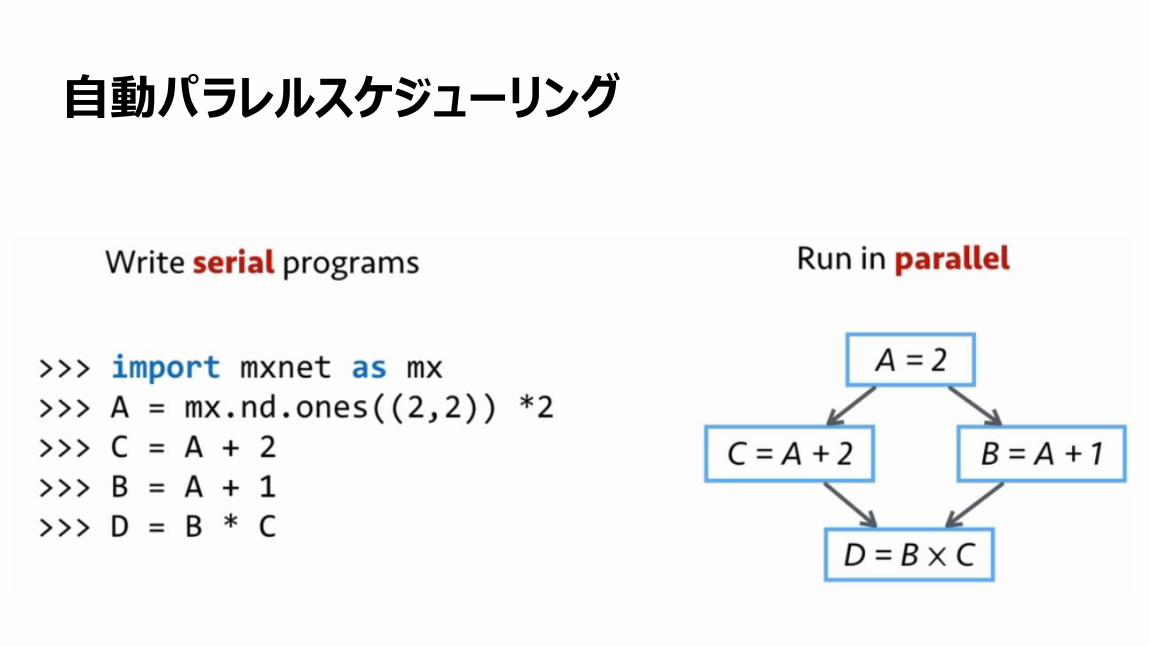
自動パラレルスケジューリング
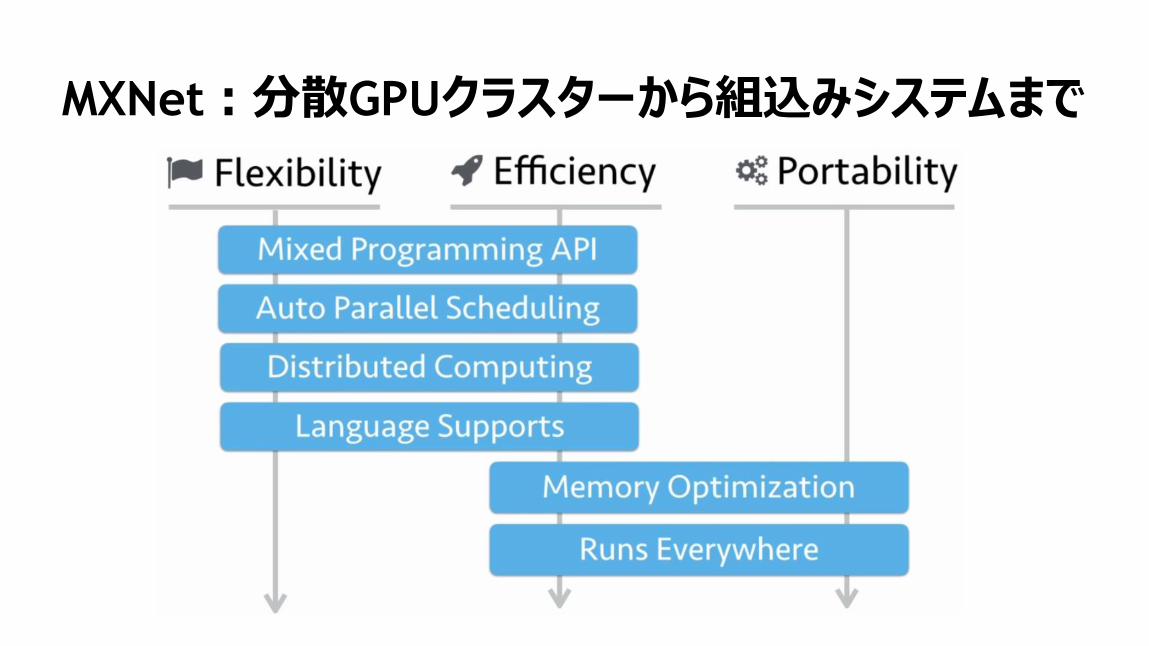
121
MXNet:分散GPUクラスターから組込みシステムまで
122
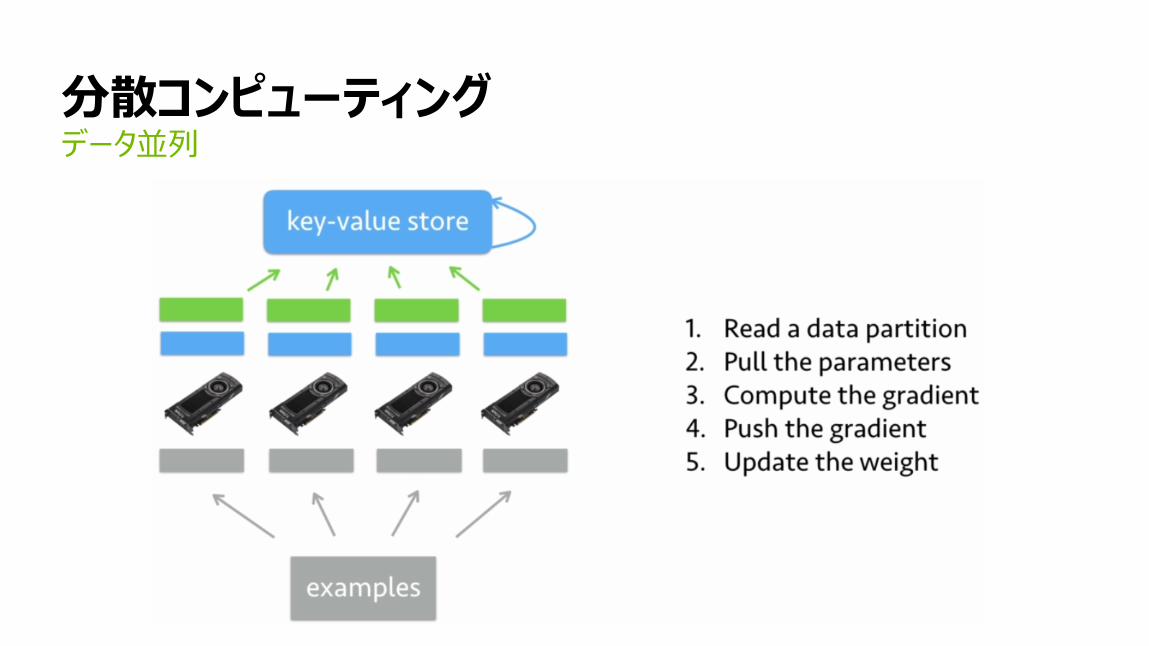
分散コンピューティングデータ並列

