hive present-and-feature-shanghai
TRANSCRIPT

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Apache Hive Present and Future
Yifeng JiangSolutions Engineer, Hortonworks, inc.July 23, 2015

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
About Me
蒋 燚峰 (Yifeng Jiang)
• Solutions Engineer, Hortonworks inc.
• HBase book author
• Hobbies: hiking, watching movie

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Agenda• Apache Hive Present
• How Hive Achieved 100x Performance
• Sub-second Response

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hadoop for the Enterprise: Implement a Modern Data Architecture with HDP
Customer Momentum• 430+ customers (as of March 31, 2015)
• 105 customers added in Q1 2015
Hortonworks Data Platform• Completely open multi-tenant platform for any app & any data.
• A centralized architecture of consistent enterprise services for resource management, security, operations, and governance.
Partner for Customer Success• Open source community leadership focus on enterprise needs
• Unrivaled world class support
• Founded in 2011
• Original 24 architects, developers, operators of Hadoop from Yahoo!
• 600+ Employees
• 1100+ Ecosystem Partners
Apache Project CommittersPMC
Members
Hadoop 27 21
Pig 5 5
Hive 18 6
Tez 16 15
HBase 6 4
Phoenix 4 4
Accumulo 2 2
Storm 3 2
Slider 11 11
Falcon 5 3
Flume 1 1
Sqoop 1 1
Ambari 36 28
Oozie 3 2
Zookeeper 2 1
Knox 13 3
Ranger 11 n/a
TOTAL 164 109

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hortonworks Data Platform (HDP) 2.2 Stack
Hive: SQL on Hadoop

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Apache Hive PresentTransaction, Security, Performance

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Apache Hive: SQL on Hadoop
• OSS data warehouse built on top of Hadoop
• First Apache Hive released in 2009
• Initial goal was to write MapReduce jobs in SQL– Most query ran from minutes to hours
– Primary used for batch processing

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hive – Single tool for all SQL use cases
OLTP, ERP, CRM Systems
Unstructured documents, emails
Clickstream
Server logs
Sentiment, Web Data
Sensor. Machine Data
Geolocation
Interactive Analytics
Batch Reports /Deep Analytics
Hive - SQL
ETL / ELT

© Hortonworks Inc. 2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015
Hive Scales to Any Workload
Page 9
Hive at Facebook• 100+ PB of data under management
• 15+ TB of data loaded daily
• 60,000+ Hive queries per day
• More than 1,000 users per day

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
TransactionsInsert, Update and Delete SQL Statements
© Hortonworks Inc. 2011 – 2015. All Rights Reserved
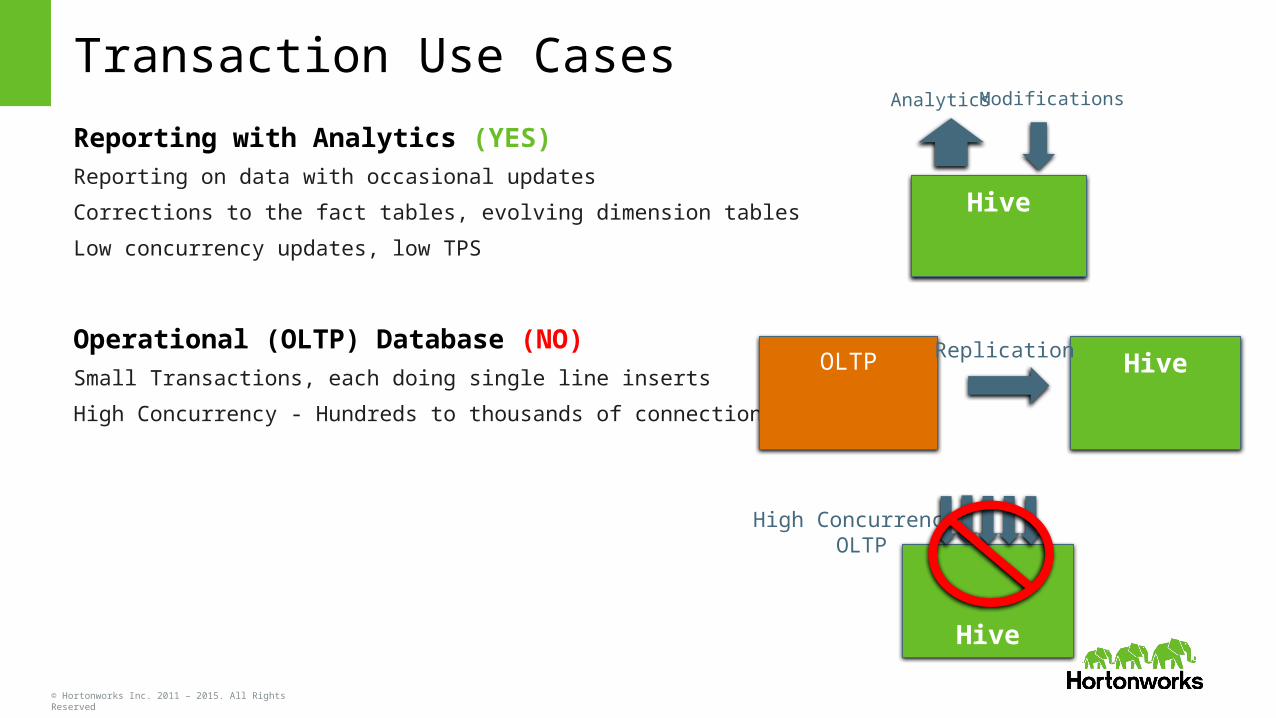
Transaction Use Cases
Reporting with Analytics (YES)Reporting on data with occasional updates
Corrections to the fact tables, evolving dimension tables
Low concurrency updates, low TPS
Operational (OLTP) Database (NO)Small Transactions, each doing single line inserts
High Concurrency - Hundreds to thousands of connections
Hive
OLTP HiveReplication
Analytics Modifications
Hive
High Concurrency OLTP

