inferenciaymodelizacion mediantecopulas - academia ... ·...
TRANSCRIPT

departamento de matemáticas
Inferencia y modelizacionmediante Copulas
presentado por directorCarlos Ayyad Prof. Dr. Jorge Mateu
co-directorProf. Dr. Emilio Porcu
curso 2007-2008


Esta memoria se presenta como Trabajo de Investigación dentro delPrograma de Doctorado MATEMATICAS MULTIDISCIPLINARES(código 11211), para optar posteriormente al Diploma de Estudios Avanza-dos.
Castellón, 25 de Junio de 2008
Firma Firma (Director) Firma(Co-director)


Agradecimientos
En primer lugar quisiera dar las gracias a los Doctores D. Jorge Mateu y D.Emilio Porcu por la inestimable ayuda y asesoramiento que me han brindadoa lo largo de la redacción de este trabajo, guiándome siempre en el caminocorrecto a seguir de una manera muy especial y efectiva. Resalto tambiénel buen ambiente y la gran motivación que ellos han logrado transmitirme,hecho ejemplar que seguro tomaré y a partir de ahora aplicaré personalmente.También es de especial mención la comprensión que ellos han depositado enmi situación, ya que al no disponer de beca ni de ningún tipo de ayudaeconómica todo ha resultado un poco más complicado. En segundo lugarquisiera también agradecer a D. Enrico Foscolo su valiosa aportación a estetrabajo, sin la cual posiblemente no hubiese adquirido la forma actual quetiene. Muchas gracias por todo a ellos tres.Dedico este trabajo a mi esposa Maricruz, a mi madre, Mayte, y a mis her-manos, Sarah y Yassid. Gracias por soportar mis malos momentos y darmela fuerza necesaria para afrontar el dia a dia. Sin vuestro incondicional apoyoeste trabajo nunca hubiese visto la luz.


A la memoria de mis abuelos, Josefa Barberá y Francisco Limonge. Graciaspor enseñarme a andar por el dificil camino de la vida.


No podemos engañar a la naturaleza,pero sí podemos ponernos de acuerdo con ella.
Albert Einstein (1879-1955).
La Ciencia siempre se equivoca.Nunca resuelve un problema sin crear otros diez.
Bernard Shaw (1856-1950).
No deberiamos pensar que heredamos la Tierra de nuestros padres, sino quela tomamos prestada a nuestros hijos.
Anónimo.
La inspiración existe, pero tiene que encontrarte trabajando.Pablo Picasso (1881-1973).
Los hombres inteligentes quieren aprender; los demás, enseñar.Anton Chejov (1860-1904).


Resumen
Este trabajo pretende ser una introducción a la teoría de cópulas. Estateoría, basada en la construcción de ciertas familias de funciones multivari-antes, explica como se puede estudiar a través de ellas la posible dependenciay grado, funcionalmente hablando, de las variables aleatorias involucradas,incluso aún éstas no estén idénticamente distribuídas. En cierta forma lapalabra cópula ya sugiere por si misma1 enlace, unión, conexión o víncu-lo de las variables, es decir, su grado de dependencia. El interés por estametodología y sus aplicaciones se volvió extremadamente importante en ladécada de los 90 del siglo pasado, básicamente gracias a los tres congre-sos internacionales, “The Symposium on Distributions with Given Marginal(Fréchet Classes)” (Roma, 1990), “Distributions with Fixed Marginals, Dou-bly Stochastic Measures, and Markov operator” (Seattle, 1993), “Distributionswith Given Marginals and Moment Problems” (Praga, 1996), en los que lapalabra cópula fue íntimamente relacionada al estudio de las distribucionesconjuntas con marginales dadas, pudiendo éstas últimas ser diferentes, in-cluso ser representantes de, unas de variables contínuas y otras de variablesdiscretas2.Desde un punto de vista más formal, las cópulas pueden ser definidas comouna función de distribución multivariante en Im = [0, 1]m = [0, 1]×· · ·×[0, 1],m ∈ N, cuyas marginales son uniformes. En la práctica, dado un problema,las marginales uniformes se sustituyen por las funciones de distribución delas variables en juego, por lo que la cópula realiza la función de interconec-tarlas, pudiendo a través de ésta realizar estudios de dependencia entre ellasestimando el parámetro poblacional, ya que es éste el que me aportará la in-formación pertinente sobre el grado de dependencia, como se explicará másadelante. Evidentemente, dada la gran cantidad de familias de cópulas exis-tentes, otra cuestión a tener en cuenta consistirá en la elección de la cópulaapropiada como estructura de dependencia para una serie de datos.
1Esta palabra proviene del latín y su significado (conexión, vínculo) es muy sugerentepara este tópico
2La modelización de un problema requiere muchas veces introducir varios tipos devariables, discretas y contínuas

El mayor impedimento que nos dificulta determinar modelos para el estudiode la relación entre varias variables aleatorias, como el modelo bivariante(multivariante) Normal, modelo bivariante (multivariante) Gamma. . . , re-side en el hecho de que aunque escojamos una función3 que nos describa elcomportamiento conjunto, no es en absoluto obvio que esa función puedarepresentar a las variables por separado. Las cópulas superan dicho handi-cap, permitiendo separar los conceptos de elección del modelo de cópula (i.e.distribución conjunta) para el estudio de la dependencia y elección de lasdistribuciones marginales. Cabe resaltar que el estudio de la dependenciamediante cópulas abarca mucho más que el modelo lineal, pudiendo rela-cionar variables con una dependencia funcional cualquiera dada.Como N. I. Fisher [19] escribió en uno de sus artículos publicados en Ency-clopaedia of Statistical Sciences, “Las cópulas son interesantes para los es-tadísticos básicamente por dos motivos: primeramente, para el estudio de lasmedidas no paramétricas de dependencia4 (por ejemplo: tau de Kendall, rhode Spearman...) y en segundo lugar, como punto de partida para construirdistribuciones multivariantes que representen estructuras de dependencia”.Sklar [59], el cual fue el autor del teorema fundamental de cópulas, fue pi-onero en entender y definir los aspectos básicos de esta teoría. A partir deentonces han sido numerosos científicos como Dall’Aglio, Hoeffding, Schweiz-er, Wolff, Deheuvels, Genest, MacKay, Marshall, Olkin, Joe, Nelsen... los quehan mostrado enorme esfuerzo e interés en profundizar dicha teoría. Elloshan desarrollado teorías sobre cópulas bajo diferentes denominaciones, comot-norms, dependence functions, double stochastic measures, Markov’s oper-ators. Así pues, ¿tiene sentido escribir a modo introductorio sobre cópulascuando ya hay una larga lista de títulos sobre ello? Genest [29] da una re-spuesta coherente: las cópulas pueden ser analizadas y estudiadas en másprofundidad de lo que está hecho principalmente por dos aspectos: renovarlos métodos de estimación de parámetros y construir contrastes de bondaden el ajuste.En el Capítulo I haremos una breve presentación de las cópulas desde un
3i.e. la función de distribución conjunta4Véase Capítulo 7, Sección 7.1

punto de vista matemático, describiendo algunas familias esenciales en lateoría y posteriormente citando las relaciones que tienen las cópulas con elestudio de la dependencia. En el Capítulo II hablaremos sobre el problemade la estimación de parámetros poblacionales mediante cópulas, citando al-gunos de los métodos existentes. En el Capítulo III abordaremos el tema de lasimulación de estructuras de dependencia mediante cópulas, para posterior-mente estudiar en el capítulo IV la efectividad de los métodos de estimaciónanteriormente descritos mediante un estudio de simulación. En el CapítuloV se exponen las pertinentes conclusiones de este trabajo, citando algunasposibles líneas abiertas de investigación. En particular, nuestra propuesta deinvestigación se presenta en el método de las densidades de área.


Índice general
1. Introducción a la teoría de cópulas 11.1. Definición formal de cópula . . . . . . . . . . . . . . . . . . . 1
1.1.1. Algunos teoremas sobre cópulas y subcópulas . . . . . 31.2. Cópulas y variables aleatorias . . . . . . . . . . . . . . . . . . 5
1.2.1. Definición formal . . . . . . . . . . . . . . . . . . . . . 81.3. Cópulas de supervivencia . . . . . . . . . . . . . . . . . . . . . 101.4. Generación de variables aleatorias . . . . . . . . . . . . . . . . 121.5. Propiedades y ventajas del modelo mediante cópulas . . . . . 141.6. La cópula Arquimediana . . . . . . . . . . . . . . . . . . . . . 18
1.6.1. Definiciones . . . . . . . . . . . . . . . . . . . . . . . . 191.7. Algunas familias de cópulas Arquimedianas . . . . . . . . . . . 25
1.7.1. La familia de Clayton . . . . . . . . . . . . . . . . . . . 251.7.2. La familia Gumbel-Hougaard . . . . . . . . . . . . . . 251.7.3. La familia de Frank . . . . . . . . . . . . . . . . . . . . 251.7.4. La familia de Ali-Mikhail-Haq . . . . . . . . . . . . . . 26
1.8. La cópula empírica . . . . . . . . . . . . . . . . . . . . . . . . 261.9. Cópulas y medidas de dependencia . . . . . . . . . . . . . . . 28
1.9.1. Concordancia . . . . . . . . . . . . . . . . . . . . . . . 281.9.2. Tau de Kendall . . . . . . . . . . . . . . . . . . . . . . 291.9.3. Versión empírica del tau de Kendall . . . . . . . . . . . 321.9.4. El coeficiente rho de Spearman . . . . . . . . . . . . . 341.9.5. Versión empírica del coeficiente rho de Spearman . . . 35
I

1.10. Medidas gráficas de dependencia . . . . . . . . . . . . . . . . . 361.10.1. Chi-plots . . . . . . . . . . . . . . . . . . . . . . . . . . 361.10.2. K-plots . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2. Inferencia estadística para cópulas 49
2.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 492.2. Método MLE: Versión paramétrica . . . . . . . . . . . . . . . 502.3. Método MLE: Versión semiparamétrica . . . . . . . . . . . . . 52
2.3.1. Estimación directa de las marginales, a partir de lamuestra . . . . . . . . . . . . . . . . . . . . . . . . . . 52
2.3.2. Estimación de las marginales utilizando rangos . . . . 532.3.3. Método L1: Estimación por distancia mínima o míni-
mos cuadrados de la cópula paramétrica . . . . . . . . 552.4. Estimaciones basadas en el tau de Kendall y rho de Spearman 57
2.4.1. Intervalo de confianza basado en el tau de Kendall . . . 592.4.2. Intervalo de confianza basado en el rho de Spearman . 59
2.5. Estimadores basados en la Mínima Distancia entre rangos.Método OLS y OLST . . . . . . . . . . . . . . . . . . . . . . . 602.5.1. El método OLS modificado y suavizado: OLST . . . . 62
3. Simulación de estructuras de dependencia mediante cópulas 69
3.1. Simulación mediante la cópula Clayton . . . . . . . . . . . . . 693.2. Simulación mediante la cópula Frank . . . . . . . . . . . . . . 783.3. Simulación mediante la cópula Gumbel . . . . . . . . . . . . . 81
4. Métodos de estimación sobre cópulas: estudio comparativo 89
4.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 894.2. Formalización de la simulación . . . . . . . . . . . . . . . . . . 904.3. Correcta especificación del modelo: Las familias de simulación
y estimación coinciden . . . . . . . . . . . . . . . . . . . . . . 914.3.1. Caso Clayton . . . . . . . . . . . . . . . . . . . . . . . 924.3.2. Caso Frank . . . . . . . . . . . . . . . . . . . . . . . . 924.3.3. Caso Gumbel . . . . . . . . . . . . . . . . . . . . . . . 95

4.4. Incorrecta especificación del modelo: Las familias de simu-lación y estimación no coinciden . . . . . . . . . . . . . . . . . 95
4.4.1. Simulación mediante la cópula Clayton y estimaciónmediante la cópula Frank . . . . . . . . . . . . . . . . . 95
4.4.2. Simulación mediante la cópula Clayton y estimaciónmediante la cópula Gumbel . . . . . . . . . . . . . . . 97
4.4.3. Simulación mediante la cópula Frank y estimación me-diante la cópula Clayton . . . . . . . . . . . . . . . . . 97
4.4.4. Simulación mediante la cópula Frank y estimación me-diante la cópula Gumbel . . . . . . . . . . . . . . . . . 100
4.4.5. Simulación mediante la cópula Gumbel y estimaciónmediante la cópula Clayton . . . . . . . . . . . . . . . 100
4.4.6. Simulación mediante la cópula Gumbel y estimaciónmediante la cópula Frank . . . . . . . . . . . . . . . . . 103
4.5. Aplicaciones. Estimación y elección del modelo de Cópula so-bre datos reales . . . . . . . . . . . . . . . . . . . . . . . . . . 103
5. Conclusiones y futuras líneas abiertas de investigación 121
6. Listado de códigos utilizados 125
6.1. Códigos utilizados en el estudio gráfico de la dependencia entredos variables aleatorias . . . . . . . . . . . . . . . . . . . . . . 125
6.1.1. Cálculo y representación de K-PLOTS . . . . . . . . . 125
6.1.2. Cálculo y representación de CHI-PLOTS . . . . . . . . 127
6.1.3. Representación de las superficies de densidad y sus con-tornos . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
6.2. Códigos utilizados en el estudio de la simulación de datos yestimación de θ . . . . . . . . . . . . . . . . . . . . . . . . . . 138
6.3. Código utilizado en la estimación de θ, dado un banco de datosreal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
6.4. Código utilizado en la elección de la cópula óptima, una vezestimado θ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189

7. Apéndice 1937.1. Un breve estudio de los coeficientes de correlación . . . . . . . 193
7.1.1. Medidas de la dependencia: Pearson, Spearman y Kendall1937.1.2. Relación entre el τ de Kendall y el ρ de Pearson . . . . 1977.1.3. Relación entre el τ de Kendall y el ρ de Spearman . . . 198
7.2. Definiciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
Bibliografía 201
IV

Capıtulo 1Introducción a la teoría de cópulas
1.1. Definición formal de cópula
El término cópula, introducido por Sklar [59], hace referencia a una fun-ción de distribución conjunta cuyas marginales son uniformes en el intervalo[0, 1]. En esta memoria vamos a restringirnos al caso bivariante sin pérdi-da alguna de generalidad, por mera simplificación y reducción del coste delos cálculos. En caso de querer extender nuestro problema a una dimensiónmayor que la bivariante, podremos remitirnos a Nelsen [47], entre otros.
Para introducir matemáticamente el concepto de cópula definido ante-riormente, vamos a proceder de acuerdo a los siguientes pasos:
En primer lugar definiremos a las subcópulas como una clase especí-fica de funciones bivariantes, decrecientes y acotadas por debajo, queademás admitan funciones marginales para cada una de sus variables.
En segundo lugar caracterizaremos una función de cópula como unasubcópula cuyo dominio sea I = [0, 1]× [0, 1].
Seguidamente se definen los conceptos de cópula y subcópula bivariantes.
Definición 1.1.1 Una subcópula bivariante C ′ es una función que posee lassiguientes propiedades:
1

Es una función decreciente, bivariante y acotada por debajo cuyasmarginales pueden ser calculadas a partir de ella 1.
Es una función cuyo dominio es S1×S2, donde S1, S2 son subconjuntosde I = [0, 1].
Para todo (u, v) ∈ S1 × S2,
C ′ (u, 1) = u,
C ′ (1, v) = v,
C ′ (1, 1) = 1.
Para todo (u, v) ∈ S1 × S2, 0 ≤ C ′ (u, v) ≤ 1. Así pues el rango de C ′
es I = [0, 1].
Definición 1.1.2 Una cópula bivariante C es una función con las siguientespropiedades:
Es una subcópula bivariante cuyo dominio es I2 = [0, 1]2 = [0, 1]×[0, 1].
Para todo u, v ∈ I, 0 ≤ C (u, v) ≤ 1, por lo que el rango de C estambién I, es decir,
C : [0, 1]× [0, 1] → [0, 1] .
Equivalentemente, una cópula es una función C de I2 en I la cual cumplelas siguientes propiedades:
Para todo u, v ∈ I se cumple,
C (u, 0) = 0 = C (0, v) ,
C (u, 1) = u,
C (1, v) = v,
1Mírese Apéndice, Sección Definiciones
2

C (1, 1) = 1.
Para todo u1, u2, v1, v2 ∈ I, con u1 ≤ u2 y v1 ≤ v2, se cumple que
VC ([u1, u2]× [v1, v2]) = C (u2, v2)− C (u2, v1)
−C (u1, v2) + C (u1, v1) ≥ 02.
Los conceptos de cópula y subcópula pueden parecer prácticamente idénticos,pero este aspecto tomará relevancia cuando veamos el teorema de Sklar [59].Por último cabe citar que muchas de las importantes propiedades de lascópulas son actualmente también propiedades de las subcópulas (lo mismoocurre también con algunos teoremas).
1.1.1. Algunos teoremas sobre cópulas y subcópulas
Teorema 1.1.1 Cotas de Fréchet-Hoeffding. Sea C′: S1 × S2 → [0, 1]
una subcópula; para todo (u, v) ∈ S1 × S2 se cumple que
max (u + v − 1, 0) ≤ C ′ (u, v) ≤ mın (u, v) .
Denotando del siguiente modo,
W (u, v) := max (u + v − 1, 0)
yM (u, v) := mın (u, v),
se tiene queW (u, v) ≤ C ′ (u, v) ≤ M (u, v).
Prueba. Sean (u, v) puntos cualesquiera de S1 × S2 y sea C ′ una sub-cópula.Por las definiciones 1.1.1 y 1.1.2 se concluye que
C ′ (u, v) ≤ C ′ (u, 1) = u,
2Mírese Apéndice, sección Definiciones, H-volumen
3

C ′ (u, v) ≤ C ′ (1, v) = v,
Por lo que resulta evidente que siempre se cumplirá
C ′ (u, v) ≤ mın (u, v) . (1.1)
Para probar la otra desigualdad, aplicamos de nuevo las definiciones 1.1.1 y1.1.2,
VC′ ([u, 1]× [v, 1]) = C ′ (1, 1)− C ′ (1, v)− C ′ (u, 1) + C ′ (u, v) ≥ 0
C ′ (u, v) ≥ 0
1− v − u + C ′ (u, v) ≥ 0
C ′ (u, v) ≥ 0
C ′ (u, v) ≥ u + v − 1
C ′ (u, v) ≥ 0
=⇒ C ′ (u, v) ≥ max (u + v − 1, 0) . (1.2)
Como toda cópula es una subcópula, la desigualdades (1.1) y (1.2) secumplen también para cópulas. La expresión W (u, v) ≤ C (u, v) ≤ M (u, v)
representa las cotas de Fréchet-Hoeffding, entre las cuales yace toda cópula.Estas cotas son singulares, en efecto
∫ u
0
∫ v
0
c (s, t) dsdt 6= C (u, v) ,
donde (u, v) ∈ I y c denota la función de densidad de una cópula. Dicho deotro modo, fuera de esos límites la densidad no integra la distribución.
El siguiente teorema establece la continuidad de las subcópulas y por lotanto de las cópulas.
Teorema 1.1.2 Sea C ′ una subcópula. Para todo (u1, v1) y (u2, v2) ∈ S1×S2
4

dominio de C ′, se tiene que
|C ′ (u2, v2)− C ′ (u1, v1)| ≤ |u2 − u1|+ |v2 − v1| ,
y por tanto C ′ es uniformemente contínua en su dominio de definición.
Concluiremos esta sección con el siguiente teorema, el cual hace referencia alas derivadas parciales de las cópulas.
Teorema 1.1.3 Sea C una cópula. Para todo v ∈ I, la derivada parcial∂∂u
C(u; ·) existe para todo u ∈ I. Para todo u y v ∈ I, se cumple que0 ≤ ∂
∂uC(u; ·) ≤ 1; de manera análoga, dado u ∈ I, la función ∂
∂vC(·; v)
existe para todo v ∈ I y también se cumple que 0 ≤ ∂∂v
C(·; v) ≤ 1. Además,las funciones ∂
∂uC(u; ·) y ∂
∂vC(·; v) están bien definidas y son no decrecientes
casi por todas partes en I, excepto en un conjunto de medida nula.
Prueba. Para ver la prueba, léase Nelsen [47], página 14.
1.2. Cópulas y variables aleatorias
Se entiende por variable aleatoria (v.a.) a una variable cuyos posiblesvalores que ella pueda tomar quedan determinados por una cierta funciónde distribución de probabilidad. Tambien es muy usual adoptar la definiciónque introdujo Gnedenko [30]: “una variable aleatoria es una variable cuyosvalores no se pueden predecir exactamente con antelación, teniendo ademásuna función de distribución íntimamente asociada”, o la que posteriormenteintrodujo Wald [62]: “una variable X es llamada aleatoria si, dado un valorc, una probabilidad definida puede ser asignada de manera única al suceso deque x sea menor que c”. Cuando se utiliza el término función de distribuciónde una v.a. nos referimos a la función que asigna para todo x ∈ R, la probabi-lidad FX (x) = P (X ≤ x) siendo ésta una función continua por la derecha yno decreciente, ademas de cumplir FX (−∞) = 0 and FX (+∞) = 1. Para dos(o mas ) v.a.’s, el objetivo del análisis del comportamiento conjunto quedarádeterminado por la función de distribución conjunta.
5

Definición 1.2.1 Una función de distribución bivariante es una funciónH : ]−∞, +∞[× ]−∞, +∞[ → [0, 1], cumpliendo lo siguiente:
H es una función no decreciente respecto las dos variables.
H (x,−∞) = H (−∞, y) = 0 y H (+∞, +∞) = 1.
Así, como el dominio de H es todo R2 y está acotada por debajo, susmarginales F y G quedan determinadas de la forma FX (x) = H (x, +∞)
y GY (y) = H (+∞, y). Puede ser probado que F y G son funciones dedistribución.
Consideremos dos v.a.’s (X, Y ), con función de distribución
HXY (x, y) := P [(X ≤ x) ∩ (Y ≤ y)] := P (X ≤ x, Y ≤ y)
y marginalesFX (x) := P (X ≤ x)
yGY (y) := P (Y ≤ y) .
Sabemos que una variable aleatoria queda identificada si conocemos su fun-ción de distribución o densidad, pudiendo calcular una a partir de la otra dela siguiente manera:
f(x, y) :=∂2
∂x∂yF (x, y) o bien F (x, y) :=
∫ x
−∞
∫ y
−∞f(z, t)dtdz.
Las marginales vienen expresadas por
FX(x) :=
∫ x
−∞
∫ +∞
−∞f(z, t)dtdz y fX(x) :=
d
dxF (x)
GY (y) :=
∫ y
−∞
∫ +∞
−∞f(z, t)dzdt y gY (y) :=
d
dyG(y)
6

Nótese que cada una de estas cantidades, FX (x), GY (y) y HXY (x, y),pertenecen al intervalo [0, 1]. Dicho de otra forma: cada par (x, y) de númerosreales tiene asociado un punto (FX (x) , GY (y)) en el rectángulo cerrado[0, 1]×[0, 1], siendo el objetivo probar si existe una relación entre (FX (x) , GY (y))
y HXY (x, y) ∈ [0, 1].Las cópulas son de hecho funciones que justifican esta correspondencia entreun valor dado de la función de distribución conjunta HXY (x, y) y pares or-denados de valores de las distribuciones marginales FX (x) y GY (y).La cuestión es ahora la siguiente: ¿Como podemos determinar la función dedistribución bivariante HXY (x, y) conocidas las marginales FX (x) y GY (y)?Dicho de otro modo: ¿Es posible relacionar directamente la distribución bi-variante con las marginales? Una posible respuesta radicaría en el hecho deque las dos v.a.’s (X, Y ) sean independientes. Dicha relación viene expresadaen el siguiente teorema.
Teorema 1.2.1 Caracterización de independencia de variables aleato-rias. Sean (X,Y ) dos variables aleatorias. (X, Y ) son independientes sí ysólamente sí
HXY (x, y) = FX (x) GY (y) ,
para todo x ∈ rang(X), y ∈ rang(Y ).
En este contexto las cópulas pueden se vistas como la pura expresión dedependencia sin influencia alguna de las distribuciones marginales. No obs-tante, es ahí donde yace el problema de cómo actuar y tratar a dos variablesaleatorias dependientes.He aquí algunas soluciones alternativas que nos llevan a la misma conclusión:
Usando una nueva variable aleatoria, como en regresión.
Usando funciones de distribución condicionales.
Usando funciones características.
Usando cópulas.
7

Así pues tenemos que las cópulas son una seria alternativa para modelizarla dependencia de dos variables aleatorias, la cual separa el comportamientomarginal del comportamiento conjunto,
HXY (x, y) = C FX (x) , GY (y) . (1.3)
Básicamente, una cópula no es más que una función de distribución biva-riante cuyos argumentos son variables aleatorias uniformes. En la ecuación(1.3) esos argumentos son los dos márgenes FX (x) y GY (y). La palabracópula fue escogida para enfatizar el modo de actuar de ella. La cópulaes en realidad un funcional que interconecta o relaciona dos funciones dedistribución marginales cualesquiera con una única función que modeliza elcomportamiento conjunto de las variables (X,Y ).
1.2.1. Definición formal
Sea C una función definida de la siguiente forma:
C : [0, 1]× [0, 1] → [0, 1] .
Decimos que C es una cópula sí y sólamente sí
C (u, v) = P (U ≤ u, V ≤ v) ,
dondeU ∼ Unif (0, 1) y V ∼ Unif (0, 1) .
Por lo tanto,C (u, v) = P (U ≤ u, V ≤ v)
8

implica que
C (FX (x) , GY (y)) = P (U ≤ FX (x) , V ≤ GY (y)) =
= P(F−1
U (u) ≤ x,G−1V (v) ≤ y
)=
= P (X ≤ x, Y ≤ y) =
= H (x, y) .
Para obtener las distribuciones marginales nos es suficiente realizar el si-guiente cálculo
C (FX (+∞) , GY (y)) = P (X ≤ +∞, Y ≤ y) = P (Y ≤ y) = GY (y) ,
C (FX (x) , GY (+∞)) = P (X ≤ x, Y ≤ +∞) = P (X ≤ x) = FX (x) .
El teorema de Sklar [59] esclarece el rol que las cópulas juegan en la relaciónentre una función de distribución bivariante y sus marginales.
Teorema 1.2.2 (Sklar, 1959) Sea HXY (x, y) una función de distribuciónbivariante con marginales FX(x) y GY (y); entonces
Existe una cópula para casi todo x, y en R
HXY (x, y) = C FX (x) , GY (y) .
Contrariamente,
C (FX (x) , GY (y)) = C (u, v) = H (x, y) = H(F−1
U (u) , G−1V (v)
).
Es más, si FX(x) y GY (x) son contínuas, la cópula C(u, v) es única. Dichode otro modo, C(u, v) queda determinada de forma única en (rang [F ]) ×(rang [G]).
Prueba. En lo relativo a la prueba, véase Sklar [59].Una consecuencia del teorema de Sklar [59] es que, si X e Y son dos variables
9

aleatorias con función de distribución conjunta HXY (x, y) y marginales FX(x)
y GY (y), entonces para todo (x, y) ∈ R2, nos es posible determinar las cotasde Fréchet-Hoeffding,
W (u, v) = max (u + v − 1, 0) ≤ C (u, v) ≤ mın (u, v) = M (u, v)
[W (FX (x) , G (y)) ≤ C (FX (x) , GY (y)) ≤ M (FX (x) , GY (y))] .
Cuando W (u, v) = max (u + v − 1, 0) = C (u, v), Y es función decrecientede X. Cuando C (u, v) = mın (u, v) = M (u, v), Y es función creciente deX. Resumiendo, cualquier cópula C representa un modelo de dependenciadefinido entre los dos extremos anteriores , W y M .Finalmente introducimos la definiciones de función de densidad de cópula yla de cópula condicional, las cuales serán usadas mas adelante. Haciendo usode la teoría de probabilidades, y recordando la regla de la cadena tenemos unmodo de pasar de la función de distribución a la función de densidad c (u, v),definida como cópula de densidad
c (u, v) =∂2
∂u∂vC (u, v) .
Esto implica que la función de densidad bivariante hXY (x, y) asociada aHXY (x, y) es igual a
hXY (x, y) =∂2
∂x∂yHXY (x, y) =
∂2
∂x∂yC (FX (x) , GY (y)) =
= fX (x) gY (y) c (FX (x) , GY (y)) .
La cópula condicional en el caso bivariante adquirirá la forma
C (u |v ) =∂
∂vC (u, v) .
1.3. Cópulas de supervivencia
En muchos campos de la ciencia las variables modelizan el tiempo devida de los individuos u objetos de una cierta población. Por ejemplo, si
10

partimos de una variable aleatoria contínua X que modelice el tiempo deduración de cierta observación, la probabilidad de que un individuo u objetosobreviva más allá de un cierto tiempo dado x viene dada por la función desupervivencia
FX (x) := P (X > x) = u = 1− FX (x) = 1− u,
cuyo dominio es R ( incluso [0, +∞)) y, como antes, FX (x) denota la funciónde distribución de X.Para un par de v.a.’s con función de distribución conjunta HXY (x, y), lafunción de supervivencia conjunta es
HXY (x, y) := P (X > x, Y > y) ,
con marginalesFX (x) = P (X > x, Y > −∞)
yGY (y) = P (X > −∞, Y > y) .
El problema yace aquí en intentar determinar una relación entre las funcionesde supervivencia marginales y la función de supervivencia conjunta, verifi-cando así el Teorema de Sklar [59].Evidentemente, a través de la cópula esta posibilidad existe:
HXY (x, y) = P (X > x, Y > y) = 1− FX (x)−GY (y) + HXY (x, y) =
= FX (x) + GY (y)− 1 + C (FX (x) , GY (y)) =
= FX (x) + GY (y)− 1 + C(1− FX (x) , 1−GY (y)
)
=⇒ HXY (x, y) = C (u, v) = C(FX (x) , GY (y)
)= u+v−1+C (1− u, 1− v)
dondeC : [0, 1]× [0, 1] → [0, 1] .
C (u, v) = u + v − 1 + C (1− u, 1− v)
11

es la cópula de supervivencia.Es importante evitar confusiones entre la cópula de supervivencia C y lafunción de distribución conjunta de supervivencia C para dos v.a.‘s uniformesen [0, 1] cuya función de distribución conjunta es la cópula C. Obsérvese que
C (u, v) = P (U > u, V > v) = 1− u− v + C (u, v) =
= H (x, y) = C (1− u, 1− v) = C (u, v) .
1.4. Generación de variables aleatorias
Una de las más tempranas aplicaciones de la teoría de cópulas estuvoenfocada a las simulaciones de Monte Carlo,3 el cual requiere simulacionesde gran cantidad de puntos. En esta sección, abordaremos el problema dela generación de una muestra para una función de distribución específica,es decir, como extraer una muestra de una familia de probabilidades. Hayvarios procedimientos válidos para generar variables uniformes independi-entes y, como consecuencia, obtener una muestra de una cierta distribuciónde probabilidad. Uno de los métodos mas conocidos es el método de la fun-ción de distribución inversa. Para introducirnos en este método definamos acontinuación la pseudo-inversa de una función de distribución.
Definición 1.4.1 Sea FX : R → I = [0, 1] una función de distribución.Entonces una pseudo-inversa de FX es otra función F−1
X : I = [0, 1] → R condominio I tal que
Si t pertenece a la imágen de FX , entonces F(−1)X (t) es una cantidad x
de R tal que FX (x) = t.
Para todo t de la imágen de FX , F (F(−1)X (t)) = t.
Si t no está en la imágen de FX , entonces F(−1)X (t) = infx|FX (x) ≥
t = supx|FX (x) ≤ t.3Mírese Apéndice, sección Definiciones
12

Si FX es estrictamente creciente, tendrá una única pseudo-inversa la cualserá, obviamente, la inversa ordinaria para la cual asignaremos la notaciónusual F−1
X .Para obtener una observación x de una variable aleatoria X con función dedistribución F, seguiremos el sencillo algoritmo:
Generar una variable u de una distribución uniforme U en (0, 1).
Obtener x = F(−1)X , donde F
(−1)X es alguna pseudo-inversa de F.
Hay varios procedimientos conocidos para generar observaciones (x, y) deun par de variables aleatorias (X,Y ) con distribución de probabilidad con-junta HXY . Nos centraremos en los métodos que utilicen cópulas para talfin. Por el teorema de Sklar [59], tan sólo necesitamos generar pares (u, v) deobservaciones de una distribución bivariante uniformemente repartida en elrectángulo I = [0, 1] × [0, 1], cuya función de distribución conjunta es CXY ,la cópula de X e Y, y a continuación transformar esas cantidades medianteel método de la función de distribución inversa.Un procedimiento para generar pares (u, v) se puede lograr a través del Méto-do de la Distribución Condicional. En este método, necesitamos la funciónde distribución condicional de V dado U = u, donde (U, V ) ∼ Unif([0, 1]),la cual está definida del siguiente modo:
cu(v) = P [V ≤ v | U = u] = lım∆u→0
C(u + ∆u, v)− C(u, v)
∆u=
∂C(u, v)
∂u.
Los pasos a seguir son los siguientes:
Generar dos cantidades uniformes e independientes en [0, 1], u y t.
Calcular v = c(−1)u (t), donde c
(−1)u es la pseudo-inversa de cu, definida
anteriormente.
El par buscado es (u, v).
Calcular x = F (−1)(u) y y = G(−1)(v), donde F (−1) y G(−1) son laspseudo-inversas de F y G, funciones de distribución de X e Y respecti-vamente.
13

Finalmente, es oportuno recalcar que las cópulas de supervivencia pueden serusadas en el método de la función de distribución condicional, en lugar degenerar variables aleatorias de una distribución con función de supervivenciadada.
1.5. Propiedades y ventajas del modelo medi-
ante cópulas
En esta sección se exponen algunos de los teoremas y propiedades más no-tables que poseen las cópulas. Una de las principales ventajas que con ellasse pueden conseguir consiste en que podemos separar el comportamientomarginal del conjunto en nuestro estudio. Este hecho es de suma importanciaya que podemos relacionar variables que provengan de distintas distribucionesde probabilidad, incluso de distintos tipos (por ejemplo una discreta y la otracontínua) y someterlas a estudio de posible relación funcional mediante laestructura de dependencia caracterizada por la cópula. Éste es un conceptodel estudio de la dependencia entre variables aleatorias relativamente nove-doso y, como ya sabemos, tiene sus orígenes en el teorema de Sklar [59].La relación que existe entre la cópula C(F (x), G(y)) y las marginales F (x),G(y), así como el papel que juegan cada una de ellas en dicho estudio, sepodría explicar mediante los siguientes pasos:
Variando C(·, ·) se altera la dependencia estructural (tipo o grado dedependencia entre las variables). Cada cópula tiene una forma de re-presentar la relación entre las variables, si ésta existe. La elección dela cópula que mejor modelice el comportamiento conjunto de dos va-riables, o lo que es lo mismo, su grado de relación, es uno de los objetivosde este trabajo, el cual viene explicado en los Capítulos 3 y 4.
Variando F (·) y G(·) uno altera el comportamiento marginal (es evi-dente que dependiendo del fenómeno físico que se pretenda modelizar,se escogerán unas marginales u otras). Este punto tiene una importan-cia muy grande en el ámbito de la investigación operativa e inferencia
14

porque a nivel práctico soluciona muchos problemas de modelizaciónmatemática, al permitir interaccionar variables aleatorias no idéntica-mente distribuidas.
Ambas operaciones están permitidas. Así pues, la elección de un modeloapropiado para el estudio del grado de dependencia entre X e Y (recorde-mos que nos interesa la dependencia), representado por la cópula, puede serescogido independientemente de la elección que hayamos tomado al elegir lasdistribuciones marginales. Las cópulas son una potente y eficaz herramienta,las cuales permiten describir el grado de dependencia bivariante, cualquieraque sean las distribuciones marginales.Otra ventaja que posee una cópula es que las transformaciones de las va-riables por medio de funciones monótonas no afectan a su comportamiento.Algunas transformaciones muy usuales aplicadas a los datos (Logaritmos,Box-Cox,...) no afectan a la cópula de ningún modo, por lo cual no es nece-sario buscar otra alternativa a nuestro modelo escogido cuando se apliquenestas técnicas.
Teorema 1.5.1 Sean X e Y v.a.’s continuas cuya cópula es C(·, ·); si α(·)y β(·) son funciones monótonas respecto al rango de X e Y respectivamente,entonces Cα(X)α(Y )(·, ·) = CXY (·, ·).
Prueba.Sean F1, F2, G1, G2 las funciones de distribución de X, α(X), Y ,β(Y ); como por hipótesis α(·) y β(·) son estrictamente crecientes, para x, y
de R, tenemos:
F2 (x) = P (α(X) ≤ x) = P(X ≤ α−1(x)
)= F1
(α−1(x)
)
G2 (x) = P (β(Y ) ≤ y) = P(Y ≤ β−1(y)
)= G1
(β−1(y)
);
15

así pues4
Cα(X)β(Y ) (F2 (x) , G2 (y)) = P (α(X) ≤ x, β(Y ) ≤ y) =
= P(X ≤ α−1(x), Y ≤ β−1(y)
)
= CXY
(F1
(α−1(x)
), G1
(β−1(y)
))=
= CXY (F2 (x) , G2 (y)) .
Teorema 1.5.2 Sean X e Y variables aleatorias absolutamente continuascon cópula asociada C(·, ·). Entonces:
Si α(·) es una función estrictamente creciente y β(·) es una funciónestrictamente decreciente:
Cα(X)β(Y ) (u, v) = u− CXY (u, 1− v) .
Si α(·) es una función estrictamente decreciente y β(·) es una funciónestrictamente creciente:
Cα(X)β(Y ) (u, v) = v − CXY (1− u, v) .
Si α(·) y β(·) son ambas estrictamente decrecientes,
Cα(X)β(Y ) (u, v) = u + v − 1 + CXY (1− u, 1− v) .
Aunque todavía no hemos hablado de la posible expresión analítica que unacópula puede adoptar, es lógico pensar que sólo una clase concreta de fun-ciones pueda definirse como tal. A continuación se enumeran unas condicionesesenciales para que una función adquiera el grado de cópula.
La condición esencial es que el rango de la cópula debe estar entre losvalores 0 y 1, para poder identificarse como una función de densidad.
4Como X e Y son variables aleatorias absolutamente contínuas, el rango de F2 y elrango de G2 ambos son iguales a I y por lo tanto Cα(X)β(Y ) = CXY está definida en I2.
16