123
分散コンピューティング:実装
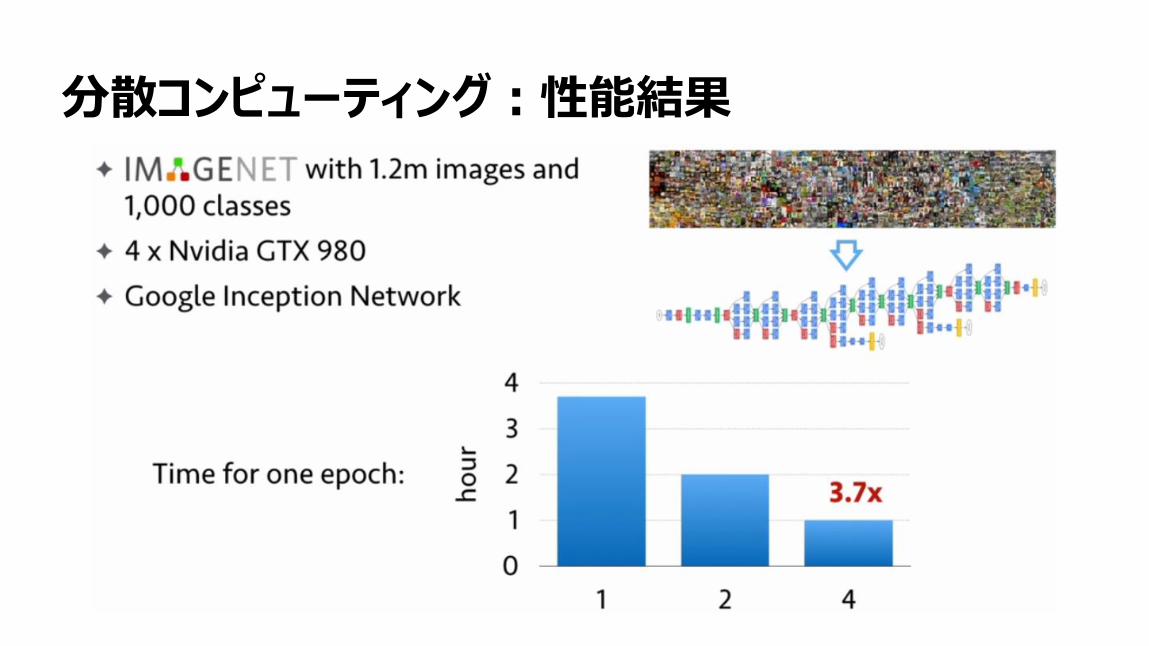
124
分散コンピューティング:性能結果
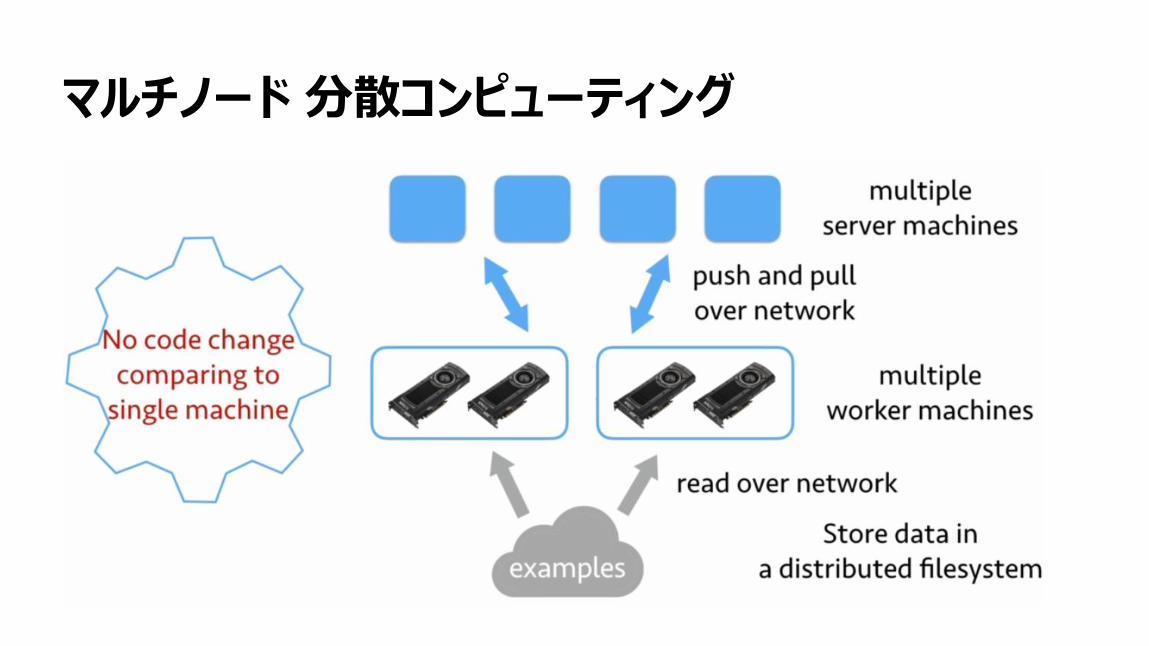
125
マルチノード 分散コンピューティング

126
マルチノード分散コンピューティング:性能結果
127
MXNet:分散GPUクラスターから組込みシステムまで
128
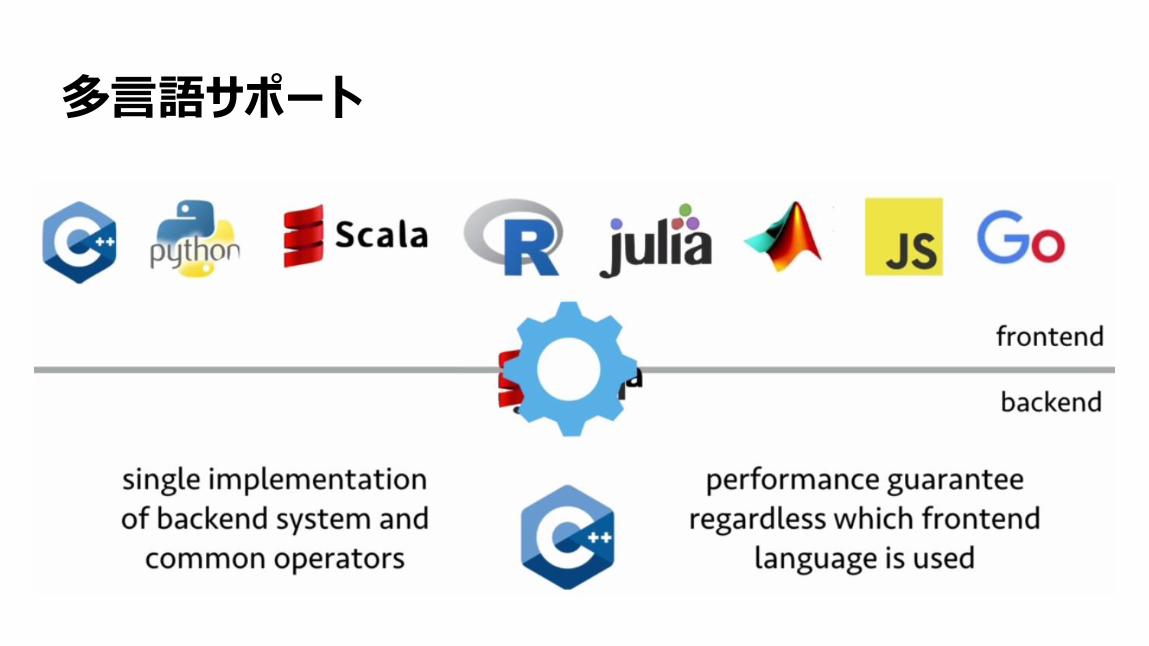
多言語サポート