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Deep Dive: Transaction
Transaction Support in Hive with ACID semantics• Hive native support for INSERT, UPDATE, DELETE.• Split Into Phases:
• Phase 1: Hive Streaming Ingest (append)• Phase 2: INSERT / UPDATE / DELETE Support• Phase 3: BEGIN / COMMIT / ROLLBACK Txn
[Done]
[Done]
[Next]
Read-Optimized ORCFile
Delta File Merged Read-
Optimized ORCFile
1. Original FileTask reads the latest
ORCFile
Task
Read-Optimized ORCFile
Task Task
2. Edits MadeTask reads the ORCFile and merges
the delta file with the edits
3. Edits MergedTask reads the
updated ORCFile
Hive ACID Compactor periodically merges the delta
files in the background.

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hive Compaction
Read-Optimized ORCFile
Delta File Merged Read-
Optimized ORCFile
Read-Optimized ORCFile
Delta File
Delta File
Delta File
Minor Compaction10% local
Major Compaction10% global
Minor / Major compaction

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
SecurityHive User’s perspective
© Hortonworks Inc. 2011 – 2015. All Rights Reserved
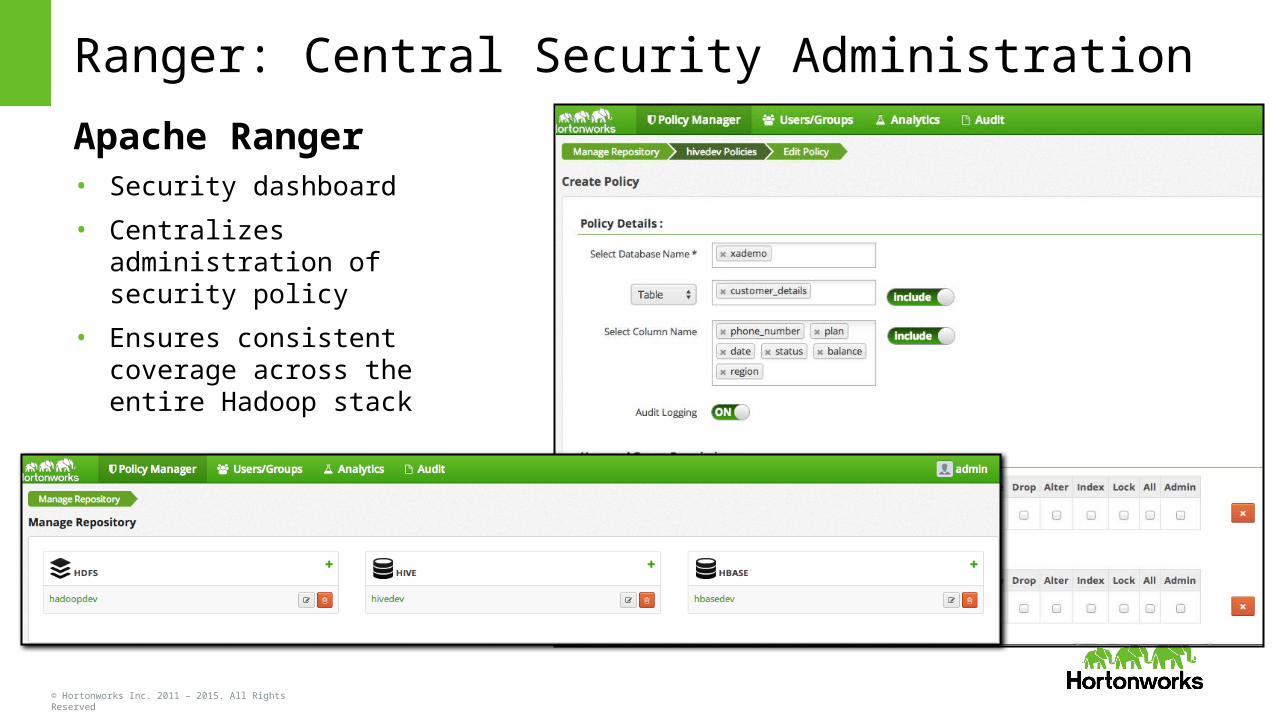
Ranger: Central Security Administration
Apache Ranger• Security dashboard
• Centralizes administration of security policy
• Ensures consistent coverage across the entire Hadoop stack