Si uno de los dos sucesos5 (por ejemplo X ≤ u) tuviese probabilidadcero de ocurrir, i.e. P (X ≤ x) = 0 ó P (Y ≤ y) = 0, entonces laprobabilidad conjunta también sería igual a cero, es decir
C (u1, 0) = C (0, u2) = 0,
equivalentemente
C(u, v) = P (U ≤ u, V ≤ v) = 0.
Si uno de los dos sucesos (por ejemplo X ≤ x) fuese el suceso seguro,i.e. P (X ≤ x) = 1 ó P (Y ≤ y) = 1, entonces la probabilidad conjuntaseria igual a la del otro suceso no fijado como seguro,
C (u, 1) = P (U ≤ F (x) , V ≤ 1) =
= P(F−1 (U) ≤ x, G−1 (V ) ≤ +∞)
=
= P (X ≤ x, Y ≤ +∞) = FX (x) = u.
Análogamente,C (1, v) = v = GY (y).
En caso de que los sucesos X ≤ x y Y ≤ y fuesen independientes, laprobabilidad conjunta correspondería al producto de las probabilidadesmarginales (en este caso la cópula se definiría como Cópula Producto),
C (u, v) = P (U ≤ FX (x) , V ≤ G (y)) =
= P(F−1 (U) ≤ x,G−1 (V ) ≤ y
)=
= P (X ≤ x, Y ≤ y) = FX (x) GY (y) = uv,
(u, v) ∈ [0, 1]× [0, 1] .
Si los sucesos X ≤ x y Y ≤ y estuviesen relacionados (positiva onegativamente), la probabilidad conjunta se encontraría comprendida
5Mírese Apéndice, sección Definiciones
17

entre las cotas de Fréchet (El límite superior correspondería al caso demáxima relación positiva - Cópula Máxima -, mientras que el límiteinferior correspondería al caso de máxima correlación, en este caso ne-gativa - Cópula Mínima),
W (u, v) ≤ C (u, v) ≤ M (u, v) .
Finalmente, si las probabilidades de los sucesos X ≤ x y Y ≤ yfueran crecientes, entonces la probabilidad conjunta de dichas ocurren-cias no debería ser ni creciente ni decreciente.
1.6. La cópula Arquimediana
La familia de cópulas Arquimedianas fue pionera de Ling [44], y pos-teriormente usada por Schweizer y Sklar [60] en el estudio de las t-normas.Antes de que se diesen a conocer a mayor escala gracias a su importante apli-cación al estudio de Finanzas y Geoestadística, las cópulas Arquimedianasya fueron de hecho aplicadas previamente a otros campos por Clayton [11],Oakes [48] y Cook y Johnson [12]. El motivo del amplio espectro de posiblesaplicaciones es debido a:
1. fácil implementación,
2. fácil acotación y simulación,
3. flexibilidad,
4. propiedades matemáticas que las hacen más "especiales".
Aún así las cópulas Arquimedianas tienen algunas desventajas como elser simétricas respecto a sus dos argumentos, es decir C (u, v) = C (v, u) ,
aunque no nos centraremos en ellas. Dividiremos esta sección en dos partes:En la primera definiremos las cópulas Arquimedianas así como sus principalespropiedades, y en la segunda presentaremos algunas familias de funcionespertenecientes a esa clase de cópulas.
18

1.6.1. Definiciones
Sean X, Y variables aleatorias absolutamente continuas con función dedistribución conjunta HXY y distribuciones marginales FX y GY , respec-tivamente. Recordemos que X e Y son independientes, sí y sólamente síH (x, y) = F (x) G (y), ∀x, y ∈ R.Siempre que sea posible escribir λ [H (x, y)] = λ [F (x)] λ [G (y)] para cier-ta función λ (·) (la cual debe ser positiva en el intervalo [0, 1]), definiendoϕ (t) = − ln [λ (t)], nos será posible escribir HXY como suma de las marginalesFX y GY de la siguiente forma:
ϕ [C (u, v)] = ϕ [H (x, y)] = ϕ (u) + ϕ (v) = ϕ [F (x)] + ϕ [G (y)] ;
ϕ [C (u, v)] = ϕ (u) + ϕ (v) .
A la cópula que cumple dicha propiedad se la denomina cópula Arquimedianay a la función ϕ generadora de la cópula. Siendo más precisos, la función ϕ sedice que es un generador aditivo de C. Además, si ϕ (0) = +∞, añadiremosque ϕ es un generador estricto.A continuación vamos a formalizar la descripción de las cópulas Arquimedi-anas, introduciendo algunos teoremas sobre ellas. Para tal fin, consideremosϕ (·) función contínua y estrictamente decreciente de I a [0, +∞], tal queϕ (1) = 0.
Definición 1.6.1 Llamamos pseudo inversa de una función ϕ (·) a otra fun-ción ϕ[−1] (·) con dominio [0, +∞] y rango I, definida del siguiente modo:
ϕ[−1] (t) =
ϕ−1 (t) 0 ≤ t ≤ ϕ (0)
0 ϕ (0) < t < +∞
Puede demostrarse que ϕ[−1] (·) es también contínua, no creciente en [0, +∞]
y estrictamente decreciente en [0, ϕ (0)]. Además, ϕ[−1] (ϕ (u)) = u en I y
ϕ(ϕ[−1] (t)
)=
t 0 ≤ t ≤ ϕ (0)
ϕ (0) ϕ (0) < t < +∞ = mın (t, ϕ (0))
19

Por último, si ϕ (0) = +∞, entonces ϕ[−1] (·) = ϕ−1 (·), y en el caso de queϕ (0) = +∞ y ϕ[−1] = ϕ−1, C (u, v) = ϕ−1 (ϕ (u) + ϕ (v)) la cópula pasa aser llamada cópula Arquimediana estricta.
Lema 1.6.1 Sean ϕ (·) y ϕ[−1] (·) las funciones definidas anteriormente ysea C : I2 → I una función dada por
C (u, v) = ϕ[−1] (ϕ (u) + ϕ (v)) .
Entonces C satisface las condiciones de cota para una cópula, o lo que es lomismo
C (u, 0) = 0 = C (0, v) ,
C (u, 1) = u y C (1, v) = v.
Prueba. Sabemos que ϕ[−1] (t) = 0 si y solo si ϕ (0) < t < +∞.
C (u, 0) = ϕ[−1] (ϕ (u) + ϕ (0)) = 0,
puesto queϕ (0) ≤ t = (ϕ (u) + ϕ (0)) ≤ +∞.
Además,
C (u, 1) = ϕ[−1] (ϕ (u) + ϕ (1)) = ϕ[−1] (ϕ (u) + 0) = ϕ[−1] (ϕ (u)) = u
por definición.
Lema 1.6.2 Sean ϕ (·), ϕ[−1] (·) y C(·, ·) tales que cumplan las hipótesis delLema 1.6.1. Entonces C(·, ·) es creciente y bivariante sí y sólo sí para todov de I, tal que u1 ≤ u2,
C (u2, v)− C (u1, v) ≤ u2 − u1 (1.4)
Prueba. La condición (1.4) anteriormente vista es equivalente a
VC ([u1, u2]× [v, 1]) ≥ 0,
20

y asumiendo la hipótesis de que C(·, ·) es creciente bivariante:
VC ([u1, u2]× [v, 1]) ≥ 0
entonces,
C (u2, 1)− C (u2, v)− C (u1, 1) + C (u1, v) ≥ 0
u2 − C (u2, v)− u1 + C (u1, v) ≥ 0
C (u2, v)− C (u1, v) ≤ u2 − u1.
con lo que queda probado que C(·, ·) satisface la condición del lema.
Para probar el recíproco, sea C(·, ·) contínua ya que ϕ (·) y ϕ[−1] (·) lo son(y es evidente que como la cópula está definida como composición y suma deestas funciones, ella también lo será) entonces al menos existe un t ∈ I talque
C (t, v2) = v1,
óϕ [C (t, v2)] = ϕ (v1) = ϕ (v2) + ϕ (t) .
De aquí,
C (u2, v1)− C (u1, v1) = ϕ[−1](ϕ (u2) + ϕ (v1)
)− ϕ[−1]
(ϕ (u1) + ϕ (v1)
)=
= ϕ[−1](ϕ (u2) + ϕ (v2) + ϕ (t)
)+
− ϕ[−1](ϕ (u1) + ϕ (v2) + ϕ (t)
)=
= C (C (u2, v2) , t) +
− C (C (u1, v2) , t) ≤ C (u2, v2)− C (u1, v2) ,
donde esto último queda justificado por la condición C (u2, v) − C (u1, v) ≤u2 − u1.No obstante,
C (u2, v1)− C (u1, v1) ≤ C (u2, v2)− C (u1, v2) ,
21

que es equivalente a obtener la desigualdad
C (u2, v2)− C (u1, v2)− C (u2, v1) + C (u1, v1) ≥ 0
VC ([u1, u2]× [v1, v2]) ≥ 0
por lo cual C(·, ·) es creciente bivariante.Para completar definiremos el concepto geométrico y el analítico de funciónconvexa.
Definición 1.6.2 Geométricamente una función convexa es una función deuna variable real definida en un subconjunto A de R tal que para dos pun-tos cualesquiera x1 ≤ x2 de A el segmento que une los puntos (x1, f (x1)) y(x2, f (x2)) en la gráfica de f está en o sobre la gráfica de f en el intervalo[x1, x2].
Definición 1.6.3 Una función de variable real f definida en un subconjuntoA de R es llamada convexa en A sí y sólo sí para cualquier par de puntos x1,x2 ∈ A y λ ∈ [0, 1] se cumple que
f (λx1 + (1− λ) x2) ≤ λf (x1) + (1− λ) f (x2)
Teorema 1.6.1 Sean ϕ (·) y ϕ[−1] (·) dos funciones definidas del mismo mo-do que en el Lema 1.6.1. Sea C : I2 → I una función definida por
C (u, v) = ϕ[−1] (ϕ (u) + ϕ (v)) .
Entonces, C(·, ·) es una cópula sí y sólamente sí ϕ es convexa.
Prueba. (Nelsen [47]) Como anteriormente ya hemos mostrado que C(·, ·)satisface las condiciones de cota de una cópula, tan solo deberemos probarque C (u2, v)− C (u1, v) ≤ u2 − u1 se cumple sí y sólo sí ϕ es convexa (ϕ esconvexa sii ϕ[−1] es convexa). Para u1 ≤ u2, esta condición puede ser reescritacomo
u1 + C (u2, v) ≤ u2 + C (u1, v) ,
22

u1 + ϕ[−1] (ϕ (u2) + ϕ (v)) ≤ u2 + ϕ[−1] (ϕ (u1) + ϕ (v)) .
Así pues, si fijamos a = ϕ (u1), b = ϕ (u2) y c = ϕ (ν), tenemos que
ϕ[−1] (ϕ (u1)) + ϕ[−1] (b + c) ≤ ϕ[−1] (ϕ (u2)) + ϕ[−1] (a + c) ,
ϕ[−1] (a) + ϕ[−1] (b + c) ≤ ϕ[−1] (b) + ϕ[−1] (a + c) ,
donde a ≥ b (ϕ es estrictamente decreciente) y c ≥ 0.Supongamos que C (u2, v)−C (u1, v) ≤ u2−u1 se cumple, por lo tanto ϕ[−1]
satisface ϕ[−1] (a) + ϕ[−1] (b + c) ≤ ϕ[−1] (b) + ϕ[−1] (a + c).Escojamos s, t de [0, +∞) tal que 0 ≤ s < t; si nosotros definimos porconstrucción a = s+t
2, b = s, c = t−s
2, obtendremos
ϕ[−1]
(s + t
2
)+ ϕ[−1]
(s +
t− s
2
)≤ ϕ[−1] (s) + ϕ[−1]
(s + t
2+
t− s
2
)
ϕ[−1]
(s + t
2
)+ ϕ[−1]
(s + t
2
)≤ ϕ[−1] (s) + ϕ[−1] (t)
2ϕ[−1]
(s + t
2
)≤ ϕ[−1] (s) + ϕ[−1] (t)
ϕ[−1]
(s + t
2
)≤ ϕ[−1] (s) + ϕ[−1] (t)
2.
De este modo ϕ[−1] es semi-convexa y como ϕ[−1] es continua, ello lleva aque ϕ[−1] es convexa (semi-convexa es equivalente para λ → 0 y λ → 1, perocomo ϕ es contínua, es siempre equivalente a convexa).Para demostrar la otra implicación, supongamos por hipótesis que ϕ[−1] esconvexa; fijamos a, b, c ∈ I tal que a ≥ b y c ≥ 0; Sea γ = a−b
a−b+c, para
el cual (1− γ) b + γ (a + c) y b + c = γb + (1− γ) (a + c); añadiendo lassiguientes desigualdades ϕ[−1] (a) + ϕ[−1] (b + c) ≤ ϕ[−1] (b) + ϕ[−1] (a + c), laprueba queda concluída, ya que:
23

ϕ[−1] (a) ≤ (1− γ) ϕ[−1] (b) + γϕ[−1] (a + c)
ϕ[−1] (b + c) ≤ γϕ[−1] (b) + (1− γ) ϕ[−1] (a + c)
ϕ[−1] (a) + ϕ[−1] (b + c) ≤ ϕ[−1] (b) + ϕ[−1] (a + c) .
Por lo tanto las cópulas Arquimedianas pueden construirse usando elTeorema 1.6.1. Tan solo necesitamos encontrar una función que nos sirva degeneradora, que sea contínua, decreciente y convexa ϕ : I → [0, +∞] conϕ (1) = 0 y con ella construiremos la correspondiente cópula (ver Genest yMackay [21]).
Ejemplo. (Construcción de la cópula producto)
Sea ϕ (t) = − ln t, para t ∈ [0, 1], tenemos que ϕ (0) = +∞, y ϕ (1) = 0,cuya función inversa ϕ[−1] (t) = ϕ−1 (t) = exp (−t), por lo que la con-strucción de la cópula queda determinada del siguiente modo C (u, v) =
ϕ[−1] (ϕ(u) + ϕ(v)) = exp − [(− ln u) + (− ln v)] = exp ln u + ln v = eln ueln v =
uv =⇒ la cópula producto es una cópula arquimediana estricta.
Ejemplo. (Construcción de la cota inferior de la cota de Fréchet-Hoeffding)
Sea ϕ (t) = 1 − t, para t ∈ [0, 1] , por lo que se cumple ϕ (0) = 1 yϕ (1) = 0, pero obsérvese que ϕ[−1] (t) 6= ϕ−1 (t) ,
ϕ−1 (t) =
1− t 0 ≤ t ≤ 1
0 1 ≤ t ≤ +∞ = max (1− t, 0) ,
por lo que la cota inferior queda definida de la siguiente forma C (u, v) =
max 1− [(1− u) + (1− v)] , 0 = max (u + v − 1, 0) =⇒la cota inferior delas cotas de Frèchet-Hoeffding es una cópula arquimediana.
24

1.7. Algunas familias de cópulas Arquimedianas
1.7.1. La familia de Clayton
(ver [11])Generador ϕθ (t) = 1
θ
(t−θ − 1
)para θ ∈ [−1, +∞)− 0
para θ ∈ [−1, +∞)− 0Cópula Arquimediana estricta θ ≥ 0
Cuando θ ∈ [−1, 0): ϕ[−1]θ (t) = (1 + θt)−
1θ para 0 ≤ t ≤ −1
θ
Cuando θ > 0: ϕ−1θ (t) = (1 + θt)−
1θ para t ≥ 0
Caso bivariante Cθ (u, v) =[max
(u−θ + v−θ − 1, 0
)]− 1θ
Casos limite C−1 (u, v) = W (u, v)
(cota inferior de Frèchet-Hoeffding: dependencia perfecta y negativa)
C0 (u, v) = uv = Π (u, v)
(cópula producto: independencia de las variables)
C1 (u, v) = uvu+v−uv
= Π(u,v)Σ(u,v)−Π(u,v)
C∞ (u, v) = M (u, v)
(cota superior de Frèchet-Hoeffding: dependencia perfecta y positiva)
1.7.2. La familia Gumbel-Hougaard
(ver [23])Generador ϕθ (t) = (− ln t)θ
para θ ∈ [1, +∞)
Cópula Arquimediana estricta Siempre
ϕ−1θ (s) = exp
−s
1θ
Caso bivariante Cθ (u, v) = exp
−
[(− ln u)θ + (− ln v)θ
] 1θ
Casos límite C1 (u, v) = Π (u, v)
C∞ (u, v) = M (u, v)
1.7.3. La familia de Frank
(ver [20])
25

Generador ϕθ (t) = − ln e−θt−1e−θ−1
para θ ∈ (−∞, +∞)− 0Cópula Arquimediana estricta Siempre
ϕ−1θ (s) = −1
θln
[1 + e−t
(e−θ − 1
)]
Caso bivariante Cθ (u, v) = −1θ ln
[1 + e
e−θu−1
e−θ−1+ e−θv−1
e−θ−1(e−θ − 1
)]
= −1θ ln
[1 + (e−θu−1)(e−θv−1)
e−θ−1
]
Casos límite C−∞ (u, v) = W (u, v)
C0 (u, v) = Π (u, v)
C∞ (u, v) = M (u, v)
1.7.4. La familia de Ali-Mikhail-Haq
(ver [1])Generador ϕθ (t) = ln 1−θ+θt
t
para θ ∈ [−1, 1)
Cópula Arquimediana estricta Siempreϕ−1
θ (s) = 1−θes−θ
Caso bivariante Cθ (u, v) = uv1−θ(1−u)(1−v)
Casos límite C0 (u, v) = Π (u, v)
C1 (u, v) = Π(u,v)Σ(u,v)−Π(u,v)
1.8. La cópula empírica
Ya se ha comentado en la Sección 1.5 sobre la invarianza de la cópula pormedio de transformaciones monótonas crecientes de las funciones de distribu-ción marginales, hecho que aquí es importante. Supongamos que partimos deuna muestra aleatoria de tamaño n, de la forma (x1, y1) , . . . , (xi, yi) , . . . , (xn, yn),dada por dos variables aleatorias contínuas, X e Y, con función de distribu-ción conjunta HXY (·, ·).Sean φ y ψ dos funciones crecientes de X e Y , respectivamente. Incluso si lanube de puntos de los pares transformados (φ (x1) , ψ (y1)) , . . . , (φ (xn) , ψ (yn))es diferente a la de los pares sin transformar (x1, y1) , . . . , (xi, yi) , . . . , (xn, yn),
26

está demostrado que ambas muestras comparten la misma cópula [29]. Pero,¿es posible determinar una estructura común de dependencia? Sí, desde luego,la solución pasa por el estudio de los rangos. De hecho, los pares de rangosde una muestra aleatoria son variables que retienen una gran cantidad deinformación. Por otra parte, suponiendo que X e Y sean absolutamente con-tínuas, los rangos están unívocamente definidos, porque lo contrario ocurrecon probabilidad cero. Por lo tanto, los rangos de la variables originales ylos rangos de las variables transformadas representan la misma estructura dedependencia. Sean Ri los rangos6 de Xi y Si los rangos de Yi. Reescalandolos ejes por el factor 1
n+1(donde n es el tamaño de la muestra), se consigue
un conjunto de puntos en el cuadrado unidad. En este dominio la Cópulaempírica [13] queda definida del siguiente modo:
Cn
(x(i), y(j)
)= Cn
(F−1
(u(i)
), G−1
(v(j)
))=
= (#(x, y) : x ≤ x(i), y ≤ y(i)
n) =
=1
n
n∑
k=1
I(xk ≤ x(i), yk ≤ y(j)
)=
=1
n
n∑
k=1
I(xk ≤ F−1
(u(i)
), yk ≤ G−1
(v(j)
))=
=1
n
n∑
k=1
I(F (xk) ≤ u(i), G (yk) ≤ v(j)
)=
=1
n
n∑
k=1
I
(Rk
n + 1≤ u(i),
Sk
n + 1≤ v(j)
),
donde I(A) es la función característica del conjunto A y x(i), y(j), u(i), v(j),1 ≤ i, j ≤ n, representan las muestras ordenadas. Vista esta definición eslógico pensar, si nos restringimos al caso bivariante, que la cópula empíricacrea una nube de puntos sobre el cuadrado unidad, que vendría a interpolarla superficie que en este caso estaría generada por la cópula teórica. Para unpar (u, v), puede ser probado que Cn(u, v) es un estimador basado en rangosde la cantidad desconocida C(u, v) [13].
6Mírese Apéndice, sección Definiciones
27

1.9. Cópulas y medidas de dependencia
Ya hemos recalcado que la cópula es en sí misma una caracterización dela dependencia de un par de variables aleatorias (X,Y ), por lo que tendríasentido usarlas para medir cúal sería ese grado de dependencia. En este sub-apartado explicaremos el papel que adoptan las cópulas en el estudio de ladependencia y cual es la relación que guardan con los conocidos coeficientesno paramétricos de dependencia, rho de Spearman y tau de Kendall7, am-bos relacionados a una forma de dependencia conocida como concordancia.La propiedad más importante que las dos medidas anteriormente citadasguardan, es que permanecen invariantes por medio de aplicaciones estricta-mente crecientes que actúen sobre las variables aleatorias.Antes de profundizar en ello, recordemos lo siguiente:
El término coeficiente de correlación es exclusivo para medidas derelación lineal entre dos variables aleatorias, como por ejemplo el coe-ficiente de Pearson.
El término medida de asociación está reservado para medidas más gen-erales, tal como el Kendall tau y rho de Spearman.
1.9.1. Concordancia
Intuitivamente, a un par de variables aleatorias se les denomina concor-dantes si “grandes” (respectivamente “pequeños”) valores de una de las varia-bles tienden a estar asociados con “grandes” (respectivamente “pequeños”)valores de la otra.
Definición 1.9.1 Sean (xi, yi) y (xj, yj) , dos observaciones de un parde variables aleatorias absolutamente contínuas (X,Y ). Entonces, (xi, yi) y(xj, yj) son concordantes si xi < xj y yi < yj ,o si xi > xj y yi > yj. Demanera análoga, (xi, yi) y (xj, yj) son discordantes si xi < xj y yi > yj, o sixi < xj y yi > yj.
7Mírese Apéndice, sección Definiciones
28

Definición 1.9.2 Decimos que (xi, yi) y (xj, yj) son concordantes si
(xi − xj) (yi − yj) > 0 y que son discordantes si (xi − xj) (yi − yj) < 0.
1.9.2. Tau de Kendall
Este coeficiente está íntimamente relacionado con ls conceptos de concor-dancia/discordancia.
Definición 1.9.3 tau de Kendall muestral [33]Sea una muestra aleatoria (x1, y1) , (x2, y2) , ..., (xn, yn) de n observacionesde un vector aleatorio contínuo (X, Y ); tendremos pues
(n2
)pares distintos
de (xi, yi) y (xj, yj) de observaciones de la muestra. Sea c el número de paresconcordantes y d el número de pares discordantes.Se define el tau de Kendall [39] como
τ =c− d
c + d=
c− d(n2
) .
Equivalentemente, τ es la probabilidad estimada de la concordancia menosla probabilidad estimada de la discordancia para un par de observaciones(xi, yi) y (xj, yj), escogidas aleatoriamente de la muestra.La versión poblacional del tau de Kendall para un vector (X, Y ) de v.a.’scontínuas con función de distribución conjunta HXY (x, y) se define de lasiguiente forma.
Definición 1.9.4 tau de Kendall poblacional Sean (X1, Y1) y (X2, Y2)8
vectores aleatorios independientes e idénticamente distribuídos con funciónde distribución conjunta HXY (x, y) igual para ambos. El tau de Kendall parael vector (X, Y ) está definido como la probabilidad de la concordancia menosla probabilidad de la discordancia, es decir
τX,Y = P [(X1 −X2) (Y1 − Y2) > 0]− P [(X1 −X2) (Y1 − Y2) < 0] .
8Notación de Genest [29]
29

Para poder mostrar el papel que juegan las cópulas cuando se trata de medirla concordancia, es recomendable tener conceptos claros sobre la función deconcordancia Q.
Definición 1.9.5 Sean (X1, Y1) y (X2, Y2) dos vectores aleatorios con-tínuos con diferentes funciones de distribución conjunta H1XY
y H2XYre-
spectivamente pero con marginales comunes FX para X1 y X2, y GY paraY1 e Y2. Definimos la función de concordancia Q como la probabilidad dela concordancia menos la probabilidad de la discordancia de los dos vectores(X1, Y1) y (X2, Y2), es decir
Q = P [(X1 −X2) (Y1 − Y2) > 0]− P [(X1 −X2) (Y1 − Y2) < 0]
Vamos a demostrar que la función Q depende de la distribución de (X1, Y1)
y (X2, Y2) solo a través de sus cópulas.
Teorema 1.9.1 Sean (X1, Y1) y (X2, Y2) vectores aleatorios contínuos e in-dependientes con función de distribución conjunta H1XY
y H2XYrespectiva-
mente, y marginales comunes FX (de X1 y X2) y GY (de Y1 y Y2). Sean C1 yC2 las cópulas de (X1, Y1) y (X2, Y2) respectivamente, así pues H1XY
(x1, y1) =
C1 (FX (x1) , GY (y1)) y H2XY(x2, y2) = C2 (FX (x2) , GY (y2)). Sea Q la difer-
encia entre la probabilidades de concordancia y discordancia entre (X1, Y1) y(X2, Y2),
Q = P [(X1 −X2) (Y1 − Y2) > 0]− P [(X1 −X2) (Y1 − Y2) < 0]
Entonces, Q = 4∫∫
I2C2 (u, v) dC1 (u, v)− 1.
Prueba. Como X1, X2, Y1, Y2 son contínuas,
P [(X1 −X2) (Y1 − Y2) < 0] = 1− P [(X1 −X2) (Y1 − Y2) > 0]
y de ahí
Q = P [(X1 −X2) (Y1 − Y2) > 0]− 1 + P [(X1 −X2) (Y1 − Y2) > 0] =
= 2P [(X1 −X2) (Y1 − Y2) > 0]− 1
30

peroP [(X1 −X2) (Y1 − Y2) > 0] = P [(X1 > X2) , (Y1 > Y2)] +
+P [(X1 < X2) , (Y1 < Y2)] .
Estas probabilidades pueden ser calculadas integrando la distribución delvector (X1, Y1) o (X2, Y2):
P [(X1 > X2) , (Y1 > Y2)] = P [(X2 < X1) , (Y2 < Y1)] =
=
∫∫
R2
P [(X2 ≤ x1) , (Y2 ≤ y1)] dC1 (FX (x1) , GY (y1)) =
=
∫∫
R2
C2 (FX (x1) , GY (y1)) dC1 (FX (x1) , GY (y1)) ,
así pues escribiendo FX (x1) = u y GY (y1) = v, tendremos
P [(X1 > X2) , (Y1 > Y2)] =
∫∫
I2C2 (u, v) dC1 (u, v) .
Ahora,
P [(X1 < X2) , (Y1 < Y2)] = P [(X2 > X1) , (Y2 > Y1)] =
=
∫∫
R2
[1− FX (x1)−GY (y1) +
+ C2 (FX (x1) , GY (y1))] dC1 (FX (x1) , GY (y1)) =
=
∫∫
I2[1− u− v + C2 (u, v)] dC1 (u, v) .
Nótese que C1 (u, v) es la función de distribución conjunta de un par (U, V )
de v.a.’s uniformes en el intervalo I = (0, 1), así que E (U) = E (V ) = 12; por
lo tanto,
P [(X1 < X2) , (Y1 < Y2)] =
∫∫
I21dC1 (u, v)−
∫∫
I2udC1 (u, v) +
−∫∫
I2vdC1 (u, v) +
∫∫
I2C2 (u, v) dC1 (u, v) =
= 1− 1
2− 1
2+
∫∫
I2C2 (u, v) dC1 (u, v) =
31

=
∫∫
I2C2 (u, v) dC1 (u, v) .
Finalmente,
P [(X1 −X2) (Y1 − Y2) > 0] =
∫∫
I2C2 (u, v) dC1 (u, v) +
+
∫∫
I2C2 (u, v) dC1 (u, v) = 2
∫∫
I2C2 (u, v) dC1 (u, v)
Q = 2P [(X1 −X2) (Y1 − Y2) > 0]− 1 = 4
∫∫
I2C2 (u, v) dC1 (u, v)− 1.
Teorema 1.9.2 tau de Kendall poblacional a partir de la cópulaSean X e Y variables aleatorias continuas cuya cópula es C. Entonces laversión poblacional del tau de Kendall para X e Y viene dada por la expresión
τX,Y = P [(X1 −X2) (Y1 − Y2) > 0]− P [(X1 −X2) (Y1 − Y2) < 0] =
= 4
∫∫
I2C (u, v) dC (u, v)− 1.
1.9.3. Versión empírica del tau de Kendall
Sea (X,Y ) un vector aleatorio y sea (R,S) el vector de rangos asocia-do. Usaremos la notación propuesta por Genest [29] para las observaciones(Xi, Yj) 1 ≤ i, j ≤ n, extraídas del vector aleatorio. La versión empírica deltau de Kendall viene dada por
τn =Pn −Qn(
n2
) =4
n (n− 1)Pn − 1
donde Pn y Qn son, respectivamente, el número de pares concordantes ydiscordantes. No debemos preocuparnos en absoluto de las colas, ya que lossucesos que satisfacen la condición
(Xi −Xj) (Yi − Yj) = 0,
32

ocurren con probabilidad cero asumiendo que (X, Y ) son contínuas.Es evidente que τn es únicamente función de los rangos de las observaciones,ya que (Xi −Xj) (Yi − Yj) > 0 sí y solo sí (Ri −Rj) (Si − Sj) > 0. Con-secuentemente, τn es también una función de la cópula empírica Cn. Paraverificar dicha conexión, introduzcamos la función indicadora
Iij =
1 si Xj < Xi y Yj < Yi
0 en otro caso
siendo 1 ≤ i, j ≤ n con i 6= j, y sea Iii = 1 para todo i ∈ 1, ..., n.Obsérvese que
Pn =1
2
n∑i=1
∑
i6=j
(Iij + Iji) =n∑
i=1
∑
i6=j
Iij = −n +n∑
i=1
n∑j=1
Iij
donde Pn es la versión empírica de P [(X1 −X2) (Y1 − Y2) > 0], por lo que(Iij + Iji) = 1 sí y solo sí los pares (Xi, Yi) y (Xj, Yj) son concordantes.Sea
Wi =1
n
n∑i=1
Iij =1
n# j : Xj ≤ Xj, Yj ≤ Yi
=⇒ nWi =n∑
i=1
Iij
=⇒ Pn = −n +n∑
i=1
nWi = −n + n2W,
donde
W =1
n
n∑i=1
Wi =⇒ nW =n∑
i=1
Wi.
33

Entonces
τn =4
n (n− 1)Pn − 1 =
4
n (n− 1)
(−n + n2W)− 1 =
=−4n− 4n2W − n2 − n
n (n− 1)=
n2(4W − 1
)
n (n− 1)− 3n
n (n− 1)=
=4nW − n− 3
n− 1=
4nW
n− 1− n + 3
n− 1.
La conexión con Cn se desprende del hecho de que por definición Wi =
Cn
(Ri
n+1, Si
n+1
).
Asumiendo que Cn → C cuando n → +∞, se concluye que el τn es unestimador asintóticamente insesgado de τX,Y .
1.9.4. El coeficiente rho de Spearman
Esta cantidad está definida también a partir de la concordancia/discor-dancia, al igual que el tau de Kendall. Para obtener la versión poblacionaldel coeficiente rho de Spearman, introducimos (X1, Y1), (X2, Y2) y (X3, Y3)
9
vectores aleatorios e independientes con distribución conjunta HXY (cuyasmarginales son de nuevo FX y GY para Xi 1 ≤ i ≤ 3, Yj 1 ≤ j ≤ 3) y cuyacópula es C; la versión poblacional de dicho coeficiente está caracterizada porser proporcional a la probabilidad de la concordancia menos la probabilidadde la discordancia de dos vectores aleatorios (X1, Y1) y (X2, Y3),
ρX,Y = 3 (P [(X1 −X2) (Y1 − Y3) > 0]− P [(X1 −X2) (Y1 − Y3) < 0]) ,
donde el 3 en la parte derecha de la igualdad actúa como constante de nor-malización.Es importante resaltar que la función de distribución conjunta (X2, Y3) esFX (x) GY (y), puesto que X2 e Y3 son independientes (mientras que la dis-tribución conjunta de (X1, Y1) es HXY (x, y)). Así la cópula de (X2, Y3) es lacópula producto.
Teorema 1.9.3 rho de Spearman poblacional a partir de la cópula.9mírese Genest [29]
34

Sean X e Y variables aleatorias contínuas cuya cópula es C. Entonces laversión poblacional del coeficiente rho de Spearman para X e Y viene dadapor
ρX,Y = 3 (P [(X1 −X2) (Y1 − Y3) > 0]− P [(X1 −X2) (Y1 − Y3) < 0]) =
= 3Q (C, Π) = 12
∫∫
I2uvdC (u, v)− 3 = 12
∫∫
I2C (u, v) dudv − 3
donde las dos últimas igualdades se obtienen teniendo en cuenta que Q essimétrica respecto a sus dos variables.
1.9.5. Versión empírica del coeficiente rho de Spearman
Un primer cálculo para la obtención del rho de Spearman muestral, con-sistiría en computar el coeficiente de correlación entre los pares (Ri, Si) derangos, o equivalentemente entre los puntos
(Ri
n+1, Si
n+1
)que forman el soporte
de Cn. Esto nos lleva directamente a la versión empírica del coeficiente rhode Spearman:
ρn =
∑ni=1
(Ri −R
) (Si − S
)√∑n
i=1
(Ri −R
)2 ∑ni=1
(Si − S
)2∈ [−1, 1] ,
donde
R =1
n
n∑i=1
Ri =n + 1
2=
1
n
n∑i=1
Si = S
Podemos expresar este coeficiente de una forma más conveniente:∑n
i=1
(Ri −R
) (Si − S
)=
∑ni=1 RiSi−
∑ni=1 RiS−
∑ni=1 RSi+
∑ni=1 RS =
=∑n
i=1 RiSi − n+12
∑ni=1 Ri − n+1
2
∑ni=1 Si + nn+1
2n+1
2=
=∑n
i=1 RiSi−n(
n+12
)2−n(
n+12
)2+n
(n+1
2
)2=
∑ni=1 RiSi−n
(n+1
2
)2;∑n
i=1
(Ri −R
)2=
∑ni=1 Ri
2 +∑n
i=1 R2 − 2
∑ni=1 RiR =
= n(n+1)(2n+1)6
+ n(
n+12
)2 − 2n(
n+12
)2=
= n(n+1)(2n+1)6
− n(
n+12
)2= n(n+1)(n−1)
12.
Así pues,
35

∑ni=1
(Si − S
)2= ... = n(n+1)(n−1)
12;
ρn =
∑ni=1
(Ri −R
) (Si − S
)√∑n
i=1
(Ri −R
)2 ∑ni=1
(Si − S
)2=
=
∑ni=1 RiSi − n
(n+1
2
)2
√[n(n+1)(n−1)
12
]2=
12
n (n + 1) (n− 1)
n∑i=1
RiSi − 3 (n + 1)
n− 1.
Este coeficiente comparte con el coeficiente de correlación de Pearson lapropiedad de que su valor esperado es cero cuando las variables son inde-pendientes. Sin embargo, ρn es teóricamente mucho mejor que el coeficientede correlación de Pearson, rn
10, por los siguientes motivos:
E (ρn) = ±1 ocurre sí y solo sí X e Y son funcionalmente dependientes,o equivalentemente, su cópula solo podrá ser una de las dos cotas deFrèchet-Hoeffding, mientras que E (rn) = ±1 si X e Y son linealmentedependientes, lo cual es mucho más restrictivo.
ρn estima un parámetro poblacional que siempre está bien definido,mientras que hay distribuciones bivariantes de cola pesada (por ejemp-lo, la distribución de Cauchy que tiene algunos momentos no existentes)para las cuales el coeficiente de correlación de Pearson rn no existe.
Como Cn → C cuando n → +∞, se puede concluir que ρn es un estimadorasintóticamente insesgado de ρX,Y .
1.10. Medidas gráficas de dependencia
1.10.1. Chi-plots
Los Chi-plots son una eficiente herramienta gráfica que nos permite re-alizar un primer estudio sobre la posible relación funcional entre dos variables
10Mírese Apéndice A
36

aleatorias. Originalmente fueron introducidos por Fisher y Switzer [18]. Suconstrucción está basada en el estadístico Chi-Cuadrado, conocido por suutilidad en el estudio de la dependencia de dos variables aleatorias repre-sentadas por una tabla de doble entrada (más conocidas como tablas decontingencia). Para calcular los Chi-plots podemos seguir los siguientes pa-sos:
Calcular los Hi, Fi y Gi como se muestra a continuación:
Hi =1
n− 1#j 6= i : Xj ≤ Xi, Yj ≤ Yi, (1.5)
Fi =1
n− 1#j 6= i : Xj ≤ Xi, (1.6)
Gi =1
n− 1#j 6= i : Yj ≤ Yi. (1.7)
Nótese que estas cantidades dependen exclusivamente de los rangos delas observaciones.
Computar λi, χi a partir de las cantidades anteriores de la siguienteforma:
λi = 4sign(FiGi) max(Fi
2, Gi
2) (1.8)
χi =Hi − FiGi
2√
Fi(1− Fi)Gi(1−Gi)(1.9)
siendo, sign la función signo 11 , y,
Fi = Fi − 1
2, Gi = Gi − 1
2. (1.10)
Representar los pares de puntos (λi, χi) ∈ [−1, 1]× [−1, 1] según [18].
Para evitar posibles desfases gráficos, Fisher y Switzer [18] recomiendandibujar únicamente los que cumplan
11Mírese Apéndice A
37

|λ| ≤ 4
(1
n− 1− 1
2
)2
(1.11)
A la hora de representar la nube de puntos, debemos tener en cuenta la posiblepérdida de pares de puntos (entre dos y cuatro, en general) al dividir porcero, por lo que en muestras pequeñas el método no es eficiente. Si queremoscontrastar las hipótesis H0: Las variables son independientes frente a H1: Lasvariables no son independientes, los valores χi que estén "muy lejos"de ceronos darán evidencia estadística para poder rechazar la hipótesis nula. Parahacer referencia al término "muy lejos", Fisher y Switzer nos proponen unoslímites de control dados por ±cp
√n donde cp es escogido aproximadamente
como el 100p%12 de los pares (λi, χi) que caen dentro de esas líneas.
Variables independientes vs. variables dependientes
Para ilustrar la técnica visual del estudio de la dependencia dada porla representación de los Chi-plots, generamos sendas muestras aleatorias detamaño 100, una extraída de una variable X ∼ Po(3) y otra Y ∼ N(0, 1),y calculamos a partir de ellas los (λi, χi), y a continuación representar estosúltimos pares de puntos. De esta forma, se logran 100 pares de observacionesprovenientes de dos variables independientes. La culminación de este procesoha quedado reflejada en la Figura 1.1, en la cual se observa como los paresde puntos caen en un porcentaje alto dentro de las bandas delimitadas por±cp
√n.
En cambio, si realizamos el mismo ejercicio pero escogiendo esta vezX ∼ Po(3) e Y = 1
1+X2 lo que obtendremos será una nube totalmente ale-jada de los márgenes delimitados por ±cp
√n, ya que las dos variables son
funcionalmente dependientes. En la Figura 1.2 puede observarse claramentecomo la nube de puntos cae fuera de las bandas, hecho consecuente de larelación funcional entre las variables.
12p es equivalente al nivel de confianza. Se suele escoger p = 0.9 p = 0.95, p = 0.99
38