129
MinPy:MXNet Numpy パッケージ
130
MXNet:分散GPUクラスターから組込みシステムまで
131
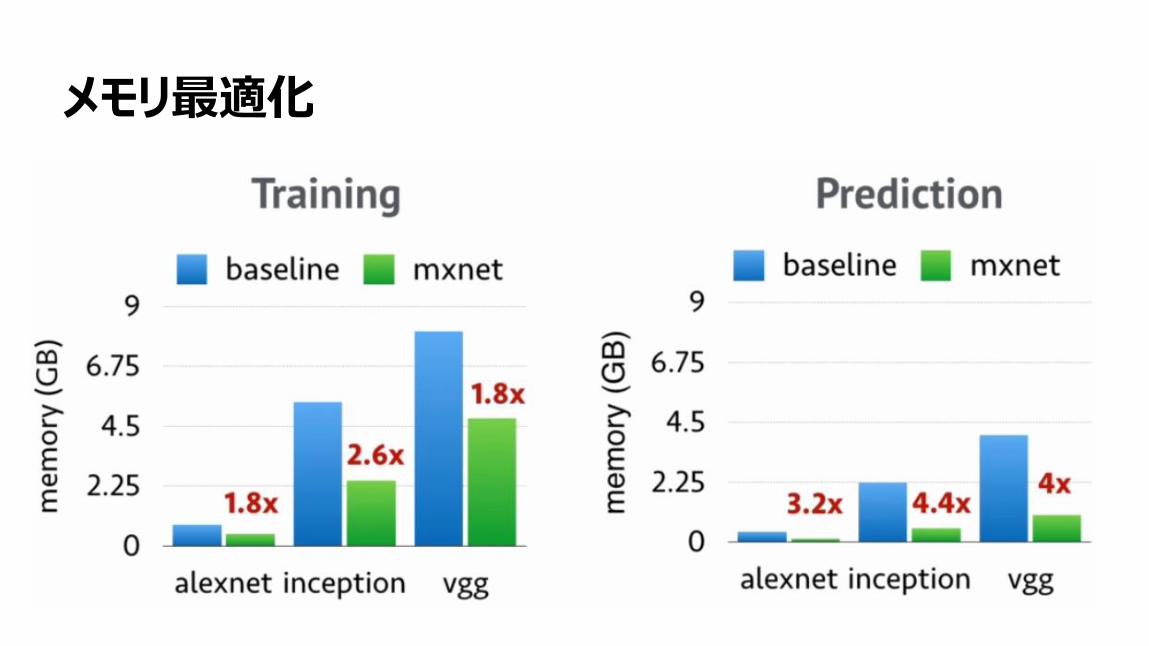
メモリ最適化
132
MXNet:分散GPUクラスターから組込みシステムまで

133
豊富な動作環境

Antonio M. López Principal Investigator & Associate Professor, Computer Vision Center & Universitat Autònoma de Barcelona
TRAINING MY CAR TO SEE: USING VIRTUAL WORLDS
SESSION 14