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Setup Authorization Policy (Hive)
16
file level access control, flexible definition
Control permissions

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
How Hive Achieved 100x PerformanceORC, Tez, CBO, Vectorization

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Need for Speed: The Stinger Initiative
Stinger: An Open Roadmap to improve Apache Hive’s performance 100x.
Launched: February 2013; Delivered: April 2014.
Delivered in 100% Apache Open Source.
SQL Engine
Vectorized SQL Engine
ColumnarStorage
ORCFile
= 100X+ +Distributed Execution
Apache Tez

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
TPC-DS Benchmark at 30 Terabyte Scale
Sample of 50 queries from TPC-DS at 30 terabyte scale.
Average 52x Query Speedup, Maximum 160x Query Speedup.
Total benchmark time decreased from 7.8 days to 9.3 hours.(3)
Cost-Based Optimizer added in Hive 14 gave additional 2.5x Speedup.

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
ORC File FormatColumnar Storage for Hive

© Hortonworks Inc. 2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015
ORCFile – Columnar Storage for Hive
• Columns stored separately
• Knows types– Uses type-specific encoders– Stores statistics (min, max, sum, count)
• Has light-weight index– Skip over blocks of rows that don’t matter
Page 21

© Hortonworks Inc. 2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015
ORCFile – Columnar Storage for Hive
Large block size ideal for map/reduce.
Columnar format enables high compression and high performance.

© Hortonworks Inc. 2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015
ORCFile – Create Table
• Defined at table or partition level
• Configurable compression codec
Page 23
create table Addresses ( name string, street string, city string, state string, zip int) stored as orc tblproperties ("orc.compress"=”ZLIB");

© Hortonworks Inc. 2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015
ORCFile – Convert Text to ORC
• Always ORC
• One SQL to convert text to ORC
Page 24
-- Create Text & ORC tablesCREATE TABLE test_details_txt( visit_id INT, store_id SMALLINT) STORED AS TEXTFILE;CREATE TABLE test_details_orc( visit_id INT, store_id SMALLINT) STORED AS ORC;
-- Load into Text tableLOAD DATA LOCAL INPATH '/home/user/test_details.csv' INTO TABLE test_details_txt;
-- Copy to ORC tableINSERT OVERWRITE INTO test_details_orc SELECT * FROM test_details_txt;

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Tez EngineBeyond MapReduce

© Hortonworks Inc. 2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015
I/O Synchronization
Barrier
I/O Synchronization
Barrier
Job 1 ( Join a & b )
Job 3 ( Group by of c )
Job 2 (Group by of a Join b)
Job 4 (Join of S & R )
Hive - MR
MR vs. Tez Example
Page 26
Single Job
Hive - Tez
Join a & b
Group by of a Join b
Group by of c
Job 4 (Join of S & R )

© Hortonworks Inc. 2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015
Tez – Introduction
Page 27
• Distributed execution framework for data-processing applications
– Target for application (framework), not end user
– Hive on Tez, Pig on Tez, Cascading on Tez, …
• Lessons learned from MapReduce– Significant performance improvement– Batch, interactive– Petabytes scale
• Run on YARN– Utilize cluster resource