−1.0 −0.5 0.0 0.5 1.0
−1.
0−
0.5
0.0
0.5
1.0
lambda
chi
Figura 1.1: Chi-plot para variables Poisson y Normal independientes. Obsér-vense los límites de control dados por ±cp
√n representados por las bandas,
habiéndose tomado cp = 0.95%.
39

−1.0 −0.8 −0.6 −0.4 −0.2 0.0
−1.
0−
0.5
0.0
0.5
1.0
lambda
chi
Figura 1.2: Chi-plot para variables dependientes, una X ∼ Po(3) y la otraY = 1
1+X2 .cp = 0.95%.
40

1.10.2. K-plots
Otra técnica gráfica para el estudio de la posible dependencia de dosvariables aleatorias también basada en rangos ha sido recientemente pro-puesta por Genest y Boies [27] y está inspirada en los QQ-plots [3]. Conc-retamente, esta técnica consite en representar los pares (Wi:n, H(i)) paratodo i ∈ 1, . . . , n donde
H(1) ≤ H(2) ≤ . . . ≤ H(n) (1.12)
es la muestra aleatoria ordenada, y siendo
Hi =1
n− 1#i 6= j : Xj ≤ Xi, Yj ≤ Yi =
nWi − 1
n− 1=
nCn( Rn
n+1, Sn
n+1)− 1
n− 1.
(1.13)Finalmente,
Wi:n = n ·(
n− 1
i− 1
) ∫ 1
0
wK0(w)i−1 · 1−K0(w)n−idK0(w), (1.14)
teniendo en cuenta que
K0(w) = P (U · V ≤ w) = w − w · log(w) w ∈ [0, 1] (1.15)
La interpretación de los K-plots es similar a la de los QQ-plots13:
A medida que la representación de H(i) vs. W (i : n) se vaya desviandorespecto a la diagonal, podremos ir asumiendo dependencia funcionalentre las dos variables involucradas. Además cuanto más fuerte seala desviación respecto a dicha diagonal, supondremos un vínculo másfuerte entre las dos variables pudiendo indicarnos gráficamente la de-pendencia funcional perfecta e incluso si ésta es positiva o negativa,como veremos a continuación en los siguientes ejemplos.
13Mírese Apéndice, sección Definiciones
41
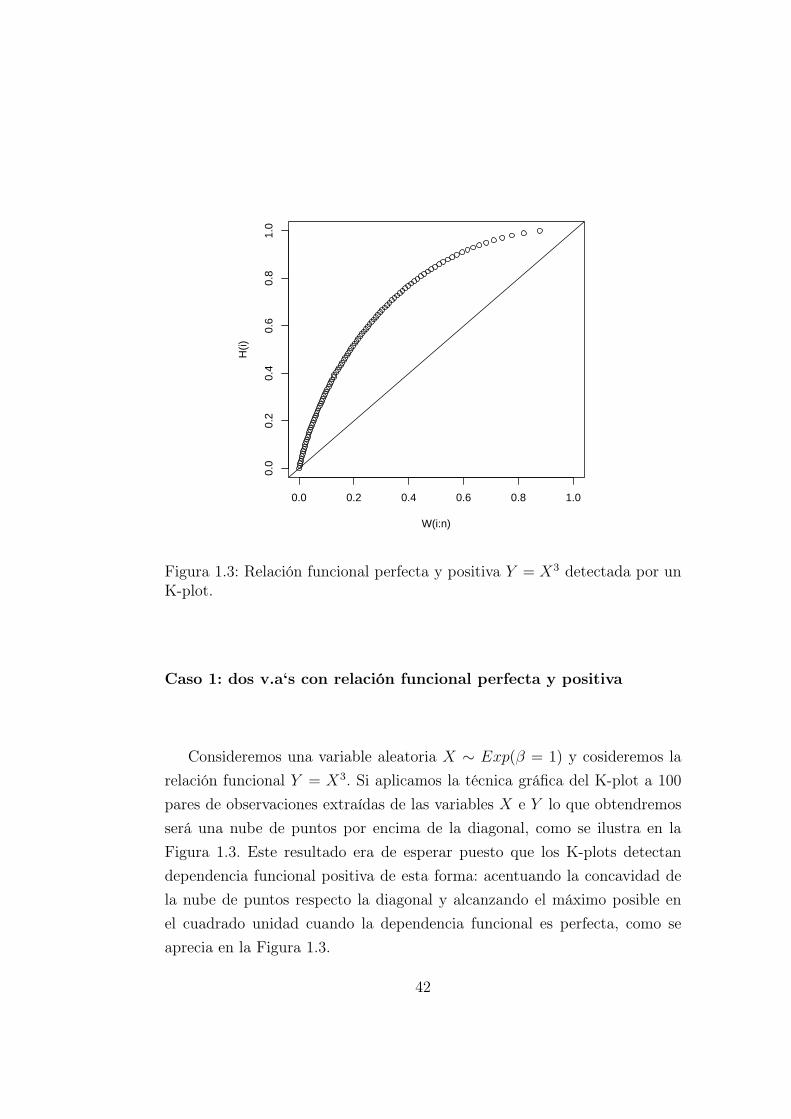
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
W(i:n)
H(i)
Figura 1.3: Relación funcional perfecta y positiva Y = X3 detectada por unK-plot.
Caso 1: dos v.a‘s con relación funcional perfecta y positiva
Consideremos una variable aleatoria X ∼ Exp(β = 1) y cosideremos larelación funcional Y = X3. Si aplicamos la técnica gráfica del K-plot a 100pares de observaciones extraídas de las variables X e Y lo que obtendremosserá una nube de puntos por encima de la diagonal, como se ilustra en laFigura 1.3. Este resultado era de esperar puesto que los K-plots detectandependencia funcional positiva de esta forma: acentuando la concavidad dela nube de puntos respecto la diagonal y alcanzando el máximo posible enel cuadrado unidad cuando la dependencia funcional es perfecta, como seaprecia en la Figura 1.3.
42

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
W(i:n)
H(i)
Figura 1.4: Pequeñas alteraciones en la relación funcional perfecta distorsio-nan levemente la concavidad del K-plot.
Caso 2: dos v.a‘s con relación funcional pseudo-perfecta y positivacon ruidos de fondo pequeños
Llamamos a este caso relación funcional pseudo-perfecta ya que considera-remos la misma variable aleatoria X ∼ Exp(β = 1) y la relación Y = X3
pero añadiéndole un ruido U ∼ Unif([0, 5 · 10−2]), es decir, una distorsión,por lo que la relación funcional quedará del siguiente modo: Y = X3 + U . Sivolvemos a dibujar el K-plot generado a partir de 100 pares de observacionesde (X,Y ), obtendremos la Figura 1.4.
Esto nos indica que pese a que X e Y tienen un vínculo muy fuerte fun-cionalmente hablando, una pequeña alteración se hace notar en los K-plot,aunque se puede ver en parte la concavidad, la cual indica dependencia fun-cional positiva. Contrastando este caso con el caso anterior, debemos resaltarque este último es más afin a la realidad cuando se manejan series de datos
43

reales.
Caso 3: dos v.a‘s con relación funcional pseudo-perfecta y positivacon ruidos de fondo grandes
En esta ocasión vamos a ver cómo ruidos importantes que afecten a de-pendencias funcionales perfectas pueden llevar a incertidumbre en la inter-pretación de los K-plots. Sea X ∼ Exp(β = 1) y sea U ∼ Unif([0, 1]) unaperturbación mucho más grande en magnitud que la anterior14 , por lo que lainterpolación de Y = X3 mediante Y = X3 + U será menos fiable. El K-plotpuede observarse en la Figura 1.5., la cual nos da evidencia de relación fun-cional positiva, pero nótense las alteraciones o puntos que se escapan de latrayectoria cóncava natural. Ello es debido al ruido introducido como variableuniforme.
Es coherente pensar que también influye el tipo de distribución, así co-mo sus parámetros poblacionales. Por ejemplo, si en lugar de trabajar conuna Exp(β = 1) trabajamos con una Exp(β = 10) y con un error U ∼Unif([0, 1]) el cual distorsiona mucho más la transformación Y = X3, ob-tendríamos el K-plot de la Figura 1.6.
Caso 4: dos v.a‘s con relación funcional perfecta y negativa
Si ahora generamos 100 pares de (X, Y ) siendo X ∼ N(0, 1) e Y = X3,relación funcional perfecta y negativa, obtenemos el K-plot de la Figura 1.8.Obsérvese como el K-plot acumula la nube en el eje W [i : n] cuando hayrelación funcional perfecta y negativa.
Caso 5: dos v.a‘s independientes
Si ahora representamos el K-plot a partir de una Exp(β = 10) y unaY ∼ N(0, 1), siendo ambas independientes, obtendremos el K-plot esperadobajo independencia: la gráfica se concentra en la diagonal. La Figura 1.7 damuestra de ello.
14Véase caso 2
44

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
W(i:n)
H(i)
Figura 1.5: Alteraciones importantes de la dependencia funcional alteran mu-cho más la concavidad.
45
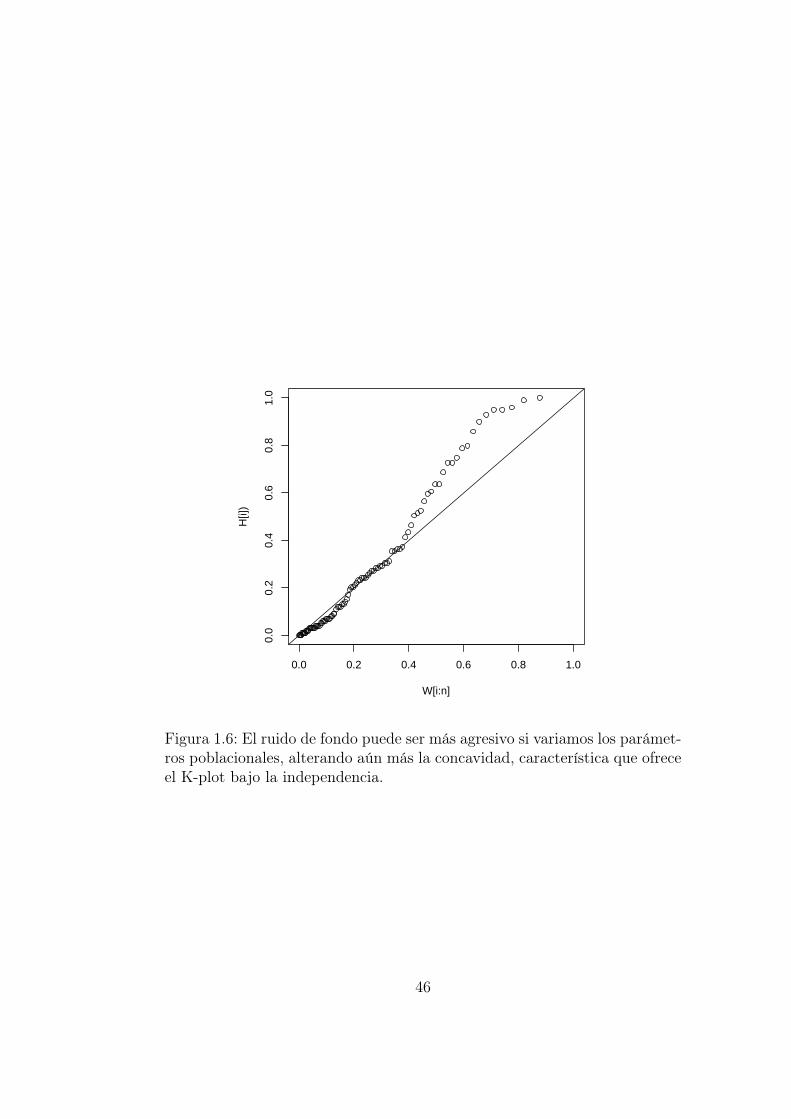
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
W[i:n]
H[i]
)
Figura 1.6: El ruido de fondo puede ser más agresivo si variamos los parámet-ros poblacionales, alterando aún más la concavidad, característica que ofreceel K-plot bajo la independencia.
46

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
W[i:n]
H[i]
)
Figura 1.7: Relación funcional perfecta y negativa de variables contínuas.
47

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
w(i:n)
H(i)
Figura 1.8: La concentración de la nube de puntos en la diagonal es garantíade que el K-plot ha detectado independencia.
48

Capıtulo 2Inferencia estadística para cópulas
2.1. Introducción
Desde un punto de vista estadístico, una cópula es básicamente una sen-cilla expresión de un modelo multivariante. Por lo tanto, es lógico pensar quepuede ser factible aplicar el método de estimación asintótica por MáximaVerosimilitud [25] MLE para la estimación de sus parámetros poblacionales,aunque hay otros posibles métodos de estimación más novedosos que hansido propuestos para poder subsanar el enorme esfuerzo computacional querequiere conseguir MLEs exactos y efectivos mediante la citada técnica an-terior. Estos métodos comparten conceptos de inferencia no paramétrica ytécnicas de simulación.Este capítulo está dedicado a la inferencia estadística en modelos de cópula,por medio del cual describiremos el estimador exacto por Máxima Verosimili-tud MLE en sus versiones paramétrica y semi-paramétrica, el estimador porMínima Distancia L1, así como los estimadores basados en Mínima Distan-cia entre rangos OLS y OLST. Es importante resaltar que el método deestimación MLE involucra una optimización numérica de cierta función aobtener en cada caso concreto (normalmente llamada función de verosimili-tud), ya que una cópula es intrínsecamente un modelo multivariante y porlo tanto la Máxima Verosimilitud requerirá cálculo de derivadas parciales y
49

posterior resolución de EDP‘s1 que contengan a éstas.
Supongamos ahora que tenemos una familia paramétrica de cópulas C =
Cθ : θ ∈ Θ la cual representa un modelo de dependencia entre las variablesX e Y a través de sus funciones de distribución.Dada una muestra aleatoria (X1, Y1), (X2, Y2),. . . , (Xn, Yn) extraída de (X,Y )
vector aleatorio, se desea estimar el parámetro poblacional θ. A continuaciónse detallan algunos métodos para lograr tal fin.
2.2. Método MLE: Versión paramétrica
Asumamos el hecho de que la muestra ha sido extraída de HXY (x, y) =
C FX (x) , GY (y), x, y ∈ R. Supongamos que los siguientes modelos paramétri-cos han sido considerados para FX , GY y C respectivamente : FX ∈ (Fδ)
GY ∈ (Gη) , C ∈ (Cθ) . Sin pérdida alguna de generalidad y como ejem-plo ilustrativo, podemos considerar las siguientes funciones de distribuciónasociadas a las variables (X, Y ), así como la cópula que las relaciona:
FX normal con parámetros δ = (µ, σ2),
GY gamma con parámetros η = (α, λ),
C ∈ Cθ = C : [0, 1]× [0, 1] → [0, 1]/ C(u, v) = uv + θuv(1− u)(1− v)
|θ| < 1 , la familia de cópulas bivariantes Farlie-Gumbel-Morgenstern.
Posteriormente calculamos las densidades asociadas a FX , GY y C que de-notaremos por fδ, gη, cθ respectivamente. La función de densidad conjuntahXY viene dada por
hXY (x, y) =∂2
∂x∂yHXY (x, y) =
∂2
∂x∂yCθ (Fδ (x) , Gη (y)) =
= fδ (x) gη (y) cθ (Fδ (x) , Gη (y)) .
1Ecuaciones en Derivadas Parciales
50

El Estimador por Máxima Verosimilitud de los parámetros (δ, η, θ), tambiénconocido como Máxima Verosimilitud Exacta (Cherubini et al. [10]) vienedefinido al maximizar la función de verosimilitud
l (δ, η, θ) =n∑
i=1
ln fδ (xi)+n∑
i=1
ln gη (yi)+n∑
i=1
ln cθ (Fδ (xi) , Gη (yi)) .
La optimización multivariante puede ser costosa computacionalmente, ademásde correr el riesgo de no llegar a la solución factible para nuestro problema.Por ese motivo, Joe [35] recomienda proceder en dos pasos ( el procedimientode Joe es también conocido como Inferencia para las marginales ; ver tambiénCherubini et al. [10]):
estimar δ y η por separado directamente del logaritmo de la función deverosimilitud de las densidades marginales,
n∑i=1
ln fδ (xi) , yn∑
i=1
ln gη (yi) ;
para i ∈ 1, ..., n establecemos Ui := Fδ (xi) y Vi := Gη (yi);
a continuación escogemos nuestra estimación buscada θ, como el valordel parámetro θ que hace máxima la función objetivo
l (θ; n) =n∑
i=1
ln
cθ
(Ui, Vi
),
por lo que el estimador quedará definido de la forma
θ = arg maxθεΘ
l (θ; n) .
La principal ventaja de este método es que es fácil de implementar, perotambién tiene una desventaja notable: una inadecuada selección de las dis-tribuciones marginales probablemente afecta a la estimación del parámetroθ, incluso cuando C ∈ Cθ sea la cópula adecuada.Además, Joe [37] mostró que el estimador construído en dos etapas es asintóti-
51

camente normal, y bajo ciertas hipótesis, es más eficiente que el construídomediante una etapa (mírese también Zhao [64]). Sin embargo, los cálculos deJoe asumen que las distribuciones marginales han sido correctamente escogi-das.
2.3. Método MLE: Versión semiparamétrica
2.3.1. Estimación directa de las marginales, a partir de
la muestra
Los modelos de cópulas semiparamétricos son los que están construídosmediante cópulas paramétricas pero las pertinentes funciones de distribuciónmarginales están estimadas mediante un método no paramétrico. Ya queestas marginales son desconocidas y deben ser estimadas, un modo seguro dehacerlo es la estimación no paramétrica mediante la marginales muestrales:
Fn (x) =1
n
n∑j=1
I (Xj ≤ x)
Gn (y) =1
n
n∑j=1
I (Yj ≤ y) .
Para evitar problemas de frontera, Fn (x) y Gn (x) son a menudo reescaladossustituyendo n por (n + 1) en el denominador.En el caso bivariante, la función de verosimilitud (Joe [37], Tsukahara [61])viene dada por
l (θ; n) =n∑
i=1
ln
cθ
(Ui, Vi
)
donde, para i ∈ 1, ..., n, Ui = Fn (Xi) y Vi = Gn (Yi). Finalmente se pro-cedería como en el caso anterior para hallar una estimación de θ, por lo quese buscaría encontrar θn tal que
d
dθl(θ; n) = 0
52

yd2
dθ2l(θ; n) < 0,
por lo que estimador tendrá la expresión
θn = arg maxθεΘ
l (θ; n) .
2.3.2. Estimación de las marginales utilizando rangos
Otra forma de estimar las marginales FX y GY consiste en considerarsolamente estimadores basados en rangos. Esta opción metodológica estarájustificada ya que la estructura de dependencia que una cópula representano tiene nada que ver con el comportamiento individual de las variables, elcual viene representado por sus marginales. Como consecuencia, cualquierinferencia sobre el parámetro poblacional de una familia de cópulas a partirlos rangos de las observaciones (los cuáles son un buen resumen del compor-tamiento conjunto de las variables aleatorias), será una seria alternativa parala solución de nuestro problema de estimación.Supongamos que (R1, S1), (R2, S2), ..., (Rn, Sn) son el conjunto de rangosasociados a las observaciones. En el presente contexto, una modificación dela estimación por máxima verosimilitud debe ser necesaria si la inferenciaque concierne a los parámetros poblacionales está basada exclusivamente enrangos 2. El método de pseudo Máxima-Verosimilitud, el cual requiere que Cθ
sea absolutamente continua respecto a la medida de Lebesgue con densidadcθ, simplemente pretende maximizar el logaritmo de la verosimilitud basadaen rangos, la cual tiene la expresión
l (θ; n) =n∑
i=1
ln
cθ
(Ri
n + 1,
Si
n + 1
)
2Una modificación fue descrita ampliamente por Oakes [49] y posteriormente estudiaday formalizada por Genest et al. [25] y por Shih y Louis [58].
53

donde, para cada i ∈ 1, ..., n, Ui = Fn (Xi) = Ri
n+1y Vi = Gn (Yi) = Si
n+1.
Este método es más fácil de implementar que el de Joe ya que sólo necesita losrangos. Como una cópula es invariante respecto a transformaciones crecientesde las marginales, parece lógico esperar lo mismo del estimador del paramétropoblacional que obtendremos, por lo que se espera que sea también invariantemediante transformaciones crecientes. El estimador θn de θ cumple lo anteriorpero por el contrario el estimador de Joe [37] no es invariante mediantetransformaciones crecientes de las distribuciones marginales.Es evidente esperar una pérdida de información si se asume la estimaciónno paramétrica de las marginales, por lo tanto si conocemos las marginalesevidentemente el método de Joe [35] es preferible.Además, denotando ·
cθ (u, v) = ∂∂θ
cθ (u, v), Genest et al. [25] muestran, bajociertas condiciones de regularidad, que la raíz θn de la ecuación
·l (θ; n) =
d
dθl(θ; n) =
n∑i=1
·cθ
(Ri
n+1, Si
n+1
)
cθ
(Ri
n+1, Si
n+1
) = 0,
es única.Genest et al. [25] prueban que el estimador θn = arg maxθεΘ l (θ; n) es asin-tóticamente normal y que, bajo ciertas condiciones, es más eficiente que elestimador máximo construído en una etapa. Estos cálculos no hacen ningunasuposición paramétrica sobre las distribuciones marginales.Así pues,
θn ∼ N
(θ,
ν2
n
)
dondeν2 =
σ2n
β2n
,
σ2n =
1
n
n∑i=1
(Mi −M
)2
y
β2n =
1
n
n∑i=1
(Ni −N
)2
54

son varianzas muestrales calculadas a partir de dos muestras de pseudo ob-servaciones con medias M = M1+...+Mn
ny N = N1+...+Nn
nrespectivamente.
Para calcular las pseudo observaciones the Mi y Ni, se podría proceder delsiguiente modo:
Reetiquetar los datos originales (X1, Y1), ..., (Xn, Yn) de tal maneraque X1 < ... < Xn; como consecuencia de esto se obtendría R1 = 1, ...,Rn = n.
Escribir T (θ, u, v) = ln cθ (u, v) y calcular Tθ (θ, u, v), Tu (θ, u, v) yTv (θ, u, v) derivadas respecto θ, u, v.
Para i ∈ 1, ..., n, fijar Ni = Tθ
(θn, i
n+1, Si
n+1
).
Para i ∈ 1, ..., n, fijar
Mi = Ni − 1
n
n∑j=1
Tθ
(θn,
j
n + 1,
Sj
n + 1
)Tu
(θn,
j
n + 1,
Sj
n + 1
)+
− 1
n
∑Sj≥Si
Tθ
(θn,
j
n + 1,
Sj
n + 1
)Tv
(θn,
j
n + 1,
Sj
n + 1
).
2.3.3. Método L1: Estimación por distancia mínima o
mínimos cuadrados de la cópula paramétrica
Recientemente, desarrollando la propuesta original de Yatracos [63], De-vroye y Lugosi [14] , Biau et al. [5] han propuesto un nuevo prototipo ométodo, denominado estimación por mínima distancia.El propósito del trabajo de Biau et al., es extender la teoría estadística de laestimación por Mínima Distancia, como alternativa a los estimadores MLEy poder hacer frente asi a los problemas que éstos presenten. En efecto, lafunción objetivo (a partir de la cual se calcula el MLE) de muchas cópulas noestá acotada en un entorno de la frontera de [0, 1]p (ver Chen et al. [8]), lo cualpuede dificultar enormemente la estimación del parámetro, ya que el métodopuede no funcionar adecuadamente cuando se presente este problema. Porel contrario, el estimador por Mínima Distancia, el cual está especificamente
55

diseñado para minimizar la distancia usual3 entre el parámetro poblacionalde la cópula teórica y su estimación, no presenta este inconveniente.Consideremos la definición de cópula empírica Cn y sus distribuciones marginalesasociadas. Biau et al. [5] asumen que la cópula C(u, v) tiene densidad c(u, v)
por lo que respecta a la medida de Lebesgue en el rectangulo unidad [0, 1]2.El propósito de sus trabajos es estimar la densidad c(u, v), dada una claseC = cθ : [0, 1]× [0, 1] → [0, 1] / θ ∈ Θ de cópulas densidad candidatas.Definiendo una clase de conjuntos
A = (u, v) ∈ [0, 1]2 : cθ(u, v) > cθ′(u, v) : (θ, θ′) ∈ Θ×Θ,
los autores anteriormente citados introducen un criterio de bondad de ajustepara la densidad cθ ∈ C ,
∆θ = supA∈A
∣∣∣∣∫
A
cθ(u, v)dudv −∫
A
dCn(u, v)
∣∣∣∣ .
Si Cn es reemplazada por C, y A por todos los conjuntos de Borel en [0, 1]2,se podría minimizar la variación total de la distancia entre cθ y cn. Ya queCn no es absolutamente contínua, Biau et al. [5] necesitan usar una pequeñacolección de conjuntos, los cuales nos darán una minimización significativa.Tsukahara [61] establece que el método de la mínima distancia es robusto,ya que la cantidad estimada se comporta de un modo estable en entornosdel modelo en cuestión. Así, cuando pronostiquemos desviaciones leves dela familia paramétrica de cópulas, resultará apropiado utilizar este método.Tsukahara prueba que el estimador por mínima distancia es consistente bajocondiciones muy generales, por lo que podría servir como estimación inicialde otros muchos procedimientos de estimación más complejos.Supongamos que la cópula asociada a la función de distribución bivarianteHXY es D(·, ·). Por otro lado, tenemos una familia paramétrica de cópulasCθ : θ ∈ Θ que representa a los datos. Definamos el funcional de minima
3Dicha distancia dependerá de la métrica con la que se trabaje
56

distancia T en Θ como
T (D) := arg mınθ
ρ (D, Cθ) ,
donde ρ es una distancia entre probabilidades en [0, 1]2. Por ejemplo, Tsuka-hara considera la distancia de Cramér-von Mises :
ρ (D,Cθ) =
∫
[0,1]2D(u, v)− Cθ(u, v)2dudv.
Otras posibles elecciones podrían ser la distancia de Kolmogorov-Smirnov yla distancia de Hellinger, respectivamente dadas por:
ρ (D,Cθ) = sup(u,v)∈[0,1]2
|D(u, v)− Cθ(u, v)| ,
ρ (d, cθ) =
∫
[0,1]2√
d(u, v)−√
cθ(u, v)2dudv.
2.4. Estimaciones basadas en el tau de Kendall
y rho de Spearman
Supongamos a modo de ejemplo que la pertinente estructura de dependen-cia para un par de variables aleatorias (X,Y ) está correctamente modelizadapor la familia de cópulas Farlie Gumbel Morgenstern, ya definida previa-mente. En este caso, θ ∈ ]−1, 1[ es un número real y por lo tanto al aplicarel Teorema 1.9.2 se llega a que existe una relación directa e inmediata entreel parámetro θ y el valor poblacional del τ de Kendall4, definido como
τ =2
9θ
para nuestro ejemplo en cuestión. Dado un valor muestral τn del parámetropoblacional τ , una aproximación simple de la estimación de θ para dicha
4Véase Apéndice, sección Definiciones
57

familia de cópulas podría considerarse calculando
θn =9
2τn.
En general, para cualquier familia de cópulas se tendrá que θn = g (τ) paraalguna función diferenciable g : R→ R asociada a la cópula escogida. Ya queτn está basado en rangos, esta estrategia de estimación puede ser construídacomo una adaptación no paramétrica del célebre método de los momentos.Dicho de otra forma, si θn = g (τ) para alguna función diferenciable g : R→R, entonces θn = g (τn) puede considerarse como el estimador de θ basado enel tau de Kendall. La popularidad de θn como un estimador del parámetrode dependencia5 θ proviene en parte del hecho de que el tau de Kendall sepuede calcular sin problemas para muchos modelos de cópula paramétricos.Tal es el caso, en particular, para varias familias de cópulas Arquimedianas,como por ejemplo, las de Clayton [11], Frank [20], Gumbel Hougaard [32],etc.
Familia tau de Kendall
Clayton θθ+2
Frank 1− 4θ
+ 4D1(θ)θ
Gumbel-Hougaard 1− 1θ
Aquí D1 es la primera función de Debye, cuya expresión viene dada por
D1 (θ) =
∫ θ
0
xθdx
expx−1.
Cuando el parámetro de dependencia θ es real, un estimador alternativobasado en rangos construído a partir del método de los momentos, consisteen calcular
θn = h (ρn)
5Recuérdese que la finalidad del parámetro poblacional de una cópula es "medir"elgrado de dependencia entre las variables X, Y
58

donde θ = h (ρ) representa la relación entre el parámetro de la cópula y elvalor poblacional de la rho de Spearman ρ6, dada por cierta función h : R→R.En el contexto de la familia de cópulas Farlie Gumbel Morgenstern, porejemplo, es fácil ver que ρ = θ
3, por lo que θn = 3ρn podría ser un estimador
no paramétrico alternativo a θn = 92τn.
2.4.1. Intervalo de confianza basado en el tau de Kendall
Siguiendo el trabajo de Genest y Rivest [24] se tiene que
√n
τn − τ
4S∼ N(0, 1),
y
S2 =1
n
n∑i=1
(Wi + Wi − 2W i).
Si tenemos en cuenta el Teorema de Slutsky [51], también conocido comoel Método Delta si n → ∞ se tiene que θ ∼ N(θ, 1
n4Sg′(τn)2) por lo que
tenemos definido el intervalo de confianza para θ:
P (θ ∈[θn − zα
2
1√n
4S∣∣∣g′(τn)
∣∣∣ , θn + zα2
1√n
4S∣∣∣g′(τn)
∣∣∣]) = (1− α).
2.4.2. Intervalo de confianza basado en el rho de Spear-
man
Bajo ciertas condiciones de regularidad sobre la función h : R → R, secumple que
θ ∼ N(θ,1
n4σnh′(ρn)2).
Sustituyendo Cn(·, ·) por C(·, ·) en las expresiones aportadas por Borkworf
6Véase Apéndice, sección Definiciones
59

[6], se obtiene un estimador consistente de σ2n dado por
σ2n = 144(−9A2
n + Bn + 2Dn + 2En + 2Fn)
donde,
An =1
n
n∑i=1
Ri
n + 1
Si
n + 1, Bn =
1
n
n∑i=1
(Ri
n + 1)2(
Si
n + 1)2,
Dn =1
n3
n∑i=1
n∑j=1
n∑
k=1
Ri
n + 1
Si
n + 1I(Rk ≤ Ri, Sk ≤ Sj) +
1
4− An,
En =1
n2
n∑i=1
n∑j=1
Si
n + 1
Sj
n + 1max(
Ri
n + 1
Rj
n + 1),
Fn =1
n2
n∑i=1
n∑j=1
Ri
n + 1
Rj
n + 1max(
Si
n + 1
Sj
n + 1).
El intervalo de confianza para θ vendrá dado por:
P (θ ∈[θn − zα
2
1√n
4σn
∣∣∣h′(ρn)∣∣∣ , θn + zα
2
1√n
4σn
∣∣∣h′(ρn)∣∣∣]) = (1− α).
2.5. Estimadores basados en la Mínima Distan-
cia entre rangos. Método OLS y OLST
Siguiendo el trabajo de Tsukahara [61] y Biau et al. [5], vamos a describira lo largo de esta sección como estimar θ de una familia de cópulas Cθ modifi-cando el método basado en la mínima distancia L1(A partir de ahora, a estamodificación la denotaremos por OLS, siglas en inglés de Ordinary LeastSquare). Dada una muestra aleatoria (Xk, Yk) : k = 1, . . . , n de la distribu-ción HXY (x, y) = Cθ (FX(x), GY (y)) , donde Cθ : [0, 1]2 → [0, 1] representacierta familia concreta de cópulas, el procedimiento consiste en determinar elvalor de θn, llamado estimador basado en la mínima distancia entre rangos
60

[61](con siglas en inglés MDRE), que minimiza la expresión
L(θ) =n∑
i=1
[Cθ
(Fn(xi), Gn(yi)
)− Hn (xi, yi)
]2
, (2.1)
i.e.θn = arg mın
θ∈ΘL(θ)
donde
Fn(xi) =1
n + 1
n∑
k=1
I (xk ≤ xi) =Ri
n + 1
y
Gn(yi) =1
n + 1
n∑
k=1
I (yk ≤ yi) =Si
n + 1
son las distribuciones marginales empíricas, Ri y Si son los rangos asociadosa Xi e Yi respectivamente, y
Hn(xi, yi) = Cn
(Fn
(x(i)
), Gn
(y(i)
))=
=1
n
n∑
k=1
I
(Rk
n + 1≤ Fn
(x(i)
),
Sk
n + 1≤ Gn
(y(i)
))=
=1
n
n∑
k=1
I
(Rk
n + 1≤ Ri
n + 1,
Sk
n + 1≤ Si
n + 1
)=
=1
n
n∑
k=1
I (Rk ≤ Ri, Sk ≤ Si)
es la cópula empírica (Deheuvels [13]).A priori, este método puede parecer menos atractivo que los métodos basa-dos en el tau de Kendall, rho de Spearman o máxima verosimilitud, ya querequiere un mayor esfuerzo numérico, pero al mismo tiempo es más aplicableen general que éstos, pues no requiere que el parámetro dependiente sea unnúmero real y por lo tanto podemos utilizarlo en problemas multivariantesde estimación de θ (lo que también se consigue mediante los métodos de Ge-nest y Joe). Sin pérdida de generalidad, consideraremos la familia de cópulasArquimedianas, por lo que para ciertas Fn
(x(i)
)G
(y(i)
)se tiene definida la
61

cópula:
Cθ = ϕ−1θ
(ϕθ Fn
(x(i)
)+ ϕθ Gn
(y(i)
)),
donde ϕ : [0, +∞) → [0, +∞) es la función generatriz de la cópula y lacomposición usual entre funciones de variable real. Sea
t(xi, yi; θ) := ϕ−1θ
(ϕθ F
(x(i)
)+ ϕθ G
(y(i)
))− Hn (xi, yi) .
Minimizando la función∑n
i=1 t(xi, yi; θ)2 respecto θ tendremos definido el
problema de la mínima distancia mediante el método OLS, es decir:
θn = arg mınθ∈Θ
n∑i=1
t(xi, yi; θ)2.
Se debe recalcar que este estimador no es insesgado, sobre todo cuando setrabaja con muestras de tamaño pequeño. Aunque, dada una muestra, siem-pre se tiene suficiente información para poder estimar las marginales FX(x)
y GY (y), no ocurre lo mismo para poder estimar la estructura de depen-dencia (i.e. la cópula), ya que siempre se verá reducido el número de datos"válidos"para llevar a cabo tal fin. Entonces, ¿es posible crear un estimadorinsesgado de θn? La respuesta es afirmativa y a continuación se detalla comollegar a tal estimador.
2.5.1. El método OLS modificado y suavizado: OLST
Recordemos que Hn (xi, yi) representa la función de distribución conjuntaempírica calculada a partir de los pares de puntos (xi, yi). Ahora, nuestramotivación consiste en intentar averiguar cúales pueden ser los efectos sobreel comportamiento de las cópulas que puedan producirse al modificar nuestrométodo de estimación. Para ello, partimos de una simulación de n pares dedatos (xi, yi), con i = 1, . . . , n extraídos de tres cópulas arquimedianas: Lacópula de Frank, La cópula de Gumbel y la cópula de Clayton. Consideremoslos siguientes valores de los parámetros poblacionales, seleccionados para las
62

cópulas Clayton y Frank:
θ ∈ 0.5, 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5, 5.5, 6.
Ya que el dominio del parámetro poblacional de una Gumbel es diferente alde la Clayton y Frank, estipulamos para ella los siguientes valores de θ :
1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5, 5.5, 6, 6.5, 7.
Para cada valor de θ variamos el tamaño muestral de la siguiente forma,todo ello para cada familia de cópulas:
n = 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000.
Modelo de cópula θ1 θ2 . . . θ12
n = 100 (x1,. . . ,x100) (x1,. . . ,x100) . . . (x1,. . . ,x100)(y1,. . . ,y100) (y1,. . . ,y100) . . . (y1,. . . ,y100)
n = 200 (x1,. . . ,x200) (x1,. . . ,x200) . . . (x1,. . . ,x200)(y1,. . . ,y200) (y1,. . . ,y200) . . . (y1,. . . ,y200)
. . . . . . . . . . . . . . .n = 1000 (x1,. . . ,x1000) (x1,. . . ,x1000) . . . (x1,. . . ,x1000)
(y1,. . . ,y1000) (y1,. . . ,y1000) . . . (y1,. . . ,y1000)
Para cada valor de n calculamos doce cantidades Hn (xi, yi), donde losvectores x =(x1,. . . ,x100) y y =(y1,. . . ,y100) son simulados mediante la cópu-la elegida en cuestión, haciendo variar para cada simulación θ como arriba seespecifica. A continuación sesenta y seis tests de Kolgomorov-Smirnov hansido aplicados para verificar las diferencias entre las funciones de distribución
obtenidas, contrastadas dos a dos, ya que tendremos
(12
2
)= 66 compara-
ciones diferentes para cada familia y para cada valor fijo de n. Todo esteproceso se repite, variando el tamaño muestral y la cópula.
63