135
車の認識

136
仮想世界が使用できる?
137
自動注釈付けのための仮想世界

138
自動注釈付けのための仮想世界

139

140

141
142

Fausto Milletari, PhD Candidate, Technical University of Munich
SEGMENTATION OF MEDICAL VOLUMES USING CONVOLUTIONAL NEURAL NETWORKS
SESSION 15
医療画像セグメンテーション
コンピュータ補助による診断
コンピュータ補助による施術
治療計画
優れた可視化
145
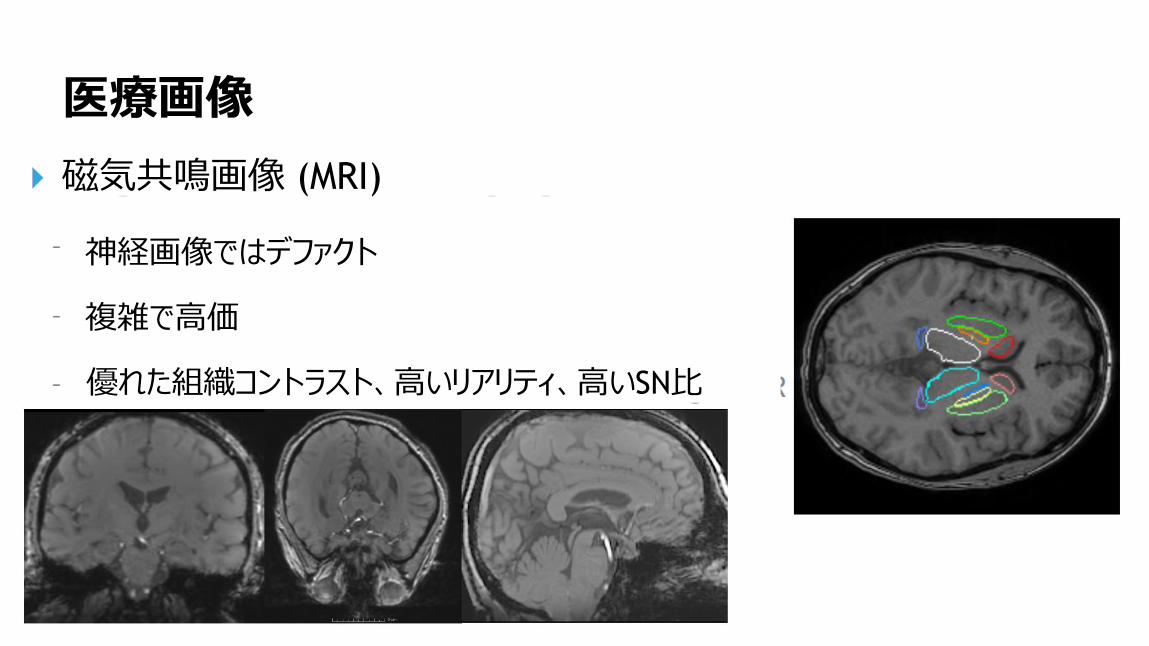
医療画像
磁気共鳴画像 (MRI)
神経画像ではデファクト
複雑で高価
優れた組織コントラスト、高いリアリティ、高いSN比
146
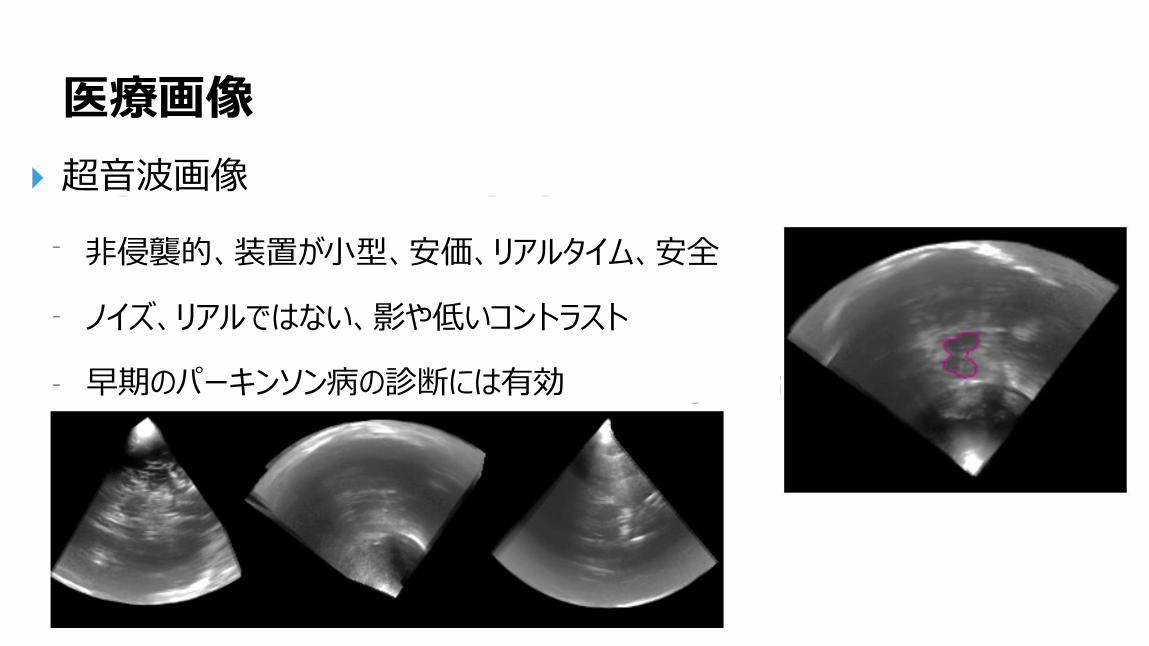
医療画像
超音波画像