© Hortonworks Inc. 2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015
Tez – Switch from MapReduce
• One command to switch from MapReduce to Tez
Page 28
set hive.execution.engine=tez;
SELECT * FROM my_table;
• Set Tez as default engine on Hadoop 2
$ vi hive-site.xml
hive.execution.engine=tez

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Cost Based OptimizerMaking the SQL smarter

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Cost Based Optimizer in Hive
Cost-Based Optimizer (CBO) creates optimized execution plan using Hive table statistics
Why cost-based optimization?
• Simple use – e.g., adjust join order automatically
• Reduce the need for SQL tuning
• Optimized plan relates to better cluster utilization
Page 30
© Hortonworks Inc. 2011 – 2015. All Rights Reserved
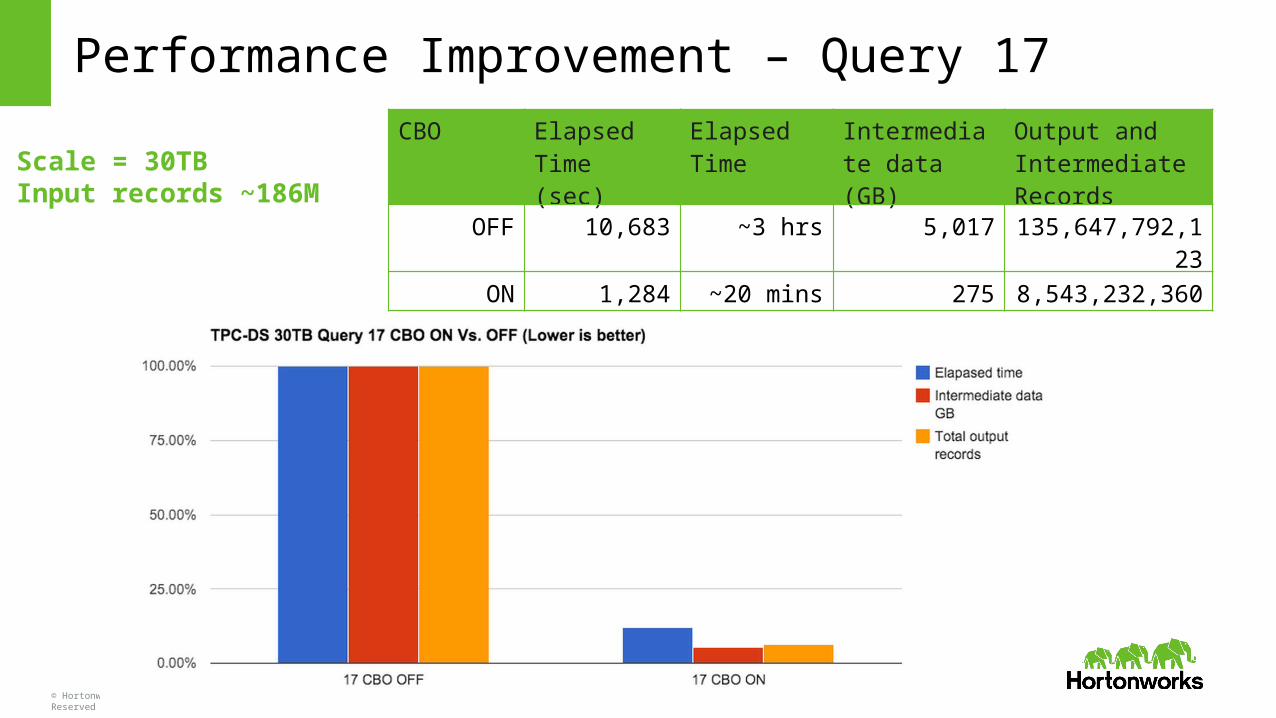
Performance Improvement – Query 17
Scale = 30TBInput records ~186M
CBO Elapsed Time (sec)
Elapsed Time
Intermediate data (GB)
Output and Intermediate Records
OFF 10,683 ~3 hrs 5,017 135,647,792,123
ON 1,284 ~20 mins 275 8,543,232,360

© Hortonworks Inc. 2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015
CBO – Enable CBO
• Enable CBO before submitting query
Page 32
set hive.cbo.enable=true;set hive.compute.query.using.stats=true;set hive.stats.fetch.column.stats=true;set hive.stats.fetch.partition.stats=true;
• Refresh statistics
ANALYZE TABLE my_table COMPUTE STATISTICS FOR COLUMNS;