Porcentajes (%) de diferencias entre H (x, y)
Clayton Frank G.-H.n = 100 18.3818 12.8667 10.5273n = 200 34.3182 30.1788 22.1455n = 300 43.2091 41.1303 30.3242n = 400 49.2697 47.9152 35.8848n = 500 54.3061 54.1818 40.5182n = 600 56.9121 56.5636 42.6667n = 700 60.4121 60.9879 46.2879n = 800 62.3848 62.8333 48.6061n = 900 64.6667 65.3333 50.6515n = 1000 66.3879 67.3576 52.7303
La Tabla anterior muestra en porcentajes las diferencias entre las dis-tribuciones empíricas con θ diferentes. Cabe mencionar el bajo porcentajede diferencias entre distribuciones cuando n ≤ 400, sobre todo en la familiaGumbel. Es decir, para muestras pequeñas no se detectan diferencias con al-ta probabilidad de hacerlo correctamente. La necesidad de sumininistrar unacorrección del estimador para evitar este problema parte desde este hecho.
Independientemente del tipo de cópula que se escoja, cuando θ aumenta,los puntos tienden a aglomerarse en la bisectriz del primer cuadrante. Estoes debido a que θ mide el grado de dependencia funcional de las dos varia-bles. Cuanto mayor sea el valor de θ, más fuerte será la interacción entrelas variables. Este fenómeno es conocido bajo el nombre dependencia en elcuadrante positivo [35]. Lógicamente, averiguar ese grado de dependenciaestimando θ es uno de los objetivos que se marcan cuando se utilizan cópulasen la inferencia estadística. Pero hay un detalle de suma importancia eneste hecho, cada cópula tiende a hacerlo de una manera específica, es decir,todas tienen en común unos "datos centrales", pero hay una serie de puntos,llamémosles puntos colindantes para los que las familias se diferencian en laforma de representarlos. Son los puntos que se alejan del centro. Trabajarcon esta clase de puntos, será esencial para poder diferenciar los términosempíricos Hn (xi, yi), objetivo primordial para poder mejorar el método de
64

estimación.El algoritmo que usamos para poder marcar los límites que nos diferencien
los puntos centrales de los puntos colindantes o exteriores es el siguiente:
Generar n valores u de una distribución U(0, 1).
Usando los valores u calculados anteriormente, generar una serie devalores v mediante el método de la distribución condicional (ver Nelsen[47]), para un número de veces preestablecido por el investigador.
Construir la siguiente matriz:
1 Simul. . . . m Simul.u1 v11 . . . v1m
. . . . . . . . . . . .un vn1 . . . vnm
y calcular las medias y las desviaciones típicas de las filas, denotadasde la forma para cada i0 = 1, ..., n fijo
vi0j =m∑
j=1
vi0j
m
y
D.T. (vi0j) =m∑
j=1
√v2
i0j
m− vi0
respectivamente.
finalmente, podemos definir las bandas que nos determinaran la dife-rencia entre puntos colindantes y centrales, de la siguiente forma:
Li0 = vi0j + KD.T. (vi0j) ,
li0 = vi0j −KD.T. (vi0j) ,
donde el valor de K es elegido por uno mismo. Para representar estasbandas simplemente se interpolan la nubes de puntos (li0, Li0) mediante
65
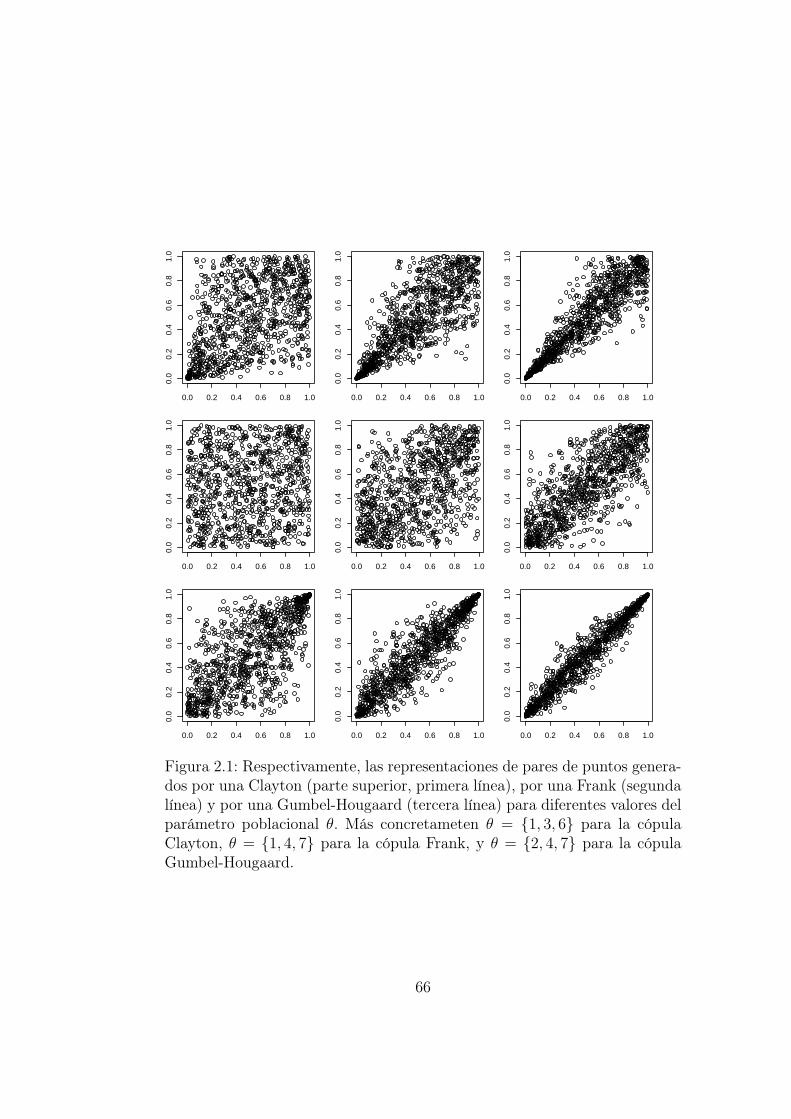
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Figura 2.1: Respectivamente, las representaciones de pares de puntos genera-dos por una Clayton (parte superior, primera línea), por una Frank (segundalínea) y por una Gumbel-Hougaard (tercera línea) para diferentes valores delparámetro poblacional θ. Más concretameten θ = 1, 3, 6 para la cópulaClayton, θ = 1, 4, 7 para la cópula Frank, y θ = 2, 4, 7 para la cópulaGumbel-Hougaard.
66

sendas curvas, cada una uniendo únicamente una clase. Los puntos quecaigan fuera de dichas bandas determinarán las observaciones buscadas(x?
(i), y?(i)
). En la Figura 2.2 se pueden observar las representaciones de
esta clase de puntos y las bandas que se obtendrían a partir del ejemplopropuesto.
Así pues, el estimador de θ propuesto y llamado como OLST se obtendráminimizando la función:
n?∑i=1
t(x∗i , y∗i ; θ)
2 =n?∑i=1
[ϕ−1
θ
(ϕθ F
(x?
(i)
)+ ϕθ G
(y?
(i)
))− H (x?i , y
?i )
]2
,
(2.2)donde n? representa el número de pares de puntos “colindantes”
(x?
(i), y?(i)
).
Nuestro problema de mejora de la estimación queda pues definido al mini-mizar
∑n?
i=1 t(x∗i , y∗i ; θ)
2 respecto θ, o equivalentemente nuestro estimadorbuscado tiene la forma
θn = arg mınθ∈Θ
n?∑i=1
t(x∗i , y∗i ; θ)
2.
67

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Figura 2.2: Las bandas para Clayton (primera línea), Frank (segunda línea)y Gumbel-Hougaard (tercera línea) para diferentes valores de θ. θ = 1, 3, 6para Clayton, θ = 1, 4, 7 para Frank, θ = 2, 4, 7 para Gumbel-Hougaard.
68

Capıtulo 3Simulación de estructuras dedependencia mediante cópulas
Este capítulo está dedicado a considerar varias familias de cópulas y simu-lar ciertas estructuras de dependencia bivariantes analizando sus característi-cas y propiedades. Nos centraremos en las familias Clayton, Frank y Gumbelpor ser tres de las más importantes familias Arquimedianas.
3.1. Simulación mediante la cópula Clayton
El objetivo de esta sección consiste en extraer mil pares de observacionesde una cópula Clayton tomando diferentes valores de θ > 0 y represen-tar las nubes de puntos asociadas, para finalmente contrastar los resultadosobtenidos. Recordemos que una cópula Clayton (caso bivariante) es una fun-ción C : [0, 1]×[0, 1] → [0, 1] definida de la forma Cθ(u, v) = (u−θ+v−θ−1)
−1θ .
Así pues, consideraremos los siguientes parámetros poblacionales para dichacópula,
θ1 = 0.1 θ2 = 10 θ3 = 30 θ4 = 1000
para obtener la siguiente matriz:
69

θ1 = 0.1 (u11, v11) (u21, v21) ... (u10001, v10001)
θ2 = 10 (u12, v12) (u22, v22) ... (u10002, v10002)
θ3 = 30 (u13, v13) (u23, v23) ... (u10003, v10003)
θ4 = 1000 (u14, v14) (u24, v24) ... (u10004, v10004)
En la parte superior izquierda de la Figura 3.1 se puede apreciar per-fectamente que al elegir valores del parámetro poblacional cercanos a 0, i.e.valor ínfimo de θ (hemos escogido θ = 0.1), la dispersión de la nube de pun-tos tiende a ser máxima, y esto se debe interpretar como independencia delas variables generadas. El parámetro poblacional θ > 0 nos determina elgrado de dependencia entre las variables aleatorias de forma que tienden atener dependencia funcional cuanto más lejos esté θ de 0, o equivalentemente,tenderán a ser independientes cuando θ → 0. Nótese que el parámetro pobla-cional de una distribución es la mayoría de veces un valor desconocido, porlo que a priori desconoceremos la posible relación funcional que puedan tenerdichas variables, si es que la tienen. Para lograr tal fin, es sugerente realizarloen las siguientes etapas:
Escoger una colección de familias de cópulas candidatas a representarnuestra estructura de dependencia1.
Estimar el parámetro poblacional para cada una de ellas, dado nues-tro banco de datos bivariante. Este proceso ya se ha detallado en elCapítulo 2 mediante los métodos de estimación allí propuestos.
Elegir la familia que mejor se ajuste a nuestro banco de datos. Porejemplo, si se escogiese el método de estimación MLE (en cualquierade sus versiones) la familia óptima sería aquella para la cual su funciónde verosimilitud asociada fuese máxima, dado el parámetro estimado ynuestro banco real de datos. Esta es la estrategia que seguiremos en elCapítulo 4, concretamente en la Sección 4.5, para determinar la familiade cópulas que mejor se ajuste a un banco bivariante real de datos.
1Para cada campo de la ciencia se proponen ciertas familias de cópulas, en acuerdo alproblema que deban solventar
70

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
u
v
−1.0 −0.5 0.0 0.5 1.0
−1.
00.
00.
51.
0
lambda
chi
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
u
v
−0.2 0.2 0.6 1.0
−1.
00.
00.
51.
0
lambda
chi
Figura 3.1: simulación de 1000 pares de observaciones mediante una cópulaClayton con θ = 0.1 (parte superior izquierda) y 1000 pares de observa-ciones con θ = 10 (parte inferior izquierda). Adjuntamente en la derecha seencuentran los Chi-plots correspondientes.
71

Una vez ya tengamos la familia que represente la estructura de depen-dencia de las variables a traves de sus distribuciones marginales, asícomo el parámetro poblacional de la cópula, el cual nos determina elgrado de dependencia entre éstas, ya podemos llevar a cabo un estudiode la posible relación funcional de las variables.
En la parte inferior izquierda de la Figura 3.1 se aprecia como la nubede puntos tiende a agruparse cuando (u, v) → (0, 0), hecho consecuente dehaber aumentado el valor de θ hasta 10. Se puede observar en la parte inferiorderecha de dicha Figura como el Chi-Plot detecta mayor dependencia al haberaumentado el valor de θ de 0.1 a 10, representando mayor cantidad de puntosfuera de las bandas de control2.
En la parte superior izquierda de la Figura 3.2 está representada la nubede puntos extraída de una Clayton con θ = 30, y puede observarse como éstase aglomera en torno a la diagonal por lo que, tal y como hemos recalcadoanteriormente, indica una dependencia más fuerte entre las variables. De he-cho, así lo muestra el Chi-Plot al alejar todavía más la nube de puntos delas bandas de control que delimitan la independencia. En la parte inferiorizquierda todavía se acumula más la nube de puntos en torno a la diagonalu = v, al haber aumentado el valor de θ hasta 100. Tal y como se ha expli-cado anteriormente, cuanto mayor sea el parámetro θ mayor será el grado dedependencia y por consiguiente más tenderá la nube de puntos a aglomerarsealrededor de la bisectriz. El hecho de que se observe gráficamente a partirde la simulación mediante cópulas que dos variables U y V estén fuerte-mente relacionadas, no implica conocer en modo alguno el tipo de relaciónque puedan tener. Esa es otra importante cuestión a estudiar, aunque enesta memoria no se hará, pero se propondrá en el Capítulo 5 como línea deinvestigación abierta. En las Figuras 3.3 y 3.4 se representan las funcionesde densidad de una familia Clayton con parámetros variando desde 2 a 15.Puede observarse cómo un aumento de θ implica una mayor concentración (ymenor dispersión) de la función de densidad hacia la diagonal del dominio.Esto queda también corroborado con las curvas de nivel de la Figura 3.5.
2Ver Sección 1.10 Medidas gráficas de dependencia
72
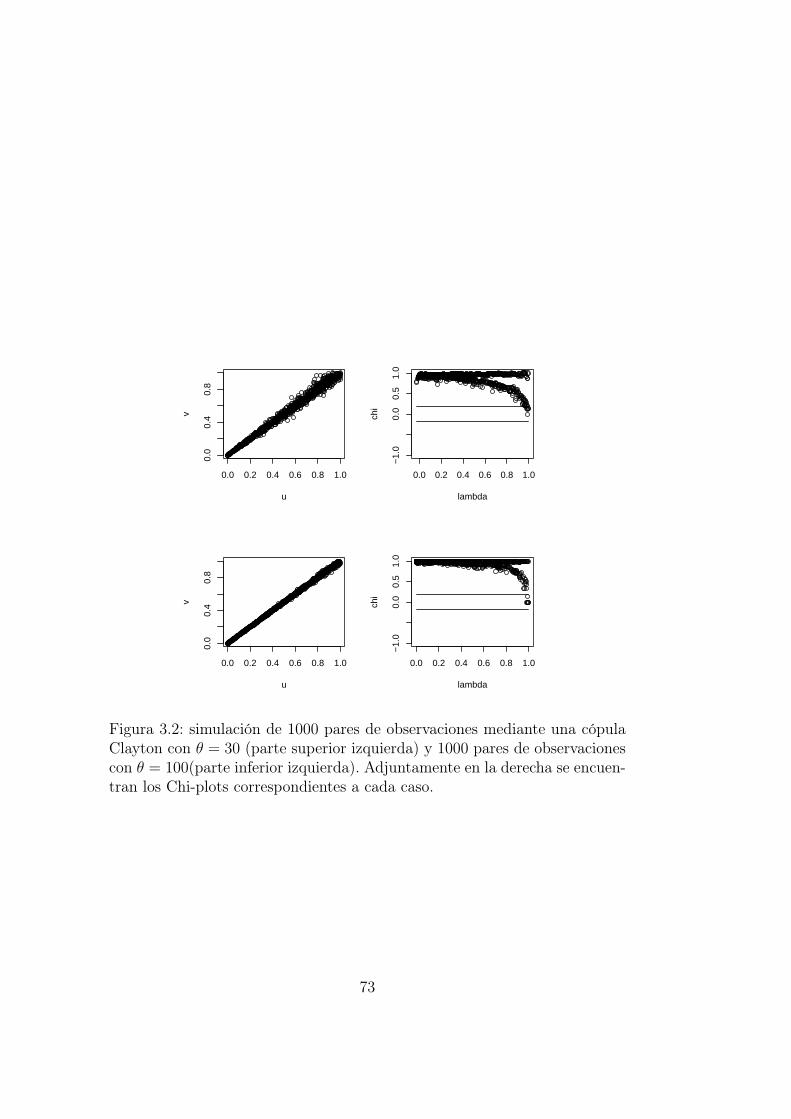
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
u
v
0.0 0.2 0.4 0.6 0.8 1.0
−1.
00.
00.
51.
0
lambda
chi
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
u
v
0.0 0.2 0.4 0.6 0.8 1.0
−1.
00.
00.
51.
0
lambda
chi
Figura 3.2: simulación de 1000 pares de observaciones mediante una cópulaClayton con θ = 30 (parte superior izquierda) y 1000 pares de observacionescon θ = 100(parte inferior izquierda). Adjuntamente en la derecha se encuen-tran los Chi-plots correspondientes a cada caso.
73

u
v
theta=2
u
v
theta=3
u
v
theta=4
u
v
theta=5
Figura 3.3: Representación de la función de densidad asociada a una cópulaClayton para los casos θ = 2, θ = 3, θ = 4 y θ = 5.
74

u
v
theta=6
u
v
theta=7
u
v
theta=8
u
v
theta=15
Figura 3.4: Representación de la función de densidad asociada a una cópulaClayton para los casos θ = 6, θ = 7, θ = 8 y θ = 15.
75

−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=2
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=3
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=4
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=5
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=6
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=7
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=8
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=12
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=15
Figura 3.5: Representación de las curvas de nivel de una Clayton para losvalores de θ indicados en la parte superior de cada cuadro.
76

En la Figura 3.5 puede observarse que a medida que la relación funcionalentre las variables tiende a ser muy débil o prácticamente nula, i.e., cuandoθ → infθ : θ ∈ Θ, la región de densidad de puntos se hace cada vez másdispersa. Entendemos por región de densidad o de masa de una función dedensidad, a la subregión del soporte cuyos puntos tengan una alta probabi-lidad de pertenecer a ella. Dicho de otro modo, si cθ(u, v) es la densidad deuna cierta cópula y D ⊆ R2 un subconjunto compacto y conexo3 de su so-porte tal que p((u, v) ∈ D) =
∫ ∫D
cθ(u, v)dudv = β β ∈ ]0,75, 1[, entoncesD ⊆ R2 será llamada región de densidad. En cambio, si θ aumenta (con loque la relación entre las variables va haciéndose más fuerte), la región dedensidad o masa tiende a estrechar cerco en torno a la diagonal principal.A partir de esta definición dada, pueden observarse y contrastar resultadosen cuanto a la estructura de dependencia que una cópula u otra pueden re-presentar. Por ejemplo, si observamos detenidamente las Figuras 3.5, 3.10 y3.15, concretamente aquellas densidades de cópula cuyas curvas de nivel secorrespondan con parámetros de valor relativamente bajo, se puede concluirque para una Clayton la región de densidad tiende a hacerse más dispersa enel primer cuadrante, por lo que los pares de puntos que se extraerían de dichaestructura de dependencia serían con probabilidad alta positivos y con mayordispersión, o pares de puntos negativos, también con probabilidad alta, perocon menor dispersión. Extraer de dicha estructura de dependencia pares depuntos con signos diferentes es menos probable, hecho que queda constatadoal observar la poca área que presenta la región de densidad para este caso.Si se observa la Figura 3.15 para los mismos valores de θ, se aprecia justolo contrario: si las variables tienden a ser independientes bajo un modelo decópula Gumbel, ésta crearía una estructura cuya extracción de puntos ten-dería a ser de pares negativos con mayor dispersión entre ellos, y pares depuntos positivos con una menor dispersión, es decir, acercándose a la diago-nal y por lo tanto a parecerse más. En cambio, para una Frank la hipótesisde independencia se corresponde con la forma de la región de densidad delmodo en que ésta tiende a ser elipsoidal hasta llegar casi a convertirse enun círculo. En la Figura 3.10 se observa que cuando θ = 2, sinónimo de in-
3Véase Ápendice, sección Definiciones
77

dependencia, extraer pares de puntos del segundo cuadrante es, debido a lasimetría, prácticamente equiprobable a hacerlo respecto del cuarto. Dicho deotro modo P (u ≥ 0, v ≤ 0) ≈ P (u ≤ 0, v ≥ 0). Respecto al segundo y cuartocuadrantes, se observa que P (u ≤ 0, v ≤ 0) ≈ P (u ≥ 0, v ≥ 0), por lo quetambién tendería a haber equiprobabilidad en dichas extracciones. En cam-bio, para una Clayton se tiene que P (u ≥ 0, v ≤ 0) ≈ P (u ≤ 0, v ≥ 0) ≈ 0
P (u ≤ 0, v ≤ 0) ≤ P (u ≥ 0, v ≥ 0), es decir, tenemos una probabili-dad relativamente alta de extraer pares de puntos estrictamente positivos oestrictamente negativos, y una probabilidad más baja de extraer pares depuntos cuyos signos sean distintos.
3.2. Simulación mediante la cópula Frank
El objetivo es el mismo que en el caso anterior, pero restringiéndonos ala familia de Frank de cópulas bivariantes. Recordemos la forma de la cópulaFrank bivariante:
C(u, v) =ln( θ+θu+v−θu−θv
θ−1)
ln(θ), (u, v) ∈ [0, 1]× [0, 1] , θ > 1
Al igual que en el caso anterior, si tomamos valores de θ cercanos a suvalor ínfimo (en este caso por la derecha), obtenemos una nube de puntosmuy dispersa respecto a la diagonal u = v.
De nuevo puede observarse en la Figura 3.7 que el aumento del parámetropoblacional implica mayor grado de dependencia entre las variables, por loque la nube de puntos tiende a agruparse en torno a la diagonal. El Chi-Plotasí nos lo confirma al representar la nube de puntos fuera de los límites decontrol, detectando dependencia entre las variables. Asímismo representamosen las Figuras 3.8, 3.9 y 3.10 las funciones de densidad de una cópula4 Frank
4Nótese la importancia de diferenciar una cópula de su densidad. Por ejemplo, en lasFiguras 3.6 y 3.7 observamos que los pares de puntos residen en el rectángulo unidadI2 (han sido extraídos de una cópula), mientras que en la Figura 3.10, asociada a unadensidad de cópula, se observa otro rango de valores mas amplio
78
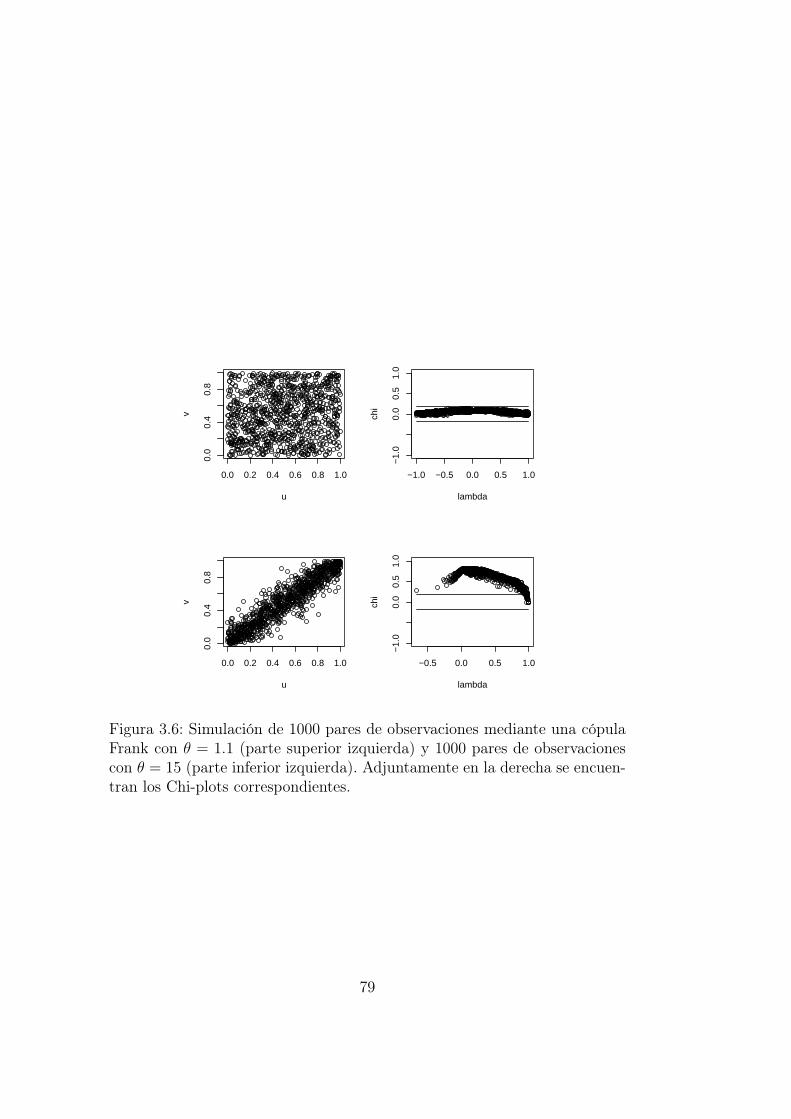
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
u
v
−1.0 −0.5 0.0 0.5 1.0
−1.
00.
00.
51.
0
lambda
chi
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
u
v
−0.5 0.0 0.5 1.0
−1.
00.
00.
51.
0
lambda
chi
Figura 3.6: Simulación de 1000 pares de observaciones mediante una cópulaFrank con θ = 1.1 (parte superior izquierda) y 1000 pares de observacionescon θ = 15 (parte inferior izquierda). Adjuntamente en la derecha se encuen-tran los Chi-plots correspondientes.
79

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
u
v
0.0 0.4 0.8
−1.
00.
00.
51.
0
lambda
chi
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
u
v
0.0 0.4 0.8
−1.
00.
00.
51.
0
lambda
chi
Figura 3.7: Simulación de 1000 pares de observaciones mediante una cópulaFrank con θ = 25 (parte superior izquierda) y 1000 pares de observaciones conθ = 35 (parte inferior izquierda). Adjuntamente en la derecha se encuentranlos Chi-plots correspondientes.
80

u
v
theta=2
u
v
theta=3
u
v
theta=4
u
v
theta=5
Figura 3.8: Representación de la función de densidad asociada a una cópulaFrank para los casos θ = 2, θ = 3, θ = 4 y θ = 5.
con parámetros variando desde θ = 2 hasta θ = 5 en formato perspectivay curvas de nivel. Podemos observar que el comportamiento de una Frankno es tan drástico en torno a la diagonal u = v como el caso Clayton, sinoque muestra un comportamiento más circular tendiendo a ovalado con el au-mento de la dependencia. Esto es una característica diferenciadora de ambasfamilias.
3.3. Simulación mediante la cópula Gumbel
Recordemos que la cópula bivariante de Gumbel adquiere la forma delfuncional
C : (Fα, Gβ) → [0, 1] C(F (u), G(v)) = e−(((− ln(F (u)))θ+(− ln(G(v)))θ))1θ
81

u
v
theta=6
u
v
theta=7
u
v
theta=8
u
v
theta=15
Figura 3.9: Representación de la función de densidad asociada a una cópulaFrank para los casos θ = 6, θ = 7, θ = 8 y θ = 15.
82

−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=2
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=3
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=4
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=5
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=6
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=7
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=8
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=12
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=15
Figura 3.10: Representación de las curvas de nivel de una Frank para losvalores de θ indicados en la parte superior de cada cuadro.
83

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
u
v
−1.0 −0.5 0.0 0.5 1.0
−1.
00.
00.
51.
0
lambda
chi
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
u
v
0.0 0.2 0.4 0.6 0.8 1.0
−1.
00.
00.
51.
0
lambda
chi
Figura 3.11: Simulación de 1000 pares de observaciones mediante una cópulaGumbel con θ = 1.1 (parte superior izquierda) y 1000 pares de observa-ciones con θ = 20 (parte inferior izquierda). Adjuntamente en la derecha seencuentran los Chi-plots correspondientes.
siendo α el parámetro poblacional de la distribución F , β el de la distribuciónG y θ > 1 el parámetro propio de la cópula Gumbel. Más precisamente:
C(u, v) = e−((− ln(u))θ+(− ln(v))θ)1θ siendo (u, v) ∼ Unif [0, 1]
En las Figuras 3.11 y 3.12 se muestran las nubes de puntos para distintassimulaciones mediante esta cópula, así como sus Chi-Plots asociados. Cabedestacar que a medida que aumentamos el valor de θ la nube de puntos tam-bién tiende a aglomerarse en torno a la diagonal u = v, eso si, de una maneradistinta a como lo hacen las simulaciones de la cópula Clayton. Mientras lospares de puntos extraídos de la cópula Clayton tienden a agruparse más rá-pidamente en torno a la recta u = v cuando sus valores oscilan entre 0 y 0.5,los simulados mediante la cópula Gumbel lo hacen respecto a los valores de
84

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
u
v
0.0 0.2 0.4 0.6 0.8 1.0
−1.
00.
00.
51.
0
lambda
chi
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.4
0.8
u
v
0.0 0.2 0.4 0.6 0.8 1.0
−1.
00.
00.
51.
0
lambda
chi
Figura 3.12: Simulación de 1000 pares de observaciones mediante una cópulaGumbel con θ = 50 (parte superior izquierda) y 1000 pares de observacionescon θ = 100 (parte inferior izquierda). Adjuntamente en la derecha se en-cuentran los Chi-plots correspondientes.
los pares que tienden a (0, 0) ó a (1, 1), hecho que puede observarse en lasFiguras 3.11 y 3.12, aglomerándose las simulaciones en torno a la recta u = v
cuando (u, v) → (0, 0) o (u, v) → (1, 1). En cambio, a medida que (u, v) seaproximan tanto por la derecha como por la izquierda a 0,5, la nube es másdispersa. Podría decirse que a medida que (u, v) → (0, 0) y (u, v) → (1, 1) elvalor de la variable u tenderá a parecerse más al valor de la variable v.
85

u
v
theta=2
u
v
theta=3
u
v
theta=4
u
v
theta=5
Figura 3.13: Representación de la función de densidad asociada a una cópulaGumbel para los casos θ = 2, θ = 3, θ = 4 y θ = 5.
86

u
v
theta=6
u
v
theta=7
u
v
theta=8
u
v
theta=15
Figura 3.14: Representación de la función de densidad asociada a una cópulaGumbel para los casos θ = 6, θ = 7, θ = 8 y θ = 15.
87

−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=2
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=3
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=4
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=5
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=6
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=7
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=8
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=12
−3 −2 −1 0 1 2 3
−3
−2
−1
01
23
theta=15
Figura 3.15: Representación de las curvas de nivel de una Gumbel para losvalores de θ indicados en la parte superior de cada cuadro.
88

Capıtulo 4Métodos de estimación sobre cópulas:estudio comparativo
4.1. Introducción
El objetivo que nos marcamos en este Capítulo es el de contrastar laeficacia de los distintos métodos de estimación propuestos en el Capítulo 2mediante un estudio de simulación. Consideraremos para ello dos situaciones:
Correcta especificación del método, es decir, simulación de los datosy estimación del parámetro poblacional de dependencia con la mismafamilia de cópulas.
Incorrecta especificación del método, simulando los pares de datos conuna familia preestablecida y seguidamente estimar el parámetro de de-pendencia mediante otras familias de cópulas.
Para llevar a cabo tal estudio nos restringiremos a las familias de cópulasClayton, Frank y Gumbel. La situación correcta nos llevará a poder determi-nar la eficacia de los métodos utilizados, que, recordemos, eran los siguientes1:
MLE: Máxima verosimilitud.1Véase Capítulo 2: Inferencia estadística para cópulas
89

L1: Mínimos cuadrados ó distancia mínima.
OLS: Mínimos cuadrados ponderados.
OLST: Mínimos cuadrados ponderados y suavizados.
La situación incorrecta nos dará información sobre el parecido o la diferen-cia que puedan tener entre si ciertas familias de cópulas, lo cual nos puedeser muy útil a la hora de elegir función de distribución (caracterizada por lacópula) para estudiar la dependencia de una serie de datos reales, ya que notiene porqué existir una única familia que modelize correctamente la relaciónfuncional que puedan tener éstas.En último lugar, en la Sección 4.5 se describirá un proceso a seguir comoaplicación en la investigación científica, realizando una breve descripción deun estudio de estimación y elección del modelo de cópula como estructura dedependencia, a partir de unos datos reales.
4.2. Formalización de la simulación
La metodología seguida en este estudio de simulación cuyos resultadosvienen en los Cuadros 4.1-4.9, es la siguiente:
Para el caso correcto. Escogemos una de las 3 familias propuestas ya partir de ellas simulamos 1500 pares de datos para cada uno de losvalores θ = 2, θ = 3, θ = 4, θ = 5, θ = 6 , θ = 7, θ = 8, θ = 15del parámetro poblacional, y luego efectuamos 100 estimaciones de θ
para cada una de esas 8 situaciones con cada uno de los 4 métodospropuestos , todo ello con la misma cópula que hemos utilizadopara simular. Tomaremos como estimación representativa la mediaaritmética de las repeticiones de cada combinación de casos, y la de-notaremos por θ
∗. El proceso se repite dos veces más, una para cadauna de las dos familias restantes. Para determinar la eficacia del méto-do utilizado se pueden comparar los valores poblacionales fijados pornosotros y los valores obtenidos en la estimación. Como la cópula esla misma tanto para simular como para estimar, si el método es fiable,
90

deberemos esperar que la estimación se parezca mucho al parámetropoblacional. Este estudio se puede llevar a cabo observando los Cuadrosde las Secciones 4.3.1. (caso Clayton, Cuadro 4.1), 4.3.2 (caso Frank,Cuadro 4.2) y 4.3.3 (caso Gumbel, Cuadro 4.3).
Para el caso incorrecto. Escogemos una de las 3 familias, por ejemploClayton, y se simulan 1500 pares de datos a partir de ella para cadauno de los parámetros poblacionales propuestos anteriormente. A conti-nuación efectuamos 100 estimaciones de θ para cada una de esas 8 situa-ciones pero usando otra de las dos cópulas restantes, por ejemploFrank. Se vuelve a considerar como estimación óptima θ
∗. El procesose repite, pero utilizando la última cópula de las 3 que aún no hemosutilizado. Podemos observar los resultados obtenidos en los Cuadrosque conforman las Secciones 4.4.1 (simulación con Clayton, estimacióncon Frank, Cuadro 4.4), 4.4.2 (simulación con Clayton, estimación conGumbel, Cuadro 4.5), 4.4.3 (simulación con Frank, estimación con Clay-ton, Cuadro 4.6), 4.4.4 (simulación con Frank, estimación con Gumbel,Cuadro 4.7), 4.4.5 (simulación con Gumbel, estimación con Clayton,Cuadro 4.8) y 4.4.6 (simulación con Gumbel, estimación con Frank,Cuadro 4.9).
4.3. Correcta especificación del modelo: Las fa-
milias de simulación y estimación coinci-
den
Los resultados se presentan en los Cuadros 4.1-4.3. En ellos se muestra
para cada caso la media de las repeticiones θ∗
=100∑i=1
θ∗i100
, el sesgo θ − θ∗,
la desviación típica DT (θ∗i ) =
√100∑i=1
θ∗2i
100− θ2 , y el error cuadrático medio
ECM(θ∗i ) =
100∑i=1|θ∗i−θ|2100
.
91

4.3.1. Caso Clayton
En el Cuadro 4.1 puede apreciarse que la estimación θ∗ de θ es bastante
exacta para los cuatro métodos, aunque el OLST tiene un sesgo mayor quelos otros tres restantes y el MLE muestra medidas de dispersión ligeramentemás pequeñas que el resto. Podría decirse que en este caso el mejor método(o más preciso) ha sido el MLE, mientras que el peor, el OLST. De formagenérica se observa que la estimación (por cualquier método) de valores altosde θ, indicativos de un fuerte grado de dependencia funcional, se correspondecon sesgos importantes y altos valores de desviación típica. El mensaje que sederiva de este comportamiento es la complejidad intrínseca de la estimaciónde parámetros asociados a altos grados de dependencia.
4.3.2. Caso Frank
En el Cuadro 4.2 puede apreciarse que las estimaciones θ∗ de θ son más
exactas para los cuatro métodos que las obtenidas en el Cuadro 4.1, a medi-da que el valor de θ aumenta. Con los métodos OLS, MLE y L1 se consigueaumentar la precisión de estimación respecto al caso anterior, reflejado enel Cuadro 4.1. El método OLST tiene un sesgo mayor que los otros tresrestantes, debido a que es el que mayor imprecisión presenta en la estimaciónde θ. El método MLE muestra de nuevo las medidas de dispersión ligera-mente más pequeñas que el resto. Podría decirse también que en este casoel mejor método (o más preciso) ha sido el MLE, mientras que el peor hasido el OLST, con un ECM muy alto respecto al resto. De forma genéricase observa que la estimación (por cualquier método) de valores altos de θ,indicativos de un fuerte grado de dependencia funcional, se corresponde consesgos importantes y altos valores de desviación típica. El mensaje que sederiva de este comportamiento es la complejidad intrínseca de la estimaciónde parámetros asociados a altos grados de dependencia. Recordemos que alestar en el caso correcto, es decir simulación y estimación bajo la mismafamilia (i.e. Frank) los métodos estiman en general con mucha precisión.
92