非侵襲的、装置が小型、安価、リアルタイム、安全
ノイズ、リアルではない、影や低いコントラスト
早期のパーキンソン病の診断には有効
147
アプローチ
自動セグメンテーション
組織のローカリゼーション
事前の形状の知識
限られた学習データ
時間効率
148
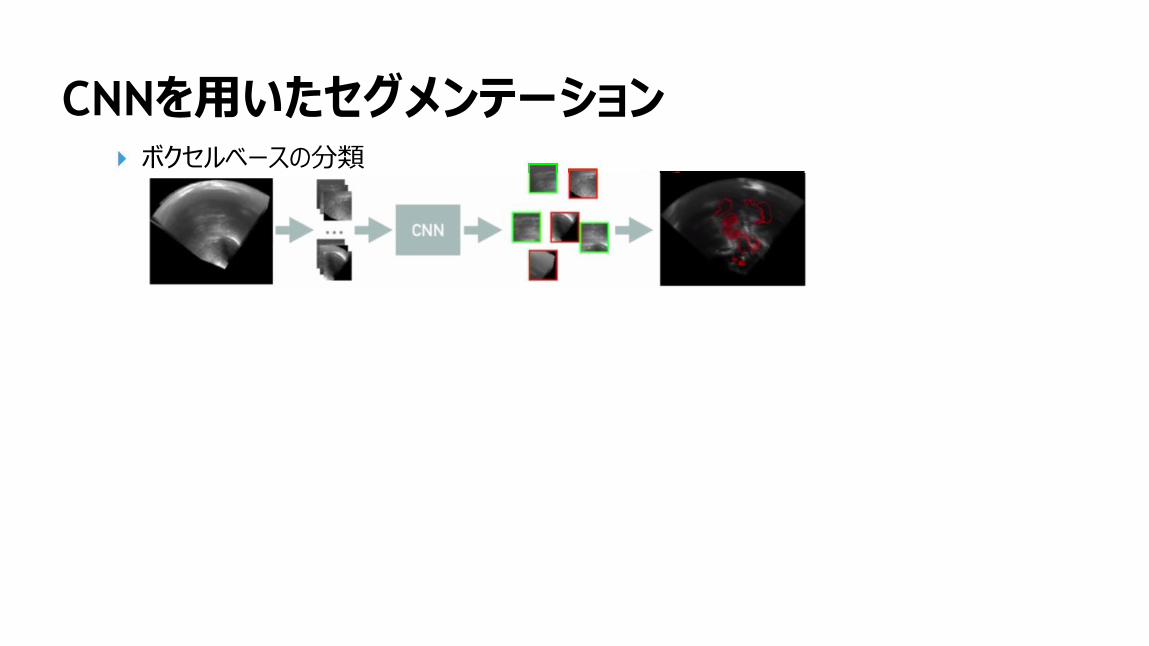
CNNを用いたセグメンテーションボクセルベースの分類
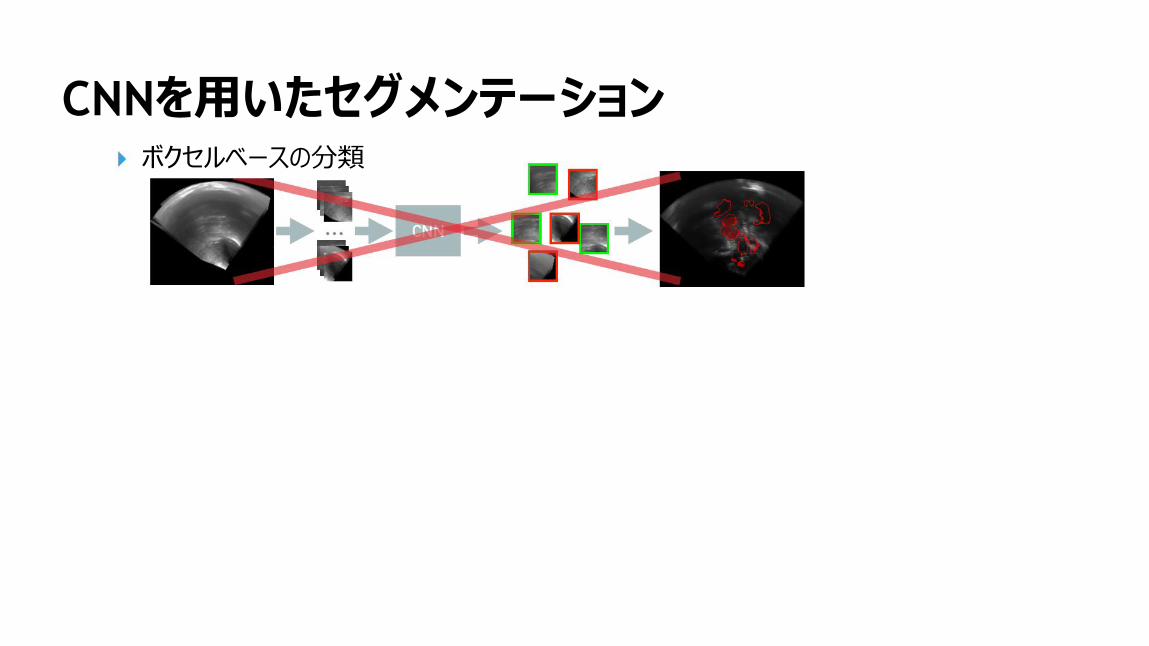
149
CNNを用いたセグメンテーションボクセルベースの分類
150
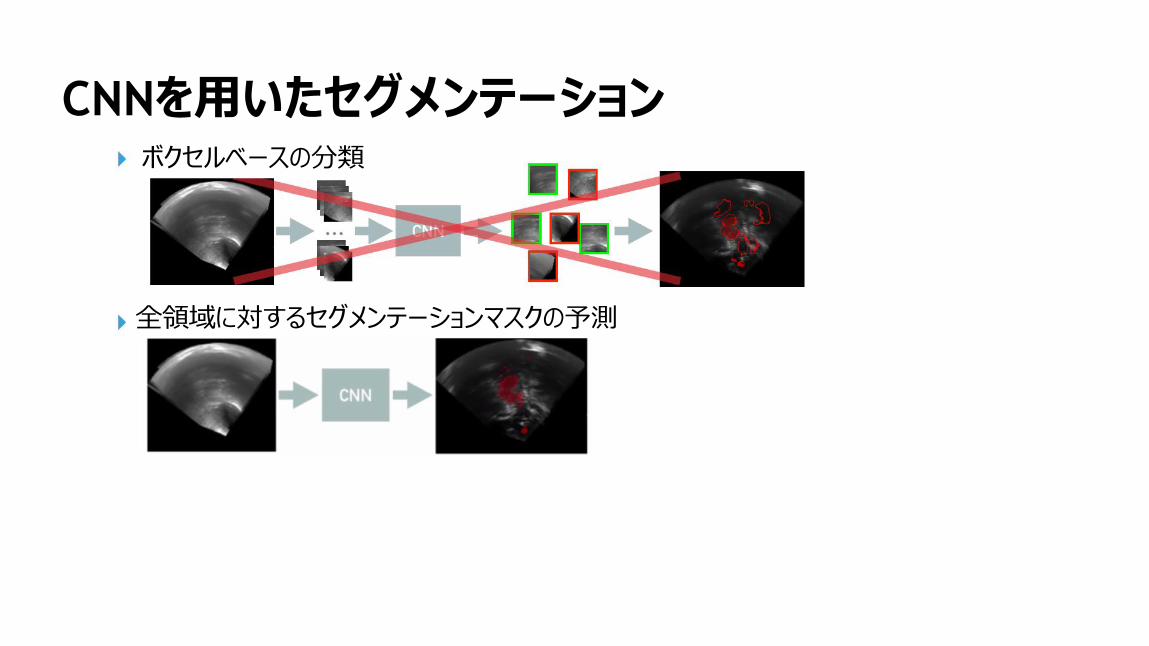
CNNを用いたセグメンテーションボクセルベースの分類
全領域に対するセグメンテーションマスクの予測
151
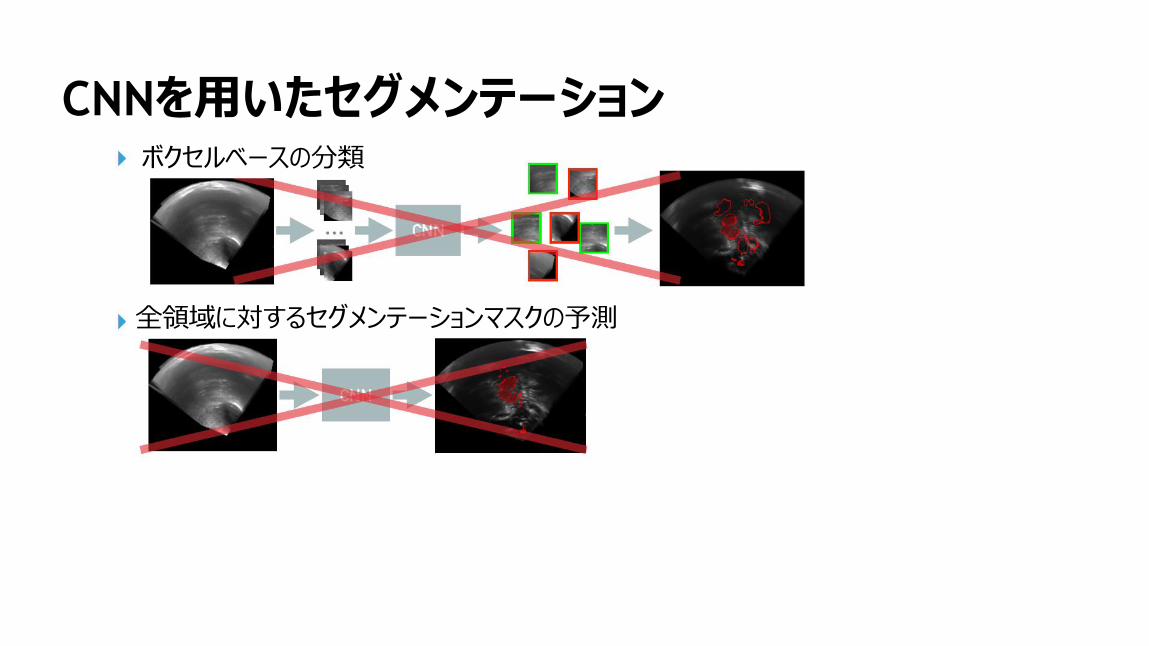
CNNを用いたセグメンテーションボクセルベースの分類
全領域に対するセグメンテーションマスクの予測
152