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Vectorized Query ExecutionProcess 1024 Rows at a Time

© Hortonworks Inc. 2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015
Vectorization – Vectorized SQL Engine
• Feature:– Process a block of 1024 rows instead of one row at a time
– Leverage modern hardware architecture
• Benefit:– Max to 3x faster for big query
– Reduce CPU time, utilize cluster resource
Page 34

© Hortonworks Inc. 2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015
Vectorization – Enable Vectorization
• Enable vectorized SQL engine
Page 35
set hive.vectorized.execution.enabled = trueset hive.vectorized.execution.reduce.enabled = true;
• Support ORC only• A few data types and features are not supported

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hive on Tez: Conclusion
Hive on Tez delivers fast batch and interactive SQL today.
But users need more speed!
Proven at petabyte scale.Scalei
The most comprehensive open-source SQL on Hadoop.
SQLiMore than 90 Hortonworks customers use Hive-on-Tez today for fast SQL.
Speedi
Hortonworks Customer Support metrics as of Feb/2015

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Sub-second Query ResponseSolving Hive’s Top Performance Challenges

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Next Stop: Stinger.next and Sub-Second SQL
Emergence of LLAP and Hive-on-Spark bring Sub-Second within reach.

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Apache Hive: Modern ArchitectureSt
orag
e
Columnar Storage
ORCFile Parquet
Unstructured Data
JSON CSV
Text Avro
Custom
Weblog
Engi
ne
SQL Engines
Row Engine Vector Engine
SQL
SQL Support
SQL:2011 Optimizer HCatalog HiveServer2
Cach
e
Block Cache
Linux Cache
Dist
ribut
edEx
ecuti
on
Hadoop 1
MapReduce
Hadoop 2
Tez
Historical
Current
In Development
Legend

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Apache Hive: Modern ArchitectureSt
orag
e
Columnar Storage
ORCFile Parquet
Unstructured Data
JSON CSV
Text Avro
Custom
Weblog
Engi
ne
SQL Engines
Row Engine Vector Engine
SQL
SQL Support
SQL:2011 Optimizer HCatalog HiveServer2
Cach
e
Block Cache
Linux Cache
Dist
ribut
edEx
ecuti
on
Hadoop 1
MapReduce
Hadoop 2
Tez
Vector Cache
LLAP
Persistent Server
Historical
Current
In Development
Legend

© Hortonworks Inc. 2011 – 2015. All Rights ReservedHive & HBase For Transaction Processing
HBase Meta store: Why?
Page 41
700+ metastore queries to create execution plan!

© Hortonworks Inc. 2011 – 2015. All Rights ReservedHive & HBase For Transaction Processing
LLAP: What
Page 42
Node
LLAP Process
HDFS
Query Fragm
ent
LLAP In-Memory columnar cache
LLAP process running read task for a query
LLAP process runs on multiple nodes, accelerating Tez tasks Node
Hive Query
Node NodeNode Node
LLAP LLAP LLAP LLAP
LLAP = Live Long And Process

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
LLAP: Why?
Page 43
• LLAP is a node resident daemon process– Low latency by reducing setup cost
• LLAP has in-memory columnar data cache– Hot data sits in memory, not HDFS
– Store data in columnar format for vectorization processing
• Use YARN for resource management– Utilize cluster resource
Node
LLAP Process
Query Fragment
LLAP In-Memory columnar cache
LLAP process running a task for a query
HDFS

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hive Sub-second Response
= Sub-SecondHive
Metadata
Fast, Scalable Metadata
Catalog
Persistent Server
LLAP
+ +SQL Engine
Vectorized Hash Join
Choice of Execution Engines
Tez
+

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Key TakeawaysHive Present and Future

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hive Present and Future
• Hive is the de facto standard of SQL on Hadoop
• One tool, batch and interactive processing
• One tool, all big data SQL use cases: ETL, reporting, BI and analytics
• Hive keeps envolving
• SQL:2011 Analytics support
• Enhance transactions
• Sub-second query response

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Try Hive Today
• Try Hive latest feature today
• Hive on Tez
• ORC file formant
• CBO
• Vectorization
• Just a few lines of configuration/SQL change
• Stay tuned for Hive evolution

© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Thank you
Yifeng Jiang, Solutions Engineer, Hortonworks@uprush