C-C
θ=
2θ
=3
θ=
4θ
=5
θ=
6θ
=7
θ=
8θ
=15
θ∗2.03
11.80
82.00
62.03
4
3.05
32.66
33.00
23.05
7
4.00
23.46
73.97
54.00
6
5.07
84.40
64.99
45.08
8
6.10
95.31
15.98
96.11
9
7.13
26.20
86.94
77.15
3
8.11
47.05
67.93
48.13
7
15.460
13.506
14.759
15.535
sesgo
0.03
13-0.192
0.00
60.03
4
0.05
3-0.337
0.00
20.05
5
0.00
2-0.531
-0.025
0.00
6
0.07
8-0.594
-0.006
0.08
8
0.10
9-0.688
-0.010
0.11
9
0.13
2-0.791
-0.052
0.15
3
0.11
4-0.943
-0.065
0.13
7
0.46
0-1.493
-0.240
0.53
5DT
0.11
00.11
60.09
70.10
9
0.15
80.15
80.13
20.15
7
0.21
70.21
10.17
10.22
0
0.27
00.25
70.19
10.27
6
0.24
90.25
10.21
00.24
8
0.32
50.31
80.25
40.32
7
0.40
60.37
60.30
80.40
0
0.69
00.64
80.49
50.66
7
ECM
0.01
30.05
00.00
90.01
3
0.02
80.13
850.01
70.02
8
0.04
70.32
70.03
00.04
9
0.07
90.41
90.03
60.08
4
0.07
30.53
70.04
40.07
5
0.12
30.72
80.06
70.13
0
0.17
81.03
00.09
90.17
9
0.68
82.65
00.30
30.73
1
Cua
dro4.1:
Resultado
sdelestudiode
simulación
enel
caso
enqu
esimulam
osba
joClayton
yestimam
osba
joClayton
.Encada
celdase
presentanlosresultad
osen
elsigu
ienteorden:
OLS,O
LST,M
LE,L
1
93

F-F
θ=
2θ
=3
θ=
4θ
=5
θ=
6θ
=7
θ=
8θ
=15
θ ∗2.0392.0172.0172.037
3.0512.9123.0193.052
4.0383.7774.0094.037
5.0314.6354.9855.041
6.0275.4975.9826.034
7.0636.4006.9997.068
8.0617.2577.9988.069
15.19213.51414.96715.237
sesgo
0.0390.01720.01770.037
0.051-0.0870.0190.052
0.038-0.2220.0090.037
0.031-0.364-0.0140.041
0.0271-0.502-0.0170.034
0.063-0.599-0.0000.068
0.061-0.742-0.0010.069
0.192-1.485-0.0320.237
DT
0.1750.1890.1740.175
0.1860.2070.1790.191
0.1930.2120.1840.189
0.1880.2030.1780.187
0.2240.2380.2130.221
0.2560.2690.2350.263
0.2830.2860.2630.295
0.4020.3930.3770.426
ECM
0.0320.0360.0300.032
0.0370.0500.0320.039
0.0390.0940.0330.037
0.0360.1740.0320.036
0.0510.3090.0450.050
0.0690.4320.0550.073
0.0830.6310.0690.092
0.1992.3620.1430.238
Cuadro
4.2:Resultados
delestudiode
simulación
enelcaso
enque
simulam
osbajo
Frankyestim
amos
bajoFrank.
Encada
celdase
presentanlos
resultadosen
elsiguienteorden:O
LS,O
LST,M
LE,L
1
94

4.3.3. Caso Gumbel
En el Cuadro 4.3 puede observarse que a medida que θ aumenta, lasestimaciones θ
∗ dadas por los métodos OLS y L1 se alejan más del valor deθ, sobre todo cuando θ = 8 y θ = 15. En estos casos los métodos más eficacesson OLST y MLE, teniendo unas medidas de dispersión más bajas. Podríadecirse que en este caso el mejor método (o más preciso) ha sido el OLST,mientras que el peor, el L1, con un ECM muy alto respecto al resto. De formagenérica se observa que la estimación (por cualquier método) de valores altosde θ, indicativos de un fuerte grado de dependencia funcional, se correspondencon sesgos y desviaciones típicas de valor más alto que en los otros casos. Elmensaje que se deriva de este comportamiento es la complejidad intrínsecade la estimación de parámetros asociados a altos grados de dependencia.Es decir, bajo independencia los métodos estiman con asombrosa exactitudpero si las variables tienden a tener dependencia funcional muy fuerte (altosvalores de θ), los métodos son menos eficaces.
4.4. Incorrecta especificación del modelo: Las
familias de simulación y estimación no co-
inciden
4.4.1. Simulación mediante la cópula Clayton y esti-
mación mediante la cópula Frank
En el Cuadro 4.4 se observa como a medida que aumenta el valor de θ, laestimación θ
∗ tiende a alejarse más del valor teórico, con las consecuenciasque ello conlleva, aumentando considerablemente el sesgo y el ECM. Eviden-temente este resultado era de esperar, puesto que estamos estimando con unaFrank y los datos han sido simulados por una Clayton, i.e. estamos anteun problema de incorrecta especificación del modelo. Esto nos da aentender que las cópulas Clayton y Frank tienen un comportamiento distintocuando se pretenda modelizar mediante ellas, asumiendo que las variables
95
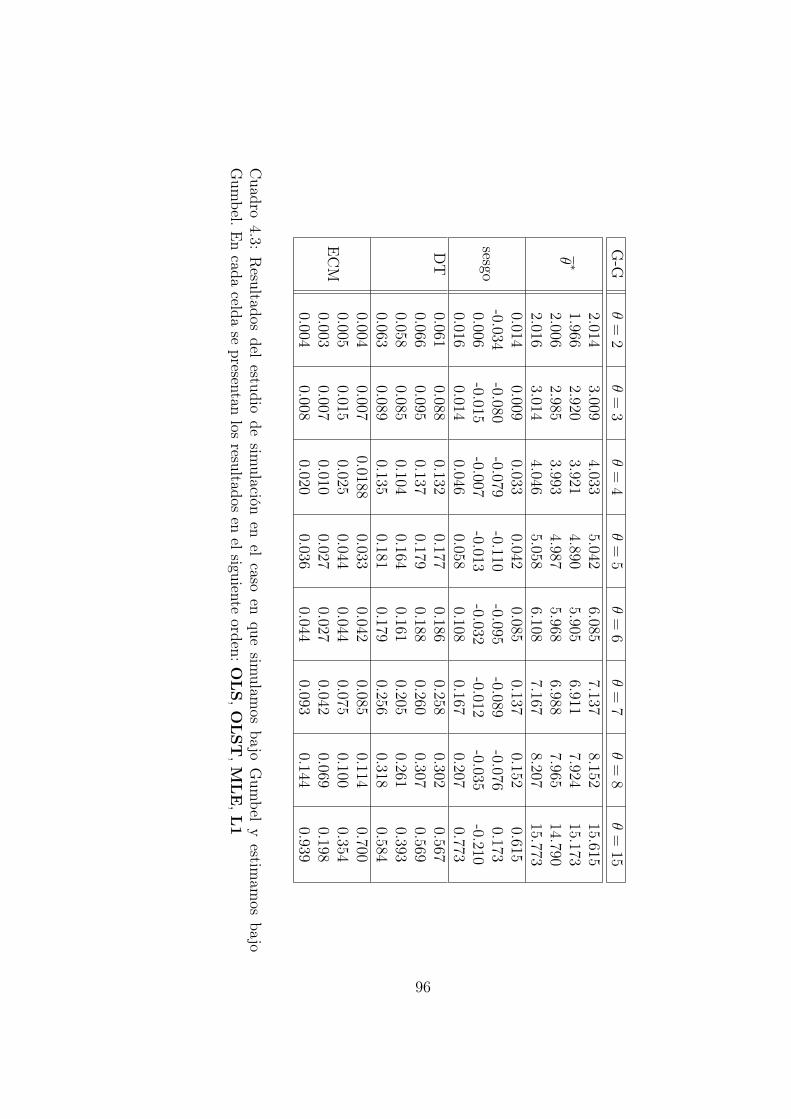
G-G
θ=
2θ
=3
θ=
4θ
=5
θ=
6θ
=7
θ=
8θ
=15
θ ∗2.0141.9662.0062.016
3.0092.9202.9853.014
4.0333.9213.9934.046
5.0424.8904.9875.058
6.0855.9055.9686.108
7.1376.9116.9887.167
8.1527.9247.9658.207
15.61515.17314.79015.773
sesgo
0.014-0.0340.0060.016
0.009-0.080-0.0150.014
0.033-0.079-0.0070.046
0.042-0.110-0.0130.058
0.085-0.095-0.0320.108
0.137-0.089-0.0120.167
0.152-0.076-0.0350.207
0.6150.173-0.2100.773
DT
0.0610.0660.0580.063
0.0880.0950.0850.089
0.1320.1370.1040.135
0.1770.1790.1640.181
0.1860.1880.1610.179
0.2580.2600.2050.256
0.3020.3070.2610.318
0.5670.5690.3930.584
ECM
0.0040.0050.0030.004
0.0070.0150.0070.008
0.01880.0250.0100.020
0.0330.0440.0270.036
0.0420.0440.0270.044
0.0850.0750.0420.093
0.1140.1000.0690.144
0.7000.3540.1980.939
Cuadro
4.3:Resultados
delestudio
desim
ulaciónen
elcaso
enque
simulam
osbajo
Gum
belyestim
amos
bajoGum
bel.Encada
celdase
presentanlos
resultadosen
elsiguienteorden:O
LS,O
LST,M
LE,L
1
96

tienden a tener dependencia funcional y por tanto θ toma valores grandes.También es importante recalcar que la DT es pequeña, por lo que las 100estimaciones θ∗ de θ deben ser todas muy parecidas entre sí, indicativo deque los métodos no producen oscilaciones y, aunque estiman mal, siempre lohacen de la misma forma obteniendo por tanto valores muy parecidos.
4.4.2. Simulación mediante la cópula Clayton y esti-
mación mediante la cópula Gumbel
En el Cuadro 4.5 se observa como a medida que aumenta el valor de θ,(i.e. las variables tienden a tener dependencia funcional), la estimación θ
∗
tiende a alejarse más, siendo dicha distancia máxima cuando se estima medi-ante MLE (i.e., el sesgo alcanza su máximo en valor absoluto). En cambio, siobservamos los métodos OLS, OLST y L1, vemos que tienden a estimar θ conuna cierta exactitud, por lo que este hecho es indicativo de que datos sim-ulados mediante una Clayton de parámetro θ, pueden ser descritosmediante una cópula Gumbel de parámetro θ, sin estar cometiendo unerror considerable. Asumiendo pues cierto grado de dependencia funcionalentre las variables, Gumbel describe bien variables generadas por una Clay-ton. Volvemos a recalcar que la DT de las estimaciones es pequeña, por loque las 100 θ∗ de θ deben ser todas muy parecidas entre sí, por lo que losmétodos vuelven a no producir oscilaciones y, aunque no estiman del todocorrectamente, siempre lo hacen de la misma forma obteniendo por lo tantovalores muy parecidos. Este es un claro caso en el que MLE no funciona cor-rectamente y una buena alternativa podría ser el OLST, método propuestoen esta memoria.
4.4.3. Simulación mediante la cópula Frank y estimación
mediante la cópula Clayton
En el Cuadro 4.6 puede apreciarse que si estimamos θ utilizando unaClayton con los métodos OLS, OLST y L1 para datos simulados a partirde una Frank con parámetro poblacional θ = 2 y θ = 3, hecho asociado a
97

C-F
θ=
2θ
=3
θ=
4θ
=5
θ=
6θ
=7
θ=
8θ
=15
θ ∗5.6256.2445.7125.260
7.9558.8727.8217.438
10.14811.2559.69599.543
12.63013.92711.77112.109
15.05616.40513.72114.613
17.43018.69115.65917.148
19.82720.87417.50620.185
29.99929.87229.87129.999
sesgo
3.6254.2443.7123.260
4.9555.8724.8214.438
6.1487.2555.6955.543
7.6308.9276.7717.109
9.05610.4057.7218.613
10.43011.6918.65910.148
11.82712.8749.50612.185
14.00114.87214.87114.001
DT
0.2520.2990.2280.292
0.3370.4430.3150.400
0.4520.5830.4010.652
0.5350.6640.4850.933
0.5320.7770.4460.983
0.6701.0970.5811.450
0.8481.2470.7202.162
0.0030.4330.3450.008
ECM
13.20618.10713.83610.718
24.6734.67723.34719.865
38.01452.98332.60431.161
58.50780.14546.08651.419
82.298108.87759.81875.162
109.254137.88375.326105.100
140.615167.30590.895153.153
22.498221.376221.27224.871
Cuadro
4.4:Resultados
delestudiode
simulación
enelcaso
enque
simulam
osbajo
Clayton
yestim
amos
bajoFrank.
Encada
celdase
presentanlos
resultadosen
elsiguienteorden:O
LS,O
LST,M
LE,L
1
98

C-G
θ=
2θ
=3
θ=
4θ
=5
θ=
6θ
=7
θ=
8θ
=15
θ∗2.09
72.06
51.73
02.17
6
2.78
82.74
02.03
03.07
2
3.49
53.44
52.28
84.07
1
4.32
14.27
02.56
55.25
6
5.14
25.09
52.81
56.39
0
5.94
55.89
53.06
27.51
7
6.77
66.70
93.28
08.69
4
12.797
12.760
4.81
616
.756
sesgo
0.09
70.06
5-0.270
0.17
6
-0.212
-0.260
-0.970
0.07
2
-0.505
-0.555
-1.712
0.07
1
-0.679
-0.730
-2.435
0.25
6
-0.858
-0.905
-3.185
0.39
0
-1.055
-1.105
-3.938
0.51
7
-1.224
-1.291
-4.720
0.69
4
-2.203
-2.240
-10.18
41.75
6DT
0.06
90.07
90.03
40.11
2
0.10
30.11
80.05
40.17
9
0.14
80.17
00.06
00.32
8
0.18
10.20
20.07
30.42
6
0.18
90.21
80.07
90.55
9
0.23
80.27
60.09
30.62
4
0.31
00.35
60.10
80.84
8
0.55
20.65
60.19
41.76
8
ECM
0.01
40.01
00.07
40.04
3
0.05
50.08
10.94
20.03
7
0.27
60.33
72.93
30.11
3
0.49
30.57
45.93
20.24
7
0.77
10.86
610
.150
0.46
5
1.16
81.29
815
.515
0.65
6
1.59
31.79
122
.292
1.20
1
5.15
85.44
510
3.74
6.21
2
Cua
dro4.5:
Resultado
sdelestudiode
simulación
enel
caso
enqu
esimulam
osba
joClayton
yestimam
osba
joGum
bel.Encada
celdase
presentanlosresultad
osen
elsigu
ienteorden:
OLS,O
LST,M
LE,L
1
99

una dependencia funcional muy débil, obtenemos valores muy altos para θ∗,(salvo al estimar mediante MLE), lo que indica que la estimación bajo Clay-ton ha interpretado una fuerte dependencia funcional de las variables. Porotra parte, al aumentar el valor de θ los métodos no estiman correctamente,alcanzando valores muy altos del ECM cuando θ = 15. Así pues, estimar me-diante Clayton datos provinientes de una cópula Frank no es una buena idea.Volvemos a recalcar que la DT de las 100 estimaciones es pequeña cuando θ
toma valores altos, por lo que las 100 θ∗ de θ deben ser todas muy parecidasentre sí, por lo que los métodos no producen oscilaciones y, aunque no esti-man del todo correctamente, siempre lo hacen de la misma forma obteniendopor lo tanto valores muy parecidos.
4.4.4. Simulación mediante la cópula Frank y estimación
mediante la cópula Gumbel
En el Cuadro 4.7 se observa que las estimaciones θ∗ de θ utilizando una
Gumbel con datos simulados mediante una Frank, no son en absoluto buenas,sobre todo cuando las variables tienden a estar relacionadas funcionalmente(i.e. θ aumenta). Los cuatro métodos tienden a detectar independencia cuan-do las variables tienen cierto grado de dependencia funcional en términosde una cópula Frank. Se concluye que estimar el parámetro de dependenciamediante una Gumbel de unos datos simulados bajo una Frank, no aportaningún resultado válido. Mientras la familia Frank tiende a detectar depen-dencia bajo simulación, la Gumbel tiende a dar información incorrecta acercade esos datos, es decir, estima independencia.
4.4.5. Simulación mediante la cópula Gumbel y esti-
mación mediante la cópula Clayton
En el Cuadro 4.8 se observa que las estimaciones θ∗ de θ utilizando una
Clayton con datos simulados mediante una Gumbel no son en absoluto bue-nas, sobre todo cuando las variables tienden a estar relacionadas funcional-mente (i.e. θ aumenta). Tres de los cuatro métodos (OLS, OLST y L1) tien-
100

F-C
θ=
2θ
=3
θ=
4θ
=5
θ=
6θ
=7
θ=
8θ
=15
θ∗30 30 1 30
27.682
30 121
.025
1.31
32.00
81
1.40
5
1.79
11.57
01.00
21.97
3
2.32
72.06
51.13
32.59
8
2.93
32.63
41.33
83.30
6
3.55
93.21
11.53
13.99
8
8.47
47.92
22.83
49.39
4
sesgo
28 28 -1 28
24.682
27 -218
.025
-2.687
-1.992
-3-2.594
-3.209
-3.430
-3.998
-3.027
-3.673
-3.935
-4.867
-3.402
-4.067
-4.366
-5.662
-3.694
-4.441
-4.789
-6.469
-4.002
-6.526
-7.078
-12.16
6-5.606
DT
0.00
010.00
010.00
010.00
01
7.89
70.00
020.00
0113
.456
0.08
74.94
70
0.11
7
0.09
60.09
10.01
00.16
3
0.12
90.12
40.05
50.22
6
0.16
00.15
50.06
10.26
2
0.19
60.18
20.06
70.32
4
0.33
80.33
90.13
30.66
7
ECM
784
784 1 784
671.61
272
9 450
6.00
1
7.22
728
.447 9
6.74
2
10.309
11.771
15.979
9.19
4
13.503
15.492
23.693
11.624
16.558
19.083
32.057
13.708
19.753
22.960
41.841
16.121
42.694
50.215
148.04
431
.879
Cua
dro4.6:
Resultado
sdele
stud
iode
simulaciónen
elcaso
enqu
esimulam
osba
joFran
kyestimam
osba
joClayton
.Encada
celdase
presentanlosresultad
osen
elsigu
ienteorden:
OLS,O
LST,M
LE,L
1
101

F-G
θ=
2θ
=3
θ=
4θ
=5
θ=
6θ
=7
θ=
8θ
=15
θ ∗1.2871.2391.2161.297
1.4751.4181.3551.496
1.6811.6201.5011.720
1.9111.8481.6501.960
2.1582.0891.8102.221
2.4302.3581.9672.512
2.7002.6222.1292.792
4.7724.6633.2004.983
sesgo
-0.713-0.761-0.784-0.702
-1.525-1.582-1.645-1.504
-2.319-2.380-2.499-2.280
-3.089-3.152-3.350-3.040
-3.842-3.911-4.190-3.779
-4.570-4.642-5.032-4.488
-5.300-5.378-5.871-5.208
-10.228-10.337-11.800-10.017
DT
0.0290.0290.0240.033
0.0360.0350.0260.041
0.0420.0390.0270.050
0.0450.0430.0300.051
0.0570.0540.0360.068
0.0690.0660.0370.077
0.0780.0750.0470.091
0.1390.1340.0720.193
ECM
0.5080.5790.6140.494
2.3292.5022.7052.261
5.3745.6636.2425.197
9.5429.93311.2179.245
14.76115.29417.55114.285
20.88721.54925.33220.143
28.08728.92034.46127.132
104.624106.861139.233100.371
Cuadro
4.7:Resultados
delestudiode
simulación
enelcaso
enque
simulam
osbajo
Frankyestim
amos
bajoGum
bel.Encada
celdase
presentanlos
resultadosen
elsiguienteorden:O
LS,O
LST,M
LE,L
1
102

den a detectar una dependencia muy fuerte cuando las variables tienen ciertogrado de dependencia funcional en términos de una cópula Gumbel. Se con-cluye que estimar el parámetro de dependencia mediante una Clayton deunos datos simulados bajo una Gumbel, no aporta ningún resultado válido.Mientras la familia Gumbel tiende a detectar cierto grado de dependenciabajo simulación, la Clayton tiende a dar información incorrecta acerca deesos datos, es decir, estima dependencia muy fuerte.
4.4.6. Simulación mediante la cópula Gumbel y esti-
mación mediante la cópula Frank
En el Cuadro 4.9 se observa que las estimaciones θ∗ de θ utilizando una
Frank con datos simulados mediante una Gumbel no son en absoluto buenas,sobre todo cuando las variables tienden a estar relacionadas funcionalmente(i.e. θ aumenta). Los cuatro métodos tienden a detectar una dependenciamuy fuerte cuando las variables tienen cierto grado de dependencia funcionalen términos de una cópula Gumbel. Se concluye que estimar el parámetro dedependencia mediante una Frank de unos datos simulados bajo una Gum-bel, no aporta ningún resultado válido. Mientras la familia Gumbel tiendea detectar cierto grado de dependencia bajo simulación, la Frank tiende adar información incorrecta acerca de esos datos, es decir, estima dependenciamuy fuerte.
4.5. Aplicaciones. Estimación y elección del mod-
elo de Cópula sobre datos reales
Supongamos que partimos de una serie de pares de datos, que eviden-temente desconocemos de ellos la relación funcional o grado de dependenciaque puedan tener. Ya hemos explicado anteriormente que las cópulas puedenmedir dicho grado de dependencia así como crear una estructura que mode-lice el comportamiento de ambas variables. De manera natural, las preguntasque le puedan surgir al investigador que trate con ciertas variables irán rela-
103

G-C
θ=
2θ
=3
θ=
4θ
=5
θ=
6θ
=7
θ=
8θ
=15
θ ∗2.0291.8831.0641.969
4.8604.9111.9765.005
8.5339.4092.8859.572
12.59214.7463.80514.952
16.93320.7164.71420.457
21.73127.3795.66625.613
26.71829.8956.54028.937
303013.06030
sesgo
0.029-0.117-0.936-0.030
1.8601.911-1.0242.005
4.5335.409-1.1155.572
7.5929.746-1.1959.952
10.93314.716-1.28614.457
14.73120.379-1.33418.613
18.71821.895-1.46020.937
1515-1.94015
DT
0.1540.1720.0500.211
0.3140.4150.1090.552
0.6220.9250.1341.684
0.9091.5600.2022.913
0.9501.9000.2264.139
1.4432.3940.2583.501
1.6270.5150.3311.864
0.00010.00010.5280.0001
ECM
0.0240.0430.8770.045
3.5583.8261.0584.327
20.93930.1141.26033.883
58.46897.4191.470
107.544
120.439220.2001.702
226.151
219.091421.0671.843358.71
353.050479.6942.242
441.850
2252254.045225
Cuadro
4.8:Resultados
delestudio
desim
ulaciónen
elcaso
enque
simulam
osbajo
Gum
belyestim
amos
bajoClayton.E
ncada
celdase
presentanlos
resultadosen
elsiguienteorden:O
LS,O
LST,M
LE,L
1
104

G-F
θ=
2θ
=3
θ=
4θ
=5
θ=
6θ
=7
θ=
8θ
=15
θ∗5.49
06.04
65.75
55.24
4
9.57
810
.999
9.83
29.02
9
13.776
16.307
13.791
13.027
17.989
21.720
17.633
16.954
22.392
27.399
21.540
20.887
26.995
29.982
25.482
25.397
29.924
29.999
29.127
29.088
29.999
29.999
29.999
29.999
sesgo
3.49
04.04
63.75
53.24
4
6.57
87.99
96.83
26.02
9
9.77
612
.307
9.79
19.02
7
12.989
16.720
12.633
11.954
16.392
21.399
15.540
14.887
19.995
22.982
18.482
18.397
21.924
21.999
21.127
21.088
14.999
14.999
14.999
14.999
DT
0.26
70.31
60.25
80.26
0
0.35
20.46
60.33
00.37
7
0.53
50.65
60.48
50.64
0
0.70
90.96
70.64
31.01
6
0.70
91.08
40.66
01.04
1
1.01
30.11
10.87
81.55
8
0.28
50
0.88
11.14
1
0 0 0 0
ECM
12.253
16.472
14.168
10.592
43.394
64.206
46.790
36.499
95.871
151.91
596
.114
81.911
169.21
828
0.51
616
0.01
914
3.95
2
269.23
459.10
524
1.94
522
2.72
400.82
952
8.20
734
2.38
234
0.91
4
480.75
148
3.92
344
7.13
744
6.03
7
224.94
722
4.94
822
4.94
422
4.94
4
Cua
dro4.9:
Resultado
sdele
stud
iode
simulaciónen
elcaso
enqu
esimulam
osba
joGum
bely
estimam
osba
joFran
k.Encada
celdase
presentanlosresultad
osen
elsigu
ienteorden:
OLS,O
LST,M
LE,L
1
105

cionadas con estos conceptos, por lo se hace necesario el poder estudiar comoestimar el grado de dependencia de una serie de pares de datos reales, el cualviene dado por el parámetro poblacional θ de la cópula, así como determi-nar la estructura de dependencia que las relaciona, la cual, obviamente es lapropia cópula. Para llevar a cabo todo este procedimiento ya se mencionaronunos posibles pasos a seguir. Recordemos, eran los siguientes:
En primer lugar, dada una serie de pares de datos, se estima el parámetropoblacional θ mediante el valor de θ∗ usando varias familias de cópulascandidatas, procediendo tal y como se ha explicado en la Sección 4.2,evidentemente omitiendo la fase de simulación.
Seguidamente, realizamos la elección de la familia que mejor descri-ba la relación entre las variables. Esta elección dependerá del métodoque hayamos escogido para estimar θ. En esta sección se va a utilizarexclusivamente el método MLE de estimación, por lo que la familia can-didata a representar la estructura de dependencia de las variables seescogerá de tal forma que su función de verosimilitud asociada2 alcanceun valor máximo respecto a las demás candidatas, dada la muestra yla estimación de θ obtenida, θ
∗.
Para llevar a la práctica estos puntos, partiremos de tres colecciones diferentesde pares de datos, las cuáles serán llamadas como BANCO DE DATOS 1,BANCO DE DATOS 2, BANCO DE DATOS 3 y trataremos de ajustarlasa alguna de las tres familias de cópulas, lo que significaría que los datosse podrían describir bajo el modelo seleccionado. Consideraremos a dichascolecciones como datos reales, es decir, asumiremos que no conocemos nadaacerca de ellos, simplemente están extraídos de cierta población desconocida.Una representación gráfica de (X,Y ) para los BANCOS DE DATOS 1,2 Y 3se muestra en las Figuras 4.1, 4.5 y 4.9. Si logramos ajustar correctamente unbanco de datos real, habríamos identificado el comportamiento de una seriede datos reales, con lo cual podriamos extraer las pertinentes conclusionesacerca de nuestro estudio.
2Véase Capítulo 2
106

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
datos.xy.caso.1[,1]
dato
s.xy
.cas
o.1[
,2]
Figura 4.1: BANCO DE DATOS 1. Representación de 500 pares de datos.
Si estimamos θ para los datos BANCO DE DATOS 1 mediante los cuatrométodos anteriormente descritos, obtenemos los siguientes resultados (verCuadro 4.10)
Una vez tengamos las estimaciones de θ mediante las tres familias usandoMLE, una método visual muy sugerente para poder determinar la que mejorse ajuste a cada una de las tres series de datos reales, consiste en superponernuestros datos a los datos teóricos que se obtendrían simulando con dichasfamilias a partir de los parámetros obtenidos en la estimación. En las Figuras
BANCO DE DATOS 1 OLS OLST ML L1Clayton 9.565 11.589 8.911 9.999Frank 23.173 27.823 19.395 18.843Gumbel 7.685 9.460 3.605 7.458
Cuadro 4.10: Resultados obtenidos de las estimaciones de Theta, θ∗, parael BANCO DE DATOS 1, usando las tres familias y los cuatro métodos deestimación propuestos.
107

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA1 VS CLAYTON THETA=9,56
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA1 VS CLAYTON THETA=11,58
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA1 VS CLAYTON THETA=8,91
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA1 VS CLAYTON THETA=9,99
Figura 4.2: Superposición del BANCO DE DATOS 1 (DATA 1), color rojo,y una simulación de pares de datos procedente de una Clayton, color verde,para un θ dado.
4.2, 4.3, 4.4, 4.6, 4.7 y 4.8 se visualiza dicho proceso.
En la Figura 4.2 puede apreciarse como los datos generados por unaClayton cuyo parámetro oscila alrededor de 9, se solapan de una manerabastante exacta alrededor de los datos reales.
Si comparamos las Figuras 4.2 y 4.4 se observa que los valores de losparámetros estimados en cada caso son bastante parecidos dentro de un ran-go, el cual podría estar comprendido entre los valores 7.5 y 11.5, salvo dis-torsiones como la de la parte inferior izquierda de la Figura 4.4, lo que indicaque las cópulas Clayton y Gumbel tienden a estimar valores parecidos de θ
para una misma serie de datos reales. Este hecho también puede ser aprecia-do en la sección anterior, concretamente en la 4.4.2. cuando simulabamos conuna Clayton y estimabamos θ con una Gumbel, llegando a obtener valoresde estimación muy parecidos entre sí cuando se utilizaba el método L1. En
108

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA1 VS FRANK THETA=23,17
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA1 VS FRANK THETA=27,82
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA1 VS FRANK THETA=19,39
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA1 VS FRANK THETA=18,84
Figura 4.3: Superposición del BANCO DE DATOS 1 (DATA 1), color rojo,y una simulación de pares de datos procedente de una Frank, color verde,para cada θ dado.
109

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA1 VS GUMBEL THETA=7.68
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA1 VS GUMBEL THETA=9,46
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA1 VS GUMBEL THETA=3,60
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA1 VS GUMBEL THETA=7,45
Figura 4.4: Superposición del BANCO DE DATOS 1 (DATA 1), color rojo,y una simulación de pares de datos procedente de una Gumbel, color verde,para cada θ dado.
110
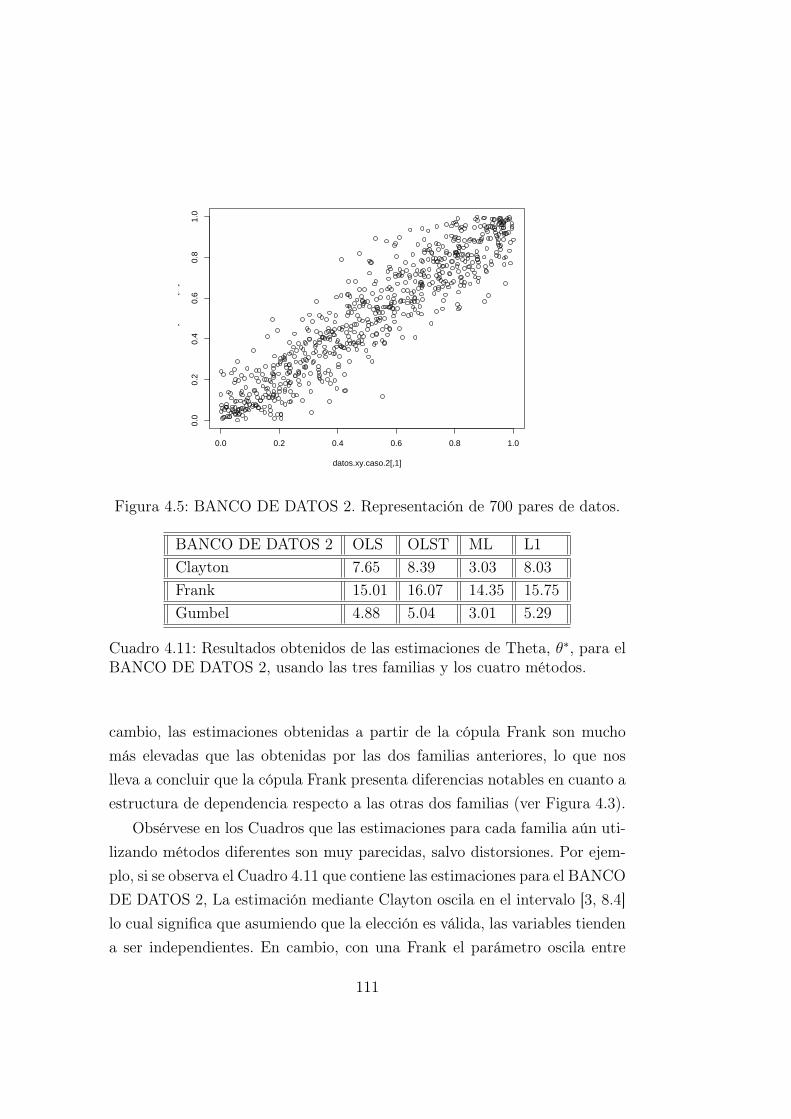
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
datos.xy.caso.2[,1]
dato
s.xy
.cas
o.2[
,2]
Figura 4.5: BANCO DE DATOS 2. Representación de 700 pares de datos.
BANCO DE DATOS 2 OLS OLST ML L1Clayton 7.65 8.39 3.03 8.03Frank 15.01 16.07 14.35 15.75Gumbel 4.88 5.04 3.01 5.29
Cuadro 4.11: Resultados obtenidos de las estimaciones de Theta, θ∗, para elBANCO DE DATOS 2, usando las tres familias y los cuatro métodos.
cambio, las estimaciones obtenidas a partir de la cópula Frank son muchomás elevadas que las obtenidas por las dos familias anteriores, lo que noslleva a concluir que la cópula Frank presenta diferencias notables en cuanto aestructura de dependencia respecto a las otras dos familias (ver Figura 4.3).
Obsérvese en los Cuadros que las estimaciones para cada familia aún uti-lizando métodos diferentes son muy parecidas, salvo distorsiones. Por ejem-plo, si se observa el Cuadro 4.11 que contiene las estimaciones para el BANCODE DATOS 2, La estimación mediante Clayton oscila en el intervalo [3, 8.4]lo cual significa que asumiendo que la elección es válida, las variables tiendena ser independientes. En cambio, con una Frank el parámetro oscila entre
111

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA2 VS CLAYTON THETA=7.65
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA2 VS CLAYTON THETA=8,39
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA2 VS CLAYTON THETA=3,03
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA2 VS CLAYTON THETA=8,03
Figura 4.6: Superposición del BANCO DE DATOS 2 (DATA 2), color rojo,y una simulación de pares de datos procedente de una Clayton, color verde,para cada θ dado.
[14, 16.1], por lo que dicha familia ha detectado mayor dependencia entrelas variables. Por último el parámetro estimado con la Gumbel oscila en elintervalo [3, 5.5], sinónimo de independencia entre las variables.
En la Figura 4.7 se aprecia claramente como los datos generados por unaFrank cuyo parámetro oscila alrededor de 15 se solapan sobre la nube dedatos reales con más exactitud que los otros modelos (ver comparativamentelas Figuras 4.6 y 4.8). Los resultados de la estimación para el BANCO DEDATOS 3 se muestran en el Cuadro 4.12. Si la familia fuera Frank los datosexhiben una fuerte estructura de dependencia. Sin embargo, si utilizasemoslas familias Clayton o Gumbel, la estructura de dependencia sería débil.
La Figura 4.11 muestra como los datos generados por una Frank deparámetro alrededor 5 se ajustan más exactamente que los otros modelossobre la nube de los datos reales.
112

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA2 VS FRANK THETA=15,01
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA2 VS FRANK THETA=16.07
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA2 VS FRANK THETA=14.35
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA2 VS FRANK THETA=15.75
Figura 4.7: Superposición del BANCO DE DATOS 2 (DATA 2), color rojo,y una simulación de pares de datos procedente de una Frank, color verde,para cada θ dado.
BANCO DE DATOS 3 OLS OLST ML L1Clayton 2.152 1.995 1.115 2.513Frank 5.726 6.207 5.709 5.774Gumbel 2.085 2.006 1.770 2.147
Cuadro 4.12: Resultados obtenidos de las estimaciones de Theta, θ∗, para elBANCO DE DATOS 3, usando las tres familias y los cuatro métodos.
113

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA2 VS GUMBEL THETA=4.88
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA2 VS GUMBEL THETA=5.04
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA2 VS GUMBEL THETA=3.01
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA2 VS GUMBEL THETA=5.29
Figura 4.8: Superposición del BANCO DE DATOS 2 (DATA 2), color rojo,y una simulación de pares de datos procedente de una Gumbel, color verde,para cada θ dado.
114

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
datos.xy.caso.3[,1]
dato
s.xy
.cas
o.3[
,2]
Figura 4.9: BANCO DE DATOS 3. Representación de 700 pares de datos.
Una vez tengamos cierta idea intuitiva a partir de la visualización delas nubes de pares de datos superpuestos de cual pueda ser la familia quemejor se ajuste, ésta debe corroborarse mediante una técnica de inferen-cia estadística que nos de cierta probabilidad alta de confianza de estarescogiendo la familia correcta. Para simplificar nuestro estudio, únicamenteconsideraremos las estimaciones dadas por el método de Máxima Verosimili-tud [25], que en esta memoria se corresponde con MLE. Para realizar laelección de la familia tan solo deberemos escoger aquella asociada a un valorde función de verosimilitud máximo, ya que dicho método consiste precisa-mente en eso, en maximizar la función de verosimilitud respecto θ, dada unaserie de datos reales. Recordemos que la función de verosimilitud descrita porGenest versión semiparamétrica por rangos3 para cierta función de densidad(i.e. densidad de cópula) viene dada por la expresión:
l(θ) =n∑
i=1
ln(cθ(Ri
n + 1,
Si
n + 1))
3Véase Capítulo 2, Sección 2.3.2
115