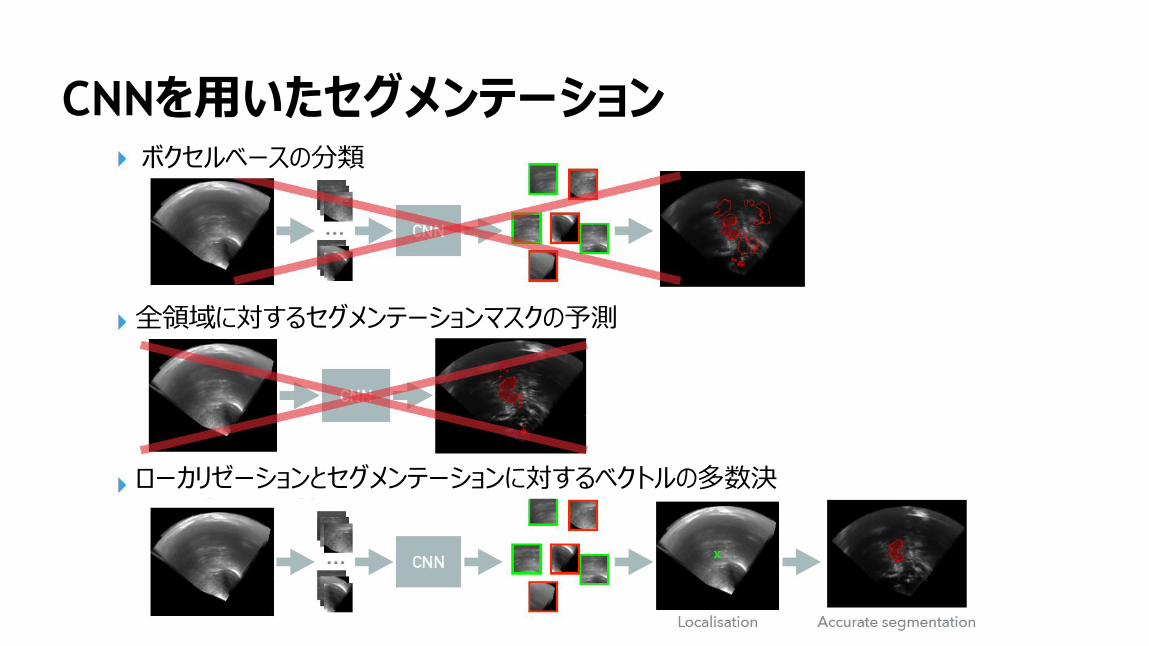
CNNを用いたセグメンテーションボクセルベースの分類
全領域に対するセグメンテーションマスクの予測
ローカリゼーションとセグメンテーションに対するベクトルの多数決
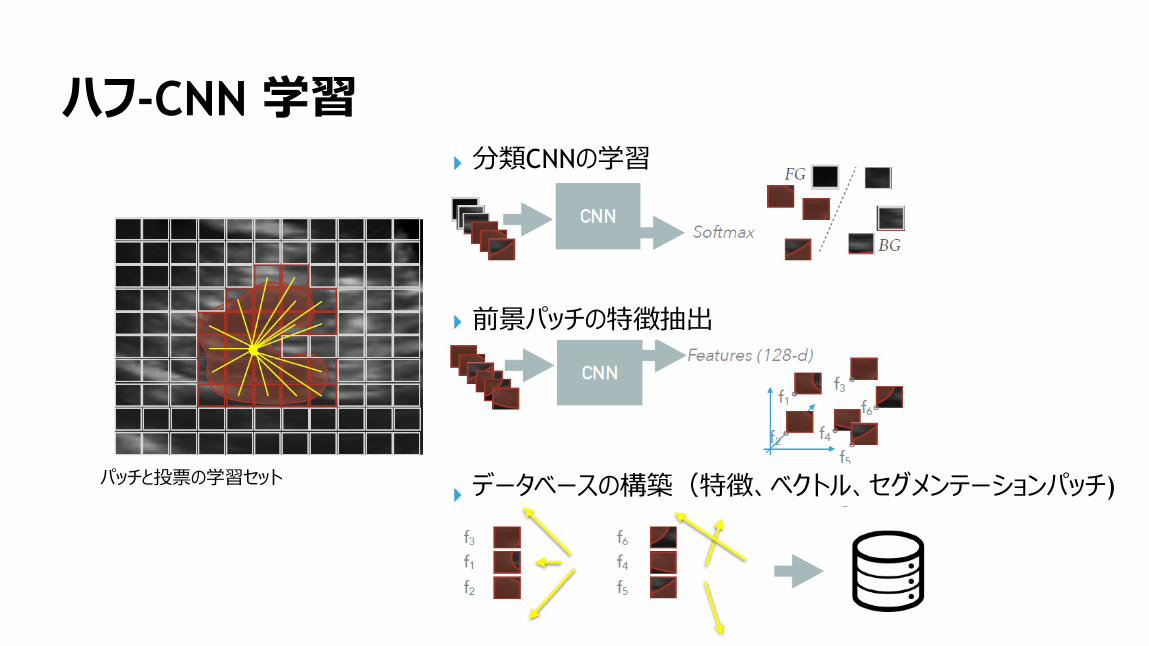
153
ハフ-CNN 学習
パッチと投票の学習セット
分類CNNの学習
前景パッチの特徴抽出
データベースの構築(特徴、ベクトル、セグメンテーションパッチ)
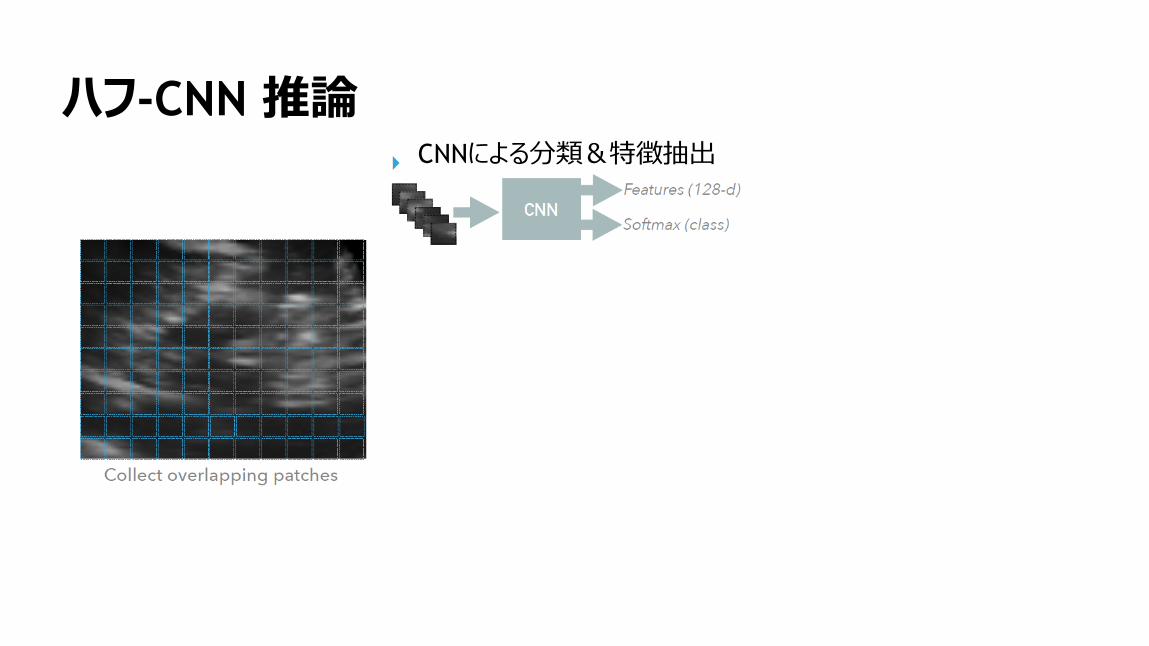
154
ハフ-CNN 推論CNNによる分類&特徴抽出
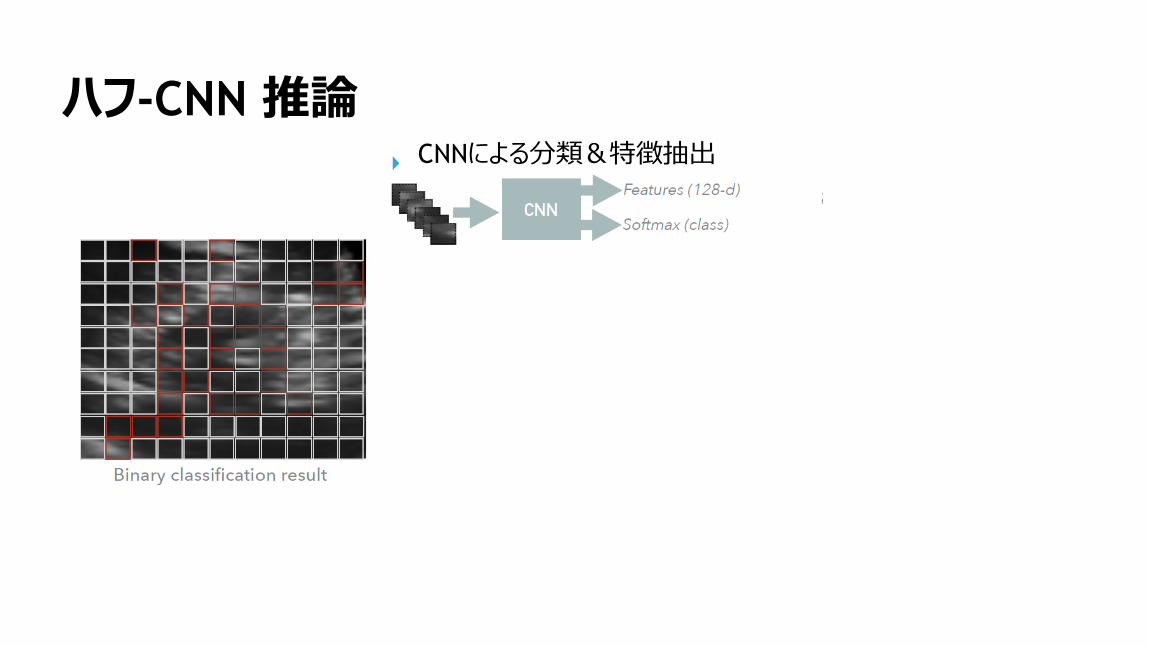
155
ハフ-CNN 推論CNNによる分類&特徴抽出
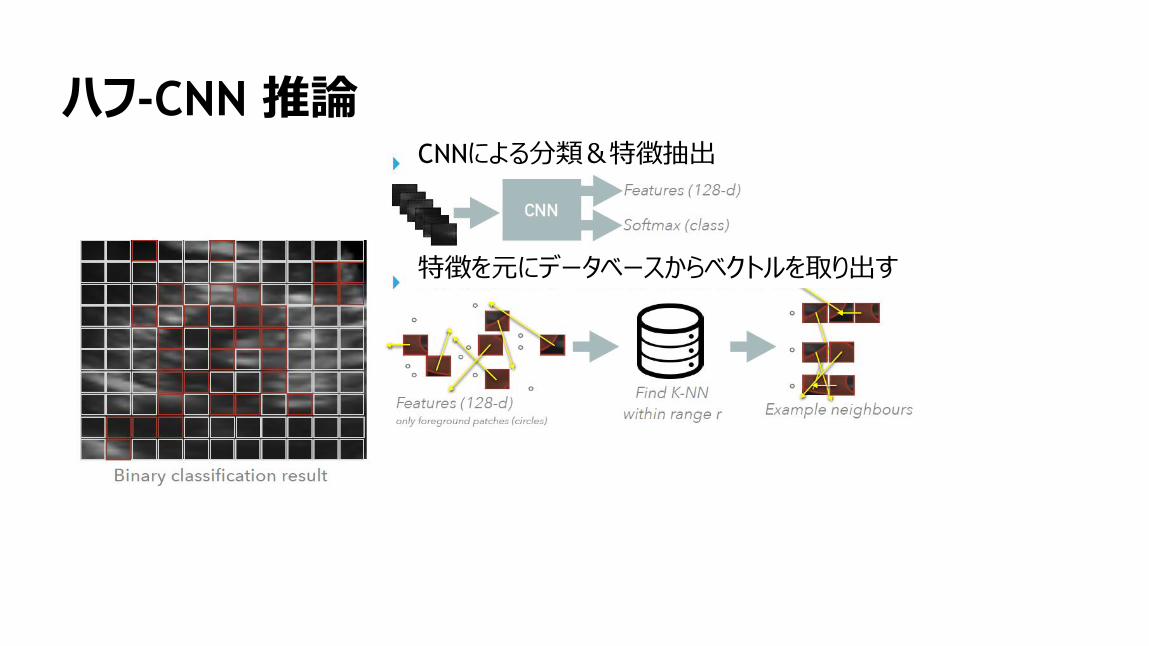
156
ハフ-CNN 推論CNNによる分類&特徴抽出