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA3 VS CLAYTON THETA=2.15
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA3 VS CLAYTON THETA=1.99
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA3 VS CLAYTON THETA=1.15
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA3 VS CLAYTON THETA=2.51
Figura 4.10: Superposición del BANCO DE DATOS 3 (DATA 3), color rojo,y una simulación de pares de datos procedente de una Clayton, color verde,para cada θ dado.
116

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA3 VS FRANK THETA=5.72
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA3 VS FRANK THETA=6.20
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA3 VS FRANK THETA=5.70
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA3 VS FRANK THETA=5.77
Figura 4.11: Superposición del BANCO DE DATOS 3 (DATA 3), color rojo,y una simulación de pares de datos procedente de una Frank, color verde,para cada θ dado.
117

0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA3 VS GUMBEL THETA=2,08
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA3 VS GUMBEL THETA=2,00
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA3 VS GUMBEL THETA=1,77
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
u
v
DATA3 VS GUMBEL THETA=2,14
Figura 4.12: Superposición del BANCO DE DATOS 3 (DATA 3), color rojo,y una simulación de pares de datos procedente de una Gumbel, color verde,para cada θ dado.
118

BANCO DE DATOS 1 θ∗ l(θ∗)Clayton 8.91 869.66Frank 19.39 762.88Gumbel 3.60 459.66
Cuadro 4.13: Estimaciones de θ dadas por θ∗ mediante MLE para las 3familias, así como el valor de la función de verosimilitud, dado el BANCODE DATOS 1 y θ∗
BANCO DE DATOS 2 θ∗ l(θ∗)Clayton 3.03 410.75Frank 14.35 626.55Gumbel 3.01 105.38
Cuadro 4.14: Estimaciones de θ dadas por θ∗ mediante MLE para las 3familias, así como el valor de la función de verosimilitud, dado el BANCODE DATOS 2 y θ∗
donde, cθ(u, v) = ∂2C(u,v)∂u∂v
y Ri, Si 1 ≤ i ≤ n representan los rangos de losdatos reales.Así pues, escogeremos el valor máximo de l(θ), i.e.
arg maxθεΘ
l(θ) = arg maxθεΘ
n∑i=1
ln(cθ(Ri
n + 1,
Si
n + 1))
.
En el Cuadro 4.13 se reflejan las estimaciones obtenidas para el BANCODE DATOS 1 mediante el método MLE, así como el valor de la función deverosimilitud, dado θ∗ y el BANCO DE DATOS 1 .
Obsérvese que el valor máximo de l(θ) se corresponde con la familia cuyanube de puntos se solapa de forma más precisa con la nube de los datos reales.Esta familia es la Clayton (ver Figura 4.2). Así pues, podríamos asegurar quelas variables que generan el BANCO DE DATOS 1, pueden ser modelizadaspor una Clayton de parámetro θ = 8.91.
119

BANCO DE DATOS 3 θ∗ l(θ∗)Clayton 1.15 141.17Frank 5.70 210.87Gumbel 1.77 183.20
Cuadro 4.15: Estimaciones de θ dadas por θ∗ mediante MLE para las 3familias, así como el valor de la función de verosimilitud, dado el BANCODE DATOS 3 y θ∗
Los resultados obtenidos en el Cuadro 4.14 nos dan evidencia de queel BANCO DE DATOS 2 está generado por una familia de cópulas Frankcuyo parámetro poblacional oscila alrededor de 15. Dicha conclusión debeser reforzada mediante el método gráfico, que puede ser extraída observandolas Figuras 4.6 4.7 y 4.8. Si se observan detenidamente las tres, la Figura4.7 es la que presenta una mayor exactitud en la solapación de las nubes,cuya información concluyente armoniza con el valor máximo alcanzado porla función de verosimilitud l(θ) al tomar θ como θ∗. Asumimos una cópulaFrank con θ = 14.35 como familia generadora del BANCO DE DATOS 2.
Si se observan los resultados obtenidos en el Cuadro 4.15, se concluyeque para el BANCO DE DATOS 3 también escogeríamos una cópula Frankcomo estructura de dependencia de las variables que lo generan, aunque eneste caso el parámetro poblacional oscila alrededor de 6. Este hecho explica lamayor dispersión que sufre la nube de puntos respecto a los otros dos casos.Aceptaríamos entonces que el BANCO DE DATOS 3 está generado por unaFrank cuyo parámetro poblacional puede ser θ = 5.7.
Como en los anteriores casos, si observamos las nubes de puntos asociadasal BANCO DE DATOS 3, que están representadas en las Figuras 4.10, 4.11 y4.12, reforzaríamos la decisión de escoger la familia como Clayton con θ = 5.7observando que la Figura 4.11 es la que presenta un solapamiento más exactoentre los datos reales (BANCO DE DATOS 3) y los artificiales (familia Frankcon θ = 5).
120

Capıtulo 5Conclusiones y futuras líneas abiertasde investigación
En esta memoria únicamente hemos hecho uso práctico de tres familias decópulas Arquimedianas: Clayton, Frank y Gumbel-Hougaard, considerandoen todas ellas el caso bivariante, pero existe un amplio abanico de familiasmultivariantes tales como las cópulas paramétricas de Valor Extremo [53](algunas cópulas de esta clase son: Galambos, Husler-Reiss, Marshall-Olkin,etc) que modelizan problemas de Finanzas y Economía (medidas de ries-go financiero usando cópulas), y otras muchas familias que lo hacen paraun amplio espectro de campos de la ciencia tales como Bioestadística (con-trol y prevención de epidemias), Psicoestadística (búsqueda de tratamientosadecuados para trastornos del comportamiento), Estadística Medioambiental(cuantificación de riesgo de inundaciones simultáneas en una región1, medidade cantidad contaminantes en un medio, prevención de incendios forestales),Geoestadística (búsqueda de acuíferos, prevención de terremotos)...Ya hemos comentado que una cópula puede representar la estructura dedependencia de dos variables aleatorias, por lo que haciendo uso de ellaspodríamos obtener un modelo que describa el comportamiento conjunto deambas. Para llegar a tal fin, los pasos que deben seguirse se han descrito enel Capítulo 3, Sección 3.1. Tenemos por lo tanto un proceso que nos per-
1Jhan Rodríguez, Departamento de Cómputo Científico y Estadística, USB.
121

mite escoger una cópula óptima de entre varias familias candidatas, perono tenemos un proceso para construír familias que puedan optar aser escogidas, dado nuestro problema concreto en cierto campo de investi-gación. Así pues, tendríamos aquí una posible línea abierta de investigación:como construír familias de cópulas candidatas a ser escogidas paramodelizar cierta estructura de dependencia, dada una colección devariables aleatorias. Nótese que extendemos el problema al caso multivari-ante, ya que en situaciones de investigación real, el caso bivariante puede noser suficiente para abordar nuestro problema.La complejidad intrínseca de un problema de estimación del parámetro pobla-cional de una cópula nos lleva a considerar las siguientes líneas abiertas deinvestigación:
Dado un problema de estimación, que método de entre los existentespuede ser el óptimo para llevar a cabo tal fin.
Como determinar un método de estimación basado en cópulas.
Como definir un método de elección de la cópula óptima, de entrevarias familias de cópulas candidatas.
En el Capítulo 3, concretamente en la sección 3.1 se gesta nuestra propuestade método para la elección de la cópula óptima:
Dado un banco real de pares de datos,
x1 x2 ... xn
y1 y2 ... yn
pretendemos asociarlos con la densidad de cierta cópula
∂2C(u, v)
∂u∂v= c(u, v),
122

es decir, buscamos la densidad de cópula de la cual puedan haber sido extraí-dos. La idea que aquí se propone consiste en determinar que área de la regiónde densidad2 se ajusta mejor al área delimitada por nuestra nube de puntos,dadas varias familias candidatas, una vez tengamos estimada una colecciónde parámetros poblacionales para cada una de ellas. En resumen, si tenemos
familia 1 c1θ11(u, v) c1θ12(u, v) ... c1θ1k(u, v)
familia 2 c2θ21(u, v) c2θ22(u, v) ... c2θ2k(u, v)
... ... ... ... ...
familia r c1θr1(u, v) c1θr2(u, v) ... c1θrk(u, v)
cuyas regiones de densidad asociada son:
familia 1 D11 D12 ... D1k
familia 2 D21 D22 ... D2k
... ... ... ... ...
familia r Dr1 Dr2 ... Drk
nuestra propuesta consiste en intentar construír un estadístico para la elec-ción de la densidad de cópula óptima para el banco de datos real, tal quesi
P ((u, v) ∈ D∗) =
∫ ∫
D∗c∗n (u, v) dudv
y
P ((u, v) ∈ Dij) =
∫ ∫
Dij
cij (u, v) dudv,
1 ≤ i ≤ r 1 ≤ j ≤ k siendo c∗n (u, v) la expresión analítica de la cópula2Léase capítulo 3, Sección 3.1
123

empírica, D∗ la región de densidad empírica construída a partir del banco dedatos. Si consideramos los
Tij = (P ((u, v) ∈ D∗)− P ((u, v) ∈ Dij))2
una primera idea consistiría en elegir el estadístico
T = mın Tij = mın(P ((u, v) ∈ D∗)− P ((u, v) ∈ Dij))2.
La clave del posible éxito en la construcción de un método de elección defamilia de cópulas basado en el estadístico propuesto anteriormente puedeencontrarse al elegir una cierta clase de conjuntos D∗ conexos, y que cum-plan además ciertas propiedades que los puedan relacionar íntimamente conlas regiones de densidad de las cópulas teóricas utilizadas en la estimación.En resumen, el método propuesto tendría como base una teoría de conjuntosque puedan representar y describir el soporte de las cópulas de densidad.En último lugar, otra posible línea de investigación tendría como base averiguarque tipo de relación funcional existe entre una colección de variablesaleatorias que miden características espaciales, concepto íntimamente ligadoa la Regresión Espacial. Finalizamos la presente memoria haciendo énfasis enel hecho de que adjuntamos todos los códigos de programación en R válidospara simular y modelar familias de cópulas. Queremos con esto brindar laoportunidad a futuros investigadores de hacer uso de ellos y ayudarles en susprimeros pasos dentro de este campo.
124

Capıtulo 6Listado de códigos utilizados
6.1. Códigos utilizados en el estudio gráfico de
la dependencia entre dos variables aleato-
rias
6.1.1. Cálculo y representación de K-PLOTS
KPLOT<-function(x,y)
n<-length(x)
result<-rep(0,n)
h<-rep(0,n)
for(i in 1:n)
w=NULL W<-function(x)
y=NULL
y=-log(x)*x*(((x-x*log(x))^(i-1))*(1-x+x*log(x))^(n-i))
return(y)
125

result[i]<-n*choose(n-1,i-1)*integrate(W,0,1)[[1]]
for(i in 1:n)
cont1<-0
for(j in 1:n)
if(j!=i)
if((x[j]<=x[i])&(y[j]<=y[i])) cont1<-cont1+1
h[i]<-cont1/(n-1)
resultado<-cbind(h,result) return(resultado)
%Generación de variables
x.data<-rexp(100,1) y.data<-(x.data)^3
y1.data<-(x.data)^3+runif(100,0,1)
%Llamada a la función
res2=KPLOT(x.data,y1.data)
%Representación de los K-Plots
plot(res2[,2],sort(res2[,1]),xlim=c(0,1),ylim=c(0,1)) abline(0,1)
126

6.1.2. Cálculo y representación de CHI-PLOTS
CHIPLOT<-function(x,y)
n<-length(x)
h<-rep(0,n)
g<-rep(0,n)
f<-rep(0,n)
fhat<-rep(0,n)
ghat<-rep(0,n)
chi<-rep(0,n)
lambda<-rep(0,n)
for(i in 1:n)
cont1<-0
cont2<-0
cont3<-0
for(j in 1:n)
if(j!=i)
if((x[j]<=x[i])&(y[j]<=y[i])) cont1<-cont1+1
if(j!=i)
if((x[j]<=x[i])) cont2<-cont2+1
if(j!=i)
if((y[j]<=y[i])) cont3<-cont3+1
127

h[i]<-cont1/(n-1) f[i]<-cont2/(n-1) g[i]<-cont3/(n-1)
chi[i]<-(h[i]-f[i]*g[i])/(sqrt(f[i]*(1-f[i])*g[i]*(1-g[i])))
fhat[i]<-f[i]-0.5 ghat[i]<-g[i]-0.5
lambda[i]<-4*(sign(fhat[i]*ghat[i]))*(max(fhat[i]^2,ghat[i]^2))
resultado<-cbind(h,f,g,chi,lambda) return(resultado)
%Llamada a la función
CHIPLOT(rexp(100,10),rexp(100,2))
%Generación de variables
funcCHIPLOT<-CHIPLOT(rexp(100,10),rexp(100,2))
%Representación de los Chi-Plots
plot(funcCHIPLOT[,5],funcCHIPLOT[,4],ylim=c(-1.0,1.0))
lines(funcCHIPLOT[,5],rep(-1.78/10,100))
lines(funcCHIPLOT[,5],rep(1.78/10,100))
6.1.3. Representación de las superficies de densidad y
sus contornos
Estos códigos han sido extraídos del Journal of Statistical Software, artícu-lo Enjoy the Joy of Copulas:With a Package copula, de Jun Yan [36].
Representación de las densidades y contornos, escogiendo comofamilia Clayton
library(copula)
myMvd2 <- mvdc(copula = archmCopula(family = "clayton", param = 2),
margins = c("norm", "norm"),
128

paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd3 <- mvdc(copula = archmCopula(family = "clayton", param = 3),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd4 <- mvdc(copula = archmCopula(family = "clayton", param = 4),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd5 <- mvdc(copula = archmCopula(family = "clayton", param = 5),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd6 <- mvdc(copula = archmCopula(family = "clayton", param = 6),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd7 <- mvdc(copula = archmCopula(family = "clayton", param = 7),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd8 <- mvdc(copula = archmCopula(family = "clayton", param = 8),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd12 <- mvdc(copula = archmCopula(family = "clayton", param = 12),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd15 <- mvdc(copula = archmCopula(family = "clayton", param = 15),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
par(mfrow = c(2, 2), mar = c(2, 2, 1, 1), oma = c(1, 1, 0, 0),mgp =
c(2, 1, 0),pty="s")
persp(myMvd2, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=heat.colors(16),zlab="",xlab="u",ylab="v")
title("theta=2")
persp(myMvd3, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=heat.colors(16),zlab="",xlab="u",ylab="v") title("theta=3")
persp(myMvd4, dmvdc, xlim = c(-3, 3), ylim = c(-3,
129

3),col=heat.colors(16),zlab="",xlab="u",ylab="v") title("theta=4")
persp(myMvd5, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=heat.colors(16),zlab="",xlab="u",ylab="v") title("theta=5")
persp(myMvd6, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=heat.colors(16),zlab="",xlab="u",ylab="v") title("theta=6")
persp(myMvd7, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=heat.colors(16),zlab="",xlab="u",ylab="v") title("theta=7")
persp(myMvd8, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=heat.colors(16),zlab="",xlab="u",ylab="v") title("theta=8")
persp(myMvd15, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=heat.colors(6),zlab="",xlab="u",ylab="v") title("theta=15")
library(copula)
myMvd2 <- mvdc(copula = archmCopula(family = "clayton", param = 2),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd3 <- mvdc(copula = archmCopula(family = "clayton", param = 3),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd4 <- mvdc(copula = archmCopula(family = "clayton", param = 4),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd5 <- mvdc(copula = archmCopula(family = "clayton", param = 5),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd6 <- mvdc(copula = archmCopula(family = "clayton", param = 6),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd7 <- mvdc(copula = archmCopula(family = "clayton", param = 7),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd8 <- mvdc(copula = archmCopula(family = "clayton", param = 8),
margins = c("norm", "norm"),
130

paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd12 <- mvdc(copula = archmCopula(family = "clayton", param = 12),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd15 <- mvdc(copula = archmCopula(family = "clayton", param = 15),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
par(mfrow = c(3, 3), mar = c(2, 2, 1, 1), oma = c(1, 1, 0, 0),mgp =
c(2, 1, 0),pty="s")
contour(myMvd2, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=heat.colors(16)) title("theta=2")
contour(myMvd3,dmvdc,
xlim = c(-3, 3), ylim = c(-3, 3),col=heat.colors(16))
title("theta=3")
contour(myMvd4, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=heat.colors(16)) title("theta=4")
contour(myMvd5,
dmvdc, xlim = c(-3, 3), ylim = c(-3, 3),col=heat.colors(16))
title("theta=5")
contour(myMvd6, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=heat.colors(16)) title("theta=6")
contour(myMvd7,
dmvdc, xlim = c(-3, 3), ylim = c(-3, 3),col=heat.colors(16))
title("theta=7")
contour(myMvd8, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=heat.colors(16)) title("theta=8")
contour(myMvd12,
dmvdc, xlim = c(-3, 3), ylim = c(-3, 3),col=heat.colors(16))
title("theta=12")
contour(myMvd15, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=heat.colors(16)) title("theta=15")
131

Representación de las densidades y contornos, escogiendo comofamilia Frank
library(copula)
myMvd2 <- mvdc(copula = archmCopula(family = "frank", param = 2),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd3 <- mvdc(copula = archmCopula(family = "frank", param = 3),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd4 <- mvdc(copula = archmCopula(family = "frank", param = 4),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd5 <- mvdc(copula = archmCopula(family = "frank", param = 5),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd6 <- mvdc(copula = archmCopula(family = "frank", param = 6),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd7 <- mvdc(copula = archmCopula(family = "frank", param = 7),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd8 <- mvdc(copula = archmCopula(family = "frank", param = 8),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd12 <- mvdc(copula = archmCopula(family = "frank", param = 12),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd15 <- mvdc(copula = archmCopula(family = "frank", param = 15),
margins = c("norm", "norm"),
132

paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
par(mfrow = c(2, 2), mar = c(2, 2, 1, 1), oma = c(1, 1, 0, 0),mgp =
c(2, 1, 0),pty="s")
persp(myMvd2, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=topo.colors(12),zlab="",xlab="u",ylab="v")
title("theta=2")
persp(myMvd3, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=topo.colors(12),zlab="",xlab="u",ylab="v") title("theta=3")
persp(myMvd4, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=topo.colors(12),zlab="",xlab="u",ylab="v") title("theta=4")
persp(myMvd5, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=topo.colors(12),zlab="",xlab="u",ylab="v") title("theta=5")
persp(myMvd6, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=topo.colors(12),zlab="",xlab="u",ylab="v") title("theta=6")
persp(myMvd7, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=topo.colors(12),zlab="",xlab="u",ylab="v") title("theta=7")
persp(myMvd8, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=topo.colors(12),zlab="",xlab="u",ylab="v") title("theta=8")
persp(myMvd15, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=topo.colors(12),zlab="",xlab="u",ylab="v") title("theta=15")
library(copula)
myMvd2 <- mvdc(copula = archmCopula(family = "frank", param = 2),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd3 <- mvdc(copula = archmCopula(family = "frank", param = 3),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd4 <- mvdc(copula = archmCopula(family = "frank", param = 4),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd5 <- mvdc(copula = archmCopula(family = "frank", param = 5),
margins = c("norm", "norm"),
133

paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd6 <- mvdc(copula = archmCopula(family = "frank", param = 6),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd7 <- mvdc(copula = archmCopula(family = "frank", param = 7),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd8 <- mvdc(copula = archmCopula(family = "frank", param = 8),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd12 <- mvdc(copula = archmCopula(family = "frank", param = 12),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd15 <- mvdc(copula = archmCopula(family = "frank", param = 15),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
par(mfrow = c(3, 3), mar = c(2, 2, 1, 1), oma = c(1, 1, 0, 0),mgp =
c(2, 1, 0),pty="s")
contour(myMvd2, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=topo.colors(12)) title("theta=2")
contour(myMvd3,
dmvdc, xlim = c(-3, 3), ylim = c(-3, 3),col=topo.colors(12))
title("theta=3")
contour(myMvd4, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=topo.colors(12)) title("theta=4")
contour(myMvd5,
dmvdc, xlim = c(-3, 3), ylim = c(-3, 3),col=topo.colors(12))
title("theta=5")
contour(myMvd6, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=topo.colors(12)) title("theta=6")
contour(myMvd7,
dmvdc, xlim = c(-3, 3), ylim = c(-3, 3),col=topo.colors(12))
title("theta=7")
134

contour(myMvd8, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=topo.colors(12)) title("theta=8")
contour(myMvd12,
dmvdc, xlim = c(-3, 3), ylim = c(-3, 3),col=topo.colors(12))
title("theta=12")
contour(myMvd15, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=topo.colors(12)) title("theta=15")
Representación de las densidades y contornos, escogiendo comofamilia Gumbel
library(copula)
myMvd2 <- mvdc(copula = archmCopula(family = "gumbel", param = 2),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd3 <- mvdc(copula = archmCopula(family = "gumbel", param = 3),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd4 <- mvdc(copula = archmCopula(family = "gumbel", param = 4),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd5 <- mvdc(copula = archmCopula(family = "gumbel", param = 5),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd6 <- mvdc(copula = archmCopula(family = "gumbel", param = 6),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd7 <- mvdc(copula = archmCopula(family = "gumbel", param = 7),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd8 <- mvdc(copula = archmCopula(family = "gumbel", param = 8),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
135

myMvd12 <- mvdc(copula = archmCopula(family = "gumbel", param = 12),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd15 <- mvdc(copula = archmCopula(family = "gumbel", param = 15),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
par(mfrow = c(2, 2), mar = c(2, 2, 1, 1), oma = c(1, 1, 0, 0),mgp =
c(2, 1, 0),pty="s")
persp(myMvd2, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=cm.colors(2),zlab="",xlab="u",ylab="v")
title("theta=2")
persp(myMvd3, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=cm.colors(2),zlab="",xlab="u",ylab="v") title("theta=3")
persp(myMvd4, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=cm.colors(2),zlab="",xlab="u",ylab="v") title("theta=4")
persp(myMvd5, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=cm.colors(2),zlab="",xlab="u",ylab="v") title("theta=5")
persp(myMvd6, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=cm.colors(2),zlab="",xlab="u",ylab="v") title("theta=6")
persp(myMvd7, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=cm.colors(2),zlab="",xlab="u",ylab="v") title("theta=7")
persp(myMvd8, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=cm.colors(2),zlab="",xlab="u",ylab="v") title("theta=8")
persp(myMvd15, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=cm.colors(2),zlab="",xlab="u",ylab="v") title("theta=15")
library(copula)
myMvd2 <- mvdc(copula = archmCopula(family = "gumbel", param = 2),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd3 <- mvdc(copula = archmCopula(family = "gumbel", param = 3),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
136

myMvd4 <- mvdc(copula = archmCopula(family = "gumbel", param = 4),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd5 <- mvdc(copula = archmCopula(family = "gumbel", param = 5),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd6 <- mvdc(copula = archmCopula(family = "gumbel", param = 6),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd7 <- mvdc(copula = archmCopula(family = "gumbel", param = 7),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd8 <- mvdc(copula = archmCopula(family = "gumbel", param = 8),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd12 <- mvdc(copula = archmCopula(family = "gumbel", param = 12),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
myMvd15 <- mvdc(copula = archmCopula(family = "gumbel", param = 15),
margins = c("norm", "norm"),
paramMargins = list(list(mean = 0,sd = 1), list(mean = 0, sd = 1)))
par(mfrow = c(3, 3), mar = c(2, 2, 1, 1), oma = c(1, 1, 0, 0),mgp =
c(2, 1, 0),pty="s")
contour(myMvd2, dmvdc, xlim = c(-3, 3), ylim =
c(-3, 3),col=cm.colors(12)) title("theta=2")
contour(myMvd3, dmvdc,
xlim = c(-3, 3), ylim = c(-3, 3),col=cm.colors(12)) title("theta=3")
contour(myMvd4, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=cm.colors(12)) title("theta=4")
contour(myMvd5, dmvdc, xlim =
c(-3, 3), ylim = c(-3, 3),col=cm.colors(12)) title("theta=5")
contour(myMvd6, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=cm.colors(12)) title("theta=6")
137

contour(myMvd7, dmvdc, xlim =
c(-3, 3), ylim = c(-3, 3),col=cm.colors(12)) title("theta=7")
contour(myMvd8, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=cm.colors(12)) title("theta=8")
contour(myMvd12, dmvdc, xlim
= c(-3, 3), ylim = c(-3, 3),col=cm.colors(12)) title("theta=12")
contour(myMvd15, dmvdc, xlim = c(-3, 3), ylim = c(-3,
3),col=cm.colors(12)) title("theta=15")
6.2. Códigos utilizados en el estudio de la simu-
lación de datos y estimación de θ
#######################
#Llamada a la librería.
#######################
library(Bolstad)
library(copula)
library(GenKern)
library(mclust)
##############################################
#Código para hallar las raíces de una función.
##############################################
unirootME<-function(f,interval,lower=min(interval),upper=max(interval),
tol=.Machine$double.eps,maxiter=1000,...)
if (!missing(interval) && length(interval) != 2)
val<-NULL
if (!is.numeric(lower) || !is.numeric(upper) || lower >=upper)
val<-NULL
if (f(lower, ...) * f(upper, ...) > 0)
val<-NULL
138

val<-.Internal(zeroin(function(arg) f(arg, ...),
lower,upper,tol,as.integer(maxiter)))
iter<-as.integer(val[2])
if (iter < 0)
val<-NULL
iter<-maxiter
return(val[1])
##########################################################
#Código para la estimación no paramétrica de la función de
#distribución mediante rangos.
##########################################################
cdf<-function(x)
n<-length(x)
rx<-rank(x)
return(rx/(n+1))
cdf_cong<-function(i,x,y)
n<-length(x)
rx<-rank(x)
ry<-rank(y)
somma<-rep(0,n)
for(k in 1:n)if(rx[i]>=rx[k] & ry[i]>=ry[k]) somma[k]<-1
copula<-(1/n)*sum(somma)
return(copula)
#############################################
#Código para la mejora de la cópula empírica.
#############################################
139

##Clayton.
rclaytonBivCopula<-function(n,simul,theta,tol=0.25)
u<-sort(runif(n))
v<-matrix(0,n,simul)
for(z in 1:simul)
t<-rep(0,n)
t<-runif(n)
val<-cbind(u,t)
v[,z]<-(val[,1]^(-theta)*(val[,2]^
(-theta/(theta+1))-1)+1)^(-1/theta)
scarto<-rep(0,n)
for(i in 1:n)scarto[i]<-sqrt(var(v[i,]))
segnalev<-rep(0,n)
segnalev<-rowSums(v)/simul
upperBound<-segnalev+tol*scarto
lowerBound<-segnalev-tol*scarto
return(cbind(u,upperBound,lowerBound))
##Frank.
rfrankBivCopula<-function(n,simul,theta,tol=0.25)
u<-sort(runif(n))
v<-matrix(0,n,simul)
for(z in 1:simul)
t<-rep(0,n)
t<-runif(n)
val<-cbind(u,t)
v[,z]<-((-1)/theta)*log(1+val[,2]*(1-exp(-theta))
/(exp(-theta*val[,1])*(val[,2]-1)-val[,2]))
140

scarto<-rep(0,n)
for(i in 1:n)scarto[i]<-sqrt(var(v[i,]))
segnalev<-rep(0,n)
segnalev<-rowSums(v)/simul
upperBound<-segnalev+tol*scarto
lowerBound<-segnalev-tol*scarto
return(cbind(u,upperBound,lowerBound))
##Gumbel.
rPosStable<-function(n,alpha)
if(alpha>=1) stop("alpha must be < 1")
t<-runif(n,0,pi)
w<-rexp(n)
a<-sin((1-alpha)*t)*(sin(alpha*t))
^(alpha/(1-alpha))/(sin(t))^(1/(1-alpha))
return((a/w)^((1-alpha)/alpha))
genInv<-function(alpha,s)
return(exp(-s^(1/alpha)))
rgumbelBivCopula<-function(n,simul,theta,tol=0.25)
b<-1/theta
# stable (b,1), 0 < b < 1, Chambers,
Mallows, and Stuck 1976, JASA,
p.341
v<-matrix(0,n,simul)
fr<-rep(0,n)
fr<-sort(rPosStable(n,b))
u_input<-sort(runif(n))
141

u<-genInv(theta,-log(u_input)/fr)
for(z in 1:simul)
v_input<-runif(n)
v[,z]<-genInv(theta,-log(v_input)/fr)
scarto<-rep(0,n)
for(i in 1:n)scarto[i]<-sqrt(var(v[i,]))
segnalev<-rep(0,n)
segnalev<-rowSums(v)/simul
upperBound<-segnalev+tol*scarto
lowerBound<-segnalev-tol*scarto
return(cbind(u,upperBound,lowerBound))
#####################################################################
#Simulación de pares de datos mediante una cópula bivariante Clayton
#con parámetro poblacional theta=realTHETA.
#####################################################################
simulazione_C<-function(scenari,ndati,
vectorTHETA=c(2:8),intervallo,toll=0.25)
teR_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teR_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teR_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teRT_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teRT_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teRT_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
tePV_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
tePV_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
tePV_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teL_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teL_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teL_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
142

for(theta invectorTHETA) cat("\n"," Calculo de la matriz
correctora de la Copula Empirica (Clayton), theta=",theta,"\n")
limiti_C<-NULL
limiti_C<-rclaytonBivCopula(5000,2000,theta,tol=toll)
cat("Calculo de la matriz correctora de la copula empirica (Frank),
theta=",theta,"\n")
limiti_F<-NULL
limiti_F<-rfrankBivCopula(5000,2000,theta,tol=toll)
cat("Calculo de la matriz correctora de la copula empirica (Gumbel),
theta=",theta,"\n")
limiti_G<-NULL
limiti_G<-rgumbelBivCopula(5000,2000,theta,tol=toll)
for(z in 1:scenari)
cat("simulacion numero",z,",
theta=",theta,"\n")
################
#inicialización.
################
dati<-matrix(0,nrow=ndati,ncol=2)
x<-rep(0,ndati)
y<-rep(0,ndati)
###################
#inicio simulación.
###################
dati<-rcopula(claytonCopula(theta,dim=2),ndati)
Copula_C<-expression((1+(F1^(-theta)-1+F2^(-theta)-1))^(-1/theta));
score_C<-expression(((1+(F1^(-theta)-1+F2^(-theta)-1))^(-1/theta)-H)^2);
score_L_C<-expression((1+(F1^(-theta)-1+F2^(-theta)-1))^(-1/theta)-H)
Copula_F<-expression(-1/theta*log(1+exp(-(-log((exp(-theta*F1)-1)/
(exp(-theta)-1))-log((exp(-theta*F2)-1)/
(exp(-theta)-1))))*(exp(-theta)-1)));
score_F<-expression((-1/theta*log(1+exp(-(-log((exp(-theta*F1)-1)/
143

(exp(-theta)-1))-log((exp(-theta*F2)-1)/
(exp(-theta)-1))))*(exp(-theta)-1))-H)^2);
score_L_F<-expression(-1/theta*log(1+exp(-(-log((exp(-theta*F1)-1)/
(exp(-theta)-1))-log((exp(-theta*F2)-1)/
(exp(-theta)-1))))*(exp(-theta)-1))-H)
Copula_G<-expression
(exp(-((-log(F1))^theta+(-log(F2))^theta)^(1/theta)));
score_G<-expression
((exp(-((-log(F1))^theta+(-log(F2))^theta)^(1/theta))-H)^2);
score_L_G<-expression
(exp(-((-log(F1))^theta+(-log(F2))^theta)^(1/theta))-H)
x<-dati[,1]
y<-dati[,2]
###############################################################
#Definición de la corrección para la cópula empírica (Clayton).
###############################################################
test_C<-rep(0,ndati)
pesi_C<-rep(0,ndati)
for(i in 1:ndati)
test_C[i]<-nearest(limiti_C[,1],x[i],outside=TRUE)
if(y[i]>limiti_C[test_C[i],2] || y[i]<limiti_C[test_C[i],3])
pesi_C[i]<-1
xstar_C<-rep(0,ndati)
ystar_C<-rep(0,ndati)
xstar_C<-x*pesi_C
ystar_C<-y*pesi_C
xstar_C<-xstar_C[xstar_C>0]
ystar_C<-ystar_C[ystar_C>0]
nxstar_C<-0
nystar_C<-0
nxstar_C<-length(xstar_C)
144

nystar_C<-length(ystar_C)
#############################################################
#Definición de la corrección para la cópula Empírica (Frank).
#############################################################
test_F<-rep(0,ndati)
pesi_F<-rep(0,ndati)
for(i in 1:ndati)
test_F[i]<-nearest(limiti_F[,1],x[i],outside=TRUE)
if(y[i]>limiti_F[test_F[i],2] || y[i]<limiti_F[test_F[i],3])
pesi_F[i]<-1
xstar_F<-rep(0,ndati)
ystar_F<-rep(0,ndati)
xstar_F<-x*pesi_F
ystar_F<-y*pesi_F
xstar_F<-xstar_F[xstar_F>0]
ystar_F<-ystar_F[ystar_F>0]
nxstar_F<-0
nystar_F<-0
nxstar_F<-length(xstar_F)
nystar_F<-length(ystar_F)
##############################################################
#Definición de la corrección para la cópula Empírica (Gumbel).
##############################################################
test_G<-rep(0,ndati)
pesi_G<-rep(0,ndati)
for(i in 1:ndati)
test_G[i]<-nearest(limiti_G[,1],x[i],outside=TRUE)
if(y[i]>limiti_G[test_G[i],2] || y[i]<limiti_G[test_G[i],3])
pesi_G[i]<-1
145

xstar_G<-rep(0,ndati)
ystar_G<-rep(0,ndati)
xstar_G<-x*pesi_G
ystar_G<-y*pesi_G
xstar_G<-xstar_G[xstar_G>0]
ystar_G<-ystar_G[ystar_G>0]
nxstar_G<-0
nystar_G<-0
nxstar_G<-length(xstar_G)
nystar_G<-length(ystar_G)
#########################################################
#Cálculo de la función de distribución marginal conjunta.
#########################################################
cat(" simulacion numero.",z,", theta=",theta,"
,estimacion funcion de distribucion marginal conjunta","\n")
Fxr<-rep(0,ndati);Fyr<-rep(0,ndati);Fxr<-cdf(x);
Fyr<-cdf(y);Fcr<-rep(0,ndati);
for(i in 1:ndati)
Fcr[i]<-cdf_cong(i,x,y)
#Clayton.
Fxrstar_C<-rep(0,nxstar_C);Fyrstar_C<-rep(0,nystar_C);
Fxrstar_C<-cdf(xstar_C);Fyrstar_C<-cdf(ystar_C)
Fcrstar_C<-rep(0,nxstar_C);
for(i in 1:nxstar_C)
Fcrstar_C[i]<-cdf_cong(i,xstar_C,ystar_C)
#Frank.
Fxrstar_F<-rep(0,nxstar_F);
Fyrstar_F<-rep(0,nystar_F);
Fxrstar_F<-cdf(xstar_F);
146

Fyrstar_F<-cdf(ystar_F)
Fcrstar_F<-rep(0,nxstar_F);
for(i in 1:nxstar_F)
Fcrstar_F[i]<-cdf_cong(i,xstar_F,ystar_F)
#Gumbel.
Fxrstar_G<-rep(0,nxstar_G);Fyrstar_G<-rep(0,nystar_G);
Fxrstar_G<-cdf(xstar_G);Fyrstar_G<-cdf(ystar_G)
Fcrstar_G<-rep(0,nxstar_G);
for(i in1:nxstar_G)
Fcrstar_G[i]<-cdf_cong(i,xstar_G,ystar_G)
########################################################
# Implementación de la función que permite estimar Theta
# mediante OLS(utilizando rangos).
########################################################
estimationR<-function(theta,F1,F2,H,score)
derivScore<-D(score,"theta")
return(sum(eval(derivScore)))
cat(" simulacion numero.",z,", theta=",theta,",stima theta OLS
(ranghi)","\n")
teR_C[z,match(theta,vectorTHETA)]<-
unirootME(estimationR,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_C)
teR_F[z,match(theta,vectorTHETA)]<-
unirootME(estimationR,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_F)
teR_G[z,match(theta,vectorTHETA)]<-
unirootME(estimationR,interval=intervallo,
147

F1=Fxr,F2=Fyr,H=Fcr,score=score_G)
teRT_C[z,match(theta,vectorTHETA)]<-
unirootME(estimationR,interval=intervallo,
F1=Fxrstar_C,F2=Fyrstar_C,H=Fcrstar_C,score=score_C)
teRT_F[z,match(theta,vectorTHETA)]<-
unirootME(estimationR,interval=intervallo,
F1=Fxrstar_F,F2=Fyrstar_F,H=Fcrstar_F,score=score_F)
teRT_G[z,match(theta,vectorTHETA)]<-
unirootME(estimationR,interval=intervallo,
F1=Fxrstar_G,F2=Fyrstar_G,H=Fcrstar_G,score=score_G)
###########################################################
# Implementación de la función que permite estimar Theta
# mediante MLE (pseudoverosimilitud, Genest).
###########################################################
f<-function(theta,x,y,Copula)
rx<-rank(x)
ry<-rank(y)
n<-length(x)
F1<-rx/(n+1)
F2<-ry/(n+1)
densidad<-D(D(Copula,"F1"),"F2")
ddensidad<-D(densidad,"theta")
dert<-(1/eval(densidad))*eval(ddensidad)
result<-sum(dert)
return(result)
cat("dentro simulacion numero.",z,", theta=",theta,",stima theta
GENEST","\n")
tePV_C[z,match(theta,vectorTHETA)]
<-unirootME(f,interval=intervallo,x=x,y=y,Copula=Copula_C)
tePV_F[z,match(theta,vectorTHETA)]
<-unirootME(f,interval=intervallo,x=x,y=y,Copula=Copula_F)
148

tePV_G[z,match(theta,vectorTHETA)]
<-unirootME(f,interval=intervallo,x=x,y=y,Copula=Copula_G)
##########################################################
# Implementación de la función que permite estimar Theta
# mediante L1 (article Biau, Wegkamp (2005)).
##########################################################
estimationL<-function(theta,F1,F2,H,score)
n<-length(F1)
segni<-rep(0,n)
distanza<-rep(0,n)
distanza<-eval(score)
for(i in 1:n)
if(distanza[i]>=0) segni[i]<-1 else segni[i]<--1
derivScore<-D(score,"theta")
return(sum(eval(derivScore)*segni))
cat("dentro simulacion numero.",z,", theta=",theta,",stima theta
Minimum Distance L1","\n")
teL_C[z,match(theta,vectorTHETA)]<-
unirootME(estimationL,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_L_C)
teL_F[z,match(theta,vectorTHETA)]<-
unirootME(estimationL,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_L_F)
teL_G[z,match(theta,vectorTHETA)]<-
unirootME(estimationL,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_L_G)
##########################
#Lista de objetos finales.
149

#########################
########################
#Resultado mediante OLS.
########################
var_teR_C<-rep(0,length(vectorTHETA))
result_teR_C<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teR_C[1,]<-colMeans(teR_C)
result_teR_C[2,]<-colMeans(teR_C)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teR_C[j]<-var(teR_C[,j])
result_teR_C[3,j]<-sqrt(var_teR_C[j])
result_teR_C[4,]<-result_teR_C[2,]^2+var_teR_C
var_teR_F<-rep(0,length(vectorTHETA))
result_teR_F<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teR_F[1,]<-colMeans(teR_F)
result_teR_F[2,]<-colMeans(teR_F)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teR_F[j]<-var(teR_F[,j])
result_teR_F[3,j]<-sqrt(var_teR_F[j])
result_teR_F[4,]<-result_teR_F[2,]^2+var_teR_F
var_teR_G<-rep(0,length(vectorTHETA))
result_teR_G<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teR_G[1,]<-colMeans(teR_G)
result_teR_G[2,]<-colMeans(teR_G)-vectorTHETA
for(j in1:length(vectorTHETA))
150

var_teR_G[j]<-var(teR_G[,j])
result_teR_G[3,j]<-sqrt(var_teR_G[j])
result_teR_G[4,]<-result_teR_G[2,]^2+var_teR_G
##################################
#Resultado mediante OLS suavizado.
##################################
var_teRT_C<-rep(0,length(vectorTHETA))
result_teRT_C<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teRT_C[1,]<-colMeans(teRT_C)
result_teRT_C[2,]<-colMeans(teRT_C)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teRT_C[j]<-var(teRT_C[,j])
result_teRT_C[3,j]<-sqrt(var_teRT_C[j])
result_teRT_C[4,]<-result_teRT_C[2,]^2+var_teRT_C
var_teRT_F<-rep(0,length(vectorTHETA))
result_teRT_F<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teRT_F[1,]<-colMeans(teRT_F)
result_teRT_F[2,]<-colMeans(teRT_F)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teRT_F[j]<-var(teRT_F[,j])
result_teRT_F[3,j]<-sqrt(var_teRT_F[j])
result_teRT_F[4,]<-result_teRT_F[2,]^2+var_teRT_F
var_teRT_G<-rep(0,length(vectorTHETA))
result_teRT_G<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
151

result_teRT_G[1,]<-colMeans(teRT_G)
result_teRT_G[2,]<-colMeans(teRT_G)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teRT_G[j]<-var(teRT_G[,j])
result_teRT_G[3,j]<-sqrt(var_teRT_G[j])
result_teRT_G[4,]<-result_teRT_G[2,]^2+var_teRT_G
#######################################################
#Resultado mediante MLE (máxima verosimilitud, Genest).
#######################################################
var_tePV_C<-rep(0,length(vectorTHETA))
result_tePV_C<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_tePV_C[1,]<-colMeans(tePV_C)
result_tePV_C[2,]<-colMeans(tePV_C)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_tePV_C[j]<-var(tePV_C[,j])
result_tePV_C[3,j]<-sqrt(var_tePV_C[j])
result_tePV_C[4,]<-result_tePV_C[2,]^2+var_tePV_C
var_tePV_F<-rep(0,length(vectorTHETA))
result_tePV_F<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_tePV_F[1,]<-colMeans(tePV_F)
result_tePV_F[2,]<-colMeans(tePV_F)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_tePV_F[j]<-var(tePV_F[,j])
result_tePV_F[3,j]<-sqrt(var_tePV_F[j])
result_tePV_F[4,]<-result_tePV_F[2,]^2+var_tePV_F
152

var_tePV_G<-rep(0,length(vectorTHETA))
result_tePV_G<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_tePV_G[1,]<-colMeans(tePV_G)
result_tePV_G[2,]<-colMeans(tePV_G)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_tePV_G[j]<-var(tePV_G[,j])
result_tePV_G[3,j]<-sqrt(var_tePV_G[j])
result_tePV_G[4,]<-result_tePV_G[2,]^2+var_tePV_G
########################################
#Resultado mediante mínima distancia L1.
########################################
var_teL_C<-rep(0,length(vectorTHETA))
result_teL_C<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teL_C[1,]<-colMeans(teL_C)
result_teL_C[2,]<-colMeans(teL_C)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teL_C[j]<-var(teL_C[,j])
result_teL_C[3,j]<-sqrt(var_teL_C[j])
result_teL_C[4,]<-result_teL_C[2,]^2+var_teL_C
var_teL_F<-rep(0,length(vectorTHETA))
result_teL_F<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teL_F[1,]<-colMeans(teL_F)
result_teL_F[2,]<-colMeans(teL_F)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teL_F[j]<-var(teL_F[,j])
result_teL_F[3,j]<-sqrt(var_teL_F[j])
153

result_teL_F[4,]<-result_teL_F[2,]^2+var_teL_F
var_teL_G<-rep(0,length(vectorTHETA))
result_teL_G<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teL_G[1,]<-colMeans(teL_G)
result_teL_G[2,]<-colMeans(teL_G)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teL_G[j]<-var(teL_G[,j])
result_teL_G[3,j]<-sqrt(var_teL_G[j])
result_teL_G[4,]<-result_teL_G[2,]^2+var_teL_G
return(list(Summary=matrix(c(scenari,ndati,toll),3,1,
dimnames=list(c("Num. simulations","Num. data","Tolerance"),
"Summary (simulations from Clayton Copula)")),
List_of_real_theta=vectorTHETA,
Estimation_by_Clayton_Copula=list
(OLS=result_teR_C,OLS_Tapering=result_teRT_C,
ML=result_tePV_C,L1=result_teL_C),
Estimation_by_Frank_Copula=list(OLS=result_teR_F,
OLS_Tapering=result_teRT_F,ML=result_tePV_F,L1=result_teL_F),
Estimation_by_Gumbel_Copula=list(OLS=result_teR_G,
OLS_Tapering=result_teRT_G,ML=result_tePV_G,L1=result_teL_G)))
#####################################################################
# Simulaciones de pares de datos de una cópula Frank bivariante con
# parámetro real theta=realTHETA.
#####################################################################
simulazione_F<-function(scenari,ndati,vectorTHETA=c(2:8),
intervallo,toll=0.25)
teR_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
154

teR_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teR_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teRT_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teRT_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teRT_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
tePV_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
tePV_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
tePV_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teL_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teL_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teL_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
for(theta in vectorTHETA)
cat("\n","Calculo de la matriz correctora
de la copula empirica (Clayton), theta=",theta,"\n")
limiti_C<-NULL
limiti_C<-rclaytonBivCopula(5000,2000,theta,tol=toll)
cat("Calculo de la matriz correctora de la copula empirica (Frank),
theta=",theta,"\n")
limiti_F<-NULL
limiti_F<-rfrankBivCopula(5000,2000,theta,tol=toll)
cat("Calculo de la matriz correctora de la copula empirica (Gumbel),
theta=",theta,"\n")
limiti_G<-NULL
limiti_G<-rgumbelBivCopula(5000,2000,theta,tol=toll)
for(z in 1:scenari)
cat("simulacion num.",z,", theta=",theta,"\n")
################
#Inicialización.
################
dati<-matrix(0,nrow=ndati,ncol=2)
x<-rep(0,ndati)
155

y<-rep(0,ndati)
###################
#Inicio simulación.
###################
dati<-rcopula(frankCopula(theta,dim=2),ndati)
Copula_C<-expression((1+(F1^(-theta)-1+F2^(-theta)-1))^(-1/theta));
score_C<-expression(((1+(F1^(-theta)-1+F2^(-theta)-1))^(-1/theta)-H)^2);
score_L_C<-expression((1+(F1^(-theta)-1+F2^(-theta)-1))^(-1/theta)-H)
Copula_F<-expression(-1/theta*log(1+exp(-(-log((exp(-theta*F1)-1)/
(exp(-theta)-1))-log((exp(-theta*F2)-1)/
(exp(-theta)-1))))*(exp(-theta)-1)));
score_F<-expression((-1/theta*log(1+exp(-(-log((exp(-theta*F1)-1)/
(exp(-theta)-1))-log((exp(-theta*F2)-1)/
(exp(-theta)-1))))*(exp(-theta)-1))-H)^2);
score_L_F<-expression(-1/theta*log(1+exp(-(-log((exp(-theta*F1)-1)/
(exp(-theta)-1))-log((exp(-theta*F2)-1)/
(exp(-theta)-1))))*(exp(-theta)-1))-H)
Copula_G<-expression
(exp(-((-log(F1))^theta+(-log(F2))^theta)^(1/theta)));
score_G<-expression
((exp(-((-log(F1))^theta+(-log(F2))^theta)^(1/theta))-H)^2);
score_L_G<-expression
(exp(-((-log(F1))^theta+(-log(F2))^theta)^(1/theta))-H)
x<-dati[,1]
y<-dati[,2]
###############################################################
#Definición de la corrección para la cópula Empírica (Clayton).
###############################################################
test_C<-rep(0,ndati)
pesi_C<-rep(0,ndati)
for(i in 1:ndati)
test_C[i]<-nearest(limiti_C[,1],x[i],outside=TRUE)
156

if(y[i]>limiti_C[test_C[i],2] ||
y[i]<limiti_C[test_C[i],3]) pesi_C[i]<-1
xstar_C<-rep(0,ndati)
ystar_C<-rep(0,ndati)
xstar_C<-x*pesi_C
ystar_C<-y*pesi_C
xstar_C<-xstar_C[xstar_C>0]
ystar_C<-ystar_C[ystar_C>0]
nxstar_C<-0
nystar_C<-0
nxstar_C<-length(xstar_C)
nystar_C<-length(ystar_C)
#############################################################
#Definición de la corrección para la cópula Empírica (Frank).
#############################################################
test_F<-rep(0,ndati)
pesi_F<-rep(0,ndati)
for(i in 1:ndati)
test_F[i]<-nearest(limiti_F[,1],x[i],outside=TRUE)
if(y[i]>limiti_F[test_F[i],2] ||
y[i]<limiti_F[test_F[i],3]) pesi_F[i]<-1
xstar_F<-rep(0,ndati)
ystar_F<-rep(0,ndati)
xstar_F<-x*pesi_F
ystar_F<-y*pesi_F
xstar_F<-xstar_F[xstar_F>0]
ystar_F<-ystar_F[ystar_F>0]
nxstar_F<-0
nystar_F<-0
nxstar_F<-length(xstar_F)
157

nystar_F<-length(ystar_F)
##############################################################
#Definición de la corrección para la cópula Empírica (Gumbel).
##############################################################
test_G<-rep(0,ndati)
pesi_G<-rep(0,ndati)
for(i in 1:ndati)
test_G[i]<-nearest(limiti_G[,1],x[i],outside=TRUE)
if(y[i]>limiti_G[test_G[i],2] ||
y[i]<limiti_G[test_G[i],3]) pesi_G[i]<-1
xstar_G<-rep(0,ndati)
ystar_G<-rep(0,ndati)
xstar_G<-x*pesi_G
ystar_G<-y*pesi_G
xstar_G<-xstar_G[xstar_G>0]
ystar_G<-ystar_G[ystar_G>0]
nxstar_G<-0
nystar_G<-0
nxstar_G<-length(xstar_G)
nystar_G<-length(ystar_G)
#####################################################
#Cálculo de las distribuciones marginales y conjunta.
#####################################################
cat("dentro simulacion numero.",z,", theta=",theta,",
stima funzioni di ripartizione marginali e congiunta","\n")
Fxr<-rep(0,ndati);Fyr<-rep(0,ndati);Fxr<-cdf(x);Fyr<-cdf(y);
Fcr<-rep(0,ndati);for(i in 1:ndati)Fcr[i]<-cdf_cong(i,x,y)
#Clayton
Fxrstar_C<-rep(0,nxstar_C);Fyrstar_C<-rep(0,nystar_C);
Fxrstar_C<-cdf(xstar_C);Fyrstar_C<-cdf(ystar_C)
Fcrstar_C<-rep(0,nxstar_C);
158

for(i in 1:nxstar_C)
Fcrstar_C[i]<-cdf_cong(i,xstar_C,ystar_C)
#Frank
Fxrstar_F<-rep(0,nxstar_F);Fyrstar_F<-rep(0,nystar_F);
Fxrstar_F<-cdf(xstar_F);Fyrstar_F<-cdf(ystar_F)
Fcrstar_F<-rep(0,nxstar_F);
for(i in 1:nxstar_F)
Fcrstar_F[i]<-cdf_cong(i,xstar_F,ystar_F)
#Gumbel
Fxrstar_G<-rep(0,nxstar_G);Fyrstar_G<-rep(0,nystar_G);
Fxrstar_G<-cdf(xstar_G);Fyrstar_G<-cdf(ystar_G)
Fcrstar_G<-rep(0,nxstar_G);
for(i in 1:nxstar_G)
Fcrstar_G[i]<-cdf_cong(i,xstar_G,ystar_G)
#############################################################
# Implementación de la función que permite estimar Theta
# mediante OLS (utilizando rangos).
#############################################################
estimationR<-function(theta,F1,F2,H,score)
derivScore<-D(score,"theta")
return(sum(eval(derivScore)))
cat("dentro simulacion numero.",z,", theta=",theta,",
stima theta OLS (ranghi)","\n")
teR_C[z,match(theta,vectorTHETA)]<-
unirootME(estimationR,interval=intervallo,
159

F1=Fxr,F2=Fyr,H=Fcr,score=score_C)
teR_F[z,match(theta,vectorTHETA)]<-
unirootME(estimationR,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_F)
teR_G[z,match(theta,vectorTHETA)]<-
unirootME(estimationR,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_G)
teRT_C[z,match(theta,vectorTHETA)]<-
unirootME(estimationR,interval=intervallo,
F1=Fxrstar_C,F2=Fyrstar_C,H=Fcrstar_C,score=score_C)
teRT_F[z,match(theta,vectorTHETA)]<-
unirootME(estimationR,interval=intervallo,
F1=Fxrstar_F,F2=Fyrstar_F,H=Fcrstar_F,score=score_F)
teRT_G[z,match(theta,vectorTHETA)]<-
unirootME(estimationR,interval=intervallo,
F1=Fxrstar_G,F2=Fyrstar_G,H=Fcrstar_G,score=score_G)
########################################################
# Implementación de la función que permite estimar Theta
# mediante máxima verosimilititud (Genest).
########################################################
f<-function(theta,x,y,Copula)
rx<-rank(x)
ry<-rank(y)
n<-length(x)
F1<-rx/(n+1)
F2<-ry/(n+1)
densidad<-D(D(Copula,"F1"),"F2")
ddensidad<-D(densidad,"theta")
dert<-(1/eval(densidad))*eval(ddensidad)
result<-sum(dert)
return(result)
160

cat("dentro simulacion numero.",z,", theta=",theta,",
stima theta GENEST","\n")
tePV_C[z,match(theta,vectorTHETA)]<-
unirootME(f,interval=intervallo,x=x,y=y,Copula=Copula_C)
tePV_F[z,match(theta,vectorTHETA)]<-
unirootME(f,interval=intervallo,x=x,y=y,Copula=Copula_F)
tePV_G[z,match(theta,vectorTHETA)]<-
unirootME(f,interval=intervallo,x=x,y=y,Copula=Copula_G)
##############################################################
# Implementación de la función que permite estimar Theta
# mediante mínima distancia L1 (articulo Biau, Wegkamp (2005))
##############################################################
estimationL<-function(theta,F1,F2,H,score)
n<-length(F1)
segni<-rep(0,n)
distanza<-rep(0,n)
distanza<-eval(score)
for(i in 1:n)if(distanza[i]>=0)
segni[i]<-1 else segni[i]<--1
derivScore<-D(score,"theta")
return(sum(eval(derivScore)*segni))
cat("dentro simulacion numero.",z,", theta=",theta,",
stima theta Minimum Distance L1","\n")
teL_C[z,match(theta,vectorTHETA)]<-
unirootME(estimationL,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_L_C)
teL_F[z,match(theta,vectorTHETA)]<-
unirootME(estimationL,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_L_F)
teL_G[z,match(theta,vectorTHETA)]<-
unirootME(estimationL,interval=intervallo,
161

F1=Fxr,F2=Fyr,H=Fcr,score=score_L_G)
##########################
#Lista de objetos finales.
##########################
########################
#Resultado mediante OLS.
########################
var_teR_C<-rep(0,length(vectorTHETA))
result_teR_C<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teR_C[1,]<-colMeans(teR_C)
result_teR_C[2,]<-colMeans(teR_C)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teR_C[j]<-var(teR_C[,j])
result_teR_C[3,j]<-sqrt(var_teR_C[j])
result_teR_C[4,]<-result_teR_C[2,]^2+var_teR_C
var_teR_F<-rep(0,length(vectorTHETA))
result_teR_F<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teR_F[1,]<-colMeans(teR_F)
result_teR_F[2,]<-colMeans(teR_F)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teR_F[j]<-var(teR_F[,j])
result_teR_F[3,j]<-sqrt(var_teR_F[j])
result_teR_F[4,]<-result_teR_F[2,]^2+var_teR_F
var_teR_G<-rep(0,length(vectorTHETA))
162

result_teR_G<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teR_G[1,]<-colMeans(teR_G)
result_teR_G[2,]<-colMeans(teR_G)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teR_G[j]<-var(teR_G[,j])
result_teR_G[3,j]<-sqrt(var_teR_G[j])
result_teR_G[4,]<-result_teR_G[2,]^2+var_teR_G
##########################################
#Resultado mediante OLS con suavizamiento.
##########################################
var_teRT_C<-rep(0,length(vectorTHETA))
result_teRT_C<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teRT_C[1,]<-colMeans(teRT_C)
result_teRT_C[2,]<-colMeans(teRT_C)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teRT_C[j]<-var(teRT_C[,j])
result_teRT_C[3,j]<-sqrt(var_teRT_C[j])
result_teRT_C[4,]<-result_teRT_C[2,]^2+var_teRT_C
var_teRT_F<-rep(0,length(vectorTHETA))
result_teRT_F<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teRT_F[1,]<-colMeans(teRT_F)
result_teRT_F[2,]<-colMeans(teRT_F)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teRT_F[j]<-var(teRT_F[,j])
result_teRT_F[3,j]<-sqrt(var_teRT_F[j])
163

result_teRT_F[4,]<-result_teRT_F[2,]^2+var_teRT_F
var_teRT_G<-rep(0,length(vectorTHETA))
result_teRT_G<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teRT_G[1,]<-colMeans(teRT_G)
result_teRT_G[2,]<-colMeans(teRT_G)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teRT_G[j]<-var(teRT_G[,j])
result_teRT_G[3,j]<-sqrt(var_teRT_G[j])
result_teRT_G[4,]<-result_teRT_G[2,]^2+var_teRT_G
##############################
#Resultado mediante ML Genest.
##############################
var_tePV_C<-rep(0,length(vectorTHETA))
result_tePV_C<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_tePV_C[1,]<-colMeans(tePV_C)
result_tePV_C[2,]<-colMeans(tePV_C)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_tePV_C[j]<-var(tePV_C[,j])
result_tePV_C[3,j]<-sqrt(var_tePV_C[j])
result_tePV_C[4,]<-result_tePV_C[2,]^2+var_tePV_C
var_tePV_F<-rep(0,length(vectorTHETA))
result_tePV_F<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_tePV_F[1,]<-colMeans(tePV_F)
result_tePV_F[2,]<-colMeans(tePV_F)-vectorTHETA
for(j in 1:length(vectorTHETA))
164

var_tePV_F[j]<-var(tePV_F[,j])
result_tePV_F[3,j]<-sqrt(var_tePV_F[j])
result_tePV_F[4,]<-result_tePV_F[2,]^2+var_tePV_F
var_tePV_G<-rep(0,length(vectorTHETA))
result_tePV_G<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_tePV_G[1,]<-colMeans(tePV_G)
result_tePV_G[2,]<-colMeans(tePV_G)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_tePV_G[j]<-var(tePV_G[,j])
result_tePV_G[3,j]<-sqrt(var_tePV_G[j])
result_tePV_G[4,]<-result_tePV_G[2,]^2+var_tePV_G
########################################
#Resultado mediante Mínima Distancia L1.
########################################
var_teL_C<-rep(0,length(vectorTHETA))
result_teL_C<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teL_C[1,]<-colMeans(teL_C)
result_teL_C[2,]<-colMeans(teL_C)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teL_C[j]<-var(teL_C[,j])
result_teL_C[3,j]<-sqrt(var_teL_C[j])
result_teL_C[4,]<-result_teL_C[2,]^2+var_teL_C
var_teL_F<-rep(0,length(vectorTHETA))
result_teL_F<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
165

result_teL_F[1,]<-colMeans(teL_F)
result_teL_F[2,]<-colMeans(teL_F)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teL_F[j]<-var(teL_F[,j])
result_teL_F[3,j]<-sqrt(var_teL_F[j])
result_teL_F[4,]<-result_teL_F[2,]^2+var_teL_F
var_teL_G<-rep(0,length(vectorTHETA))
result_teL_G<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teL_G[1,]<-colMeans(teL_G)
result_teL_G[2,]<-colMeans(teL_G)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teL_G[j]<-var(teL_G[,j])
result_teL_G[3,j]<-sqrt(var_teL_G[j])
result_teL_G[4,]<-result_teL_G[2,]^2+var_teL_G
return(list(Summary=matrix(c(scenari,ndati,toll),3,1,
dimnames=list(c("Num. simulations","Num. data","Tolerance"),
"Summary (simulations from Frank Copula)")),
List_of_real_theta=vectorTHETA,
Estimation_by_Clayton_Copula=list
(OLS=result_teR_C,OLS_Tapering=result_teRT_C,
ML=result_tePV_C,L1=result_teL_C),
Estimation_by_Frank_Copula=list
(OLS=result_teR_F,OLS_Tapering=result_teRT_F,
ML=result_tePV_F,L1=result_teL_F),
Estimation_by_Gumbel_Copula=list
(OLS=result_teR_G,OLS_Tapering=result_teRT_G,
ML=result_tePV_G,L1=result_teL_G)))
166

###################################################################
#simulación de pares de datos mediante una copula bivariante Gumbel
#con párametro real theta=realTHETA
###################################################################
simulazione_G<-function(scenari,ndati,vectorTHETA=c(2:8),intervallo,toll=0.25)
teR_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teR_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teR_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teRT_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teRT_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teRT_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
tePV_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
tePV_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
tePV_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teL_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teL_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teL_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
for(theta in vectorTHETA)
cat("\n","Calculo de la matriz correctora
de la copula empirica (Clayton), theta=",theta,"\n")
limiti_C<-NULL
limiti_C<-rclaytonBivCopula(5000,2000,theta,tol=toll)
cat("Calculo de la matriz correctora
de la copula empirica (Frank), theta=",theta,"\n")
limiti_F<-NULL
limiti_F<-rfrankBivCopula(5000,2000,theta,tol=toll)
cat("Calculo de la matriz correctora
de la copula empirica (Gumbel), theta=",theta,"\n")
limiti_G<-NULL
limiti_G<-rgumbelBivCopula(5000,2000,theta,tol=toll)
for(z in 1:scenari)
167

cat("simulacion numero.",z,", theta=",theta,"\n")
################
#inicialización.
################
dati<-matrix(0,nrow=ndati,ncol=2)
x<-rep(0,ndati)
y<-rep(0,ndati)
###################
#inicio simulación.
###################
dati<-rcopula(gumbelCopula(theta,dim=2),ndati)
Copula_C<-expression(
(1+(F1^(-theta)-1+F2^(-theta)-1))^(-1/theta));
score_C<-expression(
((1+(F1^(-theta)-1+F2^(-theta)-1))^(-1/theta)-H)^2);
score_L_C<-expression(
(1+(F1^(-theta)-1+F2^(-theta)-1))^(-1/theta)-H)
Copula_F<-expression(-1/theta*log(1+exp(-(-log((exp(-theta*F1)-1)/
(exp(-theta)-1))-log(
(exp(-theta*F2)-1)/(exp(-theta)-1))))*(exp(-theta)-1)));
score_F<-expression(
(-1/theta*log(1+exp(-(-log((exp(-theta*F1)-1)/
(exp(-theta)-1))-log((exp(-theta*F2)-1)/
(exp(-theta)-1))))*(exp(-theta)-1))-H)^2);
score_L_F<-expression(-1/theta*log(1+exp(-(-log((exp(-theta*F1)-1)/
(exp(-theta)-1))-log((exp(-theta*F2)-1)/
(exp(-theta)-1))))*(exp(-theta)-1))-H)
Copula_G<-expression(
exp(-((-log(F1))^theta+(-log(F2))^theta)^(1/theta)));
score_G<-expression(
(exp(-((-log(F1))^theta+(-log(F2))^theta)^(1/theta))-H)^2);
score_L_G<-expression(
168

exp(-((-log(F1))^theta+(-log(F2))^theta)^(1/theta))-H)
x<-dati[,1]
y<-dati[,2]
###############################################################
#Definición de la corrección para la cópula Empirica (Clayton).
###############################################################
test_C<-rep(0,ndati)
pesi_C<-rep(0,ndati)
for(i in 1:ndati)
test_C[i]<-nearest(limiti_C[,1],x[i],outside=TRUE)
if(y[i]>limiti_C[test_C[i],2] ||
y[i]<limiti_C[test_C[i],3]) pesi_C[i]<-1
xstar_C<-rep(0,ndati)
ystar_C<-rep(0,ndati)
xstar_C<-x*pesi_C
ystar_C<-y*pesi_C
xstar_C<-xstar_C[xstar_C>0]
ystar_C<-ystar_C[ystar_C>0]
nxstar_C<-0
nystar_C<-0
nxstar_C<-length(xstar_C)
nystar_C<-length(ystar_C)
#############################################################
#Definición de la corrección para la cópula Empirica (Frank).
#############################################################
test_F<-rep(0,ndati)
pesi_F<-rep(0,ndati)
for(i in 1:ndati)
test_F[i]<-nearest(limiti_F[,1],x[i],outside=TRUE)
if(y[i]>limiti_F[test_F[i],2] ||
169

y[i]<limiti_F[test_F[i],3]) pesi_F[i]<-1
xstar_F<-rep(0,ndati)
ystar_F<-rep(0,ndati)
xstar_F<-x*pesi_F
ystar_F<-y*pesi_F
xstar_F<-xstar_F[xstar_F>0]
ystar_F<-ystar_F[ystar_F>0]
nxstar_F<-0
nystar_F<-0
nxstar_F<-length(xstar_F)
nystar_F<-length(ystar_F)
##############################################################
#Definición de la corrección para la copula Empirica (Gumbel).
##############################################################
test_G<-rep(0,ndati)
pesi_G<-rep(0,ndati)
for(i in 1:ndati)
test_G[i]<-nearest(limiti_G[,1],x[i],outside=TRUE)
if(y[i]>limiti_G[test_G[i],2] ||
y[i]<limiti_G[test_G[i],3]) pesi_G[i]<-1
xstar_G<-rep(0,ndati)
ystar_G<-rep(0,ndati)
xstar_G<-x*pesi_G
ystar_G<-y*pesi_G
xstar_G<-xstar_G[xstar_G>0]
ystar_G<-ystar_G[ystar_G>0]
nxstar_G<-0
nystar_G<-0
nxstar_G<-length(xstar_G)
nystar_G<-length(ystar_G)
170

################################################################
#Cálculo de las funciones de distribución marginales y conjunta.
################################################################
cat("dentro simulacion numero.",z,", theta=",theta,",
stima funzioni di ripartizione marginali e congiunta","\n")
Fxr<-rep(0,ndati);
Fyr<-rep(0,ndati);
Fxr<-cdf(x);
Fyr<-cdf(y);
Fcr<-rep(0,ndati);
for(i in 1:ndati)
Fcr[i]<-cdf_cong(i,x,y)
#Clayton
Fxrstar_C<-rep(0,nxstar_C);
Fyrstar_C<-rep(0,nystar_C);
Fxrstar_C<-cdf(xstar_C);
Fyrstar_C<-cdf(ystar_C)
Fcrstar_C<-rep(0,nxstar_C);
for(i in 1:nxstar_C)
Fcrstar_C[i]<-cdf_cong(i,xstar_C,ystar_C)
#Frank
Fxrstar_F<-rep(0,nxstar_F);
Fyrstar_F<-rep(0,nystar_F);
Fxrstar_F<-cdf(xstar_F);
Fyrstar_F<-cdf(ystar_F)
Fcrstar_F<-rep(0,nxstar_F);
for(i in 1:nxstar_F)
Fcrstar_F[i]<-cdf_cong(i,xstar_F,ystar_F)
171

#Gumbel
Fxrstar_G<-rep(0,nxstar_G);
Fyrstar_G<-rep(0,nystar_G);
Fxrstar_G<-cdf(xstar_G);
Fyrstar_G<-cdf(ystar_G)
Fcrstar_G<-rep(0,nxstar_G);
for(i in 1:nxstar_G)
Fcrstar_G[i]<-cdf_cong(i,xstar_G,ystar_G)
#################################################
#Implementación de la función que permite estimar
#Theta mediante OLS (utilizando rangos)
#################################################
estimationR<-function(theta,F1,F2,H,score)
derivScore<-D(score,"theta")
return(sum(eval(derivScore)))
cat("dentro simulacion numero.",z,", theta=",theta,"
,stima theta OLS (ranghi)","\n")
teR_C[z,match(theta,vectorTHETA)]<-unirootME
(estimationR,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_C)
teR_F[z,match(theta,vectorTHETA)]<-unirootME
(estimationR,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_F)
teR_G[z,match(theta,vectorTHETA)]<-unirootME
(estimationR,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_G)
teRT_C[z,match(theta,vectorTHETA)]<-unirootME
(estimationR,interval=intervallo,
F1=Fxrstar_C,F2=Fyrstar_C,H=Fcrstar_C,score=score_C)
172

teRT_F[z,match(theta,vectorTHETA)]<-unirootME
(estimationR,interval=intervallo,
F1=Fxrstar_F,F2=Fyrstar_F,H=Fcrstar_F,score=score_F)
teRT_G[z,match(theta,vectorTHETA)]<-unirootME
(estimationR,interval=intervallo,
F1=Fxrstar_G,F2=Fyrstar_G,H=Fcrstar_G,score=score_G)
####################################################
#Implementación de la función que permite estimar
#theta mediante pseudo-máximaverosimilitud (Genest).
####################################################
f<-function(theta,x,y,Copula)
rx<-rank(x)
ry<-rank(y)
n<-length(x)
F1<-rx/(n+1)
F2<-ry/(n+1)
densidad<-D(D(Copula,"F1"),"F2")
ddensidad<-D(densidad,"theta")
dert<-(1/eval(densidad))*eval(ddensidad)
result<-sum(dert)
return(result)
cat("dentro simulacion numero.",z,", theta=",
theta,",stima theta GENEST","\n")
tePV_C[z,match(theta,vectorTHETA)]<-unirootME
(f,interval=intervallo,x=x,y=y,Copula=Copula_C)
tePV_F[z,match(theta,vectorTHETA)]<-unirootME
(f,interval=intervallo,x=x,y=y,Copula=Copula_F)
tePV_G[z,match(theta,vectorTHETA)]<-
unirootME(f,interval=intervallo,x=x,y=y,Copula=Copula_G)
########################################################
#Implementación de la función que permite estimar Theta
173

# Mínima Distancia L1 (articulo Biau, Wegkamp (2005))
#######################################################
estimationL<-function(theta,F1,F2,H,score)
n<-length(F1)
segni<-rep(0,n)
distanza<-rep(0,n)
distanza<-eval(score)
for(i in 1:n)
if(distanza[i]>=0)
segni[i]<-1 else segni[i]<--1
derivScore<-D(score,"theta")
return(sum(eval(derivScore)*segni))
cat("dentro simulacion numero.",z,", theta=",
theta,",stima theta Minimum Distance L1","\n")
teL_C[z,match(theta,vectorTHETA)]<-unirootME
(estimationL,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_L_C)
teL_F[z,match(theta,vectorTHETA)]<-unirootME
(estimationL,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_L_F)
teL_G[z,match(theta,vectorTHETA)]<-unirootME
(estimationL,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_L_G)
##########################
#Lista de objetos finales.
##########################
#Resultado mediante OLS.
174

var_teR_C<-rep(0,length(vectorTHETA))
result_teR_C<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teR_C[1,]<-colMeans(teR_C)
result_teR_C[2,]<-colMeans(teR_C)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teR_C[j]<-var(teR_C[,j])
result_teR_C[3,j]<-sqrt(var_teR_C[j])
result_teR_C[4,]<-result_teR_C[2,]^2+var_teR_C
var_teR_F<-rep(0,length(vectorTHETA))
result_teR_F<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teR_F[1,]<-colMeans(teR_F)
result_teR_F[2,]<-colMeans(teR_F)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teR_F[j]<-var(teR_F[,j])
result_teR_F[3,j]<-sqrt(var_teR_F[j])
result_teR_F[4,]<-result_teR_F[2,]^2+var_teR_F
var_teR_G<-rep(0,length(vectorTHETA))
result_teR_G<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teR_G[1,]<-colMeans(teR_G)
result_teR_G[2,]<-colMeans(teR_G)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teR_G[j]<-var(teR_G[,j])
result_teR_G[3,j]<-sqrt(var_teR_G[j])
result_teR_G[4,]<-result_teR_G[2,]^2+var_teR_G
175