特徴を元にデータベースからベクトルを取り出す
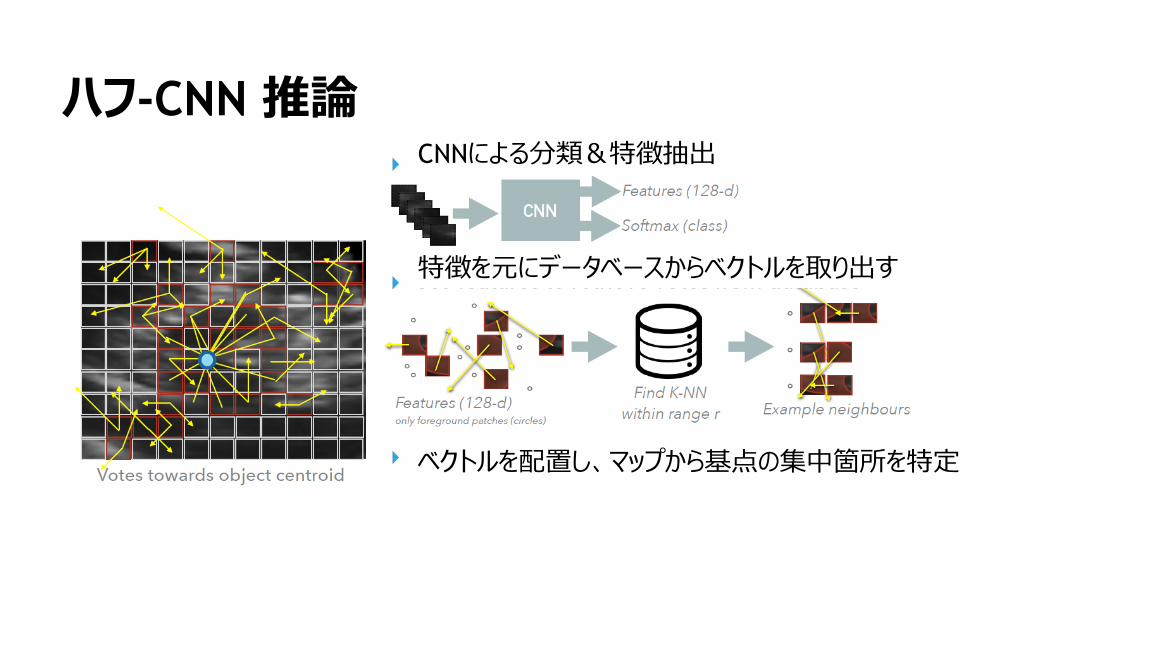
157
ハフ-CNN 推論CNNによる分類&特徴抽出
特徴を元にデータベースからベクトルを取り出す
ベクトルを配置し、マップから基点の集中箇所を特定
158
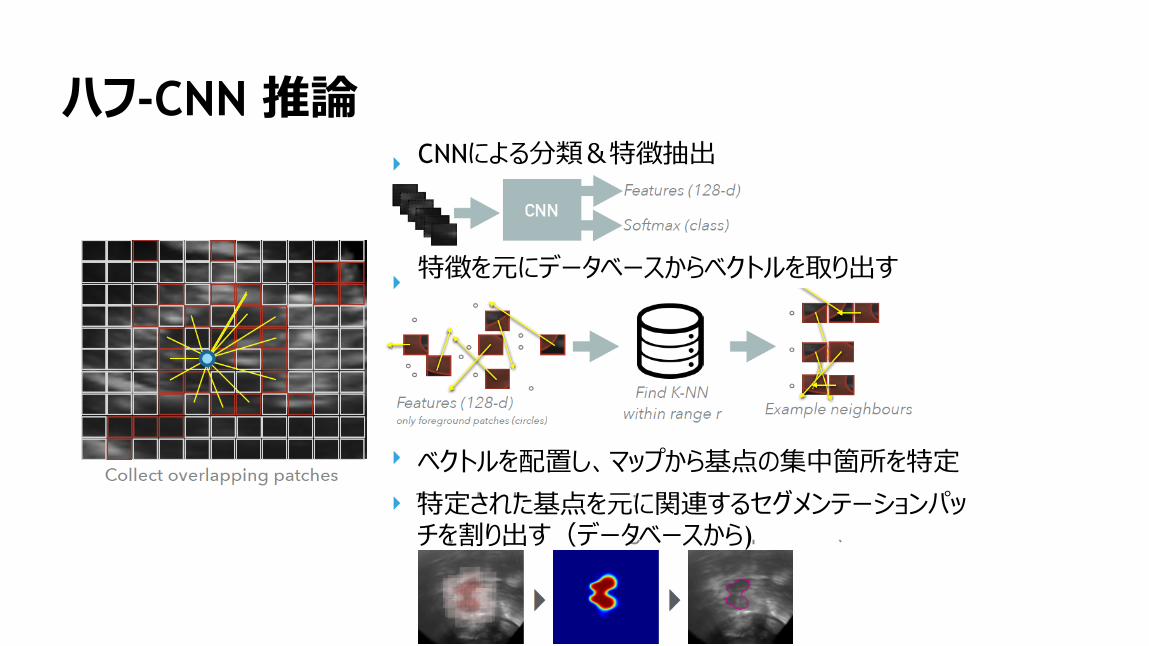
ハフ-CNN 推論CNNによる分類&特徴抽出
特徴を元にデータベースからベクトルを取り出す
ベクトルを配置し、マップから基点の集中箇所を特定
特定された基点を元に関連するセグメンテーションパッチを割り出す(データベースから)
159
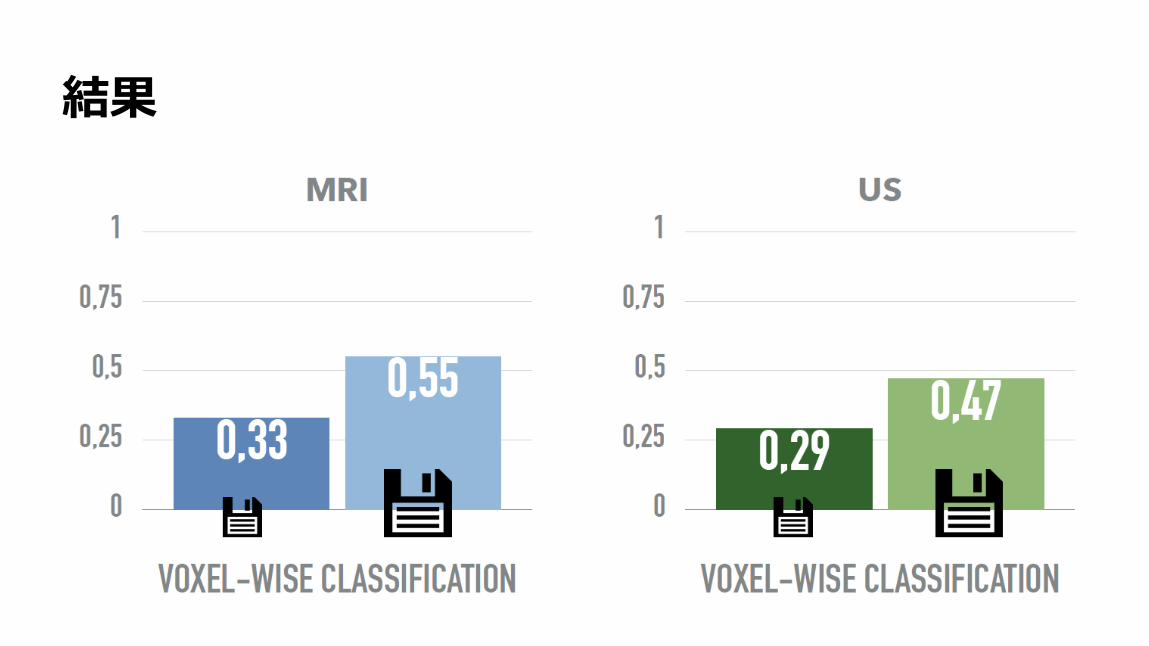
結果
160
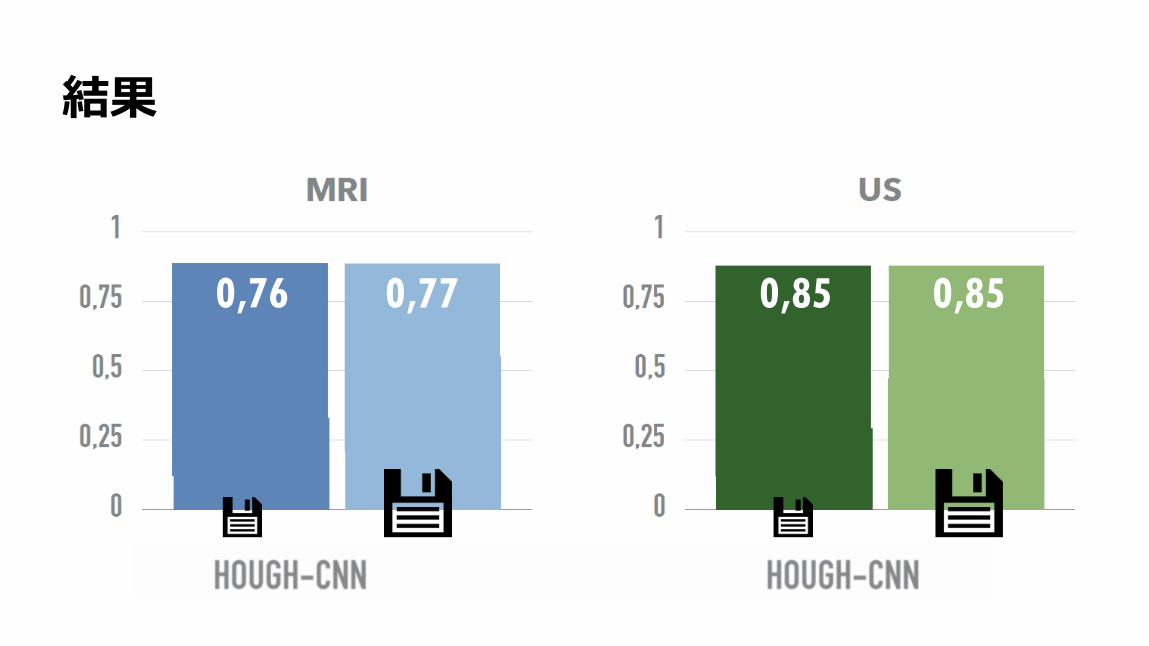
結果
0,76 0,77 0,85 0,85

Song Han PhD student, Stanford University
DEEP COMPRESSION AND EIE: DEEP NEURAL NETWORK MODEL COMPRESSION AND EFFICIENT INFERENCE ENGINE
SESSION 16

課題

163
Deep Compression

164
Deep Compression
165
Pruning

166
Pruning:背景
167
Pruningによる精度変化
168
AlexNet & ConvNet
169
Natural TalkとLSTM

170
Natural TalkとLSTM

171
ディープラーニングのシステム開発にお困りでしたら
までお問い合わせください。
内容に応じ、各種パートナー企業様をご紹介します。
コンサルティング、システムインテグレーションなど各種ご相談に応じます
ディープラーニング相談室

NVIDIA IS HIRINGYOUR LIFE’S WORK STARTS HERE
www.nvidia.com/careers

THANK YOU