##########################################
#Resultado mediante OLS con suavizamiento.
##########################################
var_teRT_C<-rep(0,length(vectorTHETA))
result_teRT_C<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teRT_C[1,]<-colMeans(teRT_C)
result_teRT_C[2,]<-colMeans(teRT_C)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teRT_C[j]<-var(teRT_C[,j])
result_teRT_C[3,j]<-sqrt(var_teRT_C[j])
result_teRT_C[4,]<-result_teRT_C[2,]^2+var_teRT_C
var_teRT_F<-rep(0,length(vectorTHETA))
result_teRT_F<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teRT_F[1,]<-colMeans(teRT_F)
result_teRT_F[2,]<-colMeans(teRT_F)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teRT_F[j]<-var(teRT_F[,j])
result_teRT_F[3,j]<-sqrt(var_teRT_F[j])
result_teRT_F[4,]<-result_teRT_F[2,]^2+var_teRT_F
var_teRT_G<-rep(0,length(vectorTHETA))
result_teRT_G<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teRT_G[1,]<-colMeans(teRT_G)
result_teRT_G[2,]<-colMeans(teRT_G)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teRT_G[j]<-var(teRT_G[,j])
176

result_teRT_G[3,j]<-sqrt(var_teRT_G[j])
result_teRT_G[4,]<-result_teRT_G[2,]^2+var_teRT_G
##################################
#Resultado mediante MLE (Genest).
##################################
var_tePV_C<-rep(0,length(vectorTHETA))
result_tePV_C<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_tePV_C[1,]<-colMeans(tePV_C)
result_tePV_C[2,]<-colMeans(tePV_C)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_tePV_C[j]<-var(tePV_C[,j])
result_tePV_C[3,j]<-sqrt(var_tePV_C[j])
result_tePV_C[4,]<-result_tePV_C[2,]^2+var_tePV_C
var_tePV_F<-rep(0,length(vectorTHETA))
result_tePV_F<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_tePV_F[1,]<-colMeans(tePV_F)
result_tePV_F[2,]<-colMeans(tePV_F)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_tePV_F[j]<-var(tePV_F[,j])
result_tePV_F[3,j]<-sqrt(var_tePV_F[j])
result_tePV_F[4,]<-result_tePV_F[2,]^2+var_tePV_F
var_tePV_G<-rep(0,length(vectorTHETA))
result_tePV_G<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_tePV_G[1,]<-colMeans(tePV_G)
result_tePV_G[2,]<-colMeans(tePV_G)-vectorTHETA
177

for(j in 1:length(vectorTHETA))
var_tePV_G[j]<-var(tePV_G[,j])
result_tePV_G[3,j]<-sqrt(var_tePV_G[j])
result_tePV_G[4,]<-result_tePV_G[2,]^2+var_tePV_G
########################################
#Resultado mediante Mínima Distancia L1.
########################################
var_teL_C<-rep(0,length(vectorTHETA))
result_teL_C<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teL_C[1,]<-colMeans(teL_C)
result_teL_C[2,]<-colMeans(teL_C)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teL_C[j]<-var(teL_C[,j])
result_teL_C[3,j]<-sqrt(var_teL_C[j])
result_teL_C[4,]<-result_teL_C[2,]^2+var_teL_C
var_teL_F<-rep(0,length(vectorTHETA))
result_teL_F<-matrix(0,nrow=4,ncol=length(vectorTHETA),
dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teL_F[1,]<-colMeans(teL_F)
result_teL_F[2,]<-colMeans(teL_F)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teL_F[j]<-var(teL_F[,j])
result_teL_F[3,j]<-sqrt(var_teL_F[j])
result_teL_F[4,]<-result_teL_F[2,]^2+var_teL_F
var_teL_G<-rep(0,length(vectorTHETA))
result_teL_G<-matrix(0,nrow=4,ncol=length(vectorTHETA),
178

dimnames=list(c("Estimation","Bias","St.D.","MSE"),vectorTHETA))
result_teL_G[1,]<-colMeans(teL_G)
result_teL_G[2,]<-colMeans(teL_G)-vectorTHETA
for(j in 1:length(vectorTHETA))
var_teL_G[j]<-var(teL_G[,j])
result_teL_G[3,j]<-sqrt(var_teL_G[j])
result_teL_G[4,]<-result_teL_G[2,]^2+var_teL_G
return(list(Summary=matrix(c(scenari,ndati,toll),3,1,
dimnames=list(c("Num. simulations","Num. data","Tolerance"),
"Summary (simulations from Gumbel Copula)")),
List_of_real_theta=vectorTHETA,
Estimation_by_Clayton_Copula=list
(OLS=result_teR_C,OLS_Tapering=result_teRT_C,
ML=result_tePV_C,L1=result_teL_C),
Estimation_by_Frank_Copula=list
(OLS=result_teR_F,OLS_Tapering=result_teRT_F,
ML=result_tePV_F,L1=result_teL_F),
Estimation_by_Gumbel_Copula=list
(OLS=result_teR_G,OLS_Tapering=result_teRT_G,
ML=result_tePV_G,L1=result_teL_G)))
6.3. Código utilizado en la estimación de θ, da-
do un banco de datos real
#########################################
#Introducción de los códigos principales.
#########################################
source("C:\\Documents and Settings\\...\\Escritorio\\
179

simulaciones definitivas\\codigo.txt")
source("C:\\Documents and Settings\\...\\Escritorio\\
estimacion real data\\codigo-estimacion.txt")
############################
#Lectura del banco de datos.
############################
data.1<-matrix(scan("C:\\Documents and Settings\\...\\
Escritorio\\estimacion real data\\datos-xy-caso-1.txt"),ncol=2,byrow=T)
###########################################################
#Llamada a la función de estimación (código de estimación).
###########################################################
resultados.datos.1<-codigo_estimacion
(scenari=1,input_data=data.1,ndati=500,
intervallo=c(1,30),toll=0.25,vectorTHETA=c(2))
##############################################
#Código de estimación (codigo-estimacion.txt).
##############################################
codigo_estimacion<-function(scenari=1,input_data,ndati,
intervallo,toll=0.25,vectorTHETA=c(2))
teR_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teR_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teR_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teRT_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teRT_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teRT_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
tePV_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
tePV_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
tePV_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teL_C<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teL_F<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
teL_G<-matrix(0,nrow=scenari,ncol=length(vectorTHETA))
for(theta in vectorTHETA)
180

cat("\n","Calcolo della matrice correttrice della
Copula Empirica (Clayton), theta=",theta,"\n")
limiti_C<-NULL
limiti_C<-rclaytonBivCopula(5000,2000,theta,tol=toll)
cat("Calcolo della matrice correttrice della Copula
Empirica (Frank), theta=",theta,"\n")
limiti_F<-NULL
limiti_F<-rfrankBivCopula(5000,2000,theta,tol=toll)
cat("Calcolo della matrice correttrice
della Copula Empirica (Gumbel), theta=",theta,"\n")
limiti_G<-NULL
limiti_G<-rgumbelBivCopula(5000,2000,theta,tol=toll)
for(z in 1:scenari)
#Inicialización.
x<-input_data[,1]
y<-input_data[,2]
##############################################
#Definición de las expresiones de las cópulas.
##############################################
Copula_C<-expression((1+(F1^(-theta)-1+F2^(-theta)-1))^(-1/theta));
score_C<-expression(((1+(F1^(-theta)-1+F2^(-theta)-1))^(-1/theta)-H)^2);
score_L_C<-expression((1+(F1^(-theta)-1+F2^(-theta)-1))^(-1/theta)-H)
Copula_F<-expression(-1/theta*log(1+exp(-(-log((exp(-theta*F1)-1)/
(exp(-theta)-1))-log((exp(-theta*F2)-1)/
(exp(-theta)-1))))*(exp(-theta)-1)));
score_F<-expression((-1/theta*log(1+exp(-(-log((exp(-theta*F1)-1)/
(exp(-theta)-1))-log((exp(-theta*F2)-1)/
(exp(-theta)-1))))*(exp(-theta)-1))-H)^2);
score_L_F<-expression(-1/theta*log(1+exp(-(-log((exp(-theta*F1)-1)/
(exp(-theta)-1))-log((exp(-theta*F2)-1)/
(exp(-theta)-1))))*(exp(-theta)-1))-H)
181

Copula_G<-expression(exp
(-((-log(F1))^theta+(-log(F2))^theta)^(1/theta)));
score_G<-expression((exp
(-((-log(F1))^theta+(-log(F2))^theta)^(1/theta))-H)^2);
score_L_G<-expression(exp
(-((-log(F1))^theta+(-log(F2))^theta)^(1/theta))-H)
###############################################################
#Definición de la corrección para la Cópula Empirica (Clayton).
###############################################################
test_C<-rep(0,ndati)
pesi_C<-rep(0,ndati)
for(i in 1:ndati)
test_C[i]<-nearest(limiti_C[,1],x[i],outside=TRUE)
if(y[i]>limiti_C[test_C[i],2]
|| y[i]<limiti_C[test_C[i],3]) pesi_C[i]<-1
xstar_C<-rep(0,ndati)
ystar_C<-rep(0,ndati)
xstar_C<-x*pesi_C
ystar_C<-y*pesi_C
xstar_C<-xstar_C[xstar_C>0]
ystar_C<-ystar_C[ystar_C>0]
nxstar_C<-0
nystar_C<-0
nxstar_C<-length(xstar_C)
nystar_C<-length(ystar_C)
#############################################################
#Definición de la corrección para la Cópula Empirica (Frank).
#############################################################
test_F<-rep(0,ndati)
pesi_F<-rep(0,ndati)
for(i in 1:ndati)
182

test_F[i]<-nearest(limiti_F[,1],x[i],outside=TRUE)
if(y[i]>limiti_F[test_F[i],2]
|| y[i]<limiti_F[test_F[i],3]) pesi_F[i]<-1
xstar_F<-rep(0,ndati)
ystar_F<-rep(0,ndati)
xstar_F<-x*pesi_F
ystar_F<-y*pesi_F
xstar_F<-xstar_F[xstar_F>0]
ystar_F<-ystar_F[ystar_F>0]
nxstar_F<-0
nystar_F<-0
nxstar_F<-length(xstar_F)
nystar_F<-length(ystar_F)
##############################################################
#Definición de la corrección para la Cópula Empirica (Gumbel).
##############################################################
test_G<-rep(0,ndati)
pesi_G<-rep(0,ndati)
for(i in 1:ndati)
test_G[i]<-nearest(limiti_G[,1],x[i],outside=TRUE)
if(y[i]>limiti_G[test_G[i],2]
|| y[i]<limiti_G[test_G[i],3]) pesi_G[i]<-1
xstar_G<-rep(0,ndati)
ystar_G<-rep(0,ndati)
xstar_G<-x*pesi_G
ystar_G<-y*pesi_G
xstar_G<-xstar_G[xstar_G>0]
ystar_G<-ystar_G[ystar_G>0]
nxstar_G<-0
183

nystar_G<-0
nxstar_G<-length(xstar_G)
nystar_G<-length(ystar_G)
#####################################################
#Cálculo de las distribuciones marginales y conjunta.
#####################################################
Fxr<-rep(0,ndati);
Fyr<-rep(0,ndati);
Fxr<-cdf(x);
Fyr<-cdf(y);
Fcr<-rep(0,ndati);
for(i in 1:ndati)
Fcr[i]<-cdf_cong(i,x,y)
#Clayton
Fxrstar_C<-rep(0,nxstar_C);Fyrstar_C<-rep(0,nystar_C);
Fxrstar_C<-cdf(xstar_C);Fyrstar_C<-cdf(ystar_C)
Fcrstar_C<-rep(0,nxstar_C);
for(i in 1:nxstar_C)
Fcrstar_C[i]<-cdf_cong(i,xstar_C,ystar_C)
#Frank
Fxrstar_F<-rep(0,nxstar_F);
Fyrstar_F<-rep(0,nystar_F);
Fxrstar_F<-cdf(xstar_F);
Fyrstar_F<-cdf(ystar_F)
Fcrstar_F<-rep(0,nxstar_F);
for(i in 1:nxstar_F)
Fcrstar_F[i]<-cdf_cong(i,xstar_F,ystar_F)
#Gumbel
184

Fxrstar_G<-rep(0,nxstar_G);
Fyrstar_G<-rep(0,nystar_G);
Fxrstar_G<-cdf(xstar_G);
Fyrstar_G<-cdf(ystar_G)
Fcrstar_G<-rep(0,nxstar_G);
for(i in 1:nxstar_G)
Fcrstar_G[i]<-cdf_cong(i,xstar_G,ystar_G)
#############################################################
#Implementación de la función para estimar Theta mediante OLS
#(utilizando rangos).
#############################################################
estimationR<-function(theta,F1,F2,H,score)
derivScore<-D(score,"theta")
return(sum(eval(derivScore)))
teR_C[z,match(theta,vectorTHETA)]<-unirootME
(estimationR,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_C)
teR_F[z,match(theta,vectorTHETA)]<-unirootME
(estimationR,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_F)
teR_G[z,match(theta,vectorTHETA)]<-unirootME
(estimationR,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_G)
teRT_C[z,match(theta,vectorTHETA)]<-unirootME
(estimationR,interval=intervallo,
F1=Fxrstar_C,F2=Fyrstar_C,H=Fcrstar_C,score=score_C)
teRT_F[z,match(theta,vectorTHETA)]<-unirootME
(estimationR,interval=intervallo,
F1=Fxrstar_F,F2=Fyrstar_F,H=Fcrstar_F,score=score_F)
185

teRT_G[z,match(theta,vectorTHETA)]<-unirootME
(estimationR,interval=intervallo,
F1=Fxrstar_G,F2=Fyrstar_G,H=Fcrstar_G,score=score_G)
#########################################################
#Implementación de la función para estimar Theta mediante
#pseudoverosimilitud (Genest).
#########################################################
f<-function(theta,x,y,Copula)
rx<-rank(x)
ry<-rank(y)
n<-length(x)
F1<-rx/(n+1)
F2<-ry/(n+1)
densidad<-D(D(Copula,"F1"),"F2")
ddensidad<-D(densidad,"theta")
dert<-(1/eval(densidad))*eval(ddensidad)
result<-sum(dert)
return(result)
tePV_C[z,match(theta,vectorTHETA)]<-unirootME
(f,interval=intervallo,x=x,y=y,Copula=Copula_C)
tePV_F[z,match(theta,vectorTHETA)]<-unirootME
(f,interval=intervallo,x=x,y=y,Copula=Copula_F)
tePV_G[z,match(theta,vectorTHETA)]<-unirootME
(f,interval=intervallo,x=x,y=y,Copula=Copula_G)
##################################################################
#Implementación de la función para estimar Theta mediante Minima
#Distancia L1 (artículo Biau, Wegkamp (2005)).
##################################################################
estimationL<-function(theta,F1,F2,H,score)
n<-length(F1)
186

segni<-rep(0,n)
distanza<-rep(0,n)
distanza<-eval(score)
for(i in 1:n)
if(distanza[i]>=0) segni[i]<-1 else segni[i]<--1
derivScore<-D(score,"theta")
return(sum(eval(derivScore)*segni))
teL_C[z,match(theta,vectorTHETA)]<-unirootME
(estimationL,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_L_C)
teL_F[z,match(theta,vectorTHETA)]<-unirootME
(estimationL,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_L_F)
teL_G[z,match(theta,vectorTHETA)]<-unirootME
(estimationL,interval=intervallo,
F1=Fxr,F2=Fyr,H=Fcr,score=score_L_G)
##########################
#Lista de objetos finales.
##########################
########################
#Resultado mediante OLS.
########################
result_teR_C<-matrix(0,nrow=1,ncol=length(vectorTHETA),
dimnames=list(c("Estimation"),vectorTHETA))
result_teR_C[1,]<-teR_C
result_teR_F<-matrix(0,nrow=1,ncol=length(vectorTHETA),
dimnames=list(c("Estimation"),vectorTHETA))
result_teR_F[1,]<-teR_F
187

result_teR_G<-matrix(0,nrow=1,ncol=length(vectorTHETA),
dimnames=list(c("Estimation"),vectorTHETA))
result_teR_G[1,]<-teR_G
##################################
#Resultado mediante OLS suavizado.
##################################
result_teRT_C<-matrix(0,nrow=1,ncol=length(vectorTHETA),
dimnames=list(c("Estimation"),vectorTHETA))
result_teRT_C[1,]<-teRT_C
result_teRT_F<-matrix(0,nrow=1,ncol=length(vectorTHETA),
dimnames=list(c("Estimation"),vectorTHETA))
result_teRT_F[1,]<-teRT_F
result_teRT_G<-matrix(0,nrow=1,ncol=length(vectorTHETA),
dimnames=list(c("Estimation"),vectorTHETA))
result_teRT_G[1,]<-teRT_G
##################################
#Resultado mediante MLE de Genest.
##################################
result_tePV_C<-matrix(0,nrow=1,ncol=length(vectorTHETA),
dimnames=list(c("Estimation"),vectorTHETA))
result_tePV_C[1,]<-tePV_C
result_tePV_F<-matrix(0,nrow=1,ncol=length(vectorTHETA),
dimnames=list(c("Estimation"),vectorTHETA))
result_tePV_F[1,]<-tePV_F
result_tePV_G<-matrix(0,nrow=1,ncol=length(vectorTHETA),
dimnames=list(c("Estimation"),vectorTHETA))
result_tePV_G[1,]<-tePV_G
########################################
#Resultado mediante mínima distancia L1.
########################################
188

result_teL_C<-matrix(0,nrow=1,ncol=length(vectorTHETA),
dimnames=list(c("Estimation"),vectorTHETA))
result_teL_C[1,]<-teL_C
result_teL_F<-matrix(0,nrow=1,ncol=length(vectorTHETA),
dimnames=list(c("Estimation"),vectorTHETA))
result_teL_F[1,]<-teL_F
result_teL_G<-matrix(0,nrow=1,ncol=length(vectorTHETA),
dimnames=list(c("Estimation"),vectorTHETA))
result_teL_G[1,]<-teL_G
return(list(OLS_C=result_teR_C,OLS_F=result_teR_F,
OLS_G=result_teR_G,OLST_C=result_teRT_C,
OLST_F=result_teRT_F,OLST_G=result_teRT_G,
ML_C=result_tePV_C,ML_F=result_tePV_F,ML_G=result_tePV_G,
L1_C=result_teL_C,L1_F=result_teL_F,L1_G=result_teL_G))
6.4. Código utilizado en la elección de la cópula
óptima, una vez estimado θ
############################
#Apertura paquetes librería.
############################
library(Bolstad)
library(copula)
library(GenKern)
library(mclust)
##################
#Lectura de datos.
##################
data.1<-matrix(scan("C:\\Documents and Settings\\Pablo
Juan\\Escritorio\\estimacion real
data\\datos-xy-caso-1.txt"),ncol=2,byrow=T)
189

#######################################################################
#Creación de la matriz de datos, datos ordenados y rangos por columnas.
#######################################################################
outputx<-cbind(data.1[,1], sort(data.1[,1]), rank(data.1[,1]))
outputy<-cbind(data.1[,2],sort(data.1[,2]),rank(data.1[,2]))
n<-length(outputx[,1]) F1<-rep(0,n) F2<-rep(0,n)
#####################################
#Definición de
#las distribuciones y sus densidades.
#####################################
Copula_C<-expression((1+(F1^(-theta)-1+F2^(-theta)-1))^(-1/theta))
densidadC<-D(D(Copula_C,"F1"),"F2")
Copula_F<-expression(-1/theta*log(1+exp(-(-log((exp(-theta*F1)-1)
/(exp(-theta)-1))-log((exp(-theta*F2)-1)/(exp(-theta)-1))))*(exp(-theta)-1)))
densidadF<-D(D(Copula_F,"F1"),"F2")
Copula_G<-expression(exp(-((-log(F1))^theta+(-log(F2))^theta)^(1/theta)))
densidadG<-D(D(Copula_G,"F1"),"F2")
###############################################################
#Función principal (evaluación de la función de verosimilitud).
###############################################################
maxver<-function(outputx,outputy,inputtheta,model)
n<-length(outputx[,1]) y<-rep(0,n)
theta<-inputtheta
h<-rep(0,n)
j<-rep(0,n)
theta<-inputtheta
for(i in 1:n)
if(model=="clayton")
F1[i]<-(outputx[,3][i])/(n+1)
F2[i]<-(outputy[,3][i])/(n+1)
190

h[i]<-eval(densidadC) j[i]<-log(h[i])
if(model=="frank")
F1[i]<-(outputx[,3][i])/(n+1)
F2[i]<-(outputy[,3][i])/(n+1)
h[i]<-eval(densidadF) j[i]<-log(h[i])
if(model=="gumbel")
F1[i]<-(outputx[,3][i])/(n+1)
F2[i]<-(outputy[,3][i])/(n+1)
h[i]<-eval(densidadG) j[i]<-log(h[i])
z<-sum(j)
return(z)
#########################################################################
#Llamada a la función que evalúa la función de verosimilitud, dado Theta.
#########################################################################
prueba<-maxver(outputx,outputy,inputtheta=9.57,model="clayton")
191


Capıtulo 7Apéndice
7.1. Un breve estudio de los coeficientes de cor-
relación
7.1.1. Medidas de la dependencia: Pearson, Spearman
y Kendall
Coeficiente de correlación de Pearson
El coeficiente de correlación de Pearson es un índice estadístico quemide la relación lineal entre dos variables cuantitativas. A diferencia dela covarianza, la correlación de Pearson es independiente de la escala demedida de las variables. El cálculo del coeficiente de correlación linealse realiza dividiendo la covarianza por el producto de las desviacionesestándar de ambas variables:
rn = rXY =σXY
σX · σY
Siendo:
σXY = Cov(X, Y ), la covarianza de (X,Y),
σX =√
V ar(X) y σY =√
V ar(Y ) las desviaciones típicas de lasdistribuciones marginales. El valor del índice de correlación varía en el
193

intervalo [−1, +1]:
• Si rn = 0, no existe ninguna correlación lineal. El índice indica,por tanto, una independencia lineal total entre las dos variablespero podría haber otro tipo de relación funcional entre ellas.
• Si rn = 1, existe una correlación positiva perfecta. El índice indicauna dependencia lineal total entre las dos variables denominadarelación directa: cuando una de ellas aumenta, la otra también lohace en idéntica proporción.
• Si 0 < rn < 1, existe una correlación positiva.
• Si rn = −1, existe una correlación negativa perfecta. El índiceindica una dependencia lineal total entre las dos variables llamadarelación inversa: cuando una de ellas aumenta, la otra disminuyeen idéntica proporción.
• Si −1 < rn < 0, existe una correlación negativa.
Coeficiente rho de SpearmanLa correlación de Spearman se define como:
ρs(X, Y ) = rn(FX(X), GY (Y )) =Cov(FX(X), GY (Y ))√
V ar(FX(X))√
V ar(GY (Y )).
La correlación de Spearman no es más que la correlación lineal de Pear-son, pero en el mundo de las distribuciones uniformes, esto es, las varia-bles aleatorias previamente se transforman en uniformes.
Coeficiente rho de Spearman calculado directamente a partirde la cópula
Teorema 7.1.1 Sean (X, Y ) variables aleatorias absolutamente con-tínuas, con cópula asociada C(·, ·). Entonces, se tiene que:
194

ρs = 12
∫∫
I2
(C(u, v)− uv)dudv = 12
∫∫
I2
C(u, v)dudv − 3.
Prueba. Léase [47].
Coeficiente tau de Kendall
Se define el tau de Kendall como:
τ(X,Y ) = P ((X1 −X2)(Y1 − Y2) > 0)− P ((X1 −X2)(Y1 − Y2) < 0)
donde
C := (X1, Y1), (X2, Y2) : (X1 −X2)(Y1 − Y2) > 0representa el conjunto de los pares de puntos concordantes,
y
D := (X1, Y1), (X2, Y2) : (X1 −X2)(Y1 − Y2) < 0el conjunto de los pares de puntos discordantes, donde
(X1, Y1) ∼ C(FX(X), GY (Y )), (X2, Y2) ∼ C(FX(X), GY (Y ))
son dos pares de observaciones independientes extraídas de
HXY = C(FX(X), GY (Y )).
Coeficiente tau de Kendall calculado directamente a partir dela cópula
195

Teorema 7.1.2 Sean (X1, Y1) y (X2, Y2) vectores independientes dedos variables aleatorias contínuas con función de distribución conjun-ta H1XY (·, ·) y H2XY (·, ·), respectivamente, cuyas marginales son FX
para X1 y X2, y GY para Y1 e Y2, por lo que H1XY = C1(FX , GY ) yH2XY = C2(FX , GY ).
Denotemos
Q = P ((X1 −X2)(Y1 − Y2) > 0)− P ((X1 −X2)(Y1 − Y2) < 0)
entonces,
Q = Q(C1, C2) = 4
∫∫
I2
(C2(u, v)dC1(u, v))− 1.
Prueba. Léase [47].
Teorema 7.1.3 Sean X e Y variables aleatorias contínuas, cuya cópu-la es C(·, ·). El tau de Kendall poblacional para X e Y viene dado por
τXY = τC = Q(C, C) = 4
∫∫
I2
C(u, v)dC(u, v)− 1.
Prueba. Léase [47].
Teorema 7.1.4 (Caso cópula Arquimediana)Sean X e Y variables aleatorias y sea C(·, ·) una cópula Arquimedianacon función generatriz ϕ ∈ Ω. Entonces
τC = 1 + 4
∫ 1
0
ϕ(t)
ϕ′(t)dt
Prueba. Sean (U, V ) ∼ Unif(0, 1) con función de distribución con-junta C(·, ·) y sea KC la función de distribución de C(U, V ). Sabemos
196

que
τC = 4E(C(U, V ))− 1 = 4
∫ 1
0
tdKC(t)− 11,
por lo que integrando por partes se llega a que
τC = 3− 4
∫ 1
0
KCdt
y asumiendo que la función de distribución KC de C(U, V ) es
KC(t) = t− ϕ(t)
ϕ′(t)2,
se obtiene que
τC = 3− 4
∫ 1
0
KCdt = 3− 4
∫ 1
0
(t− ϕ(t)
ϕ′(t+))dt = 1 + 4
∫ 1
0
ϕ(t)
ϕ′(t)dt.
7.1.2. Relación entre el τ de Kendall y el ρ de Pear-
son
Definición 7.1.1 Sean (X, Y ) ∼ N((µx, µy),
(σ2
X σXY
σXY σ2Y
)).
Entonces, se cumple que
τ(X, Y ) = 2π
arcsin(ρ(X,Y )).
Teorema 7.1.5 Extensión al caso multivariante.Sean
(X1, X2,...,Xn) ∼ N((µX1 , µX2 , ..., µXn),
σ21 σ12 ... σ1n
. . .
. . .
σ1n σ2n ... σ2n
),
1Léase [47]2Léase [47]
197

siendo σ2i la varianza de la i-ésima variable, y σij la covarianza para
cada par i 6= j.
Si P (Xi = µi) < 1 y P (Xj = µj) < 1, i 6= j
se cumple que
τ(Xi, Xj) = 2P ((Xi − Xi)(Xj − Xj) > 0)− 1 = 2π
arcsin(ρ(Xi, Yj))
donde X es una copia independiente de X.
Prueba. Léase [43]
7.1.3. Relación entre el τ de Kendall y el ρ de Spear-
man
Teorema 7.1.6 Sean X e Y variables aleatorias absolutamente con-tínuas. Entonces se cumple que
−1 ≤ 3τ(X, Y )− 2ρs(X,Y ) ≤ 1.
Prueba. Léase [47]
7.2. Definiciones
Acotada por debajo
Sean S1, S2 subconjuntos de R no vacíos, y sea H : S1 × S2 → R unafunción bivariante tal que VH(B) ≥ 0 ∀B = [x1, y1]× [x2, y2] ∈ S1×S2.Decimos que H está acotada por debajo si existen (a1, a2) ∈ S1 × S2
H(x, a2) = H(a1, y) = 0 ∀(x, y) ∈ S1 × S2.
198

Conjunto compacto
Llamamos conjunto compacto a un subconjunto C ⊆ X de un espa-cio topológico (X,T) (donde T es la colección de abiertos del espaciotopológico) tal que todo recubrimiento abierto suyo tiene un recubrim-iento finito; es decir, si ∀ Uii∈I , Ui ∈ T tal que C ⊂ ⋃
i∈I
Ui, existe
F ⊂ I finito tal que C ⊂ ⋃i∈F
Ui.
Conjunto conexo
Llamamos conjunto conexo a un subconjunto C ⊆ X de un espa-cio topológico (X,T) (donde T es la colección de abiertos del espaciotopológico) que no puede ser descrito como unión disjunta de dos con-juntos abiertos de la topología.
Función signo
Se define la función bivariante signo como:
sign(x, y) := 1 si xy<0−1 si xy>0 (7.1)
Gráficos cuantil-cuantil QQ-Plots
Un gráfico cuantil-cuantil permite observar cuan cerca está la distribu-ción de una serie de datos a alguna distribución ideal teórica, o com-parar las distribuciones de dos series de datos.
H-volumen
Sean S1 y S2 conjuntos no vacíos de R, y sea H : S1×S1 → R una fun-ción bivariante de variable real. Sea B = [x1, x2]× [y1, y2] un rectángulocuyos vértices pertenecen a S1×S1. Definimos el H-volumen de B como
VH(B) = H(x2, y2)−H(x1, y2)−H (x2, y1) + H(x1, y1).
Método de Monte Carlo
El método de Montecarlo es una técnica para obtener muestras aleato-rias simples de una v.a. X, de la que conocemos su ley de probabilidad
199

(a partir de su función de distribución F ). Con este método, el modode elegir aleatoriamente un valor de X usando su ley de probabilidades:
• A partir de una tabla de números aleatorios se toma un valor u
de una v.a. U∼Unif (0, 1).
• Si X es contínua, tomar como observación la cantidad x := F−1(u).En el caso en que X sea discreta, se toma x como el percentil 100·ude X, es decir, el valor más pequeño que verifica que F (x) ≥ u.Este proceso se debe repetir n veces para obtener una muestra detamaño n.
Suceso asociado a una cópula
Sea C : [0, 1] × [0, 1] → [0, 1] una cópula, caracterizada por C(u, v) :=
P (U ≤ u, V ≤ v) siendo U ∼ Unif([0, 1]) V ∼ Unif([0, 1]). Definimossucesos asociados a la cópula a los sucesos U ≤ u ,V ≤ v que permitencalcular probabilidades a partir de las distribuciones marginales FX yGY .
Vector rango asociado a un vector aleatorio X
Llamamos vector rango asociado a un vector aleatorio (x1, x2,......,xn)
al vector formado por las posiciones que ocupan dichas puntuacionesen el vector ordenado de menor a mayor (x(1), x(2),......,x(n)). Si hubieserepetición, se asignaria a cada una de ellas la media aritmética de lasposiciones. Esto solo puede ocurrir cuando la variable es discreta. Hayque tener en cuenta que el vector rango respeta el orden inicial delvector aleatorio, asignándole una cantidad ordinal a cada puntuación.
200

Bibliografía
[1] Ali.MM, Mikhail NN, Haq MS (1978). A class of bivariate distributionsincluding the bivariate logistic. J. Multivariate Anal., No 8, pp. 405-412.
[2] A. Bárdossy (2006). Copula Based Geostatistical Models for Ground-water Quality Parameters. Water Resources Research, Vol. 42.
[3] V. Barnett (1975). Probability Plotting Methods and Order Statistics.Appl. Stat., No 24, pp. 95-108.
[4] D. Basu (1977). On the Elimination of Nuisance Parameters. Journalof the American Statistical Association, Vol. 72, No. 358, pp. 355-366.
[5] G. Biau, M. Wegkamp (2005). A note on minimum distance estimationof copula densities. Statistics & Probability Letters, Vol. 73, pp. 105-114.
[6] C. B. Borkworf (2002). Computing the nonnull asymptotic varianceand the asymptotic relative efficiency of Spearman’s rank correlation.Comput. Stat., Data Anal., No 39, pp. 271-286.
[7] P. Capéraá, A. L. Fougéres, C. Genest (1997). A nonparametric estima-tion procedure for bivariate extreme value copulas. Biometrika, Vol. 84,Issue 3, pp. 567-577.
201

[8] X. Chen, Y. Fan (2002). Estimation of copula-based semiparametrictime series models. Journal of Econometrics, Vol. 130, pp. 307-335.
[9] S. X. Chen, T. M. Huang (2007). Nonparametric estimation of copulafunctions for dependence modelling. The Canadian Journal of Statis-tics, Vol. 35, No. 2, pp. 265-282.
[10] U. Cherubini, E. Luciano, W. Vecchiato (2004). Copula methods infinance. J. Wiley, Chichester.
[11] D. G. Clayton (1978). A model for association in bivariate life tablesand its application in epidemiological studies of famialial tendency inchronic disease incidence. Biometrika, Vol. 65, pp. 141-151.
[12] R. Cook, M. Johnson (1981). A family of distributions for modelingnon-elliptically symmetric multivariate data. J. Roy. Statist. Soc. Ser.,No 43, pp. 210-218.
[13] P. Deheuvels (1979). La fonction de dépendance empirique et ses pro-priétés: un test non paramétrique dŠindépendance. Académie Royalede Belgique - Bulletin de la Classe des Sciences, Vol. 65, No. 6, pp.274-292.
[14] L. Devroye, G. Lugosi (2002). Almost sure classification of densities.Journal of Nonparametric Statistics, vol. 14, pp. 675–698.
[15] T. S. Ferguson, C. Genest, M. Hallin (2000). Kendall’s tau for serialdependence. The Canadian Journal of Statistics, Vol. 28, No. 3, pp.587-604.
[16] J. D. Fermanian, O. Scaillet (2003). Nonparametric estimation of cop-ulas for time series. Journal of Risk, Vol. 5, No. 4, pp. 25-54.
[17] J. D. Fermanian (2005). Goodness-of-fit tests for copulas. Journal ofMultivariate Analysis, Vol. 95, pp. 119-152.
[18] N. I. Fisher, P. Switzer (1985). Chi-plots for assessing dependence.Biometrika, Vol. 72, No. 2, pp. 253-265.
202

[19] N. I. Fisher (1997). Encyclopaedia of Statistical Sciences. S. Kotz,N. L. Johnson, C.B. Read, Editors, New York: Wiley.
[20] M. J. Frank (1979). On the simultaneous associativity of F (x, y) andx + y − F (x, y). Aequationes Mathematicae, Vol. 19, pp. 194-226.
[21] C. Genest, J. MacKay (1986). The Joy of Copulas: Bivariate Distri-butions with Uniform Marginals. The American Statistician, Vol. 40,Issue 4, pp. 280-283.
[22] C. Genest (1987). Frank’s Family of Bivariate Distributions. Biometri-ka, Vol. 74, Issue 3, pp. 549-555.
[23] C. Genest, L. P. Rivest (1989). A Characterization of Gumbel’s Familyof Extreme Value Distributions. Statistics & Probability Letters, Vol. 8,pp. 207-211.
[24] C. Genest, L. P. Rivest (1993). Statistical Inference Procedures forBiavariate Archimedean Copulas. Journal of the American StatisticalAssociation, Vol. 88, Issue 423, pp. 1034-1043.
[25] C. Genest, K. Ghoudi, L. P. Rivest (1995). A Semiparametric Estima-tion Procedures of Dependence Parameters in Multivariat Families ofDistributions. Biometrika, Vol. 82, Issue 3, pp. 543-552.
[26] C. Genest, J. J. Q. Molina, J. A. Rodríguez Lallena, C. Sempi (1999).A Characterization of Quasi-copulas. Journal of Multivariate Analysis,Vol. 69, pp. 193-205.
[27] C. Genest, Boies (2003). Detecting dependence with Kendall plots.Journal of the American Statistical Association, Vol. 57, Issue 4, pp.275-284.
[28] C. Genest, J. F. Quessy, B. Rémillard (2006). Goodness-of-fit Proce-dures for Copula Models Based on the Probability Integral Transfor-mation. Scandinavian Journal of Statistics, Vol. 33, pp. 337-366.
203

[29] C. Genest, A. C. Favre (2007). Everything you always wanted to knowabout copula modeling but were afraid to ask. Journal of HydrologicEngineering, Vol. 12, No. 4, pp. 347-368.
[30] B. Gnedenko, A. Ya. Khinchin, L. F. Boron (1962). An ElementaryIntroduction to the Theory of Probability. Ed. Eudeba, Buenos Aires.
[31] G. Gong, F. J. Samaniego (1981). Pseudo Maximum Likelihood Es-timation: Theory and Applications. The Annals of Statistics, Vol. 9,No. 4, pp. 861-869.
[32] E. J. Gumbel (1960). Distributions del valeurs extrémes en plusiersdimensions. Publications de l’Institut de Statistique de L’Université deParis, Vol. 9, pp. 171-173.
[33] M. Hollander, D. A. Wolfe (1973). Nonparametric Statistical Methods,Wiley, New York.
[34] P. Hougaard (1986). A class of multivariate failure time distributions.Biometrika, Vol. 73, pp. 671-678.
[35] H. Joe (1997). Multivariate Models and Dependence Concepts. Chap-man & Hall, London.
[36] Jun Yan (2007). Enjoy the Joy of Copulas: With a Package copula.Journal of Statistical Software, Vol.21, Issue 4, pp. 34-78.
[37] H. Joe (2005). Asymptotic efficiency of the two-stage estimationmethod for copula-based models. Journal of Multivariate Analysis,Vol. 94, pp. 401-419.
[38] J. D. Kalbfleisch, D. A. Sprott (1970). Application of Likelihood Me-thods to Models Involving Large Numbers of Parameters. Journal ofthe Royal Statistical Society, Series B (Methodological), Vol. 32,No. 2,pp. 175-208.
[39] W. H. Kruskal (1958). Ordinal measures of association. Journal ofAmerican Statistical Association, Vol. 53, pp. 814-861.
204

[40] E. L. Lehmann (1966). Some concepts of dependence. Annals of theInstitute of Mathematical Statistics, Vol. 37, pp. 1137-1153.
[41] E. L. Lehmann (1975). Nonparametrics: Statistical Methods Based onRanks. Holden-Day, San Francisco.
[42] B. G. Lindsay (1988). Composite Likelihood Methods. ContemporaryMathematics, Vol. 80, pp. 221-239.
[43] F. Lindskog et al. (2001). Kendall’s tau for elliptical distributions.
[44] C. H. Ling (1965). Representation of associative functions. Publ. Math.Debrecen, No 12, pp. 189-212.
[45] D. O. Loftsgaarden, C. P. Quesenberry (1965). A Nonparametric Esti-mate of a Multivariate Density Function. The Annals of MathematicalStatistics, Vol. 36, No. 3, pp. 1049-1051.
[46] R. B.Nelsen (1995). Copulas, Characterization, Correlation and Coun-terexamples. Mathematics Magazine, Vol. 68,No. 3, pp. 193-198.
[47] R. B.Nelsen (2006). An introduction to copulas. Springer, New York.
[48] D. Oakes (1982). A model for association in bivariate survival data. J.Roy. Statist. Soc. Ser., No 44, pp. 414-422.
[49] D. Oakes (1994). Multivariate survival distributions. J. Nonparam.Statist., 3-4, pp. 343-354.
[50] D. Oakes, J. Ritz (2000). Regression in a Bivariate Copula Model.Biometrika, Vol. 87, Issue 2, pp. 345-352.
[51] Oehlert, G. W. (1992). A Note on the Delta Method. The AmericanStatistician, Vol. 46, No. 1, pp. 27-29.
[52] E. Parzen (1962). On Estimation of a Probability Density Functionand Mode. The Annals of Mathematical Statistics, Vol. 33, No. 3, pp.1065-1076.
205

[53] J. Pickhands (1981). Multivariate extreme value distributions. Bull.Internat. Statist., pp.859-878.
[54] E. Porcu, R. Pini, J. Mateu (2006). On the construction of classesof spatio-temporal covariance functions. Department of Mathematics,Universidad Jaume I, Castellon De la Plana.
[55] C. Romano (2002). Calibrating and Simulating Copula Functions: Ap-plications to Italian Stock Market. working paper.
[56] M. Rosenblatt (1956). Remarks on Some Nonparametric Estimates ofa Density Function. The Annals of Mathematical Statistics, Vol. 27,No. 3, pp. 832-837.
[57] B. Schweizer, E. F. Wolff (1981). On Nonparametric Measures of De-pedence for Random Variables. The Annals of Statistics, Vol. 9, No. 4,pp.879-885.
[58] J. H. Shih, T. A. Louis (1995). Inferences on the Association Parameterin Copula Models for Bivariate Survival Data. Biometrics, Vol. 51,No. 4, pp. 1384-1399.
[59] A. Sklar (1959). Fonctions de répartition á n dimensions et leursmarges. Publications de l’Institut de Statistique de L’Université deParis, Vol. 8, pp. 229-231.
[60] A. Sklar, B. Schweizer (1983). Probabilistic Metric Spaces. North-Holland, New york.
[61] H. Tsukahara (2005). Semiparametric estimation in copula models. TheCanadian Journal of Statistics, Vol. 33, No. 3, pp. 357-375.
[62] A. Wald, (1947). Sequential analysis. Wiley, NY.
[63] Y. Yatracos (1985). Rates of convergence of minimum distance esti-mators and Kolmogorov’s entropy. Annals of Statistics, vol. 13, pp.768–774.
206

[64] Y. Zhao, H. Joe (2005). Composite likelihood estimation in multivariatedata analysis. The Canadian Journal of Statistics, Vol. 33, No. 3, pp.335-356.
207